Talend - Guide rapide
Talend est une plateforme d'intégration logicielle qui fournit des solutions pour l'intégration des données, la qualité des données, la gestion des données, la préparation des données et le Big Data. La demande de professionnels ETL ayant des connaissances sur Talend est élevée. En outre, c'est le seul outil ETL avec tous les plugins pour s'intégrer facilement à l'écosystème Big Data.
Selon Gartner, Talend se situe dans le quadrant magique des Leaders pour les outils d'intégration de données.
Talend propose différents produits commerciaux listés ci-dessous -
- Qualité des données Talend
- Intégration de données Talend
- Préparation des données Talend
- Cloud Talend
- Talend Big Data
- Plateforme Talend MDM (Master Data Management)
- Plateforme Talend Data Services
- Talend Metadata Manager
- Talend Data Fabric
Talend propose également Open Studio, un outil gratuit open source largement utilisé pour l'intégration de données et le Big Data.
Voici la configuration système requise pour télécharger et travailler sur Talend Open Studio -
Système d'exploitation recommandé
- Microsoft Windows 10
- Ubuntu 16.04 LTS
- Apple macOS 10.13 / High Sierra
Mémoire nécessaire
- Mémoire - Minimum 4 Go, recommandé 8 Go
- Espace de stockage - 30 Go
En outre, vous avez également besoin d'un cluster Hadoop opérationnel (de préférence Cloudera.
Note - Java 8 doit être disponible avec des variables d'environnement déjà définies.
Pour télécharger Talend Open Studio for Big Data et l'intégration de données, veuillez suivre les étapes ci-dessous -
Step 1 - Aller à la page: https://www.talend.com/products/big-data/big-data-open-studio/et cliquez sur le bouton de téléchargement. Vous pouvez voir que le téléchargement du fichier TOS_BD_xxxxxxx.zip démarre.
Step 2 - Une fois le téléchargement terminé, extrayez le contenu du fichier zip, il créera un dossier contenant tous les fichiers Talend.
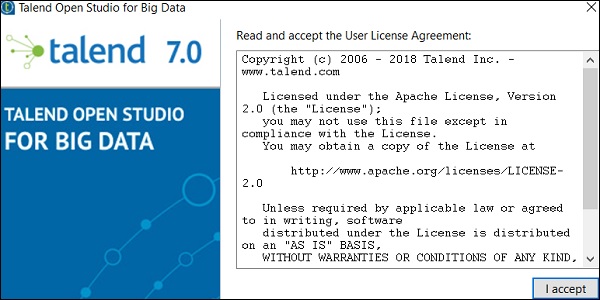
Step 3- Ouvrez le dossier Talend et double-cliquez sur le fichier exécutable: TOS_BD-win-x86_64.exe. Acceptez le contrat de licence utilisateur.
Step 4 - Créez un nouveau projet et cliquez sur Terminer.
Step 5 - Cliquez sur Autoriser l'accès au cas où vous obtenez une alerte de sécurité Windows.
Step 6 - La page d'accueil de Talend Open Studio va maintenant s'ouvrir.
Step 7 - Cliquez sur Terminer pour installer les bibliothèques tierces requises.
Step 8 - Acceptez les conditions et cliquez sur Terminer.
Step 9 - Cliquez sur Oui.
Votre Talend Open Studio est maintenant prêt avec les bibliothèques nécessaires.
Talend Open Studio est un outil ETL open source gratuit pour l'intégration de données et le Big Data. C'est un outil de développement basé sur Eclipse et un concepteur de tâches. Il vous suffit de glisser-déposer des composants et de les connecter pour créer et exécuter des travaux ETL ou ETL. L'outil crée automatiquement le code Java du travail et vous n'avez pas besoin d'écrire une seule ligne de code.
Il existe plusieurs options pour se connecter à des sources de données telles que le SGBDR, Excel, l'écosystème SaaS Big Data, ainsi que des applications et des technologies telles que SAP, CRM, Dropbox et bien d'autres.
Voici quelques avantages importants offerts par Talend Open Studio:
Fournit toutes les fonctionnalités nécessaires à l'intégration et à la synchronisation des données avec 900 composants, des connecteurs intégrés, la conversion automatique des travaux en code Java et bien plus encore.
L'outil est entièrement gratuit, d'où de grosses économies.
Au cours des 12 dernières années, plusieurs organisations géantes ont adopté TOS pour l'intégration de données, ce qui montre un facteur de confiance très élevé dans cet outil.
La communauté Talend pour l'intégration de données est très active.
Talend continue d'ajouter des fonctionnalités à ces outils et les documentations sont bien structurées et très faciles à suivre.
La plupart des organisations obtiennent des données de plusieurs endroits et les stockent séparément. Maintenant, si l'organisation doit prendre des décisions, elle doit prendre des données provenant de différentes sources, les mettre dans une vue unifiée, puis les analyser pour obtenir un résultat. Ce processus est appelé intégration de données.
Avantages
L'intégration de données offre de nombreux avantages décrits ci-dessous -
Améliore la collaboration entre les différentes équipes de l'organisation qui tentent d'accéder aux données de l'organisation.
Gain de temps et facilite l'analyse des données, car les données sont intégrées efficacement.
Le processus automatisé d'intégration des données synchronise les données et facilite les rapports en temps réel et périodiques, qui autrement prend du temps s'ils sont effectués manuellement.
Les données qui sont intégrées à partir de plusieurs sources mûrissent et s'améliorent avec le temps, ce qui contribue finalement à une meilleure qualité des données.
Travailler avec des projets
Dans cette section, voyons comment travailler sur des projets Talend -
Créer un projet
Double-cliquez sur le fichier exécutable TOS Big Data, la fenêtre ci-dessous s'ouvrira.
Sélectionnez l'option Créer un nouveau projet, mentionnez le nom du projet et cliquez sur Créer.

Sélectionnez le projet que vous avez créé et cliquez sur Terminer.

Importer un projet
Double-cliquez sur le fichier exécutable TOS Big Data, vous pouvez voir la fenêtre ci-dessous. Sélectionnez l'option Importer un projet de démonstration et cliquez sur Sélectionner.

Vous pouvez choisir parmi les options ci-dessous. Ici, nous choisissons des démos d'intégration de données. Maintenant, cliquez sur Terminer.

Maintenant, donnez le nom et la description du projet. Cliquez sur Terminer.

Vous pouvez voir votre projet importé dans la liste des projets existants.
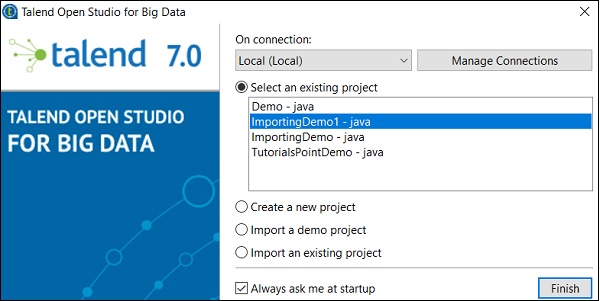
Voyons maintenant comment importer un projet Talend existant.
Sélectionnez l'option Importer un projet existant et cliquez sur Sélectionner.

Donnez le nom du projet et sélectionnez l'option «Sélectionner le répertoire racine».

Parcourez le répertoire de base de votre projet Talend existant et cliquez sur Terminer.

Votre projet Talend existant sera importé.
Ouverture d'un projet
Sélectionnez un projet dans un projet existant et cliquez sur Terminer. Cela ouvrira ce projet Talend.

Supprimer un projet
Pour supprimer un projet, cliquez sur Gérer les connexions.

Cliquez sur Supprimer le (s) projet (s) existant (s)

Sélectionnez le projet que vous souhaitez supprimer et cliquez sur OK.
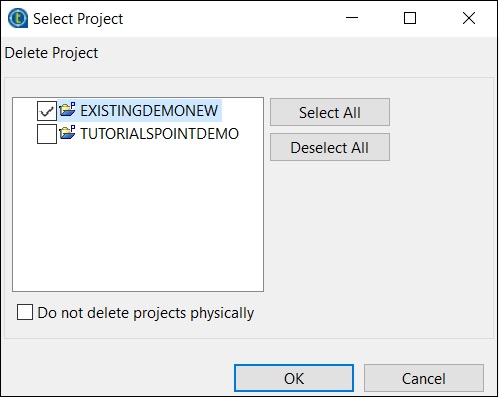
Cliquez à nouveau sur OK.
Exporter un projet
Cliquez sur l'option Exporter le projet.

Sélectionnez le projet que vous souhaitez exporter et indiquez un chemin vers l'endroit où il doit être exporté. Cliquez sur Terminer.

Business Model est une représentation graphique d'un projet d'intégration de données. Il s'agit d'une représentation non technique du flux de travail de l'entreprise.
Pourquoi avez-vous besoin d'un modèle d'entreprise?
Un modèle d'entreprise est conçu pour montrer à la haute direction ce que vous faites et il permet également à votre équipe de comprendre ce que vous essayez d'accomplir. La conception d'un modèle d'entreprise est considérée comme l'une des meilleures pratiques que les organisations adoptent au début de leur projet d'intégration de données. En outre, en aidant à réduire les coûts, il trouve et résout les goulots d'étranglement dans votre projet. Le modèle peut être modifié pendant et après la mise en œuvre du projet, si nécessaire.
Créer un Business Model dans Talend Open Studio
Talend open studio fournit plusieurs formes et connecteurs pour créer et concevoir un modèle commercial. Chaque module d'un modèle d'entreprise peut avoir une documentation attachée à lui-même.
Talend Open Studio propose les formes et options de connecteurs suivantes pour créer un modèle commercial -
Decision - Cette forme est utilisée pour mettre la condition if dans le modèle.
Action - Cette forme est utilisée pour montrer toute transformation, traduction ou mise en forme.
Terminal - Cette forme montre le type de borne de sortie.
Data - Cette forme est utilisée pour afficher le type de données.
Document - Cette forme est utilisée pour insérer un objet document qui peut être utilisé pour l'entrée / sortie des données traitées.
Input - Cette forme est utilisée pour insérer un objet d'entrée à l'aide duquel l'utilisateur peut transmettre les données manuellement.
List - Cette forme contient les données extraites et peut être définie pour ne contenir que certains types de données dans la liste.
Database - Cette forme est utilisée pour contenir les données d'entrée / sortie.
Actor - Cette forme symbolise les individus impliqués dans la prise de décision et les processus techniques
Ellipse - Insère une forme Ellipse.
Gear - Cette forme montre les programmes manuels qui doivent être remplacés par des jobs Talend.
Toutes les opérations dans Talend sont effectuées par des connecteurs et des composants. Talend propose plus de 800 connecteurs et composants pour effectuer plusieurs opérations. Ces composants sont présents dans la palette, et il existe 21 catégories principales auxquelles appartiennent les composants. Vous pouvez choisir les connecteurs et simplement les glisser-déposer dans le volet du concepteur, cela créera automatiquement du code java qui sera compilé lorsque vous sauvegarderez le code Talend.
Les principales catégories qui contiennent des composants sont indiquées ci-dessous -
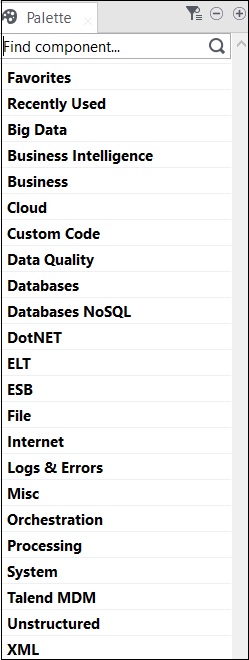
Voici la liste des connecteurs et composants largement utilisés pour l'intégration de données dans Talend Open Studio -
tMysqlConnection - Se connecte à la base de données MySQL définie dans le composant.
tMysqlInput - Exécute une requête de base de données pour lire une base de données et extraire des champs (tables, vues, etc.) en fonction de la requête.
tMysqlOutput - Utilisé pour écrire, mettre à jour, modifier des données dans une base de données MySQL.
tFileInputDelimited - Lit un fichier délimité ligne par ligne et les divise en champs séparés et le transmet au composant suivant.
tFileInputExcel - Lit un fichier Excel ligne par ligne et le divise en champs séparés et le transmet au composant suivant.
tFileList - Obtient tous les fichiers et répertoires à partir d'un modèle de masque de fichier donné.
tFileArchive - Compresse un ensemble de fichiers ou de dossiers dans un fichier d'archive zip, gzip ou tar.gz.
tRowGenerator - Fournit un éditeur dans lequel vous pouvez écrire des fonctions ou choisir des expressions pour générer vos exemples de données.
tMsgBox - Renvoie une boîte de dialogue avec le message spécifié et un bouton OK.
tLogRow- Surveille les données traitées. Il affiche les données / la sortie dans la console d'exécution.
tPreJob - Définit les sous-travaux qui seront exécutés avant le début de votre travail réel.
tMap- Agit comme un plugin dans le studio Talend. Il prend les données d'une ou plusieurs sources, les transforme, puis envoie les données transformées vers une ou plusieurs destinations.
tJoin - Joint 2 tables en effectuant des jointures internes et externes entre le flux principal et le flux de recherche.
tJava - Vous permet d'utiliser du code java personnalisé dans le programme Talend.
tRunJob - Gère les systèmes de jobs complexes en exécutant un job Talend après l'autre.
Il s'agit de la mise en œuvre technique / représentation graphique du modèle commercial. Dans cette conception, un ou plusieurs composants sont connectés les uns aux autres pour exécuter un processus d'intégration de données. Ainsi, lorsque vous faites glisser et déposez des composants dans le volet de conception et que vous vous connectez ensuite avec des connecteurs, une conception de travail convertit tout en code et crée un programme exécutable complet qui forme le flux de données.
Créer un travail
Dans la fenêtre du référentiel, cliquez avec le bouton droit de la souris sur Job Design et cliquez sur Create Job.
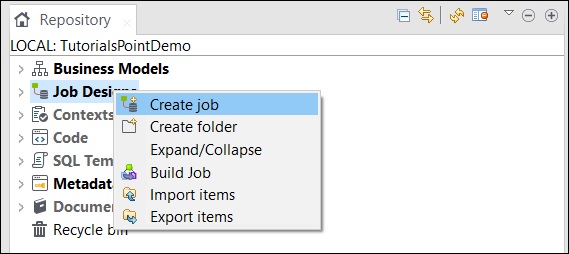
Fournissez le nom, le but et la description du travail et cliquez sur Terminer.
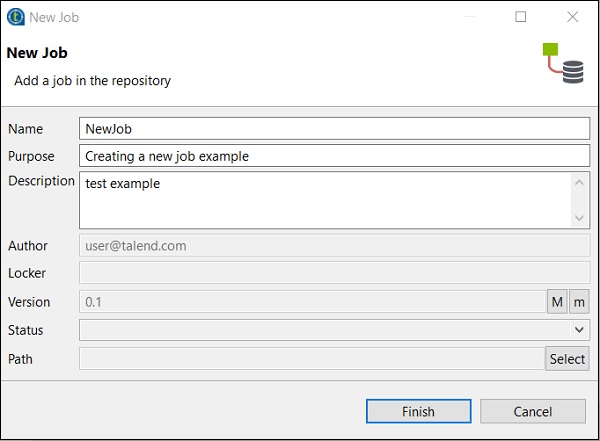
Vous pouvez voir que votre travail a été créé sous Job Design.
Maintenant, utilisons ce travail pour ajouter des composants, les connecter et les configurer. Ici, nous prendrons un fichier Excel comme entrée et produirons un fichier Excel comme sortie avec les mêmes données.
Ajout de composants à un travail
Il existe plusieurs composants dans la palette à choisir. Il existe également une option de recherche dans laquelle vous pouvez entrer le nom du composant pour le sélectionner.
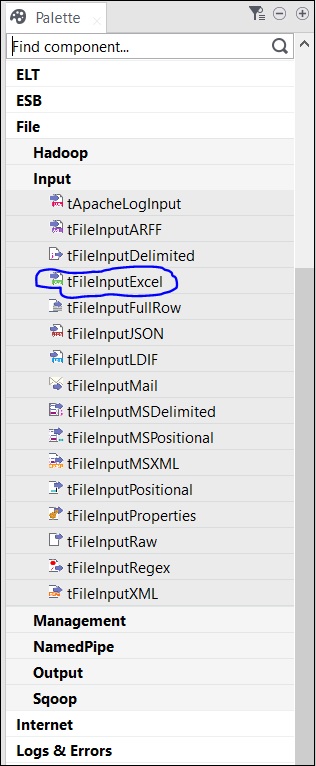
Puisque, ici, nous prenons un fichier Excel comme entrée, nous allons faire glisser et déposer le composant tFileInputExcel de la palette vers la fenêtre Designer.

Maintenant, si vous cliquez n'importe où dans la fenêtre du concepteur, une zone de recherche apparaîtra. Trouvez le tLogRow et sélectionnez-le pour l'amener dans la fenêtre du concepteur.

Enfin, sélectionnez le composant tFileOutputExcel dans la palette et faites-le glisser dans la fenêtre du concepteur.
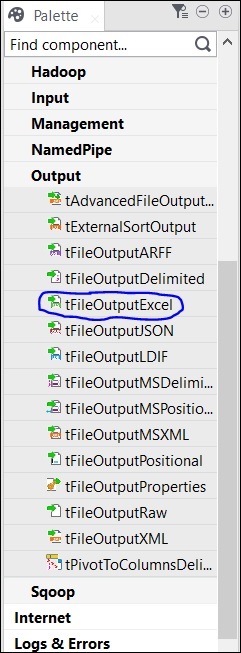
Maintenant, l'ajout des composants est terminé.
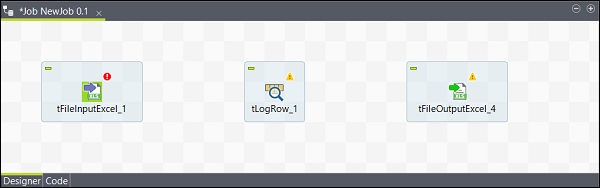
Connexion des composants
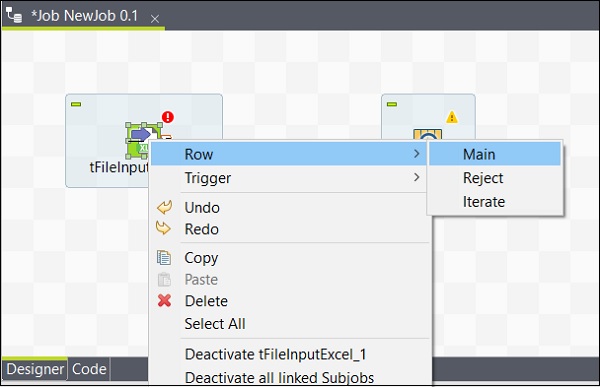
Après avoir ajouté des composants, vous devez les connecter. Cliquez avec le bouton droit sur le premier composant tFileInputExcel et tracez une ligne principale vers le tLogRow comme indiqué ci-dessous.
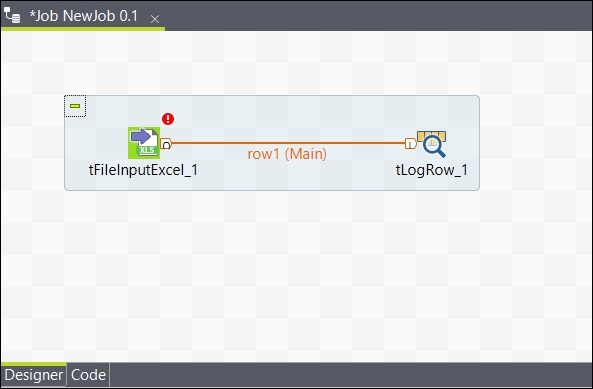
De même, faites un clic droit sur le tLogRow et tracez une ligne principale sur le tFileOutputExcel. Maintenant, vos composants sont connectés.
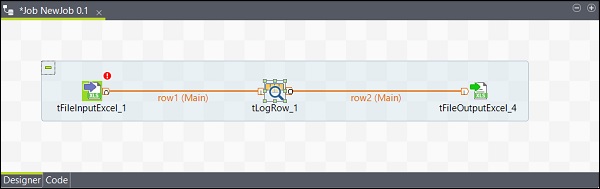
Configurer les composants
Après avoir ajouté et connecté les composants dans le travail, vous devez les configurer. Pour cela, double-cliquez sur le premier composant tFileInputExcel pour le configurer. Donnez le chemin de votre fichier d'entrée dans Nom de fichier / flux comme indiqué ci-dessous.
Si votre 1ère ligne dans Excel contient les noms de colonne, mettez 1 dans l'option En-tête.
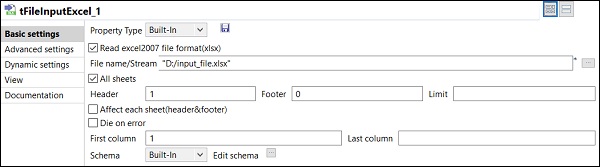
Cliquez sur Modifier le schéma et ajoutez les colonnes et son type en fonction de votre fichier Excel d'entrée. Cliquez sur OK après avoir ajouté le schéma.
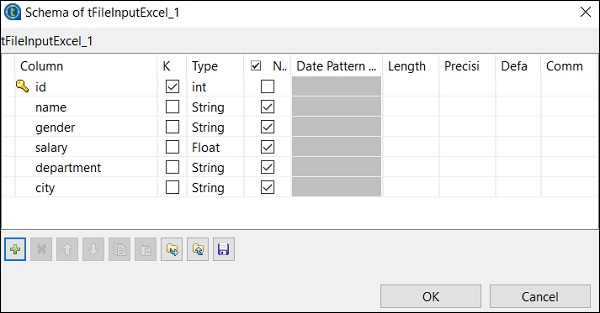
Cliquez sur Oui.
Dans le composant tLogRow, cliquez sur synchroniser les colonnes et sélectionnez le mode dans lequel vous souhaitez générer les lignes à partir de votre entrée. Ici, nous avons sélectionné le mode de base avec «,» comme séparateur de champ.
Enfin, dans le composant tFileOutputExcel, indiquez le chemin du nom du fichier où vous souhaitez stocker
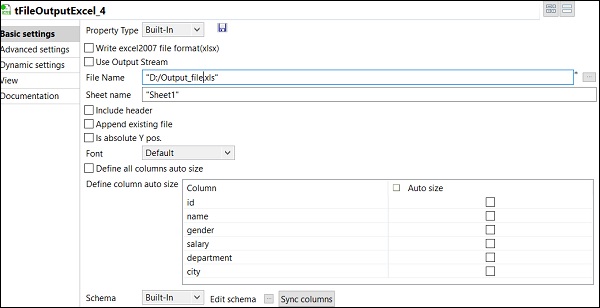
votre fichier Excel de sortie avec le nom de la feuille. Click on sync columns.
Exécution du travail
Une fois que vous avez terminé d'ajouter, de connecter et de configurer vos composants, vous êtes prêt à exécuter votre job Talend. Cliquez sur le bouton Exécuter pour commencer l'exécution.

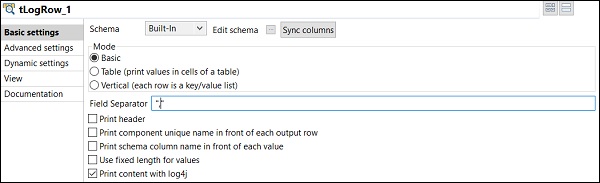
Vous verrez la sortie en mode de base avec le séparateur «,».
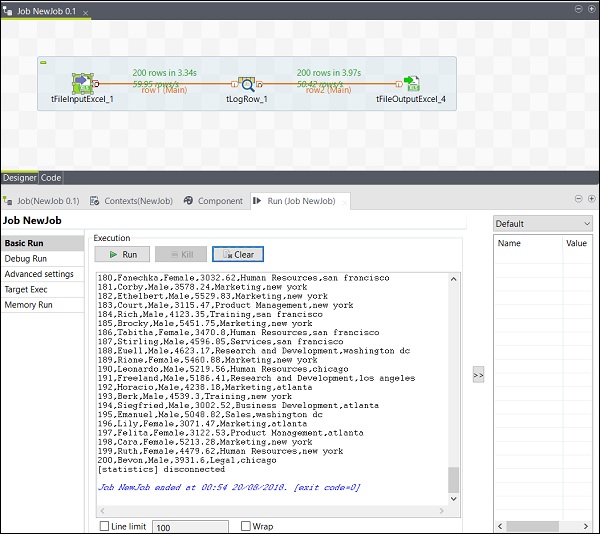
Vous pouvez également voir que votre sortie est enregistrée en tant que fichier Excel dans le chemin de sortie que vous avez mentionné.
Les métadonnées désignent essentiellement des données sur les données. Il raconte quoi, quand, pourquoi, qui, où, lesquels et comment des données. Dans Talend, les métadonnées contiennent toutes les informations sur les données présentes dans Talend studio. L'option metadata est présente dans le volet Repository de Talend Open Studio.
Diverses sources telles que DB Connections, différents types de fichiers, LDAP, Azure, Salesforce, Web Services FTP, Hadoop Cluster et bien d'autres options sont présentes sous Talend Metadata.
L'utilisation principale des métadonnées dans Talend Open Studio est que vous pouvez utiliser ces sources de données dans plusieurs jobs simplement par un simple glisser-déposer depuis le panneau Métadonnées dans le référentiel.
Les variables de contexte sont les variables qui peuvent avoir différentes valeurs dans différents environnements. Vous pouvez créer un groupe de contexte pouvant contenir plusieurs variables de contexte. Vous n'avez pas besoin d'ajouter chaque variable de contexte une par une à un travail, vous pouvez simplement ajouter le groupe de contexte au travail.
Ces variables sont utilisées pour préparer la production de code. Cela signifie qu'en utilisant des variables de contexte, vous pouvez déplacer le code dans des environnements de développement, de test ou de production, il fonctionnera dans tous les environnements.
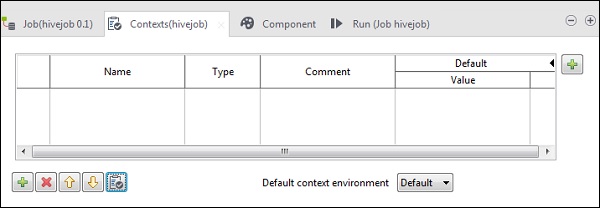
Dans n'importe quel travail, vous pouvez accéder à l'onglet Contextes comme indiqué ci-dessous et ajouter des variables de contexte.
Dans ce chapitre, examinons la gestion des jobs et les fonctionnalités correspondantes incluses dans Talend.
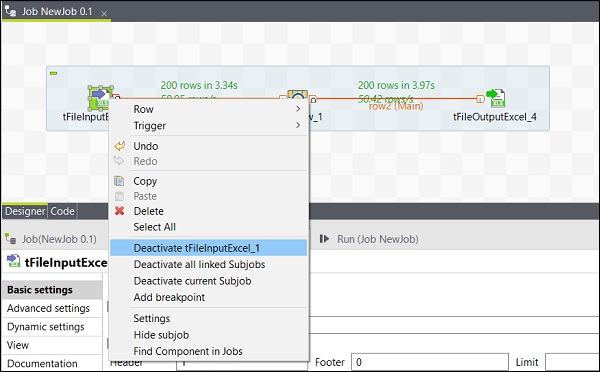
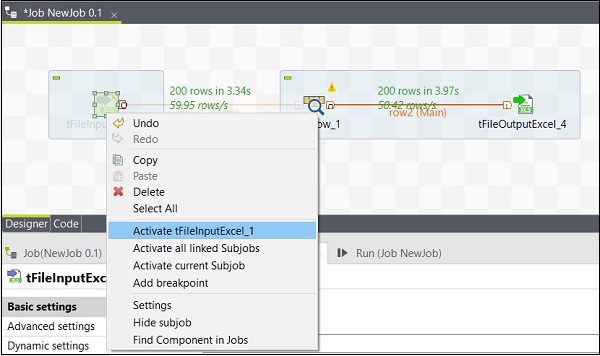
Activation / Désactivation d'un composant
L'activation / la désactivation d'un composant est très simple. Il vous suffit de sélectionner le composant, de faire un clic droit dessus et de choisir l'option désactiver ou activer ce composant.
Importation / exportation d'articles et de travaux de construction
Pour exporter l'élément du travail, cliquez avec le bouton droit sur le travail dans les conceptions du travail et cliquez sur Exporter les éléments.
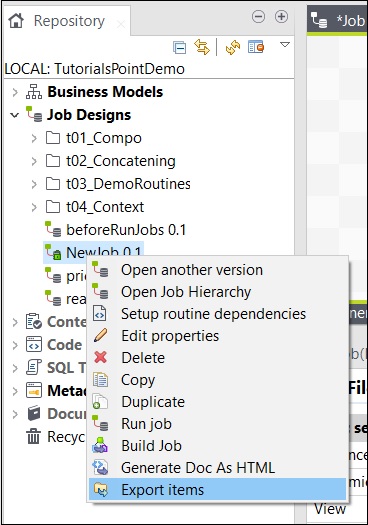
Entrez le chemin vers lequel vous souhaitez exporter l'élément et cliquez sur Terminer.
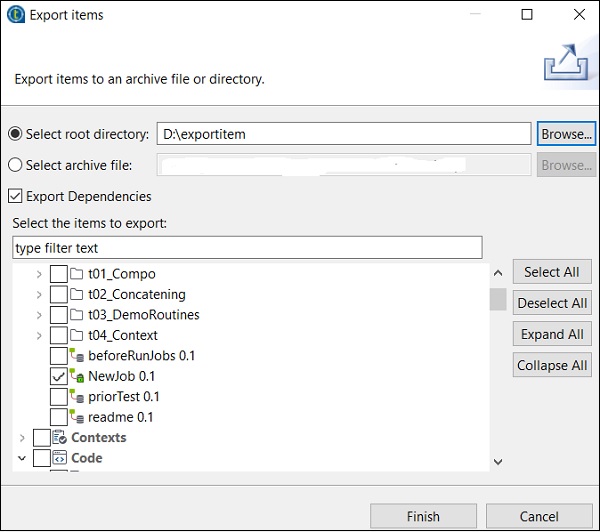
Pour importer un élément du travail, cliquez avec le bouton droit sur le travail dans les conceptions du travail et cliquez sur Importer des éléments.
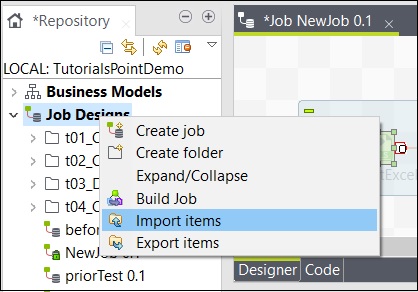
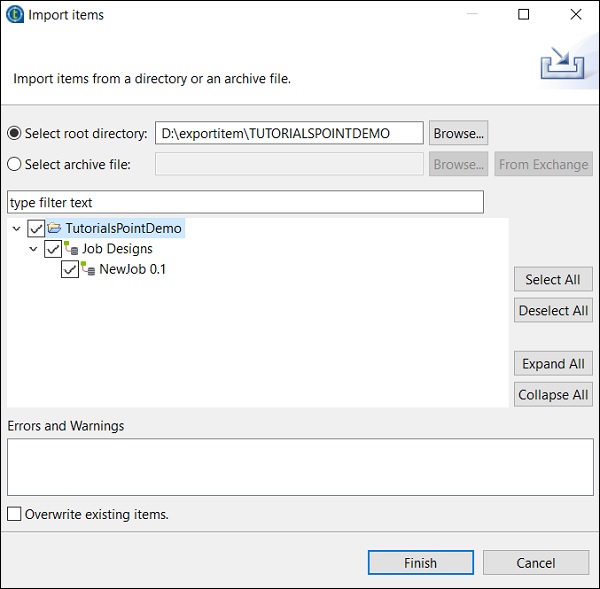
Parcourez le répertoire racine à partir duquel vous souhaitez importer les éléments.
Cochez toutes les cases et cliquez sur Terminer.
Dans ce chapitre, apprenons à gérer l'exécution d'une tâche dans Talend.
Pour créer une tâche, cliquez avec le bouton droit sur la tâche et sélectionnez l'option Créer une tâche.
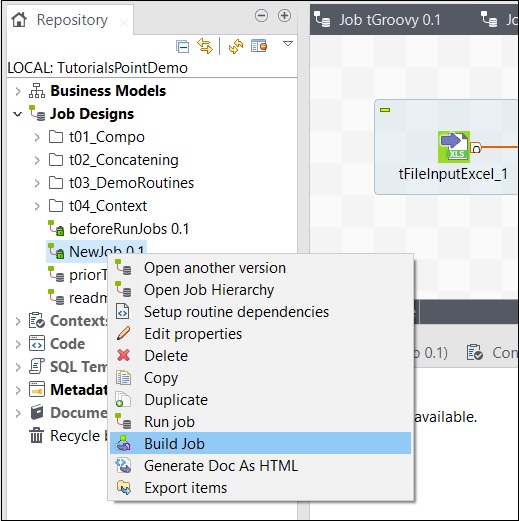
Mentionnez le chemin où vous souhaitez archiver le travail, sélectionnez la version du travail et le type de construction, puis cliquez sur Terminer.
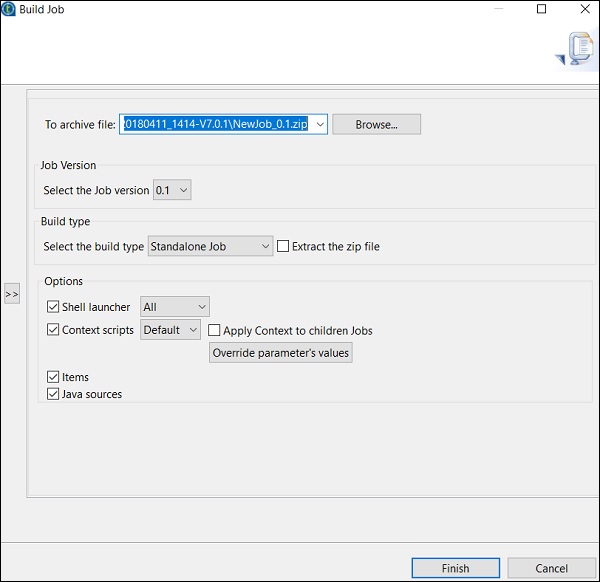
Comment exécuter une tâche en mode normal
Pour exécuter un travail dans un nœud normal, vous devez sélectionner «Exécution de base» et cliquer sur le bouton Exécuter pour que l'exécution commence.
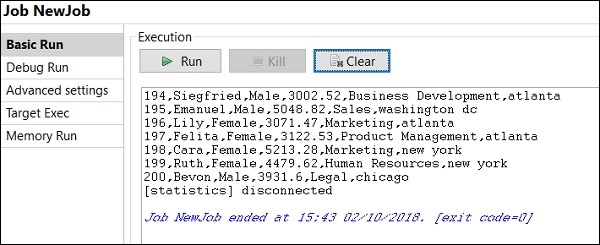
Comment exécuter une tâche en mode débogage
Pour exécuter le travail en mode débogage, ajoutez un point d'arrêt aux composants que vous souhaitez déboguer.
Ensuite, sélectionnez et faites un clic droit sur le composant, cliquez sur l'option Ajouter un point d'arrêt. Notez qu'ici nous avons ajouté des points d'arrêt aux composants tFileInputExcel et tLogRow. Ensuite, accédez à Debug Run et cliquez sur le bouton Java Debug.
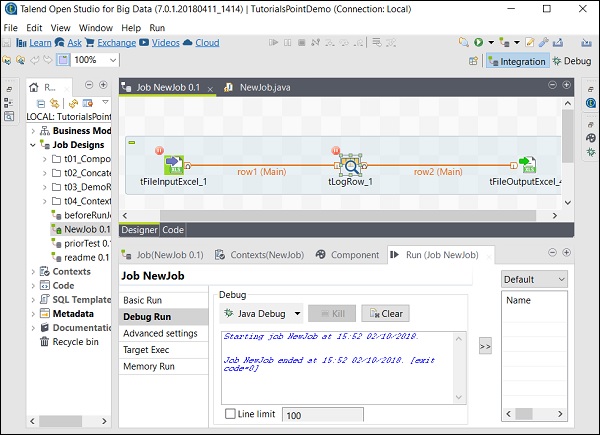
Vous pouvez observer à partir de la capture d'écran suivante que le travail va maintenant s'exécuter en mode débogage et en fonction des points d'arrêt que nous avons mentionnés.
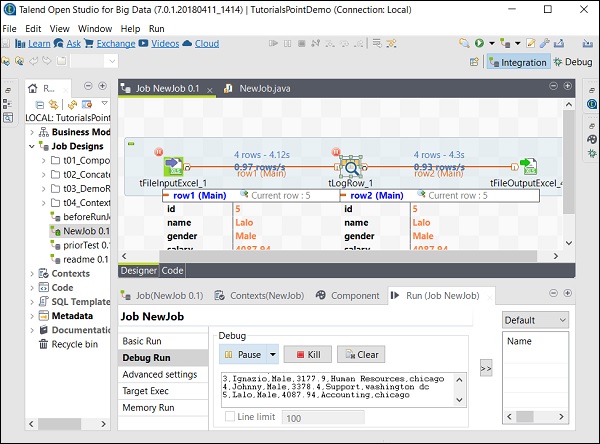
Réglages avancés
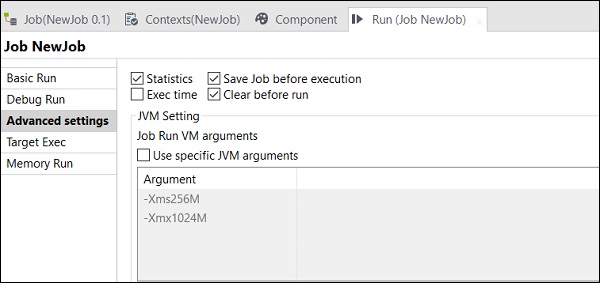
Dans Paramètres avancés, vous pouvez sélectionner les paramètres Statistiques, Temps d'exécution, Enregistrer le travail avant exécution, Effacer avant exécution et JVM. Chacune de cette option a la fonctionnalité comme expliqué ici -
Statistics - Il affiche le taux de performance du traitement;
Exec Time - Le temps nécessaire pour exécuter le travail.
Save Job before Execution - Enregistre automatiquement le travail avant le début de l'exécution.
Clear before Run - Supprime tout de la console de sortie.
JVM Settings - Nous aide à configurer nos propres arguments Java.
Le slogan d'Open Studio avec Big Data est «Simplifiez ETL et ELT avec le principal outil ETL open source gratuit pour le Big Data.» Dans ce chapitre, examinons l'utilisation de Talend comme outil de traitement de données dans un environnement Big Data.
introduction
Talend Open Studio - Big Data est un outil gratuit et open source pour traiter vos données très facilement dans un environnement Big Data. Vous disposez de nombreux composants Big Data disponibles dans Talend Open Studio, qui vous permettent de créer et d'exécuter des jobs Hadoop simplement par un simple glisser-déposer de quelques composants Hadoop.
De plus, nous n'avons pas besoin d'écrire de grandes lignes de codes MapReduce; Talend Open Studio Big data vous aide à le faire avec les composants qui y sont présents. Il génère automatiquement du code MapReduce pour vous, il vous suffit de faire glisser et déposer les composants et de configurer quelques paramètres.
Il vous donne également la possibilité de vous connecter à plusieurs distributions Big Data comme Cloudera, HortonWorks, MapR, Amazon EMR et même Apache.
Composants Talend pour Big Data
La liste des catégories avec des composants pour exécuter un travail sur un environnement Big Data inclus sous Big Data, est présentée ci-dessous -
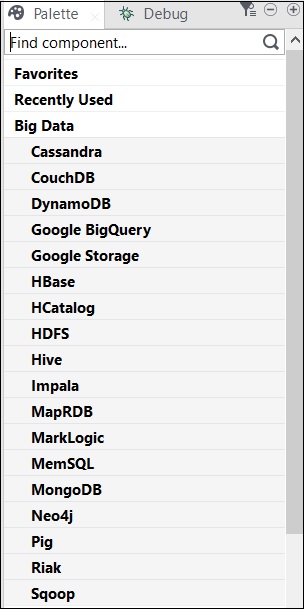
La liste des connecteurs et composants Big Data dans Talend Open Studio est présentée ci-dessous -
tHDFSConnection - Utilisé pour se connecter à HDFS (Hadoop Distributed File System).
tHDFSInput - Lit les données à partir du chemin hdfs donné, les met dans le schéma talend, puis les transmet au composant suivant du travail.
tHDFSList - Récupère tous les fichiers et dossiers dans le chemin hdfs donné.
tHDFSPut - Copie le fichier / dossier du système de fichiers local (défini par l'utilisateur) vers hdfs au chemin donné.
tHDFSGet - Copie le fichier / dossier de hdfs vers le système de fichiers local (défini par l'utilisateur) au chemin donné.
tHDFSDelete - Supprime le fichier de HDFS
tHDFSExist - Vérifie si un fichier est présent sur HDFS ou non.
tHDFSOutput - Ecrit les flux de données sur HDFS.
tCassandraConnection - Ouvre la connexion au serveur Cassandra.
tCassandraRow - Exécute des requêtes CQL (Cassandra query language) sur la base de données spécifiée.
tHBaseConnection - Ouvre la connexion à la base de données HBase.
tHBaseInput - lit les données de la base de données HBase.
tHiveConnection - Ouvre la connexion à la base de données Hive.
tHiveCreateTable - Crée une table dans une base de données Hive.
tHiveInput - Lit les données de la base de données Hive.
tHiveLoad - Écrit les données dans la table Hive ou dans un répertoire spécifié.
tHiveRow - exécute des requêtes HiveQL sur la base de données spécifiée.
tPigLoad - Charge les données d'entrée dans le flux de sortie.
tPigMap - Utilisé pour transformer et acheminer les données dans un processus porcin.
tPigJoin - Effectue l'opération de jointure de 2 fichiers en fonction des clés de jointure.
tPigCoGroup - Regroupe et agrège les données provenant de plusieurs entrées.
tPigSort - Trie les données données en fonction d'une ou plusieurs clés de tri définies.
tPigStoreResult - Stocke le résultat de l'exploitation du porc dans un espace de stockage défini.
tPigFilterRow - Filtre les colonnes spécifiées afin de fractionner les données en fonction de la condition donnée.
tPigDistinct - Supprime les tuples en double de la relation.
tSqoopImport - Transfère les données d'une base de données relationnelle comme MySQL, Oracle DB vers HDFS.
tSqoopExport - Transfère les données de HDFS vers une base de données relationnelle comme MySQL, Oracle DB
Dans ce chapitre, apprenons en détail comment Talend fonctionne avec le système de fichiers distribué Hadoop.
Paramètres et pré-requis
Avant de passer à Talend avec HDFS, nous devons nous renseigner sur les paramètres et les pré-requis à remplir à cet effet.
Ici, nous exécutons Cloudera quickstart 5.10 VM sur une boîte virtuelle. Un réseau d'hôte uniquement doit être utilisé dans cette machine virtuelle.
IP du réseau hôte uniquement: 192.168.56.101

Vous devez également avoir le même hôte fonctionnant sur cloudera manager.

Maintenant, sur votre système Windows, accédez à c: \ Windows \ System32 \ Drivers \ etc \ hosts et modifiez ce fichier à l'aide du Bloc-notes comme indiqué ci-dessous.

De même, sur votre VM de démarrage rapide cloudera, modifiez votre fichier / etc / hosts comme indiqué ci-dessous.
sudo gedit /etc/hosts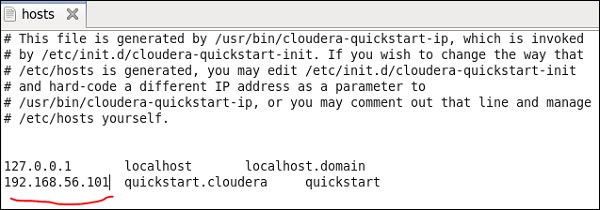
Configuration de la connexion Hadoop
Dans le panneau du référentiel, accédez à Métadonnées. Cliquez avec le bouton droit sur Hadoop Cluster et créez un nouveau cluster. Donnez le nom, le but et la description de cette connexion de cluster Hadoop.
Cliquez sur Suivant.

Sélectionnez la distribution comme cloudera et choisissez la version que vous utilisez. Sélectionnez l'option de configuration de récupération et cliquez sur Suivant.

Entrez les informations d'identification du gestionnaire (URI avec port, nom d'utilisateur, mot de passe) comme indiqué ci-dessous et cliquez sur Se connecter. Si les détails sont corrects, vous obtiendrez Cloudera QuickStart sous les clusters découverts.
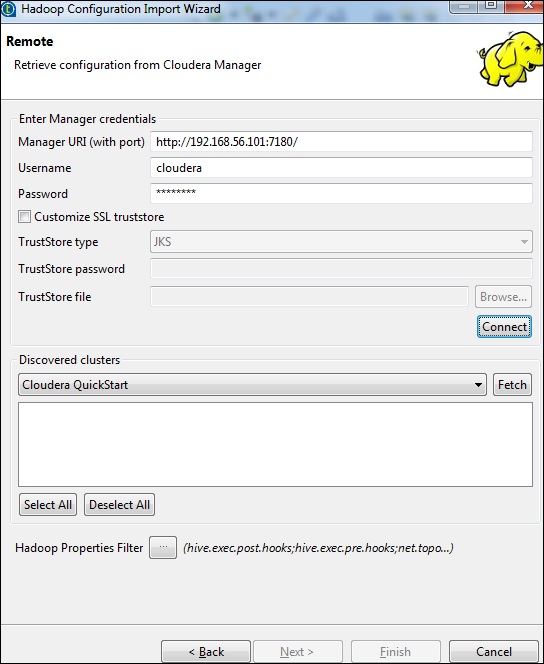
Cliquez sur Extraire. Cela récupérera toutes les connexions et configurations pour HDFS, YARN, HBASE, HIVE.
Sélectionnez Tout et cliquez sur Terminer.

Notez que tous les paramètres de connexion seront remplis automatiquement. Mentionnez cloudera dans le nom d'utilisateur et cliquez sur Terminer.

Avec cela, vous vous êtes connecté avec succès à un cluster Hadoop.

Connexion à HDFS
Dans ce travail, nous listerons tous les répertoires et fichiers présents sur HDFS.
Tout d'abord, nous allons créer un travail, puis y ajouter des composants HDFS. Faites un clic droit sur Job Design et créez un nouvel emploi - hadoopjob.
Ajoutez maintenant 2 composants de la palette - tHDFSConnection et tHDFSList. Faites un clic droit sur le tHDFSConnection et connectez ces 2 composants à l'aide du déclencheur 'OnSubJobOk'.
Maintenant, configurez les deux composants talend hdfs.

Dans le tHDFSConnection, choisissez Référentiel comme Type de propriété et sélectionnez le cluster Hadoop cloudera que vous avez créé précédemment. Il remplira automatiquement tous les détails nécessaires requis pour ce composant.

Dans le tHDFSList, sélectionnez «Utiliser une connexion existante» et dans la liste des composants, choisissez le tHDFSConnection que vous avez configuré.
Donnez le chemin d'accès à la maison de HDFS dans l'option Répertoire HDFS et cliquez sur le bouton Parcourir à droite.

Si vous avez correctement établi la connexion avec les configurations mentionnées ci-dessus, vous verrez une fenêtre comme illustré ci-dessous. Il listera tous les répertoires et fichiers présents sur l'accueil HDFS.

Vous pouvez vérifier cela en vérifiant votre HDFS sur cloudera.

Lire un fichier depuis HDFS
Dans cette section, voyons comment lire un fichier depuis HDFS dans Talend. Vous pouvez créer un nouvel emploi à cette fin, mais ici nous utilisons l'existant.
Faites glisser et déposez 3 composants - tHDFSConnection, tHDFSInput et tLogRow de la palette vers la fenêtre du concepteur.
Cliquez avec le bouton droit sur le tHDFSConnection et connectez le composant tHDFSInput à l'aide du déclencheur 'OnSubJobOk'.
Cliquez avec le bouton droit sur le tHDFSInput et faites glisser un lien principal vers le tLogRow.

Notez que le tHDFSConnection aura la même configuration que précédemment. Dans le tHDFSInput, sélectionnez «Utiliser une connexion existante» et dans la liste des composants, choisissez le tHDFSConnection.
Dans le nom de fichier, indiquez le chemin HDFS du fichier que vous souhaitez lire. Ici, nous lisons un simple fichier texte, donc notre type de fichier est Fichier texte. De même, en fonction de votre saisie, remplissez le séparateur de ligne, le séparateur de champ et les détails d'en-tête comme indiqué ci-dessous. Enfin, cliquez sur le bouton Modifier le schéma.

Puisque notre fichier ne contient que du texte brut, nous ajoutons une seule colonne de type String. Maintenant, cliquez sur Ok.
Note - Lorsque votre entrée comporte plusieurs colonnes de types différents, vous devez mentionner le schéma ici en conséquence.

Dans le composant tLogRow, cliquez sur Synchroniser les colonnes dans modifier le schéma.
Sélectionnez le mode dans lequel vous souhaitez que votre sortie soit imprimée.

Enfin, cliquez sur Exécuter pour exécuter le travail.
Une fois que vous avez réussi à lire un fichier HDFS, vous pouvez voir la sortie suivante.

Écriture d'un fichier sur HDFS
Voyons comment écrire un fichier depuis HDFS dans Talend. Faites glisser et déposez 3 composants - tHDFSConnection, tFileInputDelimited et tHDFSOutput de la palette vers la fenêtre du concepteur.
Faites un clic droit sur le tHDFSConnection et connectez le composant tFileInputDelimited à l'aide du déclencheur 'OnSubJobOk'.
Faites un clic droit sur le tFileInputDelimited et faites glisser un lien principal vers le tHDFSOutput.

Notez que le tHDFSConnection aura la même configuration que précédemment.
Maintenant, dans le tFileInputDelimited, donnez le chemin du fichier d'entrée dans l'option Nom de fichier / Stream. Ici, nous utilisons un fichier csv comme entrée, donc le séparateur de champ est «,».
Sélectionnez l'en-tête, le pied de page, la limite en fonction de votre fichier d'entrée. Notez qu'ici notre en-tête est 1 car la ligne 1 contient les noms de colonne et la limite est 3 car nous n'écrivons que les 3 premières lignes sur HDFS.
Maintenant, cliquez sur modifier le schéma.
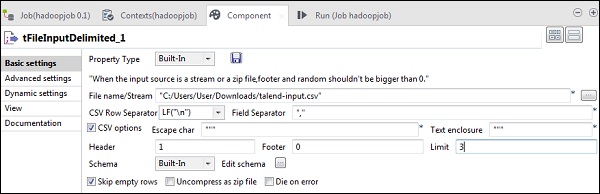
Maintenant, selon notre fichier d'entrée, définissez le schéma. Notre fichier d'entrée comporte 3 colonnes comme mentionné ci-dessous.

Dans le composant tHDFSOutput, cliquez sur synchroniser les colonnes. Ensuite, sélectionnez le tHDFSConnection dans Utiliser une connexion existante. De plus, dans Nom de fichier, indiquez un chemin HDFS où vous souhaitez écrire votre fichier.
Notez que le type de fichier sera un fichier texte, l'action sera «créer», le séparateur de ligne sera «\ n» et le séparateur de champ sera «;»

Enfin, cliquez sur Exécuter pour exécuter votre travail. Une fois le travail exécuté avec succès, vérifiez si votre fichier est présent sur HDFS.

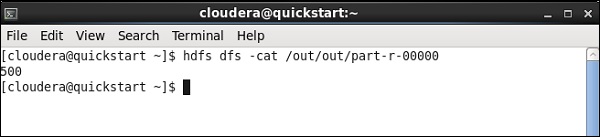
Exécutez la commande hdfs suivante avec le chemin de sortie que vous avez mentionné dans votre tâche.
hdfs dfs -cat /input/talendwriteVous verrez la sortie suivante si vous réussissez à écrire sur HDFS.

Dans le chapitre précédent, nous avons vu comment Talend fonctionne avec le Big Data. Dans ce chapitre, voyons comment utiliser map Reduce avec Talend.
Créer un Job Talend MapReduce
Apprenons à exécuter un job MapReduce sur Talend. Ici, nous allons exécuter un exemple de décompte de mots MapReduce.
Pour cela, cliquez avec le bouton droit sur Job Design et créez un nouveau job - MapreduceJob. Mentionnez les détails du travail et cliquez sur Terminer.
Ajout de composants à une tâche MapReduce
Pour ajouter des composants à un job MapReduce, faites glisser et déposez cinq composants de Talend - tHDFSInput, tNormalize, tAggregateRow, tMap, tOutput de la palette vers la fenêtre du concepteur. Faites un clic droit sur le tHDFSInput et créez le lien principal vers le tNormalize.
Faites un clic droit sur le tNormalize et créez le lien principal vers le tAggregateRow. Ensuite, faites un clic droit sur le tAggregateRow et créez le lien principal vers le tMap. Maintenant, faites un clic droit sur le tMap et créez le lien principal vers le tHDFSOutput.
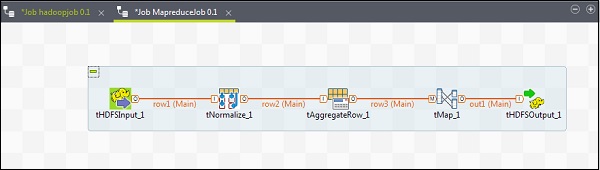
Configuration des composants et des transformations
Dans le tHDFSInput, sélectionnez la distribution cloudera et sa version. Notez que l'URI Namenode doit être «hdfs: //quickstart.cloudera: 8020» et le nom d'utilisateur doit être «cloudera». Dans l'option de nom de fichier, indiquez le chemin de votre fichier d'entrée vers le travail MapReduce. Assurez-vous que ce fichier d'entrée est présent sur HDFS.
Maintenant, sélectionnez le type de fichier, le séparateur de ligne, le séparateur de fichiers et l'en-tête en fonction de votre fichier d'entrée.
Cliquez sur modifier le schéma et ajoutez le champ «ligne» comme type de chaîne.
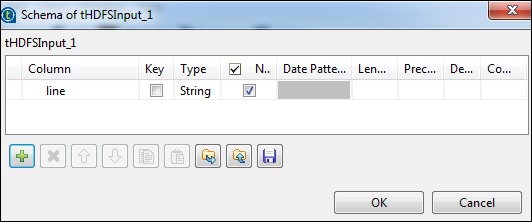
Dans le tNomalize, la colonne à normaliser sera line et le séparateur d'élément sera un espace -> ““. Maintenant, cliquez sur modifier le schéma. Le tNormalize aura une colonne de ligne et le tAggregateRow aura 2 colonnes word et wordcount comme indiqué ci-dessous.
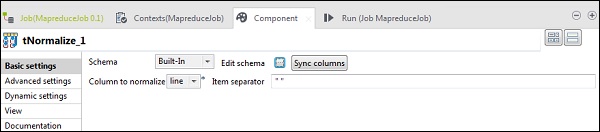
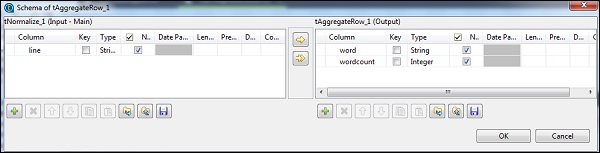
Dans le tAggregateRow, placez le mot comme colonne de sortie dans l'option Group by. Dans les opérations, placez wordcount comme colonne de sortie, fonction comme nombre et position de colonne d'entrée comme ligne.
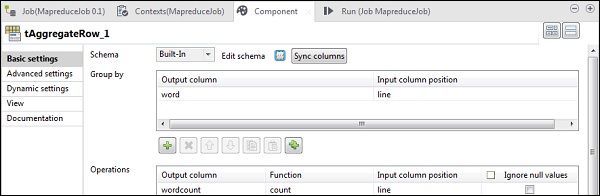
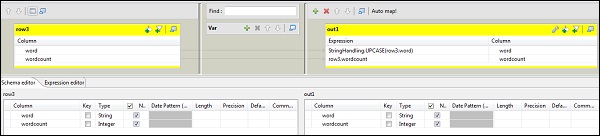
Maintenant, double-cliquez sur le composant tMap pour entrer dans l'éditeur de carte et mapper l'entrée avec la sortie requise. Dans cet exemple, le mot est mappé avec word et wordcount est mappé avec wordcount. Dans la colonne d'expression, cliquez sur […] pour entrer dans le générateur d'expression.
Maintenant, sélectionnez StringHandling dans la liste des catégories et la fonction UPCASE. Modifiez l'expression en «StringHandling.UPCASE (row3.word)» et cliquez sur OK. Conservez row3.wordcount dans la colonne d'expression correspondant à wordcount comme indiqué ci-dessous.
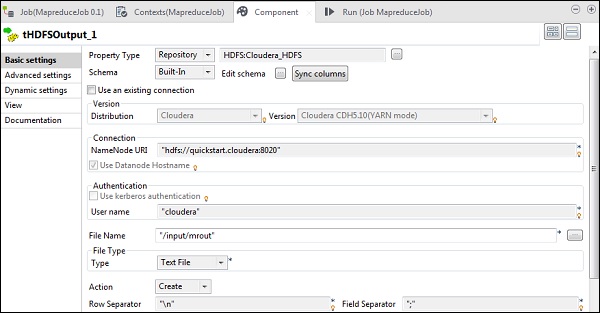
Dans le tHDFSOutput, connectez-vous au cluster Hadoop que nous avons créé à partir du type de propriété en tant que référentiel. Observez que les champs seront remplis automatiquement. Dans Nom du fichier, indiquez le chemin de sortie où vous souhaitez stocker la sortie. Conservez l'action, le séparateur de ligne et le séparateur de champ comme indiqué ci-dessous.
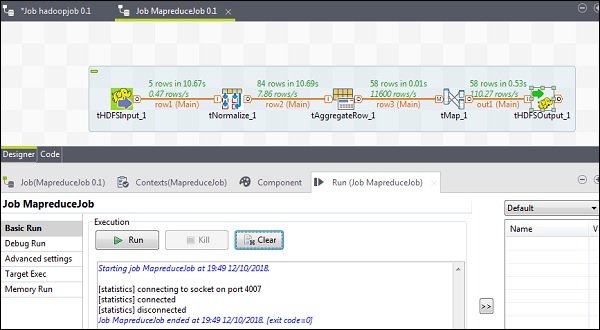
Exécution du travail MapReduce
Une fois votre configuration terminée, cliquez sur Exécuter et exécutez votre tâche MapReduce.
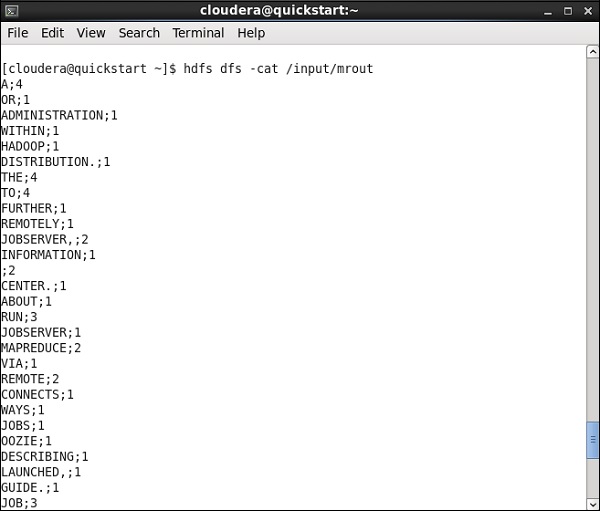
Accédez à votre chemin HDFS et vérifiez la sortie. Notez que tous les mots seront en majuscules avec leur nombre de mots.
Dans ce chapitre, apprenons à travailler avec un job Pig dans Talend.
Créer un Job Talend Pig
Dans cette section, apprenons à exécuter un job Pig sur Talend. Ici, nous traiterons les données du NYSE pour connaître le volume moyen des stocks d'IBM.
Pour cela, faites un clic droit sur Job Design et créez un nouveau job - pigjob. Mentionnez les détails du travail et cliquez sur Terminer.
Ajout de composants au travail Pig
Pour ajouter des composants à la tâche Pig, faites glisser et déposez quatre composants Talend: tPigLoad, tPigFilterRow, tPigAggregate, tPigStoreResult, de la palette vers la fenêtre du concepteur.
Ensuite, faites un clic droit sur le tPigLoad et créez la ligne Pig Combine sur le tPigFilterRow. Ensuite, faites un clic droit sur le tPigFilterRow et créez la ligne Pig Combine sur le tPigAggregate. Cliquez avec le bouton droit sur le tPigAggregate et créez la ligne de combinaison Pig vers le tPigStoreResult.
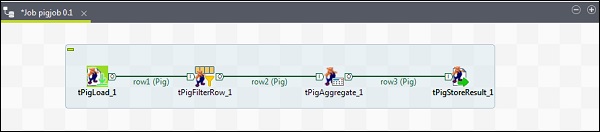
Configuration des composants et des transformations
Dans le tPigLoad, mentionnez la distribution comme cloudera et la version de cloudera. Notez que l'URI Namenode doit être «hdfs: //quickstart.cloudera: 8020» et que Resource Manager doit être «quickstart.cloudera: 8020». De plus, le nom d'utilisateur doit être «cloudera».
Dans l'URI du fichier d'entrée, indiquez le chemin de votre fichier d'entrée NYSE vers le travail de porc. Notez que ce fichier d'entrée doit être présent sur HDFS.
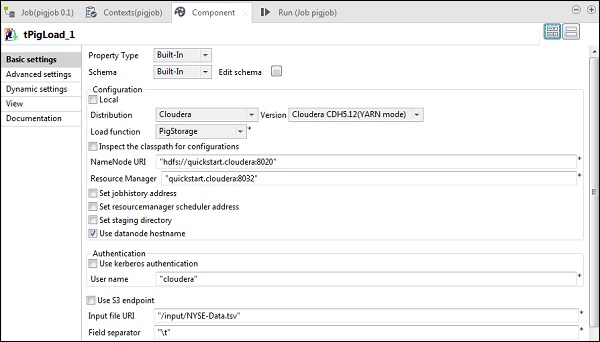
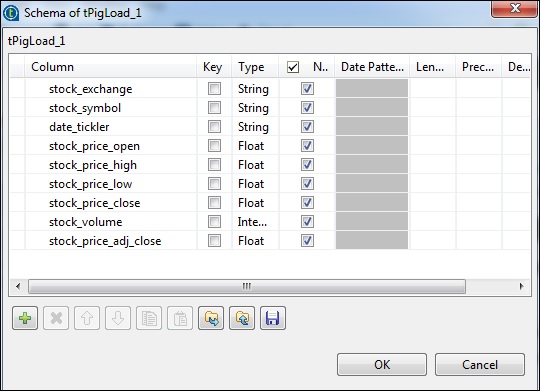
Cliquez sur modifier le schéma, ajoutez les colonnes et son type comme indiqué ci-dessous.
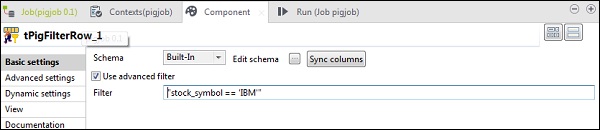
Dans le tPigFilterRow, sélectionnez l'option «Utiliser le filtre avancé» et mettez «stock_symbol = = 'IBM'» dans l'option Filtre.
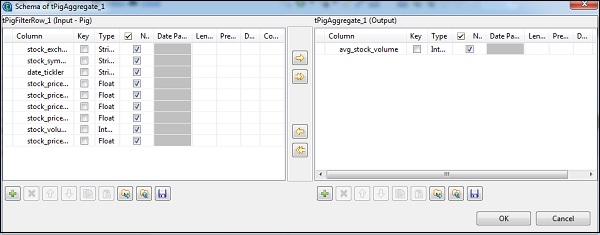
Dans le tAggregateRow, cliquez sur modifier le schéma et ajoutez la colonne avg_stock_volume en sortie comme indiqué ci-dessous.
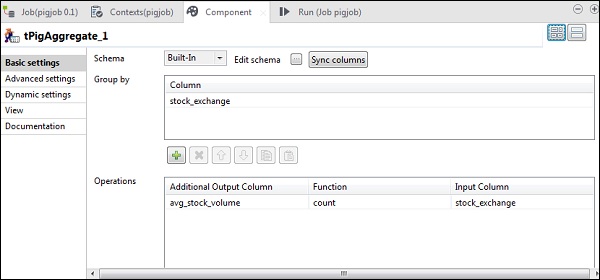
Maintenant, placez la colonne stock_exchange dans l'option Group by. Ajoutez la colonne avg_stock_volume dans le champ Opérations avec la fonction count et stock_exchange comme colonne d'entrée.
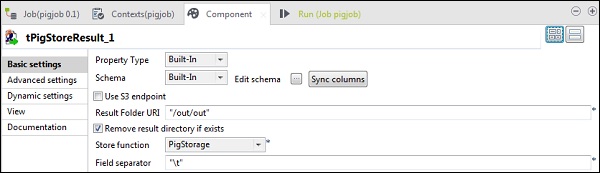
Dans le tPigStoreResult, indiquez le chemin de sortie dans l'URI du dossier de résultats où vous souhaitez stocker le résultat du travail Pig. Sélectionnez la fonction de stockage comme PigStorage et le séparateur de champ (non obligatoire) comme «\ t».
Exécution du travail Pig
Cliquez maintenant sur Exécuter pour exécuter votre tâche Pig. (Ignorez les avertissements)
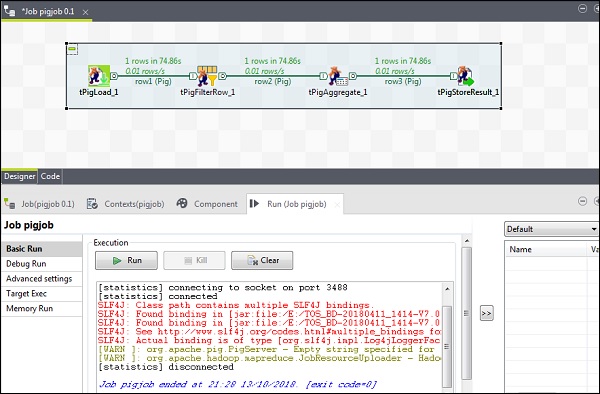
Une fois le travail terminé, vérifiez votre sortie sur le chemin HDFS que vous avez mentionné pour stocker le résultat du travail de porc. Le volume de stock moyen d'IBM est de 500.
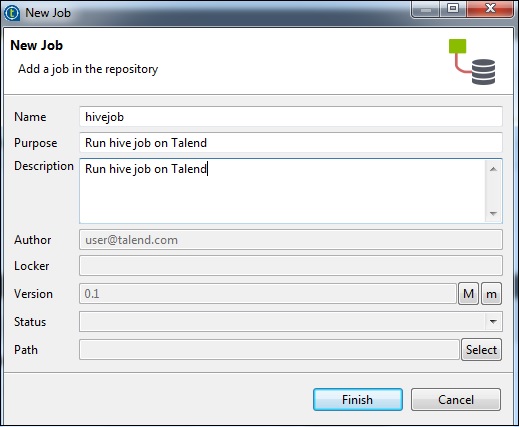
Dans ce chapitre, voyons comment travailler avec Hive job sur Talend.
Créer un Job Talend Hive
À titre d'exemple, nous allons charger les données NYSE dans une table Hive et exécuter une requête Hive de base. Faites un clic droit sur Job Design et créez un nouveau job - hivejob. Mentionnez les détails du travail et cliquez sur Terminer.
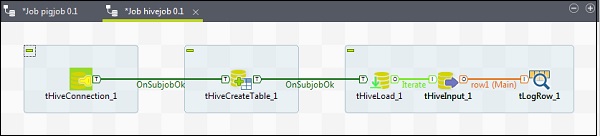
Ajout de composants à Hive Job
Pour associer des composants à un travail Hive, faites glisser et déposez cinq composants talend - tHiveConnection, tHiveCreateTable, tHiveLoad, tHiveInput et tLogRow de la palette vers la fenêtre du concepteur. Ensuite, faites un clic droit sur le tHiveConnection et créez le déclencheur OnSubjobOk sur le tHiveCreateTable. Maintenant, faites un clic droit sur le tHiveCreateTable et créez le déclencheur OnSubjobOk sur le tHiveLoad. Faites un clic droit sur le tHiveLoad et créez un trigger d'itération sur le tHiveInput. Enfin, faites un clic droit sur le tHiveInput et créez une ligne principale vers le tLogRow.
Configuration des composants et des transformations
Dans le tHiveConnection, sélectionnez la distribution en tant que cloudera et sa version que vous utilisez. Notez que le mode de connexion sera autonome et Hive Service sera Hive 2. Vérifiez également si les paramètres suivants sont définis en conséquence -
- Hôte: "quickstart.cloudera"
- Port: "10000"
- Base de données: "par défaut"
- Nom d'utilisateur: "hive"
Notez que le mot de passe sera rempli automatiquement, vous n'avez pas besoin de le modifier. D'autres propriétés Hadoop seront également prédéfinies et définies par défaut.
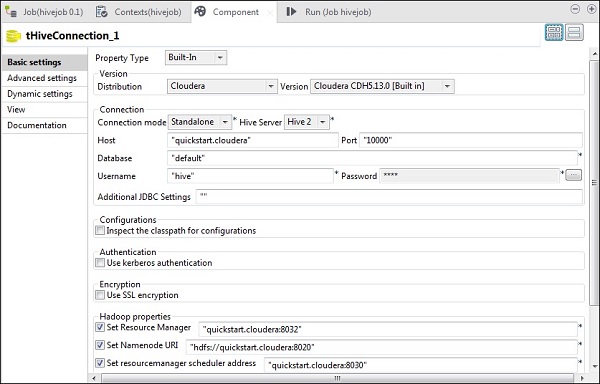
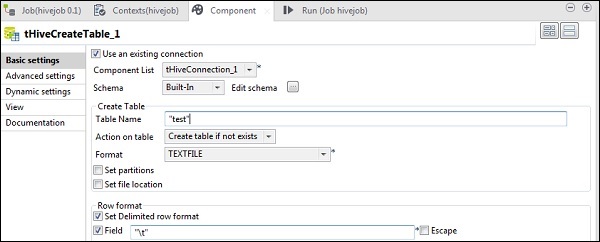
Dans le tHiveCreateTable, sélectionnez Use an existing connection et placez le tHiveConnection dans la liste Component. Donnez le nom de la table que vous souhaitez créer dans la base de données par défaut. Conservez les autres paramètres comme indiqué ci-dessous.
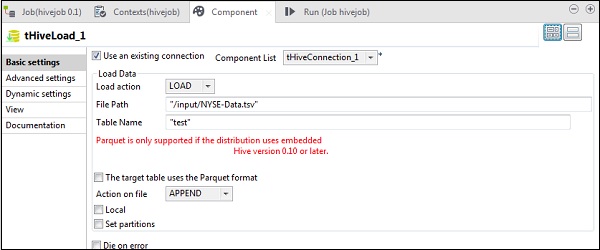
Dans le tHiveLoad, sélectionnez «Utiliser une connexion existante» et placez le tHiveConnection dans la liste des composants. Sélectionnez CHARGER dans l'action Charger. Dans File Path, indiquez le chemin HDFS de votre fichier d'entrée NYSE. Mentionnez la table dans Nom de la table, dans laquelle vous souhaitez charger l'entrée. Conservez les autres paramètres comme indiqué ci-dessous.
Dans le tHiveInput, sélectionnez Utiliser une connexion existante et placez le tHiveConnection dans la liste des composants. Cliquez sur modifier le schéma, ajoutez les colonnes et son type comme indiqué dans l'instantané de schéma ci-dessous. Donnez maintenant le nom de la table que vous avez créée dans le tHiveCreateTable.
Mettez votre requête en option de requête que vous souhaitez exécuter sur la table Hive. Ici, nous imprimons toutes les colonnes des 10 premières lignes de la table de test de la ruche.
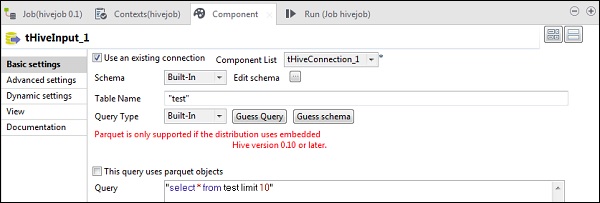
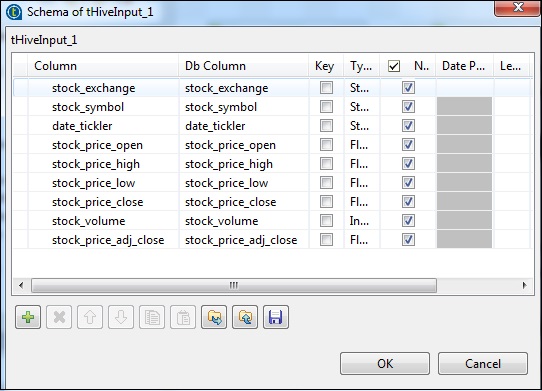
Dans le tLogRow, cliquez sur synchroniser les colonnes et sélectionnez le mode Table pour afficher la sortie.
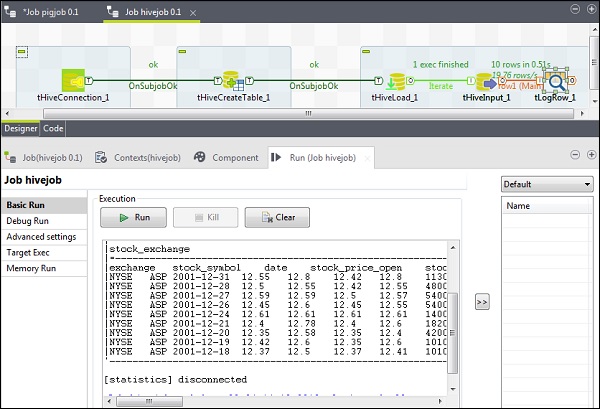
Exécution du travail Hive
Cliquez sur Exécuter pour commencer l'exécution. Si toute la connexion et les paramètres ont été définis correctement, vous verrez la sortie de votre requête comme indiqué ci-dessous.