अपाचे सोलर - त्वरित गाइड
Solr एक ओपन-सोर्स सर्च प्लेटफॉर्म है, जिसे बनाने के लिए उपयोग किया जाता है search applications। इसके शीर्ष पर बनाया गया थाLucene(पूर्ण पाठ खोज इंजन)। सोलर उद्यम के लिए तैयार है, तेज और उच्च स्केलेबल। सोलर का उपयोग करके बनाए गए एप्लिकेशन परिष्कृत हैं और उच्च प्रदर्शन प्रदान करते हैं।
ये था Yonik Seelyजिन्होंने 2004 में CNET नेटवर्क्स की कंपनी वेबसाइट में खोज क्षमताओं को जोड़ने के लिए सोलर का निर्माण किया। जनवरी 2006 में, इसे Apache Software Foundation के तहत एक ओपन-सोर्स प्रोजेक्ट बनाया गया था। इसका नवीनतम संस्करण, सोलर 6.0, 2016 में समानांतर SQL प्रश्नों के निष्पादन के लिए समर्थन के साथ जारी किया गया था।
Hadoop के साथ Solr का भी इस्तेमाल किया जा सकता है। जैसे कि Hadoop बड़ी मात्रा में डेटा को संभालता है, Solr हमें इतने बड़े स्रोत से आवश्यक जानकारी खोजने में मदद करता है। केवल खोज ही नहीं, सोल्र का उपयोग भंडारण के उद्देश्य से भी किया जा सकता है। अन्य NoSQL डेटाबेस की तरह, यह एक हैnon-relational data storage तथा processing technology।
संक्षेप में, सोलर एक स्केलेबल है, जो टेक्स्ट-केंद्रित डेटा के बड़े संस्करणों की खोज करने के लिए अनुकूलित, खोज / भंडारण इंजन के लिए तैयार है।
अपाचे सोलर की विशेषताएं
Solr Lucene's Java API के चारों ओर एक आवरण है। इसलिए, Solr का उपयोग करके, आप Lucene की सभी विशेषताओं का लाभ उठा सकते हैं। आइए एक नजर डालते हैं सोलर की कुछ प्रमुख विशेषताओं पर -
Restful APIs- सोलर के साथ संवाद करने के लिए, जावा प्रोग्रामिंग कौशल होना अनिवार्य नहीं है। इसके बजाय आप इसके साथ संचार करने के लिए आरामदायक सेवाओं का उपयोग कर सकते हैं। हम XML, JSON और .CSV जैसे फ़ाइल स्वरूपों में सोलर में दस्तावेज़ दर्ज करते हैं और समान फ़ाइल स्वरूपों में परिणाम प्राप्त करते हैं।
Full text search - सोलर एक पूर्ण पाठ खोज के लिए आवश्यक सभी क्षमताएं प्रदान करता है जैसे टोकन, वाक्यांश, वर्तनी जांच, वाइल्डकार्ड और ऑटो-पूर्ण।
Enterprise ready - संगठन की आवश्यकता के अनुसार, सोलर को किसी भी तरह के सिस्टम (बड़े या छोटे) जैसे स्टैंडअलोन, वितरित, क्लाउड आदि में तैनात किया जा सकता है।
Flexible and Extensible - जावा कक्षाओं का विस्तार करके और तदनुसार कॉन्फ़िगर करके, हम आसानी से सोलर के घटकों को अनुकूलित कर सकते हैं।
NoSQL database - सोलर का उपयोग बड़े डेटा स्केल NOSQL डेटाबेस के रूप में भी किया जा सकता है जहां हम क्लस्टर के साथ खोज कार्यों को वितरित कर सकते हैं।
Admin Interface - सोलर एक आसान उपयोग, उपयोगकर्ता के अनुकूल, सुविधा संचालित, उपयोगकर्ता इंटरफ़ेस प्रदान करता है, जिसके उपयोग से हम लॉग, ऐड, डिलीट, अपडेट और खोज दस्तावेजों को प्रबंधित करने जैसे सभी संभावित कार्य कर सकते हैं।
Highly Scalable - हमदोप के साथ सोल का उपयोग करते समय, हम प्रतिकृतियों को जोड़कर इसकी क्षमता को माप सकते हैं।
Text-Centric and Sorted by Relevance - Solr का उपयोग ज्यादातर टेक्स्ट डॉक्यूमेंट्स को खोजने के लिए किया जाता है और परिणाम उपयोगकर्ता की क्वेरी के क्रम में प्रासंगिकता के अनुसार दिए जाते हैं।
ल्यूसिने के विपरीत, आपको अपाचे सोलर के साथ काम करते समय जावा प्रोग्रामिंग कौशल की आवश्यकता नहीं है। यह स्वत: पूर्ण की विशेषता वाले एक खोज बॉक्स का निर्माण करने के लिए एक अद्भुत रेडी-टू-परिनियोजित सेवा प्रदान करता है, जो ल्यूसीन प्रदान नहीं करता है। सोलर का उपयोग करके, हम बड़े पैमाने पर (बिग डेटा) अनुप्रयोगों के लिए सूचकांक को स्केल, वितरित और प्रबंधित कर सकते हैं।
खोज अनुप्रयोगों में ल्यूसिन
ल्यूसिन सरल अभी तक शक्तिशाली जावा-आधारित खोज पुस्तकालय है। इसका उपयोग किसी भी एप्लिकेशन में खोज क्षमता को जोड़ने के लिए किया जा सकता है। Lucene एक स्केलेबल और हाई-परफॉर्मेंस लाइब्रेरी है जिसका इस्तेमाल लगभग किसी भी तरह के टेक्स्ट को इंडेक्स और सर्च करने के लिए किया जाता है। ल्यूसिन लाइब्रेरी कोर संचालन प्रदान करती है जो किसी भी खोज एप्लिकेशन द्वारा आवश्यक होती है, जैसे किIndexing तथा Searching।
यदि हमारे पास भारी मात्रा में डेटा वाला एक वेब पोर्टल है, तो हमें डेटा के विशाल पूल से प्रासंगिक जानकारी निकालने के लिए अपने पोर्टल में संभवतः सबसे अधिक खोज इंजन की आवश्यकता होगी। ल्यूसिन किसी भी खोज अनुप्रयोग के दिल के रूप में काम करता है और अनुक्रमण और खोज से संबंधित महत्वपूर्ण संचालन प्रदान करता है।
एक खोज इंजन इंटरनेट संसाधनों के एक विशाल डेटाबेस को संदर्भित करता है जैसे कि वेबपेज, समाचार समूह, कार्यक्रम, चित्र आदि। यह वर्ल्ड वाइड वेब पर जानकारी का पता लगाने में मदद करता है।
उपयोगकर्ता कीवर्ड या वाक्यांश के रूप में खोज इंजन में प्रश्नों को पास करके जानकारी खोज सकते हैं। खोज इंजन तब अपने डेटाबेस में खोज करता है और उपयोगकर्ता के लिए प्रासंगिक लिंक देता है।
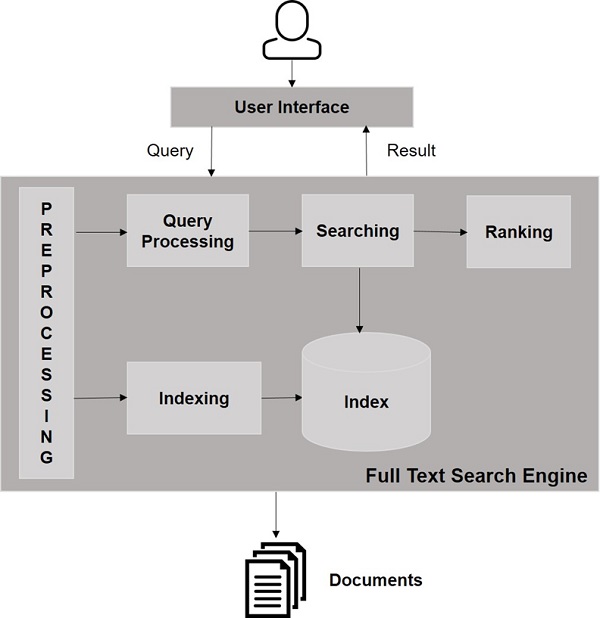
खोज इंजन घटक
आमतौर पर, नीचे सूचीबद्ध के रूप में एक खोज इंजन के तीन बुनियादी घटक हैं -
Web Crawler - वेब क्रॉलर के रूप में भी जाने जाते हैं spiders या bots। यह एक सॉफ्टवेयर घटक है जो जानकारी इकट्ठा करने के लिए वेब का पता लगाता है।
Database- वेब पर सभी जानकारी डेटाबेस में संग्रहीत होती है। इनमें भारी मात्रा में वेब संसाधन होते हैं।
Search Interfaces- यह घटक उपयोगकर्ता और डेटाबेस के बीच एक इंटरफेस है। यह उपयोगकर्ता को डेटाबेस के माध्यम से खोजने में मदद करता है।
खोज इंजन कैसे काम करते हैं?
निम्नलिखित में से कुछ या सभी कार्यों को करने के लिए किसी भी खोज एप्लिकेशन की आवश्यकता होती है।
| कदम | शीर्षक | विवरण |
|---|---|---|
1 |
कच्ची सामग्री ग्रहण करें |
किसी भी खोज एप्लिकेशन का पहला कदम लक्ष्य सामग्री एकत्र करना है, जिस पर खोज की जानी है। |
2 |
दस्तावेज़ बनाएँ |
अगला चरण कच्चे सामग्रियों से दस्तावेज़ (ओं) का निर्माण करना है जिसे खोज एप्लिकेशन आसानी से समझ और व्याख्या कर सकता है। |
3 |
दस्तावेज़ का विश्लेषण करें |
इंडेक्सिंग शुरू करने से पहले, दस्तावेज़ का विश्लेषण किया जाना है। |
4 |
दस्तावेज़ अनुक्रमणिका |
एक बार जब दस्तावेज़ों का निर्माण और विश्लेषण किया जाता है, तो अगला कदम उन्हें अनुक्रमित करना होता है ताकि दस्तावेज़ की संपूर्ण सामग्री के बजाय, यह दस्तावेज़ कुछ कुंजियों के आधार पर पुनर्प्राप्त किया जा सके। अनुक्रमणिका अनुक्रमणिका के समान होती है जो हमारे पास एक पुस्तक के अंत में होती है जहां आम शब्दों को उनके पृष्ठ संख्याओं के साथ दिखाया जाता है ताकि इन शब्दों को पूर्ण पुस्तक खोजने के बजाय जल्दी से ट्रैक किया जा सके। |
5 |
खोज के लिए यूजर इंटरफेस |
एक बार जब अनुक्रमित का एक डेटाबेस तैयार हो जाता है, तो एप्लिकेशन सर्च ऑपरेशन कर सकता है। उपयोगकर्ता को खोज करने में मदद करने के लिए, एप्लिकेशन को एक उपयोगकर्ता इंटरफ़ेस प्रदान करना होगा जहां उपयोगकर्ता पाठ में प्रवेश कर सकता है और खोज प्रक्रिया शुरू कर सकता है |
6 |
क्वेरी बनाएँ |
एक बार जब उपयोगकर्ता किसी पाठ को खोजने के लिए अनुरोध करता है, तो अनुप्रयोग को उस पाठ का उपयोग करके एक क्वेरी ऑब्जेक्ट तैयार करना चाहिए, जिसका उपयोग प्रासंगिक विवरण प्राप्त करने के लिए सूचकांक डेटाबेस की पूछताछ के लिए किया जा सकता है। |
7 |
पूछताछ कीजिए |
क्वेरी ऑब्जेक्ट का उपयोग करके, संबंधित विवरण और सामग्री दस्तावेजों को प्राप्त करने के लिए सूचकांक डेटाबेस की जाँच की जाती है। |
8 |
परिणाम प्रस्तुत करना |
एक बार आवश्यक परिणाम प्राप्त होने के बाद, एप्लिकेशन को यह तय करना चाहिए कि उपयोगकर्ता को उसके यूजर इंटरफेस का उपयोग करके परिणाम कैसे प्रदर्शित किया जाए। |
निम्नलिखित दृष्टांत पर एक नज़र डालें। यह खोज इंजनों के कार्य को देखने का एक समग्र दृष्टिकोण दिखाता है।
इन बुनियादी कार्यों के अलावा, खोज अनुप्रयोग प्रशासन-उपयोगकर्ता इंटरफ़ेस भी प्रदान कर सकते हैं ताकि व्यवस्थापकों को उपयोगकर्ता प्रोफाइल के आधार पर खोज के स्तर को नियंत्रित करने में मदद मिल सके। खोज परिणाम का विश्लेषण किसी भी खोज एप्लिकेशन का एक अन्य महत्वपूर्ण और उन्नत पहलू है।
इस अध्याय में, हम चर्चा करेंगे कि विंडोज वातावरण में सोलर कैसे स्थापित करें। अपने विंडोज सिस्टम पर सोलर स्थापित करने के लिए, आपको नीचे दिए गए चरणों का पालन करना होगा -
Apache Solr के होमपेज पर जाएं और डाउनलोड बटन पर क्लिक करें।
अपाचे सोलर का एक सूचकांक प्राप्त करने के लिए दर्पण में से एक का चयन करें। वहां से नाम की फाइल डाउनलोड करेंSolr-6.2.0.zip।
से फ़ाइल ले जाएँ downloads folder आवश्यक निर्देशिका के लिए और इसे खोलना।
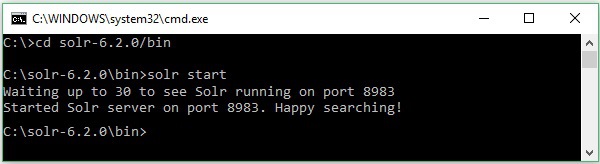
मान लीजिए कि आपने सोल ड्राइव डाउनलोड किया है और इसे सी ड्राइव पर निकाला है। ऐसे मामले में, आप सोलर को शुरू कर सकते हैं जैसा कि निम्नलिखित स्क्रीनशॉट में दिखाया गया है।
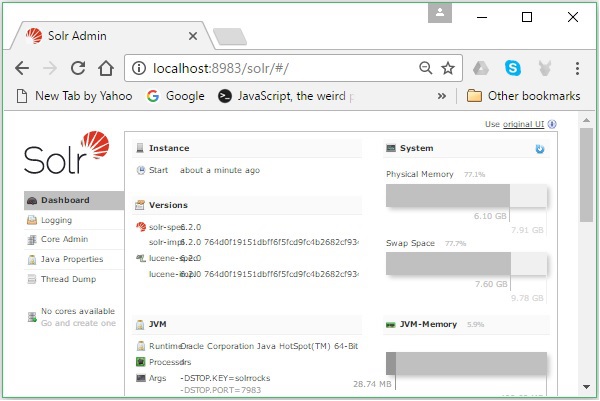
स्थापना को सत्यापित करने के लिए, अपने ब्राउज़र में निम्न URL का उपयोग करें।
http://localhost:8983/
यदि स्थापना प्रक्रिया सफल होती है, तो आपको अपाचे सोलर यूजर इंटरफेस का डैशबोर्ड देखने को मिलेगा जैसा कि नीचे दिखाया गया है।
जावा पर्यावरण की स्थापना
हम जावा पुस्तकालयों का उपयोग करके अपाचे सोलर के साथ भी संवाद कर सकते हैं; लेकिन जावा एपीआई का उपयोग करके सोल्र तक पहुंचने से पहले, आपको उन पुस्तकालयों के लिए क्लासपैथ सेट करना होगा।
कक्षापथ की स्थापना
ठीक classpath में Solr पुस्तकालयों के लिए .bashrcफ़ाइल। खुला हुआ.bashrc नीचे दिखाए गए संपादकों में से किसी में।
$ gedit ~/.bashrcसोलर पुस्तकालयों के लिए सेट करेंlib HBase में फ़ोल्डर) जैसा कि नीचे दिखाया गया है।
export CLASSPATH = $CLASSPATH://home/hadoop/Solr/lib/*यह जावा एपीआई का उपयोग करते हुए HBase का उपयोग करते समय "वर्ग नहीं मिला" अपवाद को रोकने के लिए है।
Hadoop के साथ Solr का भी इस्तेमाल किया जा सकता है। जैसे कि Hadoop बड़ी मात्रा में डेटा को संभालता है, Solr हमें इतने बड़े स्रोत से आवश्यक जानकारी खोजने में मदद करता है। इस खंड में, हम समझते हैं कि आप अपने सिस्टम पर Hadoop कैसे स्थापित कर सकते हैं।
Hadoop डाउनलोड करना
नीचे दिए गए चरणों को आपके सिस्टम पर Hadoop डाउनलोड करने के लिए अनुसरण किया जाना है।
Step 1- Hadoop के होमपेज पर जाएं। आप लिंक का उपयोग कर सकते हैं - www.hadoop.apache.org/ । लिंक पर क्लिक करेंReleases, जैसा कि निम्नलिखित स्क्रीनशॉट में दिखाया गया है।
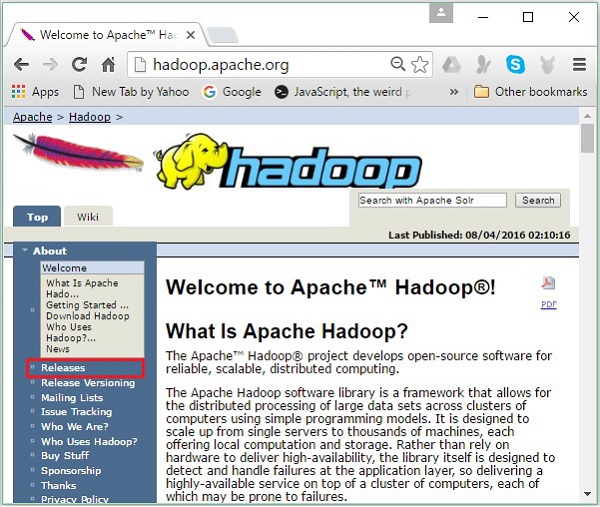
यह आपको रीडायरेक्ट करेगा Apache Hadoop Releases वह पृष्ठ जिसमें स्रोत के दर्पणों के लिए लिंक और Hadoop के विभिन्न संस्करणों की बाइनरी फाइलें निम्नानुसार हैं -
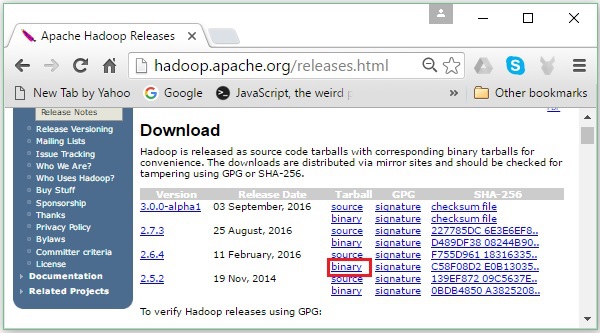
Step 2 - Hadoop के नवीनतम संस्करण का चयन करें (हमारे ट्यूटोरियल में, यह 2.6.4 है) और इसके क्लिक करें binary link। यह आपको एक ऐसे पृष्ठ पर ले जाएगा जहाँ Hadoop बाइनरी के लिए दर्पण उपलब्ध हैं। Hadoop डाउनलोड करने के लिए इनमें से किसी एक दर्पण पर क्लिक करें।
कमांड प्रॉम्प्ट से Hadoop डाउनलोड करें
लिनक्स टर्मिनल खोलें और सुपर-उपयोगकर्ता के रूप में लॉगिन करें।
$ su
password:उस निर्देशिका पर जाएं जहां आपको Hadoop को स्थापित करने की आवश्यकता है, और पहले कॉपी किए गए लिंक का उपयोग करके फ़ाइल को वहां सहेजें, जैसा कि निम्नलिखित कोड ब्लॉक में दिखाया गया है।
# cd /usr/local
# wget http://redrockdigimark.com/apachemirror/hadoop/common/hadoop-
2.6.4/hadoop-2.6.4.tar.gzHadoop डाउनलोड करने के बाद, इसे निम्न कमांड का उपयोग करके निकालें।
# tar zxvf hadoop-2.6.4.tar.gz
# mkdir hadoop
# mv hadoop-2.6.4/* to hadoop/
# exitHadoop स्थापित करना
इंस्टॉल करने के लिए नीचे दिए गए चरणों का पालन करें Hadoop छद्म वितरित मोड में।
चरण 1: Hadoop की स्थापना
आप निम्न आदेशों को जोड़कर Hadoop वातावरण चर सेट कर सकते हैं ~/.bashrc फ़ाइल।
export HADOOP_HOME = /usr/local/hadoop export
HADOOP_MAPRED_HOME = $HADOOP_HOME export
HADOOP_COMMON_HOME = $HADOOP_HOME export
HADOOP_HDFS_HOME = $HADOOP_HOME export
YARN_HOME = $HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR = $HADOOP_HOME/lib/native
export PATH = $PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL = $HADOOP_HOMEइसके बाद, वर्तमान चल रहे सिस्टम में सभी परिवर्तन लागू करें।
$ source ~/.bashrcचरण 2: Hadoop कॉन्फ़िगरेशन
आप "HADOOP_HOME / etc / hadoop" स्थान में सभी Hadoop कॉन्फ़िगरेशन फ़ाइलों को पा सकते हैं। यह आपके Hadoop इन्फ्रास्ट्रक्चर के अनुसार उन कॉन्फ़िगरेशन फ़ाइलों में परिवर्तन करने के लिए आवश्यक है।
$ cd $HADOOP_HOME/etc/hadoopजावा में Hadoop प्रोग्राम विकसित करने के लिए, आपको जावा वातावरण चर को रीसेट करना होगा hadoop-env.sh फ़ाइल को प्रतिस्थापित करके JAVA_HOME आपके सिस्टम में जावा के स्थान के साथ मूल्य।
export JAVA_HOME = /usr/local/jdk1.7.0_71निम्न फ़ाइलों की सूची है जिन्हें आपको Hadoop को कॉन्फ़िगर करने के लिए संपादित करना है -
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
core-site.xml
core-site.xml फ़ाइल में Hadoop उदाहरण के लिए उपयोग की जाने वाली पोर्ट संख्या, फ़ाइल सिस्टम के लिए आवंटित मेमोरी, डेटा को संग्रहीत करने के लिए मेमोरी की सीमा और पढ़ने / लिखने के बफ़र्स के आकार जैसी जानकारी शामिल है।
कोर- site.xml खोलें और <कॉन्फ़िगरेशन>, </ कॉन्फ़िगरेशन> टैग के अंदर निम्न गुण जोड़ें।
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xml
hdfs-site.xml फ़ाइल में प्रतिकृति डेटा का मान जैसी जानकारी है, namenode पथ, और datanodeआपके स्थानीय फ़ाइल सिस्टम के पथ। इसका अर्थ है वह स्थान जहाँ आप Hadoop अवसंरचना को संग्रहीत करना चाहते हैं।
आइए हम निम्नलिखित आंकड़ों को मानते हैं।
dfs.replication (data replication value) = 1
(In the below given path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanodeइस फ़ाइल को खोलें और <कॉन्फ़िगरेशन>, </ कॉन्फ़िगरेशन> टैग के अंदर निम्न गुण जोड़ें।
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>Note - उपरोक्त फ़ाइल में, सभी संपत्ति मूल्य उपयोगकर्ता-परिभाषित हैं और आप अपने Hadoop बुनियादी ढांचे के अनुसार परिवर्तन कर सकते हैं।
yarn-site.xml
इस फ़ाइल का उपयोग यार्न को Hadoop में कॉन्फ़िगर करने के लिए किया जाता है। यार्न-site.xml फ़ाइल खोलें और इस फ़ाइल में <कॉन्फ़िगरेशन>, </ कॉन्फ़िगरेशन> टैग के बीच निम्न गुण जोड़ें।
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
इस फ़ाइल का उपयोग यह निर्दिष्ट करने के लिए किया जाता है कि हम किस MapReduce ढांचे का उपयोग कर रहे हैं। डिफ़ॉल्ट रूप से, Hadoop में यार्न-site.xml का टेम्प्लेट होता है। सबसे पहले, फ़ाइल से कॉपी करना आवश्यक हैmapred-site,xml.template सेवा mapred-site.xml निम्न कमांड का उपयोग करके फ़ाइल।
$ cp mapred-site.xml.template mapred-site.xmlखुला हुआ mapred-site.xml <कॉन्फ़िगरेशन>, </ कॉन्फ़िगरेशन> टैग के अंदर निम्न गुणों को फ़ाइल करें और जोड़ें।
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>Hadoop स्थापना का सत्यापन
Hadoop स्थापना को सत्यापित करने के लिए निम्न चरणों का उपयोग किया जाता है।
चरण 1: नाम नोड सेटअप
निम्नानुसार "hdfs namenode -format" कमांड का उपयोग करके नामेनोड सेट करें।
$ cd ~
$ hdfs namenode -formatअपेक्षित परिणाम इस प्रकार है।
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.6.4
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1
images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/चरण 2: Hadoop dfs का सत्यापन करना
Hadoop dfs को शुरू करने के लिए निम्न कमांड का उपयोग किया जाता है। इस आदेश को निष्पादित करने से आपका Hadoop फ़ाइल सिस्टम प्रारंभ हो जाएगा।
$ start-dfs.shअपेक्षित उत्पादन निम्नानुसार है -
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop-2.6.4/logs/hadoop-
hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop-2.6.4/logs/hadoop-
hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]चरण 3: यार्न स्क्रिप्ट का सत्यापन
यार्न स्क्रिप्ट को शुरू करने के लिए निम्न कमांड का उपयोग किया जाता है। इस आदेश को निष्पादित करने से आपके यार्न दानव शुरू हो जाएंगे।
$ start-yarn.shअपेक्षित उत्पादन निम्नानुसार है -
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-2.6.4/logs/yarn-
hadoop-resourcemanager-localhost.out
localhost: starting nodemanager, logging to /home/hadoop/hadoop-
2.6.4/logs/yarn-hadoop-nodemanager-localhost.outचरण 4: ब्राउज़र पर Hadoop तक पहुँचना
Hadoop तक पहुँचने के लिए डिफ़ॉल्ट पोर्ट संख्या 50070 है। ब्राउज़र पर Hadoop सेवाएँ प्राप्त करने के लिए निम्न URL का उपयोग करें।
http://localhost:50070/
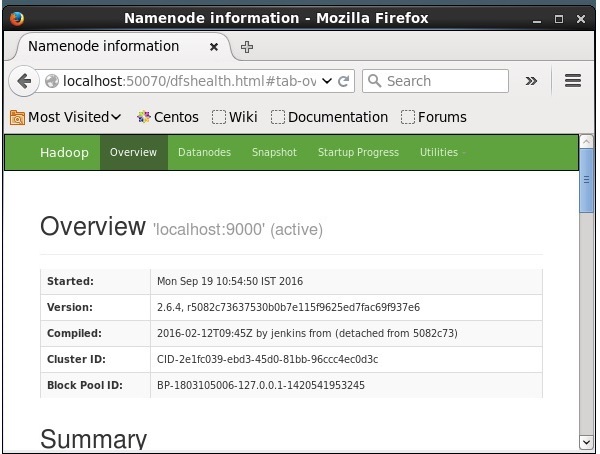
होदोप पर सोलर स्थापित करना
सोलर डाउनलोड और इंस्टॉल करने के लिए नीचे दिए गए चरणों का पालन करें।
चरण 1
निम्नलिखित लिंक पर क्लिक करके अपाचे सोलर का होमपेज खोलें - https://lucene.apache.org/solr/
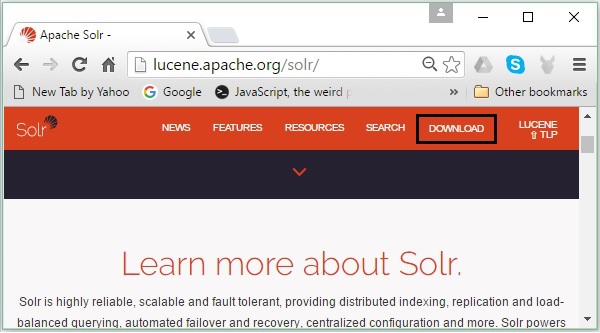
चरण 2
दबाएं download button(उपरोक्त स्क्रीनशॉट में हाइलाइट किया गया है)। क्लिक करने पर, आपको उस पृष्ठ पर भेज दिया जाएगा जहाँ आपके पास अपाचे सोलर के विभिन्न दर्पण हैं। एक दर्पण का चयन करें और उस पर क्लिक करें, जो आपको एक पृष्ठ पर रीडायरेक्ट करेगा जहां आप अपाचे सोलर के स्रोत और बाइनरी फ़ाइलों को डाउनलोड कर सकते हैं, जैसा कि निम्नलिखित स्क्रीनशॉट में दिखाया गया है।
चरण 3
क्लिक करने पर एक फोल्डर जिसका नाम है Solr-6.2.0.tqzआपके सिस्टम के डाउनलोड फ़ोल्डर में डाउनलोड किया जाएगा। डाउनलोड किए गए फ़ोल्डर की सामग्री निकालें।
चरण 4
Hadoop होम डायरेक्टरी में Solr नाम का एक फोल्डर बनाएं और निकाले गए फोल्डर की सामग्री को नीचे ले जाएं, जैसा कि नीचे दिखाया गया है।
$ mkdir Solr
$ cd Downloads
$ mv Solr-6.2.0 /home/Hadoop/सत्यापन
के माध्यम से ब्राउज़ करें bin सोलर होम निर्देशिका का फ़ोल्डर और स्थापना का उपयोग करके सत्यापित करें version विकल्प, जैसा कि निम्नलिखित कोड ब्लॉक में दिखाया गया है।
$ cd bin/
$ ./Solr version
6.2.0घर और रास्ता तय करना
को खोलो .bashrc निम्न कमांड का उपयोग करके फ़ाइल -
[Hadoop@localhost ~]$ source ~/.bashrcअब अपाचे सोलर के लिए घर और मार्ग निर्देशिका इस प्रकार निर्धारित करें -
export SOLR_HOME = /home/Hadoop/Solr
export PATH = $PATH:/$SOLR_HOME/bin/टर्मिनल खोलें और निम्नलिखित कमांड निष्पादित करें -
[Hadoop@localhost Solr]$ source ~/.bashrcअब, आप किसी भी डायरेक्टरी से सोल्र की कमांड को निष्पादित कर सकते हैं।
इस अध्याय में, हम अपाचे सोलर की वास्तुकला पर चर्चा करेंगे। निम्नलिखित दृष्टांत अपाचे सोलर की वास्तुकला का एक ब्लॉक आरेख दिखाता है।
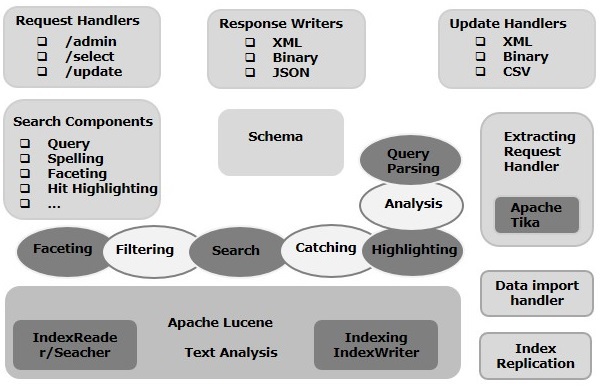
सोलर आर्किटेक्चर Block बिल्डिंग ब्लॉक
अपाचे सोलर के प्रमुख भवन खंड (घटक) निम्नलिखित हैं -
Request Handler- हम अपाचे सोलर को जो अनुरोध भेजते हैं, वे इन अनुरोध हैंडलर द्वारा संसाधित किए जाते हैं। अनुरोध क्वेरी अनुरोध या अनुक्रमणिका अद्यतन अनुरोध हो सकते हैं। हमारी आवश्यकता के आधार पर, हमें अनुरोध हैंडलर का चयन करना होगा। सोल्र के लिए एक अनुरोध पारित करने के लिए, हम आम तौर पर हैंडलर को एक निश्चित यूआरआई अंत-बिंदु पर मैप करेंगे और निर्दिष्ट अनुरोध इसके द्वारा प्रदान किया जाएगा।
Search Component- एक खोज घटक अपाचे सोलर में प्रदान की गई खोज का एक प्रकार (सुविधा) है। यह वर्तनी जांच, क्वेरी, फेसिंग, हिट हाइलाइटिंग आदि हो सकता है। ये खोज घटक इस प्रकार पंजीकृत हैंsearch handlers। एकाधिक घटकों को एक खोज हैंडलर में पंजीकृत किया जा सकता है।
Query Parser- अपाचे सोलर क्वेरी पार्सर उन प्रश्नों को पार्स करता है जो हम सोलर के पास जाते हैं और वाक्यविन्यास त्रुटियों के लिए प्रश्नों का सत्यापन करते हैं। प्रश्नों को पार्स करने के बाद, यह उन्हें एक प्रारूप में बदल देता है जिसे ल्यूसिन समझता है।
Response Writer- अपाचे सोलर में एक प्रतिक्रिया लेखक घटक है जो उपयोगकर्ता प्रश्नों के लिए स्वरूपित आउटपुट उत्पन्न करता है। Solr XML, JSON, CSV आदि जैसे प्रतिक्रिया स्वरूपों का समर्थन करता है। हमारे पास प्रत्येक प्रकार की प्रतिक्रिया के लिए अलग-अलग प्रतिक्रिया लेखक हैं।
Analyzer/tokenizer- ल्यूसीन टोकन के रूप में डेटा को पहचानता है। Apache Solr सामग्री का विश्लेषण करता है, इसे टोकन में विभाजित करता है, और इन टोकन को Lucene को पास करता है। अपाचे सोलर में एक विश्लेषक खेतों के पाठ की जांच करता है और एक टोकन स्ट्रीम उत्पन्न करता है। एक टोकन विश्लेषक द्वारा टोकन में तैयार टोकन स्ट्रीम को तोड़ता है।
Update Request Processor - जब भी हम अपाचे सोलर को एक अद्यतन अनुरोध भेजते हैं, अनुरोध को प्लगइन्स के एक सेट (हस्ताक्षर, लॉगिंग, इंडेक्सिंग) के माध्यम से चलाया जाता है, जिसे सामूहिक रूप से जाना जाता है update request processor। यह प्रोसेसर संशोधनों के लिए ज़िम्मेदार है जैसे किसी क्षेत्र को गिराना, किसी क्षेत्र को जोड़ना आदि।
इस अध्याय में, हम कुछ ऐसे शब्दों के वास्तविक अर्थ को समझने की कोशिश करेंगे जो अक्सर सोलर पर काम करते समय उपयोग किए जाते हैं।
सामान्य शब्दावली
निम्नलिखित सामान्य शब्दों की एक सूची है जो सभी प्रकार के सोलर सेटअपों में उपयोग की जाती है -
Instance - जैसे ए tomcat instance या ए jetty instance, यह शब्द अनुप्रयोग सर्वर को संदर्भित करता है, जो एक JVM के अंदर चलता है। सोलर की होम डायरेक्टरी इनमें से प्रत्येक सोलर इंस्टेंस का संदर्भ प्रदान करती है, जिसमें प्रत्येक उदाहरण में चलाने के लिए एक या अधिक कोर को कॉन्फ़िगर किया जा सकता है।
Core - आपके एप्लिकेशन में कई इंडेक्स चलाते समय, आपके पास प्रत्येक कोर में एक से अधिक कोर होने के बजाय कई इंस्टेंस हो सकते हैं।
Home - $ SOLR_HOME शब्द का अर्थ उस होम डायरेक्टरी से है जिसमें कोर और उनके अनुक्रमित, कॉन्फ़िगरेशन और निर्भरता के बारे में सभी जानकारी है।
Shard - वितरित वातावरण में, डेटा को कई सोलर इंस्टेंस के बीच विभाजित किया जाता है, जहां डेटा के प्रत्येक भाग को एक के रूप में कहा जा सकता है Shard। इसमें पूरे सूचकांक का एक सबसेट होता है।
सोलरक्लाउड शब्दावली
पहले के एक अध्याय में, हमने चर्चा की कि कैसे अपाले सोल को स्टैंडअलोन मोड में स्थापित किया जाए। ध्यान दें कि हम सोल को वितरित मोड (क्लाउड वातावरण) में भी स्थापित कर सकते हैं जहां सोलर को मास्टर-दास पैटर्न में स्थापित किया गया है। वितरित मोड में, इंडेक्स मास्टर सर्वर पर बनाया जाता है और इसे एक या एक से अधिक स्लेव सर्वर में दोहराया जाता है।
सोलर क्लाउड से जुड़ी प्रमुख शर्तें इस प्रकार हैं -
Node - सोलर क्लाउड में, सोलर के प्रत्येक एकल उदाहरण को माना जाता है node।
Cluster - संयुक्त पर्यावरण के सभी नोड मिलकर बनाते हैं cluster।
Collection - क्लस्टर में एक लॉजिकल इंडेक्स होता है जिसे a के रूप में जाना जाता है collection।
Shard - एक शार्क संग्रह का हिस्सा है जिसमें सूचकांक की एक या अधिक प्रतिकृतियां होती हैं।
Replica - सोलर कोर में, नोड में चलने वाले शार्क की एक प्रति को ए के रूप में जाना जाता है replica।
Leader - यह शार्प की प्रतिकृति भी है, जो बचे हुए प्रतिकृतियों को सोलर क्लाउड के अनुरोधों को वितरित करती है।
Zookeeper - यह एक अपाचे परियोजना है जिसे सोलर क्लाउड केंद्रीकृत विन्यास और समन्वय के लिए उपयोग करता है, क्लस्टर का प्रबंधन करने और एक नेता का चुनाव करने के लिए।
कॉन्फ़िगरेशन फ़ाइलें
Apache Solr में मुख्य विन्यास फाइल इस प्रकार हैं -
Solr.xml- यह $ SOLR_HOME निर्देशिका में फ़ाइल है जिसमें सोलर क्लाउड से संबंधित जानकारी है। कोर को लोड करने के लिए, सोलर इस फ़ाइल को संदर्भित करता है, जो उन्हें पहचानने में मदद करता है।
Solrconfig.xml - इस फाइल में इंडेक्सिंग, कॉन्फिगरिंग, मेमोरी को मैनेज करने और कमिट करने के साथ-साथ रिक्वेस्ट हैंडलिंग और रिस्पॉन्स फॉर्मेटिंग से जुड़ी परिभाषाएं और कोर-स्पेसिफिक कॉन्फिगरेशन हैं।
Schema.xml - इस फ़ाइल में फ़ील्ड और फ़ील्ड प्रकारों के साथ संपूर्ण स्कीमा शामिल है।
Core.properties- इस फ़ाइल में कोर के लिए विशिष्ट कॉन्फ़िगरेशन हैं। इसके लिए संदर्भित हैcore discovery, क्योंकि इसमें डेटा निर्देशिका के मूल और पथ का नाम शामिल है। यह किसी भी निर्देशिका में उपयोग किया जा सकता है, जिसे तब के रूप में माना जाएगाcore directory।
सोलर को शुरू करना
Solr स्थापित करने के बाद, ब्राउज़ करें bin सोलर होम निर्देशिका में फ़ोल्डर और निम्नलिखित कमांड का उपयोग करके सोल्र शुरू करें।
[Hadoop@localhost ~]$ cd
[Hadoop@localhost ~]$ cd Solr/
[Hadoop@localhost Solr]$ cd bin/
[Hadoop@localhost bin]$ ./Solr startयह आदेश पृष्ठभूमि में सोल्र शुरू होता है, पोर्ट 8983 पर निम्न संदेश प्रदर्शित करके सुन रहा है।
Waiting up to 30 seconds to see Solr running on port 8983 [\]
Started Solr server on port 8983 (pid = 6035). Happy searching!सोलर को अग्रभूमि में शुरू करना
यदि आप शुरू करते हैं Solr का उपयोग करते हुए startकमांड, फिर सोल्र बैकग्राउंड में शुरू होगा। इसके बजाय, आप का उपयोग कर अग्रभूमि में Solr शुरू कर सकते हैं–f option।
[Hadoop@localhost bin]$ ./Solr start –f
5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader
Adding 'file:/home/Hadoop/Solr/contrib/extraction/lib/xmlbeans-2.6.0.jar' to
classloader
5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader
Adding 'file:/home/Hadoop/Solr/dist/Solr-cell-6.2.0.jar' to classloader
5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader
Adding 'file:/home/Hadoop/Solr/contrib/clustering/lib/carrot2-guava-18.0.jar'
to classloader
5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader
Adding 'file:/home/Hadoop/Solr/contrib/clustering/lib/attributes-binder1.3.1.jar'
to classloader
5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader
Adding 'file:/home/Hadoop/Solr/contrib/clustering/lib/simple-xml-2.7.1.jar'
to classloader
……………………………………………………………………………………………………………………………………………………………………………………………………………
………………………………………………………………………………………………………………………………………………………………………………………………….
12901 INFO (coreLoadExecutor-6-thread-1) [ x:Solr_sample] o.a.s.u.UpdateLog
Took 24.0ms to seed version buckets with highest version 1546058939881226240 12902
INFO (coreLoadExecutor-6-thread-1) [ x:Solr_sample]
o.a.s.c.CoreContainer registering core: Solr_sample
12904 INFO (coreLoadExecutor-6-thread-2) [ x:my_core] o.a.s.u.UpdateLog Took
16.0ms to seed version buckets with highest version 1546058939894857728
12904 INFO (coreLoadExecutor-6-thread-2) [ x:my_core] o.a.s.c.CoreContainer
registering core: my_coreएक और बंदरगाह पर सोलर शुरू करना
का उपयोग करते हुए –p option का start कमांड, हम एक और पोर्ट में सोलर शुरू कर सकते हैं, जैसा कि निम्नलिखित कोड ब्लॉक में दिखाया गया है।
[Hadoop@localhost bin]$ ./Solr start -p 8984
Waiting up to 30 seconds to see Solr running on port 8984 [-]
Started Solr server on port 8984 (pid = 10137). Happy searching!सोलर को रोकना
आप सोल का उपयोग बंद कर सकते हैं stop आदेश।
$ ./Solr stopयह कमांड सोलर को रोकता है, एक संदेश प्रदर्शित करता है जैसा कि नीचे दिखाया गया है।
Sending stop command to Solr running on port 8983 ... waiting 5 seconds to
allow Jetty process 6035 to stop gracefully.सोलर को फिर से शुरू करना
restartSolr की कमांड Solr को 5 सेकंड के लिए रोक देती है और इसे फिर से शुरू करती है। आप निम्न आदेश का उपयोग करके सोल को पुनः आरंभ कर सकते हैं -
./Solr restartयह आदेश सोल को पुनः आरंभ करता है, जो निम्न संदेश प्रदर्शित करता है -
Sending stop command to Solr running on port 8983 ... waiting 5 seconds to
allow Jetty process 6671 to stop gracefully.
Waiting up to 30 seconds to see Solr running on port 8983 [|] [/]
Started Solr server on port 8983 (pid = 6906). Happy searching!सोलर ─ हेल्प कमांड
help सोलर कमांड का उपयोग सोलर प्रॉम्प्ट और इसके विकल्पों के उपयोग की जांच के लिए किया जा सकता है।
[Hadoop@localhost bin]$ ./Solr -help
Usage: Solr COMMAND OPTIONS
where COMMAND is one of: start, stop, restart, status, healthcheck,
create, create_core, create_collection, delete, version, zk
Standalone server example (start Solr running in the background on port 8984):
./Solr start -p 8984
SolrCloud example (start Solr running in SolrCloud mode using localhost:2181
to connect to Zookeeper, with 1g max heap size and remote Java debug options enabled):
./Solr start -c -m 1g -z localhost:2181 -a "-Xdebug -
Xrunjdwp:transport = dt_socket,server = y,suspend = n,address = 1044"
Pass -help after any COMMAND to see command-specific usage information,
such as: ./Solr start -help or ./Solr stop -helpसोलर ─ स्थिति कमान
यह statusSolr की कमांड का उपयोग आपके कंप्यूटर पर चल रहे Solr उदाहरणों को खोजने और खोजने के लिए किया जा सकता है। यह आपको एक Solr उदाहरण के बारे में जानकारी प्रदान कर सकता है जैसे कि इसका संस्करण, मेमोरी उपयोग इत्यादि।
आप निम्न के रूप में स्थिति आदेश का उपयोग कर, एक Solr उदाहरण की स्थिति देख सकते हैं -
[Hadoop@localhost bin]$ ./Solr statusनिष्पादित करने पर, उपरोक्त आदेश सोल की स्थिति को निम्नानुसार प्रदर्शित करता है -
Found 1 Solr nodes:
Solr process 6906 running on port 8983 {
"Solr_home":"/home/Hadoop/Solr/server/Solr",
"version":"6.2.0 764d0f19151dbff6f5fcd9fc4b2682cf934590c5 -
mike - 2016-08-20 05:41:37",
"startTime":"2016-09-20T06:00:02.877Z",
"uptime":"0 days, 0 hours, 5 minutes, 14 seconds",
"memory":"30.6 MB (%6.2) of 490.7 MB"
}सोलर एडमिन
Apache Solr शुरू करने के बाद, आप के होमपेज पर जा सकते हैं Solr web interface निम्न URL का उपयोग करके।
Localhost:8983/Solr/सोलर एडमिन का इंटरफ़ेस निम्नानुसार है -
एक सोलर कोर एक ल्यूसीन इंडेक्स का एक चालू उदाहरण है जिसमें सभी सोलर कॉन्फ़िगरेशन फ़ाइलों का उपयोग करना आवश्यक है। हमें अनुक्रमण और विश्लेषण जैसे संचालन करने के लिए एक सोलर कोर बनाने की आवश्यकता है।
सोलर एप्लिकेशन में एक या एकाधिक कोर हो सकते हैं। यदि आवश्यक हो, तो एक सोल आवेदन में दो कोर एक दूसरे के साथ संवाद कर सकते हैं।
एक कोर बनाना
सोल्र को स्थापित करने और शुरू करने के बाद, आप सोलर के ग्राहक (वेब इंटरफेस) से जुड़ सकते हैं।
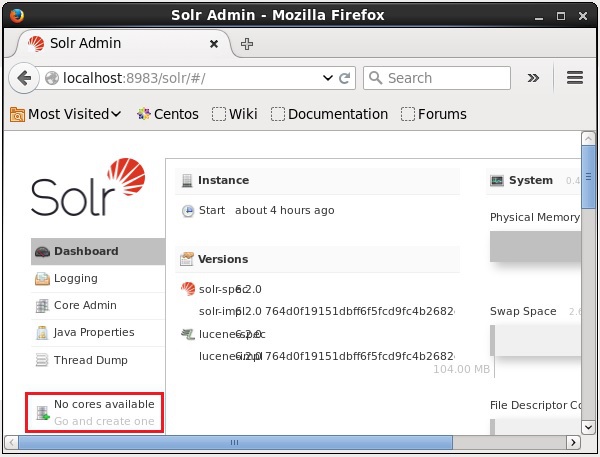
जैसा कि निम्नलिखित स्क्रीनशॉट में दिखाया गया है, शुरू में Apache Solr में कोर नहीं हैं। अब, हम देखेंगे कि सोल में एक कोर कैसे बनाया जाए।
Create कमांड का उपयोग करना
कोर बनाने का एक तरीका है, क्रिएट करना schema-less core का उपयोग करते हुए create कमांड, जैसा कि नीचे दिखाया गया है -
[Hadoop@localhost bin]$ ./Solr create -c Solr_sampleयहां, हम एक कोर नाम बनाने की कोशिश कर रहे हैं Solr_sampleअपाचे सोलर में। यह कमांड निम्नलिखित संदेश को प्रदर्शित करता है।
Copying configuration to new core instance directory:
/home/Hadoop/Solr/server/Solr/Solr_sample
Creating new core 'Solr_sample' using command:
http://localhost:8983/Solr/admin/cores?action=CREATE&name=Solr_sample&instanceD
ir = Solr_sample {
"responseHeader":{
"status":0,
"QTime":11550
},
"core":"Solr_sample"
}आप सोल में कई कोर बना सकते हैं। सोलर एडमिन के बाईं ओर, आप देख सकते हैंcore selector जहाँ आप नए बनाए गए कोर का चयन कर सकते हैं, जैसा कि निम्नलिखित स्क्रीनशॉट में दिखाया गया है।
Create_core कमांड का उपयोग करना
वैकल्पिक रूप से, आप एक कोर का उपयोग कर बना सकते हैं create_coreआदेश। इस आदेश में निम्नलिखित विकल्प हैं -
| -सी core_name | उस कोर का नाम जिसे आप बनाना चाहते थे |
| -पी port_name | पोर्ट जिस पर आप कोर बनाना चाहते हैं |
| डी conf_dir | पोर्ट की कॉन्फ़िगरेशन निर्देशिका |
आइए देखें कि आप कैसे उपयोग कर सकते हैं create_coreआदेश। यहां, हम एक कोर नाम बनाने की कोशिश करेंगेmy_core।
[Hadoop@localhost bin]$ ./Solr create_core -c my_coreनिष्पादित करने पर, उपरोक्त कमांड निम्नलिखित संदेश को प्रदर्शित करने वाला एक कोर बनाता है -
Copying configuration to new core instance directory:
/home/Hadoop/Solr/server/Solr/my_core
Creating new core 'my_core' using command:
http://localhost:8983/Solr/admin/cores?action=CREATE&name=my_core&instanceD
ir = my_core {
"responseHeader":{
"status":0,
"QTime":1346
},
"core":"my_core"
}एक कोर हटाना
आप का उपयोग करके एक कोर को हटा सकते हैं deleteअपाचे सोलर की कमान। मान लीजिए कि हमारे पास एक कोर नाम हैmy_core सोलर में, जैसा कि निम्नलिखित स्क्रीनशॉट में दिखाया गया है।
आप इस कोर का उपयोग करके हटा सकते हैं delete इस कमांड के लिए कोर का नाम इस प्रकार है -
[Hadoop@localhost bin]$ ./Solr delete -c my_coreउपरोक्त कमांड निष्पादित करने पर, निर्दिष्ट कोर को निम्न संदेश प्रदर्शित करते हुए हटा दिया जाएगा।
Deleting core 'my_core' using command:
http://localhost:8983/Solr/admin/cores?action=UNLOAD&core = my_core&deleteIndex
= true&deleteDataDir = true&deleteInstanceDir = true {
"responseHeader" :{
"status":0,
"QTime":170
}
}आप यह सत्यापित करने के लिए सोल का वेब इंटरफ़ेस खोल सकते हैं कि कोर को हटा दिया गया है या नहीं।
सामान्य रूप में, indexingदस्तावेजों की एक व्यवस्था है या (अन्य संस्थाओं) व्यवस्थित रूप से। इंडेक्सिंग उपयोगकर्ताओं को एक दस्तावेज़ में जानकारी का पता लगाने में सक्षम बनाता है।
इंडेक्सिंग संग्रह, पर्स और स्टोर दस्तावेजों को संग्रहीत करता है।
आवश्यक दस्तावेज़ ढूंढते समय खोज क्वेरी की गति और प्रदर्शन को बढ़ाने के लिए अनुक्रमण किया जाता है।
अपाचे सोलर में अनुक्रमण
Apache Solr में, हम विभिन्न डॉक्यूमेंट फॉर्मेट जैसे xml, csv, pdf आदि को इंडेक्स (जोड़, हटा, संशोधित कर सकते हैं) कर सकते हैं। हम कई तरह से सोलर इंडेक्स में डेटा जोड़ सकते हैं।
इस अध्याय में, हम अनुक्रमण पर चर्चा करने जा रहे हैं -
- सोलर वेब इंटरफेस का उपयोग करना।
- जावा, पायथन आदि जैसे किसी भी क्लाइंट एपीआई का उपयोग करना।
- का उपयोग करते हुए post tool।
इस अध्याय में, हम चर्चा करेंगे कि विभिन्न इंटरफेस (कमांड लाइन, वेब इंटरफेस और जावा क्लाइंट एपीआई) का उपयोग करके अपाचे सोलर के सूचकांक में डेटा कैसे जोड़ा जाए।
पोस्ट कमांड का उपयोग करके दस्तावेज़ जोड़ना
सोलर ने ए post इसकी कमान में bin/निर्देशिका। इस कमांड का उपयोग करके, आप Apache Solr में JSON, XML, CSV जैसी फ़ाइलों के विभिन्न स्वरूपों को अनुक्रमित कर सकते हैं।
के माध्यम से ब्राउज़ करें bin अपाचे सोलर की निर्देशिका और निष्पादित करें –h option पोस्ट कमांड के अनुसार, निम्न कोड ब्लॉक में दिखाया गया है।
[Hadoop@localhost bin]$ cd $SOLR_HOME
[Hadoop@localhost bin]$ ./post -hउपरोक्त कमांड को निष्पादित करने पर, आपको विकल्पों के एक सूची मिलेगी post command, जैसा की नीचे दिखाया गया।
Usage: post -c <collection> [OPTIONS] <files|directories|urls|-d [".."]>
or post –help
collection name defaults to DEFAULT_SOLR_COLLECTION if not specified
OPTIONS
=======
Solr options:
-url <base Solr update URL> (overrides collection, host, and port)
-host <host> (default: localhost)
-p or -port <port> (default: 8983)
-commit yes|no (default: yes)
Web crawl options:
-recursive <depth> (default: 1)
-delay <seconds> (default: 10)
Directory crawl options:
-delay <seconds> (default: 0)
stdin/args options:
-type <content/type> (default: application/xml)
Other options:
-filetypes <type>[,<type>,...] (default:
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,
rtf,htm,html,txt,log)
-params "<key> = <value>[&<key> = <value>...]" (values must be
URL-encoded; these pass through to Solr update request)
-out yes|no (default: no; yes outputs Solr response to console)
-format Solr (sends application/json content as Solr commands
to /update instead of /update/json/docs)
Examples:
* JSON file:./post -c wizbang events.json
* XML files: ./post -c records article*.xml
* CSV file: ./post -c signals LATEST-signals.csv
* Directory of files: ./post -c myfiles ~/Documents
* Web crawl: ./post -c gettingstarted http://lucene.apache.org/Solr -recursive 1 -delay 1
* Standard input (stdin): echo '{commit: {}}' | ./post -c my_collection -
type application/json -out yes –d
* Data as string: ./post -c signals -type text/csv -out yes -d $'id,value\n1,0.47'उदाहरण
मान लीजिए हमारे पास एक फाइल है जिसका नाम है sample.csv निम्नलिखित सामग्री के साथ (में bin निर्देशिका)।
| छात्र आईडी | पहला नाम | अंतिम नाम | फ़ोन | Faridabad |
|---|---|---|---|---|
| 001 | राजीव | रेड्डी | 9848022337 | हैदराबाद |
| 002 | सिद्धार्थ | भट्टाचार्य | 9848022338 | कोलकाता |
| 003 | राजेश | खन्ना | 9848022339 | दिल्ली |
| 004 | प्रीती | अग्रवाल | 9848022330 | पुणे |
| 005 | Trupthi | मोहंती | 9848022336 | भुवनेश्वर |
| 006 | अर्चना | मिश्रा | 9848022335 | चेन्नई |
उपरोक्त डेटासेट में छात्र आईडी, प्रथम नाम, अंतिम नाम, फोन और शहर जैसे व्यक्तिगत विवरण शामिल हैं। डेटासेट का CSV फ़ाइल नीचे दिखाया गया है। यहां, आपको ध्यान देना चाहिए कि आपको अपनी पहली पंक्ति का दस्तावेजीकरण करते हुए स्कीमा का उल्लेख करना होगा।
id, first_name, last_name, phone_no, location
001, Pruthvi, Reddy, 9848022337, Hyderabad
002, kasyap, Sastry, 9848022338, Vishakapatnam
003, Rajesh, Khanna, 9848022339, Delhi
004, Preethi, Agarwal, 9848022330, Pune
005, Trupthi, Mohanty, 9848022336, Bhubaneshwar
006, Archana, Mishra, 9848022335, Chennaiआप इस डेटा को नामित कोर के तहत अनुक्रमित कर सकते हैं sample_Solr का उपयोग करते हुए post आदेश निम्नानुसार है -
[Hadoop@localhost bin]$ ./post -c Solr_sample sample.csvउपरोक्त आदेश को निष्पादित करने पर, दिए गए दस्तावेज़ को निर्दिष्ट आउटपुट के तहत अनुक्रमित किया गया है, जो निम्न आउटपुट उत्पन्न करता है।
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core
6.2.0.jar -Dauto = yes -Dc = Solr_sample -Ddata = files
org.apache.Solr.util.SimplePostTool sample.csv
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/Solr_sample/update...
Entering auto mode. File endings considered are
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,
htm,html,txt,log
POSTing file sample.csv (text/csv) to [base]
1 files indexed.
COMMITting Solr index changes to
http://localhost:8983/Solr/Solr_sample/update...
Time spent: 0:00:00.228निम्नलिखित URL का उपयोग करके सोल वेब यूआई के होमपेज पर जाएं -
http://localhost:8983/
कोर का चयन करें Solr_sample। डिफ़ॉल्ट रूप से, अनुरोध हैंडलर है/selectऔर क्वेरी ":" है। कोई भी संशोधन किए बिना, क्लिक करेंExecuteQuery पृष्ठ के नीचे बटन।
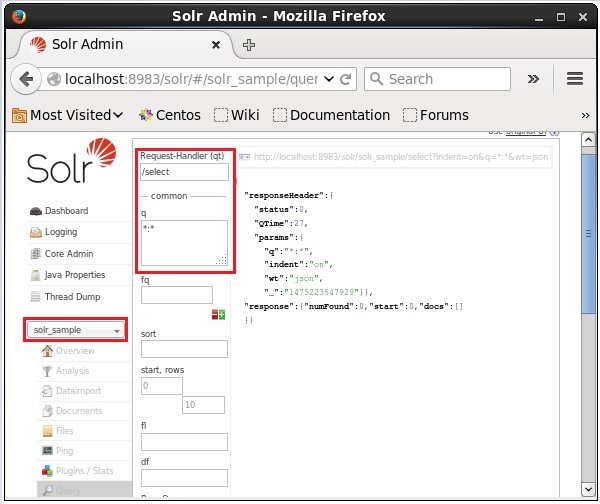
क्वेरी निष्पादित करने पर, आप JSON प्रारूप (डिफ़ॉल्ट) में अनुक्रमित CSV दस्तावेज़ की सामग्री का निरीक्षण कर सकते हैं, जैसा कि निम्नलिखित स्क्रीनशॉट में दिखाया गया है।
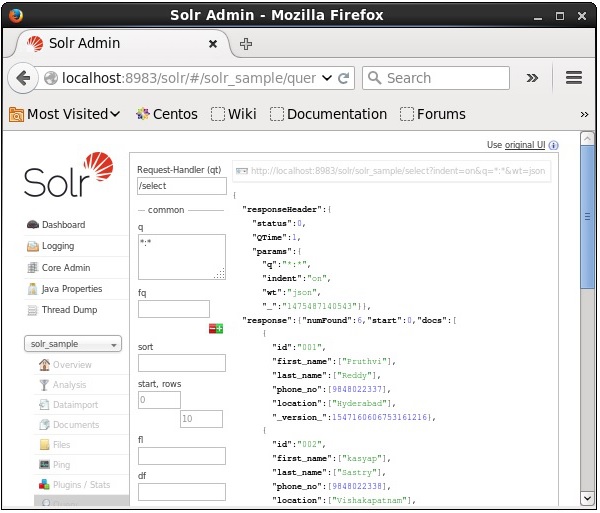
Note - इसी तरह, आप अन्य फाइल फॉर्मेट जैसे कि JSON, XML, CSV इत्यादि को इंडेक्स कर सकते हैं।
सोलर वेब इंटरफ़ेस का उपयोग करके दस्तावेज़ जोड़ना
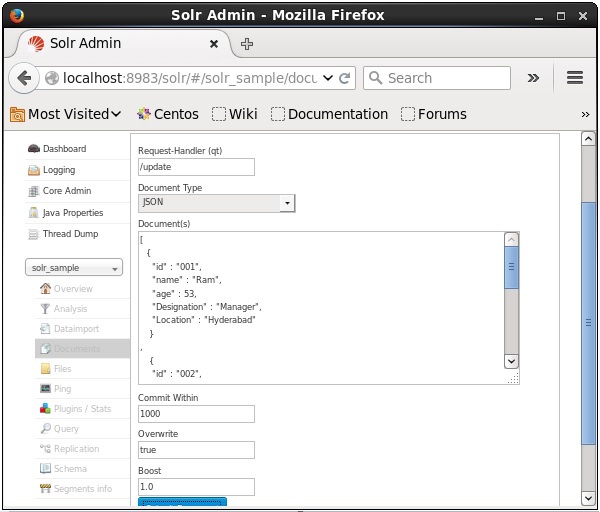
आप सोल द्वारा प्रदान किए गए वेब इंटरफ़ेस का उपयोग करके दस्तावेज़ों को भी अनुक्रमित कर सकते हैं। आइए देखें कि JSON डॉक्यूमेंट को कैसे इंडेक्स किया जाए।
[
{
"id" : "001",
"name" : "Ram",
"age" : 53,
"Designation" : "Manager",
"Location" : "Hyderabad",
},
{
"id" : "002",
"name" : "Robert",
"age" : 43,
"Designation" : "SR.Programmer",
"Location" : "Chennai",
},
{
"id" : "003",
"name" : "Rahim",
"age" : 25,
"Designation" : "JR.Programmer",
"Location" : "Delhi",
}
]चरण 1
निम्नलिखित URL का उपयोग करके सोल्र वेब इंटरफ़ेस खोलें -
http://localhost:8983/
Step 2
कोर का चयन करें Solr_sample। डिफ़ॉल्ट रूप से, फ़ील्ड के मान अनुरोध हैंडलर, सामान्य भीतर, अधिलेखित और बूस्ट क्रमशः / अपडेट, 1000, सत्य और 1.0 हैं, जैसा कि निम्नलिखित स्क्रीनशॉट में दिखाया गया है।
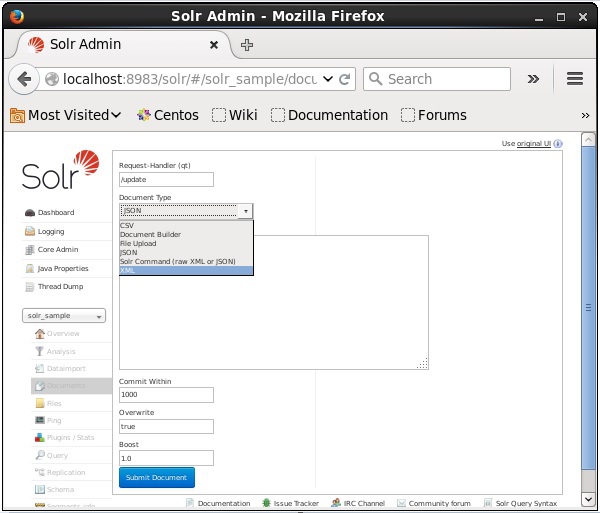
अब, JSON, CSV, XML आदि से इच्छित दस्तावेज़ प्रारूप चुनें, पाठ क्षेत्र में अनुक्रमित किए जाने वाले दस्तावेज़ को टाइप करें और क्लिक करें Submit Document बटन, जैसा कि निम्नलिखित स्क्रीनशॉट में दिखाया गया है।
जावा क्लाइंट एपीआई का उपयोग करके दस्तावेज़ जोड़ना
Apache Solr इंडेक्स में दस्तावेज़ जोड़ने के लिए जावा प्रोग्राम है। इस कोड को नाम वाली फ़ाइल में सहेजेंAddingDocument.java।
import java.io.IOException;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.common.SolrInputDocument;
public class AddingDocument {
public static void main(String args[]) throws Exception {
//Preparing the Solr client
String urlString = "http://localhost:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
//Adding fields to the document
doc.addField("id", "003");
doc.addField("name", "Rajaman");
doc.addField("age","34");
doc.addField("addr","vishakapatnam");
//Adding the document to Solr
Solr.add(doc);
//Saving the changes
Solr.commit();
System.out.println("Documents added");
}
}टर्मिनल में निम्नलिखित कमांड निष्पादित करके उपरोक्त कोड संकलित करें -
[Hadoop@localhost bin]$ javac AddingDocument
[Hadoop@localhost bin]$ java AddingDocumentउपरोक्त कमांड निष्पादित करने पर, आपको निम्न आउटपुट मिलेगा।
Documents addedपिछले अध्याय में, हमने समझाया कि सोल में डेटा कैसे जोड़ा जाए जो कि JSON और .CSV फ़ाइल स्वरूपों में है। इस अध्याय में, हम एक्सपी दस्तावेज़ प्रारूप का उपयोग करके अपाचे सोलर इंडेक्स में डेटा जोड़ने का तरीका प्रदर्शित करेंगे।
नमूना डेटा
मान लें कि हमें XML फाइल फॉर्मेट का उपयोग करके निम्नलिखित डेटा को सोलर इंडेक्स में जोड़ना है।
| छात्र आईडी | पहला नाम | उपनाम | फ़ोन | Faridabad |
|---|---|---|---|---|
| 001 | राजीव | रेड्डी | 9848022337 | हैदराबाद |
| 002 | सिद्धार्थ | भट्टाचार्य | 9848022338 | कोलकाता |
| 003 | राजेश | खन्ना | 9848022339 | दिल्ली |
| 004 | प्रीती | अग्रवाल | 9848022330 | पुणे |
| 005 | Trupthi | मोहंती | 9848022336 | भुवनेश्वर |
| 006 | अर्चना | मिश्रा | 9848022335 | चेन्नई |
XML का उपयोग करके दस्तावेज़ जोड़ना
उपरोक्त डेटा को सोलर इंडेक्स में जोड़ने के लिए, हमें एक XML दस्तावेज़ तैयार करने की आवश्यकता है, जैसा कि नीचे दिखाया गया है। नाम के साथ एक फ़ाइल में इस दस्तावेज़ को सहेजेंsample.xml।
<add>
<doc>
<field name = "id">001</field>
<field name = "first name">Rajiv</field>
<field name = "last name">Reddy</field>
<field name = "phone">9848022337</field>
<field name = "city">Hyderabad</field>
</doc>
<doc>
<field name = "id">002</field>
<field name = "first name">Siddarth</field>
<field name = "last name">Battacharya</field>
<field name = "phone">9848022338</field>
<field name = "city">Kolkata</field>
</doc>
<doc>
<field name = "id">003</field>
<field name = "first name">Rajesh</field>
<field name = "last name">Khanna</field>
<field name = "phone">9848022339</field>
<field name = "city">Delhi</field>
</doc>
<doc>
<field name = "id">004</field>
<field name = "first name">Preethi</field>
<field name = "last name">Agarwal</field>
<field name = "phone">9848022330</field>
<field name = "city">Pune</field>
</doc>
<doc>
<field name = "id">005</field>
<field name = "first name">Trupthi</field>
<field name = "last name">Mohanthy</field>
<field name = "phone">9848022336</field>
<field name = "city">Bhuwaeshwar</field>
</doc>
<doc>
<field name = "id">006</field>
<field name = "first name">Archana</field>
<field name = "last name">Mishra</field>
<field name = "phone">9848022335</field>
<field name = "city">Chennai</field>
</doc>
</add>जैसा कि आप देख सकते हैं, डेटा को इंडेक्स में जोड़ने के लिए लिखी गई XML फ़ाइल में तीन महत्वपूर्ण टैग हैं, <add> </ add>, <doc> </ doc>, और <फ़ील्ड> </ फ़ील्ड>।
add- यह इंडेक्स में दस्तावेजों को जोड़ने के लिए रूट टैग है। इसमें एक या एक से अधिक दस्तावेज़ हैं जिन्हें जोड़ा जाना है।
doc- हमारे द्वारा जोड़े गए दस्तावेजों को <doc> </ doc> टैग के भीतर लपेटा जाना चाहिए। इस दस्तावेज़ में फ़ील्ड के रूप में डेटा है।
field - फ़ील्ड टैग दस्तावेज़ के क्षेत्रों का नाम और मूल्य रखता है।
दस्तावेज़ तैयार करने के बाद, आप पिछले अध्याय में चर्चा किए गए किसी भी साधन का उपयोग करके इस दस्तावेज़ को सूचकांक में जोड़ सकते हैं।
मान लीजिए कि XML फ़ाइल में मौजूद है bin सोलर की निर्देशिका और इसे नामित कोर में अनुक्रमित किया जाना है my_core, तो आप इसका उपयोग कर सोलर इंडेक्स में जोड़ सकते हैं post उपकरण इस प्रकार है -
[Hadoop@localhost bin]$ ./post -c my_core sample.xmlउपरोक्त कमांड निष्पादित करने पर, आपको निम्न आउटपुट मिलेगा।
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-
core6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files
org.apache.Solr.util.SimplePostTool sample.xml
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/my_core/update...
Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,
xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,htm,html,txt,log
POSTing file sample.xml (application/xml) to [base]
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/Solr/my_core/update...
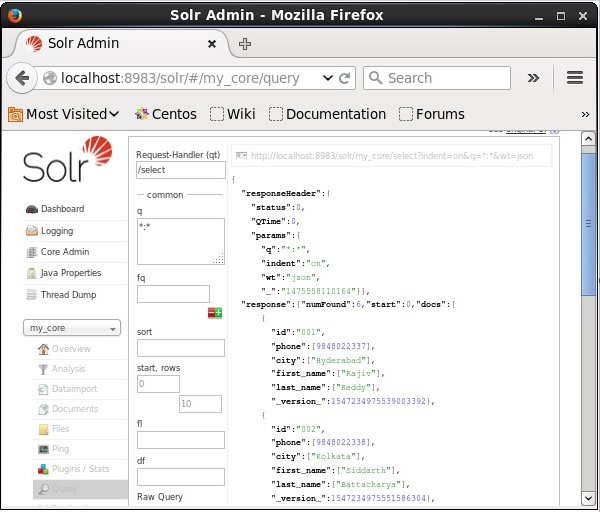
Time spent: 0:00:00.201सत्यापन
Apache Solr वेब इंटरफेस के होमपेज पर जाएं और कोर का चयन करें my_core। पाठ क्षेत्र में ":" क्वेरी पास करके सभी दस्तावेजों को पुनः प्राप्त करने का प्रयास करेंqऔर क्वेरी निष्पादित करें। निष्पादित करने पर, आप देख सकते हैं कि वांछित डेटा सोलर इंडेक्स में जोड़ा गया है।
XML का उपयोग करके दस्तावेज़ को अद्यतन करना
मौजूदा दस्तावेज़ में फ़ील्ड को अपडेट करने के लिए XML फ़ाइल का उपयोग किया जाता है। नाम वाली फाइल में इसे सेव करेंupdate.xml।
<add>
<doc>
<field name = "id">001</field>
<field name = "first name" update = "set">Raj</field>
<field name = "last name" update = "add">Malhotra</field>
<field name = "phone" update = "add">9000000000</field>
<field name = "city" update = "add">Delhi</field>
</doc>
</add>जैसा कि आप देख सकते हैं, डेटा अपडेट करने के लिए लिखी गई XML फ़ाइल ठीक उसी तरह है जैसे हम दस्तावेजों को जोड़ने के लिए उपयोग करते हैं। लेकिन फर्क सिर्फ इतना है कि हम इसका इस्तेमाल करते हैंupdate क्षेत्र की विशेषता।
हमारे उदाहरण में, हम उपरोक्त दस्तावेज़ का उपयोग करेंगे और आईडी के साथ दस्तावेज़ के क्षेत्रों को अपडेट करने का प्रयास करेंगे 001।
मान लीजिए कि XML दस्तावेज़ में मौजूद है binसोलर की निर्देशिका। चूंकि हम उस इंडेक्स को अपडेट कर रहे हैं जो नाम के कोर में मौजूद हैmy_core, आप का उपयोग कर अद्यतन कर सकते हैं post उपकरण इस प्रकार है -
[Hadoop@localhost bin]$ ./post -c my_core update.xmlउपरोक्त कमांड निष्पादित करने पर, आपको निम्न आउटपुट मिलेगा।
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core
6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files
org.apache.Solr.util.SimplePostTool update.xml
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/my_core/update...
Entering auto mode. File endings considered are
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,
htm,html,txt,log
POSTing file update.xml (application/xml) to [base]
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/Solr/my_core/update...
Time spent: 0:00:00.159सत्यापन
Apache Solr वेब इंटरफेस के होमपेज पर जाएं और कोर को चुनें my_core। पाठ क्षेत्र में ":" क्वेरी पास करके सभी दस्तावेजों को पुनः प्राप्त करने का प्रयास करेंqऔर क्वेरी निष्पादित करें। निष्पादित करने पर, आप देख सकते हैं कि दस्तावेज़ अपडेट किया गया है।
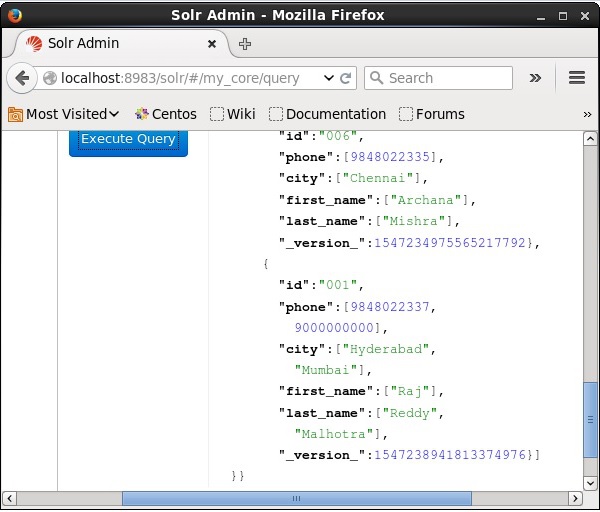
जावा (क्लाइंट एपीआई) का उपयोग कर दस्तावेज़ को अद्यतन करना
Apache Solr इंडेक्स में दस्तावेज़ जोड़ने के लिए जावा प्रोग्राम है। इस कोड को नाम वाली फ़ाइल में सहेजेंUpdatingDocument.java।
import java.io.IOException;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.client.Solrj.request.UpdateRequest;
import org.apache.Solr.client.Solrj.response.UpdateResponse;
import org.apache.Solr.common.SolrInputDocument;
public class UpdatingDocument {
public static void main(String args[]) throws SolrServerException, IOException {
//Preparing the Solr client
String urlString = "http://localhost:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
UpdateRequest updateRequest = new UpdateRequest();
updateRequest.setAction( UpdateRequest.ACTION.COMMIT, false, false);
SolrInputDocument myDocumentInstantlycommited = new SolrInputDocument();
myDocumentInstantlycommited.addField("id", "002");
myDocumentInstantlycommited.addField("name", "Rahman");
myDocumentInstantlycommited.addField("age","27");
myDocumentInstantlycommited.addField("addr","hyderabad");
updateRequest.add( myDocumentInstantlycommited);
UpdateResponse rsp = updateRequest.process(Solr);
System.out.println("Documents Updated");
}
}टर्मिनल में निम्नलिखित कमांड निष्पादित करके उपरोक्त कोड संकलित करें -
[Hadoop@localhost bin]$ javac UpdatingDocument
[Hadoop@localhost bin]$ java UpdatingDocumentउपरोक्त कमांड निष्पादित करने पर, आपको निम्न आउटपुट मिलेगा।
Documents updatedदस्तावेज़ हटाना
अपाचे सोलर के सूचकांक से दस्तावेजों को हटाने के लिए, हमें <हटाना> </ डिलीट> टैग के बीच हटाए जाने वाले दस्तावेजों की आईडी निर्दिष्ट करने की आवश्यकता है।
<delete>
<id>003</id>
<id>005</id>
<id>004</id>
<id>002</id>
</delete>यहां, यह XML कोड का उपयोग आईडी के साथ दस्तावेजों को हटाने के लिए किया जाता है 003 तथा 005। इस कोड को नाम वाली फ़ाइल में सहेजेंdelete.xml।
यदि आप इंडेक्स से उन दस्तावेजों को हटाना चाहते हैं जो नाम के कोर से संबंधित हैं my_core, तो आप पोस्ट कर सकते हैं delete.xml का उपयोग कर फ़ाइल post उपकरण, जैसा कि नीचे दिखाया गया है।
[Hadoop@localhost bin]$ ./post -c my_core delete.xmlउपरोक्त कमांड निष्पादित करने पर, आपको निम्न आउटपुट मिलेगा।
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core
6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files
org.apache.Solr.util.SimplePostTool delete.xml
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/my_core/update...
Entering auto mode. File endings considered are
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,
rtf,htm,html,txt,log
POSTing file delete.xml (application/xml) to [base]
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/Solr/my_core/update...
Time spent: 0:00:00.179सत्यापन
अपाचे सोलर वेब इंटरफेस के होमपेज पर जाएं और कोर का चयन करें my_core। पाठ क्षेत्र में ":" क्वेरी पास करके सभी दस्तावेजों को पुनः प्राप्त करने का प्रयास करेंqऔर क्वेरी निष्पादित करें। निष्पादित करने पर, आप देख सकते हैं कि निर्दिष्ट दस्तावेज़ हटा दिए गए हैं।
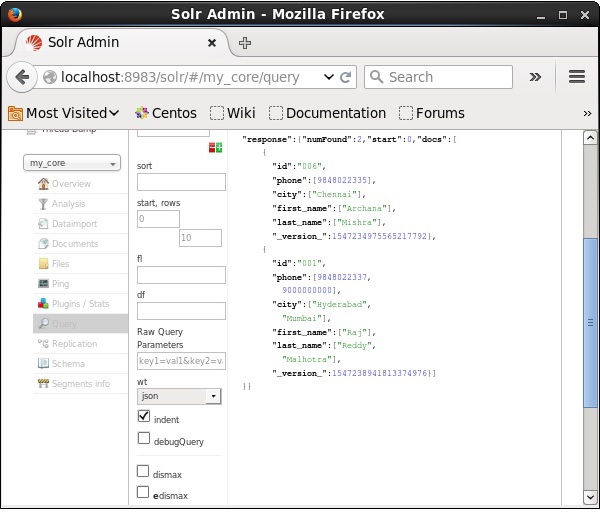
एक खेत को हटाना
कभी-कभी हमें आईडी के अलावा अन्य फ़ील्ड के आधार पर दस्तावेज़ों को हटाने की आवश्यकता होती है। उदाहरण के लिए, हमें उन दस्तावेजों को हटाना पड़ सकता है जहां शहर चेन्नई है।
ऐसे मामलों में, आपको <क्वेरी> </ क्वेरी> टैग जोड़ी के भीतर फ़ील्ड का नाम और मान निर्दिष्ट करना होगा।
<delete>
<query>city:Chennai</query>
</delete>इसे इस रूप में सहेजें delete_field.xml और नामित नाम पर डिलीट ऑपरेशन करें my_core का उपयोग करते हुए post सोलर का उपकरण।
[Hadoop@localhost bin]$ ./post -c my_core delete_field.xmlउपरोक्त कमांड निष्पादित करने पर, यह निम्नलिखित आउटपुट का उत्पादन करता है।
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core
6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files
org.apache.Solr.util.SimplePostTool delete_field.xml
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/my_core/update...
Entering auto mode. File endings considered are
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,
rtf,htm,html,txt,log
POSTing file delete_field.xml (application/xml) to [base]
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/Solr/my_core/update...
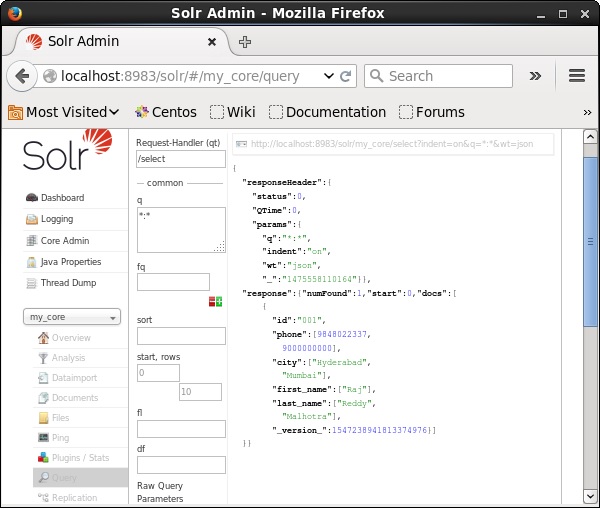
Time spent: 0:00:00.084सत्यापन
अपाचे सोलर वेब इंटरफेस के होमपेज पर जाएं और कोर का चयन करें my_core। पाठ क्षेत्र में ":" क्वेरी पास करके सभी दस्तावेजों को पुनः प्राप्त करने का प्रयास करेंqऔर क्वेरी निष्पादित करें। निष्पादित करने पर, आप देख सकते हैं कि निर्दिष्ट फ़ील्ड वैल्यू पेयर वाले दस्तावेज़ हटा दिए गए हैं।
सभी दस्तावेज़ हटाना
किसी विशिष्ट फ़ील्ड को हटाने की तरह, यदि आप किसी अनुक्रमणिका से सभी दस्तावेज़ों को हटाना चाहते हैं, तो आपको केवल <<>> टैग के बीच के टैग के बीच प्रतीक ":" को पास करना होगा, जैसा कि नीचे दिखाया गया है।
<delete>
<query>*:*</query>
</delete>इसे इस रूप में सहेजें delete_all.xml और नामित नाम पर डिलीट ऑपरेशन करें my_core का उपयोग करते हुए post सोलर का उपकरण।
[Hadoop@localhost bin]$ ./post -c my_core delete_all.xmlउपरोक्त कमांड निष्पादित करने पर, यह निम्नलिखित आउटपुट का उत्पादन करता है।
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core
6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files
org.apache.Solr.util.SimplePostTool deleteAll.xml
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/my_core/update...
Entering auto mode. File endings considered are
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,
htm,html,txt,log
POSTing file deleteAll.xml (application/xml) to [base]
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/Solr/my_core/update...
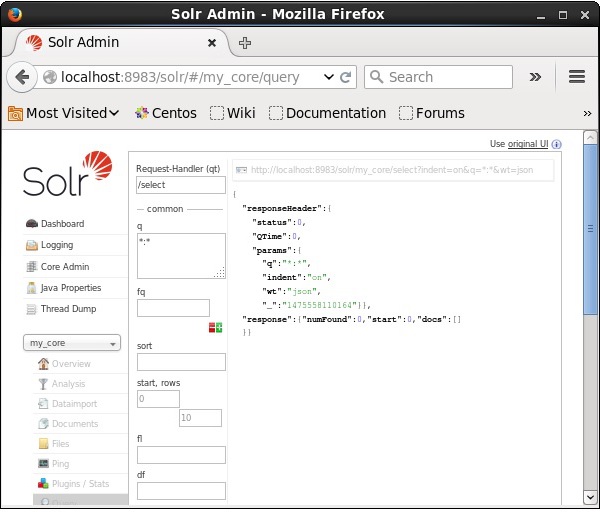
Time spent: 0:00:00.138सत्यापन
Apache Solr वेब इंटरफेस के होमपेज पर जाएं और कोर को चुनें my_core। पाठ क्षेत्र में ":" क्वेरी पास करके सभी दस्तावेजों को पुनः प्राप्त करने का प्रयास करेंqऔर क्वेरी निष्पादित करें। निष्पादित करने पर, आप देख सकते हैं कि निर्दिष्ट फ़ील्ड वैल्यू पेयर वाले दस्तावेज़ हटा दिए गए हैं।
जावा (क्लाइंट एपीआई) का उपयोग कर सभी दस्तावेजों को हटाना
Apache Solr इंडेक्स में दस्तावेज़ जोड़ने के लिए जावा प्रोग्राम है। इस कोड को नाम वाली फ़ाइल में सहेजेंUpdatingDocument.java।
import java.io.IOException;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.common.SolrInputDocument;
public class DeletingAllDocuments {
public static void main(String args[]) throws SolrServerException, IOException {
//Preparing the Solr client
String urlString = "http://localhost:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
//Deleting the documents from Solr
Solr.deleteByQuery("*");
//Saving the document
Solr.commit();
System.out.println("Documents deleted");
}
}टर्मिनल में निम्नलिखित कमांड निष्पादित करके उपरोक्त कोड संकलित करें -
[Hadoop@localhost bin]$ javac DeletingAllDocuments
[Hadoop@localhost bin]$ java DeletingAllDocumentsउपरोक्त कमांड निष्पादित करने पर, आपको निम्न आउटपुट मिलेगा।
Documents deletedइस अध्याय में, हम चर्चा करेंगे कि जावा क्लाइंट एपीआई का उपयोग करके डेटा को कैसे पुनः प्राप्त किया जाए। मान लीजिए कि हमारे पास .csv नाम का एक दस्तावेज हैsample.csv निम्नलिखित सामग्री के साथ।
001,9848022337,Hyderabad,Rajiv,Reddy
002,9848022338,Kolkata,Siddarth,Battacharya
003,9848022339,Delhi,Rajesh,Khannaआप इस डेटा को नामित कोर के तहत अनुक्रमित कर सकते हैं sample_Solr का उपयोग करते हुए post आदेश।
[Hadoop@localhost bin]$ ./post -c Solr_sample sample.csvApache Solr इंडेक्स में दस्तावेज़ जोड़ने के लिए जावा प्रोग्राम है। इस कोड को नाम वाली फ़ाइल में सहेजेंRetrievingData.java।
import java.io.IOException;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrQuery;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.client.Solrj.response.QueryResponse;
import org.apache.Solr.common.SolrDocumentList;
public class RetrievingData {
public static void main(String args[]) throws SolrServerException, IOException {
//Preparing the Solr client
String urlString = "http://localhost:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing Solr query
SolrQuery query = new SolrQuery();
query.setQuery("*:*");
//Adding the field to be retrieved
query.addField("*");
//Executing the query
QueryResponse queryResponse = Solr.query(query);
//Storing the results of the query
SolrDocumentList docs = queryResponse.getResults();
System.out.println(docs);
System.out.println(docs.get(0));
System.out.println(docs.get(1));
System.out.println(docs.get(2));
//Saving the operations
Solr.commit();
}
}टर्मिनल में निम्नलिखित कमांड निष्पादित करके उपरोक्त कोड संकलित करें -
[Hadoop@localhost bin]$ javac RetrievingData
[Hadoop@localhost bin]$ java RetrievingDataउपरोक्त कमांड निष्पादित करने पर, आपको निम्न आउटपुट मिलेगा।
{numFound = 3,start = 0,docs = [SolrDocument{id=001, phone = [9848022337],
city = [Hyderabad], first_name = [Rajiv], last_name = [Reddy],
_version_ = 1547262806014820352}, SolrDocument{id = 002, phone = [9848022338],
city = [Kolkata], first_name = [Siddarth], last_name = [Battacharya],
_version_ = 1547262806026354688}, SolrDocument{id = 003, phone = [9848022339],
city = [Delhi], first_name = [Rajesh], last_name = [Khanna],
_version_ = 1547262806029500416}]}
SolrDocument{id = 001, phone = [9848022337], city = [Hyderabad], first_name = [Rajiv],
last_name = [Reddy], _version_ = 1547262806014820352}
SolrDocument{id = 002, phone = [9848022338], city = [Kolkata], first_name = [Siddarth],
last_name = [Battacharya], _version_ = 1547262806026354688}
SolrDocument{id = 003, phone = [9848022339], city = [Delhi], first_name = [Rajesh],
last_name = [Khanna], _version_ = 1547262806029500416}डेटा संग्रहीत करने के अलावा, अपाचे सोलर इसे आवश्यक होने पर वापस क्वेरी करने की सुविधा भी प्रदान करता है। Solr कुछ निश्चित पैरामीटर प्रदान करता है, जिनके उपयोग से हम इसमें संग्रहीत डेटा को क्वेरी कर सकते हैं।
निम्न तालिका में, हमने अपाचे सोलर में उपलब्ध विभिन्न क्वेरी मापदंडों को सूचीबद्ध किया है।
| पैरामीटर | विवरण |
|---|---|
| क्यू | यह अपाचे सोलर का मुख्य क्वेरी पैरामीटर है, इस पैरामीटर में शर्तों के लिए दस्तावेजों की समानता उनके द्वारा बनाई गई है। |
| fq | यह पैरामीटर Apache Solr की फ़िल्टर क्वेरी का प्रतिनिधित्व करता है जो इस फ़िल्टर से मेल खाते दस्तावेज़ों के लिए सेट किए गए परिणाम को प्रतिबंधित करता है। |
| शुरू | प्रारंभ पैरामीटर एक पृष्ठ के लिए प्रारंभिक ऑफसेट का प्रतिनिधित्व करता है, इस पैरामीटर का डिफ़ॉल्ट मान 0 है। |
| पंक्तियों | यह पैरामीटर उन दस्तावेजों की संख्या को दर्शाता है जिन्हें प्रति पृष्ठ पुनर्प्राप्त किया जाना है। इस पैरामीटर का डिफ़ॉल्ट मान 10 है। |
| तरह | यह पैरामीटर फ़ील्ड की सूची को निर्दिष्ट करता है, जिसे अल्पविराम द्वारा अलग किया जाता है, जिसके आधार पर क्वेरी के परिणामों को क्रमबद्ध किया जाना है। |
| फ्लोरिडा | यह पैरामीटर परिणाम सेट में प्रत्येक दस्तावेज़ के लिए फ़ील्ड की सूची निर्दिष्ट करता है। |
| wt | यह पैरामीटर उस प्रतिक्रिया लेखक के प्रकार का प्रतिनिधित्व करता है जिसे हम परिणाम देखना चाहते थे। |
आप इन सभी मापदंडों को अपाचे सोलर के विकल्प के रूप में देख सकते हैं। Apache Solr के होमपेज पर जाएं। पृष्ठ के बाईं ओर, विकल्प क्वेरी पर क्लिक करें। यहां, आप क्वेरी के मापदंडों के लिए फ़ील्ड देख सकते हैं।
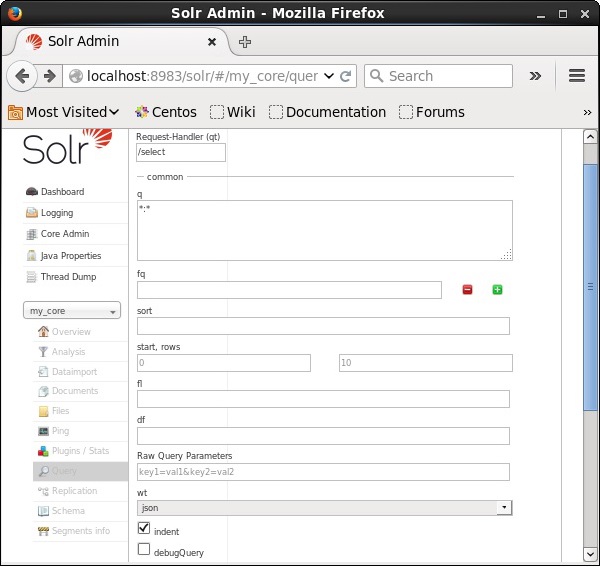
अभिलेखों को पुनः प्राप्त करना
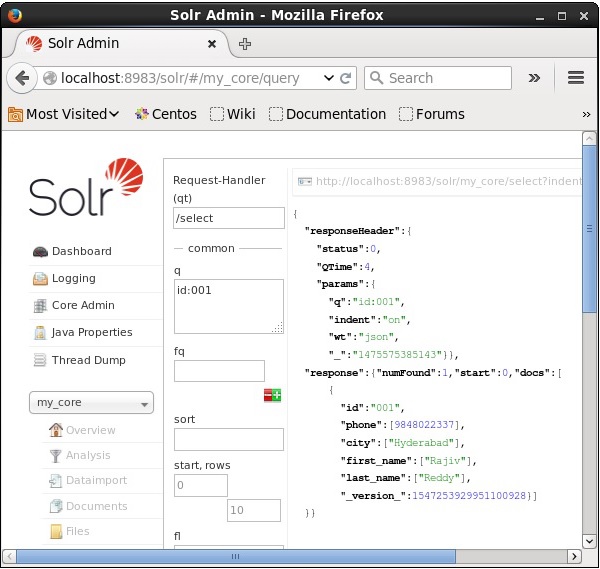
मान लें कि हमारे नाम पर 3 रिकॉर्ड हैं my_core। चयनित कोर से एक विशेष रिकॉर्ड प्राप्त करने के लिए, आपको किसी विशेष दस्तावेज़ के फ़ील्ड के नाम और मूल्य जोड़े को पास करने की आवश्यकता है। उदाहरण के लिए, यदि आप फ़ील्ड के मान के साथ रिकॉर्ड प्राप्त करना चाहते हैंid, आपको क्षेत्र के नाम-मूल्य जोड़ी को पास करने की आवश्यकता है - Id:001 पैरामीटर के लिए मान के रूप में q और क्वेरी निष्पादित करें।
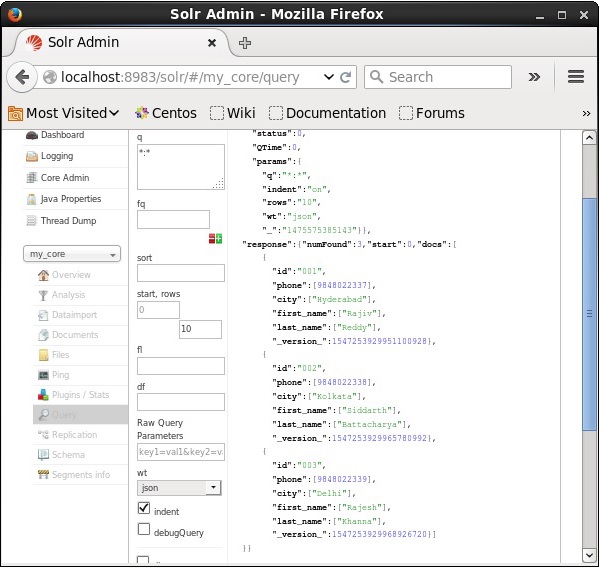
उसी तरह, आप एक पैरामीटर से एक पैरामीटर के रूप में *: * पास करके सभी रिकॉर्ड को पुनः प्राप्त कर सकते हैं q, जैसा कि निम्नलिखित स्क्रीनशॉट में दिखाया गया है।
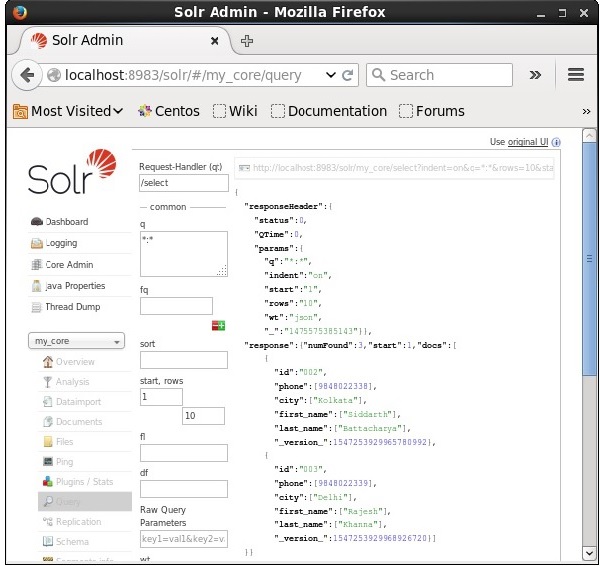
2 एन डी रिकॉर्ड से पुनः प्राप्त
हम पैरामीटर के मान के रूप में 2 पास करके दूसरे रिकॉर्ड से रिकॉर्ड प्राप्त कर सकते हैं start, जैसा कि निम्नलिखित स्क्रीनशॉट में दिखाया गया है।
अभिलेखों की संख्या को प्रतिबंधित करना
में मान निर्दिष्ट करके आप रिकॉर्ड की संख्या को सीमित कर सकते हैं rowsपैरामीटर। उदाहरण के लिए, हम मान में पैरामीटर 2 में पास करके क्वेरी के परिणाम में कुल रिकॉर्ड को 2 तक सीमित कर सकते हैंrows, जैसा कि निम्नलिखित स्क्रीनशॉट में दिखाया गया है।
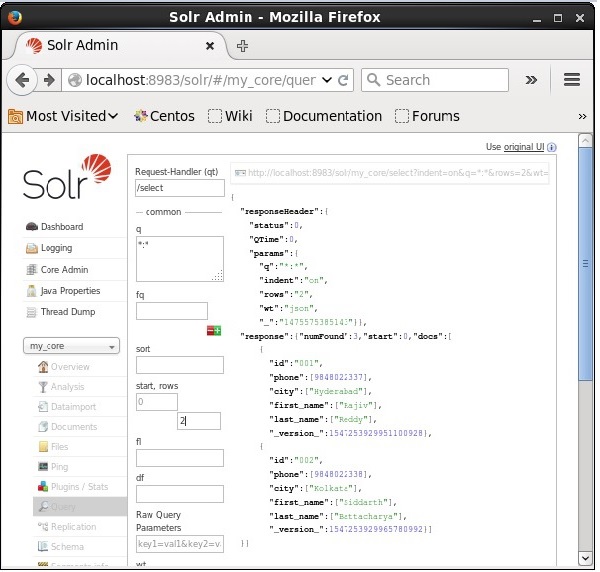
रिस्पांस राइटर टाइप
आप पैरामीटर के प्रदान किए गए मानों में से एक का चयन करके आवश्यक दस्तावेज़ प्रकार में प्रतिक्रिया प्राप्त कर सकते हैं wt।
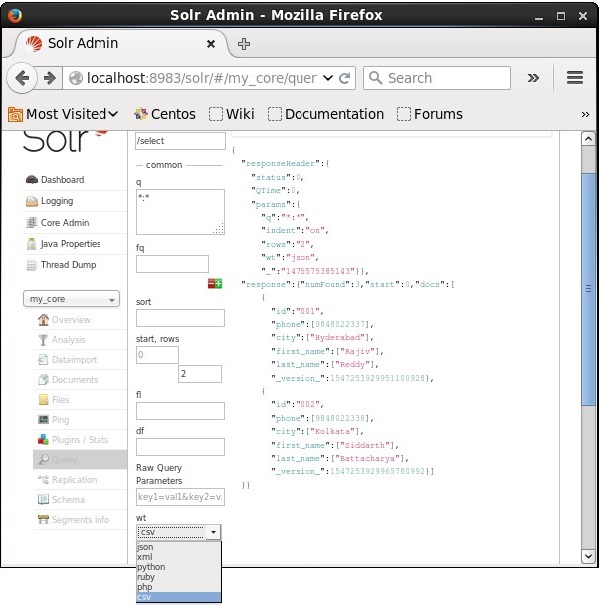
उपरोक्त उदाहरण में, हमने चुना है .csv प्रतिक्रिया पाने के लिए प्रारूप।
फ़ील्ड्स की सूची
यदि हम परिणामी दस्तावेजों में विशेष क्षेत्र रखना चाहते हैं, तो हमें संपत्ति के मूल्य के रूप में अल्पविराम द्वारा अलग किए गए आवश्यक क्षेत्रों की सूची को पास करना होगा। fl।
निम्नलिखित उदाहरण में, हम खेतों को पुनः प्राप्त करने की कोशिश कर रहे हैं - id, phone, तथा first_name।
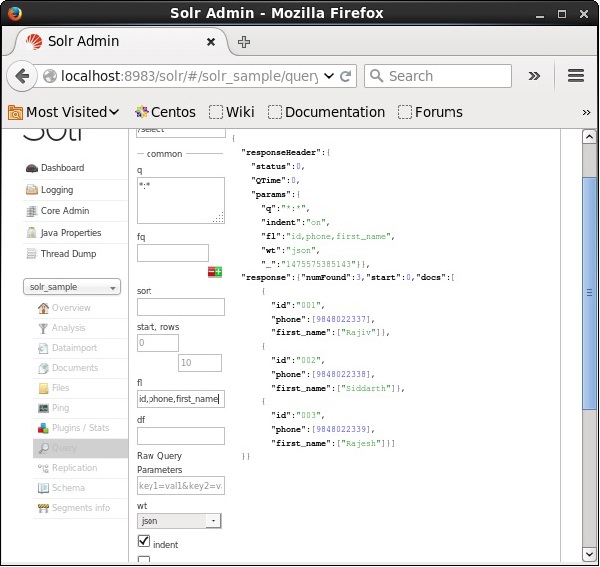
अपाचे सोलर में फेसिंग को विभिन्न श्रेणियों में खोज परिणामों के वर्गीकरण के लिए संदर्भित किया जाता है। इस अध्याय में, हम अपाचे सोलर में उपलब्ध फेसिंग के प्रकारों पर चर्चा करेंगे -
Query faceting - यह वर्तमान खोज परिणामों में दस्तावेजों की संख्या देता है जो दिए गए क्वेरी से मेल खाते हैं।
Date faceting - यह उन दस्तावेजों की संख्या लौटाता है जो कुछ निश्चित तिथि सीमाओं के भीतर आते हैं।
Faceting कमांड्स को किसी भी सामान्य Solr क्वेरी रिक्वेस्ट में जोड़ा जाता है, और faceting काउंट्स उसी क्वेरी रिस्पॉन्स में वापस आते हैं।
क्वेरी का उदाहरण उदाहरण
खेत का उपयोग करना faceting, हम किसी भी क्षेत्र में सभी शर्तों के लिए मायने रखते हैं, या सिर्फ शीर्ष शर्तें।
एक उदाहरण के रूप में, आइए हम निम्नलिखित पर विचार करें books.csv ऐसी फ़ाइल जिसमें विभिन्न पुस्तकों के बारे में डेटा हो।
id,cat,name,price,inStock,author,series_t,sequence_i,genre_s
0553573403,book,A Game of Thrones,5.99,true,George R.R. Martin,"A Song of Ice
and Fire",1,fantasy
0553579908,book,A Clash of Kings,10.99,true,George R.R. Martin,"A Song of Ice
and Fire",2,fantasy
055357342X,book,A Storm of Swords,7.99,true,George R.R. Martin,"A Song of Ice
and Fire",3,fantasy
0553293354,book,Foundation,7.99,true,Isaac Asimov,Foundation Novels,1,scifi
0812521390,book,The Black Company,4.99,false,Glen Cook,The Chronicles of The
Black Company,1,fantasy
0812550706,book,Ender's Game,6.99,true,Orson Scott Card,Ender,1,scifi
0441385532,book,Jhereg,7.95,false,Steven Brust,Vlad Taltos,1,fantasy
0380014300,book,Nine Princes In Amber,6.99,true,Roger Zelazny,the Chronicles of
Amber,1,fantasy
0805080481,book,The Book of Three,5.99,true,Lloyd Alexander,The Chronicles of
Prydain,1,fantasy
080508049X,book,The Black Cauldron,5.99,true,Lloyd Alexander,The Chronicles of
Prydain,2,fantasyचलिए इस फाइल को Apache Solr में पोस्ट करते हैं post उपकरण।
[Hadoop@localhost bin]$ ./post -c Solr_sample sample.csvउपरोक्त कमांड को निष्पादित करने पर, दिए गए सभी दस्तावेजों का उल्लेख किया गया है .csv फाइल अपाचे सोलर में अपलोड की जाएगी।
अब हम फ़ील्ड पर एक मुखरित क्वेरी निष्पादित करते हैं author संग्रह / कोर पर 0 पंक्तियों के साथ my_core।
Apache Solr का वेब UI खोलें और पेज के बायीं तरफ, चेकबॉक्स को चेक करें facet, जैसा कि निम्नलिखित स्क्रीनशॉट में दिखाया गया है।
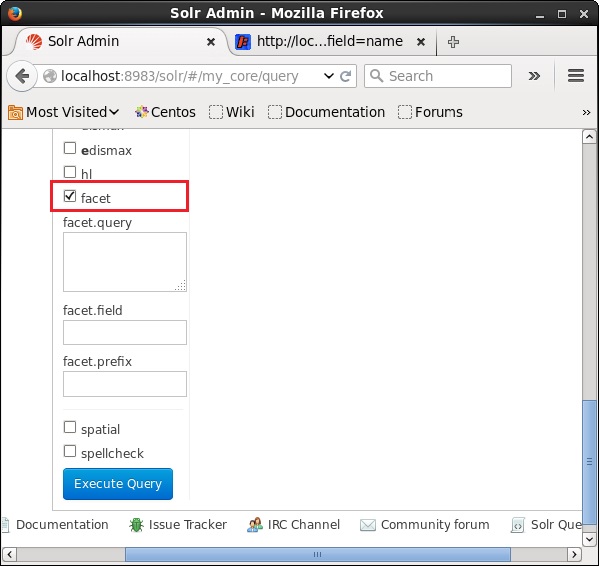
चेकबॉक्स की जाँच करने पर, पहलू खोज के मापदंडों को पारित करने के लिए आपके पास तीन और पाठ क्षेत्र होंगे। अब, क्वेरी के मापदंडों के रूप में, निम्न मान पास करें।
q = *:*, rows = 0, facet.field = authorअंत में, क्वेरी पर क्लिक करके निष्पादित करें Execute Query बटन।
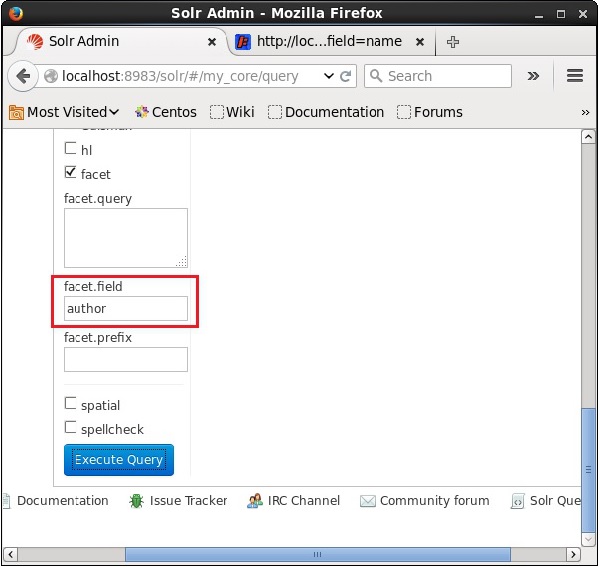
निष्पादित करने पर, यह निम्नलिखित परिणाम देगा।
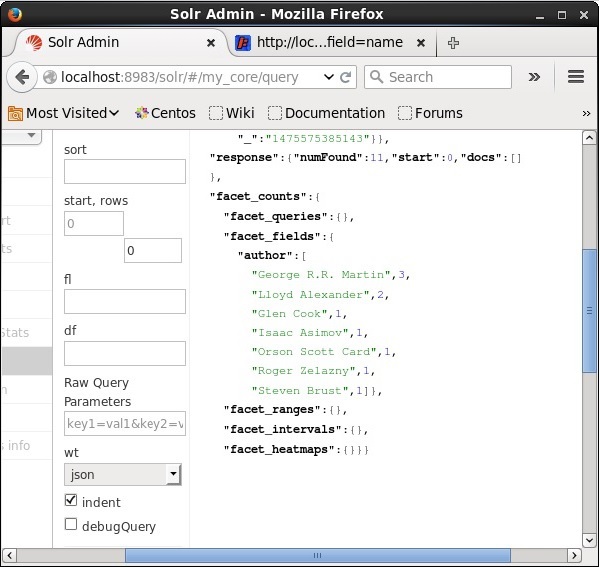
यह लेखक पर आधारित सूचकांक में दस्तावेजों को वर्गीकृत करता है और प्रत्येक लेखक द्वारा योगदान की गई पुस्तकों की संख्या को निर्दिष्ट करता है।
जावा क्लाइंट एपीआई का उपयोग करना
Apache Solr इंडेक्स में दस्तावेज़ जोड़ने के लिए जावा प्रोग्राम है। इस कोड को नाम वाली फ़ाइल में सहेजेंHitHighlighting.java।
import java.io.IOException;
import java.util.List;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrQuery;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.client.Solrj.request.QueryRequest;
import org.apache.Solr.client.Solrj.response.FacetField;
import org.apache.Solr.client.Solrj.response.FacetField.Count;
import org.apache.Solr.client.Solrj.response.QueryResponse;
import org.apache.Solr.common.SolrInputDocument;
public class HitHighlighting {
public static void main(String args[]) throws SolrServerException, IOException {
//Preparing the Solr client
String urlString = "http://localhost:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
//String query = request.query;
SolrQuery query = new SolrQuery();
//Setting the query string
query.setQuery("*:*");
//Setting the no.of rows
query.setRows(0);
//Adding the facet field
query.addFacetField("author");
//Creating the query request
QueryRequest qryReq = new QueryRequest(query);
//Creating the query response
QueryResponse resp = qryReq.process(Solr);
//Retrieving the response fields
System.out.println(resp.getFacetFields());
List<FacetField> facetFields = resp.getFacetFields();
for (int i = 0; i > facetFields.size(); i++) {
FacetField facetField = facetFields.get(i);
List<Count> facetInfo = facetField.getValues();
for (FacetField.Count facetInstance : facetInfo) {
System.out.println(facetInstance.getName() + " : " +
facetInstance.getCount() + " [drilldown qry:" +
facetInstance.getAsFilterQuery());
}
System.out.println("Hello");
}
}
}टर्मिनल में निम्नलिखित कमांड निष्पादित करके उपरोक्त कोड संकलित करें -
[Hadoop@localhost bin]$ javac HitHighlighting
[Hadoop@localhost bin]$ java HitHighlightingउपरोक्त कमांड निष्पादित करने पर, आपको निम्न आउटपुट मिलेगा।
[author:[George R.R. Martin (3), Lloyd Alexander (2), Glen Cook (1), Isaac
Asimov (1), Orson Scott Card (1), Roger Zelazny (1), Steven Brust (1)]]