Python Forensics - Guide rapide
Python est un langage de programmation à usage général avec un code facile et lisible qui peut être facilement compris par les développeurs professionnels ainsi que par les programmeurs novices. Python comprend de nombreuses bibliothèques utiles qui peuvent être utilisées avec n'importe quel framework de pile. De nombreux laboratoires s'appuient sur Python pour créer des modèles de base pour les prédictions et pour exécuter des expériences. Il permet également de contrôler les systèmes opérationnels critiques.
Python a des capacités intégrées pour prendre en charge les enquêtes numériques et protéger l'intégrité des preuves lors d'une enquête. Dans ce tutoriel, nous expliquerons les concepts fondamentaux de l'application de Python en criminalistique numérique ou de calcul.
Qu'est-ce que la criminalistique informatique?
Computational Forensics est un domaine de recherche émergent. Il traite de la résolution de problèmes médico-légaux à l'aide de méthodes numériques. Il utilise la science informatique pour étudier les preuves numériques.
La criminalistique informatique comprend un large éventail de sujets sur lesquels des objets, des substances et des processus ont été étudiés, principalement sur la base de preuves de modèle, telles que des marques d'outils, des empreintes digitales, des empreintes de chaussures, des documents, etc., et comprend également des modèles physiologiques et comportementaux, de l'ADN et des preuves numériques à scènes de crime.
Le diagramme suivant montre le large éventail de sujets abordés sous Computational Forensics.

La criminalistique informatique est implémentée à l'aide de certains algorithmes. Ces algorithmes sont utilisés pour le traitement du signal et de l'image, la vision par ordinateur et les graphiques. Il comprend également l'exploration de données, l'apprentissage automatique et la robotique.
La criminalistique informatique implique diverses méthodes numériques. La meilleure solution pour simplifier toutes les méthodes numériques en criminalistique est d'utiliser un langage de programmation à usage général comme Python.
Comme nous avons besoin de Python pour toutes les activités de la criminalistique computationnelle, nous allons avancer étape par étape et comprendre comment l'installer.
Step 1 - Aller à https://www.python.org/downloads/ et téléchargez les fichiers d'installation de Python en fonction du système d'exploitation que vous avez sur votre système.

Step 2 - Après avoir téléchargé le package / programme d'installation, cliquez sur le fichier exe pour démarrer le processus d'installation.

Vous verrez l'écran suivant une fois l'installation terminée.
Step 3 - L'étape suivante consiste à définir les variables d'environnement de Python dans votre système.
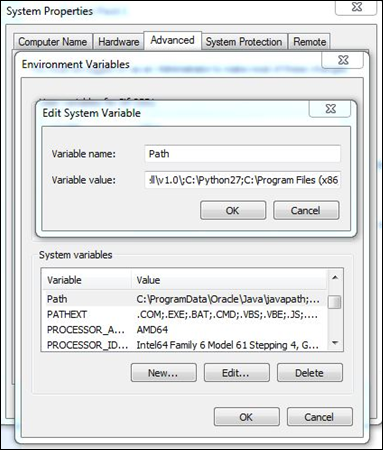
Step 4 - Une fois les variables d'environnement définies, tapez la commande "python" sur l'invite de commande pour vérifier si l'installation a réussi ou non.
Si l'installation a réussi, vous obtiendrez la sortie suivante sur la console.

Les codes écrits en Python ressemblent assez aux codes écrits dans d'autres langages de programmation conventionnels tels que C ou Pascal. On dit aussi que la syntaxe de Python est fortement empruntée à C. Cela inclut de nombreux mots-clés Python qui sont similaires au langage C.
Python comprend des instructions conditionnelles et en boucle, qui peuvent être utilisées pour extraire les données avec précision à des fins d'investigation. Pour le contrôle de flux, il fournitif/else, while, et un haut niveau for instruction qui boucle sur n'importe quel objet "itérable".
if a < b:
max = b
else:
max = aLe principal domaine dans lequel Python diffère des autres langages de programmation réside dans son utilisation de dynamic typing. Il utilise des noms de variables qui font référence à des objets. Ces variables n'ont pas besoin d'être déclarées.
Types de données
Python inclut un ensemble de types de données intégrés tels que des chaînes, des booléens, des nombres, etc. Il existe également des types immuables, ce qui signifie les valeurs qui ne peuvent pas être modifiées pendant l'exécution.
Python a également des types de données intégrés composés qui incluent tuples qui sont des tableaux immuables, lists, et dictionariesqui sont des tables de hachage. Tous sont utilisés dans la criminalistique numérique pour stocker des valeurs tout en rassemblant des preuves.
Modules et packages tiers
Python prend en charge des groupes de modules et / ou de packages qui sont également appelés third-party modules (code associé regroupé dans un seul fichier source) utilisé pour organiser les programmes.
Python comprend une bibliothèque standard étendue, ce qui est l'une des principales raisons de sa popularité dans la criminalistique informatique.
Cycle de vie du code Python
Au début, lorsque vous exécutez un code Python, l'interpréteur vérifie le code pour les erreurs de syntaxe. Si l'interpréteur découvre des erreurs de syntaxe, elles sont immédiatement affichées sous forme de messages d'erreur.
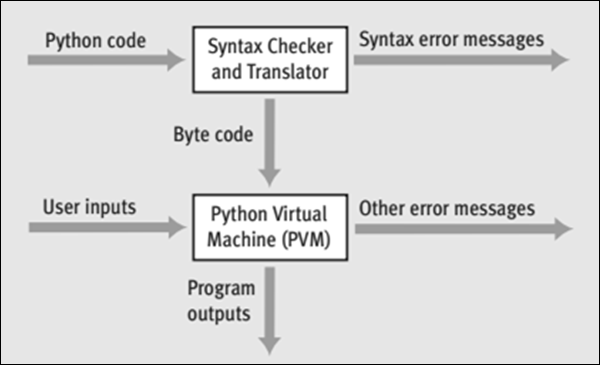
S'il n'y a pas d'erreurs de syntaxe, le code est compilé pour produire un bytecode et envoyé à PVM (Python Virtual Machine).
Le PVM vérifie le bytecode pour toute erreur d'exécution ou logique. Si le PVM trouve des erreurs d'exécution, elles sont immédiatement signalées sous forme de messages d'erreur.
Si le bytecode est sans erreur, le code est traité et vous obtenez sa sortie.
L'illustration suivante montre de manière graphique comment le code Python est d'abord interprété pour produire un bytecode et comment le bytecode est traité par le PVM pour produire la sortie.
Pour créer une application conformément aux directives Forensic, il est important de comprendre et de suivre ses conventions de dénomination et ses modèles.
Conventions de nommage
Lors du développement des applications d'investigation Python, les règles et conventions à suivre sont décrites dans le tableau suivant.
| Constantes | Majuscules avec séparation de soulignement | HAUTE TEMPÉRATURE |
| Nom de la variable locale | Minuscules avec des majuscules bosselées (les traits de soulignement sont facultatifs) | température actuelle |
| Nom de la variable globale | Préfixe gl minuscule avec des majuscules bosselées (les traits de soulignement sont facultatifs) | gl_maximumRecordedTemperature |
| Nom des fonctions | Majuscules avec majuscules bosselées (traits de soulignement en option) avec voix active | ConvertirFarenheitToCentigrade (...) |
| Nom de l'objet | Préfixe ob_ minuscule avec majuscules bosselées | ob_myTempRecorder |
| Module | Un trait de soulignement suivi de minuscules avec des majuscules bosselées | _tempRecorder |
| Noms de classe | Préfixez class_ puis casquettes bosselées et restez bref | class_TempSystem |
Prenons un scénario pour comprendre l'importance des conventions de dénomination dans Computational Forensics. Supposons que nous ayons un algorithme de hachage qui est normalement utilisé pour chiffrer les données. L'algorithme de hachage unidirectionnel prend l'entrée comme un flux de données binaires; cela peut être un mot de passe, un fichier, des données binaires ou des données numériques. L'algorithme de hachage produit alors unmessage digest (md) par rapport aux données reçues dans l'entrée.
Il est pratiquement impossible de créer une nouvelle entrée binaire qui générera un résumé de message donné. Même un seul bit des données d'entrée binaires, s'il est modifié, générera un message unique, différent du précédent.
Exemple
Jetez un œil à l'exemple de programme suivant qui respecte les conventions mentionnées ci-dessus.
import sys, string, md5 # necessary libraries
print "Please enter your full name"
line = sys.stdin.readline()
line = line.rstrip()
md5_object = md5.new()
md5_object.update(line)
print md5_object.hexdigest() # Prints the output as per the hashing algorithm i.e. md5
exitLe programme ci-dessus produit la sortie suivante.
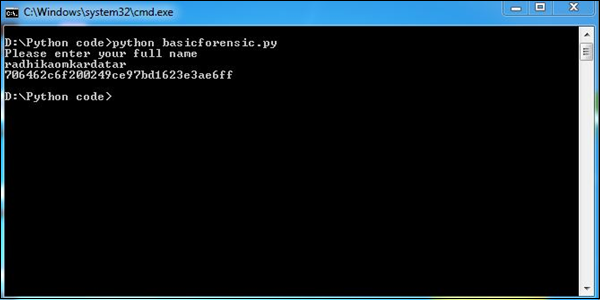
Dans ce programme, le script Python accepte l'entrée (votre nom complet) et la convertit selon l'algorithme de hachage md5. Il crypte les données et sécurise les informations, si nécessaire. Conformément aux directives médico-légales, le nom des preuves ou toute autre preuve peut être sécurisé dans ce modèle.
UNE hash functionest définie comme la fonction qui mappe une grande quantité de données à une valeur fixe avec une longueur spécifiée. Cette fonction garantit que la même entrée aboutit à la même sortie, qui est en fait définie comme une somme de hachage. La somme de hachage comprend une caractéristique avec des informations spécifiques.
Cette fonction est pratiquement impossible à rétablir. Ainsi, toute attaque tierce comme une attaque par force brute est pratiquement impossible. De plus, ce type d'algorithme est appeléone-way cryptographic algorithm.
Une fonction de hachage cryptographique idéale a quatre propriétés principales -
- Il doit être facile de calculer la valeur de hachage pour une entrée donnée.
- Il doit être impossible de générer l'entrée d'origine à partir de son hachage.
- Il doit être impossible de modifier l'entrée sans changer le hachage.
- Il doit être impossible de trouver deux entrées différentes avec le même hachage.
Exemple
Prenons l'exemple suivant qui aide à faire correspondre les mots de passe à l'aide de caractères au format hexadécimal.
import uuid
import hashlib
def hash_password(password):
# userid is used to generate a random number
salt = uuid.uuid4().hex #salt is stored in hexadecimal value
return hashlib.sha256(salt.encode() + password.encode()).hexdigest() + ':' + salt
def check_password(hashed_password, user_password):
# hexdigest is used as an algorithm for storing passwords
password, salt = hashed_password.split(':')
return password == hashlib.sha256(salt.encode()
+ user_password.encode()).hexdigest()
new_pass = raw_input('Please enter required password ')
hashed_password = hash_password(new_pass)
print('The string to store in the db is: ' + hashed_password)
old_pass = raw_input('Re-enter new password ')
if check_password(hashed_password, old_pass):
print('Yuppie!! You entered the right password')
else:
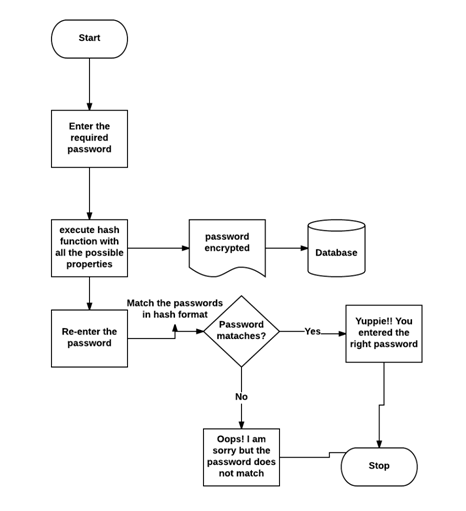
print('Oops! I am sorry but the password does not match')Organigramme
Nous avons expliqué la logique de ce programme à l'aide de l'organigramme suivant -
Production
Notre code produira la sortie suivante -
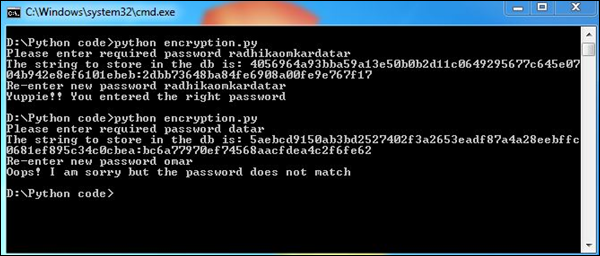
Le mot de passe entré deux fois correspond à la fonction de hachage. Cela garantit que le mot de passe entré deux fois est exact, ce qui aide à collecter des données utiles et à les enregistrer dans un format crypté.
Dans ce chapitre, nous allons apprendre à casser des données textuelles récupérées lors de l'analyse et des preuves.
Un texte brut en cryptographie est un texte lisible normal, tel qu'un message. Un texte chiffré, en revanche, est la sortie d'un algorithme de chiffrement récupéré après avoir saisi du texte brut.
L'algorithme simple permettant de transformer un message en texte brut en texte chiffré est le chiffrement César, inventé par Jules César pour garder le texte brut secret de ses ennemis. Ce chiffre consiste à déplacer chaque lettre du message «vers l'avant» de trois places dans l'alphabet.
Voici une illustration de démonstration.
a → D
b → E
c → F
....
w → Z
x → A
y → B
z → C
Exemple
Un message entré lorsque vous exécutez un script Python donne toutes les possibilités de caractères, qui est utilisé pour la preuve de modèle.
Les types de preuves de modèle utilisés sont les suivants:
- Traces et marques de pneus
- Impressions
- Fingerprints
Chaque donnée biométrique comprend des données vectorielles, que nous devons déchiffrer pour recueillir des preuves à toute épreuve.
Le code Python suivant montre comment vous pouvez produire un texte chiffré à partir de texte brut -
import sys
def decrypt(k,cipher):
plaintext = ''
for each in cipher:
p = (ord(each)-k) % 126
if p < 32:
p+=95
plaintext += chr(p)
print plaintext
def main(argv):
if (len(sys.argv) != 1):
sys.exit('Usage: cracking.py')
cipher = raw_input('Enter message: ')
for i in range(1,95,1):
decrypt(i,cipher)
if __name__ == "__main__":
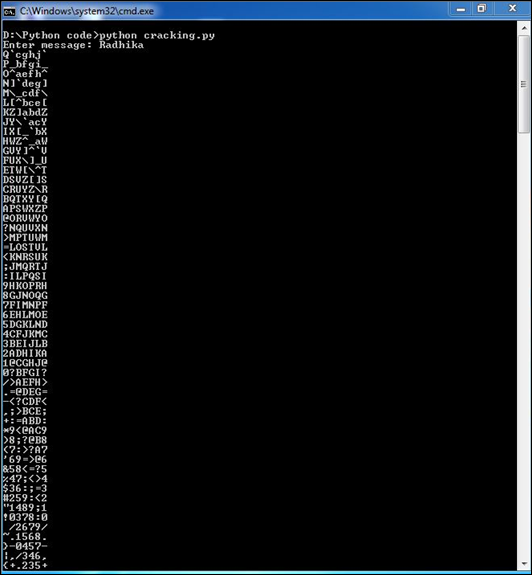
main(sys.argv[1:])Production
Maintenant, vérifiez la sortie de ce code. Lorsque nous entrons un texte simple "Radhika", le programme produira le texte chiffré suivant.
Virtualizationest le processus d'émulation des systèmes informatiques tels que les serveurs, les postes de travail, les réseaux et le stockage. Ce n'est rien d'autre que la création d'une version virtuelle plutôt que réelle d'un système d'exploitation, d'un serveur, d'un périphérique de stockage ou de processus réseau.
Le composant principal qui aide à l'émulation du matériel virtuel est défini comme un hyper-visor.
La figure suivante explique les deux principaux types de virtualisation de système utilisés.
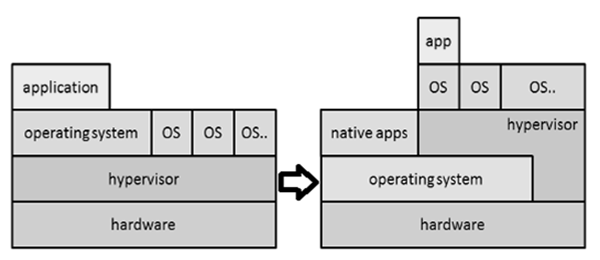
La virtualisation a été utilisée dans l'informatique légale de plusieurs manières. Il aide l'analyste de manière à ce que le poste de travail puisse être utilisé dans un état validé pour chaque enquête. La récupération de données est possible en attachant l'image dd d'un lecteur en tant que lecteur secondaire sur une machine virtuelle en particulier. La même machine peut être utilisée comme logiciel de récupération pour recueillir les preuves.
L'exemple suivant aide à comprendre la création d'une machine virtuelle à l'aide du langage de programmation Python.
Step 1 - Laissez la machine virtuelle être nommée «dummy1».
Chaque machine virtuelle doit disposer de 512 Mo de mémoire dans une capacité minimale, exprimée en octets.
vm_memory = 512 * 1024 * 1024Step 2 - La machine virtuelle doit être attachée au cluster par défaut, qui a été calculé.
vm_cluster = api.clusters.get(name = "Default")Step 3 - La machine virtuelle doit démarrer à partir du disque dur virtuel.
vm_os = params.OperatingSystem(boot = [params.Boot(dev = "hd")])Toutes les options sont combinées dans un objet de paramètre de machine virtuelle, avant d'utiliser la méthode add de la collection vms à la machine virtuelle.
Exemple
Voici le script Python complet pour ajouter une machine virtuelle.
from ovirtsdk.api import API #importing API library
from ovirtsdk.xml import params
try: #Api credentials is required for virtual machine
api = API(url = "https://HOST",
username = "Radhika",
password = "a@123",
ca_file = "ca.crt")
vm_name = "dummy1"
vm_memory = 512 * 1024 * 1024 #calculating the memory in bytes
vm_cluster = api.clusters.get(name = "Default")
vm_template = api.templates.get(name = "Blank")
#assigning the parameters to operating system
vm_os = params.OperatingSystem(boot = [params.Boot(dev = "hd")])
vm_params = params.VM(name = vm_name,
memory = vm_memory,
cluster = vm_cluster,
template = vm_template
os = vm_os)
try:
api.vms.add(vm = vm_params)
print "Virtual machine '%s' added." % vm_name #output if it is successful.
except Exception as ex:
print "Adding virtual machine '%s' failed: %s" % (vm_name, ex)
api.disconnect()
except Exception as ex:
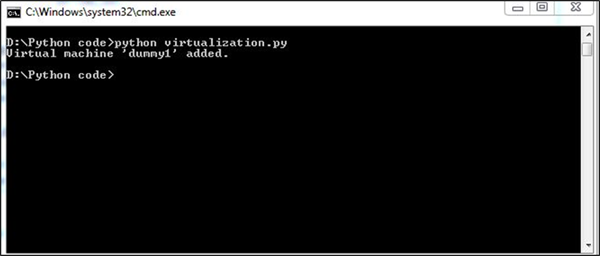
print "Unexpected error: %s" % exProduction
Notre code produira la sortie suivante -
Le scénario des environnements réseau modernes est tel que les enquêtes peuvent être difficiles en raison d'un certain nombre de difficultés. Cela peut se produire que vous répondiez à une assistance en cas de violation, que vous enquêtiez sur des activités internes, que vous effectuiez des évaluations liées à la vulnérabilité ou que vous validiez une conformité réglementaire.
Concept de programmation réseau
Les définitions suivantes sont utilisées dans la programmation réseau.
Client - Le client fait partie de l'architecture client-serveur de la programmation réseau qui s'exécute sur un ordinateur personnel et un poste de travail.
Server - Le serveur fait partie de l'architecture client-serveur qui fournit des services à d'autres programmes informatiques sur le même ordinateur ou sur d'autres.
WebSockets- Les WebSockets fournissent un protocole entre le client et le serveur, qui s'exécute sur une connexion TCP persistante. Grâce à cela, des messages bidirectionnels peuvent être envoyés entre la connexion de socket TCP (simultanément).
Les WebSockets viennent après de nombreuses autres technologies qui permettent aux serveurs d'envoyer des informations au client. Hormis la négociation de l'en-tête de mise à niveau, WebSockets est indépendant de HTTP.

Ces protocoles permettent de valider les informations envoyées ou reçues par les utilisateurs tiers. Le cryptage étant l'une des méthodes utilisées pour sécuriser les messages, il est également important de sécuriser le canal par lequel les messages ont été transférés.
Considérez le programme Python suivant, que le client utilise pour handshaking.
Exemple
# client.py
import socket
# create a socket object
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# get local machine name
host = socket.gethostname()
port = 8080
# connection to hostname on the port.
s.connect((host, port))
# Receive no more than 1024 bytes
tm = s.recv(1024)
print("The client is waiting for connection")
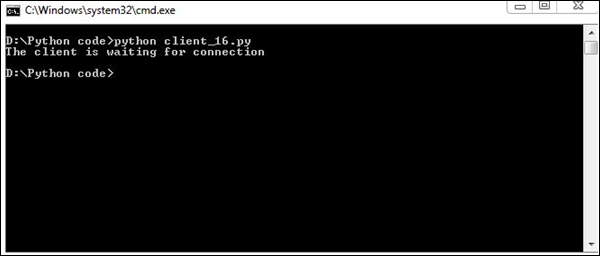
s.close()Production
Il produira la sortie suivante -
Le serveur acceptant la demande de canal de communication inclura le script suivant.
# server.py
import socket
import time
# create a socket object
serversocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# get local machine name
host = socket.gethostname()
port = 8080
# bind to the port
serversocket.bind((host, port))
# queue up to 5 requests
serversocket.listen(5)
while True:
# establish a connection
clientsocket,addr = serversocket.accept()
print("Got a connection from %s" % str(addr))
currentTime = time.ctime(time.time()) + "\r\n"
clientsocket.send(currentTime.encode('ascii'))
clientsocket.close()Le client et le serveur créés à l'aide de la programmation Python écoutent le numéro d'hôte. Au départ, le client envoie une demande au serveur concernant les données envoyées dans le numéro d'hôte et le serveur accepte la demande et envoie une réponse immédiatement. De cette façon, nous pouvons avoir un canal de communication sécurisé.
Les modules des programmes Python aident à organiser le code. Ils aident à regrouper le code associé en un seul module, ce qui le rend plus facile à comprendre et à utiliser. Il comprend des valeurs nommées arbitrairement, qui peuvent être utilisées pour la liaison et la référence. En termes simples, un module est un fichier composé de code Python qui comprend des fonctions, des classes et des variables.
Le code Python d'un module (fichier) est enregistré avec .py extension qui est compilée au fur et à mesure des besoins.
Example
def print_hello_func( par ):
print "Hello : ", par
returnDéclaration d'importation
Le fichier source Python peut être utilisé comme module en exécutant un importinstruction qui importe d'autres packages ou bibliothèques tierces. La syntaxe utilisée est la suivante -
import module1[, module2[,... moduleN]Lorsque l'interpréteur Python rencontre l'instruction d'importation, il importe le module spécifié qui est présent dans le chemin de recherche.
Example
Prenons l'exemple suivant.
#!/usr/bin/python
# Import module support
import support
# Now you can call defined function that module as follows
support.print_func("Radhika")Il produira la sortie suivante -
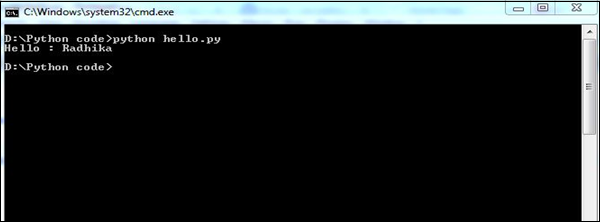
Un module n'est chargé qu'une seule fois, quel que soit le nombre de fois où il a été importé par du code Python.
From ... instruction d'importation
FromL'attribut permet d'importer des attributs spécifiques d'un module dans un espace de noms courant. Voici sa syntaxe.
from modname import name1[, name2[, ... nameN]]Example
Pour importer la fonction fibonacci du module fib, utilisez l'instruction suivante.
from fib import fibonacciLocalisation des modules
Lors de l'importation du module, l'interpréteur Python recherche les séquences suivantes -
Le répertoire actuel.
Si le module n'existe pas, Python recherche alors chaque répertoire dans la variable shell PYTHONPATH.
Si l'emplacement de la variable shell échoue, Python vérifie le chemin par défaut.
La criminalistique informatique utilise des modules Python et des modules tiers pour obtenir les informations et extraire les preuves plus facilement. D'autres chapitres se concentrent sur la mise en œuvre de modules pour obtenir les résultats nécessaires.
DShell
Dshellest une boîte à outils d'analyse légale de réseau basée sur Python. Cette boîte à outils a été développée par le US Army Research Laboratory. La sortie de cette boîte à outils open source a eu lieu en 2014. Le principal objectif de cette boîte à outils est de faire des enquêtes médico-légales avec facilité.
La boîte à outils comprend un grand nombre de décodeurs répertoriés dans le tableau suivant.
| Sr.No. | Nom et description du décodeur |
|---|---|
| 1 | dns Ceci est utilisé pour extraire les requêtes liées au DNS |
| 2 | reservedips Identifie les solutions aux problèmes DNS |
| 3 | large-flows Liste des flux nets |
| 4 | rip-http Il est utilisé pour extraire les fichiers du trafic HTTP |
| 5 | Protocols Utilisé pour l'identification des protocoles non standard |
Le laboratoire de l'armée américaine a maintenu le référentiel de clones dans GitHub dans le lien suivant -
https://github.com/USArmyResearchLab/Dshell
Le clone consiste en un script install-ubuntu.py () utilisé pour l'installation de cette boîte à outils.
Une fois l'installation réussie, il construira automatiquement les exécutables et les dépendances qui seront utilisés plus tard.
Les dépendances sont les suivantes -
dependencies = {
"Crypto": "crypto",
"dpkt": "dpkt",
"IPy": "ipy",
"pcap": "pypcap"
}Cette boîte à outils peut être utilisée contre les fichiers pcap (capture de paquets), qui sont généralement enregistrés lors des incidents ou pendant l'alerte. Ces fichiers pcap sont soit créés par libpcap sur la plate-forme Linux ou WinPcap sur la plate-forme Windows.
Scapy
Scapy est un outil basé sur Python utilisé pour analyser et manipuler le trafic réseau. Voici le lien pour la boîte à outils Scapy -
http://www.secdev.org/projects/scapy/
Cette boîte à outils est utilisée pour analyser la manipulation des paquets. Il est très capable de décoder des paquets d'un grand nombre de protocoles et de les capturer. Scapy diffère de la boîte à outils Dshell en fournissant une description détaillée à l'enquêteur du trafic réseau. Ces descriptions ont été enregistrées en temps réel.
Scapy a la capacité de tracer à l'aide d'outils tiers ou d'empreintes digitales du système d'exploitation.
Prenons l'exemple suivant.
import scapy, GeoIP #Imports scapy and GeoIP toolkit
from scapy import *
geoIp = GeoIP.new(GeoIP.GEOIP_MEMORY_CACHE) #locates the Geo IP address
def locatePackage(pkg):
src = pkg.getlayer(IP).src #gets source IP address
dst = pkg.getlayer(IP).dst #gets destination IP address
srcCountry = geoIp.country_code_by_addr(src) #gets Country details of source
dstCountry = geoIp.country_code_by_addr(dst) #gets country details of destination
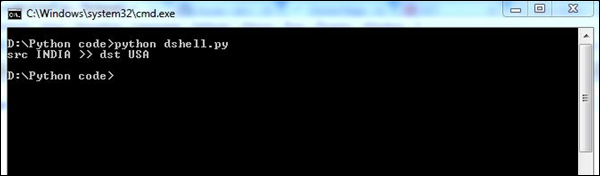
print src+"("+srcCountry+") >> "+dst+"("+dstCountry+")\n"Ce script donne la description détaillée des détails du pays dans le paquet réseau, qui communiquent entre eux.
Le script ci-dessus produira la sortie suivante.
Searchingest certainement l'un des piliers de l'enquête médico-légale. De nos jours, la recherche ne vaut que pour l'enquêteur qui gère les preuves.
La recherche d'un mot-clé dans le message joue un rôle essentiel dans la criminalistique, lorsque nous recherchons une preuve à l'aide d'un mot-clé. La connaissance de ce qui doit être recherché dans un fichier particulier ainsi que de celles des fichiers supprimés nécessite à la fois de l'expérience et des connaissances.
Python a divers mécanismes intégrés avec des modules de bibliothèque standard pour prendre en charge searchopération. Fondamentalement, les enquêteurs utilisent l'opération de recherche pour trouver des réponses à des questions telles que «qui», «quoi», «où», «quand», etc.
Exemple
Dans l'exemple suivant, nous avons déclaré deux chaînes, puis nous avons utilisé la fonction de recherche pour vérifier si la première chaîne contient la deuxième chaîne ou non.
# Searching a particular word from a message
str1 = "This is a string example for Computational forensics of gathering evidence!";
str2 = "string";
print str1.find(str2)
print str1.find(str2, 10)
print str1.find(str2, 40)Le script ci-dessus produira la sortie suivante.
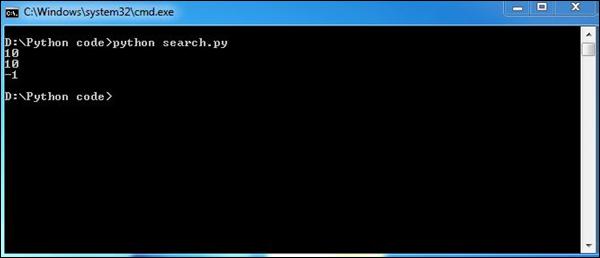
“find”La fonction en Python aide à rechercher un mot-clé dans un message ou un paragraphe. Ceci est essentiel pour recueillir des preuves appropriées.
Indexingfournit en fait à l'enquêteur un regard complet sur un dossier et en recueille des preuves potentielles. Les preuves peuvent être contenues dans un fichier, une image disque, un instantané de la mémoire ou une trace réseau.
L'indexation aide à réduire le temps pour les tâches chronophages telles que keyword searching. L'enquête médico-légale implique également une phase de recherche interactive, où l'index est utilisé pour localiser rapidement des mots-clés.
L'indexation aide également à répertorier les mots-clés dans une liste triée.
Exemple
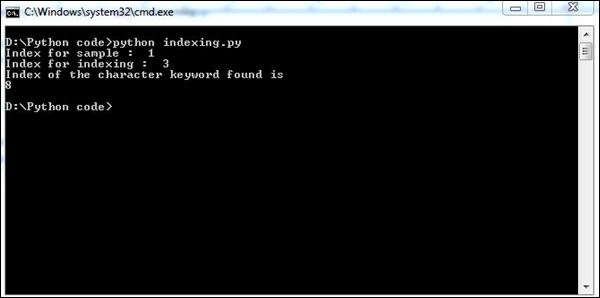
L'exemple suivant montre comment utiliser indexing en Python.
aList = [123, 'sample', 'zara', 'indexing'];
print "Index for sample : ", aList.index('sample')
print "Index for indexing : ", aList.index('indexing')
str1 = "This is sample message for forensic investigation indexing";
str2 = "sample";
print "Index of the character keyword found is "
print str1.index(str2)Le script ci-dessus produira la sortie suivante.
L'extraction d'informations précieuses à partir des ressources disponibles est un élément essentiel de la criminalistique numérique. L'accès à toutes les informations disponibles est essentiel pour un processus d'enquête car cela aide à récupérer les preuves appropriées.
Les ressources qui contiennent des données peuvent être des structures de données simples telles que des bases de données ou des structures de données complexes telles qu'une image JPEG. Les structures de données simples sont facilement accessibles à l'aide d'outils de bureau simples, tandis que l'extraction d'informations à partir de structures de données complexes nécessite des outils de programmation sophistiqués.
Bibliothèque d'imagerie Python
La bibliothèque d'imagerie Python (PIL) ajoute des capacités de traitement d'image à votre interpréteur Python. Cette bibliothèque prend en charge de nombreux formats de fichiers et offre de puissantes capacités de traitement d'images et de graphiques. Vous pouvez télécharger les fichiers source de PIL à partir de:http://www.pythonware.com/products/pil/
L'illustration suivante montre le diagramme de flux complet d'extraction de données à partir d'images (structures de données complexes) dans PIL.

Exemple
Maintenant, prenons un exemple de programmation pour comprendre comment cela fonctionne réellement.
Step 1 - Supposons que nous ayons l'image suivante à partir de laquelle nous devons extraire des informations.

Step 2- Lorsque nous ouvrons cette image à l'aide de PIL, il notera d'abord les points nécessaires à l'extraction des preuves, qui incluent diverses valeurs de pixels. Voici le code pour ouvrir l'image et enregistrer ses valeurs de pixels -
from PIL import Image
im = Image.open('Capture.jpeg', 'r')
pix_val = list(im.getdata())
pix_val_flat = [x for sets in pix_val for x in sets]
print pix_val_flatStep 3 - Notre code produira la sortie suivante, après avoir extrait les valeurs de pixels de l'image.
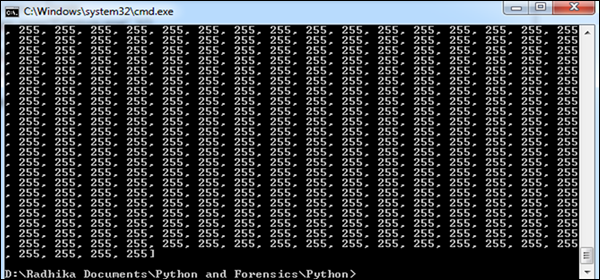
La sortie fournie représente les valeurs de pixel de la combinaison RVB, ce qui donne une meilleure image des données nécessaires pour la preuve. Les données récupérées sont représentées sous la forme d'un tableau.
L'enquête et l'analyse médico-légale du matériel informatique standard tel que les disques durs sont devenues une discipline stable et sont suivies à l'aide de techniques permettant d'analyser du matériel non standard ou des preuves transitoires.
Bien que les smartphones soient de plus en plus utilisés dans les enquêtes numériques, ils sont toujours considérés comme non standard.
Analyse médico-légale
Les enquêtes médico-légales recherchent des données telles que les appels reçus ou les numéros composés à partir du smartphone. Il peut inclure des messages texte, des photos ou toute autre preuve incriminante. La plupart des smartphones disposent de fonctions de verrouillage d'écran à l'aide de mots de passe ou de caractères alphanumériques.
Ici, nous allons prendre un exemple pour montrer comment Python peut aider à déchiffrer le mot de passe de verrouillage d'écran pour récupérer des données à partir d'un smartphone.
Examen manuel
Android prend en charge le verrouillage par mot de passe avec code PIN ou mot de passe alphanumérique. La limite des deux phrases de passe doit être comprise entre 4 et 16 chiffres ou caractères. Le mot de passe d'un smartphone est stocké dans le système Android dans un fichier spécial appelépassword.key dans /data/system.
Android stocke un hashsum SHA1 salé et un hashsum MD5 du mot de passe. Ces mots de passe peuvent être traités dans le code suivant.
public byte[] passwordToHash(String password) {
if (password == null) {
return null;
}
String algo = null;
byte[] hashed = null;
try {
byte[] saltedPassword = (password + getSalt()).getBytes();
byte[] sha1 = MessageDigest.getInstance(algo = "SHA-1").digest(saltedPassword);
byte[] md5 = MessageDigest.getInstance(algo = "MD5").digest(saltedPassword);
hashed = (toHex(sha1) + toHex(md5)).getBytes();
} catch (NoSuchAlgorithmException e) {
Log.w(TAG, "Failed to encode string because of missing algorithm: " + algo);
}
return hashed;
}Il n'est pas possible de déchiffrer le mot de passe à l'aide de dictionary attack car le mot de passe haché est stocké dans un salt file. Cesaltest une chaîne de représentation hexadécimale d'un entier aléatoire de 64 bits. Il est facile d'accéder ausalt en utilisant Rooted Smartphone ou JTAG Adapter.
Smartphone enraciné
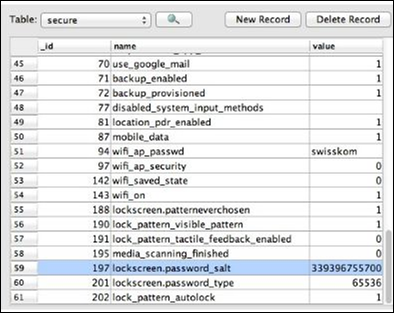
Le vidage du fichier /data/system/password.key est stocké dans la base de données SQLite sous le lockscreen.password_saltclé. En dessous desettings.db, le mot de passe est stocké et la valeur est clairement visible dans la capture d'écran suivante.
Adaptateur JTAG
Un matériel spécial appelé adaptateur JTAG (Joint Test Action Group) peut être utilisé pour accéder au salt. De même, unRiff-Box ou un JIG-Adapter peut également être utilisé pour la même fonctionnalité.
En utilisant les informations obtenues à partir de Riff-box, nous pouvons trouver la position des données cryptées, c'est-à-dire le salt. Voici les règles -
Recherchez la chaîne associée "lockscreen.password_salt".
L'octet représente la largeur réelle du sel, qui est son length.
Il s'agit de la longueur qui est réellement recherchée pour obtenir le mot de passe / la broche stockés des smartphones.
Cet ensemble de règles aide à obtenir les données de sel appropriées.
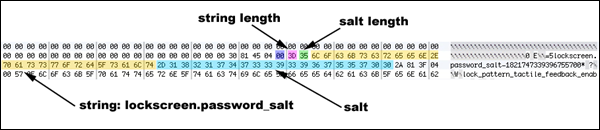
Le protocole le plus largement utilisé pour la synchronisation de l'heure et qui a été largement accepté comme pratique se fait par le biais du protocole NTP (Network Time Protocol).
NTP utilise le protocole UDP (User Datagram Protocol) qui utilise un temps minimum pour communiquer les paquets entre le serveur et le client qui souhaitent se synchroniser avec la source de temps donnée.
Features of Network Time Protocol are as follows −
The default server port is 123.
This protocol consists of many accessible time servers synchronized to national laboratories.
The NTP protocol standard is governed by the IETF and the Proposed Standard is RFC 5905, titled “Network Time Protocol Version 4: Protocol and Algorithms Specification” [NTP RFC]
Operating systems, programs, and applications use NTP to synchronize time in a proper way.
In this chapter, we will focus on the usage of NTP with Python, which is feasible from third-party Python Library ntplib. This library efficiently handles the heavy lifting, which compares the results to my local system clock.
Installing the NTP Library
The ntplib is available for download at https://pypi.python.org/pypi/ntplib/ as shown in the following figure.
The library provides a simple interface to NTP servers with the help of methods that can translate NTP protocol fields. This helps access other key values such as leap seconds.

The following Python program helps in understanding the usage of NTP.
import ntplib
import time
NIST = 'nist1-macon.macon.ga.us'
ntp = ntplib.NTPClient()
ntpResponse = ntp.request(NIST)
if (ntpResponse):
now = time.time()
diff = now-ntpResponse.tx_time
print diff;The above program will produce the following output.
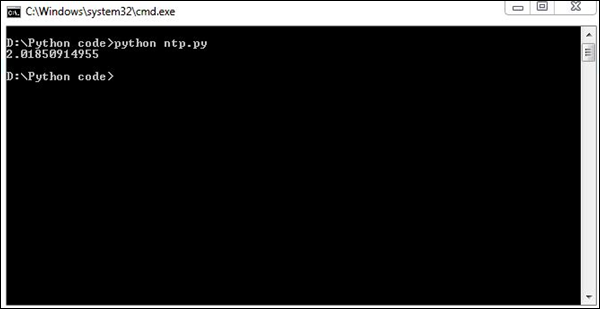
The difference in time is calculated in the above program. These calculations help in forensic investigations. The network data obtained is fundamentally different than the analysis of data found on the hard drive.
The difference in time zones or getting accurate time zones can help in gathering evidence for capturing the messages through this protocol.
Forensic specialists normally find it difficult to apply digital solutions to analyze the mountains of digital evidence in common crimes. Most digital investigation tools are single threaded and they can execute only one command at a time.
In this chapter, we will focus on the multiprocessing capabilities of Python, which can relate to the common forensic challenges.
Multiprocessing
Multiprocessing is defined as the computer system's ability to support more than one process. The operating systems that support multiprocessing enable several programs to run concurrently.
There are various types of multiprocessing such as symmetric and asymmetric processing. The following diagram refers to a symmetric multiprocessing system which is usually followed in forensic investigation.
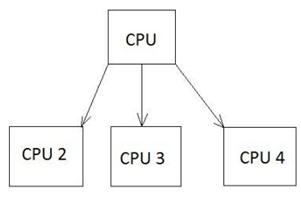
Example
The following code shows how different processes are listed internally in Python programming.
import random
import multiprocessing
def list_append(count, id, out_list):
#appends the count of number of processes which takes place at a time
for i in range(count):
out_list.append(random.random())
if __name__ == "__main__":
size = 999
procs = 2
# Create a list of jobs and then iterate through
# the number of processes appending each process to
# the job list
jobs = []
for i in range(0, procs):
out_list = list() #list of processes
process1 = multiprocessing.Process(
target = list_append, args = (size, i, out_list))
# appends the list of processes
jobs.append(process)
# Calculate the random number of processes
for j in jobs:
j.start() #initiate the process
# After the processes have finished execution
for j in jobs:
j.join()
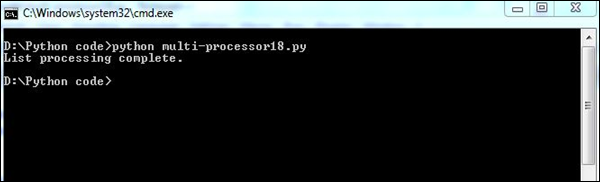
print "List processing complete."Here, the function list_append() helps in listing the set of processes in the system.
Output
Our code will produce the following output −
In this chapter, we will focus on investigating the volatile memory with the help of Volatility, a Python-based forensics framework applicable on the following platforms: Android and Linux.
Volatile Memory
Volatile memory is a type of storage where the contents get erased when the system's power is turned off or interrupted. RAM is the best example of a volatile memory. It means, if you were working on a document that has not been saved to a non-volatile memory, such as a hard drive, and the computer lost power, then all the data will be lost.
In general, volatile memory forensics follow the same pattern as other forensic investigations −
- Selecting the target of the investigation
- Acquiring forensic data
- Forensic analysis
The basic volatility plugins which are used for Android gathers RAM dump for analysis. Once the RAM dump is gathered for analysis, it is important to start hunting for malware in RAM.
YARA Rules
YARA is a popular tool which provides a robust language, is compatible with Perl-based Regular Expressions, and is used to examine the suspected files/directories and match strings.
In this section, we will use YARA based on the pattern matching implementation and combine them with utility power. The complete process will be beneficial for forensic analysis.
Example
Consider the following code. This code helps in extracting the code.
import operator
import os
import sys
sys.path.insert(0, os.getcwd())
import plyara.interp as interp
# Plyara is a script that lexes and parses a file consisting of one more Yara
# rules into a python dictionary representation.
if __name__ == '__main__':
file_to_analyze = sys.argv[1]
rulesDict = interp.parseString(open(file_to_analyze).read())
authors = {}
imps = {}
meta_keys = {}
max_strings = []
max_string_len = 0
tags = {}
rule_count = 0
for rule in rulesDict:
rule_count += 1
# Imports
if 'imports' in rule:
for imp in rule['imports']:
imp = imp.replace('"','')
if imp in imps:
imps[imp] += 1
else:
imps[imp] = 1
# Tags
if 'tags' in rule:
for tag in rule['tags']:
if tag in tags:
tags[tag] += 1
else:
tags[tag] = 1
# Metadata
if 'metadata' in rule:
for key in rule['metadata']:
if key in meta_keys:
meta_keys[key] += 1
else:
meta_keys[key] = 1
if key in ['Author', 'author']:
if rule['metadata'][key] in authors:
authors[rule['metadata'][key]] += 1
else:
authors[rule['metadata'][key]] = 1
#Strings
if 'strings' in rule:
for strr in rule['strings']:
if len(strr['value']) > max_string_len:
max_string_len = len(strr['value'])
max_strings = [(rule['rule_name'], strr['name'], strr['value'])]
elif len(strr['value']) == max_string_len:
max_strings.append((rule['rule_name'], strr['key'], strr['value']))
print("\nThe number of rules implemented" + str(rule_count))
ordered_meta_keys = sorted(meta_keys.items(), key = operator.itemgetter(1),
reverse = True)
ordered_authors = sorted(authors.items(), key = operator.itemgetter(1),
reverse = True)
ordered_imps = sorted(imps.items(), key = operator.itemgetter(1), reverse = True)
ordered_tags = sorted(tags.items(), key = operator.itemgetter(1), reverse = True)The above code will produce the following output.
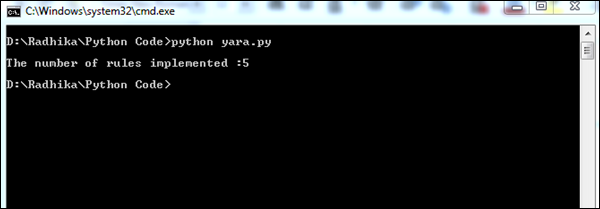
The number of YARA rules implemented helps in giving a better picture of the suspected files. Indirectly, the list of suspected files help in gathering appropriate information for forensics.
Following is the source code in github: https://github.com/radhikascs/Python_yara
The major concern of digital investigations is to secure important evidences or data with encryption or any other format. The basic example is storing the passwords. It is therefore necessary to understand the usage of Linux operating system for digital forensic implementation to secure these valuable data.
Information for all the local users are mostly stored in the following two files −
- /etc/passwd
- etc/shadow
The first one is mandatory, which stores all the passwords. The second file is optional and it stores information about the local users including the hashed passwords.
Issues arise regarding the security issue of storing the password information in a file, which is readable by every user. Therefore, hashed passwords are stored in /etc/passwd, where the content is replaced by a special value "x".
The corresponding hashes have to be looked up in /etc/shadow. The settings in /etc/passwd may override the details in /etc/shadow.
Both the text files in Linux include one entry per line and the entry consists of multiple fields, separated by colons.
The format of /etc/passwd is as follows −
| Sr.No. | Field Name & Description |
|---|---|
| 1 | Username This field consists of the attributes of human-readable format |
| 2 | Password hash It consists of the password in an encoded form according to the Posix crypt function |
If the hash password is saved as empty, then the corresponding user will not require any password to log into the system. If this field contains a value that cannot be generated by the hash algorithm, such as an exclamation mark, then the user cannot log on using a password.
A user with a locked password can still log on using other authentication mechanisms, for example, SSH keys. As mentioned earlier, the special value "x" means that the password hash has to be found in the shadow file.
The password hash includes the following −
Encrypted salt − The encrypted salt helps maintain the screen locks, pins, and passwords.
Numerical user ID − This field denotes the ID of the user. The Linux kernel assigns this user ID to the system.
Numerical group ID − This field refers to the primary group of the user.
Home directory − The new processes are started with a reference of this directory.
Command shell − This optional field denotes the default shell that is to be started after a successful login to the system.
Digital forensics include collecting the information which is relevant to tracking an evidence. Hence, the user ids are useful in maintaining the records.
Using Python, all of this information can be automatically analyzed for the Indicators of Analysis, reconstructing the recent system activity. Tracking is simple and easy with the implementation of Linux Shell.
Python Programming with Linux
Example
import sys
import hashlib
import getpass
def main(argv):
print '\nUser & Password Storage Program in Linux for forensic detection v.01\n'
if raw_input('The file ' + sys.argv[1] + ' will be erased or overwrite if
it exists .\nDo you wish to continue (Y/n): ') not in ('Y','y') :
sys.exit('\nChanges were not recorded\n')
user_name = raw_input('Please Enter a User Name: ')
password = hashlib.sha224(getpass.getpass('Please Enter a Password:')).hexdigest()
# Passwords which are hashed
try:
file_conn = open(sys.argv[1],'w')
file_conn.write(user_name + '\n')
file_conn.write(password + '\n')
file_conn.close()
except:
sys.exit('There was a problem writing the passwords to file!')
if __name__ == "__main__":
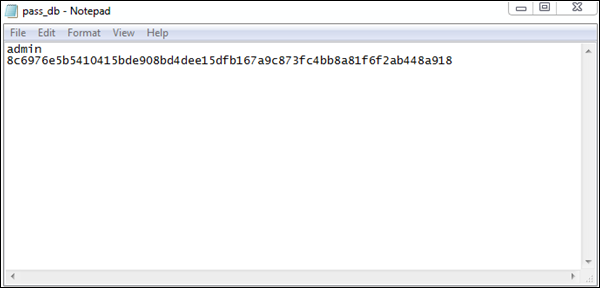
main(sys.argv[1:])Output
The password is stored in a hexadecimal format in pass_db.txt as shown in the following screenshot. The text files are saved for further use in computational forensics.
Indicators of Compromise (IOC) is defined as "pieces of forensic data, which includes data found in system log entries or files, that identify potentially malicious activity on a system or network."
By monitoring for IOC, organizations can detect attacks and act quickly to prevent such breaches from occurring or limit damages by stopping attacks in earlier stages.
There are some use-cases, which allow querying the forensic artifacts such as −
- Recherche d'un fichier spécifique par MD5
- Recherche d'une entité spécifique, qui est en fait stockée dans la mémoire
- Entrée spécifique ou ensemble d'entrées, qui est stocké dans le registre Windows
La combinaison de tout ce qui précède donne de meilleurs résultats dans la recherche d'artefacts. Comme mentionné ci-dessus, le registre Windows offre une plate-forme parfaite pour générer et maintenir IOC, ce qui aide directement à l'investigation informatique.
Méthodologie
Recherchez les emplacements dans le système de fichiers et spécifiquement pour l'instant dans le registre Windows.
Recherchez l'ensemble des artefacts, qui ont été conçus par des outils médico-légaux.
Recherchez les signes de toute activité indésirable.
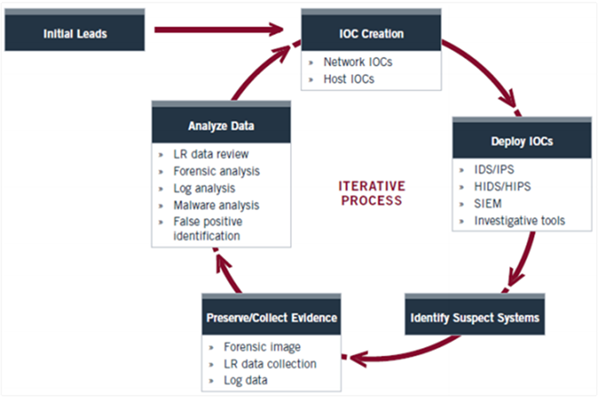
Cycle de vie d'enquête
Investigative Life Cycle suit IOC et recherche des entrées spécifiques dans un registre.
Stage 1: Initial Evidence- La preuve de la compromission est détectée sur un hôte ou sur le réseau. Les intervenants étudieront et identifieront la solution exacte, qui est un indicateur médico-légal concret.
Stage 2: Create IOCs for Host & Network- Suite aux données collectées, le CIO est créé, ce qui est facilement possible avec le registre Windows. La flexibilité d'OpenIOC donne un nombre illimité de permutations sur la façon dont un indicateur peut être conçu.
Stage 3: Deploy IOCs in the Enterprise - Une fois le CIO spécifié créé, l'enquêteur déploiera ces technologies à l'aide de l'API dans les registres Windows.
Stage 4: Identification of Suspects- Le déploiement de l'IOC aide à l'identification des suspects de manière normale. Même des systèmes supplémentaires seront identifiés.
Stage 5: Collect and Analyze Evidence - Les preuves contre les suspects sont rassemblées et analysées en conséquence.
Stage 6: Refine & Create New IOCs - L'équipe d'enquête peut créer de nouveaux CIO en fonction de leurs preuves et données trouvées dans l'entreprise et de renseignements supplémentaires, et continuer à affiner leur cycle.
L'illustration suivante montre les phases du cycle de vie d'enquête -
Cloud computingpeut être défini comme un ensemble de services hébergés fournis aux utilisateurs sur Internet. Il permet aux organisations de consommer ou même de calculer la ressource, qui comprend des machines virtuelles (VM), du stockage ou une application en tant qu'utilitaire.
L'un des avantages les plus importants de la création d'applications en langage de programmation Python est qu'il inclut la possibilité de déployer des applications virtuellement sur n'importe quelle plate-forme, ce qui inclut cloudainsi que. Cela implique que Python peut être exécuté sur des serveurs cloud et peut également être lancé sur des appareils pratiques tels qu'un ordinateur de bureau, une tablette ou un smartphone.
L'une des perspectives intéressantes est la création d'une base cloud avec la génération de Rainbow tables. Il aide à intégrer des versions mono et multitraitement de l'application, ce qui nécessite quelques considérations.
Nuage Pi
Pi Cloud est la plate-forme de cloud computing, qui intègre le langage de programmation Python à la puissance de calcul d'Amazon Web Services.
Jetons un coup d'œil à un exemple d'implémentation de nuages Pi avec rainbow tables.
Tables arc-en-ciel
UNE rainbow table est défini comme une liste de toutes les permutations possibles en texte brut de mots de passe chiffrés spécifiques à un algorithme de hachage donné.
Les tables arc-en-ciel suivent un modèle standard, qui crée une liste de mots de passe hachés.
Un fichier texte est utilisé pour générer des mots de passe, qui incluent des caractères ou du texte brut des mots de passe à chiffrer.
Le fichier est utilisé par Pi cloud, qui appelle la fonction principale à stocker.
La sortie des mots de passe hachés est également stockée dans le fichier texte.
Cet algorithme peut également être utilisé pour enregistrer les mots de passe dans la base de données et disposer d'un stockage de sauvegarde dans le système cloud.
Le programme intégré suivant crée une liste de mots de passe chiffrés dans un fichier texte.
Exemple
import os
import random
import hashlib
import string
import enchant #Rainbow tables with enchant
import cloud #importing pi-cloud
def randomword(length):
return ''.join(random.choice(string.lowercase) for i in range(length))
print('Author- Radhika Subramanian')
def mainroutine():
engdict = enchant.Dict("en_US")
fileb = open("password.txt","a+")
# Capture the values from the text file named password
while True:
randomword0 = randomword(6)
if engdict.check(randomword0) == True:
randomkey0 = randomword0+str(random.randint(0,99))
elif engdict.check(randomword0) == False:
englist = engdict.suggest(randomword0)
if len(englist) > 0:
randomkey0 = englist[0]+str(random.randint(0,99))
else:
randomkey0 = randomword0+str(random.randint(0,99))
randomword3 = randomword(5)
if engdict.check(randomword3) == True:
randomkey3 = randomword3+str(random.randint(0,99))
elif engdict.check(randomword3) == False:
englist = engdict.suggest(randomword3)
if len(englist) > 0:
randomkey3 = englist[0]+str(random.randint(0,99))
else:
randomkey3 = randomword3+str(random.randint(0,99))
if 'randomkey0' and 'randomkey3' and 'randomkey1' in locals():
whasher0 = hashlib.new("md5")
whasher0.update(randomkey0)
whasher3 = hashlib.new("md5")
whasher3.update(randomkey3)
whasher1 = hashlib.new("md5")
whasher1.update(randomkey1)
print(randomkey0+" + "+str(whasher0.hexdigest())+"\n")
print(randomkey3+" + "+str(whasher3.hexdigest())+"\n")
print(randomkey1+" + "+str(whasher1.hexdigest())+"\n")
fileb.write(randomkey0+" + "+str(whasher0.hexdigest())+"\n")
fileb.write(randomkey3+" + "+str(whasher3.hexdigest())+"\n")
fileb.write(randomkey1+" + "+str(whasher1.hexdigest())+"\n")
jid = cloud.call(randomword) #square(3) evaluated on PiCloud
cloud.result(jid)
print('Value added to cloud')
print('Password added')
mainroutine()Production
Ce code produira la sortie suivante -

Les mots de passe sont stockés dans les fichiers texte, qui sont visibles, comme illustré dans la capture d'écran suivante.
