Weka - Classificateurs
De nombreuses applications d'apprentissage automatique sont liées à la classification. Par exemple, vous pouvez classer une tumeur comme maligne ou bénigne. Vous voudrez peut-être décider de jouer à un jeu extérieur en fonction des conditions météorologiques. En général, cette décision dépend de plusieurs caractéristiques / conditions météorologiques. Vous préférerez peut-être utiliser un classificateur d'arbre pour décider de jouer ou non.
Dans ce chapitre, nous allons apprendre à construire un tel classificateur d'arbres sur les données météorologiques pour décider des conditions de jeu.
Définition des données de test
Nous utiliserons le fichier de données météorologiques prétraité de la leçon précédente. Ouvrez le fichier enregistré en utilisant leOpen file ... option sous le Preprocess onglet, cliquez sur Classify onglet, et vous verriez l'écran suivant -
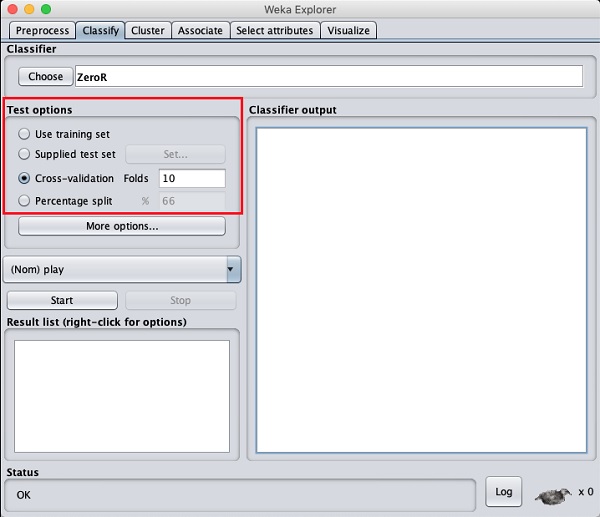
Avant de vous renseigner sur les classificateurs disponibles, examinons les options de test. Vous remarquerez quatre options de test énumérées ci-dessous -
- Ensemble d'entraînement
- Kit de test fourni
- Cross-validation
- Partage en pourcentage
À moins que vous n'ayez votre propre ensemble de formation ou un ensemble de test fourni par le client, vous utiliserez des options de validation croisée ou de répartition en pourcentage. Dans le cadre de la validation croisée, vous pouvez définir le nombre de plis dans lesquels des données entières seraient divisées et utilisées lors de chaque itération d'entraînement. Dans la répartition en pourcentage, vous diviserez les données entre la formation et les tests en utilisant le pourcentage de répartition défini.
Maintenant, gardez la valeur par défaut play option pour la classe de sortie -
Ensuite, vous sélectionnerez le classificateur.
Sélection du classificateur
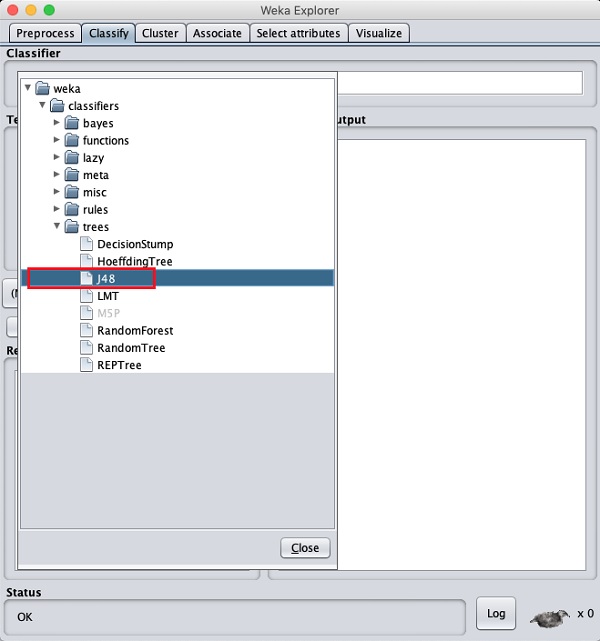
Cliquez sur le bouton Choisir et sélectionnez le classificateur suivant -
weka→classifiers>trees>J48
Ceci est montré dans la capture d'écran ci-dessous -
Clique sur le Startbouton pour démarrer le processus de classification. Après un certain temps, les résultats de la classification seraient présentés sur votre écran comme indiqué ici -
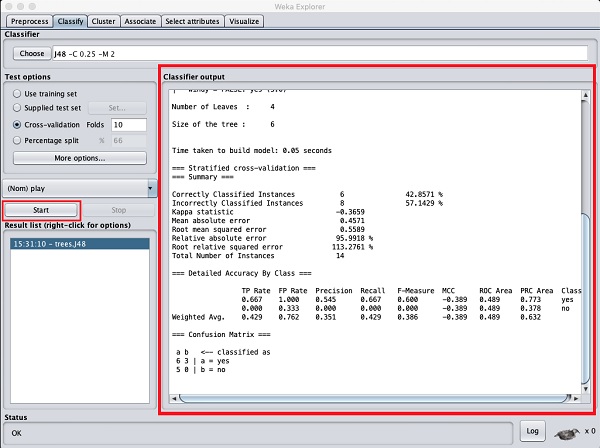
Examinons la sortie affichée sur le côté droit de l'écran.
Il indique que la taille de l'arbre est de 6. Vous verrez très bientôt la représentation visuelle de l'arbre. Dans le résumé, il indique que les instances correctement classées comme 2 et les instances incorrectement classées comme 3, Il indique également que l'erreur absolue relative est de 110%. Il montre également la matrice de confusion. Entrer dans l'analyse de ces résultats dépasse le cadre de ce tutoriel. Cependant, vous pouvez facilement comprendre à partir de ces résultats que la classification n'est pas acceptable et que vous aurez besoin de plus de données pour l'analyse, pour affiner votre sélection de fonctionnalités, reconstruire le modèle, etc. jusqu'à ce que vous soyez satisfait de la précision du modèle. Quoi qu'il en soit, c'est ce qu'est WEKA. Il vous permet de tester vos idées rapidement.
Visualisez les résultats
Pour voir la représentation visuelle des résultats, faites un clic droit sur le résultat dans le Result listboîte. Plusieurs options apparaîtraient à l'écran comme indiqué ici -
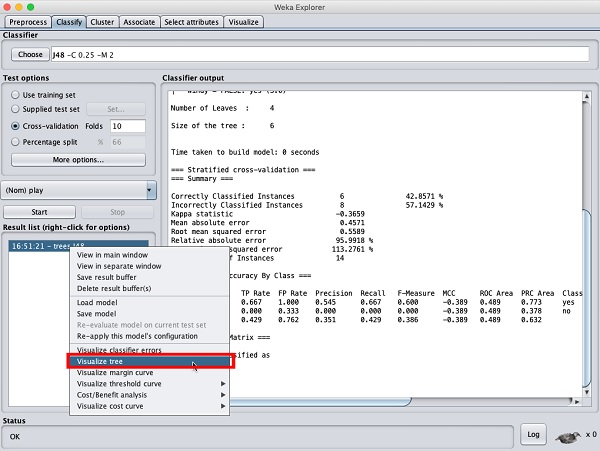
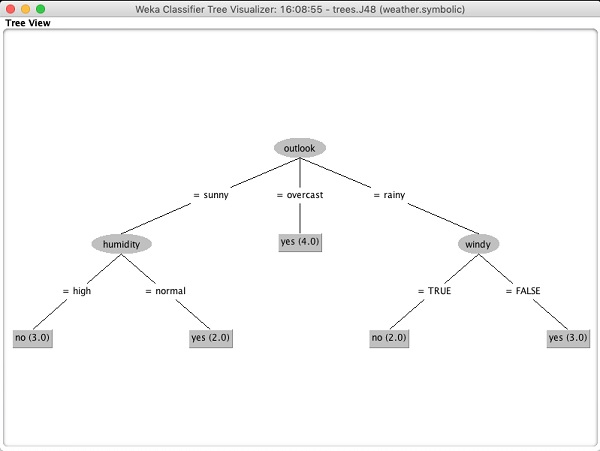
Sélectionner Visualize tree pour obtenir une représentation visuelle de l'arborescence de parcours comme le montre la capture d'écran ci-dessous -
Sélection Visualize classifier errors tracerait les résultats de la classification comme indiqué ici -
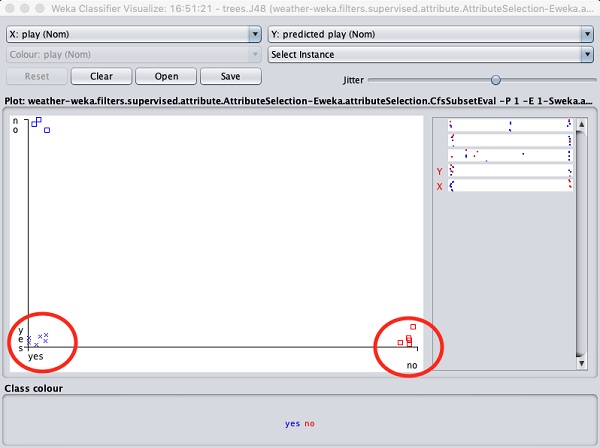
UNE cross représente une instance correctement classée tandis que squaresreprésente des instances incorrectement classées. Dans le coin inférieur gauche de l'intrigue, vous voyez uncross cela indique si outlook est ensoleillé alors playle jeu. Il s'agit donc d'une instance correctement classée. Pour localiser des instances, vous pouvez y introduire une certaine gigue en faisant glisser lejitter barre coulissante.
Le tracé actuel est outlook contre play. Celles-ci sont indiquées par les deux listes déroulantes en haut de l'écran.
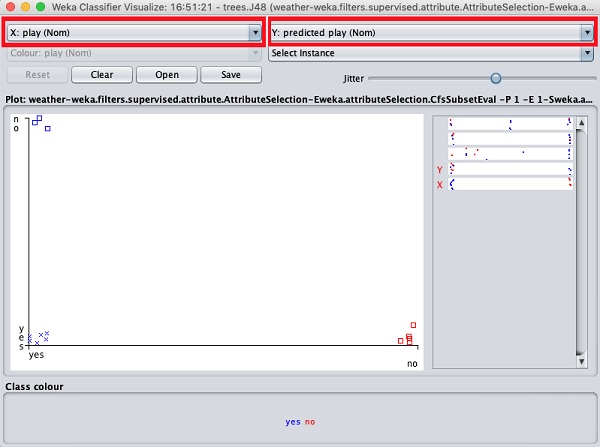
Maintenant, essayez une sélection différente dans chacune de ces cases et remarquez comment les axes X et Y changent. La même chose peut être obtenue en utilisant les bandes horizontales sur le côté droit de la parcelle. Chaque bande représente un attribut. Un clic gauche sur la bande définit l'attribut sélectionné sur l'axe X tandis qu'un clic droit le place sur l'axe Y.
Il existe plusieurs autres graphiques fournis pour votre analyse plus approfondie. Utilisez-les judicieusement pour affiner votre modèle. Un tel complot deCost/Benefit analysis est illustré ci-dessous pour votre référence rapide.
Expliquer l'analyse dans ces graphiques dépasse le cadre de ce didacticiel. Le lecteur est encouragé à parfaire ses connaissances en analyse des algorithmes d'apprentissage automatique.
Dans le chapitre suivant, nous allons apprendre le prochain ensemble d'algorithmes d'apprentissage automatique, à savoir le clustering.