अपाचे एमएक्सनेट - पायथन पैकेज
इस अध्याय में हम Apache MXNet में उपलब्ध पायथन पैकेज के बारे में जानेंगे।
महत्वपूर्ण एमएक्सनेट पायथन पैकेज
एमएक्सनेट में निम्नलिखित महत्वपूर्ण पायथन पैकेज हैं जिनकी चर्चा हम एक-एक करके करेंगे -
ऑटोग्राड (स्वचालित भेदभाव)
NDArray
KVStore
Gluon
Visualization
पहले हम शुरुआत करते हैं Autograd Apache MXNet के लिए पायथन पैकेज।
Autograd
Autograd के लिए खड़ा है automatic differentiationनुकसान मीट्रिक से ग्रेडिएटर्स को बैकप्रॉपैगेट करने के लिए उपयोग किया जाता है जो प्रत्येक पैरामीटर में वापस होता है। बैकप्रॉपैगैनेशन के साथ यह ग्रेडिएंट्स की कुशलता से गणना करने के लिए एक गतिशील प्रोग्रामिंग दृष्टिकोण का उपयोग करता है। इसे रिवर्स मोड स्वचालित भेदभाव भी कहा जाता है। यह तकनीक 'फैन-इन' स्थितियों में बहुत कुशल है, जहाँ कई पैरामीटर एकल हानि मीट्रिक को प्रभावित करते हैं।
ग्रेडिएंट्स क्या हैं?
तंत्रिका नेटवर्क प्रशिक्षण की प्रक्रिया के लिए मूल बातें हैं। वे मूल रूप से हमें बताते हैं कि अपने प्रदर्शन को बेहतर बनाने के लिए नेटवर्क के मापदंडों को कैसे बदलना है।
जैसा कि हम जानते हैं कि, तंत्रिका नेटवर्क (NN) संचालक, उत्पाद, दीक्षांत आदि जैसे संचालकों से बने होते हैं। ये संचालक, अपनी संगणना के लिए, संवेग गुठली में भार जैसे मापदंडों का उपयोग करते हैं। हमें इन मापदंडों के लिए इष्टतम मूल्यों को खोजना चाहिए और ग्रेडिएंट हमें रास्ता दिखाता है और हमें समाधान तक भी ले जाता है।
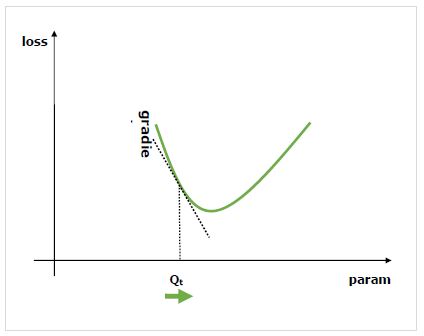
हम नेटवर्क के प्रदर्शन पर एक पैरामीटर को बदलने के प्रभाव में रुचि रखते हैं और ग्रेडिएंट हमें बताते हैं कि जब हम किसी चर को बदलते हैं तो यह किसी चर को बढ़ाता या घटता है। प्रदर्शन आमतौर पर एक नुकसान मीट्रिक का उपयोग करके परिभाषित किया जाता है जिसे हम कम करने की कोशिश करते हैं। उदाहरण के लिए, प्रतिगमन के लिए हम न्यूनतम करने का प्रयास कर सकते हैंL2 हमारी भविष्यवाणियों और सटीक मूल्य के बीच का नुकसान, जबकि वर्गीकरण के लिए हम इसे कम कर सकते हैं cross-entropy loss।
एक बार जब हम नुकसान के संदर्भ में प्रत्येक पैरामीटर के ग्रेडिएंट की गणना करते हैं, तो हम एक आशावादी का उपयोग कर सकते हैं, जैसे स्टोचस्टिक ग्रेडिएंट वंश।
ग्रेडिएंट्स की गणना कैसे करें?
हमारे पास ग्रेडिएंट्स की गणना करने के लिए निम्नलिखित विकल्प हैं -
Symbolic Differentiation- सबसे पहला विकल्प प्रतीकात्मक विभेदीकरण है, जो प्रत्येक ढाल के लिए सूत्रों की गणना करता है। इस पद्धति की खामी यह है कि, यह जल्दी से अविश्वसनीय रूप से लंबे फार्मूले को जन्म देगा क्योंकि नेटवर्क गहरा हो जाता है और ऑपरेटरों को अधिक जटिल हो जाता है।
Finite Differencing- एक अन्य विकल्प, परिमित विभेदक का उपयोग करना है जो प्रत्येक पैरामीटर पर थोड़े अंतर की कोशिश करता है और देखता है कि नुकसान मीट्रिक कैसे प्रतिक्रिया करता है। इस पद्धति का दोष यह है कि, यह कम्प्यूटेशनल रूप से महंगा होगा और इसमें संख्यात्मक संख्यात्मक परिशुद्धता हो सकती है।
Automatic differentiation- उपरोक्त विधियों की कमियों का समाधान है, स्वचालित मापदंडों का उपयोग करने के लिए नुकसान मेट्रिक वापस प्रत्येक पैरामीटर में ग्रेडिएटर्स को बैकप्रोपैगेट का उपयोग करना। प्रसार हमें एक गतिशील प्रोग्रामिंग दृष्टिकोण को कुशलता से गणना करने के लिए अनुमति देता है। इस विधि को रिवर्स मोड स्वचालित भेदभाव भी कहा जाता है।
स्वचालित भेदभाव (ऑटोग्रैड)
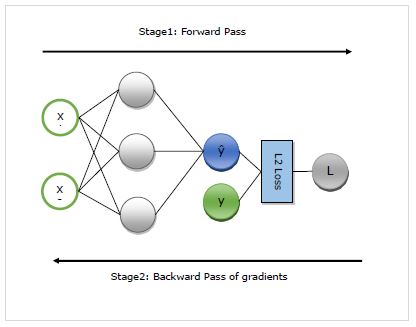
यहां, हम ऑटोग्राड के कामकाज के बारे में विस्तार से समझेंगे। यह मूल रूप से दो चरणों में काम करता है -
Stage 1 - इस अवस्था को कहा जाता है ‘Forward Pass’प्रशिक्षण की। जैसा कि नाम का तात्पर्य है, इस चरण में यह नेटवर्क द्वारा उपयोग किए जाने वाले ऑपरेटर का रिकॉर्ड बनाता है जो पूर्वानुमान बनाने और हानि मीट्रिक की गणना करता है।
Stage 2 - इस अवस्था को कहा जाता है ‘Backward Pass’प्रशिक्षण की। जैसा कि नाम से ही स्पष्ट है, इस अवस्था में यह इस रिकॉर्ड के माध्यम से पीछे की ओर काम करता है। पीछे की ओर जाते हुए, यह प्रत्येक ऑपरेटर के आंशिक डेरिवेटिव का मूल्यांकन करता है, जो सभी नेटवर्क पैरामीटर पर वापस जाता है।
ऑटोग्राड के लाभ
स्वचालित विभेदन (ऑटोग्रैड) का उपयोग करने के फायदे निम्नलिखित हैं -
Flexible- लचीलापन, कि यह हमें देता है जब हमारे नेटवर्क को परिभाषित करता है, ऑटोग्राद का उपयोग करने के विशाल लाभों में से एक है। हम हर पुनरावृत्ति पर परिचालन को बदल सकते हैं। इन्हें डायनेमिक ग्राफ़ कहा जाता है, जो स्थैतिक ग्राफ़ की आवश्यकता वाले फ्रेमवर्क में लागू करने के लिए बहुत अधिक जटिल होते हैं। ऑटोग्राड, यहां तक कि ऐसे मामलों में, अभी भी ग्रेडिएंट को सही ढंग से बैकप्रोपैगेट करने में सक्षम होगा।
Automatic- ऑटोग्रैड स्वचालित है, अर्थात बैकप्रोपैजेशन प्रक्रिया की जटिलताओं को आपके द्वारा ध्यान में रखा जाता है। हमें केवल यह निर्दिष्ट करने की आवश्यकता है कि गणना करने में हमारी रुचि के कौन से ग्रेडिएंट हैं।
Efficient - ऑटोगार्ड बहुत कुशलता से ग्रेडिएंट की गणना करता है।
Can use native Python control flow operators- हम देशी अजगर नियंत्रण प्रवाह संचालकों का उपयोग कर सकते हैं जैसे कि अगर हालत और लूप। ऑटोग्राद अभी भी कुशलतापूर्वक और सही ढंग से ग्रेडिएंट को बैकप्रोपैगेट कर सकेगा।
एमएक्सनेट ग्लोन में ऑटोग्रैड का उपयोग करना
यहां, एक उदाहरण की मदद से, हम देखेंगे कि हम कैसे उपयोग कर सकते हैं autograd एमएक्सनेट ग्लूऑन में।
कार्यान्वयन उदाहरण
निम्नलिखित उदाहरण में, हम दो परतों वाले प्रतिगमन मॉडल को लागू करेंगे। लागू करने के बाद, हम प्रत्येक वज़न मापदंडों के संदर्भ में नुकसान की ग्रेडिएंट की स्वचालित रूप से गणना करने के लिए ऑटोग्राड का उपयोग करेंगे -
पहले ऑटोग्रार्ड और अन्य आवश्यक पैकेजों को निम्नानुसार आयात करें -
from mxnet import autograd
import mxnet as mx
from mxnet.gluon.nn import HybridSequential, Dense
from mxnet.gluon.loss import L2Lossअब, हमें निम्नानुसार नेटवर्क को परिभाषित करने की आवश्यकता है -
N_net = HybridSequential()
N_net.add(Dense(units=3))
N_net.add(Dense(units=1))
N_net.initialize()अब हमें नुकसान को परिभाषित करने की आवश्यकता है -
loss_function = L2Loss()अगला, हमें डमी डेटा बनाने की आवश्यकता है -
x = mx.nd.array([[0.5, 0.9]])
y = mx.nd.array([[1.5]])अब, हम नेटवर्क के माध्यम से अपने पहले फॉरवर्ड पास के लिए तैयार हैं। हम चाहते हैं कि ऑटोग्राद कम्प्यूटेशनल ग्राफ को रिकॉर्ड करें ताकि हम ग्रेडिएंट्स की गणना कर सकें। इसके लिए, हमें इसके दायरे में नेटवर्क कोड को चलाने की आवश्यकता हैautograd.record संदर्भ इस प्रकार है -
with autograd.record():
y_hat = N_net(x)
loss = loss_function(y_hat, y)अब, हम पिछड़े पास के लिए तैयार हैं, जिसे हम ब्याज की मात्रा पर पिछड़े तरीके से कॉल करके शुरू करते हैं। हमारे उदाहरण में ब्याज की कमी नुकसान है क्योंकि हम मापदंडों के संदर्भ में नुकसान की प्रवणता की गणना करने की कोशिश कर रहे हैं -
loss.backward()अब, हमारे पास नेटवर्क के प्रत्येक पैरामीटर के लिए ग्रेडिएंट्स हैं, जिनका उपयोग ऑप्टिमाइज़र द्वारा बेहतर प्रदर्शन के लिए पैरामीटर मान को अपडेट करने के लिए किया जाएगा। आइए 1 परत के ग्रेडिएंट को निम्न प्रकार से देखें -
N_net[0].weight.grad()Output
आउटपुट निम्नानुसार है
[[-0.00470527 -0.00846948]
[-0.03640365 -0.06552657]
[ 0.00800354 0.01440637]]
<NDArray 3x2 @cpu(0)>पूरा कार्यान्वयन उदाहरण
नीचे दिया गया पूरा कार्यान्वयन उदाहरण है।
from mxnet import autograd
import mxnet as mx
from mxnet.gluon.nn import HybridSequential, Dense
from mxnet.gluon.loss import L2Loss
N_net = HybridSequential()
N_net.add(Dense(units=3))
N_net.add(Dense(units=1))
N_net.initialize()
loss_function = L2Loss()
x = mx.nd.array([[0.5, 0.9]])
y = mx.nd.array([[1.5]])
with autograd.record():
y_hat = N_net(x)
loss = loss_function(y_hat, y)
loss.backward()
N_net[0].weight.grad()