Assemblage - Guide rapide
Qu'est-ce que le langage d'assemblage?
Chaque ordinateur personnel possède un microprocesseur qui gère les activités arithmétiques, logiques et de contrôle de l'ordinateur.
Chaque famille de processeurs dispose de son propre ensemble d'instructions pour gérer diverses opérations telles que la saisie à partir du clavier, l'affichage d'informations à l'écran et l'exécution de diverses autres tâches. Cet ensemble d'instructions est appelé «instructions en langage machine».
Un processeur ne comprend que les instructions en langage machine, qui sont des chaînes de 1 et de 0. Cependant, le langage machine est trop obscur et complexe pour être utilisé dans le développement de logiciels. Ainsi, le langage d'assemblage de bas niveau est conçu pour une famille spécifique de processeurs qui représente diverses instructions sous forme de code symbolique et sous une forme plus compréhensible.
Avantages du langage d'assemblage
Avoir une compréhension du langage d'assemblage permet de prendre conscience de -
- L'interface des programmes avec le système d'exploitation, le processeur et le BIOS;
- Comment les données sont représentées dans la mémoire et d'autres périphériques externes;
- Comment le processeur accède et exécute l'instruction;
- Comment les instructions accèdent et traitent les données;
- Comment un programme accède aux périphériques externes.
Les autres avantages de l'utilisation du langage d'assemblage sont:
Cela nécessite moins de mémoire et de temps d'exécution;
Il permet des travaux complexes spécifiques au matériel d'une manière plus simple;
Il convient aux travaux urgents;
Il est le plus approprié pour écrire des routines de service d'interruption et d'autres programmes résidant en mémoire.
Caractéristiques de base du matériel PC
Le matériel interne principal d'un PC se compose du processeur, de la mémoire et des registres. Les registres sont des composants de processeur qui contiennent des données et des adresses. Pour exécuter un programme, le système le copie du périphérique externe dans la mémoire interne. Le processeur exécute les instructions du programme.
L'unité fondamentale de stockage informatique est un peu; il peut être ON (1) ou OFF (0) et un groupe de 8 bits associés fait un octet sur la plupart des ordinateurs modernes.
Ainsi, le bit de parité est utilisé pour rendre le nombre de bits dans un octet impair. Si la parité est égale, le système suppose qu'il y a eu une erreur de parité (bien que rare), qui aurait pu être due à un défaut matériel ou à une perturbation électrique.
Le processeur prend en charge les tailles de données suivantes -
- Word: une donnée sur 2 octets
- Mot double: élément de données de 4 octets (32 bits)
- Quadword: un élément de données de 8 octets (64 bits)
- Paragraphe: une zone de 16 octets (128 bits)
- Kilo-octets: 1024 octets
- Mégaoctet: 1 048 576 octets
Système de numération binaire
Chaque système numérique utilise la notation positionnelle, c'est-à-dire que chaque position dans laquelle un chiffre est écrit a une valeur positionnelle différente. Chaque position est la puissance de la base, qui est de 2 pour le système de nombres binaires, et ces puissances commencent à 0 et augmentent de 1.
Le tableau suivant montre les valeurs de position pour un nombre binaire de 8 bits, où tous les bits sont mis à ON.
| Valeur de bit | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
|---|---|---|---|---|---|---|---|---|
| Valeur de position en tant que puissance de base 2 | 128 | 64 | 32 | 16 | 8 | 4 | 2 | 1 |
| Numéro de bit | sept | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
La valeur d'un nombre binaire est basée sur la présence de 1 bits et leur valeur de position. Ainsi, la valeur d'un nombre binaire donné est -
1 + 2 + 4 + 8 +16 + 32 + 64 + 128 = 255
qui est identique à 2 8 - 1.
Système de nombres hexadécimaux
Le système de nombres hexadécimaux utilise la base 16. Les chiffres de ce système vont de 0 à 15. Par convention, les lettres A à F sont utilisées pour représenter les chiffres hexadécimaux correspondant aux valeurs décimales 10 à 15.
Les nombres hexadécimaux en informatique sont utilisés pour abréger de longues représentations binaires. Fondamentalement, le système de nombres hexadécimaux représente une donnée binaire en divisant chaque octet en deux et en exprimant la valeur de chaque demi-octet. Le tableau suivant fournit les équivalents décimaux, binaires et hexadécimaux -
| Nombre décimal | Représentation binaire | Représentation hexadécimale |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 1 | 1 |
| 2 | dix | 2 |
| 3 | 11 | 3 |
| 4 | 100 | 4 |
| 5 | 101 | 5 |
| 6 | 110 | 6 |
| sept | 111 | sept |
| 8 | 1000 | 8 |
| 9 | 1001 | 9 |
| dix | 1010 | UNE |
| 11 | 1011 | B |
| 12 | 1100 | C |
| 13 | 1101 | ré |
| 14 | 1110 | E |
| 15 | 1111 | F |
Pour convertir un nombre binaire en son équivalent hexadécimal, divisez-le en groupes de 4 groupes consécutifs chacun, en commençant par la droite, et écrivez ces groupes sur les chiffres correspondants du nombre hexadécimal.
Example - Le nombre binaire 1000 1100 1101 0001 équivaut à hexadécimal - 8CD1
Pour convertir un nombre hexadécimal en nombre binaire, écrivez simplement chaque chiffre hexadécimal dans son équivalent binaire à 4 chiffres.
Example - Le nombre hexadécimal FAD8 équivaut à binaire - 1111 1010 1101 1000
Arithmétique binaire
Le tableau suivant illustre quatre règles simples pour l'addition binaire -
| (je) | (ii) | (iii) | (iv) |
|---|---|---|---|
| 1 | |||
| 0 | 1 | 1 | 1 |
| +0 | +0 | +1 | +1 |
| = 0 | = 1 | = 10 | = 11 |
Les règles (iii) et (iv) montrent un report de 1 bit dans la position suivante à gauche.
Example
| Décimal | Binaire |
|---|---|
| 60 | 00111100 |
| +42 | 00101010 |
| 102 | 01100110 |
Une valeur binaire négative est exprimée en two's complement notation. Selon cette règle, pour convertir un nombre binaire en sa valeur négative, il faut inverser ses valeurs de bits et ajouter 1 .
Example
| Numéro 53 | 00110101 |
| Inverser les bits | 11001010 |
| Ajouter 1 | 0000000 1 |
| Numéro -53 | 11001011 |
Pour soustraire une valeur d'une autre, convertissez le nombre soustrait au format de complément à deux et ajoutez les nombres .
Example
Soustraire 42 de 53
| Numéro 53 | 00110101 |
| Numéro 42 | 00101010 |
| Inverser les bits de 42 | 11010101 |
| Ajouter 1 | 0000000 1 |
| Numéro -42 | 11010110 |
| 53 - 42 = 11 | 00001011 |
Le débordement du dernier bit est perdu.
Adressage des données en mémoire
Le processus par lequel le processeur contrôle l'exécution des instructions est appelé fetch-decode-execute cycle ou la execution cycle. Il se compose de trois étapes continues -
- Récupérer l'instruction de la mémoire
- Décodage ou identification de l'instruction
- Exécution de l'instruction
Le processeur peut accéder à un ou plusieurs octets de mémoire à la fois. Considérons un nombre hexadécimal 0725H. Ce nombre nécessitera deux octets de mémoire. L'octet de poids fort ou l'octet le plus significatif est 07 et l'octet de poids faible est 25.
Le processeur stocke les données dans une séquence d'octets inversés, c'est-à-dire qu'un octet de poids faible est stocké dans une adresse de mémoire basse et un octet de poids fort dans une adresse de mémoire haute. Ainsi, si le processeur amène la valeur 0725H du registre à la mémoire, il transférera d'abord 25 à l'adresse mémoire inférieure et 07 à l'adresse mémoire suivante.
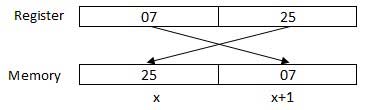
x: adresse mémoire
Lorsque le processeur récupère les données numériques de la mémoire vers le registre, il inverse à nouveau les octets. Il existe deux types d'adresses mémoire -
Adresse absolue - une référence directe d'un emplacement spécifique.
Adresse de segment (ou décalage) - adresse de départ d'un segment de mémoire avec la valeur de décalage.
Configuration de l'environnement local
Le langage d'assemblage dépend du jeu d'instructions et de l'architecture du processeur. Dans ce tutoriel, nous nous concentrons sur les processeurs Intel-32 comme Pentium. Pour suivre ce tutoriel, vous aurez besoin de -
- Un PC IBM ou tout autre ordinateur compatible équivalent
- Une copie du système d'exploitation Linux
- Une copie du programme d'assembleur NASM
Il existe de nombreux bons programmes assembleurs, tels que -
- Assembleur Microsoft (MASM)
- Assembleur Borland Turbo (TASM)
- L'assembleur GNU (GAS)
Nous utiliserons l'assembleur NASM, tel quel -
- Libre. Vous pouvez le télécharger à partir de diverses sources Web.
- Bien documenté et vous obtiendrez beaucoup d'informations sur le net.
- Peut être utilisé à la fois sous Linux et Windows.
Installation du NASM
Si vous sélectionnez "Outils de développement" lors de l'installation de Linux, vous pouvez installer NASM avec le système d'exploitation Linux et vous n'avez pas besoin de le télécharger et de l'installer séparément. Pour vérifier si vous avez déjà installé NASM, procédez comme suit -
Ouvrez un terminal Linux.
Type whereis nasm et appuyez sur ENTER.
S'il est déjà installé, une ligne telle que nasm: / usr / bin / nasm apparaît. Sinon, vous verrez juste nasm:, alors vous devez installer NASM.
Pour installer NASM, procédez comme suit -
Consultez le site Web de l'assembleur réseau (NASM) pour la dernière version.
Téléchargez l'archive source Linux
nasm-X.XX.ta.gz, où seX.XXtrouve le numéro de version NASM dans l'archive.Décompressez l'archive dans un répertoire qui crée un sous-répertoire
nasm-X. XX.cd
nasm-X.XXet tapez./configure. Ce script shell trouvera le meilleur compilateur C à utiliser et configurera les Makefiles en conséquence.Type make pour construire les binaires nasm et ndisasm.
Type make install pour installer nasm et ndisasm dans / usr / local / bin et pour installer les pages de manuel.
Cela devrait installer NASM sur votre système. Vous pouvez également utiliser une distribution RPM pour Fedora Linux. Cette version est plus simple à installer, il suffit de double-cliquer sur le fichier RPM.
Un programme d'assemblage peut être divisé en trois sections -
le data section,
le bss section, et
le text section.
La section des données
le dataLa section est utilisée pour déclarer des données ou des constantes initialisées. Ces données ne changent pas lors de l'exécution. Vous pouvez déclarer diverses valeurs constantes, noms de fichiers ou taille de tampon, etc., dans cette section.
La syntaxe pour déclarer la section de données est -
section.dataLa section bss
le bssLa section est utilisée pour déclarer des variables. La syntaxe pour déclarer la section bss est -
section.bssLa section texte
le textLa section est utilisée pour conserver le code réel. Cette section doit commencer par la déclarationglobal _start, qui indique au noyau où commence l'exécution du programme.
La syntaxe pour déclarer la section de texte est -
section.text
global _start
_start:commentaires
Le commentaire du langage d'assemblage commence par un point-virgule (;). Il peut contenir n'importe quel caractère imprimable, y compris le blanc. Il peut apparaître seul sur une ligne, comme -
; This program displays a message on screenou, sur la même ligne avec une instruction, comme -
add eax, ebx ; adds ebx to eaxInstructions de langage d'assemblage
Les programmes en langage d'assemblage se composent de trois types d'instructions -
- Instructions ou instructions exécutables,
- Directives d'assembleur ou pseudo-opérations, et
- Macros.
le executable instructions ou simplement instructionsdites au processeur quoi faire. Chaque instruction se compose d'unoperation code(opcode). Chaque instruction exécutable génère une instruction en langage machine.
le assembler directives ou pseudo-opsinformer l'assembleur des différents aspects du processus d'assemblage. Ceux-ci ne sont pas exécutables et ne génèrent pas d'instructions en langage machine.
Macros sont essentiellement un mécanisme de substitution de texte.
Syntaxe des instructions du langage d'assemblage
Les instructions en langage d'assemblage sont entrées une instruction par ligne. Chaque instruction suit le format suivant -
[label] mnemonic [operands] [;comment]Les champs entre crochets sont facultatifs. Une instruction de base comporte deux parties, la première est le nom de l'instruction (ou le mnémonique), qui doit être exécutée, et la seconde sont les opérandes ou les paramètres de la commande.
Voici quelques exemples d'instructions typiques du langage assembleur -
INC COUNT ; Increment the memory variable COUNT
MOV TOTAL, 48 ; Transfer the value 48 in the
; memory variable TOTAL
ADD AH, BH ; Add the content of the
; BH register into the AH register
AND MASK1, 128 ; Perform AND operation on the
; variable MASK1 and 128
ADD MARKS, 10 ; Add 10 to the variable MARKS
MOV AL, 10 ; Transfer the value 10 to the AL registerLe programme Hello World en assemblée
Le code de langage d'assemblage suivant affiche la chaîne «Hello World» à l'écran -
section .text
global _start ;must be declared for linker (ld)
_start: ;tells linker entry point
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db 'Hello, world!', 0xa ;string to be printed
len equ $ - msg ;length of the stringLorsque le code ci-dessus est compilé et exécuté, il produit le résultat suivant -
Hello, world!Compilation et liaison d'un programme d'assemblage dans NASM
Assurez-vous d'avoir défini le chemin de nasm et ldbinaires dans votre variable d'environnement PATH. Maintenant, suivez les étapes suivantes pour compiler et lier le programme ci-dessus -
Tapez le code ci-dessus à l'aide d'un éditeur de texte et enregistrez-le sous hello.asm.
Assurez-vous que vous êtes dans le même répertoire que celui où vous avez enregistré hello.asm.
Pour assembler le programme, tapez nasm -f elf hello.asm
S'il y a une erreur, vous en serez informé à ce stade. Sinon, un fichier objet de votre programme nomméhello.o sera créé.
Pour lier le fichier objet et créer un fichier exécutable nommé hello, tapez ld -m elf_i386 -s -o hello hello.o
Exécutez le programme en tapant ./hello
Si vous avez tout fait correctement, il affichera "Hello, world!" sur l'écran.
Nous avons déjà discuté des trois sections d'un programme d'assemblage. Ces sections représentent également divers segments de mémoire.
Fait intéressant, si vous remplacez le mot-clé de section par segment, vous obtiendrez le même résultat. Essayez le code suivant -
segment .text ;code segment
global _start ;must be declared for linker
_start: ;tell linker entry point
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
segment .data ;data segment
msg db 'Hello, world!',0xa ;our dear string
len equ $ - msg ;length of our dear stringLorsque le code ci-dessus est compilé et exécuté, il produit le résultat suivant -
Hello, world!Segments de mémoire
Un modèle de mémoire segmentée divise la mémoire système en groupes de segments indépendants référencés par des pointeurs situés dans les registres de segments. Chaque segment est utilisé pour contenir un type spécifique de données. Un segment est utilisé pour contenir des codes d'instructions, un autre segment stocke les éléments de données et un troisième segment conserve la pile de programmes.
À la lumière de la discussion ci-dessus, nous pouvons spécifier divers segments de mémoire comme -
Data segment - Il est représenté par .data section et le .bss. La section .data est utilisée pour déclarer la région mémoire, où les éléments de données sont stockés pour le programme. Cette section ne peut pas être développée après la déclaration des éléments de données et elle reste statique tout au long du programme.
La section .bss est également une section de mémoire statique qui contient des tampons pour les données à déclarer ultérieurement dans le programme. Cette mémoire tampon est remplie de zéro.
Code segment - Il est représenté par .textsection. Ceci définit une zone en mémoire qui stocke les codes d'instructions. C'est aussi une zone fixe.
Stack - Ce segment contient des valeurs de données transmises aux fonctions et procédures du programme.
Les opérations du processeur impliquent principalement le traitement des données. Ces données peuvent être stockées en mémoire et accessibles à partir de celle-ci. Cependant, la lecture et le stockage de données dans la mémoire ralentissent le processeur, car cela implique des processus compliqués d'envoi de la demande de données sur le bus de commande et dans l'unité de stockage de mémoire et d'obtenir les données via le même canal.
Pour accélérer les opérations du processeur, le processeur inclut certains emplacements de stockage de la mémoire interne, appelés registers.
Les registres stockent des éléments de données à traiter sans avoir à accéder à la mémoire. Un nombre limité de registres est intégré à la puce du processeur.
Registres du processeur
Il existe dix registres de processeur 32 bits et six registres de processeur 16 bits dans l'architecture IA-32. Les registres sont regroupés en trois catégories -
- Registres généraux,
- Registres de contrôle, et
- Registres de segment.
Les registres généraux sont divisés en groupes suivants -
- Registres de données,
- Registres de pointeur, et
- Registres d'index.
Registres de données
Quatre registres de données 32 bits sont utilisés pour les opérations arithmétiques, logiques et autres. Ces registres 32 bits peuvent être utilisés de trois manières:
En tant que registres de données 32 bits complets: EAX, EBX, ECX, EDX.
Les moitiés inférieures des registres 32 bits peuvent être utilisées comme quatre registres de données 16 bits: AX, BX, CX et DX.
Les moitiés inférieure et supérieure des quatre registres de 16 bits mentionnés ci-dessus peuvent être utilisées comme huit registres de données de 8 bits: AH, AL, BH, BL, CH, CL, DH et DL.

Certains de ces registres de données ont une utilisation spécifique dans les opérations arithmétiques.
AX is the primary accumulator; il est utilisé dans les entrées / sorties et la plupart des instructions arithmétiques. Par exemple, lors d'une opération de multiplication, un opérande est stocké dans le registre EAX ou AX ou AL selon la taille de l'opérande.
BX is known as the base register, car il pourrait être utilisé dans l'adressage indexé.
CX is known as the count register, comme l'ECX, les registres CX stockent le nombre de boucles dans des opérations itératives.
DX is known as the data register. Il est également utilisé dans les opérations d'entrée / sortie. Il est également utilisé avec le registre AX avec DX pour les opérations de multiplication et de division impliquant de grandes valeurs.
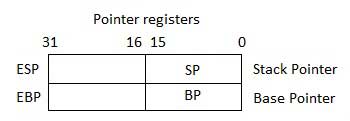
Registres de pointeurs
Les registres de pointeur sont des registres EIP, ESP et EBP 32 bits et les parties droites 16 bits correspondantes IP, SP et BP. Il existe trois catégories de registres de pointeurs -
Instruction Pointer (IP)- Le registre IP 16 bits stocke l'adresse d'offset de la prochaine instruction à exécuter. IP en association avec le registre CS (comme CS: IP) donne l'adresse complète de l'instruction courante dans le segment de code.
Stack Pointer (SP)- Le registre SP 16 bits fournit la valeur de décalage dans la pile de programmes. SP en association avec le registre SS (SS: SP) se réfère à la position actuelle des données ou à l'adresse dans la pile de programmes.
Base Pointer (BP)- Le registre BP 16 bits aide principalement à référencer les variables de paramètres passées à un sous-programme. L'adresse dans le registre SS est combinée avec le décalage dans BP pour obtenir l'emplacement du paramètre. BP peut également être combiné avec DI et SI comme registre de base pour un adressage spécial.
Registres d'index
Les registres d'index 32 bits, ESI et EDI, et leurs parties 16 bits les plus à droite. SI et DI, sont utilisés pour l'adressage indexé et parfois utilisés en addition et soustraction. Il existe deux ensembles de pointeurs d'index -
Source Index (SI) - Il est utilisé comme index source pour les opérations de chaîne.
Destination Index (DI) - Il est utilisé comme index de destination pour les opérations de chaîne.

Registres de contrôle
Le registre de pointeur d'instruction de 32 bits et le registre d'indicateurs de 32 bits combinés sont considérés comme les registres de contrôle.
De nombreuses instructions impliquent des comparaisons et des calculs mathématiques et modifient l'état des indicateurs et certaines autres instructions conditionnelles testent la valeur de ces indicateurs d'état pour amener le flux de contrôle vers un autre emplacement.
Les bits d'indicateur communs sont:
Overflow Flag (OF) - Il indique le débordement d'un bit de poids fort (bit le plus à gauche) de données après une opération arithmétique signée.
Direction Flag (DF)- Il détermine la direction gauche ou droite pour déplacer ou comparer des données de chaîne. Lorsque la valeur DF est 0, l'opération de chaîne prend la direction de gauche à droite et lorsque la valeur est définie sur 1, l'opération de chaîne prend la direction de droite à gauche.
Interrupt Flag (IF)- Il détermine si les interruptions externes telles que la saisie au clavier, etc., doivent être ignorées ou traitées. Elle désactive l'interruption externe lorsque la valeur est 0 et active les interruptions lorsqu'elle est définie sur 1.
Trap Flag (TF)- Il permet de paramétrer le fonctionnement du processeur en mode pas à pas. Le programme DEBUG que nous avons utilisé définit l'indicateur d'interruption, de sorte que nous pourrions parcourir l'exécution une instruction à la fois.
Sign Flag (SF)- Il montre le signe du résultat d'une opération arithmétique. Cet indicateur est positionné en fonction du signe d'une donnée après l'opération arithmétique. Le signe est indiqué par l'ordre supérieur du bit le plus à gauche. Un résultat positif efface la valeur de SF à 0 et un résultat négatif la définit à 1.
Zero Flag (ZF)- Il indique le résultat d'une opération d'arithmétique ou de comparaison. Un résultat différent de zéro efface l'indicateur zéro sur 0 et un résultat zéro le définit sur 1.
Auxiliary Carry Flag (AF)- Il contient le report du bit 3 au bit 4 suite à une opération arithmétique; utilisé pour l'arithmétique spécialisée. L'AF est défini lorsqu'une opération arithmétique sur 1 octet provoque un report du bit 3 au bit 4.
Parity Flag (PF)- Il indique le nombre total de 1 bits dans le résultat obtenu à partir d'une opération arithmétique. Un nombre pair de 1 bits efface l'indicateur de parité à 0 et un nombre impair de 1 bits définit l'indicateur de parité sur 1.
Carry Flag (CF)- Il contient le report de 0 ou 1 à partir d'un bit de poids fort (le plus à gauche) après une opération arithmétique. Il stocke également le contenu du dernier bit d'une opération de décalage ou de rotation .
Le tableau suivant indique la position des bits d'indicateur dans le registre d'indicateurs 16 bits:
| Drapeau: | O | ré | je | T | S | Z | UNE | P | C | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Bit non: | 15 | 14 | 13 | 12 | 11 | dix | 9 | 8 | sept | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
Registres de segments
Les segments sont des zones spécifiques définies dans un programme pour contenir des données, du code et une pile. Il existe trois segments principaux -
Code Segment- Il contient toutes les instructions à exécuter. Un registre de segment de code de 16 bits ou un registre CS stocke l'adresse de début du segment de code.
Data Segment- Il contient des données, des constantes et des zones de travail. Un registre de segment de données de 16 bits ou registre DS stocke l'adresse de départ du segment de données.
Stack Segment- Il contient des données et des adresses de retour de procédures ou de sous-programmes. Il est implémenté comme une structure de données «pile». Le registre de segment de pile ou registre SS stocke l'adresse de départ de la pile.
Outre les registres DS, CS et SS, il existe d'autres registres de segments supplémentaires - ES (segment supplémentaire), FS et GS, qui fournissent des segments supplémentaires pour le stockage des données.
Dans la programmation d'assemblage, un programme doit accéder aux emplacements de mémoire. Tous les emplacements de mémoire dans un segment sont relatifs à l'adresse de départ du segment. Un segment commence dans une adresse uniformément divisible par 16 ou hexadécimal 10. Ainsi, le chiffre hexadécimal le plus à droite dans toutes ces adresses de mémoire est 0, qui n'est généralement pas stocké dans les registres de segment.
Les registres de segments stockent les adresses de départ d'un segment. Pour obtenir l'emplacement exact des données ou des instructions dans un segment, une valeur de décalage (ou déplacement) est nécessaire. Pour référencer n'importe quel emplacement de mémoire dans un segment, le processeur combine l'adresse de segment dans le registre de segment avec la valeur de décalage de l'emplacement.
Exemple
Regardez le programme simple suivant pour comprendre l'utilisation des registres dans la programmation d'assemblage. Ce programme affiche 9 étoiles à l'écran avec un message simple -
section .text
global _start ;must be declared for linker (gcc)
_start: ;tell linker entry point
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov edx,9 ;message length
mov ecx,s2 ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db 'Displaying 9 stars',0xa ;a message
len equ $ - msg ;length of message
s2 times 9 db '*'Lorsque le code ci-dessus est compilé et exécuté, il produit le résultat suivant -
Displaying 9 stars
*********Les appels système sont des API pour l'interface entre l'espace utilisateur et l'espace noyau. Nous avons déjà utilisé les appels système. sys_write et sys_exit, respectivement pour écrire dans l'écran et sortir du programme.
Appels système Linux
Vous pouvez utiliser les appels système Linux dans vos programmes d'assemblage. Vous devez suivre les étapes suivantes pour utiliser les appels système Linux dans votre programme -
- Mettez le numéro d'appel système dans le registre EAX.
- Stockez les arguments de l'appel système dans les registres EBX, ECX, etc.
- Appelez l'interruption correspondante (80h).
- Le résultat est généralement renvoyé dans le registre EAX.
Il existe six registres qui stockent les arguments de l'appel système utilisé. Ce sont les EBX, ECX, EDX, ESI, EDI et EBP. Ces registres prennent les arguments consécutifs, en commençant par le registre EBX. S'il y a plus de six arguments, l'emplacement de mémoire du premier argument est stocké dans le registre EBX.
L'extrait de code suivant montre l'utilisation de l'appel système sys_exit -
mov eax,1 ; system call number (sys_exit)
int 0x80 ; call kernelL'extrait de code suivant montre l'utilisation de l'appel système sys_write -
mov edx,4 ; message length
mov ecx,msg ; message to write
mov ebx,1 ; file descriptor (stdout)
mov eax,4 ; system call number (sys_write)
int 0x80 ; call kernelTous les appels système sont répertoriés dans /usr/include/asm/unistd.h , avec leurs numéros (la valeur à mettre dans EAX avant d'appeler int 80h).
Le tableau suivant présente certains des appels système utilisés dans ce didacticiel -
| % eax | Nom | % ebx | % ecx | % edx | % esx | % edi |
|---|---|---|---|---|---|---|
| 1 | sys_exit | int | - | - | - | - |
| 2 | sys_fork | struct pt_regs | - | - | - | - |
| 3 | sys_read | int non signé | char * | size_t | - | - |
| 4 | sys_write | int non signé | const char * | size_t | - | - |
| 5 | sys_open | const char * | int | int | - | - |
| 6 | sys_close | int non signé | - | - | - | - |
Exemple
L'exemple suivant lit un nombre sur le clavier et l'affiche à l'écran -
section .data ;Data segment
userMsg db 'Please enter a number: ' ;Ask the user to enter a number
lenUserMsg equ $-userMsg ;The length of the message
dispMsg db 'You have entered: '
lenDispMsg equ $-dispMsg
section .bss ;Uninitialized data
num resb 5
section .text ;Code Segment
global _start
_start: ;User prompt
mov eax, 4
mov ebx, 1
mov ecx, userMsg
mov edx, lenUserMsg
int 80h
;Read and store the user input
mov eax, 3
mov ebx, 2
mov ecx, num
mov edx, 5 ;5 bytes (numeric, 1 for sign) of that information
int 80h
;Output the message 'The entered number is: '
mov eax, 4
mov ebx, 1
mov ecx, dispMsg
mov edx, lenDispMsg
int 80h
;Output the number entered
mov eax, 4
mov ebx, 1
mov ecx, num
mov edx, 5
int 80h
; Exit code
mov eax, 1
mov ebx, 0
int 80hLorsque le code ci-dessus est compilé et exécuté, il produit le résultat suivant -
Please enter a number:
1234
You have entered:1234La plupart des instructions en langage d'assemblage nécessitent le traitement d'opérandes. Une adresse d'opérande fournit l'emplacement où les données à traiter sont stockées. Certaines instructions ne nécessitent pas d'opérande, tandis que d'autres instructions peuvent nécessiter un, deux ou trois opérandes.
Lorsqu'une instruction nécessite deux opérandes, le premier opérande est généralement la destination, qui contient des données dans un registre ou un emplacement mémoire et le second opérande est la source. La source contient soit les données à livrer (adressage immédiat), soit l'adresse (en registre ou en mémoire) des données. En règle générale, les données source restent inchangées après l'opération.
Les trois modes d'adressage de base sont:
- Inscription adressage
- Adressage immédiat
- Adressage mémoire
Inscription adressage
Dans ce mode d'adressage, un registre contient l'opérande. En fonction de l'instruction, le registre peut être le premier opérande, le deuxième opérande ou les deux.
Par exemple,
MOV DX, TAX_RATE ; Register in first operand
MOV COUNT, CX ; Register in second operand
MOV EAX, EBX ; Both the operands are in registersComme le traitement des données entre les registres n'implique pas de mémoire, il permet un traitement des données le plus rapide.
Adressage immédiat
Un opérande immédiat a une valeur constante ou une expression. Lorsqu'une instruction avec deux opérandes utilise un adressage immédiat, le premier opérande peut être un registre ou un emplacement mémoire, et le second opérande est une constante immédiate. Le premier opérande définit la longueur des données.
Par exemple,
BYTE_VALUE DB 150 ; A byte value is defined
WORD_VALUE DW 300 ; A word value is defined
ADD BYTE_VALUE, 65 ; An immediate operand 65 is added
MOV AX, 45H ; Immediate constant 45H is transferred to AXAdressage direct de la mémoire
Lorsque des opérandes sont spécifiés en mode d'adressage mémoire, un accès direct à la mémoire principale, généralement au segment de données, est requis. Cette façon d'adresser entraîne un traitement plus lent des données. Pour localiser l'emplacement exact des données en mémoire, nous avons besoin de l'adresse de début du segment, qui se trouve généralement dans le registre DS et d'une valeur de décalage. Cette valeur de décalage est également appeléeeffective address.
En mode d'adressage direct, la valeur de décalage est spécifiée directement dans le cadre de l'instruction, généralement indiquée par le nom de la variable. L'assembleur calcule la valeur de décalage et gère une table de symboles, qui stocke les valeurs de décalage de toutes les variables utilisées dans le programme.
Dans l'adressage mémoire direct, l'un des opérandes fait référence à un emplacement mémoire et l'autre opérande fait référence à un registre.
Par exemple,
ADD BYTE_VALUE, DL ; Adds the register in the memory location
MOV BX, WORD_VALUE ; Operand from the memory is added to registerAdressage par décalage direct
Ce mode d'adressage utilise les opérateurs arithmétiques pour modifier une adresse. Par exemple, regardez les définitions suivantes qui définissent les tables de données -
BYTE_TABLE DB 14, 15, 22, 45 ; Tables of bytes
WORD_TABLE DW 134, 345, 564, 123 ; Tables of wordsLes opérations suivantes permettent d'accéder aux données des tables de la mémoire dans les registres -
MOV CL, BYTE_TABLE[2] ; Gets the 3rd element of the BYTE_TABLE
MOV CL, BYTE_TABLE + 2 ; Gets the 3rd element of the BYTE_TABLE
MOV CX, WORD_TABLE[3] ; Gets the 4th element of the WORD_TABLE
MOV CX, WORD_TABLE + 3 ; Gets the 4th element of the WORD_TABLEAdressage mémoire indirect
Ce mode d'adressage utilise la capacité de l'ordinateur d' adressage Segment: Offset . Généralement, les registres de base EBX, EBP (ou BX, BP) et les registres d'index (DI, SI), codés entre crochets pour les références mémoire, sont utilisés à cet effet.
L'adressage indirect est généralement utilisé pour les variables contenant plusieurs éléments comme les tableaux. L'adresse de départ du tableau est stockée, par exemple, dans le registre EBX.
L'extrait de code suivant montre comment accéder à différents éléments de la variable.
MY_TABLE TIMES 10 DW 0 ; Allocates 10 words (2 bytes) each initialized to 0
MOV EBX, [MY_TABLE] ; Effective Address of MY_TABLE in EBX
MOV [EBX], 110 ; MY_TABLE[0] = 110
ADD EBX, 2 ; EBX = EBX +2
MOV [EBX], 123 ; MY_TABLE[1] = 123L'instruction MOV
Nous avons déjà utilisé l'instruction MOV qui est utilisée pour déplacer des données d'un espace de stockage à un autre. L'instruction MOV prend deux opérandes.
Syntaxe
La syntaxe de l'instruction MOV est -
MOV destination, sourceL'instruction MOV peut avoir l'une des cinq formes suivantes:
MOV register, register
MOV register, immediate
MOV memory, immediate
MOV register, memory
MOV memory, registerVeuillez noter que -
- Les deux opérandes en fonctionnement MOV doivent être de la même taille
- La valeur de l'opérande source reste inchangée
L'instruction MOV provoque parfois une ambiguïté. Par exemple, regardez les déclarations -
MOV EBX, [MY_TABLE] ; Effective Address of MY_TABLE in EBX
MOV [EBX], 110 ; MY_TABLE[0] = 110Il n'est pas clair si vous souhaitez déplacer un octet équivalent ou un équivalent mot du nombre 110. Dans de tels cas, il est sage d'utiliser un type specifier.
Le tableau suivant montre certains des spécificateurs de type courants -
| Spécificateur de type | Octets adressés |
|---|---|
| OCTET | 1 |
| MOT | 2 |
| DWORD | 4 |
| QWORD | 8 |
| TBYTE | dix |
Exemple
Le programme suivant illustre certains des concepts évoqués ci-dessus. Il stocke un nom «Zara Ali» dans la section de données de la mémoire, puis change sa valeur en un autre nom «Nuha Ali» par programmation et affiche les deux noms.
section .text
global _start ;must be declared for linker (ld)
_start: ;tell linker entry point
;writing the name 'Zara Ali'
mov edx,9 ;message length
mov ecx, name ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov [name], dword 'Nuha' ; Changed the name to Nuha Ali
;writing the name 'Nuha Ali'
mov edx,8 ;message length
mov ecx,name ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
name db 'Zara Ali 'Lorsque le code ci-dessus est compilé et exécuté, il produit le résultat suivant -
Zara Ali Nuha AliNASM fournit divers define directivespour réserver de l'espace de stockage pour les variables. La directive define assembler est utilisée pour l'allocation de l'espace de stockage. Il peut être utilisé pour réserver ainsi qu'initialiser un ou plusieurs octets.
Allocation d'espace de stockage pour les données initialisées
La syntaxe de l'instruction d'allocation de stockage pour les données initialisées est -
[variable-name] define-directive initial-value [,initial-value]...Où, nom-variable est l'identifiant de chaque espace de stockage. L'assembleur associe une valeur de décalage pour chaque nom de variable défini dans le segment de données.
Il existe cinq formes de base de la directive define -
| Directif | Objectif | Espace de stockage |
|---|---|---|
| DB | Définir l'octet | alloue 1 octet |
| DW | Définir le mot | alloue 2 octets |
| DD | Définir un double mot | alloue 4 octets |
| DQ | Définir Quadword | alloue 8 octets |
| DT | Définir dix octets | alloue 10 octets |
Voici quelques exemples d'utilisation des directives define -
choice DB 'y'
number DW 12345
neg_number DW -12345
big_number DQ 123456789
real_number1 DD 1.234
real_number2 DQ 123.456Veuillez noter que -
Chaque octet de caractère est stocké sous la forme de sa valeur ASCII en hexadécimal.
Chaque valeur décimale est automatiquement convertie en son équivalent binaire 16 bits et stockée sous forme de nombre hexadécimal.
Le processeur utilise l'ordre des octets petit-boutiste.
Les nombres négatifs sont convertis en représentation complémentaire de 2.
Les nombres à virgule flottante courts et longs sont représentés en utilisant respectivement 32 ou 64 bits.
Le programme suivant montre l'utilisation de la directive define -
section .text
global _start ;must be declared for linker (gcc)
_start: ;tell linker entry point
mov edx,1 ;message length
mov ecx,choice ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
choice DB 'y'Lorsque le code ci-dessus est compilé et exécuté, il produit le résultat suivant -
yAllocation d'espace de stockage pour les données non initialisées
Les directives reserve sont utilisées pour réserver de l'espace pour les données non initialisées. Les directives reserve prennent un seul opérande qui spécifie le nombre d'unités d'espace à réserver. Chaque directive de définition a une directive de réserve associée.
Il existe cinq formes de base de la directive sur les réserves -
| Directif | Objectif |
|---|---|
| RESB | Réserver un octet |
| RESW | Réserver un mot |
| RESD | Réserver un mot double |
| RESQ | Réserver un Quadword |
| DU REPOS | Réserver dix octets |
Définitions multiples
Vous pouvez avoir plusieurs instructions de définition de données dans un programme. Par exemple -
choice DB 'Y' ;ASCII of y = 79H
number1 DW 12345 ;12345D = 3039H
number2 DD 12345679 ;123456789D = 75BCD15HL'assembleur alloue une mémoire contiguë pour plusieurs définitions de variables.
Initialisations multiples
La directive TIMES autorise plusieurs initialisations à la même valeur. Par exemple, un tableau nommé marks de taille 9 peut être défini et initialisé à zéro à l'aide de l'instruction suivante -
marks TIMES 9 DW 0La directive TIMES est utile pour définir des tableaux et des tableaux. Le programme suivant affiche 9 astérisques à l'écran -
section .text
global _start ;must be declared for linker (ld)
_start: ;tell linker entry point
mov edx,9 ;message length
mov ecx, stars ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
stars times 9 db '*'Lorsque le code ci-dessus est compilé et exécuté, il produit le résultat suivant -
*********Il existe plusieurs directives fournies par NASM qui définissent des constantes. Nous avons déjà utilisé la directive EQU dans les chapitres précédents. Nous discuterons en particulier de trois directives -
- EQU
- %assign
- %define
La directive EQU
le EQUdirective est utilisée pour définir des constantes. La syntaxe de la directive EQU est la suivante -
CONSTANT_NAME EQU expressionPar exemple,
TOTAL_STUDENTS equ 50Vous pouvez ensuite utiliser cette valeur constante dans votre code, comme -
mov ecx, TOTAL_STUDENTS
cmp eax, TOTAL_STUDENTSL'opérande d'une instruction EQU peut être une expression -
LENGTH equ 20
WIDTH equ 10
AREA equ length * widthLe segment de code ci-dessus définirait AREA comme 200.
Exemple
L'exemple suivant illustre l'utilisation de la directive EQU -
SYS_EXIT equ 1
SYS_WRITE equ 4
STDIN equ 0
STDOUT equ 1
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg1
mov edx, len1
int 0x80
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg2
mov edx, len2
int 0x80
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg3
mov edx, len3
int 0x80
mov eax,SYS_EXIT ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg1 db 'Hello, programmers!',0xA,0xD
len1 equ $ - msg1
msg2 db 'Welcome to the world of,', 0xA,0xD
len2 equ $ - msg2 msg3 db 'Linux assembly programming! ' len3 equ $- msg3Lorsque le code ci-dessus est compilé et exécuté, il produit le résultat suivant -
Hello, programmers!
Welcome to the world of,
Linux assembly programming!La directive% assign
le %assignLa directive peut être utilisée pour définir des constantes numériques comme la directive EQU. Cette directive permet la redéfinition. Par exemple, vous pouvez définir la constante TOTAL comme -
%assign TOTAL 10Plus loin dans le code, vous pouvez le redéfinir comme -
%assign TOTAL 20Cette directive est sensible à la casse.
Les% définissent la directive
le %definedirective permet de définir à la fois des constantes numériques et des chaînes. Cette directive est similaire à la #define en C. Par exemple, vous pouvez définir la constante PTR comme -
%define PTR [EBP+4]Le code ci-dessus remplace PTR par [EBP + 4].
Cette directive permet également une redéfinition et est sensible à la casse.
L'instruction INC
L'instruction INC est utilisée pour incrémenter un opérande de un. Il fonctionne sur un seul opérande qui peut être dans un registre ou en mémoire.
Syntaxe
L'instruction INC a la syntaxe suivante -
INC destinationLa destination de l' opérande peut être un opérande 8 bits, 16 bits ou 32 bits.
Exemple
INC EBX ; Increments 32-bit register
INC DL ; Increments 8-bit register
INC [count] ; Increments the count variableL'instruction DEC
L'instruction DEC est utilisée pour décrémenter un opérande de un. Il fonctionne sur un seul opérande qui peut être dans un registre ou en mémoire.
Syntaxe
L'instruction DEC a la syntaxe suivante -
DEC destinationLa destination de l' opérande peut être un opérande 8 bits, 16 bits ou 32 bits.
Exemple
segment .data
count dw 0
value db 15
segment .text
inc [count]
dec [value]
mov ebx, count
inc word [ebx]
mov esi, value
dec byte [esi]Les instructions ADD et SUB
Les instructions ADD et SUB sont utilisées pour effectuer une simple addition / soustraction de données binaires en octets, en mot et en double mot, c'est-à-dire pour ajouter ou soustraire des opérandes de 8 bits, 16 bits ou 32 bits, respectivement.
Syntaxe
Les instructions ADD et SUB ont la syntaxe suivante -
ADD/SUB destination, sourceL'instruction ADD / SUB peut avoir lieu entre -
- Inscrivez-vous pour vous inscrire
- Mémoire à enregistrer
- Enregistrez-vous en mémoire
- S'inscrire aux données constantes
- Mémoire aux données constantes
Cependant, comme les autres instructions, les opérations de mémoire à mémoire ne sont pas possibles à l'aide des instructions ADD / SUB. Une opération ADD ou SUB définit ou efface les indicateurs de dépassement de capacité et de report.
Exemple
L'exemple suivant demandera deux chiffres à l'utilisateur, stockera les chiffres dans le registre EAX et EBX, respectivement, ajoutera les valeurs, stockera le résultat dans un emplacement de mémoire « res » et affichera finalement le résultat.
SYS_EXIT equ 1
SYS_READ equ 3
SYS_WRITE equ 4
STDIN equ 0
STDOUT equ 1
segment .data
msg1 db "Enter a digit ", 0xA,0xD
len1 equ $- msg1 msg2 db "Please enter a second digit", 0xA,0xD len2 equ $- msg2
msg3 db "The sum is: "
len3 equ $- msg3
segment .bss
num1 resb 2
num2 resb 2
res resb 1
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg1
mov edx, len1
int 0x80
mov eax, SYS_READ
mov ebx, STDIN
mov ecx, num1
mov edx, 2
int 0x80
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg2
mov edx, len2
int 0x80
mov eax, SYS_READ
mov ebx, STDIN
mov ecx, num2
mov edx, 2
int 0x80
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg3
mov edx, len3
int 0x80
; moving the first number to eax register and second number to ebx
; and subtracting ascii '0' to convert it into a decimal number
mov eax, [num1]
sub eax, '0'
mov ebx, [num2]
sub ebx, '0'
; add eax and ebx
add eax, ebx
; add '0' to to convert the sum from decimal to ASCII
add eax, '0'
; storing the sum in memory location res
mov [res], eax
; print the sum
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, res
mov edx, 1
int 0x80
exit:
mov eax, SYS_EXIT
xor ebx, ebx
int 0x80Lorsque le code ci-dessus est compilé et exécuté, il produit le résultat suivant -
Enter a digit:
3
Please enter a second digit:
4
The sum is:
7The program with hardcoded variables −
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov eax,'3'
sub eax, '0'
mov ebx, '4'
sub ebx, '0'
add eax, ebx
add eax, '0'
mov [sum], eax
mov ecx,msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx,sum
mov edx, 1
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db "The sum is:", 0xA,0xD
len equ $ - msg
segment .bss
sum resb 1Lorsque le code ci-dessus est compilé et exécuté, il produit le résultat suivant -
The sum is:
7L'instruction MUL / IMUL
Il existe deux instructions pour multiplier les données binaires. L'instruction MUL (Multiply) gère les données non signées et IMUL (Integer Multiply) gère les données signées. Les deux instructions affectent l'indicateur Carry et Overflow.
Syntaxe
La syntaxe des instructions MUL / IMUL est la suivante -
MUL/IMUL multiplierLe multiplicande dans les deux cas sera dans un accumulateur, en fonction de la taille du multiplicande et du multiplicateur et le produit généré est également stocké dans deux registres en fonction de la taille des opérandes. La section suivante explique les instructions MUL avec trois cas différents -
| Sr.No. | Scénarios |
|---|---|
| 1 | When two bytes are multiplied − Le multiplicande est dans le registre AL et le multiplicateur est un octet dans la mémoire ou dans un autre registre. Le produit est en AX. Les 8 bits de poids fort du produit sont stockés dans AH et les 8 bits de poids faible sont stockés dans AL.

|
| 2 | When two one-word values are multiplied − Le multiplicande doit être dans le registre AX et le multiplicateur est un mot en mémoire ou un autre registre. Par exemple, pour une instruction comme MUL DX, vous devez stocker le multiplicateur dans DX et le multiplicande dans AX. Le produit résultant est un double mot, qui aura besoin de deux registres. La partie d'ordre supérieur (la plus à gauche) est stockée dans DX et la partie d'ordre inférieur (la plus à droite) est stockée dans AX.

|
| 3 | When two doubleword values are multiplied − Lorsque deux valeurs de mot double sont multipliées, le multiplicande doit être en EAX et le multiplicateur est une valeur de mot double stockée en mémoire ou dans un autre registre. Le produit généré est stocké dans les registres EDX: EAX, c'est-à-dire que les 32 bits de poids fort sont stockés dans le registre EDX et les 32 bits de poids faible sont stockés dans le registre EAX.

|
Exemple
MOV AL, 10
MOV DL, 25
MUL DL
...
MOV DL, 0FFH ; DL= -1
MOV AL, 0BEH ; AL = -66
IMUL DLExemple
L'exemple suivant multiplie 3 par 2 et affiche le résultat -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov al,'3'
sub al, '0'
mov bl, '2'
sub bl, '0'
mul bl
add al, '0'
mov [res], al
mov ecx,msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx,res
mov edx, 1
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db "The result is:", 0xA,0xD
len equ $- msg
segment .bss
res resb 1Lorsque le code ci-dessus est compilé et exécuté, il produit le résultat suivant -
The result is:
6Les instructions DIV / IDIV
L'opération de division génère deux éléments - un quotient et un remainder. En cas de multiplication, le débordement ne se produit pas car des registres à double longueur sont utilisés pour conserver le produit. Cependant, en cas de division, un débordement peut se produire. Le processeur génère une interruption en cas de dépassement de capacité.
L'instruction DIV (Divide) est utilisée pour les données non signées et l'IDIV (Integer Divide) est utilisée pour les données signées.
Syntaxe
Le format de l'instruction DIV / IDIV -
DIV/IDIV divisorLe dividende est dans un accumulateur. Les deux instructions peuvent fonctionner avec des opérandes 8 bits, 16 bits ou 32 bits. L'opération affecte les six indicateurs d'état. La section suivante explique trois cas de division avec une taille d'opérande différente -
| Sr.No. | Scénarios |
|---|---|
| 1 | When the divisor is 1 byte − Le dividende est supposé être dans le registre AX (16 bits). Après la division, le quotient va au registre AL et le reste va au registre AH.

|
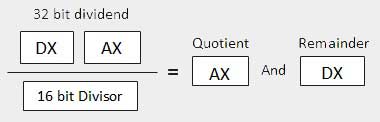
| 2 | When the divisor is 1 word − Le dividende est supposé avoir une longueur de 32 bits et dans les registres DX: AX. Les 16 bits de poids fort sont en DX et les 16 bits de poids faible sont en AX. Après la division, le quotient 16 bits va au registre AX et le reste 16 bits va au registre DX.
|
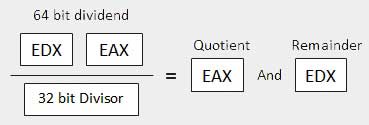
| 3 | When the divisor is doubleword − Le dividende est supposé avoir une longueur de 64 bits et dans les registres EDX: EAX. Les 32 bits de poids fort sont en EDX et les 32 bits de poids faible sont en EAX. Après la division, le quotient 32 bits va au registre EAX et le reste 32 bits va au registre EDX.
|
Exemple
L'exemple suivant divise 8 par 2. Le dividend 8 est stocké dans le 16-bit AX register et le divisor 2 est stocké dans le 8-bit BL register.
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov ax,'8'
sub ax, '0'
mov bl, '2'
sub bl, '0'
div bl
add ax, '0'
mov [res], ax
mov ecx,msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx,res
mov edx, 1
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db "The result is:", 0xA,0xD
len equ $- msg
segment .bss
res resb 1Lorsque le code ci-dessus est compilé et exécuté, il produit le résultat suivant -
The result is:
4Le jeu d'instructions du processeur fournit les instructions de logique booléenne AND, OR, XOR, TEST et NOT, qui teste, définit et efface les bits en fonction des besoins du programme.
Le format de ces instructions -
| Sr.No. | Instruction | Format |
|---|---|---|
| 1 | ET | ET opérande1, opérande2 |
| 2 | OU | OU opérande1, opérande2 |
| 3 | XOR | Opérande XOR1, opérande2 |
| 4 | TESTER | TEST opérande1, opérande2 |
| 5 | NE PAS | NOT opérande1 |
Le premier opérande dans tous les cas peut être soit en registre, soit en mémoire. Le deuxième opérande peut être soit dans le registre / mémoire, soit dans une valeur immédiate (constante). Cependant, les opérations de mémoire à mémoire ne sont pas possibles. Ces instructions comparent ou correspondent aux bits des opérandes et définissent les indicateurs CF, OF, PF, SF et ZF.
L'instruction AND
L'instruction AND est utilisée pour prendre en charge les expressions logiques en exécutant une opération AND au niveau du bit. L'opération AND au niveau du bit renvoie 1, si les bits correspondants des deux opérandes sont 1, sinon elle renvoie 0. Par exemple -
Operand1: 0101
Operand2: 0011
----------------------------
After AND -> Operand1: 0001L'opération ET peut être utilisée pour effacer un ou plusieurs bits. Par exemple, disons que le registre BL contient 0011 1010. Si vous devez effacer les bits de poids fort à zéro, vous ET avec 0FH.
AND BL, 0FH ; This sets BL to 0000 1010Prenons un autre exemple. Si vous voulez vérifier si un nombre donné est pair ou impair, un test simple serait de vérifier le bit le moins significatif du nombre. Si c'est 1, le nombre est impair, sinon le nombre est pair.
En supposant que le nombre est dans le registre AL, nous pouvons écrire -
AND AL, 01H ; ANDing with 0000 0001
JZ EVEN_NUMBERLe programme suivant illustre cela -
Exemple
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov ax, 8h ;getting 8 in the ax
and ax, 1 ;and ax with 1
jz evnn
mov eax, 4 ;system call number (sys_write)
mov ebx, 1 ;file descriptor (stdout)
mov ecx, odd_msg ;message to write
mov edx, len2 ;length of message
int 0x80 ;call kernel
jmp outprog
evnn:
mov ah, 09h
mov eax, 4 ;system call number (sys_write)
mov ebx, 1 ;file descriptor (stdout)
mov ecx, even_msg ;message to write
mov edx, len1 ;length of message
int 0x80 ;call kernel
outprog:
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
even_msg db 'Even Number!' ;message showing even number
len1 equ $ - even_msg odd_msg db 'Odd Number!' ;message showing odd number len2 equ $ - odd_msgLorsque le code ci-dessus est compilé et exécuté, il produit le résultat suivant -
Even Number!Changez la valeur dans le registre de la hache avec un chiffre impair, comme -
mov ax, 9h ; getting 9 in the axLe programme afficherait:
Odd Number!De même, pour effacer tout le registre, vous pouvez ET avec 00H.
L'instruction OR
L'instruction OR est utilisée pour prendre en charge l'expression logique en exécutant une opération OR au niveau du bit. L'opérateur OR au niveau du bit renvoie 1, si les bits correspondants de l'un ou des deux opérandes sont un. Il renvoie 0, si les deux bits sont nuls.
Par exemple,
Operand1: 0101
Operand2: 0011
----------------------------
After OR -> Operand1: 0111L'opération OR peut être utilisée pour définir un ou plusieurs bits. Par exemple, supposons que le registre AL contient 0011 1010, vous devez définir les quatre bits de poids faible, vous pouvez OU avec une valeur 0000 1111, c'est-à-dire FH.
OR BL, 0FH ; This sets BL to 0011 1111Exemple
L'exemple suivant illustre l'instruction OR. Stockons respectivement la valeur 5 et 3 dans les registres AL et BL, puis l'instruction,
OR AL, BLdevrait stocker 7 dans le registre AL -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov al, 5 ;getting 5 in the al
mov bl, 3 ;getting 3 in the bl
or al, bl ;or al and bl registers, result should be 7
add al, byte '0' ;converting decimal to ascii
mov [result], al
mov eax, 4
mov ebx, 1
mov ecx, result
mov edx, 1
int 0x80
outprog:
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .bss
result resb 1Lorsque le code ci-dessus est compilé et exécuté, il produit le résultat suivant -
7L'instruction XOR
L'instruction XOR implémente l'opération XOR au niveau du bit. L'opération XOR met le bit résultant à 1, si et seulement si les bits des opérandes sont différents. Si les bits des opérandes sont identiques (tous les deux 0 ou les deux 1), le bit résultant est remis à 0.
Par exemple,
Operand1: 0101
Operand2: 0011
----------------------------
After XOR -> Operand1: 0110XORing un opérande avec lui-même change l'opérande en 0. Ceci est utilisé pour effacer un registre.
XOR EAX, EAXL'instruction TEST
L'instruction TEST fonctionne de la même manière que l'opération AND, mais contrairement à l'instruction AND, elle ne change pas le premier opérande. Donc, si nous avons besoin de vérifier si un nombre dans un registre est pair ou impair, nous pouvons également le faire en utilisant l'instruction TEST sans changer le nombre d'origine.
TEST AL, 01H
JZ EVEN_NUMBERL'instruction NOT
L'instruction NOT implémente l'opération NOT au niveau du bit. L'opération NOT inverse les bits d'un opérande. L'opérande peut être dans un registre ou dans la mémoire.
Par exemple,
Operand1: 0101 0011
After NOT -> Operand1: 1010 1100L'exécution conditionnelle en langage assembleur est réalisée par plusieurs instructions de bouclage et de branchement. Ces instructions peuvent modifier le flux de contrôle dans un programme. L'exécution conditionnelle est observée dans deux scénarios -
| Sr.No. | Instructions conditionnelles |
|---|---|
| 1 | Unconditional jump Ceci est effectué par l'instruction JMP. L'exécution conditionnelle implique souvent un transfert de contrôle à l'adresse d'une instruction qui ne suit pas l'instruction en cours d'exécution. Le transfert de contrôle peut être vers l'avant, pour exécuter un nouvel ensemble d'instructions ou vers l'arrière, pour réexécuter les mêmes étapes. |
| 2 | Conditional jump Ceci est effectué par un ensemble d'instructions de saut j <condition> en fonction de la condition. Les instructions conditionnelles transfèrent le contrôle en interrompant le flux séquentiel et elles le font en modifiant la valeur de décalage dans IP. |
Laissez-nous discuter de l'instruction CMP avant de discuter des instructions conditionnelles.
Instruction CMP
L'instruction CMP compare deux opérandes. Il est généralement utilisé dans l'exécution conditionnelle. Cette instruction soustrait essentiellement un opérande de l'autre pour comparer si les opérandes sont égaux ou non. Il ne perturbe pas les opérandes de destination ou de source. Il est utilisé avec l'instruction de saut conditionnel pour la prise de décision.
Syntaxe
CMP destination, sourceCMP compare deux champs de données numériques. L'opérande de destination peut être soit dans le registre, soit en mémoire. L'opérande source peut être une donnée constante (immédiate), un registre ou une mémoire.
Exemple
CMP DX, 00 ; Compare the DX value with zero
JE L7 ; If yes, then jump to label L7
.
.
L7: ...CMP est souvent utilisé pour comparer si une valeur de compteur a atteint le nombre de fois qu'une boucle doit être exécutée. Considérez la condition typique suivante -
INC EDX
CMP EDX, 10 ; Compares whether the counter has reached 10
JLE LP1 ; If it is less than or equal to 10, then jump to LP1Saut inconditionnel
Comme mentionné précédemment, ceci est effectué par l'instruction JMP. L'exécution conditionnelle implique souvent un transfert de contrôle à l'adresse d'une instruction qui ne suit pas l'instruction en cours d'exécution. Le transfert de contrôle peut être vers l'avant, pour exécuter un nouvel ensemble d'instructions ou vers l'arrière, pour réexécuter les mêmes étapes.
Syntaxe
L'instruction JMP fournit un nom d'étiquette où le flux de contrôle est transféré immédiatement. La syntaxe de l'instruction JMP est -
JMP labelExemple
L'extrait de code suivant illustre l'instruction JMP -
MOV AX, 00 ; Initializing AX to 0
MOV BX, 00 ; Initializing BX to 0
MOV CX, 01 ; Initializing CX to 1
L20:
ADD AX, 01 ; Increment AX
ADD BX, AX ; Add AX to BX
SHL CX, 1 ; shift left CX, this in turn doubles the CX value
JMP L20 ; repeats the statementsSaut conditionnel
Si une condition spécifiée est satisfaite dans le saut conditionnel, le flux de contrôle est transféré vers une instruction cible. Il existe de nombreuses instructions de saut conditionnel en fonction de la condition et des données.
Voici les instructions de saut conditionnel utilisées sur les données signées utilisées pour les opérations arithmétiques -
| Instruction | La description | Drapeaux testés |
|---|---|---|
| JE / JZ | Jump Equal ou Jump Zero | ZF |
| JNE / JNZ | Sauter pas égal ou sauter pas zéro | ZF |
| JG / JNLE | Sauter plus grand ou sauter pas moins / égal | DE, SF, ZF |
| JGE / JNL | Sauter plus grand / égal ou sauter pas moins | DE, SF |
| JL / JNGE | Sauter moins ou sauter pas plus grand / égal | DE, SF |
| JLE / JNG | Sauter moins / égal ou sauter pas plus grand | DE, SF, ZF |
Voici les instructions de saut conditionnel utilisées sur les données non signées utilisées pour les opérations logiques -
| Instruction | La description | Drapeaux testés |
|---|---|---|
| JE / JZ | Jump Equal ou Jump Zero | ZF |
| JNE / JNZ | Sauter pas égal ou sauter pas zéro | ZF |
| JA / JNBE | Sauter au-dessus ou sauter pas en dessous / égal | CF, ZF |
| JAE / JNB | Sauter au-dessus / égal ou sauter pas en dessous | CF |
| JB / JNAE | Sauter en dessous ou sauter pas au-dessus / égal | CF |
| JBE / JNA | Sauter en dessous / égal ou sauter pas au-dessus | AF, CF |
Les instructions de saut conditionnel suivantes ont des utilisations spéciales et vérifient la valeur des indicateurs -
| Instruction | La description | Drapeaux testés |
|---|---|---|
| JXCZ | Sauter si CX est zéro | aucun |
| JC | Sauter si porter | CF |
| JNC | Sauter si non | CF |
| JO | Sauter en cas de débordement | DE |
| JNO | Sauter si aucun débordement | DE |
| JP / JPE | Parité de saut ou parité de saut même | PF |
| JNP / JPO | Jump No Parity ou Jump Parity Odd | PF |
| JS | Saut de signe (valeur négative) | SF |
| JNS | Jump No Sign (valeur positive) | SF |
La syntaxe de l'ensemble d'instructions J <condition> -
Exemple,
CMP AL, BL
JE EQUAL
CMP AL, BH
JE EQUAL
CMP AL, CL
JE EQUAL
NON_EQUAL: ...
EQUAL: ...Exemple
Le programme suivant affiche la plus grande des trois variables. Les variables sont des variables à deux chiffres. Les trois variables num1, num2 et num3 ont respectivement les valeurs 47, 22 et 31 -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov ecx, [num1]
cmp ecx, [num2]
jg check_third_num
mov ecx, [num2]
check_third_num:
cmp ecx, [num3]
jg _exit
mov ecx, [num3]
_exit:
mov [largest], ecx
mov ecx,msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx,largest
mov edx, 2
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax, 1
int 80h
section .data
msg db "The largest digit is: ", 0xA,0xD
len equ $- msg
num1 dd '47'
num2 dd '22'
num3 dd '31'
segment .bss
largest resb 2Lorsque le code ci-dessus est compilé et exécuté, il produit le résultat suivant -
The largest digit is:
47L'instruction JMP peut être utilisée pour implémenter des boucles. Par exemple, l'extrait de code suivant peut être utilisé pour exécuter le corps de la boucle 10 fois.
MOV CL, 10
L1:
<LOOP-BODY>
DEC CL
JNZ L1Le jeu d'instructions du processeur, cependant, comprend un groupe d'instructions de boucle pour mettre en œuvre l'itération. L'instruction LOOP de base a la syntaxe suivante -
LOOP labelOù, étiquette est l'étiquette cible qui identifie l'instruction cible comme dans les instructions de saut. L'instruction LOOP suppose que leECX register contains the loop count. Lorsque l'instruction de boucle est exécutée, le registre ECX est décrémenté et la commande saute sur l'étiquette cible, jusqu'à ce que la valeur du registre ECX, c'est-à-dire que le compteur atteigne la valeur zéro.
L'extrait de code ci-dessus peut être écrit comme suit:
mov ECX,10
l1:
<loop body>
loop l1Exemple
Le programme suivant imprime le nombre 1 à 9 sur l'écran -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov ecx,10
mov eax, '1'
l1:
mov [num], eax
mov eax, 4
mov ebx, 1
push ecx
mov ecx, num
mov edx, 1
int 0x80
mov eax, [num]
sub eax, '0'
inc eax
add eax, '0'
pop ecx
loop l1
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .bss
num resb 1Lorsque le code ci-dessus est compilé et exécuté, il produit le résultat suivant -
123456789:Les données numériques sont généralement représentées en système binaire. Les instructions arithmétiques fonctionnent sur des données binaires. Lorsque les nombres sont affichés à l'écran ou saisis à partir du clavier, ils sont sous forme ASCII.
Jusqu'à présent, nous avons converti ces données d'entrée sous forme ASCII en binaire pour les calculs arithmétiques et reconverti le résultat en binaire. Le code suivant montre ceci -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov eax,'3'
sub eax, '0'
mov ebx, '4'
sub ebx, '0'
add eax, ebx
add eax, '0'
mov [sum], eax
mov ecx,msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx,sum
mov edx, 1
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db "The sum is:", 0xA,0xD
len equ $ - msg
segment .bss
sum resb 1Lorsque le code ci-dessus est compilé et exécuté, il produit le résultat suivant -
The sum is:
7De telles conversions ont cependant une surcharge et la programmation en langage assembleur permet de traiter les nombres de manière plus efficace, sous forme binaire. Les nombres décimaux peuvent être représentés sous deux formes -
- Forme ASCII
- BCD ou forme décimale codée binaire
Représentation ASCII
Dans la représentation ASCII, les nombres décimaux sont stockés sous forme de chaîne de caractères ASCII. Par exemple, la valeur décimale 1234 est stockée sous la forme -
31 32 33 34HOù, 31H est la valeur ASCII pour 1, 32H est la valeur ASCII pour 2, et ainsi de suite. Il existe quatre instructions pour traiter les nombres en représentation ASCII -
AAA - Ajustement ASCII après addition
AAS - Ajustement ASCII après soustraction
AAM - Ajustement ASCII après multiplication
AAD - Ajustement ASCII avant la division
Ces instructions ne prennent aucun opérande et supposent que l'opérande requis se trouve dans le registre AL.
L'exemple suivant utilise l'instruction AAS pour démontrer le concept -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
sub ah, ah
mov al, '9'
sub al, '3'
aas
or al, 30h
mov [res], ax
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov edx,1 ;message length
mov ecx,res ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db 'The Result is:',0xa
len equ $ - msg
section .bss
res resb 1Lorsque le code ci-dessus est compilé et exécuté, il produit le résultat suivant -
The Result is:
6Représentation BCD
Il existe deux types de représentation BCD -
- Représentation BCD déballée
- Représentation BCD emballée
Dans la représentation BCD décompressée, chaque octet stocke l'équivalent binaire d'un chiffre décimal. Par exemple, le nombre 1234 est stocké sous la forme -
01 02 03 04HIl y a deux instructions pour traiter ces nombres -
AAM - Ajustement ASCII après multiplication
AAD - Ajustement ASCII avant la division
Les quatre instructions de réglage ASCII, AAA, AAS, AAM et AAD, peuvent également être utilisées avec une représentation BCD décompressée. Dans la représentation BCD compressée, chaque chiffre est stocké en utilisant quatre bits. Deux chiffres décimaux sont regroupés dans un octet. Par exemple, le nombre 1234 est stocké sous la forme -
12 34HIl y a deux instructions pour traiter ces nombres -
DAA - Ajustement décimal après addition
DAS - Réglage décimal après soustraction
Il n'y a pas de support pour la multiplication et la division dans la représentation BCD compressée.
Exemple
Le programme suivant additionne deux nombres décimaux à 5 chiffres et affiche la somme. Il utilise les concepts ci-dessus -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov esi, 4 ;pointing to the rightmost digit
mov ecx, 5 ;num of digits
clc
add_loop:
mov al, [num1 + esi]
adc al, [num2 + esi]
aaa
pushf
or al, 30h
popf
mov [sum + esi], al
dec esi
loop add_loop
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov edx,5 ;message length
mov ecx,sum ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db 'The Sum is:',0xa
len equ $ - msg
num1 db '12345'
num2 db '23456'
sum db ' 'Lorsque le code ci-dessus est compilé et exécuté, il produit le résultat suivant -
The Sum is:
35801Nous avons déjà utilisé des chaînes de longueur variable dans nos exemples précédents. Les chaînes de longueur variable peuvent comporter autant de caractères que nécessaire. Généralement, nous spécifions la longueur de la chaîne de l'une des deux manières -
- Stockage explicite de la longueur de la chaîne
- Utiliser un personnage sentinelle
Nous pouvons stocker la longueur de la chaîne de manière explicite en utilisant le symbole de compteur $ location qui représente la valeur actuelle du compteur de localisation. Dans l'exemple suivant -
msg db 'Hello, world!',0xa ;our dear string
len equ $ - msg ;length of our dear string$ pointe vers l'octet après le dernier caractère de la variable chaîne msg . Par conséquent,$-msgdonne la longueur de la chaîne. On peut aussi écrire
msg db 'Hello, world!',0xa ;our dear string
len equ 13 ;length of our dear stringVous pouvez également stocker des chaînes avec un caractère sentinelle de fin pour délimiter une chaîne au lieu de stocker explicitement la longueur de la chaîne. Le caractère sentinelle doit être un caractère spécial qui n'apparaît pas dans une chaîne.
Par exemple -
message DB 'I am loving it!', 0Instructions de chaîne
Chaque instruction de chaîne peut nécessiter un opérande source, un opérande de destination ou les deux. Pour les segments 32 bits, les instructions de chaîne utilisent les registres ESI et EDI pour pointer respectivement vers les opérandes source et destination.
Pour les segments de 16 bits, cependant, les registres SI et DI sont utilisés pour pointer respectivement vers la source et la destination.
Il existe cinq instructions de base pour le traitement des chaînes. Ils sont -
MOVS - Cette instruction déplace 1 octet, mot ou double mot de données d'un emplacement de mémoire à un autre.
LODS- Cette instruction se charge depuis la mémoire. Si l'opérande est d'un octet, il est chargé dans le registre AL, si l'opérande est d'un mot, il est chargé dans le registre AX et un double mot est chargé dans le registre EAX.
STOS - Cette instruction stocke les données du registre (AL, AX ou EAX) dans la mémoire.
CMPS- Cette instruction compare deux éléments de données en mémoire. Les données peuvent être d'une taille d'octet, d'un mot ou d'un double mot.
SCAS - Cette instruction compare le contenu d'un registre (AL, AX ou EAX) avec le contenu d'un élément en mémoire.
Chacune des instructions ci-dessus a une version octet, mot et double mot, et les instructions de chaîne peuvent être répétées en utilisant un préfixe de répétition.
Ces instructions utilisent la paire de registres ES: DI et DS: SI, où les registres DI et SI contiennent des adresses de décalage valides qui se réfèrent aux octets stockés en mémoire. SI est normalement associé à DS (segment de données) et DI est toujours associé à ES (segment supplémentaire).
Les registres DS: SI (ou ESI) et ES: DI (ou EDI) pointent respectivement vers les opérandes source et destination. L'opérande source est supposé être à DS: SI (ou ESI) et l'opérande de destination à ES: DI (ou EDI) en mémoire.
Pour les adresses 16 bits, les registres SI et DI sont utilisés, et pour les adresses 32 bits, les registres ESI et EDI sont utilisés.
Le tableau suivant fournit différentes versions des instructions de chaîne et l'espace supposé des opérandes.
| Instruction de base | Opérandes à | Opération d'octet | Opération Word | Opération de double mot |
|---|---|---|---|---|
| MOVS | ES: DI, DS: SI | MOVSB | MOVSW | MOVSD |
| LODS | AX, DS: SI | LODSB | LODSW | LODSD |
| STOS | ES: DI, AX | STOSB | STOSW | STOSD |
| CMPS | DS: SI, ES: DI | CMPSB | CMPSW | CMPSD |
| SCAS | ES: DI, AX | SCASB | SCASW | SCASD |
Préfixes de répétition
Le préfixe REP, lorsqu'il est défini avant une instruction de chaîne, par exemple - REP MOVSB, provoque la répétition de l'instruction basée sur un compteur placé dans le registre CX. REP exécute l'instruction, diminue CX de 1 et vérifie si CX est égal à zéro. Il répète le traitement des instructions jusqu'à ce que CX soit nul.
Le drapeau de direction (DF) détermine la direction de l'opération.
- Utilisez CLD (Clear Direction Flag, DF = 0) pour effectuer l'opération de gauche à droite.
- Utilisez STD (Set Direction Flag, DF = 1) pour effectuer l'opération de droite à gauche.
Le préfixe REP a également les variations suivantes:
REP: C'est la répétition inconditionnelle. Il répète l'opération jusqu'à ce que CX soit nul.
REPE ou REPZ: C'est une répétition conditionnelle. Il répète l'opération tandis que l'indicateur zéro indique égal / zéro. Il s'arrête lorsque le ZF indique pas égal / zéro ou lorsque CX est nul.
REPNE ou REPNZ: C'est aussi une répétition conditionnelle. Il répète l'opération tandis que l'indicateur zéro indique pas égal / zéro. Il s'arrête lorsque le ZF indique égal / zéro ou lorsque CX est décrémenté à zéro.
Nous avons déjà expliqué que les directives de définition de données à l'assembleur sont utilisées pour allouer du stockage pour les variables. La variable peut également être initialisée avec une valeur spécifique. La valeur initialisée peut être spécifiée sous forme hexadécimale, décimale ou binaire.
Par exemple, nous pouvons définir une variable mot 'mois' de l'une des manières suivantes -
MONTHS DW 12
MONTHS DW 0CH
MONTHS DW 0110BLes directives de définition de données peuvent également être utilisées pour définir un tableau unidimensionnel. Définissons un tableau unidimensionnel de nombres.
NUMBERS DW 34, 45, 56, 67, 75, 89La définition ci-dessus déclare un tableau de six mots chacun initialisé avec les nombres 34, 45, 56, 67, 75, 89. Cela alloue 2x6 = 12 octets d'espace mémoire consécutif. L'adresse symbolique du premier nombre sera NUMBERS et celle du second nombre sera NUMBERS + 2 et ainsi de suite.
Prenons un autre exemple. Vous pouvez définir un tableau nommé inventaire de taille 8 et initialiser toutes les valeurs avec zéro, comme -
INVENTORY DW 0
DW 0
DW 0
DW 0
DW 0
DW 0
DW 0
DW 0Qui peut être abrégé en -
INVENTORY DW 0, 0 , 0 , 0 , 0 , 0 , 0 , 0La directive TIMES peut également être utilisée pour plusieurs initialisations à la même valeur. En utilisant TIMES, le tableau INVENTORY peut être défini comme:
INVENTORY TIMES 8 DW 0Exemple
L'exemple suivant illustre les concepts ci-dessus en définissant un tableau à 3 éléments x, qui stocke trois valeurs: 2, 3 et 4. Il ajoute les valeurs dans le tableau et affiche la somme 9 -
section .text
global _start ;must be declared for linker (ld)
_start:
mov eax,3 ;number bytes to be summed
mov ebx,0 ;EBX will store the sum
mov ecx, x ;ECX will point to the current element to be summed
top: add ebx, [ecx]
add ecx,1 ;move pointer to next element
dec eax ;decrement counter
jnz top ;if counter not 0, then loop again
done:
add ebx, '0'
mov [sum], ebx ;done, store result in "sum"
display:
mov edx,1 ;message length
mov ecx, sum ;message to write
mov ebx, 1 ;file descriptor (stdout)
mov eax, 4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax, 1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
global x
x:
db 2
db 4
db 3
sum:
db 0Lorsque le code ci-dessus est compilé et exécuté, il produit le résultat suivant -
9Les procédures ou sous-routines sont très importantes en langage assembleur, car les programmes en langage assembleur ont tendance à être de grande taille. Les procédures sont identifiées par un nom. Après ce nom, le corps de la procédure est décrit, ce qui effectue un travail bien défini. La fin de la procédure est indiquée par une déclaration de retour.
Syntaxe
Voici la syntaxe pour définir une procédure -
proc_name:
procedure body
...
retLa procédure est appelée à partir d'une autre fonction à l'aide de l'instruction CALL. L'instruction CALL doit avoir le nom de la procédure appelée comme argument comme indiqué ci-dessous -
CALL proc_nameLa procédure appelée renvoie le contrôle à la procédure appelante à l'aide de l'instruction RET.
Exemple
Écrivons une procédure très simple nommée sum qui ajoute les variables stockées dans le registre ECX et EDX et renvoie la somme dans le registre EAX -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov ecx,'4'
sub ecx, '0'
mov edx, '5'
sub edx, '0'
call sum ;call sum procedure
mov [res], eax
mov ecx, msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx, res
mov edx, 1
mov ebx, 1 ;file descriptor (stdout)
mov eax, 4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
sum:
mov eax, ecx
add eax, edx
add eax, '0'
ret
section .data
msg db "The sum is:", 0xA,0xD
len equ $- msg
segment .bss
res resb 1Lorsque le code ci-dessus est compilé et exécuté, il produit le résultat suivant -
The sum is:
9Structure des données des piles
Une pile est une structure de données de type tableau dans la mémoire dans laquelle les données peuvent être stockées et supprimées d'un emplacement appelé le «sommet» de la pile. Les données qui doivent être stockées sont «poussées» dans la pile et les données à récupérer sont «extraites» de la pile. Stack est une structure de données LIFO, c'est-à-dire que les données stockées en premier sont récupérées en dernier.
Le langage d'assemblage fournit deux instructions pour les opérations de pile: PUSH et POP. Ces instructions ont des syntaxes comme -
PUSH operand
POP address/registerL'espace mémoire réservé dans le segment de pile est utilisé pour l'implémentation de la pile. Les registres SS et ESP (ou SP) sont utilisés pour l'implémentation de la pile. Le haut de la pile, qui pointe vers le dernier élément de données inséré dans la pile, est pointé par le registre SS: ESP, où le registre SS pointe vers le début du segment de pile et le SP (ou ESP) donne le décalage dans le segment de pile.
L'implémentation de la pile présente les caractéristiques suivantes -
Seulement words ou doublewords pourrait être enregistré dans la pile, pas un octet.
La pile se développe dans le sens inverse, c'est-à-dire vers l'adresse mémoire inférieure
Le haut de la pile pointe vers le dernier élément inséré dans la pile; il pointe vers l'octet inférieur du dernier mot inséré.
Comme nous l'avons vu sur le stockage des valeurs des registres dans la pile avant de les utiliser pour une certaine utilisation; cela peut être fait de la manière suivante -
; Save the AX and BX registers in the stack
PUSH AX
PUSH BX
; Use the registers for other purpose
MOV AX, VALUE1
MOV BX, VALUE2
...
MOV VALUE1, AX
MOV VALUE2, BX
; Restore the original values
POP BX
POP AXExemple
Le programme suivant affiche l'ensemble du jeu de caractères ASCII. Le programme principal appelle une procédure nommée display , qui affiche le jeu de caractères ASCII.
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
call display
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
display:
mov ecx, 256
next:
push ecx
mov eax, 4
mov ebx, 1
mov ecx, achar
mov edx, 1
int 80h
pop ecx
mov dx, [achar]
cmp byte [achar], 0dh
inc byte [achar]
loop next
ret
section .data
achar db '0'Lorsque le code ci-dessus est compilé et exécuté, il produit le résultat suivant -
0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}
...
...Une procédure récursive est une procédure qui s'appelle elle-même. Il existe deux types de récursivité: directe et indirecte. En récursivité directe, la procédure s'appelle elle-même et en récursivité indirecte, la première procédure appelle une seconde procédure, qui à son tour appelle la première procédure.
La récursivité a pu être observée dans de nombreux algorithmes mathématiques. Par exemple, considérons le cas du calcul de la factorielle d'un nombre. La factorielle d'un nombre est donnée par l'équation -
Fact (n) = n * fact (n-1) for n > 0Par exemple: factorielle de 5 est 1 x 2 x 3 x 4 x 5 = 5 x factorielle de 4 et cela peut être un bon exemple de représentation d'une procédure récursive. Chaque algorithme récursif doit avoir une condition de fin, c'est-à-dire que l'appel récursif du programme doit être arrêté lorsqu'une condition est remplie. Dans le cas de l'algorithme factoriel, la condition de fin est atteinte lorsque n vaut 0.
Le programme suivant montre comment factoriel n est implémenté en langage assembleur. Pour garder le programme simple, nous allons calculer factoriel 3.
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov bx, 3 ;for calculating factorial 3
call proc_fact
add ax, 30h
mov [fact], ax
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov edx,1 ;message length
mov ecx,fact ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
proc_fact:
cmp bl, 1
jg do_calculation
mov ax, 1
ret
do_calculation:
dec bl
call proc_fact
inc bl
mul bl ;ax = al * bl
ret
section .data
msg db 'Factorial 3 is:',0xa
len equ $ - msg
section .bss
fact resb 1Lorsque le code ci-dessus est compilé et exécuté, il produit le résultat suivant -
Factorial 3 is:
6L'écriture d'une macro est un autre moyen d'assurer une programmation modulaire en langage assembleur.
Une macro est une séquence d'instructions, assignée par un nom et pouvant être utilisée n'importe où dans le programme.
Dans NASM, les macros sont définies avec %macro et %endmacro directives.
La macro commence par la directive% macro et se termine par la directive% endmacro.
La syntaxe pour la définition de macro -
%macro macro_name number_of_params
<macro body>
%endmacroOù, number_of_params spécifie les paramètres numériques , macro_name spécifie le nom de la macro.
La macro est appelée en utilisant le nom de la macro avec les paramètres nécessaires. Lorsque vous devez utiliser une séquence d'instructions plusieurs fois dans un programme, vous pouvez placer ces instructions dans une macro et l'utiliser au lieu d'écrire les instructions tout le temps.
Par exemple, un besoin très courant pour les programmes est d'écrire une chaîne de caractères à l'écran. Pour afficher une chaîne de caractères, vous avez besoin de la séquence d'instructions suivante -
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernelDans l'exemple ci-dessus d'affichage d'une chaîne de caractères, les registres EAX, EBX, ECX et EDX ont été utilisés par l'appel de fonction INT 80H. Ainsi, chaque fois que vous devez afficher à l'écran, vous devez sauvegarder ces registres sur la pile, appeler INT 80H puis restaurer la valeur d'origine des registres de la pile. Ainsi, il peut être utile d'écrire deux macros pour enregistrer et restaurer les données.
Nous avons observé que certaines instructions comme IMUL, IDIV, INT, etc. ont besoin que certaines des informations soient stockées dans certains registres particuliers et retournent même des valeurs dans certains registres spécifiques. Si le programme utilisait déjà ces registres pour conserver des données importantes, les données existantes de ces registres doivent être sauvegardées dans la pile et restaurées après l'exécution de l'instruction.
Exemple
L'exemple suivant montre la définition et l'utilisation de macros -
; A macro with two parameters
; Implements the write system call
%macro write_string 2
mov eax, 4
mov ebx, 1
mov ecx, %1
mov edx, %2
int 80h
%endmacro
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
write_string msg1, len1
write_string msg2, len2
write_string msg3, len3
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg1 db 'Hello, programmers!',0xA,0xD
len1 equ $ - msg1 msg2 db 'Welcome to the world of,', 0xA,0xD len2 equ $- msg2
msg3 db 'Linux assembly programming! '
len3 equ $- msg3Lorsque le code ci-dessus est compilé et exécuté, il produit le résultat suivant -
Hello, programmers!
Welcome to the world of,
Linux assembly programming!Le système considère toutes les données d'entrée ou de sortie comme un flux d'octets. Il existe trois flux de fichiers standard -
- Entrée standard (stdin),
- Sortie standard (stdout), et
- Erreur standard (stderr).
Descripteur de fichier
UNE file descriptorest un entier de 16 bits attribué à un fichier en tant qu'ID de fichier. Lorsqu'un nouveau fichier est créé ou qu'un fichier existant est ouvert, le descripteur de fichier est utilisé pour accéder au fichier.
Descripteur de fichier des flux de fichiers standard - stdin, stdout et stderr sont 0, 1 et 2, respectivement.
Pointeur de fichier
UNE file pointerspécifie l'emplacement d'une opération de lecture / écriture ultérieure dans le fichier en octets. Chaque fichier est considéré comme une séquence d'octets. Chaque fichier ouvert est associé à un pointeur de fichier qui spécifie un décalage en octets, par rapport au début du fichier. Lorsqu'un fichier est ouvert, le pointeur de fichier est mis à zéro.
Appels système de gestion de fichiers
Le tableau suivant décrit brièvement les appels système liés à la gestion des fichiers -
| % eax | Nom | % ebx | % ecx | % edx |
|---|---|---|---|---|
| 2 | sys_fork | struct pt_regs | - | - |
| 3 | sys_read | int non signé | char * | size_t |
| 4 | sys_write | int non signé | const char * | size_t |
| 5 | sys_open | const char * | int | int |
| 6 | sys_close | int non signé | - | - |
| 8 | sys_creat | const char * | int | - |
| 19 | sys_lseek | int non signé | off_t | int non signé |
Les étapes requises pour utiliser les appels système sont les mêmes, comme nous l'avons vu précédemment -
- Mettez le numéro d'appel système dans le registre EAX.
- Stockez les arguments de l'appel système dans les registres EBX, ECX, etc.
- Appelez l'interruption correspondante (80h).
- Le résultat est généralement renvoyé dans le registre EAX.
Créer et ouvrir un fichier
Pour créer et ouvrir un fichier, effectuez les tâches suivantes -
- Mettez l'appel système sys_creat () numéro 8, dans le registre EAX.
- Mettez le nom de fichier dans le registre EBX.
- Mettez les autorisations de fichier dans le registre ECX.
L'appel système renvoie le descripteur de fichier du fichier créé dans le registre EAX, en cas d'erreur, le code d'erreur se trouve dans le registre EAX.
Ouverture d'un fichier existant
Pour ouvrir un fichier existant, effectuez les tâches suivantes -
- Mettez l'appel système sys_open () numéro 5, dans le registre EAX.
- Mettez le nom de fichier dans le registre EBX.
- Mettez le mode d'accès aux fichiers dans le registre ECX.
- Mettez les autorisations de fichier dans le registre EDX.
L'appel système renvoie le descripteur de fichier du fichier créé dans le registre EAX, en cas d'erreur, le code d'erreur se trouve dans le registre EAX.
Parmi les modes d'accès aux fichiers, les plus couramment utilisés sont: lecture seule (0), écriture seule (1) et lecture-écriture (2).
Lecture à partir d'un fichier
Pour lire à partir d'un fichier, effectuez les tâches suivantes -
Mettez l'appel système sys_read () numéro 3, dans le registre EAX.
Mettez le descripteur de fichier dans le registre EBX.
Placez le pointeur sur le tampon d'entrée dans le registre ECX.
Mettez la taille du tampon, c'est-à-dire le nombre d'octets à lire, dans le registre EDX.
L'appel système renvoie le nombre d'octets lus dans le registre EAX, en cas d'erreur, le code d'erreur se trouve dans le registre EAX.
Ecrire dans un fichier
Pour écrire dans un fichier, effectuez les tâches suivantes -
Mettez l'appel système sys_write () numéro 4, dans le registre EAX.
Mettez le descripteur de fichier dans le registre EBX.
Placez le pointeur sur le tampon de sortie dans le registre ECX.
Mettez la taille du tampon, c'est-à-dire le nombre d'octets à écrire, dans le registre EDX.
L'appel système renvoie le nombre réel d'octets écrits dans le registre EAX, en cas d'erreur, le code d'erreur se trouve dans le registre EAX.
Fermer un fichier
Pour fermer un fichier, effectuez les tâches suivantes -
- Mettez l'appel système sys_close () numéro 6, dans le registre EAX.
- Mettez le descripteur de fichier dans le registre EBX.
L'appel système renvoie, en cas d'erreur, le code d'erreur dans le registre EAX.
Mettre à jour un fichier
Pour mettre à jour un fichier, effectuez les tâches suivantes -
- Mettez l'appel système sys_lseek () numéro 19, dans le registre EAX.
- Mettez le descripteur de fichier dans le registre EBX.
- Mettez la valeur de décalage dans le registre ECX.
- Mettez la position de référence pour le décalage dans le registre EDX.
La position de référence pourrait être:
- Début de fichier - valeur 0
- Position actuelle - valeur 1
- Fin de fichier - valeur 2
L'appel système renvoie, en cas d'erreur, le code d'erreur dans le registre EAX.
Exemple
Le programme suivant crée et ouvre un fichier nommé myfile.txt et écrit un texte «Welcome to Tutorials Point» dans ce fichier. Ensuite, le programme lit le fichier et stocke les données dans un tampon nommé info . Enfin, il affiche le texte tel qu'il est stocké dans les informations .
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
;create the file
mov eax, 8
mov ebx, file_name
mov ecx, 0777 ;read, write and execute by all
int 0x80 ;call kernel
mov [fd_out], eax
; write into the file
mov edx,len ;number of bytes
mov ecx, msg ;message to write
mov ebx, [fd_out] ;file descriptor
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
; close the file
mov eax, 6
mov ebx, [fd_out]
; write the message indicating end of file write
mov eax, 4
mov ebx, 1
mov ecx, msg_done
mov edx, len_done
int 0x80
;open the file for reading
mov eax, 5
mov ebx, file_name
mov ecx, 0 ;for read only access
mov edx, 0777 ;read, write and execute by all
int 0x80
mov [fd_in], eax
;read from file
mov eax, 3
mov ebx, [fd_in]
mov ecx, info
mov edx, 26
int 0x80
; close the file
mov eax, 6
mov ebx, [fd_in]
int 0x80
; print the info
mov eax, 4
mov ebx, 1
mov ecx, info
mov edx, 26
int 0x80
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
file_name db 'myfile.txt'
msg db 'Welcome to Tutorials Point'
len equ $-msg
msg_done db 'Written to file', 0xa
len_done equ $-msg_done
section .bss
fd_out resb 1
fd_in resb 1
info resb 26Lorsque le code ci-dessus est compilé et exécuté, il produit le résultat suivant -
Written to file
Welcome to Tutorials Pointle sys_brk()l'appel système est fourni par le noyau, pour allouer de la mémoire sans avoir besoin de la déplacer plus tard. Cet appel alloue de la mémoire juste derrière l'image de l'application dans la mémoire. Cette fonction système vous permet de définir l'adresse disponible la plus élevée dans la section des données.
Cet appel système prend un paramètre, qui est l'adresse mémoire la plus élevée à définir. Cette valeur est stockée dans le registre EBX.
En cas d'erreur, sys_brk () renvoie -1 ou renvoie le code d'erreur négatif lui-même. L'exemple suivant illustre l'allocation de mémoire dynamique.
Exemple
Le programme suivant alloue 16 ko de mémoire en utilisant l'appel système sys_brk () -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov eax, 45 ;sys_brk
xor ebx, ebx
int 80h
add eax, 16384 ;number of bytes to be reserved
mov ebx, eax
mov eax, 45 ;sys_brk
int 80h
cmp eax, 0
jl exit ;exit, if error
mov edi, eax ;EDI = highest available address
sub edi, 4 ;pointing to the last DWORD
mov ecx, 4096 ;number of DWORDs allocated
xor eax, eax ;clear eax
std ;backward
rep stosd ;repete for entire allocated area
cld ;put DF flag to normal state
mov eax, 4
mov ebx, 1
mov ecx, msg
mov edx, len
int 80h ;print a message
exit:
mov eax, 1
xor ebx, ebx
int 80h
section .data
msg db "Allocated 16 kb of memory!", 10
len equ $ - msgLorsque le code ci-dessus est compilé et exécuté, il produit le résultat suivant -
Allocated 16 kb of memory!