Seaborn - Guía rápida
En el mundo de Analytics, la mejor forma de obtener información es visualizando los datos. Los datos se pueden visualizar representándolos como diagramas que son fáciles de entender, explorar y captar. Estos datos ayudan a llamar la atención sobre elementos clave.
Para analizar un conjunto de datos usando Python, utilizamos Matplotlib, una biblioteca de trazado 2D ampliamente implementada. Asimismo, Seaborn es una biblioteca de visualización en Python. Está construido sobre Matplotlib.
Seaborn Vs Matplotlib
Se resume que si Matplotlib "intenta hacer las cosas fáciles fáciles y las difíciles posibles", Seaborn intenta hacer que un conjunto bien definido de cosas difíciles también sea fácil ".
Seaborn ayuda a resolver los dos problemas principales que enfrenta Matplotlib; los problemas son -
- Parámetros predeterminados de Matplotlib
- Trabajar con marcos de datos
Como Seaborn complementa y amplía Matplotlib, la curva de aprendizaje es bastante gradual. Si conoce Matplotlib, ya está a la mitad de Seaborn.
Características importantes de Seaborn
Seaborn se basa en la biblioteca de visualización central de Python, Matplotlib. Está destinado a servir como complemento y no como reemplazo. Sin embargo, Seaborn viene con algunas características muy importantes. Veamos algunos de ellos aquí. Las funciones ayudan en:
- Temas integrados para diseñar gráficos matplotlib
- Visualización de datos univariados y bivariados
- Ajustar y visualizar modelos de regresión lineal
- Trazar datos estadísticos de series de tiempo
- Seaborn funciona bien con estructuras de datos NumPy y Pandas
- Viene con temas integrados para diseñar gráficos Matplotlib
En la mayoría de los casos, seguirá usando Matplotlib para un trazado simple. Se recomienda el conocimiento de Matplotlib para modificar los gráficos predeterminados de Seaborn.
En este capítulo, analizaremos la configuración del entorno para Seaborn. Comencemos con la instalación y entendamos cómo comenzar a medida que avanzamos.
Instalar Seaborn y comenzar
En esta sección, comprenderemos los pasos involucrados en la instalación de Seaborn.
Usando Pip Installer
Para instalar la última versión de Seaborn, puede usar pip -
pip install seabornPara Windows, Linux y Mac con Anaconda
Anaconda (de https://www.anaconda.com/es una distribución gratuita de Python para SciPy stack. También está disponible para Linux y Mac.
También es posible instalar la versión publicada usando conda -
conda install seabornPara instalar la versión de desarrollo de Seaborn directamente desde github
https://github.com/mwaskom/seaborn"
Dependencias
Considere las siguientes dependencias de Seaborn:
- Python 2.7 o 3.4+
- numpy
- scipy
- pandas
- matplotlib
En este capítulo, analizaremos cómo importar conjuntos de datos y bibliotecas. Comencemos por comprender cómo importar bibliotecas.
Importación de bibliotecas
Comencemos por importar Pandas, que es una gran biblioteca para administrar conjuntos de datos relacionales (formato de tabla). Seaborn es útil cuando se trata de DataFrames, que es la estructura de datos más utilizada para el análisis de datos.
El siguiente comando te ayudará a importar Pandas:
# Pandas for managing datasets
import pandas as pdAhora, importemos la biblioteca Matplotlib, que nos ayuda a personalizar nuestros gráficos.
# Matplotlib for additional customization
from matplotlib import pyplot as pltImportaremos la biblioteca de Seaborn con el siguiente comando:
# Seaborn for plotting and styling
import seaborn as sbImportación de conjuntos de datos
Hemos importado las bibliotecas necesarias. En esta sección, entenderemos cómo importar los conjuntos de datos necesarios.
Seaborn viene con algunos conjuntos de datos importantes en la biblioteca. Cuando se instala Seaborn, los conjuntos de datos se descargan automáticamente.
Puede utilizar cualquiera de estos conjuntos de datos para su aprendizaje. Con la ayuda de la siguiente función, puede cargar el conjunto de datos requerido
load_dataset()Importando datos como Pandas DataFrame
En esta sección, importaremos un conjunto de datos. Este conjunto de datos se carga como Pandas DataFrame de forma predeterminada. Si hay alguna función en Pandas DataFrame, funciona en este DataFrame.
La siguiente línea de código le ayudará a importar el conjunto de datos:
# Seaborn for plotting and styling
import seaborn as sb
df = sb.load_dataset('tips')
print df.head()La línea de código anterior generará el siguiente resultado:
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4Para ver todos los conjuntos de datos disponibles en la biblioteca de Seaborn, puede utilizar el siguiente comando con el get_dataset_names() funciona como se muestra a continuación -
import seaborn as sb
print sb.get_dataset_names()La línea de código anterior devolverá la lista de conjuntos de datos disponibles como la siguiente salida
[u'anscombe', u'attention', u'brain_networks', u'car_crashes', u'dots',
u'exercise', u'flights', u'fmri', u'gammas', u'iris', u'planets', u'tips',
u'titanic']DataFramesalmacenar datos en forma de cuadrículas rectangulares mediante las cuales los datos se pueden ver fácilmente. Cada fila de la cuadrícula rectangular contiene valores de una instancia y cada columna de la cuadrícula es un vector que contiene datos para una variable específica. Esto significa que las filas de un DataFrame no necesitan contener valores del mismo tipo de datos, pueden ser numéricos, de caracteres, lógicos, etc. Los DataFrames para Python vienen con la biblioteca Pandas y se definen como estructuras de datos etiquetadas bidimensionales. con tipos de columnas potencialmente diferentes.
Para obtener más detalles sobre DataFrames, visite nuestro tutorial sobre pandas.
Visualizar datos es un paso y hacer que los datos visualizados sean más agradables es otro paso. La visualización juega un papel vital en la comunicación de conocimientos cuantitativos a una audiencia para captar su atención.
Estética significa un conjunto de principios relacionados con la naturaleza y la apreciación de la belleza, especialmente en el arte. La visualización es un arte de representar datos de la forma más eficaz y sencilla posible.
La biblioteca de Matplotlib admite en gran medida la personalización, pero saber qué configuraciones modificar para lograr una trama atractiva y anticipada es lo que uno debe tener en cuenta para hacer uso de ella. A diferencia de Matplotlib, Seaborn viene con temas personalizados y una interfaz de alto nivel para personalizar y controlar el aspecto de las figuras de Matplotlib.
Ejemplo
import numpy as np
from matplotlib import pyplot as plt
def sinplot(flip = 1):
x = np.linspace(0, 14, 100)
for i in range(1, 5):
plt.plot(x, np.sin(x + i * .5) * (7 - i) * flip)
sinplot()
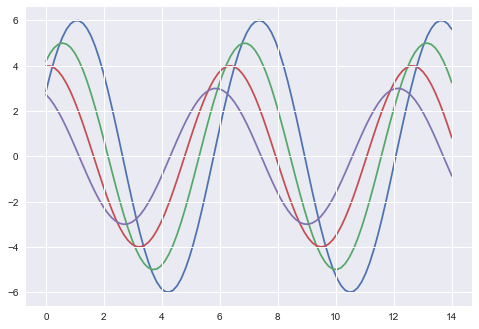
plt.show()Así es como se ve una trama con los valores predeterminados de Matplotlib:

Para cambiar el mismo gráfico a los valores predeterminados de Seaborn, use el set() función -
Ejemplo
import numpy as np
from matplotlib import pyplot as plt
def sinplot(flip = 1):
x = np.linspace(0, 14, 100)
for i in range(1, 5):
plt.plot(x, np.sin(x + i * .5) * (7 - i) * flip)
import seaborn as sb
sb.set()
sinplot()
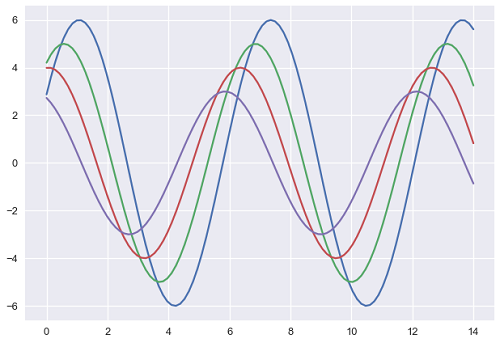
plt.show()Salida
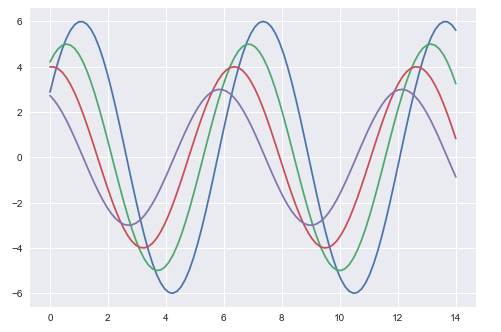
Las dos figuras anteriores muestran la diferencia en los gráficos predeterminados de Matplotlib y Seaborn. La representación de los datos es la misma, pero el estilo de representación varía en ambos.
Básicamente, Seaborn divide los parámetros de Matplotlib en dos grupos
- Estilos de trama
- Escala de parcela
Estilos de figuras de Seaborn
La interfaz para manipular los estilos es set_style(). Con esta función puede establecer el tema de la trama. Según la última versión actualizada, a continuación se muestran los cinco temas disponibles.
- Darkgrid
- Whitegrid
- Dark
- White
- Ticks
Intentemos aplicar un tema de la lista mencionada anteriormente. El tema predeterminado de la trama serádarkgrid que hemos visto en el ejemplo anterior.
Ejemplo
import numpy as np
from matplotlib import pyplot as plt
def sinplot(flip=1):
x = np.linspace(0, 14, 100)
for i in range(1, 5):
plt.plot(x, np.sin(x + i * .5) * (7 - i) * flip)
import seaborn as sb
sb.set_style("whitegrid")
sinplot()
plt.show()Salida
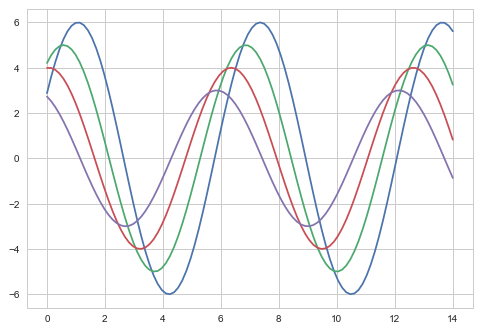
La diferencia entre los dos gráficos anteriores es el color de fondo
Eliminación de espinas de ejes
En los temas de blanco y garrapatas, podemos eliminar las espinas del eje superior y derecho usando el despine() función.
Ejemplo
import numpy as np
from matplotlib import pyplot as plt
def sinplot(flip=1):
x = np.linspace(0, 14, 100)
for i in range(1, 5):
plt.plot(x, np.sin(x + i * .5) * (7 - i) * flip)
import seaborn as sb
sb.set_style("white")
sinplot()
sb.despine()
plt.show()Salida
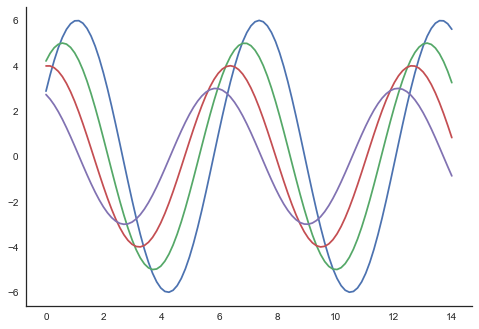
En los gráficos regulares, usamos solo los ejes izquierdo e inferior. Utilizando eldespine() función, podemos evitar las espinas innecesarias de los ejes derecho y superior, que no es compatible con Matplotlib.
Anulando los elementos
Si desea personalizar los estilos de Seaborn, puede pasar un diccionario de parámetros al set_style() función. Los parámetros disponibles se ven usandoaxes_style() función.
Ejemplo
import seaborn as sb
print sb.axes_styleSalida
{'axes.axisbelow' : False,
'axes.edgecolor' : 'white',
'axes.facecolor' : '#EAEAF2',
'axes.grid' : True,
'axes.labelcolor' : '.15',
'axes.linewidth' : 0.0,
'figure.facecolor' : 'white',
'font.family' : [u'sans-serif'],
'font.sans-serif' : [u'Arial', u'Liberation
Sans', u'Bitstream Vera Sans', u'sans-serif'],
'grid.color' : 'white',
'grid.linestyle' : u'-',
'image.cmap' : u'Greys',
'legend.frameon' : False,
'legend.numpoints' : 1,
'legend.scatterpoints': 1,
'lines.solid_capstyle': u'round',
'text.color' : '.15',
'xtick.color' : '.15',
'xtick.direction' : u'out',
'xtick.major.size' : 0.0,
'xtick.minor.size' : 0.0,
'ytick.color' : '.15',
'ytick.direction' : u'out',
'ytick.major.size' : 0.0,
'ytick.minor.size' : 0.0}La alteración de los valores de cualquiera de los parámetros alterará el estilo del gráfico.
Ejemplo
import numpy as np
from matplotlib import pyplot as plt
def sinplot(flip=1):
x = np.linspace(0, 14, 100)
for i in range(1, 5):
plt.plot(x, np.sin(x + i * .5) * (7 - i) * flip)
import seaborn as sb
sb.set_style("darkgrid", {'axes.axisbelow': False})
sinplot()
sb.despine()
plt.show()Salida
Escalar elementos de la gráfica
También tenemos control sobre los elementos de la trama y podemos controlar la escala de la trama usando el set_context()función. Tenemos cuatro plantillas preestablecidas para contextos, según el tamaño relativo, los contextos se nombran de la siguiente manera
- Paper
- Notebook
- Talk
- Poster
De forma predeterminada, el contexto se establece en cuaderno; y se utilizó en las parcelas anteriores.
Ejemplo
import numpy as np
from matplotlib import pyplot as plt
def sinplot(flip = 1):
x = np.linspace(0, 14, 100)
for i in range(1, 5):
plt.plot(x, np.sin(x + i * .5) * (7 - i) * flip)
import seaborn as sb
sb.set_style("darkgrid", {'axes.axisbelow': False})
sinplot()
sb.despine()
plt.show()Salida
El tamaño de salida de la parcela real es mayor en tamaño en comparación con las parcelas anteriores.
Note - Debido a la escala de las imágenes en nuestra página web, es posible que se pierda la diferencia real en nuestros gráficos de ejemplo.
El color juega un papel importante que cualquier otro aspecto en las visualizaciones. Cuando se usa de manera efectiva, el color agrega más valor al gráfico. Una paleta significa una superficie plana sobre la que un pintor arregla y mezcla pinturas.
Paleta de colores de construcción
Seaborn proporciona una función llamada color_palette(), que se puede utilizar para dar color a las tramas y agregarle más valor estético.
Uso
seaborn.color_palette(palette = None, n_colors = None, desat = None)Parámetro
La siguiente tabla enumera los parámetros para la construcción de la paleta de colores:
| No Señor. | Palatte y descripción |
|---|---|
| 1 | n_colors Número de colores en la paleta. Si es Ninguno, el valor predeterminado dependerá de cómo se especifique la paleta. Por defecto, el valor den_colors es de 6 colores. |
| 2 | desat Proporción para desaturar cada color. |
Regreso
Retorno se refiere a la lista de tuplas RGB. A continuación se muestran las paletas de Seaborn disponibles:
- Deep
- Muted
- Bright
- Pastel
- Dark
- Colorblind
Además de estos, también se puede generar una nueva paleta
Es difícil decidir qué paleta se debe usar para un conjunto de datos dado sin conocer las características de los datos. Siendo conscientes de ello, clasificaremos las diferentes formas de usocolor_palette() tipos -
- qualitative
- sequential
- diverging
Tenemos otra función seaborn.palplot()que se ocupa de las paletas de colores. Esta función traza la paleta de colores como una matriz horizontal. Sabremos más sobreseaborn.palplot() en los siguientes ejemplos.
Paletas de colores cualitativos
Las paletas cualitativas o categóricas son las más adecuadas para trazar los datos categóricos.
Ejemplo
from matplotlib import pyplot as plt
import seaborn as sb
current_palette = sb.color_palette()
sb.palplot(current_palette)
plt.show()Salida

No hemos pasado ningún parámetro en color_palette();por defecto, estamos viendo 6 colores. Puede ver el número deseado de colores pasando un valor aln_colorsparámetro. Aquí elpalplot() se utiliza para trazar la matriz de colores horizontalmente.
Paletas de colores secuenciales
Los gráficos secuenciales son adecuados para expresar la distribución de datos que van desde valores relativamente más bajos hasta valores más altos dentro de un rango.
Agregar un carácter adicional 's' al color pasado al parámetro de color trazará la trama secuencial.
Ejemplo
from matplotlib import pyplot as plt
import seaborn as sb
current_palette = sb.color_palette()
sb.palplot(sb.color_palette("Greens"))
plt.show()
Note −Necesitamos agregar 's' al parámetro como 'Verdes' en el ejemplo anterior.
Paleta de colores divergentes
Las paletas divergentes utilizan dos colores diferentes. Cada color representa una variación en el valor que va desde un punto común en cualquier dirección.
Suponga que grafica los datos que van de -1 a 1. Los valores de -1 a 0 toman un color y 0 a +1 toman otro color.
De forma predeterminada, los valores están centrados desde cero. Puede controlarlo con el centro de parámetros pasando un valor.
Ejemplo
from matplotlib import pyplot as plt
import seaborn as sb
current_palette = sb.color_palette()
sb.palplot(sb.color_palette("BrBG", 7))
plt.show()Salida

Configuración de la paleta de colores predeterminada
Las funciones color_palette() tiene un compañero llamado set_palette()La relación entre ellos es similar a los pares cubiertos en el capítulo de estética. Los argumentos son los mismos para ambosset_palette() y color_palette(), pero los parámetros predeterminados de Matplotlib se cambian para que la paleta se use para todos los gráficos.
Ejemplo
import numpy as np
from matplotlib import pyplot as plt
def sinplot(flip = 1):
x = np.linspace(0, 14, 100)
for i in range(1, 5):
plt.plot(x, np.sin(x + i * .5) * (7 - i) * flip)
import seaborn as sb
sb.set_style("white")
sb.set_palette("husl")
sinplot()
plt.show()Salida

Trazado de distribución univariante
La distribución de datos es lo más importante que debemos comprender al analizar los datos. Aquí, veremos cómo seaborn nos ayuda a comprender la distribución univariante de los datos.
Función distplot()proporciona la forma más conveniente de echar un vistazo rápido a la distribución univariante. Esta función trazará un histograma que se ajusta a la estimación de la densidad del núcleo de los datos.
Uso
seaborn.distplot()Parámetros
La siguiente tabla enumera los parámetros y su descripción:
| No Señor. | Descripción de parámetros |
|---|---|
| 1 | data Serie, matriz 1d o lista |
| 2 | bins Especificación de contenedores de hist |
| 3 | hist bool |
| 4 | kde bool |
Estos son parámetros básicos e importantes a tener en cuenta.
Los histogramas representan la distribución de datos formando contenedores a lo largo del rango de datos y luego dibujando barras para mostrar el número de observaciones que caen en cada contenedor.
Seaborn viene con algunos conjuntos de datos y hemos utilizado pocos conjuntos de datos en nuestros capítulos anteriores. Hemos aprendido cómo cargar el conjunto de datos y cómo buscar la lista de conjuntos de datos disponibles.
Seaborn viene con algunos conjuntos de datos y hemos utilizado pocos conjuntos de datos en nuestros capítulos anteriores. Hemos aprendido cómo cargar el conjunto de datos y cómo buscar la lista de conjuntos de datos disponibles.
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.distplot(df['petal_length'],kde = False)
plt.show()Salida
Aquí, kdela bandera está establecida en Falso. Como resultado, se eliminará la representación de la gráfica de estimación del kernel y solo se representará el histograma.
La estimación de densidad de kernel (KDE) es una forma de estimar la función de densidad de probabilidad de una variable aleatoria continua. Se utiliza para análisis no paramétricos.
Establecer el hist bandera a Falso en distplot producirá la gráfica de estimación de densidad de kernel.
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.distplot(df['petal_length'],hist=False)
plt.show()Salida
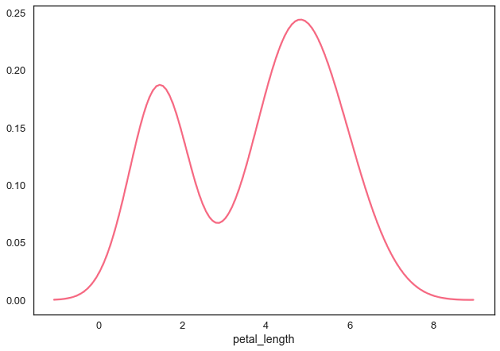
Ajuste de distribución paramétrica
distplot() se utiliza para visualizar la distribución paramétrica de un conjunto de datos.
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.distplot(df['petal_length'])
plt.show()Salida
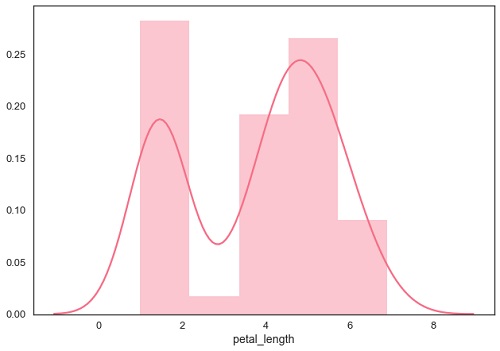
Trazado de distribución bivariada
La distribución bivariada se utiliza para determinar la relación entre dos variables. Se trata principalmente de la relación entre dos variables y cómo se comporta una variable con respecto a la otra.
La mejor manera de analizar la distribución bivariada en seaborn es utilizando el jointplot() función.
Jointplot crea una figura de varios paneles que proyecta la relación bivariada entre dos variables y también la distribución univariante de cada variable en ejes separados.
Gráfico de dispersión
El diagrama de dispersión es la forma más conveniente de visualizar la distribución donde cada observación se representa en un diagrama bidimensional a través de los ejes xey.
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.jointplot(x = 'petal_length',y = 'petal_width',data = df)
plt.show()Salida
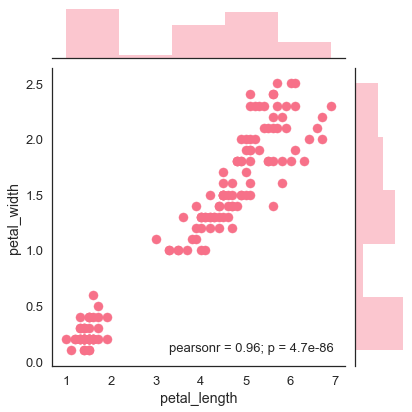
La figura anterior muestra la relación entre el petal_length y petal_widthen los datos de Iris. Una tendencia en el gráfico dice que existe una correlación positiva entre las variables en estudio.
Parcela Hexbin
El agrupamiento hexagonal se utiliza en el análisis de datos bivariados cuando la densidad de los datos es escasa, es decir, cuando los datos están muy dispersos y son difíciles de analizar mediante diagramas de dispersión.
Un parámetro de adición llamado 'tipo' y valor 'hex' traza el diagrama de hexbin.
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.jointplot(x = 'petal_length',y = 'petal_width',data = df,kind = 'hex')
plt.show()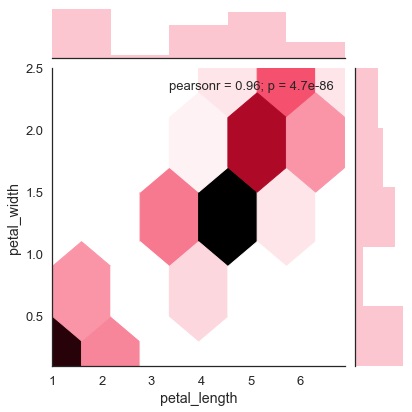
Estimación de la densidad del kernel
La estimación de la densidad del kernel es una forma no paramétrica de estimar la distribución de una variable. En seaborn, podemos trazar un kde usandojointplot().
Pase el valor 'kde' al tipo de parámetro para trazar la gráfica del núcleo.
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.jointplot(x = 'petal_length',y = 'petal_width',data = df,kind = 'hex')
plt.show()Salida
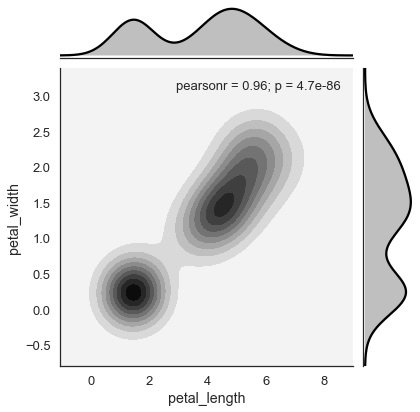
Los conjuntos de datos en estudio en tiempo real contienen muchas variables. En tales casos, se debe analizar la relación entre todas y cada una de las variables. Trazar la distribución bivariada para (n, 2) combinaciones será un proceso muy complejo y que llevará mucho tiempo.
Para trazar múltiples distribuciones bivariadas por pares en un conjunto de datos, puede usar el pairplot()función. Esto muestra la relación para (n, 2) combinación de variables en un DataFrame como una matriz de gráficos y los gráficos diagonales son los gráficos univariados.
Ejes
En esta sección, aprenderemos qué son los ejes, su uso, parámetros, etc.
Uso
seaborn.pairplot(data,…)Parámetros
La siguiente tabla enumera los parámetros de los ejes:
| No Señor. | Descripción de parámetros |
|---|---|
| 1 | data Marco de datos |
| 2 | hue Variable en datos para mapear aspectos de la trama a diferentes colores. |
| 3 | palette Conjunto de colores para mapear la variable de tono |
| 4 | kind Tipo de trama para las relaciones de no identidad. {'dispersión', 'reg'} |
| 5 | diag_kind Tipo de trama para las subtramas diagonales. {'hist', 'kde'} |
Excepto los datos, todos los demás parámetros son opcionales. Hay algunos otros parámetros quepairplotpoder aceptar. Los mencionados anteriormente son params de uso frecuente.
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.set_style("ticks")
sb.pairplot(df,hue = 'species',diag_kind = "kde",kind = "scatter",palette = "husl")
plt.show()Salida
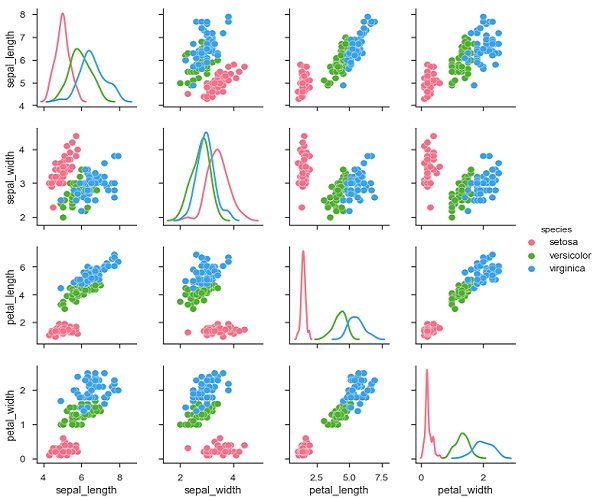
Podemos observar las variaciones en cada parcela. Los gráficos están en formato de matriz donde el nombre de la fila representa el eje xy el nombre de la columna representa el eje y.
Las gráficas diagonales son gráficas de densidad de kernel donde las otras gráficas son gráficas de dispersión como se mencionó.
En nuestros capítulos anteriores aprendimos sobre diagramas de dispersión, diagramas de hexbin y diagramas de kde que se utilizan para analizar las variables continuas en estudio. Estos gráficos no son adecuados cuando la variable en estudio es categórica.
Cuando una o ambas variables en estudio son categóricas, usamos gráficos como striplot (), swarmplot (), etc. Seaborn proporciona una interfaz para hacerlo.
Gráficos de dispersión categóricos
En esta sección, aprenderemos sobre diagramas de dispersión categóricos.
stripplot ()
stripplot () se utiliza cuando una de las variables en estudio es categórica. Representa los datos en orden ordenado a lo largo de cualquiera de los ejes.
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.stripplot(x = "species", y = "petal_length", data = df)
plt.show()Salida
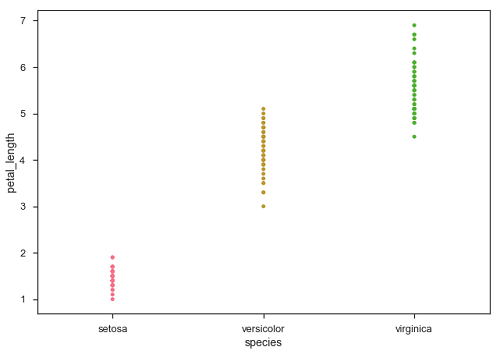
En el gráfico anterior, podemos ver claramente la diferencia de petal_lengthen cada especie. Pero, el principal problema con el diagrama de dispersión anterior es que los puntos en el diagrama de dispersión se superponen. Usamos el parámetro 'Jitter' para manejar este tipo de escenario.
Jitter agrega algo de ruido aleatorio a los datos. Este parámetro ajustará las posiciones a lo largo del eje categórico.
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.stripplot(x = "species", y = "petal_length", data = df, jitter = Ture)
plt.show()Salida
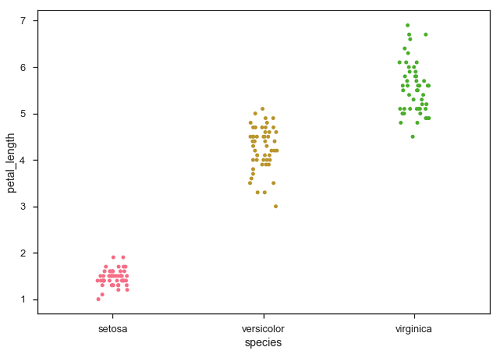
Ahora, la distribución de puntos se puede ver fácilmente.
Swarmplot ()
Otra opción que se puede utilizar como alternativa a 'Jitter' es función swarmplot(). Esta función coloca cada punto del gráfico de dispersión en el eje categórico y, por lo tanto, evita puntos superpuestos:
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.swarmplot(x = "species", y = "petal_length", data = df)
plt.show()Salida
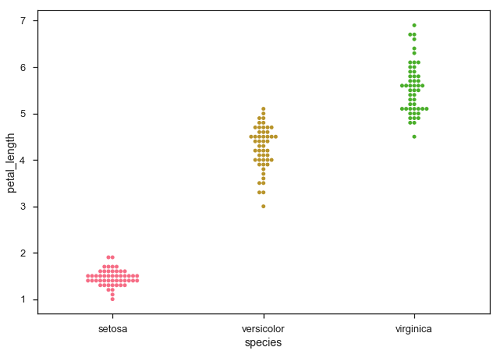
En los gráficos de dispersión categóricos que tratamos en el capítulo anterior, el enfoque se vuelve limitado en la información que puede proporcionar sobre la distribución de valores dentro de cada categoría. Ahora, yendo más allá, veamos qué puede facilitarnos la realización de comparaciones en categorías.
Diagramas de caja
Boxplot es una forma conveniente de visualizar la distribución de datos a través de sus cuartiles.
Los diagramas de caja suelen tener líneas verticales que se extienden desde las cajas y que se denominan bigotes. Estos bigotes indican variabilidad fuera de los cuartiles superior e inferior, por lo tanto, los diagramas de caja también se denominan comobox-and-whisker trama y box-and-whisker diagrama. Cualquier valor atípico en los datos se representa como puntos individuales.
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.swarmplot(x = "species", y = "petal_length", data = df)
plt.show()Salida
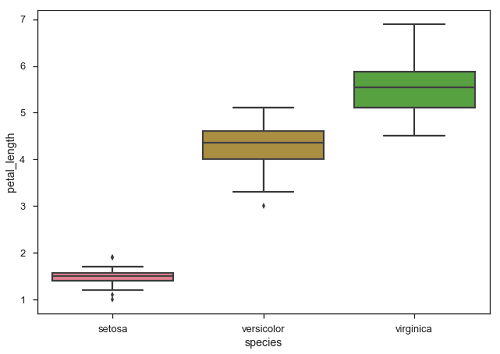
Los puntos en la gráfica indican el valor atípico.
Tramas de violín
Los gráficos de violín son una combinación del gráfico de caja con las estimaciones de densidad del núcleo. Por lo tanto, estos gráficos son más fáciles de analizar y comprender la distribución de los datos.
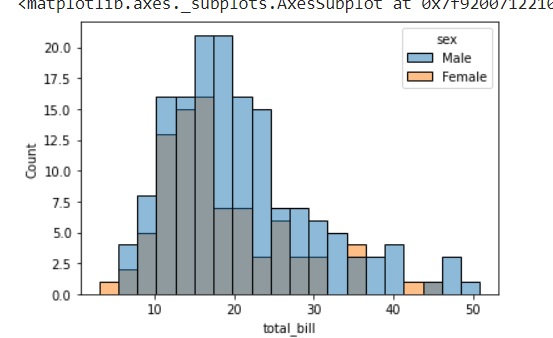
Usemos el conjunto de datos de sugerencias llamado para aprender más sobre las tramas de violín. Este conjunto de datos contiene la información relacionada con los consejos dados por los clientes en un restaurante.
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
sb.violinplot(x = "day", y = "total_bill", data=df)
plt.show()Salida
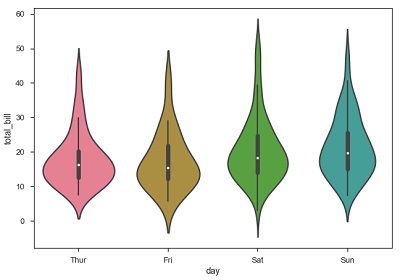
Los valores de los cuartiles y bigotes del diagrama de caja se muestran dentro del violín. Como la trama del violín usa KDE, la parte más ancha del violín indica que la densidad más alta y la región estrecha representa una densidad relativamente más baja. El rango intercuartil en el diagrama de caja y la porción de mayor densidad en kde caen en la misma región de cada categoría de diagrama de violín.
El gráfico anterior muestra la distribución de total_bill en cuatro días de la semana. Pero, además de eso, si queremos ver cómo se comporta la distribución con respecto al sexo, explorémosla en el siguiente ejemplo.
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
sb.violinplot(x = "day", y = "total_bill",hue = 'sex', data = df)
plt.show()Salida

Ahora podemos ver claramente el comportamiento de gasto entre hombres y mujeres. Podemos decir fácilmente que los hombres ganan más facturas que las mujeres mirando la trama.
Y, si la variable de tono tiene solo dos clases, podemos embellecer la trama dividiendo cada violín en dos en lugar de dos violines en un día determinado. Cualquiera de las partes del violín se refiere a cada clase en la variable de tono.
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
sb.violinplot(x = "day", y="total_bill",hue = 'sex', data = df)
plt.show()Salida

En la mayoría de las situaciones, tratamos con estimaciones de la distribución total de los datos. Pero cuando se trata de la estimación de tendencia central, necesitamos una forma específica de resumir la distribución. La media y la mediana son las técnicas más utilizadas para estimar la tendencia central de la distribución.
En todas las tramas que aprendimos en el apartado anterior, realizamos la visualización de toda la distribución. Ahora, analicemos las parcelas con las que podemos estimar la tendencia central de la distribución.
Gráfico de barras
los barplot()muestra la relación entre una variable categórica y una variable continua. Los datos se representan en barras rectangulares donde la longitud de la barra representa la proporción de los datos en esa categoría.
El diagrama de barras representa la estimación de la tendencia central. Usemos el conjunto de datos 'titánico' para aprender diagramas de barras.
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('titanic')
sb.barplot(x = "sex", y = "survived", hue = "class", data = df)
plt.show()Salida
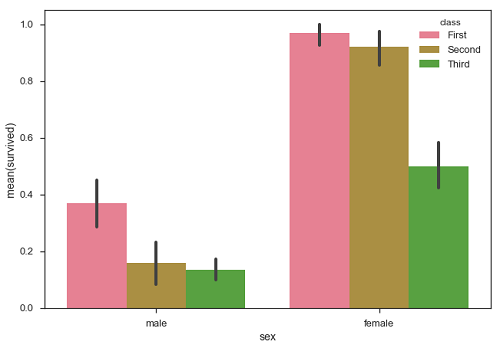
En el ejemplo anterior, podemos ver que el número promedio de supervivencias de hombres y mujeres en cada clase. De la trama podemos entender que sobrevivieron más hembras que machos. Tanto en machos como en hembras, la mayor parte de las supervivencias son de primera clase.
Un caso especial en el diagrama de barras es mostrar el número de observaciones en cada categoría en lugar de calcular una estadística para una segunda variable. Para esto usamoscountplot().
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('titanic')
sb.countplot(x = " class ", data = df, palette = "Blues");
plt.show()Salida
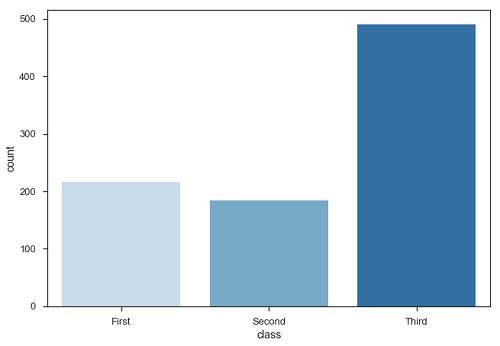
Plot dice que el número de pasajeros en la tercera clase es mayor que en la primera y segunda clase.
Gráficos de puntos
Los gráficos de puntos sirven igual que los gráficos de barras pero con un estilo diferente. En lugar de la barra completa, el valor de la estimación está representado por el punto a una cierta altura en el otro eje.
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('titanic')
sb.pointplot(x = "sex", y = "survived", hue = "class", data = df)
plt.show()Salida

Siempre es preferible utilizar conjuntos de datos "largos desde" o "ordenados". Pero en los momentos en que no nos queda otra opción que utilizar un conjunto de datos de "formato ancho", las mismas funciones también se pueden aplicar a datos de "formato amplio" en una variedad de formatos, incluidos Pandas Data Frames o NumPy bidimensional. matrices. Estos objetos deben pasarse directamente al parámetro de datos, las variables xey deben especificarse como cadenas
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.boxplot(data = df, orient = "h")
plt.show()Salida
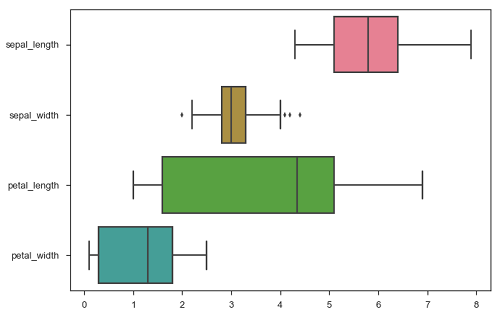
Además, estas funciones aceptan vectores de objetos Pandas o NumPy en lugar de variables en un DataFrame.
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.boxplot(data = df, orient = "h")
plt.show()Salida
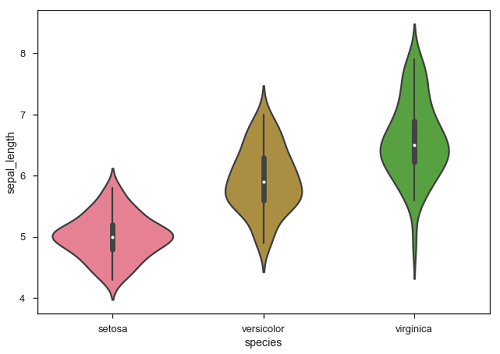
La principal ventaja de usar Seaborn para muchos desarrolladores en el mundo de Python es que puede tomar el objeto pandas DataFrame como parámetro.
Los datos categóricos se pueden visualizar usando dos gráficos, puede usar las funciones pointplot(), o la función de nivel superior factorplot().
Factorplot
Factorplot dibuja un gráfico categórico en un FacetGrid. Usando el parámetro 'kind' podemos elegir la trama como boxplot, violinplot, barplot y stripplot. FacetGrid usa la gráfica de puntos de forma predeterminada.
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('exercise')
sb.factorplot(x = "time", y = pulse", hue = "kind",data = df);
plt.show()Salida
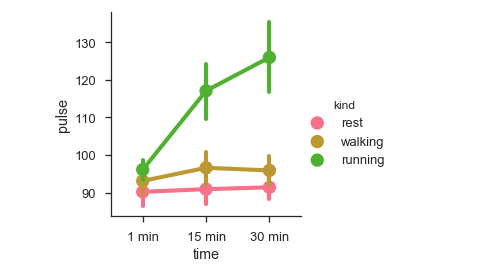
Podemos usar diferentes gráficos para visualizar los mismos datos usando el kind parámetro.
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('exercise')
sb.factorplot(x = "time", y = "pulse", hue = "kind", kind = 'violin',data = df);
plt.show()Salida
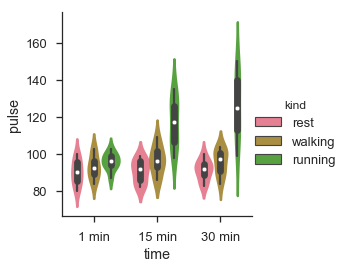
En factorplot, los datos se trazan en una cuadrícula de facetas.
¿Qué es Facet Grid?
Facet grid forma una matriz de paneles definidos por fila y columna dividiendo las variables. Debido a los paneles, un solo gráfico se parece a varios gráficos. Es muy útil analizar todas las combinaciones en dos variables discretas.
Visualicemos la definición anterior con un ejemplo.
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('exercise')
sb.factorplot(x = "time", y = "pulse", hue = "kind", kind = 'violin', col = "diet", data = df);
plt.show()Salida
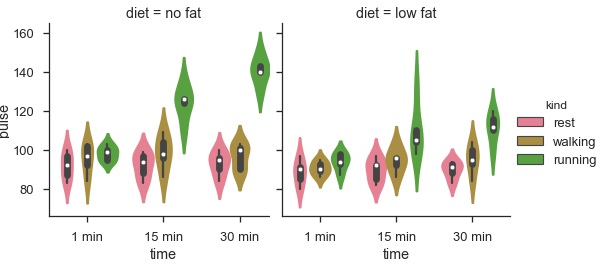
La ventaja de usar Facet es que podemos ingresar otra variable en la gráfica. El gráfico anterior se divide en dos gráficos basados en una tercera variable llamada 'dieta' utilizando el parámetro 'col'.
Podemos hacer muchas facetas de columna y alinearlas con las filas de la cuadrícula -
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('titanic')
sb.factorplot("alive", col = "deck", col_wrap = 3,data = df[df.deck.notnull()],kind = "count")
plt.show()salida
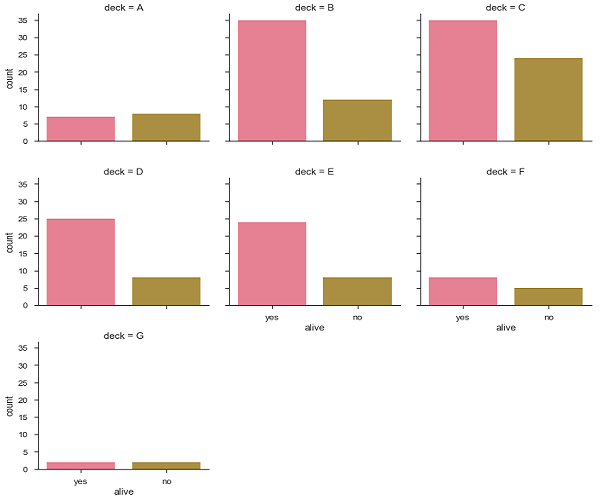
La mayoría de las veces, utilizamos conjuntos de datos que contienen múltiples variables cuantitativas, y el objetivo de un análisis suele ser relacionar esas variables entre sí. Esto se puede hacer a través de las líneas de regresión.
Mientras construimos los modelos de regresión, a menudo buscamos multicollinearity,donde teníamos que ver la correlación entre todas las combinaciones de variables continuas y tomaremos las acciones necesarias para eliminar la multicolinealidad si existe. En tales casos, las siguientes técnicas ayudan.
Funciones para dibujar modelos de regresión lineal
Hay dos funciones principales en Seaborn para visualizar una relación lineal determinada mediante regresión. Estas funciones sonregplot() y lmplot().
regplot vs lmplot
| tramar | lmplot |
|---|---|
| acepta las variables xey en una variedad de formatos que incluyen matrices numpy simples, objetos de la serie pandas o como referencias a variables en un DataFrame de pandas | tiene datos como parámetro obligatorio y las variables xey deben especificarse como cadenas. Este formato de datos se denomina datos de "formato largo". |
Dibujemos ahora las gráficas.
Ejemplo
Graficar el gráfico de registro y luego empalmar con los mismos datos en este ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
sb.regplot(x = "total_bill", y = "tip", data = df)
sb.lmplot(x = "total_bill", y = "tip", data = df)
plt.show()Salida
Puede ver la diferencia de tamaño entre dos parcelas.
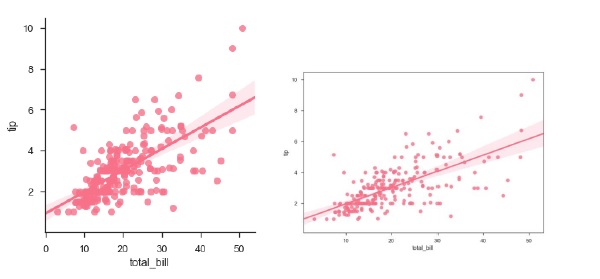
También podemos ajustar una regresión lineal cuando una de las variables toma valores discretos
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
sb.lmplot(x = "size", y = "tip", data = df)
plt.show()Salida
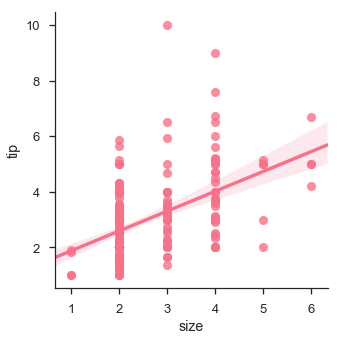
Adaptación a diferentes tipos de modelos
El modelo de regresión lineal simple utilizado anteriormente es muy simple de ajustar, pero en la mayoría de los casos, los datos no son lineales y los métodos anteriores no pueden generalizar la línea de regresión.
Usemos el conjunto de datos de Anscombe con las gráficas de regresión:
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('anscombe')
sb.lmplot(x="x", y="y", data=df.query("dataset == 'I'"))
plt.show()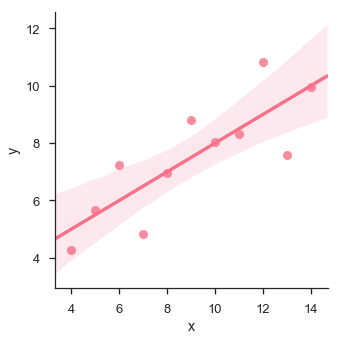
En este caso, los datos se ajustan bien al modelo de regresión lineal con menos varianza.
Veamos otro ejemplo donde los datos tienen una gran desviación, lo que muestra que la línea de mejor ajuste no es buena.
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('anscombe')
sb.lmplot(x = "x", y = "y", data = df.query("dataset == 'II'"))
plt.show()Salida
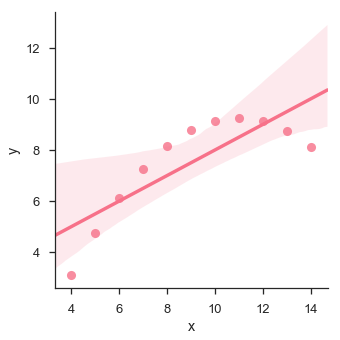
El gráfico muestra la alta desviación de los puntos de datos de la línea de regresión. Dicho orden superior no lineal se puede visualizar utilizando ellmplot() y regplot()Estos pueden ajustarse a un modelo de regresión polinomial para explorar tipos simples de tendencias no lineales en el conjunto de datos:
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('anscombe')
sb.lmplot(x = "x", y = "y", data = df.query("dataset == 'II'"),order = 2)
plt.show()Salida
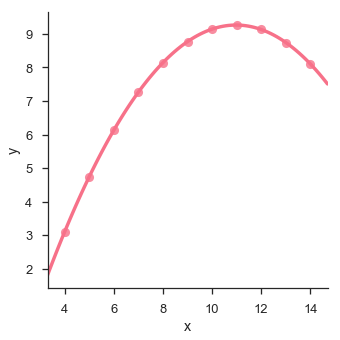
Un enfoque útil para explorar datos de dimensiones medias es dibujar varias instancias de la misma gráfica en diferentes subconjuntos de su conjunto de datos.
Esta técnica se denomina comúnmente como trazado de "celosía" o "enrejado" y está relacionada con la idea de "múltiplos pequeños".
Para usar estas funciones, sus datos deben estar en un Pandas DataFrame.
Trazar pequeños múltiplos de subconjuntos de datos
En el capítulo anterior, hemos visto el ejemplo de FacetGrid donde la clase FacetGrid ayuda a visualizar la distribución de una variable, así como la relación entre múltiples variables por separado dentro de subconjuntos de su conjunto de datos usando múltiples paneles.
Un FacetGrid se puede dibujar con hasta tres dimensiones: fila, columna y tono. Los dos primeros tienen una correspondencia obvia con el conjunto de ejes resultante; Piense en la variable de tono como una tercera dimensión a lo largo de un eje de profundidad, donde se trazan diferentes niveles con diferentes colores.
FacetGrid El objeto toma un marco de datos como entrada y los nombres de las variables que formarán las dimensiones de fila, columna o tono de la cuadrícula.
Las variables deben ser categóricas y los datos de cada nivel de la variable se utilizarán para una faceta a lo largo de ese eje.
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
g = sb.FacetGrid(df, col = "time")
plt.show()Salida
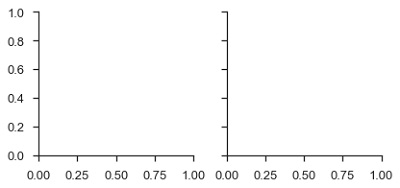
En el ejemplo anterior, acabamos de inicializar el facetgrid objeto que no dibuja nada sobre ellos.
El enfoque principal para visualizar datos en esta cuadrícula es con el FacetGrid.map()método. Veamos la distribución de sugerencias en cada uno de estos subconjuntos, usando un histograma.
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
g = sb.FacetGrid(df, col = "time")
g.map(plt.hist, "tip")
plt.show()Salida
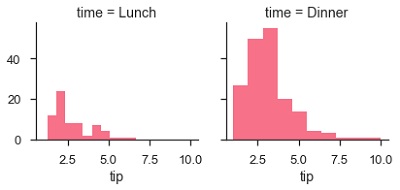
El número de parcelas es más de uno debido al parámetro col. Hablamos sobre el parámetro col en nuestros capítulos anteriores.
Para hacer una gráfica relacional, pase los nombres de múltiples variables.
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('tips')
g = sb.FacetGrid(df, col = "sex", hue = "smoker")
g.map(plt.scatter, "total_bill", "tip")
plt.show()Salida
PairGrid nos permite dibujar una cuadrícula de subparcelas usando el mismo tipo de parcela para visualizar datos.
A diferencia de FacetGrid, utiliza un par de variables diferente para cada subparcela. Forma una matriz de subparcelas. A veces también se le llama como "matriz de diagrama de dispersión".
El uso de pairgrid es similar a facetgrid. Primero inicialice la cuadrícula y luego pase la función de trazado.
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
g = sb.PairGrid(df)
g.map(plt.scatter);
plt.show()
También es posible graficar una función diferente en la diagonal para mostrar la distribución univariante de la variable en cada columna.
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
g = sb.PairGrid(df)
g.map_diag(plt.hist)
g.map_offdiag(plt.scatter);
plt.show()Salida
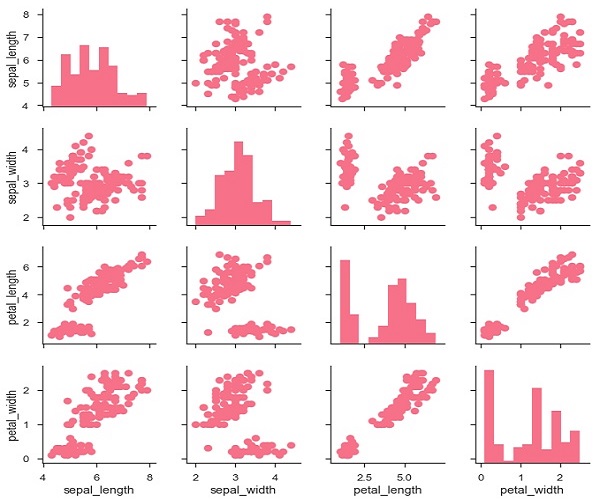
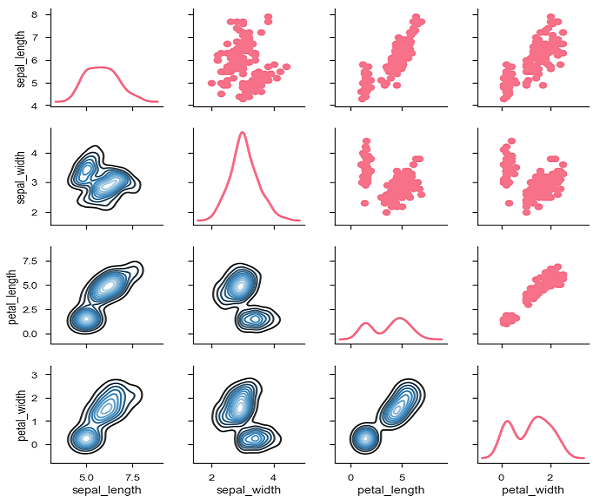
Podemos personalizar el color de estos gráficos usando otra variable categórica. Por ejemplo, el conjunto de datos de iris tiene cuatro medidas para cada una de las tres especies diferentes de flores de iris para que pueda ver en qué se diferencian.
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
g = sb.PairGrid(df)
g.map_diag(plt.hist)
g.map_offdiag(plt.scatter);
plt.show()Salida
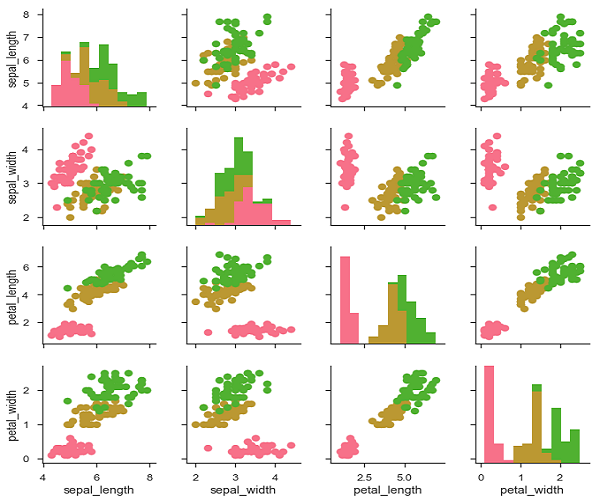
Podemos usar una función diferente en los triángulos superior e inferior para ver diferentes aspectos de la relación.
Ejemplo
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
g = sb.PairGrid(df)
g.map_upper(plt.scatter)
g.map_lower(sb.kdeplot, cmap = "Blues_d")
g.map_diag(sb.kdeplot, lw = 3, legend = False);
plt.show()Salida