Elasticsearch - Guide rapide
Elasticsearch est un serveur de recherche basé sur Apache Lucene. Il a été développé par Shay Banon et publié en 2010. Il est maintenant maintenu par Elasticsearch BV. Sa dernière version est la 7.0.0.
Elasticsearch est un moteur de recherche et d'analyse en texte intégral distribué et open source en temps réel. Il est accessible à partir de l'interface de service Web RESTful et utilise des documents JSON (JavaScript Object Notation) sans schéma pour stocker les données. Il est construit sur le langage de programmation Java et par conséquent Elasticsearch peut fonctionner sur différentes plates-formes. Il permet aux utilisateurs d'explorer de très grandes quantités de données à très haute vitesse.
Caractéristiques générales
Les caractéristiques générales d'Elasticsearch sont les suivantes -
Elasticsearch est évolutif jusqu'à pétaoctets de données structurées et non structurées.
Elasticsearch peut être utilisé en remplacement des magasins de documents tels que MongoDB et RavenDB.
Elasticsearch utilise la dénormalisation pour améliorer les performances de recherche.
Elasticsearch est l'un des moteurs de recherche d'entreprise les plus populaires et est actuellement utilisé par de nombreuses grandes organisations telles que Wikipedia, The Guardian, StackOverflow, GitHub, etc.
Elasticsearch est une open source et disponible sous la licence Apache version 2.0.
Concepts clés
Les concepts clés d'Elasticsearch sont les suivants -
Nœud
Il fait référence à une seule instance en cours d'exécution d'Elasticsearch. Un seul serveur physique et virtuel accueille plusieurs nœuds en fonction des capacités de leurs ressources physiques telles que la RAM, le stockage et la puissance de traitement.
Grappe
C'est une collection d'un ou plusieurs nœuds. Cluster fournit des capacités d'indexation et de recherche collectives sur tous les nœuds pour des données entières.
Indice
C'est une collection de différents types de documents et de leurs propriétés. Index utilise également le concept de fragments pour améliorer les performances. Par exemple, un ensemble de documents contient des données d'une application de réseautage social.
Document
C'est une collection de champs d'une manière spécifique définie au format JSON. Chaque document appartient à un type et réside dans un index. Chaque document est associé à un identifiant unique appelé UID.
Tesson
Les index sont subdivisés horizontalement en fragments. Cela signifie que chaque partition contient toutes les propriétés du document mais contient moins d'objets JSON que l'index. La séparation horizontale fait du shard un nœud indépendant, qui peut être stocké dans n'importe quel nœud. La partition principale est la partie horizontale d'origine d'un index, puis ces partitions principales sont répliquées en fragments de réplique.
Répliques
Elasticsearch permet à un utilisateur de créer des répliques de leurs index et fragments. La réplication permet non seulement d'augmenter la disponibilité des données en cas d'échec, mais améliore également les performances de recherche en effectuant une opération de recherche parallèle dans ces répliques.
Avantages
Elasticsearch est développé sur Java, ce qui le rend compatible sur presque toutes les plates-formes.
Elasticsearch est en temps réel, c'est-à-dire qu'au bout d'une seconde, le document ajouté est consultable dans ce moteur
Elasticsearch est distribué, ce qui facilite sa mise à l'échelle et son intégration dans toute grande organisation.
La création de sauvegardes complètes est facile en utilisant le concept de passerelle, présent dans Elasticsearch.
La gestion de la multi-location est très simple dans Elasticsearch par rapport à Apache Solr.
Elasticsearch utilise des objets JSON comme réponses, ce qui permet d'appeler le serveur Elasticsearch avec un grand nombre de langages de programmation différents.
Elasticsearch prend en charge presque tous les types de documents, sauf ceux qui ne prennent pas en charge le rendu de texte.
Désavantages
Elasticsearch n'a pas de support multilingue en termes de traitement des données de demande et de réponse (uniquement possible en JSON) contrairement à Apache Solr, où cela est possible aux formats CSV, XML et JSON.
Parfois, Elasticsearch a un problème de situations de fractionnement du cerveau.
Comparaison entre Elasticsearch et RDBMS
Dans Elasticsearch, l'index est similaire aux tables du SGBDR (Relation Database Management System). Chaque table est une collection de lignes, tout comme chaque index est une collection de documents dans Elasticsearch.
Le tableau suivant donne une comparaison directe entre ces termes -
| Elasticsearch | SGBDR |
|---|---|
| Grappe | Base de données |
| Tesson | Tesson |
| Indice | Table |
| Champ | Colonne |
| Document | Rangée |
Dans ce chapitre, nous comprendrons en détail la procédure d'installation d'Elasticsearch.
Pour installer Elasticsearch sur votre ordinateur local, vous devrez suivre les étapes ci-dessous -
Step 1- Vérifiez la version de java installée sur votre ordinateur. Il doit être java 7 ou supérieur. Vous pouvez vérifier en procédant comme suit -
Dans le système d'exploitation Windows (OS) (à l'aide de l'invite de commande) -
> java -versionSous UNIX OS (à l'aide du terminal) -
$ echo $JAVA_HOMEStep 2 - En fonction de votre système d'exploitation, téléchargez Elasticsearch depuis www.elastic.co comme indiqué ci-dessous -
Pour Windows OS, téléchargez le fichier ZIP.
Pour UNIX OS, téléchargez le fichier TAR.
Pour le système d'exploitation Debian, téléchargez le fichier DEB.
Pour Red Hat et les autres distributions Linux, téléchargez le fichier RPN.
Les utilitaires APT et Yum peuvent également être utilisés pour installer Elasticsearch dans de nombreuses distributions Linux.
Step 3 - Le processus d'installation d'Elasticsearch est simple et est décrit ci-dessous pour différents systèmes d'exploitation -
Windows OS- Décompressez le package zip et Elasticsearch est installé.
UNIX OS- Extrayez le fichier tar dans n'importe quel emplacement et Elasticsearch est installé.
$wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch7.0.0-linux-x86_64.tar.gz $tar -xzf elasticsearch-7.0.0-linux-x86_64.tar.gzUsing APT utility for Linux OS- Téléchargez et installez la clé de signature publique
$ wget -qo - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo
apt-key add -Enregistrez la définition du référentiel comme indiqué ci-dessous -
$ echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" |
sudo tee -a /etc/apt/sources.list.d/elastic-7.x.listExécutez la mise à jour à l'aide de la commande suivante -
$ sudo apt-get updateVous pouvez maintenant installer en utilisant la commande suivante -
$ sudo apt-get install elasticsearchDownload and install the Debian package manually using the command given here −
$wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch7.0.0-amd64.deb $sudo dpkg -i elasticsearch-7.0.0-amd64.deb0Using YUM utility for Debian Linux OS
Téléchargez et installez la clé de signature publique -
$ rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearchAJOUTEZ le texte suivant dans le fichier avec le suffixe .repo dans votre répertoire «/etc/yum.repos.d/». Par exemple, elasticsearch.repo
elasticsearch-7.x]
name=Elasticsearch repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-mdVous pouvez maintenant installer Elasticsearch en utilisant la commande suivante
sudo yum install elasticsearchStep 4- Allez dans le répertoire de base d'Elasticsearch et dans le dossier bin. Exécutez le fichier elasticsearch.bat dans le cas de Windows ou vous pouvez faire la même chose en utilisant l'invite de commande et via le terminal dans le cas du fichier UNIX rum Elasticsearch.
Sous Windows
> cd elasticsearch-2.1.0/bin
> elasticsearchSous Linux
$ cd elasticsearch-2.1.0/bin
$ ./elasticsearchNote - Dans le cas de Windows, vous pourriez obtenir une erreur indiquant que JAVA_HOME n'est pas défini, veuillez le définir dans les variables d'environnement sur «C: \ Program Files \ Java \ jre1.8.0_31» ou l'emplacement où vous avez installé java.
Step 5- Le port par défaut de l'interface Web d'Elasticsearch est 9200 ou vous pouvez le modifier en modifiant http.port dans le fichier elasticsearch.yml présent dans le répertoire bin. Vous pouvez vérifier si le serveur est opérationnel en parcouranthttp://localhost:9200. Il renverra un objet JSON, qui contient les informations sur Elasticsearch installé de la manière suivante -
{
"name" : "Brain-Child",
"cluster_name" : "elasticsearch", "version" : {
"number" : "2.1.0",
"build_hash" : "72cd1f1a3eee09505e036106146dc1949dc5dc87",
"build_timestamp" : "2015-11-18T22:40:03Z",
"build_snapshot" : false,
"lucene_version" : "5.3.1"
},
"tagline" : "You Know, for Search"
}Step 6- Dans cette étape, installons Kibana. Suivez le code respectif ci-dessous pour l'installation sur Linux et Windows -
For Installation on Linux −
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.0.0-linuxx86_64.tar.gz
tar -xzf kibana-7.0.0-linux-x86_64.tar.gz
cd kibana-7.0.0-linux-x86_64/
./bin/kibanaFor Installation on Windows −
Téléchargez Kibana pour Windows à partir de https://www.elastic.co/products/kibana. Une fois que vous cliquez sur le lien, vous trouverez la page d'accueil comme indiqué ci-dessous -
Décompressez et accédez au répertoire de base de Kibana, puis exécutez-le.
CD c:\kibana-7.0.0-windows-x86_64
.\bin\kibana.batDans ce chapitre, apprenons comment ajouter des index, des mappages et des données à Elasticsearch. Notez que certaines de ces données seront utilisées dans les exemples expliqués dans ce didacticiel.
Créer un index
Vous pouvez utiliser la commande suivante pour créer un index -
PUT schoolRéponse
Si l'index est créé, vous pouvez voir la sortie suivante -
{"acknowledged": true}Ajouter des données
Elasticsearch stockera les documents que nous ajoutons à l'index comme indiqué dans le code suivant. Les documents reçoivent des identifiants utilisés pour identifier le document.
Demander le corps
POST school/_doc/10
{
"name":"Saint Paul School", "description":"ICSE Afiliation",
"street":"Dawarka", "city":"Delhi", "state":"Delhi", "zip":"110075",
"location":[28.5733056, 77.0122136], "fees":5000,
"tags":["Good Faculty", "Great Sports"], "rating":"4.5"
}Réponse
{
"_index" : "school",
"_type" : "_doc",
"_id" : "10",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}Ici, nous ajoutons un autre document similaire.
POST school/_doc/16
{
"name":"Crescent School", "description":"State Board Affiliation",
"street":"Tonk Road",
"city":"Jaipur", "state":"RJ", "zip":"176114","location":[26.8535922,75.7923988],
"fees":2500, "tags":["Well equipped labs"], "rating":"4.5"
}Réponse
{
"_index" : "school",
"_type" : "_doc",
"_id" : "16",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 9,
"_primary_term" : 7
}De cette façon, nous continuerons à ajouter tous les exemples de données dont nous avons besoin pour notre travail dans les prochains chapitres.
Ajout d'exemples de données dans Kibana
Kibana est un outil piloté par GUI pour accéder aux données et créer la visualisation. Dans cette section, voyons comment nous pouvons y ajouter des exemples de données.
Dans la page d'accueil de Kibana, choisissez l'option suivante pour ajouter des exemples de données de commerce électronique -
L'écran suivant affichera une visualisation et un bouton pour ajouter des données -
Cliquez sur Ajouter des données pour afficher l'écran suivant qui confirme que les données ont été ajoutées à un index nommé eCommerce.
Dans tout système ou logiciel, lorsque nous mettons à niveau vers une version plus récente, nous devons suivre quelques étapes pour maintenir les paramètres de l'application, les configurations, les données et autres. Ces étapes sont nécessaires pour rendre l'application stable dans un nouveau système ou pour maintenir l'intégrité des données (éviter que les données ne soient corrompues).
Vous devez suivre les étapes suivantes pour mettre à niveau Elasticsearch -
Lire les documents de mise à niveau sur https://www.elastic.co/
Testez la version mise à niveau dans vos environnements hors production comme dans l'environnement UAT, E2E, SIT ou DEV.
Notez que la restauration vers la version précédente d'Elasticsearch n'est pas possible sans sauvegarde des données. Par conséquent, une sauvegarde des données est recommandée avant la mise à niveau vers une version supérieure.
Nous pouvons mettre à niveau en utilisant un redémarrage complet du cluster ou une mise à niveau progressive. La mise à niveau progressive concerne les nouvelles versions. Notez qu'il n'y a pas de panne de service lorsque vous utilisez la méthode de mise à niveau progressive pour la migration.
Étapes de la mise à niveau
Testez la mise à niveau dans un environnement de développement avant de mettre à niveau votre cluster de production.
Sauvegardez vos données. Vous ne pouvez pas revenir à une version antérieure sauf si vous disposez d'un instantané de vos données.
Envisagez de fermer les tâches de machine learning avant de démarrer le processus de mise à niveau. Bien que les tâches d'apprentissage automatique puissent continuer à s'exécuter pendant une mise à niveau progressive, cela augmente la surcharge sur le cluster pendant le processus de mise à niveau.
Mettez à niveau les composants de votre Elastic Stack dans l'ordre suivant -
- Elasticsearch
- Kibana
- Logstash
- Beats
- Serveur APM
Mise à niveau à partir de la version 6.6 ou antérieure
Pour mettre à niveau directement vers Elasticsearch 7.1.0 à partir des versions 6.0-6.6, vous devez réindexer manuellement tous les index 5.x que vous devez reporter et effectuer un redémarrage complet du cluster.
Redémarrage complet du cluster
Le processus de redémarrage complet du cluster implique l'arrêt de chaque nœud du cluster, la mise à niveau de chaque nœud vers 7x, puis le redémarrage du cluster.
Voici les étapes de haut niveau à effectuer pour le redémarrage complet du cluster:
- Désactiver l'allocation de partition
- Arrêtez l'indexation et effectuez un vidage synchronisé
- Arrêtez tous les nœuds
- Mettre à niveau tous les nœuds
- Mettez à niveau tous les plugins
- Démarrez chaque nœud mis à niveau
- Attendez que tous les nœuds rejoignent le cluster et signalez un état jaune
- Réactiver l'allocation
Une fois l'allocation réactivée, le cluster commence à allouer les fragments de réplique aux nœuds de données. À ce stade, vous pouvez reprendre l'indexation et la recherche en toute sécurité, mais votre cluster récupérera plus rapidement si vous pouvez attendre que toutes les partitions principales et de réplique aient été allouées avec succès et que l'état de tous les nœuds soit vert.
L'interface de programmation d'application (API) dans le Web est un groupe d'appels de fonction ou d'autres instructions de programmation pour accéder au composant logiciel dans cette application Web particulière. Par exemple, l'API Facebook aide un développeur à créer des applications en accédant aux données ou à d'autres fonctionnalités de Facebook; il peut s'agir de la date de naissance ou de la mise à jour du statut.
Elasticsearch fournit une API REST, accessible par JSON via HTTP. Elasticsearch utilise certaines conventions dont nous allons discuter maintenant.
Indices multiples
La plupart des opérations, principalement les opérations de recherche et autres, dans les API concernent un ou plusieurs index. Cela aide l'utilisateur à rechercher dans plusieurs endroits ou dans toutes les données disponibles en exécutant simplement une requête une fois. De nombreuses notations différentes sont utilisées pour effectuer des opérations dans plusieurs index. Nous en discuterons quelques-uns ici dans ce chapitre.
Notation séparée par des virgules
POST /index1,index2,index3/_searchDemander le corps
{
"query":{
"query_string":{
"query":"any_string"
}
}
}Réponse
Objets JSON de index1, index2, index3 contenant any_string.
_all mot-clé pour tous les indices
POST /_all/_searchDemander le corps
{
"query":{
"query_string":{
"query":"any_string"
}
}
}Réponse
Objets JSON de tous les index et contenant any_string.
Caractères génériques (*, +, -)
POST /school*/_searchDemander le corps
{
"query":{
"query_string":{
"query":"CBSE"
}
}
}Réponse
Objets JSON de tous les index qui commencent par l'école contenant CBSE.
Vous pouvez également utiliser le code suivant -
POST /school*,-schools_gov /_searchDemander le corps
{
"query":{
"query_string":{
"query":"CBSE"
}
}
}Réponse
Objets JSON de tous les index qui commencent par «school» mais pas de schools_gov et qui contiennent CBSE.
Il existe également des paramètres de chaîne de requête URL -
- ignore_unavailable- Aucune erreur ne se produira ou aucune opération ne sera arrêtée, si le ou les index (s) présents dans l'URL n'existent pas. Par exemple, l'index des écoles existe, mais book_shops n'existe pas.
POST /school*,book_shops/_searchDemander le corps
{
"query":{
"query_string":{
"query":"CBSE"
}
}
}Demander le corps
{
"error":{
"root_cause":[{
"type":"index_not_found_exception", "reason":"no such index",
"resource.type":"index_or_alias", "resource.id":"book_shops",
"index":"book_shops"
}],
"type":"index_not_found_exception", "reason":"no such index",
"resource.type":"index_or_alias", "resource.id":"book_shops",
"index":"book_shops"
},"status":404
}Considérez le code suivant -
POST /school*,book_shops/_search?ignore_unavailable = trueDemander le corps
{
"query":{
"query_string":{
"query":"CBSE"
}
}
}Réponse (pas d'erreur)
Objets JSON de tous les index qui commencent par l'école contenant CBSE.
allow_no_indices
trueLa valeur de ce paramètre empêchera les erreurs, si une URL avec un caractère générique ne produit aucun index. Par exemple, il n'y a pas d'index commençant par schools_pri -
POST /schools_pri*/_search?allow_no_indices = trueDemander le corps
{
"query":{
"match_all":{}
}
}Réponse (aucune erreur)
{
"took":1,"timed_out": false, "_shards":{"total":0, "successful":0, "failed":0},
"hits":{"total":0, "max_score":0.0, "hits":[]}
}expand_wildcards
Ce paramètre décide si les caractères génériques doivent être développés pour ouvrir des index ou des index fermés ou effectuer les deux. La valeur de ce paramètre peut être ouverte et fermée ou aucune et toutes.
Par exemple, fermer les écoles index -
POST /schools/_closeRéponse
{"acknowledged":true}Considérez le code suivant -
POST /school*/_search?expand_wildcards = closedDemander le corps
{
"query":{
"match_all":{}
}
}Réponse
{
"error":{
"root_cause":[{
"type":"index_closed_exception", "reason":"closed", "index":"schools"
}],
"type":"index_closed_exception", "reason":"closed", "index":"schools"
}, "status":403
}Prise en charge mathématique des dates dans les noms d'index
Elasticsearch propose une fonctionnalité de recherche d'index en fonction de la date et de l'heure. Nous devons spécifier la date et l'heure dans un format spécifique. Par exemple, accountdetail-2015.12.30, index stockera les détails du compte bancaire du 30 décembre 2015. Des opérations mathématiques peuvent être effectuées pour obtenir des détails pour une date particulière ou une plage de dates et d'heures.
Format du nom de l'index mathématique de date -
<static_name{date_math_expr{date_format|time_zone}}>
/<accountdetail-{now-2d{YYYY.MM.dd|utc}}>/_searchstatic_name est une partie de l'expression qui reste la même dans chaque index mathématique de date comme le détail du compte. date_math_expr contient l'expression mathématique qui détermine la date et l'heure de manière dynamique comme now-2d. date_format contient le format dans lequel la date est écrite dans un index comme AAAA.MM.dd. Si la date d'aujourd'hui est le 30 décembre 2015, <accountdetail- {now-2d {YYYY.MM.dd}}> renverra accountdetail-2015.12.28.
| Expression | Décide de |
|---|---|
| <accountdetail- {now-d}> | accountdetail-2015.12.29 |
| <accountdetail- {now-M}> | accountdetail-2015.11.30 |
| <accountdetail- {now {YYYY.MM}}> | accountdetail-2015.12 |
Nous allons maintenant voir certaines des options courantes disponibles dans Elasticsearch qui peuvent être utilisées pour obtenir la réponse dans un format spécifié.
Jolis résultats
Nous pouvons obtenir une réponse dans un objet JSON bien formaté en ajoutant simplement un paramètre de requête URL, c'est-à-dire pretty = true.
POST /schools/_search?pretty = trueDemander le corps
{
"query":{
"match_all":{}
}
}Réponse
……………………..
{
"_index" : "schools", "_type" : "school", "_id" : "1", "_score" : 1.0,
"_source":{
"name":"Central School", "description":"CBSE Affiliation",
"street":"Nagan", "city":"paprola", "state":"HP", "zip":"176115",
"location": [31.8955385, 76.8380405], "fees":2000,
"tags":["Senior Secondary", "beautiful campus"], "rating":"3.5"
}
}
………………….Sortie lisible par l'homme
Cette option peut changer les réponses statistiques sous une forme lisible par l'homme (si humain = vrai) ou sous une forme lisible par ordinateur (si humain = faux). Par exemple, si human = true alors distance_kilometer = 20KM et si human = false alors distance_meter = 20000, lorsque la réponse doit être utilisée par un autre programme informatique.
Filtrage des réponses
Nous pouvons filtrer la réponse à moins de champs en les ajoutant dans le paramètre field_path. Par exemple,
POST /schools/_search?filter_path = hits.totalDemander le corps
{
"query":{
"match_all":{}
}
}Réponse
{"hits":{"total":3}}Elasticsearch fournit des API de document unique et des API multi-documents, dans lesquelles l'appel d'API cible un seul document et plusieurs documents respectivement.
API d'index
Il est utile d'ajouter ou de mettre à jour le document JSON dans un index lorsqu'une demande est faite à cet index respectif avec un mappage spécifique. Par exemple, la demande suivante ajoutera l'objet JSON aux écoles d'index et sous le mappage scolaire -
PUT schools/_doc/5
{
name":"City School", "description":"ICSE", "street":"West End",
"city":"Meerut",
"state":"UP", "zip":"250002", "location":[28.9926174, 77.692485],
"fees":3500,
"tags":["fully computerized"], "rating":"4.5"
}En exécutant le code ci-dessus, nous obtenons le résultat suivant -
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}Création d'index automatique
Lorsqu'une demande est faite pour ajouter un objet JSON à un index particulier et si cet index n'existe pas, cette API crée automatiquement cet index ainsi que le mappage sous-jacent pour cet objet JSON particulier. Cette fonctionnalité peut être désactivée en modifiant les valeurs des paramètres suivants sur false, qui sont présents dans le fichier elasticsearch.yml.
action.auto_create_index:false
index.mapper.dynamic:falseVous pouvez également restreindre la création automatique d'index, où seul le nom d'index avec des modèles spécifiques est autorisé en modifiant la valeur du paramètre suivant -
action.auto_create_index:+acc*,-bank*Note - Ici + indique autorisé et - indique non autorisé.
Gestion des versions
Elasticsearch fournit également une fonction de contrôle de version. Nous pouvons utiliser un paramètre de requête de version pour spécifier la version d'un document particulier.
PUT schools/_doc/5?version=7&version_type=external
{
"name":"Central School", "description":"CBSE Affiliation", "street":"Nagan",
"city":"paprola", "state":"HP", "zip":"176115", "location":[31.8955385, 76.8380405],
"fees":2200, "tags":["Senior Secondary", "beautiful campus"], "rating":"3.3"
}En exécutant le code ci-dessus, nous obtenons le résultat suivant -
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 7,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 1
}Le contrôle de version est un processus en temps réel et il n'est pas affecté par les opérations de recherche en temps réel.
Il existe deux types de contrôle de version les plus importants:
Versionnage interne
Le contrôle de version interne est la version par défaut qui commence par 1 et s'incrémente à chaque mise à jour, suppressions incluses.
Versionnage externe
Il est utilisé lorsque la gestion des versions des documents est stockée dans un système externe comme les systèmes de gestion des versions tiers. Pour activer cette fonctionnalité, nous devons définir version_type sur external. Ici, Elasticsearch stockera le numéro de version comme indiqué par le système externe et ne les incrémentera pas automatiquement.
Type d'opération
Le type d'opération est utilisé pour forcer une opération de création. Cela permet d'éviter l'écrasement du document existant.
PUT chapter/_doc/1?op_type=create
{
"Text":"this is chapter one"
}En exécutant le code ci-dessus, nous obtenons le résultat suivant -
{
"_index" : "chapter",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}Génération automatique d'ID
Lorsque l'ID n'est pas spécifié dans l'opération d'index, Elasticsearch génère automatiquement l'ID de ce document.
POST chapter/_doc/
{
"user" : "tpoint",
"post_date" : "2018-12-25T14:12:12",
"message" : "Elasticsearch Tutorial"
}En exécutant le code ci-dessus, nous obtenons le résultat suivant -
{
"_index" : "chapter",
"_type" : "_doc",
"_id" : "PVghWGoB7LiDTeV6LSGu",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}Obtenir l'API
L'API aide à extraire un objet JSON de type en effectuant une demande d'obtention pour un document particulier.
pre class="prettyprint notranslate" > GET schools/_doc/5En exécutant le code ci-dessus, nous obtenons le résultat suivant -
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 7,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
}Cette opération est en temps réel et n'est pas affectée par le taux de rafraîchissement de l'Index.
Vous pouvez également spécifier la version, puis Elasticsearch ne récupérera que cette version du document.
Vous pouvez également spécifier le _all dans la requête, afin qu'Elasticsearch puisse rechercher cet identifiant de document dans chaque type et il renverra le premier document correspondant.
Vous pouvez également spécifier les champs souhaités dans votre résultat à partir de ce document particulier.
GET schools/_doc/5?_source_includes=name,feesEn exécutant le code ci-dessus, nous obtenons le résultat suivant -
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 7,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"fees" : 2200,
"name" : "Central School"
}
}Vous pouvez également récupérer la partie source dans votre résultat en ajoutant simplement la partie _source dans votre demande d'obtention.
GET schools/_doc/5?_sourceEn exécutant le code ci-dessus, nous obtenons le résultat suivant -
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 7,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
}Vous pouvez également actualiser la partition avant d'effectuer l'opération get en définissant le paramètre d'actualisation sur true.
Supprimer l'API
Vous pouvez supprimer un index, un mappage ou un document particulier en envoyant une requête HTTP DELETE à Elasticsearch.
DELETE schools/_doc/4En exécutant le code ci-dessus, nous obtenons le résultat suivant -
{
"found":true, "_index":"schools", "_type":"school", "_id":"4", "_version":2,
"_shards":{"total":2, "successful":1, "failed":0}
}La version du document peut être spécifiée pour supprimer cette version particulière. Le paramètre de routage peut être spécifié pour supprimer le document d'un utilisateur particulier et l'opération échoue si le document n'appartient pas à cet utilisateur particulier. Dans cette opération, vous pouvez spécifier les options d'actualisation et d'expiration de la même manière que l'API GET.
Mettre à jour l'API
Le script est utilisé pour effectuer cette opération et le contrôle de version est utilisé pour s'assurer qu'aucune mise à jour ne s'est produite pendant l'obtention et la réindexation. Par exemple, vous pouvez mettre à jour les frais de scolarité en utilisant le script -
POST schools/_update/4
{
"script" : {
"source": "ctx._source.name = params.sname",
"lang": "painless",
"params" : {
"sname" : "City Wise School"
}
}
}En exécutant le code ci-dessus, nous obtenons le résultat suivant -
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "4",
"_version" : 3,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 4,
"_primary_term" : 2
}Vous pouvez vérifier la mise à jour en envoyant une demande d'obtention au document mis à jour.
Cette API est utilisée pour rechercher du contenu dans Elasticsearch. Un utilisateur peut effectuer une recherche en envoyant une demande d'obtention avec une chaîne de requête comme paramètre ou il peut publier une requête dans le corps du message de la demande de publication. Principalement tous les APIS de recherche sont multi-index, multi-types.
Multi-index
Elasticsearch nous permet de rechercher les documents présents dans tous les index ou dans certains index spécifiques. Par exemple, si nous devons rechercher tous les documents avec un nom qui contient central, nous pouvons faire comme indiqué ici -
GET /_all/_search?q=city:paprolaEn exécutant le code ci-dessus, nous obtenons la réponse suivante -
{
"took" : 33,
"timed_out" : false,
"_shards" : {
"total" : 7,
"successful" : 7,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.9808292,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 0.9808292,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
}
]
}
}Recherche URI
De nombreux paramètres peuvent être passés dans une opération de recherche à l'aide de l'identificateur de ressource uniforme -
| S. Non | Paramètre et description |
|---|---|
| 1 | Q Ce paramètre est utilisé pour spécifier la chaîne de requête. |
| 2 | lenient Ce paramètre est utilisé pour spécifier la chaîne de requête. Les erreurs basées sur le format peuvent être ignorées en définissant simplement ce paramètre sur true. C'est faux par défaut. |
| 3 | fields Ce paramètre est utilisé pour spécifier la chaîne de requête. |
| 4 | sort Nous pouvons obtenir un résultat trié en utilisant ce paramètre, les valeurs possibles pour ce paramètre sont fieldName, fieldName: asc / fieldname: desc |
| 5 | timeout Nous pouvons restreindre le temps de recherche en utilisant ce paramètre et la réponse ne contient que les résultats dans ce temps spécifié. Par défaut, il n'y a pas de délai. |
| 6 | terminate_after Nous pouvons limiter la réponse à un nombre spécifié de documents pour chaque partition, lorsque la requête se terminera prématurément. Par défaut, il n'y a pas de terminate_after. |
| sept | from L'index de départ des hits à renvoyer. La valeur par défaut est 0. |
| 8 | size Il indique le nombre de hits à renvoyer. La valeur par défaut est 10. |
Demander une recherche corporelle
Nous pouvons également spécifier une requête en utilisant la requête DSL dans le corps de la requête et de nombreux exemples sont déjà donnés dans les chapitres précédents. Un tel exemple est donné ici -
POST /schools/_search
{
"query":{
"query_string":{
"query":"up"
}
}
}En exécutant le code ci-dessus, nous obtenons la réponse suivante -
{
"took" : 11,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.47000363,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 0.47000363,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
}
}Le cadre d'agrégation collecte toutes les données sélectionnées par la requête de recherche et se compose de nombreux blocs de construction, qui aident à créer des résumés complexes des données. La structure de base d'une agrégation est présentée ici -
"aggregations" : {
"" : {
"" : {
}
[,"meta" : { [] } ]?
[,"aggregations" : { []+ } ]?
}
[,"" : { ... } ]*
}Il existe différents types d'agrégations, chacun ayant son propre objectif. Ils sont discutés en détail dans ce chapitre.
Agrégations de métriques
Ces agrégations aident à calculer des matrices à partir des valeurs de champ des documents agrégés et parfois certaines valeurs peuvent être générées à partir de scripts.
Les matrices numériques sont soit à valeur unique comme l'agrégation moyenne, soit à valeurs multiples comme les statistiques.
Agrégation moyenne
Cette agrégation est utilisée pour obtenir la moyenne de tout champ numérique présent dans les documents agrégés. Par exemple,
POST /schools/_search
{
"aggs":{
"avg_fees":{"avg":{"field":"fees"}}
}
}En exécutant le code ci-dessus, nous obtenons le résultat suivant -
{
"took" : 41,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
},
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
},
"aggregations" : {
"avg_fees" : {
"value" : 2850.0
}
}
}Agrégation de cardinalité
Cette agrégation donne le nombre de valeurs distinctes d'un champ particulier.
POST /schools/_search?size=0
{
"aggs":{
"distinct_name_count":{"cardinality":{"field":"fees"}}
}
}En exécutant le code ci-dessus, nous obtenons le résultat suivant -
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"distinct_name_count" : {
"value" : 2
}
}
}Note - La valeur de la cardinalité est de 2 car il existe deux valeurs distinctes dans les frais.
Agrégation étendue des statistiques
Cette agrégation génère toutes les statistiques sur un champ numérique spécifique dans les documents agrégés.
POST /schools/_search?size=0
{
"aggs" : {
"fees_stats" : { "extended_stats" : { "field" : "fees" } }
}
}En exécutant le code ci-dessus, nous obtenons le résultat suivant -
{
"took" : 8,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"fees_stats" : {
"count" : 2,
"min" : 2200.0,
"max" : 3500.0,
"avg" : 2850.0,
"sum" : 5700.0,
"sum_of_squares" : 1.709E7,
"variance" : 422500.0,
"std_deviation" : 650.0,
"std_deviation_bounds" : {
"upper" : 4150.0,
"lower" : 1550.0
}
}
}
}Agrégation maximale
Cette agrégation trouve la valeur maximale d'un champ numérique spécifique dans les documents agrégés.
POST /schools/_search?size=0
{
"aggs" : {
"max_fees" : { "max" : { "field" : "fees" } }
}
}En exécutant le code ci-dessus, nous obtenons le résultat suivant -
{
"took" : 16,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"max_fees" : {
"value" : 3500.0
}
}
}Agrégation minimale
Cette agrégation trouve la valeur minimale d'un champ numérique spécifique dans les documents agrégés.
POST /schools/_search?size=0
{
"aggs" : {
"min_fees" : { "min" : { "field" : "fees" } }
}
}En exécutant le code ci-dessus, nous obtenons le résultat suivant -
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"min_fees" : {
"value" : 2200.0
}
}
}Agrégation de somme
Cette agrégation calcule la somme d'un champ numérique spécifique dans les documents agrégés.
POST /schools/_search?size=0
{
"aggs" : {
"total_fees" : { "sum" : { "field" : "fees" } }
}
}En exécutant le code ci-dessus, nous obtenons le résultat suivant -
{
"took" : 8,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"total_fees" : {
"value" : 5700.0
}
}
}Il existe d'autres agrégations de métriques qui sont utilisées dans des cas particuliers, tels que l'agrégation de limites géographiques et l'agrégation de géocentres à des fins de géolocalisation.
Agrégations de statistiques
Agrégation de métriques à valeurs multiples qui calcule des statistiques sur des valeurs numériques extraites des documents agrégés.
POST /schools/_search?size=0
{
"aggs" : {
"grades_stats" : { "stats" : { "field" : "fees" } }
}
}En exécutant le code ci-dessus, nous obtenons le résultat suivant -
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"grades_stats" : {
"count" : 2,
"min" : 2200.0,
"max" : 3500.0,
"avg" : 2850.0,
"sum" : 5700.0
}
}
}Métadonnées d'agrégation
Vous pouvez ajouter des données sur l'agrégation au moment de la demande à l'aide de la balise Meta et obtenir cela en réponse.
POST /schools/_search?size=0
{
"aggs" : {
"min_fees" : { "avg" : { "field" : "fees" } ,
"meta" :{
"dsc" :"Lowest Fees This Year"
}
}
}
}En exécutant le code ci-dessus, nous obtenons le résultat suivant -
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"min_fees" : {
"meta" : {
"dsc" : "Lowest Fees This Year"
},
"value" : 2850.0
}
}
}Ces API sont chargées de gérer tous les aspects de l'index comme les paramètres, les alias, les mappages, les modèles d'index.
Créer un index
Cette API vous aide à créer un index. Un index peut être créé automatiquement lorsqu'un utilisateur transmet des objets JSON à n'importe quel index ou il peut être créé avant cela. Pour créer un index, il vous suffit d'envoyer une requête PUT avec paramètres, mappages et alias ou simplement une simple requête sans corps.
PUT collegesEn exécutant le code ci-dessus, nous obtenons la sortie comme indiqué ci-dessous -
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "colleges"
}Nous pouvons également ajouter quelques paramètres à la commande ci-dessus -
PUT colleges
{
"settings" : {
"index" : {
"number_of_shards" : 3,
"number_of_replicas" : 2
}
}
}En exécutant le code ci-dessus, nous obtenons la sortie comme indiqué ci-dessous -
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "colleges"
}Supprimer l'index
Cette API vous aide à supprimer n'importe quel index. Il vous suffit de transmettre une demande de suppression avec le nom de cet index particulier.
DELETE /collegesVous pouvez supprimer tous les index en utilisant simplement _all ou *.
Obtenir l'index
Cette API peut être appelée en envoyant simplement une requête get à un ou plusieurs index. Cela renvoie les informations sur l'index.
GET collegesEn exécutant le code ci-dessus, nous obtenons la sortie comme indiqué ci-dessous -
{
"colleges" : {
"aliases" : {
"alias_1" : { },
"alias_2" : {
"filter" : {
"term" : {
"user" : "pkay"
}
},
"index_routing" : "pkay",
"search_routing" : "pkay"
}
},
"mappings" : { },
"settings" : {
"index" : {
"creation_date" : "1556245406616",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "3ExJbdl2R1qDLssIkwDAug",
"version" : {
"created" : "7000099"
},
"provided_name" : "colleges"
}
}
}
}Vous pouvez obtenir les informations de tous les indices en utilisant _all ou *.
L'index existe
L'existence d'un index peut être déterminée en envoyant simplement une requête get à cet index. Si la réponse HTTP est 200, elle existe; s'il est 404, il n'existe pas.
HEAD collegesEn exécutant le code ci-dessus, nous obtenons la sortie comme indiqué ci-dessous -
200-OKParamètres d'index
Vous pouvez obtenir les paramètres d'index en ajoutant simplement le mot-clé _settings à la fin de l'URL.
GET /colleges/_settingsEn exécutant le code ci-dessus, nous obtenons la sortie comme indiqué ci-dessous -
{
"colleges" : {
"settings" : {
"index" : {
"creation_date" : "1556245406616",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "3ExJbdl2R1qDLssIkwDAug",
"version" : {
"created" : "7000099"
},
"provided_name" : "colleges"
}
}
}
}Statistiques d'index
Cette API vous aide à extraire des statistiques sur un index particulier. Il vous suffit d'envoyer une demande d'obtention avec l'URL d'index et le mot-clé _stats à la fin.
GET /_statsEn exécutant le code ci-dessus, nous obtenons la sortie comme indiqué ci-dessous -
………………………………………………
},
"request_cache" : {
"memory_size_in_bytes" : 849,
"evictions" : 0,
"hit_count" : 1171,
"miss_count" : 4
},
"recovery" : {
"current_as_source" : 0,
"current_as_target" : 0,
"throttle_time_in_millis" : 0
}
} ………………………………………………Affleurer
Le processus de vidage d'un index garantit que toutes les données qui ne sont actuellement conservées que dans le journal des transactions sont également persistantes de manière permanente dans Lucene. Cela réduit les temps de récupération car ces données n'ont pas besoin d'être réindexées à partir des journaux de transactions après l'ouverture de Lucene indexé.
POST colleges/_flushEn exécutant le code ci-dessus, nous obtenons la sortie comme indiqué ci-dessous -
{
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
}
}Habituellement, les résultats de diverses API Elasticsearch sont affichés au format JSON. Mais JSON n'est pas toujours facile à lire. Ainsi, la fonctionnalité d'API de chat est disponible dans Elasticsearch pour aider à donner un format d'impression plus facile à lire et à comprendre des résultats. Il existe divers paramètres utilisés dans l'API cat qui ont des objectifs différents du serveur, par exemple - le terme V rend la sortie verbeuse.
Apprenons plus en détail les API cat dans ce chapitre.
Verbeux
La sortie détaillée donne un bel affichage des résultats d'une commande cat. Dans l'exemple ci-dessous, nous obtenons les détails des différents indices présents dans le cluster.
GET /_cat/indices?vEn exécutant le code ci-dessus, nous obtenons la réponse comme indiqué ci-dessous -
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open schools RkMyEn2SQ4yUgzT6EQYuAA 1 1 2 1 21.6kb 21.6kb
yellow open index_4_analysis zVmZdM1sTV61YJYrNXf1gg 1 1 0 0 283b 283b
yellow open sensor-2018-01-01 KIrrHwABRB-ilGqTu3OaVQ 1 1 1 0 4.2kb 4.2kb
yellow open colleges 3ExJbdl2R1qDLssIkwDAug 1 1 0 0 283b 283bEn-têtes
Le paramètre h, également appelé en-tête, est utilisé pour afficher uniquement les colonnes mentionnées dans la commande.
GET /_cat/nodes?h=ip,portEn exécutant le code ci-dessus, nous obtenons la réponse comme indiqué ci-dessous -
127.0.0.1 9300Trier
La commande sort accepte la chaîne de requête qui peut trier la table par colonne spécifiée dans la requête. Le tri par défaut est ascendant mais cela peut être modifié en ajoutant: desc à une colonne.
L'exemple ci-dessous donne un résultat de modèles organisés dans l'ordre décroissant des modèles d'index classés.
GET _cat/templates?v&s=order:desc,index_patternsEn exécutant le code ci-dessus, nous obtenons la réponse comme indiqué ci-dessous -
name index_patterns order version
.triggered_watches [.triggered_watches*] 2147483647
.watch-history-9 [.watcher-history-9*] 2147483647
.watches [.watches*] 2147483647
.kibana_task_manager [.kibana_task_manager] 0 7000099Compter
Le paramètre count fournit le nombre total de documents dans l'ensemble du cluster.
GET /_cat/count?vEn exécutant le code ci-dessus, nous obtenons la réponse comme indiqué ci-dessous -
epoch timestamp count
1557633536 03:58:56 17809L'API de cluster est utilisée pour obtenir des informations sur le cluster et ses nœuds et pour y apporter des modifications. Pour appeler cette API, nous devons spécifier le nom du nœud, l'adresse ou _local.
GET /_nodes/_localEn exécutant le code ci-dessus, nous obtenons la réponse comme indiqué ci-dessous -
………………………………………………
cluster_name" : "elasticsearch",
"nodes" : {
"FKH-5blYTJmff2rJ_lQOCg" : {
"name" : "ubuntu",
"transport_address" : "127.0.0.1:9300",
"host" : "127.0.0.1",
"ip" : "127.0.0.1",
"version" : "7.0.0",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "b7e28a7",
"total_indexing_buffer" : 106502553,
"roles" : [
"master",
"data",
"ingest"
],
"attributes" : {
………………………………………………Santé du cluster
Cette API est utilisée pour obtenir l'état de la santé du cluster en ajoutant le mot clé 'health'.
GET /_cluster/healthEn exécutant le code ci-dessus, nous obtenons la réponse comme indiqué ci-dessous -
{
"cluster_name" : "elasticsearch",
"status" : "yellow",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 7,
"active_shards" : 7,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 4,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 63.63636363636363
}État du cluster
Cette API est utilisée pour obtenir des informations d'état sur un cluster en ajoutant l'URL du mot clé "state". Les informations d'état contiennent la version, le nœud maître, d'autres nœuds, la table de routage, les métadonnées et les blocs.
GET /_cluster/stateEn exécutant le code ci-dessus, nous obtenons la réponse comme indiqué ci-dessous -
………………………………………………
{
"cluster_name" : "elasticsearch",
"cluster_uuid" : "IzKu0OoVTQ6LxqONJnN2eQ",
"version" : 89,
"state_uuid" : "y3BlwvspR1eUQBTo0aBjig",
"master_node" : "FKH-5blYTJmff2rJ_lQOCg",
"blocks" : { },
"nodes" : {
"FKH-5blYTJmff2rJ_lQOCg" : {
"name" : "ubuntu",
"ephemeral_id" : "426kTGpITGixhEzaM-5Qyg",
"transport
}
………………………………………………Statistiques du cluster
Cette API permet de récupérer des statistiques sur le cluster à l'aide du mot clé «stats». Cette API renvoie le numéro de partition, la taille du magasin, l'utilisation de la mémoire, le nombre de nœuds, les rôles, le système d'exploitation et le système de fichiers.
GET /_cluster/statsEn exécutant le code ci-dessus, nous obtenons la réponse comme indiqué ci-dessous -
………………………………………….
"cluster_name" : "elasticsearch",
"cluster_uuid" : "IzKu0OoVTQ6LxqONJnN2eQ",
"timestamp" : 1556435464704,
"status" : "yellow",
"indices" : {
"count" : 7,
"shards" : {
"total" : 7,
"primaries" : 7,
"replication" : 0.0,
"index" : {
"shards" : {
"min" : 1,
"max" : 1,
"avg" : 1.0
},
"primaries" : {
"min" : 1,
"max" : 1,
"avg" : 1.0
},
"replication" : {
"min" : 0.0,
"max" : 0.0,
"avg" : 0.0
}
………………………………………….Paramètres de mise à jour du cluster
Cette API vous permet de mettre à jour les paramètres d'un cluster à l'aide du mot-clé "settings". Il existe deux types de paramètres: persistants (appliqués lors des redémarrages) et transitoires (ne survivent pas à un redémarrage complet du cluster).
Statistiques des nœuds
Cette API est utilisée pour récupérer les statistiques d'un ou plusieurs nœuds du cluster. Les statistiques des nœuds sont presque les mêmes que celles du cluster.
GET /_nodes/statsEn exécutant le code ci-dessus, nous obtenons la réponse comme indiqué ci-dessous -
{
"_nodes" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"cluster_name" : "elasticsearch",
"nodes" : {
"FKH-5blYTJmff2rJ_lQOCg" : {
"timestamp" : 1556437348653,
"name" : "ubuntu",
"transport_address" : "127.0.0.1:9300",
"host" : "127.0.0.1",
"ip" : "127.0.0.1:9300",
"roles" : [
"master",
"data",
"ingest"
],
"attributes" : {
"ml.machine_memory" : "4112797696",
"xpack.installed" : "true",
"ml.max_open_jobs" : "20"
},
………………………………………………………….Nœuds hot_threads
Cette API vous aide à récupérer des informations sur les threads actifs actuels sur chaque nœud du cluster.
GET /_nodes/hot_threadsEn exécutant le code ci-dessus, nous obtenons la réponse comme indiqué ci-dessous -
:::{ubuntu}{FKH-5blYTJmff2rJ_lQOCg}{426kTGpITGixhEzaM5Qyg}{127.0.0.1}{127.0.0.1:9300}{ml.machine_memory=4112797696,
xpack.installed=true, ml.max_open_jobs=20}
Hot threads at 2019-04-28T07:43:58.265Z, interval=500ms, busiestThreads=3,
ignoreIdleThreads=true:Dans Elasticsearch, la recherche est effectuée à l'aide d'une requête basée sur JSON. Une requête est composée de deux clauses -
Leaf Query Clauses - Ces clauses sont des correspondances, des termes ou des plages, qui recherchent une valeur spécifique dans un champ spécifique.
Compound Query Clauses - Ces requêtes sont une combinaison de clauses de requête feuille et d'autres requêtes composées pour extraire les informations souhaitées.
Elasticsearch prend en charge un grand nombre de requêtes. Une requête commence par un mot clé de requête, puis contient des conditions et des filtres sous la forme d'un objet JSON. Les différents types de requêtes ont été décrits ci-dessous.
Faire correspondre toutes les requêtes
C'est la requête la plus basique; il renvoie tout le contenu et avec le score de 1,0 pour chaque objet.
POST /schools/_search
{
"query":{
"match_all":{}
}
}En exécutant le code ci-dessus, nous obtenons le résultat suivant -
{
"took" : 7,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
},
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
}
}Requêtes en texte intégral
Ces requêtes sont utilisées pour rechercher un corps de texte complet comme un chapitre ou un article de presse. Cette requête fonctionne en fonction de l'analyseur associé à cet index ou document particulier. Dans cette section, nous aborderons les différents types de requêtes de texte intégral.
Requête de correspondance
Cette requête met en correspondance un texte ou une expression avec les valeurs d'un ou plusieurs champs.
POST /schools*/_search
{
"query":{
"match" : {
"rating":"4.5"
}
}
}En exécutant le code ci-dessus, nous obtenons la réponse comme indiqué ci-dessous -
{
"took" : 44,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.47000363,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 0.47000363,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
}
}Requête multi-correspondance
Cette requête correspond à un texte ou à une expression avec plusieurs champs.
POST /schools*/_search
{
"query":{
"multi_match" : {
"query": "paprola",
"fields": [ "city", "state" ]
}
}
}En exécutant le code ci-dessus, nous obtenons la réponse comme indiqué ci-dessous -
{
"took" : 12,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.9808292,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 0.9808292,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
}
]
}
}Requête Requête de chaîne
Cette requête utilise un analyseur de requête et un mot clé query_string.
POST /schools*/_search
{
"query":{
"query_string":{
"query":"beautiful"
}
}
}En exécutant le code ci-dessus, nous obtenons la réponse comme indiqué ci-dessous -
{
"took" : 60,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
………………………………….Requêtes au niveau du terme
Ces requêtes traitent principalement de données structurées telles que des nombres, des dates et des énumérations.
POST /schools*/_search
{
"query":{
"term":{"zip":"176115"}
}
}En exécutant le code ci-dessus, nous obtenons la réponse comme indiqué ci-dessous -
……………………………..
hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 0.9808292,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
}
}
]
…………………………………………..Requête de plage
Cette requête est utilisée pour trouver les objets ayant des valeurs entre les plages de valeurs données. Pour cela, nous devons utiliser des opérateurs tels que -
- gte - supérieur à égal à
- gt - supérieur à
- lte - inférieur à égal à
- lt - moins de
Par exemple, observez le code ci-dessous -
POST /schools*/_search
{
"query":{
"range":{
"rating":{
"gte":3.5
}
}
}
}En exécutant le code ci-dessus, nous obtenons la réponse comme indiqué ci-dessous -
{
"took" : 24,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
}
}Il existe d'autres types de requêtes au niveau du terme, telles que -
Exists query - Si un certain champ a une valeur non nulle.
Missing query - Ceci est complètement opposé à la requête existe, cette requête recherche des objets sans champs spécifiques ou des champs ayant une valeur nulle.
Wildcard or regexp query - Cette requête utilise des expressions régulières pour rechercher des modèles dans les objets.
Requêtes composées
Ces requêtes sont une collection de différentes requêtes fusionnées les unes avec les autres à l'aide d'opérateurs booléens tels que et, ou, pas ou pour différents index ou ayant des appels de fonction, etc.
POST /schools/_search
{
"query": {
"bool" : {
"must" : {
"term" : { "state" : "UP" }
},
"filter": {
"term" : { "fees" : "2200" }
},
"minimum_should_match" : 1,
"boost" : 1.0
}
}
}En exécutant le code ci-dessus, nous obtenons la réponse comme indiqué ci-dessous -
{
"took" : 6,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}Requêtes géographiques
Ces requêtes concernent les emplacements géographiques et les points géographiques. Ces requêtes aident à trouver des écoles ou tout autre objet géographique à proximité de n'importe quel endroit. Vous devez utiliser le type de données de point géographique.
PUT /geo_example
{
"mappings": {
"properties": {
"location": {
"type": "geo_shape"
}
}
}
}En exécutant le code ci-dessus, nous obtenons la réponse comme indiqué ci-dessous -
{ "acknowledged" : true,
"shards_acknowledged" : true,
"index" : "geo_example"
}Maintenant, nous publions les données dans l'index créé ci-dessus.
POST /geo_example/_doc?refresh
{
"name": "Chapter One, London, UK",
"location": {
"type": "point",
"coordinates": [11.660544, 57.800286]
}
}En exécutant le code ci-dessus, nous obtenons la réponse comme indiqué ci-dessous -
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
"_index" : "geo_example",
"_type" : "_doc",
"_id" : "hASWZ2oBbkdGzVfiXHKD",
"_score" : 1.0,
"_source" : {
"name" : "Chapter One, London, UK",
"location" : {
"type" : "point",
"coordinates" : [
11.660544,
57.800286
]
}
}
}
}Le mappage est le contour des documents stockés dans un index. Il définit le type de données comme geo_point ou string et le format des champs présents dans les documents et les règles pour contrôler le mappage des champs ajoutés dynamiquement.
PUT bankaccountdetails
{
"mappings":{
"properties":{
"name": { "type":"text"}, "date":{ "type":"date"},
"balance":{ "type":"double"}, "liability":{ "type":"double"}
}
}
}Lorsque nous exécutons le code ci-dessus, nous obtenons la réponse comme indiqué ci-dessous -
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "bankaccountdetails"
}Types de données de champ
Elasticsearch prend en charge un certain nombre de types de données différents pour les champs d'un document. Les types de données utilisés pour stocker les champs dans Elasticsearch sont décrits en détail ici.
Types de données de base
Ce sont les types de données de base tels que texte, mot-clé, date, long, double, booléen ou ip, qui sont pris en charge par presque tous les systèmes.
Types de données complexes
Ces types de données sont une combinaison de types de données de base. Ceux-ci incluent un tableau, un objet JSON et un type de données imbriqué. Un exemple de type de données imbriqué est présenté ci-dessous & moins
POST /tabletennis/_doc/1
{
"group" : "players",
"user" : [
{
"first" : "dave", "last" : "jones"
},
{
"first" : "kevin", "last" : "morris"
}
]
}Lorsque nous exécutons le code ci-dessus, nous obtenons la réponse comme indiqué ci-dessous -
{
"_index" : "tabletennis",
"_type" : "_doc",
"_id" : "1",
_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}Un autre exemple de code est présenté ci-dessous -
POST /accountdetails/_doc/1
{
"from_acc":"7056443341", "to_acc":"7032460534",
"date":"11/1/2016", "amount":10000
}Lorsque nous exécutons le code ci-dessus, nous obtenons la réponse comme indiqué ci-dessous -
{ "_index" : "accountdetails",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}Nous pouvons vérifier le document ci-dessus en utilisant la commande suivante -
GET /accountdetails/_mappings?include_type_name=falseSuppression des types de mappage
Les indices créés dans Elasticsearch 7.0.0 ou version ultérieure n'acceptent plus un mappage _default_. Les indices créés dans 6.x continueront de fonctionner comme auparavant dans Elasticsearch 6.x. Les types sont obsolètes dans les API de la version 7.0.
Lorsqu'une requête est traitée lors d'une opération de recherche, le contenu de n'importe quel index est analysé par le module d'analyse. Ce module comprend un analyseur, un tokenizer, des tokenfilters et des charfilters. Si aucun analyseur n'est défini, les analyseurs, jetons, filtres et tokenizers intégrés sont par défaut enregistrés avec le module d'analyse.
Dans l'exemple suivant, nous utilisons un analyseur standard qui est utilisé lorsqu'aucun autre analyseur n'est spécifié. Il analysera la phrase en fonction de la grammaire et produira les mots utilisés dans la phrase.
POST _analyze
{
"analyzer": "standard",
"text": "Today's weather is beautiful"
}En exécutant le code ci-dessus, nous obtenons la réponse comme indiqué ci-dessous -
{
"tokens" : [
{
"token" : "today's",
"start_offset" : 0,
"end_offset" : 7,
"type" : "",
"position" : 0
},
{
"token" : "weather",
"start_offset" : 8,
"end_offset" : 15,
"type" : "",
"position" : 1
},
{
"token" : "is",
"start_offset" : 16,
"end_offset" : 18,
"type" : "",
"position" : 2
},
{
"token" : "beautiful",
"start_offset" : 19,
"end_offset" : 28,
"type" : "",
"position" : 3
}
]
}Configuration de l'analyseur standard
Nous pouvons configurer l'analyseur standard avec divers paramètres pour obtenir nos exigences personnalisées.
Dans l'exemple suivant, nous configurons l'analyseur standard pour avoir un max_token_length de 5.
Pour cela, nous créons d'abord un index avec l'analyseur ayant le paramètre max_length_token.
PUT index_4_analysis
{
"settings": {
"analysis": {
"analyzer": {
"my_english_analyzer": {
"type": "standard",
"max_token_length": 5,
"stopwords": "_english_"
}
}
}
}
}Ensuite, nous appliquons l'analyseur avec un texte comme indiqué ci-dessous. Veuillez noter que le jeton n'apparaît pas car il comporte deux espaces au début et deux espaces à la fin. Pour le mot «est», il y a un espace au début et un espace à la fin de celui-ci. En les prenant toutes, cela devient 4 lettres avec des espaces et cela n'en fait pas un mot. Il devrait y avoir un caractère non espace au moins au début ou à la fin, pour en faire un mot à compter.
POST index_4_analysis/_analyze
{
"analyzer": "my_english_analyzer",
"text": "Today's weather is beautiful"
}En exécutant le code ci-dessus, nous obtenons la réponse comme indiqué ci-dessous -
{
"tokens" : [
{
"token" : "today",
"start_offset" : 0,
"end_offset" : 5,
"type" : "",
"position" : 0
},
{
"token" : "s",
"start_offset" : 6,
"end_offset" : 7,
"type" : "",
"position" : 1
},
{
"token" : "weath",
"start_offset" : 8,
"end_offset" : 13,
"type" : "",
"position" : 2
},
{
"token" : "er",
"start_offset" : 13,
"end_offset" : 15,
"type" : "",
"position" : 3
},
{
"token" : "beaut",
"start_offset" : 19,
"end_offset" : 24,
"type" : "",
"position" : 5
},
{
"token" : "iful",
"start_offset" : 24,
"end_offset" : 28,
"type" : "",
"position" : 6
}
]
}La liste des différents analyseurs et leur description sont données dans le tableau ci-dessous -
| S. Non | Analyseur et description |
|---|---|
| 1 | Standard analyzer (standard) Les paramètres stopwords et max_token_length peuvent être définis pour cet analyseur. Par défaut, la liste des mots vides est vide et max_token_length vaut 255. |
| 2 | Simple analyzer (simple) Cet analyseur est composé de jetons minuscules. |
| 3 | Whitespace analyzer (whitespace) Cet analyseur est composé d'un tokenizer d'espace blanc. |
| 4 | Stop analyzer (stop) stopwords et stopwords_path peuvent être configurés. Par défaut, les mots vides initialisés aux mots vides anglais et stopwords_path contient le chemin vers un fichier texte avec des mots vides. |
Tokenizers
Les jetons sont utilisés pour générer des jetons à partir d'un texte dans Elasticsearch. Le texte peut être décomposé en jetons en tenant compte des espaces ou d'autres ponctuations. Elasticsearch dispose de nombreux jetons intégrés, qui peuvent être utilisés dans un analyseur personnalisé.
Un exemple de tokenizer qui décompose le texte en termes chaque fois qu'il rencontre un caractère qui n'est pas une lettre, mais qui minuscule également tous les termes, est illustré ci-dessous
POST _analyze
{
"tokenizer": "lowercase",
"text": "It Was a Beautiful Weather 5 Days ago."
}En exécutant le code ci-dessus, nous obtenons la réponse comme indiqué ci-dessous -
{
"tokens" : [
{
"token" : "it",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
},
{
"token" : "was",
"start_offset" : 3,
"end_offset" : 6,
"type" : "word",
"position" : 1
},
{
"token" : "a",
"start_offset" : 7,
"end_offset" : 8,
"type" : "word",
"position" : 2
},
{
"token" : "beautiful",
"start_offset" : 9,
"end_offset" : 18,
"type" : "word",
"position" : 3
},
{
"token" : "weather",
"start_offset" : 19,
"end_offset" : 26,
"type" : "word",
"position" : 4
},
{
"token" : "days",
"start_offset" : 29,
"end_offset" : 33,
"type" : "word",
"position" : 5
},
{
"token" : "ago",
"start_offset" : 34,
"end_offset" : 37,
"type" : "word",
"position" : 6
}
]
}Une liste des Tokenizers et leurs descriptions sont présentées ici dans le tableau ci-dessous -
| S. Non | Tokenizer et description |
|---|---|
| 1 | Standard tokenizer (standard) Ceci est construit sur un tokenizer basé sur la grammaire et max_token_length peut être configuré pour ce tokenizer. |
| 2 | Edge NGram tokenizer (edgeNGram) Des paramètres tels que min_gram, max_gram, token_chars peuvent être définis pour ce tokenizer. |
| 3 | Keyword tokenizer (keyword) Cela génère une entrée entière en tant que sortie et buffer_size peut être défini pour cela. |
| 4 | Letter tokenizer (letter) Cela capture le mot entier jusqu'à ce qu'une non-lettre soit rencontrée. |
Elasticsearch est composé d'un certain nombre de modules, qui sont responsables de sa fonctionnalité. Ces modules ont deux types de paramètres comme suit -
Static Settings- Ces paramètres doivent être configurés dans le fichier config (elasticsearch.yml) avant de démarrer Elasticsearch. Vous devez mettre à jour tous les nœuds de préoccupation du cluster pour refléter les modifications apportées par ces paramètres.
Dynamic Settings - Ces paramètres peuvent être définis sur Elasticsearch en direct.
Nous aborderons les différents modules d'Elasticsearch dans les sections suivantes de ce chapitre.
Routage au niveau du cluster et allocation de fragments
Les paramètres au niveau du cluster décident de l'allocation des fragments à différents nœuds et de la réallocation des fragments pour rééquilibrer le cluster. Voici les paramètres suivants pour contrôler l'allocation des partitions.
Allocation de fragments au niveau du cluster
| Réglage | Valeur possible | La description |
|---|---|---|
| cluster.routing.allocation.enable | ||
| tout | Cette valeur par défaut autorise l'allocation de partitions pour tous les types de partitions. | |
| primaires | Cela autorise l'allocation de partitions uniquement pour les partitions principales. | |
| new_primaries | Cela permet l'allocation de fragments uniquement pour les fragments primaires pour les nouveaux indices. | |
| aucun | Cela n'autorise aucune allocation de partition. | |
| cluster.routing.allocation .node_concurrent_recoveries | Valeur numérique (par défaut 2) | Cela limite le nombre de récupération de partition simultanée. |
| cluster.routing.allocation .node_initial_primaries_recoveries | Valeur numérique (par défaut 4) | Cela limite le nombre de récupérations primaires initiales parallèles. |
| cluster.routing.allocation .same_shard.host | Valeur booléenne (par défaut false) | Cela limite l'allocation de plusieurs répliques du même fragment dans le même nœud physique. |
| indices.recovery.concurrent _streams | Valeur numérique (par défaut 3) | Cela contrôle le nombre de flux réseau ouverts par nœud au moment de la récupération de partition à partir de partitions homologues. |
| indices.recovery.concurrent _small_file_streams | Valeur numérique (par défaut 2) | Cela contrôle le nombre de flux ouverts par nœud pour les petits fichiers dont la taille est inférieure à 5 Mo au moment de la récupération de la partition. |
| cluster.routing.rebalance.enable | ||
| tout | Cette valeur par défaut permet l'équilibrage pour tous les types de fragments. | |
| primaires | Cela permet l'équilibrage des partitions uniquement pour les partitions principales. | |
| répliques | Cela permet l'équilibrage des fragments uniquement pour les fragments de réplique. | |
| aucun | Cela n'autorise aucun type d'équilibrage de partition. | |
| cluster.routing.allocation .allow_rebalance | ||
| toujours | Cette valeur par défaut autorise toujours le rééquilibrage. | |
| indices_primaries _active | Cela permet le rééquilibrage lorsque toutes les partitions principales du cluster sont allouées. | |
| Indices_all_active | Cela permet le rééquilibrage lorsque toutes les partitions principales et de réplique sont allouées. | |
| cluster.routing.allocation.cluster _concurrent_rebalance | Valeur numérique (par défaut 2) | Cela limite le nombre d'équilibrages de partition simultanés dans le cluster. |
| cluster.routing.allocation .balance.shard | Valeur flottante (par défaut 0.45f) | Cela définit le facteur de pondération des fragments alloués sur chaque nœud. |
| cluster.routing.allocation .balance.index | Valeur flottante (par défaut 0,55f) | Ceci définit le rapport du nombre de fragments par index alloué sur un nœud spécifique. |
| cluster.routing.allocation .balance.threshold | Valeur flottante non négative (par défaut 1.0f) | Il s'agit de la valeur d'optimisation minimale des opérations à effectuer. |
Allocation de fragments basée sur le disque
| Réglage | Valeur possible | La description |
|---|---|---|
| cluster.routing.allocation.disk.threshold_enabled | Valeur booléenne (par défaut true) | Cela active et désactive le décideur d'allocation de disque. |
| cluster.routing.allocation.disk.watermark.low | Valeur de chaîne (par défaut 85%) | Cela dénote une utilisation maximale du disque; après ce point, aucun autre fragment ne peut être alloué à ce disque. |
| cluster.routing.allocation.disk.watermark.high | Valeur de chaîne (par défaut 90%) | Cela indique l'utilisation maximale au moment de l'attribution; si ce point est atteint au moment de l'allocation, Elasticsearch allouera cette partition à un autre disque. |
| cluster.info.update.interval | Valeur de chaîne (par défaut 30 s) | Il s'agit de l'intervalle entre les vérifications d'utilisation du disque. |
| cluster.routing.allocation.disk.include_relocations | Valeur booléenne (par défaut true) | Cela décide s'il faut prendre en compte les fragments actuellement alloués, lors du calcul de l'utilisation du disque. |
Découverte
Ce module aide un cluster à découvrir et à maintenir l'état de tous les nœuds qu'il contient. L'état du cluster change lorsqu'un nœud y est ajouté ou supprimé. Le paramètre de nom de cluster est utilisé pour créer une différence logique entre différents clusters. Certains modules vous aident à utiliser les API fournies par les fournisseurs de cloud et ceux-ci sont indiqués ci-dessous -
- Découverte Azure
- Découverte EC2
- Découverte du moteur de calcul Google
- Découverte zen
passerelle
Ce module gère l'état du cluster et les données de partition lors des redémarrages complets du cluster. Voici les paramètres statiques de ce module -
| Réglage | Valeur possible | La description |
|---|---|---|
| gateway.expected_nodes | valeur numérique (par défaut 0) | Nombre de nœuds censés se trouver dans le cluster pour la récupération des fragments locaux. |
| gateway.expected_master_nodes | valeur numérique (par défaut 0) | Nombre de nœuds maîtres censés se trouver dans le cluster avant de démarrer la récupération. |
| gateway.expected_data_nodes | valeur numérique (par défaut 0) | Nombre de nœuds de données attendus dans le cluster avant de démarrer la récupération. |
| gateway.recover_after_time | Valeur de chaîne (par défaut 5 m) | Il s'agit de l'intervalle entre les vérifications d'utilisation du disque. |
| cluster.routing.allocation. disk.include_relocations | Valeur booléenne (par défaut true) | Ceci spécifie la durée pendant laquelle le processus de récupération attendra pour démarrer quel que soit le nombre de nœuds joints dans le cluster. gateway.recover_ after_nodes |
HTTP
Ce module gère la communication entre le client HTTP et les API Elasticsearch. Ce module peut être désactivé en modifiant la valeur de http.enabled sur false.
Voici les paramètres (configurés dans elasticsearch.yml) pour contrôler ce module -
| S. Non | Réglage et description |
|---|---|
| 1 | http.port Il s'agit d'un port pour accéder à Elasticsearch et il va de 9200 à 9300. |
| 2 | http.publish_port Ce port est destiné aux clients http et est également utile en cas de pare-feu. |
| 3 | http.bind_host Il s'agit d'une adresse d'hôte pour le service http. |
| 4 | http.publish_host Il s'agit d'une adresse d'hôte pour le client http. |
| 5 | http.max_content_length Il s'agit de la taille maximale du contenu dans une requête http. Sa valeur par défaut est de 100 Mo. |
| 6 | http.max_initial_line_length Il s'agit de la taille maximale de l'URL et sa valeur par défaut est de 4 Ko. |
| sept | http.max_header_size Il s'agit de la taille maximale de l'en-tête http et sa valeur par défaut est de 8 Ko. |
| 8 | http.compression Cela active ou désactive la prise en charge de la compression et sa valeur par défaut est false. |
| 9 | http.pipelinig Cela active ou désactive le pipeline HTTP. |
| dix | http.pipelining.max_events Cela limite le nombre d'événements à mettre en file d'attente avant de fermer une requête HTTP. |
Les indices
Ce module gère les paramètres, qui sont définis globalement pour chaque index. Les paramètres suivants sont principalement liés à l'utilisation de la mémoire -
Disjoncteur
Ceci est utilisé pour empêcher l'opération de provoquer une OutOfMemroyError. Le paramètre limite principalement la taille du tas JVM. Par exemple, le paramètre indices.breaker.total.limit, qui correspond par défaut à 70% du tas JVM.
Cache de données de champ
Ceci est principalement utilisé lors de l'agrégation sur un champ. Il est recommandé de disposer de suffisamment de mémoire pour l'allouer. La quantité de mémoire utilisée pour le cache de données de champ peut être contrôlée à l'aide du paramètre indices.fielddata.cache.size.
Cache de requête de nœud
Cette mémoire est utilisée pour la mise en cache des résultats de la requête. Ce cache utilise la politique d'éviction LRU (Least Recent Used). Le paramètre Indices.queries.cahce.size contrôle la taille de la mémoire de ce cache.
Tampon d'indexation
Ce tampon stocke les documents nouvellement créés dans l'index et les vide lorsque le tampon est plein. Un paramètre comme indices.memory.index_buffer_size contrôle la quantité de tas allouée pour ce tampon.
Cache de demande d'éclat
Ce cache est utilisé pour stocker les données de recherche locales pour chaque partition. Le cache peut être activé lors de la création de l'index ou peut être désactivé en envoyant le paramètre URL.
Disable cache - ?request_cache = true
Enable cache "index.requests.cache.enable": trueRécupération des indices
Il contrôle les ressources pendant le processus de récupération. Voici les paramètres -
| Réglage | Valeur par défaut |
|---|---|
| indices.recovery.concurrent_streams | 3 |
| indices.recovery.concurrent_small_file_streams | 2 |
| indices.recovery.file_chunk_size | 512 Ko |
| indices.recovery.translog_ops | 1000 |
| indices.recovery.translog_size | 512 Ko |
| indices.recovery.compress | vrai |
| indices.recovery.max_bytes_per_sec | 40 Mo |
Intervalle TTL
L'intervalle de durée de vie (TTL) définit la durée d'un document, après laquelle le document est supprimé. Voici les paramètres dynamiques pour contrôler ce processus -
| Réglage | Valeur par défaut |
|---|---|
| indices.ttl.interval | Années 60 |
| indices.ttl.bulk_size | 1000 |
Nœud
Chaque nœud a la possibilité d'être un nœud de données ou non. Vous pouvez modifier cette propriété en modifiantnode.dataréglage. Définition de la valeur commefalse définit que le nœud n'est pas un nœud de données.
Ce sont les modules qui sont créés pour chaque index et contrôlent les paramètres et le comportement des index. Par exemple, le nombre de partitions qu'un index peut utiliser ou le nombre de répliques qu'une partition principale peut avoir pour cet index, etc. Il existe deux types de paramètres d'index -
- Static - Ceux-ci ne peuvent être définis qu'au moment de la création de l'index ou sur un index fermé.
- Dynamic - Ceux-ci peuvent être modifiés sur un index en direct.
Paramètres d'index statique
Le tableau suivant présente la liste des paramètres d'index statique -
| Réglage | Valeur possible | La description |
|---|---|---|
| index.number_of_shards | La valeur par défaut est 5, maximum 1024 | Le nombre de fragments primaires qu'un index doit avoir. |
| index.shard.check_on_startup | La valeur par défaut est false. Peut être vrai | Si oui ou non les fragments doivent être vérifiés pour la corruption avant l'ouverture. |
| index.codec | Compression LZ4. | Type de compression utilisé pour stocker les données. |
| index.routing_partition_size | 1 | Nombre de fragments auxquels une valeur de routage personnalisée peut aller. |
| index.load_fixed_bitset_filters_eagerly | faux | Indique si les filtres mis en cache sont préchargés pour les requêtes imbriquées |
Paramètres d'index dynamique
Le tableau suivant présente la liste des paramètres d'index dynamique -
| Réglage | Valeur possible | La description |
|---|---|---|
| index.number_of_replicas | La valeur par défaut est 1 | Le nombre de répliques de chaque partition principale. |
| index.auto_expand_replicas | Un tiret délimité par la limite inférieure et supérieure (0-5) | Augmentez automatiquement le nombre de réplicas en fonction du nombre de nœuds de données dans le cluster. |
| index.search.idle.after | 30 secondes | Durée pendant laquelle une partition ne peut pas recevoir une recherche ou obtenir une demande tant qu'elle n'est pas considérée comme inactive. |
| index.refresh_interval | 1 seconde | Fréquence à laquelle effectuer une opération d'actualisation, ce qui rend les modifications récentes de l'index visibles pour la recherche. |
| index.blocks.read_only | 1 vrai / faux | Défini sur true pour rendre les métadonnées d'index et d'index en lecture seule, false pour autoriser les écritures et les modifications de métadonnées. |
Parfois, nous devons transformer un document avant de l'indexer. Par exemple, nous voulons supprimer un champ du document ou renommer un champ puis l'indexer. Ceci est géré par le nœud Ingest.
Chaque nœud du cluster peut être ingéré, mais il peut également être personnalisé pour être traité uniquement par des nœuds spécifiques.
Étapes impliquées
Il y a deux étapes impliquées dans le fonctionnement du nœud d'acquisition -
- Créer un pipeline
- Créer un document
Créer un pipeline
Commencez par créer un pipeline qui contient les processeurs, puis exécutez le pipeline, comme indiqué ci-dessous -
PUT _ingest/pipeline/int-converter
{
"description": "converts the content of the seq field to an integer",
"processors" : [
{
"convert" : {
"field" : "seq",
"type": "integer"
}
}
]
}En exécutant le code ci-dessus, nous obtenons le résultat suivant -
{
"acknowledged" : true
}Créer un document
Ensuite, nous créons un document à l'aide du convertisseur de pipeline.
PUT /logs/_doc/1?pipeline=int-converter
{
"seq":"21",
"name":"Tutorialspoint",
"Addrs":"Hyderabad"
}En exécutant le code ci-dessus, nous obtenons la réponse comme indiqué ci-dessous -
{
"_index" : "logs",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}Ensuite, nous recherchons le document créé ci-dessus en utilisant la commande GET comme indiqué ci-dessous -
GET /logs/_doc/1En exécutant le code ci-dessus, nous obtenons le résultat suivant -
{
"_index" : "logs",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"Addrs" : "Hyderabad",
"name" : "Tutorialspoint",
"seq" : 21
}
}Vous pouvez voir ci-dessus que 21 est devenu un entier.
Sans pipeline
Maintenant, nous créons un document sans utiliser le pipeline.
PUT /logs/_doc/2
{
"seq":"11",
"name":"Tutorix",
"Addrs":"Secunderabad"
}
GET /logs/_doc/2En exécutant le code ci-dessus, nous obtenons le résultat suivant -
{
"_index" : "logs",
"_type" : "_doc",
"_id" : "2",
"_version" : 1,
"_seq_no" : 1,
"_primary_term" : 1,
"found" : true,
"_source" : {
"seq" : "11",
"name" : "Tutorix",
"Addrs" : "Secunderabad"
}
}Vous pouvez voir ci-dessus que 11 est une chaîne sans le pipeline utilisé.
La gestion du cycle de vie de l'index implique l'exécution d'actions de gestion basées sur des facteurs tels que la taille de la partition et les exigences de performances. Les API de gestion du cycle de vie des index (ILM) vous permettent d'automatiser la façon dont vous souhaitez gérer vos index au fil du temps.
Ce chapitre donne une liste des API ILM et leur utilisation.
API de gestion des politiques
| Nom de l'API | Objectif | Exemple |
|---|---|---|
| Créez une politique de cycle de vie. | Crée une politique de cycle de vie. Si la stratégie spécifiée existe, la stratégie est remplacée et la version de la stratégie est incrémentée. | PUT_ilm / policy / policy_id |
| Obtenez la politique de cycle de vie. | Renvoie la définition de stratégie spécifiée. Inclut la version de la politique et la date de la dernière modification. Si aucune politique n'est spécifiée, renvoie toutes les politiques définies. | GET_ilm / policy / policy_id |
| Supprimer la politique de cycle de vie | Supprime la définition de stratégie de cycle de vie spécifiée. Vous ne pouvez pas supprimer les stratégies actuellement utilisées. Si la stratégie est utilisée pour gérer des index, la demande échoue et renvoie une erreur. | DELETE_ilm / policy / policy_id |
API de gestion d'index
| Nom de l'API | Objectif | Exemple |
|---|---|---|
| Passer à l'API de l'étape du cycle de vie. | Déplace manuellement un index dans l'étape spécifiée et exécute cette étape. | POST_ilm / déplacer / index |
| Politique de nouvelle tentative. | Rétablit la stratégie à l'étape où l'erreur s'est produite et exécute l'étape. | Index POST / _ilm / réessayer |
| Supprimer la stratégie de la modification de l'API d'index. | Supprime la stratégie de cycle de vie affectée et arrête de gérer l'index spécifié. Si un modèle d'index est spécifié, supprime les stratégies affectées de tous les index correspondants. | Index POST / _ilm / supprimer |
API de gestion des opérations
| Nom de l'API | Objectif | Exemple |
|---|---|---|
| Obtenez l'API de statut de gestion du cycle de vie des index. | Renvoie l'état du plug-in ILM. Le champ operation_mode de la réponse affiche l'un des trois états suivants: STARTED, STOPPING ou STOPPED. | GET / _ilm / statut |
| Démarrez l'API de gestion du cycle de vie des index. | Démarre le plugin ILM s'il est actuellement arrêté. ILM est démarré automatiquement lorsque le cluster est formé. | POST / _ilm / début |
| Arrêtez l'API de gestion du cycle de vie des index. | Arrête toutes les opérations de gestion du cycle de vie et arrête le plug-in ILM. Cela est utile lorsque vous effectuez une maintenance sur le cluster et que vous devez empêcher ILM d'effectuer des actions sur vos index. | POST / _ilm / arrêt |
| Expliquez l'API du cycle de vie. | Récupère des informations sur l'état actuel du cycle de vie de l'index, telles que la phase, l'action et l'étape en cours d'exécution. Affiche le moment où l'index est entré dans chacun d'eux, la définition de la phase en cours d'exécution et des informations sur les échecs éventuels. | GET index / _ilm / expliquer |
C'est un composant qui permet d'exécuter des requêtes de type SQL en temps réel sur Elasticsearch. Vous pouvez considérer Elasticsearch SQL comme un traducteur, qui comprend à la fois SQL et Elasticsearch et facilite la lecture et le traitement des données en temps réel, à grande échelle en exploitant les capacités d'Elasticsearch.
Avantages d'Elasticsearch SQL
It has native integration - Chaque requête est exécutée efficacement sur les nœuds concernés en fonction du stockage sous-jacent.
No external parts - Pas besoin de matériel, de processus, d'exécutables ou de bibliothèques supplémentaires pour interroger Elasticsearch.
Lightweight and efficient - il embrasse et expose SQL pour permettre une recherche en texte intégral appropriée, en temps réel.
Exemple
PUT /schoollist/_bulk?refresh
{"index":{"_id": "CBSE"}}
{"name": "GleanDale", "Address": "JR. Court Lane", "start_date": "2011-06-02",
"student_count": 561}
{"index":{"_id": "ICSE"}}
{"name": "Top-Notch", "Address": "Gachibowli Main Road", "start_date": "1989-
05-26", "student_count": 482}
{"index":{"_id": "State Board"}}
{"name": "Sunshine", "Address": "Main Street", "start_date": "1965-06-01",
"student_count": 604}En exécutant le code ci-dessus, nous obtenons la réponse comme indiqué ci-dessous -
{
"took" : 277,
"errors" : false,
"items" : [
{
"index" : {
"_index" : "schoollist",
"_type" : "_doc",
"_id" : "CBSE",
"_version" : 1,
"result" : "created",
"forced_refresh" : true,
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : {
"_index" : "schoollist",
"_type" : "_doc",
"_id" : "ICSE",
"_version" : 1,
"result" : "created",
"forced_refresh" : true,
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : {
"_index" : "schoollist",
"_type" : "_doc",
"_id" : "State Board",
"_version" : 1,
"result" : "created",
"forced_refresh" : true,
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1,
"status" : 201
}
}
]
}Requête SQL
L'exemple suivant montre comment nous encadrons la requête SQL -
POST /_sql?format=txt
{
"query": "SELECT * FROM schoollist WHERE start_date < '2000-01-01'"
}En exécutant le code ci-dessus, nous obtenons la réponse comme indiqué ci-dessous -
Address | name | start_date | student_count
--------------------+---------------+------------------------+---------------
Gachibowli Main Road|Top-Notch |1989-05-26T00:00:00.000Z|482
Main Street |Sunshine |1965-06-01T00:00:00.000Z|604Note - En modifiant la requête SQL ci-dessus, vous pouvez obtenir différents ensembles de résultats.
Pour surveiller la santé du cluster, la fonction de surveillance collecte les métriques de chaque nœud et les stocke dans les indices Elasticsearch. Tous les paramètres associés à la surveillance dans Elasticsearch doivent être définis dans le fichier elasticsearch.yml pour chaque nœud ou, si possible, dans les paramètres du cluster dynamique.
Pour commencer la surveillance, nous devons vérifier les paramètres du cluster, ce qui peut être fait de la manière suivante -
GET _cluster/settings
{
"persistent" : { },
"transient" : { }
}Chaque composant de la pile est chargé de se surveiller, puis de transmettre ces documents au cluster de production Elasticsearch pour le routage et l'indexation (stockage). Les processus de routage et d'indexation dans Elasticsearch sont gérés par ce que l'on appelle des collecteurs et des exportateurs.
Collectionneurs
Collector s'exécute une fois par intervalle de collecte pour obtenir des données des API publiques d'Elasticsearch qu'il choisit de surveiller. Lorsque la collecte de données est terminée, les données sont transmises en masse aux exportateurs pour être envoyées au cluster de surveillance.
Il n'y a qu'un seul collecteur par type de données collecté. Chaque collecteur peut créer zéro ou plusieurs documents de surveillance.
Exportateurs
Les exportateurs récupèrent les données collectées à partir de n'importe quelle source Elastic Stack et les acheminent vers le cluster de surveillance. Il est possible de configurer plus d'un exportateur, mais la configuration générale et par défaut consiste à utiliser un seul exportateur. Les exportateurs sont configurables au niveau du nœud et du cluster.
Il existe deux types d'exportateurs dans Elasticsearch -
local - Cet exportateur achemine les données vers le même cluster
http - L'exportateur préféré, que vous pouvez utiliser pour acheminer les données vers n'importe quel cluster Elasticsearch pris en charge accessible via HTTP.
Avant que les exportateurs puissent acheminer les données de surveillance, ils doivent configurer certaines ressources Elasticsearch. Ces ressources incluent des modèles et des pipelines d'ingestion
Un travail de cumul est une tâche périodique qui récapitule les données des index spécifiés par un modèle d'index et les roule dans un nouvel index. Dans l'exemple suivant, nous créons un index nommé sensor avec différents horodatages. Ensuite, nous créons une tâche de cumul pour cumuler les données de ces index périodiquement à l'aide de la tâche cron.
PUT /sensor/_doc/1
{
"timestamp": 1516729294000,
"temperature": 200,
"voltage": 5.2,
"node": "a"
}En exécutant le code ci-dessus, nous obtenons le résultat suivant -
{
"_index" : "sensor",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}Maintenant, ajoutez un deuxième document et ainsi de suite pour d'autres documents également.
PUT /sensor-2018-01-01/_doc/2
{
"timestamp": 1413729294000,
"temperature": 201,
"voltage": 5.9,
"node": "a"
}Créer un travail de cumul
PUT _rollup/job/sensor
{
"index_pattern": "sensor-*",
"rollup_index": "sensor_rollup",
"cron": "*/30 * * * * ?",
"page_size" :1000,
"groups" : {
"date_histogram": {
"field": "timestamp",
"interval": "60m"
},
"terms": {
"fields": ["node"]
}
},
"metrics": [
{
"field": "temperature",
"metrics": ["min", "max", "sum"]
},
{
"field": "voltage",
"metrics": ["avg"]
}
]
}Le paramètre cron contrôle quand et à quelle fréquence le travail s'active. Lorsque la planification cron d'une tâche de cumul se déclenche, elle commencera à remonter là où elle s'était arrêtée après la dernière activation.
Une fois le travail exécuté et traité certaines données, nous pouvons utiliser la requête DSL pour effectuer des recherches.
GET /sensor_rollup/_rollup_search
{
"size": 0,
"aggregations": {
"max_temperature": {
"max": {
"field": "temperature"
}
}
}
}Les index fréquemment recherchés sont conservés en mémoire car leur reconstruction prend du temps et contribue à une recherche efficace. D'un autre côté, il peut y avoir des indices auxquels nous avons rarement accès. Ces index n'ont pas besoin d'occuper la mémoire et peuvent être reconstruits quand ils sont nécessaires. Ces indices sont appelés indices gelés.
Elasticsearch crée les structures de données transitoires de chaque partition d'un index gelé chaque fois que cette partition est recherchée et supprime ces structures de données dès que la recherche est terminée. Étant donné qu'Elasticsearch ne conserve pas ces structures de données transitoires en mémoire, les index gelés consomment beaucoup moins de tas que les index normaux. Cela permet un rapport disque / tas beaucoup plus élevé que ce qui serait autrement possible.
Exemple de gel et de dégel
L'exemple suivant gèle et dégèle un index -
POST /index_name/_freeze
POST /index_name/_unfreezeLes recherches sur les index gelés devraient s'exécuter lentement. Les index gelés ne sont pas destinés à une charge de recherche élevée. Il est possible qu'une recherche dans un index figé puisse prendre quelques secondes ou minutes, même si les mêmes recherches se sont terminées en millisecondes alors que les index n'étaient pas figés.
Recherche d'un index gelé
Le nombre d'index gelés chargés simultanément par nœud est limité par le nombre de threads dans le pool de threads search_throttled, qui est 1 par défaut. Pour inclure des index gelés, une demande de recherche doit être exécutée avec le paramètre de requête - ignore_throttled = false.
GET /index_name/_search?q=user:tpoint&ignore_throttled=falseSurveillance des indices gelés
Les index gelés sont des index ordinaires qui utilisent la limitation de la recherche et une implémentation de partition efficace en mémoire.
GET /_cat/indices/index_name?v&h=i,sthElasticsearch fournit un fichier jar, qui peut être ajouté à n'importe quel IDE java et peut être utilisé pour tester le code lié à Elasticsearch. Une gamme de tests peut être effectuée en utilisant le framework fourni par Elasticsearch. Dans ce chapitre, nous discuterons de ces tests en détail -
- Test unitaire
- Test d'intégration
- Tests randomisés
Conditions préalables
Pour commencer les tests, vous devez ajouter la dépendance de test Elasticsearch à votre programme. Vous pouvez utiliser maven à cette fin et ajouter ce qui suit dans pom.xml.
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>2.1.0</version>
</dependency>EsSetup a été initialisé pour démarrer et arrêter le nœud Elasticsearch et également pour créer des index.
EsSetup esSetup = new EsSetup();La fonction esSetup.execute () avec createIndex créera les index, vous devez spécifier les paramètres, le type et les données.
Test unitaire
Le test unitaire est effectué à l'aide du framework de test JUnit et Elasticsearch. Le nœud et les index peuvent être créés à l'aide des classes Elasticsearch et dans la méthode de test peuvent être utilisés pour effectuer les tests. Les classes ESTestCase et ESTokenStreamTestCase sont utilisées pour ce test.
Test d'intégration
Les tests d'intégration utilisent plusieurs nœuds dans un cluster. La classe ESIntegTestCase est utilisée pour ce test. Il existe différentes méthodes qui facilitent la préparation d'un cas de test.
| S. Non | Méthode et description |
|---|---|
| 1 | refresh() Tous les index d'un cluster sont actualisés |
| 2 | ensureGreen() Garantit un état de cluster de santé vert |
| 3 | ensureYellow() Garantit un état de cluster d'intégrité jaune |
| 4 | createIndex(name) Créer un index avec le nom passé à cette méthode |
| 5 | flush() Tous les index du cluster sont vidés |
| 6 | flushAndRefresh() flush () et refresh () |
| sept | indexExists(name) Vérifie l'existence de l'index spécifié |
| 8 | clusterService() Renvoie la classe Java du service de cluster |
| 9 | cluster() Renvoie la classe de cluster de test |
Tester les méthodes de cluster
| S. Non | Méthode et description |
|---|---|
| 1 | ensureAtLeastNumNodes(n) Garantit que le nombre minimum de nœuds dans un cluster est supérieur ou égal au nombre spécifié. |
| 2 | ensureAtMostNumNodes(n) Garantit que le nombre maximal de nœuds dans un cluster est inférieur ou égal au nombre spécifié. |
| 3 | stopRandomNode() Pour arrêter un nœud aléatoire dans un cluster |
| 4 | stopCurrentMasterNode() Pour arrêter le nœud maître |
| 5 | stopRandomNonMaster() Pour arrêter un nœud aléatoire dans un cluster, qui n'est pas un nœud maître. |
| 6 | buildNode() Créer un nouveau nœud |
| sept | startNode(settings) Démarrer un nouveau nœud |
| 8 | nodeSettings() Remplacez cette méthode pour modifier les paramètres de nœud. |
Accéder aux clients
Un client est utilisé pour accéder à différents nœuds dans un cluster et effectuer certaines actions. La méthode ESIntegTestCase.client () est utilisée pour obtenir un client aléatoire. Elasticsearch propose également d'autres méthodes pour accéder au client et ces méthodes sont accessibles à l'aide de la méthode ESIntegTestCase.internalCluster ().
| S. Non | Méthode et description |
|---|---|
| 1 | iterator() Cela vous aide à accéder à tous les clients disponibles. |
| 2 | masterClient() Cela renvoie un client, qui communique avec le nœud maître. |
| 3 | nonMasterClient() Cela renvoie un client, qui ne communique pas avec le nœud maître. |
| 4 | clientNodeClient() Cela renvoie un client actuellement sur le poste client. |
Test randomisé
Ce test est utilisé pour tester le code de l'utilisateur avec toutes les données possibles, afin qu'il n'y ait pas d'échec à l'avenir avec n'importe quel type de données. Les données aléatoires sont la meilleure option pour effectuer ces tests.
Générer des données aléatoires
Dans ce test, la classe Random est instanciée par l'instance fournie par RandomizedTest et propose de nombreuses méthodes pour obtenir différents types de données.
| Méthode | Valeur de retour |
|---|---|
| getRandom () | Instance de classe aléatoire |
| randomBoolean () | Booléen aléatoire |
| randomByte () | Octet aléatoire |
| randomShort () | Court aléatoire |
| randomInt () | Entier aléatoire |
| randomLong () | Aléatoire long |
| randomFloat () | Flotteur aléatoire |
| randomDouble () | Double aléatoire |
| randomLocale () | Paramètres régionaux aléatoires |
| randomTimeZone () | Fuseau horaire aléatoire |
| randomFrom () | Élément aléatoire du tableau |
Assertions
Les classes ElasticsearchAssertions et ElasticsearchGeoAssertions contiennent des assertions, qui sont utilisées pour effectuer certaines vérifications courantes au moment du test. Par exemple, observez le code donné ici -
SearchResponse seearchResponse = client().prepareSearch();
assertHitCount(searchResponse, 6);
assertFirstHit(searchResponse, hasId("6"));
assertSearchHits(searchResponse, "1", "2", "3", "4",”5”,”6”);Un tableau de bord Kibana est une collection de visualisations et de recherches. Vous pouvez organiser, redimensionner et modifier le contenu du tableau de bord, puis enregistrer le tableau de bord afin de pouvoir le partager. Dans ce chapitre, nous verrons comment créer et modifier un tableau de bord.
Création de tableau de bord
Sur la page d'accueil de Kibana, sélectionnez l'option de tableau de bord dans les barres de contrôle de gauche, comme indiqué ci-dessous. Cela vous invitera à créer un nouveau tableau de bord.
Pour ajouter des visualisations au tableau de bord, nous choisissons le menu Ajouter et la sélection parmi les visualisations prédéfinies disponibles. Nous avons choisi les options de visualisation suivantes dans la liste.
En sélectionnant les visualisations ci-dessus, nous obtenons le tableau de bord comme indiqué ici. Nous pouvons plus tard ajouter et éditer le tableau de bord pour changer les éléments et ajouter les nouveaux éléments.
Inspection des éléments
Nous pouvons inspecter les éléments du tableau de bord en choisissant le menu du panneau de visualisation et en sélectionnant Inspect. Cela fera ressortir les données derrière l'élément qui peuvent également être téléchargées.
Tableau de bord de partage
Nous pouvons partager le tableau de bord en choisissant le menu de partage et en sélectionnant l'option pour obtenir un lien hypertexte comme indiqué ci-dessous -

La fonctionnalité de découverte disponible sur la page d'accueil de Kibana nous permet d'explorer les ensembles de données sous différents angles. Vous pouvez rechercher et filtrer les données pour les modèles d'index sélectionnés. Les données sont généralement disponibles sous forme de distribution de valeurs sur une période de temps.
Pour explorer l'exemple de données de commerce électronique, nous cliquons sur le Discovercomme indiqué dans l'image ci-dessous. Cela fera apparaître les données avec le graphique.
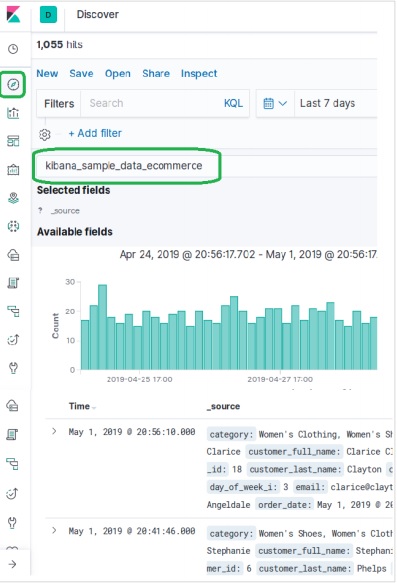
Filtrage par heure
Pour filtrer les données par intervalle de temps spécifique, nous utilisons l'option de filtre temporel comme indiqué ci-dessous. Par défaut, le filtre est réglé sur 15 minutes.
Filtrage par champs
L'ensemble de données peut également être filtré par champs à l'aide du Add Filteroption comme indiqué ci-dessous. Ici, nous ajoutons un ou plusieurs champs et obtenons le résultat correspondant une fois les filtres appliqués. Dans notre exemple nous choisissons le champday_of_week puis l'opérateur pour ce champ comme is et valoriser comme Sunday.
Ensuite, nous cliquons sur Enregistrer avec les conditions de filtre ci-dessus. L'ensemble de résultats contenant les conditions de filtre appliquées est illustré ci-dessous.
La table de données est un type de visualisation utilisé pour afficher les données brutes d'une agrégation composée. Il existe différents types d'agrégations qui sont présentés à l'aide de tableaux de données. Afin de créer une table de données, nous devons suivre les étapes décrites ici en détail.
Visualiser
Dans l'écran d'accueil de Kibana, nous trouvons le nom d'option Visualize qui nous permet de créer une visualisation et des agrégations à partir des index stockés dans Elasticsearch. L'image suivante montre l'option.
Sélectionnez la table de données
Ensuite, nous sélectionnons l'option Table de données parmi les différentes options de visualisation disponibles. L'option est montrée dans l'image suivante & miuns;
Sélectionnez les métriques
Nous sélectionnons ensuite les métriques nécessaires à la création de la visualisation de la table de données. Ce choix décide du type d'agrégation que nous allons utiliser. Pour cela, nous sélectionnons les champs spécifiques indiqués ci-dessous dans l'ensemble de données de commerce électronique.
En exécutant la configuration ci-dessus pour la table de données, nous obtenons le résultat comme indiqué dans l'image ici -
Les cartes de région affichent des métriques sur une carte géographique. Elle est utile pour examiner les données ancrées à différentes régions géographiques avec une intensité variable. Les nuances plus foncées indiquent généralement des valeurs plus élevées et les nuances plus claires indiquent des valeurs inférieures.
Les étapes pour créer cette visualisation sont expliquées en détail comme suit -
Visualiser
Dans cette étape, nous allons au bouton de visualisation disponible dans la barre de gauche de l'écran d'accueil de Kibana, puis en choisissant l'option pour ajouter une nouvelle visualisation.
L'écran suivant montre comment nous choisissons l'option Carte de la région.
Choisissez les métriques
L'écran suivant nous invite à choisir les métriques qui seront utilisées pour créer la carte de région. Ici, nous choisissons le prix moyen comme métrique et country_iso_code comme champ dans le bucket qui sera utilisé pour créer la visualisation.
Le résultat final ci-dessous montre la carte de la région une fois que nous avons appliqué la sélection. Veuillez noter les nuances de la couleur et leurs valeurs mentionnées sur l'étiquette.
Les graphiques à secteurs sont l'un des outils de visualisation les plus simples et les plus connus. Il représente les données sous forme de tranches de cercle, chacune colorée différemment. Les étiquettes ainsi que les valeurs de données en pourcentage peuvent être présentées avec le cercle. Le cercle peut également prendre la forme d'un beignet.
Visualiser
Dans l'écran d'accueil de Kibana, nous trouvons le nom d'option Visualize qui nous permet de créer des visualisations et des agrégations à partir des index stockés dans Elasticsearch. Nous choisissons d'ajouter une nouvelle visualisation et sélectionnons le graphique à secteurs comme option ci-dessous.
Choisissez les métriques
L'écran suivant nous invite à choisir les métriques qui seront utilisées pour créer le graphique à secteurs. Ici, nous choisissons le décompte du prix unitaire de base comme métrique et l'agrégation par compartiment comme histogramme. En outre, l'intervalle minimum est choisi comme 20. Ainsi, les prix seront affichés sous forme de blocs de valeurs avec 20 comme plage.
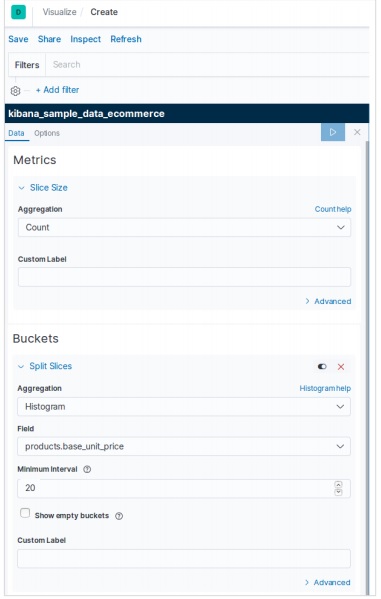
Le résultat ci-dessous montre le graphique à secteurs après avoir appliqué la sélection. Veuillez noter les nuances de la couleur et leurs valeurs mentionnées sur l'étiquette.

Options de graphique à secteurs
En passant à l'onglet Options sous le graphique à secteurs, nous pouvons voir diverses options de configuration pour changer l'apparence ainsi que la disposition de l'affichage des données dans le graphique à secteurs. Dans l'exemple suivant, le graphique à secteurs apparaît sous forme d'anneau et les étiquettes apparaissent en haut.
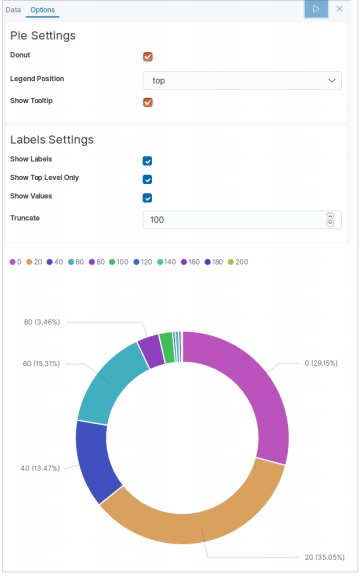
Un graphique en aires est une extension du graphique en courbes où la zone entre le graphique en courbes et les axes est mise en évidence avec des couleurs. Un graphique à barres représente des données organisées en une plage de valeurs, puis tracées par rapport aux axes. Il peut être constitué de barres horizontales ou de barres verticales.
Dans ce chapitre, nous verrons ces trois types de graphiques créés à l'aide de Kibana. Comme indiqué dans les chapitres précédents, nous continuerons à utiliser les données de l'index du commerce électronique.
Graphique de zone
Dans l'écran d'accueil de Kibana, nous trouvons le nom d'option Visualize qui nous permet de créer des visualisations et des agrégations à partir des index stockés dans Elasticsearch. Nous choisissons d'ajouter une nouvelle visualisation et sélectionnons Chart Area comme option montrée dans l'image ci-dessous.
Choisissez les métriques
L'écran suivant nous invite à choisir les métriques qui seront utilisées pour créer le graphique en aires. Ici, nous choisissons la somme comme type de métrique d'agrégation. Ensuite, nous choisissons le champ total_quantity comme champ à utiliser comme métrique. Sur l'axe X, nous avons choisi le champ order_date et fractionné la série avec la métrique donnée dans une taille de 5.

En exécutant la configuration ci-dessus, nous obtenons le graphique en aires suivant comme sortie -
Graphique à barres horizontales
De même, pour le graphique à barres horizontales, nous choisissons une nouvelle visualisation à partir de l'écran d'accueil de Kibana et choisissons l'option Barre horizontale. Ensuite, nous choisissons les métriques comme indiqué dans l'image ci-dessous. Ici, nous choisissons Somme comme agrégation pour la quantité de produit nommé classé. Ensuite, nous choisissons des seaux avec un histogramme de date pour la date de commande du champ.
En exécutant la configuration ci-dessus, nous pouvons voir un graphique à barres horizontales comme indiqué ci-dessous -
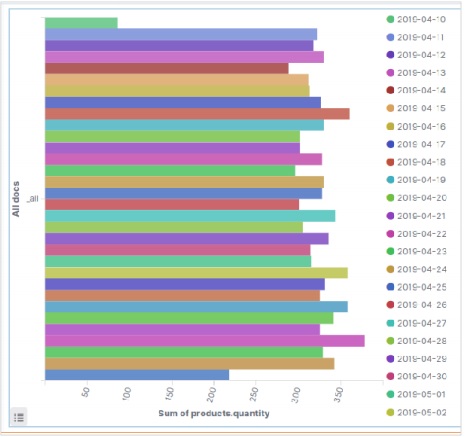
Graphique à barres verticales
Pour le graphique à barres verticales, nous choisissons une nouvelle visualisation depuis l'écran d'accueil de Kibana et choisissons l'option Barre verticale. Ensuite, nous choisissons les métriques comme indiqué dans l'image ci-dessous.
Ici, nous choisissons Somme comme agrégation pour le champ nommé quantité de produit. Ensuite, nous choisissons des seaux avec un histogramme de date pour la date de commande de champ avec un intervalle hebdomadaire.
Lors de l'exécution de la configuration ci-dessus, un graphique sera généré comme indiqué ci-dessous -
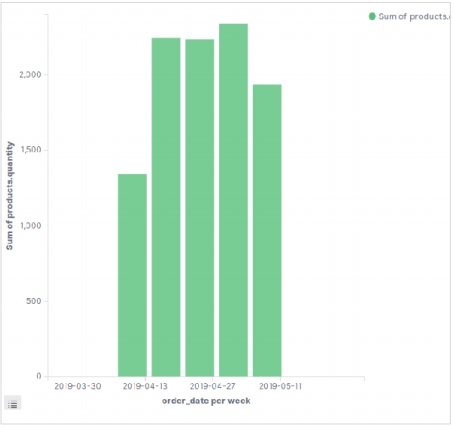
La série chronologique est une représentation de la séquence de données dans une séquence temporelle spécifique. Par exemple, les données pour chaque jour du premier jour du mois au dernier jour. L'intervalle entre les points de données reste constant. Tout ensemble de données comportant une composante temporelle peut être représenté sous forme de série chronologique.
Dans ce chapitre, nous utiliserons l'exemple d'ensemble de données de commerce électronique et tracerons le nombre de commandes pour chaque jour pour créer une série chronologique.
Choisissez les métriques
Tout d'abord, nous choisissons le modèle d'index, le champ de données et l'intervalle qui seront utilisés pour créer la série chronologique. À partir de l'exemple d'ensemble de données de commerce électronique, nous choisissons order_date comme champ et 1d comme intervalle. Nous utilisons lePanel Optionsonglet pour faire ces choix. Nous laissons également les autres valeurs de cet onglet par défaut pour obtenir une couleur et un format par défaut pour la série chronologique.
dans le Data onglet, nous choisissons compter comme option d'agrégation, regrouper par option comme tout et mettre une étiquette pour le graphique de série chronologique.
Résultat
Le résultat final de cette configuration apparaît comme suit. Veuillez noter que nous utilisons une période deMonth to Datepour ce graphique. Différentes périodes donneront des résultats différents.
Un nuage de balises représente du texte qui sont principalement des mots-clés et des métadonnées sous une forme visuellement attrayante. Ils sont alignés sous différents angles et représentés dans différentes couleurs et tailles de police. Cela aide à découvrir les termes les plus importants dans les données. L'importance peut être décidée par un ou plusieurs facteurs tels que la fréquence du terme, l'unicité de la balise ou basée sur une pondération attachée à des termes spécifiques, etc. Ci-dessous, nous voyons les étapes pour créer un nuage de tags.
Visualiser
Dans l'écran d'accueil de Kibana, nous trouvons le nom d'option Visualize qui nous permet de créer des visualisations et des agrégations à partir des index stockés dans Elasticsearch. Nous choisissons d'ajouter une nouvelle visualisation et sélectionnons Tag Cloud comme option ci-dessous -
Choisissez les métriques
L'écran suivant nous invite à choisir les métriques qui seront utilisées pour créer le Tag Cloud. Ici, nous choisissons le nombre comme type de métrique d'agrégation. Ensuite, nous choisissons le champ productname comme mot-clé à utiliser comme balises.
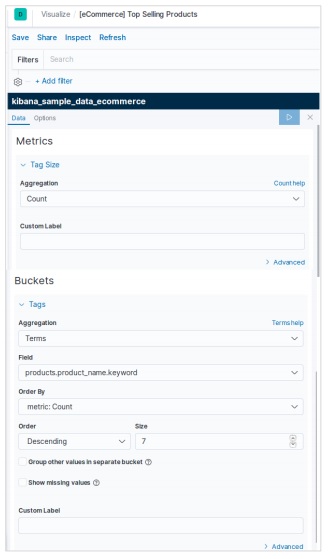
Le résultat affiché ici montre le graphique à secteurs après avoir appliqué la sélection. Veuillez noter les nuances de la couleur et leurs valeurs mentionnées sur l'étiquette.

Options de nuage de tags
En passant au optionssous Tag Cloud, nous pouvons voir différentes options de configuration pour changer l'apparence ainsi que la disposition de l'affichage des données dans le Tag Cloud. Dans l'exemple ci-dessous, le nuage de tags apparaît avec des tags répartis à la fois dans les directions horizontale et verticale.
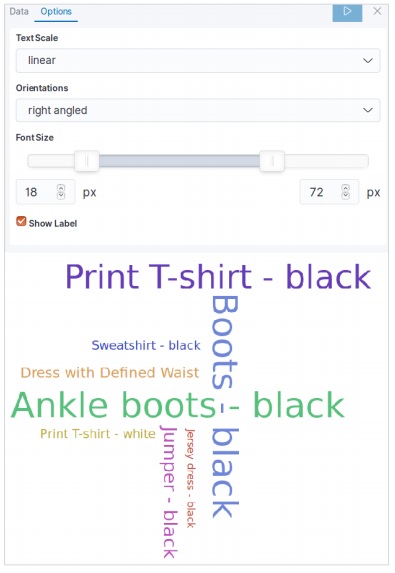
La carte thermique est un type de visualisation dans lequel différentes nuances de couleur représentent différentes zones du graphique. Les valeurs peuvent varier continuellement et par conséquent les nuances de couleur r d'une couleur varient avec les valeurs. Ils sont très utiles pour représenter à la fois les données à variation continue et les données discrètes.
Dans ce chapitre, nous utiliserons l'ensemble de données nommé sample_data_flights pour créer un graphique de carte thermique. Nous y considérons les variables nommées pays d'origine et pays de destination des vols et effectuons un décompte.
Dans l'écran d'accueil de Kibana, nous trouvons le nom d'option Visualize qui nous permet de créer des visualisations et des agrégations à partir des index stockés dans Elasticsearch. Nous choisissons d'ajouter une nouvelle visualisation et sélectionnons Heat Map comme option ci-dessous & mimus;
Choisissez les métriques
L'écran suivant nous invite à choisir les métriques qui seront utilisées pour créer le graphique Heat Map. Ici, nous choisissons le nombre comme type de métrique d'agrégation. Ensuite, pour les buckets de l'axe Y, nous choisissons Termes comme agrégation pour le champ OriginCountry. Pour l'axe X, nous choisissons la même agrégation mais DestCountry comme champ à utiliser. Dans les deux cas, nous choisissons la taille du godet comme 5.

En exécutant la configuration ci-dessus, nous obtenons le graphique de carte thermique généré comme suit.
Note - Vous devez autoriser la plage de dates comme Cette année afin que le graphique rassemble les données d'une année pour produire un graphique de carte thermique efficace.
L'application Canvas fait partie de Kibana, ce qui nous permet de créer des affichages de données dynamiques, multipages et parfaits en pixels. Sa capacité à créer des infographies et pas seulement des graphiques et des métrices est ce qui le rend unique et attrayant. Dans ce chapitre, nous verrons diverses fonctionnalités de Canvas et comment utiliser les blocs de travail Canvas.
Ouverture d'une toile
Accédez à la page d'accueil de Kibana et sélectionnez l'option comme indiqué dans le diagramme ci-dessous. Il ouvre la liste des blocs de travail sur toile que vous avez. Nous choisissons le suivi des revenus du commerce électronique pour notre étude.
Cloner un Workpad
Nous clonons le [eCommerce] Revenue TrackingWorkpad à utiliser dans notre étude. Pour le cloner, nous mettons en surbrillance la ligne avec le nom de ce workpad puis utilisons le bouton de clonage comme indiqué dans le diagramme ci-dessous -
À la suite du clone ci-dessus, nous obtiendrons un nouveau bloc de travail nommé [eCommerce] Revenue Tracking – Copy qui à l'ouverture montrera les infographies ci-dessous.
Il décrit les ventes totales et les revenus par catégorie ainsi que de belles images et des graphiques.
Modifier le Workpad
Nous pouvons modifier le style et les chiffres du bloc de travail en utilisant les options disponibles dans l'onglet de droite. Ici, nous visons à changer la couleur d'arrière-plan du workpad en choisissant une couleur différente comme indiqué dans le diagramme ci-dessous. La sélection de couleur entre en vigueur immédiatement et nous obtenons le résultat comme indiqué ci-dessous -

Kibana peut également aider à visualiser les données de journal provenant de diverses sources. Les journaux sont des sources importantes d'analyse pour la santé de l'infrastructure, les besoins de performance et l'analyse des failles de sécurité, etc. Kibana peut se connecter à divers journaux tels que les journaux de serveur Web, les journaux elasticsearch et les journaux cloudwatch, etc.
Journaux Logstash
Dans Kibana, nous pouvons nous connecter aux journaux logstash pour la visualisation. Nous choisissons d'abord le bouton Journaux de l'écran d'accueil de Kibana comme indiqué ci-dessous -
Ensuite, nous choisissons l'option Modifier la configuration de la source qui nous offre la possibilité de choisir Logstash comme source. L'écran ci-dessous montre également d'autres types d'options que nous avons comme source de journal.
Vous pouvez diffuser des données pour la fin du journal en direct ou suspendre la diffusion pour vous concentrer sur les données du journal historique. Lorsque vous diffusez des journaux en continu, le journal le plus récent apparaît en bas de la console.
Pour plus d'informations, vous pouvez vous référer à notre tutoriel Logstash .