MuleSoft - Guide rapide
ESB signifie Enterprise Service Busqui est essentiellement un outil middleware pour intégrer diverses applications ensemble sur une infrastructure de type bus. Fondamentalement, il s'agit d'une architecture conçue pour fournir un moyen uniforme de déplacer le travail entre les applications intégrées. De cette manière, à l'aide de l'architecture ESB, nous pouvons connecter différentes applications via un bus de communication et leur permettre de communiquer sans dépendre les unes des autres.
Mettre en œuvre ESB
L'objectif principal de l'architecture ESB est de découpler les systèmes les uns des autres et de leur permettre de communiquer de manière stable et contrôlable. La mise en œuvre d'ESB peut se faire à l'aide de‘Bus’ et ‘Adapter’ de la manière suivante -
Le concept de «bus», qui est réalisé via un serveur de messagerie comme JMS ou AMQP, est utilisé pour découpler différentes applications les unes des autres.
Le concept d '«adaptateur», chargé de communiquer avec l'application backend et de transformer les données du format d'application au format bus, est utilisé entre les applications et le bus.
Les données ou le message passant d'une application à une autre via le bus sont dans un format canonique, ce qui signifie qu'il y aurait un format de message cohérent.
L'adaptateur peut également effectuer d'autres activités telles que la sécurité, la surveillance, la gestion des erreurs et la gestion du routage des messages.
Principes directeurs de l'ESB
Nous pouvons appeler ces principes des principes d'intégration fondamentaux. Ils sont les suivants -
Orchestration - Intégration de deux ou plusieurs services pour réaliser la synchronisation entre les données et les processus.
Transformation - Transformation des données du format canonique au format spécifique à l'application.
Transportation - Gestion de la négociation de protocole entre des formats comme FTP, HTTP, JMS, etc.
Mediation - Fournir plusieurs interfaces pour prendre en charge plusieurs versions d'un service.
Non-functional consistency - Fournir un mécanisme pour gérer les transactions et la sécurité également.
Besoin d'ESB
L'architecture ESB nous permet d'intégrer différentes applications où chaque application peut communiquer à travers elle. Vous trouverez ci-dessous quelques instructions sur l'utilisation d'ESB -
Integrating two or more applications - L'utilisation de l'architecture ESB est avantageuse lorsqu'il est nécessaire d'intégrer au moins deux services ou applications.
Integration of more applications in future - Supposons que si nous voulons ajouter plus de services ou d'applications à l'avenir, cela peut être facilement fait à l'aide de l'architecture ESB.
Using multiple protocols - Si nous devons utiliser plusieurs protocoles tels que HTTP, FTP, JMS, etc., ESB est la bonne option.
Message routing - Nous pouvons utiliser ESB au cas où nous aurions besoin d'un routage de message basé sur le contenu du message et d'autres paramètres similaires.
Composition and consumption - ESB peut être utilisé si nous devons publier des services de composition et de consommation.
Intégration P2P vs intégration ESB
Avec l'augmentation du nombre d'applications, une grande question devant les développeurs était de savoir comment connecter différentes applications? La situation a été gérée en codant manuellement une connexion entre diverses applications. C'est appelépoint-to-point integration.
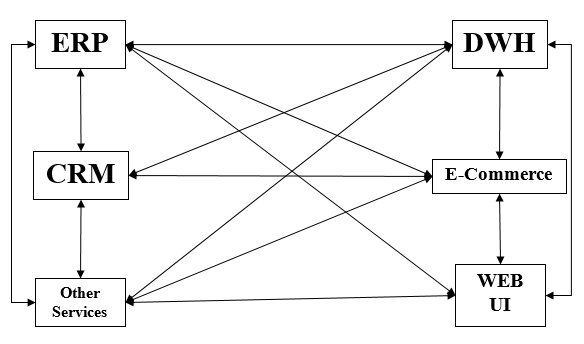
Rigidityest l'inconvénient le plus évident de l'intégration point à point. La complexité augmente avec l'augmentation du nombre de connexions et d'interfaces. Les inconvénients de l'intégration P-2-P nous amènent à l'intégration ESB.
ESB est une approche plus flexible de l'intégration d'applications. Il encapsule et expose chaque fonctionnalité d'application sous la forme d'un ensemble de capacités réutilisables discrètes. Aucune application ne s'intègre directement à une autre, à la place, elles s'intègrent via un ESB comme indiqué ci-dessous -
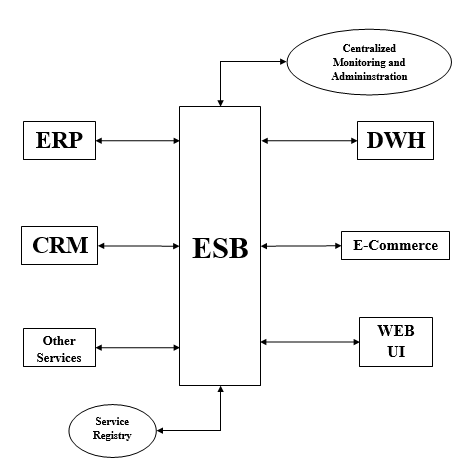
Pour gérer l'intégration, ESB comprend les deux composants suivants -
Service Registry- Mule ESB a Service Registry / Repository où tous les services exposés dans l'ESB sont publiés et enregistrés. Il agit comme un point de découverte à partir duquel on peut consommer les services et les capacités d'autres applications.
Centralized Administration - Comme son nom l'indique, il fournit une vue des flux transactionnels de performance des interactions se produisant à l'intérieur du ESB.
ESB Functionality- L'abréviation VETRO est généralement utilisée pour résumer les fonctionnalités d'ESB. C'est comme suit -
V(Valider) - Comme son nom l'indique, il valide la validation du schéma. Il nécessite un analyseur de validation et un schéma à jour. Un exemple est un document XML confirmant un schéma à jour.
E(Enrichir) - Il ajoute des données supplémentaires à un message. Le but est de rendre le message plus significatif et utile à un service cible.
T(Transformer) - Il convertit la structure de données dans un format canonique ou à partir d'un format canonique. Des exemples sont la conversion de la date / heure, de la devise, etc.
R(Routing) - Il acheminera le message et agira en tant que portier du point d'extrémité d'un service.
O(Exploiter) - La tâche principale de cette fonction est d'appeler le service cible ou d'interagir avec l'application cible. Ils fonctionnent au niveau du backend.
Le modèle VETRO offre une flexibilité globale à l'intégration et garantit que seules des données cohérentes et validées seront acheminées dans tout l'ESB.
Qu'est-ce que Mule ESB?
Mule ESB est un bus de services d'entreprise (ESB) Java léger et hautement évolutif et une plate-forme d'intégration fournis par MuleSoft. Mule ESB permet au développeur de connecter des applications facilement et rapidement. Indépendamment des diverses technologies utilisées par les applications, Mule ESB permet une intégration facile des applications, leur permettant d'échanger des données. Mule ESB a les deux éditions suivantes -
- Edition communautaire
- Edition pour entreprise
Un avantage de Mule ESB est que nous pouvons facilement passer de la communauté Mule ESB à l'entreprise Mule ESB car les deux éditions sont construites sur une base de code commune.
Caractéristiques et capacités de Mule ESB
Les fonctionnalités suivantes sont possédées par Mule ESB -
- Il a une conception graphique simple par glisser-déposer.
- Mule ESB est capable de cartographier et de transformer visuellement les données.
- L'utilisateur peut obtenir l'installation de centaines de connecteurs certifiés pré-construits.
- Surveillance et administration centralisées.
- Il fournit de solides capacités d'application de la sécurité d'entreprise.
- Il fournit la facilité de gestion des API.
- Il existe une passerelle de données sécurisée pour la connectivité cloud / sur site.
- Il fournit le registre des services où tous les services exposés dans l'ESB sont publiés et enregistrés.
- Les utilisateurs peuvent avoir le contrôle via une console de gestion Web.
- Un débogage rapide peut être effectué à l'aide de l'analyseur de flux de service.
Les motivations du projet Mule étaient -
pour simplifier les choses pour les programmeurs,
le besoin d'une solution légère et modulaire qui pourrait évoluer d'un cadre de messagerie au niveau de l'application à un cadre hautement distribuable à l'échelle de l'entreprise.
Mule ESB est conçu comme un cadre événementiel et programmatique. Il est piloté par les événements car il est combiné avec une représentation unifiée des messages et peut être extensible avec des modules enfichables. Il est programmatique car les programmeurs peuvent facilement implémenter certains comportements supplémentaires tels que le traitement de messages spécifiques ou la transformation de données personnalisée.
L'histoire
La perspective historique du projet Mule est la suivante -
Projet SourceForge
Le projet Mule a été lancé en tant que projet SourceForge en avril 2003, et après 2 ans, sa première version a été publiée et déplacée vers CodeHaus. L'API UMO (Universal Message Object) était au cœur de son architecture. L'idée derrière l'API UMO était d'unifier la logique tout en les isolant des transports sous-jacents.
Version 1.0
Il a été publié en avril 2005 contenant de nombreux transports. Le principal objectif de nombreuses autres versions suivies était le débogage et l'ajout de nouvelles fonctionnalités.
Version 2.0 (adoption du printemps 2)
Spring 2 comme cadre de configuration et de câblage a été adopté dans Mule 2 mais il s'est avéré être une révision majeure en raison du manque d'expressivité de la configuration XML requise. Ce problème a été résolu lorsque la configuration basée sur le schéma XML a été introduite dans Spring 2.
Construire avec Maven
La plus grande amélioration qui a simplifié l'utilisation de Mule, à la fois au moment du développement et du déploiement, a été l'utilisation de Maven. À partir de la version 1.3, il a commencé à être construit avec Maven.
MuleSource
En 2006, MuleSource a été incorporé «pour aider à soutenir et permettre à la communauté en croissance rapide d'utiliser Mule dans des applications d'entreprise critiques». Cela s'est avéré être le jalon clé du projet Mule.
Concurrents de Mule ESB
Voici quelques-uns des principaux concurrents de Mule ESB -
- WSO2 ESB
- Oracle Service Bus
- Agent de messages WebSphere
- Plateforme Aurea CX
- Fiorano ESB
- WebSphere DataPower Gateway
- Cadre de processus d'entreprise Workday
- Bus de service d'entreprise Talend
- Bus de service d'entreprise JBoss
- Gestionnaire de service iWay
Concept de base de Mule
Comme indiqué précédemment, Mule ESB est une plate-forme d'intégration et de bus de services d'entreprise Java légère et hautement évolutive. Indépendamment des diverses technologies utilisées par les applications, Mule ESB permet une intégration facile des applications, leur permettant d'échanger des données. Dans cette section, nous discuterons du concept de base de Mule entrant en jeu pour permettre une telle intégration.
Pour cela, nous devons comprendre son architecture ainsi que ses éléments constitutifs.
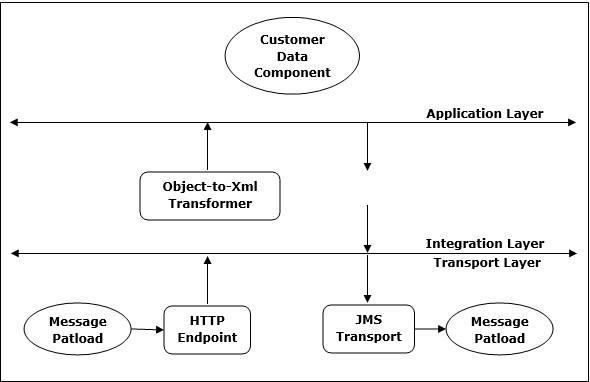
Architecture
L'architecture de Mule ESB comporte trois couches à savoir, la couche de transport, la couche d'intégration et la couche d'application, comme indiqué dans le diagramme suivant -
En règle générale, trois types de tâches peuvent être effectuées pour configurer et personnaliser le déploiement de Mule:
Développement de composants de service
Cette tâche implique le développement ou la réutilisation des POJO existants, ou Spring Beans. POJOs est une classe avec des attributs qui génère les méthodes get et set, les connecteurs cloud. D'autre part, Spring Beans contient la logique métier pour enrichir les messages.
Orchestration des services
Cette tâche fournit essentiellement la médiation de service qui implique la configuration du processeur de messages, des routeurs, des transformateurs et des filtres.
L'intégration
La tâche la plus importante de Mule ESB est l'intégration de diverses applications quels que soient les protocoles qu'elles utilisent. À cette fin, Mule fournit des méthodes de transport qui permettent de recevoir et d'envoyer les messages sur différents connecteurs de protocole. Mule prend en charge de nombreuses méthodes de transport existantes, ou nous pouvons également utiliser une méthode de transport personnalisée.
Blocs de construction
La configuration Mule comprend les blocs de construction suivants -
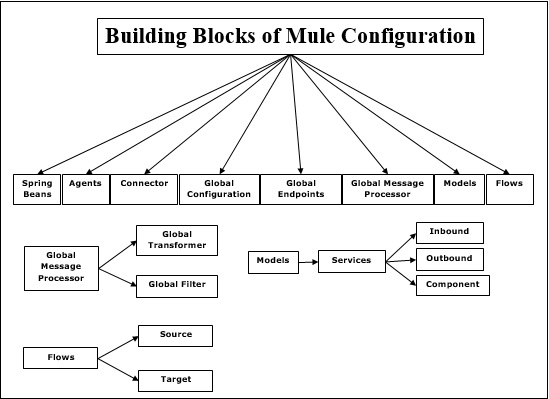
Haricots de printemps
L'utilisation principale des beans Spring est de construire un composant de service. Après avoir construit le composant de service Spring, nous pouvons le définir via un fichier de configuration ou manuellement, au cas où vous n'auriez pas de fichier de configuration.
Agents
Il s'agit essentiellement d'un service créé dans Anypoint Studio avant Mule Studio. Un agent est créé une fois que vous démarrez un serveur et sera détruit une fois que vous arrêtez le serveur.
Connecteur
Il s'agit d'un composant logiciel configuré avec les paramètres spécifiques aux protocoles. Il est principalement utilisé pour contrôler l'utilisation d'un protocole. Par exemple, un connecteur JMS est configuré avec unConnection et ce connecteur sera partagé entre différentes entités en charge de la communication proprement dite.
Configuration globale
Comme son nom l'indique, ce bloc de construction est utilisé pour définir les propriétés et les paramètres globaux.
Points de terminaison mondiaux
Il peut être utilisé dans l'onglet Éléments globaux qui peut être utilisé autant de fois dans un flux -
Processeur de messages global
Comme son nom l'indique, il observe ou modifie un message ou un flux de messages. Les transformateurs et les filtres sont des exemples de Global Message Processor.
Transformers- Le travail principal d'un transformateur est de convertir des données d'un format à un autre. Il peut être défini globalement et peut être utilisé dans plusieurs flux.
Filters- C'est le filtre qui décidera quel message Mule doit être traité. Le filtre spécifie essentiellement les conditions qui doivent être remplies pour qu'un message soit traité et acheminé vers un service.
Des modèles
Contrairement aux agents, il s'agit d'un regroupement logique de services qui sont créés en studio. Nous avons la liberté de démarrer et d'arrêter tous les services à l'intérieur d'un modèle spécifique.
Services- Les services sont ceux qui englobent notre logique métier ou nos composants. Il configure également les routeurs, les points de terminaison, les transformateurs et les filtres spécifiquement pour ce service.
Endpoints- Il peut être défini comme un objet sur lequel les services recevront des messages entrants (recevoir) et sortants (envoyer). Les services sont connectés via des points de terminaison.
Couler
Le processeur de messages utilise des flux pour définir un flux de messages entre une source et une cible.
Structure des messages Mule
Un message Mule, totalement enveloppé sous Mule Message Object, sont les données qui transitent par les applications via les flux Mule. Le message de la structure Mule est illustré dans le diagramme suivant -
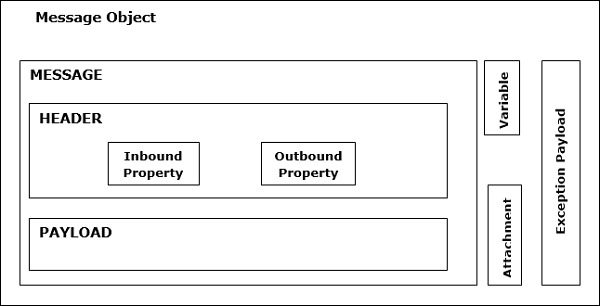
Comme le montre le diagramme ci-dessus, Mule Message se compose de deux parties principales -
Entête
Ce ne sont rien d'autre que les métadonnées du message qui sont en outre représentées par les deux propriétés suivantes -
Inbound Properties- Ce sont les propriétés qui sont automatiquement définies par la source du message. Ils ne peuvent pas être manipulés ou définis par l'utilisateur. Dans la nature, les propriétés entrantes sont immuables.
Outbound Properties- Ce sont les propriétés qui contiennent des métadonnées comme une propriété entrante et qui peuvent être définies au cours du flux. Ils peuvent être définis automatiquement par Mule ou manuellement par un utilisateur. Dans la nature, les propriétés sortantes sont modifiables.
Les propriétés sortantes deviennent des propriétés entrantes lorsque le message passe du point de terminaison sortant d'un flux au point de terminaison entrant d'un flux différent via un transport.
Les propriétés sortantes restent des propriétés sortantes lorsque le message est passé à un nouveau flux via une référence de flux plutôt qu'un connecteur.
Charge utile
Le message commercial réel transporté par l'objet de message est appelé charge utile.
Variables
Il peut être défini comme les métadonnées définies par l'utilisateur sur un message. Fondamentalement, les variables sont des informations temporaires sur un message utilisé par l'application qui le traite. Il n'est pas destiné à être transmis avec les messages à sa destination. Ils sont de trois types comme indiqué ci-dessous -
Flow variables - Ces variables s'appliquent uniquement au flux dans lequel elles existent.
Session variables - Ces variables s'appliquent à tous les flux d'une même application.
Record variables - Ces variables s'appliquent uniquement aux enregistrements traités dans le cadre d'un lot.
Pièces jointes et charge utile supplémentaire
Ce sont des métadonnées supplémentaires sur la charge utile du message qui n'apparaissent pas nécessairement à chaque fois dans l'objet message.
Dans les chapitres précédents, nous avons appris les bases de Mule ESB. Dans ce chapitre, apprenons comment l'installer et le configurer.
Conditions préalables
Nous devons satisfaire les conditions préalables suivantes avant d'installer Mule sur notre ordinateur -
Kit de développement Java (JDK)
Avant d'installer MULE, vérifiez que vous disposez d'une version prise en charge de Java sur votre système. JDK 1.8.0 est recommandé pour installer correctement Mule sur votre système.
Système opérateur
Les systèmes d'exploitation suivants sont pris en charge par Mule -
- MacOS 10.11.x
- HP-UX 11iV3
- AIX 7.2
- Serveur Windows 2016
- Serveur Windows 2012 R2
- Windows 10
- Windows 8.1
- Solaris 11.3
- RHEL 7
- Serveur Ubuntu 18.04
- Linux Kernel 3.13+
Base de données
Un serveur d'applications ou une base de données n'est pas requis car le Mule Runtime s'exécute en tant que serveur autonome. Mais si nous avons besoin d'accéder à un magasin de données ou si nous voulons utiliser un serveur d'applications, les serveurs d'applications ou bases de données pris en charge peuvent être utilisés -
- Oracle 11g
- Oracle 12c
- MySQL 5.5+
- IBM DB2 10
- PostgreSQL 9
- Derby 10
- Microsoft SQL Server 2014
Configuration requise
Avant d'installer Mule sur votre système, il doit remplir la configuration système requise suivante -
- Au moins 2 GHz CPU ou 1 CPU virtuel dans les environnements virtualisés
- Minimum 1 Go de RAM
- Stockage minimum de 4 Go
Télécharger Mule
Pour télécharger le fichier binaire de Mule 4, cliquez sur le lien https://www.mulesoft.com/lp/dl/mule-esb-enterprise et cela vous mènera à la page Web officielle de MuleSoft comme suit -

En fournissant les détails nécessaires, vous pouvez obtenir le fichier binaire Mule 4 au format Zip.
Installer et exécuter Mule
Maintenant, après avoir téléchargé le fichier binaire Mule 4, décompressez-le et définissez une variable d'environnement appelée MULE_HOME pour le répertoire Mule dans le dossier extrait.
Par exemple, la variable d'environnement, sur les environnements Windows et Linux / Unix, peut être définie pour la version 4.1.5 dans le répertoire Téléchargements comme suit -
Environnements Windows
$ env:MULE_HOME=C:\Downloads\mule-enterprise-standalone-4.1.5\Environnements Unix / Linux
$ export MULE_HOME=~/Downloads/mule-enterprise-standalone-4.1.5/Maintenant, pour tester si Mule fonctionne dans votre système sans aucune erreur, utilisez les commandes suivantes -
Environnements Windows
$ $MULE_HOME\bin\mule.batEnvironnements Unix / Linux
$ $MULE_HOME/bin/muleLes commandes ci-dessus exécuteront Mule en mode premier plan. Si Mule est en cours d'exécution, nous ne pouvons pas émettre d'autres commandes sur le terminal. Pressagectrl-c commande dans le terminal, arrêtera Mule.
Démarrer les services Mule
Nous pouvons démarrer Mule en tant que service Windows et en tant que démon Linux / Unix également.
Mule en tant que service Windows
Pour exécuter Mule en tant que service Windows, nous devons suivre les étapes ci-dessous -
Step 1 - Tout d'abord, installez-le à l'aide de la commande suivante -
$ $MULE_HOME\bin\mule.bat installStep 2 - Une fois installé, nous pouvons exécuter mule en tant que service Windows à l'aide de la commande suivante:
$ $MULE_HOME\bin\mule.bat startMule en tant que démon Linux / Unix
Pour exécuter Mule en tant que démon Linux / Unix, nous devons suivre les étapes ci-dessous -
Step 1 - Installez-le à l'aide de la commande suivante -
$ $MULE_HOME/bin/mule installStep 2 - Une fois installé, nous pouvons exécuter mule en tant que service Windows à l'aide de la commande suivante -
$ $MULE_HOME/bin/mule startExample
L'exemple suivant démarre Mule en tant que démon Unix -
$ $MULE_HOME/bin/mule start
MULE_HOME is set to ~/Downloads/mule-enterprise-standalone-4.1.5
MULE_BASE is set to ~/Downloads/mule-enterprise-standalone-4.1.5
Starting Mule Enterprise Edition...
Waiting for Mule Enterprise Edition.................
running: PID:87329Déployer des applications Mule
Nous pouvons déployer nos applications Mule à l'aide des étapes suivantes -
Step 1 - Commencez par lancer Mule.
Step 2 - Une fois que Mule démarre, nous pouvons déployer nos applications Mule en déplaçant nos fichiers de package JAR vers le apps répertoire dans $MULE_HOME.
Arrêter les services Mule
On peut utiliser stopcommande d'arrêter Mule. Par exemple, l'exemple suivant démarre Mule en tant que démon Unix -
$ $MULE_HOME/bin/mule stop
MULE_HOME is set to /Applications/mule-enterprise-standalone-4.1.5
MULE_BASE is set to /Applications/mule-enterprise-standalone-4.1.5
Stopping Mule Enterprise Edition...
Stopped Mule Enterprise Edition.Nous pouvons également utiliser removepour supprimer le service Mule ou le démon de notre système. L'exemple suivant supprime Mule en tant que démon Unix -
$ $MULE_HOME/bin/mule remove
MULE_HOME is set to /Applications/mule-enterprise-standalone-4.1.5
MULE_BASE is set to /Applications/mule-enterprise-standalone-4.1.5
Detected Mac OSX:
Mule Enterprise Edition is not running.
Removing Mule Enterprise Edition daemon...Anypoint Studio de MuleSoft est un IDE (integration development environment)utilisé pour concevoir et tester des applications Mule. C'est un IDE basé sur Eclipse. Nous pouvons facilement faire glisser les connecteurs de la palette Mule. En d'autres termes, Anypoint Studio est un IDE basé sur Eclipse pour le développement de flux, etc.
Conditions préalables
Nous devons satisfaire les conditions préalables suivantes avant d'installer Mule sur tous les systèmes d'exploitation, c'est-à-dire Windows, Mac et Linux / Unix.
Java Development Kit (JDK)- Avant d'installer Mule, vérifiez que vous disposez d'une version prise en charge de Java sur votre système. JDK 1.8.0 est recommandé pour installer correctement Anypoint sur votre système.
Téléchargement et installation d'Anypoint Studio
La procédure de téléchargement et d'installation d'Anypoint Studio sur différents systèmes d'exploitation peut varier. Ensuite, il y a des étapes à suivre pour télécharger et installer Anypoint Studio sur divers systèmes d'exploitation -
Sous Windows
Pour télécharger et installer Anypoint Studio sur Windows, nous devons suivre les étapes ci-dessous -
Step 1 - Tout d'abord, cliquez sur le lien https://www.mulesoft.com/lp/dl/studio et choisissez le système d'exploitation Windows dans la liste descendante pour télécharger le studio.
Step 2 - Maintenant, extrayez-le dans le ‘C:\’ dossier racine.
Step 3 - Ouvrez le Studio Anypoint extrait.
Step 4- Pour accepter l'espace de travail par défaut, cliquez sur OK. Vous recevrez un message de bienvenue lors de son premier chargement.
Step 5 - Maintenant, cliquez sur le bouton Commencer pour utiliser Anypoint Studio.
Sur OS X
Pour télécharger et installer Anypoint Studio sur OS X, nous devons suivre les étapes ci-dessous -
Step 1 - Tout d'abord, cliquez sur le lien https://www.mulesoft.com/lp/dl/studio et téléchargez le studio.
Step 2- Maintenant, extrayez-le. Si vous utilisez la version du système d'exploitation Sierra, assurez-vous de déplacer l'application extraite vers/Applications folder avant de le lancer.
Step 3 - Ouvrez le Studio Anypoint extrait.
Step 4- Pour accepter l'espace de travail par défaut, cliquez sur OK. Vous recevrez un message de bienvenue lors de son premier chargement.
Step 5 - Maintenant, cliquez sur Get Started pour utiliser Anypoint Studio.
Si vous envisagez d'utiliser un chemin personnalisé vers votre espace de travail, veuillez noter qu'Anypoint Studio n'étend pas le ~ tilde utilisé dans les systèmes Linux / Unix. Par conséquent, il est recommandé d'utiliser le chemin absolu lors de la définition de l'espace de travail.
Sous Linux
Pour télécharger et installer Anypoint Studio sur Linux, nous devons suivre les étapes ci-dessous -
Step 1 - Tout d'abord, cliquez sur le lien https://www.mulesoft.com/lp/dl/studio et choisissez le système d'exploitation Linux dans la liste descendante pour télécharger le studio.
Step 2 - Maintenant, extrayez-le.
Step 3 - Ensuite, ouvrez le Studio Anypoint extrait.
Step 4- Pour accepter l'espace de travail par défaut, cliquez sur OK. Vous recevrez un message de bienvenue lors de son premier chargement.
Step 5 - Maintenant, cliquez sur le bouton Commencer pour utiliser Anypoint Studio.
Si vous envisagez d'utiliser un chemin personnalisé vers votre espace de travail, veuillez noter qu'Anypoint Studio n'étend pas le ~ tilde utilisé dans les systèmes Linux / Unix. Par conséquent, il est recommandé d'utiliser le chemin absolu lors de la définition de l'espace de travail.
Il est également recommandé d'installer GTK version 2 pour utiliser des thèmes Studio complets sous Linux.
Caractéristiques d'Anypoint Studio
Voici quelques fonctionnalités du studio Anypoint améliorant la productivité lors de la création d'applications Mule -
Il fournit une exécution instantanée de l'application Mule dans un environnement d'exécution local.
Anypoint studio nous fournit un éditeur visuel pour configurer les fichiers de définition d'API et les domaines Mule.
Il a un cadre de test unitaire intégré améliorant la productivité.
Anypoint studio nous fournit le support intégré pour déployer sur CloudHub.
Il a la possibilité de s'intégrer à Exchange pour importer des modèles, des exemples, des définitions et d'autres ressources d'une autre organisation de la plate-forme Anypoint.
Les éditeurs d'Anypoint Studio nous aident à concevoir nos applications, API, propriétés et fichiers de configuration. En plus de la conception, cela nous aide également à les éditer. Nous avons l'éditeur de fichier de configuration Mule à cet effet. Pour ouvrir cet éditeur, double-cliquez sur le fichier XML de l'application dans/src/main/mule.
Pour travailler avec notre application, nous avons les trois onglets suivants sous l'éditeur de fichiers de configuration Mule.
L'onglet Flux de messages
Cet onglet donne une représentation visuelle du flux de travail. Il contient essentiellement un canevas qui nous aide à vérifier visuellement nos flux. Si vous souhaitez ajouter des processeurs d'événements de la palette Mule dans le canevas, faites simplement un glisser-déposer et cela se reflétera dans le canevas.
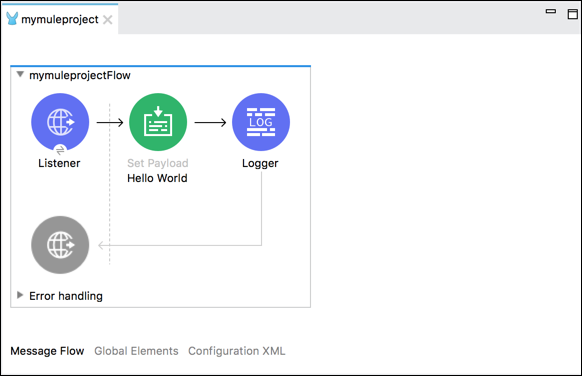
En cliquant sur un processeur d'événements, vous pouvez obtenir la vue des propriétés du mule avec les attributs du processeur sélectionné. Nous pouvons également les éditer.
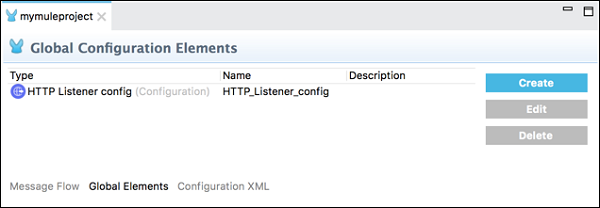
L'onglet Éléments globaux
Cet onglet contient les éléments de configuration globale Mule pour les modules. Sous cet onglet, nous pouvons créer, modifier ou supprimer des fichiers de configuration.
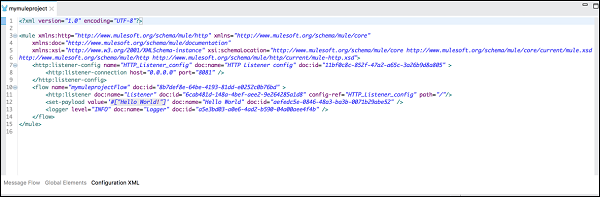
L'onglet XML de configuration
Comme son nom l'indique, il contient le XML qui définit votre application Mule. Toutes les modifications que vous effectuez ici seront reflétées dans le canevas ainsi que dans la vue des propriétés du processeur d'événements sous l'onglet Flux de messages.
Vues
Pour l'éditeur actif, Anypoint studio nous donne la représentation graphique de nos métadonnées de projet, propriétés à l'aide de vues. Un utilisateur peut déplacer, fermer et ajouter des vues dans le projet Mule. Voici quelques vues par défaut dans Anypoint studio -
Explorateur de packages
La tâche principale de la vue Explorateur de packages est d'afficher les dossiers et fichiers du projet constitués dans un projet Mule. Nous pouvons étendre ou réduire le dossier du projet Mule en cliquant sur la flèche à côté. Un dossier ou un fichier peut être ouvert en double-cliquant dessus. Jetez un œil à sa capture d'écran -
Palette de mule
La vue Mule Palette montre les processeurs d'événements tels que les étendues, les filtres et les routeurs de contrôle de flux, ainsi que les modules et leurs opérations associées. Les principales tâches de la vue Mule Palette sont les suivantes:
- Cette vue nous aide à gérer les modules et les connecteurs de notre projet.
- Nous pouvons également ajouter de nouveaux éléments depuis Exchange.
Jetez un œil à sa capture d'écran -
Propriétés de la mule
Comme son nom l'indique, il nous permet d'éditer les propriétés du module actuellement sélectionné dans notre canevas. La vue Propriétés de Mule comprend les éléments suivants:
DataSense Explorer qui fournit des informations en temps réel sur la structure de données de notre charge utile.
Propriétés entrantes et sortantes, si disponibles ou variables.
Ci-dessous la capture d'écran -
Console
Chaque fois que nous créons ou exécutons l'application Mule, le serveur Mule intégré affiche une liste d'événements et de problèmes, le cas échéant, signalés par Studio. La vue Console contient la console de ce serveur Mule intégré. Jetez un œil à sa capture d'écran -
Affichage des problèmes
Nous pouvons rencontrer de nombreux problèmes en travaillant sur notre projet Mule. Tous ces problèmes sont affichés dans la vue Problèmes. Ci-dessous la capture d'écran

Points de vue
Dans Anypoint Studio, il s'agit d'un ensemble de vues et d'éditeurs dans un arrangement spécifié. Il existe deux types de perspectives dans Anypoint Studio -
Mule Design Perspective - C'est la perspective par défaut que nous obtenons dans Studio.
Mule Debug Perspective - Une autre perspective fournie par Anypoint Studio est Mule Debug Perspective.
D'autre part, nous pouvons également créer notre propre perspective et ajouter ou supprimer l'une des vues par défaut.
Dans ce chapitre, nous allons créer notre première application Mule dans Anypoint Studio de MuleSoft. Pour le créer, nous devons d'abord lancer Anypoint Studio.
Lancement d'Anypoint Studio
Cliquez sur Anypoint Studio pour le lancer. Si vous le lancez pour la première fois, vous verrez la fenêtre suivante -
Interface utilisateur d'Anypoint Studio
Une fois que vous avez cliqué sur le bouton Aller à l'espace de travail, cela vous mènera à l'interface utilisateur d'Anypoint Studio comme suit -
Étapes de création d'une application Mule
Afin de créer votre application Mule, suivez les étapes ci-dessous -
Créer un nouveau projet
La toute première étape pour créer une application Mule est de créer un nouveau projet. Cela peut être fait en suivant le cheminFILE → NEW → Mule Project comme indiqué ci-dessous -
Nommer le projet
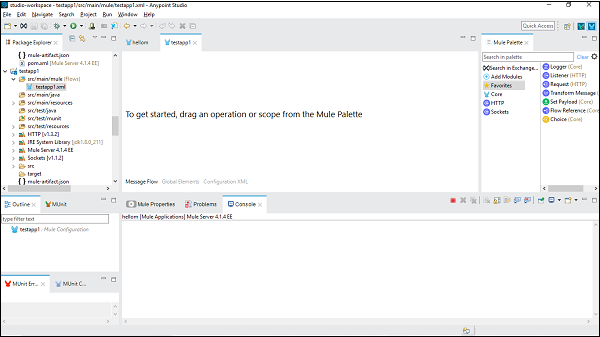
Après avoir cliqué sur le nouveau projet Mule, comme décrit ci-dessus, il ouvrira une nouvelle fenêtre demandant le nom du projet et d'autres spécifications. Donnez le nom du projet, 'TestAPP1'puis cliquez sur le bouton Terminer.
Une fois que vous avez cliqué sur le bouton Terminer, cela ouvrira l'espace de travail créé pour votre MuleProject à savoir ‘TestAPP1’. Vous pouvez voir tous lesEditors et Views décrit dans le chapitre précédent.
Configuration du connecteur
Ici, nous allons créer une application Mule simple pour HTTP Listener. Pour cela, nous devons faire glisser le connecteur HTTP Listener de Mule Palette et le déposer dans l'espace de travail comme indiqué ci-dessous -
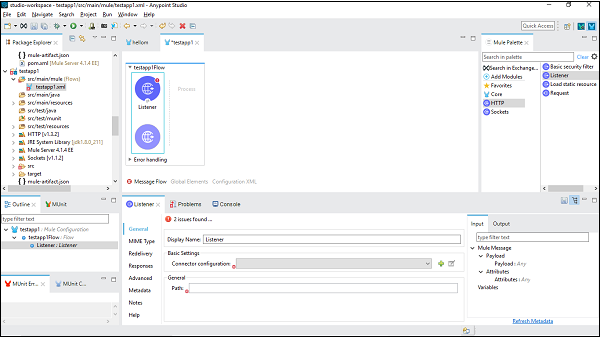
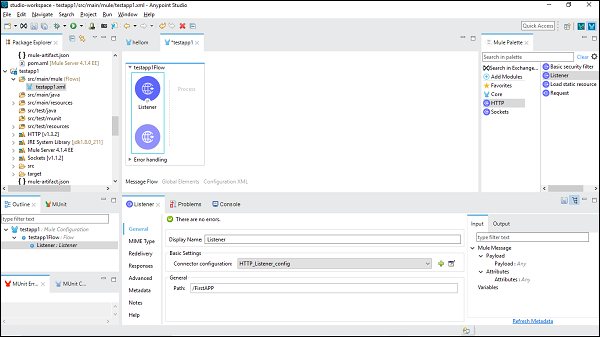
Maintenant, nous devons le configurer. Cliquez sur la couleur verte + signe après la configuration du connecteur sous Paramètres de base comme indiqué ci-dessus.

En cliquant sur ok, cela vous ramènera sur la page de propriétés HTTP Listener. Nous devons maintenant fournir le chemin sous l'onglet Général. Dans cet exemple particulier, nous avons fourni/FirstAPP comme nom de chemin.
Configuration du connecteur Set Payload
Maintenant, nous devons prendre un connecteur Set Payload. Nous devons également donner sa valeur sous l'onglet Paramètres comme suit -
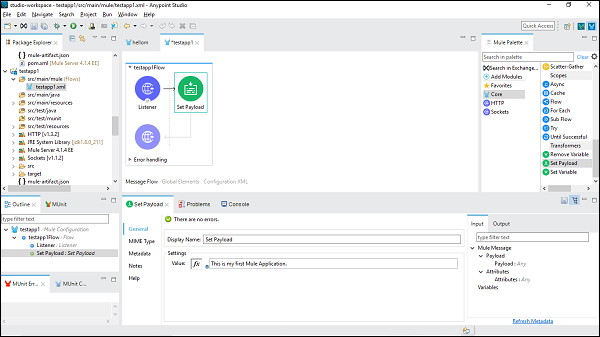
This is my first Mule Application, est le nom fourni dans cet exemple.
Exécution de l'application Mule
Maintenant, enregistrez-le et cliquez sur Run as Mule Application comme indiqué ci-dessous -
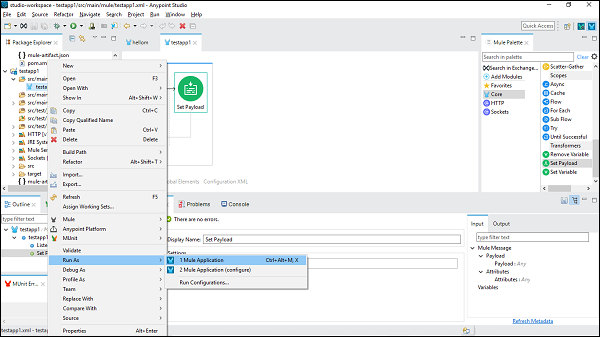
Nous pouvons le vérifier sous Console qui déploie l'application comme suit -
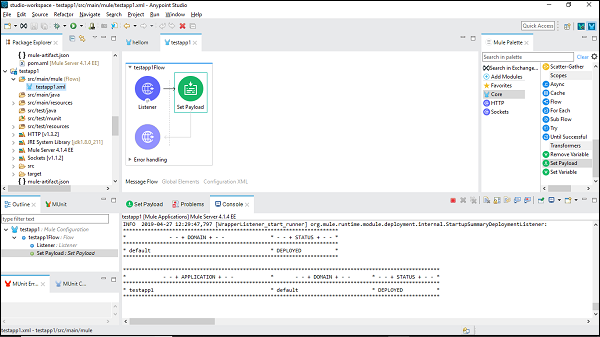
Cela montre que vous avez créé avec succès votre première application Mule.
Vérification de l'application Mule
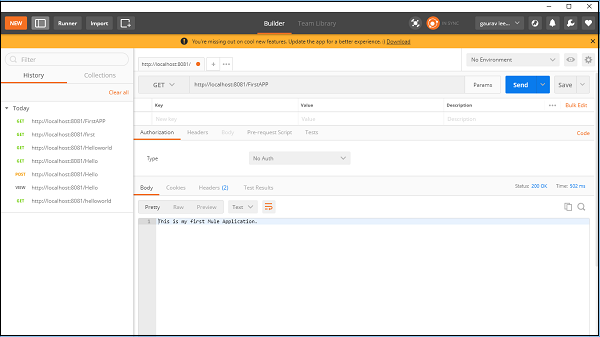
Maintenant, nous devons tester si notre application est en cours d'exécution ou non. Go to POSTMAN, une application Chrome et saisissez l'URL: http:/localhost:8081. Il montre le message que nous avons fourni lors de la création de l'application Mule comme indiqué ci-dessous -
DataWeave est essentiellement un langage d'expression MuleSoft. Il est principalement utilisé pour accéder et transformer les données reçues via une application Mule. Le runtime Mule est responsable de l'exécution du script et des expressions dans notre application Mule, DataWeave est fortement intégré au runtime Mule.
Caractéristiques du langage DataWeave
Voici quelques caractéristiques importantes du langage DataWeave -
Les données peuvent être transformées très facilement d'un format à un autre. Par exemple, nous pouvons transformer application / json en application / xml. La charge utile d'entrée est la suivante -
{
"title": "MuleSoft",
"author": " tutorialspoint.com ",
"year": 2019
}Voici le code dans DataWeave pour la transformation -
%dw 2.0
output application/xml
---
{
order: {
'type': 'Tutorial',
'title': payload.title,
'author': upper(payload.author),
'year': payload.year
}
}Ensuite, le output la charge utile est la suivante -
<?xml version = '1.0' encoding = 'UTF-8'?>
<order>
<type>Tutorial</type>
<title>MuleSoft</title>
<author>tutorialspoint.com</author>
<year>2019</year>
</order>Le composant de transformation peut être utilisé pour créer des scripts qui effectuent à la fois des transformations de données simples et complexes.
Nous pouvons accéder et utiliser les fonctions principales de DataWeave sur des parties de l'événement Mule dont nous avons besoin car la plupart des processeurs de messages Mule prennent en charge les expressions DataWeave.
Conditions préalables
Nous devons satisfaire les conditions préalables suivantes avant d'utiliser les scripts DataWeave sur notre ordinateur -
Anypoint Studio 7 est requis pour utiliser les scripts Dataweave.
Après avoir installé Anypoint Studio, nous devons configurer un projet avec un composant Transform Message afin d'utiliser les scripts DataWeave.
Procédure d'utilisation du script DataWeave avec un exemple
Pour utiliser le script DataWeave, nous devons suivre les étapes ci-dessous -
Step 1
Tout d'abord, nous devons mettre en place un nouveau projet, comme nous l'avons fait dans le chapitre précédent, en utilisant File → New → Mule Project.
Step 2
Ensuite, nous devons fournir le nom du projet. Pour cet exemple, nous donnons le nom,Mule_test_script.
Step 3
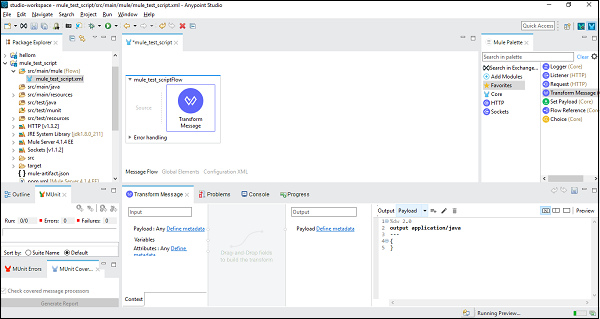
Maintenant, nous devons faire glisser le Transform Message component de Mule Palette tab dans canvas. Il est montré comme ci-dessous -
Step 4
Ensuite, dans le Transform Message componentonglet, cliquez sur Aperçu pour ouvrir le volet Aperçu. Nous pouvons étendre la zone de code source en cliquant sur le rectangle vide à côté de Aperçu.
Step 5
Maintenant, nous pouvons commencer à créer des scripts avec le langage DataWeave.
Exemple
Voici un exemple simple de concaténation de deux chaînes en une seule -
Le script DataWeave ci-dessus a une paire clé-valeur ({ myString: ("hello" ++ "World") }) qui concaténera deux chaînes en une seule.
Les modules de script permettent aux utilisateurs d'utiliser le langage de script dans Mule. En termes simples, le module de script peut échanger une logique personnalisée écrite en langage de script. Les scripts peuvent être utilisés comme implémentations ou transformateurs. Ils peuvent être utilisés pour l'évaluation d'expression, c'est-à-dire pour contrôler l'acheminement des messages.
Mule a les langages de script pris en charge suivants -
- Groovy
- Python
- JavaScript
- Ruby
Comment installer des modules de script?
En fait, Anypoint Studio est livré avec les modules de script. Si vous ne trouvez pas le module dans Mule Palette, il peut être ajouté en utilisant+Add Module. Après l'ajout, nous pouvons utiliser les opérations du module de script dans notre application Mule.
Exemple de mise en œuvre
Comme indiqué, nous devons faire glisser et déposer le module dans le canevas pour créer un espace de travail et l'utiliser dans notre application. Voici un exemple de celui-ci -
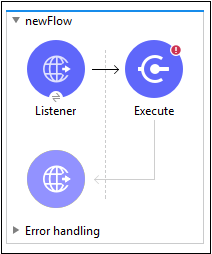
Nous savons déjà comment configurer le composant HTTP Listener; par conséquent, nous allons discuter de la configuration des modules de script. Nous devons suivre les étapes écrites ci-dessous pour configurer le module de script -
Step 1
Recherchez le module Scripting dans Mule Palette et faites glisser le EXECUTE fonctionnement du module de script dans votre flux comme indiqué ci-dessus.
Step 2
Maintenant, ouvrez l'onglet Exécuter la configuration en double-cliquant dessus.
Step 3
Sous le General onglet, nous devons fournir le code dans le Code text window comme indiqué ci-dessous -
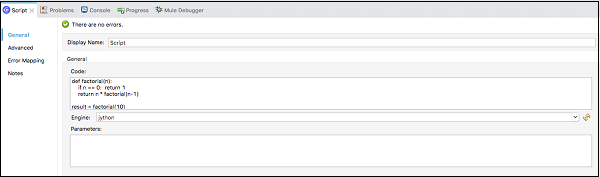
Step 4
Enfin, nous devons choisir le Enginedu composant d'exécution. La liste des moteurs est comme ci-dessous -
- Groovy
- Nashorn(javaScript)
- jython(Python)
- jRuby(Ruby)
Le XML de l'exemple d'exécution ci-dessus dans l'éditeur XML de configuration est le suivant -
<scripting:execute engine="jython" doc:name = "Script">
<scripting:code>
def factorial(n):
if n == 0: return 1
return n * factorial(n-1)
result = factorial(10)
</scripting:code>
</scripting:execute>Sources de message
Mule 4 a un modèle simplifié que le message Mule 3, ce qui facilite le travail avec les données de manière cohérente entre les connecteurs sans écraser les informations. Dans le modèle de message Mule 4, chaque événement Mule se compose de deux choses:a message and variables associated with it.
Un message Mule a une charge utile et ses attributs, où l'attribut est principalement des métadonnées telles que la taille du fichier.
Et une variable contient les informations utilisateur arbitraires telles que le résultat de l'opération, les valeurs auxiliaires, etc.
Entrant
Les propriétés entrantes dans Mule 3 deviennent maintenant Attributs dans Mule 4. Comme nous le savons, les propriétés entrantes stockent des informations supplémentaires sur la charge utile obtenue via une source de message, mais c'est maintenant, dans Mule 4, fait à l'aide d'attributs. Les attributs présentent les avantages suivants -
À l'aide d'attributs, nous pouvons facilement voir quelles données sont disponibles, car les attributs sont fortement typés.
Nous pouvons facilement accéder aux informations contenues dans les attributs.
Voici l'exemple d'un message typique dans Mule 4 -
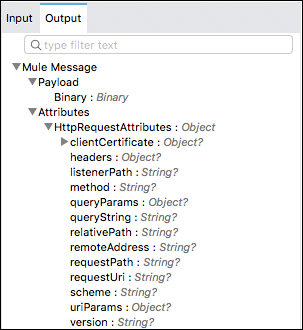
Sortant
Les propriétés sortantes dans Mule 3 doivent être explicitement spécifiées par les connecteurs et les transports Mule afin d'envoyer des données supplémentaires. Mais dans Mule 4, chacun de ceux-ci peut être défini séparément, en utilisant une expression DataWeave pour chacun d'entre eux. Il ne produit aucun effet secondaire dans le flux principal.
Par exemple, ci-dessous, l'expression DataWeave effectuera une requête HTTP et générera des en-têtes et des paramètres de requête sans qu'il soit nécessaire de définir les propriétés du message. Ceci est indiqué dans le code ci-dessous -
<http:request path = "M_issue" config-ref="http" method = "GET">
<http:headers>#[{'path':'input/issues-list.json'}]</http:headers>
<http:query-params>#[{'provider':'memory-provider'}]</http:query-params>
</http:request>Processeur de messages
Une fois que Mule reçoit un message d'une source de message, le travail du processeur de message commence. Le Mule utilise un ou plusieurs processeurs de messages pour traiter le message via un flux. La tâche principale du processeur de messages est de transformer, filtrer, enrichir et traiter le message lorsqu'il passe dans le flux Mule.
Catégorisation du processeur Mule
Voici les catégories de processeur Mule, basées sur les fonctions -
Connectors- Ces processeurs de messages envoient et reçoivent des données. Ils connectent également des données à des sources de données externes via des protocoles standard ou des API tierces.
Components - Ces processeurs de messages sont de nature flexible et exécutent une logique métier implémentée dans divers langages tels que Java, JavaScript, Groovy, Python ou Ruby.
Filters - Ils filtrent les messages et permettent uniquement à des messages spécifiques de continuer à être traités dans un flux, en fonction de critères spécifiques.
Routers - Ce processeur de messages est utilisé pour contrôler le flux de messages à acheminer, reséquencer ou fractionner.
Scopes - hey encapsule essentiellement des extraits de code dans le but de définir un comportement à granularité fine dans un flux.
Transformers - Le rôle des transformateurs est de convertir le type de charge utile des messages et le format des données pour faciliter la communication entre les systèmes.
Business Events - Ils capturent essentiellement les données associées aux indicateurs de performance clés.
Exception strategies - Ces processeurs de messages gèrent les erreurs de tout type qui se produisent pendant le traitement des messages.
L'une des capacités les plus importantes de Mule est qu'il peut effectuer le routage, la transformation et le traitement avec les composants, grâce à quoi le fichier de configuration de l'application Mule qui combine divers éléments est de très grande taille.
Voici les types de modèles de configuration fournis par Mule -
- Modèle de service simple
- Bridge
- Validator
- Http proxy
- Proxy WS
Configurer le composant
Dans Anypoint studio, nous pouvons suivre les étapes ci-dessous pour configurer un composant -
Step 1
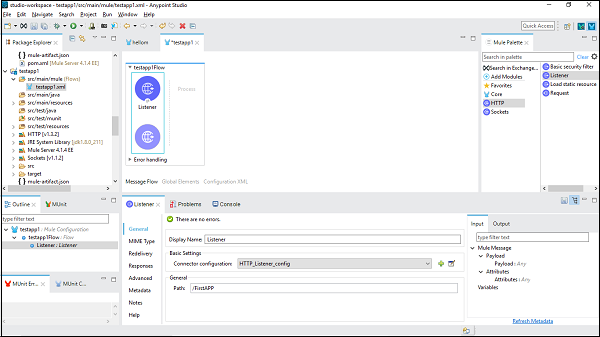
Nous devons faire glisser le composant que nous souhaitons utiliser dans notre application Mule. Par exemple, ici, nous utilisons le composant d'écoute HTTP comme suit -

Step 2
Ensuite, double-cliquez sur le composant pour obtenir la fenêtre de configuration. Pour l'écouteur HTTP, il est montré ci-dessous -
Step 3
Nous pouvons configurer le composant selon les exigences de notre projet. Disons par exemple que nous l'avons fait pour le composant d'écoute HTTP -
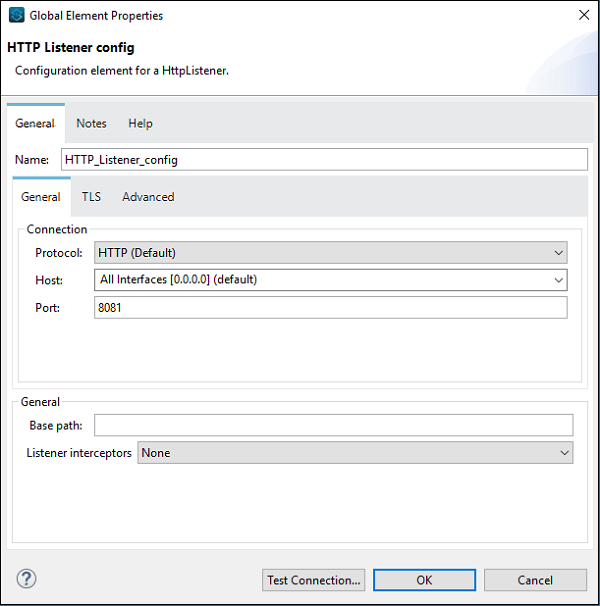
Les composants de base sont l'un des éléments constitutifs importants du flux de travail dans l'application Mule. La logique de traitement d'un événement Mule est fournie par ces composants de base. Dans le studio Anypoint, pour accéder à ces composants de base, vous pouvez cliquer sur la palette Core from Mule comme indiqué ci-dessous -
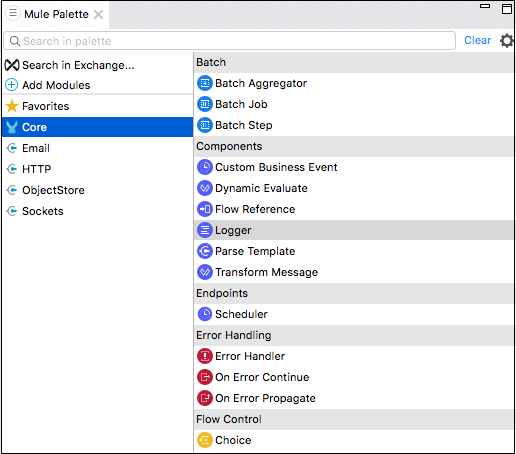
Voici divers core components and their working in Mule 4 -
Événements commerciaux personnalisés
Ce composant principal est utilisé pour la collecte d'informations sur les flux ainsi que pour les processeurs de messages qui gèrent les transactions commerciales dans l'application Mule. En d'autres termes, nous pouvons utiliser le composant Custom Business Event pour ajouter les éléments suivants à notre flux de travail:
- Metadata
- Indicateurs clés de performance (KPI)
Comment ajouter des KPI?
Voici les étapes pour ajouter des KPI dans notre flux dans l'application Mule -
Step 1 - Suivez Mule Palette → Core → Components → Custom Business Event, pour ajouter un composant d'événement professionnel personnalisé à un flux de travail dans votre application Mule.
Step 2 - Cliquez sur le composant pour l'ouvrir.
Step 3 - Maintenant, nous devons fournir des valeurs pour le nom d'affichage et le nom de l'événement.
Step 4 - Pour capturer des informations à partir de la charge utile du message, ajoutez les KPI comme suit -
Donnez un nom (clé) pour le KPI ( tracking: élément de méta-données ) et une valeur. Le nom sera utilisé dans l'interface de recherche de Runtime Manager.
Donnez une valeur qui peut être n'importe quelle expression Mule.
Exemple
Le tableau suivant comprend la liste des indicateurs de performance clés avec le nom et la valeur -
| Nom | Expression / Valeur |
|---|---|
| Rouleau étudiant Non | # [payload ['RollNo']] |
| Nom d'étudiant | # [payload ['Name']] |
Évaluation dynamique
Ce composant principal est utilisé pour sélectionner dynamiquement un script dans l'application Mule. Nous pouvons également utiliser un script hardcore via le composant Transform Message, mais l'utilisation du composant Dynamic Evaluate est un meilleur moyen. Ce composant de base fonctionne comme suit -
- Premièrement, il évalue une expression qui devrait aboutir à un autre script.
- Ensuite, il évalue ce script pour le résultat final.
De cette façon, cela nous permet de sélectionner dynamiquement le script plutôt que de le coder en dur.
Exemple
Voici un exemple de sélection d'un script dans la base de données via un paramètre de requête Id et de stockage de ce script dans une variable nommée MyScript . Maintenant, le composant d'évaluation dynamique accédera à la variable pour appeler les scripts afin qu'il puisse ajouter une variable de nom à partir deUName paramètre de requête.
La configuration XML du flux est donnée ci-dessous -
<flow name = "DynamicE-example-flow">
<http:listener config-ref = "HTTP_Listener_Configuration" path = "/"/>
<db:select config-ref = "dbConfig" target = "myScript">
<db:sql>#["SELECT script FROM SCRIPTS WHERE ID =
$(attributes.queryParams.Id)"]
</db:sql>
</db:select>
<ee:dynamic-evaluate expression = "#[vars.myScript]">
<ee:parameters>#[{name: attributes.queryParams.UName}]</ee:parameters>
</ee:dynamic-evaluate>
</flow>Le script peut utiliser des variables de contexte telles que message, charge utile, vars ou attributs. Toutefois, si vous souhaitez ajouter une variable de contexte personnalisée, vous devez fournir un ensemble de paires clé-valeur.
Configuration de l'évaluation dynamique
Le tableau suivant fournit un moyen de configurer le composant Dynamic Evaluate -
| Champ | Valeur | La description | Exemple |
|---|---|---|---|
| Expression | Expression DataWeave | Il spécifie l'expression à évaluer dans le script final. | expression = "# [vars.generateOrderScript]" |
| Paramètres | Expression DataWeave | Il spécifie des paires clé-valeur. | # [{joiner: 'and', id: payload.user.id}] |
Composant de référence de flux
Si vous souhaitez acheminer l'événement Mule vers un autre flux ou sous-flux et revenir dans la même application Mule, le composant de référence de flux est la bonne option.
Caractéristiques
Voici les caractéristiques de ce composant de base -
Ce composant de base nous permet de traiter l'ensemble du flux référencé comme un composant unique dans le flux de courant.
Il divise l'application Mule en unités discrètes et réutilisables. Par exemple, un flux répertorie les fichiers régulièrement. Il peut faire référence à un autre flux qui traite la sortie de l'opération de liste.
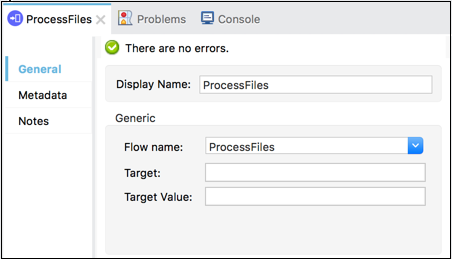
De cette façon, plutôt que d'ajouter toutes les étapes de traitement, nous pouvons ajouter des références de flux qui pointent vers le flux de traitement. La capture d'écran ci-dessous montre que le composant principal de référence de flux pointe vers un sous-flux nomméProcessFiles.
Travail
Le fonctionnement du composant Flow Ref peut être compris à l'aide du diagramme suivant -

Le diagramme montre l'ordre de traitement dans l'application Mule lorsqu'un flux fait référence à un autre flux dans la même application. Lorsque le flux de travail principal de l'application Mule est déclenché, l'événement Mule parcourt et exécute le flux jusqu'à ce que l'événement Mule atteigne la référence de flux.
Après avoir atteint la référence de flux, l'événement Mule exécute le flux référencé du début à la fin. Une fois que l'événement Mule a terminé d'exécuter le flux de référence, il revient au flux principal.
Exemple
Pour une meilleure compréhension, let us use this component in Anypoint Studio. Dans cet exemple, nous utilisons un écouteur HTTP pour GET un message, comme nous l'avons fait dans le chapitre précédent. Ainsi, nous pouvons faire glisser et déposer le composant et configurer. Mais pour cet exemple, nous devons ajouter un composant de sous-flux et définir le composant Payload sous celui-ci, comme indiqué ci-dessous -
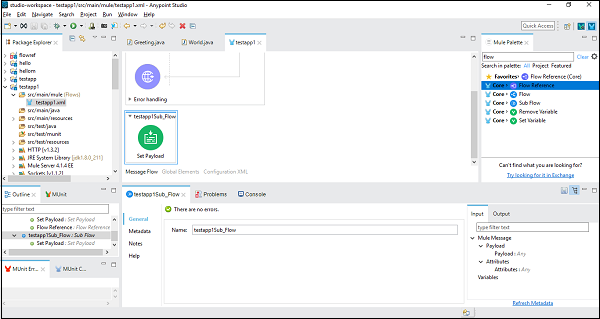
Ensuite, nous devons configurer Set Payload, en double-cliquant dessus. Ici, nous donnons la valeur «Sous-flux exécuté» comme indiqué ci-dessous -
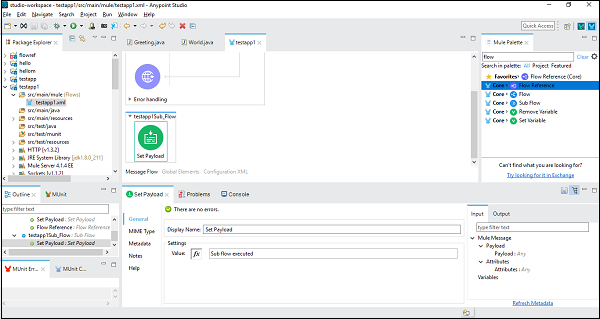
Une fois la configuration du composant de sous-flux réussie, nous avons besoin du composant de référence de flux à définir après Set Payload of Main Flow, que nous pouvons faire glisser et déposer à partir de la palette Mule comme indiqué ci-dessous -
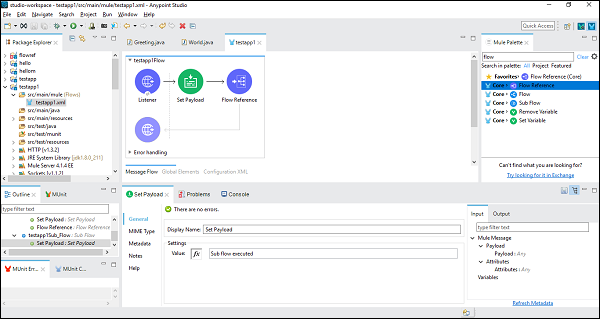
Ensuite, lors de la configuration du composant de référence de flux, nous devons choisir Nom du flux sous l'onglet Générique comme indiqué ci-dessous -
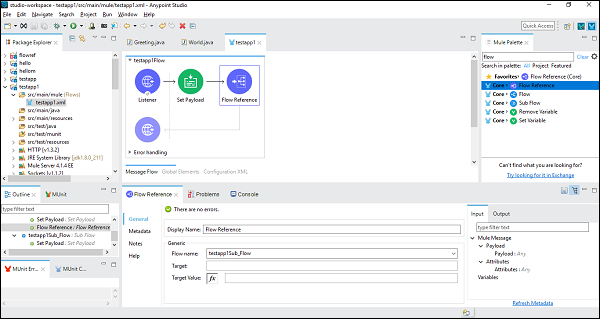
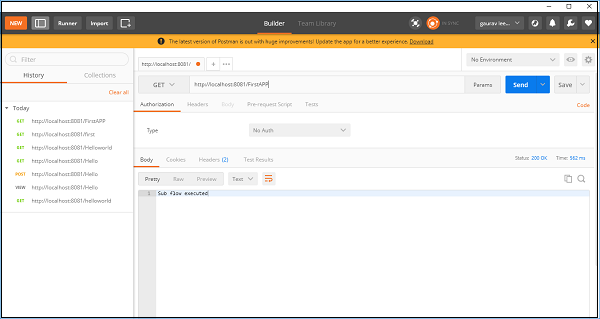
Maintenant, enregistrez et exécutez cette application. Pour tester cela, allez dans POSTMAN et tapezhttp:/localhost:8181/FirstAPP dans la barre d'URL, et vous obtiendrez le message, Sous-flux exécuté.
Composant enregistreur
Le composant de base appelé logger nous aide à surveiller et déboguer notre application Mule en enregistrant des informations importantes telles que les messages d'erreur, les notifications d'état, les charges utiles, etc. Dans AnyPoint studio, elles apparaissent dans le Console.
Avantages
Voici quelques avantages du composant Logger -
- Nous pouvons ajouter ce composant de base n'importe où dans le flux de travail.
- Nous pouvons le configurer pour enregistrer une chaîne que nous avons spécifiée.
- Nous pouvons le configurer sur la sortie d'une expression DataWeave écrite par nos soins.
- Nous pouvons également le configurer sur n'importe quelle combinaison de chaînes et d'expressions.
Exemple
L'exemple ci-dessous affiche le message «Hello World» dans Set Payload dans un navigateur et enregistre également le message.
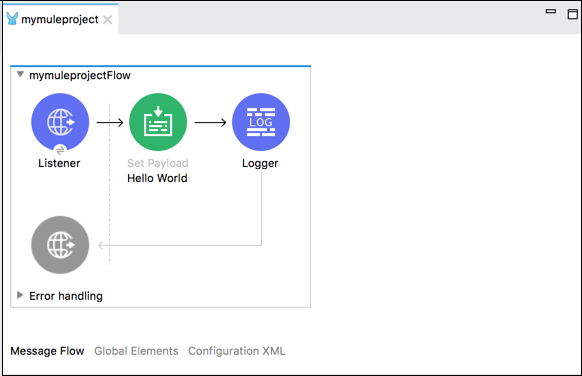
Voici la configuration XML du flux dans l'exemple ci-dessus -
<http:listener-config name = "HTTP_Listener_Configuration" host = "localhost" port = "8081"/>
<flow name = "mymuleprojectFlow">
<http:listener config-ref="HTTP_Listener_Configuration" path="/"/>
<set-payload value="Hello World"/>
<logger message = "#[payload]" level = "INFO"/>
</flow>Composant de message de transfert
Le composant de message de transformation, également appelé composant de transfert, nous permet de convertir les données d'entrée dans un nouveau format de sortie.
Méthodes pour construire la transformation
Nous pouvons construire notre transformation à l'aide des deux méthodes suivantes -
Drag-and-Drop Editor (Graphical View)- C'est la première méthode et la plus utilisée pour construire notre transformation. Dans cette méthode, nous pouvons utiliser le mappeur visuel de ce composant pour glisser-déposer les éléments de la structure de données entrantes. Par exemple, dans le diagramme suivant, deux arborescences montrent les structures de métadonnées attendues de l'entrée et de la sortie. Les lignes qui connectent l'entrée au champ de sortie représentent le mappage entre deux vues arborescentes.
Script View- La cartographie visuelle de Transformation peut également être représentée à l'aide de DataWeave, un langage pour le code Mule. Nous pouvons coder certaines transformations avancées telles que l'agrégation, la normalisation, le regroupement, la jonction, le partitionnement, le pivotement et le filtrage. L'exemple est donné ci-dessous -
Ce composant de base accepte essentiellement les métadonnées d'entrée et de sortie pour une variable, un attribut ou une charge utile de message. Nous pouvons fournir des ressources spécifiques au format pour ce qui suit -
- CSV
- Schema
- Schéma de fichier plat
- JSON
- Classe d'objets
- Type simple
- Schéma XML
- Nom et type de colonne Excel
- Nom et type de colonne à largeur fixe
Les points de terminaison incluent essentiellement les composants qui déclenchent ou lancent le traitement dans un flux de travail de l'application Mule. Ils s'appellentSource dans Anypoint Studio et Triggersdans le centre de design de Mule. Un point final important dans Mule 4 estScheduler component.
Point de terminaison du planificateur
Ce composant fonctionne sur des conditions basées sur le temps, ce qui signifie qu'il nous permet de déclencher un flux chaque fois qu'une condition basée sur le temps est remplie. Par exemple, un planificateur peut déclencher un événement pour démarrer un flux de travail Mule toutes les 10 secondes, par exemple. Nous pouvons également utiliser une expression Cron flexible pour déclencher un point de terminaison de planificateur.
Points importants sur Scheduler
Lors de l'utilisation de l'événement Scheduler, nous devons prendre soin de certains points importants comme indiqué ci-dessous -
Scheduler Endpoint suit le fuseau horaire de la machine sur laquelle s'exécute Mule runtime.
Supposons que si une application Mule s'exécute dans CloudHub, le planificateur suivra le fuseau horaire de la région dans laquelle le worker CloudHub s'exécute.
À tout moment, un seul flux déclenché par le point de terminaison du planificateur peut être actif.
Dans le cluster d'exécution Mule, le point de terminaison du planificateur s'exécute ou se déclenche uniquement sur le nœud principal.
Façons de configurer un planificateur
Comme indiqué ci-dessus, nous pouvons configurer un point de terminaison de planificateur pour qu'il soit déclenché à un intervalle fixe ou nous pouvons également donner une expression Cron.
Paramètres pour configurer un planificateur (pour un intervalle fixe)
Voici les paramètres pour définir un programmateur pour déclencher un flux à intervalles réguliers -
Frequency- Il décrit essentiellement à quelle fréquence le point de terminaison du planificateur déclenchera le flux Mule. L'unité de temps pour cela peut être sélectionnée dans le champ Unité de temps. Dans le cas où vous ne fournissez aucune valeur pour cela, il utilisera la valeur par défaut qui est 1000. De l'autre côté, si vous fournissez 0 ou une valeur négative, il utilise également la valeur par défaut.
Start Delay- C'est le temps qu'il faut attendre avant de déclencher le flux Mule pour la première fois une fois l'application démarrée. La valeur du délai de démarrage est exprimée dans la même unité de temps que la fréquence. Sa valeur par défaut est 0.
Time Unit- Il décrit l'unité de temps pour la fréquence et le délai de démarrage. Les valeurs possibles de l'unité de temps sont Millisecondes, Seconds, Minute, Hours, Days. La valeur par défaut est Millisecondes.
Paramètres pour configurer un planificateur (pour l'expression Cron)
En fait, Cron est une norme utilisée pour décrire les informations d'heure et de date. Si vous utilisez l'expression Cron flexible pour déclencher le planificateur, le point de terminaison du planificateur effectue le suivi de chaque seconde et crée un événement Mule chaque fois que l'expression Quartz Cron correspond au paramètre de date et d'heure. Avec l'expression Cron, l'événement peut être déclenché une seule fois ou à intervalles réguliers.
Le tableau suivant donne l'expression date-heure de six paramètres requis -
| Attribut | Valeur |
|---|---|
| Secondes | 0-59 |
| Minutes | 0-59 |
| Heures | 0-23 |
| Jour du mois | 1-31 |
| Mois | 1-12 ou JAN-DEC |
| Jour de la semaine | 1-7 ou SUN-SAT |
Quelques exemples d'expressions Quartz Cron prises en charge par le point de terminaison du planificateur sont donnés ci-dessous -
½ * * * * ? - signifie que le planificateur s'exécute toutes les 2 secondes de la journée, tous les jours.
0 0/5 16 ** ? - signifie que le planificateur s'exécute toutes les 5 minutes à partir de 16 heures et se terminant à 16 h 55, tous les jours.
1 1 1 1, 5 * ? - signifie que l'ordonnanceur fonctionne le premier jour de janvier et le premier jour d'avril, chaque année.
Exemple
Le code suivant enregistre le message «salut» toutes les secondes -
<flow name = "cronFlow" doc:id = "ae257a5d-6b4f-4006-80c8-e7c76d2f67a0">
<doc:name = "Scheduler" doc:id = "e7b6scheduler8ccb-c6d8-4567-87af-aa7904a50359">
<scheduling-strategy>
<cron expression = "* * * * * ?" timeZone = "America/Los_Angeles"/>
</scheduling-strategy>
</scheduler>
<logger level = "INFO" doc:name = "Logger"
doc:id = "e2626dbb-54a9-4791-8ffa-b7c9a23e88a1" message = '"hi"'/>
</flow>Contrôle de flux (routeurs)
La tâche principale du composant Flow Control est de prendre l'événement Mule d'entrée et de le router vers une ou plusieurs séquences distinctes de composants. Il achemine essentiellement l'événement Mule d'entrée vers d'autres séquences de composants. Par conséquent, il est également appelé Routeurs. Les routeurs Choice et Scatter-Gather sont les routeurs les plus utilisés sous le composant Flow Control.
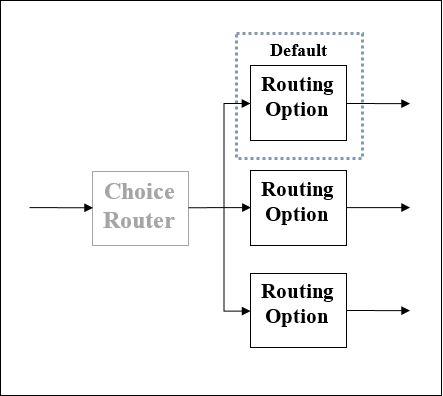
Routeur de choix
Comme son nom l'indique, ce routeur applique la logique DataWeave pour choisir une ou plusieurs routes. Comme indiqué précédemment, chaque itinéraire est une séquence distincte de processeurs d'événements Mule. Nous pouvons définir des routeurs de choix comme le routeur qui achemine dynamiquement le message à travers un flux en fonction d'un ensemble d'expressions DataWeave utilisées pour évaluer le contenu du message.
Schéma de principe du routeur Choice
L'effet de l'utilisation du routeur Choice est comme l'ajout d'un traitement conditionnel à un flux ou à un if/then/elsebloc de code dans la plupart des langages de programmation. Voici le diagramme schématique d'un routeur Choice, avec trois options. Parmi ceux-ci, l'un est le routeur par défaut.
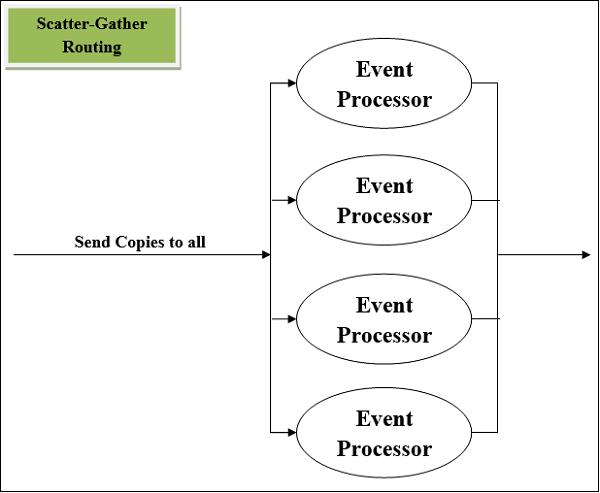
Routeur Scatter-Gather
Un autre processeur d'événements de routage le plus utilisé est Scatter-Gather component. Comme son nom l'indique, il travaille sur les principes fondamentaux de la dispersion (copie) et de la collecte (consolidation). Nous pouvons comprendre son fonctionnement à l'aide de deux points suivants -
Tout d'abord, ce routeur copie (Scatter) un événement Mule sur deux ou plusieurs routes parallèles. La condition est que chaque route doit être une séquence d'un ou plusieurs processeurs d'événements qui est comme un sous-flux. Chaque itinéraire dans ce cas créera un événement Mule en utilisant un thread distinct. Chaque événement Mule aura sa propre charge utile, des attributs ainsi que des variables.
Ensuite, ce routeur rassemble les événements Mule créés à partir de chaque itinéraire, puis les consolide dans un nouvel événement Mule. Après cela, il transmet cet événement Mule consolidé au processeur d'événements suivant. Ici, la condition est que le routeur SG transmettra un événement Mule consolidé au processeur d'événements suivant uniquement lorsque chaque itinéraire est terminé avec succès.
Diagramme schématique du routeur Scatter-Gather
Voici le diagramme schématique d'un routeur Scatter-Gather ayant quatre processeurs d'événements. Il exécute chaque route en parallèle et non séquentiellement.
Gestion des erreurs par le routeur Scatter-Gather
Tout d'abord, nous devons avoir des connaissances sur le type d'erreur qui peut être généré dans le composant Scatter-Gather. Toute erreur peut être générée dans les processeurs d'événements conduisant le composant Scatter-Gather à générer une erreur de typeMule: COMPOSITE_ERROR. Cette erreur sera renvoyée par le composant SG uniquement après l'échec ou la fin de chaque route.
Pour gérer ce type d'erreur, un try scopepeut être utilisé dans chaque route du composant Scatter-Gather. Si l'erreur est gérée avec succès partry scope, alors l'itinéraire pourra générer un événement Mule, c'est sûr.
Transformateurs
Supposons que si nous voulons définir ou supprimer une partie d'un événement Mule, le composant Transformer est le meilleur choix. Les composants du transformateur sont des types suivants -
Retirer le transformateur variable
Comme son nom l'indique, ce composant prend un nom de variable et supprime cette variable de l'événement Mule.
Configuration de la suppression du transformateur variable
Le tableau ci-dessous montre le nom des champs et leur description à prendre en compte lors de la configuration de la suppression du transformateur de variable -
| Sr.Non | Champ et explication |
|---|---|
| 1 | Display Name (doc:name) Nous pouvons le personnaliser pour afficher un nom unique pour ce composant dans notre flux de travail Mule. |
| 2 | Name (variableName) Il représente le nom de la variable à supprimer. |
Définir le transformateur de charge utile
Avec l'aide de set-payloadcomposant, nous pouvons mettre à jour la charge utile, qui peut être une chaîne littérale ou une expression DataWeave, du message. Il n'est pas recommandé d'utiliser ce composant pour des expressions complexes ou des transformations. Il peut être utilisé pour des applications simples commeselections.
Le tableau ci-dessous montre le nom des champs et leur description à prendre en compte lors de la configuration du transformateur de charge utile set -
| Champ | Usage | Explication |
|---|---|---|
| Valeur (valeur) | Obligatoire | La valeur enregistrée est requise pour définir une charge utile. Il acceptera une chaîne littérale ou une expression DataWeave définissant comment définir la charge utile. Les exemples sont comme "une chaîne" |
| Type Mime (mimeType) | Optionnel | Il est facultatif mais représente le type mime de la valeur affectée à la charge utile du message. Les exemples sont comme text / plain. |
| Encodage (encodage) | Optionnel | Il est également facultatif mais représente l'encodage de la valeur affectée à la charge utile du message. Les exemples sont comme UTF-8. |
Nous pouvons définir une charge utile via le code de configuration XML -
With Static Content - Le code de configuration XML suivant définira la charge utile en utilisant du contenu statique -
<set-payload value = "{ 'name' : 'Gaurav', 'Id' : '2510' }"
mimeType = "application/json" encoding = "UTF-8"/>With Expression Content - Le code de configuration XML suivant définira la charge utile en utilisant le contenu d'expression -
<set-payload value = "#['Hi' ++ ' Today is ' ++ now()]"/>L'exemple ci-dessus ajoutera la date du jour avec la charge utile du message «Salut».
Définir le transformateur variable
Avec l'aide de set variablecomposant, nous pouvons créer ou mettre à jour une variable pour stocker des valeurs qui peuvent être de simples valeurs littérales telles que des chaînes, des charges utiles de message ou des objets d'attribut, à utiliser dans le flux de l'application Mule. Il n'est pas recommandé d'utiliser ce composant pour des expressions complexes ou des transformations. Il peut être utilisé pour des applications simples commeselections.
Configurer le transformateur variable défini
Le tableau ci-dessous montre le nom des champs et leur description à prendre en compte lors de la configuration du transformateur de charge utile set -
| Champ | Usage | Explication |
|---|---|---|
| Nom de variable (variableName) | Obligatoire | Il est obligatoire et représente le nom de la variable. Lorsque vous donnez le nom, suivez la convention de dénomination car elle doit contenir des nombres, des caractères et des traits de soulignement. |
| Valeur (valeur) | Obligatoire | La valeur enregistrée est requise pour définir une variable. Il acceptera une chaîne littérale ou une expression DataWeave. |
| Type Mime (mimeType) | Optionnel | C'est facultatif mais représente le type mime de la variable. Les exemples sont comme text / plain. |
| Encodage (encodage) | Optionnel | Il est également facultatif mais représente l'encodage de la variable. Les exemples sont comme ISO 10646 / Unicode (UTF-8). |
Exemple
L'exemple ci-dessous définira la variable sur la charge utile du message -
Variable Name = msg_var
Value = payload in Design center and #[payload] in Anypoint StudioDe même, l'exemple ci-dessous définira la variable sur la charge utile du message -
Variable Name = msg_var
Value = attributes in Design center and #[attributes] in Anypoint Studio.Service Web REST
La forme complète de REST est le transfert d'état de représentation qui est lié à HTTP. Par conséquent, si vous souhaitez concevoir une application à utiliser exclusivement sur le Web, REST est la meilleure option.
Consommation de services Web RESTful
Dans l'exemple suivant, nous utiliserons le composant REST et un service RESTful public fourni par Mule Soft appelé American Flights details. Il a plusieurs détails mais nous allons utiliser GET:http://training-american-ws.cloudhub.io/api/flightsqui renverra tous les détails du vol. Comme indiqué précédemment, REST est lié à HTTP, nous avons donc besoin de deux composants HTTP - l'un est Listener et l'autre Request, pour cette application également. La capture d'écran ci-dessous montre la configuration de l'écouteur HTTP -
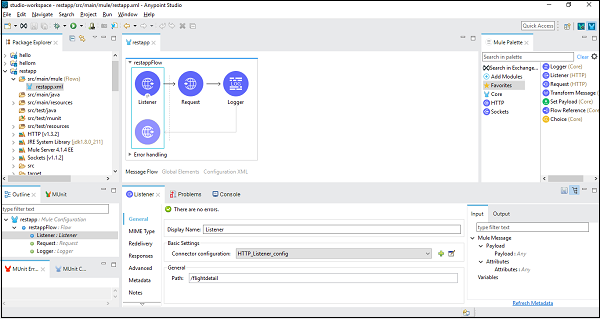
Configurer et transmettre des arguments
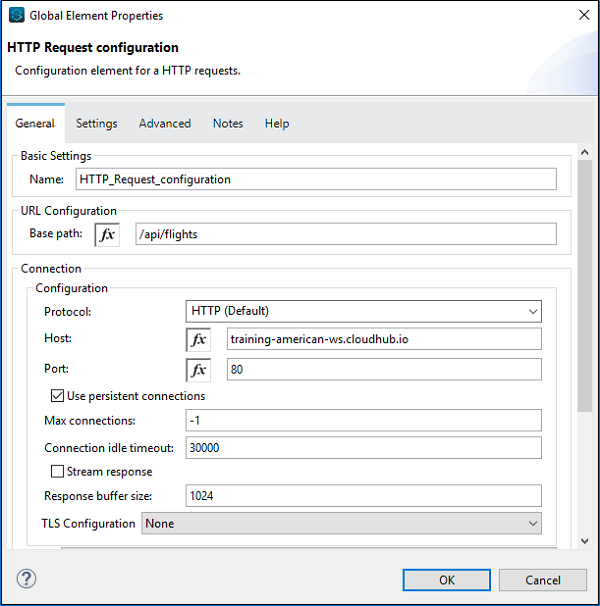
La configuration de la requête HTTP est donnée ci-dessous -
Maintenant, selon notre flux d'espace de travail, nous avons pris un enregistreur afin qu'il puisse être configuré comme ci-dessous -
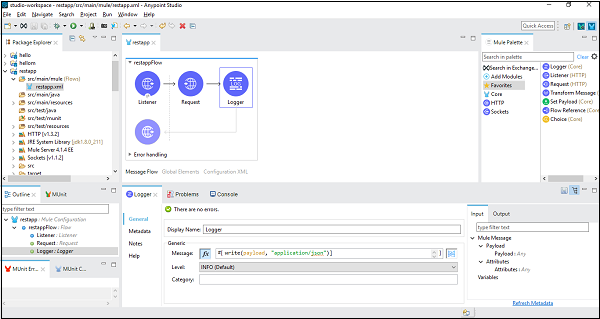
Dans l'onglet message, nous écrivons du code pour convertir la charge utile en chaînes.
Test de l'application
Maintenant, enregistrez et exécutez l'application et accédez à POSTMAN pour vérifier la sortie finale comme indiqué ci-dessous -
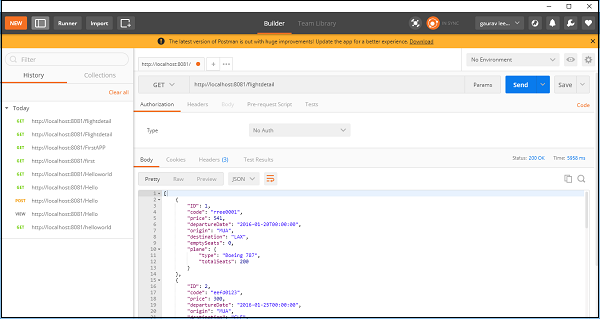
Vous pouvez voir qu'il donne les détails du vol en utilisant le composant REST.
Composant SOAP
La forme complète de SOAP est Simple Object Access Protocol. Il s'agit essentiellement d'une spécification de protocole de messagerie pour l'échange d'informations dans la mise en œuvre de services Web. Ensuite, nous allons utiliser l'API SOAP dans Anypoint Studio pour accéder aux informations à l'aide des services Web.
Consommation de services Web SOAP
Pour cet exemple, nous allons utiliser le service SOAP public dont le nom est Country Info Service qui conserve les services liés aux informations sur le pays. Son adresse WSDL est:http://www.oorsprong.org/websamples.countryinfo/countryinfoservice.wso?WSDL
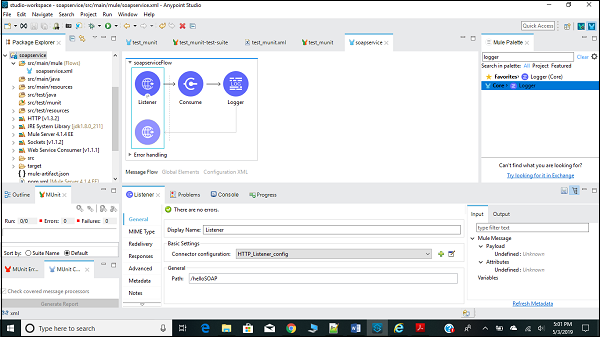
Tout d'abord, nous devons faire glisser SOAP consommer dans notre canevas à partir de la palette Mule comme indiqué ci-dessous -
Configurer et transmettre des arguments
Ensuite, nous devons configurer la requête HTTP comme indiqué dans l'exemple ci-dessus, comme indiqué ci-dessous -
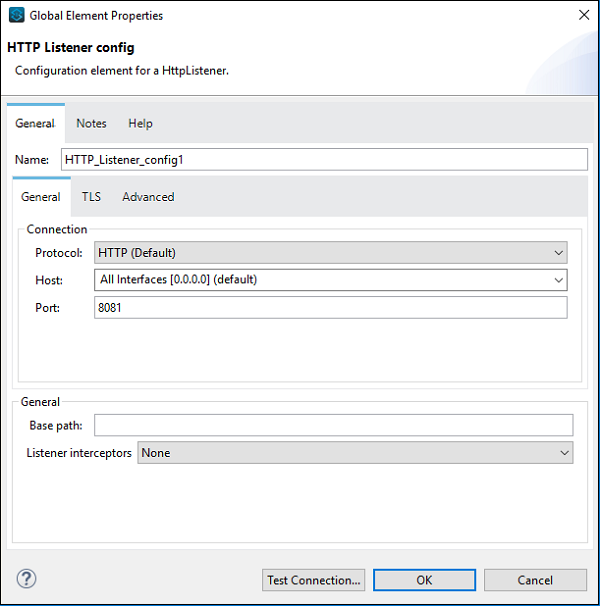
Maintenant, nous devons également configurer le consommateur de service Web comme indiqué ci-dessous -
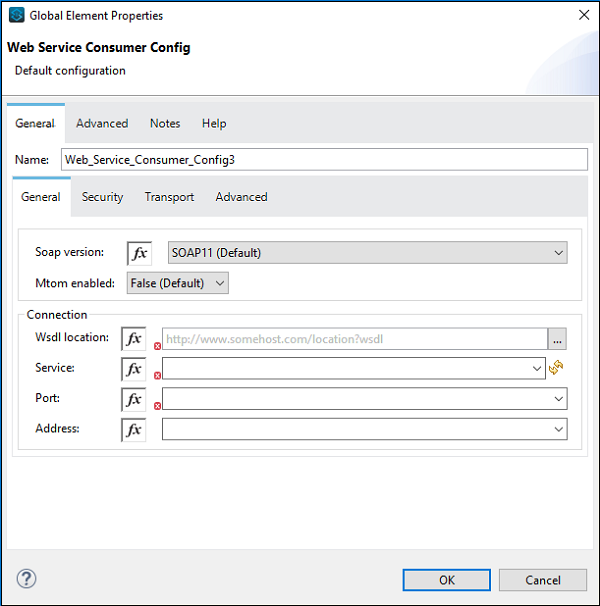
À la place de l'emplacement WSDL, nous devons fournir l'adresse Web de WSDL, qui est fournie ci-dessus (pour cet exemple). Une fois que vous avez donné l'adresse Web, Studio recherchera le service, le port et l'adresse par lui-même. Vous n'avez pas besoin de le fournir manuellement.
Transférer la réponse du service Web
Pour cela, nous devons ajouter un enregistreur dans le flux Mule et le configurer pour donner la charge utile comme indiqué ci-dessous -
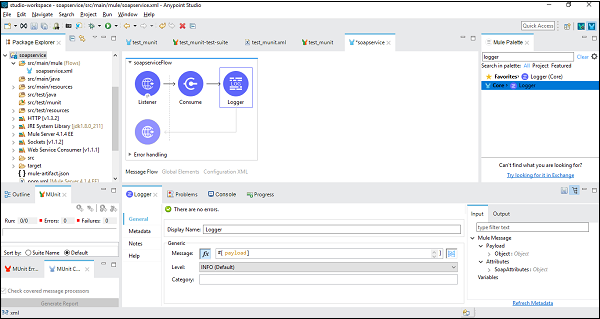
Test de l'application
Enregistrez et exécutez l'application et accédez à Google Chrome pour vérifier la sortie finale. Typehttp://localhist:8081/helloSOAP (pour cet exemple) et il affichera le nom du pays par code comme indiqué dans la capture d'écran ci-dessous -

La nouvelle gestion des erreurs de Mule est l'un des changements les plus importants et les plus importants effectués dans Mule 4. La nouvelle gestion des erreurs peut sembler complexe, mais elle est meilleure et plus efficace. Dans ce chapitre, nous allons discuter des composants d'erreur Mule, des types d'erreur, des catégories d'erreur Mule et des composants de gestion des erreurs Mule.
Composants de l'erreur de mule
L'erreur Mule est le résultat de l'échec d'exception Mule a les composants suivants -
La description
C'est un élément important de l'erreur Mule qui donnera une description du problème. Son expression est la suivante -
#[error.description]Type
Le composant Type de l'erreur Mule est utilisé pour caractériser le problème. Il permet également le routage dans un gestionnaire d'erreurs. Son expression est la suivante -
#[error.errorType]Cause
Le composant Cause de l'erreur Mule donne le java sous-jacent à l'origine de l'échec. Son expression est la suivante -
#[error.cause]Message
Le composant Message de l'erreur Mule affiche un message facultatif concernant l'erreur. Son expression est la suivante -
#[error.errorMessage]Erreurs enfants
Le composant Erreurs enfants de l'erreur Mule donne une collection facultative d'erreurs internes. Ces erreurs internes sont principalement utilisées par des éléments comme Scatter-Gather pour fournir des erreurs de route agrégées. Son expression est la suivante -
#[error.childErrors]Exemple
En cas d'échec de la requête HTTP avec un code d'état 401, les erreurs Mule sont les suivantes -
Description: HTTP GET on resource ‘http://localhost:8181/TestApp’
failed: unauthorized (401)
Type: HTTP:UNAUTHORIZED
Cause: a ResponseValidatorTypedException instance
Error Message: { "message" : "Could not authorize the user." }| Sr.NO | Type d'erreur et description |
|---|---|
| 1 | TRANSFORMATION Ce type d'erreur indique qu'une erreur s'est produite lors de la transformation d'une valeur. La transformation est la transformation interne de Mule Runtime et non les transformations DataWeave. |
| 2 | EXPRESSION Ce type de type d'erreur indique qu'une erreur s'est produite lors de l'évaluation d'une expression. |
| 3 | VALIDATION Ce type de type d'erreur indique qu'une erreur de validation s'est produite. |
| 4 | DUPLICATE_MESSAGE Une sorte d'erreur de validation qui se produit lorsqu'un message est traité deux fois. |
| 5 | REDELIVERY_EXHAUSTED Ce type de type d'erreur se produit lorsque le nombre maximal de tentatives de retraitement d'un message d'une source a été épuisé. |
| 6 | CONNECTIVITY Ce type d'erreur indique un problème lors de l'établissement d'une connexion. |
| sept | ROUTING Ce type d'erreur indique qu'une erreur s'est produite lors du routage d'un message. |
| 8 | SECURITY Ce type d'erreur indique qu'une erreur de sécurité s'est produite. Par exemple, des informations d'identification non valides reçues. |
| 9 | STREAM_MAXIMUM_SIZE_EXCEEDED Ce type d'erreur se produit lorsque la taille maximale autorisée pour un flux est épuisée. |
| dix | TIMEOUT Il indique le délai d'expiration du traitement d'un message. |
| 11 | UNKNOWN Ce type d'erreur indique qu'une erreur inattendue s'est produite. |
| 12 | SOURCE Il représente l'occurrence d'une erreur dans la source du flux. |
| 13 | SOURCE_RESPONSE Il représente l'occurrence d'une erreur dans la source du flux lors du traitement d'une réponse réussie. |
Dans l'exemple ci-dessus, vous pouvez voir le composant de message d'erreur mule.
Types d'erreur
Comprenons les types d'erreur à l'aide de ses caractéristiques -
La première caractéristique des types d'erreur de mule est qu'il se compose des deux, a namespace and an identifier. Cela nous permet de distinguer les types en fonction de leur domaine. Dans l'exemple ci-dessus, le type d'erreur estHTTP: UNAUTHORIZED.
La deuxième caractéristique importante est que le type d'erreur peut avoir un type parent. Par exemple, le type d'erreurHTTP: UNAUTHORIZED a MULE:CLIENT_SECURITY en tant que parent qui à son tour a également un parent nommé MULE:SECURITY. Cette caractéristique établit le type d'erreur comme spécification d'un article plus global.
Types de types d'erreur
Voici les catégories sous lesquelles toutes les erreurs tombent -
TOUT
Les erreurs de cette catégorie sont les erreurs qui peuvent se produire dans un flux. Ils ne sont pas si graves et peuvent être manipulés facilement.
CRITIQUE
Les erreurs de cette catégorie sont les erreurs graves qui ne peuvent pas être traitées. Voici la liste des types d'erreur dans cette catégorie -
| Sr.NO | Type d'erreur et description |
|---|---|
| 1 | OVERLOAD Ce type d'erreur indique qu'une erreur s'est produite en raison d'un problème de surcharge. Dans ce cas, l'exécution sera rejetée. |
| 2 | FATAL_JVM_ERROR Ce type de type d'erreur indique l'occurrence d'une erreur fatale. Par exemple, débordement de pile. |
Type d'erreur CUSTOM
Les types d'erreur CUSTOM sont les erreurs que nous définissons. Ils peuvent être définis lors du mappage ou lors de la levée des erreurs. Nous devons donner un espace de noms personnalisé spécifique à ces types d'erreur pour les distinguer des autres types d'erreur existants dans l'application Mule. Par exemple, dans l'application Mule utilisant HTTP, nous ne pouvons pas utiliser HTTP comme type d'erreur personnalisé.
Catégories d'erreur de mule
Au sens large, les erreurs dans Mule peuvent être divisées en deux catégories à savoir, Messaging Errors and System Errors.
Erreur de messagerie
Cette catégorie d'erreur Mule est liée au flux Mule. Chaque fois qu'un problème survient dans un flux Mule, Mule renvoie une erreur de messagerie. Nous pouvons mettre en placeOn Error composant à l'intérieur du composant de gestionnaire d'erreurs pour gérer ces erreurs Mule.
Erreur système
Une erreur système indique une exception au niveau du système. S'il n'y a pas d'événement Mule, l'erreur système est gérée par un gestionnaire d'erreurs système. Le type d'exceptions suivant géré par un gestionnaire d'erreurs système -
- Exception qui se produit lors du démarrage d'une application.
- Exception qui se produit lorsqu'une connexion à un système externe échoue.
En cas d'erreur système, Mule envoie une notification d'erreur aux auditeurs enregistrés. Il enregistre également l'erreur. D'autre part, Mule exécute une stratégie de reconnexion si l'erreur a été causée par un échec de connexion.
Gestion des erreurs Mule
Mule a les deux gestionnaires d'erreurs suivants pour gérer les erreurs -
Gestionnaires d'erreurs en cas d'erreur
Le premier gestionnaire d'erreurs Mule est le composant On-Error, qui définit les types d'erreurs qu'ils peuvent gérer. Comme indiqué précédemment, nous pouvons configurer les composants On-Error dans le composant Error Handler de type étendue. Chaque flux Mule contient un seul gestionnaire d'erreurs, mais ce gestionnaire d'erreurs peut contenir autant d'étendues On-Error que nécessaire. Les étapes de gestion de l'erreur Mule dans le flux, à l'aide du composant On-Error, sont les suivantes:
Tout d'abord, chaque fois qu'un flux Mule génère une erreur, l'exécution du flux normal s'arrête.
Ensuite, le processus sera transféré au Error Handler Component qui ont déjà On Error component pour faire correspondre les types d'erreur et les expressions.
Enfin, le composant Error Handler achemine l'erreur vers le premier On Error scope qui correspond à l'erreur.

Voici les deux types de composants On-Error pris en charge par Mule -
Propagation en cas d'erreur
Le composant On-Error Propagate s'exécute mais propage l'erreur au niveau suivant et interrompt l'exécution du propriétaire. La transaction sera annulée si elle est gérée parOn Error Propagate composant.
En cas d'erreur Continuer
Comme le composant Propagation en cas d'erreur, le composant Continuer en cas d'erreur exécute également la transaction. La seule condition est que si le propriétaire a terminé l'exécution avec succès, ce composant utilisera le résultat de l'exécution comme le résultat de son propriétaire. La transaction sera validée si elle est gérée par le composant Continuer en cas d'erreur.
Essayez le composant Scope
Try Scope est l'une des nombreuses nouvelles fonctionnalités disponibles dans Mule 4. Il fonctionne de la même manière que le bloc try de JAVA dans lequel nous avions l'habitude de renfermer le code ayant la possibilité d'être une exception, afin qu'il puisse être géré sans casser tout le code.
Nous pouvons encapsuler un ou plusieurs processeurs d'événements Mule dans Try Scope et ensuite, try scope capturera et gérera toute exception levée par ces processeurs d'événements. Le fonctionnement principal de la portée try tourne autour de sa propre stratégie de gestion des erreurs qui prend en charge la gestion des erreurs sur son composant interne au lieu de tout le flux. C'est pourquoi nous n'avons pas besoin d'extraire le flux dans un flux séparé.
Example
Voici un exemple d'utilisation de try scope -
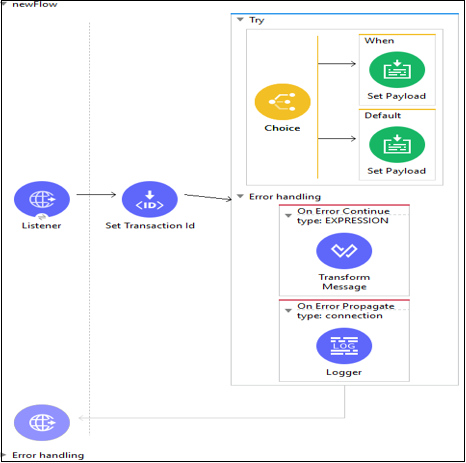
Configuration de l'étendue try pour la gestion des transactions
Comme nous le savons, une transaction est une série d'actions qui ne doivent jamais être exécutées partiellement. Toutes les opérations dans le cadre d'une transaction sont exécutées dans le même thread et si une erreur se produit, elle doit conduire à une annulation ou une validation. Nous pouvons configurer l'étendue try, de la manière suivante, afin qu'elle traite les opérations enfants comme une transaction.
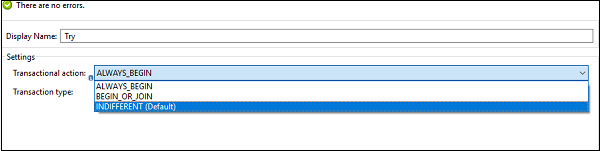
INDIFFERENT [Default]- Si nous choisissons cette configuration sur le bloc try, alors les actions enfants ne seront pas traitées comme une transaction. Dans ce cas, l'erreur ne provoque ni annulation ni validation.
ALWAYS_BEGIN - Il indique qu'une nouvelle transaction sera lancée chaque fois que l'oscilloscope est exécuté.
BEGIN_OR_JOIN- Il indique que si le traitement en cours du flux a déjà démarré une transaction, rejoignez-la. Sinon, commencez-en un nouveau.
Dans le cas de chaque projet, le fait à propos des exceptions est qu'elles sont inévitables. C'est pourquoi il est important d'attraper, de classer et de gérer les exceptions afin que le système / l'application ne soit pas laissé dans un état incohérent. Il existe une stratégie d'exception par défaut qui est implicitement appliquée à toutes les applications Mule. Annuler automatiquement toute transaction en attente est la stratégie d'exception par défaut.
Exceptions à Mule
Avant de plonger profondément dans la gestion exceptionnelle, nous devons comprendre quels types d'exceptions peuvent se produire ainsi que trois questions de base qu'un développeur doit se poser lors de la conception de gestionnaires d'exceptions.
Quel transport est important?
Cette question a une grande pertinence avant de concevoir des gestionnaires d'exceptions car tous les transports ne prennent pas en charge la transnationalité.
File ou HTTPne prend pas en charge les transactions. C'est pourquoi, si une exception survient dans ces cas, nous devons la gérer manuellement.
Databasessoutenir les transactions. Lors de la conception de gestionnaires d'exceptions dans ce cas, nous devons garder à l'esprit que les transactions de base de données peuvent automatiquement être annulées (si nécessaire).
En cas de REST APIs, nous devons garder à l'esprit qu'ils doivent renvoyer les bons codes d'état HTTP. Par exemple, 404 pour une ressource introuvable.
Quel modèle d'échange de messages utiliser?
Lors de la conception des gestionnaires d'exceptions, nous devons prendre soin du modèle d'échange de messages. Il peut y avoir un modèle de message synchrone (demande-réponse) ou asynchrone (oubli d'incendie).
Synchronous message pattern est basé sur le format demande-réponse, ce qui signifie que ce modèle attendra une réponse et sera bloqué jusqu'à ce qu'une réponse soit renvoyée ou que le délai expire.
Asynchronous message pattern est basé sur le format Fire-forget, ce qui signifie que ce modèle suppose que les demandes seront finalement traitées.
De quel type d'exception s'agit-il?
La règle très simple est que vous gérerez l'exception en fonction de son type. Il est très important de savoir si l'exception est causée par un problème système / technique ou un problème commercial?
Une exception est survenue par system/technical issue (comme une panne de réseau) doit être automatiquement gérée par un mécanisme de nouvelle tentative.
En revanche, une exception s'est produite by a business issue (comme les données non valides) ne doit pas être résolu en appliquant un mécanisme de nouvelle tentative car il n'est pas utile de réessayer sans corriger la cause sous-jacente.
Pourquoi catégoriser les exceptions?
Comme nous savons que toutes les exceptions ne sont pas les mêmes, il est très important de catégoriser les exceptions. Au niveau élevé, les exceptions peuvent être classées dans les deux types suivants -
Exceptions commerciales
Les principales raisons de l'apparition d'exceptions commerciales sont des données incorrectes ou un flux de processus incorrect. Ces types d'exceptions sont généralement de nature non récupérable et il n'est donc pas bon de configurer unrollback. Même en appliquantretrymécanisme n'aurait aucun sens car il n'est pas utile de réessayer sans corriger la cause sous-jacente. Afin de gérer ces exceptions, le traitement doit s'arrêter immédiatement et l'exception renvoyée en réponse à une file d'attente de lettres mortes. Une notification doit également être envoyée aux opérations.
Exceptions non commerciales
Les principales raisons de l'apparition d'exceptions non commerciales sont un problème système ou un problème technique. Ces types d'exceptions peuvent être récupérés par nature et il est donc bon de configurer unretry mécanisme afin de résoudre ces exceptions.
Stratégies de gestion des exceptions
Mule a les cinq stratégies de gestion des exceptions suivantes -
Stratégie d'exception par défaut
Mule applique implicitement cette stratégie aux flux Mule. Il peut gérer toutes les exceptions de notre flux, mais il peut également être remplacé en ajoutant une stratégie d'exception catch, Choice ou Rollback. Cette stratégie d'exception annulera toutes les transactions en attente et enregistrera également les exceptions. Une caractéristique importante de cette stratégie d'exception est qu'elle enregistrera également l'exception s'il n'y a pas de transaction.
En tant que stratégie par défaut, Mule l'implémente lorsqu'une erreur se produit dans le flux. Nous ne pouvons pas configurer dans AnyPoint studio.
Stratégie d'exception d'annulation
Supposons que s'il n'y a pas de solution possible pour corriger l'erreur, que faire? Une solution consiste à utiliser une stratégie d'exception d'annulation qui annulera la transaction et enverra un message au connecteur entrant du flux parent pour retraiter le message. Cette stratégie est également très utile lorsque nous voulons retraiter un message.
Example
Cette stratégie peut être appliquée aux transactions bancaires où les fonds sont déposés dans un compte chèque / épargne. Nous pouvons configurer ici une stratégie d'exception d'annulation car au cas où une erreur se produirait lors de la transaction, cette stratégie ramène le message au début dans le flux pour tenter à nouveau le traitement.
Stratégie d'exception de capture
Cette stratégie intercepte toutes les exceptions qui sont levées dans son flux parent. Il remplace la stratégie d'exception par défaut de Mule en traitant toutes les exceptions levées par le flux parent. Nous pouvons également utiliser une stratégie d'exception de capture pour éviter de propager des exceptions aux connecteurs entrants et aux flux parents.
Cette stratégie garantit également qu'une transaction traitée par le flux n'est pas annulée lorsqu'une exception se produit.
Example
Cette stratégie peut être appliquée au système de réservation de vol dans lequel nous avons un flux de traitement des messages d'une file d'attente. Un enricher de message ajoute une propriété sur le message pour l'attribution de siège, puis envoie le message à une autre file d'attente.
Maintenant, si une erreur se produit dans ce flux, le message lèvera une exception. Ici, notre stratégie d'exception de capture peut ajouter un en-tête avec un message approprié et peut pousser ce message hors du flux vers la file d'attente suivante.
Stratégie d'exception de choix
Si vous souhaitez gérer l'exception en fonction du contenu du message, le choix de la stratégie d'exception serait le meilleur choix. Le fonctionnement de cette stratégie d'exception sera le suivant -
- Premièrement, il intercepte toutes les exceptions levées dans le flux parent.
- Ensuite, il vérifie le contenu du message et le type d'exception.
- Et enfin, il achemine le message vers la stratégie d'exception appropriée.
Il y aurait plus d'une stratégie d'exception comme Catch ou Rollback, définie dans la stratégie d'exception de choix. Si aucune stratégie n'est définie dans le cadre de cette stratégie d'exception, elle achemine le message vers la stratégie d'exception par défaut. Il n'effectue jamais d'activités de validation, de restauration ou de consommation.
Stratégie d'exception de référence
Cela fait référence à une stratégie d'exception commune définie dans un fichier de configuration distinct. Dans le cas où un message lève une exception, cette stratégie d'exception fera référence aux paramètres de gestion des erreurs définis dans une stratégie d'exception globale de capture, de restauration ou de choix. Comme la stratégie d'exception de choix, elle n'effectue jamais d'activités de validation, de restauration ou de consommation.
Nous comprenons que les tests unitaires sont une méthode par laquelle des unités individuelles de code source peuvent être testées pour déterminer si elles sont aptes à être utilisées ou non. Les programmeurs Java peuvent utiliser le framework Junit pour écrire des cas de test. De même, MuleSoft dispose également d'un framework appelé MUnit nous permettant d'écrire des cas de test automatisés pour nos API et intégrations. C'est un ajustement parfait pour un environnement d'intégration / de déploiement continu. L'un des plus grands avantages du framework MUnit est que nous pouvons l'intégrer à Maven et Surefire.
Caractéristiques de MUnit
Voici quelques-unes des fonctionnalités très utiles du framework de test Mule MUnit -
Dans le framework MUnit, nous pouvons créer notre test Mule en utilisant le code Mule ainsi que le code Java.
Nous pouvons concevoir et tester nos applications et API Mule, graphiquement ou en XML, dans Anypoint Studio.
MUnit nous permet d'intégrer facilement les tests dans le processus CI / CD existant.
Il fournit des tests générés automatiquement et des rapports de couverture; par conséquent, le travail manuel est minime.
Nous pouvons également utiliser des serveurs DB / FTP / mail locaux pour rendre les tests plus portables via le processus CI.
Cela nous permet d'activer ou de désactiver les tests.
Nous pouvons également étendre le framework MUnit avec des plugins.
Cela nous permet de vérifier les appels du processeur de messages.
Avec l'aide du framework de test MUnit, nous pouvons désactiver les connecteurs de point de terminaison ainsi que les points de terminaison entrants de flux.
Nous pouvons vérifier les rapports d'erreur avec la trace de pile Mule.
Dernière version de Mule MUnit Testing Framework
MUnit 2.1.4 est la dernière version du framework de test Mule MUnit. Il nécessite les exigences matérielles et logicielles suivantes -
- MS Windows 8+
- Apple Mac OS X 10.10+
- Linux
- Java 8
- Maven 3.3.3, 3.3.9, 3.5.4, 3.6.0
Il est compatible avec Mule 4.1.4 et Anypoint Studio 7.3.0.
MUnit et Anypoint Studio
Comme indiqué, MUnit est entièrement intégré dans Anypoint studio et nous pouvons concevoir et tester nos applications et API Mule graphiquement ou en XML dans Anypoint studio. En d'autres termes, nous pouvons utiliser l'interface graphique d'Anypoint Studio pour faire ce qui suit -
- Pour créer et concevoir des tests MUnit
- Pour exécuter nos tests
- Pour afficher les résultats des tests ainsi que le rapport de couverture
- Pour déboguer les tests
Alors, commençons à discuter de chaque tâche une par une.
Création et conception de tests MUnit
Une fois que vous démarrez un nouveau projet, il ajoutera automatiquement un nouveau dossier à savoir src/test/munità notre projet. Par exemple, nous avons lancé un nouveau projet Mule à savoirtest_munit, vous pouvez voir dans l'image ci-dessous, il ajoute le dossier mentionné ci-dessus sous notre projet.
Maintenant, une fois que vous avez commencé un nouveau projet, il existe deux méthodes de base pour créer un nouveau test MUnit dans Anypoint Studio -
By Right-Clicking the Flow - Dans cette méthode, nous devons cliquer avec le bouton droit sur le flux spécifique et sélectionner MUnit dans le menu déroulant.
By Using the Wizard- Dans cette méthode, nous devons utiliser l'assistant pour créer un test. Cela nous permet de créer un test pour n'importe quel flux dans l'espace de travail.
Nous allons utiliser la méthode «Cliquez avec le bouton droit sur le flux» pour créer un test pour un flux spécifique.
Tout d'abord, nous devons créer un flux dans l'espace de travail comme suit -
Maintenant, faites un clic droit sur ce flux et sélectionnez MUnit pour créer un test pour ce flux, comme indiqué ci-dessous -
Il créera une nouvelle suite de tests nommée d'après le fichier XML où réside le flux. Dans ce cas,test_munit-test-suite est le nom de la nouvelle suite de tests comme indiqué ci-dessous -
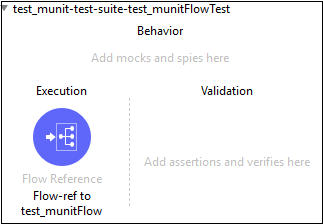
Voici l'éditeur XML pour le flux de messages ci-dessus -
Maintenant, nous pouvons ajouter un MUnit le processeur de messages vers la suite de tests en le faisant glisser depuis Mule Palette.
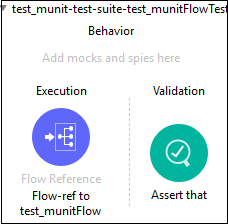
Si vous souhaitez créer un test via l'assistant, suivez File → New → MUnit et cela vous mènera à la suite de tests MUnit suivante -
Configurer le test
Dans Mule 4, nous avons deux nouvelles sections à savoir MUnit et MUnit Tools, ayant collectivement tous les processeurs de messages MUnit. Vous pouvez faire glisser n'importe quel processeur de messages dans votre zone de test MUnit. Il est montré dans la capture d'écran ci-dessous -
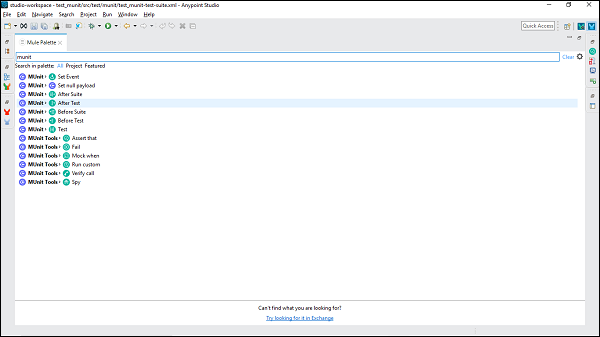
Maintenant, si vous souhaitez modifier la configuration de votre combinaison ou tester dans Anypoint Studio, vous devez suivre les étapes ci-dessous -
Step 1
Aller au Package Explorer et faites un clic droit sur le .xml filepour votre suite ou test. Ensuite, sélectionnez leProperties.
Step 2
Maintenant, dans la fenêtre Propriétés, nous devons cliquer sur Run/Debug Settings. Après ce clicNew.
Step 3
Dans la dernière étape, cliquez sur MUnit en dessous de Select Configuration Type fenêtre, puis cliquez sur OK.
Exécution du test
Nous pouvons exécuter une suite de tests ainsi qu'un test. Tout d'abord, nous verrons comment exécuter une suite de tests.
Exécution d'une suite de tests
Pour exécuter une suite de tests, cliquez avec le bouton droit de la souris sur la partie vide du Mule Canvas où réside votre suite de tests. Cela ouvrira un menu déroulant. Maintenant, cliquez sur leRun MUnit suite comme indiqué ci-dessous -
Plus tard, nous pouvons voir la sortie dans la console.
Exécution d'un test
Pour exécuter un test spécifique, nous devons sélectionner le test spécifique et faire un clic droit dessus. Nous obtiendrons le même menu déroulant que lors de l'exécution de la suite de tests. Maintenant, cliquez sur leRun MUnit Test option comme indiqué ci-dessous -

Là après la sortie peut être vue dans la console.
Affichage et analyse des résultats du test
Anypoint studio affiche le résultat du test MUnit dans le MUnit tabdu volet d'exploration de gauche. Vous pouvez trouver des tests réussis en vert et des tests échoués en rouge comme indiqué ci-dessous -
Nous pouvons analyser notre résultat de test en consultant le rapport de couverture. La principale caractéristique de Coverage Report est de fournir une métrique sur la mesure dans laquelle une application Mule a été exécutée avec succès par un ensemble de tests MUnit. La couverture MUnit est essentiellement basée sur la quantité de processeurs de messages MUnit exécutés. Le rapport de couverture MUnit fournit des métriques pour les éléments suivants:
- Couverture globale de l'application
- Couverture des ressources
- Couverture de flux
Pour obtenir le rapport de couverture, nous devons cliquer sur `` Générer un rapport '' sous l'onglet MUnit comme indiqué ci-dessous -
Débogage du test
Nous pouvons déboguer une suite de tests ainsi qu'un test. Tout d'abord, nous verrons comment déboguer une suite de tests.
Débogage d'une suite de tests
Pour déboguer une suite de tests, faites un clic droit sur la partie vide du Mule Canvas où réside votre suite de tests. Cela ouvrira un menu déroulant. Maintenant, cliquez sur leDebug MUnit Suite comme indiqué dans l'image ci-dessous -
Ensuite, nous pouvons voir la sortie dans la console.
Débogage d'un test
Pour déboguer un test spécifique, nous devons sélectionner le test spécifique et faire un clic droit dessus. Nous obtiendrons le même menu déroulant que lors du débogage de la suite de tests. Maintenant, cliquez sur leDebug MUnit Testoption. Il est illustré dans la capture d'écran ci-dessous.