Arquitectura centrada en datos
En la arquitectura centrada en datos, los datos se centralizan y otros componentes acceden con frecuencia a ellos, que modifican los datos. El objetivo principal de este estilo es lograr la integralidad de los datos. La arquitectura centrada en datos consta de diferentes componentes que se comunican a través de repositorios de datos compartidos. Los componentes acceden a una estructura de datos compartida y son relativamente independientes, ya que interactúan solo a través del almacén de datos.
Los ejemplos más conocidos de la arquitectura centrada en datos es una arquitectura de base de datos, en la que el esquema de base de datos común se crea con el protocolo de definición de datos, por ejemplo, un conjunto de tablas relacionadas con campos y tipos de datos en un RDBMS.
Otro ejemplo de arquitecturas centradas en datos es la arquitectura web que tiene un esquema de datos común (es decir, una metaestructura de la web) y sigue el modelo de datos hipermedia y los procesos se comunican mediante el uso de servicios de datos compartidos basados en web.

Tipos de componentes
Hay dos tipos de componentes:
UN central dataestructura o almacén de datos o repositorio de datos, que se encarga de proporcionar almacenamiento permanente de datos. Representa el estado actual.
UN data accessor o una colección de componentes independientes que operan en el almacén de datos central, realizan cálculos y pueden retrasar los resultados.
Las interacciones o la comunicación entre los que acceden a los datos se realizan únicamente a través del almacén de datos. Los datos son el único medio de comunicación entre clientes. El flujo de control diferencia la arquitectura en dos categorías:
- Estilo de arquitectura de repositorio
- Estilo de arquitectura de pizarra
Estilo de arquitectura de repositorio
En el estilo de arquitectura de repositorio, el almacén de datos es pasivo y los clientes (componentes de software o agentes) del almacén de datos están activos, que controlan el flujo lógico. Los componentes participantes revisan el almacén de datos para ver si hay cambios.
El cliente envía una solicitud al sistema para realizar acciones (por ejemplo, insertar datos).
Los procesos computacionales son independientes y se activan con las solicitudes entrantes.
Si los tipos de transacciones en un flujo de entrada de transacciones desencadenan la selección de procesos a ejecutar, entonces se trata de una arquitectura de repositorio o base de datos tradicional, o un repositorio pasivo.
Este enfoque es ampliamente utilizado en DBMS, sistemas de información de bibliotecas, el repositorio de interfaces en CORBA, compiladores y entornos CASE (ingeniería de software asistida por computadora).

Ventajas
Proporciona funciones de integridad, copia de seguridad y restauración de datos.
Proporciona escalabilidad y reutilización de agentes, ya que no tienen comunicación directa entre ellos.
Reduce la sobrecarga de datos transitorios entre componentes de software.
Desventajas
Es más vulnerable a fallas y es posible la replicación o duplicación de datos.
Gran dependencia entre la estructura de datos del almacén de datos y sus agentes.
Los cambios en la estructura de datos afectan en gran medida a los clientes.
La evolución de los datos es difícil y cara.
Costo de mover datos en la red para datos distribuidos.
Estilo de arquitectura de pizarra
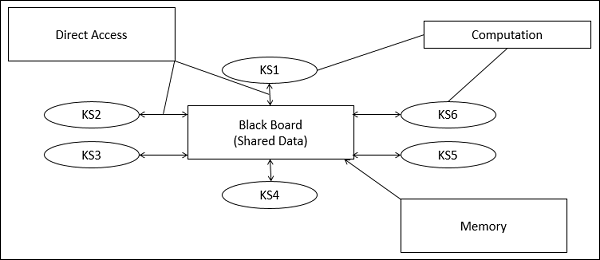
En Blackboard Architecture Style, el almacén de datos está activo y sus clientes son pasivos. Por lo tanto, el flujo lógico está determinado por el estado actual de los datos en el almacén de datos. Tiene un componente de pizarra, que actúa como un repositorio central de datos, y se construye una representación interna y se actúa sobre ella mediante diferentes elementos computacionales.
Una serie de componentes que actúan de forma independiente sobre la estructura de datos común se almacenan en la pizarra.
En este estilo, los componentes interactúan solo a través de la pizarra. El almacén de datos alerta a los clientes cuando se produce un cambio en el almacén de datos.
El estado actual de la solución se almacena en la pizarra y el procesamiento se activa por el estado de la pizarra.
El sistema envía notificaciones conocidas como trigger y datos a los clientes cuando ocurren cambios en los datos.
Este enfoque se encuentra en ciertas aplicaciones de inteligencia artificial y aplicaciones complejas, como el reconocimiento de voz, el reconocimiento de imágenes, el sistema de seguridad y los sistemas de gestión de recursos comerciales, etc.
Si el estado actual de la estructura de datos central es el desencadenante principal de la selección de procesos a ejecutar, el repositorio puede ser una pizarra y esta fuente de datos compartida es un agente activo.
Una diferencia importante con los sistemas de bases de datos tradicionales es que la invocación de elementos computacionales en una arquitectura de pizarra se activa por el estado actual de la pizarra y no por entradas externas.
Partes del modelo de pizarra
El modelo de pizarra generalmente se presenta con tres partes principales:
Knowledge Sources (KS)
Fuentes de conocimiento, también conocidas como Listeners o Subscribersson unidades distintas e independientes. Resuelven partes de un problema y agregan resultados parciales. La interacción entre las fuentes de conocimiento se produce de forma única a través de la pizarra.
Blackboard Data Structure
Los datos de estado de resolución de problemas se organizan en una jerarquía dependiente de la aplicación. Las fuentes de conocimiento realizan cambios en el pizarrón que conducen gradualmente a una solución al problema.
Control
Control gestiona tareas y comprueba el estado de trabajo.
Ventajas
Proporciona escalabilidad que facilita la adición o actualización de fuentes de conocimientos.
Proporciona simultaneidad que permite que todas las fuentes de conocimiento funcionen en paralelo, ya que son independientes entre sí.
Apoya la experimentación de hipótesis.
Admite la reutilización de agentes de fuentes de conocimiento.
Desventajas
El cambio de estructura de la pizarra puede tener un impacto significativo en todos sus agentes, ya que existe una estrecha dependencia entre la pizarra y la fuente de conocimiento.
Puede ser difícil decidir cuándo terminar el razonamiento, ya que solo se espera una solución aproximada.
Problemas en la sincronización de múltiples agentes.
Principales desafíos en el diseño y prueba del sistema.