Talend - Réduire la carte
Dans le chapitre précédent, nous avons vu comment Talend fonctionne avec le Big Data. Dans ce chapitre, voyons comment utiliser map Reduce avec Talend.
Créer un Job Talend MapReduce
Apprenons à exécuter un job MapReduce sur Talend. Ici, nous allons exécuter un exemple de décompte de mots MapReduce.
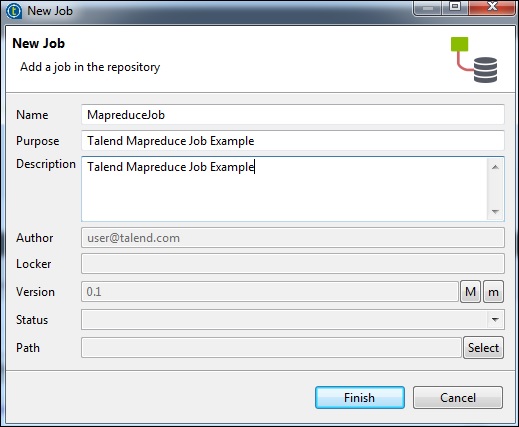
Pour cela, cliquez avec le bouton droit sur Job Design et créez un nouveau job - MapreduceJob. Mentionnez les détails du travail et cliquez sur Terminer.
Ajout de composants à une tâche MapReduce
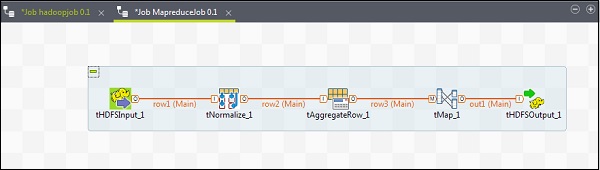
Pour ajouter des composants à un job MapReduce, faites glisser et déposez cinq composants de Talend - tHDFSInput, tNormalize, tAggregateRow, tMap, tOutput de la palette vers la fenêtre du concepteur. Faites un clic droit sur le tHDFSInput et créez le lien principal vers le tNormalize.
Faites un clic droit sur le tNormalize et créez le lien principal vers le tAggregateRow. Ensuite, faites un clic droit sur le tAggregateRow et créez le lien principal vers le tMap. Maintenant, faites un clic droit sur le tMap et créez le lien principal vers le tHDFSOutput.
Configuration des composants et des transformations
Dans le tHDFSInput, sélectionnez la distribution cloudera et sa version. Notez que l'URI Namenode doit être «hdfs: //quickstart.cloudera: 8020» et le nom d'utilisateur doit être «cloudera». Dans l'option de nom de fichier, indiquez le chemin de votre fichier d'entrée vers le travail MapReduce. Assurez-vous que ce fichier d'entrée est présent sur HDFS.
Maintenant, sélectionnez le type de fichier, le séparateur de ligne, le séparateur de fichiers et l'en-tête en fonction de votre fichier d'entrée.
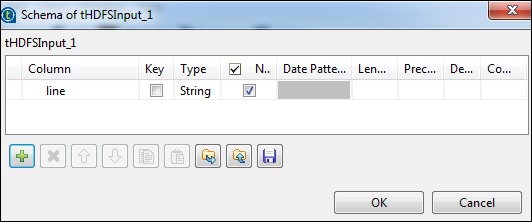
Cliquez sur modifier le schéma et ajoutez le champ «ligne» comme type de chaîne.
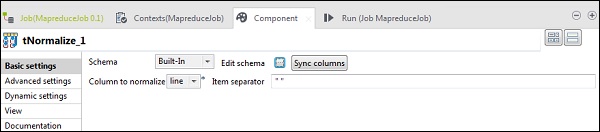
Dans le tNomalize, la colonne à normaliser sera line et le séparateur d'élément sera un espace -> ““. Maintenant, cliquez sur modifier le schéma. Le tNormalize aura une colonne de ligne et le tAggregateRow aura 2 colonnes word et wordcount comme indiqué ci-dessous.
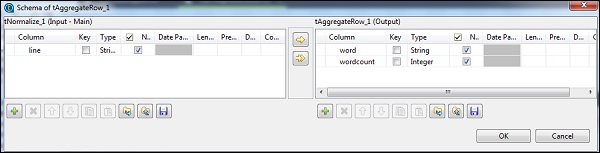
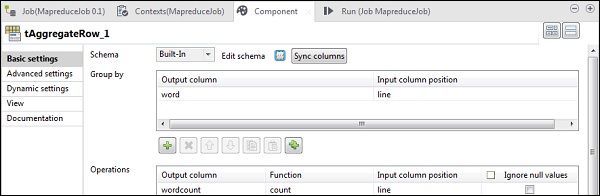
Dans le tAggregateRow, placez le mot comme colonne de sortie dans l'option Group by. Dans les opérations, placez wordcount comme colonne de sortie, fonction comme nombre et position de colonne d'entrée comme ligne.
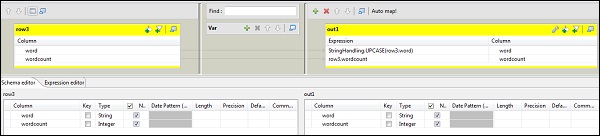
Maintenant, double-cliquez sur le composant tMap pour entrer dans l'éditeur de carte et mapper l'entrée avec la sortie requise. Dans cet exemple, le mot est mappé avec word et wordcount est mappé avec wordcount. Dans la colonne d'expression, cliquez sur […] pour entrer dans le générateur d'expression.
Maintenant, sélectionnez StringHandling dans la liste des catégories et la fonction UPCASE. Modifiez l'expression en «StringHandling.UPCASE (row3.word)» et cliquez sur OK. Conservez row3.wordcount dans la colonne d'expression correspondant à wordcount comme indiqué ci-dessous.
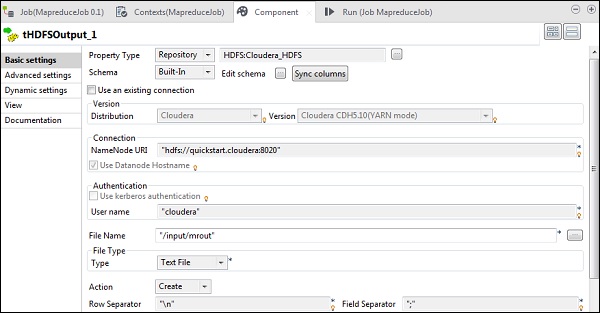
Dans le tHDFSOutput, connectez-vous au cluster Hadoop que nous avons créé à partir du type de propriété en tant que référentiel. Observez que les champs seront remplis automatiquement. Dans Nom du fichier, indiquez le chemin de sortie où vous souhaitez stocker la sortie. Conservez l'action, le séparateur de ligne et le séparateur de champ comme indiqué ci-dessous.
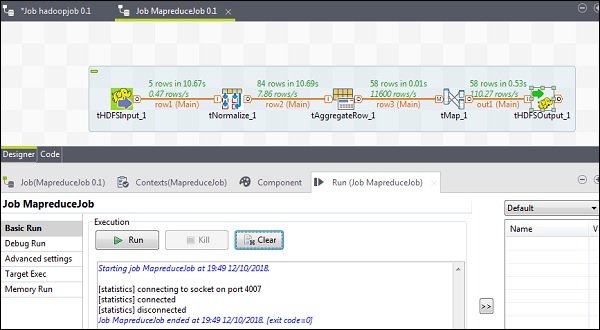
Exécution du travail MapReduce
Une fois votre configuration terminée, cliquez sur Exécuter et exécutez votre tâche MapReduce.
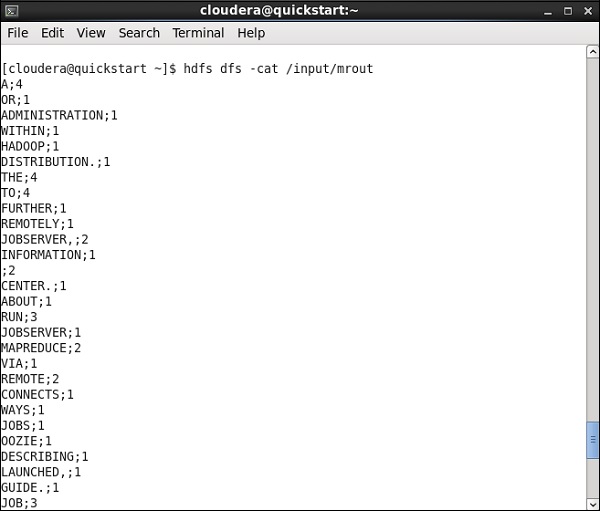
Accédez à votre chemin HDFS et vérifiez la sortie. Notez que tous les mots seront en majuscules avec leur nombre de mots.