Keras - Guía rápida
Keras - Introducción
El aprendizaje profundo es uno de los principales subcampos del marco de aprendizaje automático. El aprendizaje automático es el estudio del diseño de algoritmos, inspirado en el modelo del cerebro humano. El aprendizaje profundo se está volviendo más popular en los campos de la ciencia de datos como la robótica, la inteligencia artificial (IA), el reconocimiento de audio y video y el reconocimiento de imágenes. La red neuronal artificial es el núcleo de las metodologías de aprendizaje profundo. El aprendizaje profundo es compatible con varias bibliotecas como Theano, TensorFlow, Caffe, Mxnet, etc., Keras es una de las bibliotecas de Python más potentes y fáciles de usar, que se basa en bibliotecas populares de aprendizaje profundo como TensorFlow, Theano, etc. , para crear modelos de aprendizaje profundo.
Descripción general de Keras
Keras se ejecuta sobre bibliotecas de máquinas de código abierto como TensorFlow, Theano o Cognitive Toolkit (CNTK). Theano es una biblioteca de Python utilizada para tareas de cálculo numérico rápido. TensorFlow es la biblioteca matemática simbólica más famosa utilizada para crear redes neuronales y modelos de aprendizaje profundo. TensorFlow es muy flexible y el beneficio principal es la computación distribuida. CNTK es un marco de aprendizaje profundo desarrollado por Microsoft. Utiliza bibliotecas como Python, C #, C ++ o kits de herramientas de aprendizaje automático independientes. Theano y TensorFlow son bibliotecas muy poderosas pero difíciles de entender para crear redes neuronales.
Keras se basa en una estructura mínima que proporciona una forma limpia y sencilla de crear modelos de aprendizaje profundo basados en TensorFlow o Theano. Keras está diseñado para definir rápidamente modelos de aprendizaje profundo. Bueno, Keras es una opción óptima para aplicaciones de aprendizaje profundo.
Caracteristicas
Keras aprovecha varias técnicas de optimización para hacer que la API de red neuronal de alto nivel sea más fácil y más eficiente. Admite las siguientes funciones:
API consistente, simple y extensible.
Estructura mínima: fácil de lograr el resultado sin lujos.
Es compatible con múltiples plataformas y backends.
Es un marco fácil de usar que se ejecuta tanto en CPU como en GPU.
Gran escalabilidad de la computación.
Beneficios
Keras es un marco muy potente y dinámico y ofrece las siguientes ventajas:
Mayor apoyo de la comunidad.
Fácil de probar.
Las redes neuronales de Keras están escritas en Python, lo que simplifica las cosas.
Keras admite redes convolucionales y recurrentes.
Los modelos de aprendizaje profundo son componentes discretos, por lo que puede combinarlos de muchas formas.
Keras - Instalación
Este capítulo explica cómo instalar Keras en su máquina. Antes de pasar a la instalación, repasemos los requisitos básicos de Keras.
Prerrequisitos
Debe cumplir con los siguientes requisitos:
- Cualquier tipo de sistema operativo (Windows, Linux o Mac)
- Python versión 3.5 o superior.
Pitón
Keras es una biblioteca de redes neuronales basada en Python, por lo que Python debe estar instalado en su máquina. Si python está instalado correctamente en su máquina, abra su terminal y escriba python, podría ver la respuesta similar a la que se especifica a continuación,
Python 3.6.5 (v3.6.5:f59c0932b4, Mar 28 2018, 17:00:18)
[MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>>A partir de ahora, la última versión es '3.7.2'. Si Python no está instalado, visite el enlace oficial de Python - www.python.org y descargue la última versión basada en su sistema operativo e instálela inmediatamente en su sistema.
Pasos de instalación de Keras
La instalación de Keras es bastante sencilla. Siga los pasos a continuación para instalar correctamente Keras en su sistema.
Paso 1: crear un entorno virtual
Virtualenvse utiliza para administrar paquetes de Python para diferentes proyectos. Esto será útil para evitar romper los paquetes instalados en los otros entornos. Por lo tanto, siempre se recomienda utilizar un entorno virtual al desarrollar aplicaciones Python.
Linux/Mac OS
Usuarios de Linux o Mac OS, vaya al directorio raíz de su proyecto y escriba el siguiente comando para crear un entorno virtual,
python3 -m venv kerasenvDespués de ejecutar el comando anterior, se crea el directorio "kerasenv" con bin,lib and include folders en su ubicación de instalación.
Windows
El usuario de Windows puede usar el siguiente comando,
py -m venv kerasPaso 2: activa el medio ambiente
Este paso configurará los ejecutables de python y pip en su ruta de shell.
Linux/Mac OS
Ahora hemos creado un entorno virtual llamado "kerasvenv". Vaya a la carpeta y escriba el siguiente comando,
$ cd kerasvenv kerasvenv $ source bin/activateWindows
Los usuarios de Windows se mueven dentro de la carpeta "kerasenv" y escriben el siguiente comando,
.\env\Scripts\activatePaso 3: bibliotecas de Python
Keras depende de las siguientes bibliotecas de Python.
- Numpy
- Pandas
- Scikit-learn
- Matplotlib
- Scipy
- Seaborn
Con suerte, ha instalado todas las bibliotecas anteriores en su sistema. Si estas bibliotecas no están instaladas, utilice el siguiente comando para instalar una por una.
numpy
pip install numpypodría ver la siguiente respuesta,
Collecting numpy
Downloading
https://files.pythonhosted.org/packages/cf/a4/d5387a74204542a60ad1baa84cd2d3353c330e59be8cf2d47c0b11d3cde8/
numpy-3.1.1-cp36-cp36m-macosx_10_6_intel.
macosx_10_9_intel.macosx_10_9_x86_64.
macosx_10_10_intel.macosx_10_10_x86_64.whl (14.4MB)
|████████████████████████████████| 14.4MB 2.8MB/spandas
pip install pandasPudimos ver la siguiente respuesta,
Collecting pandas
Downloading
https://files.pythonhosted.org/packages/cf/a4/d5387a74204542a60ad1baa84cd2d3353c330e59be8cf2d47c0b11d3cde8/
pandas-3.1.1-cp36-cp36m-macosx_10_6_intel.
macosx_10_9_intel.macosx_10_9_x86_64.
macosx_10_10_intel.macosx_10_10_x86_64.whl (14.4MB)
|████████████████████████████████| 14.4MB 2.8MB/smatplotlib
pip install matplotlibPudimos ver la siguiente respuesta,
Collecting matplotlib
Downloading
https://files.pythonhosted.org/packages/cf/a4/d5387a74204542a60ad1baa84cd2d3353c330e59be8cf2d47c0b11d3cde8/
matplotlib-3.1.1-cp36-cp36m-macosx_10_6_intel.
macosx_10_9_intel.macosx_10_9_x86_64.
macosx_10_10_intel.macosx_10_10_x86_64.whl (14.4MB)
|████████████████████████████████| 14.4MB 2.8MB/sscipy
pip install scipyPudimos ver la siguiente respuesta,
Collecting scipy
Downloading
https://files.pythonhosted.org/packages/cf/a4/d5387a74204542a60ad1baa84cd2d3353c330e59be8cf2d47c0b11d3cde8
/scipy-3.1.1-cp36-cp36m-macosx_10_6_intel.
macosx_10_9_intel.macosx_10_9_x86_64.
macosx_10_10_intel.macosx_10_10_x86_64.whl (14.4MB)
|████████████████████████████████| 14.4MB 2.8MB/sscikit-learn
Es una biblioteca de aprendizaje automático de código abierto. Se utiliza para algoritmos de clasificación, regresión y agrupación. Antes de pasar a la instalación, se requiere lo siguiente:
- Python versión 3.5 o superior
- NumPy versión 1.11.0 o superior
- SciPy versión 0.17.0 o superior
- joblib 0.11 o superior.
Ahora, instalamos scikit-learn usando el siguiente comando:
pip install -U scikit-learnSeaborn
Seaborn es una biblioteca increíble que le permite visualizar fácilmente sus datos. Utilice el siguiente comando para instalar:
pip pip install seaborninstall -U scikit-learnPuede ver un mensaje similar al que se especifica a continuación:
Collecting seaborn
Downloading
https://files.pythonhosted.org/packages/a8/76/220ba4420459d9c4c9c9587c6ce607bf56c25b3d3d2de62056efe482dadc
/seaborn-0.9.0-py3-none-any.whl (208kB) 100%
|████████████████████████████████| 215kB 4.0MB/s
Requirement already satisfied: numpy> = 1.9.3 in
./lib/python3.7/site-packages (from seaborn) (1.17.0)
Collecting pandas> = 0.15.2 (from seaborn)
Downloading
https://files.pythonhosted.org/packages/39/b7/441375a152f3f9929ff8bc2915218ff1a063a59d7137ae0546db616749f9/
pandas-0.25.0-cp37-cp37m-macosx_10_9_x86_64.
macosx_10_10_x86_64.whl (10.1MB) 100%
|████████████████████████████████| 10.1MB 1.8MB/s
Requirement already satisfied: scipy>=0.14.0 in
./lib/python3.7/site-packages (from seaborn) (1.3.0)
Collecting matplotlib> = 1.4.3 (from seaborn)
Downloading
https://files.pythonhosted.org/packages/c3/8b/af9e0984f
5c0df06d3fab0bf396eb09cbf05f8452de4e9502b182f59c33b/
matplotlib-3.1.1-cp37-cp37m-macosx_10_6_intel.
macosx_10_9_intel.macosx_10_9_x86_64
.macosx_10_10_intel.macosx_10_10_x86_64.whl (14.4MB) 100%
|████████████████████████████████| 14.4MB 1.4MB/s
......................................
......................................
Successfully installed cycler-0.10.0 kiwisolver-1.1.0
matplotlib-3.1.1 pandas-0.25.0 pyparsing-2.4.2
python-dateutil-2.8.0 pytz-2019.2 seaborn-0.9.0Instalación de Keras usando Python
A partir de ahora, hemos completado los requisitos básicos para la instalación de Kera. Ahora, instale Keras usando el mismo procedimiento que se especifica a continuación:
pip install kerasSalir del entorno virtual
Después de finalizar todos los cambios en su proyecto, simplemente ejecute el siguiente comando para salir del entorno:
deactivateNube Anaconda
Creemos que ha instalado anaconda cloud en su máquina. Si anaconda no está instalado, visite el enlace oficial, www.anaconda.com/distribution y elija descargar según su sistema operativo.
Crea un nuevo entorno de conda
Inicie el indicador de anaconda, esto abrirá el entorno base de Anaconda. Creemos un nuevo entorno conda. Este proceso es similar al virtualenv. Escriba el siguiente comando en su terminal conda:
conda create --name PythonCPUSi lo desea, también puede crear e instalar módulos usando GPU. En este tutorial, seguimos las instrucciones de la CPU.
Activar entorno conda
Para activar el entorno, use el siguiente comando:
activate PythonCPUInstalar spyder
Spyder es un IDE para ejecutar aplicaciones de Python. Instalemos este IDE en nuestro entorno conda usando el siguiente comando:
conda install spyderInstalar bibliotecas de Python
Ya conocemos las bibliotecas de Python numpy, pandas, etc., necesarias para keras. Puede instalar todos los módulos utilizando la siguiente sintaxis:
Syntax
conda install -c anaconda <module-name>Por ejemplo, desea instalar pandas:
conda install -c anaconda pandasComo el mismo método, inténtelo usted mismo para instalar los módulos restantes.
Instalar Keras
Ahora, todo se ve bien, por lo que puede iniciar la instalación de keras usando el siguiente comando:
conda install -c anaconda kerasLanzar spyder
Finalmente, inicie spyder en su terminal conda usando el siguiente comando:
spyderPara asegurarse de que todo se instaló correctamente, importe todos los módulos, agregará todo y si algo salió mal, obtendrá module not found mensaje de error.
Keras - Configuración de backend
Este capítulo explica en detalle las implementaciones de backend de Keras, TensorFlow y Theano. Repasemos cada implementación una por una.
TensorFlow
TensorFlow es una biblioteca de aprendizaje automático de código abierto que se utiliza para tareas computacionales numéricas desarrolladas por Google. Keras es una API de alto nivel construida sobre TensorFlow o Theano. Ya sabemos cómo instalar TensorFlow usando pip.
Si no está instalado, puede instalar usando el siguiente comando:
pip install TensorFlowUna vez que ejecutamos keras, podríamos ver que el archivo de configuración está ubicado en su directorio de inicio dentro y vamos a .keras / keras.json.
keras.json
{
"image_data_format": "channels_last",
"epsilon": 1e-07, "floatx": "float32", "backend": "tensorflow"
}Aquí,
image_data_format representan el formato de datos.
epsilonrepresenta una constante numérica. Se usa para evitarDivideByZero error.
floatx representa el tipo de datos predeterminado float32. También puede cambiarlo afloat16 o float64 utilizando set_floatx() método.
image_data_format representan el formato de datos.
Supongamos que, si el archivo no se crea, muévase a la ubicación y cree siguiendo los pasos a continuación:
> cd home
> mkdir .keras
> vi keras.jsonRecuerde, debe especificar .keras como su nombre de carpeta y agregar la configuración anterior dentro del archivo keras.json. Podemos realizar algunas operaciones predefinidas para conocer las funciones de backend.
Theano
Theano es una biblioteca de aprendizaje profundo de código abierto que le permite evaluar matrices multidimensionales de manera efectiva. Podemos instalar fácilmente usando el siguiente comando:
pip install theanoDe forma predeterminada, keras usa el backend de TensorFlow. Si desea cambiar la configuración de backend de TensorFlow a Theano, simplemente cambie backend = theano en el archivo keras.json. Se describe a continuación:
keras.json
{
"image_data_format": "channels_last",
"epsilon": 1e-07,
"floatx": "float32",
"backend": "theano"
}Ahora guarda tu archivo, reinicia tu terminal e inicia keras, tu backend será cambiado.
>>> import keras as k
using theano backend.Keras: descripción general del aprendizaje profundo
El aprendizaje profundo es un subcampo en evolución del aprendizaje automático. El aprendizaje profundo implica analizar la entrada capa por capa, donde cada capa extrae progresivamente información de nivel superior sobre la entrada.
Tomemos un escenario simple de analizar una imagen. Supongamos que su imagen de entrada está dividida en una cuadrícula rectangular de píxeles. Ahora, la primera capa abstrae los píxeles. La segunda capa comprende los bordes de la imagen. La siguiente capa construye nodos a partir de los bordes. Luego, el siguiente encontraría ramas de los nodos. Finalmente, la capa de salida detectará el objeto completo. Aquí, el proceso de extracción de características va desde la salida de una capa hasta la entrada de la siguiente capa posterior.
Al utilizar este enfoque, podemos procesar una gran cantidad de funciones, lo que hace que el aprendizaje profundo sea una herramienta muy poderosa. Los algoritmos de aprendizaje profundo también son útiles para el análisis de datos no estructurados. Repasemos los conceptos básicos del aprendizaje profundo en este capítulo.
Redes neuronales artificiales
El enfoque más popular y principal del aprendizaje profundo es el uso de una "red neuronal artificial" (ANN). Están inspirados en el modelo del cerebro humano, que es el órgano más complejo de nuestro cuerpo. El cerebro humano está formado por más de 90 mil millones de células diminutas llamadas "neuronas". Las neuronas están interconectadas a través de fibras nerviosas llamadas "axones" y "dendritas". La función principal del axón es transmitir información de una neurona a otra a la que está conectado.
Del mismo modo, la función principal de las dendritas es recibir la información que transmiten los axones de otra neurona a la que están conectadas. Cada neurona procesa una pequeña información y luego pasa el resultado a otra neurona y este proceso continúa. Este es el método básico utilizado por nuestro cerebro humano para procesar una gran cantidad de información como el habla, visual, etc., y extraer información útil de ella.
Basado en este modelo, el psicólogo inventó la primera Red Neural Artificial (ANN). Frank Rosenblatt, en el año de 1958. Las ANN están formadas por múltiples nodos que es similar a las neuronas. Los nodos están estrechamente interconectados y organizados en diferentes capas ocultas. La capa de entrada recibe los datos de entrada y los datos pasan por una o más capas ocultas secuencialmente y finalmente la capa de salida predice algo útil sobre los datos de entrada. Por ejemplo, la entrada puede ser una imagen y la salida puede ser la cosa identificada en la imagen, digamos un "gato".
Una sola neurona (llamada perceptrón en ANN) se puede representar de la siguiente manera:
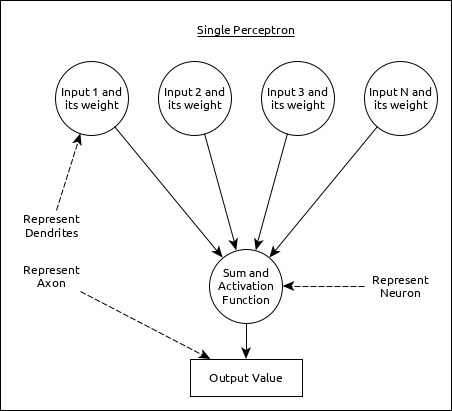
Aquí,
La entrada múltiple junto con el peso representan dendritas.
La suma de la entrada junto con la función de activación representa las neuronas. Sum en realidad significa que el valor calculado de todas las entradas y la función de activación representan una función, que modifica el Sum valor en 0, 1 o 0 a 1.
La salida real representa el axón y la salida será recibida por la neurona en la siguiente capa.
Entendamos los diferentes tipos de redes neuronales artificiales en esta sección.
Perceptrón multicapa
El perceptrón multicapa es la forma más simple de ANN. Consiste en una sola capa de entrada, una o más capas ocultas y finalmente una capa de salida. Una capa consta de una colección de perceptrón. La capa de entrada es básicamente una o más características de los datos de entrada. Cada capa oculta consta de una o más neuronas y procesa cierto aspecto de la característica y envía la información procesada a la siguiente capa oculta. El proceso de la capa de salida recibe los datos de la última capa oculta y finalmente genera el resultado.

Red neuronal convolucional (CNN)
La red neuronal convolucional es una de las ANN más populares. Es ampliamente utilizado en los campos del reconocimiento de imágenes y video. Se basa en el concepto de convolución, un concepto matemático. Es casi similar al perceptrón multicapa, excepto que contiene una serie de capas de convolución y una capa de agrupación antes de la capa de neuronas ocultas completamente conectadas. Tiene tres capas importantes:
Convolution layer - Es el bloque de construcción principal y realiza tareas computacionales basadas en la función de convolución.
Pooling layer - Se organiza junto a la capa de convolución y se utiliza para reducir el tamaño de las entradas eliminando información innecesaria para que el cálculo se pueda realizar más rápido.
Fully connected layer - Está organizado junto a una serie de convolución y capa de agrupación y clasifica la entrada en varias categorías.
Una CNN simple se puede representar de la siguiente manera:

Aquí,
Se utilizan 2 series de capas de convolución y agrupación, que reciben y procesan la entrada (por ejemplo, imagen).
Se utiliza una única capa completamente conectada y se utiliza para generar los datos (por ejemplo, clasificación de la imagen)
Red neuronal recurrente (RNN)
Las redes neuronales recurrentes (RNN) son útiles para abordar la falla en otros modelos de ANN. Bueno, la mayoría de la ANN no recuerda los pasos de situaciones anteriores y aprendió a tomar decisiones basadas en el contexto en el entrenamiento. Mientras tanto, RNN almacena la información pasada y todas sus decisiones se toman de lo que ha aprendido del pasado.
Este enfoque es principalmente útil en la clasificación de imágenes. A veces, es posible que debamos mirar hacia el futuro para arreglar el pasado. En este caso, la RNN bidireccional es útil para aprender del pasado y predecir el futuro. Por ejemplo, tenemos muestras escritas a mano en múltiples entradas. Supongamos que tenemos confusión en una entrada y luego necesitamos volver a comprobar otras entradas para reconocer el contexto correcto que toma la decisión del pasado.
Flujo de trabajo de ANN
Primero entendamos las diferentes fases del aprendizaje profundo y luego, aprendamos cómo Keras ayuda en el proceso de aprendizaje profundo.
Recopile los datos requeridos
El aprendizaje profundo requiere muchos datos de entrada para aprender y predecir con éxito el resultado. Entonces, primero recopile la mayor cantidad de datos posible.
Analizar datos
Analice los datos y adquiera una buena comprensión de los datos. Se requiere una mejor comprensión de los datos para seleccionar el algoritmo ANN correcto.
Elija un algoritmo (modelo)
Elija un algoritmo que se adapte mejor al tipo de proceso de aprendizaje (por ejemplo, clasificación de imágenes, procesamiento de texto, etc.) y los datos de entrada disponibles. El algoritmo está representado porModelen Keras. El algoritmo incluye una o más capas. Cada capa en ANN se puede representar porKeras Layer en Keras.
Prepare data - Procesar, filtrar y seleccionar solo la información requerida de los datos.
Split data- Divida los datos en conjuntos de datos de prueba y entrenamiento. Los datos de prueba se utilizarán para evaluar la predicción del algoritmo / modelo (una vez que la máquina aprenda) y para verificar la eficiencia del proceso de aprendizaje.
Compile the model- Compilar el algoritmo / modelo, de modo que se pueda utilizar más para aprender mediante el entrenamiento y finalmente hacer la predicción. Este paso nos obliga a elegir la función de pérdida y el Optimizador. La función de pérdida y el Optimizador se utilizan en la fase de aprendizaje para encontrar el error (desviación de la salida real) y realizar la optimización para que el error se minimice.
Fit the model - El proceso de aprendizaje real se realizará en esta fase utilizando el conjunto de datos de entrenamiento.
Predict result for unknown value - Predecir la salida de los datos de entrada desconocidos (distintos de los datos de prueba y entrenamiento existentes)
Evaluate model - Evalúe el modelo prediciendo la salida de los datos de prueba y comparando la predicción con el resultado real de los datos de prueba.
Freeze, Modify or choose new algorithm- Verificar si la evaluación del modelo es exitosa. Si es así, guarde el algoritmo para fines de predicción futura. Si no es así, modifique o elija un nuevo algoritmo / modelo y, finalmente, entrene, prediga y evalúe el modelo nuevamente. Repita el proceso hasta encontrar el mejor algoritmo (modelo).
Los pasos anteriores se pueden representar utilizando el siguiente diagrama de flujo:

Keras - Aprendizaje profundo
Keras proporciona un marco completo para crear cualquier tipo de redes neuronales. Keras es innovador y muy fácil de aprender. Admite una red neuronal simple a un modelo de red neuronal muy grande y complejo. Entendamos la arquitectura del marco de Keras y cómo Keras ayuda en el aprendizaje profundo en este capítulo.
Arquitectura de Keras
La API de Keras se puede dividir en tres categorías principales:
- Model
- Layer
- Módulos centrales
En Keras, cada RNA está representada por Keras Models. A su vez, cada modelo de Keras es una composición deKeras Layers y representa capas ANN como entrada, capa oculta, capas de salida, capa de convolución, capa de agrupación, etc., modelo de Keras y acceso a la capa Keras modules para la función de activación, función de pérdida, función de regularización, etc. Utilizando el modelo Keras, Keras Layer y los módulos Keras, cualquier algoritmo ANN (CNN, RNN, etc.,) se puede representar de manera simple y eficiente.
El siguiente diagrama muestra la relación entre el modelo, la capa y los módulos centrales:

Veamos la descripción general de los modelos Keras, capas Keras y módulos Keras.
Modelo
Los modelos Keras son de dos tipos, como se menciona a continuación:
Sequential Model- El modelo secuencial es básicamente una composición lineal de capas de Keras. El modelo secuencial es sencillo, mínimo y tiene la capacidad de representar casi todas las redes neuronales disponibles.
Un modelo secuencial simple es el siguiente:
from keras.models import Sequential
from keras.layers import Dense, Activation
model = Sequential()
model.add(Dense(512, activation = 'relu', input_shape = (784,)))Dónde,
Line 1 importaciones Sequential modelo de los modelos Keras
Line 2 importaciones Dense capa y Activation módulo
Line 4 crear un nuevo modelo secuencial usando Sequential API
Line 5 agrega una capa densa (API densa) con relu función de activación (usando el módulo de activación).
Sequential modelo expone Modelclass para crear modelos personalizados también. Podemos utilizar el concepto de subclasificación para crear nuestro propio modelo complejo.
Functional API - La API funcional se utiliza básicamente para crear modelos complejos.
Capa
Cada capa de Keras en el modelo de Keras representa la capa correspondiente (capa de entrada, capa oculta y capa de salida) en el modelo de red neuronal propuesto. Keras proporciona muchas capas preconstruidas para que cualquier red neuronal compleja se pueda crear fácilmente. Algunas de las capas importantes de Keras se especifican a continuación,
- Capas centrales
- Capas de convolución
- Capas de agrupación
- Capas recurrentes
Un código Python simple para representar un modelo de red neuronal usando sequential El modelo es el siguiente:
from keras.models import Sequential
from keras.layers import Dense, Activation, Dropout model = Sequential()
model.add(Dense(512, activation = 'relu', input_shape = (784,)))
model.add(Dropout(0.2))
model.add(Dense(512, activation = 'relu')) model.add(Dropout(0.2))
model.add(Dense(num_classes, activation = 'softmax'))Dónde,
Line 1 importaciones Sequential modelo de los modelos Keras
Line 2 importaciones Dense capa y Activation módulo
Line 4 crear un nuevo modelo secuencial usando Sequential API
Line 5 agrega una capa densa (API densa) con relu función de activación (usando el módulo de activación).
Line 6 agrega una capa de abandono (API de abandono) para manejar el ajuste excesivo.
Line 7 agrega otra capa densa (API densa) con relu función de activación (usando el módulo de activación).
Line 8 agrega otra capa de abandono (API de abandono) para manejar el ajuste excesivo.
Line 9 agrega una capa densa final (API densa) con softmax función de activación (usando el módulo de activación).
Keras también ofrece opciones para crear nuestras propias capas personalizadas. La capa personalizada se puede crear subclasificando elKeras.Layer class y es similar a la subclasificación de modelos de Keras.
Módulos centrales
Keras también proporciona muchas funciones integradas relacionadas con la red neuronal para crear correctamente el modelo de Keras y las capas de Keras. Algunas de las funciones son las siguientes:
Activations module - La función de activación es un concepto importante en ANN y los módulos de activación proporcionan muchas funciones de activación como softmax, relu, etc.,
Loss module - El módulo de pérdida proporciona funciones de pérdida como mean_squared_error, mean_absolute_error, poisson, etc.
Optimizer module - El módulo optimizador proporciona una función optimizadora como adam, sgd, etc.,
Regularizers - El módulo regularizador proporciona funciones como regularizador L1, regularizador L2, etc.
Aprendamos los módulos de Keras en detalle en el próximo capítulo.
Keras - Módulos
Como aprendimos anteriormente, los módulos de Keras contienen clases, funciones y variables predefinidas que son útiles para el algoritmo de aprendizaje profundo. Aprendamos los módulos proporcionados por Keras en este capítulo.
Módulos disponibles
Veamos primero la lista de módulos disponibles en Keras.
Initializers- Proporciona una lista de funciones de inicializadores. Podemos aprenderlo en detalle en el capítulo de capas de Keras . durante la fase de creación de modelos de aprendizaje automático.
Regularizers- Proporciona una lista de funciones de regularizadores. Podemos aprenderlo en detalle en el capítulo Capas de Keras .
Constraints- Proporciona una función de lista de restricciones. Podemos aprenderlo en detalle en el capítulo Capas de Keras .
Activations- Proporciona una lista de funciones de activador. Podemos aprenderlo en detalle en el capítulo Capas de Keras .
Losses- Proporciona una lista de funciones de pérdida. Podemos aprenderlo en detalle en el capítulo Entrenamiento de modelos .
Metrics- Proporciona una lista de funciones de métricas. Podemos aprenderlo en detalle en el capítulo Entrenamiento de modelos .
Optimizers- Proporciona una lista de funciones optimizadoras. Podemos aprenderlo en detalle en el capítulo Entrenamiento de modelos .
Callback- Proporciona una lista de funciones de devolución de llamada. Podemos usarlo durante el proceso de entrenamiento para imprimir los datos intermedios, así como para detener el entrenamiento en sí (EarlyStopping método) basado en alguna condición.
Text processing- Proporciona funciones para convertir texto en una matriz NumPy adecuada para el aprendizaje automático. Podemos usarlo en la fase de preparación de datos del aprendizaje automático.
Image processing- Proporciona funciones para convertir imágenes en una matriz NumPy adecuada para el aprendizaje automático. Podemos usarlo en la fase de preparación de datos del aprendizaje automático.
Sequence processing- Proporciona funciones para generar datos basados en el tiempo a partir de los datos de entrada dados. Podemos usarlo en la fase de preparación de datos del aprendizaje automático.
Backend- Proporciona la función de la biblioteca de backend como TensorFlow y Theano .
Utilities - Proporciona muchas funciones útiles en el aprendizaje profundo.
Dejanos ver backend módulo y utils modelo en este capítulo.
módulo de backend
backend modulese utiliza para las operaciones de backend de keras. De forma predeterminada, keras se ejecuta sobre el backend de TensorFlow. Si lo desea, puede cambiar a otros backends como Theano o CNTK. La configuración de backend defualt se define dentro de su directorio raíz en el archivo .keras / keras.json.
El módulo backend de Keras se puede importar usando el siguiente código
>>> from keras import backend as kSi usamos TensorFlow backend predeterminado , la siguiente función devuelve información basada en TensorFlow como se especifica a continuación:
>>> k.backend()
'tensorflow'
>>> k.epsilon()
1e-07
>>> k.image_data_format()
'channels_last'
>>> k.floatx()
'float32'Entendamos brevemente algunas de las funciones de backend importantes utilizadas para el análisis de datos:
get_uid ()
Es el identificador del gráfico predeterminado. Se define a continuación:
>>> k.get_uid(prefix='')
1
>>> k.get_uid(prefix='') 2reset_uids
Se utiliza restablece el valor de uid.
>>> k.reset_uids()Ahora, vuelva a ejecutar get_uid () . Esto se restablecerá y volverá a cambiar a 1.
>>> k.get_uid(prefix='')
1marcador de posición
Se utiliza instancia un tensor de marcador de posición. A continuación se muestra un marcador de posición simple para mantener la forma 3D:
>>> data = k.placeholder(shape = (1,3,3))
>>> data
<tf.Tensor 'Placeholder_9:0' shape = (1, 3, 3) dtype = float32>
If you use int_shape(), it will show the shape.
>>> k.int_shape(data) (1, 3, 3)punto
Se utiliza para multiplicar dos tensores. Considere que ayb son dos tensores yc será el resultado de multiplicar ab. Suponga que una forma es (4,2) y la forma b es (2,3). Se define a continuación,
>>> a = k.placeholder(shape = (4,2))
>>> b = k.placeholder(shape = (2,3))
>>> c = k.dot(a,b)
>>> c
<tf.Tensor 'MatMul_3:0' shape = (4, 3) dtype = float32>
>>>unos
Se usa para inicializar todo como one valor.
>>> res = k.ones(shape = (2,2))
#print the value
>>> k.eval(res)
array([[1., 1.], [1., 1.]], dtype = float32)batch_dot
Se utiliza para realizar el producto de dos datos en lotes. La dimensión de entrada debe ser 2 o superior. Se muestra a continuación:
>>> a_batch = k.ones(shape = (2,3))
>>> b_batch = k.ones(shape = (3,2))
>>> c_batch = k.batch_dot(a_batch,b_batch)
>>> c_batch
<tf.Tensor 'ExpandDims:0' shape = (2, 1) dtype = float32>variable
Se utiliza para inicializar una variable. Realicemos una operación de transposición simple en esta variable.
>>> data = k.variable([[10,20,30,40],[50,60,70,80]])
#variable initialized here
>>> result = k.transpose(data)
>>> print(result)
Tensor("transpose_6:0", shape = (4, 2), dtype = float32)
>>> print(k.eval(result))
[[10. 50.]
[20. 60.]
[30. 70.]
[40. 80.]]Si desea acceder desde numpy -
>>> data = np.array([[10,20,30,40],[50,60,70,80]])
>>> print(np.transpose(data))
[[10 50]
[20 60]
[30 70]
[40 80]]
>>> res = k.variable(value = data)
>>> print(res)
<tf.Variable 'Variable_7:0' shape = (2, 4) dtype = float32_ref>is_sparse (tensor)
Se utiliza para comprobar si el tensor es escaso o no.
>>> a = k.placeholder((2, 2), sparse=True)
>>> print(a) SparseTensor(indices =
Tensor("Placeholder_8:0",
shape = (?, 2), dtype = int64),
values = Tensor("Placeholder_7:0", shape = (?,),
dtype = float32), dense_shape = Tensor("Const:0", shape = (2,), dtype = int64))
>>> print(k.is_sparse(a)) Trueto_dense ()
Se utiliza para convertir escaso en denso.
>>> b = k.to_dense(a)
>>> print(b) Tensor("SparseToDense:0", shape = (2, 2), dtype = float32)
>>> print(k.is_sparse(b)) Falsevariable_uniforme_aleatoria
Se usa para inicializar usando uniform distribution concepto.
k.random_uniform_variable(shape, mean, scale)Aquí,
shape - denota las filas y columnas en formato de tuplas.
mean - media de distribución uniforme.
scale - desviación estándar de distribución uniforme.
Echemos un vistazo al uso de ejemplo a continuación:
>>> a = k.random_uniform_variable(shape = (2, 3), low=0, high = 1)
>>> b = k. random_uniform_variable(shape = (3,2), low = 0, high = 1)
>>> c = k.dot(a, b)
>>> k.int_shape(c)
(2, 2)módulo utils
utilsproporciona una función de utilidades útiles para el aprendizaje profundo. Algunos de los métodos proporcionados porutils módulo es el siguiente:
HDF5Matrix
Se utiliza para representar los datos de entrada en formato HDF5.
from keras.utils import HDF5Matrix data = HDF5Matrix('data.hdf5', 'data')to_categorical
Se utiliza para convertir el vector de clase en una matriz de clase binaria.
>>> from keras.utils import to_categorical
>>> labels = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> to_categorical(labels)
array([[1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 1., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 1., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 1., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 1., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 1., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 1., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 1., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.]], dtype = float32)
>>> from keras.utils import normalize
>>> normalize([1, 2, 3, 4, 5])
array([[0.13483997, 0.26967994, 0.40451992, 0.53935989, 0.67419986]])print_summary
Se utiliza para imprimir el resumen del modelo.
from keras.utils import print_summary print_summary(model)plot_model
Se utiliza para crear la representación del modelo en formato de puntos y guardarla en un archivo.
from keras.utils import plot_model
plot_model(model,to_file = 'image.png')Esta plot_model generará una imagen para comprender el desempeño del modelo.
Keras - Capas
Como se aprendió anteriormente, las capas de Keras son el componente principal de los modelos de Keras. Cada capa recibe información de entrada, realiza algunos cálculos y finalmente genera la información transformada. La salida de una capa fluirá a la siguiente capa como entrada. Aprendamos todos los detalles sobre las capas en este capítulo.
Introducción
Una capa de Keras requiere shape of the input (input_shape) comprender la estructura de los datos de entrada, initializerpara establecer el peso de cada entrada y finalmente los activadores para transformar la salida para que no sea lineal. En el medio, las restricciones restringen y especifican el rango en el que el peso de los datos de entrada que se generarán y el regularizador tratará de optimizar la capa (y el modelo) aplicando dinámicamente las penalizaciones en los pesos durante el proceso de optimización.
Para resumir, la capa de Keras requiere detalles mínimos por debajo para crear una capa completa.
- Forma de los datos de entrada
- Número de neuronas / unidades en la capa
- Initializers
- Regularizers
- Constraints
- Activations
Entendamos el concepto básico en el próximo capítulo. Antes de comprender el concepto básico, creemos una capa de Keras simple utilizando la API de modelo secuencial para tener una idea de cómo funcionan el modelo y la capa de Keras.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
from keras import regularizers
from keras import constraints
model = Sequential()
model.add(Dense(32, input_shape=(16,), kernel_initializer = 'he_uniform',
kernel_regularizer = None, kernel_constraint = 'MaxNorm', activation = 'relu'))
model.add(Dense(16, activation = 'relu'))
model.add(Dense(8))dónde,
Line 1-5 importa los módulos necesarios.
Line 7 crea un nuevo modelo usando API secuencial.
Line 9 crea un nuevo Dense capa y agréguela al modelo. Densees una capa de nivel de entrada proporcionada por Keras, que acepta el número de neuronas o unidades (32) como parámetro requerido. Si la capa es la primera capa, entonces debemos proporcionarInput Shape, (16,)también. De lo contrario, la salida de la capa anterior se utilizará como entrada de la siguiente capa. Todos los demás parámetros son opcionales.
El primer parámetro representa el número de unidades (neuronas).
input_shape representar la forma de los datos de entrada.
kernel_initializer representan el inicializador que se utilizará. he_uniform la función se establece como valor.
kernel_regularizer representar regularizerpara ser utilizado. Ninguno se establece como valor.
kernel_constraint representan la restricción que se utilizará. MaxNorm la función se establece como valor.
activationrepresentan la activación que se utilizará. La función relu se establece como valor.
Line 10 crea segundo Dense capa con 16 unidades y conjunto relu como función de activación.
Line 11 crea una capa densa final con 8 unidades.
Concepto básico de capas
Entendamos el concepto básico de capa y cómo Keras apoya cada concepto.
Forma de entrada
En el aprendizaje automático, todo tipo de datos de entrada como texto, imágenes o videos se convertirán primero en una matriz de números y luego se incorporarán al algoritmo. Los números de entrada pueden ser una matriz unidimensional, una matriz bidimensional (matriz) o una matriz multidimensional. Podemos especificar la información dimensional usandoshape, una tupla de números enteros. Por ejemplo,(4,2) representar una matriz con cuatro filas y dos columnas.
>>> import numpy as np
>>> shape = (4, 2)
>>> input = np.zeros(shape)
>>> print(input)
[
[0. 0.]
[0. 0.]
[0. 0.]
[0. 0.]
]
>>>Similar, (3,4,2) matriz tridimensional que tiene tres colecciones de matriz de 4x2 (dos filas y cuatro columnas).
>>> import numpy as np
>>> shape = (3, 4, 2)
>>> input = np.zeros(shape)
>>> print(input)
[
[[0. 0.] [0. 0.] [0. 0.] [0. 0.]]
[[0. 0.] [0. 0.] [0. 0.] [0. 0.]]
[[0. 0.] [0. 0.] [0. 0.] [0. 0.]]
]
>>>Para crear la primera capa del modelo (o capa de entrada del modelo), se debe especificar la forma de los datos de entrada.
Inicializadores
En Machine Learning, se asignará peso a todos los datos de entrada. InitializersEl módulo proporciona diferentes funciones para establecer estos pesos iniciales. Algunos de losKeras Initializer función son las siguientes:
Ceros
Genera 0 para todos los datos de entrada.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.Zeros()
model = Sequential()
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_initializer = my_init))Dónde, kernel_initializer representan el inicializador del kernel del modelo.
Unos
Genera 1 para todos los datos de entrada.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.Ones()
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_initializer = my_init))Constante
Genera un valor constante (digamos, 5) especificado por el usuario para todos los datos de entrada.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.Constant(value = 0) model.add(
Dense(512, activation = 'relu', input_shape = (784,), kernel_initializer = my_init)
)dónde, value representar el valor constante
AleatorioNormal
Genera valor utilizando la distribución normal de datos de entrada.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.RandomNormal(mean=0.0,
stddev = 0.05, seed = None)
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_initializer = my_init))dónde,
mean representar la media de los valores aleatorios para generar
stddev representar la desviación estándar de los valores aleatorios para generar
seed representar los valores para generar un número aleatorio
AleatorioUniforme
Genera valor mediante la distribución uniforme de los datos de entrada.
from keras import initializers
my_init = initializers.RandomUniform(minval = -0.05, maxval = 0.05, seed = None)
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_initializer = my_init))dónde,
minval representar el límite inferior de los valores aleatorios para generar
maxval representar el límite superior de los valores aleatorios para generar
TruncatedNormal
Genera valor utilizando una distribución normal truncada de datos de entrada.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.TruncatedNormal(mean = 0.0, stddev = 0.05, seed = None
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_initializer = my_init))VarianceScaling
Genera un valor basado en la forma de entrada y la forma de salida de la capa junto con la escala especificada.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.VarianceScaling(
scale = 1.0, mode = 'fan_in', distribution = 'normal', seed = None)
model.add(Dense(512, activation = 'relu', input_shape = (784,),
skernel_initializer = my_init))dónde,
scale representar el factor de escala
mode representar a cualquiera de fan_in, fan_out y fan_avg valores
distribution representar cualquiera de normal o uniform
VarianceScaling
Encuentra el stddev valor para la distribución normal usando la fórmula siguiente y luego encuentre los pesos usando la distribución normal,
stddev = sqrt(scale / n)dónde n representar,
número de unidades de entrada para mode = fan_in
número de unidades de salida para mode = fan_out
número medio de unidades de entrada y salida para mode = fan_avg
De manera similar, encuentra el límite para la distribución uniforme usando la siguiente fórmula y luego encuentra los pesos usando la distribución uniforme,
limit = sqrt(3 * scale / n)lecun_normal
Genera valor usando la distribución normal de lecun de datos de entrada.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.RandomUniform(minval = -0.05, maxval = 0.05, seed = None)
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_initializer = my_init))Encuentra el stddev usando la fórmula siguiente y luego aplique la distribución normal
stddev = sqrt(1 / fan_in)dónde, fan_in representan el número de unidades de entrada.
lecun_uniform
Genera valor mediante la distribución uniforme de lecun de los datos de entrada.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.lecun_uniform(seed = None)
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_initializer = my_init))Encuentra el limit usando la fórmula siguiente y luego aplique una distribución uniforme
limit = sqrt(3 / fan_in)dónde,
fan_in representa el número de unidades de entrada
fan_out representa el número de unidades de salida
glorot_normal
Genera valor utilizando la distribución normal de glorot de datos de entrada.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.glorot_normal(seed=None) model.add(
Dense(512, activation = 'relu', input_shape = (784,), kernel_initializer = my_init)
)Encuentra el stddev usando la fórmula siguiente y luego aplique la distribución normal
stddev = sqrt(2 / (fan_in + fan_out))dónde,
fan_in representa el número de unidades de entrada
fan_out representa el número de unidades de salida
glorot_uniform
Genera valor mediante la distribución uniforme Glorot de los datos de entrada.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.glorot_uniform(seed = None)
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_initializer = my_init))Encuentra el limit usando la fórmula siguiente y luego aplique una distribución uniforme
limit = sqrt(6 / (fan_in + fan_out))dónde,
fan_in representan el número de unidades de entrada.
fan_out representa el número de unidades de salida
él_normal
Genera valor utilizando la distribución normal de datos de entrada.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.RandomUniform(minval = -0.05, maxval = 0.05, seed = None)
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_initializer = my_init))Encuentra el stddev usando la siguiente fórmula y luego aplica la distribución normal.
stddev = sqrt(2 / fan_in)dónde, fan_in representan el número de unidades de entrada.
él_uniforme
Genera valor utilizando la distribución uniforme de los datos de entrada.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.he_normal(seed = None)
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_initializer = my_init))Encuentra el limit usando la fórmula siguiente y luego aplique una distribución uniforme.
limit = sqrt(6 / fan_in)dónde, fan_in representan el número de unidades de entrada.
Ortogonal
Genera una matriz ortogonal aleatoria.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.Orthogonal(gain = 1.0, seed = None)
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_initializer = my_init))dónde, gain representan el factor de multiplicación de la matriz.
Identidad
Genera matriz de identidad.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.Identity(gain = 1.0) model.add(
Dense(512, activation = 'relu', input_shape = (784,), kernel_initializer = my_init)
)Restricciones
En el aprendizaje automático, se establecerá una restricción en el parámetro (peso) durante la fase de optimización. <> El módulo de restricciones proporciona diferentes funciones para establecer la restricción en la capa. Algunas de las funciones de restricción son las siguientes.
NonNeg
Restringe los pesos para que no sean negativos.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import initializers
my_init = initializers.Identity(gain = 1.0) model.add(
Dense(512, activation = 'relu', input_shape = (784,),
kernel_initializer = my_init)
)dónde, kernel_constraint representan la restricción que se utilizará en la capa.
UnitNorm
Restringe los pesos para que sean la norma unitaria.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import constraints
my_constrain = constraints.UnitNorm(axis = 0)
model = Sequential()
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_constraint = my_constrain))MaxNorm
Restringe el peso a la norma menor o igual al valor dado.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import constraints
my_constrain = constraints.MaxNorm(max_value = 2, axis = 0)
model = Sequential()
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_constraint = my_constrain))dónde,
max_value representar el límite superior
El eje representa la dimensión en la que se aplicará la restricción. Por ejemplo, en Shape (2, 3, 4) el eje 0 indica la primera dimensión, 1 indica la segunda dimensión y 2 indica la tercera dimensión
MinMaxNorm
Restringe los pesos para que sean la norma entre los valores mínimos y máximos especificados.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import constraints
my_constrain = constraints.MinMaxNorm(min_value = 0.0, max_value = 1.0, rate = 1.0, axis = 0)
model = Sequential()
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_constraint = my_constrain))dónde, rate representan la tasa a la que se aplica la restricción de peso.
Regularizadores
En el aprendizaje automático, los regularizadores se utilizan en la fase de optimización. Aplica algunas penalizaciones en el parámetro de capa durante la optimización. El módulo de regularización de Keras proporciona las siguientes funciones para establecer penalizaciones en la capa. La regularización se aplica solo por capa.
Regularizador L1
Proporciona regularización basada en L1.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import regularizers
my_regularizer = regularizers.l1(0.)
model = Sequential()
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_regularizer = my_regularizer))dónde, kernel_regularizer representan la tasa a la que se aplica la restricción de peso.
Regularizador L2
Proporciona regularización basada en L2.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import regularizers
my_regularizer = regularizers.l2(0.)
model = Sequential()
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_regularizer = my_regularizer))Regularizador L1 y L2
Proporciona regularización basada en L1 y L2.
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras import regularizers
my_regularizer = regularizers.l2(0.)
model = Sequential()
model.add(Dense(512, activation = 'relu', input_shape = (784,),
kernel_regularizer = my_regularizer))Activaciones
En el aprendizaje automático, la función de activación es una función especial que se utiliza para encontrar si una neurona específica está activada o no. Básicamente, la función de activación realiza una transformación no lineal de los datos de entrada y, por lo tanto, permite que las neuronas aprendan mejor. La salida de una neurona depende de la función de activación.
Como recordará el concepto de percepción única, la salida de un perceptrón (neurona) es simplemente el resultado de la función de activación, que acepta la suma de todas las entradas multiplicadas por su peso correspondiente más el sesgo general, si hay alguno disponible.
result = Activation(SUMOF(input * weight) + bias)Entonces, la función de activación juega un papel importante en el aprendizaje exitoso del modelo. Keras proporciona muchas funciones de activación en el módulo de activaciones. Aprendamos todas las activaciones disponibles en el módulo.
lineal
Aplica la función lineal. No hace nada.
from keras.models import Sequential
from keras.layers import Activation, Dense
model = Sequential()
model.add(Dense(512, activation = 'linear', input_shape = (784,)))Dónde, activationse refiere a la función de activación de la capa. Se puede especificar simplemente por el nombre de la función y la capa utilizará los activadores correspondientes.
elu
Aplica unidad lineal exponencial.
from keras.models import Sequential
from keras.layers import Activation, Dense
model = Sequential()
model.add(Dense(512, activation = 'elu', input_shape = (784,)))selu
Aplica la unidad lineal exponencial escalada.
from keras.models import Sequential
from keras.layers import Activation, Dense
model = Sequential()
model.add(Dense(512, activation = 'selu', input_shape = (784,)))relu
Aplica unidad lineal rectificada.
from keras.models import Sequential
from keras.layers import Activation, Dense
model = Sequential()
model.add(Dense(512, activation = 'relu', input_shape = (784,)))softmax
Aplica la función Softmax.
from keras.models import Sequential
from keras.layers import Activation, Dense
model = Sequential()
model.add(Dense(512, activation = 'softmax', input_shape = (784,)))softplus
Aplica la función Softplus.
from keras.models import Sequential
from keras.layers import Activation, Dense
model = Sequential()
model.add(Dense(512, activation = 'softplus', input_shape = (784,)))softsign
Aplica la función Softsign.
from keras.models import Sequential
from keras.layers import Activation, Dense
model = Sequential()
model.add(Dense(512, activation = 'softsign', input_shape = (784,)))tanh
Aplica la función de tangente hiperbólica.
from keras.models import Sequential
from keras.layers import Activation, Dense
model = Sequential()
model.add(Dense(512, activation = 'tanh', input_shape = (784,)))sigmoideo
Aplica la función sigmoidea.
from keras.models import Sequential
from keras.layers import Activation, Dense
model = Sequential()
model.add(Dense(512, activation = 'sigmoid', input_shape = (784,)))hard_sigmoid
Aplica la función sigmoidea dura.
from keras.models import Sequential
from keras.layers import Activation, Dense
model = Sequential()
model.add(Dense(512, activation = 'hard_sigmoid', input_shape = (784,)))exponencial
Aplica función exponencial.
from keras.models import Sequential
from keras.layers import Activation, Dense
model = Sequential()
model.add(Dense(512, activation = 'exponential', input_shape = (784,)))| No Señor | Capas y descripción |
|---|---|
| 1 | Capa densa Dense layer es la capa regular de la red neuronal profundamente conectada. |
| 2 | Capas de abandono Dropout es uno de los conceptos importantes en el aprendizaje automático. |
| 3 | Aplanar capas Flatten se utiliza para aplanar la entrada. |
| 4 | Cambiar la forma de las capas Reshape se utiliza para cambiar la forma de la entrada. |
| 5 | Permutar capas Permute también se usa para cambiar la forma de la entrada usando patrón. |
| 6 | Repetir Capas vectoriales RepeatVector se utiliza para repetir la entrada para el número establecido, n veces. |
| 7 | Capas Lambda Lambda se utiliza para transformar los datos de entrada mediante una expresión o función. |
| 8 | Capas de convolución Keras contiene muchas capas para crear ANN basado en convolución, popularmente llamado como red neuronal de convolución (CNN) . |
| 9 | Capa de agrupación Se utiliza para realizar operaciones de agrupación máxima en datos temporales. |
| 10 | Capa conectada localmente Las capas conectadas localmente son similares a la capa Conv1D, pero la diferencia es que los pesos de las capas Conv1D se comparten, pero aquí los pesos no se comparten. |
| 11 | Fusionar capa Se utiliza para fusionar una lista de entradas. |
| 12 | Capa de incrustación Realiza operaciones de incrustación en la capa de entrada. |
Keras - Capa personalizada
Keras permite crear nuestra propia capa personalizada. Una vez que se crea una nueva capa, se puede utilizar en cualquier modelo sin ninguna restricción. Aprendamos a crear una nueva capa en este capítulo.
Keras proporciona una base layerclase, capa que se puede subclasificar para crear nuestra propia capa personalizada. Creemos una capa simple que encuentre el peso basado en la distribución normal y luego hagamos el cálculo básico de encontrar la suma del producto de entrada y su peso durante el entrenamiento.
Paso 1: Importa el módulo necesario
Primero, importemos los módulos necesarios:
from keras import backend as K
from keras.layers import LayerAquí,
backend se utiliza para acceder al dot función.
Layer es la clase base y la subclasificaremos para crear nuestra capa
Paso 2: definir una clase de capa
Creemos una nueva clase, MyCustomLayer subclasificando Layer class -
class MyCustomLayer(Layer):
...Paso 3: inicializar la clase de capa
Inicialicemos nuestra nueva clase como se especifica a continuación:
def __init__(self, output_dim, **kwargs):
self.output_dim = output_dim
super(MyCustomLayer, self).__init__(**kwargs)Aquí,
Line 2 establece la dimensión de salida.
Line 3 llama a la base o supercapa init función.
Paso 4: implementar el método de construcción
buildes el método principal y su único propósito es construir la capa correctamente. Puede hacer cualquier cosa relacionada con el funcionamiento interno de la capa. Una vez que se realiza la funcionalidad personalizada, podemos llamar a la clase basebuildfunción. Nuestra costumbrebuild la función es la siguiente:
def build(self, input_shape):
self.kernel = self.add_weight(name = 'kernel',
shape = (input_shape[1], self.output_dim),
initializer = 'normal', trainable = True)
super(MyCustomLayer, self).build(input_shape)Aquí,
Line 1 define el build método con un argumento, input_shape. La forma de los datos de entrada se refiere a input_shape.
Line 2crea el peso correspondiente a la forma de entrada y lo establece en el kernel. Es nuestra funcionalidad personalizada de la capa. Crea el peso usando un inicializador 'normal'.
Line 6 llama a la clase base, build método.
Paso 5: implementar el método de llamada
call El método hace el trabajo exacto de la capa durante el proceso de entrenamiento.
Nuestra costumbre call el método es el siguiente
def call(self, input_data):
return K.dot(input_data, self.kernel)Aquí,
Line 1 define el call método con un argumento, input_data. input_data son los datos de entrada para nuestra capa.
Line 2 devolver el producto escalar de los datos de entrada, input_data y el núcleo de nuestra capa, self.kernel
Paso 6: implementar el método compute_output_shape
def compute_output_shape(self, input_shape): return (input_shape[0], self.output_dim)Aquí,
Line 1 define compute_output_shape método con un argumento input_shape
Line 2 calcula la forma de salida usando la forma de los datos de entrada y la dimensión de salida establecida mientras inicializa la capa.
Implementando el build, call y compute_output_shapecompleta la creación de una capa personalizada. El código final y completo es el siguiente
from keras import backend as K from keras.layers import Layer
class MyCustomLayer(Layer):
def __init__(self, output_dim, **kwargs):
self.output_dim = output_dim
super(MyCustomLayer, self).__init__(**kwargs)
def build(self, input_shape): self.kernel =
self.add_weight(name = 'kernel',
shape = (input_shape[1], self.output_dim),
initializer = 'normal', trainable = True)
super(MyCustomLayer, self).build(input_shape) #
Be sure to call this at the end
def call(self, input_data): return K.dot(input_data, self.kernel)
def compute_output_shape(self, input_shape): return (input_shape[0], self.output_dim)Usando nuestra capa personalizada
Creemos un modelo simple usando nuestra capa personalizada como se especifica a continuación:
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
model.add(MyCustomLayer(32, input_shape = (16,)))
model.add(Dense(8, activation = 'softmax')) model.summary()Aquí,
Nuestra MyCustomLayer se agrega al modelo usando 32 unidades y (16,) como forma de entrada
Al ejecutar la aplicación, se imprimirá el resumen del modelo como se muestra a continuación:
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param
#================================================================
my_custom_layer_1 (MyCustomL (None, 32) 512
_________________________________________________________________
dense_1 (Dense) (None, 8) 264
=================================================================
Total params: 776
Trainable params: 776
Non-trainable params: 0
_________________________________________________________________Keras - Modelos
Como se aprendió anteriormente, el modelo de Keras representa el modelo de red neuronal real. Keras proporciona dos modos para crear el modelo, API secuencial simple y fácil de usar , así como API funcional más flexible y avanzada . Aprendamos ahora a crear modelos usando API secuenciales y funcionales en este capítulo.
Secuencial
La idea central de Sequential APIes simplemente organizar las capas de Keras en un orden secuencial y, por lo tanto, se llama API secuencial . La mayor parte de la ANN también tiene capas en orden secuencial y los datos fluyen de una capa a otra en el orden dado hasta que los datos finalmente llegan a la capa de salida.
Se puede crear un modelo ANN simplemente llamando Sequential() API como se especifica a continuación -
from keras.models import Sequential
model = Sequential()Agregar capas
Para agregar una capa, simplemente cree una capa usando la API de capa de Keras y luego pase la capa a través de la función add () como se especifica a continuación:
from keras.models import Sequential
model = Sequential()
input_layer = Dense(32, input_shape=(8,)) model.add(input_layer)
hidden_layer = Dense(64, activation='relu'); model.add(hidden_layer)
output_layer = Dense(8)
model.add(output_layer)Aquí, hemos creado una capa de entrada, una capa oculta y una capa de salida.
Accede al modelo
Keras proporciona algunos métodos para obtener la información del modelo, como capas, datos de entrada y datos de salida. Son los siguientes:
model.layers - Devuelve todas las capas del modelo como lista.
>>> layers = model.layers
>>> layers
[
<keras.layers.core.Dense object at 0x000002C8C888B8D0>,
<keras.layers.core.Dense object at 0x000002C8C888B7B8>
<keras.layers.core.Dense object at 0x 000002C8C888B898>
]model.inputs - Devuelve todos los tensores de entrada del modelo como lista.
>>> inputs = model.inputs
>>> inputs
[<tf.Tensor 'dense_13_input:0' shape=(?, 8) dtype=float32>]model.outputs - Devuelve todos los tensores de salida del modelo como lista.
>>> outputs = model.outputs
>>> outputs
<tf.Tensor 'dense_15/BiasAdd:0' shape=(?, 8) dtype=float32>]model.get_weights - Devuelve todos los pesos como matrices NumPy.
model.set_weights(weight_numpy_array) - Establecer los pesos del modelo.
Serializar el modelo
Keras proporciona métodos para serializar el modelo en un objeto y json y volver a cargarlo más tarde. Son los siguientes:
get_config() - I Devuelve el modelo como objeto.
config = model.get_config()from_config() - Acepta el objeto de configuración del modelo como argumento y crea el modelo en consecuencia.
new_model = Sequential.from_config(config)to_json() - Devuelve el modelo como un objeto json.
>>> json_string = model.to_json()
>>> json_string '{"class_name": "Sequential", "config":
{"name": "sequential_10", "layers":
[{"class_name": "Dense", "config":
{"name": "dense_13", "trainable": true, "batch_input_shape":
[null, 8], "dtype": "float32", "units": 32, "activation": "linear",
"use_bias": true, "kernel_initializer":
{"class_name": "Vari anceScaling", "config":
{"scale": 1.0, "mode": "fan_avg", "distribution": "uniform", "seed": null}},
"bias_initializer": {"class_name": "Zeros", "conf
ig": {}}, "kernel_regularizer": null, "bias_regularizer": null,
"activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null}},
{" class_name": "Dense", "config": {"name": "dense_14", "trainable": true,
"dtype": "float32", "units": 64, "activation": "relu", "use_bias": true,
"kern el_initializer": {"class_name": "VarianceScaling", "config":
{"scale": 1.0, "mode": "fan_avg", "distribution": "uniform", "seed": null}},
"bias_initia lizer": {"class_name": "Zeros",
"config": {}}, "kernel_regularizer": null, "bias_regularizer": null,
"activity_regularizer": null, "kernel_constraint" : null, "bias_constraint": null}},
{"class_name": "Dense", "config": {"name": "dense_15", "trainable": true,
"dtype": "float32", "units": 8, "activation": "linear", "use_bias": true,
"kernel_initializer": {"class_name": "VarianceScaling", "config":
{"scale": 1.0, "mode": "fan_avg", "distribution": " uniform", "seed": null}},
"bias_initializer": {"class_name": "Zeros", "config": {}},
"kernel_regularizer": null, "bias_regularizer": null, "activity_r egularizer":
null, "kernel_constraint": null, "bias_constraint":
null}}]}, "keras_version": "2.2.5", "backend": "tensorflow"}'
>>>model_from_json() - Acepta la representación json del modelo y crea un nuevo modelo.
from keras.models import model_from_json
new_model = model_from_json(json_string)to_yaml() - Devuelve el modelo como una cadena yaml.
>>> yaml_string = model.to_yaml()
>>> yaml_string 'backend: tensorflow\nclass_name:
Sequential\nconfig:\n layers:\n - class_name: Dense\n config:\n
activation: linear\n activity_regular izer: null\n batch_input_shape:
!!python/tuple\n - null\n - 8\n bias_constraint: null\n bias_initializer:\n
class_name : Zeros\n config: {}\n bias_regularizer: null\n dtype:
float32\n kernel_constraint: null\n
kernel_initializer:\n cla ss_name: VarianceScaling\n config:\n
distribution: uniform\n mode: fan_avg\n
scale: 1.0\n seed: null\n kernel_regularizer: null\n name: dense_13\n
trainable: true\n units: 32\n
use_bias: true\n - class_name: Dense\n config:\n activation: relu\n activity_regularizer: null\n
bias_constraint: null\n bias_initializer:\n class_name: Zeros\n
config : {}\n bias_regularizer: null\n dtype: float32\n
kernel_constraint: null\n kernel_initializer:\n class_name: VarianceScalin g\n
config:\n distribution: uniform\n mode: fan_avg\n scale: 1.0\n
seed: null\n kernel_regularizer: nu ll\n name: dense_14\n trainable: true\n
units: 64\n use_bias: true\n - class_name: Dense\n config:\n
activation: linear\n activity_regularizer: null\n
bias_constraint: null\n bias_initializer:\n
class_name: Zeros\n config: {}\n bias_regu larizer: null\n
dtype: float32\n kernel_constraint: null\n
kernel_initializer:\n class_name: VarianceScaling\n config:\n
distribution: uniform\n mode: fan_avg\n
scale: 1.0\n seed: null\n kernel_regularizer: null\n name: dense _15\n
trainable: true\n units: 8\n
use_bias: true\n name: sequential_10\nkeras_version: 2.2.5\n'
>>>model_from_yaml() - Acepta la representación yaml del modelo y crea un nuevo modelo.
from keras.models import model_from_yaml
new_model = model_from_yaml(yaml_string)Resume el modelo
Comprender el modelo es una fase muy importante para utilizarlo correctamente con fines de entrenamiento y predicción. Keras proporciona un método simple, resumen para obtener la información completa sobre el modelo y sus capas.
Un resumen del modelo creado en la sección anterior es el siguiente:
>>> model.summary() Model: "sequential_10"
_________________________________________________________________
Layer (type) Output Shape Param
#================================================================
dense_13 (Dense) (None, 32) 288
_________________________________________________________________
dense_14 (Dense) (None, 64) 2112
_________________________________________________________________
dense_15 (Dense) (None, 8) 520
=================================================================
Total params: 2,920
Trainable params: 2,920
Non-trainable params: 0
_________________________________________________________________
>>>Entrenar y predecir el modelo
El modelo proporciona una función para el proceso de entrenamiento, evaluación y predicción. Son los siguientes:
compile - Configurar el proceso de aprendizaje del modelo
fit - Entrena el modelo usando los datos de entrenamiento
evaluate - Evaluar el modelo utilizando los datos de prueba.
predict - Predecir los resultados para nuevas entradas.
API funcional
La API secuencial se utiliza para crear modelos capa por capa. La API funcional es un enfoque alternativo para crear modelos más complejos. Modelo funcional, puede definir múltiples entradas o salidas que comparten capas. Primero, creamos una instancia para el modelo y nos conectamos a las capas para acceder a la entrada y salida del modelo. Esta sección explica brevemente el modelo funcional.
Crea un modelo
Importe una capa de entrada utilizando el módulo siguiente:
>>> from keras.layers import InputAhora, cree una capa de entrada que especifique la forma de la dimensión de entrada para el modelo usando el siguiente código:
>>> data = Input(shape=(2,3))Defina la capa para la entrada usando el módulo siguiente:
>>> from keras.layers import DenseAgregue una capa densa para la entrada usando la siguiente línea de código:
>>> layer = Dense(2)(data)
>>> print(layer)
Tensor("dense_1/add:0", shape =(?, 2, 2), dtype = float32)Defina el modelo utilizando el módulo siguiente:
from keras.models import ModelCree un modelo de manera funcional especificando tanto la capa de entrada como la de salida -
model = Model(inputs = data, outputs = layer)El código completo para crear un modelo simple se muestra a continuación:
from keras.layers import Input
from keras.models import Model
from keras.layers import Dense
data = Input(shape=(2,3))
layer = Dense(2)(data) model =
Model(inputs=data,outputs=layer) model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) (None, 2, 3) 0
_________________________________________________________________
dense_2 (Dense) (None, 2, 2) 8
=================================================================
Total params: 8
Trainable params: 8
Non-trainable params: 0
_________________________________________________________________Keras - Compilación de modelos
Anteriormente, estudiamos los conceptos básicos de cómo crear un modelo utilizando API secuencial y funcional. Este capítulo explica cómo compilar el modelo. La compilación es el paso final para crear un modelo. Una vez realizada la compilación, podemos pasar a la fase de entrenamiento.
Aprendamos algunos conceptos necesarios para comprender mejor el proceso de compilación.
Pérdida
En el aprendizaje automático, LossLa función se utiliza para encontrar errores o desviaciones en el proceso de aprendizaje. Keras requiere la función de pérdida durante el proceso de compilación del modelo.
Keras proporciona bastantes funciones de pérdida en el losses módulo y son los siguientes:
- mean_squared_error
- mean_absolute_error
- mean_absolute_percentage_error
- mean_squared_logarithmic_error
- squared_hinge
- hinge
- categorical_hinge
- logcosh
- huber_loss
- categorical_crossentropy
- sparse_categorical_crossentropy
- binary_crossentropy
- kullback_leibler_divergence
- poisson
- cosine_proximity
- is_categorical_crossentropy
Toda la función de pérdida anterior acepta dos argumentos:
y_true - etiquetas verdaderas como tensores
y_pred - predicción con la misma forma que y_true
Importe el módulo de pérdidas antes de usar la función de pérdida como se especifica a continuación:
from keras import lossesOptimizador
En el aprendizaje automático, Optimizationes un proceso importante que optimiza los pesos de entrada comparando la predicción y la función de pérdida. Keras proporciona bastantes optimizadores como módulo, optimizadores y son los siguientes:
SGD - Optimizador de descenso de gradiente estocástico.
keras.optimizers.SGD(learning_rate = 0.01, momentum = 0.0, nesterov = False)RMSprop - Optimizador RMSProp.
keras.optimizers.RMSprop(learning_rate = 0.001, rho = 0.9)Adagrad - Optimizador Adagrad.
keras.optimizers.Adagrad(learning_rate = 0.01)Adadelta - Optimizador Adadelta.
keras.optimizers.Adadelta(learning_rate = 1.0, rho = 0.95)Adam - Optimizador de Adam.
keras.optimizers.Adam(
learning_rate = 0.001, beta_1 = 0.9, beta_2 = 0.999, amsgrad = False
)Adamax - Optimizador Adamax de Adam.
keras.optimizers.Adamax(learning_rate = 0.002, beta_1 = 0.9, beta_2 = 0.999)Nadam - Optimizador de Nesterov Adam.
keras.optimizers.Nadam(learning_rate = 0.002, beta_1 = 0.9, beta_2 = 0.999)Importe el módulo de optimizadores antes de usar los optimizadores como se especifica a continuación:
from keras import optimizersMétrica
En el aprendizaje automático, Metricsse utiliza para evaluar el rendimiento de su modelo. Es similar a la función de pérdida, pero no se usa en el proceso de entrenamiento. Keras proporciona bastantes métricas como módulo,metrics y son los siguientes
- accuracy
- binary_accuracy
- categorical_accuracy
- sparse_categorical_accuracy
- top_k_categorical_accuracy
- sparse_top_k_categorical_accuracy
- cosine_proximity
- clone_metric
Similar a la función de pérdida, las métricas también aceptan debajo de dos argumentos:
y_true - etiquetas verdaderas como tensores
y_pred - predicción con la misma forma que y_true
Importe el módulo de métricas antes de usar las métricas como se especifica a continuación:
from keras import metricsCompila el modelo
El modelo de Keras proporciona un método, compile()para compilar el modelo. El argumento y el valor predeterminado de lacompile() el método es el siguiente
compile(
optimizer,
loss = None,
metrics = None,
loss_weights = None,
sample_weight_mode = None,
weighted_metrics = None,
target_tensors = None
)Los argumentos importantes son los siguientes:
- función de pérdida
- Optimizer
- metrics
Un código de muestra para compilar el modo es el siguiente:
from keras import losses
from keras import optimizers
from keras import metrics
model.compile(loss = 'mean_squared_error',
optimizer = 'sgd', metrics = [metrics.categorical_accuracy])dónde,
la función de pérdida se establece como mean_squared_error
el optimizador está configurado como sgd
las métricas se establecen como metrics.categorical_accuracy
Entrenamiento de modelos
Los modelos son entrenados por matrices NumPy usando fit(). El objetivo principal de esta función de ajuste se utiliza para evaluar su modelo en el entrenamiento. Esto también se puede utilizar para graficar el rendimiento del modelo. Tiene la siguiente sintaxis:
model.fit(X, y, epochs = , batch_size = )Aquí,
X, y - Es una tupla para evaluar sus datos.
epochs - ninguna de las veces que es necesario evaluar el modelo durante el entrenamiento.
batch_size - instancias de formación.
Tomemos un ejemplo simple de numerosos datos aleatorios para usar este concepto.
Crear datos
Creemos datos aleatorios usando numpy para xey con la ayuda del comando mencionado a continuación:
import numpy as np
x_train = np.random.random((100,4,8))
y_train = np.random.random((100,10))Ahora, cree datos de validación aleatorios,
x_val = np.random.random((100,4,8))
y_val = np.random.random((100,10))Crear modelo
Creemos un modelo secuencial simple:
from keras.models import Sequential model = Sequential()Agregar capas
Crear capas para agregar modelo -
from keras.layers import LSTM, Dense
# add a sequence of vectors of dimension 16
model.add(LSTM(16, return_sequences = True))
model.add(Dense(10, activation = 'softmax'))compilar modelo
Ahora el modelo está definido. Puede compilar usando el siguiente comando:
model.compile(
loss = 'categorical_crossentropy', optimizer = 'sgd', metrics = ['accuracy']
)Aplicar ajuste ()
Ahora aplicamos la función fit () para entrenar nuestros datos -
model.fit(x_train, y_train, batch_size = 32, epochs = 5, validation_data = (x_val, y_val))Crear una ANN de perceptrón multicapa
Hemos aprendido a crear, compilar y entrenar los modelos de Keras.
Apliquemos nuestro aprendizaje y creemos una RNA basada en MPL simple.
Módulo de conjunto de datos
Antes de crear un modelo, debemos elegir un problema, recopilar los datos necesarios y convertir los datos en una matriz NumPy. Una vez que se recopilan los datos, podemos preparar el modelo y entrenarlo utilizando los datos recopilados. La recopilación de datos es una de las fases más difíciles del aprendizaje automático. Keras proporciona un módulo especial, conjuntos de datos para descargar los datos de aprendizaje automático en línea con fines de capacitación. Obtiene los datos del servidor en línea, procesa los datos y devuelve los datos como conjunto de entrenamiento y prueba. Comprobemos los datos proporcionados por el módulo del conjunto de datos de Keras. Los datos disponibles en el módulo son los siguientes,
- Clasificación de imágenes pequeñas CIFAR10
- Clasificación de imágenes pequeñas CIFAR100
- Clasificación de sentimiento de reseñas de películas de IMDB
- Clasificación de temas de Reuters Newswire
- Base de datos MNIST de dígitos escritos a mano
- Base de datos Fashion-MNIST de artículos de moda
- Conjunto de datos de regresión del precio de la vivienda en Boston
Usemos el MNIST database of handwritten digits(o minst) como nuestra entrada. minst es una colección de 60.000 imágenes en escala de grises de 28x28. Contiene 10 dígitos. También contiene 10,000 imágenes de prueba.
El siguiente código se puede usar para cargar el conjunto de datos:
from keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()dónde
Line 1 importaciones minst desde el módulo de conjunto de datos de keras.
Line 3 llama al load_data función, que obtendrá los datos del servidor en línea y devolverá los datos como 2 tuplas, Primera tupla, (x_train, y_train) representar los datos de entrenamiento con forma, (number_sample, 28, 28) y su etiqueta de dígitos con forma, (number_samples, ). Segunda tupla,(x_test, y_test) representan datos de prueba con la misma forma.
También se pueden obtener otros conjuntos de datos utilizando una API similar y cada API también devuelve datos similares, excepto la forma de los datos. La forma de los datos depende del tipo de datos.
Crea un modelo
Elijamos un perceptrón multicapa simple (MLP) como se representa a continuación e intentemos crear el modelo usando Keras.

Las características principales del modelo son las siguientes:
La capa de entrada consta de 784 valores (28 x 28 = 784).
Primera capa oculta, Dense consta de 512 neuronas y función de activación 'relu'.
Segunda capa oculta, Dropout tiene 0,2 como valor.
La tercera capa oculta, nuevamente Densa, consta de 512 neuronas y la función de activación 'relu'.
Cuarta capa oculta, Dropout tiene 0,2 como valor.
La quinta y última capa consta de 10 neuronas y la función de activación 'softmax'.
Utilizar categorical_crossentropy como función de pérdida.
Utilizar RMSprop() como Optimizador.
Utilizar accuracy como métricas.
Utilice 128 como tamaño de lote.
Usa 20 como épocas.
Step 1 − Import the modules
Importamos los módulos necesarios.
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import RMSprop
import numpy as npStep 2 − Load data
Importemos el conjunto de datos mnist.
(x_train, y_train), (x_test, y_test) = mnist.load_data()Step 3 − Process the data
Cambiemos el conjunto de datos de acuerdo con nuestro modelo, para que se pueda incorporar a nuestro modelo.
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)Dónde
reshape se usa para remodelar la entrada de (28, 28) tupla a (784,)
to_categorical se utiliza para convertir vector a matriz binaria
Step 4 − Create the model
Creemos el modelo real.
model = Sequential()
model.add(Dense(512, activation = 'relu', input_shape = (784,)))
model.add(Dropout(0.2))
model.add(Dense(512, activation = 'relu'))
model.add(Dropout(0.2))
model.add(Dense(10, activation = 'softmax'))Step 5 − Compile the model
Compilemos el modelo utilizando la función de pérdida seleccionada, el optimizador y las métricas.
model.compile(loss = 'categorical_crossentropy',
optimizer = RMSprop(),
metrics = ['accuracy'])Step 6 − Train the model
Entrenemos el modelo usando fit() método.
history = model.fit(
x_train, y_train,
batch_size = 128,
epochs = 20,
verbose = 1,
validation_data = (x_test, y_test)
)Pensamientos finales
Hemos creado el modelo, hemos cargado los datos y también hemos entrenado los datos al modelo. Todavía necesitamos evaluar el modelo y predecir la salida para la entrada desconocida, lo que aprenderemos en el próximo capítulo.
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import RMSprop
import numpy as np
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)
model = Sequential()
model.add(Dense(512, activation='relu', input_shape = (784,)))
model.add(Dropout(0.2))
model.add(Dense(512, activation = 'relu')) model.add(Dropout(0.2))
model.add(Dense(10, activation = 'softmax'))
model.compile(loss = 'categorical_crossentropy',
optimizer = RMSprop(),
metrics = ['accuracy'])
history = model.fit(x_train, y_train,
batch_size = 128, epochs = 20, verbose = 1, validation_data = (x_test, y_test))La ejecución de la aplicación dará como resultado el siguiente contenido:
Train on 60000 samples, validate on 10000 samples Epoch 1/20
60000/60000 [==============================] - 7s 118us/step - loss: 0.2453
- acc: 0.9236 - val_loss: 0.1004 - val_acc: 0.9675 Epoch 2/20
60000/60000 [==============================] - 7s 110us/step - loss: 0.1023
- acc: 0.9693 - val_loss: 0.0797 - val_acc: 0.9761 Epoch 3/20
60000/60000 [==============================] - 7s 110us/step - loss: 0.0744
- acc: 0.9770 - val_loss: 0.0727 - val_acc: 0.9791 Epoch 4/20
60000/60000 [==============================] - 7s 110us/step - loss: 0.0599
- acc: 0.9823 - val_loss: 0.0704 - val_acc: 0.9801 Epoch 5/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0504
- acc: 0.9853 - val_loss: 0.0714 - val_acc: 0.9817 Epoch 6/20
60000/60000 [==============================] - 7s 111us/step - loss: 0.0438
- acc: 0.9868 - val_loss: 0.0845 - val_acc: 0.9809 Epoch 7/20
60000/60000 [==============================] - 7s 114us/step - loss: 0.0391
- acc: 0.9887 - val_loss: 0.0823 - val_acc: 0.9802 Epoch 8/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0364
- acc: 0.9892 - val_loss: 0.0818 - val_acc: 0.9830 Epoch 9/20
60000/60000 [==============================] - 7s 113us/step - loss: 0.0308
- acc: 0.9905 - val_loss: 0.0833 - val_acc: 0.9829 Epoch 10/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0289
- acc: 0.9917 - val_loss: 0.0947 - val_acc: 0.9815 Epoch 11/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0279
- acc: 0.9921 - val_loss: 0.0818 - val_acc: 0.9831 Epoch 12/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0260
- acc: 0.9927 - val_loss: 0.0945 - val_acc: 0.9819 Epoch 13/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0257
- acc: 0.9931 - val_loss: 0.0952 - val_acc: 0.9836 Epoch 14/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0229
- acc: 0.9937 - val_loss: 0.0924 - val_acc: 0.9832 Epoch 15/20
60000/60000 [==============================] - 7s 115us/step - loss: 0.0235
- acc: 0.9937 - val_loss: 0.1004 - val_acc: 0.9823 Epoch 16/20
60000/60000 [==============================] - 7s 113us/step - loss: 0.0214
- acc: 0.9941 - val_loss: 0.0991 - val_acc: 0.9847 Epoch 17/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0219
- acc: 0.9943 - val_loss: 0.1044 - val_acc: 0.9837 Epoch 18/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0190
- acc: 0.9952 - val_loss: 0.1129 - val_acc: 0.9836 Epoch 19/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0197
- acc: 0.9953 - val_loss: 0.0981 - val_acc: 0.9841 Epoch 20/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0198
- acc: 0.9950 - val_loss: 0.1215 - val_acc: 0.9828Keras - Evaluación de modelos y predicción de modelos
Este capítulo trata sobre la evaluación y la predicción del modelo en Keras.
Comencemos por comprender la evaluación del modelo.
Evaluación del modelo
La evaluación es un proceso durante el desarrollo del modelo para verificar si el modelo se ajusta mejor al problema dado y los datos correspondientes. El modelo de Keras proporciona una función, evaluar cuál hace la evaluación del modelo. Tiene tres argumentos principales,
- Datos de prueba
- Etiqueta de datos de prueba
- detallado - verdadero o falso
Evaluemos el modelo que creamos en el capítulo anterior usando datos de prueba.
score = model.evaluate(x_test, y_test, verbose = 0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])La ejecución del código anterior generará la siguiente información.
0La precisión de la prueba es del 98,28%. Hemos creado el mejor modelo para identificar los dígitos de la escritura a mano. En el lado positivo, todavía podemos mejorar nuestro modelo.
Predicción del modelo
Predictiones el paso final y nuestro resultado esperado de la generación del modelo. Keras proporciona un método de predicción para obtener la predicción del modelo entrenado. La firma del método de predicción es la siguiente,
predict(
x,
batch_size = None,
verbose = 0,
steps = None,
callbacks = None,
max_queue_size = 10,
workers = 1,
use_multiprocessing = False
)Aquí, todos los argumentos son opcionales excepto el primer argumento, que se refiere a los datos de entrada desconocidos. La forma debe mantenerse para obtener la predicción adecuada.
Hagamos predicciones para nuestro modelo MPL creado en el capítulo anterior usando el siguiente código:
pred = model.predict(x_test)
pred = np.argmax(pred, axis = 1)[:5]
label = np.argmax(y_test,axis = 1)[:5]
print(pred)
print(label)Aquí,
Line 1 Llame a la función de predicción utilizando datos de prueba.
Line 2 obtiene las cinco primeras predicciones
Line 3 obtiene las primeras cinco etiquetas de los datos de prueba.
Line 5 - 6 imprime la predicción y la etiqueta real.
El resultado de la aplicación anterior es el siguiente:
[7 2 1 0 4]
[7 2 1 0 4]La salida de ambas matrices es idéntica e indica que nuestro modelo predice correctamente las primeras cinco imágenes.
Keras - Red neuronal de convolución
Modifiquemos el modelo de MPL a Convolution Neural Network (CNN) para nuestro problema de identificación de dígitos anterior.
CNN se puede representar de la siguiente manera:
Las características principales del modelo son las siguientes:
La capa de entrada consta de (1, 8, 28) valores.
Primera capa, Conv2D consta de 32 filtros y función de activación 'relu' con tamaño de kernel, (3,3).
Segunda capa, Conv2D consta de 64 filtros y función de activación 'relu' con tamaño de kernel, (3,3).
Tercera capa, MaxPooling Tiene un tamaño de piscina de (2, 2).
Quinta capa, Flatten se utiliza para aplanar toda su entrada en una sola dimensión.
Sexta capa, Dense consta de 128 neuronas y función de activación 'relu'.
Séptima capa, Dropout tiene 0,5 como valor.
La octava y última capa consta de 10 neuronas y la función de activación 'softmax'.
Utilizar categorical_crossentropy como función de pérdida.
Utilizar Adadelta() como Optimizador.
Utilizar accuracy como métricas.
Utilice 128 como tamaño de lote.
Usa 20 como épocas.
Step 1 − Import the modules
Importamos los módulos necesarios.
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras import backend as K
import numpy as npStep 2 − Load data
Importemos el conjunto de datos mnist.
(x_train, y_train), (x_test, y_test) = mnist.load_data()Step 3 − Process the data
Cambiemos el conjunto de datos de acuerdo con nuestro modelo, para que se pueda incorporar a nuestro modelo.
img_rows, img_cols = 28, 28
if K.image_data_format() == 'channels_first':
x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
else:
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)El procesamiento de datos es similar al modelo MPL excepto la forma de los datos de entrada y la configuración del formato de imagen.
Step 4 − Create the model
Creemos el modelo actual.
model = Sequential()
model.add(Conv2D(32, kernel_size = (3, 3),
activation = 'relu', input_shape = input_shape))
model.add(Conv2D(64, (3, 3), activation = 'relu'))
model.add(MaxPooling2D(pool_size = (2, 2)))
model.add(Dropout(0.25)) model.add(Flatten())
model.add(Dense(128, activation = 'relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation = 'softmax'))Step 5 − Compile the model
Compilemos el modelo utilizando la función de pérdida seleccionada, el optimizador y las métricas.
model.compile(loss = keras.losses.categorical_crossentropy,
optimizer = keras.optimizers.Adadelta(), metrics = ['accuracy'])Step 6 − Train the model
Entrenemos el modelo usando fit() método.
model.fit(
x_train, y_train,
batch_size = 128,
epochs = 12,
verbose = 1,
validation_data = (x_test, y_test)
)La ejecución de la aplicación generará la siguiente información:
Train on 60000 samples, validate on 10000 samples Epoch 1/12
60000/60000 [==============================] - 84s 1ms/step - loss: 0.2687
- acc: 0.9173 - val_loss: 0.0549 - val_acc: 0.9827 Epoch 2/12
60000/60000 [==============================] - 86s 1ms/step - loss: 0.0899
- acc: 0.9737 - val_loss: 0.0452 - val_acc: 0.9845 Epoch 3/12
60000/60000 [==============================] - 83s 1ms/step - loss: 0.0666
- acc: 0.9804 - val_loss: 0.0362 - val_acc: 0.9879 Epoch 4/12
60000/60000 [==============================] - 81s 1ms/step - loss: 0.0564
- acc: 0.9830 - val_loss: 0.0336 - val_acc: 0.9890 Epoch 5/12
60000/60000 [==============================] - 86s 1ms/step - loss: 0.0472
- acc: 0.9861 - val_loss: 0.0312 - val_acc: 0.9901 Epoch 6/12
60000/60000 [==============================] - 83s 1ms/step - loss: 0.0414
- acc: 0.9877 - val_loss: 0.0306 - val_acc: 0.9902 Epoch 7/12
60000/60000 [==============================] - 89s 1ms/step - loss: 0.0375
-acc: 0.9883 - val_loss: 0.0281 - val_acc: 0.9906 Epoch 8/12
60000/60000 [==============================] - 91s 2ms/step - loss: 0.0339
- acc: 0.9893 - val_loss: 0.0280 - val_acc: 0.9912 Epoch 9/12
60000/60000 [==============================] - 89s 1ms/step - loss: 0.0325
- acc: 0.9901 - val_loss: 0.0260 - val_acc: 0.9909 Epoch 10/12
60000/60000 [==============================] - 89s 1ms/step - loss: 0.0284
- acc: 0.9910 - val_loss: 0.0250 - val_acc: 0.9919 Epoch 11/12
60000/60000 [==============================] - 86s 1ms/step - loss: 0.0287
- acc: 0.9907 - val_loss: 0.0264 - val_acc: 0.9916 Epoch 12/12
60000/60000 [==============================] - 86s 1ms/step - loss: 0.0265
- acc: 0.9920 - val_loss: 0.0249 - val_acc: 0.9922Step 7 − Evaluate the model
Evaluemos el modelo usando datos de prueba.
score = model.evaluate(x_test, y_test, verbose = 0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])La ejecución del código anterior generará la siguiente información:
Test loss: 0.024936060590433316
Test accuracy: 0.9922La precisión de la prueba es del 99,22%. Hemos creado el mejor modelo para identificar los dígitos de la escritura a mano.
Step 8 − Predict
Finalmente, predice el dígito a partir de imágenes como se muestra a continuación:
pred = model.predict(x_test)
pred = np.argmax(pred, axis = 1)[:5]
label = np.argmax(y_test,axis = 1)[:5]
print(pred)
print(label)El resultado de la aplicación anterior es el siguiente:
[7 2 1 0 4]
[7 2 1 0 4]La salida de ambas matrices es idéntica e indica que nuestro modelo predice correctamente las primeras cinco imágenes.
Keras - Predicción de regresión usando MPL
En este capítulo, escribiremos una RNA basada en MPL simple para realizar predicciones de regresión. Hasta ahora, solo hemos realizado la predicción basada en la clasificación. Ahora, intentaremos predecir el siguiente valor posible analizando los valores anteriores (continuos) y sus factores de influencia.
El MPL de regresión se puede representar de la siguiente manera:

Las características principales del modelo son las siguientes:
La capa de entrada consta de (13,) valores.
La primera capa, Dense , consta de 64 unidades y la función de activación 'relu' con un inicializador de kernel 'normal'.
Segunda capa, Dense consta de 64 unidades y función de activación 'relu'.
Capa de salida, Densa consta de 1 unidad.
Utilizar mse como función de pérdida.
Utilizar RMSprop como Optimizador.
Utilizar accuracy como métricas.
Utilice 128 como tamaño de lote.
Usa 500 como épocas.
Step 1 − Import the modules
Importamos los módulos necesarios.
import keras
from keras.datasets import boston_housing
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import RMSprop
from keras.callbacks import EarlyStopping
from sklearn import preprocessing
from sklearn.preprocessing import scaleStep 2 − Load data
Importemos el conjunto de datos de viviendas de Boston.
(x_train, y_train), (x_test, y_test) = boston_housing.load_data()Aquí,
boston_housinges un conjunto de datos proporcionado por Keras. Representa una colección de información sobre viviendas en el área de Boston, cada una con 13 características.
Step 3 − Process the data
Cambiemos el conjunto de datos de acuerdo con nuestro modelo, para que podamos alimentar nuestro modelo. Los datos se pueden cambiar usando el siguiente código:
x_train_scaled = preprocessing.scale(x_train)
scaler = preprocessing.StandardScaler().fit(x_train)
x_test_scaled = scaler.transform(x_test)Aquí, hemos normalizado los datos de entrenamiento usando sklearn.preprocessing.scale función. preprocessing.StandardScaler().fit La función devuelve un escalar con la media normalizada y la desviación estándar de los datos de entrenamiento, que podemos aplicar a los datos de prueba usando scalar.transformfunción. Esto normalizará los datos de la prueba también con la misma configuración que la de los datos de entrenamiento.
Step 4 − Create the model
Creemos el modelo real.
model = Sequential()
model.add(Dense(64, kernel_initializer = 'normal', activation = 'relu',
input_shape = (13,)))
model.add(Dense(64, activation = 'relu')) model.add(Dense(1))Step 5 − Compile the model
Compilemos el modelo utilizando la función de pérdida seleccionada, el optimizador y las métricas.
model.compile(
loss = 'mse',
optimizer = RMSprop(),
metrics = ['mean_absolute_error']
)Step 6 − Train the model
Entrenemos el modelo usando fit() método.
history = model.fit(
x_train_scaled, y_train,
batch_size=128,
epochs = 500,
verbose = 1,
validation_split = 0.2,
callbacks = [EarlyStopping(monitor = 'val_loss', patience = 20)]
)Aquí, hemos utilizado la función de devolución de llamada, EarlyStopping. El propósito de esta devolución de llamada es monitorear el valor de pérdida durante cada época y compararlo con el valor de pérdida de la época anterior para encontrar la mejora en el entrenamiento. Si no hay mejora para elpatience veces, entonces todo el proceso se detendrá.
La ejecución de la aplicación dará como resultado la siguiente información:
Train on 323 samples, validate on 81 samples Epoch 1/500 2019-09-24 01:07:03.889046: I
tensorflow/core/platform/cpu_feature_guard.cc:142]
Your CPU supports instructions that this
TensorFlow binary was not co mpiled to use: AVX2 323/323
[==============================] - 0s 515us/step - loss: 562.3129
- mean_absolute_error: 21.8575 - val_loss: 621.6523 - val_mean_absolute_erro
r: 23.1730 Epoch 2/500
323/323 [==============================] - 0s 11us/step - loss: 545.1666
- mean_absolute_error: 21.4887 - val_loss: 605.1341 - val_mean_absolute_error
: 22.8293 Epoch 3/500
323/323 [==============================] - 0s 12us/step - loss: 528.9944
- mean_absolute_error: 21.1328 - val_loss: 588.6594 - val_mean_absolute_error
: 22.4799 Epoch 4/500
323/323 [==============================] - 0s 12us/step - loss: 512.2739
- mean_absolute_error: 20.7658 - val_loss: 570.3772 - val_mean_absolute_error
: 22.0853 Epoch 5/500
323/323 [==============================] - 0s 9us/step - loss: 493.9775
- mean_absolute_error: 20.3506 - val_loss: 550.9548 - val_mean_absolute_error: 21.6547
..........
..........
..........
Epoch 143/500
323/323 [==============================] - 0s 15us/step - loss: 8.1004
- mean_absolute_error: 2.0002 - val_loss: 14.6286 - val_mean_absolute_error:
2. 5904 Epoch 144/500
323/323 [==============================] - 0s 19us/step - loss: 8.0300
- mean_absolute_error: 1.9683 - val_loss: 14.5949 - val_mean_absolute_error:
2. 5843 Epoch 145/500
323/323 [==============================] - 0s 12us/step - loss: 7.8704
- mean_absolute_error: 1.9313 - val_loss: 14.3770 - val_mean_absolute_error: 2. 4996Step 7 − Evaluate the model
Evaluemos el modelo usando datos de prueba.
score = model.evaluate(x_test_scaled, y_test, verbose = 0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])La ejecución del código anterior generará la siguiente información:
Test loss: 21.928471583946077 Test accuracy: 2.9599233234629914Step 8 − Predict
Finalmente, prediga usando datos de prueba como se muestra a continuación:
prediction = model.predict(x_test_scaled)
print(prediction.flatten())
print(y_test)El resultado de la aplicación anterior es el siguiente:
[ 7.5612316 17.583357 21.09344 31.859276 25.055613 18.673872 26.600405 22.403967 19.060272 22.264952
17.4191 17.00466 15.58924 41.624374 20.220217 18.985565 26.419338 19.837091 19.946192 36.43445
12.278508 16.330965 20.701359 14.345301 21.741161 25.050423 31.046402 27.738455 9.959419 20.93039
20.069063 14.518344 33.20235 24.735163 18.7274 9.148898 15.781284 18.556862 18.692865 26.045074
27.954073 28.106823 15.272034 40.879818 29.33896 23.714525 26.427515 16.483374 22.518442 22.425386
33.94826 18.831465 13.2501955 15.537227 34.639984 27.468002 13.474407 48.134598 34.39617
22.8503124.042334 17.747198 14.7837715 18.187277 23.655672 22.364983 13.858193 22.710032 14.371148
7.1272087 35.960033 28.247292 25.3014 14.477208 25.306196 17.891165 20.193708 23.585173 34.690193
12.200583 20.102983 38.45882 14.741723 14.408362 17.67158 18.418497 21.151712 21.157492 22.693687
29.809034 19.366991 20.072294 25.880817 40.814568 34.64087 19.43741 36.2591 50.73806 26.968863 43.91787
32.54908 20.248306 ] [ 7.2 18.8 19. 27. 22.2 24.5 31.2 22.9 20.5 23.2 18.6 14.5 17.8 50. 20.8 24.3 24.2
19.8 19.1 22.7 12. 10.2 20. 18.5 20.9 23. 27.5 30.1 9.5 22. 21.2 14.1 33.1 23.4 20.1 7.4 15.4 23.8 20.1
24.5 33. 28.4 14.1 46.7 32.5 29.6 28.4 19.8 20.2 25. 35.4 20.3 9.7 14.5 34.9 26.6 7.2 50. 32.4 21.6 29.8
13.1 27.5 21.2 23.1 21.9 13. 23.2 8.1 5.6 21.7 29.6 19.6 7. 26.4 18.9 20.9 28.1 35.4 10.2 24.3 43.1 17.6
15.4 16.2 27.1 21.4 21.5 22.4 25. 16.6 18.6 22. 42.8 35.1 21.5 36. 21.9 24.1 50. 26.7 25. ]La salida de ambas matrices tiene una diferencia de alrededor del 10-30% e indica que nuestro modelo predice con un rango razonable.
Keras - Predicción de series temporales usando LSTM RNN
En este capítulo, vamos a escribir un RNN simple basado en la memoria a corto plazo (LSTM) para realizar análisis de secuencia. Una secuencia es un conjunto de valores donde cada valor corresponde a una instancia particular de tiempo. Consideremos un ejemplo simple de lectura de una oración. Leer y comprender una oración implica leer la palabra en el orden dado y tratar de comprender cada palabra y su significado en el contexto dado y finalmente comprender la oración en un sentimiento positivo o negativo.
Aquí, las palabras se consideran valores, y el primer valor corresponde a la primera palabra, el segundo valor corresponde a la segunda palabra, etc., y el orden se mantendrá estrictamente. Sequence Analysis se utiliza con frecuencia en el procesamiento del lenguaje natural para encontrar el análisis de sentimientos del texto dado.
Creemos un modelo LSTM para analizar las críticas de películas de IMDB y encontrar su sentimiento positivo / negativo.
El modelo para el análisis de secuencia se puede representar de la siguiente manera:
Las características principales del modelo son las siguientes:
Capa de entrada usando la capa de incrustación con 128 entidades.
La primera capa, Densa, consta de 128 unidades con deserción normal y deserción recurrente configuradas en 0.2.
Capa de salida, Dense consta de 1 unidad y función de activación 'sigmoide'.
Utilizar binary_crossentropy como función de pérdida.
Utilizar adam como Optimizador.
Utilizar accuracy como métricas.
Utilice 32 como tamaño de lote.
Usa 15 como épocas.
Utilice 80 como longitud máxima de la palabra.
Utilice 2000 como el número máximo de palabras en una oración dada.
Paso 1: importar los módulos
Importamos los módulos necesarios.
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers import Dense, Embedding
from keras.layers import LSTM
from keras.datasets import imdbPaso 2: cargar datos
Vamos a importar el conjunto de datos imdb.
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words = 2000)Aquí,
imdbes un conjunto de datos proporcionado por Keras. Representa una colección de películas y sus críticas.
num_words representan el número máximo de palabras en la reseña.
Paso 3: procesa los datos
Cambiemos el conjunto de datos de acuerdo con nuestro modelo, para que se pueda introducir en nuestro modelo. Los datos se pueden cambiar usando el siguiente código:
x_train = sequence.pad_sequences(x_train, maxlen=80)
x_test = sequence.pad_sequences(x_test, maxlen=80)Aquí,
sequence.pad_sequences convertir la lista de datos de entrada con forma, (data) en matriz de forma 2D NumPy (data, timesteps). Básicamente, agrega el concepto de pasos de tiempo a los datos proporcionados. Genera los pasos de tiempo de longitud,maxlen.
Paso 4: crea el modelo
Creemos el modelo real.
model = Sequential()
model.add(Embedding(2000, 128))
model.add(LSTM(128, dropout = 0.2, recurrent_dropout = 0.2))
model.add(Dense(1, activation = 'sigmoid'))Aquí,
Hemos usado Embedding layercomo capa de entrada y luego agregó la capa LSTM. Finalmente, unDense layer se utiliza como capa de salida.
Paso 5: compila el modelo
Compilemos el modelo utilizando la función de pérdida seleccionada, el optimizador y las métricas.
model.compile(loss = 'binary_crossentropy',
optimizer = 'adam', metrics = ['accuracy'])Paso 6: Entrena el modelo
LEntrenemos el modelo usando fit() método.
model.fit(
x_train, y_train,
batch_size = 32,
epochs = 15,
validation_data = (x_test, y_test)
)La ejecución de la aplicación generará la siguiente información:
Epoch 1/15 2019-09-24 01:19:01.151247: I
tensorflow/core/platform/cpu_feature_guard.cc:142]
Your CPU supports instructions that this
TensorFlow binary was not co mpiled to use: AVX2
25000/25000 [==============================] - 101s 4ms/step - loss: 0.4707
- acc: 0.7716 - val_loss: 0.3769 - val_acc: 0.8349 Epoch 2/15
25000/25000 [==============================] - 95s 4ms/step - loss: 0.3058
- acc: 0.8756 - val_loss: 0.3763 - val_acc: 0.8350 Epoch 3/15
25000/25000 [==============================] - 91s 4ms/step - loss: 0.2100
- acc: 0.9178 - val_loss: 0.5065 - val_acc: 0.8110 Epoch 4/15
25000/25000 [==============================] - 90s 4ms/step - loss: 0.1394
- acc: 0.9495 - val_loss: 0.6046 - val_acc: 0.8146 Epoch 5/15
25000/25000 [==============================] - 90s 4ms/step - loss: 0.0973
- acc: 0.9652 - val_loss: 0.5969 - val_acc: 0.8147 Epoch 6/15
25000/25000 [==============================] - 98s 4ms/step - loss: 0.0759
- acc: 0.9730 - val_loss: 0.6368 - val_acc: 0.8208 Epoch 7/15
25000/25000 [==============================] - 95s 4ms/step - loss: 0.0578
- acc: 0.9811 - val_loss: 0.6657 - val_acc: 0.8184 Epoch 8/15
25000/25000 [==============================] - 97s 4ms/step - loss: 0.0448
- acc: 0.9850 - val_loss: 0.7452 - val_acc: 0.8136 Epoch 9/15
25000/25000 [==============================] - 95s 4ms/step - loss: 0.0324
- acc: 0.9894 - val_loss: 0.7616 - val_acc: 0.8162Epoch 10/15
25000/25000 [==============================] - 100s 4ms/step - loss: 0.0247
- acc: 0.9922 - val_loss: 0.9654 - val_acc: 0.8148 Epoch 11/15
25000/25000 [==============================] - 99s 4ms/step - loss: 0.0169
- acc: 0.9946 - val_loss: 1.0013 - val_acc: 0.8104 Epoch 12/15
25000/25000 [==============================] - 90s 4ms/step - loss: 0.0154
- acc: 0.9948 - val_loss: 1.0316 - val_acc: 0.8100 Epoch 13/15
25000/25000 [==============================] - 89s 4ms/step - loss: 0.0113
- acc: 0.9963 - val_loss: 1.1138 - val_acc: 0.8108 Epoch 14/15
25000/25000 [==============================] - 89s 4ms/step - loss: 0.0106
- acc: 0.9971 - val_loss: 1.0538 - val_acc: 0.8102 Epoch 15/15
25000/25000 [==============================] - 89s 4ms/step - loss: 0.0090
- acc: 0.9972 - val_loss: 1.1453 - val_acc: 0.8129
25000/25000 [==============================] - 10s 390us/stepPaso 7: evaluar el modelo
Evaluemos el modelo usando datos de prueba.
score, acc = model.evaluate(x_test, y_test, batch_size = 32)
print('Test score:', score)
print('Test accuracy:', acc)La ejecución del código anterior generará la siguiente información:
Test score: 1.145306069601178
Test accuracy: 0.81292Keras - Aplicaciones
El módulo de aplicaciones de Keras se utiliza para proporcionar un modelo previamente entrenado para redes neuronales profundas. Los modelos de Keras se utilizan para la predicción, la extracción de características y el ajuste fino. Este capítulo explica en detalle las aplicaciones de Keras.
Modelos pre-entrenados
El modelo entrenado consta de dos partes: modelo de arquitectura y modelo de pesos. Los pesos del modelo son archivos grandes, por lo que tenemos que descargar y extraer la función de la base de datos de ImageNet. Algunos de los modelos populares previamente entrenados se enumeran a continuación,
- ResNet
- VGG16
- MobileNet
- InceptionResNetV2
- InceptionV3
Cargando un modelo
Los modelos pre-entrenados de Keras se pueden cargar fácilmente como se especifica a continuación:
import keras
import numpy as np
from keras.applications import vgg16, inception_v3, resnet50, mobilenet
#Load the VGG model
vgg_model = vgg16.VGG16(weights = 'imagenet')
#Load the Inception_V3 model
inception_model = inception_v3.InceptionV3(weights = 'imagenet')
#Load the ResNet50 model
resnet_model = resnet50.ResNet50(weights = 'imagenet')
#Load the MobileNet model mobilenet_model = mobilenet.MobileNet(weights = 'imagenet')Una vez que se carga el modelo, podemos usarlo inmediatamente con fines de predicción. Revisemos cada modelo previamente entrenado en los próximos capítulos.
Predicción en tiempo real usando el modelo ResNet
ResNet es un modelo previamente entrenado. Está entrenado usando ImageNet . Pesos de modelo ResNet previamente entrenados en ImageNet . Tiene la siguiente sintaxis:
keras.applications.resnet.ResNet50 (
include_top = True,
weights = 'imagenet',
input_tensor = None,
input_shape = None,
pooling = None,
classes = 1000
)Aquí,
include_top se refiere a la capa completamente conectada en la parte superior de la red.
weights consulte la formación previa en ImageNet.
input_tensor hace referencia al tensor de Keras opcional para usar como entrada de imagen para el modelo.
input_shapese refiere a la tupla de forma opcional. El tamaño de entrada predeterminado para este modelo es 224x224.
classes Consulte el número opcional de clases para clasificar imágenes.
Entendamos el modelo escribiendo un ejemplo simple:
Paso 1: importar los módulos
Carguemos los módulos necesarios como se especifica a continuación:
>>> import PIL
>>> from keras.preprocessing.image import load_img
>>> from keras.preprocessing.image import img_to_array
>>> from keras.applications.imagenet_utils import decode_predictions
>>> import matplotlib.pyplot as plt
>>> import numpy as np
>>> from keras.applications.resnet50 import ResNet50
>>> from keras.applications import resnet50Paso 2: seleccione una entrada
Elijamos una imagen de entrada, Lotus como se especifica a continuación -
>>> filename = 'banana.jpg'
>>> ## load an image in PIL format
>>> original = load_img(filename, target_size = (224, 224))
>>> print('PIL image size',original.size)
PIL image size (224, 224)
>>> plt.imshow(original)
<matplotlib.image.AxesImage object at 0x1304756d8>
>>> plt.show()Aquí, hemos cargado una imagen. (banana.jpg) y lo mostró.
Paso 3: convierte imágenes en una matriz NumPy
Convirtamos nuestra entrada, Banana en la matriz NumPy, de modo que se pueda pasar al modelo con fines de predicción.
>>> #convert the PIL image to a numpy array
>>> numpy_image = img_to_array(original)
>>> plt.imshow(np.uint8(numpy_image))
<matplotlib.image.AxesImage object at 0x130475ac8>
>>> print('numpy array size',numpy_image.shape)
numpy array size (224, 224, 3)
>>> # Convert the image / images into batch format
>>> image_batch = np.expand_dims(numpy_image, axis = 0)
>>> print('image batch size', image_batch.shape)
image batch size (1, 224, 224, 3)
>>>Paso 4: predicción del modelo
Introduzcamos nuestra información en el modelo para obtener las predicciones.
>>> prepare the image for the resnet50 model >>>
>>> processed_image = resnet50.preprocess_input(image_batch.copy())
>>> # create resnet model
>>>resnet_model = resnet50.ResNet50(weights = 'imagenet')
>>> Downloavding data from https://github.com/fchollet/deep-learning-models/releas
es/download/v0.2/resnet50_weights_tf_dim_ordering_tf_kernels.h5
102858752/102853048 [==============================] - 33s 0us/step
>>> # get the predicted probabilities for each class
>>> predictions = resnet_model.predict(processed_image)
>>> # convert the probabilities to class labels
>>> label = decode_predictions(predictions)
Downloading data from https://storage.googleapis.com/download.tensorflow.org/
data/imagenet_class_index.json
40960/35363 [==================================] - 0s 0us/step
>>> print(label)Salida
[
[
('n07753592', 'banana', 0.99229723),
('n03532672', 'hook', 0.0014551596),
('n03970156', 'plunger', 0.0010738898),
('n07753113', 'fig', 0.0009359837) ,
('n03109150', 'corkscrew', 0.00028538404)
]
]Aquí, el modelo predijo correctamente las imágenes como banana.
Keras - Modelos pre-entrenados
En este capítulo, aprenderemos sobre los modelos entrenados previamente en Keras. Comencemos con VGG16.
VGG16
VGG16es otro modelo previamente entrenado. También está capacitado con ImageNet. La sintaxis para cargar el modelo es la siguiente:
keras.applications.vgg16.VGG16(
include_top = True,
weights = 'imagenet',
input_tensor = None,
input_shape = None,
pooling = None,
classes = 1000
)El tamaño de entrada predeterminado para este modelo es 224x224.
MobileNetV2
MobileNetV2es otro modelo previamente entrenado. También se entrena uingImageNet.
La sintaxis para cargar el modelo es la siguiente:
keras.applications.mobilenet_v2.MobileNetV2 (
input_shape = None,
alpha = 1.0,
include_top = True,
weights = 'imagenet',
input_tensor = None,
pooling = None,
classes = 1000
)Aquí,
alphacontrola el ancho de la red. Si el valor es inferior a 1, disminuye el número de filtros en cada capa. Si el valor es superior a 1, aumenta el número de filtros en cada capa. Si alfa = 1, el número predeterminado de filtros del papel se utiliza en cada capa.
El tamaño de entrada predeterminado para este modelo es 224x224.
InceptionResNetV2
InceptionResNetV2es otro modelo previamente entrenado. También se entrena usandoImageNet. La sintaxis para cargar el modelo es la siguiente:
keras.applications.inception_resnet_v2.InceptionResNetV2 (
include_top = True,
weights = 'imagenet',
input_tensor = None,
input_shape = None,
pooling = None,
classes = 1000)Este modelo se puede construir tanto con el formato de datos 'channels_first' (canales, alto, ancho) como con el formato de datos 'channels_last' (alto, ancho, canales).
El tamaño de entrada predeterminado para este modelo es 299x299.
InceptionV3
InceptionV3es otro modelo previamente entrenado. También se entrena uingImageNet. La sintaxis para cargar el modelo es la siguiente:
keras.applications.inception_v3.InceptionV3 (
include_top = True,
weights = 'imagenet',
input_tensor = None,
input_shape = None,
pooling = None,
classes = 1000
)Aquí,
El tamaño de entrada predeterminado para este modelo es 299x299.
Conclusión
Keras es una API de red neuronal muy simple, extensible y fácil de implementar, que se puede usar para construir aplicaciones de aprendizaje profundo con abstracción de alto nivel. Keras es una opción óptima para modelos de inclinación profunda.