कंपाइलर डिज़ाइन - कोड ऑप्टिमाइज़ेशन
अनुकूलन एक कार्यक्रम परिवर्तन तकनीक है, जो कम संसाधनों (यानी सीपीयू, मेमोरी) का उपभोग करके और उच्च गति प्रदान करके कोड को बेहतर बनाने की कोशिश करता है।
अनुकूलन में, उच्च-स्तरीय सामान्य प्रोग्रामिंग निर्माणों को बहुत कुशल निम्न-स्तरीय प्रोग्रामिंग कोड द्वारा प्रतिस्थापित किया जाता है। एक कोड अनुकूलन प्रक्रिया को नीचे दिए गए तीन नियमों का पालन करना चाहिए:
आउटपुट कोड को किसी भी तरह से प्रोग्राम का अर्थ नहीं बदलना चाहिए।
अनुकूलन से कार्यक्रम की गति बढ़नी चाहिए और यदि संभव हो, तो कार्यक्रम को संसाधनों की कम संख्या की मांग करनी चाहिए।
अनुकूलन स्वयं तेज होना चाहिए और समग्र संकलन प्रक्रिया में देरी नहीं करनी चाहिए।
एक अनुकूलित कोड के लिए प्रक्रिया के संकलन के विभिन्न स्तरों पर प्रयास किए जा सकते हैं।
शुरुआत में, उपयोगकर्ता कोड को बदलने / पुनर्व्यवस्थित करने या कोड लिखने के लिए बेहतर एल्गोरिदम का उपयोग कर सकते हैं।
मध्यवर्ती कोड उत्पन्न करने के बाद, संकलक पता गणना और छोरों में सुधार करके मध्यवर्ती कोड को संशोधित कर सकता है।
लक्ष्य मशीन कोड का उत्पादन करते समय, कंपाइलर मेमोरी पदानुक्रम और सीपीयू रजिस्टर का उपयोग कर सकता है।
अनुकूलन को मोटे तौर पर दो प्रकारों में वर्गीकृत किया जा सकता है: मशीन स्वतंत्र और मशीन निर्भर।
मशीन-स्वतंत्र अनुकूलन
इस अनुकूलन में, कंपाइलर इंटरमीडिएट कोड में लेता है और कोड का एक हिस्सा बदल देता है जिसमें कोई सीपीयू रजिस्टर और / या पूर्ण मेमोरी लोकेशन शामिल नहीं होता है। उदाहरण के लिए:
do
{
item = 10;
value = value + item;
} while(value<100);इस कोड में पहचानकर्ता आइटम का बार-बार असाइनमेंट शामिल है, जिसे यदि हम इस तरह से रखते हैं:
Item = 10;
do
{
value = value + item;
} while(value<100);न केवल सीपीयू चक्र को बचाना चाहिए, बल्कि किसी भी प्रोसेसर पर उपयोग किया जा सकता है।
मशीन पर निर्भर अनुकूलन
मशीन-निर्भर अनुकूलन लक्ष्य कोड उत्पन्न होने के बाद किया जाता है और जब कोड को लक्ष्य मशीन वास्तुकला के अनुसार बदल दिया जाता है। इसमें सीपीयू रजिस्टर शामिल हैं और रिश्तेदार संदर्भों के बजाय पूर्ण मेमोरी संदर्भ हो सकते हैं। मशीन-आश्रित ऑप्टिमाइज़र स्मृति पदानुक्रम का अधिकतम लाभ लेने के लिए प्रयास करते हैं।
बुनियादी ब्लॉक
स्रोत कोड में आमतौर पर कई निर्देश होते हैं, जिन्हें हमेशा अनुक्रम में निष्पादित किया जाता है और उन्हें कोड के बुनियादी ब्लॉक के रूप में माना जाता है। इन बुनियादी ब्लॉकों में उनके बीच कोई जम्प स्टेटमेंट नहीं होता है, अर्थात, जब पहला निर्देश निष्पादित किया जाता है, तो प्रोग्राम के प्रवाह नियंत्रण को खोए बिना एक ही मूल ब्लॉक के सभी निर्देशों को उनकी उपस्थिति के अनुक्रम में निष्पादित किया जाएगा।
एक कार्यक्रम में बुनियादी ब्लॉक के रूप में विभिन्न निर्माण हो सकते हैं, जैसे IF-THEN-ELSE, SWITCH-CASE सशर्त कथन और लूप जैसे DO-WHILE, FOR, और REPEAT-UNTIL, आदि।
बुनियादी ब्लॉक की पहचान
हम एक कार्यक्रम में बुनियादी ब्लॉकों को खोजने के लिए निम्नलिखित एल्गोरिदम का उपयोग कर सकते हैं:
उन सभी बुनियादी ब्लॉकों के हेडर स्टेटमेंट खोजें जहां से एक बुनियादी ब्लॉक शुरू होता है:
- एक कार्यक्रम का पहला बयान।
- कथन जो किसी भी शाखा (सशर्त / बिना शर्त) के लक्ष्य हैं।
- कथन जो किसी भी शाखा विवरण का अनुसरण करते हैं।
हेडर के बयान और उनके बाद के बयान एक बुनियादी ब्लॉक बनाते हैं।
एक बुनियादी ब्लॉक में किसी भी अन्य बुनियादी ब्लॉक का हेडर स्टेटमेंट शामिल नहीं है।
बुनियादी ब्लॉक कोड पीढ़ी और दृष्टिकोण के दृष्टिकोण से महत्वपूर्ण अवधारणाएं हैं।
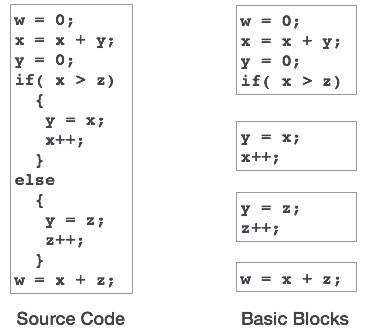
बुनियादी ब्लॉक वैरिएबल की पहचान करने में महत्वपूर्ण भूमिका निभाते हैं, जिनका उपयोग एक ही मूल ब्लॉक में एक से अधिक बार किया जा रहा है। यदि किसी चर का एक से अधिक बार उपयोग किया जा रहा है, तो उस चर के लिए आवंटित रजिस्टर मेमोरी को तब तक खाली नहीं किया जाना चाहिए जब तक कि ब्लॉक निष्पादन समाप्त न हो जाए।
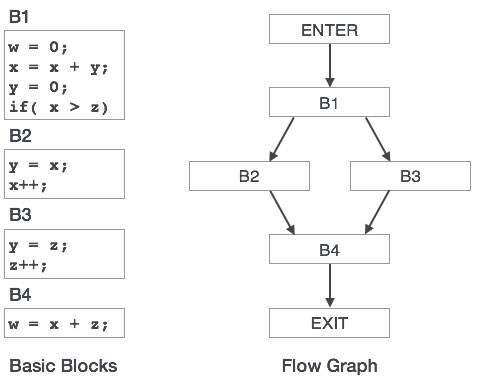
नियंत्रण प्रवाह ग्राफ
एक कार्यक्रम में बुनियादी ब्लॉकों को नियंत्रण प्रवाह ग्राफ के माध्यम से दर्शाया जा सकता है। एक नियंत्रण प्रवाह ग्राफ में दर्शाया गया है कि ब्लॉक के बीच प्रोग्राम नियंत्रण कैसे पारित किया जा रहा है। यह एक उपयोगी उपकरण है जो कार्यक्रम में किसी भी अवांछित छोरों का पता लगाने में मदद करके अनुकूलन में मदद करता है।
लूप ऑप्टिमाइज़ेशन
अधिकांश प्रोग्राम सिस्टम में एक लूप के रूप में चलते हैं। सीपीयू साइकिल और मेमोरी को बचाने के लिए छोरों को अनुकूलित करना आवश्यक हो जाता है। लूप्स को निम्नलिखित तकनीकों द्वारा अनुकूलित किया जा सकता है:
Invariant code: कोड का एक टुकड़ा जो लूप में रहता है और प्रत्येक पुनरावृत्ति पर समान मान की गणना करता है जिसे लूप-इनवेरिएंट कोड कहा जाता है। इस कोड को लूप से बाहर निकाला जा सकता है, ताकि इसे प्रत्येक पुनरावृत्ति के बजाय केवल एक बार गणना की जा सके।
Induction analysis : एक चर को एक प्रेरण चर कहा जाता है यदि इसका मान पाश-अपरिवर्तनीय मूल्य द्वारा लूप के भीतर बदल दिया जाता है।
Strength reduction: ऐसे भाव हैं जो अधिक सीपीयू चक्र, समय और स्मृति का उपभोग करते हैं। इन अभिव्यक्तियों को अभिव्यक्ति के आउटपुट से समझौता किए बिना सस्ते भावों से प्रतिस्थापित किया जाना चाहिए। उदाहरण के लिए, गुणा (x * 2) CPU चक्र (x << 1) की तुलना में महंगा है और समान परिणाम देता है।
मृत-कोड उन्मूलन
डेड कोड एक या एक से अधिक कोड स्टेटमेंट हैं, जो हैं:
- या तो कभी निष्पादित या अगम्य नहीं,
- या यदि निष्पादित किया जाता है, तो उनके आउटपुट का उपयोग कभी नहीं किया जाता है।
इस प्रकार, मृत कोड किसी भी कार्यक्रम के संचालन में कोई भूमिका नहीं निभाता है और इसलिए इसे केवल समाप्त किया जा सकता है।
आंशिक रूप से मृत कोड
कुछ कोड स्टेटमेंट होते हैं जिनके गणना किए गए मान केवल कुछ परिस्थितियों में उपयोग किए जाते हैं, अर्थात कभी-कभी मान का उपयोग किया जाता है और कभी-कभी वे नहीं होते हैं। ऐसे कोड आंशिक रूप से मृत-कोड के रूप में जाने जाते हैं।
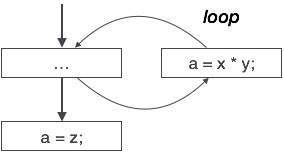
उपरोक्त नियंत्रण प्रवाह ग्राफ में कार्यक्रम का एक हिस्सा दर्शाया गया है जहाँ चर 'a' का प्रयोग अभिव्यक्ति 'x * y' के उत्पादन को नियत करने के लिए किया जाता है। आइए हम मान लें कि 'a' को दिया गया मान कभी भी लूप के अंदर प्रयोग नहीं किया जाता है। इसके तुरंत बाद नियंत्रण लूप को छोड़ देता है, 'a' को वेरिएबल 'z' का मान दिया जाता है, जिसे बाद में प्रोग्राम में उपयोग किया जाएगा। हम यहाँ निष्कर्ष देते हैं कि 'a' का असाइनमेंट कोड कभी भी कहीं भी उपयोग नहीं किया जाता है, इसलिए इसे समाप्त करने के योग्य है।
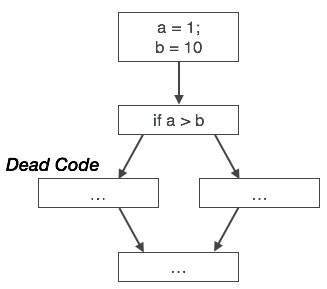
इसी तरह, ऊपर दी गई तस्वीर बताती है कि सशर्त बयान हमेशा गलत होता है, जिसका अर्थ है कि कोड, सच्चे मामले में लिखा गया है, कभी भी निष्पादित नहीं किया जाएगा, इसलिए इसे हटाया जा सकता है।
आंशिक अतिरेक
निरर्थक भावों की गणना समानांतर पथ में एक से अधिक बार की जाती है, बिना ऑपरेंड में कोई परिवर्तन किए।। आंशिक-निरर्थक अभिव्यक्तियों को ऑपरेंड में किसी भी परिवर्तन के बिना, पथ में एक से अधिक बार गणना की जाती है। उदाहरण के लिए,
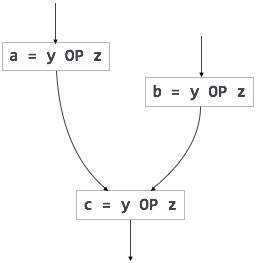
[निरर्थक अभिव्यक्ति] |
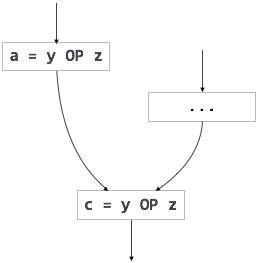
[आंशिक रूप से निरर्थक अभिव्यक्ति] |
लूप-इनवेरिएंट कोड आंशिक रूप से निरर्थक है और कोड-मोशन तकनीक का उपयोग करके इसे समाप्त किया जा सकता है।
आंशिक रूप से निरर्थक कोड का एक और उदाहरण हो सकता है:
If (condition)
{
a = y OP z;
}
else
{
...
}
c = y OP z;हम मानते हैं कि ऑपरेंड का मान (y तथा z) चर के असाइनमेंट से नहीं बदले गए हैं a चर करने के लिए c। यहाँ, यदि शर्त कथन सत्य है, तो y OP z की गणना दो बार की जाती है, अन्यथा एक बार। इस अतिरेक को समाप्त करने के लिए कोड गति का उपयोग किया जा सकता है, जैसा कि नीचे दिखाया गया है:
If (condition)
{
...
tmp = y OP z;
a = tmp;
...
}
else
{
...
tmp = y OP z;
}
c = tmp;यहाँ, चाहे वह शर्त सही हो या गलत; y ओपी z की गणना केवल एक बार की जानी चाहिए।