Guía rápida
La arquitectura de un sistema describe sus componentes principales, sus relaciones (estructuras) y cómo interactúan entre sí. La arquitectura y el diseño del software incluyen varios factores que contribuyen, como la estrategia empresarial, los atributos de calidad, la dinámica humana, el diseño y el entorno de TI.

Podemos segregar Arquitectura y Diseño de Software en dos fases distintas: Arquitectura de Software y Diseño de Software. EnArchitecture, las decisiones no funcionales son emitidas y separadas por los requisitos funcionales. En Diseño, se cumplen los requisitos funcionales.
Arquitectura de software
La arquitectura sirve como blueprint for a system. Proporciona una abstracción para gestionar la complejidad del sistema y establecer un mecanismo de comunicación y coordinación entre los componentes.
Define un structured solution para cumplir con todos los requisitos técnicos y operativos, optimizando al mismo tiempo los atributos de calidad comunes como el rendimiento y la seguridad.
Además, implica un conjunto de decisiones importantes sobre la organización relacionadas con el desarrollo de software y cada una de estas decisiones puede tener un impacto considerable en la calidad, la capacidad de mantenimiento, el rendimiento y el éxito general del producto final. Estas decisiones comprenden:
Selección de elementos estructurales y sus interfaces por las que se compone el sistema.
Comportamiento según lo especificado en colaboraciones entre esos elementos.
Composición de estos elementos estructurales y de comportamiento en un gran subsistema.
Las decisiones arquitectónicas se alinean con los objetivos comerciales.
Los estilos arquitectónicos guían la organización.
Diseño de software
El diseño de software proporciona una design planque describe los elementos de un sistema, cómo encajan y cómo funcionan juntos para cumplir con los requisitos del sistema. Los objetivos de tener un plan de diseño son los siguientes:
Negociar los requisitos del sistema y establecer expectativas con los clientes, el personal de marketing y de gestión.
Actuar como modelo durante el proceso de desarrollo.
Guíe las tareas de implementación, incluido el diseño detallado, la codificación, la integración y las pruebas.
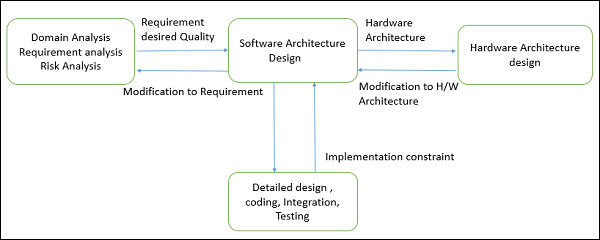
Viene antes del diseño detallado, la codificación, la integración y las pruebas y después del análisis de dominio, el análisis de requisitos y el análisis de riesgos.
Objetivos de la arquitectura
El objetivo principal de la arquitectura es identificar los requisitos que afectan la estructura de la aplicación. Una arquitectura bien diseñada reduce los riesgos comerciales asociados con la creación de una solución técnica y crea un puente entre los requisitos comerciales y técnicos.
Algunos de los otros objetivos son los siguientes:
Exponga la estructura del sistema, pero oculte sus detalles de implementación.
Realice todos los casos de uso y escenarios.
Intente abordar los requisitos de varias partes interesadas.
Manejar requisitos tanto funcionales como de calidad.
Reducir el objetivo de propiedad y mejorar la posición de mercado de la organización.
Mejorar la calidad y funcionalidad que ofrece el sistema.
Mejorar la confianza externa en la organización o el sistema.
Limitaciones
La arquitectura de software sigue siendo una disciplina emergente dentro de la ingeniería de software. Tiene las siguientes limitaciones:
Falta de herramientas y formas estandarizadas de representar la arquitectura.
Falta de métodos de análisis para predecir si la arquitectura dará como resultado una implementación que cumpla con los requisitos.
Falta de conciencia de la importancia del diseño arquitectónico para el desarrollo de software.
Falta de comprensión del papel del arquitecto de software y mala comunicación entre las partes interesadas.
Falta de comprensión del proceso de diseño, experiencia en diseño y evaluación del diseño.
Rol del arquitecto de software
Un arquitecto de software proporciona una solución que el equipo técnico puede crear y diseñar para toda la aplicación. Un arquitecto de software debe tener experiencia en las siguientes áreas:
Experiencia en diseño
Experto en diseño de software, incluyendo diversos métodos y enfoques como diseño orientado a objetos, diseño impulsado por eventos, etc.
Liderar el equipo de desarrollo y coordinar los esfuerzos de desarrollo para la integridad del diseño.
Debería poder revisar las propuestas de diseño y las compensaciones entre ellos.
Experiencia en el campo
Experto en el sistema en desarrollo y plan de evolución del software.
Asistir en el proceso de investigación de requisitos, asegurando la integridad y coherencia.
Coordinar la definición del modelo de dominio para el sistema que se está desarrollando.
Experiencia en tecnología
Experto en tecnologías disponibles que ayuda en la implementación del sistema.
Coordinar la selección de lenguaje de programación, framework, plataformas, bases de datos, etc.
Experiencia metodológica
Experto en metodologías de desarrollo de software que pueden ser adoptadas durante SDLC (Software Development Life Cycle).
Elija los enfoques adecuados para el desarrollo que ayuden a todo el equipo.
Papel oculto del arquitecto de software
Facilita el trabajo técnico entre los miembros del equipo y refuerza la relación de confianza en el equipo.
Especialista en información que comparte conocimientos y tiene una vasta experiencia.
Proteja a los miembros del equipo de fuerzas externas que los distraerían y aportarían menos valor al proyecto.
Entregables del arquitecto
Un conjunto de objetivos funcionales claros, completos, consistentes y alcanzables
Una descripción funcional del sistema, con al menos dos capas de descomposición.
Un concepto para el sistema
Un diseño en forma de sistema, con al menos dos capas de descomposición.
Una noción del tiempo, los atributos del operador y los planes de implementación y operación.
Un documento o proceso que garantiza que se sigue la descomposición funcional y se controla la forma de las interfaces.
Atributos de calidad
La calidad es una medida de excelencia o el estado de estar libre de deficiencias o defectos. Los atributos de calidad son las propiedades del sistema que están separadas de la funcionalidad del sistema.
La implementación de atributos de calidad hace que sea más fácil diferenciar un buen sistema de uno malo. Los atributos son factores generales que afectan el comportamiento en tiempo de ejecución, el diseño del sistema y la experiencia del usuario.
Se pueden clasificar como:
Atributos de calidad estática
Reflejar la estructura de un sistema y una organización, directamente relacionada con la arquitectura, el diseño y el código fuente. Son invisibles para el usuario final, pero afectan el costo de desarrollo y mantenimiento, por ejemplo: modularidad, capacidad de prueba, mantenibilidad, etc.
Atributos de calidad dinámica
Refleja el comportamiento del sistema durante su ejecución. Están directamente relacionados con la arquitectura, el diseño, el código fuente, la configuración, los parámetros de implementación, el entorno y la plataforma del sistema.
Son visibles para el usuario final y existen en tiempo de ejecución, por ejemplo, rendimiento, robustez, escalabilidad, etc.
Escenarios de calidad
Los escenarios de calidad especifican cómo evitar que una falla se convierta en falla. Se pueden dividir en seis partes según las especificaciones de sus atributos:
Source - Una entidad interna o externa como personas, hardware, software o infraestructura física que genera el estímulo.
Stimulus - Una condición que debe tenerse en cuenta cuando llega a un sistema.
Environment - El estímulo se produce en determinadas condiciones.
Artifact - Un sistema completo o una parte de él, como procesadores, canales de comunicación, almacenamiento persistente, procesos, etc.
Response - Una actividad realizada después de la llegada del estímulo, como detectar fallas, recuperarse de fallas, desactivar la fuente de eventos, etc.
Response measure - Deben medir las respuestas ocurridas para que se puedan probar los requisitos.
Atributos de calidad comunes
La siguiente tabla enumera los atributos de calidad comunes que debe tener una arquitectura de software:
| Categoría | Atributo de calidad | Descripción |
|---|---|---|
| Cualidades de diseño | Integridad conceptual | Define la consistencia y coherencia del diseño general. Esto incluye la forma en que se diseñan los componentes o módulos. |
| Mantenibilidad | Capacidad del sistema para sufrir cambios con cierta facilidad. | |
| Reutilización | Define la capacidad de los componentes y subsistemas para ser adecuados para su uso en otras aplicaciones. | |
| Cualidades en tiempo de ejecución | Interoperabilidad | Capacidad de un sistema o de diferentes sistemas para operar con éxito mediante la comunicación e intercambio de información con otros sistemas externos escritos y administrados por partes externas. |
| Manejabilidad | Define qué tan fácil es para los administradores del sistema administrar la aplicación. | |
| Fiabilidad | Capacidad de un sistema para permanecer operativo a lo largo del tiempo. | |
| Escalabilidad | Capacidad de un sistema para manejar el aumento de carga sin afectar el rendimiento del sistema o la capacidad de ampliarse fácilmente. | |
| Seguridad | Capacidad de un sistema para prevenir acciones maliciosas o accidentales fuera de los usos diseñados. | |
| Actuación | Indicación de la capacidad de respuesta de un sistema para ejecutar cualquier acción dentro de un intervalo de tiempo determinado. | |
| Disponibilidad | Define la proporción de tiempo que el sistema está funcional y en funcionamiento. Puede medirse como un porcentaje del tiempo de inactividad total del sistema durante un período predefinido. | |
| Cualidades del sistema | Compatibilidad | Capacidad del sistema para proporcionar información útil para identificar y resolver problemas cuando no funciona correctamente. |
| Probabilidad | Medida de lo fácil que es crear criterios de prueba para el sistema y sus componentes. | |
| Cualidades del usuario | Usabilidad | Define qué tan bien la aplicación cumple con los requisitos del usuario y consumidor al ser intuitiva. |
| Calidad Arquitectura | Exactitud | Responsabilidad por satisfacer todos los requisitos del sistema. |
| Calidad fuera del tiempo de ejecución | Portabilidad | Capacidad del sistema para ejecutarse en diferentes entornos informáticos. |
| Integridad | Capacidad para hacer que los componentes del sistema desarrollados por separado funcionen correctamente juntos. | |
| Modificabilidad | Facilidad con la que cada sistema de software puede adaptarse a cambios en su software. | |
| Atributos de calidad empresarial | Costo y cronograma | Costo del sistema con respecto al tiempo de comercialización, la vida útil esperada del proyecto y la utilización del legado. |
| Comerciabilidad | Uso del sistema con respecto a la competencia del mercado. |
La arquitectura de software se describe como la organización de un sistema, donde el sistema representa un conjunto de componentes que cumplen las funciones definidas.
Estilo arquitectónico
los architectural style, también llamado como architectural pattern, es un conjunto de principios que da forma a una aplicación. Define un marco abstracto para una familia de sistemas en términos del patrón de organización estructural.
El estilo arquitectónico es responsable de:
Proporcione un léxico de componentes y conectores con reglas sobre cómo se pueden combinar.
Mejore la partición y permita la reutilización del diseño dando soluciones a problemas frecuentes.
Describa una forma particular de configurar una colección de componentes (un módulo con interfaces bien definidas, reutilizables y reemplazables) y conectores (enlace de comunicación entre módulos).
El software creado para sistemas basados en computadora exhibe uno de los muchos estilos arquitectónicos. Cada estilo describe una categoría de sistema que abarca:
Un conjunto de tipos de componentes que realizan una función requerida por el sistema.
Un conjunto de conectores (llamada de subrutina, llamada de procedimiento remoto, flujo de datos y socket) que permiten la comunicación, coordinación y cooperación entre diferentes componentes.
Restricciones semánticas que definen cómo se pueden integrar los componentes para formar el sistema.
Un diseño topológico de los componentes que indica sus interrelaciones en tiempo de ejecución.
Diseño arquitectónico común
La siguiente tabla enumera los estilos arquitectónicos que se pueden organizar por su área de enfoque clave:
| Categoría | Diseño arquitectonico | Descripción |
|---|---|---|
| Comunicación | Bus de mensajes | Prescribe el uso de un sistema de software que puede recibir y enviar mensajes utilizando uno o más canales de comunicación. |
| Arquitectura orientada a servicios (SOA) | Define las aplicaciones que exponen y consumen la funcionalidad como un servicio mediante contratos y mensajes. | |
| Despliegue | Servidor de cliente | Separe el sistema en dos aplicaciones, donde el cliente realiza solicitudes al servidor. |
| 3 niveles o N niveles | Separa la funcionalidad en segmentos separados y cada segmento es un nivel ubicado en una computadora físicamente separada. | |
| Dominio | Diseño controlado por dominio | Enfocado en modelar un dominio comercial y definir objetos comerciales basados en entidades dentro del dominio comercial. |
| Estructura | Basado en componentes | Divida el diseño de la aplicación en componentes lógicos o funcionales reutilizables que exponen interfaces de comunicación bien definidas. |
| En capas | Divida las preocupaciones de la aplicación en grupos apilados (capas). | |
| Orientado a objetos | Basado en la división de responsabilidades de una aplicación o sistema en objetos, cada uno de los cuales contiene los datos y el comportamiento relevante para el objeto. |
Tipos de Arquitectura
Hay cuatro tipos de arquitectura desde el punto de vista de una empresa y, colectivamente, estas arquitecturas se denominan enterprise architecture.
Business architecture - Define la estrategia de negocios, gobierno, organización y procesos comerciales clave dentro de una empresa y se enfoca en el análisis y diseño de procesos comerciales.
Application (software) architecture - Sirve como modelo para los sistemas de aplicaciones individuales, sus interacciones y sus relaciones con los procesos comerciales de la organización.
Information architecture - Define los activos de datos lógicos y físicos y los recursos de gestión de datos.
Information technology (IT) architecture - Define los componentes básicos de hardware y software que componen el sistema de información general de la organización.
Proceso de diseño de arquitectura
El proceso de diseño de la arquitectura se centra en la descomposición de un sistema en diferentes componentes y sus interacciones para satisfacer los requisitos funcionales y no funcionales. Las entradas clave para el diseño de la arquitectura de software son:
Los requisitos producidos por las tareas de análisis.
La arquitectura de hardware (el arquitecto de software, a su vez, proporciona requisitos al arquitecto del sistema, quien configura la arquitectura de hardware).
El resultado o salida del proceso de diseño de la arquitectura es un architectural description. El proceso de diseño de la arquitectura básica se compone de los siguientes pasos:
Entender el problema
Este es el paso más crucial porque afecta la calidad del diseño que sigue.
Sin una comprensión clara del problema, no es posible crear una solución eficaz.
Muchos proyectos y productos de software se consideran fallas porque en realidad no resolvieron un problema comercial válido o no tienen un retorno de la inversión (ROI) reconocible.
Identificar elementos de diseño y sus relaciones
En esta fase, construya una línea de base para definir los límites y el contexto del sistema.
Descomposición del sistema en sus componentes principales en función de los requisitos funcionales. La descomposición se puede modelar utilizando una matriz de estructura de diseño (DSM), que muestra las dependencias entre los elementos de diseño sin especificar la granularidad de los elementos.
En este paso, la primera validación de la arquitectura se realiza mediante la descripción de una serie de instancias del sistema y este paso se denomina diseño arquitectónico basado en la funcionalidad.
Evaluar el diseño de la arquitectura
A cada atributo de calidad se le da una estimación, por lo que para recopilar medidas cualitativas o datos cuantitativos, se evalúa el diseño.
Implica evaluar la arquitectura para determinar su conformidad con los requisitos de los atributos de calidad arquitectónica.
Si todos los atributos de calidad estimados cumplen con el estándar requerido, el proceso de diseño arquitectónico está terminado.
Si no es así, se ingresa a la tercera fase del diseño de la arquitectura de software: transformación de la arquitectura. Si el atributo de calidad observado no cumple con sus requisitos, se debe crear un nuevo diseño.
Transformar el diseño de la arquitectura
Este paso se realiza después de una evaluación del diseño arquitectónico. El diseño arquitectónico debe cambiarse hasta que satisfaga completamente los requisitos del atributo de calidad.
Se ocupa de seleccionar soluciones de diseño para mejorar los atributos de calidad mientras se preserva la funcionalidad del dominio.
Un diseño se transforma mediante la aplicación de patrones, estilos o operadores de diseño. Para la transformación, tome el diseño existente y aplique el operador de diseño, como descomposición, replicación, compresión, abstracción y uso compartido de recursos.
El diseño se evalúa nuevamente y el mismo proceso se repite varias veces si es necesario e incluso se realiza de forma recursiva.
Las transformaciones (es decir, las soluciones de optimización de atributos de calidad) generalmente mejoran uno o algunos atributos de calidad mientras afectan a otros de manera negativa
Principios clave de la arquitectura
Los siguientes son los principios clave que se deben considerar al diseñar una arquitectura:
Construir para cambiar en lugar de construir para durar
Considere cómo la aplicación puede necesitar cambiar con el tiempo para abordar nuevos requisitos y desafíos, y desarrolle la flexibilidad para respaldar esto.
Reducir el riesgo y el modelo para analizar
Utilice herramientas de diseño, visualizaciones, sistemas de modelado como UML para capturar requisitos y decisiones de diseño. También se pueden analizar los impactos. No formalice el modelo en la medida en que suprima la capacidad de iterar y adaptar el diseño fácilmente.
Utilice modelos y visualizaciones como herramienta de comunicación y colaboración
La comunicación eficiente del diseño, las decisiones y los cambios continuos en el diseño es fundamental para una buena arquitectura. Utilice modelos, vistas y otras visualizaciones de la arquitectura para comunicar y compartir el diseño de manera eficiente con todas las partes interesadas. Esto permite una rápida comunicación de cambios en el diseño.
Identifique y comprenda las decisiones clave de ingeniería y las áreas donde se cometen errores con mayor frecuencia. Invierta en tomar las decisiones clave correctamente la primera vez para hacer que el diseño sea más flexible y menos probable que se rompa con los cambios.
Utilice un enfoque incremental e iterativo
Comience con la arquitectura de referencia y luego desarrolle las arquitecturas candidatas mediante pruebas iterativas para mejorar la arquitectura. Agregue iterativamente detalles al diseño en múltiples pasadas para obtener la imagen grande o correcta y luego enfóquese en los detalles.
Principios clave de diseño
Los siguientes son los principios de diseño que se deben considerar para minimizar el costo, los requisitos de mantenimiento y maximizar la extensibilidad y la usabilidad de la arquitectura:
Separación de intereses
Divida los componentes del sistema en características específicas para que no haya superposición entre la funcionalidad de los componentes. Esto proporcionará una alta cohesión y un bajo acoplamiento. Este enfoque evita la interdependencia entre los componentes del sistema, lo que ayuda a mantener el sistema fácil.
Principio de responsabilidad única
Todos y cada uno de los módulos de un sistema deben tener una responsabilidad específica, que ayude al usuario a comprender claramente el sistema. También debería ayudar con la integración del componente con otros componentes.
Principio de conocimiento mínimo
Ningún componente u objeto debe tener conocimiento sobre los detalles internos de otros componentes. Este enfoque evita la interdependencia y ayuda a la mantenibilidad.
Minimice el diseño grande por adelantado
Minimice el diseño grande por adelantado si los requisitos de una aplicación no están claros. Si existe la posibilidad de modificar los requisitos, evite hacer un diseño grande para todo el sistema.
No repita la funcionalidad
No repetir la funcionalidad especifica que la funcionalidad de los componentes no debe repetirse y, por lo tanto, una parte del código debe implementarse en un solo componente. La duplicación de funciones dentro de una aplicación puede dificultar la implementación de cambios, disminuir la claridad e introducir posibles inconsistencias.
Prefiera la composición sobre la herencia mientras reutiliza la funcionalidad
La herencia crea dependencia entre las clases secundarias y las clases principales y, por lo tanto, bloquea el uso gratuito de las clases secundarias. Por el contrario, la composición proporciona un gran nivel de libertad y reduce las jerarquías de herencia.
Identificar componentes y agruparlos en capas lógicas
Los componentes de identidad y el área de interés que se necesitan en el sistema para satisfacer los requisitos. Luego, agrupe estos componentes relacionados en una capa lógica, lo que ayudará al usuario a comprender la estructura del sistema a un alto nivel. Evite mezclar componentes de diferentes tipos de preocupaciones en la misma capa.
Definir el protocolo de comunicación entre capas
Comprender cómo se comunicarán los componentes entre sí, lo que requiere un conocimiento completo de los escenarios de implementación y el entorno de producción.
Definir formato de datos para una capa
Varios componentes interactuarán entre sí a través del formato de datos. No mezcle los formatos de datos para que las aplicaciones sean fáciles de implementar, ampliar y mantener. Intente mantener el mismo formato de datos para una capa, de modo que varios componentes no necesiten codificar / decodificar los datos mientras se comunican entre sí. Reduce una sobrecarga de procesamiento.
Los componentes del servicio del sistema deben ser abstractos
El código relacionado con la seguridad, las comunicaciones o los servicios del sistema, como el registro, la creación de perfiles y la configuración, debe resumirse en componentes separados. No mezcle este código con la lógica empresarial, ya que es fácil ampliar el diseño y mantenerlo.
Excepciones de diseño y mecanismo de manejo de excepciones
Definir las excepciones de antemano ayuda a los componentes a gestionar errores o situaciones no deseadas de manera elegante. La gestión de excepciones será la misma en todo el sistema.
Convenciones de nombres
Las convenciones de nomenclatura deben definirse de antemano. Proporcionan un modelo coherente que ayuda a los usuarios a comprender el sistema fácilmente. Es más fácil para los miembros del equipo validar el código escrito por otros y, por lo tanto, aumentará la capacidad de mantenimiento.
La arquitectura de software implica la estructura de alto nivel de abstracción del sistema de software, mediante el uso de descomposición y composición, con estilo arquitectónico y atributos de calidad. Un diseño de arquitectura de software debe cumplir con los principales requisitos de funcionalidad y rendimiento del sistema, así como satisfacer los requisitos no funcionales, como confiabilidad, escalabilidad, portabilidad y disponibilidad.
Una arquitectura de software debe describir su grupo de componentes, sus conexiones, interacciones entre ellos y la configuración de implementación de todos los componentes.
Una arquitectura de software se puede definir de muchas formas:
UML (Unified Modeling Language) - UML es una de las soluciones orientadas a objetos que se utilizan en el modelado y diseño de software.
Architecture View Model (4+1 view model) - El modelo de vista de arquitectura representa los requisitos funcionales y no funcionales de la aplicación de software.
ADL (Architecture Description Language) - ADL define la arquitectura del software de manera formal y semántica.
UML
UML son las siglas de Unified Modeling Language. Es un lenguaje pictórico utilizado para hacer planos de software. UML fue creado por Object Management Group (OMG). El borrador de la especificación UML 1.0 se propuso al OMG en enero de 1997. Sirve como estándar para el análisis de requisitos de software y los documentos de diseño que son la base para el desarrollo de un software.
UML se puede describir como un lenguaje de modelado visual de propósito general para visualizar, especificar, construir y documentar un sistema de software. Aunque UML se usa generalmente para modelar el sistema de software, no está limitado dentro de este límite. También se utiliza para modelar sistemas que no son de software, como los flujos de procesos en una unidad de fabricación.
Los elementos son como componentes que se pueden asociar de diferentes formas para hacer una imagen UML completa, que se conoce como diagram. Por lo tanto, es muy importante comprender los diferentes diagramas para implementar el conocimiento en sistemas de la vida real. Tenemos dos categorías amplias de diagramas y se dividen en subcategorías, es decirStructural Diagrams y Behavioral Diagrams.
Diagramas estructurales
Los diagramas estructurales representan los aspectos estáticos de un sistema. Estos aspectos estáticos representan las partes de un diagrama que forman la estructura principal y, por lo tanto, es estable.
Estas partes estáticas están representadas por clases, interfaces, objetos, componentes y nodos. Los diagramas estructurales se pueden subdividir de la siguiente manera:
- Diagrama de clase
- Diagrama de objetos
- Diagrama de componentes
- Diagrama de implementación
- Diagrama del paquete
- Estructura compuesta
La siguiente tabla proporciona una breve descripción de estos diagramas:
| No Señor. | Diagrama y descripción |
|---|---|
| 1 | Class Representa la orientación a objetos de un sistema. Muestra cómo las clases están relacionadas estáticamente. |
| 2 | Object Representa un conjunto de objetos y sus relaciones en tiempo de ejecución y también representa la vista estática del sistema. |
| 3 | Component Describe todos los componentes, su interrelación, interacciones e interfaz del sistema. |
| 4 | Composite structure Describe la estructura interna del componente, incluidas todas las clases, interfaces del componente, etc. |
| 5 | Package Describe la estructura y organización del paquete. Cubre clases en el paquete y paquetes dentro de otro paquete. |
| 6 | Deployment Los diagramas de implementación son un conjunto de nodos y sus relaciones. Estos nodos son entidades físicas donde se implementan los componentes. |
Diagramas de comportamiento
Los diagramas de comportamiento capturan básicamente el aspecto dinámico de un sistema. Los aspectos dinámicos son básicamente las partes cambiantes / móviles de un sistema. UML tiene los siguientes tipos de diagramas de comportamiento:
- Use el diagrama del caso
- Diagrama de secuencia
- Diagrama de comunicación
- Diagrama de gráfico de estado
- Diagrama de actividad
- Descripción general de la interacción
- Diagrama de secuencia de tiempo
La siguiente tabla proporciona una breve descripción de estos diagramas:
| No Señor. | Diagrama y descripción |
|---|---|
| 1 | Use case Describe las relaciones entre las funcionalidades y sus controladores internos / externos. Estos controladores se conocen como actores. |
| 2 | Activity Describe el flujo de control en un sistema. Consta de actividades y enlaces. El flujo puede ser secuencial, concurrente o ramificado. |
| 3 | State Machine/state chart Representa el cambio de estado de un sistema impulsado por eventos. Básicamente describe el cambio de estado de una clase, interfaz, etc. Se utiliza para visualizar la reacción de un sistema por factores internos / externos. |
| 4 | Sequence Visualiza la secuencia de llamadas en un sistema para realizar una funcionalidad específica. |
| 5 | Interaction Overview Combina diagramas de secuencia y actividad para proporcionar una descripción general del flujo de control del sistema y el proceso empresarial. |
| 6 | Communication Igual que el diagrama de secuencia, excepto que se centra en la función del objeto. Cada comunicación está asociada con un orden de secuencia, número más los mensajes pasados. |
| 7 | Time Sequenced Describe los cambios por mensajes en estado, condición y eventos. |
Modelo de vista de arquitectura
Un modelo es una descripción completa, básica y simplificada de la arquitectura de software que se compone de múltiples vistas desde una perspectiva o punto de vista particular.
Una vista es una representación de un sistema completo desde la perspectiva de un conjunto de preocupaciones relacionadas. Se utiliza para describir el sistema desde el punto de vista de diferentes partes interesadas, como usuarios finales, desarrolladores, directores de proyectos y probadores.
Modelo de vista 4 + 1
El modelo de vista 4 + 1 fue diseñado por Philippe Kruchten para describir la arquitectura de un sistema intensivo en software basado en el uso de vistas múltiples y concurrentes. Es unmultiple viewmodelo que aborda diferentes características y preocupaciones del sistema. Estandariza los documentos de diseño del software y hace que el diseño sea fácil de entender por todas las partes interesadas.
Es un método de verificación de la arquitectura para estudiar y documentar el diseño de la arquitectura del software y cubre todos los aspectos de la arquitectura del software para todas las partes interesadas. Proporciona cuatro vistas esenciales:
The logical view or conceptual view - Describe el modelo de objetos del diseño.
The process view - Describe las actividades del sistema, captura los aspectos de concurrencia y sincronización del diseño.
The physical view - Describe el mapeo de software en hardware y refleja su aspecto distribuido.
The development view - Describe la organización o estructura estática del software en su entorno de desarrollo.
Este modelo de vista se puede ampliar agregando una vista más llamada scenario view o use case viewpara usuarios finales o clientes de sistemas de software. Es coherente con otras cuatro vistas y se utiliza para ilustrar la arquitectura que sirve como vista “más uno”, modelo de vista (4 + 1). La siguiente figura describe la arquitectura del software mediante el modelo de cinco vistas simultáneas (4 + 1).

¿Por qué se llama 4 + 1 en lugar de 5?
los use case viewtiene un significado especial, ya que detalla los requisitos de alto nivel de un sistema, mientras que otros visualizan detalles: cómo se cumplen esos requisitos. Cuando se completan las otras cuatro vistas, es efectivamente redundante. Sin embargo, todas las demás vistas no serían posibles sin él. La siguiente imagen y tabla muestra la vista 4 + 1 en detalle:
| Lógico | Proceso | Desarrollo | Físico | Guión | |
|---|---|---|---|---|---|
| Descripción | Muestra el componente (objeto) del sistema, así como su interacción. | Muestra los procesos / reglas de flujo de trabajo del sistema y cómo se comunican esos procesos, se centra en la vista dinámica del sistema | Proporciona vistas de bloques de construcción del sistema y describe la organización estática de los módulos del sistema. | Muestra la instalación, configuración e implementación de la aplicación de software. | Muestra que el diseño está completo al realizar la validación y la ilustración. |
| Visor / titular de estaca | Usuario final, analistas y diseñador | Integradores y desarrolladores | Programadores y gerentes de proyectos de software | Ingeniero de sistemas, operadores, administradores de sistemas e instaladores de sistemas | Todas las opiniones de sus puntos de vista y evaluadores |
| Considerar | Requerimientos funcionales | Requerimientos no funcionales | Organización del módulo de software (reutilización de la gestión de software, limitación de herramientas) | Requisito no funcional con respecto al hardware subyacente | Consistencia y validez del sistema |
| UML - Diagrama | Clase, Estado, Objeto, secuencia, Diagrama de comunicación | Diagrama de actividad | Componente, diagrama de paquete | Diagrama de implementación | Use el diagrama del caso |
Lenguajes de descripción de arquitectura (ADL)
Una ADL es un lenguaje que proporciona sintaxis y semántica para definir una arquitectura de software. Es una especificación de notación que proporciona características para modelar la arquitectura conceptual de un sistema de software, que se distingue de la implementación del sistema.
Las ADL deben admitir los componentes de la arquitectura, sus conexiones, interfaces y configuraciones, que son el componente básico de la descripción de la arquitectura. Es una forma de expresión para usar en descripciones de arquitectura y proporciona la capacidad de descomponer componentes, combinar los componentes y definir las interfaces de los componentes.
Un lenguaje de descripción de arquitectura es un lenguaje de especificación formal, que describe las características del software como procesos, subprocesos, datos y subprogramas, así como componentes de hardware como procesadores, dispositivos, buses y memoria.
Es difícil clasificar o diferenciar una ADL y un lenguaje de programación o un lenguaje de modelado. Sin embargo, existen los siguientes requisitos para que un idioma se clasifique como ADL:
Debería ser apropiado para comunicar la arquitectura a todas las partes interesadas.
Debe ser adecuado para tareas de creación, perfeccionamiento y validación de arquitectura.
Debe proporcionar una base para una mayor implementación, por lo que debe poder agregar información a la especificación ADL para permitir que la especificación final del sistema se derive de la ADL.
Debe tener la capacidad de representar la mayoría de los estilos arquitectónicos comunes.
Debe admitir capacidades analíticas o proporcionar implementaciones de prototipos de generación rápida.
El paradigma orientado a objetos (OO) tomó su forma a partir del concepto inicial de un nuevo enfoque de programación, mientras que el interés por los métodos de diseño y análisis llegó mucho más tarde. El paradigma de análisis y diseño de OO es el resultado lógico de la amplia adopción de lenguajes de programación OO.
El primer lenguaje orientado a objetos fue Simula (Simulación de sistemas reales) que fue desarrollado en 1960 por investigadores del Norwegian Computing Center.
En 1970, Alan Kay y su grupo de investigación en Xerox PARC crearon una computadora personal llamada Dynabook y el primer lenguaje de programación puro orientado a objetos (OOPL), Smalltalk, para programar Dynabook.
En la década de 1980, Grady Boochpublicó un artículo titulado Object Oriented Design que presentaba principalmente un diseño para el lenguaje de programación Ada. En las siguientes ediciones, amplió sus ideas a un método de diseño completo orientado a objetos.
En la década de 1990, Coad incorporó ideas de comportamiento a métodos orientados a objetos.
Las otras innovaciones importantes fueron las técnicas de modelado de objetos (OMT) de James Rum Baugh e ingeniería de software orientada a objetos (OOSE) por Ivar Jacobson.
Introducción al paradigma de OO
El paradigma OO es una metodología significativa para el desarrollo de cualquier software. La mayoría de los estilos o patrones de arquitectura, como la canalización y el filtro, el repositorio de datos y los basados en componentes, se pueden implementar utilizando este paradigma.
Conceptos básicos y terminologías de sistemas orientados a objetos -
Objeto
Un objeto es un elemento del mundo real en un entorno orientado a objetos que puede tener una existencia física o conceptual. Cada objeto tiene -
Identidad que lo distingue de otros objetos del sistema.
Estado que determina las propiedades características de un objeto, así como los valores de las propiedades que posee el objeto.
Comportamiento que representa actividades visibles externamente realizadas por un objeto en términos de cambios en su estado.
Los objetos se pueden modelar según las necesidades de la aplicación. Un objeto puede tener existencia física, como un cliente, un automóvil, etc .; o una existencia conceptual intangible, como un proyecto, un proceso, etc.
Clase
Una clase representa una colección de objetos que tienen las mismas propiedades características que exhiben un comportamiento común. Proporciona el plano o la descripción de los objetos que se pueden crear a partir de él. La creación de un objeto como miembro de una clase se denomina instanciación. Por tanto, un objeto es uninstance de una clase.
Los componentes de una clase son:
Un conjunto de atributos para los objetos que se van a instanciar desde la clase. Generalmente, los diferentes objetos de una clase tienen alguna diferencia en los valores de los atributos. Los atributos a menudo se denominan datos de clase.
Un conjunto de operaciones que retratan el comportamiento de los objetos de la clase. Las operaciones también se denominan funciones o métodos.
Example
Consideremos una clase simple, Circle, que representa el círculo de la figura geométrica en un espacio bidimensional. Los atributos de esta clase se pueden identificar de la siguiente manera:
- x – coord, para denotar x – coordenada del centro
- y – coord, para denotar la coordenada y del centro
- a, para denotar el radio del círculo
Algunas de sus operaciones se pueden definir de la siguiente manera:
- findArea (), un método para calcular el área
- findCircumference (), un método para calcular la circunferencia
- scale (), un método para aumentar o disminuir el radio
Encapsulamiento
La encapsulación es el proceso de vincular atributos y métodos dentro de una clase. A través del encapsulado, los detalles internos de una clase se pueden ocultar desde el exterior. Permite acceder a los elementos de la clase desde el exterior solo a través de la interfaz proporcionada por la clase.
Polimorfismo
El polimorfismo es originalmente una palabra griega que significa la capacidad de adoptar múltiples formas. En el paradigma orientado a objetos, el polimorfismo implica el uso de operaciones de diferentes maneras, dependiendo de las instancias en las que operan. El polimorfismo permite que los objetos con diferentes estructuras internas tengan una interfaz externa común. El polimorfismo es particularmente efectivo al implementar la herencia.
Example
Consideremos dos clases, Circle y Square, cada una con un método findArea (). Aunque el nombre y el propósito de los métodos en las clases son los mismos, la implementación interna, es decir, el procedimiento de cálculo de un área es diferente para cada clase. Cuando un objeto de la clase Circle invoca su método findArea (), la operación encuentra el área del círculo sin ningún conflicto con el método findArea () de la clase Square.
Relationships
Para describir un sistema, se deben proporcionar especificaciones tanto dinámicas (de comportamiento) como estáticas (lógicas) de un sistema. La especificación dinámica describe las relaciones entre los objetos, por ejemplo, el paso de mensajes. Y la especificación estática describe las relaciones entre clases, por ejemplo, agregación, asociación y herencia.
Paso de mensajes
Cualquier aplicación requiere que varios objetos interactúen de manera armoniosa. Los objetos de un sistema pueden comunicarse entre sí mediante el paso de mensajes. Suponga que un sistema tiene dos objetos: obj1 y obj2. El objeto obj1 envía un mensaje al objeto obj2, si obj1 quiere que obj2 ejecute uno de sus métodos.
Composición o agregación
La agregación o composición es una relación entre clases mediante la cual una clase puede estar formada por cualquier combinación de objetos de otras clases. Permite colocar objetos directamente dentro del cuerpo de otras clases. La agregación se conoce como una relación de “parte de” o “tiene una”, con la capacidad de navegar desde el todo hasta sus partes. Un objeto agregado es un objeto que se compone de uno o más objetos.
Asociación
La asociación es un grupo de vínculos que tienen una estructura y un comportamiento comunes. Asociación describe la relación entre objetos de una o más clases. Un enlace se puede definir como una instancia de una asociación. El grado de una asociación denota el número de clases involucradas en una conexión. El grado puede ser unario, binario o ternario.
- Una relación unaria conecta objetos de la misma clase.
- Una relación binaria conecta objetos de dos clases.
- Una relación ternaria conecta objetos de tres o más clases.
Herencia
Es un mecanismo que permite crear nuevas clases a partir de las clases existentes ampliando y perfeccionando sus capacidades. Las clases existentes se denominan clases base / clases padre / superclases, y las nuevas clases se denominan clases derivadas / clases hijo / subclases.
La subclase puede heredar o derivar los atributos y métodos de la superclase (s) siempre que la superclase lo permita. Además, la subclase puede agregar sus propios atributos y métodos y puede modificar cualquiera de los métodos de la superclase. La herencia define una relación "es - a".
Example
A partir de una clase Mamífero, se pueden derivar varias clases como Humano, Gato, Perro, Vaca, etc. Los seres humanos, gatos, perros y vacas tienen todas las características distintivas de los mamíferos. Además, cada uno tiene sus propias características particulares. Se puede decir que una vaca "es - un" mamífero.
Análisis OO
En la fase de análisis orientado a objetos del desarrollo de software, se determinan los requisitos del sistema, se identifican las clases y se reconocen las relaciones entre las clases. El objetivo del análisis OO es comprender el dominio de la aplicación y los requisitos específicos del sistema. El resultado de esta fase es la especificación de requisitos y el análisis inicial de la estructura lógica y la viabilidad de un sistema.
Las tres técnicas de análisis que se utilizan conjuntamente para el análisis orientado a objetos son el modelado de objetos, el modelado dinámico y el modelado funcional.
Modelado de objetos
El modelado de objetos desarrolla la estructura estática del sistema de software en términos de objetos. Identifica los objetos, las clases en las que se pueden agrupar los objetos y las relaciones entre los objetos. También identifica los principales atributos y operaciones que caracterizan a cada clase.
El proceso de modelado de objetos se puede visualizar en los siguientes pasos:
- Identificar objetos y agruparlos en clases.
- Identificar las relaciones entre clases.
- Crear un diagrama de modelo de objetos de usuario
- Definir los atributos de un objeto de usuario
- Definir las operaciones que se deben realizar en las clases.
Modelado dinámico
Una vez analizado el comportamiento estático del sistema, es necesario examinar su comportamiento con respecto al tiempo y los cambios externos. Este es el propósito del modelado dinámico.
El modelado dinámico puede definirse como "una forma de describir cómo un objeto individual responde a los eventos, ya sean eventos internos desencadenados por otros objetos o eventos externos desencadenados por el mundo exterior".
El proceso de modelado dinámico se puede visualizar en los siguientes pasos:
- Identificar estados de cada objeto
- Identificar eventos y analizar la aplicabilidad de acciones.
- Construir un diagrama de modelo dinámico, que comprende diagramas de transición de estado.
- Exprese cada estado en términos de atributos de objeto.
- Validar los diagramas de transición de estado dibujados
Modelado funcional
El modelado funcional es el componente final del análisis orientado a objetos. El modelo funcional muestra los procesos que se realizan dentro de un objeto y cómo cambian los datos, a medida que se mueven entre métodos. Especifica el significado de las operaciones de un modelado de objetos y las acciones de un modelado dinámico. El modelo funcional corresponde al diagrama de flujo de datos del análisis estructurado tradicional.
El proceso de modelado funcional se puede visualizar en los siguientes pasos:
- Identificar todas las entradas y salidas
- Construya diagramas de flujo de datos que muestren dependencias funcionales
- Indique el propósito de cada función
- Identificar las limitaciones
- Especificar criterios de optimización
Diseño orientado a objetos
Después de la fase de análisis, el modelo conceptual se desarrolla aún más en un modelo orientado a objetos utilizando diseño orientado a objetos (OOD). En OOD, los conceptos independientes de la tecnología en el modelo de análisis se asignan a las clases de implementación, se identifican las restricciones y se diseñan las interfaces, lo que da como resultado un modelo para el dominio de la solución. El objetivo principal del diseño OO es desarrollar la arquitectura estructural de un sistema.
Las etapas del diseño orientado a objetos se pueden identificar como:
- Definiendo el contexto del sistema
- Diseñar la arquitectura del sistema
- Identificación de los objetos en el sistema
- Construcción de modelos de diseño
- Especificación de interfaces de objetos
OO Design se puede dividir en dos etapas: diseño conceptual y diseño detallado.
Conceptual design
En esta etapa, se identifican todas las clases que se necesitan para construir el sistema. Además, se asignan responsabilidades específicas a cada clase. El diagrama de clases se usa para aclarar las relaciones entre clases y el diagrama de interacción se usa para mostrar el flujo de eventos. También se conoce comohigh-level design.
Detailed design
En esta etapa, los atributos y operaciones se asignan a cada clase en función de su diagrama de interacción. Los diagramas de la máquina de estados se desarrollan para describir los detalles adicionales del diseño. También se conoce comolow-level design.
Criterios de diseño
Los siguientes son los principales principios de diseño:
Principle of Decoupling
Es difícil mantener un sistema con un conjunto de clases altamente interdependientes, ya que la modificación en una clase puede resultar en actualizaciones en cascada de otras clases. En un diseño orientado a objetos, el acoplamiento estrecho se puede eliminar mediante la introducción de nuevas clases o herencia.
Ensuring Cohesion
Una clase cohesiva realiza un conjunto de funciones estrechamente relacionadas. La falta de cohesión significa: una clase realiza funciones no relacionadas, aunque no afecta el funcionamiento de todo el sistema. Hace que toda la estructura del software sea difícil de administrar, expandir, mantener y cambiar.
Open-closed Principle
Según este principio, un sistema debería poder ampliarse para cumplir con los nuevos requisitos. La implementación existente y el código del sistema no deben modificarse como resultado de una expansión del sistema. Además, las siguientes pautas deben seguirse en el principio de abierto-cerrado:
Para cada clase concreta, se deben mantener interfaces e implementaciones separadas.
En un entorno multiproceso, mantenga los atributos privados.
Minimice el uso de variables globales y variables de clase.
En la arquitectura de flujo de datos, todo el sistema de software se ve como una serie de transformaciones en piezas consecutivas o conjunto de datos de entrada, donde los datos y las operaciones son independientes entre sí. En este enfoque, los datos ingresan al sistema y luego fluyen a través de los módulos uno a la vez hasta que se asignan a algún destino final (salida o un almacén de datos).
Las conexiones entre los componentes o módulos pueden implementarse como flujo de E / S, búferes de E / S, canalizaciones u otros tipos de conexiones. Los datos se pueden volar en la topología del gráfico con ciclos, en una estructura lineal sin ciclos o en una estructura de tipo árbol.
El principal objetivo de este enfoque es lograr las cualidades de reutilización y modificabilidad. Es adecuado para aplicaciones que involucran una serie bien definida de transformaciones de datos independientes o cálculos sobre entradas y salidas definidas ordenadamente, como compiladores y aplicaciones de procesamiento de datos comerciales. Hay tres tipos de secuencias de ejecución entre módulos.
- Lote secuencial
- Modo de canalización y filtro o canalización no secuencial
- Control de procesos
Lote secuencial
El secuencial por lotes es un modelo clásico de procesamiento de datos, en el que un subsistema de transformación de datos puede iniciar su proceso solo después de que su subsistema anterior haya terminado por completo:
El flujo de datos transporta un lote de datos como un todo de un subsistema a otro.
Las comunicaciones entre los módulos se realizan a través de archivos intermedios temporales que pueden ser eliminados por subsistemas sucesivos.
Es aplicable para aquellas aplicaciones donde los datos se almacenan por lotes y cada subsistema lee archivos de entrada relacionados y escribe archivos de salida.
La aplicación típica de esta arquitectura incluye el procesamiento de datos comerciales, como la facturación bancaria y de servicios públicos.

Ventajas
Proporciona divisiones más simples en subsistemas.
Cada subsistema puede ser un programa independiente que trabaja con datos de entrada y produce datos de salida.
Desventajas
Proporciona alta latencia y bajo rendimiento.
No proporciona simultaneidad ni interfaz interactiva.
Se requiere control externo para la implementación.
Arquitectura de tuberías y filtros
Este enfoque pone énfasis en la transformación incremental de datos por componente sucesivo. En este enfoque, el flujo de datos es impulsado por datos y todo el sistema se descompone en componentes de fuente de datos, filtros, tuberías y sumideros de datos.
Las conexiones entre módulos son un flujo de datos que es un búfer de primero en entrar / primero en salir que puede ser un flujo de bytes, caracteres o cualquier otro tipo de este tipo. La característica principal de esta arquitectura es su ejecución concurrente e incremental.
Filtrar
Un filtro es un transformador de flujo de datos independiente o transductores de flujo. Transforma los datos del flujo de datos de entrada, los procesa y escribe el flujo de datos transformado en una tubería para que lo procese el siguiente filtro. Funciona en modo incremental, en el que comienza a funcionar tan pronto como llegan los datos a través de la tubería conectada. Hay dos tipos de filtros:active filter y passive filter.
Active filter
El filtro activo permite que las tuberías conectadas extraigan datos y expulsen los datos transformados. Opera con tubería pasiva, que proporciona mecanismos de lectura / escritura para tirar y empujar. Este modo se utiliza en el mecanismo de filtro y tubería de UNIX.
Passive filter
El filtro pasivo permite que las tuberías conectadas ingresen y extraigan datos. Funciona con una tubería activa, que extrae datos de un filtro y los envía al siguiente filtro. Debe proporcionar un mecanismo de lectura / escritura.

Ventajas
Proporciona simultaneidad y alto rendimiento para un procesamiento de datos excesivo.
Proporciona reutilización y simplifica el mantenimiento del sistema.
Proporciona modificabilidad y bajo acoplamiento entre filtros.
Proporciona simplicidad al ofrecer divisiones claras entre dos filtros cualesquiera conectados por tubería.
Proporciona flexibilidad al admitir la ejecución secuencial y paralela.
Desventajas
No apto para interacciones dinámicas.
Se necesita un denominador común bajo para la transmisión de datos en formatos ASCII.
Sobrecarga de transformación de datos entre filtros.
No proporciona una forma de que los filtros interactúen cooperativamente para resolver un problema.
Difícil de configurar esta arquitectura de forma dinámica.
Tubo
Las tuberías no tienen estado y transportan un flujo binario o de caracteres que existe entre dos filtros. Puede mover un flujo de datos de un filtro a otro. Las canalizaciones utilizan un poco de información contextual y no retienen información de estado entre instancias.
Arquitectura de control de procesos
Es un tipo de arquitectura de flujo de datos donde los datos no son secuenciales ni secuenciales por lotes. El flujo de datos proviene de un conjunto de variables, que controla la ejecución del proceso. Descompone todo el sistema en subsistemas o módulos y los conecta.
Tipos de subsistemas
Una arquitectura de control de procesos tendría una processing unit para cambiar las variables de control del proceso y un controller unit para calcular la cantidad de cambios.
Una unidad de controlador debe tener los siguientes elementos:
Controlled Variable- Variable controlada proporciona valores para el sistema subyacente y debe medirse mediante sensores. Por ejemplo, velocidad en el sistema de control de crucero.
Input Variable- Mide una entrada al proceso. Por ejemplo, temperatura del aire de retorno en el sistema de control de temperatura.
Manipulated Variable - El controlador ajusta o cambia el valor de la variable manipulada.
Process Definition - Incluye mecanismos de manipulación de algunas variables de proceso.
Sensor - Obtiene valores de las variables de proceso pertinentes al control y se puede utilizar como referencia de retroalimentación para recalcular las variables manipuladas.
Set Point - Es el valor deseado para una variable controlada.
Control Algorithm - Se utiliza para decidir cómo manipular las variables del proceso.
Áreas de aplicación
La arquitectura de control de procesos es adecuada en los siguientes dominios:
Diseño de software de sistema integrado, donde el sistema es manipulado por datos de variables de control de proceso.
Aplicaciones, cuyo objetivo es mantener propiedades específicas de las salidas del proceso en valores de referencia dados.
Aplicable para control de crucero de automóviles y sistemas de control de temperatura de edificios.
Software de sistema en tiempo real para controlar frenos antibloqueo de automóviles, centrales nucleares, etc.
En la arquitectura centrada en datos, los datos se centralizan y otros componentes acceden con frecuencia a ellos, que modifican los datos. El objetivo principal de este estilo es lograr la integralidad de los datos. La arquitectura centrada en datos consta de diferentes componentes que se comunican a través de repositorios de datos compartidos. Los componentes acceden a una estructura de datos compartida y son relativamente independientes, ya que interactúan solo a través del almacén de datos.
Los ejemplos más conocidos de la arquitectura centrada en datos es una arquitectura de base de datos, en la que el esquema de base de datos común se crea con el protocolo de definición de datos, por ejemplo, un conjunto de tablas relacionadas con campos y tipos de datos en un RDBMS.
Otro ejemplo de arquitecturas centradas en datos es la arquitectura web que tiene un esquema de datos común (es decir, una metaestructura de la web) y sigue el modelo de datos hipermedia y los procesos se comunican mediante el uso de servicios de datos compartidos basados en web.

Tipos de componentes
Hay dos tipos de componentes:
UN central dataestructura o almacén de datos o repositorio de datos, que se encarga de proporcionar almacenamiento permanente de datos. Representa el estado actual.
UN data accessor o una colección de componentes independientes que operan en el almacén de datos central, realizan cálculos y pueden retrasar los resultados.
Las interacciones o la comunicación entre los que acceden a los datos se realizan únicamente a través del almacén de datos. Los datos son el único medio de comunicación entre clientes. El flujo de control diferencia la arquitectura en dos categorías:
- Estilo de arquitectura de repositorio
- Estilo de arquitectura de pizarra
Estilo de arquitectura de repositorio
En el estilo de arquitectura de repositorio, el almacén de datos es pasivo y los clientes (componentes de software o agentes) del almacén de datos están activos, que controlan el flujo lógico. Los componentes participantes revisan el almacén de datos para ver si hay cambios.
El cliente envía una solicitud al sistema para realizar acciones (por ejemplo, insertar datos).
Los procesos computacionales son independientes y se activan con las solicitudes entrantes.
Si los tipos de transacciones en un flujo de entrada de transacciones desencadenan la selección de procesos a ejecutar, entonces se trata de una arquitectura de repositorio o base de datos tradicional, o un repositorio pasivo.
Este enfoque es ampliamente utilizado en DBMS, sistemas de información de bibliotecas, el repositorio de interfaces en CORBA, compiladores y entornos CASE (ingeniería de software asistida por computadora).

Ventajas
Proporciona funciones de integridad, copia de seguridad y restauración de datos.
Proporciona escalabilidad y reutilización de agentes, ya que no tienen comunicación directa entre ellos.
Reduce la sobrecarga de datos transitorios entre componentes de software.
Desventajas
Es más vulnerable a fallas y es posible la replicación o duplicación de datos.
Gran dependencia entre la estructura de datos del almacén de datos y sus agentes.
Los cambios en la estructura de datos afectan en gran medida a los clientes.
La evolución de los datos es difícil y cara.
Costo de mover datos en la red para datos distribuidos.
Estilo de arquitectura de pizarra
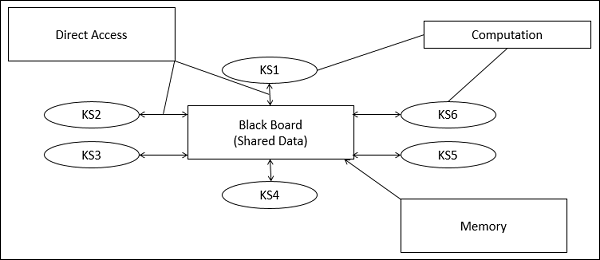
En Blackboard Architecture Style, el almacén de datos está activo y sus clientes son pasivos. Por lo tanto, el flujo lógico está determinado por el estado actual de los datos en el almacén de datos. Tiene un componente de pizarra, que actúa como un repositorio central de datos, y se construye una representación interna y se actúa sobre ella mediante diferentes elementos computacionales.
Una serie de componentes que actúan de forma independiente sobre la estructura de datos común se almacenan en la pizarra.
En este estilo, los componentes interactúan solo a través de la pizarra. El almacén de datos alerta a los clientes cuando se produce un cambio en el almacén de datos.
El estado actual de la solución se almacena en la pizarra y el procesamiento se activa por el estado de la pizarra.
El sistema envía notificaciones conocidas como trigger y datos a los clientes cuando ocurren cambios en los datos.
Este enfoque se encuentra en ciertas aplicaciones de inteligencia artificial y aplicaciones complejas, como el reconocimiento de voz, el reconocimiento de imágenes, el sistema de seguridad y los sistemas de gestión de recursos comerciales, etc.
Si el estado actual de la estructura de datos central es el desencadenante principal de la selección de procesos a ejecutar, el repositorio puede ser una pizarra y esta fuente de datos compartida es un agente activo.
Una diferencia importante con los sistemas de bases de datos tradicionales es que la invocación de elementos computacionales en una arquitectura de pizarra se activa por el estado actual de la pizarra y no por entradas externas.
Partes del modelo de pizarra
El modelo de pizarra generalmente se presenta con tres partes principales:
Knowledge Sources (KS)
Fuentes de conocimiento, también conocidas como Listeners o Subscribersson unidades distintas e independientes. Resuelven partes de un problema y agregan resultados parciales. La interacción entre las fuentes de conocimiento se produce de forma única a través de la pizarra.
Blackboard Data Structure
Los datos de estado de resolución de problemas se organizan en una jerarquía dependiente de la aplicación. Las fuentes de conocimiento realizan cambios en el pizarrón que conducen gradualmente a una solución al problema.
Control
Control gestiona tareas y comprueba el estado de trabajo.
Ventajas
Proporciona escalabilidad que facilita la adición o actualización de fuentes de conocimientos.
Proporciona simultaneidad que permite que todas las fuentes de conocimiento funcionen en paralelo, ya que son independientes entre sí.
Apoya la experimentación de hipótesis.
Admite la reutilización de agentes de fuentes de conocimiento.
Desventajas
El cambio de estructura de la pizarra puede tener un impacto significativo en todos sus agentes, ya que existe una estrecha dependencia entre la pizarra y la fuente de conocimiento.
Puede ser difícil decidir cuándo terminar el razonamiento, ya que solo se espera una solución aproximada.
Problemas en la sincronización de múltiples agentes.
Principales desafíos en el diseño y prueba del sistema.
La arquitectura jerárquica ve todo el sistema como una estructura jerárquica, en la que el sistema de software se descompone en módulos lógicos o subsistemas en diferentes niveles de la jerarquía. Este enfoque se utiliza normalmente en el diseño de software de sistema, como protocolos de red y sistemas operativos.
En el diseño de la jerarquía del software del sistema, un subsistema de bajo nivel brinda servicios a sus subsistemas de nivel superior adyacentes, que invocan los métodos en el nivel inferior. La capa inferior proporciona una funcionalidad más específica, como servicios de E / S, transacciones, programación, servicios de seguridad, etc. La capa intermedia proporciona más funciones dependientes del dominio, como la lógica empresarial y los servicios de procesamiento central. Y la capa superior proporciona una funcionalidad más abstracta en forma de interfaz de usuario, como GUI, funciones de programación de shell, etc.
También se utiliza en la organización de las bibliotecas de clases, como la biblioteca de clases .NET en la jerarquía de espacios de nombres. Todos los tipos de diseño pueden implementar esta arquitectura jerárquica y, a menudo, combinarlos con otros estilos de arquitectura.
Los estilos arquitectónicos jerárquicos se dividen como:
- Main-subroutine
- Master-slave
- Máquina virtual
Subrutina principal
El objetivo de este estilo es reutilizar los módulos y desarrollar libremente módulos o subrutinas individuales. En este estilo, un sistema de software se divide en subrutinas utilizando un refinamiento de arriba hacia abajo de acuerdo con la funcionalidad deseada del sistema.
Estos refinamientos conducen verticalmente hasta que los módulos descompuestos son lo suficientemente simples como para tener su exclusiva responsabilidad independiente. La funcionalidad puede ser reutilizada y compartida por varios llamantes en las capas superiores.
Hay dos formas en las que los datos se pasan como parámetros a subrutinas, a saber:
Pass by Value - Las subrutinas solo usan los datos pasados, pero no pueden modificarlos.
Pass by Reference - Las subrutinas utilizan y cambian el valor de los datos referenciados por el parámetro.

Ventajas
Fácil de descomponer el sistema basado en el refinamiento de la jerarquía.
Puede utilizarse en un subsistema de diseño orientado a objetos.
Desventajas
Vulnerable ya que contiene datos compartidos globalmente.
El acoplamiento estrecho puede causar más efectos en cadena de los cambios.
Maestro-esclavo
Este enfoque aplica el principio de "divide y vencerás" y admite el cálculo de fallas y la precisión computacional. Es una modificación de la arquitectura de la subrutina principal que proporciona confiabilidad del sistema y tolerancia a fallas.
En esta arquitectura, los esclavos proporcionan servicios duplicados al maestro y el maestro elige un resultado particular entre los esclavos mediante una determinada estrategia de selección. Los esclavos pueden realizar la misma tarea funcional mediante diferentes algoritmos y métodos o funcionalidades totalmente diferentes. Incluye computación en paralelo en la que todos los esclavos se pueden ejecutar en paralelo.

La implementación del patrón Maestro-Esclavo sigue cinco pasos:
Especifique cómo se puede dividir el cálculo de la tarea en un conjunto de subtareas iguales e identifique los sub-servicios que se necesitan para procesar una subtarea.
Especifique cómo se puede calcular el resultado final de todo el servicio con la ayuda de los resultados obtenidos del procesamiento de subtareas individuales.
Defina una interfaz para el subservicio identificado en el paso 1. Será implementada por el esclavo y utilizada por el maestro para delegar el procesamiento de subtareas individuales.
Implemente los componentes esclavos de acuerdo con las especificaciones desarrolladas en el paso anterior.
Implemente el maestro de acuerdo con las especificaciones desarrolladas en los pasos 1 a 3.
Aplicaciones
Adecuado para aplicaciones donde la confiabilidad del software es un problema crítico.
Ampliamente aplicado en las áreas de computación paralela y distribuida.
Ventajas
Cálculo más rápido y fácil escalabilidad.
Aporta robustez ya que se pueden duplicar esclavos.
El esclavo se puede implementar de manera diferente para minimizar los errores semánticos.
Desventajas
Gastos generales de comunicación.
No todos los problemas se pueden dividir.
Difícil de implementar y problema de portabilidad.
Arquitectura de la máquina virtual
La arquitectura de la máquina virtual pretende alguna funcionalidad, que no es nativa del hardware y / o software en el que se implementa. Una máquina virtual se basa en un sistema existente y proporciona una abstracción virtual, un conjunto de atributos y operaciones.
En la arquitectura de la máquina virtual, el maestro utiliza el "mismo" subservicio "del esclavo y realiza funciones como dividir el trabajo, llamar a los esclavos y combinar los resultados. Permite a los desarrolladores simular y probar plataformas, que aún no se han construido, y simular modos de "desastre" que serían demasiado complejos, costosos o peligrosos para probar con el sistema real.
En la mayoría de los casos, una máquina virtual divide un lenguaje de programación o un entorno de aplicación de una plataforma de ejecución. El principal objetivo es proporcionarportability. La interpretación de un módulo en particular a través de una máquina virtual puede percibirse como:
El motor de interpretación elige una instrucción del módulo que se está interpretando.
Según la instrucción, el motor actualiza el estado interno de la máquina virtual y se repite el proceso anterior.
La siguiente figura muestra la arquitectura de una infraestructura de VM estándar en una sola máquina física.

los hypervisor, también llamado el virtual machine monitor, se ejecuta en el sistema operativo host y asigna los recursos correspondientes a cada sistema operativo invitado. Cuando el invitado realiza una llamada al sistema, el hipervisor la intercepta y la traduce a la correspondiente llamada al sistema admitida por el sistema operativo host. El hipervisor controla el acceso de cada máquina virtual a la CPU, la memoria, el almacenamiento persistente, los dispositivos de E / S y la red.
Aplicaciones
La arquitectura de la máquina virtual es adecuada en los siguientes dominios:
Adecuado para resolver un problema mediante simulación o traducción si no existe una solución directa.
Las aplicaciones de muestra incluyen intérpretes de microprogramación, procesamiento XML, ejecución de lenguaje de comandos de script, ejecución de sistema basado en reglas, Smalltalk y lenguaje de programación con intérprete de Java.
Ejemplos comunes de máquinas virtuales son intérpretes, sistemas basados en reglas, shells sintácticos y procesadores de lenguaje de comandos.
Ventajas
Portabilidad e independencia de la plataforma de la máquina.
Sencillez de desarrollo de software.
Proporciona flexibilidad a través de la capacidad de interrumpir y consultar el programa.
Simulación del modelo de trabajo ante desastres.
Introduce modificaciones en tiempo de ejecución.
Desventajas
Ejecución lenta del intérprete debido a la naturaleza del intérprete.
Hay un costo de rendimiento debido al cálculo adicional involucrado en la ejecución.
Estilo en capas
En este enfoque, el sistema se descompone en una serie de capas superiores e inferiores en una jerarquía, y cada capa tiene su propia responsabilidad en el sistema.
Cada capa consta de un grupo de clases relacionadas que se encapsulan en un paquete, en un componente implementado o como un grupo de subrutinas en el formato de biblioteca de métodos o archivo de encabezado.
Cada capa proporciona servicio a la capa superior y sirve como cliente de la capa inferior, es decir, la solicitud a la capa i + 1 invoca los servicios proporcionados por la capa i a través de la interfaz de la capa i. La respuesta puede volver a la capa i +1 si se completa la tarea; de lo contrario, la capa i invoca continuamente los servicios de la capa i -1 a continuación.
Aplicaciones
El estilo en capas es adecuado en las siguientes áreas:
Aplicaciones que involucran distintas clases de servicios que se pueden organizar jerárquicamente.
Cualquier aplicación que pueda descomponerse en partes específicas de la aplicación y de la plataforma.
Aplicaciones que tienen divisiones claras entre servicios centrales, servicios críticos y servicios de interfaz de usuario, etc.
Ventajas
Diseño basado en niveles incrementales de abstracción.
Proporciona independencia mejorada ya que los cambios en la función de una capa afectan como máximo a otras dos capas.
Separación de la interfaz estándar y su implementación.
Implementado mediante el uso de tecnología basada en componentes que hace que el sistema sea mucho más fácil para permitir el plug-and-play de nuevos componentes.
Cada capa puede ser una máquina abstracta implementada de forma independiente que admita la portabilidad.
Fácil de descomponer el sistema basado en la definición de las tareas de una manera de refinamiento de arriba hacia abajo
Se pueden usar indistintamente diferentes implementaciones (con interfaces idénticas) de la misma capa
Desventajas
Muchas aplicaciones o sistemas no se estructuran fácilmente en capas.
Menor rendimiento en tiempo de ejecución ya que la solicitud de un cliente o una respuesta al cliente debe pasar potencialmente por varias capas.
También existen preocupaciones de rendimiento sobre la sobrecarga en la clasificación de datos y el almacenamiento en búfer de cada capa.
La apertura de la comunicación entre capas puede causar puntos muertos y el "puente" puede causar un acoplamiento apretado.
Las excepciones y el manejo de errores son un problema en la arquitectura en capas, ya que las fallas en una capa deben extenderse hacia arriba a todas las capas de llamada.
El objetivo principal de la arquitectura orientada a la interacción es separar la interacción del usuario de la abstracción de datos y el procesamiento de datos comerciales. La arquitectura de software orientada a la interacción descompone el sistema en tres particiones principales:
Data module - El módulo de datos proporciona la abstracción de datos y toda la lógica empresarial.
Control module - El módulo de control identifica el flujo de acciones de control y configuración del sistema.
View presentation module - El módulo Ver presentación es responsable de la presentación visual o de audio de la salida de datos y también proporciona una interfaz para la entrada del usuario.
La arquitectura orientada a la interacción tiene dos estilos principales: Model-View-Controller (MVC) y Presentation-Abstraction-Control(PAC). Tanto MVC como PAC proponen la descomposición de tres componentes y se utilizan para aplicaciones interactivas como aplicaciones web con múltiples charlas e interacciones de usuario. Son diferentes en su flujo de control y organización. PAC es una arquitectura jerárquica basada en agentes, pero MVC no tiene una estructura jerárquica clara.
Modelo-Vista-Controlador (MVC)
MVC descompone una aplicación de software determinada en tres partes interconectadas que ayudan a separar las representaciones internas de la información de la información presentada o aceptada por el usuario.
| Módulo | Función |
|---|---|
| Modelo | Encapsulación de los datos subyacentes y la lógica empresarial |
| Controlador | Responder a la acción del usuario y dirigir el flujo de la aplicación |
| Ver | Formatea y presenta los datos del modelo al usuario. |
Modelo
El modelo es un componente central de MVC que administra directamente los datos, la lógica y las restricciones de una aplicación. Consiste en componentes de datos, que mantienen los datos sin procesar de la aplicación y la lógica de la aplicación para la interfaz.
Es una interfaz de usuario independiente y captura el comportamiento del dominio del problema de la aplicación.
Es la simulación o implementación de software específico del dominio de la estructura central de la aplicación.
Cuando ha habido un cambio en su estado, notifica a su vista asociada para producir una salida actualizada y al controlador para cambiar el conjunto de comandos disponibles.
Ver
La vista se puede utilizar para representar cualquier salida de información en forma gráfica, como un diagrama o un gráfico. Consiste en componentes de presentación que proporcionan las representaciones visuales de los datos.
Las vistas solicitan información de su modelo y generan una representación de salida para el usuario.
Son posibles varias vistas de la misma información, como un gráfico de barras para la gestión y una vista tabular para los contables.
Controlador
Un controlador acepta una entrada y la convierte en comandos para el modelo o la vista. Consiste en componentes de procesamiento de entrada que manejan la entrada del usuario modificando el modelo.
Actúa como una interfaz entre los modelos y vistas asociados y los dispositivos de entrada.
Puede enviar comandos al modelo para actualizar el estado del modelo y a su vista asociada para cambiar la presentación de la vista del modelo.

MVC - I
Es una versión simple de la arquitectura MVC donde el sistema se divide en dos subsistemas:
The Controller-View - La vista del controlador actúa como interfaz de entrada / salida y se realiza el procesamiento.
The Model - El modelo proporciona todos los datos y servicios de dominio.
MVC-I Architecture
El módulo de modelo notifica al módulo de vista del controlador de cualquier cambio de datos para que cualquier visualización de datos gráficos se cambie en consecuencia. El controlador también toma las medidas adecuadas ante los cambios.

La conexión entre la vista del controlador y el modelo se puede diseñar en un patrón (como se muestra en la imagen de arriba) de suscripción-notificación mediante el cual la vista del controlador se suscribe al modelo y el modelo notifica a la vista del controlador de cualquier cambio.
MVC - II
MVC-II es una mejora de la arquitectura MVC-I en la que el módulo de vista y el módulo del controlador están separados. El módulo de modelo juega un papel activo como en MVC-I al proporcionar toda la funcionalidad principal y los datos admitidos por la base de datos.
El módulo de vista presenta datos mientras que el módulo controlador acepta la solicitud de entrada, valida los datos de entrada, inicia el modelo, la vista, su conexión y también distribuye la tarea.
MVC-II Architecture

Aplicaciones MVC
Las aplicaciones MVC son efectivas para aplicaciones interactivas donde se necesitan múltiples vistas para un solo modelo de datos y es fácil conectar una vista de interfaz nueva o cambiar.
Las aplicaciones MVC son adecuadas para aplicaciones en las que existen claras divisiones entre los módulos, de modo que se pueden asignar diferentes profesionales para trabajar en diferentes aspectos de dichas aplicaciones al mismo tiempo.
Advantages
Hay muchos kits de herramientas de marcos de proveedores de MVC disponibles.
Varias vistas sincronizadas con el mismo modelo de datos.
Fácil de instalar o reemplazar vistas de interfaz.
Se utiliza para el desarrollo de aplicaciones donde los profesionales con experiencia en gráficos, los profesionales de programación y los profesionales de desarrollo de bases de datos están trabajando en un equipo de proyecto diseñado.
Disadvantages
No apto para aplicaciones orientadas a agentes, como aplicaciones móviles y robóticas interactivas.
Múltiples pares de controladores y vistas basados en el mismo modelo de datos hacen que cualquier cambio de modelo de datos sea costoso.
La división entre la vista y el controlador no está clara en algunos casos.
Presentación-Abstracción-Control (PAC)
En PAC, el sistema está organizado en una jerarquía de muchos agentes cooperantes (tríadas). Se desarrolló a partir de MVC para admitir los requisitos de aplicación de múltiples agentes además de los requisitos interactivos.
Cada agente tiene tres componentes:
The presentation component - Formatea la presentación visual y de audio de datos.
The abstraction component - Recupera y procesa los datos.
The control component - Maneja la tarea como el flujo de control y comunicación entre los otros dos componentes.
La arquitectura PAC es similar a MVC, en el sentido de que el módulo de presentación es como el módulo de vista de MVC. El módulo de abstracción parece un módulo modelo de MVC y el módulo de control es como el módulo controlador de MVC, pero difieren en su flujo de control y organización.
No hay conexiones directas entre el componente de abstracción y el componente de presentación en cada agente. El componente de control de cada agente está a cargo de las comunicaciones con otros agentes.
La siguiente figura muestra un diagrama de bloques para un solo agente en el diseño de PAC.

PAC con múltiples agentes
En los PAC que constan de varios agentes, el agente de nivel superior proporciona datos básicos y lógica empresarial. Los agentes de nivel inferior definen presentaciones y datos específicos detallados. El agente de nivel intermedio o medio actúa como coordinador de los agentes de nivel bajo.
Cada agente tiene su propio trabajo asignado específico.
Para algunos agentes de nivel medio, las presentaciones interactivas no son necesarias, por lo que no tienen un componente de presentación.
El componente de control es necesario para todos los agentes a través del cual todos los agentes se comunican entre sí.
La siguiente figura muestra los múltiples agentes que participan en PAC.

Applications
Eficaz para un sistema interactivo donde el sistema se puede descomponer en muchos agentes cooperantes de manera jerárquica.
Efectivo cuando se espera que el acoplamiento entre los agentes sea flojo de modo que los cambios en un agente no afecten a otros.
Eficaz para sistema distribuido donde todos los agentes están distribuidos a distancia y cada uno de ellos tiene sus propias funcionalidades con datos e interfaz interactiva.
Adecuado para aplicaciones con ricos componentes GUI donde cada uno de ellos mantiene sus propios datos actuales e interfaz interactiva y necesita comunicarse con otros componentes.
Ventajas
Soporte para multitarea y visualización múltiple
Soporte para reutilización y extensibilidad de agentes
Fácil de conectar un nuevo agente o cambiar uno existente
Soporte para simultaneidad donde múltiples agentes se ejecutan en paralelo en diferentes subprocesos o diferentes dispositivos o computadoras
Desventajas
Sobrecarga debido al puente de control entre presentación y abstracción y la comunicación de controles entre agentes.
Es difícil determinar el número correcto de agentes debido al acoplamiento flojo y la alta independencia entre los agentes.
La separación completa de presentación y abstracción por control en cada agente genera complejidad en el desarrollo ya que las comunicaciones entre agentes solo tienen lugar entre los controles de agentes
En la arquitectura distribuida, los componentes se presentan en diferentes plataformas y varios componentes pueden cooperar entre sí a través de una red de comunicación para lograr un objetivo u objetivo específico.
En esta arquitectura, el procesamiento de la información no se limita a una sola máquina, sino que se distribuye en varias computadoras independientes.
Un sistema distribuido puede demostrarse mediante la arquitectura cliente-servidor que forma la base de las arquitecturas de varios niveles; Las alternativas son la arquitectura de intermediarios como CORBA y la Arquitectura orientada a servicios (SOA).
Hay varios marcos de tecnología para admitir arquitecturas distribuidas, incluidos los servicios web .NET, J2EE, CORBA, .NET, los servicios web AXIS Java y los servicios Globus Grid.
Middleware es una infraestructura que soporta adecuadamente el desarrollo y ejecución de aplicaciones distribuidas. Proporciona un búfer entre las aplicaciones y la red.
Se encuentra en el medio del sistema y administra o da soporte a los diferentes componentes de un sistema distribuido. Algunos ejemplos son monitores de procesamiento de transacciones, convertidores de datos y controladores de comunicaciones, etc.
Middleware como infraestructura para sistema distribuido

La base de una arquitectura distribuida es su transparencia, confiabilidad y disponibilidad.
La siguiente tabla enumera las diferentes formas de transparencia en un sistema distribuido:
| No Señor. | Transparencia y descripción |
|---|---|
| 1 | Access Oculta la forma en que se accede a los recursos y las diferencias en la plataforma de datos. |
| 2 | Location Se esconde donde se encuentran los recursos. |
| 3 | Technology Oculta al usuario diferentes tecnologías, como el lenguaje de programación y el sistema operativo. |
| 4 | Migration / Relocation Ocultar los recursos que se pueden mover a otra ubicación que están en uso. |
| 5 | Replication Oculte los recursos que pueden copiarse en varias ubicaciones. |
| 6 | Concurrency Ocultar recursos que puedan compartirse con otros usuarios. |
| 7 | Failure Oculta la falla y la recuperación de recursos del usuario. |
| 8 | Persistence Oculta si un recurso (software) está en la memoria o en el disco. |
Ventajas
Resource sharing - Compartir recursos de hardware y software.
Openness - Flexibilidad de uso de hardware y software de diferentes proveedores.
Concurrency - Procesamiento concurrente para mejorar el rendimiento.
Scalability - Mayor rendimiento al agregar nuevos recursos.
Fault tolerance - La capacidad de continuar en funcionamiento después de que haya ocurrido una falla.
Desventajas
Complexity - Son más complejos que los sistemas centralizados.
Security - Más susceptible al ataque externo.
Manageability - Se requiere más esfuerzo para la gestión del sistema.
Unpredictability - Respuestas impredecibles según la organización del sistema y la carga de la red.
Sistema centralizado frente a sistema distribuido
| Criterios | Sistema centralizado | Sistema distribuido |
|---|---|---|
| Ciencias económicas | Bajo | Alto |
| Disponibilidad | Bajo | Alto |
| Complejidad | Bajo | Alto |
| Consistencia | Simple | Alto |
| Escalabilidad | Pobre | Bueno |
| Tecnología | Homogéneo | Heterogéneo |
| Seguridad | Alto | Bajo |
Arquitectura cliente-servidor
La arquitectura cliente-servidor es la arquitectura de sistema distribuido más común que descompone el sistema en dos subsistemas principales o procesos lógicos:
Client - Este es el primer proceso que envía una solicitud al segundo proceso, es decir, el servidor.
Server - Este es el segundo proceso que recibe la solicitud, la ejecuta y envía una respuesta al cliente.
En esta arquitectura, la aplicación se modela como un conjunto de servicios que son proporcionados por servidores y un conjunto de clientes que utilizan estos servicios. Los servidores no necesitan saber acerca de los clientes, pero los clientes deben conocer la identidad de los servidores, y la asignación de procesadores a procesos no es necesariamente 1: 1

La arquitectura cliente-servidor se puede clasificar en dos modelos según la funcionalidad del cliente:
Modelo de cliente ligero
En el modelo de cliente ligero, todo el procesamiento de la aplicación y la gestión de datos lo realiza el servidor. El cliente es simplemente responsable de ejecutar el software de presentación.
Se utiliza cuando los sistemas heredados se migran a arquitecturas de servidor cliente en las que el sistema heredado actúa como un servidor por derecho propio con una interfaz gráfica implementada en un cliente.
Una desventaja importante es que coloca una gran carga de procesamiento tanto en el servidor como en la red.
Modelo de cliente grueso / gordo
En el modelo de cliente pesado, el servidor solo se encarga de la gestión de datos. El software del cliente implementa la lógica de la aplicación y las interacciones con el usuario del sistema.
Más apropiado para nuevos sistemas C / S donde las capacidades del sistema cliente se conocen de antemano
Más complejo que un modelo de cliente ligero, especialmente para la gestión. Se deben instalar nuevas versiones de la aplicación en todos los clientes.
Ventajas
Separación de responsabilidades como la presentación de la interfaz de usuario y el procesamiento de la lógica empresarial.
Reutilización de los componentes del servidor y potencial de simultaneidad
Simplifica el diseño y desarrollo de aplicaciones distribuidas
Facilita la migración o integración de aplicaciones existentes en un entorno distribuido.
También hace un uso eficaz de los recursos cuando una gran cantidad de clientes acceden a un servidor de alto rendimiento.
Desventajas
Falta de infraestructura heterogénea para hacer frente a los cambios de requisitos.
Complicaciones de seguridad.
Disponibilidad y confiabilidad limitadas del servidor.
Capacidad de prueba y escalabilidad limitadas.
Clientes gordos con presentación y lógica de negocios juntas.
Arquitectura de varios niveles (arquitectura de n niveles)
La arquitectura de varios niveles es una arquitectura cliente-servidor en la que las funciones como la presentación, el procesamiento de aplicaciones y la gestión de datos están separadas físicamente. Al separar una aplicación en niveles, los desarrolladores obtienen la opción de cambiar o agregar una capa específica, en lugar de reelaborar toda la aplicación. Proporciona un modelo mediante el cual los desarrolladores pueden crear aplicaciones flexibles y reutilizables.

El uso más generalizado de la arquitectura de varios niveles es la arquitectura de tres niveles. Una arquitectura de tres niveles generalmente se compone de un nivel de presentación, un nivel de aplicación y un nivel de almacenamiento de datos y puede ejecutarse en un procesador separado.
Nivel de presentación
La capa de presentación es el nivel superior de la aplicación mediante el cual los usuarios pueden acceder directamente, como una página web o una GUI (interfaz gráfica de usuario) del sistema operativo. La función principal de esta capa es traducir las tareas y los resultados a algo que el usuario pueda comprender. Se comunica con otros niveles para que coloque los resultados en el nivel de navegador / cliente y en todos los demás niveles de la red.
Nivel de aplicación (lógica empresarial, nivel lógico o nivel medio)
El nivel de aplicación coordina la aplicación, procesa los comandos, toma decisiones lógicas, evalúa y realiza cálculos. Controla la funcionalidad de una aplicación realizando un procesamiento detallado. También mueve y procesa datos entre las dos capas circundantes.
Nivel de datos
En esta capa, la información se almacena y se recupera de la base de datos o del sistema de archivos. Luego, la información se devuelve para su procesamiento y luego al usuario. Incluye los mecanismos de persistencia de datos (servidores de bases de datos, archivos compartidos, etc.) y proporciona API (Interfaz de programación de aplicaciones) al nivel de la aplicación que proporciona métodos para administrar los datos almacenados.
Advantages
Mejor rendimiento que un enfoque de cliente ligero y es más sencillo de administrar que un enfoque de cliente pesado.
Mejora la reutilización y la escalabilidad: a medida que aumentan las demandas, se pueden agregar servidores adicionales.
Proporciona compatibilidad con subprocesos múltiples y también reduce el tráfico de red.
Proporciona facilidad de mantenimiento y flexibilidad
Disadvantages
Probabilidad insatisfactoria debido a la falta de herramientas de prueba.
Más fiabilidad y disponibilidad del servidor.
Estilo arquitectónico del corredor
Broker Architectural Style es una arquitectura de middleware utilizada en computación distribuida para coordinar y habilitar la comunicación entre servidores y clientes registrados. Aquí, la comunicación de objetos se lleva a cabo a través de un sistema de middleware llamado intermediario de solicitud de objetos (bus de software).
El cliente y el servidor no interactúan entre sí directamente. El cliente y el servidor tienen una conexión directa a su proxy que se comunica con el mediador-corredor.
Un servidor proporciona servicios mediante el registro y la publicación de sus interfaces con el corredor y los clientes pueden solicitar los servicios del corredor de forma estática o dinámica mediante búsqueda.
CORBA (Common Object Request Broker Architecture) es un buen ejemplo de implementación de la arquitectura de intermediario.
Componentes del estilo arquitectónico del corredor
Los componentes del estilo arquitectónico del corredor se analizan a través de los siguientes encabezados:
Broker
El corredor es responsable de coordinar la comunicación, como reenviar y enviar los resultados y las excepciones. Puede ser un servicio orientado a la invocación, un documento o un intermediario orientado a mensajes al que los clientes envían un mensaje.
Es responsable de gestionar las solicitudes de servicio, ubicar un servidor adecuado, transmitir solicitudes y enviar respuestas a los clientes.
Conserva la información de registro de los servidores, incluida su funcionalidad y servicios, así como la información de ubicación.
Proporciona API para que los clientes las soliciten, los servidores respondan, registren o cancelen el registro de componentes del servidor, transfieran mensajes y localicen servidores.
Stub
Los stubs se generan en el momento de la compilación estática y luego se implementan en el lado del cliente, que se utiliza como proxy para el cliente. El proxy del lado del cliente actúa como mediador entre el cliente y el corredor y proporciona transparencia adicional entre ellos y el cliente; un objeto remoto aparece como uno local.
El proxy oculta el IPC (comunicación entre procesos) a nivel de protocolo y realiza la clasificación de los valores de los parámetros y la eliminación de la clasificación de los resultados del servidor.
Skeleton
El esqueleto se genera mediante la compilación de la interfaz de servicio y luego se implementa en el lado del servidor, que se utiliza como proxy para el servidor. El proxy del lado del servidor encapsula las funciones de red específicas del sistema de bajo nivel y proporciona API de alto nivel para mediar entre el servidor y el intermediario.
Recibe las solicitudes, descomprime las solicitudes, descompone los argumentos del método, llama al servicio adecuado y también clasifica el resultado antes de devolverlo al cliente.
Bridge
Un puente puede conectar dos redes diferentes basadas en diferentes protocolos de comunicación. Actúa como mediador de diferentes corredores, incluidos DCOM, .NET remoto y corredores Java CORBA.
Los puentes son un componente opcional, que oculta los detalles de implementación cuando dos intermediarios interoperan y toman solicitudes y parámetros en un formato y los traducen a otro formato.

Broker implementation in CORBA
CORBA es un estándar internacional para Object Request Broker, un middleware para administrar las comunicaciones entre objetos distribuidos definidos por OMG (grupo de administración de objetos).

Arquitectura orientada a servicios (SOA)
Un servicio es un componente de la funcionalidad empresarial que está bien definido, es autónomo, independiente, está publicado y está disponible para su uso a través de una interfaz de programación estándar. Las conexiones entre servicios se llevan a cabo mediante protocolos orientados a mensajes comunes y universales, como el protocolo de servicio web SOAP, que puede entregar solicitudes y respuestas entre servicios de manera flexible.
La arquitectura orientada a servicios es un diseño de cliente / servidor que admite un enfoque de TI impulsado por el negocio en el que una aplicación consta de servicios de software y consumidores de servicios de software (también conocidos como clientes o solicitantes de servicios).
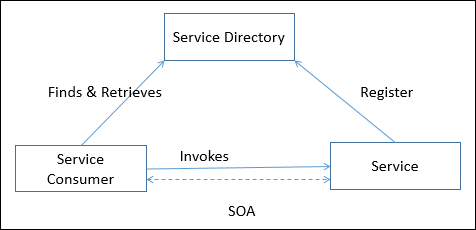
Características de SOA
Una arquitectura orientada a servicios proporciona las siguientes características:
Distributed Deployment - Exponga los datos empresariales y la lógica empresarial como unidades de funcionalidad sin estado, poco estrictas, acopladas, detectables, estructuradas, basadas en estándares, de grano grueso, llamadas servicios.
Composability - Ensamblar nuevos procesos a partir de servicios existentes que se exponen con la granularidad deseada a través de interfaces de quejas estándar, bien definidas y publicadas.
Interoperability - Comparta capacidades y reutilice servicios compartidos en una red independientemente de los protocolos subyacentes o la tecnología de implementación.
Reusability - Elija un proveedor de servicios y acceda a los recursos existentes expuestos como servicios.
Operación SOA
La siguiente figura ilustra cómo funciona SOA:

Advantages
El acoplamiento flexible de la orientación al servicio proporciona una gran flexibilidad para que las empresas hagan uso de todos los recursos de servicio disponibles, independientemente de las restricciones de plataforma y tecnología.
Cada componente de servicio es independiente de otros servicios debido a la característica de servicio sin estado.
La implementación de un servicio no afectará la aplicación del servicio mientras no se cambie la interfaz expuesta.
Un cliente o cualquier servicio puede acceder a otros servicios independientemente de su plataforma, tecnología, proveedores o implementaciones de idioma.
Reutilización de activos y servicios ya que los clientes de un servicio solo necesitan conocer sus interfaces públicas, composición del servicio.
El desarrollo de aplicaciones comerciales basadas en SOA es mucho más eficiente en términos de tiempo y costo.
Mejora la escalabilidad y proporciona una conexión estándar entre sistemas.
Uso eficiente y eficaz de los 'Servicios comerciales'.
La integración se vuelve mucho más fácil y mejora la interoperabilidad intrínseca.
Resuma la complejidad para los desarrolladores y dinamice los procesos comerciales más cerca de los usuarios finales.
La arquitectura basada en componentes se centra en la descomposición del diseño en componentes funcionales o lógicos individuales que representan interfaces de comunicación bien definidas que contienen métodos, eventos y propiedades. Proporciona un mayor nivel de abstracción y divide el problema en subproblemas, cada uno asociado con particiones de componentes.
El objetivo principal de la arquitectura basada en componentes es garantizar component reusability. Un componente encapsula la funcionalidad y los comportamientos de un elemento de software en una unidad binaria reutilizable y autodesplegable. Hay muchos marcos de componentes estándar como COM / DCOM, JavaBean, EJB, CORBA, .NET, servicios web y servicios grid. Estas tecnologías se utilizan ampliamente en el diseño de aplicaciones GUI de escritorio local, como componentes gráficos JavaBean, componentes MS ActiveX y componentes COM que se pueden reutilizar simplemente arrastrando y soltando.
El diseño de software orientado a componentes tiene muchas ventajas sobre los enfoques tradicionales orientados a objetos, tales como:
Reducción del tiempo en el mercado y el costo de desarrollo al reutilizar componentes existentes.
Mayor fiabilidad con la reutilización de los componentes existentes.
¿Qué es un componente?
Un componente es un conjunto modular, portátil, reemplazable y reutilizable de funcionalidad bien definida que encapsula su implementación y la exporta como una interfaz de nivel superior.
Un componente es un objeto de software, destinado a interactuar con otros componentes, encapsulando cierta funcionalidad o un conjunto de funcionalidades. Tiene una interfaz claramente definida y se ajusta a un comportamiento recomendado común a todos los componentes dentro de una arquitectura.
Un componente de software puede definirse como una unidad de composición con una interfaz especificada contractualmente y dependencias de contexto explícitas únicamente. Es decir, un componente de software se puede implementar de forma independiente y está sujeto a composición por parte de terceros.
Vistas de un componente
Un componente puede tener tres vistas diferentes: vista orientada a objetos, vista convencional y vista relacionada con procesos.
Object-oriented view
Un componente se ve como un conjunto de una o más clases cooperantes. Se explica cada clase de dominio del problema (análisis) y clase de infraestructura (diseño) para identificar todos los atributos y operaciones que se aplican a su implementación. También implica definir las interfaces que permiten a las clases comunicarse y cooperar.
Conventional view
Se ve como un elemento funcional o un módulo de un programa que integra la lógica de procesamiento, las estructuras de datos internas que se requieren para implementar la lógica de procesamiento y una interfaz que permite invocar el componente y pasarle datos.
Process-related view
En esta vista, en lugar de crear cada componente desde cero, el sistema se está construyendo a partir de componentes existentes mantenidos en una biblioteca. A medida que se formula la arquitectura del software, los componentes se seleccionan de la biblioteca y se utilizan para completar la arquitectura.
Un componente de interfaz de usuario (UI) incluye cuadrículas, botones denominados controles y componentes de utilidades que exponen un subconjunto específico de funciones utilizadas en otros componentes.
Otros tipos comunes de componentes son los que consumen muchos recursos, no se accede con frecuencia y deben activarse mediante el enfoque Just-In-Time (JIT).
Muchos componentes son invisibles y se distribuyen en aplicaciones empresariales empresariales y aplicaciones web de Internet como Enterprise JavaBean (EJB), componentes .NET y componentes CORBA.
Características de los componentes
Reusability- Los componentes suelen estar diseñados para ser reutilizados en diferentes situaciones en diferentes aplicaciones. Sin embargo, algunos componentes pueden estar diseñados para una tarea específica.
Replaceable - Los componentes se pueden sustituir libremente por otros componentes similares.
Not context specific - Los componentes están diseñados para operar en diferentes entornos y contextos.
Extensible - Un componente se puede ampliar a partir de componentes existentes para proporcionar un nuevo comportamiento.
Encapsulated - El componente AA describe las interfaces, que permiten a la persona que llama utilizar su funcionalidad, y no exponen detalles de los procesos internos o cualquier variable o estado internos.
Independent - Los componentes están diseñados para tener dependencias mínimas de otros componentes.
Principios del diseño basado en componentes
Un diseño a nivel de componente se puede representar utilizando alguna representación intermedia (por ejemplo, gráfica, tabular o basada en texto) que se puede traducir al código fuente. El diseño de estructuras de datos, interfaces y algoritmos debe ajustarse a pautas bien establecidas para ayudarnos a evitar la introducción de errores.
El sistema de software se descompone en unidades de componentes reutilizables, cohesivas y encapsuladas.
Cada componente tiene su propia interfaz que especifica los puertos requeridos y los puertos proporcionados; cada componente oculta su implementación detallada.
Un componente debe ampliarse sin necesidad de realizar modificaciones de diseño o código interno en las partes existentes del componente.
Dependen del componente de abstracciones no dependen de otros componentes concretos, que aumentan la dificultad en la prescindibilidad.
Los conectores conectan componentes, especificando y gobernando la interacción entre componentes. El tipo de interacción viene especificado por las interfaces de los componentes.
La interacción de los componentes puede tomar la forma de invocaciones de métodos, invocaciones asincrónicas, difusión, interacciones impulsadas por mensajes, comunicaciones de flujo de datos y otras interacciones específicas de protocolo.
Para una clase de servidor, deben crearse interfaces especializadas para servir a las principales categorías de clientes. Solo aquellas operaciones que son relevantes para una categoría particular de clientes deben especificarse en la interfaz.
Un componente puede extenderse a otros componentes y aún ofrecer sus propios puntos de extensión. Es el concepto de arquitectura basada en plug-in. Esto permite que un complemento ofrezca otra API de complemento.

Pautas de diseño a nivel de componente
Crea convenciones de nomenclatura para componentes que se especifican como parte del modelo arquitectónico y luego refina o elabora como parte del modelo a nivel de componente.
Obtiene nombres de componentes arquitectónicos del dominio del problema y garantiza que tengan significado para todas las partes interesadas que ven el modelo arquitectónico.
Extrae las entidades de procesos empresariales que pueden existir de forma independiente sin ninguna dependencia asociada de otras entidades.
Reconoce y descubre estas entidades independientes como nuevos componentes.
Utiliza nombres de componentes de infraestructura que reflejan su significado específico de implementación.
Modela cualquier dependencia de izquierda a derecha y la herencia de arriba (clase base) a abajo (clases derivadas).
Modele las dependencias de cualquier componente como interfaces en lugar de representarlas como una dependencia directa de componente a componente.
Realización de diseño a nivel de componentes
Reconoce todas las clases de diseño que corresponden al dominio del problema según se define en el modelo de análisis y el modelo arquitectónico.
Reconoce todas las clases de diseño que corresponden al dominio de la infraestructura.
Describe todas las clases de diseño que no se adquieren como componentes reutilizables y especifica los detalles del mensaje.
Identifica las interfaces adecuadas para cada componente y elabora atributos y define los tipos de datos y las estructuras de datos necesarios para implementarlos.
Describe el flujo de procesamiento dentro de cada operación en detalle mediante pseudocódigo o diagramas de actividad UML.
Describe las fuentes de datos persistentes (bases de datos y archivos) e identifica las clases necesarias para administrarlas.
Desarrolla y elabora representaciones de comportamiento para una clase o componente. Esto se puede hacer elaborando los diagramas de estado UML creados para el modelo de análisis y examinando todos los casos de uso que son relevantes para la clase de diseño.
Elabora diagramas de implementación para proporcionar detalles de implementación adicionales.
Demuestra la ubicación de paquetes clave o clases de componentes en un sistema mediante el uso de instancias de clase y la designación de un entorno de sistema operativo y hardware específico.
La decisión final se puede tomar utilizando principios y pautas de diseño establecidos. Los diseñadores experimentados consideran todas (o la mayoría) de las soluciones de diseño alternativas antes de decidirse por el modelo de diseño final.
Ventajas
Ease of deployment - A medida que están disponibles nuevas versiones compatibles, es más fácil reemplazar las versiones existentes sin impacto en los otros componentes o el sistema en su conjunto.
Reduced cost - El uso de componentes de terceros le permite repartir el costo de desarrollo y mantenimiento.
Ease of development - Los componentes implementan interfaces conocidas para proporcionar una funcionalidad definida, lo que permite el desarrollo sin afectar otras partes del sistema.
Reusable - El uso de componentes reutilizables significa que pueden usarse para distribuir el costo de desarrollo y mantenimiento entre varias aplicaciones o sistemas.
Modification of technical complexity - Un componente modifica la complejidad mediante el uso de un contenedor de componentes y sus servicios.
Reliability - La fiabilidad general del sistema aumenta, ya que la fiabilidad de cada componente individual mejora la fiabilidad de todo el sistema mediante la reutilización.
System maintenance and evolution - Fácil de cambiar y actualizar la implementación sin afectar al resto del sistema.
Independent- Independencia y conectividad flexible de componentes. Desarrollo independiente de componentes por diferentes grupos en paralelo. Productividad para el desarrollo de software y el desarrollo de software futuro.
La interfaz de usuario es la primera impresión de un sistema de software desde el punto de vista del usuario. Por lo tanto, cualquier sistema de software debe satisfacer los requisitos del usuario. La interfaz de usuario realiza principalmente dos funciones:
Aceptando la entrada del usuario
Visualización de la salida
La interfaz de usuario juega un papel crucial en cualquier sistema de software. Posiblemente sea el único aspecto visible de un sistema de software como:
Los usuarios verán inicialmente la arquitectura de la interfaz de usuario externa del sistema de software sin considerar su arquitectura interna.
Una buena interfaz de usuario debe atraer al usuario a utilizar el sistema de software sin errores. Debería ayudar al usuario a comprender el sistema de software fácilmente sin información engañosa. Una mala interfaz de usuario puede causar fallas en el mercado frente a la competencia del sistema de software.
La interfaz de usuario tiene su sintaxis y semántica. La sintaxis comprende tipos de componentes como texto, icono, botón, etc. y la usabilidad resume la semántica de la interfaz de usuario. La calidad de la interfaz de usuario se caracteriza por su apariencia (sintaxis) y su usabilidad (semántica).
Básicamente, existen dos tipos principales de interfaz de usuario: a) Textual b) Gráfica.
El software en diferentes dominios puede requerir un estilo diferente de su interfaz de usuario, por ejemplo, la calculadora solo necesita un área pequeña para mostrar números numéricos, pero un área grande para comandos, una página web necesita formularios, enlaces, pestañas, etc.
Interfaz gráfica del usuario
Una interfaz gráfica de usuario es el tipo más común de interfaz de usuario disponible en la actualidad. Es muy fácil de usar porque hace uso de imágenes, gráficos e iconos, de ahí que se le llame "gráfico".
También se conoce como WIMP interface porque hace uso de -
Windows - Un área rectangular en la pantalla donde se ejecutan las aplicaciones de uso común.
Icons - Una imagen o símbolo que se utiliza para representar una aplicación de software o un dispositivo de hardware.
Menus - Una lista de opciones entre las que el usuario puede elegir lo que requiera.
Pointers- Un símbolo como una flecha que se mueve por la pantalla cuando el usuario mueve el mouse. Ayuda al usuario a seleccionar objetos.
Diseño de interfaz de usuario
Comienza con el análisis de tareas que comprende las tareas principales del usuario y el dominio del problema. Debe diseñarse en términos de la terminología del usuario y el comienzo del trabajo del usuario en lugar de la del programador.
Para realizar el análisis de la interfaz de usuario, el profesional debe estudiar y comprender cuatro elementos:
los users quién interactuará con el sistema a través de la interfaz
los tasks que los usuarios finales deben realizar para hacer su trabajo
los content que se presenta como parte de la interfaz
los work environment en el que se realizarán estas tareas
El diseño de la interfaz de usuario adecuado o bueno se basa en las capacidades y limitaciones del usuario, no en las máquinas. Al diseñar la interfaz de usuario, el conocimiento de la naturaleza del trabajo y el entorno del usuario también es fundamental.
La tarea a realizar se puede dividir y asignar al usuario o máquina, en función del conocimiento de las capacidades y limitaciones de cada uno. El diseño de una interfaz de usuario a menudo se divide en cuatro niveles diferentes:
The conceptual level - Describe las entidades básicas considerando la visión del usuario del sistema y las acciones posibles sobre ellas.
The semantic level - Describe las funciones realizadas por el sistema, es decir, una descripción de los requisitos funcionales del sistema, pero no aborda cómo el usuario invocará las funciones.
The syntactic level - Describe las secuencias de entradas y salidas necesarias para invocar las funciones descritas.
The lexical level - Determina cómo se forman realmente las entradas y salidas a partir de operaciones de hardware primitivas.
El diseño de la interfaz de usuario es un proceso iterativo, donde toda la iteración explica y refina la información desarrollada en los pasos anteriores. Pasos generales para el diseño de la interfaz de usuario
Define objetos y acciones (operaciones) de la interfaz de usuario.
Define eventos (acciones del usuario) que harán que cambie el estado de la interfaz de usuario.
Indica cómo el usuario interpreta el estado del sistema a partir de la información proporcionada a través de la interfaz.
Describa el estado de cada interfaz como lo verá el usuario final.
Creado por un usuario o ingeniero de software, que establece el perfil de los usuarios finales del sistema en base a edad, género, habilidades físicas, educación, motivación, metas y personalidad.
Considera el conocimiento sintáctico y semántico del usuario y clasifica a los usuarios como novatos, conocedores intermitentes y conocedores frecuentes.
Creado por un ingeniero de software que incorpora datos, arquitectura, interfaz y representaciones de procedimientos del software.
Derivado del modelo de análisis de los requisitos y controlado por la información de la especificación de requisitos que ayuda a definir el usuario del sistema.
Creado por los implementadores de software que trabajan en la apariencia de la interfaz combinada con toda la información de apoyo (libros, videos, archivos de ayuda) que describe la sintaxis y la semántica del sistema.
Sirve como traducción del modelo de diseño e intenta estar de acuerdo con el modelo mental del usuario para que los usuarios se sientan cómodos con el software y lo utilicen de forma eficaz.
Creado por el usuario al interactuar con la aplicación. Contiene la imagen del sistema que los usuarios llevan en la cabeza.
A menudo llamado percepción del sistema del usuario y la exactitud de la descripción depende del perfil del usuario y la familiaridad general con el software en el dominio de la aplicación.
- Identifique sus objetivos de arquitectura desde el principio.
- Identificar al consumidor de nuestra arquitectura.
- Identifica las limitaciones.
Revise la arquitectura con frecuencia en los principales hitos del proyecto y en respuesta a otros cambios arquitectónicos importantes.
El objetivo principal de una revisión de arquitectura es determinar la viabilidad de arquitecturas de línea base y candidatas, que verifican la arquitectura correctamente.
Vincula los requisitos funcionales y los atributos de calidad con la solución técnica propuesta. También ayuda a identificar problemas y reconocer áreas de mejora.
Proceso de desarrollo de la interfaz de usuario
Sigue un proceso en espiral como se muestra en el siguiente diagrama:

Interface analysis
Se concentra o se centra en los usuarios, las tareas, el contenido y el entorno de trabajo que interactuarán con el sistema. Define las tareas orientadas a personas y computadoras que se requieren para lograr el funcionamiento del sistema.
Interface design
Define un conjunto de objetos de interfaz, acciones y sus representaciones de pantalla que permiten al usuario realizar todas las tareas definidas de una manera que cumpla con todos los objetivos de usabilidad definidos para el sistema.
Interface construction
Comienza con un prototipo que permite evaluar escenarios de uso y continúa con herramientas de desarrollo para completar la construcción.
Interface validation
Se centra en la capacidad de la interfaz para implementar correctamente todas las tareas del usuario, adaptarse a todas las variaciones de tareas, lograr todos los requisitos generales del usuario y el grado en que la interfaz es fácil de usar y de aprender.
User Interface Models
Cuando se analiza y diseña una interfaz de usuario, se utilizan los siguientes cuatro modelos:
User profile model
Design model
Implementation model
User's mental model
Consideraciones de diseño de la interfaz de usuario
Centrado en el usuario
Una interfaz de usuario debe ser un producto centrado en el usuario que involucre a los usuarios durante todo el ciclo de vida de desarrollo de un producto. El prototipo de una interfaz de usuario debe estar disponible para los usuarios y los comentarios de los usuarios deben incorporarse al producto final.
Simple e intuitivo
La interfaz de usuario proporciona simplicidad e intuición para que se pueda utilizar de forma rápida y eficaz sin instrucciones. La GUI es mejor que la interfaz de usuario textual, ya que la GUI consta de menús, ventanas y botones y se opera simplemente con el mouse.
Ponga a los usuarios en control
No obligue a los usuarios a completar secuencias predefinidas. Bríndeles opciones: cancelar o guardar y regresar a donde lo dejaron. Utilice términos en toda la interfaz que los usuarios puedan comprender, en lugar de términos del sistema o del desarrollador.
Proporcione a los usuarios alguna indicación de que se ha realizado una acción, ya sea mostrándoles los resultados de la acción o reconociendo que la acción se ha realizado correctamente.
Transparencia
La interfaz de usuario debe ser transparente para ayudar a los usuarios a sentir que están llegando directamente a través de la computadora y manipulando directamente los objetos con los que están trabajando. La interfaz se puede hacer transparente proporcionando a los usuarios objetos de trabajo en lugar de objetos del sistema. Por ejemplo, los usuarios deben entender que la contraseña del sistema debe tener al menos 6 caracteres, no cuántos bytes de almacenamiento debe tener una contraseña.
Utilice la divulgación progresiva
Proporcione siempre fácil acceso a funciones comunes y acciones de uso frecuente. Oculte funciones y acciones menos comunes y permita a los usuarios navegar por ellas. No intente poner toda la información en una ventana principal. Utilice la ventana secundaria para obtener información que no sea información clave.
Consistencia
La interfaz de usuario mantiene la coherencia dentro y en todo el producto, mantiene los mismos resultados de interacción, los comandos y menús de la interfaz de usuario deben tener el mismo formato, las puntuaciones de los comandos deben ser similares y los parámetros deben pasarse a todos los comandos de la misma manera. La interfaz de usuario no debe tener comportamientos que puedan sorprender a los usuarios y debe incluir los mecanismos que permitan a los usuarios recuperarse de sus errores.
Integración
El sistema de software debe integrarse sin problemas con otras aplicaciones como el bloc de notas de MS y MS-Office. Puede usar los comandos del Portapapeles directamente para realizar el intercambio de datos.
Orientado a componentes
El diseño de la interfaz de usuario debe ser modular e incorporar una arquitectura orientada a componentes para que el diseño de la interfaz de usuario tenga los mismos requisitos que el diseño del cuerpo principal del sistema de software. Los módulos se pueden modificar y reemplazar fácilmente sin afectar otras partes del sistema.
Personalizable
La arquitectura de todo el sistema de software incorpora módulos enchufables que permiten que muchas personas diferentes extiendan el software de forma independiente. Permite a los usuarios individuales seleccionar entre varios formularios disponibles para adaptarse a sus preferencias y necesidades personales.
Reducir la carga de memoria de los usuarios
No obligue a los usuarios a tener que recordar y repetir lo que la computadora debería hacer por ellos. Por ejemplo, al completar formularios en línea, el sistema debe recordar los nombres, direcciones y números de teléfono de los clientes una vez que el usuario los haya ingresado o una vez que se haya abierto un registro de cliente.
Las interfaces de usuario apoyan la recuperación de la memoria a largo plazo al proporcionar a los usuarios elementos para que los reconozcan en lugar de tener que recordar información.
Separación
La interfaz de usuario debe separarse de la lógica del sistema a través de su implementación para aumentar la reutilización y el mantenimiento.
Enfoque iterativo e incremental
Es un enfoque iterativo e incremental que consta de cinco pasos principales que ayudan a generar soluciones candidatas. Esta solución candidata se puede refinar aún más repitiendo estos pasos y finalmente crear un diseño de arquitectura que se adapte mejor a nuestra aplicación. Al final del proceso, podemos revisar y comunicar nuestra arquitectura a todas las partes interesadas.
Es solo un enfoque posible. Hay muchos otros enfoques más formales que definen, revisan y comunican su arquitectura.
Identificar el objetivo de la arquitectura
Identificar el objetivo de la arquitectura que forma el proceso de arquitectura y diseño. Los objetivos impecables y definidos hacen hincapié en la arquitectura, resuelven los problemas correctos en el diseño y ayudan a determinar cuándo se ha completado la fase actual y están listos para pasar a la siguiente fase.
Este paso incluye las siguientes actividades:
Los ejemplos de actividades de arquitectura incluyen la construcción de un prototipo para obtener comentarios sobre la interfaz de usuario de procesamiento de pedidos para una aplicación web, la construcción de una aplicación de seguimiento de pedidos del cliente y el diseño de la arquitectura de autenticación y autorización para una aplicación con el fin de realizar una revisión de seguridad.
Escenarios clave
Este paso pone énfasis en el diseño que más importa. Un escenario es una descripción extensa y que cubre la interacción de un usuario con el sistema.
Los escenarios clave son aquellos que se consideran los escenarios más importantes para el éxito de su aplicación. Ayuda a tomar decisiones sobre la arquitectura. El objetivo es lograr un equilibrio entre los objetivos del usuario, la empresa y el sistema. Por ejemplo, la autenticación de usuario es un escenario clave porque es una intersección de un atributo de calidad (seguridad) con una funcionalidad importante (cómo un usuario inicia sesión en su sistema).
Descripción general de la aplicación
Cree una descripción general de la aplicación, lo que hace que la arquitectura sea más accesible, conectándola a las restricciones y decisiones del mundo real. Consta de las siguientes actividades:
Identificar el tipo de aplicación
Identifique el tipo de aplicación, ya sea una aplicación móvil, un cliente enriquecido, una aplicación de Internet enriquecida, un servicio, una aplicación web o alguna combinación de estos tipos.
Identificar las restricciones de implementación
Elija una topología de implementación adecuada y resuelva los conflictos entre la aplicación y la infraestructura de destino.
Identificar estilos de diseño arquitectónicos importantes
Identifique estilos de diseño de arquitectura importantes, como cliente / servidor, en capas, bus de mensajes, diseño controlado por dominios, etc. para mejorar la partición y promover la reutilización del diseño al proporcionar soluciones a problemas que se repiten con frecuencia. Las aplicaciones suelen utilizar una combinación de estilos.
Identificar las tecnologías relevantes
Identifique las tecnologías relevantes considerando el tipo de aplicación que estamos desarrollando, nuestras opciones preferidas para la topología de implementación de aplicaciones y los estilos arquitectónicos. La elección de tecnologías también estará dirigida por las políticas de la organización, las limitaciones de la infraestructura, las habilidades de recursos, etc.
Problemas clave o puntos clave
Al diseñar una aplicación, los puntos calientes son las zonas donde se cometen errores con mayor frecuencia. Identificar problemas clave basados en atributos de calidad y preocupaciones transversales. Los problemas potenciales incluyen la aparición de nuevas tecnologías y requisitos comerciales críticos.
Los atributos de calidad son las características generales de su arquitectura que afectan el comportamiento en tiempo de ejecución, el diseño del sistema y la experiencia del usuario. Las preocupaciones transversales son las características de nuestro diseño que pueden aplicarse a todas las capas, componentes y niveles.
Estas son también las áreas en las que se cometen con mayor frecuencia errores de diseño de alto impacto. Ejemplos de preocupaciones transversales son autenticación y autorización, comunicación, gestión de la configuración, gestión y validación de excepciones, etc.
Soluciones candidatas
Después de definir los puntos clave, cree la arquitectura de referencia inicial o el primer diseño de alto nivel y luego comience a completar los detalles para generar la arquitectura candidata.
La arquitectura candidata incluye el tipo de aplicación, la arquitectura de implementación, el estilo arquitectónico, las opciones de tecnología, los atributos de calidad y las preocupaciones transversales. Si la arquitectura candidata es una mejora, puede convertirse en la línea de base a partir de la cual se pueden crear y probar nuevas arquitecturas candidatas.
Valide el diseño de la solución candidata contra los escenarios y requisitos clave que ya se han definido, antes de seguir iterativamente el ciclo y mejorar el diseño.
Podemos utilizar picos arquitectónicos para descubrir áreas específicas del diseño o para validar nuevos conceptos. Los picos arquitectónicos son un prototipo de diseño, que determinan la viabilidad de una ruta de diseño específica, reducen el riesgo y determinan rápidamente la viabilidad de diferentes enfoques. Pruebe los picos arquitectónicos en escenarios clave y puntos de acceso.
Revisión de arquitectura
La revisión de la arquitectura es la tarea más importante para reducir el costo de los errores y para encontrar y solucionar los problemas arquitectónicos lo antes posible. Es una forma rentable y bien establecida de reducir los costos del proyecto y las posibilidades de que el proyecto fracase.
Las evaluaciones basadas en escenarios son un método dominante para revisar un diseño de arquitectura que se enfoca en los escenarios que son más importantes desde la perspectiva empresarial y que tienen el mayor impacto en la arquitectura. A continuación se presentan las metodologías de revisión comunes:
Método de análisis de arquitectura de software (SAAM)
Originalmente está diseñado para evaluar la modificabilidad, pero luego se amplió para revisar la arquitectura con respecto a los atributos de calidad.
Método de análisis de compensación de arquitectura (ATAM)
Es una versión pulida y mejorada de SAAM, que revisa las decisiones arquitectónicas con respecto a los requisitos de atributos de calidad y qué tan bien satisfacen objetivos de calidad particulares.
Revisión de diseño activo (ADR)
Es más adecuado para arquitecturas incompletas o en progreso, que se centran más en un conjunto de problemas o secciones individuales de la arquitectura a la vez, en lugar de realizar una revisión general.
Revisiones activas de diseños intermedios (ARID)
Combina el aspecto ADR de la revisión de la arquitectura en curso con un enfoque en un conjunto de cuestiones, y el enfoque ATAM y SAAM de revisión basada en escenarios centrados en atributos de calidad.
Método de análisis de costo-beneficio (CBAM)
Se centra en analizar los costos, los beneficios y las implicaciones de programación de las decisiones arquitectónicas.
Análisis de modificabilidad a nivel de arquitectura (ALMA)
Estima la modificabilidad de la arquitectura para los sistemas de información empresarial (BIS).
Método de evaluación de arquitectura familiar (FAAM)
Estima las arquitecturas de la familia de sistemas de información para la interoperabilidad y la extensibilidad.
Comunicando el diseño de la arquitectura
Después de completar el diseño de la arquitectura, debemos comunicar el diseño a las otras partes interesadas, que incluyen al equipo de desarrollo, administradores de sistemas, operadores, propietarios de negocios y otras partes interesadas.
Existen varios métodos conocidos siguientes para describir la arquitectura a otros: -
Modelo 4 + 1
Este enfoque utiliza cinco vistas de la arquitectura completa. Entre ellos, cuatro vistas (ellogical view, la process view, la physical view, y el development view) describen la arquitectura desde diferentes enfoques. Una quinta vista muestra los escenarios y casos de uso del software. Permite a las partes interesadas ver las características de la arquitectura que les interesan específicamente.
Lenguaje de descripción de arquitectura (ADL)
Este enfoque se utiliza para describir la arquitectura del software antes de la implementación del sistema. Aborda las siguientes preocupaciones: comportamiento, protocolo y conector.
La principal ventaja de ADL es que podemos analizar la arquitectura en cuanto a integridad, coherencia, ambigüedad y rendimiento antes de comenzar formalmente el uso del diseño.
Modelado ágil
Este enfoque sigue el concepto de que "el contenido es más importante que la representación". Asegura que los modelos creados sean simples y fáciles de entender, suficientemente precisos, detallados y consistentes.
Los documentos modelo ágiles se dirigen a clientes específicos y cumplen con los esfuerzos laborales de ese cliente. La simplicidad del documento asegura que haya una participación activa de las partes interesadas en el modelado del artefacto.
IEEE 1471
IEEE 1471 es el nombre corto de un estándar formalmente conocido como ANSI / IEEE 1471-2000, "Práctica recomendada para la descripción de la arquitectura de sistemas intensivos en software". IEEE 1471 mejora el contenido de una descripción arquitectónica, en particular, dando un significado específico al contexto, las vistas y los puntos de vista.
Lenguaje unificado de modelado UML)
Este enfoque representa tres vistas de un modelo de sistema. losfunctional requirements view (requisitos funcionales del sistema desde el punto de vista del usuario, incluidos los casos de uso); the static structural view(objetos, atributos, relaciones y operaciones, incluidos los diagramas de clases); y eldynamic behavior view (colaboración entre objetos y cambios en el estado interno de los objetos, incluidos diagramas de secuencia, actividad y estado).