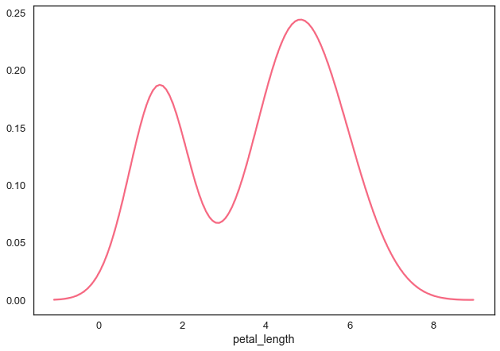
Seaborn - Estimaciones de densidad de kernel
La estimación de densidad de kernel (KDE) es una forma de estimar la función de densidad de probabilidad de una variable aleatoria continua. Se utiliza para análisis no paramétricos.
Establecer el hist bandera a Falso en distplot producirá la gráfica de estimación de densidad de kernel.
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.distplot(df['petal_length'],hist=False)
plt.show()Salida
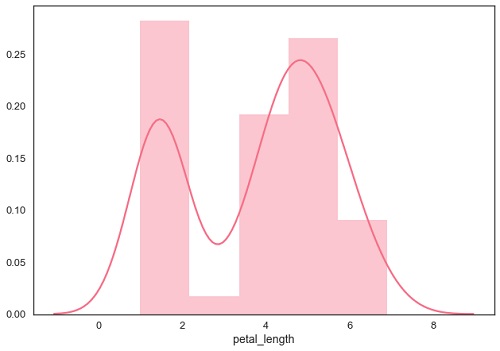
Ajuste de distribución paramétrica
distplot() se utiliza para visualizar la distribución paramétrica de un conjunto de datos.
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.distplot(df['petal_length'])
plt.show()Salida
Trazado de distribución bivariada
La distribución bivariada se utiliza para determinar la relación entre dos variables. Se trata principalmente de la relación entre dos variables y cómo se comporta una variable con respecto a la otra.
La mejor manera de analizar la distribución bivariada en seaborn es utilizando el jointplot() función.
Jointplot crea una figura de varios paneles que proyecta la relación bivariada entre dos variables y también la distribución univariante de cada variable en ejes separados.
Gráfico de dispersión
El diagrama de dispersión es la forma más conveniente de visualizar la distribución donde cada observación se representa en un diagrama bidimensional a través de los ejes xey.
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.jointplot(x = 'petal_length',y = 'petal_width',data = df)
plt.show()Salida
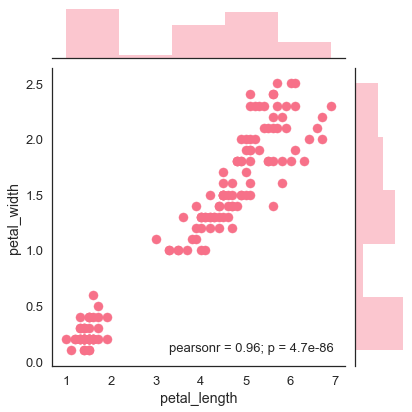
La figura anterior muestra la relación entre el petal_length y petal_widthen los datos de Iris. Una tendencia en el gráfico dice que existe una correlación positiva entre las variables en estudio.
Parcela Hexbin
El agrupamiento hexagonal se utiliza en el análisis de datos bivariados cuando la densidad de los datos es escasa, es decir, cuando los datos están muy dispersos y son difíciles de analizar mediante diagramas de dispersión.
Un parámetro de adición llamado 'tipo' y valor 'hex' traza el diagrama de hexbin.
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.jointplot(x = 'petal_length',y = 'petal_width',data = df,kind = 'hex')
plt.show()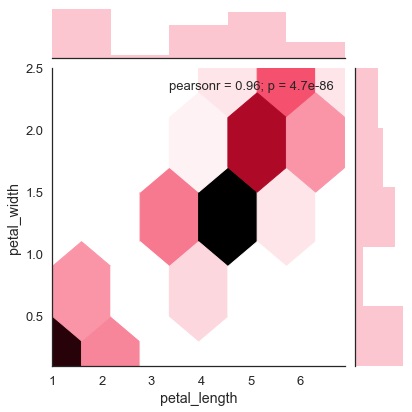
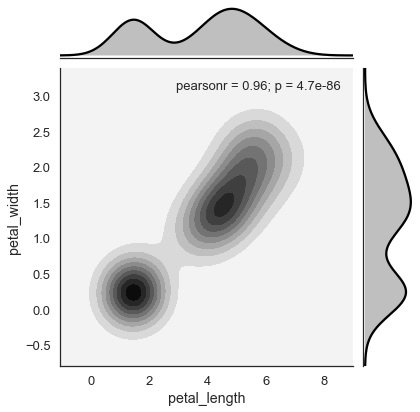
Estimación de la densidad del kernel
La estimación de la densidad del kernel es una forma no paramétrica de estimar la distribución de una variable. En seaborn, podemos trazar un kde usandojointplot().
Pase el valor 'kde' al tipo de parámetro para trazar la gráfica del núcleo.
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.jointplot(x = 'petal_length',y = 'petal_width',data = df,kind = 'hex')
plt.show()Salida