Apache Solr - Guide rapide
Solr est une plateforme de recherche open source utilisée pour construire search applications. Il a été construit au-dessus deLucene(moteur de recherche plein texte). Solr est prêt pour l'entreprise, rapide et hautement évolutif. Les applications créées avec Solr sont sophistiquées et offrent des performances élevées.
C'était Yonik Seelyqui a créé Solr en 2004 afin d'ajouter des fonctionnalités de recherche au site Web de l'entreprise de CNET Networks. En janvier 2006, il est devenu un projet open source sous Apache Software Foundation. Sa dernière version, Solr 6.0, a été publiée en 2016 avec la prise en charge de l'exécution de requêtes SQL parallèles.
Solr peut être utilisé avec Hadoop. Comme Hadoop gère une grande quantité de données, Solr nous aide à trouver les informations requises à partir d'une source aussi importante. Non seulement la recherche, Solr peut également être utilisé à des fins de stockage. Comme les autres bases de données NoSQL, il s'agit d'unnon-relational data storage et processing technology.
En bref, Solr est un moteur de recherche / stockage évolutif, prêt à être déployé, optimisé pour rechercher de grands volumes de données orientées texte.
Caractéristiques d'Apache Solr
Solr est une enveloppe autour de l'API Java de Lucene. Par conséquent, en utilisant Solr, vous pouvez tirer parti de toutes les fonctionnalités de Lucene. Jetons un coup d'œil à certaines des fonctionnalités les plus importantes de Solr -
Restful APIs- Pour communiquer avec Solr, il n'est pas obligatoire d'avoir des compétences en programmation Java. Au lieu de cela, vous pouvez utiliser des services reposants pour communiquer avec lui. Nous entrons des documents dans Solr dans des formats de fichiers tels que XML, JSON et .CSV et obtenons des résultats dans les mêmes formats de fichiers.
Full text search - Solr fournit toutes les fonctionnalités nécessaires pour une recherche en texte intégral telles que les jetons, les phrases, la vérification orthographique, les caractères génériques et la saisie semi-automatique.
Enterprise ready - Selon les besoins de l'organisation, Solr peut être déployé dans tout type de système (grand ou petit) tel que autonome, distribué, cloud, etc.
Flexible and Extensible - En étendant les classes Java et en les configurant en conséquence, nous pouvons personnaliser les composants de Solr facilement.
NoSQL database - Solr peut également être utilisé comme base de données NOSQL à grande échelle de données où nous pouvons répartir les tâches de recherche le long d'un cluster.
Admin Interface - Solr fournit une interface utilisateur facile à utiliser, conviviale, alimentée par des fonctionnalités, à l'aide de laquelle nous pouvons effectuer toutes les tâches possibles telles que gérer les journaux, ajouter, supprimer, mettre à jour et rechercher des documents.
Highly Scalable - Tout en utilisant Solr avec Hadoop, nous pouvons augmenter sa capacité en ajoutant des répliques.
Text-Centric and Sorted by Relevance - Solr est principalement utilisé pour rechercher des documents texte et les résultats sont fournis en fonction de la pertinence avec la requête de l'utilisateur dans l'ordre.
Contrairement à Lucene, vous n'avez pas besoin d'avoir des compétences en programmation Java lorsque vous travaillez avec Apache Solr. Il fournit un merveilleux service prêt à être déployé pour créer un champ de recherche avec la saisie semi-automatique, ce que Lucene ne fournit pas. En utilisant Solr, nous pouvons mettre à l'échelle, distribuer et gérer l'index, pour des applications à grande échelle (Big Data).
Lucene dans les applications de recherche
Lucene est une bibliothèque de recherche Java simple mais puissante. Il peut être utilisé dans n'importe quelle application pour ajouter une fonction de recherche. Lucene est une bibliothèque évolutive et performante utilisée pour indexer et rechercher pratiquement tout type de texte. La bibliothèque Lucene fournit les opérations de base requises par toute application de recherche, telle queIndexing et Searching.
Si nous avons un portail Web avec un volume énorme de données, nous aurons très probablement besoin d'un moteur de recherche dans notre portail pour extraire les informations pertinentes de l'énorme pool de données. Lucene fonctionne comme le cœur de toute application de recherche et fournit les opérations vitales relatives à l'indexation et à la recherche.
Un moteur de recherche fait référence à une énorme base de données de ressources Internet telles que des pages Web, des groupes de discussion, des programmes, des images, etc. Il permet de localiser des informations sur le World Wide Web.
Les utilisateurs peuvent rechercher des informations en passant des requêtes dans le moteur de recherche sous la forme de mots-clés ou d'expressions. Le moteur de recherche recherche ensuite dans sa base de données et renvoie des liens pertinents à l'utilisateur.
Composants du moteur de recherche
En règle générale, il existe trois composants de base d'un moteur de recherche, comme indiqué ci-dessous:
Web Crawler - Les robots d'exploration Web sont également connus sous le nom de spiders ou bots. C'est un composant logiciel qui parcourt le Web pour recueillir des informations.
Database- Toutes les informations sur le Web sont stockées dans des bases de données. Ils contiennent un volume énorme de ressources Web.
Search Interfaces- Ce composant est une interface entre l'utilisateur et la base de données. Il aide l'utilisateur à rechercher dans la base de données.
Comment fonctionnent les moteurs de recherche?
Toute application de recherche est requise pour effectuer certaines ou toutes les opérations suivantes.
| Étape | Titre | La description |
|---|---|---|
1 |
Acquérir du contenu brut |
La toute première étape de toute application de recherche consiste à collecter le contenu cible sur lequel la recherche doit être effectuée. |
2 |
Construire le document |
L'étape suivante consiste à créer le ou les documents à partir du contenu brut que l'application de recherche peut comprendre et interpréter facilement. |
3 |
Analyser le document |
Avant que l'indexation puisse commencer, le document doit être analysé. |
4 |
Indexation du document |
Une fois que les documents sont construits et analysés, l'étape suivante consiste à les indexer afin que ce document puisse être récupéré en fonction de certaines clés, au lieu de tout le contenu du document. L'indexation est similaire aux index que nous avons à la fin d'un livre où les mots communs sont affichés avec leurs numéros de page afin que ces mots puissent être suivis rapidement, au lieu de rechercher le livre complet. |
5 |
Interface utilisateur pour la recherche |
Une fois qu'une base de données d'index est prête, l'application peut effectuer des opérations de recherche. Pour aider l'utilisateur à effectuer une recherche, l'application doit fournir une interface utilisateur dans laquelle l'utilisateur peut saisir du texte et lancer le processus de recherche |
6 |
Créer une requête |
Une fois que l'utilisateur fait une demande de recherche dans un texte, l'application doit préparer un objet de requête à l'aide de ce texte, qui peut ensuite être utilisé pour interroger la base de données d'index pour obtenir des détails pertinents. |
sept |
Requête de recherche |
À l'aide de l'objet de requête, la base de données d'index est vérifiée pour obtenir les détails pertinents et les documents de contenu. |
8 |
Résultats du rendu |
Une fois que le résultat requis est reçu, l'application doit décider comment afficher les résultats à l'utilisateur à l'aide de son interface utilisateur. |
Jetez un œil à l'illustration suivante. Il montre une vue d'ensemble du fonctionnement des moteurs de recherche.
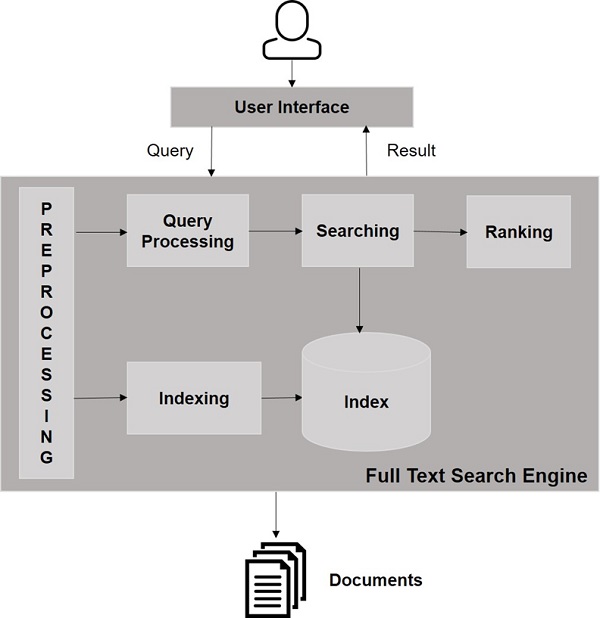
Outre ces opérations de base, les applications de recherche peuvent également fournir une interface utilisateur d'administration pour aider les administrateurs à contrôler le niveau de recherche en fonction des profils utilisateur. L'analyse des résultats de recherche est un autre aspect important et avancé de toute application de recherche.
Dans ce chapitre, nous verrons comment configurer Solr dans un environnement Windows. Pour installer Solr sur votre système Windows, vous devez suivre les étapes ci-dessous -
Visitez la page d'accueil d'Apache Solr et cliquez sur le bouton de téléchargement.
Sélectionnez l'un des miroirs pour obtenir un index d'Apache Solr. De là, téléchargez le fichier nomméSolr-6.2.0.zip.
Déplacez le fichier du downloads folder dans le répertoire requis et décompressez-le.
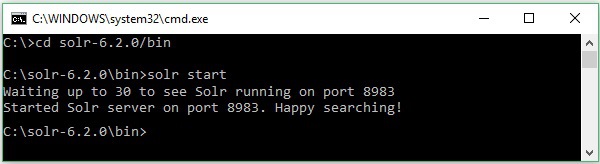
Supposons que vous ayez téléchargé le fichier Solr et que vous l'ayez extrait sur le lecteur C. Dans ce cas, vous pouvez démarrer Solr comme indiqué dans la capture d'écran suivante.
Pour vérifier l'installation, utilisez l'URL suivante dans votre navigateur.
http://localhost:8983/
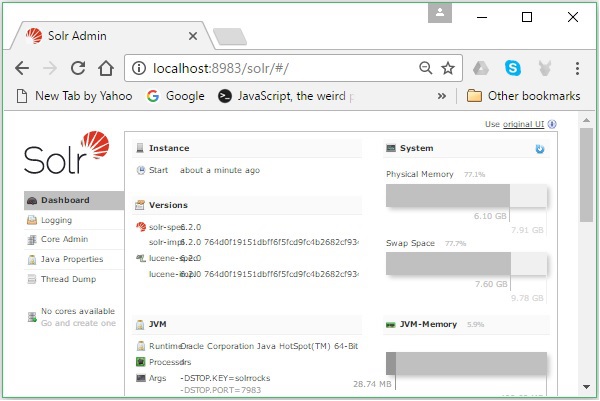
Si le processus d'installation réussit, vous pourrez voir le tableau de bord de l'interface utilisateur d'Apache Solr comme indiqué ci-dessous.
Définition de l'environnement Java
Nous pouvons également communiquer avec Apache Solr en utilisant les bibliothèques Java; mais avant d'accéder à Solr à l'aide de l'API Java, vous devez définir le chemin de classe pour ces bibliothèques.
Définition du chemin de classe
Met le classpath aux bibliothèques Solr dans le .bashrcfichier. Ouvert.bashrc dans l'un des éditeurs comme indiqué ci-dessous.
$ gedit ~/.bashrcDéfinir le chemin de classe pour les bibliothèques Solr (lib dossier dans HBase) comme indiqué ci-dessous.
export CLASSPATH = $CLASSPATH://home/hadoop/Solr/lib/*Cela permet d'éviter l'exception «classe non trouvée» lors de l'accès à HBase à l'aide de l'API Java.
Solr peut être utilisé avec Hadoop. Comme Hadoop gère une grande quantité de données, Solr nous aide à trouver les informations requises à partir d'une source aussi importante. Dans cette section, voyons comment vous pouvez installer Hadoop sur votre système.
Téléchargement de Hadoop
Vous trouverez ci-dessous les étapes à suivre pour télécharger Hadoop sur votre système.
Step 1- Accédez à la page d'accueil de Hadoop. Vous pouvez utiliser le lien - www.hadoop.apache.org/ . Cliquer sur le lienReleases, comme mis en évidence dans la capture d'écran suivante.
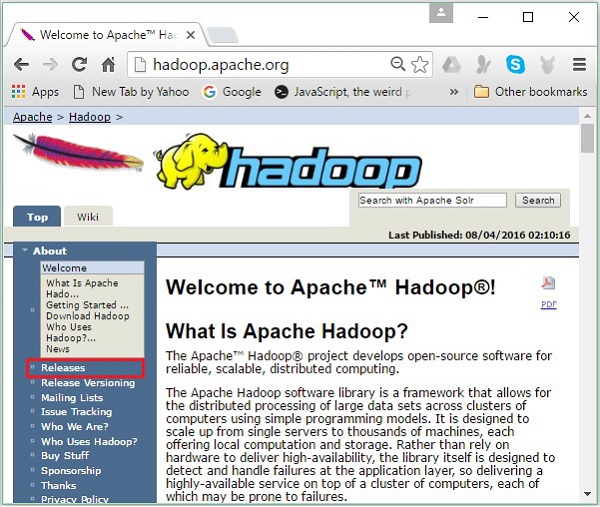
Il vous redirigera vers le Apache Hadoop Releases page qui contient des liens vers des miroirs de fichiers source et binaires de différentes versions de Hadoop comme suit -
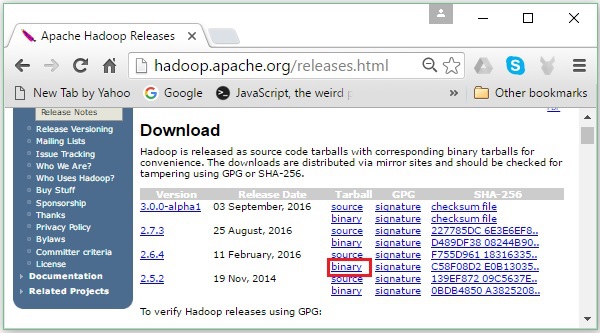
Step 2 - Sélectionnez la dernière version de Hadoop (dans notre tutoriel, il s'agit de la 2.6.4) et cliquez sur sa binary link. Cela vous mènera à une page où des miroirs pour le binaire Hadoop sont disponibles. Cliquez sur l'un de ces miroirs pour télécharger Hadoop.
Télécharger Hadoop à partir de l'invite de commande
Ouvrez le terminal Linux et connectez-vous en tant que super-utilisateur.
$ su
password:Accédez au répertoire dans lequel vous devez installer Hadoop et enregistrez-y le fichier en utilisant le lien copié précédemment, comme indiqué dans le bloc de code suivant.
# cd /usr/local
# wget http://redrockdigimark.com/apachemirror/hadoop/common/hadoop-
2.6.4/hadoop-2.6.4.tar.gzAprès avoir téléchargé Hadoop, extrayez-le à l'aide des commandes suivantes.
# tar zxvf hadoop-2.6.4.tar.gz
# mkdir hadoop
# mv hadoop-2.6.4/* to hadoop/
# exitInstaller Hadoop
Suivez les étapes ci-dessous pour installer Hadoop en mode pseudo-distribué.
Étape 1: Configurer Hadoop
Vous pouvez définir les variables d'environnement Hadoop en ajoutant les commandes suivantes à ~/.bashrc fichier.
export HADOOP_HOME = /usr/local/hadoop export
HADOOP_MAPRED_HOME = $HADOOP_HOME export
HADOOP_COMMON_HOME = $HADOOP_HOME export
HADOOP_HDFS_HOME = $HADOOP_HOME export
YARN_HOME = $HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR = $HADOOP_HOME/lib/native
export PATH = $PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL = $HADOOP_HOMEEnsuite, appliquez toutes les modifications dans le système en cours d'exécution.
$ source ~/.bashrcÉtape 2: Configuration Hadoop
Vous pouvez trouver tous les fichiers de configuration Hadoop à l'emplacement «$ HADOOP_HOME / etc / hadoop». Il est nécessaire d'apporter des modifications à ces fichiers de configuration en fonction de votre infrastructure Hadoop.
$ cd $HADOOP_HOME/etc/hadoopPour développer des programmes Hadoop en Java, vous devez réinitialiser les variables d'environnement Java dans hadoop-env.sh fichier en remplaçant JAVA_HOME valeur avec l'emplacement de Java dans votre système.
export JAVA_HOME = /usr/local/jdk1.7.0_71Voici la liste des fichiers que vous devez modifier pour configurer Hadoop -
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
core-site.xml
le core-site.xml fichier contient des informations telles que le numéro de port utilisé pour l'instance Hadoop, la mémoire allouée au système de fichiers, la limite de mémoire pour stocker les données et la taille des tampons de lecture / écriture.
Ouvrez le fichier core-site.xml et ajoutez les propriétés suivantes dans les balises <configuration>, </configuration>.
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xml
le hdfs-site.xml le fichier contient des informations telles que la valeur des données de réplication, namenode chemin, et datanodechemins de vos systèmes de fichiers locaux. Cela signifie l'endroit où vous souhaitez stocker l'infrastructure Hadoop.
Supposons les données suivantes.
dfs.replication (data replication value) = 1
(In the below given path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanodeOuvrez ce fichier et ajoutez les propriétés suivantes dans les balises <configuration>, </configuration>.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>Note - Dans le fichier ci-dessus, toutes les valeurs de propriété sont définies par l'utilisateur et vous pouvez apporter des modifications en fonction de votre infrastructure Hadoop.
yarn-site.xml
Ce fichier est utilisé pour configurer le fil dans Hadoop. Ouvrez le fichier yarn-site.xml et ajoutez les propriétés suivantes entre les balises <configuration>, </configuration> de ce fichier.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
Ce fichier est utilisé pour spécifier le framework MapReduce que nous utilisons. Par défaut, Hadoop contient un modèle de yarn-site.xml. Tout d'abord, il est nécessaire de copier le fichier à partir demapred-site,xml.template à mapred-site.xml fichier à l'aide de la commande suivante.
$ cp mapred-site.xml.template mapred-site.xmlOuvert mapred-site.xml et ajoutez les propriétés suivantes dans les balises <configuration>, </configuration>.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>Vérification de l'installation de Hadoop
Les étapes suivantes sont utilisées pour vérifier l'installation de Hadoop.
Étape 1: Configuration du nœud de nom
Configurez le namenode en utilisant la commande "hdfs namenode –format" comme suit.
$ cd ~
$ hdfs namenode -formatLe résultat attendu est le suivant.
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.6.4
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1
images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/Étape 2: vérification des fichiers DFS Hadoop
La commande suivante est utilisée pour démarrer le dfs Hadoop. L'exécution de cette commande démarrera votre système de fichiers Hadoop.
$ start-dfs.shLe résultat attendu est le suivant -
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop-2.6.4/logs/hadoop-
hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop-2.6.4/logs/hadoop-
hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]Étape 3: vérification du script de fil
La commande suivante est utilisée pour démarrer le script Yarn. L'exécution de cette commande démarrera vos démons Yarn.
$ start-yarn.shLa production attendue comme suit -
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-2.6.4/logs/yarn-
hadoop-resourcemanager-localhost.out
localhost: starting nodemanager, logging to /home/hadoop/hadoop-
2.6.4/logs/yarn-hadoop-nodemanager-localhost.outÉtape 4: Accéder à Hadoop sur le navigateur
Le numéro de port par défaut pour accéder à Hadoop est 50070. Utilisez l'URL suivante pour obtenir les services Hadoop sur le navigateur.
http://localhost:50070/
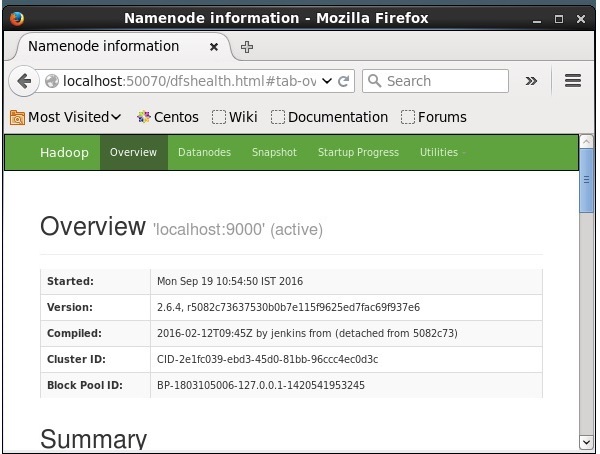
Installer Solr sur Hadoop
Suivez les étapes ci-dessous pour télécharger et installer Solr.
Étape 1
Ouvrez la page d'accueil d'Apache Solr en cliquant sur le lien suivant - https://lucene.apache.org/solr/
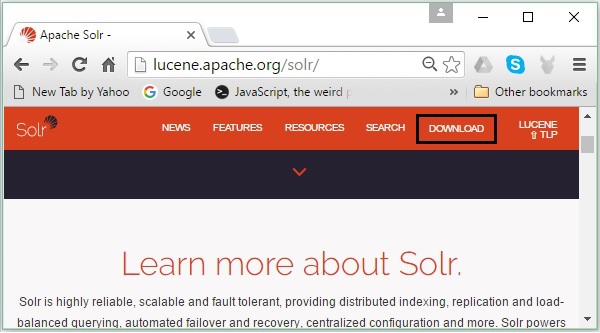
Étape 2
Clique le download button(mis en évidence dans la capture d'écran ci-dessus). En cliquant, vous serez redirigé vers la page où vous avez différents miroirs d'Apache Solr. Sélectionnez un miroir et cliquez dessus, ce qui vous redirigera vers une page où vous pourrez télécharger les fichiers source et binaire d'Apache Solr, comme indiqué dans la capture d'écran suivante.
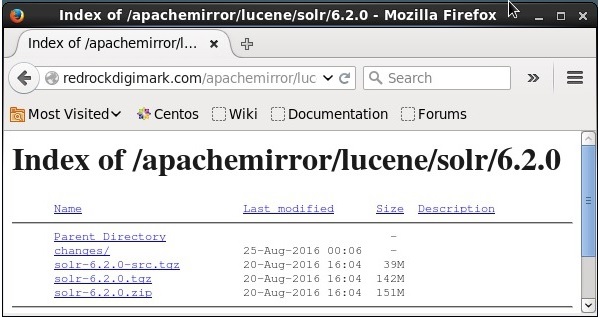
Étape 3
En cliquant, un dossier nommé Solr-6.2.0.tqzsera téléchargé dans le dossier de téléchargement de votre système. Extrayez le contenu du dossier téléchargé.
Étape 4
Créez un dossier nommé Solr dans le répertoire de base Hadoop et déplacez-y le contenu du dossier extrait, comme indiqué ci-dessous.
$ mkdir Solr
$ cd Downloads
$ mv Solr-6.2.0 /home/Hadoop/Vérification
Parcourez le bin dossier du répertoire Solr Home et vérifiez l'installation à l'aide du version option, comme indiqué dans le bloc de code suivant.
$ cd bin/
$ ./Solr version
6.2.0Définition de la maison et du chemin
Ouvrez le .bashrc fichier en utilisant la commande suivante -
[Hadoop@localhost ~]$ source ~/.bashrcMaintenant, définissez les répertoires home et path pour Apache Solr comme suit -
export SOLR_HOME = /home/Hadoop/Solr
export PATH = $PATH:/$SOLR_HOME/bin/Ouvrez le terminal et exécutez la commande suivante -
[Hadoop@localhost Solr]$ source ~/.bashrcMaintenant, vous pouvez exécuter les commandes de Solr à partir de n'importe quel répertoire.
Dans ce chapitre, nous aborderons l'architecture d'Apache Solr. L'illustration suivante montre un schéma de principe de l'architecture d'Apache Solr.
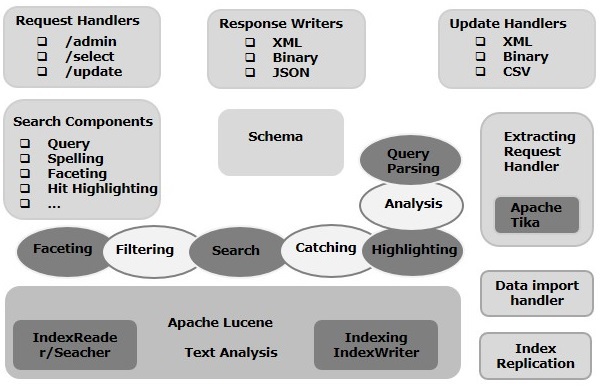
Architecture Solr ─ Blocs de construction
Voici les principaux blocs de construction (composants) d'Apache Solr -
Request Handler- Les requêtes que nous envoyons à Apache Solr sont traitées par ces gestionnaires de requêtes. Les demandes peuvent être des demandes de requête ou des demandes de mise à jour d'index. En fonction de nos besoins, nous devons sélectionner le gestionnaire de requêtes. Pour transmettre une requête à Solr, nous mapperons généralement le gestionnaire à un certain point de terminaison d'URI et la requête spécifiée sera servie par lui.
Search Component- Un composant de recherche est un type (fonctionnalité) de recherche fourni dans Apache Solr. Il peut s'agir de vérification orthographique, de requête, de facettage, de mise en évidence des résultats, etc. Ces composants de recherche sont enregistrés commesearch handlers. Plusieurs composants peuvent être enregistrés dans un gestionnaire de recherche.
Query Parser- L'analyseur de requêtes Apache Solr analyse les requêtes que nous transmettons à Solr et vérifie les requêtes pour les erreurs syntaxiques. Après avoir analysé les requêtes, il les traduit dans un format que Lucene comprend.
Response Writer- Un rédacteur de réponse dans Apache Solr est le composant qui génère la sortie formatée pour les requêtes utilisateur. Solr prend en charge les formats de réponse tels que XML, JSON, CSV, etc. Nous avons différents rédacteurs de réponses pour chaque type de réponse.
Analyzer/tokenizer- Lucene reconnaît les données sous forme de jetons. Apache Solr analyse le contenu, le divise en jetons et passe ces jetons à Lucene. Un analyseur dans Apache Solr examine le texte des champs et génère un flux de jetons. Un tokenizer divise le flux de jetons préparé par l'analyseur en jetons.
Update Request Processor - Chaque fois que nous envoyons une demande de mise à jour à Apache Solr, la demande est exécutée via un ensemble de plugins (signature, journalisation, indexation), collectivement appelés update request processor. Ce processeur est responsable des modifications telles que la suppression d'un champ, l'ajout d'un champ, etc.
Dans ce chapitre, nous essaierons de comprendre la signification réelle de certains des termes fréquemment utilisés lorsque vous travaillez sur Solr.
Terminologie générale
Voici une liste de termes généraux utilisés dans tous les types de configurations Solr -
Instance - Tout comme un tomcat instance ou un jetty instance, ce terme fait référence au serveur d'applications, qui s'exécute dans une machine virtuelle Java. Le répertoire home de Solr fournit une référence à chacune de ces instances Solr, dans lesquelles un ou plusieurs cœurs peuvent être configurés pour s'exécuter dans chaque instance.
Core - Lors de l'exécution de plusieurs index dans votre application, vous pouvez avoir plusieurs cœurs dans chaque instance, au lieu de plusieurs instances ayant chacune un cœur.
Home - Le terme $ SOLR_HOME fait référence au répertoire personnel qui contient toutes les informations concernant les cœurs et leurs index, configurations et dépendances.
Shard - Dans les environnements distribués, les données sont partitionnées entre plusieurs instances Solr, où chaque bloc de données peut être appelé comme un Shard. Il contient un sous-ensemble de l'index entier.
Terminologie SolrCloud
Dans un chapitre précédent, nous avons expliqué comment installer Apache Solr en mode autonome. Notez que nous pouvons également installer Solr en mode distribué (environnement cloud) où Solr est installé dans un modèle maître-esclave. En mode distribué, l'index est créé sur le serveur maître et répliqué sur un ou plusieurs serveurs esclaves.
Les termes clés associés à Solr Cloud sont les suivants -
Node - Dans le cloud Solr, chaque instance de Solr est considérée comme un node.
Cluster - Tous les nœuds de l'environnement combinés forment un cluster.
Collection - Un cluster a un index logique appelé collection.
Shard - Un fragment est une partie de la collection qui a une ou plusieurs répliques de l'index.
Replica - Dans Solr Core, une copie de la partition qui s'exécute dans un nœud est appelée replica.
Leader - C'est aussi une réplique de shard, qui distribue les requêtes du Solr Cloud aux répliques restantes.
Zookeeper - C'est un projet Apache que Solr Cloud utilise pour la configuration et la coordination centralisées, pour gérer le cluster et pour élire un leader.
Fichiers de configuration
Les principaux fichiers de configuration d'Apache Solr sont les suivants -
Solr.xml- C'est le fichier du répertoire $ SOLR_HOME qui contient les informations relatives à Solr Cloud. Pour charger les cœurs, Solr se réfère à ce fichier, ce qui aide à les identifier.
Solrconfig.xml - Ce fichier contient les définitions et les configurations spécifiques au cœur liées à la gestion des demandes et au formatage des réponses, ainsi qu'à l'indexation, à la configuration, à la gestion de la mémoire et aux validations.
Schema.xml - Ce fichier contient le schéma complet ainsi que les champs et les types de champs.
Core.properties- Ce fichier contient les configurations spécifiques au cœur. Il est référé pourcore discovery, car il contient le nom du noyau et le chemin du répertoire de données. Il peut être utilisé dans n'importe quel répertoire, qui sera alors traité comme lecore directory.
Démarrage de Solr
Après avoir installé Solr, accédez au bin dans le répertoire de base de Solr et démarrez Solr à l'aide de la commande suivante.
[Hadoop@localhost ~]$ cd
[Hadoop@localhost ~]$ cd Solr/
[Hadoop@localhost Solr]$ cd bin/
[Hadoop@localhost bin]$ ./Solr startCette commande démarre Solr en arrière-plan, en écoutant sur le port 8983 en affichant le message suivant.
Waiting up to 30 seconds to see Solr running on port 8983 [\]
Started Solr server on port 8983 (pid = 6035). Happy searching!Démarrage de Solr au premier plan
Si vous commencez Solr en utilisant le startcommande, puis Solr démarrera en arrière-plan. Au lieu de cela, vous pouvez démarrer Solr au premier plan en utilisant le–f option.
[Hadoop@localhost bin]$ ./Solr start –f
5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader
Adding 'file:/home/Hadoop/Solr/contrib/extraction/lib/xmlbeans-2.6.0.jar' to
classloader
5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader
Adding 'file:/home/Hadoop/Solr/dist/Solr-cell-6.2.0.jar' to classloader
5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader
Adding 'file:/home/Hadoop/Solr/contrib/clustering/lib/carrot2-guava-18.0.jar'
to classloader
5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader
Adding 'file:/home/Hadoop/Solr/contrib/clustering/lib/attributes-binder1.3.1.jar'
to classloader
5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader
Adding 'file:/home/Hadoop/Solr/contrib/clustering/lib/simple-xml-2.7.1.jar'
to classloader
……………………………………………………………………………………………………………………………………………………………………………………………………………
………………………………………………………………………………………………………………………………………………………………………………………………….
12901 INFO (coreLoadExecutor-6-thread-1) [ x:Solr_sample] o.a.s.u.UpdateLog
Took 24.0ms to seed version buckets with highest version 1546058939881226240 12902
INFO (coreLoadExecutor-6-thread-1) [ x:Solr_sample]
o.a.s.c.CoreContainer registering core: Solr_sample
12904 INFO (coreLoadExecutor-6-thread-2) [ x:my_core] o.a.s.u.UpdateLog Took
16.0ms to seed version buckets with highest version 1546058939894857728
12904 INFO (coreLoadExecutor-6-thread-2) [ x:my_core] o.a.s.c.CoreContainer
registering core: my_coreDémarrer Solr sur un autre port
En utilisant –p option du start commande, nous pouvons démarrer Solr dans un autre port, comme indiqué dans le bloc de code suivant.
[Hadoop@localhost bin]$ ./Solr start -p 8984
Waiting up to 30 seconds to see Solr running on port 8984 [-]
Started Solr server on port 8984 (pid = 10137). Happy searching!Arrêter Solr
Vous pouvez arrêter Solr en utilisant le stop commander.
$ ./Solr stopCette commande arrête Solr, affichant un message comme indiqué ci-dessous.
Sending stop command to Solr running on port 8983 ... waiting 5 seconds to
allow Jetty process 6035 to stop gracefully.Redémarrer Solr
le restartLa commande de Solr arrête Solr pendant 5 secondes et le redémarre. Vous pouvez redémarrer Solr à l'aide de la commande suivante -
./Solr restartCette commande redémarre Solr, affichant le message suivant -
Sending stop command to Solr running on port 8983 ... waiting 5 seconds to
allow Jetty process 6671 to stop gracefully.
Waiting up to 30 seconds to see Solr running on port 8983 [|] [/]
Started Solr server on port 8983 (pid = 6906). Happy searching!Commande Solr ─ help
le help La commande de Solr peut être utilisée pour vérifier l'utilisation de l'invite Solr et ses options.
[Hadoop@localhost bin]$ ./Solr -help
Usage: Solr COMMAND OPTIONS
where COMMAND is one of: start, stop, restart, status, healthcheck,
create, create_core, create_collection, delete, version, zk
Standalone server example (start Solr running in the background on port 8984):
./Solr start -p 8984
SolrCloud example (start Solr running in SolrCloud mode using localhost:2181
to connect to Zookeeper, with 1g max heap size and remote Java debug options enabled):
./Solr start -c -m 1g -z localhost:2181 -a "-Xdebug -
Xrunjdwp:transport = dt_socket,server = y,suspend = n,address = 1044"
Pass -help after any COMMAND to see command-specific usage information,
such as: ./Solr start -help or ./Solr stop -helpCommande Solr ─ status
Ce statusLa commande de Solr peut être utilisée pour rechercher et découvrir les instances Solr en cours d'exécution sur votre ordinateur. Il peut vous fournir des informations sur une instance Solr telles que sa version, l'utilisation de la mémoire, etc.
Vous pouvez vérifier l'état d'une instance Solr, en utilisant la commande status comme suit -
[Hadoop@localhost bin]$ ./Solr statusLors de l'exécution, la commande ci-dessus affiche l'état de Solr comme suit -
Found 1 Solr nodes:
Solr process 6906 running on port 8983 {
"Solr_home":"/home/Hadoop/Solr/server/Solr",
"version":"6.2.0 764d0f19151dbff6f5fcd9fc4b2682cf934590c5 -
mike - 2016-08-20 05:41:37",
"startTime":"2016-09-20T06:00:02.877Z",
"uptime":"0 days, 0 hours, 5 minutes, 14 seconds",
"memory":"30.6 MB (%6.2) of 490.7 MB"
}Administrateur Solr
Après avoir démarré Apache Solr, vous pouvez visiter la page d'accueil du Solr web interface en utilisant l'URL suivante.
Localhost:8983/Solr/L'interface de Solr Admin apparaît comme suit -
Un Solr Core est une instance en cours d'exécution d'un index Lucene qui contient tous les fichiers de configuration Solr requis pour l'utiliser. Nous devons créer un Solr Core pour effectuer des opérations telles que l'indexation et l'analyse.
Une application Solr peut contenir un ou plusieurs cœurs. Si nécessaire, deux cœurs d'une application Solr peuvent communiquer entre eux.
Créer un noyau
Après avoir installé et démarré Solr, vous pouvez vous connecter au client (interface Web) de Solr.
Comme le montre la capture d'écran suivante, il n'y a initialement aucun cœur dans Apache Solr. Maintenant, nous allons voir comment créer un noyau dans Solr.
Utilisation de la commande create
Une façon de créer un noyau est de créer un schema-less core en utilisant le create commande, comme indiqué ci-dessous -
[Hadoop@localhost bin]$ ./Solr create -c Solr_sampleIci, nous essayons de créer un noyau nommé Solr_sampledans Apache Solr. Cette commande crée un noyau affichant le message suivant.
Copying configuration to new core instance directory:
/home/Hadoop/Solr/server/Solr/Solr_sample
Creating new core 'Solr_sample' using command:
http://localhost:8983/Solr/admin/cores?action=CREATE&name=Solr_sample&instanceD
ir = Solr_sample {
"responseHeader":{
"status":0,
"QTime":11550
},
"core":"Solr_sample"
}Vous pouvez créer plusieurs cœurs dans Solr. Sur le côté gauche de Solr Admin, vous pouvez voir uncore selector où vous pouvez sélectionner le noyau nouvellement créé, comme indiqué dans la capture d'écran suivante.
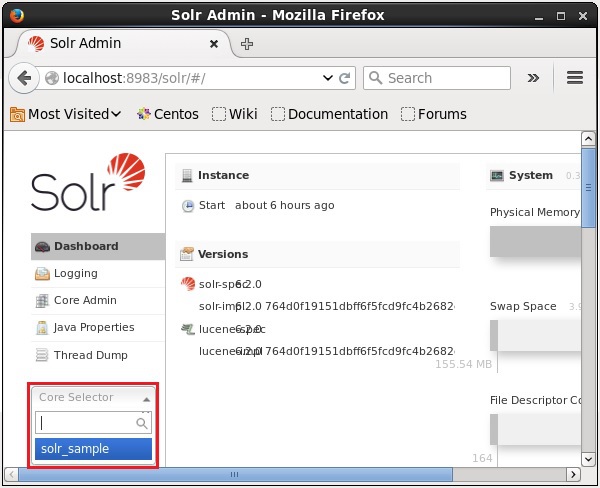
Utilisation de la commande create_core
Vous pouvez également créer un noyau en utilisant le create_corecommander. Cette commande a les options suivantes -
| –C core_name | Nom du noyau que vous vouliez créer |
| -p port_name | Port sur lequel vous souhaitez créer le noyau |
| -ré conf_dir | Répertoire de configuration du port |
Voyons comment vous pouvez utiliser le create_corecommander. Ici, nous allons essayer de créer un noyau nommémy_core.
[Hadoop@localhost bin]$ ./Solr create_core -c my_coreLors de l'exécution, la commande ci-dessus crée un noyau affichant le message suivant -
Copying configuration to new core instance directory:
/home/Hadoop/Solr/server/Solr/my_core
Creating new core 'my_core' using command:
http://localhost:8983/Solr/admin/cores?action=CREATE&name=my_core&instanceD
ir = my_core {
"responseHeader":{
"status":0,
"QTime":1346
},
"core":"my_core"
}Supprimer un Core
Vous pouvez supprimer un noyau en utilisant le deletecommande d'Apache Solr. Supposons que nous ayons un noyau nommémy_core dans Solr, comme illustré dans la capture d'écran suivante.
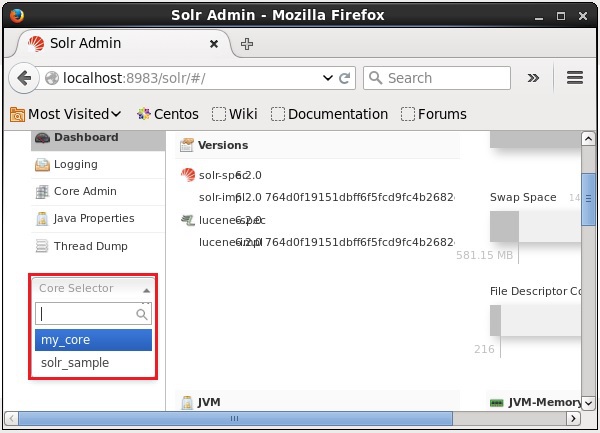
Vous pouvez supprimer ce noyau en utilisant le delete commande en passant le nom du noyau à cette commande comme suit -
[Hadoop@localhost bin]$ ./Solr delete -c my_coreLors de l'exécution de la commande ci-dessus, le noyau spécifié sera supprimé en affichant le message suivant.
Deleting core 'my_core' using command:
http://localhost:8983/Solr/admin/cores?action=UNLOAD&core = my_core&deleteIndex
= true&deleteDataDir = true&deleteInstanceDir = true {
"responseHeader" :{
"status":0,
"QTime":170
}
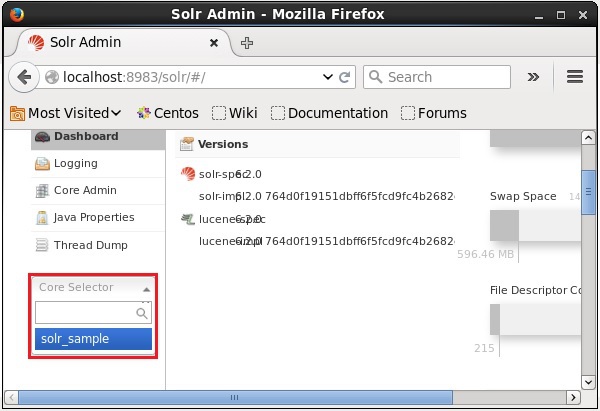
}Vous pouvez ouvrir l'interface Web de Solr pour vérifier si le noyau a été supprimé ou non.
En général, indexingest un agencement de documents ou (d'autres entités) systématiquement. L'indexation permet aux utilisateurs de localiser des informations dans un document.
L'indexation collecte, analyse et stocke les documents.
L'indexation est effectuée pour augmenter la vitesse et les performances d'une requête de recherche tout en trouvant un document requis.
Indexation dans Apache Solr
Dans Apache Solr, nous pouvons indexer (ajouter, supprimer, modifier) divers formats de documents tels que xml, csv, pdf, etc. Nous pouvons ajouter des données à l'index Solr de plusieurs manières.
Dans ce chapitre, nous allons discuter de l'indexation -
- Utilisation de l'interface Web Solr.
- Utilisation de l'une des API clientes telles que Java, Python, etc.
- En utilisant le post tool.
Dans ce chapitre, nous verrons comment ajouter des données à l'index d'Apache Solr à l'aide de diverses interfaces (ligne de commande, interface Web et API client Java)
Ajout de documents à l'aide de la commande Post
Solr a un post commande dans son bin/annuaire. À l'aide de cette commande, vous pouvez indexer différents formats de fichiers tels que JSON, XML, CSV dans Apache Solr.
Parcourez le bin répertoire d'Apache Solr et exécutez le –h option de la commande post, comme indiqué dans le bloc de code suivant.
[Hadoop@localhost bin]$ cd $SOLR_HOME
[Hadoop@localhost bin]$ ./post -hEn exécutant la commande ci-dessus, vous obtiendrez une liste d'options du post command, comme indiqué ci-dessous.
Usage: post -c <collection> [OPTIONS] <files|directories|urls|-d [".."]>
or post –help
collection name defaults to DEFAULT_SOLR_COLLECTION if not specified
OPTIONS
=======
Solr options:
-url <base Solr update URL> (overrides collection, host, and port)
-host <host> (default: localhost)
-p or -port <port> (default: 8983)
-commit yes|no (default: yes)
Web crawl options:
-recursive <depth> (default: 1)
-delay <seconds> (default: 10)
Directory crawl options:
-delay <seconds> (default: 0)
stdin/args options:
-type <content/type> (default: application/xml)
Other options:
-filetypes <type>[,<type>,...] (default:
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,
rtf,htm,html,txt,log)
-params "<key> = <value>[&<key> = <value>...]" (values must be
URL-encoded; these pass through to Solr update request)
-out yes|no (default: no; yes outputs Solr response to console)
-format Solr (sends application/json content as Solr commands
to /update instead of /update/json/docs)
Examples:
* JSON file:./post -c wizbang events.json
* XML files: ./post -c records article*.xml
* CSV file: ./post -c signals LATEST-signals.csv
* Directory of files: ./post -c myfiles ~/Documents
* Web crawl: ./post -c gettingstarted http://lucene.apache.org/Solr -recursive 1 -delay 1
* Standard input (stdin): echo '{commit: {}}' | ./post -c my_collection -
type application/json -out yes –d
* Data as string: ./post -c signals -type text/csv -out yes -d $'id,value\n1,0.47'Exemple
Supposons que nous ayons un fichier nommé sample.csv avec le contenu suivant (dans le bin annuaire).
| Carte d'étudiant | Prénom | Nom de famille | Téléphone | Ville |
|---|---|---|---|---|
| 001 | Rajiv | Reddy | 9848022337 | Hyderabad |
| 002 | Siddharth | Bhattacharya | 9848022338 | Calcutta |
| 003 | Rajesh | Khanna | 9848022339 | Delhi |
| 004 | Preethi | Agarwal | 9848022330 | Pune |
| 005 | Trupthi | Mohanty | 9848022336 | Bhubaneshwar |
| 006 | Archana | Mishra | 9848022335 | Chennai |
L'ensemble de données ci-dessus contient des informations personnelles telles que l'identifiant de l'étudiant, le prénom, le nom, le téléphone et la ville. Le fichier CSV de l'ensemble de données est illustré ci-dessous. Ici, vous devez noter que vous devez mentionner le schéma, en documentant sa première ligne.
id, first_name, last_name, phone_no, location
001, Pruthvi, Reddy, 9848022337, Hyderabad
002, kasyap, Sastry, 9848022338, Vishakapatnam
003, Rajesh, Khanna, 9848022339, Delhi
004, Preethi, Agarwal, 9848022330, Pune
005, Trupthi, Mohanty, 9848022336, Bhubaneshwar
006, Archana, Mishra, 9848022335, ChennaiVous pouvez indexer ces données sous le noyau nommé sample_Solr en utilisant le post commande comme suit -
[Hadoop@localhost bin]$ ./post -c Solr_sample sample.csvLors de l'exécution de la commande ci-dessus, le document donné est indexé sous le noyau spécifié, générant la sortie suivante.
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core
6.2.0.jar -Dauto = yes -Dc = Solr_sample -Ddata = files
org.apache.Solr.util.SimplePostTool sample.csv
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/Solr_sample/update...
Entering auto mode. File endings considered are
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,
htm,html,txt,log
POSTing file sample.csv (text/csv) to [base]
1 files indexed.
COMMITting Solr index changes to
http://localhost:8983/Solr/Solr_sample/update...
Time spent: 0:00:00.228Visitez la page d'accueil de Solr Web UI en utilisant l'URL suivante -
http://localhost:8983/
Sélectionnez le noyau Solr_sample. Par défaut, le gestionnaire de requêtes est/selectet la requête est «:». Sans apporter de modifications, cliquez sur leExecuteQuery bouton en bas de page.
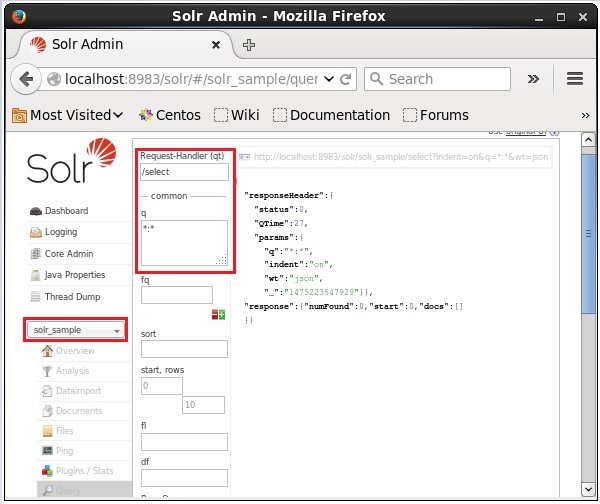
Lors de l'exécution de la requête, vous pouvez observer le contenu du document CSV indexé au format JSON (par défaut), comme illustré dans la capture d'écran suivante.
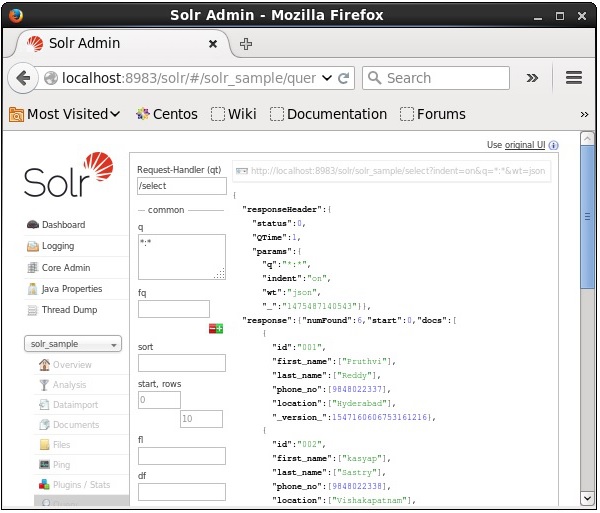
Note - De la même manière, vous pouvez indexer d'autres formats de fichiers tels que JSON, XML, CSV, etc.
Ajout de documents à l'aide de l'interface Web Solr
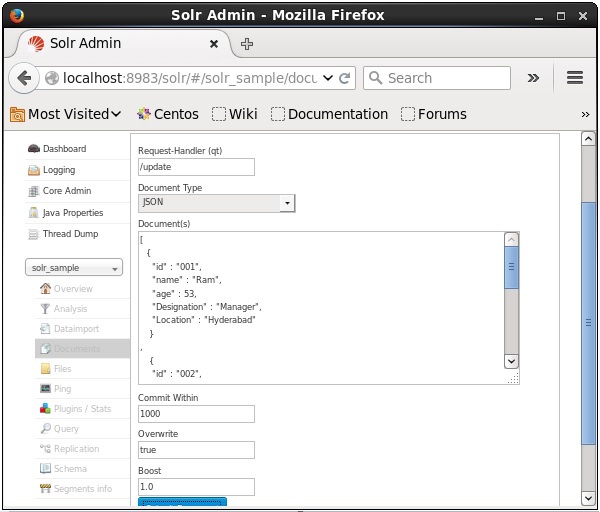
Vous pouvez également indexer des documents à l'aide de l'interface Web fournie par Solr. Voyons comment indexer le document JSON suivant.
[
{
"id" : "001",
"name" : "Ram",
"age" : 53,
"Designation" : "Manager",
"Location" : "Hyderabad",
},
{
"id" : "002",
"name" : "Robert",
"age" : 43,
"Designation" : "SR.Programmer",
"Location" : "Chennai",
},
{
"id" : "003",
"name" : "Rahim",
"age" : 25,
"Designation" : "JR.Programmer",
"Location" : "Delhi",
}
]Étape 1
Ouvrez l'interface Web de Solr à l'aide de l'URL suivante -
http://localhost:8983/
Step 2
Sélectionnez le noyau Solr_sample. Par défaut, les valeurs des champs Request Handler, Common Within, Overwrite et Boost sont / update, 1000, true et 1.0 respectivement, comme illustré dans la capture d'écran suivante.
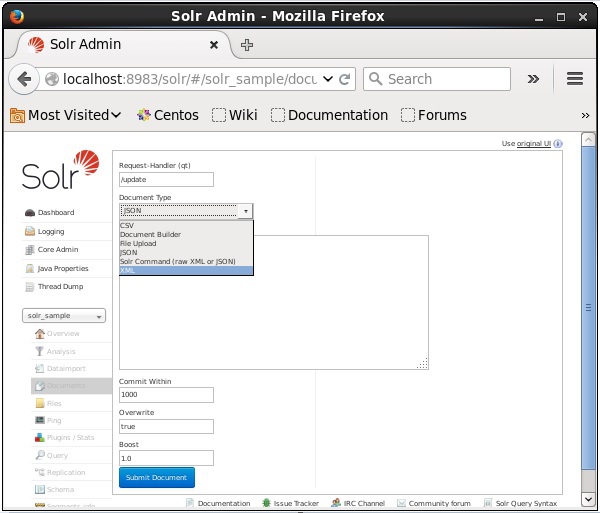
Maintenant, choisissez le format de document souhaité parmi JSON, CSV, XML, etc. Tapez le document à indexer dans la zone de texte et cliquez sur le bouton Submit Document bouton, comme indiqué dans la capture d'écran suivante.
Ajout de documents à l'aide de l'API client Java
Voici le programme Java pour ajouter des documents à l'index Apache Solr. Enregistrez ce code dans un fichier avec le nomAddingDocument.java.
import java.io.IOException;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.common.SolrInputDocument;
public class AddingDocument {
public static void main(String args[]) throws Exception {
//Preparing the Solr client
String urlString = "http://localhost:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
//Adding fields to the document
doc.addField("id", "003");
doc.addField("name", "Rajaman");
doc.addField("age","34");
doc.addField("addr","vishakapatnam");
//Adding the document to Solr
Solr.add(doc);
//Saving the changes
Solr.commit();
System.out.println("Documents added");
}
}Compilez le code ci-dessus en exécutant les commandes suivantes dans le terminal -
[Hadoop@localhost bin]$ javac AddingDocument
[Hadoop@localhost bin]$ java AddingDocumentEn exécutant la commande ci-dessus, vous obtiendrez la sortie suivante.
Documents addedDans le chapitre précédent, nous avons expliqué comment ajouter des données dans Solr au format de fichier JSON et .CSV. Dans ce chapitre, nous montrerons comment ajouter des données dans un index Apache Solr à l'aide du format de document XML.
Exemple de données
Supposons que nous devions ajouter les données suivantes à l'index Solr en utilisant le format de fichier XML.
| Carte d'étudiant | Prénom | Nom de famille | Téléphone | Ville |
|---|---|---|---|---|
| 001 | Rajiv | Reddy | 9848022337 | Hyderabad |
| 002 | Siddharth | Bhattacharya | 9848022338 | Calcutta |
| 003 | Rajesh | Khanna | 9848022339 | Delhi |
| 004 | Preethi | Agarwal | 9848022330 | Pune |
| 005 | Trupthi | Mohanty | 9848022336 | Bhubaneshwar |
| 006 | Archana | Mishra | 9848022335 | Chennai |
Ajout de documents à l'aide de XML
Pour ajouter les données ci-dessus dans l'index Solr, nous devons préparer un document XML, comme indiqué ci-dessous. Enregistrez ce document dans un fichier avec le nomsample.xml.
<add>
<doc>
<field name = "id">001</field>
<field name = "first name">Rajiv</field>
<field name = "last name">Reddy</field>
<field name = "phone">9848022337</field>
<field name = "city">Hyderabad</field>
</doc>
<doc>
<field name = "id">002</field>
<field name = "first name">Siddarth</field>
<field name = "last name">Battacharya</field>
<field name = "phone">9848022338</field>
<field name = "city">Kolkata</field>
</doc>
<doc>
<field name = "id">003</field>
<field name = "first name">Rajesh</field>
<field name = "last name">Khanna</field>
<field name = "phone">9848022339</field>
<field name = "city">Delhi</field>
</doc>
<doc>
<field name = "id">004</field>
<field name = "first name">Preethi</field>
<field name = "last name">Agarwal</field>
<field name = "phone">9848022330</field>
<field name = "city">Pune</field>
</doc>
<doc>
<field name = "id">005</field>
<field name = "first name">Trupthi</field>
<field name = "last name">Mohanthy</field>
<field name = "phone">9848022336</field>
<field name = "city">Bhuwaeshwar</field>
</doc>
<doc>
<field name = "id">006</field>
<field name = "first name">Archana</field>
<field name = "last name">Mishra</field>
<field name = "phone">9848022335</field>
<field name = "city">Chennai</field>
</doc>
</add>Comme vous pouvez le constater, le fichier XML écrit pour ajouter des données à l'index contient trois balises importantes à savoir, <add> </add>, <doc> </doc> et <field> </ field>.
add- Il s'agit de la balise racine pour ajouter des documents à l'index. Il contient un ou plusieurs documents à ajouter.
doc- Les documents que nous ajoutons doivent être enveloppés dans les balises <doc> </doc>. Ce document contient les données sous forme de champs.
field - La balise de champ contient le nom et la valeur des champs du document.
Après avoir préparé le document, vous pouvez ajouter ce document à l'index en utilisant l'un des moyens décrits dans le chapitre précédent.
Supposons que le fichier XML existe dans le bin répertoire de Solr et il doit être indexé dans le noyau nommé my_core, vous pouvez l'ajouter à l'index Solr en utilisant le post outil comme suit -
[Hadoop@localhost bin]$ ./post -c my_core sample.xmlEn exécutant la commande ci-dessus, vous obtiendrez la sortie suivante.
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-
core6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files
org.apache.Solr.util.SimplePostTool sample.xml
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/my_core/update...
Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,
xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,htm,html,txt,log
POSTing file sample.xml (application/xml) to [base]
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/Solr/my_core/update...
Time spent: 0:00:00.201Vérification
Visitez la page d'accueil de l'interface Web d'Apache Solr et sélectionnez le noyau my_core. Essayez de récupérer tous les documents en passant la requête «:» dans la zone de texteqet exécutez la requête. Lors de l'exécution, vous pouvez observer que les données souhaitées sont ajoutées à l'index Solr.
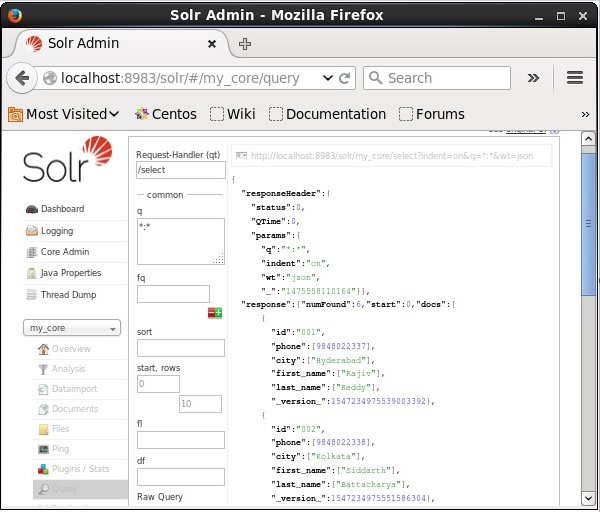
Mise à jour du document à l'aide de XML
Voici le fichier XML utilisé pour mettre à jour un champ dans le document existant. Enregistrez-le dans un fichier avec le nomupdate.xml.
<add>
<doc>
<field name = "id">001</field>
<field name = "first name" update = "set">Raj</field>
<field name = "last name" update = "add">Malhotra</field>
<field name = "phone" update = "add">9000000000</field>
<field name = "city" update = "add">Delhi</field>
</doc>
</add>Comme vous pouvez le constater, le fichier XML écrit pour mettre à jour les données est exactement comme celui que nous utilisons pour ajouter des documents. Mais la seule différence est que nous utilisons leupdate attribut du champ.
Dans notre exemple, nous utiliserons le document ci-dessus et essayerons de mettre à jour les champs du document avec l'id 001.
Supposons que le document XML existe dans le binrépertoire de Solr. Puisque nous mettons à jour l'index qui existe dans le noyau nommémy_core, vous pouvez mettre à jour à l'aide du post outil comme suit -
[Hadoop@localhost bin]$ ./post -c my_core update.xmlEn exécutant la commande ci-dessus, vous obtiendrez la sortie suivante.
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core
6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files
org.apache.Solr.util.SimplePostTool update.xml
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/my_core/update...
Entering auto mode. File endings considered are
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,
htm,html,txt,log
POSTing file update.xml (application/xml) to [base]
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/Solr/my_core/update...
Time spent: 0:00:00.159Vérification
Visitez la page d'accueil de l'interface Web d'Apache Solr et sélectionnez le noyau comme my_core. Essayez de récupérer tous les documents en passant la requête «:» dans la zone de texteqet exécutez la requête. Lors de l'exécution, vous pouvez constater que le document est mis à jour.
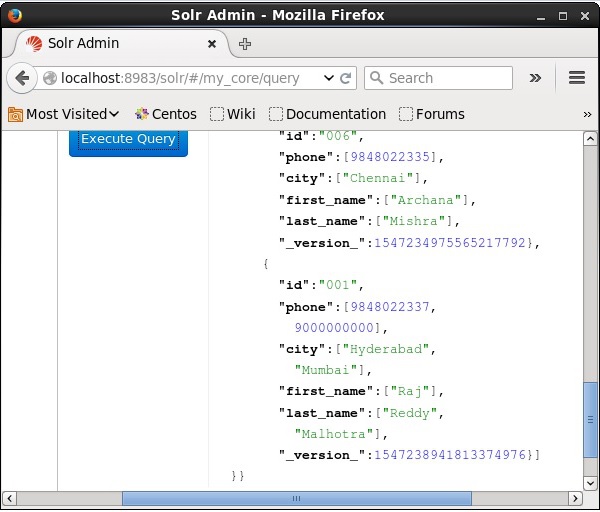
Mise à jour du document à l'aide de Java (API client)
Voici le programme Java pour ajouter des documents à l'index Apache Solr. Enregistrez ce code dans un fichier avec le nomUpdatingDocument.java.
import java.io.IOException;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.client.Solrj.request.UpdateRequest;
import org.apache.Solr.client.Solrj.response.UpdateResponse;
import org.apache.Solr.common.SolrInputDocument;
public class UpdatingDocument {
public static void main(String args[]) throws SolrServerException, IOException {
//Preparing the Solr client
String urlString = "http://localhost:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
UpdateRequest updateRequest = new UpdateRequest();
updateRequest.setAction( UpdateRequest.ACTION.COMMIT, false, false);
SolrInputDocument myDocumentInstantlycommited = new SolrInputDocument();
myDocumentInstantlycommited.addField("id", "002");
myDocumentInstantlycommited.addField("name", "Rahman");
myDocumentInstantlycommited.addField("age","27");
myDocumentInstantlycommited.addField("addr","hyderabad");
updateRequest.add( myDocumentInstantlycommited);
UpdateResponse rsp = updateRequest.process(Solr);
System.out.println("Documents Updated");
}
}Compilez le code ci-dessus en exécutant les commandes suivantes dans le terminal -
[Hadoop@localhost bin]$ javac UpdatingDocument
[Hadoop@localhost bin]$ java UpdatingDocumentEn exécutant la commande ci-dessus, vous obtiendrez la sortie suivante.
Documents updatedSuppression du document
Pour supprimer des documents de l'index d'Apache Solr, nous devons spécifier les ID des documents à supprimer entre les balises <delete> </delete>.
<delete>
<id>003</id>
<id>005</id>
<id>004</id>
<id>002</id>
</delete>Ici, ce code XML est utilisé pour supprimer les documents avec des ID 003 et 005. Enregistrez ce code dans un fichier avec le nomdelete.xml.
Si vous souhaitez supprimer les documents de l'index qui appartient au noyau nommé my_core, alors vous pouvez publier le delete.xml fichier en utilisant le post outil, comme indiqué ci-dessous.
[Hadoop@localhost bin]$ ./post -c my_core delete.xmlEn exécutant la commande ci-dessus, vous obtiendrez la sortie suivante.
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core
6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files
org.apache.Solr.util.SimplePostTool delete.xml
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/my_core/update...
Entering auto mode. File endings considered are
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,
rtf,htm,html,txt,log
POSTing file delete.xml (application/xml) to [base]
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/Solr/my_core/update...
Time spent: 0:00:00.179Vérification
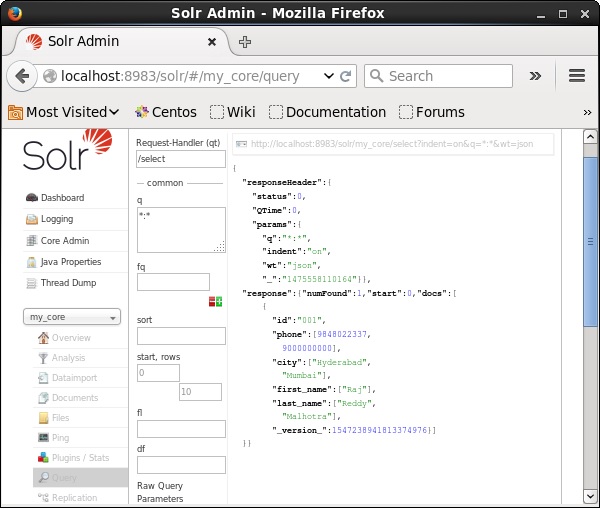
Visitez la page d'accueil de l'interface Web d'Apache Solr et sélectionnez le noyau comme my_core. Essayez de récupérer tous les documents en passant la requête «:» dans la zone de texteqet exécutez la requête. Lors de l'exécution, vous pouvez observer que les documents spécifiés sont supprimés.
Supprimer un champ
Parfois, nous devons supprimer des documents en fonction de champs autres que ID. Par exemple, il se peut que nous devions supprimer les documents où la ville est Chennai.
Dans ce cas, vous devez spécifier le nom et la valeur du champ dans la paire de balises <query> </query>.
<delete>
<query>city:Chennai</query>
</delete>Enregistrez-le sous delete_field.xml et effectuez l'opération de suppression sur le noyau nommé my_core en utilisant le post outil de Solr.
[Hadoop@localhost bin]$ ./post -c my_core delete_field.xmlLors de l'exécution de la commande ci-dessus, il produit la sortie suivante.
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core
6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files
org.apache.Solr.util.SimplePostTool delete_field.xml
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/my_core/update...
Entering auto mode. File endings considered are
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,
rtf,htm,html,txt,log
POSTing file delete_field.xml (application/xml) to [base]
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/Solr/my_core/update...
Time spent: 0:00:00.084Vérification
Visitez la page d'accueil de l'interface Web d'Apache Solr et sélectionnez le noyau comme my_core. Essayez de récupérer tous les documents en passant la requête «:» dans la zone de texteqet exécutez la requête. Lors de l'exécution, vous pouvez observer que les documents contenant la paire de valeurs de champ spécifiée sont supprimés.
Suppression de tous les documents
Tout comme la suppression d'un champ spécifique, si vous souhaitez supprimer tous les documents d'un index, il vous suffit de passer le symbole «:» entre les balises <query> </ query>, comme indiqué ci-dessous.
<delete>
<query>*:*</query>
</delete>Enregistrez-le sous delete_all.xml et effectuez l'opération de suppression sur le noyau nommé my_core en utilisant le post outil de Solr.
[Hadoop@localhost bin]$ ./post -c my_core delete_all.xmlLors de l'exécution de la commande ci-dessus, il produit la sortie suivante.
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core
6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files
org.apache.Solr.util.SimplePostTool deleteAll.xml
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/my_core/update...
Entering auto mode. File endings considered are
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,
htm,html,txt,log
POSTing file deleteAll.xml (application/xml) to [base]
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/Solr/my_core/update...
Time spent: 0:00:00.138Vérification
Visitez la page d'accueil de l'interface Web d'Apache Solr et sélectionnez le noyau comme my_core. Essayez de récupérer tous les documents en passant la requête «:» dans la zone de texteqet exécutez la requête. Lors de l'exécution, vous pouvez observer que les documents contenant la paire de valeurs de champ spécifiée sont supprimés.
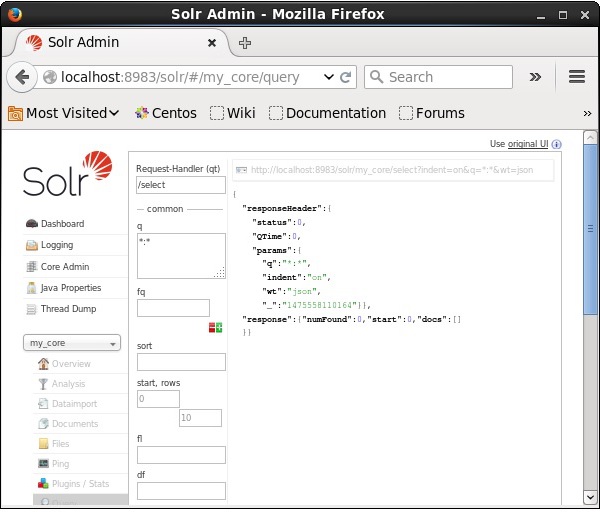
Suppression de tous les documents à l'aide de Java (API client)
Voici le programme Java pour ajouter des documents à l'index Apache Solr. Enregistrez ce code dans un fichier avec le nomUpdatingDocument.java.
import java.io.IOException;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.common.SolrInputDocument;
public class DeletingAllDocuments {
public static void main(String args[]) throws SolrServerException, IOException {
//Preparing the Solr client
String urlString = "http://localhost:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
//Deleting the documents from Solr
Solr.deleteByQuery("*");
//Saving the document
Solr.commit();
System.out.println("Documents deleted");
}
}Compilez le code ci-dessus en exécutant les commandes suivantes dans le terminal -
[Hadoop@localhost bin]$ javac DeletingAllDocuments
[Hadoop@localhost bin]$ java DeletingAllDocumentsEn exécutant la commande ci-dessus, vous obtiendrez la sortie suivante.
Documents deletedDans ce chapitre, nous verrons comment récupérer des données à l'aide de l'API client Java. Supposons que nous ayons un document .csv nommésample.csv avec le contenu suivant.
001,9848022337,Hyderabad,Rajiv,Reddy
002,9848022338,Kolkata,Siddarth,Battacharya
003,9848022339,Delhi,Rajesh,KhannaVous pouvez indexer ces données sous le noyau nommé sample_Solr en utilisant le post commander.
[Hadoop@localhost bin]$ ./post -c Solr_sample sample.csvVoici le programme Java pour ajouter des documents à l'index Apache Solr. Enregistrez ce code dans un fichier nomméRetrievingData.java.
import java.io.IOException;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrQuery;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.client.Solrj.response.QueryResponse;
import org.apache.Solr.common.SolrDocumentList;
public class RetrievingData {
public static void main(String args[]) throws SolrServerException, IOException {
//Preparing the Solr client
String urlString = "http://localhost:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing Solr query
SolrQuery query = new SolrQuery();
query.setQuery("*:*");
//Adding the field to be retrieved
query.addField("*");
//Executing the query
QueryResponse queryResponse = Solr.query(query);
//Storing the results of the query
SolrDocumentList docs = queryResponse.getResults();
System.out.println(docs);
System.out.println(docs.get(0));
System.out.println(docs.get(1));
System.out.println(docs.get(2));
//Saving the operations
Solr.commit();
}
}Compilez le code ci-dessus en exécutant les commandes suivantes dans le terminal -
[Hadoop@localhost bin]$ javac RetrievingData
[Hadoop@localhost bin]$ java RetrievingDataEn exécutant la commande ci-dessus, vous obtiendrez la sortie suivante.
{numFound = 3,start = 0,docs = [SolrDocument{id=001, phone = [9848022337],
city = [Hyderabad], first_name = [Rajiv], last_name = [Reddy],
_version_ = 1547262806014820352}, SolrDocument{id = 002, phone = [9848022338],
city = [Kolkata], first_name = [Siddarth], last_name = [Battacharya],
_version_ = 1547262806026354688}, SolrDocument{id = 003, phone = [9848022339],
city = [Delhi], first_name = [Rajesh], last_name = [Khanna],
_version_ = 1547262806029500416}]}
SolrDocument{id = 001, phone = [9848022337], city = [Hyderabad], first_name = [Rajiv],
last_name = [Reddy], _version_ = 1547262806014820352}
SolrDocument{id = 002, phone = [9848022338], city = [Kolkata], first_name = [Siddarth],
last_name = [Battacharya], _version_ = 1547262806026354688}
SolrDocument{id = 003, phone = [9848022339], city = [Delhi], first_name = [Rajesh],
last_name = [Khanna], _version_ = 1547262806029500416}En plus de stocker des données, Apache Solr offre également la possibilité de les interroger en cas de besoin. Solr fournit certains paramètres à l'aide desquels nous pouvons interroger les données qui y sont stockées.
Dans le tableau suivant, nous avons répertorié les différents paramètres de requête disponibles dans Apache Solr.
| Paramètre | La description |
|---|---|
| q | Il s'agit du principal paramètre de requête d'Apache Solr, les documents sont notés en fonction de leur similitude avec les termes de ce paramètre. |
| fq | Ce paramètre représente la requête de filtre d'Apache Solr et limite le jeu de résultats aux documents correspondant à ce filtre. |
| début | Le paramètre de début représente les décalages de départ pour les résultats d'une page, la valeur par défaut de ce paramètre est 0. |
| Lignes | Ce paramètre représente le nombre de documents à récupérer par page. La valeur par défaut de ce paramètre est 10. |
| Trier | Ce paramètre spécifie la liste des champs, séparés par des virgules, en fonction de laquelle les résultats de la requête doivent être triés. |
| fl | Ce paramètre spécifie la liste des champs à renvoyer pour chaque document du jeu de résultats. |
| wt | Ce paramètre représente le type de rédacteur de réponse dont nous voulions afficher le résultat. |
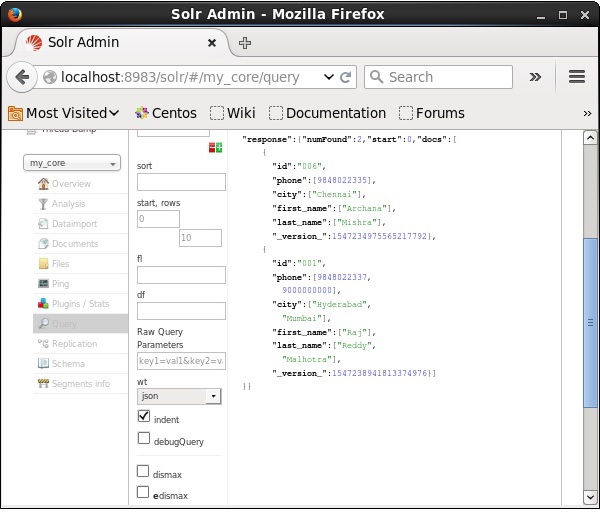
Vous pouvez voir tous ces paramètres comme des options pour interroger Apache Solr. Visitez la page d'accueil d'Apache Solr. Sur le côté gauche de la page, cliquez sur l'option Requête. Ici, vous pouvez voir les champs pour les paramètres d'une requête.
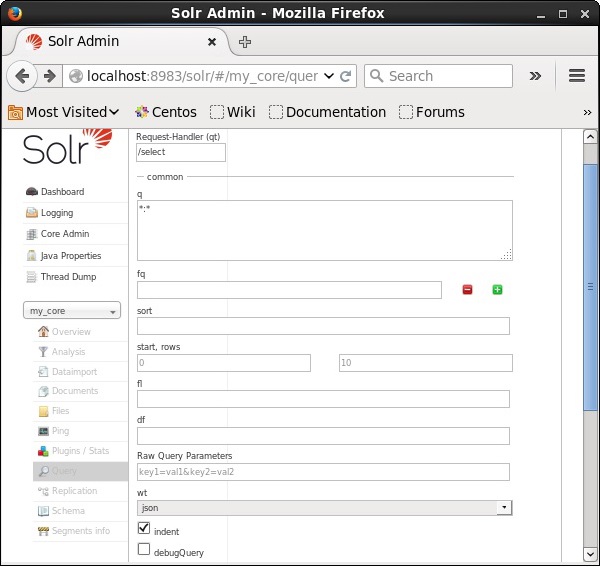
Récupération des enregistrements
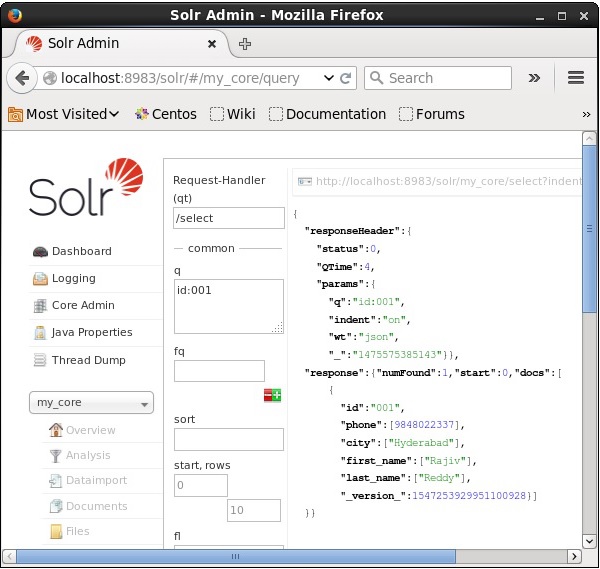
Supposons que nous ayons 3 enregistrements dans le noyau nommés my_core. Pour récupérer un enregistrement particulier du noyau sélectionné, vous devez transmettre les paires nom et valeur des champs d'un document particulier. Par exemple, si vous souhaitez récupérer l'enregistrement avec la valeur du champid, vous devez transmettre la paire nom-valeur du champ comme - Id:001 comme valeur du paramètre q et exécutez la requête.
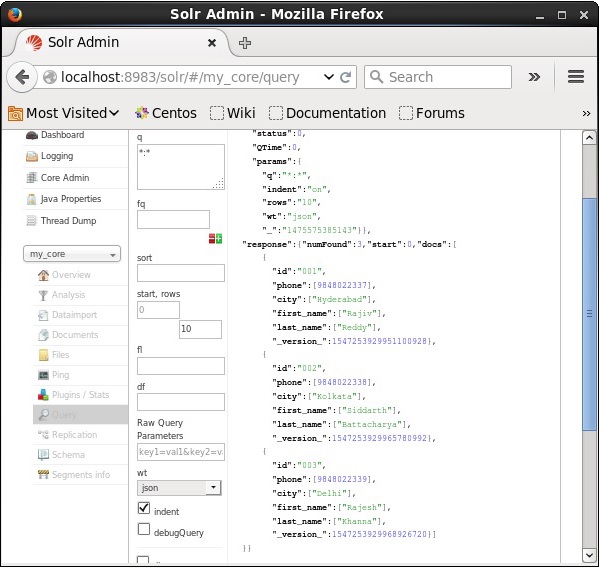
De la même manière, vous pouvez récupérer tous les enregistrements d'un index en passant *: * comme valeur au paramètre q, comme illustré dans la capture d'écran suivante.
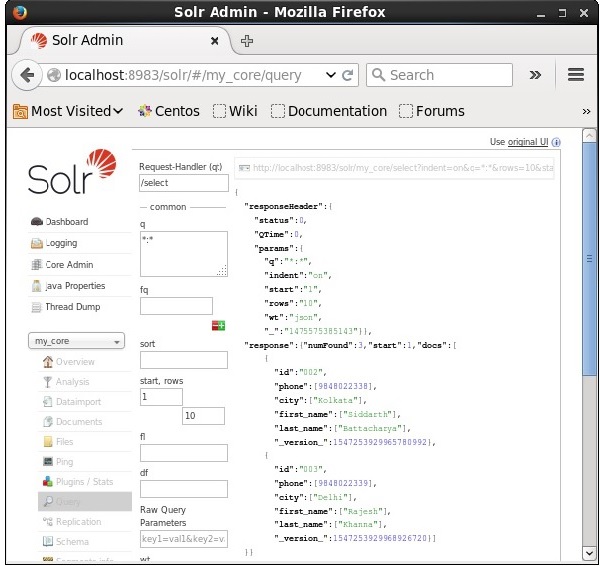
Récupération du 2 ème enregistrement
Nous pouvons récupérer les enregistrements du deuxième enregistrement en passant 2 comme valeur au paramètre start, comme illustré dans la capture d'écran suivante.
Limitation du nombre d'enregistrements
Vous pouvez limiter le nombre d'enregistrements en spécifiant une valeur dans le rowsparamètre. Par exemple, nous pouvons limiter le nombre total d'enregistrements dans le résultat de la requête à 2 en passant la valeur 2 dans le paramètrerows, comme illustré dans la capture d'écran suivante.
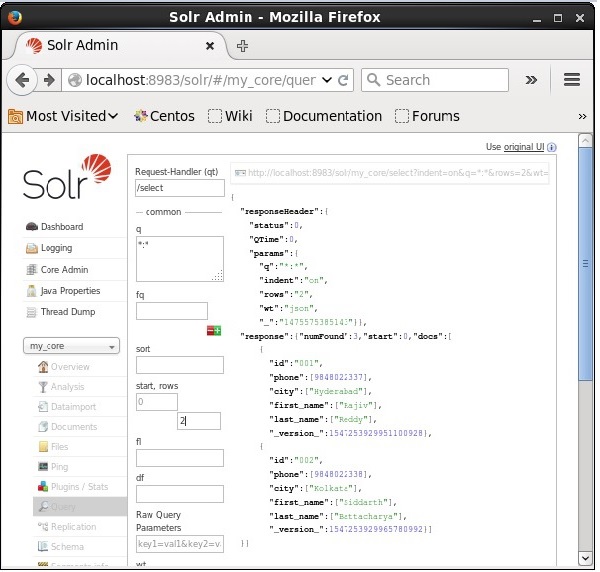
Type de rédacteur de réponse
Vous pouvez obtenir la réponse dans le type de document requis en en sélectionnant une parmi les valeurs fournies du paramètre wt.
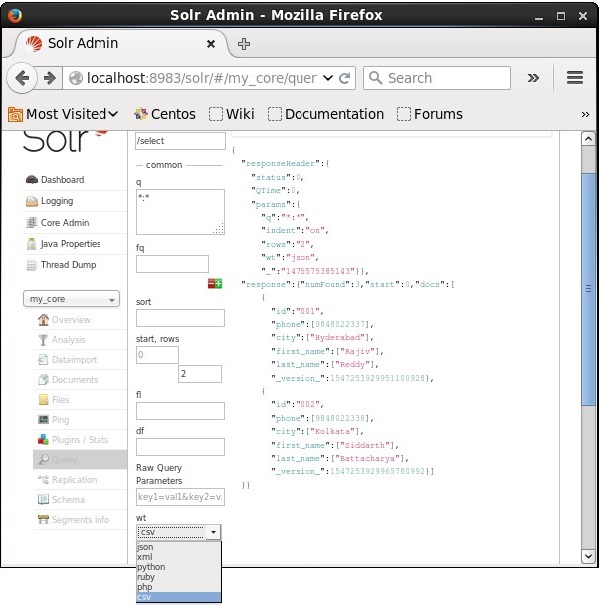
Dans l'exemple ci-dessus, nous avons choisi le .csv format pour obtenir la réponse.
Liste des champs
Si nous voulons avoir des champs particuliers dans les documents résultants, nous devons transmettre la liste des champs obligatoires, séparés par des virgules, en tant que valeur à la propriété fl.
Dans l'exemple suivant, nous essayons de récupérer les champs - id, phone, et first_name.
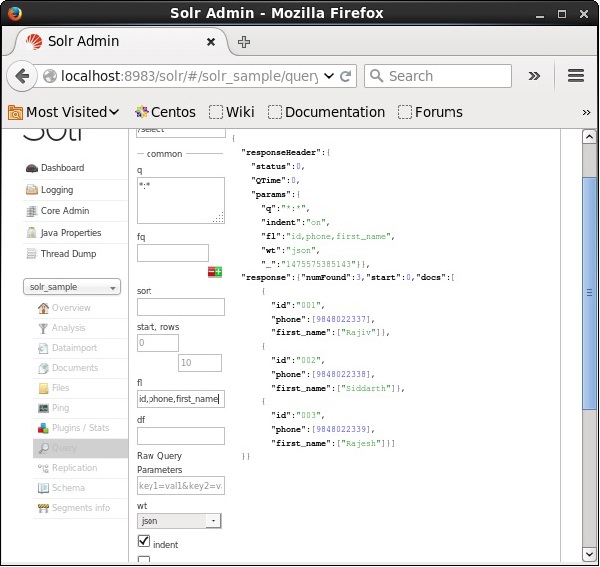
La facette dans Apache Solr fait référence à la classification des résultats de la recherche en différentes catégories. Dans ce chapitre, nous discuterons des types de facettage disponibles dans Apache Solr -
Query faceting - Il renvoie le nombre de documents dans les résultats de recherche actuels qui correspondent également à la requête donnée.
Date faceting - Il renvoie le nombre de documents compris dans certaines plages de dates.
Les commandes de facettage sont ajoutées à toute demande de requête Solr normale et le nombre de facettes revient dans la même réponse de requête.
Exemple de requête de facettes
Utiliser le terrain faceting, nous pouvons récupérer les décomptes de tous les termes, ou uniquement les premiers termes dans un champ donné.
À titre d'exemple, considérons ce qui suit books.csv fichier contenant des données sur divers livres.
id,cat,name,price,inStock,author,series_t,sequence_i,genre_s
0553573403,book,A Game of Thrones,5.99,true,George R.R. Martin,"A Song of Ice
and Fire",1,fantasy
0553579908,book,A Clash of Kings,10.99,true,George R.R. Martin,"A Song of Ice
and Fire",2,fantasy
055357342X,book,A Storm of Swords,7.99,true,George R.R. Martin,"A Song of Ice
and Fire",3,fantasy
0553293354,book,Foundation,7.99,true,Isaac Asimov,Foundation Novels,1,scifi
0812521390,book,The Black Company,4.99,false,Glen Cook,The Chronicles of The
Black Company,1,fantasy
0812550706,book,Ender's Game,6.99,true,Orson Scott Card,Ender,1,scifi
0441385532,book,Jhereg,7.95,false,Steven Brust,Vlad Taltos,1,fantasy
0380014300,book,Nine Princes In Amber,6.99,true,Roger Zelazny,the Chronicles of
Amber,1,fantasy
0805080481,book,The Book of Three,5.99,true,Lloyd Alexander,The Chronicles of
Prydain,1,fantasy
080508049X,book,The Black Cauldron,5.99,true,Lloyd Alexander,The Chronicles of
Prydain,2,fantasyPosons ce fichier dans Apache Solr en utilisant le post outil.
[Hadoop@localhost bin]$ ./post -c Solr_sample sample.csvLors de l'exécution de la commande ci-dessus, tous les documents mentionnés dans le .csv Le fichier sera téléchargé dans Apache Solr.
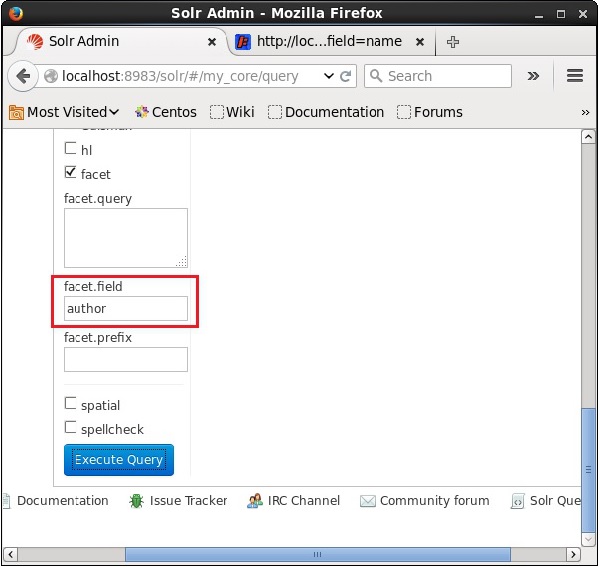
Maintenant, exécutons une requête à facettes sur le terrain author avec 0 ligne sur la collection / core my_core.
Ouvrez l'interface utilisateur Web d'Apache Solr et sur le côté gauche de la page, cochez la case facet, comme illustré dans la capture d'écran suivante.
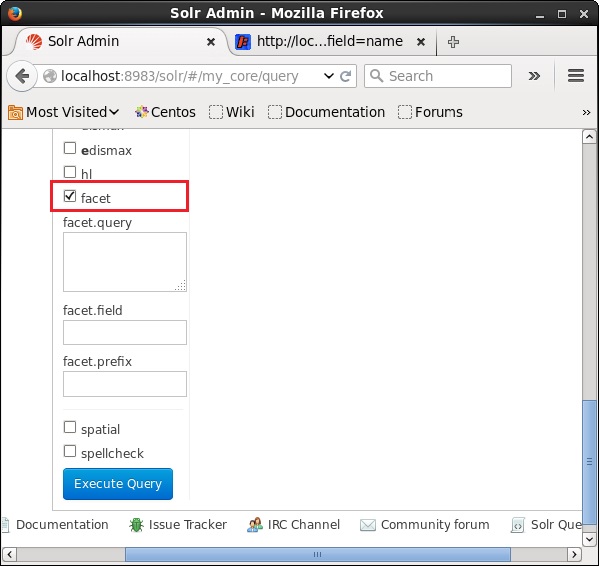
En cochant la case, vous aurez trois autres champs de texte afin de passer les paramètres de la recherche de facette. Maintenant, en tant que paramètres de la requête, transmettez les valeurs suivantes.
q = *:*, rows = 0, facet.field = authorEnfin, exécutez la requête en cliquant sur le bouton Execute Query bouton.
Lors de l'exécution, il produira le résultat suivant.
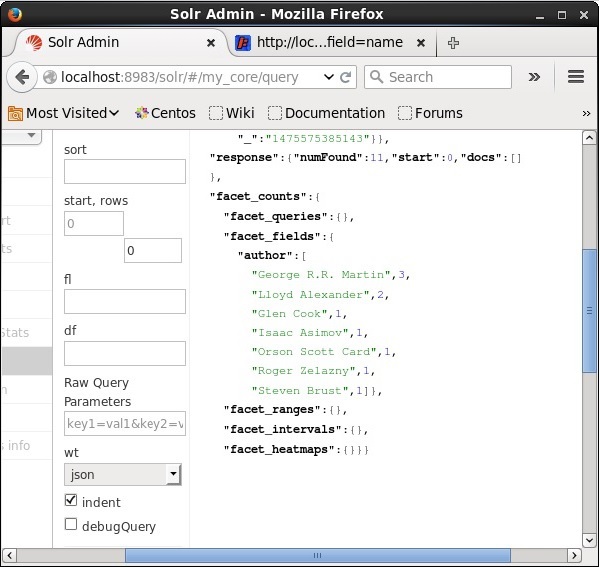
Il catégorise les documents de l'index en fonction de l'auteur et spécifie le nombre de livres fournis par chaque auteur.
Facettes à l'aide de l'API client Java
Voici le programme Java pour ajouter des documents à l'index Apache Solr. Enregistrez ce code dans un fichier avec le nomHitHighlighting.java.
import java.io.IOException;
import java.util.List;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrQuery;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.client.Solrj.request.QueryRequest;
import org.apache.Solr.client.Solrj.response.FacetField;
import org.apache.Solr.client.Solrj.response.FacetField.Count;
import org.apache.Solr.client.Solrj.response.QueryResponse;
import org.apache.Solr.common.SolrInputDocument;
public class HitHighlighting {
public static void main(String args[]) throws SolrServerException, IOException {
//Preparing the Solr client
String urlString = "http://localhost:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
//String query = request.query;
SolrQuery query = new SolrQuery();
//Setting the query string
query.setQuery("*:*");
//Setting the no.of rows
query.setRows(0);
//Adding the facet field
query.addFacetField("author");
//Creating the query request
QueryRequest qryReq = new QueryRequest(query);
//Creating the query response
QueryResponse resp = qryReq.process(Solr);
//Retrieving the response fields
System.out.println(resp.getFacetFields());
List<FacetField> facetFields = resp.getFacetFields();
for (int i = 0; i > facetFields.size(); i++) {
FacetField facetField = facetFields.get(i);
List<Count> facetInfo = facetField.getValues();
for (FacetField.Count facetInstance : facetInfo) {
System.out.println(facetInstance.getName() + " : " +
facetInstance.getCount() + " [drilldown qry:" +
facetInstance.getAsFilterQuery());
}
System.out.println("Hello");
}
}
}Compilez le code ci-dessus en exécutant les commandes suivantes dans le terminal -
[Hadoop@localhost bin]$ javac HitHighlighting
[Hadoop@localhost bin]$ java HitHighlightingEn exécutant la commande ci-dessus, vous obtiendrez la sortie suivante.
[author:[George R.R. Martin (3), Lloyd Alexander (2), Glen Cook (1), Isaac
Asimov (1), Orson Scott Card (1), Roger Zelazny (1), Steven Brust (1)]]