Weka - Guide rapide
Les données sont à la base de toute application d'apprentissage automatique, pas seulement de petites données, mais aussi d'énormes Big Data dans la terminologie actuelle.
Pour entraîner la machine à analyser le Big Data, vous devez avoir plusieurs considérations sur les données -
- Les données doivent être propres.
- Il ne doit pas contenir de valeurs nulles.
En outre, toutes les colonnes du tableau de données ne seraient pas utiles pour le type d'analyse que vous essayez de réaliser. Les colonnes de données ou `` fonctionnalités '' non pertinentes, telles que décrites dans la terminologie d'apprentissage automatique, doivent être supprimées avant que les données ne soient introduites dans un algorithme d'apprentissage automatique.
En bref, votre Big Data a besoin de beaucoup de prétraitement avant de pouvoir être utilisé pour le Machine Learning. Une fois que les données sont prêtes, vous appliquerez divers algorithmes d'apprentissage automatique tels que la classification, la régression, le clustering, etc. pour résoudre le problème de votre côté.
Le type d'algorithmes que vous appliquez repose en grande partie sur votre connaissance du domaine. Même au sein d'un même type, par exemple la classification, plusieurs algorithmes sont disponibles. Vous voudrez peut-être tester les différents algorithmes dans la même classe pour créer un modèle d'apprentissage automatique efficace. Ce faisant, vous préférez la visualisation des données traitées et vous avez donc également besoin d'outils de visualisation.
Dans les prochains chapitres, vous découvrirez Weka, un logiciel qui accomplit tout ce qui précède avec facilité et vous permet de travailler confortablement avec le Big Data.
WEKA - un logiciel open source fournit des outils pour le prétraitement des données, la mise en œuvre de plusieurs algorithmes d'apprentissage automatique et des outils de visualisation afin que vous puissiez développer des techniques d'apprentissage automatique et les appliquer à des problèmes d'exploration de données réels. Ce que propose WEKA est résumé dans le schéma suivant -
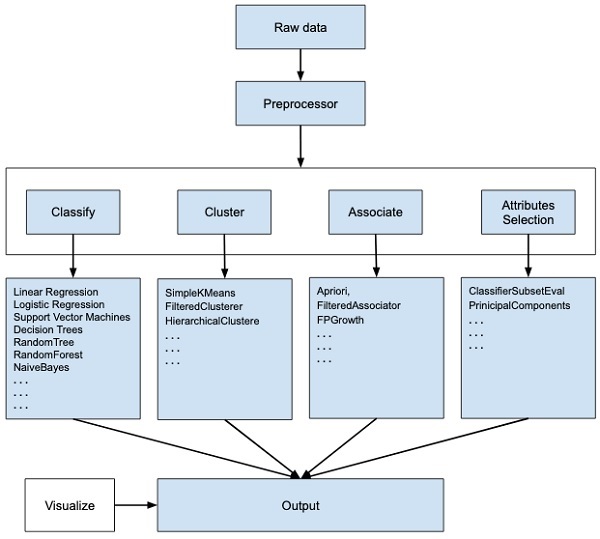
Si vous observez le début du flux de l'image, vous comprendrez qu'il existe de nombreuses étapes dans la gestion du Big Data pour le rendre adapté au machine learning -
Tout d'abord, vous commencerez par les données brutes collectées sur le terrain. Ces données peuvent contenir plusieurs valeurs nulles et des champs non pertinents. Vous utilisez les outils de prétraitement des données fournis dans WEKA pour nettoyer les données.
Ensuite, vous enregistrez les données prétraitées dans votre stockage local pour appliquer des algorithmes de ML.
Ensuite, en fonction du type de modèle ML que vous essayez de développer, vous sélectionnerez l'une des options telles que Classify, Cluster, ou Associate. leAttributes Selection permet la sélection automatique d'entités pour créer un jeu de données réduit.
A noter que dans chaque catégorie, WEKA fournit la mise en œuvre de plusieurs algorithmes. Vous choisiriez un algorithme de votre choix, définiriez les paramètres souhaités et l'exécuter sur l'ensemble de données.
Ensuite, WEKA vous donnerait la sortie statistique du traitement du modèle. Il vous fournit un outil de visualisation pour inspecter les données.
Les différents modèles peuvent être appliqués sur le même jeu de données. Vous pouvez ensuite comparer les sorties de différents modèles et sélectionner le meilleur qui correspond à votre objectif.
Ainsi, l'utilisation de WEKA se traduit par un développement plus rapide des modèles d'apprentissage automatique dans l'ensemble.
Maintenant que nous avons vu ce qu'est WEKA et ce qu'il fait, dans le chapitre suivant, apprenons comment installer WEKA sur votre ordinateur local.
Pour installer WEKA sur votre machine, visitez le site officiel de WEKA et téléchargez le fichier d'installation. WEKA prend en charge l'installation sur Windows, Mac OS X et Linux. Il vous suffit de suivre les instructions de cette page pour installer WEKA pour votre OS.
Les étapes d'installation sur Mac sont les suivantes -
- Téléchargez le fichier d'installation Mac.
- Double-cliquez sur le fichier téléchargé weka-3-8-3-corretto-jvm.dmg file.
Vous verrez l'écran suivant une fois l'installation réussie.
- Clique sur le weak-3-8-3-corretto-jvm icône pour démarrer Weka.
- Vous pouvez éventuellement le démarrer à partir de la ligne de commande -
java -jar weka.jarL'application WEKA GUI Chooser démarre et vous verrez l'écran suivant -
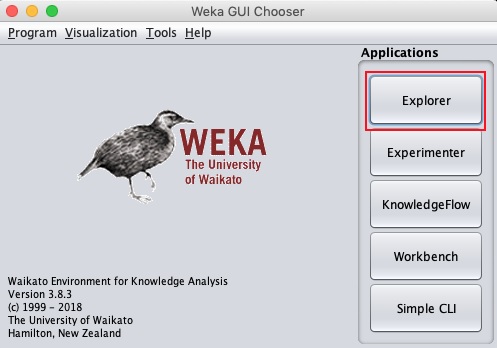
L'application GUI Chooser vous permet d'exécuter cinq types d'applications différents, comme indiqué ici -
- Explorer
- Experimenter
- KnowledgeFlow
- Workbench
- CLI simple
Nous utiliserons Explorer dans ce tutoriel.
Dans ce chapitre, examinons les différentes fonctionnalités fournies par l'explorateur pour travailler avec le Big Data.
Lorsque vous cliquez sur le Explorer bouton dans le Applications sélecteur, il ouvre l'écran suivant -
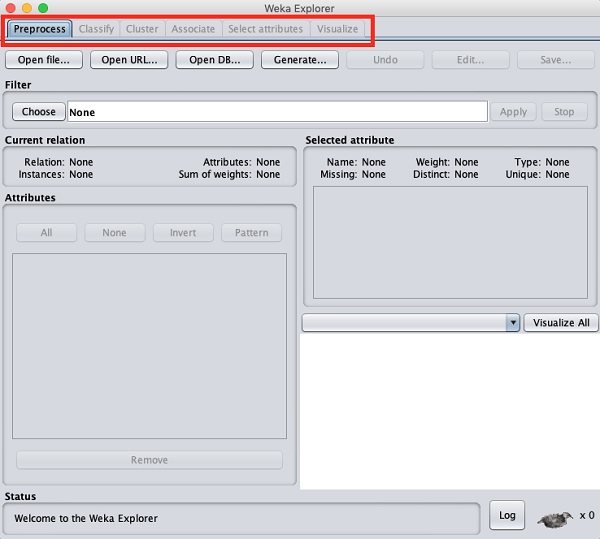
En haut, vous verrez plusieurs onglets répertoriés ici -
- Preprocess
- Classify
- Cluster
- Associate
- Sélectionnez les attributs
- Visualize
Sous ces onglets, il existe plusieurs algorithmes d'apprentissage automatique pré-implémentés. Examinons chacun d'eux en détail maintenant.
Onglet Preprocess
Au départ, lorsque vous ouvrez l'explorateur, seul le Preprocessl'onglet est activé. La première étape de l'apprentissage automatique consiste à prétraiter les données. Ainsi, dans lePreprocess option, vous sélectionnerez le fichier de données, le traiterez et l'adapterez à l'application des différents algorithmes d'apprentissage automatique.
Onglet Classer
le ClassifyL'onglet vous propose plusieurs algorithmes d'apprentissage automatique pour la classification de vos données. Pour en énumérer quelques-uns, vous pouvez appliquer des algorithmes tels que la régression linéaire, la régression logistique, les machines vectorielles de support, les arbres de décision, RandomTree, RandomForest, NaiveBayes, etc. La liste est très exhaustive et fournit des algorithmes d'apprentissage automatique supervisés et non supervisés.
Onglet Cluster
Sous le Cluster onglet, il existe plusieurs algorithmes de clustering fournis - tels que SimpleKMeans, FilteredClusterer, HierarchicalClusterer, etc.
Onglet Associer
Sous le Associate onglet, vous trouverez Apriori, FilteredAssociator et FPGrowth.
Sélectionnez l'onglet Attributs
Select Attributes vous permet de sélectionner des fonctionnalités basées sur plusieurs algorithmes tels que ClassifierSubsetEval, PrinicipalComponents, etc.
Onglet Visualiser
Enfin, le Visualize L'option vous permet de visualiser vos données traitées pour analyse.
Comme vous l'avez remarqué, WEKA fournit plusieurs algorithmes prêts à l'emploi pour tester et créer vos applications d'apprentissage automatique. Pour utiliser WEKA efficacement, vous devez avoir une bonne connaissance de ces algorithmes, de leur fonctionnement, de celui à choisir dans quelles circonstances, de ce qu'il faut rechercher dans leur sortie traitée, etc. En bref, vous devez avoir une base solide en apprentissage automatique pour utiliser efficacement WEKA dans la création de vos applications.
Dans les prochains chapitres, vous étudierez en profondeur chaque onglet de l'explorateur.
Dans ce chapitre, nous commençons par le premier onglet que vous utilisez pour prétraiter les données. Ceci est commun à tous les algorithmes que vous appliqueriez à vos données pour construire le modèle et constitue une étape commune pour toutes les opérations ultérieures dans WEKA.
Pour qu'un algorithme d'apprentissage automatique donne une précision acceptable, il est important que vous deviez d'abord nettoyer vos données. En effet, les données brutes collectées à partir du champ peuvent contenir des valeurs nulles, des colonnes non pertinentes, etc.
Dans ce chapitre, vous apprendrez à prétraiter les données brutes et à créer un jeu de données propre et significatif pour une utilisation ultérieure.
Tout d'abord, vous apprendrez à charger le fichier de données dans l'explorateur WEKA. Les données peuvent être chargées à partir des sources suivantes -
- Système de fichiers local
- Web
- Database
Dans ce chapitre, nous verrons en détail les trois options de chargement des données.
Chargement de données à partir du système de fichiers local
Juste sous les onglets Machine Learning que vous avez étudiés dans la leçon précédente, vous trouverez les trois boutons suivants -
- Fichier ouvert …
- Ouvrir le lien …
- Ouvrir DB…
Clique sur le Open file... bouton. Une fenêtre de navigateur de répertoire s'ouvre comme indiqué dans l'écran suivant -
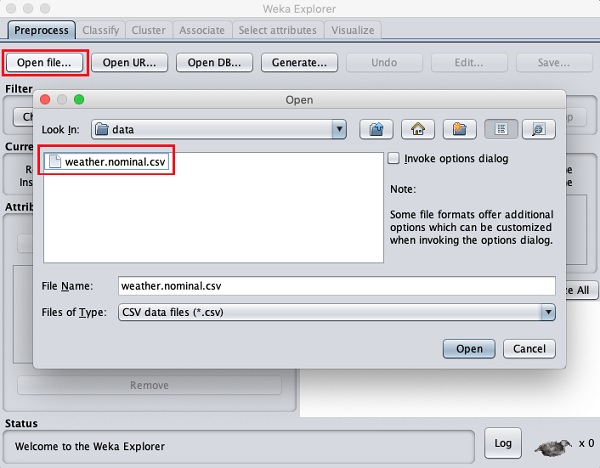
Maintenant, accédez au dossier dans lequel vos fichiers de données sont stockés. L'installation de WEKA propose de nombreux exemples de bases de données que vous pouvez expérimenter. Ceux-ci sont disponibles dans ledata dossier de l'installation WEKA.
À des fins d'apprentissage, sélectionnez n'importe quel fichier de données dans ce dossier. Le contenu du fichier serait chargé dans l'environnement WEKA. Nous apprendrons très prochainement à inspecter et traiter ces données chargées. Avant cela, voyons comment charger le fichier de données à partir du Web.
Chargement de données depuis le Web
Une fois que vous cliquez sur le Open URL … bouton, vous pouvez voir une fenêtre comme suit -
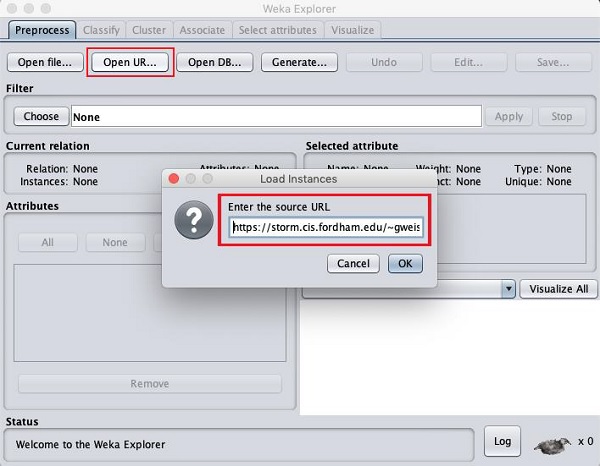
Nous allons ouvrir le fichier à partir d'une URL publique Tapez l'URL suivante dans la boîte contextuelle -
https://storm.cis.fordham.edu/~gweiss/data-mining/weka-data/weather.nominal.arff
Vous pouvez spécifier toute autre URL où vos données sont stockées. leExplorer chargera les données du site distant dans son environnement.
Chargement de données à partir de la base de données
Une fois que vous cliquez sur le Open DB ..., vous pouvez voir une fenêtre comme suit -
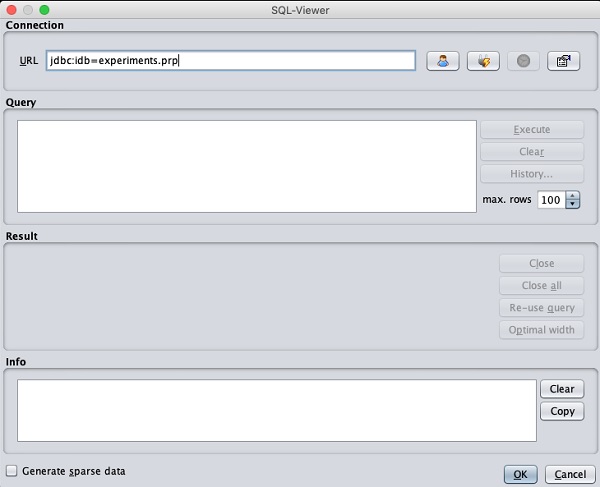
Définissez la chaîne de connexion à votre base de données, configurez la requête pour la sélection des données, traitez la requête et chargez les enregistrements sélectionnés dans WEKA.
WEKA prend en charge un grand nombre de formats de fichiers pour les données. Voici la liste complète -
- arff
- arff.gz
- bsi
- csv
- dat
- data
- json
- json.gz
- libsvm
- m
- names
- xrff
- xrff.gz
Les types de fichiers qu'il prend en charge sont répertoriés dans la zone de liste déroulante au bas de l'écran. Ceci est montré dans la capture d'écran ci-dessous.
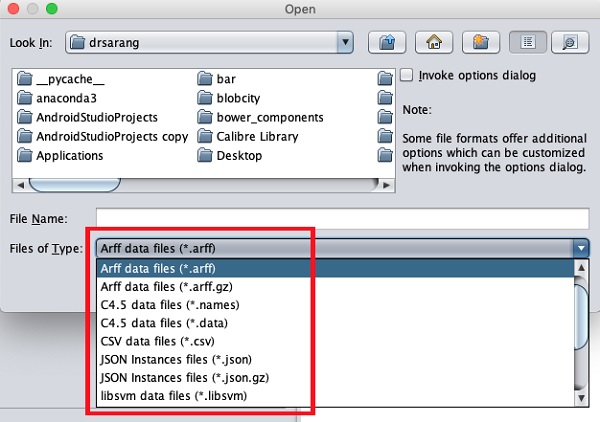
Comme vous le remarquerez, il prend en charge plusieurs formats, notamment CSV et JSON. Le type de fichier par défaut est Arff.
Format Arff
Un Arff Le fichier contient deux sections - en-tête et données.
- L'en-tête décrit les types d'attributs.
- La section de données contient une liste de données séparées par des virgules.
À titre d'exemple pour le format Arff, le Weather Le fichier de données chargé à partir des exemples de bases de données WEKA est illustré ci-dessous -

À partir de la capture d'écran, vous pouvez déduire les points suivants -
La balise @relation définit le nom de la base de données.
La balise @attribute définit les attributs.
La balise @data démarre la liste des lignes de données contenant chacune les champs séparés par des virgules.
Les attributs peuvent prendre des valeurs nominales comme dans le cas des perspectives présentées ici -
@attribute outlook (sunny, overcast, rainy)Les attributs peuvent prendre des valeurs réelles comme dans ce cas -
@attribute temperature realVous pouvez également définir une cible ou une variable de classe appelée play, comme indiqué ici -
@attribute play (yes, no)La cible suppose deux valeurs nominales oui ou non.
Autres formats
L'explorateur peut charger les données dans l'un des formats mentionnés précédemment. Comme arff est le format préféré dans WEKA, vous pouvez charger les données de n'importe quel format et les enregistrer au format arff pour une utilisation ultérieure. Après avoir prétraité les données, enregistrez-les simplement au format arff pour une analyse plus approfondie.
Maintenant que vous avez appris à charger des données dans WEKA, dans le chapitre suivant, vous apprendrez comment prétraiter les données.
Les données collectées sur le terrain contiennent de nombreux éléments indésirables qui conduisent à une analyse erronée. Par exemple, les données peuvent contenir des champs nuls, elles peuvent contenir des colonnes qui ne sont pas pertinentes pour l'analyse en cours, etc. Ainsi, les données doivent être prétraitées pour répondre aux exigences du type d'analyse que vous recherchez. Ceci est fait dans le module de prétraitement.
Pour démontrer les fonctionnalités disponibles en prétraitement, nous utiliserons le Weather base de données fournie dans l'installation.
En utilisant le Open file ... option sous le Preprocess tag sélectionnez le weather-nominal.arff fichier.
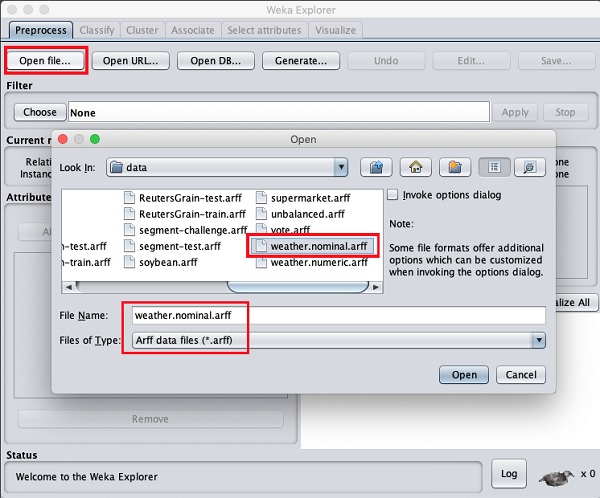
Lorsque vous ouvrez le fichier, votre écran ressemble à celui illustré ici -
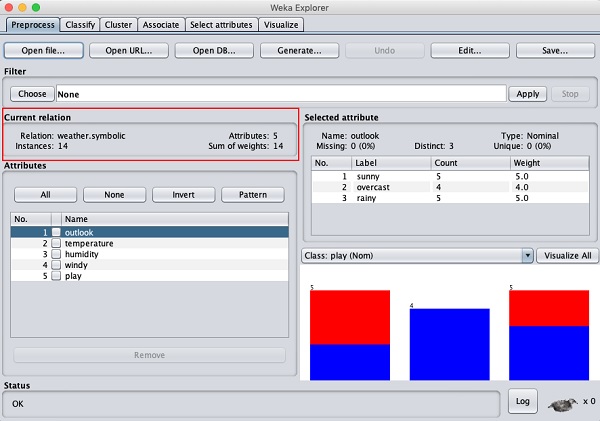
Cet écran nous dit plusieurs choses sur les données chargées, qui sont abordées plus loin dans ce chapitre.
Comprendre les données
Regardons d'abord le surligné Current relationsous-fenêtre. Il affiche le nom de la base de données actuellement chargée. Vous pouvez déduire deux points à partir de cette sous-fenêtre -
Il y a 14 instances - le nombre de lignes dans le tableau.
Le tableau contient 5 attributs - les champs, qui sont traités dans les sections à venir.
Sur le côté gauche, remarquez le Attributes sous-fenêtre qui affiche les différents champs de la base de données.
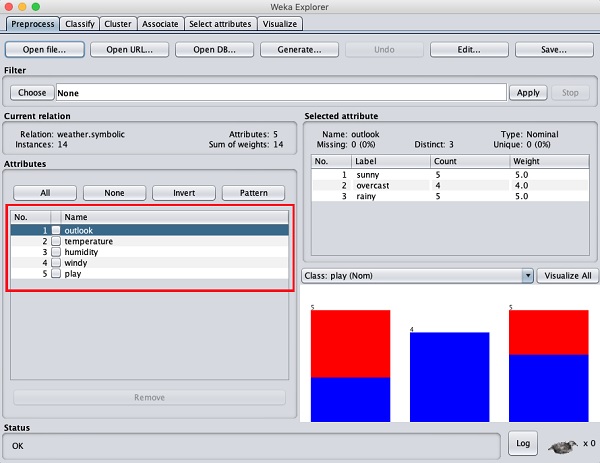
le weatherLa base de données contient cinq champs - perspectives, température, humidité, vent et jeu. Lorsque vous sélectionnez un attribut dans cette liste en cliquant dessus, des détails supplémentaires sur l'attribut lui-même sont affichés sur le côté droit.
Sélectionnons d'abord l'attribut température. Lorsque vous cliquez dessus, vous verrez l'écran suivant -
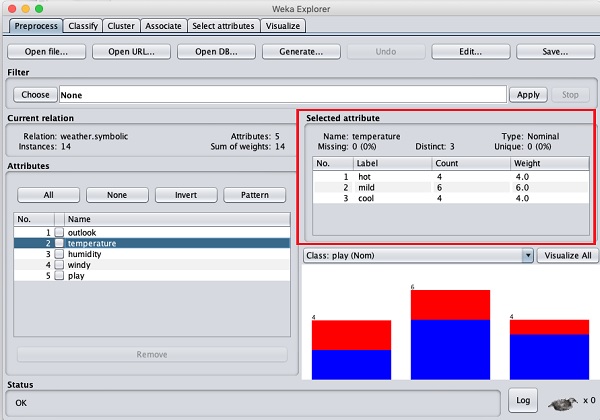
dans le Selected Attribute sous-fenêtre, vous pouvez observer ce qui suit -
Le nom et le type de l'attribut sont affichés.
Le type pour le temperature l'attribut est Nominal.
Le nombre de Missing valeurs est zéro.
Il existe trois valeurs distinctes sans valeur unique.
Le tableau sous ces informations montre les valeurs nominales pour ce champ comme chaud, doux et froid.
Il montre également le nombre et le poids en termes de pourcentage pour chaque valeur nominale.
Au bas de la fenêtre, vous voyez la représentation visuelle du class valeurs.
Si vous cliquez sur le Visualize All bouton, vous pourrez voir toutes les fonctionnalités dans une seule fenêtre comme indiqué ici -
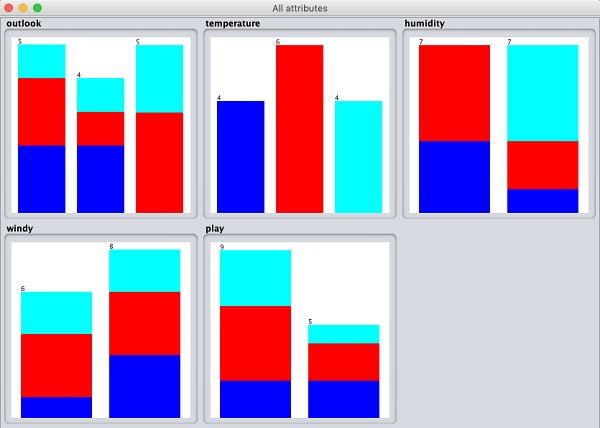
Suppression d'attributs
Souvent, les données que vous souhaitez utiliser pour la création de modèles sont fournies avec de nombreux champs non pertinents. Par exemple, la base de données clients peut contenir son numéro de mobile qui est pertinent pour l'analyse de sa cote de crédit.
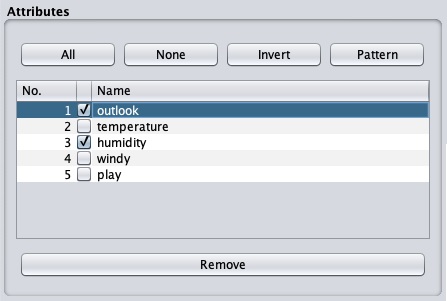
Pour supprimer les attributs, sélectionnez-les et cliquez sur le Remove bouton en bas.
Les attributs sélectionnés seraient supprimés de la base de données. Après avoir prétraité complètement les données, vous pouvez les enregistrer pour la création de modèles.
Ensuite, vous apprendrez à prétraiter les données en appliquant des filtres sur ces données.
Appliquer des filtres
Certaines des techniques d'apprentissage automatique telles que l'exploration de règles d'association nécessitent des données catégorielles. Pour illustrer l'utilisation des filtres, nous utiliseronsweather-numeric.arff base de données qui contient deux numeric les attributs - temperature et humidity.
Nous allons les convertir en nominalen appliquant un filtre sur nos données brutes. Clique sur leChoose bouton dans le Filter sous-fenêtre et sélectionnez le filtre suivant -
weka→filters→supervised→attribute→Discretize

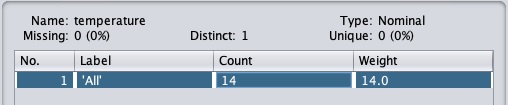
Clique sur le Apply et examinez le temperature et / ou humidityattribut. Vous remarquerez que ceux-ci sont passés du type numérique au type nominal.
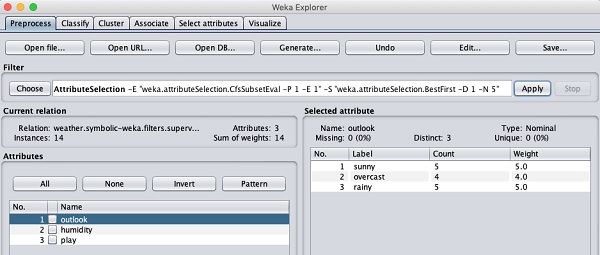
Examinons maintenant un autre filtre. Supposons que vous souhaitiez sélectionner les meilleurs attributs pour décider duplay. Sélectionnez et appliquez le filtre suivant -
weka→filters→supervised→attribute→AttributeSelection
Vous remarquerez qu'il supprime les attributs de température et d'humidité de la base de données.
Une fois que vous êtes satisfait du prétraitement de vos données, enregistrez les données en cliquant sur le bouton Save... bouton. Vous utiliserez ce fichier enregistré pour la construction du modèle.
Dans le chapitre suivant, nous explorerons la construction de modèles à l'aide de plusieurs algorithmes de ML prédéfinis.
De nombreuses applications d'apprentissage automatique sont liées à la classification. Par exemple, vous pouvez classer une tumeur comme maligne ou bénigne. Vous voudrez peut-être décider de jouer à un jeu extérieur en fonction des conditions météorologiques. En général, cette décision dépend de plusieurs caractéristiques / conditions météorologiques. Vous préférerez peut-être utiliser un classificateur d'arbre pour décider de jouer ou non.
Dans ce chapitre, nous allons apprendre à construire un tel classificateur d'arbres sur les données météorologiques pour décider des conditions de jeu.
Définition des données de test
Nous utiliserons le fichier de données météorologiques prétraité de la leçon précédente. Ouvrez le fichier enregistré en utilisant leOpen file ... option sous le Preprocess onglet, cliquez sur Classify onglet, et vous verriez l'écran suivant -
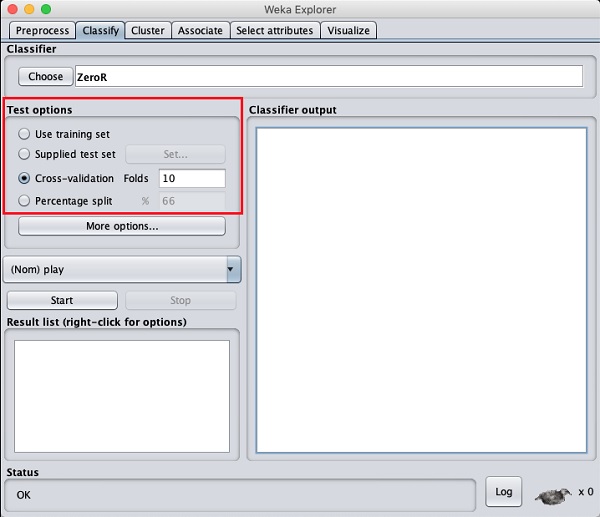
Avant de vous renseigner sur les classificateurs disponibles, examinons les options de test. Vous remarquerez quatre options de test énumérées ci-dessous -
- Ensemble d'entraînement
- Kit de test fourni
- Cross-validation
- Partage en pourcentage
À moins que vous n'ayez votre propre ensemble de formation ou un ensemble de test fourni par le client, vous utiliserez des options de validation croisée ou de répartition en pourcentage. Dans le cadre de la validation croisée, vous pouvez définir le nombre de plis dans lesquels des données entières seraient divisées et utilisées lors de chaque itération d'entraînement. Dans la répartition en pourcentage, vous diviserez les données entre la formation et les tests en utilisant le pourcentage de répartition défini.
Maintenant, gardez la valeur par défaut play option pour la classe de sortie -
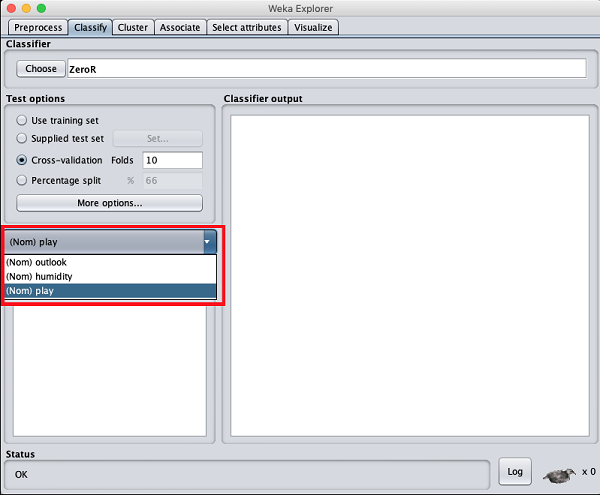
Ensuite, vous sélectionnerez le classificateur.
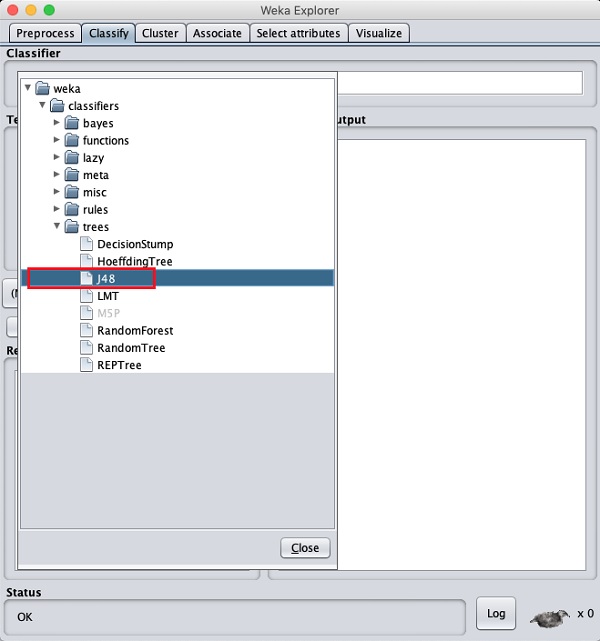
Sélection du classificateur
Cliquez sur le bouton Choisir et sélectionnez le classificateur suivant -
weka→classifiers>trees>J48
Ceci est montré dans la capture d'écran ci-dessous -
Clique sur le Startbouton pour démarrer le processus de classification. Après un certain temps, les résultats de la classification seraient présentés sur votre écran comme indiqué ici -
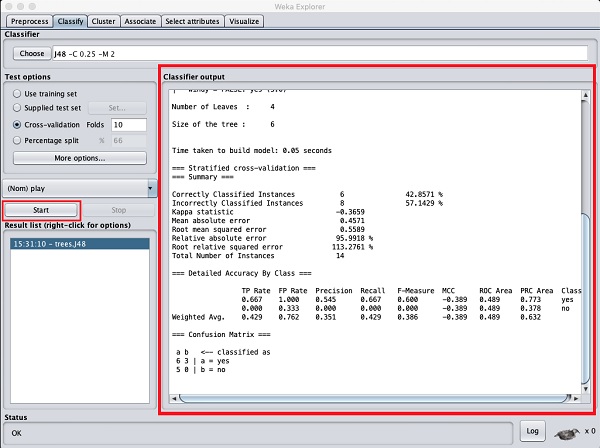
Examinons la sortie affichée sur le côté droit de l'écran.
Il indique que la taille de l'arbre est de 6. Vous verrez très bientôt la représentation visuelle de l'arbre. Dans le résumé, il est indiqué que les instances correctement classées comme 2 et les instances incorrectement classées comme 3, Il indique également que l'erreur absolue relative est de 110%. Il montre également la matrice de confusion. Entrer dans l'analyse de ces résultats dépasse le cadre de ce tutoriel. Cependant, vous pouvez facilement comprendre à partir de ces résultats que la classification n'est pas acceptable et que vous aurez besoin de plus de données pour l'analyse, pour affiner votre sélection de fonctionnalités, reconstruire le modèle, etc. jusqu'à ce que vous soyez satisfait de la précision du modèle. Quoi qu'il en soit, c'est ce qu'est WEKA. Il vous permet de tester vos idées rapidement.
Visualisez les résultats
Pour voir la représentation visuelle des résultats, faites un clic droit sur le résultat dans le Result listboîte. Plusieurs options apparaîtraient à l'écran comme indiqué ici -
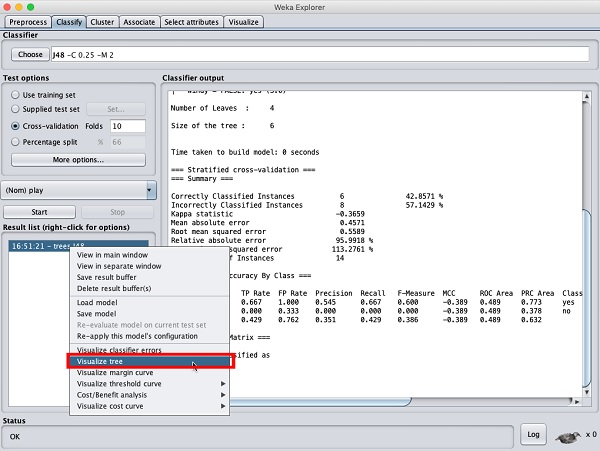
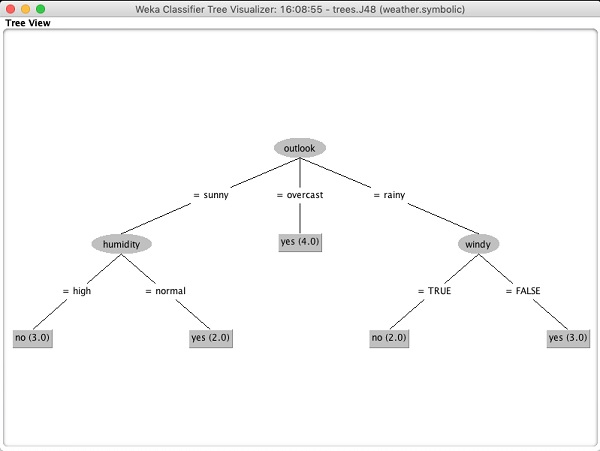
Sélectionner Visualize tree pour obtenir une représentation visuelle de l'arborescence de parcours comme le montre la capture d'écran ci-dessous -
Sélection Visualize classifier errors tracerait les résultats de la classification comme indiqué ici -
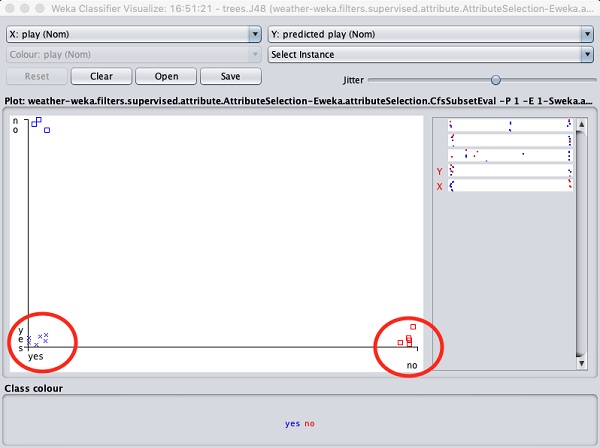
UNE cross représente une instance correctement classée tandis que squaresreprésente des instances incorrectement classées. Dans le coin inférieur gauche de l'intrigue, vous voyez uncross cela indique si outlook est ensoleillé alors playle jeu. Il s'agit donc d'une instance correctement classée. Pour localiser des instances, vous pouvez y introduire une certaine gigue en faisant glisser lejitter barre coulissante.
Le tracé actuel est outlook contre play. Celles-ci sont indiquées par les deux listes déroulantes en haut de l'écran.
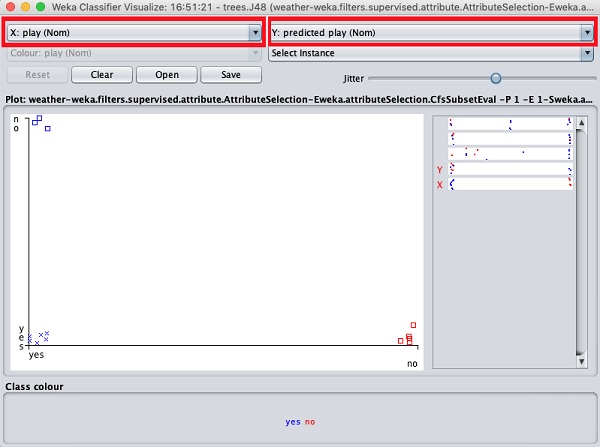
Maintenant, essayez une sélection différente dans chacune de ces cases et remarquez comment les axes X et Y changent. La même chose peut être obtenue en utilisant les bandes horizontales sur le côté droit de la parcelle. Chaque bande représente un attribut. Un clic gauche sur la bande définit l'attribut sélectionné sur l'axe X tandis qu'un clic droit le place sur l'axe Y.
Il existe plusieurs autres graphiques fournis pour votre analyse plus approfondie. Utilisez-les judicieusement pour affiner votre modèle. Un tel complot deCost/Benefit analysis est illustré ci-dessous pour votre référence rapide.
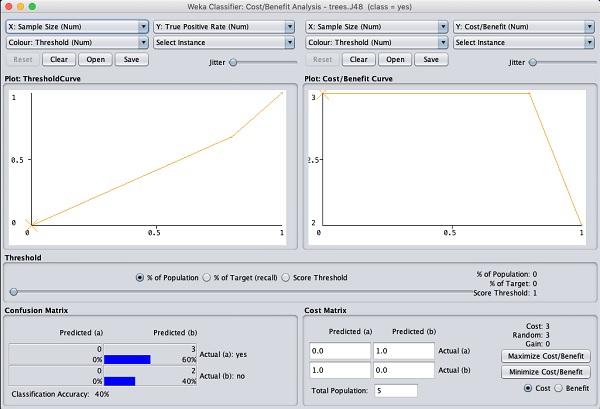
Expliquer l'analyse dans ces graphiques dépasse le cadre de ce didacticiel. Le lecteur est encouragé à parfaire ses connaissances en analyse des algorithmes d'apprentissage automatique.
Dans le chapitre suivant, nous allons apprendre le prochain ensemble d'algorithmes d'apprentissage automatique, à savoir le clustering.
Un algorithme de clustering trouve des groupes d'instances similaires dans l'ensemble de données. WEKA prend en charge plusieurs algorithmes de clustering tels que EM, FilteredClusterer, HierarchicalClusterer, SimpleKMeans, etc. Vous devez comprendre complètement ces algorithmes pour exploiter pleinement les capacités WEKA.
Comme dans le cas de la classification, WEKA permet de visualiser graphiquement les clusters détectés. Pour démontrer le clustering, nous utiliserons la base de données iris fournie. L'ensemble de données contient trois classes de 50 instances chacune. Chaque classe fait référence à un type de plante iris.
Chargement des données
Dans l'explorateur WEKA, sélectionnez le Preprocesslanguette. Clique sur leOpen file ... et sélectionnez l'option iris.arfffichier dans la boîte de dialogue de sélection de fichier. Lorsque vous chargez les données, l'écran ressemble à celui ci-dessous -
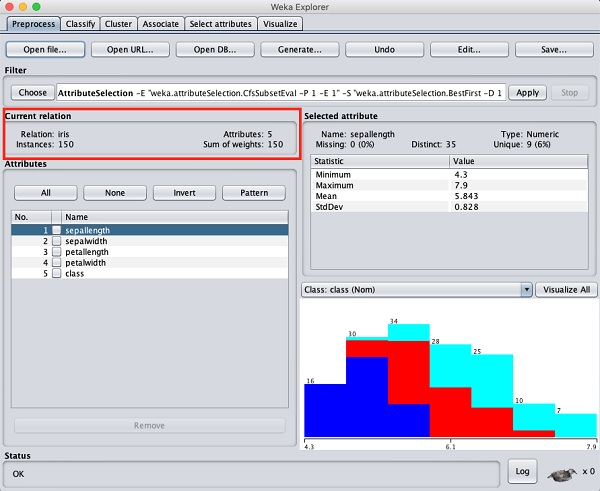
Vous pouvez observer qu'il existe 150 instances et 5 attributs. Les noms des attributs sont répertoriés commesepallength, sepalwidth, petallength, petalwidth et class. Les quatre premiers attributs sont de type numérique tandis que la classe est un type nominal avec 3 valeurs distinctes. Examinez chaque attribut pour comprendre les fonctionnalités de la base de données. Nous n'effectuerons aucun prétraitement sur ces données et procéderons immédiatement à la construction du modèle.
Clustering
Clique sur le ClusterTAB pour appliquer les algorithmes de clustering à nos données chargées. Clique sur leChoosebouton. Vous verrez l'écran suivant -

Maintenant, sélectionnez EMcomme algorithme de clustering. dans leCluster mode sous-fenêtre, sélectionnez le Classes to clusters evaluation option comme indiqué dans la capture d'écran ci-dessous -

Clique sur le Startbouton pour traiter les données. Après un certain temps, les résultats seront présentés à l'écran.
Ensuite, étudions les résultats.
Examen de la sortie
La sortie du traitement des données est affichée dans l'écran ci-dessous -
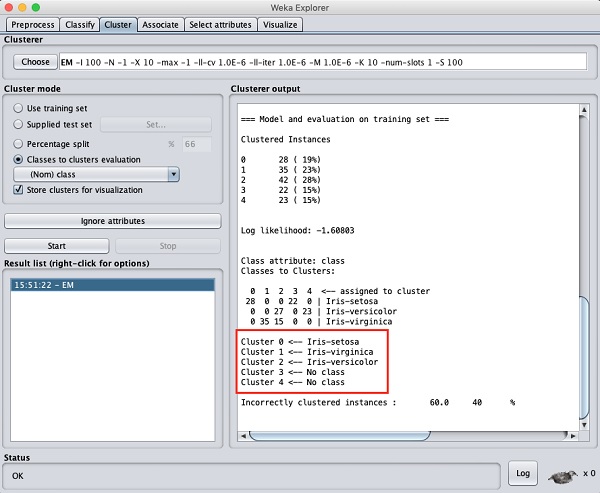
Depuis l'écran de sortie, vous pouvez observer que -
Il y a 5 instances en cluster détectées dans la base de données.
le Cluster 0 représente setosa, Cluster 1 représente virginica, Cluster 2 représente le versicolor, tandis que les deux derniers clusters ne sont associés à aucune classe.
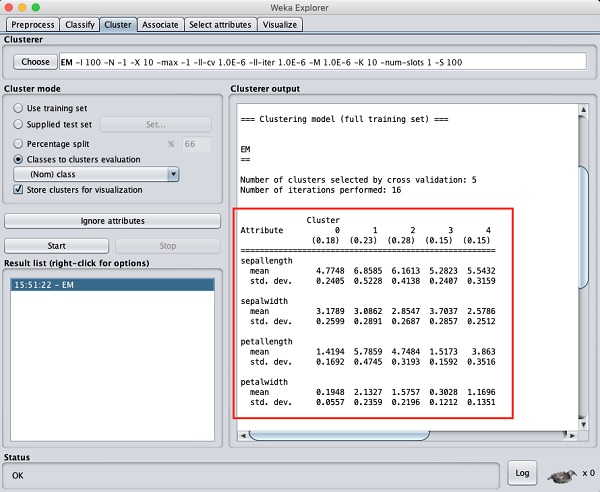
Si vous faites défiler la fenêtre de sortie, vous verrez également des statistiques qui donnent la moyenne et l'écart type pour chacun des attributs dans les différents clusters détectés. Ceci est montré dans la capture d'écran ci-dessous -
Ensuite, nous examinerons la représentation visuelle des clusters.
Visualiser les clusters
Pour visualiser les clusters, faites un clic droit sur le EM aboutir à la Result list. Vous verrez les options suivantes -
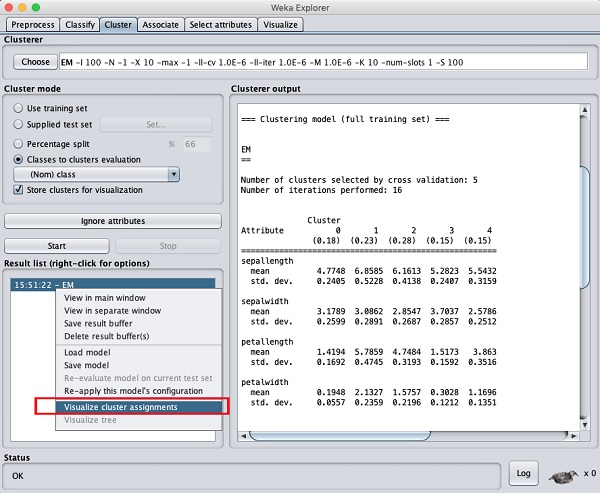
Sélectionner Visualize cluster assignments. Vous verrez la sortie suivante -
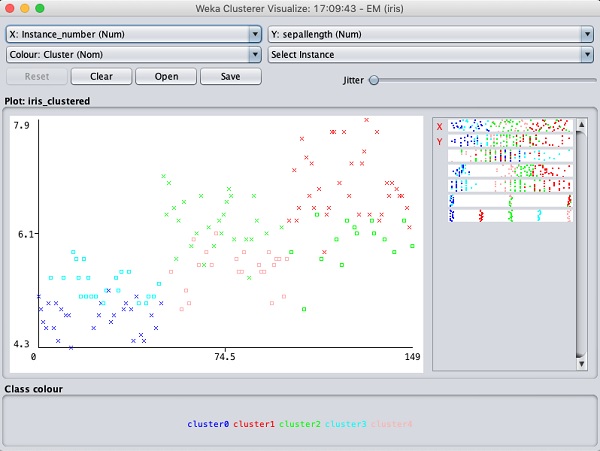
Comme dans le cas de la classification, vous remarquerez la distinction entre les instances correctement et incorrectement identifiées. Vous pouvez jouer en modifiant les axes X et Y pour analyser les résultats. Vous pouvez utiliser la gigue comme dans le cas de la classification pour connaître la concentration d'instances correctement identifiées. Les opérations dans le tracé de visualisation sont similaires à celle que vous avez étudiée dans le cas de la classification.
Application du clustering hiérarchique
Pour démontrer la puissance de WEKA, examinons maintenant une application d'un autre algorithme de clustering. Dans l'explorateur WEKA, sélectionnez leHierarchicalClusterer comme votre algorithme ML comme indiqué dans la capture d'écran ci-dessous -
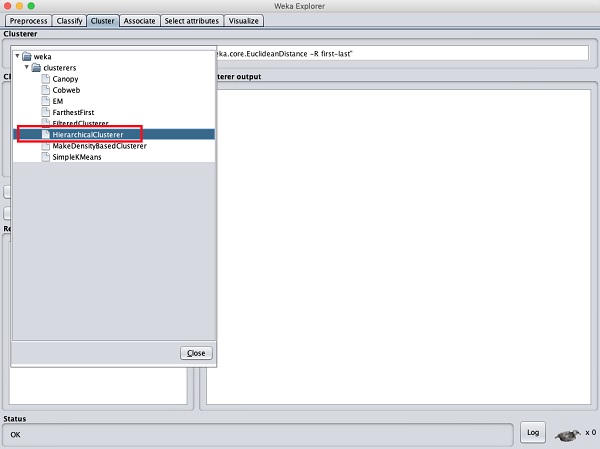
Choisir la Cluster mode sélection à Classes to cluster evaluation, et cliquez sur le Startbouton. Vous verrez la sortie suivante -
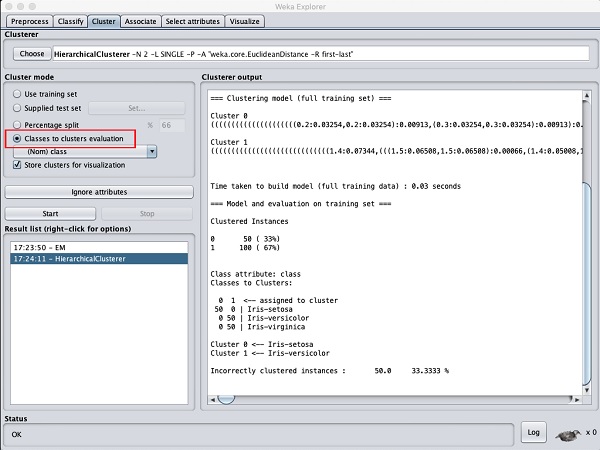
Notez que dans le Result list, deux résultats sont répertoriés: le premier est le résultat EM et le second est le résultat hiérarchique actuel. De même, vous pouvez appliquer plusieurs algorithmes ML au même jeu de données et comparer rapidement leurs résultats.
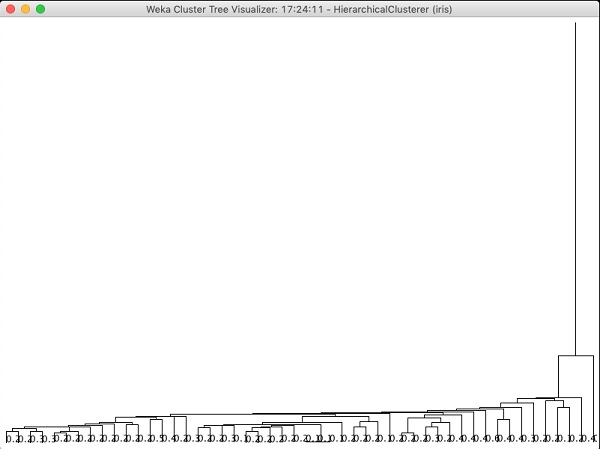
Si vous examinez l'arborescence produite par cet algorithme, vous verrez la sortie suivante -
Dans le chapitre suivant, vous étudierez les Associate type d'algorithmes ML.
Il a été observé que les personnes qui achètent de la bière achètent également des couches en même temps. C'est qu'il y a une association qui achète de la bière et des couches ensemble. Bien que cela ne semble pas très convaincant, cette règle d'association a été extraite d'énormes bases de données de supermarchés. De même, une association peut être trouvée entre le beurre d'arachide et le pain.
Trouver de telles associations devient vital pour les supermarchés, car ils stockent des couches à côté des bières afin que les clients puissent localiser facilement les deux articles, ce qui entraîne une augmentation des ventes pour le supermarché.
le AprioriL'algorithme est l'un de ces algorithmes dans ML qui découvre les associations probables et crée des règles d'association. WEKA fournit la mise en œuvre de l'algorithme Apriori. Vous pouvez définir la prise en charge minimale et un niveau de confiance acceptable lors du calcul de ces règles. Vous appliquerez leApriori algorithme au supermarket données fournies dans l'installation WEKA.
Chargement des données
Dans l'explorateur WEKA, ouvrez le Preprocess onglet, cliquez sur Open file ... et sélectionnez supermarket.arffbase de données du dossier d'installation. Une fois les données chargées, vous verrez l'écran suivant -
La base de données contient 4627 instances et 217 attributs. Vous pouvez facilement comprendre à quel point il serait difficile de détecter l'association entre un si grand nombre d'attributs. Heureusement, cette tâche est automatisée à l'aide de l'algorithme Apriori.
Associateur
Clique sur le Associate TAB et cliquez sur le Choosebouton. Sélectionnez leApriori association comme indiqué sur la capture d'écran -
Pour définir les paramètres de l'algorithme Apriori, cliquez sur son nom, une fenêtre apparaîtra comme indiqué ci-dessous qui vous permet de définir les paramètres -
Après avoir défini les paramètres, cliquez sur le bouton Startbouton. Après un certain temps, vous verrez les résultats comme indiqué dans la capture d'écran ci-dessous -
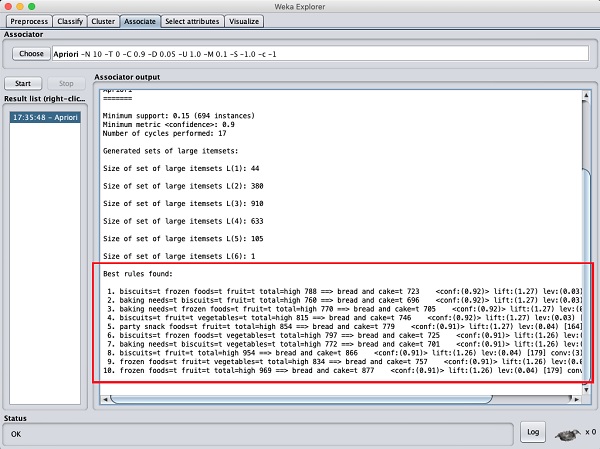
En bas, vous trouverez les meilleures règles d'associations détectées. Cela aidera le supermarché à stocker ses produits dans les rayons appropriés.
Lorsqu'une base de données contient un grand nombre d'attributs, il y aura plusieurs attributs qui ne deviennent pas significatifs dans l'analyse que vous recherchez actuellement. Ainsi, la suppression des attributs indésirables de l'ensemble de données devient une tâche importante dans le développement d'un bon modèle d'apprentissage automatique.
Vous pouvez examiner l'ensemble de données visuellement et décider des attributs non pertinents. Cela pourrait être une tâche énorme pour les bases de données contenant un grand nombre d'attributs comme le cas de supermarché que vous avez vu dans une leçon précédente. Heureusement, WEKA fournit un outil automatisé pour la sélection des fonctionnalités.
Ce chapitre présente cette fonctionnalité sur une base de données contenant un grand nombre d'attributs.
Chargement des données
dans le Preprocess balise de l'explorateur WEKA, sélectionnez le labor.arfffichier à charger dans le système. Lorsque vous chargez les données, vous verrez l'écran suivant -
Notez qu'il y a 17 attributs. Notre tâche est de créer un ensemble de données réduit en éliminant certains des attributs qui ne sont pas pertinents pour notre analyse.
Extraction de fonctionnalités
Clique sur le Select attributesTAB Vous verrez l'écran suivant -
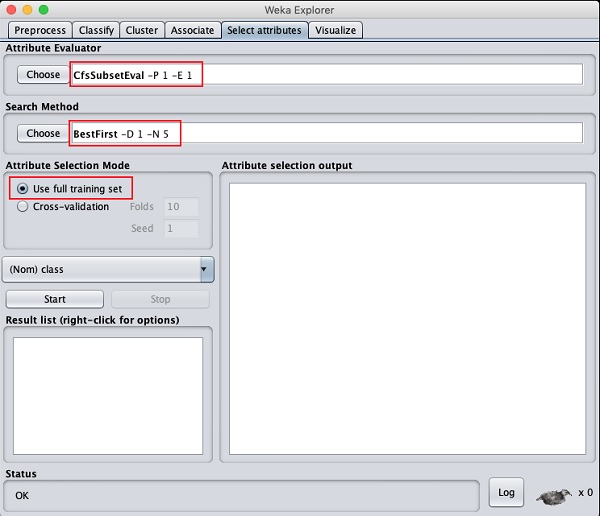
Sous le Attribute Evaluator et Search Method, vous trouverez plusieurs options. Nous utiliserons simplement les valeurs par défaut ici. dans leAttribute Selection Mode, utilisez l'option d'ensemble d'entraînement complet.
Cliquez sur le bouton Démarrer pour traiter l'ensemble de données. Vous verrez la sortie suivante -

Au bas de la fenêtre de résultats, vous obtiendrez la liste des Selectedles attributs. Pour obtenir la représentation visuelle, faites un clic droit sur le résultat dans leResult liste.
La sortie est affichée dans la capture d'écran suivante -
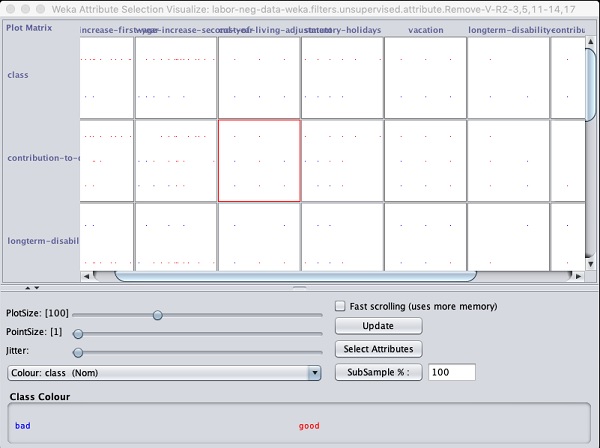
En cliquant sur l'un des carrés, vous obtiendrez le graphique de données pour votre analyse ultérieure. Un graphique de données typique est présenté ci-dessous -
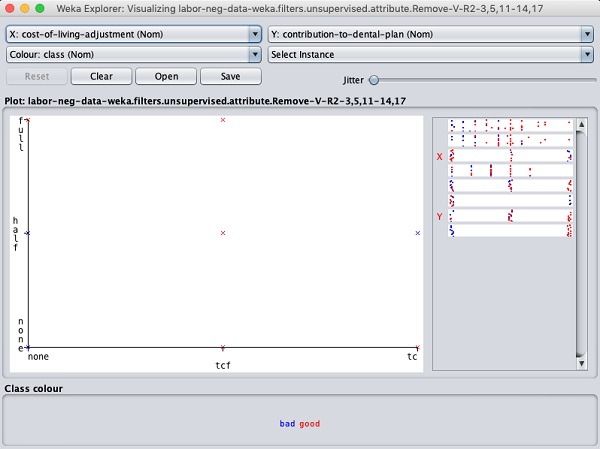
Ceci est similaire à ceux que nous avons vus dans les chapitres précédents. Jouez avec les différentes options disponibles pour analyser les résultats.
Et après?
Vous avez vu jusqu'à présent la puissance de WEKA dans le développement rapide de modèles d'apprentissage automatique. Ce que nous avons utilisé est un outil graphique appeléExplorerpour développer ces modèles. WEKA fournit également une interface de ligne de commande qui vous donne plus de puissance que celle fournie dans l'explorateur.
En cliquant sur le Simple CLI bouton dans le GUI Chooser l'application démarre cette interface de ligne de commande qui est montrée dans la capture d'écran ci-dessous -
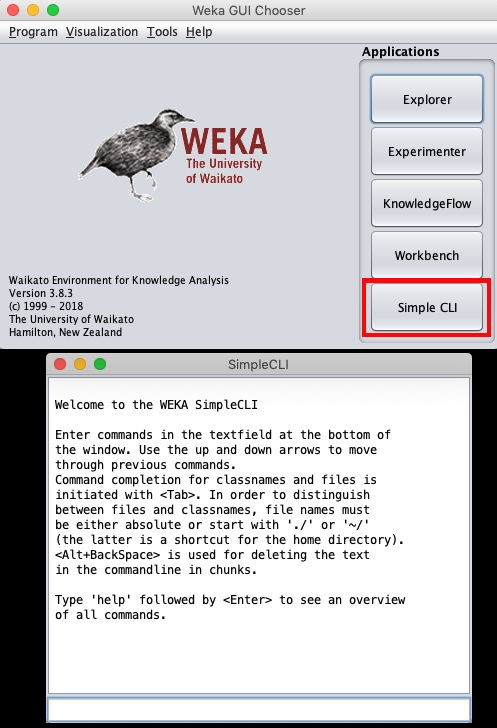
Tapez vos commandes dans la zone de saisie en bas. Vous pourrez faire tout ce que vous avez fait jusqu'à présent dans l'explorateur et bien plus encore. Reportez-vous à la documentation WEKA (https://www.cs.waikato.ac.nz/ml/weka/documentation.html) pour plus de détails.
Enfin, WEKA est développé en Java et fournit une interface à son API. Donc, si vous êtes un développeur Java et que vous souhaitez inclure des implémentations WEKA ML dans vos propres projets Java, vous pouvez le faire facilement.
Conclusion
WEKA est un outil puissant pour développer des modèles d'apprentissage automatique. Il fournit la mise en œuvre de plusieurs algorithmes de ML les plus largement utilisés. Avant que ces algorithmes ne soient appliqués à votre ensemble de données, cela vous permet également de prétraiter les données. Les types d'algorithmes pris en charge sont classés sous les attributs Classify, Cluster, Associate et Select. Le résultat à différentes étapes du traitement peut être visualisé avec une représentation visuelle belle et puissante. Cela permet à un Data Scientist d'appliquer rapidement les différentes techniques d'apprentissage automatique sur son ensemble de données, de comparer les résultats et de créer le meilleur modèle pour l'utilisation finale.