AVRO - Guide rapide
Pour transférer des données sur un réseau ou pour son stockage persistant, vous devez sérialiser les données. Avant leserialization APIs fourni par Java et Hadoop, nous avons un utilitaire spécial, appelé Avro, une technique de sérialisation basée sur des schémas.
Ce didacticiel vous apprend à sérialiser et désérialiser les données à l'aide d'Avro. Avro fournit des bibliothèques pour divers langages de programmation. Dans ce didacticiel, nous présentons les exemples utilisant la bibliothèque Java.
Qu'est-ce qu'Avro?
Apache Avro est un système de sérialisation de données indépendant du langage. Il a été développé par Doug Cutting, le père de Hadoop. Étant donné que les classes inscriptibles Hadoop manquent de portabilité de langue, Avro devient très utile, car il traite des formats de données pouvant être traités par plusieurs langues. Avro est un outil privilégié pour sérialiser les données dans Hadoop.
Avro a un système basé sur des schémas. Un schéma indépendant du langage est associé à ses opérations de lecture et d'écriture. Avro sérialise les données qui ont un schéma intégré. Avro sérialise les données dans un format binaire compact, qui peut être désérialisé par n'importe quelle application.
Avro utilise le format JSON pour déclarer les structures de données. Actuellement, il prend en charge des langages tels que Java, C, C ++, C #, Python et Ruby.
Schémas Avro
Avro dépend fortement de son schema. Il permet à toutes les données d'être écrites sans connaissance préalable du schéma. Il sérialise rapidement et les données sérialisées qui en résultent sont de moindre taille. Le schéma est stocké avec les données Avro dans un fichier pour tout traitement ultérieur.
Dans RPC, le client et le serveur échangent des schémas pendant la connexion. Cet échange aide à la communication entre les mêmes champs nommés, les champs manquants, les champs supplémentaires, etc.
Les schémas Avro sont définis avec JSON qui simplifie son implémentation dans les langages avec des bibliothèques JSON.
Comme Avro, il existe d'autres mécanismes de sérialisation dans Hadoop tels que Sequence Files, Protocol Buffers, et Thrift.
Comparaison avec les tampons Thrift et Protocol
Thrift et Protocol Bufferssont les bibliothèques les plus compétentes avec Avro. Avro diffère de ces frameworks des manières suivantes -
Avro prend en charge les types dynamiques et statiques selon l'exigence. Protocol Buffers et Thrift utilisent des langages de définition d'interface (IDL) pour spécifier les schémas et leurs types. Ces IDL sont utilisés pour générer du code pour la sérialisation et la désérialisation.
Avro est construit dans l'écosystème Hadoop. Les tampons d'épargne et de protocole ne sont pas intégrés à l'écosystème Hadoop.
Contrairement à Thrift et Protocol Buffer, la définition de schéma d'Avro est en JSON et non dans un IDL propriétaire.
| Propriété | Avro | Tampon d'économie et de protocole |
|---|---|---|
| Schéma dynamique | Oui | Non |
| Intégré à Hadoop | Oui | Non |
| Schéma en JSON | Oui | Non |
| Pas besoin de compiler | Oui | Non |
| Pas besoin de déclarer les identifiants | Oui | Non |
| Bord de saignement | Oui | Non |
Caractéristiques d'Avro
Voici quelques-unes des principales caractéristiques d'Avro -
Avro est un language-neutral système de sérialisation des données.
Il peut être traité par de nombreux langages (actuellement C, C ++, C #, Java, Python et Ruby).
Avro crée un format structuré binaire qui est à la fois compressible et splittable. Par conséquent, il peut être utilisé efficacement comme entrée des travaux Hadoop MapReduce.
Avro fournit rich data structures. Par exemple, vous pouvez créer un enregistrement contenant un tableau, un type énuméré et un sous-enregistrement. Ces types de données peuvent être créés dans n'importe quelle langue, peuvent être traités dans Hadoop et les résultats peuvent être transmis à une troisième langue.
Avro schemas défini dans JSON, facilite l'implémentation dans les langages qui ont déjà des bibliothèques JSON.
Avro crée un fichier auto-descriptif nommé Avro Data File, dans lequel il stocke les données avec son schéma dans la section des métadonnées.
Avro est également utilisé dans les appels de procédure à distance (RPC). Pendant le RPC, le client et le serveur échangent des schémas lors de la négociation de connexion.
Fonctionnement général d'Avro
Pour utiliser Avro, vous devez suivre le flux de travail donné -
Step 1- Créez des schémas. Ici, vous devez concevoir le schéma Avro en fonction de vos données.
Step 2- Lisez les schémas dans votre programme. Cela se fait de deux manières -
By Generating a Class Corresponding to Schema- Compilez le schéma à l'aide d'Avro. Cela génère un fichier de classe correspondant au schéma
By Using Parsers Library - Vous pouvez lire directement le schéma à l'aide de la bibliothèque d'analyseurs.
Step 3 - Sérialiser les données à l'aide de l'API de sérialisation fournie pour Avro, qui se trouve dans le package org.apache.avro.specific.
Step 4 - Désérialiser les données à l'aide de l'API de désérialisation fournie pour Avro, qui se trouve dans le package org.apache.avro.specific.
Les données sont sérialisées pour deux objectifs -
Pour un stockage persistant
Pour transporter les données sur le réseau
Qu'est-ce que la sérialisation?
La sérialisation est le processus de traduction des structures de données ou de l'état des objets sous forme binaire ou textuelle pour transporter les données sur le réseau ou les stocker sur un stockage persistant. Une fois que les données sont transportées sur le réseau ou extraites du stockage persistant, elles doivent à nouveau être désérialisées. La sérialisation est appeléemarshalling et la désérialisation est appelée unmarshalling.
Sérialisation en Java
Java fournit un mécanisme, appelé object serialization où un objet peut être représenté comme une séquence d'octets qui inclut les données de l'objet ainsi que des informations sur le type de l'objet et les types de données stockées dans l'objet.
Une fois qu'un objet sérialisé est écrit dans un fichier, il peut être lu à partir du fichier et désérialisé. Autrement dit, les informations de type et les octets qui représentent l'objet et ses données peuvent être utilisés pour recréer l'objet en mémoire.
ObjectInputStream et ObjectOutputStream Les classes sont utilisées pour sérialiser et désérialiser un objet respectivement en Java.
Sérialisation dans Hadoop
Généralement dans les systèmes distribués comme Hadoop, le concept de sérialisation est utilisé pour Interprocess Communication et Persistent Storage.
Communication interprocessus
Pour établir la communication interprocessus entre les nœuds connectés dans un réseau, la technique RPC a été utilisée.
RPC a utilisé la sérialisation interne pour convertir le message au format binaire avant de l'envoyer au nœud distant via le réseau. À l'autre extrémité, le système distant désérialise le flux binaire dans le message d'origine.
Le format de sérialisation RPC doit être le suivant -
Compact - Utiliser au mieux la bande passante du réseau, qui est la ressource la plus rare dans un centre de données.
Fast - La communication entre les nœuds étant cruciale dans les systèmes distribués, le processus de sérialisation et de désérialisation devrait être rapide, produisant moins de frais généraux.
Extensible - Les protocoles changent au fil du temps pour répondre aux nouvelles exigences, il devrait donc être simple de faire évoluer le protocole de manière contrôlée pour les clients et les serveurs.
Interoperable - Le format de message doit prendre en charge les nœuds écrits dans différentes langues.
Stockage persistant
Le stockage persistant est une installation de stockage numérique qui ne perd pas ses données en cas de perte d'alimentation électrique. Les fichiers, dossiers, bases de données sont des exemples de stockage persistant.
Interface inscriptible
Il s'agit de l'interface dans Hadoop qui fournit des méthodes de sérialisation et de désérialisation. Le tableau suivant décrit les méthodes -
| S.No. | Méthodes et description |
|---|---|
| 1 | void readFields(DataInput in) Cette méthode est utilisée pour désérialiser les champs de l'objet donné. |
| 2 | void write(DataOutput out) Cette méthode est utilisée pour sérialiser les champs de l'objet donné. |
Interface comparable inscriptible
C'est la combinaison de Writable et Comparableles interfaces. Cette interface hériteWritable interface de Hadoop ainsi que Comparableinterface de Java. Par conséquent, il fournit des méthodes pour la sérialisation, la désérialisation et la comparaison des données.
| S.No. | Méthodes et description |
|---|---|
| 1 | int compareTo(class obj) Cette méthode compare l'objet actuel avec l'objet obj donné. |
En plus de ces classes, Hadoop prend en charge un certain nombre de classes wrapper qui implémentent l'interface WritableComparable. Chaque classe encapsule un type primitif Java. La hiérarchie des classes de la sérialisation Hadoop est donnée ci-dessous -
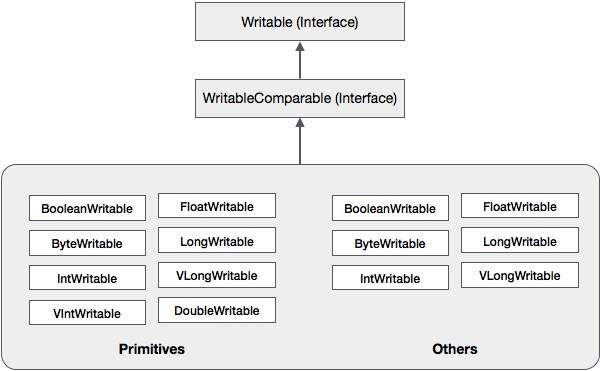
Ces classes sont utiles pour sérialiser divers types de données dans Hadoop. Par exemple, considérons leIntWritableclasse. Voyons comment cette classe est utilisée pour sérialiser et désérialiser les données dans Hadoop.
Classe IntWritable
Cette classe implémente Writable, Comparable, et WritableComparableles interfaces. Il enveloppe un type de données entier. Cette classe fournit des méthodes utilisées pour sérialiser et désérialiser le type entier de données.
Constructeurs
| S.No. | Sommaire |
|---|---|
| 1 | IntWritable() |
| 2 | IntWritable( int value) |
Méthodes
| S.No. | Sommaire |
|---|---|
| 1 | int get() En utilisant cette méthode, vous pouvez obtenir la valeur entière présente dans l'objet actuel. |
| 2 | void readFields(DataInput in) Cette méthode est utilisée pour désérialiser les données dans le DataInput objet. |
| 3 | void set(int value) Cette méthode est utilisée pour définir la valeur du courant IntWritable objet. |
| 4 | void write(DataOutput out) Cette méthode est utilisée pour sérialiser les données de l'objet courant vers le DataOutput objet. |
Sérialisation des données dans Hadoop
La procédure de sérialisation du type entier de données est décrite ci-dessous.
Instancier IntWritable classe en y enveloppant une valeur entière.
Instancier ByteArrayOutputStream classe.
Instancier DataOutputStream classe et passez l'objet de ByteArrayOutputStream classe à elle.
Sérialiser la valeur entière dans l'objet IntWritable à l'aide de write()méthode. Cette méthode nécessite un objet de la classe DataOutputStream.
Les données sérialisées seront stockées dans l'objet tableau d'octets qui est passé en paramètre au DataOutputStreamclasse au moment de l'instanciation. Convertissez les données de l'objet en tableau d'octets.
Exemple
L'exemple suivant montre comment sérialiser des données de type entier dans Hadoop -
import java.io.ByteArrayOutputStream;
import java.io.DataOutputStream;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
public class Serialization {
public byte[] serialize() throws IOException{
//Instantiating the IntWritable object
IntWritable intwritable = new IntWritable(12);
//Instantiating ByteArrayOutputStream object
ByteArrayOutputStream byteoutputStream = new ByteArrayOutputStream();
//Instantiating DataOutputStream object
DataOutputStream dataOutputStream = new
DataOutputStream(byteoutputStream);
//Serializing the data
intwritable.write(dataOutputStream);
//storing the serialized object in bytearray
byte[] byteArray = byteoutputStream.toByteArray();
//Closing the OutputStream
dataOutputStream.close();
return(byteArray);
}
public static void main(String args[]) throws IOException{
Serialization serialization= new Serialization();
serialization.serialize();
System.out.println();
}
}Désérialisation des données dans Hadoop
La procédure pour désérialiser le type entier de données est décrite ci-dessous -
Instancier IntWritable classe en y enveloppant une valeur entière.
Instancier ByteArrayOutputStream classe.
Instancier DataOutputStream classe et passez l'objet de ByteArrayOutputStream classe à elle.
Désérialiser les données dans l'objet de DataInputStream en utilisant readFields() méthode de la classe IntWritable.
Les données désérialisées seront stockées dans l'objet de la classe IntWritable. Vous pouvez récupérer ces données en utilisantget() méthode de cette classe.
Exemple
L'exemple suivant montre comment désérialiser les données de type entier dans Hadoop -
import java.io.ByteArrayInputStream;
import java.io.DataInputStream;
import org.apache.hadoop.io.IntWritable;
public class Deserialization {
public void deserialize(byte[]byteArray) throws Exception{
//Instantiating the IntWritable class
IntWritable intwritable =new IntWritable();
//Instantiating ByteArrayInputStream object
ByteArrayInputStream InputStream = new ByteArrayInputStream(byteArray);
//Instantiating DataInputStream object
DataInputStream datainputstream=new DataInputStream(InputStream);
//deserializing the data in DataInputStream
intwritable.readFields(datainputstream);
//printing the serialized data
System.out.println((intwritable).get());
}
public static void main(String args[]) throws Exception {
Deserialization dese = new Deserialization();
dese.deserialize(new Serialization().serialize());
}
}Avantage de Hadoop sur la sérialisation Java
La sérialisation basée sur Writable de Hadoop est capable de réduire la surcharge de création d'objets en réutilisant les objets Writable, ce qui n'est pas possible avec le framework de sérialisation natif de Java.
Inconvénients de la sérialisation Hadoop
Pour sérialiser les données Hadoop, il existe deux façons:
Vous pouvez utiliser le Writable classes, fournies par la bibliothèque native de Hadoop.
Vous pouvez aussi utiliser Sequence Files qui stockent les données au format binaire.
Le principal inconvénient de ces deux mécanismes est que Writables et SequenceFiles n'ont qu'une API Java et ils ne peuvent être écrits ou lus dans aucun autre langage.
Par conséquent, aucun des fichiers créés dans Hadoop avec les deux mécanismes ci-dessus ne peut être lu par un autre langage tiers, ce qui fait de Hadoop une boîte limitée. Pour remédier à cet inconvénient, Doug Cutting a crééAvro, qui est un language independent data structure.
La fondation logicielle Apache fournit à Avro diverses versions. Vous pouvez télécharger la version requise à partir des miroirs Apache. Voyons, comment configurer l'environnement pour travailler avec Avro -
Téléchargement d'Avro
Pour télécharger Apache Avro, procédez comme suit -
Ouvrez la page Web Apache.org . Vous verrez la page d'accueil d'Apache Avro comme indiqué ci-dessous -
Cliquez sur projet → versions. Vous obtiendrez une liste des versions.
Sélectionnez la dernière version qui vous mène à un lien de téléchargement.
mirror.nexcess est l'un des liens où vous pouvez trouver la liste de toutes les bibliothèques de différentes langues prises en charge par Avro, comme indiqué ci-dessous -

Vous pouvez sélectionner et télécharger la bibliothèque pour l'une des langues fournies. Dans ce tutoriel, nous utilisons Java. Téléchargez donc les fichiers jaravro-1.7.7.jar et avro-tools-1.7.7.jar.
Avro avec Eclipse
Pour utiliser Avro dans l'environnement Eclipse, vous devez suivre les étapes ci-dessous -
Step 1. Ouvrez l'éclipse.
Step 2. Créez un projet.
Step 3.Cliquez avec le bouton droit sur le nom du projet. Vous obtiendrez un menu contextuel.
Step 4. Cliquer sur Build Path. Cela vous mène à un autre menu contextuel.
Step 5. Cliquer sur Configure Build Path... Vous pouvez voir la fenêtre Propriétés de votre projet comme indiqué ci-dessous -

Step 6. Sous l'onglet bibliothèques, cliquez sur ADD EXternal JARs... bouton.
Step 7. Sélectionnez le fichier jar avro-1.77.jar vous avez téléchargé.
Step 8. Cliquer sur OK.
Avro avec Maven
Vous pouvez également intégrer la bibliothèque Avro à votre projet à l'aide de Maven. Vous trouverez ci-dessous le fichier pom.xml pour Avro.
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi=" http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>Test</groupId>
<artifactId>Test</artifactId>
<version>0.0.1-SNAPSHOT</version>
<build>
<sourceDirectory>src</sourceDirectory>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro-tools</artifactId>
<version>1.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.0-beta9</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.0-beta9</version>
</dependency>
</dependencies>
</project>Définition du chemin de classe
Pour travailler avec Avro dans un environnement Linux, téléchargez les fichiers jar suivants -
- avro-1.77.jar
- avro-tools-1.77.jar
- log4j-api-2.0-beta9.jar
- og4j-core-2.0.beta9.jar.
Copiez ces fichiers dans un dossier et définissez le chemin d'accès aux classes dans le dossier, dans le./bashrc fichier comme indiqué ci-dessous.
#class path for Avro
export CLASSPATH=$CLASSPATH://home/Hadoop/Avro_Work/jars/*
Avro, étant un utilitaire de sérialisation basé sur des schémas, accepte les schémas en entrée. En dépit de divers schémas disponibles, Avro suit ses propres normes de définition des schémas. Ces schémas décrivent les détails suivants -
- type de fichier (enregistrement par défaut)
- lieu d'enregistrement
- nom du dossier
- champs de l'enregistrement avec leurs types de données correspondants
À l'aide de ces schémas, vous pouvez stocker des valeurs sérialisées au format binaire en utilisant moins d'espace. Ces valeurs sont stockées sans aucune métadonnée.
Création de schémas Avro
Le schéma Avro est créé au format de document JavaScript Object Notation (JSON), qui est un format léger d'échange de données basé sur du texte. Il est créé de l'une des manières suivantes -
- Une chaîne JSON
- Un objet JSON
- Un tableau JSON
Example - L'exemple suivant montre un schéma, qui définit un document, sous l'espace de nom Tutorialspoint, avec le nom Employee, avec les champs name et age.
{
"type" : "record",
"namespace" : "Tutorialspoint",
"name" : "Employee",
"fields" : [
{ "name" : "Name" , "type" : "string" },
{ "name" : "Age" , "type" : "int" }
]
}Dans cet exemple, vous pouvez observer qu'il y a quatre champs pour chaque enregistrement -
type - Ce champ se trouve sous le document ainsi que sous le champ nommé champs.
Dans le cas d'un document, il montre le type du document, généralement un enregistrement car il y a plusieurs champs.
Lorsqu'il s'agit d'un champ, le type décrit le type de données.
namespace - Ce champ décrit le nom de l'espace de noms dans lequel réside l'objet.
name - Ce champ se trouve sous le document ainsi que sous le champ nommé champs.
Dans le cas d'un document, il décrit le nom du schéma. Ce nom de schéma avec l'espace de noms identifie de manière unique le schéma dans le magasin (Namespace.schema name). Dans l'exemple ci-dessus, le nom complet du schéma sera Tutorialspoint.Employee.
Dans le cas des champs, il décrit le nom du champ.
Types de données primitifs d'Avro
Le schéma Avro a des types de données primitifs ainsi que des types de données complexes. Le tableau suivant décrit lesprimitive data types d'Avro -
| Type de données | La description |
|---|---|
| nul | Null est un type sans valeur. |
| int | Entier signé 32 bits. |
| longue | Entier signé 64 bits. |
| flotte | nombre à virgule flottante IEEE 754 simple précision (32 bits). |
| double | nombre à virgule flottante IEEE 754 double précision (64 bits). |
| octets | séquence d'octets non signés de 8 bits. |
| chaîne | Séquence de caractères Unicode. |
Types de données complexes d'Avro
Outre les types de données primitifs, Avro fournit six types de données complexes, à savoir les enregistrements, les énumérations, les tableaux, les cartes, les unions et les fixes.
Record
Un type de données d'enregistrement dans Avro est une collection de plusieurs attributs. Il prend en charge les attributs suivants -
name - La valeur de ce champ contient le nom de l'enregistrement.
namespace - La valeur de ce champ contient le nom de l'espace de noms dans lequel l'objet est stocké.
type - La valeur de cet attribut contient soit le type du document (enregistrement), soit le type de données du champ dans le schéma.
fields - Ce champ contient un tableau JSON, qui contient la liste de tous les champs du schéma, chacun ayant des attributs de nom et de type.
Example
Ci-dessous est l'exemple d'un enregistrement.
{
" type " : "record",
" namespace " : "Tutorialspoint",
" name " : "Employee",
" fields " : [
{ "name" : " Name" , "type" : "string" },
{ "name" : "age" , "type" : "int" }
]
}Enum
Une énumération est une liste d'éléments dans une collection, l'énumération Avro prend en charge les attributs suivants -
name - La valeur de ce champ contient le nom de l'énumération.
namespace - La valeur de ce champ contient la chaîne qui qualifie le nom de l'énumération.
symbols - La valeur de ce champ contient les symboles de l'énumération sous forme de tableau de noms.
Example
Ci-dessous, un exemple d'énumération.
{
"type" : "enum",
"name" : "Numbers",
"namespace": "data",
"symbols" : [ "ONE", "TWO", "THREE", "FOUR" ]
}Tableaux
Ce type de données définit un champ de tableau ayant un seul élément d'attribut. Cet attribut d'éléments spécifie le type d'éléments dans le tableau.
Example
{ " type " : " array ", " items " : " int " }Plans
Le type de données de carte est un tableau de paires clé-valeur, il organise les données sous forme de paires clé-valeur. La clé d'une carte Avro doit être une chaîne. Les valeurs d'une carte contiennent le type de données du contenu de la carte.
Example
{"type" : "map", "values" : "int"}Les syndicats
Un type de données union est utilisé chaque fois que le champ a un ou plusieurs types de données. Ils sont représentés sous forme de tableaux JSON. Par exemple, si un champ peut être un entier ou nul, alors l'union est représentée par ["int", "null"].
Example
Vous trouverez ci-dessous un exemple de document utilisant des syndicats -
{
"type" : "record",
"namespace" : "tutorialspoint",
"name" : "empdetails ",
"fields" :
[
{ "name" : "experience", "type": ["int", "null"] }, { "name" : "age", "type": "int" }
]
}Fixé
Ce type de données est utilisé pour déclarer un champ de taille fixe qui peut être utilisé pour stocker des données binaires. Il a un nom de champ et des données comme attributs. Name contient le nom du champ et la taille contient la taille du champ.
Example
{ "type" : "fixed" , "name" : "bdata", "size" : 1048576}Dans le chapitre précédent, nous avons décrit le type d'entrée d'Avro, c'est-à-dire les schémas Avro. Dans ce chapitre, nous expliquerons les classes et les méthodes utilisées dans la sérialisation et la désérialisation des schémas Avro.
Classe SpecificDatumWriter
Cette classe appartient au package org.apache.avro.specific. Il met en œuvre leDatumWriter interface qui convertit les objets Java en un format sérialisé en mémoire.
Constructeur
| S.No. | La description |
|---|---|
| 1 | SpecificDatumWriter(Schema schema) |
Méthode
| S.No. | La description |
|---|---|
| 1 | SpecificData getSpecificData() Renvoie l'implémentation SpecificData utilisée par cet enregistreur. |
SpecificDatumReader, classe
Cette classe appartient au package org.apache.avro.specific. Il met en œuvre leDatumReader interface qui lit les données d'un schéma et détermine la représentation des données en mémoire. SpecificDatumReader est la classe qui prend en charge les classes java générées.
Constructeur
| S.No. | La description |
|---|---|
| 1 | SpecificDatumReader(Schema schema) Construisez où les schémas de l'écrivain et du lecteur sont les mêmes. |
Méthodes
| S.No. | La description |
|---|---|
| 1 | SpecificData getSpecificData() Renvoie le SpecificData contenu. |
| 2 | void setSchema(Schema actual) Cette méthode est utilisée pour définir le schéma de l'écrivain. |
DataFileWriter
Instancie DataFileWrite pour empclasse. Cette classe écrit une séquence d'enregistrements sérialisés de données conformes à un schéma, avec le schéma dans un fichier.
Constructeur
| S.No. | La description |
|---|---|
| 1 | DataFileWriter(DatumWriter<D> dout) |
Méthodes
| S.Non | La description |
|---|---|
| 1 | void append(D datum) Ajoute une donnée à un fichier. |
| 2 | DataFileWriter<D> appendTo(File file) Cette méthode est utilisée pour ouvrir un enregistreur en ajoutant à un fichier existant. |
Data FileReader
Cette classe fournit un accès aléatoire aux fichiers écrits avec DataFileWriter. Il hérite de la classeDataFileStream.
Constructeur
| S.No. | La description |
|---|---|
| 1 | DataFileReader(File file, DatumReader<D> reader)) |
Méthodes
| S.No. | La description |
|---|---|
| 1 | next() Lit la donnée suivante dans le fichier. |
| 2 | Boolean hasNext() Renvoie vrai si plus d'entrées restent dans ce fichier. |
Classe Schema.parser
Cette classe est un analyseur pour les schémas au format JSON. Il contient des méthodes pour analyser le schéma. Il appartient àorg.apache.avro paquet.
Constructeur
| S.No. | La description |
|---|---|
| 1 | Schema.Parser() |
Méthodes
| S.No. | La description |
|---|---|
| 1 | parse (File file) Analyse le schéma fourni dans le file. |
| 2 | parse (InputStream in) Analyse le schéma fourni dans le InputStream. |
| 3 | parse (String s) Analyse le schéma fourni dans le String. |
Interface GenricRecord
Cette interface fournit des méthodes pour accéder aux champs par nom ainsi que par index.
Méthodes
| S.No. | La description |
|---|---|
| 1 | Object get(String key) Renvoie la valeur d'un champ donné. |
| 2 | void put(String key, Object v) Définit la valeur d'un champ en fonction de son nom. |
Classe GenericData.Record
Constructeur
| S.No. | La description |
|---|---|
| 1 | GenericData.Record(Schema schema) |
Méthodes
| S.No. | La description |
|---|---|
| 1 | Object get(String key) Renvoie la valeur d'un champ du nom donné. |
| 2 | Schema getSchema() Renvoie le schéma de cette instance. |
| 3 | void put(int i, Object v) Définit la valeur d'un champ en fonction de sa position dans le schéma. |
| 4 | void put(String key, Object value) Définit la valeur d'un champ en fonction de son nom. |
On peut lire un schéma Avro dans le programme soit en générant une classe correspondant à un schéma soit en utilisant la bibliothèque d'analyseurs. Ce chapitre décrit comment lire le schémaby generating a class et Serializing les données en utilisant Avr.

Sérialisation en générant une classe
Pour sérialiser les données à l'aide d'Avro, suivez les étapes ci-dessous -
Écrivez un schéma Avro.
Compilez le schéma à l'aide de l'utilitaire Avro. Vous obtenez le code Java correspondant à ce schéma.
Remplissez le schéma avec les données.
Sérialisez-le à l'aide de la bibliothèque Avro.
Définition d'un schéma
Supposons que vous vouliez un schéma avec les détails suivants -
| Field | Nom | id | âge | un salaire | adresse |
| type | Chaîne | int | int | int | chaîne |
Créez un schéma Avro comme indiqué ci-dessous.
Enregistrez-le sous emp.avsc.
{
"namespace": "tutorialspoint.com",
"type": "record",
"name": "emp",
"fields": [
{"name": "name", "type": "string"},
{"name": "id", "type": "int"},
{"name": "salary", "type": "int"},
{"name": "age", "type": "int"},
{"name": "address", "type": "string"}
]
}Compiler le schéma
Après avoir créé un schéma Avro, vous devez compiler le schéma créé à l'aide des outils Avro. avro-tools-1.7.7.jar est le pot contenant les outils.
Syntaxe pour compiler un schéma Avro
java -jar <path/to/avro-tools-1.7.7.jar> compile schema <path/to/schema-file> <destination-folder>Ouvrez le terminal dans le dossier de départ.
Créez un nouveau répertoire pour travailler avec Avro comme indiqué ci-dessous -
$ mkdir Avro_WorkDans le répertoire nouvellement créé, créez trois sous-répertoires -
Premier nommé schema, pour placer le schéma.
Deuxième nommé with_code_gen, pour placer le code généré.
Troisième nommé jars, pour placer les fichiers jar.
$ mkdir schema
$ mkdir with_code_gen
$ mkdir jarsLa capture d'écran suivante montre comment votre Avro_work Le dossier doit ressembler à après avoir créé tous les répertoires.
Maintenant /home/Hadoop/Avro_work/jars/avro-tools-1.7.7.jar est le chemin du répertoire dans lequel vous avez téléchargé le fichier avro-tools-1.7.7.jar.
/home/Hadoop/Avro_work/schema/ est le chemin du répertoire dans lequel votre fichier de schéma emp.avsc est stocké.
/home/Hadoop/Avro_work/with_code_gen est le répertoire dans lequel vous souhaitez stocker les fichiers de classe générés.
Maintenant, compilez le schéma comme indiqué ci-dessous -
$ java -jar /home/Hadoop/Avro_work/jars/avro-tools-1.7.7.jar compile schema /home/Hadoop/Avro_work/schema/emp.avsc /home/Hadoop/Avro/with_code_genAprès la compilation, un package en fonction de l'espace de nom du schéma est créé dans le répertoire de destination. Dans ce package, le code source Java avec le nom du schéma est créé. Ce code source généré est le code Java du schéma donné qui peut être utilisé directement dans les applications.
Par exemple, dans ce cas, un package / dossier, nommé tutorialspoint est créé qui contient un autre dossier nommé com (puisque l'espace de nom est tutorialspoint.com) et à l'intérieur de celui-ci, vous pouvez observer le fichier généré emp.java. L'instantané suivant montreemp.java -

Cette classe est utile pour créer des données selon le schéma.
La classe générée contient -
- Constructeur par défaut et constructeur paramétré qui acceptent toutes les variables du schéma.
- Les méthodes setter et getter pour toutes les variables du schéma.
- Get () méthode qui renvoie le schéma.
- Méthodes du constructeur.
Création et sérialisation des données
Tout d'abord, copiez le fichier java généré utilisé dans ce projet dans le répertoire courant ou importez-le d'où il se trouve.
Nous pouvons maintenant écrire un nouveau fichier Java et instancier la classe dans le fichier généré (emp) pour ajouter les données des employés au schéma.
Voyons la procédure pour créer des données selon le schéma à l'aide d'apache Avro.
Étape 1
Instancier le généré emp classe.
emp e1=new emp( );Étape 2
À l'aide des méthodes de setter, insérez les données du premier employé. Par exemple, nous avons créé les coordonnées de l'employé nommé Omar.
e1.setName("omar");
e1.setAge(21);
e1.setSalary(30000);
e1.setAddress("Hyderabad");
e1.setId(001);De même, remplissez tous les détails de l'employé à l'aide des méthodes de définition.
Étape 3
Créer un objet de DatumWriter interface utilisant le SpecificDatumWriterclasse. Cela convertit les objets Java en un format sérialisé en mémoire. L'exemple suivant instancieSpecificDatumWriter objet de classe pour emp classe.
DatumWriter<emp> empDatumWriter = new SpecificDatumWriter<emp>(emp.class);Étape 4
Instancier DataFileWriter pour empclasse. Cette classe écrit une séquence d'enregistrements sérialisés de données conformes à un schéma, avec le schéma lui-même, dans un fichier. Cette classe nécessite leDatumWriter object, en tant que paramètre du constructeur.
DataFileWriter<emp> empFileWriter = new DataFileWriter<emp>(empDatumWriter);Étape 5
Ouvrez un nouveau fichier pour stocker les données correspondant au schéma donné en utilisant create()méthode. Cette méthode requiert le schéma et le chemin du fichier dans lequel les données doivent être stockées en tant que paramètres.
Dans l'exemple suivant, le schéma est transmis à l'aide de getSchema() méthode, et le fichier de données est stocké dans le chemin - /home/Hadoop/Avro/serialized_file/emp.avro.
empFileWriter.create(e1.getSchema(),new File("/home/Hadoop/Avro/serialized_file/emp.avro"));Étape 6
Ajoutez tous les enregistrements créés au fichier en utilisant append() méthode comme indiqué ci-dessous -
empFileWriter.append(e1);
empFileWriter.append(e2);
empFileWriter.append(e3);Exemple - Sérialisation en générant une classe
Le programme complet suivant montre comment sérialiser des données dans un fichier à l'aide d'Apache Avro -
import java.io.File;
import java.io.IOException;
import org.apache.avro.file.DataFileWriter;
import org.apache.avro.io.DatumWriter;
import org.apache.avro.specific.SpecificDatumWriter;
public class Serialize {
public static void main(String args[]) throws IOException{
//Instantiating generated emp class
emp e1=new emp();
//Creating values according the schema
e1.setName("omar");
e1.setAge(21);
e1.setSalary(30000);
e1.setAddress("Hyderabad");
e1.setId(001);
emp e2=new emp();
e2.setName("ram");
e2.setAge(30);
e2.setSalary(40000);
e2.setAddress("Hyderabad");
e2.setId(002);
emp e3=new emp();
e3.setName("robbin");
e3.setAge(25);
e3.setSalary(35000);
e3.setAddress("Hyderabad");
e3.setId(003);
//Instantiate DatumWriter class
DatumWriter<emp> empDatumWriter = new SpecificDatumWriter<emp>(emp.class);
DataFileWriter<emp> empFileWriter = new DataFileWriter<emp>(empDatumWriter);
empFileWriter.create(e1.getSchema(), new File("/home/Hadoop/Avro_Work/with_code_gen/emp.avro"));
empFileWriter.append(e1);
empFileWriter.append(e2);
empFileWriter.append(e3);
empFileWriter.close();
System.out.println("data successfully serialized");
}
}Parcourez le répertoire dans lequel le code généré est placé. Dans ce cas, àhome/Hadoop/Avro_work/with_code_gen.
In Terminal −
$ cd home/Hadoop/Avro_work/with_code_gen/In GUI −
Maintenant, copiez et enregistrez le programme ci-dessus dans le fichier nommé Serialize.java
Compilez et exécutez-le comme indiqué ci-dessous -
$ javac Serialize.java
$ java SerializeProduction
data successfully serializedSi vous vérifiez le chemin indiqué dans le programme, vous pouvez trouver le fichier sérialisé généré comme indiqué ci-dessous.
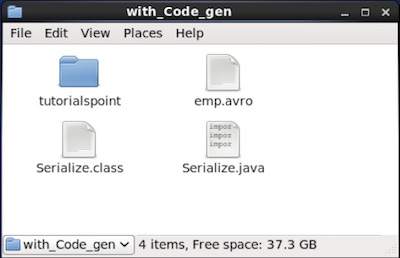
Comme décrit précédemment, on peut lire un schéma Avro dans un programme soit en générant une classe correspondant au schéma soit en utilisant la bibliothèque d'analyseurs. Ce chapitre décrit comment lire le schémaby generating a class et Deserialize les données en utilisant Avro.
Désérialisation en générant une classe
Les données sérialisées sont stockées dans le fichier emp.avro. Vous pouvez le désérialiser et le lire à l'aide d'Avro.

Suivez la procédure ci-dessous pour désérialiser les données sérialisées d'un fichier.
Étape 1
Créer un objet de DatumReader interface utilisant SpecificDatumReader classe.
DatumReader<emp>empDatumReader = new SpecificDatumReader<emp>(emp.class);Étape 2
Instancier DataFileReader pour empclasse. Cette classe lit les données sérialisées à partir d'un fichier. Cela nécessite leDataumeader objet et chemin du fichier dans lequel les données sérialisées existent, en tant que paramètres du constructeur.
DataFileReader<emp> dataFileReader = new DataFileReader(new File("/path/to/emp.avro"), empDatumReader);Étape 3
Imprimez les données désérialisées, en utilisant les méthodes de DataFileReader.
le hasNext() La méthode retournera un booléen s'il y a des éléments dans le Reader.
le next() méthode de DataFileReader renvoie les données dans le Reader.
while(dataFileReader.hasNext()){
em=dataFileReader.next(em);
System.out.println(em);
}Exemple - Désérialisation en générant une classe
Le programme complet suivant montre comment désérialiser les données d'un fichier à l'aide d'Avro.
import java.io.File;
import java.io.IOException;
import org.apache.avro.file.DataFileReader;
import org.apache.avro.io.DatumReader;
import org.apache.avro.specific.SpecificDatumReader;
public class Deserialize {
public static void main(String args[]) throws IOException{
//DeSerializing the objects
DatumReader<emp> empDatumReader = new SpecificDatumReader<emp>(emp.class);
//Instantiating DataFileReader
DataFileReader<emp> dataFileReader = new DataFileReader<emp>(new
File("/home/Hadoop/Avro_Work/with_code_genfile/emp.avro"), empDatumReader);
emp em=null;
while(dataFileReader.hasNext()){
em=dataFileReader.next(em);
System.out.println(em);
}
}
}Naviguez dans le répertoire où le code généré est placé. Dans ce cas, àhome/Hadoop/Avro_work/with_code_gen.
$ cd home/Hadoop/Avro_work/with_code_gen/Maintenant, copiez et enregistrez le programme ci-dessus dans le fichier nommé DeSerialize.java. Compilez et exécutez-le comme indiqué ci-dessous -
$ javac Deserialize.java
$ java DeserializeProduction
{"name": "omar", "id": 1, "salary": 30000, "age": 21, "address": "Hyderabad"}
{"name": "ram", "id": 2, "salary": 40000, "age": 30, "address": "Hyderabad"}
{"name": "robbin", "id": 3, "salary": 35000, "age": 25, "address": "Hyderabad"}On peut lire un schéma Avro dans un programme soit en générant une classe correspondant à un schéma soit en utilisant la bibliothèque d'analyseurs. Dans Avro, les données sont toujours stockées avec leur schéma correspondant. Par conséquent, nous pouvons toujours lire un schéma sans génération de code.
Ce chapitre décrit comment lire le schéma by using parsers library et à serialize les données en utilisant Avro.

Sérialisation à l'aide de la bibliothèque d'analyseurs
Pour sérialiser les données, nous devons lire le schéma, créer des données selon le schéma et sérialiser le schéma à l'aide de l'API Avro. La procédure suivante sérialise les données sans générer de code -
Étape 1
Tout d'abord, lisez le schéma à partir du fichier. Pour ce faire, utilisezSchema.Parserclasse. Cette classe fournit des méthodes pour analyser le schéma dans différents formats.
Instancier le Schema.Parser class en passant le chemin du fichier où le schéma est stocké.
Schema schema = new Schema.Parser().parse(new File("/path/to/emp.avsc"));Étape 2
Créer l'objet de GenericRecord interface, en instanciant GenericData.Recordclasse comme indiqué ci-dessous. Passez l'objet de schéma créé ci-dessus à son constructeur.
GenericRecord e1 = new GenericData.Record(schema);Étape 3
Insérez les valeurs dans le schéma à l'aide du put() méthode de la GenericData classe.
e1.put("name", "ramu");
e1.put("id", 001);
e1.put("salary",30000);
e1.put("age", 25);
e1.put("address", "chennai");Étape 4
Créer un objet de DatumWriter interface utilisant le SpecificDatumWriterclasse. Il convertit les objets Java en un format sérialisé en mémoire. L'exemple suivant instancieSpecificDatumWriter objet de classe pour emp classe -
DatumWriter<emp> empDatumWriter = new SpecificDatumWriter<emp>(emp.class);Étape 5
Instancier DataFileWriter pour empclasse. Cette classe écrit des enregistrements sérialisés de données conformes à un schéma, avec le schéma lui-même, dans un fichier. Cette classe nécessite leDatumWriter object, en tant que paramètre du constructeur.
DataFileWriter<emp> dataFileWriter = new DataFileWriter<emp>(empDatumWriter);Étape 6
Ouvrez un nouveau fichier pour stocker les données correspondant au schéma donné en utilisant create()méthode. Cette méthode requiert le schéma et le chemin du fichier dans lequel les données doivent être stockées en tant que paramètres.
Dans l'exemple ci-dessous, le schéma est passé en utilisant getSchema() méthode et le fichier de données est stocké dans le chemin
/home/Hadoop/Avro/serialized_file/emp.avro.
empFileWriter.create(e1.getSchema(), new
File("/home/Hadoop/Avro/serialized_file/emp.avro"));Étape 7
Ajoutez tous les enregistrements créés au fichier en utilisant append( ) méthode comme indiqué ci-dessous.
empFileWriter.append(e1);
empFileWriter.append(e2);
empFileWriter.append(e3);Exemple - Sérialisation à l'aide d'analyseurs
Le programme complet suivant montre comment sérialiser les données à l'aide d'analyseurs -
import java.io.File;
import java.io.IOException;
import org.apache.avro.Schema;
import org.apache.avro.file.DataFileWriter;
import org.apache.avro.generic.GenericData;
import org.apache.avro.generic.GenericDatumWriter;
import org.apache.avro.generic.GenericRecord;
import org.apache.avro.io.DatumWriter;
public class Seriali {
public static void main(String args[]) throws IOException{
//Instantiating the Schema.Parser class.
Schema schema = new Schema.Parser().parse(new File("/home/Hadoop/Avro/schema/emp.avsc"));
//Instantiating the GenericRecord class.
GenericRecord e1 = new GenericData.Record(schema);
//Insert data according to schema
e1.put("name", "ramu");
e1.put("id", 001);
e1.put("salary",30000);
e1.put("age", 25);
e1.put("address", "chenni");
GenericRecord e2 = new GenericData.Record(schema);
e2.put("name", "rahman");
e2.put("id", 002);
e2.put("salary", 35000);
e2.put("age", 30);
e2.put("address", "Delhi");
DatumWriter<GenericRecord> datumWriter = new GenericDatumWriter<GenericRecord>(schema);
DataFileWriter<GenericRecord> dataFileWriter = new DataFileWriter<GenericRecord>(datumWriter);
dataFileWriter.create(schema, new File("/home/Hadoop/Avro_work/without_code_gen/mydata.txt"));
dataFileWriter.append(e1);
dataFileWriter.append(e2);
dataFileWriter.close();
System.out.println(“data successfully serialized”);
}
}Naviguez dans le répertoire où le code généré est placé. Dans ce cas, àhome/Hadoop/Avro_work/without_code_gen.
$ cd home/Hadoop/Avro_work/without_code_gen/
Maintenant, copiez et enregistrez le programme ci-dessus dans le fichier nommé Serialize.java. Compilez et exécutez-le comme indiqué ci-dessous -
$ javac Serialize.java
$ java SerializeProduction
data successfully serializedSi vous vérifiez le chemin indiqué dans le programme, vous pouvez trouver le fichier sérialisé généré comme indiqué ci-dessous.
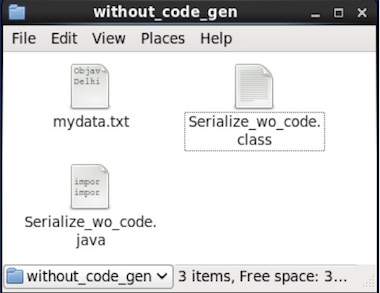
Comme mentionné précédemment, on peut lire un schéma Avro dans un programme soit en générant une classe correspondant à un schéma soit en utilisant la bibliothèque d'analyseurs. Dans Avro, les données sont toujours stockées avec leur schéma correspondant. Par conséquent, nous pouvons toujours lire un article sérialisé sans génération de code.
Ce chapitre décrit comment lire le schéma using parsers library et Deserializing les données en utilisant Avro.
Désérialisation à l'aide de la bibliothèque d'analyseurs
Les données sérialisées sont stockées dans le fichier mydata.txt. Vous pouvez le désérialiser et le lire à l'aide d'Avro.
Suivez la procédure ci-dessous pour désérialiser les données sérialisées d'un fichier.
Étape 1
Tout d'abord, lisez le schéma à partir du fichier. Pour ce faire, utilisezSchema.Parserclasse. Cette classe fournit des méthodes pour analyser le schéma dans différents formats.
Instancier le Schema.Parser class en passant le chemin du fichier où le schéma est stocké.
Schema schema = new Schema.Parser().parse(new File("/path/to/emp.avsc"));Étape 2
Créer un objet de DatumReader interface utilisant SpecificDatumReader classe.
DatumReader<emp>empDatumReader = new SpecificDatumReader<emp>(emp.class);Étape 3
Instancier DataFileReaderclasse. Cette classe lit les données sérialisées à partir d'un fichier. Cela nécessite leDatumReader objet et chemin du fichier où les données sérialisées existent, en tant que paramètres du constructeur.
DataFileReader<GenericRecord> dataFileReader = new DataFileReader<GenericRecord>(new File("/path/to/mydata.txt"), datumReader);Étape 4
Imprimez les données désérialisées, en utilisant les méthodes de DataFileReader.
le hasNext() renvoie un booléen s'il y a des éléments dans le Reader.
le next() méthode de DataFileReader renvoie les données dans le Reader.
while(dataFileReader.hasNext()){
em=dataFileReader.next(em);
System.out.println(em);
}Exemple - Désérialisation à l'aide de la bibliothèque d'analyseurs
Le programme complet suivant montre comment désérialiser les données sérialisées à l'aide de la bibliothèque Parsers -
public class Deserialize {
public static void main(String args[]) throws Exception{
//Instantiating the Schema.Parser class.
Schema schema = new Schema.Parser().parse(new File("/home/Hadoop/Avro/schema/emp.avsc"));
DatumReader<GenericRecord> datumReader = new GenericDatumReader<GenericRecord>(schema);
DataFileReader<GenericRecord> dataFileReader = new DataFileReader<GenericRecord>(new File("/home/Hadoop/Avro_Work/without_code_gen/mydata.txt"), datumReader);
GenericRecord emp = null;
while (dataFileReader.hasNext()) {
emp = dataFileReader.next(emp);
System.out.println(emp);
}
System.out.println("hello");
}
}Naviguez dans le répertoire où le code généré est placé. Dans ce cas, c'est àhome/Hadoop/Avro_work/without_code_gen.
$ cd home/Hadoop/Avro_work/without_code_gen/Maintenant, copiez et enregistrez le programme ci-dessus dans le fichier nommé DeSerialize.java. Compilez et exécutez-le comme indiqué ci-dessous -
$ javac Deserialize.java
$ java DeserializeProduction
{"name": "ramu", "id": 1, "salary": 30000, "age": 25, "address": "chennai"}
{"name": "rahman", "id": 2, "salary": 35000, "age": 30, "address": "Delhi"}