अपाचे सोलर - इंडेक्सिंग डेटा
सामान्य रूप में, indexingदस्तावेजों की एक व्यवस्था है या (अन्य संस्थाओं) व्यवस्थित रूप से। इंडेक्सिंग उपयोगकर्ताओं को एक दस्तावेज़ में जानकारी का पता लगाने में सक्षम बनाता है।
इंडेक्सिंग संग्रह, पर्स, और दस्तावेजों को संग्रहीत करता है।
आवश्यक दस्तावेज़ ढूंढते समय खोज क्वेरी की गति और प्रदर्शन को बढ़ाने के लिए अनुक्रमण किया जाता है।
अपाचे सोलर में अनुक्रमण
Apache Solr में, हम विभिन्न डॉक्यूमेंट फॉर्मेट जैसे xml, csv, pdf आदि को इंडेक्स (जोड़, हटा, संशोधित कर सकते हैं) कर सकते हैं। हम कई तरीकों से Solr इंडेक्स में डेटा जोड़ सकते हैं।
इस अध्याय में, हम अनुक्रमण पर चर्चा करने जा रहे हैं -
- सोलर वेब इंटरफेस का उपयोग करना।
- जावा, पायथन आदि जैसे किसी भी क्लाइंट एपीआई का उपयोग करना।
- का उपयोग करते हुए post tool।
इस अध्याय में, हम चर्चा करेंगे कि विभिन्न इंटरफेस (कमांड लाइन, वेब इंटरफेस और जावा क्लाइंट एपीआई) का उपयोग करके अपाचे सोलर के सूचकांक में डेटा कैसे जोड़ा जाए।
पोस्ट कमांड का उपयोग करके दस्तावेज़ जोड़ना
सोलर ने ए post इसकी कमान में bin/निर्देशिका। इस कमांड का उपयोग करके, आप Apache Solr में JSON, XML, CSV जैसी फ़ाइलों के विभिन्न स्वरूपों को अनुक्रमित कर सकते हैं।
के माध्यम से ब्राउज़ करें bin अपाचे सोलर की निर्देशिका और निष्पादित करें –h option पोस्ट कमांड के अनुसार, निम्न कोड ब्लॉक में दिखाया गया है।
[Hadoop@localhost bin]$ cd $SOLR_HOME
[Hadoop@localhost bin]$ ./post -hउपरोक्त कमांड निष्पादित करने पर, आपको विकल्पों की एक सूची मिलेगी post command, जैसा की नीचे दिखाया गया।
Usage: post -c <collection> [OPTIONS] <files|directories|urls|-d [".."]>
or post –help
collection name defaults to DEFAULT_SOLR_COLLECTION if not specified
OPTIONS
=======
Solr options:
-url <base Solr update URL> (overrides collection, host, and port)
-host <host> (default: localhost)
-p or -port <port> (default: 8983)
-commit yes|no (default: yes)
Web crawl options:
-recursive <depth> (default: 1)
-delay <seconds> (default: 10)
Directory crawl options:
-delay <seconds> (default: 0)
stdin/args options:
-type <content/type> (default: application/xml)
Other options:
-filetypes <type>[,<type>,...] (default:
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,
rtf,htm,html,txt,log)
-params "<key> = <value>[&<key> = <value>...]" (values must be
URL-encoded; these pass through to Solr update request)
-out yes|no (default: no; yes outputs Solr response to console)
-format Solr (sends application/json content as Solr commands
to /update instead of /update/json/docs)
Examples:
* JSON file:./post -c wizbang events.json
* XML files: ./post -c records article*.xml
* CSV file: ./post -c signals LATEST-signals.csv
* Directory of files: ./post -c myfiles ~/Documents
* Web crawl: ./post -c gettingstarted http://lucene.apache.org/Solr -recursive 1 -delay 1
* Standard input (stdin): echo '{commit: {}}' | ./post -c my_collection -
type application/json -out yes –d
* Data as string: ./post -c signals -type text/csv -out yes -d $'id,value\n1,0.47'उदाहरण
मान लीजिए हमारे पास एक फाइल है जिसका नाम है sample.csv निम्नलिखित सामग्री के साथ (में bin निर्देशिका)।
| छात्र आईडी | पहला नाम | अंतिम नाम | फ़ोन | Faridabad |
|---|---|---|---|---|
| 001 | राजीव | रेड्डी | 9848022337 | हैदराबाद |
| 002 | सिद्धार्थ | भट्टाचार्य | 9848022338 | कोलकाता |
| 003 | राजेश | खन्ना | 9848022339 | दिल्ली |
| 004 | प्रीती | अग्रवाल | 9848022330 | पुणे |
| 005 | Trupthi | मोहंती | 9848022336 | भुवनेश्वर |
| 006 | अर्चना | मिश्रा | 9848022335 | चेन्नई |
उपर्युक्त डेटासेट में छात्र आईडी, प्रथम नाम, अंतिम नाम, फोन और शहर जैसे व्यक्तिगत विवरण हैं। डेटासेट का CSV फ़ाइल नीचे दिखाया गया है। यहां, आपको ध्यान देना चाहिए कि आपको अपनी पहली पंक्ति का दस्तावेजीकरण करते हुए स्कीमा का उल्लेख करना होगा।
id, first_name, last_name, phone_no, location
001, Pruthvi, Reddy, 9848022337, Hyderabad
002, kasyap, Sastry, 9848022338, Vishakapatnam
003, Rajesh, Khanna, 9848022339, Delhi
004, Preethi, Agarwal, 9848022330, Pune
005, Trupthi, Mohanty, 9848022336, Bhubaneshwar
006, Archana, Mishra, 9848022335, Chennaiआप इस डेटा को नामित कोर के तहत अनुक्रमित कर सकते हैं sample_Solr का उपयोग करते हुए post आदेश निम्नानुसार है -
[Hadoop@localhost bin]$ ./post -c Solr_sample sample.csvउपरोक्त कमांड को निष्पादित करने पर, दिए गए दस्तावेज़ को निर्दिष्ट कोर के तहत अनुक्रमित किया जाता है, जो निम्न आउटपुट उत्पन्न करता है।
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core
6.2.0.jar -Dauto = yes -Dc = Solr_sample -Ddata = files
org.apache.Solr.util.SimplePostTool sample.csv
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/Solr_sample/update...
Entering auto mode. File endings considered are
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,
htm,html,txt,log
POSTing file sample.csv (text/csv) to [base]
1 files indexed.
COMMITting Solr index changes to
http://localhost:8983/Solr/Solr_sample/update...
Time spent: 0:00:00.228निम्नलिखित URL का उपयोग करके सोल वेब यूआई के होमपेज पर जाएं -
http://localhost:8983/
कोर का चयन करें Solr_sample। डिफ़ॉल्ट रूप से, अनुरोध हैंडलर है/selectऔर क्वेरी ":" है। कोई भी संशोधन किए बिना, क्लिक करेंExecuteQuery पृष्ठ के नीचे बटन।
क्वेरी निष्पादित करने पर, आप JSON प्रारूप (डिफ़ॉल्ट) में अनुक्रमित CSV दस्तावेज़ की सामग्री का निरीक्षण कर सकते हैं, जैसा कि निम्नलिखित स्क्रीनशॉट में दिखाया गया है।
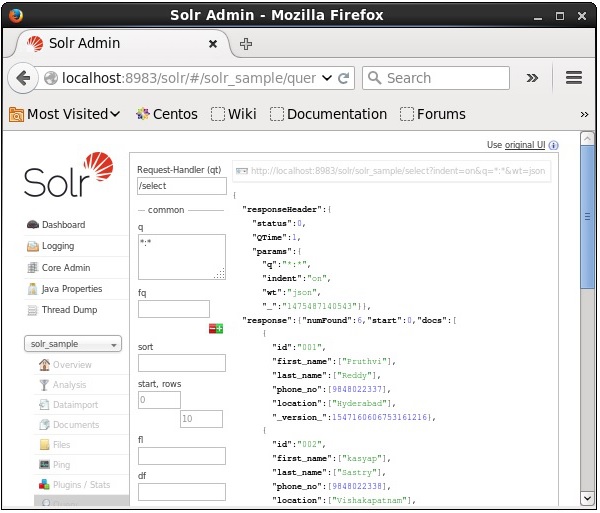
Note - इसी तरह, आप अन्य फाइल फॉर्मेट जैसे कि JSON, XML, CSV इत्यादि को इंडेक्स कर सकते हैं।
सोलर वेब इंटरफ़ेस का उपयोग करके दस्तावेज़ जोड़ना
आप सोल द्वारा प्रदान किए गए वेब इंटरफ़ेस का उपयोग करके दस्तावेज़ों को भी अनुक्रमित कर सकते हैं। आइए देखें कि निम्न JSON डॉक्यूमेंट को कैसे इंडेक्स किया जाए।
[
{
"id" : "001",
"name" : "Ram",
"age" : 53,
"Designation" : "Manager",
"Location" : "Hyderabad",
},
{
"id" : "002",
"name" : "Robert",
"age" : 43,
"Designation" : "SR.Programmer",
"Location" : "Chennai",
},
{
"id" : "003",
"name" : "Rahim",
"age" : 25,
"Designation" : "JR.Programmer",
"Location" : "Delhi",
}
]चरण 1
निम्नलिखित URL का उपयोग करके सोल्र वेब इंटरफ़ेस खोलें -
http://localhost:8983/
Step 2
कोर का चयन करें Solr_sample। डिफ़ॉल्ट रूप से, फ़ील्ड के मान अनुरोध हैंडलर, सामान्य भीतर, ओवरराइट और बूस्ट क्रमशः / अपडेट, 1000, सत्य और 1.0 हैं, जैसा कि निम्नलिखित स्क्रीनशॉट में दिखाया गया है।
अब, JSON, CSV, XML, आदि से इच्छित दस्तावेज़ प्रारूप चुनें। पाठ क्षेत्र में अनुक्रमित किए जाने वाले दस्तावेज़ को टाइप करें और क्लिक करें Submit Document बटन, जैसा कि निम्नलिखित स्क्रीनशॉट में दिखाया गया है।
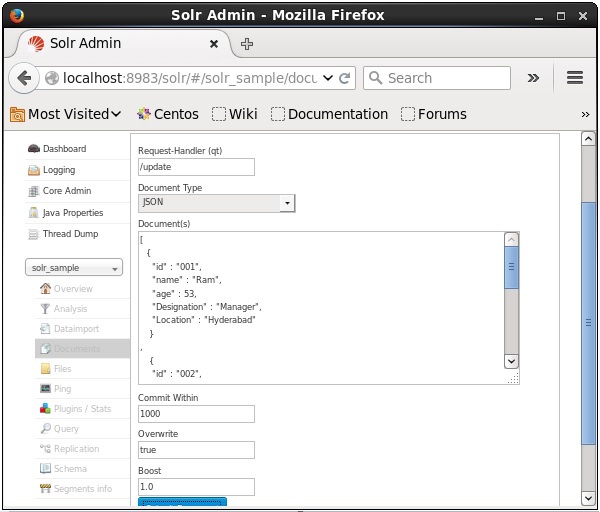
जावा क्लाइंट एपीआई का उपयोग करके दस्तावेज़ जोड़ना
Apache Solr इंडेक्स में दस्तावेज़ों को जोड़ने के लिए जावा प्रोग्राम है। इस कोड को नाम वाली फ़ाइल में सहेजेंAddingDocument.java।
import java.io.IOException;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.common.SolrInputDocument;
public class AddingDocument {
public static void main(String args[]) throws Exception {
//Preparing the Solr client
String urlString = "http://localhost:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
//Adding fields to the document
doc.addField("id", "003");
doc.addField("name", "Rajaman");
doc.addField("age","34");
doc.addField("addr","vishakapatnam");
//Adding the document to Solr
Solr.add(doc);
//Saving the changes
Solr.commit();
System.out.println("Documents added");
}
}टर्मिनल में निम्नलिखित कमांड निष्पादित करके उपरोक्त कोड संकलित करें -
[Hadoop@localhost bin]$ javac AddingDocument
[Hadoop@localhost bin]$ java AddingDocumentउपरोक्त कमांड निष्पादित करने पर, आपको निम्न आउटपुट मिलेगा।
Documents added