Apache Solr - Sur Hadoop
Solr peut être utilisé avec Hadoop. Comme Hadoop gère une grande quantité de données, Solr nous aide à trouver les informations requises à partir d'une source aussi importante. Dans cette section, voyons comment vous pouvez installer Hadoop sur votre système.
Téléchargement de Hadoop
Vous trouverez ci-dessous les étapes à suivre pour télécharger Hadoop sur votre système.
Step 1- Accédez à la page d'accueil de Hadoop. Vous pouvez utiliser le lien - www.hadoop.apache.org/ . Cliquer sur le lienReleases, comme mis en évidence dans la capture d'écran suivante.
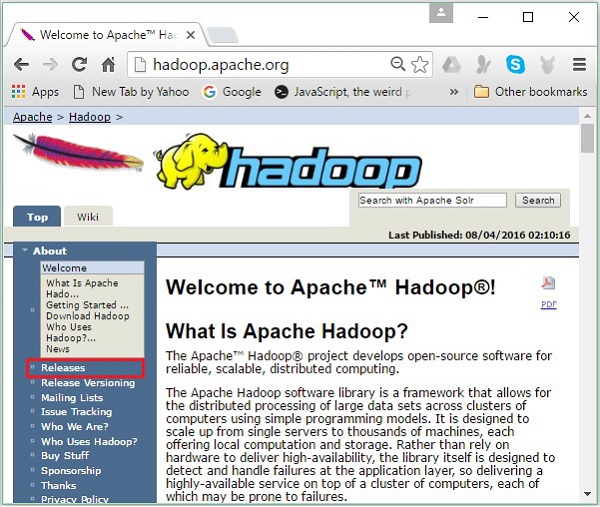
Il vous redirigera vers le Apache Hadoop Releases page qui contient des liens vers des miroirs de fichiers source et binaires de différentes versions de Hadoop comme suit -
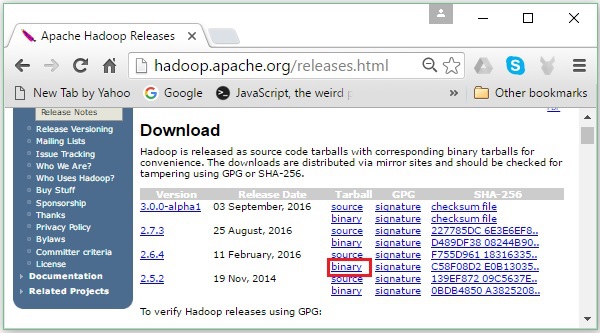
Step 2 - Sélectionnez la dernière version de Hadoop (dans notre tutoriel, il s'agit de la 2.6.4) et cliquez sur sa binary link. Cela vous mènera à une page où des miroirs pour le binaire Hadoop sont disponibles. Cliquez sur l'un de ces miroirs pour télécharger Hadoop.
Télécharger Hadoop à partir de l'invite de commande
Ouvrez le terminal Linux et connectez-vous en tant que super-utilisateur.
$ su
password:Accédez au répertoire dans lequel vous devez installer Hadoop et enregistrez-y le fichier en utilisant le lien copié précédemment, comme indiqué dans le bloc de code suivant.
# cd /usr/local
# wget http://redrockdigimark.com/apachemirror/hadoop/common/hadoop-
2.6.4/hadoop-2.6.4.tar.gzAprès avoir téléchargé Hadoop, extrayez-le à l'aide des commandes suivantes.
# tar zxvf hadoop-2.6.4.tar.gz
# mkdir hadoop
# mv hadoop-2.6.4/* to hadoop/
# exitInstaller Hadoop
Suivez les étapes ci-dessous pour installer Hadoop en mode pseudo-distribué.
Étape 1: Configurer Hadoop
Vous pouvez définir les variables d'environnement Hadoop en ajoutant les commandes suivantes à ~/.bashrc fichier.
export HADOOP_HOME = /usr/local/hadoop export
HADOOP_MAPRED_HOME = $HADOOP_HOME export
HADOOP_COMMON_HOME = $HADOOP_HOME export
HADOOP_HDFS_HOME = $HADOOP_HOME export
YARN_HOME = $HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR = $HADOOP_HOME/lib/native
export PATH = $PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL = $HADOOP_HOMEEnsuite, appliquez toutes les modifications dans le système en cours d'exécution.
$ source ~/.bashrcÉtape 2: Configuration Hadoop
Vous pouvez trouver tous les fichiers de configuration Hadoop à l'emplacement «$ HADOOP_HOME / etc / hadoop». Il est nécessaire d'apporter des modifications à ces fichiers de configuration en fonction de votre infrastructure Hadoop.
$ cd $HADOOP_HOME/etc/hadoopPour développer des programmes Hadoop en Java, vous devez réinitialiser les variables d'environnement Java dans hadoop-env.sh fichier en remplaçant JAVA_HOME valeur avec l'emplacement de Java dans votre système.
export JAVA_HOME = /usr/local/jdk1.7.0_71Voici la liste des fichiers que vous devez modifier pour configurer Hadoop -
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
core-site.xml
le core-site.xml fichier contient des informations telles que le numéro de port utilisé pour l'instance Hadoop, la mémoire allouée au système de fichiers, la limite de mémoire pour stocker les données et la taille des tampons de lecture / écriture.
Ouvrez le fichier core-site.xml et ajoutez les propriétés suivantes dans les balises <configuration>, </configuration>.
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xml
le hdfs-site.xml le fichier contient des informations telles que la valeur des données de réplication, namenode chemin, et datanodechemins de vos systèmes de fichiers locaux. Cela signifie l'endroit où vous souhaitez stocker l'infrastructure Hadoop.
Supposons les données suivantes.
dfs.replication (data replication value) = 1
(In the below given path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanodeOuvrez ce fichier et ajoutez les propriétés suivantes dans les balises <configuration>, </configuration>.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>Note - Dans le fichier ci-dessus, toutes les valeurs de propriété sont définies par l'utilisateur et vous pouvez apporter des modifications en fonction de votre infrastructure Hadoop.
yarn-site.xml
Ce fichier est utilisé pour configurer le fil dans Hadoop. Ouvrez le fichier yarn-site.xml et ajoutez les propriétés suivantes entre les balises <configuration>, </configuration> de ce fichier.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
Ce fichier est utilisé pour spécifier le framework MapReduce que nous utilisons. Par défaut, Hadoop contient un modèle de yarn-site.xml. Tout d'abord, il est nécessaire de copier le fichier à partir demapred-site,xml.template à mapred-site.xml fichier à l'aide de la commande suivante.
$ cp mapred-site.xml.template mapred-site.xmlOuvert mapred-site.xml et ajoutez les propriétés suivantes dans les balises <configuration>, </configuration>.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>Vérification de l'installation de Hadoop
Les étapes suivantes sont utilisées pour vérifier l'installation de Hadoop.
Étape 1: Configuration du nœud de nom
Configurez le namenode en utilisant la commande "hdfs namenode –format" comme suit.
$ cd ~
$ hdfs namenode -formatLe résultat attendu est le suivant.
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.6.4
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1
images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/Étape 2: vérification des fichiers DFS Hadoop
La commande suivante est utilisée pour démarrer le dfs Hadoop. L'exécution de cette commande démarrera votre système de fichiers Hadoop.
$ start-dfs.shLe résultat attendu est le suivant -
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop-2.6.4/logs/hadoop-
hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop-2.6.4/logs/hadoop-
hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]Étape 3: vérification du script de fil
La commande suivante est utilisée pour démarrer le script Yarn. L'exécution de cette commande démarrera vos démons Yarn.
$ start-yarn.shLa production attendue comme suit -
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-2.6.4/logs/yarn-
hadoop-resourcemanager-localhost.out
localhost: starting nodemanager, logging to /home/hadoop/hadoop-
2.6.4/logs/yarn-hadoop-nodemanager-localhost.outÉtape 4: Accéder à Hadoop sur le navigateur
Le numéro de port par défaut pour accéder à Hadoop est 50070. Utilisez l'URL suivante pour obtenir les services Hadoop sur le navigateur.
http://localhost:50070/
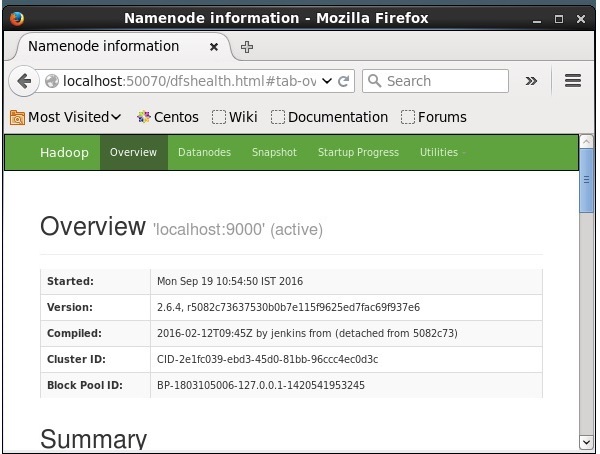
Installer Solr sur Hadoop
Suivez les étapes ci-dessous pour télécharger et installer Solr.
Étape 1
Ouvrez la page d'accueil d'Apache Solr en cliquant sur le lien suivant - https://lucene.apache.org/solr/
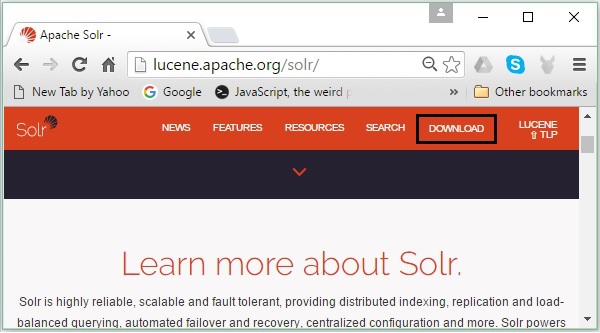
Étape 2
Clique le download button(mis en évidence dans la capture d'écran ci-dessus). En cliquant, vous serez redirigé vers la page où vous avez différents miroirs d'Apache Solr. Sélectionnez un miroir et cliquez dessus, ce qui vous redirigera vers une page où vous pourrez télécharger les fichiers source et binaire d'Apache Solr, comme indiqué dans la capture d'écran suivante.
Étape 3
En cliquant, un dossier nommé Solr-6.2.0.tqzsera téléchargé dans le dossier de téléchargement de votre système. Extrayez le contenu du dossier téléchargé.
Étape 4
Créez un dossier nommé Solr dans le répertoire de base Hadoop et déplacez-y le contenu du dossier extrait, comme indiqué ci-dessous.
$ mkdir Solr
$ cd Downloads
$ mv Solr-6.2.0 /home/Hadoop/Vérification
Parcourez le bin dossier du répertoire Solr Home et vérifiez l'installation à l'aide du version option, comme indiqué dans le bloc de code suivant.
$ cd bin/
$ ./Solr version
6.2.0Définition de la maison et du chemin
Ouvrez le .bashrc fichier en utilisant la commande suivante -
[Hadoop@localhost ~]$ source ~/.bashrcMaintenant, définissez les répertoires home et path pour Apache Solr comme suit -
export SOLR_HOME = /home/Hadoop/Solr
export PATH = $PATH:/$SOLR_HOME/bin/Ouvrez le terminal et exécutez la commande suivante -
[Hadoop@localhost Solr]$ source ~/.bashrcMaintenant, vous pouvez exécuter les commandes de Solr à partir de n'importe quel répertoire.