CherryPy - Guide rapide
CherryPy est un framework Web de Python qui fournit une interface conviviale au protocole HTTP pour les développeurs Python. Elle est également appelée bibliothèque d'applications Web.
CherryPy utilise les atouts de Python en tant que langage dynamique pour modéliser et lier le protocole HTTP dans une API. C'est l'un des plus anciens frameworks Web pour Python, qui fournit une interface propre et une plate-forme fiable.
Histoire de CherryPy
Remi Delon a publié la première version de CherryPy fin juin 2002. C'était le point de départ d'une bibliothèque Web Python réussie. Remi est un hacker français qui a fait confiance à Python pour être l'une des meilleures alternatives pour le développement d'applications Web.
Le projet développé par Remi a attiré un certain nombre de développeurs intéressés par l'approche. L'approche comprenait les caractéristiques suivantes -
CherryPy était proche du modèle modèle-vue-contrôleur.
Une classe CherryPy doit être traitée et compilée par le moteur CherryPy pour produire un module Python autonome intégrant l'application complète ainsi que son propre serveur Web intégré.
CherryPy peut mapper une URL et sa chaîne de requête dans un appel de méthode Python, par exemple -
http://somehost.net/echo?message=hello would map to echo(message='hello')Au cours des deux années de développement du projet CherryPy, il a été soutenu par la communauté et Remi a publié plusieurs versions améliorées.
En juin 2004, une discussion a commencé sur l'avenir du projet et sur l'opportunité de continuer avec la même architecture. Le brainstorming et la discussion de plusieurs habitués du projet ont ensuite conduit au concept de moteur de publication d'objets et de filtres, qui est rapidement devenu un élément central de CherryPy2 Plus tard, en octobre 2004, la première version de CherryPy 2 alpha a été publiée comme preuve de concept ces idées fondamentales. CherryPy 2.0 a été un vrai succès; cependant, il a été reconnu que sa conception pouvait encore être améliorée et devait être remaniée.
Après des discussions basées sur des retours d'expérience, l'API de CherryPy a été encore modifiée pour améliorer son élégance, conduisant à la sortie de CherryPy 2.1.0 en octobre 2005. Après divers changements, l'équipe a publié CherryPy 2.2.0 en avril 2006.
Points forts de CherryPy
Les caractéristiques suivantes de CherryPy sont considérées comme ses points forts -
Simplicité
Développer un projet dans CherryPy est une tâche simple avec quelques lignes de code développées selon les conventions et les indentations de Python.
CherryPy est également très modulaire. Les composants principaux sont bien gérés avec un concept logique correct et les classes parentes sont extensibles aux classes enfants.
Puissance
CherryPy exploite toute la puissance de Python. Il fournit également des outils et des plugins, qui sont de puissants points d'extension nécessaires pour développer des applications de classe mondiale.
Open source
CherryPy est un framework Web Python open source (sous licence open-source BSD), ce qui signifie que ce framework peut être utilisé commercialement à un coût nul.
Aide communautaire
Il dispose d'une communauté dévouée qui fournit un support complet avec différents types de questions et réponses. La communauté essaie de fournir une assistance complète aux développeurs du niveau débutant au niveau avancé.
Déploiement
Il existe des moyens rentables de déployer l'application. CherryPy inclut son propre serveur HTTP prêt pour la production pour héberger votre application. CherryPy peut également être déployé sur n'importe quelle passerelle compatible WSGI.
CherryPy est livré dans des packages comme la plupart des projets open-source, qui peuvent être téléchargés et installés de différentes manières, mentionnées ci-dessous
- Utiliser une Tarball
- Utilisation d'easy_install
- Utiliser Subversion
Exigences
Les exigences de base pour l'installation du framework CherryPy incluent:
- Python avec la version 2.4 ou supérieure
- CherryPy 3.0
L'installation d'un module Python est considérée comme un processus simple. L'installation comprend l'utilisation des commandes suivantes.
python setup.py build
python setup.py installLes packages de Python sont stockés dans les répertoires par défaut suivants -
- Sous UNIX ou Linux,
/usr/local/lib/python2.4/site-packages
or
/usr/lib/python2.4/site-packages- Sur Microsoft Windows,
C:\Python or C:\Python2x- Sur Mac OS,
Python:Lib:site-packageInstallation à l'aide de Tarball
Un Tarball est une archive compressée de fichiers ou un répertoire. Le framework CherryPy fournit un Tarball pour chacune de ses versions (alpha, bêta et stable).
Il contient le code source complet de la bibliothèque. Le nom vient de l'utilitaire utilisé sous UNIX et d'autres systèmes d'exploitation.
Voici les étapes à suivre pour l'installation de CherryPy à l'aide d'une boule tar -
Step 1 - Téléchargez la version selon les besoins de l'utilisateur à partir de http://download.cherrypy.org/
Step 2- Recherchez le répertoire dans lequel Tarball a été téléchargé et décompressez-le. Pour le système d'exploitation Linux, tapez la commande suivante -
tar zxvf cherrypy-x.y.z.tgzPour Microsoft Windows, l'utilisateur peut utiliser un utilitaire tel que 7-Zip ou Winzip pour décompresser l'archive via une interface graphique.
Step 3 - Accédez au répertoire nouvellement créé et utilisez la commande suivante pour construire CherryPy -
python setup.py buildPour l'installation globale, la commande suivante doit être utilisée -
python setup.py installInstallation avec easy_install
Python Enterprise Application Kit (PEAK) fournit un module python nommé Easy Install. Cela facilite le déploiement des packages Python. Ce module simplifie la procédure de téléchargement, de création et de déploiement d'applications et de produits Python.
Easy Install doit être installé dans le système avant d'installer CherryPy.
Step 1 - Téléchargez le module ez_setup.py depuis http://peak.telecommunity.com et exécutez-le en utilisant les droits d'administration sur l'ordinateur: python ez_setup.py.
Step 2 - La commande suivante est utilisée pour installer Easy Install.
easy_install product_nameStep 3- easy_install recherchera l'index de package Python (PyPI) pour trouver le produit donné. PyPI est un référentiel centralisé d'informations pour tous les produits Python.
Utilisez la commande suivante pour déployer la dernière version disponible de CherryPy -
easy_install cherrypyStep 4 - easy_install téléchargera ensuite CherryPy, le compilera et l'installera globalement dans votre environnement Python.
Installation avec Subversion
L'installation de CherryPy à l'aide de Subversion est recommandée dans les situations suivantes -
Une fonctionnalité existe ou un bogue a été corrigé et n'est disponible que dans le code en cours de développement.
Lorsque le développeur travaille sur CherryPy lui-même.
Lorsque l'utilisateur a besoin d'une branche de la branche principale dans le référentiel de contrôle de version.
Pour la correction des bogues de la version précédente.
Le principe de base de la subversion est d'enregistrer un référentiel et de garder une trace de chacune des versions, qui incluent une série de changements.
Suivez ces étapes pour comprendre l'installation de CherryPy à l'aide de Subversion−
Step 1 - Pour utiliser la version la plus récente du projet, il est nécessaire d'extraire le dossier trunk trouvé sur le référentiel Subversion.
Step 2 - Entrez la commande suivante depuis un shell -
svn co http://svn.cherrypy.org/trunk cherrypyStep 3 - Maintenant, créez un répertoire CherryPy et téléchargez-y le code source complet.
Test de l'installation
Il faut vérifier si l'application a été correctement installée dans le système ou non de la même manière que nous le faisons pour des applications comme Java.
Vous pouvez choisir l'une des trois méthodes mentionnées dans le chapitre précédent pour installer et déployer CherryPy dans votre environnement. CherryPy doit pouvoir importer depuis le shell Python comme suit -
import cherrypy
cherrypy.__version__
'3.0.0'Si CherryPy n'est pas installé globalement dans l'environnement Python du système local, vous devez définir la variable d'environnement PYTHONPATH, sinon il affichera une erreur de la manière suivante -
import cherrypy
Traceback (most recent call last):
File "<stdin>", line 1, in ?
ImportError: No module named cherrypyIl y a quelques mots-clés importants qui doivent être définis afin de comprendre le fonctionnement de CherryPy. Les mots-clés et les définitions sont les suivants -
| S. Non | Mot-clé et définition |
|---|---|
| 1. | Web Server C'est une interface traitant du protocole HTTP. Son objectif est de transformer les requêtes HTTP vers le serveur d'application afin qu'ils obtiennent les réponses. |
| 2. | Application C'est un logiciel qui rassemble des informations. |
| 3. | Application server C'est le composant contenant une ou plusieurs applications |
| 4. | Web application server C'est la combinaison d'un serveur Web et d'un serveur d'applications. |
Exemple
L'exemple suivant montre un exemple de code de CherryPy -
import cherrypy
class demoExample:
def index(self):
return "Hello World!!!"
index.exposed = True
cherrypy.quickstart(demoExample())Voyons maintenant comment fonctionne le code -
Le package nommé CherryPy est toujours importé dans la classe spécifiée pour garantir un bon fonctionnement.
Dans l'exemple ci-dessus, la fonction nommée index renvoie le paramètre «Hello World !!!».
La dernière ligne démarre le serveur Web et appelle la classe spécifiée (ici, demoExample) et renvoie la valeur mentionnée dans l'index de fonction par défaut.
L'exemple de code renvoie la sortie suivante -

CherryPy est livré avec son propre serveur Web (HTTP). C'est pourquoi CherryPy est autonome et permet aux utilisateurs d'exécuter une application CherryPy quelques minutes après avoir obtenu la bibliothèque.
le web server agit comme la passerelle vers l'application à l'aide de laquelle toutes les demandes et réponses sont conservées.
Pour démarrer le serveur Web, un utilisateur doit effectuer l'appel suivant -
cherryPy.server.quickstart()le internal engine of CherryPy est responsable des activités suivantes -
- Création et gestion des objets de demande et de réponse.
- Contrôle et gestion du processus CherryPy.
CherryPy - Configuration
Le framework est livré avec son propre système de configuration vous permettant de paramétrer le serveur HTTP. Les paramètres de configuration peuvent être stockés soit dans un fichier texte avec une syntaxe proche du format INI, soit sous forme de dictionnaire Python complet.
Pour configurer l'instance de serveur CherryPy, le développeur doit utiliser la section globale des paramètres.
global_conf = {
'global': {
'server.socket_host': 'localhost',
'server.socket_port': 8080,
},
}
application_conf = {
'/style.css': {
'tools.staticfile.on': True,
'tools.staticfile.filename': os.path.join(_curdir, 'style.css'),
}
}
This could be represented in a file like this:
[global]
server.socket_host = "localhost"
server.socket_port = 8080
[/style.css]
tools.staticfile.on = True
tools.staticfile.filename = "/full/path/to.style.css"Conformité HTTP
CherryPy a évolué lentement mais il inclut la compilation de spécifications HTTP avec le support de HTTP / 1.0 transférant plus tard avec le support de HTTP / 1.1.
CherryPy est censé être conditionnellement conforme à HTTP / 1.1 car il implémente tous les niveaux obligatoires et requis mais pas tous les niveaux devraient de la spécification. Par conséquent, CherryPy prend en charge les fonctionnalités suivantes de HTTP / 1.1 -
Si un client prétend prendre en charge HTTP / 1.1, il doit envoyer un champ d'en-tête dans toute demande effectuée avec la version de protocole spécifiée. Si ce n'est pas fait, CherryPy arrêtera immédiatement le traitement de la demande.
CherryPy génère un champ d'en-tête Date qui est utilisé dans toutes les configurations.
CherryPy peut gérer le code d'état de réponse (100) avec le soutien des clients.
Le serveur HTTP intégré de CherryPy prend en charge les connexions persistantes qui sont la valeur par défaut dans HTTP / 1.1, via l'utilisation de l'en-tête Connection: Keep-Alive.
CherryPy gère les demandes et les réponses correctement fragmentées.
CherryPy prend en charge les demandes de deux manières distinctes - les en-têtes If-Modified-Since et If-Unmodified-Since et envoie des réponses selon les demandes en conséquence.
CherryPy autorise n'importe quelle méthode HTTP.
CherryPy gère les combinaisons de versions HTTP entre le client et le jeu de paramètres pour le serveur.
Serveur d'applications multithread
CherryPy est conçu sur la base du concept multithreading. Chaque fois qu'un développeur obtient ou définit une valeur dans l'espace de noms CherryPy, cela se fait dans l'environnement multi-thread.
Cherrypy.request et cherrypy.response sont des conteneurs de données de thread, ce qui implique que votre application les appelle indépendamment en sachant quelle requête leur est envoyée par proxy au moment de l'exécution.
Les serveurs d'applications utilisant le modèle de thread ne sont pas très appréciés, car l'utilisation de threads est considérée comme augmentant la probabilité de problèmes dus aux exigences de synchronisation.
Les autres alternatives incluent -
Modèle multi-processus
Chaque requête est gérée par son propre processus Python. Ici, les performances et la stabilité du serveur peuvent être considérées comme meilleures.
Motif asynchrone
Ici, l'acceptation de nouvelles connexions et le renvoi des données au client se font de manière asynchrone à partir du processus de demande. Cette technique est connue pour son efficacité.
Distribution d'URL
La communauté CherryPy veut être plus flexible et que d'autres solutions pour les répartiteurs seraient appréciées. CherryPy 3 fournit d'autres répartiteurs intégrés et offre un moyen simple d'écrire et d'utiliser vos propres répartiteurs.
- Applications utilisées pour développer des méthodes HTTP. (GET, POST, PUT, etc.)
- Celui qui définit les routes dans l'URL - Routes Dispatcher
Répartiteur de méthode HTTP
Dans certaines applications, les URI sont indépendants de l'action, qui doit être effectuée par le serveur sur la ressource.
Par exemple,http://xyz.com/album/delete/10
L'URI contient l'opération que le client souhaite effectuer.
Par défaut, le répartiteur CherryPy serait mappé de la manière suivante -
album.delete(12)Le répartiteur mentionné ci-dessus est mentionné correctement, mais peut être rendu indépendant de la manière suivante -
http://xyz.com/album/10L'utilisateur peut se demander comment le serveur distribue la page exacte. Ces informations sont portées par la requête HTTP elle-même. Lorsqu'il y a une demande du client au serveur, CherryPy recherche le meilleur gestionnaire, le gestionnaire est une représentation de la ressource ciblée par l'URI.
DELETE /album/12 HTTP/1.1Répartiteur d'itinéraires
Voici une liste des paramètres de la méthode requise pour la répartition -
Le paramètre name est le nom unique de la route à connecter.
La route est le modèle correspondant aux URI.
Le contrôleur est l'instance contenant les gestionnaires de page.
L'utilisation du répartiteur de routes connecte un modèle qui correspond aux URI et associe un gestionnaire de page spécifique.
Exemple
Prenons un exemple pour comprendre comment cela fonctionne -
import random
import string
import cherrypy
class StringMaker(object):
@cherrypy.expose
def index(self):
return "Hello! How are you?"
@cherrypy.expose
def generate(self, length=9):
return ''.join(random.sample(string.hexdigits, int(length)))
if __name__ == '__main__':
cherrypy.quickstart(StringMaker ())Suivez les étapes ci-dessous pour obtenir la sortie du code ci-dessus -
Step 1 - Enregistrez le fichier mentionné ci-dessus sous tutRoutes.py.
Step 2 - Visitez l'URL suivante -
http://localhost:8080/generate?length=10Step 3 - Vous recevrez la sortie suivante -

Dans CherryPy, les outils intégrés offrent une interface unique pour appeler la bibliothèque CherryPy. Les outils définis dans CherryPy peuvent être implémentés des manières suivantes -
- À partir des paramètres de configuration
- En tant que décorateur Python ou via l'attribut spécial _cp_config d'un gestionnaire de page
- En tant que Python appelable qui peut être appliqué à partir de n'importe quelle fonction
Outil d'authentification de base
Le but de cet outil est de fournir une authentification de base à l'application conçue dans l'application.
Arguments
Cet outil utilise les arguments suivants -
| Nom | Défaut | La description |
|---|---|---|
| domaine | N / A | Chaîne définissant la valeur du domaine. |
| utilisateurs | N / A | Dictionnaire de la forme - username: mot de passe ou une fonction appelable Python renvoyant un tel dictionnaire. |
| Crypter | Aucun | Python appelable utilisé pour crypter le mot de passe renvoyé par le client et le comparer avec le mot de passe crypté fourni dans le dictionnaire des utilisateurs. |
Exemple
Prenons un exemple pour comprendre comment cela fonctionne -
import sha
import cherrypy
class Root:
@cherrypy.expose
def index(self):
return """
<html>
<head></head>
<body>
<a href = "admin">Admin </a>
</body>
</html>
"""
class Admin:
@cherrypy.expose
def index(self):
return "This is a private area"
if __name__ == '__main__':
def get_users():
# 'test': 'test'
return {'test': 'b110ba61c4c0873d3101e10871082fbbfd3'}
def encrypt_pwd(token):
return sha.new(token).hexdigest()
conf = {'/admin': {'tools.basic_auth.on': True,
tools.basic_auth.realm': 'Website name',
'tools.basic_auth.users': get_users,
'tools.basic_auth.encrypt': encrypt_pwd}}
root = Root()
root.admin = Admin()
cherrypy.quickstart(root, '/', config=conf)le get_usersLa fonction retourne un dictionnaire codé en dur mais récupère également les valeurs d'une base de données ou n'importe où ailleurs. L'administrateur de classe inclut cette fonction qui utilise un outil d'authentification intégré de CherryPy. L'authentification crypte le mot de passe et l'ID utilisateur.
L'outil d'authentification de base n'est pas vraiment sécurisé, car le mot de passe peut être encodé et décodé par un intrus.
Outil de mise en cache
Le but de cet outil est de fournir une mise en cache mémoire du contenu généré par CherryPy.
Arguments
Cet outil utilise les arguments suivants -
| Nom | Défaut | La description |
|---|---|---|
| invalid_methods | ("POST", "PUT", "DELETE") | Tuples de chaînes de méthodes HTTP à ne pas mettre en cache. Ces méthodes invalideront également (supprimeront) toute copie mise en cache de la ressource. |
| cache_Class | MemoryCache | Objet de classe à utiliser pour la mise en cache |
Outil de décodage
Le but de cet outil est de décoder les paramètres de la requête entrante.
Arguments
Cet outil utilise les arguments suivants -
| Nom | Défaut | La description |
|---|---|---|
| codage | Aucun | Il recherche l'en-tête de type de contenu |
| Default_encoding | «UTF-8» | Codage par défaut à utiliser quand aucun n'est fourni ou trouvé. |
Exemple
Prenons un exemple pour comprendre comment cela fonctionne -
import cherrypy
from cherrypy import tools
class Root:
@cherrypy.expose
def index(self):
return """
<html>
<head></head>
<body>
<form action = "hello.html" method = "post">
<input type = "text" name = "name" value = "" />
<input type = ”submit” name = "submit"/>
</form>
</body>
</html>
"""
@cherrypy.expose
@tools.decode(encoding='ISO-88510-1')
def hello(self, name):
return "Hello %s" % (name, )
if __name__ == '__main__':
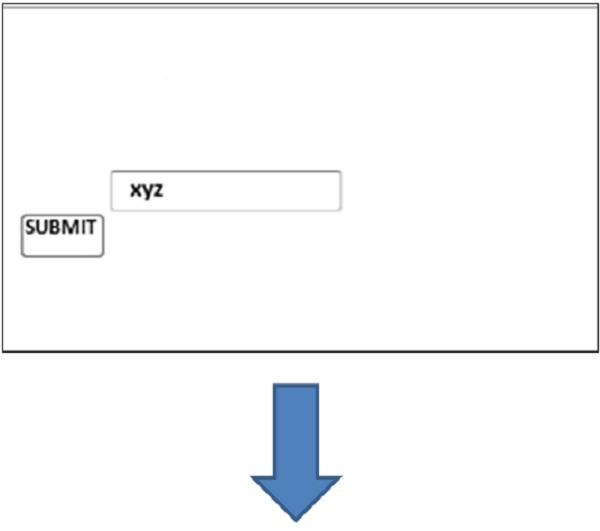
cherrypy.quickstart(Root(), '/')Le code ci-dessus prend une chaîne de l'utilisateur et il redirigera l'utilisateur vers la page "hello.html" où il sera affiché comme "Bonjour" avec le nom donné.
La sortie du code ci-dessus est la suivante -
hello.html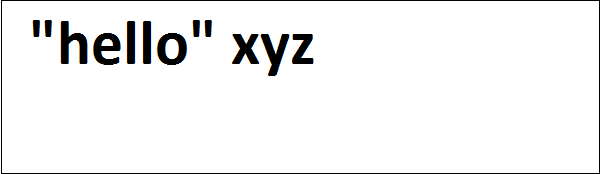
Les applications de pile complète fournissent une possibilité de créer une nouvelle application via une commande ou une exécution du fichier.
Considérez les applications Python comme le framework web2py; l'ensemble du projet / application est créé en termes de framework MVC. De même, CherryPy permet à l'utilisateur de configurer et de configurer la mise en page du code selon ses besoins.
Dans ce chapitre, nous allons apprendre en détail comment créer une application CherryPy et l'exécuter.
Système de fichiers
Le système de fichiers de l'application est illustré dans la capture d'écran suivante -
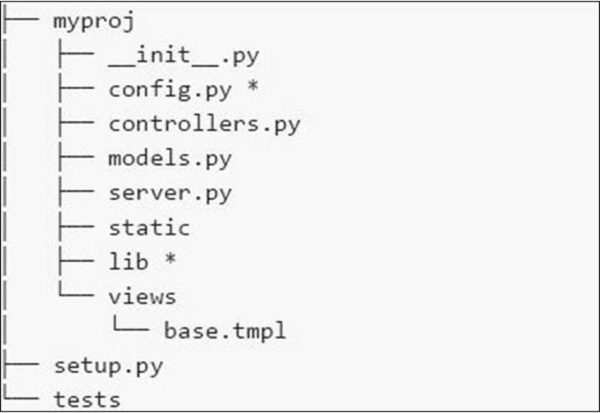
Voici une brève description des différents fichiers que nous avons dans le système de fichiers -
config.py- Chaque application a besoin d'un fichier de configuration et d'un moyen de le charger. Cette fonctionnalité peut être définie dans config.py.
controllers.py- MVC est un modèle de conception populaire suivi par les utilisateurs. Le controllers.py est l'endroit où tous les objets sont implémentés qui seront montés sur cherrypy.tree .
models.py - Ce fichier interagit avec la base de données directement pour certains services ou pour stocker des données persistantes.
server.py - Ce fichier interagit avec le serveur Web prêt pour la production qui fonctionne correctement avec le proxy d'équilibrage de charge.
Static - Il comprend tous les fichiers CSS et image.
Views - Il comprend tous les fichiers modèles pour une application donnée.
Exemple
Apprenons en détail les étapes pour créer une application CherryPy.
Step 1 - Créez une application qui doit contenir l'application.
Step 2- Dans le répertoire, créez un package python correspondant au projet. Créez le répertoire gedit et incluez le fichier _init_.py dans le même.
Step 3 - Dans le package, incluez le fichier controllers.py avec le contenu suivant -
#!/usr/bin/env python
import cherrypy
class Root(object):
def __init__(self, data):
self.data = data
@cherrypy.expose
def index(self):
return 'Hi! Welcome to your application'
def main(filename):
data = {} # will be replaced with proper functionality later
# configuration file
cherrypy.config.update({
'tools.encode.on': True, 'tools.encode.encoding': 'utf-8',
'tools.decode.on': True,
'tools.trailing_slash.on': True,
'tools.staticdir.root': os.path.abspath(os.path.dirname(__file__)),
})
cherrypy.quickstart(Root(data), '/', {
'/media': {
'tools.staticdir.on': True,
'tools.staticdir.dir': 'static'
}
})
if __name__ == '__main__':
main(sys.argv[1])Step 4- Considérons une application où l'utilisateur entre la valeur via un formulaire. Incluons deux formulaires - index.html et submit.html dans l'application.
Step 5 - Dans le code ci-dessus pour les contrôleurs, nous avons index(), qui est une fonction par défaut et se charge en premier si un contrôleur particulier est appelé.
Step 6 - La mise en œuvre du index() La méthode peut être modifiée de la manière suivante -
@cherrypy.expose
def index(self):
tmpl = loader.load('index.html')
return tmpl.generate(title='Sample').render('html', doctype='html')Step 7- Cela chargera index.html au démarrage de l'application donnée et la dirigera vers le flux de sortie donné. Le fichier index.html est le suivant -
index.html
<!DOCTYPE html >
<html>
<head>
<title>Sample</title>
</head>
<body class = "index">
<div id = "header">
<h1>Sample Application</h1>
</div>
<p>Welcome!</p>
<div id = "footer">
<hr>
</div>
</body>
</html>Step 8 - Il est important d'ajouter une méthode à la classe Root dans controller.py si vous souhaitez créer un formulaire qui accepte des valeurs telles que des noms et des titres.
@cherrypy.expose
def submit(self, cancel = False, **value):
if cherrypy.request.method == 'POST':
if cancel:
raise cherrypy.HTTPRedirect('/') # to cancel the action
link = Link(**value)
self.data[link.id] = link
raise cherrypy.HTTPRedirect('/')
tmp = loader.load('submit.html')
streamValue = tmp.generate()
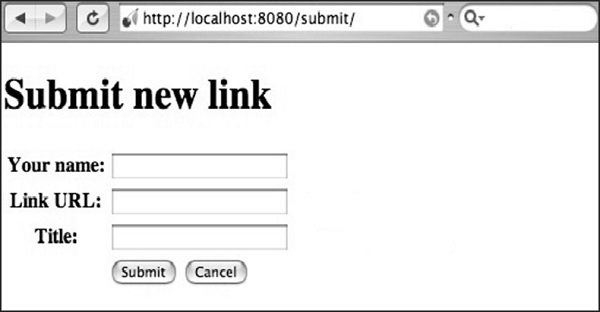
return streamValue.render('html', doctype='html')Step 9 - Le code à inclure dans submit.html est le suivant -
<!DOCTYPE html>
<head>
<title>Input the new link</title>
</head>
<body class = "submit">
<div id = " header">
<h1>Submit new link</h1>
</div>
<form action = "" method = "post">
<table summary = "">
<tr>
<th><label for = " username">Your name:</label></th>
<td><input type = " text" id = " username" name = " username" /></td>
</tr>
<tr>
<th><label for = " url">Link URL:</label></th>
<td><input type = " text" id=" url" name= " url" /></td>
</tr>
<tr>
<th><label for = " title">Title:</label></th>
<td><input type = " text" name = " title" /></td>
</tr>
<tr>
<td></td>
<td>
<input type = " submit" value = " Submit" />
<input type = " submit" name = " cancel" value = "Cancel" />
</td>
</tr>
</table>
</form>
<div id = "footer">
</div>
</body>
</html>Step 10 - Vous recevrez la sortie suivante -
Ici, le nom de la méthode est défini comme «POST». Il est toujours important de vérifier la méthode spécifiée dans le fichier. Si la méthode inclut la méthode «POST», les valeurs doivent être revérifiées dans la base de données dans les champs appropriés.
Si la méthode inclut la méthode «GET», les valeurs à enregistrer seront visibles dans l'URL.
Un service Web est un ensemble de composants Web qui facilite l'échange de données entre l'application ou les systèmes, qui comprend également des protocoles et des normes ouverts. Il peut être publié, utilisé et trouvé sur le Web.
Les services Web sont de divers types comme RWS (RESTfUL Web Service), WSDL, SOAP et bien d'autres.
REST - Transfert d'état de représentation
Type de protocole d'accès distant, qui transfère l'état du client au serveur, ce qui peut être utilisé pour manipuler l'état au lieu d'appeler des procédures distantes.
Ne définit pas d'encodage ou de structure spécifique et les moyens de renvoyer des messages d'erreur utiles.
Utilise des "verbes" HTTP pour effectuer des opérations de transfert d'état.
Les ressources sont identifiées de manière unique à l'aide de l'URL.
Ce n'est pas une API mais plutôt une couche de transport API.
REST maintient la nomenclature des ressources sur un réseau et fournit un mécanisme unifié pour effectuer des opérations sur ces ressources. Chaque ressource est identifiée par au moins un identifiant. Si l'infrastructure REST est implémentée avec la base de HTTP, ces identifiants sont appelésUniform Resource Identifiers (URIs).
Voici les deux sous-ensembles communs de l'ensemble d'URI -
| Sous-ensemble | Forme complète | Exemple |
|---|---|---|
| URL | Localisateur de ressources uniformes | http://www.gmail.com/ |
| URNE | Nom de ressource uniforme | urn: isbn: 0-201-71088-9 urn: uuid: 13e8cf26-2a25-11db-8693-000ae4ea7d46 |
Avant de comprendre l'implémentation de l'architecture CherryPy, concentrons-nous sur l'architecture de CherryPy.
CherryPy comprend les trois composants suivants -
cherrypy.engine - Il contrôle le démarrage / démontage des processus et la gestion des événements.
cherrypy.server - Il configure et contrôle le serveur WSGI ou HTTP.
cherrypy.tools - Une boîte à outils d'utilitaires orthogonaux au traitement d'une requête HTTP.
Interface REST via CherryPy
Le service Web RESTful implémente chaque section de l'architecture CherryPy à l'aide des éléments suivants:
- Authentication
- Authorization
- Structure
- Encapsulation
- La gestion des erreurs
Authentification
L'authentification aide à valider les utilisateurs avec lesquels nous interagissons. CherryPy comprend des outils pour gérer chaque méthode d'authentification.
def authenticate():
if not hasattr(cherrypy.request, 'user') or cherrypy.request.user is None:
# < Do stuff to look up your users >
cherrypy.request.authorized = False # This only authenticates.
Authz must be handled separately.
cherrypy.request.unauthorized_reasons = []
cherrypy.request.authorization_queries = []
cherrypy.tools.authenticate = \
cherrypy.Tool('before_handler', authenticate, priority=10)La fonction authenticate () ci-dessus aidera à valider l'existence des clients ou des utilisateurs. Les outils intégrés aident à terminer le processus de manière systématique.
Autorisation
L'autorisation aide à maintenir la cohérence du processus via URI. Le processus aide également à transformer les objets par des pistes de jetons utilisateur.
def authorize_all():
cherrypy.request.authorized = 'authorize_all'
cherrypy.tools.authorize_all = cherrypy.Tool('before_handler', authorize_all, priority=11)
def is_authorized():
if not cherrypy.request.authorized:
raise cherrypy.HTTPError("403 Forbidden",
','.join(cherrypy.request.unauthorized_reasons))
cherrypy.tools.is_authorized = cherrypy.Tool('before_handler', is_authorized,
priority = 49)
cherrypy.config.update({
'tools.is_authorized.on': True,
'tools.authorize_all.on': True
})Les outils d'autorisation intégrés aident à gérer les routines de manière systématique, comme mentionné dans l'exemple précédent.
Structure
Le maintien d'une structure d'API permet de réduire la charge de travail du mappage de l'URI de l'application. Il est toujours nécessaire de garder l'API détectable et propre. La structure de base de l'API pour le framework CherryPy devrait avoir les éléments suivants:
- Comptes et utilisateur
- Autoresponder
- Contact
- File
- Folder
- Liste et champ
- Message et lot
Encapsulation
L'encapsulation aide à créer une API légère, lisible par l'homme et accessible à divers clients. La liste des éléments ainsi que la création, la récupération, la mise à jour et la suppression nécessitent l'encapsulation de l'API.
La gestion des erreurs
Ce processus gère les erreurs, le cas échéant, si l'API ne s'exécute pas à l'instinct particulier. Par exemple, 400 correspond à une demande incorrecte et 403 correspond à une demande non autorisée.
Exemple
Considérez ce qui suit comme exemple d'erreurs de base de données, de validation ou d'application.
import cherrypy
import json
def error_page_default(status, message, traceback, version):
ret = {
'status': status,
'version': version,
'message': [message],
'traceback': traceback
}
return json.dumps(ret)
class Root:
_cp_config = {'error_page.default': error_page_default}
@cherrypy.expose
def index(self):
raise cherrypy.HTTPError(500, "Internal Sever Error")
cherrypy.quickstart(Root())Le code ci-dessus produira la sortie suivante -

La gestion de l'API (Application Programming Interface) est facile grâce à CherryPy grâce aux outils d'accès intégrés.
Méthodes HTTP
La liste des méthodes HTTP qui opèrent sur les ressources est la suivante -
| S. Non | Méthode et opération HTTP |
|---|---|
| 1. | HEAD Récupère les métadonnées de la ressource. |
| 2. | GET Récupère les métadonnées et le contenu de la ressource. |
| 3. | POST Demande au serveur de créer une nouvelle ressource à l'aide des données incluses dans le corps de la demande. |
| 4. | PUT Demande au serveur de remplacer une ressource existante par celle incluse dans le corps de la demande. |
| 5. | DELETE Demande au serveur de supprimer la ressource identifiée par cet URI. |
| 6. | OPTIONS Demande au serveur de renvoyer des détails sur les capacités soit globalement, soit spécifiquement pour une ressource. |
Protocole de publication Atom (APP)
APP est né de la communauté Atom en tant que protocole de niveau application en plus de HTTP pour permettre la publication et l'édition de ressources Web. L'unité de messages entre un serveur APP et un client est basée sur le format de document XML Atom.
Le protocole de publication Atom définit un ensemble d'opérations entre un service APP et un agent utilisateur utilisant HTTP et ses mécanismes et le format de document XML Atom comme unité de messages.
APP définit d'abord un document de service, qui fournit à l'agent utilisateur l'URI des différentes collections servies par le service APP.
Exemple
Prenons un exemple pour montrer comment fonctionne l'APP -
<?xml version = "1.0" encoding = "UTF-8"?>
<service xmlns = "http://purl.org/atom/app#" xmlns:atom = "http://www.w3.org/2005/Atom">
<workspace>
<collection href = "http://host/service/atompub/album/">
<atom:title> Albums</atom:title>
<categories fixed = "yes">
<atom:category term = "friends" />
</categories>
</collection>
<collection href = "http://host/service/atompub/film/">
<atom:title>Films</atom:title>
<accept>image/png,image/jpeg</accept>
</collection>
</workspace>
</service>APP spécifie comment effectuer les opérations CRUD de base sur un membre d'une collection ou la collection elle-même à l'aide des méthodes HTTP comme décrit dans le tableau suivant -
| Opération | Méthode HTTP | Code d'état | Contenu |
|---|---|---|---|
| Récupérer | AVOIR | 200 | Une entrée Atom représentant la ressource |
| Créer | PUBLIER | 201 | L'URI de la ressource nouvellement créée via les en-têtes Location et Content-Location |
| Mettre à jour | METTRE | 200 | Une entrée Atom représentant la ressource |
| Effacer | EFFACER | 200 | Aucun |
La couche de présentation garantit que la communication qui la traverse cible les destinataires prévus. CherryPy maintient le fonctionnement de la couche de présentation par divers moteurs de modèles.
Un moteur de modèle prend l'entrée de la page à l'aide de la logique métier, puis la traite vers la page finale qui cible uniquement le public visé.
Kid - Le moteur de modèles
Kid est un moteur de modèle simple qui inclut le nom du modèle à traiter (ce qui est obligatoire) et l'entrée des données à transmettre lors du rendu du modèle.
Lors de la création du modèle pour la première fois, Kid crée un module Python qui peut être servi comme une version mise en cache du modèle.
le kid.Template La fonction retourne une instance de la classe de modèle qui peut être utilisée pour rendre le contenu de sortie.
La classe de modèle fournit l'ensemble de commandes suivant -
| S. Non | Commande et description |
|---|---|
| 1. | serialize Il renvoie le contenu de sortie sous forme de chaîne. |
| 2. | generate Il renvoie le contenu de sortie sous forme d'itérateur. |
| 3. | write Il vide le contenu de sortie dans un objet fichier. |
Les paramètres utilisés par ces commandes sont les suivants -
| S. Non | Commande et description |
|---|---|
| 1. | encoding Il explique comment encoder le contenu de sortie |
| 2. | fragment C'est une valeur booléenne qui indique au prologue XML ou au Doctype |
| 3. | output Ce type de sérialisation est utilisé pour rendre le contenu |
Exemple
Prenons un exemple pour comprendre comment kid fonctionne -
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
<html xmlns:py = "http://purl.org/kid/ns#">
<head>
<title>${title}</title> <link rel = "stylesheet" href = "style.css" /> </head> <body> <p>${message}</p>
</body>
</html>
The next step after saving the file is to process the template via the Kid engine.
import kid
params = {'title': 'Hello world!!', 'message': 'CherryPy.'}
t = kid.Template('helloworld.kid', **params)
print t.serialize(output='html')Attributs de l'enfant
Voici les attributs de Kid -
Langage de modélisation basé sur XML
C'est un langage basé sur XML. Un modèle Kid doit être un document XML bien formé avec des conventions de dénomination appropriées.
Kid implémente des attributs dans les éléments XML pour mettre à jour le moteur sous-jacent sur l'action à suivre pour atteindre l'élément. Pour éviter le chevauchement avec d'autres attributs existants dans le document XML, Kid a introduit son propre espace de noms.
<p py:if = "...">...</p>Substitution de variable
Kid est livré avec un schéma de substitution de variable et une approche simple - $ {variable-name}.
Les variables peuvent être utilisées dans des attributs d'éléments ou comme contenu textuel d'un élément. Kid évaluera la variable à chaque fois que l'exécution a lieu.
Si l'utilisateur a besoin de la sortie d'une chaîne littérale comme $ {quelque chose}, il peut être échappé en utilisant la substitution de variable en doublant le signe dollar.
Déclaration conditionnelle
Pour basculer entre différents cas dans le modèle, la syntaxe suivante est utilisée -
<tag py:if = "expression">...</tag>Ici, tag est le nom de l'élément, par exemple DIV ou SPAN.
L'expression est une expression Python. Si, en tant que booléen, il donne la valeur True, l'élément sera inclus dans le contenu de sortie ou bien il ne fera pas partie du contenu de sortie.
Mécanisme de boucle
Pour boucler un élément dans Kid, la syntaxe suivante est utilisée -
<tag py:for = "expression">...</tag>Ici, tag est le nom de l'élément. L'expression est une expression Python, par exemple pour value in [...].
Exemple
Le code suivant montre comment fonctionne le mécanisme de bouclage -
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
<html>
<head>
<title>${title}</title> <link rel = "stylesheet" href = "style.css" /> </head> <body> <table> <caption>A few songs</caption> <tr> <th>Artist</th> <th>Album</th> <th>Title</th> </tr> <tr py:for = "info in infos"> <td>${info['artist']}</td>
<td>${info['album']}</td> <td>${info['song']}</td>
</tr>
</table>
</body>
</html>
import kid
params = discography.retrieve_songs()
t = kid.Template('songs.kid', **params)
print t.serialize(output='html')le output pour le code ci-dessus avec le mécanisme de bouclage est le suivant -
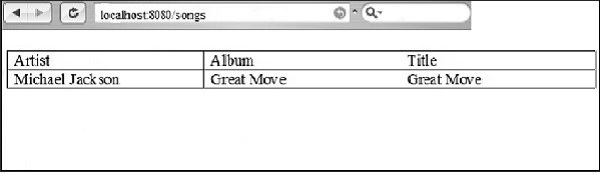
Jusqu'en 2005, le modèle suivi dans toutes les applications Web était de gérer une requête HTTP par page. La navigation d'une page vers une autre a nécessité le chargement de la page complète. Cela réduirait les performances à un niveau supérieur.
Ainsi, il y a eu une augmentation de rich client applications qui les intégrait avec AJAX, XML et JSON.
AJAX
JavaScript et XML asynchrones (AJAX) est une technique permettant de créer des pages Web rapides et dynamiques. AJAX permet aux pages Web d'être mises à jour de manière asynchrone en échangeant de petites quantités de données en arrière-plan avec le serveur. Cela signifie qu'il est possible de mettre à jour des parties d'une page Web, sans recharger la page entière.
Google Maps, Gmail, YouTube et Facebook sont quelques exemples d'applications AJAX.
Ajax est basé sur l'idée d'envoyer des requêtes HTTP en utilisant JavaScript; plus spécifiquement AJAX s'appuie sur l'objet XMLHttpRequest et son API pour effectuer ces opérations.
JSON
JSON est un moyen de transporter des objets JavaScript sérialisés de telle sorte que l'application JavaScript puisse les évaluer et les transformer en objets JavaScript qui peuvent être manipulés ultérieurement.
Par exemple, lorsque l'utilisateur demande au serveur un objet d'album au format JSON, le serveur renvoie la sortie comme suit -
{'description': 'This is a simple demo album for you to test', 'author': ‘xyz’}Désormais, les données sont un tableau associatif JavaScript et le champ de description est accessible via -
data ['description'];Application d'AJAX à l'application
Considérez l'application qui comprend un dossier nommé «media» avec index.html et le plugin Jquery, et un fichier avec l'implémentation AJAX. Considérons le nom du fichier comme "ajax_app.py"
ajax_app.py
import cherrypy
import webbrowser
import os
import simplejson
import sys
MEDIA_DIR = os.path.join(os.path.abspath("."), u"media")
class AjaxApp(object):
@cherrypy.expose
def index(self):
return open(os.path.join(MEDIA_DIR, u'index.html'))
@cherrypy.expose
def submit(self, name):
cherrypy.response.headers['Content-Type'] = 'application/json'
return simplejson.dumps(dict(title="Hello, %s" % name))
config = {'/media':
{'tools.staticdir.on': True,
'tools.staticdir.dir': MEDIA_DIR,}
}
def open_page():
webbrowser.open("http://127.0.0.1:8080/")
cherrypy.engine.subscribe('start', open_page)
cherrypy.tree.mount(AjaxApp(), '/', config=config)
cherrypy.engine.start()La classe «AjaxApp» redirige vers la page Web de «index.html», qui est incluse dans le dossier multimédia.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
" http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns = "http://www.w3.org/1999/xhtml" lang = "en" xml:lang = "en">
<head>
<title>AJAX with jQuery and cherrypy</title>
<meta http-equiv = " Content-Type" content = " text/html; charset=utf-8" />
<script type = " text/javascript" src = " /media/jquery-1.4.2.min.js"></script>
<script type = " text/javascript">
$(function() { // When the testform is submitted... $("#formtest").submit(function() {
// post the form values via AJAX...
$.post('/submit', {name: $("#name").val()}, function(data) {
// and set the title with the result
$("#title").html(data['title']) ;
});
return false ;
});
});
</script>
</head>
<body>
<h1 id = "title">What's your name?</h1>
<form id = " formtest" action = " #" method = " post">
<p>
<label for = " name">Name:</label>
<input type = " text" id = "name" /> <br />
<input type = " submit" value = " Set" />
</p>
</form>
</body>
</html>La fonction pour AJAX est incluse dans les balises <script>.
Production
Le code ci-dessus produira la sortie suivante -

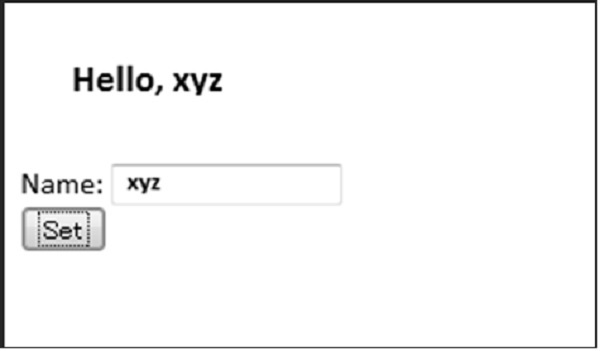
Une fois la valeur soumise par l'utilisateur, la fonctionnalité AJAX est implémentée et l'écran est redirigé vers le formulaire comme indiqué ci-dessous -
Dans ce chapitre, nous nous concentrerons sur la manière dont une application est créée dans le framework CherryPy.
Considérer Photoblogapplication pour l'application de démonstration de CherryPy. Une application Photoblog est un blog normal mais le texte principal sera des photos à la place du texte. Le principal inconvénient de l'application Photoblog est que le développeur peut se concentrer davantage sur la conception et la mise en œuvre.
Structure de base - Conception des entités
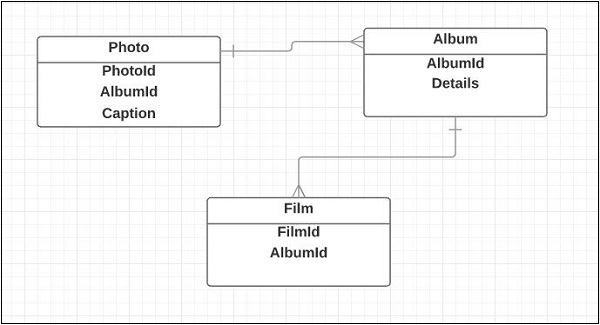
Les entités conçoivent la structure de base d'une application. Voici les entités de l'application Photoblog -
- Film
- Photo
- Album
Ce qui suit est un diagramme de classes de base pour la relation d'entité -
Structure de conception
Comme indiqué dans le chapitre précédent, la structure de conception du projet serait celle illustrée dans la capture d'écran suivante -

Considérez l'application donnée, qui a des sous-répertoires pour l'application Photoblog. Les sous-répertoires sont Photo, Album et Film qui incluraient controllers.py, models.py et server.py.
Sur le plan fonctionnel, l'application Photoblog fournira des API pour manipuler ces entités via l'interface CRUD traditionnelle - Créer, récupérer, mettre à jour et supprimer.
Connexion à la base de données
Un module de stockage comprend un ensemble d'opérations; la connexion avec la base de données étant l'une des opérations.
Comme il s'agit d'une application complète, la connexion avec la base de données est obligatoire pour l'API et pour maintenir la fonctionnalité de création, de récupération, de mise à jour et de suppression.
import dejavu
arena = dejavu.Arena()
from model import Album, Film, Photo
def connect():
conf = {'Connect': "host=localhost dbname=Photoblog user=test password=test"}
arena.add_store("main", "postgres", conf)
arena.register_all(globals())L'arène dans le code ci-dessus sera notre interface entre le gestionnaire de stockage sous-jacent et la couche de logique métier.
La fonction de connexion ajoute un gestionnaire de stockage à l'objet d'arène pour un SGBDR PostgreSQL.
Une fois que la connexion est obtenue, nous pouvons créer des formulaires selon les exigences de l'entreprise et terminer le fonctionnement de l'application.
La chose la plus importante avant la création d'une application est entity mapping et la conception de la structure de l'application.
Le test est un processus au cours duquel l'application est conduite sous différents angles afin de -
- Trouvez la liste des problèmes
- Trouvez les différences entre le résultat attendu et réel, la sortie, les états, etc.
- Comprenez la phase de mise en œuvre.
- Trouvez l'application utile à des fins réalistes.
Le but des tests n'est pas de mettre le développeur en faute mais de fournir des outils et d'améliorer la qualité pour estimer l'état de santé de l'application à un moment donné.
Les tests doivent être planifiés à l'avance. Cela nécessite de définir l'objectif du test, de comprendre la portée des cas de test, de dresser la liste des besoins métiers et d'être conscient des risques impliqués dans les différentes phases du projet.
Les tests sont définis comme une gamme d'aspects à valider sur un système ou une application. Voici une liste descommon test approaches -
Unit testing- Ceci est généralement effectué par les développeurs eux-mêmes. Cela vise à vérifier si une unité de code fonctionne comme prévu ou non.
Usability testing- Les développeurs peuvent généralement oublier qu'ils écrivent une application pour les utilisateurs finaux qui ne connaissent pas le système. Les tests d'utilisabilité vérifient les avantages et les inconvénients du produit.
Functional/Acceptance testing - Alors que les tests d'utilisabilité vérifient si une application ou un système est utilisable, les tests fonctionnels garantissent que chaque fonctionnalité spécifiée est mise en œuvre.
Load and performance testing- Ceci est effectué pour comprendre si le système peut s'adapter aux tests de charge et de performance à effectuer. Cela peut entraîner des modifications du matériel, l'optimisation des requêtes SQL, etc.
Regression testing - Il vérifie que les versions successives d'un produit ne cassent aucune des fonctionnalités précédentes.
Reliability and resilience testing - Les tests de fiabilité aident à valider l'application du système avec la panne d'un ou plusieurs composants.
Test unitaire
Les applications Photoblog utilisent constamment des tests unitaires pour vérifier les éléments suivants:
- Les nouvelles fonctionnalités fonctionnent correctement et comme prévu.
- Les fonctionnalités existantes ne sont pas interrompues par la nouvelle version du code.
- Les défauts sont corrigés et restent fixes.
Python est livré avec un module standard unittest offrant une approche différente des tests unitaires.
Test de l'unité
unittest est enraciné dans JUnit, un package de test unitaire Java développé par Kent Beck et Erich Gamma. Les tests unitaires renvoient simplement des données définies. Des objets simulés peuvent être définis. Ces objets permettent de tester par rapport à une interface de notre conception sans avoir à s'appuyer sur l'application globale. Ils fournissent également un moyen d'exécuter des tests en mode isolement avec d'autres tests inclus.
Définissons une classe factice de la manière suivante -
import unittest
class DummyTest(unittest.TestCase):
def test_01_forward(self):
dummy = Dummy(right_boundary=3)
self.assertEqual(dummy.forward(), 1)
self.assertEqual(dummy.forward(), 2)
self.assertEqual(dummy.forward(), 3)
self.assertRaises(ValueError, dummy.forward)
def test_02_backward(self):
dummy = Dummy(left_boundary=-3, allow_negative=True)
self.assertEqual(dummy.backward(), -1)
self.assertEqual(dummy.backward(), -2)
self.assertEqual(dummy.backward(), -3)
self.assertRaises(ValueError, dummy.backward)
def test_03_boundaries(self):
dummy = Dummy(right_boundary=3, left_boundary=-3,allow_negative=True)
self.assertEqual(dummy.backward(), -1)
self.assertEqual(dummy.backward(), -2)
self.assertEqual(dummy.forward(), -1)
self.assertEqual(dummy.backward(), -2)
self.assertEqual(dummy.backward(), -3)L'explication du code est la suivante -
Le module unittest doit être importé pour fournir des capacités de test unitaire pour la classe donnée.
Une classe doit être créée en sous-classant unittest.
Chaque méthode du code ci-dessus commence par un test de mot. Toutes ces méthodes sont appelées par le gestionnaire unittest.
Les méthodes assert / fail sont appelées par le scénario de test pour gérer les exceptions.
Considérez ceci comme un exemple pour exécuter un cas de test -
if __name__ == '__main__':
unittest.main()Le résultat (sortie) pour exécuter le cas de test sera le suivant -
----------------------------------------------------------------------
Ran 3 tests in 0.000s
OKTest fonctionel
Une fois que les fonctionnalités de l'application commencent à prendre forme conformément aux exigences, un ensemble de tests fonctionnels peut valider l'exactitude de l'application par rapport à la spécification. Cependant, le test doit être automatisé pour de meilleures performances, ce qui nécessiterait l'utilisation de produits tiers tels que Selenium.
CherryPy fournit une classe d'aide comme des fonctions intégrées pour faciliter l'écriture des tests fonctionnels.
Test de charge
En fonction de l'application que vous écrivez et de vos attentes en termes de volume, vous devrez peut-être exécuter des tests de charge et de performances afin de détecter les goulots d'étranglement potentiels dans l'application qui l'empêchent d'atteindre un certain niveau de performances.
Cette section ne détaillera pas comment effectuer un test de performance ou de charge car il est hors de son package FunkLoad.
L'exemple très basique de FunkLoad est le suivant -
from funkload.FunkLoadTestCase
import FunkLoadTestCase
class LoadHomePage(FunkLoadTestCase):
def test_homepage(self):
server_url = self.conf_get('main', 'url')
nb_time = self.conf_getInt('test_homepage', 'nb_time')
home_page = "%s/" % server_url
for i in range(nb_time):
self.logd('Try %i' % i)
self.get(home_page, description='Get gome page')
if __name__ in ('main', '__main__'):
import unittest
unittest.main()Voici une explication détaillée du code ci-dessus -
Le scénario de test doit hériter de la classe FunkLoadTestCase afin que le FunkLoad puisse effectuer son travail interne de suivi de ce qui se passe pendant le test.
Le nom de la classe est important car FunkLoad recherchera un fichier basé sur le nom de la classe.
Les cas de test conçus ont un accès direct aux fichiers de configuration. Les méthodes Get () et post () sont simplement appelées contre le serveur pour obtenir la réponse.
Ce chapitre se concentrera davantage sur l'application SSL basée sur CherryPy activée via le serveur HTTP CherryPy intégré.
Configuration
Il existe différents niveaux de paramètres de configuration requis dans une application Web -
Web server - Paramètres liés au serveur HTTP
Engine - Paramètres associés à l'hébergement du moteur
Application - Application utilisée par l'utilisateur
Déploiement
Le déploiement de l'application CherryPy est considéré comme une méthode assez simple où tous les packages requis sont disponibles à partir du chemin système Python. Dans un environnement hébergé sur le Web partagé, le serveur Web résidera dans le frontal, ce qui permet au fournisseur hôte d'exécuter les actions de filtrage. Le serveur frontal peut être Apache oulighttpd.
Cette section présente quelques solutions pour exécuter une application CherryPy derrière les serveurs Web Apache et lighttpd.
cherrypy
def setup_app():
class Root:
@cherrypy.expose
def index(self):
# Return the hostname used by CherryPy and the remote
# caller IP address
return "Hello there %s from IP: %s " %
(cherrypy.request.base, cherrypy.request.remote.ip)
cherrypy.config.update({'server.socket_port': 9091,
'environment': 'production',
'log.screen': False,
'show_tracebacks': False})
cherrypy.tree.mount(Root())
if __name__ == '__main__':
setup_app()
cherrypy.server.quickstart()
cherrypy.engine.start()SSL
SSL (Secure Sockets Layer)peut être pris en charge dans les applications basées sur CherryPy. Pour activer la prise en charge SSL, les conditions suivantes doivent être remplies -
- Avoir le package PyOpenSSL installé dans l'environnement de l'utilisateur
- Avoir un certificat SSL et une clé privée sur le serveur
Créer un certificat et une clé privée
Traitons les exigences du certificat et de la clé privée -
- Tout d'abord, l'utilisateur a besoin d'une clé privée -
openssl genrsa -out server.key 2048- Cette clé n'est pas protégée par un mot de passe et a donc une faible protection.
- La commande suivante sera émise -
openssl genrsa -des3 -out server.key 2048Le programme nécessitera une phrase secrète. Si votre version d'OpenSSL vous permet de fournir une chaîne vide, faites-le. Sinon, entrez une phrase de passe par défaut, puis supprimez-la de la clé générée comme suit -
openssl rsa -in server.key -out server.key- La création du certificat est la suivante -
openssl req -new -key server.key -out server.csrCe processus vous demandera de saisir quelques détails. Pour ce faire, la commande suivante doit être émise -
openssl x509 -req -days 60 -in server.csr -signkey
server.key -out server.crtLe certificat nouvellement signé sera valide pendant 60 jours.
Le code suivant montre son implémentation -
import cherrypy
import os, os.path
localDir = os.path.abspath(os.path.dirname(__file__))
CA = os.path.join(localDir, 'server.crt')
KEY = os.path.join(localDir, 'server.key')
def setup_server():
class Root:
@cherrypy.expose
def index(self):
return "Hello there!"
cherrypy.tree.mount(Root())
if __name__ == '__main__':
setup_server()
cherrypy.config.update({'server.socket_port': 8443,
'environment': 'production',
'log.screen': True,
'server.ssl_certificate': CA,
'server.ssl_private_key': KEY})
cherrypy.server.quickstart()
cherrypy.engine.start()L'étape suivante consiste à démarrer le serveur; si vous réussissez, vous verrez le message suivant sur votre écran -
HTTP Serving HTTPS on https://localhost:8443/