Keras - Predicción de series temporales con LSTM RNN
En este capítulo, vamos a escribir un RNN simple basado en la memoria a largo plazo (LSTM) para realizar análisis de secuencia. Una secuencia es un conjunto de valores donde cada valor corresponde a una instancia particular de tiempo. Consideremos un ejemplo simple de lectura de una oración. Leer y comprender una oración implica leer la palabra en el orden dado y tratar de comprender cada palabra y su significado en el contexto dado y finalmente comprender la oración en un sentimiento positivo o negativo.
Aquí, las palabras se consideran valores, y el primer valor corresponde a la primera palabra, el segundo valor corresponde a la segunda palabra, etc., y el orden se mantendrá estrictamente. Sequence Analysis se utiliza con frecuencia en el procesamiento del lenguaje natural para encontrar el análisis de sentimientos del texto dado.
Creemos un modelo LSTM para analizar las críticas de películas de IMDB y encontrar su sentimiento positivo / negativo.
El modelo para el análisis de secuencia se puede representar de la siguiente manera:
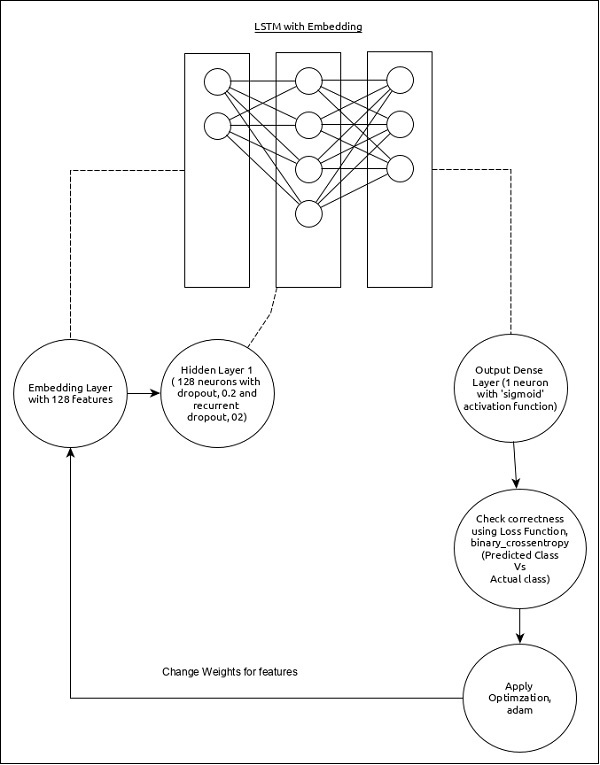
Las características principales del modelo son las siguientes:
Capa de entrada usando la capa de incrustación con 128 entidades.
La primera capa, Densa, consta de 128 unidades con deserción normal y deserción recurrente configuradas en 0.2.
Capa de salida, Dense consta de 1 unidad y función de activación 'sigmoide'.
Utilizar binary_crossentropy como función de pérdida.
Utilizar adam como Optimizador.
Utilizar accuracy como métricas.
Utilice 32 como tamaño de lote.
Usa 15 como épocas.
Utilice 80 como longitud máxima de la palabra.
Utilice 2000 como el número máximo de palabras en una oración dada.
Paso 1: importar los módulos
Importamos los módulos necesarios.
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers import Dense, Embedding
from keras.layers import LSTM
from keras.datasets import imdbPaso 2: cargar datos
Importemos el conjunto de datos imdb.
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words = 2000)Aquí,
imdbes un conjunto de datos proporcionado por Keras. Representa una colección de películas y sus críticas.
num_words representan el número máximo de palabras en la reseña.
Paso 3: procesa los datos
Cambiemos el conjunto de datos de acuerdo con nuestro modelo, para que se pueda introducir en nuestro modelo. Los datos se pueden cambiar usando el siguiente código:
x_train = sequence.pad_sequences(x_train, maxlen=80)
x_test = sequence.pad_sequences(x_test, maxlen=80)Aquí,
sequence.pad_sequences convertir la lista de datos de entrada con forma, (data) en matriz de forma 2D NumPy (data, timesteps). Básicamente, agrega el concepto de pasos de tiempo a los datos proporcionados. Genera los pasos de tiempo de longitud,maxlen.
Paso 4: crea el modelo
Creemos el modelo real.
model = Sequential()
model.add(Embedding(2000, 128))
model.add(LSTM(128, dropout = 0.2, recurrent_dropout = 0.2))
model.add(Dense(1, activation = 'sigmoid'))Aquí,
Hemos usado Embedding layercomo capa de entrada y luego agregó la capa LSTM. Finalmente, unDense layer se utiliza como capa de salida.
Paso 5: compila el modelo
Compilemos el modelo utilizando la función de pérdida seleccionada, el optimizador y las métricas.
model.compile(loss = 'binary_crossentropy',
optimizer = 'adam', metrics = ['accuracy'])Paso 6: Entrena el modelo
Entrenemos el modelo usando fit() método.
model.fit(
x_train, y_train,
batch_size = 32,
epochs = 15,
validation_data = (x_test, y_test)
)La ejecución de la aplicación generará la siguiente información:
Epoch 1/15 2019-09-24 01:19:01.151247: I
tensorflow/core/platform/cpu_feature_guard.cc:142]
Your CPU supports instructions that this
TensorFlow binary was not co mpiled to use: AVX2
25000/25000 [==============================] - 101s 4ms/step - loss: 0.4707
- acc: 0.7716 - val_loss: 0.3769 - val_acc: 0.8349 Epoch 2/15
25000/25000 [==============================] - 95s 4ms/step - loss: 0.3058
- acc: 0.8756 - val_loss: 0.3763 - val_acc: 0.8350 Epoch 3/15
25000/25000 [==============================] - 91s 4ms/step - loss: 0.2100
- acc: 0.9178 - val_loss: 0.5065 - val_acc: 0.8110 Epoch 4/15
25000/25000 [==============================] - 90s 4ms/step - loss: 0.1394
- acc: 0.9495 - val_loss: 0.6046 - val_acc: 0.8146 Epoch 5/15
25000/25000 [==============================] - 90s 4ms/step - loss: 0.0973
- acc: 0.9652 - val_loss: 0.5969 - val_acc: 0.8147 Epoch 6/15
25000/25000 [==============================] - 98s 4ms/step - loss: 0.0759
- acc: 0.9730 - val_loss: 0.6368 - val_acc: 0.8208 Epoch 7/15
25000/25000 [==============================] - 95s 4ms/step - loss: 0.0578
- acc: 0.9811 - val_loss: 0.6657 - val_acc: 0.8184 Epoch 8/15
25000/25000 [==============================] - 97s 4ms/step - loss: 0.0448
- acc: 0.9850 - val_loss: 0.7452 - val_acc: 0.8136 Epoch 9/15
25000/25000 [==============================] - 95s 4ms/step - loss: 0.0324
- acc: 0.9894 - val_loss: 0.7616 - val_acc: 0.8162Epoch 10/15
25000/25000 [==============================] - 100s 4ms/step - loss: 0.0247
- acc: 0.9922 - val_loss: 0.9654 - val_acc: 0.8148 Epoch 11/15
25000/25000 [==============================] - 99s 4ms/step - loss: 0.0169
- acc: 0.9946 - val_loss: 1.0013 - val_acc: 0.8104 Epoch 12/15
25000/25000 [==============================] - 90s 4ms/step - loss: 0.0154
- acc: 0.9948 - val_loss: 1.0316 - val_acc: 0.8100 Epoch 13/15
25000/25000 [==============================] - 89s 4ms/step - loss: 0.0113
- acc: 0.9963 - val_loss: 1.1138 - val_acc: 0.8108 Epoch 14/15
25000/25000 [==============================] - 89s 4ms/step - loss: 0.0106
- acc: 0.9971 - val_loss: 1.0538 - val_acc: 0.8102 Epoch 15/15
25000/25000 [==============================] - 89s 4ms/step - loss: 0.0090
- acc: 0.9972 - val_loss: 1.1453 - val_acc: 0.8129
25000/25000 [==============================] - 10s 390us/stepPaso 7: evaluar el modelo
Evaluemos el modelo usando datos de prueba.
score, acc = model.evaluate(x_test, y_test, batch_size = 32)
print('Test score:', score)
print('Test accuracy:', acc)La ejecución del código anterior generará la siguiente información:
Test score: 1.145306069601178
Test accuracy: 0.81292