AVRO - Sérialisation
Les données sont sérialisées pour deux objectifs -
Pour un stockage persistant
Pour transporter les données sur le réseau
Qu'est-ce que la sérialisation?
La sérialisation est le processus de traduction des structures de données ou de l'état des objets sous forme binaire ou textuelle pour transporter les données sur le réseau ou les stocker sur un stockage persistant. Une fois que les données sont transportées sur le réseau ou extraites du stockage persistant, elles doivent à nouveau être désérialisées. La sérialisation est appeléemarshalling et la désérialisation est appelée unmarshalling.
Sérialisation en Java
Java fournit un mécanisme, appelé object serialization où un objet peut être représenté comme une séquence d'octets qui inclut les données de l'objet ainsi que des informations sur le type de l'objet et les types de données stockées dans l'objet.
Une fois qu'un objet sérialisé est écrit dans un fichier, il peut être lu à partir du fichier et désérialisé. Autrement dit, les informations de type et les octets qui représentent l'objet et ses données peuvent être utilisés pour recréer l'objet en mémoire.
ObjectInputStream et ObjectOutputStream Les classes sont utilisées pour sérialiser et désérialiser un objet respectivement en Java.
Sérialisation dans Hadoop
Généralement dans les systèmes distribués comme Hadoop, le concept de sérialisation est utilisé pour Interprocess Communication et Persistent Storage.
Communication interprocessus
Pour établir la communication interprocessus entre les nœuds connectés dans un réseau, la technique RPC a été utilisée.
RPC a utilisé la sérialisation interne pour convertir le message au format binaire avant de l'envoyer au nœud distant via le réseau. À l'autre extrémité, le système distant désérialise le flux binaire dans le message d'origine.
Le format de sérialisation RPC doit être le suivant -
Compact - Utiliser au mieux la bande passante du réseau, qui est la ressource la plus rare dans un centre de données.
Fast - La communication entre les nœuds étant cruciale dans les systèmes distribués, le processus de sérialisation et de désérialisation devrait être rapide, produisant moins de frais généraux.
Extensible - Les protocoles changent au fil du temps pour répondre aux nouvelles exigences, il devrait donc être simple de faire évoluer le protocole de manière contrôlée pour les clients et les serveurs.
Interoperable - Le format de message doit prendre en charge les nœuds écrits dans différentes langues.
Stockage persistant
Le stockage persistant est une installation de stockage numérique qui ne perd pas ses données en cas de perte d'alimentation électrique. Les fichiers, dossiers, bases de données sont des exemples de stockage persistant.
Interface inscriptible
Il s'agit de l'interface dans Hadoop qui fournit des méthodes de sérialisation et de désérialisation. Le tableau suivant décrit les méthodes -
| S.No. | Méthodes et description |
|---|---|
| 1 | void readFields(DataInput in) Cette méthode est utilisée pour désérialiser les champs de l'objet donné. |
| 2 | void write(DataOutput out) Cette méthode est utilisée pour sérialiser les champs de l'objet donné. |
Interface comparable inscriptible
C'est la combinaison de Writable et Comparableles interfaces. Cette interface hériteWritable interface de Hadoop ainsi que Comparableinterface de Java. Par conséquent, il fournit des méthodes pour la sérialisation, la désérialisation et la comparaison des données.
| S.No. | Méthodes et description |
|---|---|
| 1 | int compareTo(class obj) Cette méthode compare l'objet actuel avec l'objet obj donné. |
En plus de ces classes, Hadoop prend en charge un certain nombre de classes wrapper qui implémentent l'interface WritableComparable. Chaque classe encapsule un type primitif Java. La hiérarchie des classes de la sérialisation Hadoop est donnée ci-dessous -
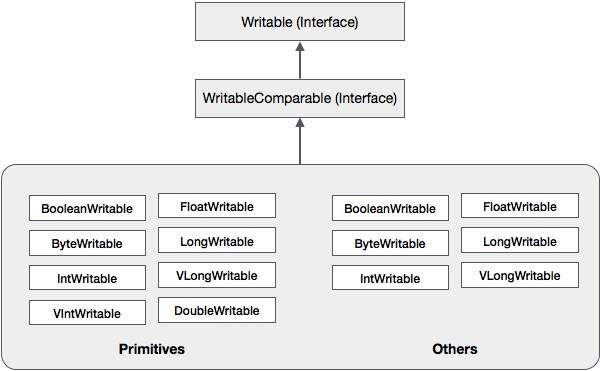
Ces classes sont utiles pour sérialiser divers types de données dans Hadoop. Par exemple, considérons leIntWritableclasse. Voyons comment cette classe est utilisée pour sérialiser et désérialiser les données dans Hadoop.
Classe IntWritable
Cette classe implémente Writable, Comparable, et WritableComparableles interfaces. Il enveloppe un type de données entier. Cette classe fournit des méthodes utilisées pour sérialiser et désérialiser le type entier de données.
Constructeurs
| S.No. | Sommaire |
|---|---|
| 1 | IntWritable() |
| 2 | IntWritable( int value) |
Méthodes
| S.No. | Sommaire |
|---|---|
| 1 | int get() En utilisant cette méthode, vous pouvez obtenir la valeur entière présente dans l'objet actuel. |
| 2 | void readFields(DataInput in) Cette méthode est utilisée pour désérialiser les données dans le DataInput objet. |
| 3 | void set(int value) Cette méthode est utilisée pour définir la valeur du courant IntWritable objet. |
| 4 | void write(DataOutput out) Cette méthode est utilisée pour sérialiser les données de l'objet courant vers le DataOutput objet. |
Sérialisation des données dans Hadoop
La procédure de sérialisation du type entier de données est décrite ci-dessous.
Instancier IntWritable classe en y enveloppant une valeur entière.
Instancier ByteArrayOutputStream classe.
Instancier DataOutputStream classe et passez l'objet de ByteArrayOutputStream classe à elle.
Sérialiser la valeur entière dans l'objet IntWritable à l'aide de write()méthode. Cette méthode nécessite un objet de la classe DataOutputStream.
Les données sérialisées seront stockées dans l'objet tableau d'octets qui est passé en paramètre au DataOutputStreamclasse au moment de l'instanciation. Convertissez les données de l'objet en tableau d'octets.
Exemple
L'exemple suivant montre comment sérialiser des données de type entier dans Hadoop -
import java.io.ByteArrayOutputStream;
import java.io.DataOutputStream;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
public class Serialization {
public byte[] serialize() throws IOException{
//Instantiating the IntWritable object
IntWritable intwritable = new IntWritable(12);
//Instantiating ByteArrayOutputStream object
ByteArrayOutputStream byteoutputStream = new ByteArrayOutputStream();
//Instantiating DataOutputStream object
DataOutputStream dataOutputStream = new
DataOutputStream(byteoutputStream);
//Serializing the data
intwritable.write(dataOutputStream);
//storing the serialized object in bytearray
byte[] byteArray = byteoutputStream.toByteArray();
//Closing the OutputStream
dataOutputStream.close();
return(byteArray);
}
public static void main(String args[]) throws IOException{
Serialization serialization= new Serialization();
serialization.serialize();
System.out.println();
}
}Désérialisation des données dans Hadoop
La procédure pour désérialiser le type entier de données est décrite ci-dessous -
Instancier IntWritable classe en y enveloppant une valeur entière.
Instancier ByteArrayOutputStream classe.
Instancier DataOutputStream classe et passez l'objet de ByteArrayOutputStream classe à elle.
Désérialiser les données dans l'objet de DataInputStream en utilisant readFields() méthode de la classe IntWritable.
Les données désérialisées seront stockées dans l'objet de la classe IntWritable. Vous pouvez récupérer ces données en utilisantget() méthode de cette classe.
Exemple
L'exemple suivant montre comment désérialiser les données de type entier dans Hadoop -
import java.io.ByteArrayInputStream;
import java.io.DataInputStream;
import org.apache.hadoop.io.IntWritable;
public class Deserialization {
public void deserialize(byte[]byteArray) throws Exception{
//Instantiating the IntWritable class
IntWritable intwritable =new IntWritable();
//Instantiating ByteArrayInputStream object
ByteArrayInputStream InputStream = new ByteArrayInputStream(byteArray);
//Instantiating DataInputStream object
DataInputStream datainputstream=new DataInputStream(InputStream);
//deserializing the data in DataInputStream
intwritable.readFields(datainputstream);
//printing the serialized data
System.out.println((intwritable).get());
}
public static void main(String args[]) throws Exception {
Deserialization dese = new Deserialization();
dese.deserialize(new Serialization().serialize());
}
}Avantage de Hadoop sur la sérialisation Java
La sérialisation basée sur Writable de Hadoop est capable de réduire la surcharge de création d'objets en réutilisant les objets Writable, ce qui n'est pas possible avec le framework de sérialisation natif de Java.
Inconvénients de la sérialisation Hadoop
Pour sérialiser les données Hadoop, il existe deux façons:
Vous pouvez utiliser le Writable classes, fournies par la bibliothèque native de Hadoop.
Vous pouvez aussi utiliser Sequence Files qui stockent les données au format binaire.
Le principal inconvénient de ces deux mécanismes est que Writables et SequenceFiles n'ont qu'une API Java et ils ne peuvent être écrits ou lus dans aucun autre langage.
Par conséquent, aucun des fichiers créés dans Hadoop avec les deux mécanismes ci-dessus ne peut être lu par un autre langage tiers, ce qui fait de Hadoop une boîte limitée. Pour remédier à cet inconvénient, Doug Cutting a crééAvro, qui est un language independent data structure.