डाटा माइनिंग - क्विक गाइड
सूचना उद्योग में भारी मात्रा में डेटा उपलब्ध है। जब तक इसे उपयोगी जानकारी में परिवर्तित नहीं किया जाता है, तब तक यह डेटा किसी काम का नहीं है। डेटा की इस बड़ी मात्रा का विश्लेषण करना और उससे उपयोगी जानकारी निकालना आवश्यक है।
जानकारी का निष्कर्षण एकमात्र प्रक्रिया नहीं है जिसे हमें करने की आवश्यकता है; डेटा माइनिंग में डेटा क्लीनिंग, डेटा इंटीग्रेशन, डेटा ट्रांसफ़ॉर्मेशन, डेटा माइनिंग, पैटर्न इवैल्यूएशन और डेटा प्रेजेंटेशन जैसी अन्य प्रक्रियाएँ भी शामिल हैं। एक बार जब ये सभी प्रक्रियाएं समाप्त हो जाती हैं, तो हम इस जानकारी का उपयोग कई अनुप्रयोगों जैसे कि धोखाधड़ी का पता लगाने, बाजार विश्लेषण, उत्पादन नियंत्रण, विज्ञान अन्वेषण आदि में कर पाएंगे।
डाटा माइनिंग क्या है?
डेटा माइनिंग को डेटा के विशाल सेट से जानकारी निकालने के रूप में परिभाषित किया गया है। दूसरे शब्दों में, हम कह सकते हैं कि डेटा माइनिंग डेटा से खनन ज्ञान की प्रक्रिया है। निकाली गई जानकारी या ज्ञान का उपयोग निम्नलिखित में से किसी भी अनुप्रयोग के लिए किया जा सकता है -
- बाजार का विश्लेषण
- धोखाधड़ी का पता लगाना
- ग्राहक प्रतिधारण
- प्रोडक्शन नियंत्रण
- विज्ञान अन्वेषण
डेटा खनन अनुप्रयोग
निम्न डोमेन में डेटा खनन अत्यधिक उपयोगी है -
- बाजार विश्लेषण और प्रबंधन
- कॉर्पोरेट विश्लेषण और जोखिम प्रबंधन
- धोखाधड़ी का पता लगाना
इनके अलावा, डेटा माइनिंग का उपयोग उत्पादन नियंत्रण, ग्राहक प्रतिधारण, विज्ञान अन्वेषण, खेल, ज्योतिष और इंटरनेट वेब सर्फ-एड के क्षेत्रों में भी किया जा सकता है।
बाजार विश्लेषण और प्रबंधन
नीचे सूचीबद्ध बाजार के विभिन्न क्षेत्र हैं जहां डेटा खनन का उपयोग किया जाता है -
Customer Profiling - डेटा माइनिंग यह निर्धारित करने में मदद करता है कि लोग किस तरह के उत्पाद खरीदते हैं।
Identifying Customer Requirements- डाटा माइनिंग विभिन्न ग्राहकों के लिए सर्वोत्तम उत्पादों की पहचान करने में मदद करता है। यह उन कारकों को खोजने के लिए भविष्यवाणी का उपयोग करता है जो नए ग्राहकों को आकर्षित कर सकते हैं।
Cross Market Analysis - डाटा माइनिंग उत्पाद की बिक्री के बीच एसोसिएशन / सहसंबंध करता है।
Target Marketing - डेटा माइनिंग उन मॉडल ग्राहकों के समूहों को खोजने में मदद करता है जो समान विशेषताओं जैसे रुचियों, खर्च करने की आदतों, आय आदि को साझा करते हैं।
Determining Customer purchasing pattern - डाटा माइनिंग ग्राहक की खरीदारी के पैटर्न को निर्धारित करने में मदद करता है।
Providing Summary Information - डेटा खनन हमें विभिन्न बहुआयामी सारांश रिपोर्ट प्रदान करता है।
कॉर्पोरेट विश्लेषण और जोखिम प्रबंधन
डेटा माइनिंग का उपयोग कॉर्पोरेट सेक्टर के निम्नलिखित क्षेत्रों में किया जाता है -
Finance Planning and Asset Evaluation - इसमें नकदी प्रवाह विश्लेषण और भविष्यवाणी, परिसंपत्तियों का मूल्यांकन करने के लिए आकस्मिक दावा विश्लेषण शामिल है।
Resource Planning - इसमें संसाधनों का सारांश और तुलना और खर्च शामिल है।
Competition - इसमें प्रतियोगियों और बाजार की दिशाओं की निगरानी शामिल है।
धोखाधड़ी का पता लगाना
धोखाधड़ी का पता लगाने के लिए क्रेडिट कार्ड सेवाओं और दूरसंचार के क्षेत्रों में डेटा माइनिंग का भी उपयोग किया जाता है। धोखाधड़ी वाले टेलीफोन कॉल में, यह कॉल के गंतव्य, कॉल की अवधि, दिन या सप्ताह का समय आदि को खोजने में मदद करता है। यह उन पैटर्न का भी विश्लेषण करता है जो अपेक्षित मानदंडों से विचलित होते हैं।
डेटा माइनिंग उस तरह के पैटर्न से संबंधित है, जिनका खनन किया जा सकता है। खनन किए जाने वाले डेटा के प्रकार के आधार पर, डेटा माइनिंग में शामिल कार्यों की दो श्रेणियां हैं -
- Descriptive
- वर्गीकरण और भविष्यवाणी
वर्णनात्मक कार्य
वर्णनात्मक फ़ंक्शन डेटाबेस में डेटा के सामान्य गुणों से संबंधित है। यहाँ वर्णनात्मक कार्यों की सूची दी गई है -
- कक्षा / अवधारणा विवरण
- बार-बार पैटर्न का खनन
- संघों का खनन
- सहसंबंधों का खनन
- क्लस्टरों का खनन
कक्षा / अवधारणा विवरण
क्लास / कॉन्सेप्ट से तात्पर्य उन आंकड़ों से है जो कक्षाओं या अवधारणाओं से जुड़े होते हैं। उदाहरण के लिए, एक कंपनी में, बिक्री के लिए वस्तुओं के वर्ग में कंप्यूटर और प्रिंटर शामिल हैं, और ग्राहकों की अवधारणाओं में बड़े खर्च करने वाले और बजट खर्च करने वाले शामिल हैं। किसी वर्ग या अवधारणा के ऐसे विवरणों को वर्ग / अवधारणा विवरण कहा जाता है। इन विवरणों को निम्नलिखित दो तरीकों से प्राप्त किया जा सकता है -
Data Characterization- यह अध्ययन के तहत कक्षा के डेटा को सारांशित करने के लिए संदर्भित करता है। अध्ययन के तहत इस वर्ग को लक्ष्य वर्ग कहा जाता है।
Data Discrimination - यह किसी पूर्वनिर्धारित समूह या वर्ग के साथ वर्ग के मानचित्रण या वर्गीकरण को संदर्भित करता है।
बार-बार पैटर्न का खनन
बार-बार आने वाले पैटर्न वे पैटर्न होते हैं जो अक्सर ट्रांजेक्शनल डेटा में होते हैं। यहाँ लगातार प्रकार के पैटर्न की सूची दी गई है -
Frequent Item Set - यह उन वस्तुओं के एक समूह को संदर्भित करता है जो अक्सर एक साथ दिखाई देते हैं, उदाहरण के लिए, दूध और ब्रेड।
Frequent Subsequence - पैटर्न का एक क्रम जो अक्सर होता है जैसे कि कैमरा खरीदना मेमोरी कार्ड द्वारा पीछा किया जाता है।
Frequent Sub Structure - सबस्ट्रक्चर अलग-अलग संरचनात्मक रूपों को संदर्भित करता है, जैसे कि रेखांकन, पेड़, या जाली, जिन्हें आइटम-सेट या बाद के साथ जोड़ा जा सकता है।
एसोसिएशन का खनन
खुदरा बिक्री में संघों का उपयोग उन पैटर्न की पहचान करने के लिए किया जाता है जो अक्सर एक साथ खरीदे जाते हैं। यह प्रक्रिया डेटा के बीच संबंध को उजागर करने और एसोसिएशन के नियमों का निर्धारण करने की प्रक्रिया को संदर्भित करती है।
उदाहरण के लिए, एक रिटेलर एक एसोसिएशन नियम बनाता है जो दर्शाता है कि 70% समय दूध ब्रेड के साथ बेचा जाता है और केवल 30% बिस्कुट को ब्रेड के साथ बेचा जाता है।
सहसंबंधों का खनन
यह एक तरह का अतिरिक्त विश्लेषण है जो संबद्ध-विशेषता-मूल्य जोड़े के बीच या दो आइटम सेट के बीच दिलचस्प सांख्यिकीय सहसंबंधों को उजागर करने के लिए किया जाता है ताकि यह विश्लेषण किया जा सके कि क्या उनका सकारात्मक, नकारात्मक या एक दूसरे पर कोई प्रभाव नहीं है।
क्लस्टरों का खनन
क्लस्टर इसी तरह की वस्तुओं के समूह को संदर्भित करता है। क्लस्टर विश्लेषण से तात्पर्य उन वस्तुओं के समूह से है जो एक-दूसरे से बहुत मिलते-जुलते हैं लेकिन अन्य समूहों में मौजूद वस्तुओं से अत्यधिक भिन्न होते हैं।
वर्गीकरण और भविष्यवाणी
वर्गीकरण एक मॉडल खोजने की प्रक्रिया है जो डेटा कक्षाओं या अवधारणाओं का वर्णन करता है। उद्देश्य इस मॉडल का उपयोग उन वस्तुओं के वर्ग की भविष्यवाणी करने में सक्षम है, जिनका वर्ग लेबल अज्ञात है। यह व्युत्पन्न मॉडल प्रशिक्षण डेटा के सेट के विश्लेषण पर आधारित है। व्युत्पन्न मॉडल निम्नलिखित रूपों में प्रस्तुत किया जा सकता है -
- वर्गीकरण (IF-THEN) नियम
- निर्णय के पेड़
- गणितीय सूत्र
- तंत्रिका जाल
इन प्रक्रियाओं में शामिल कार्यों की सूची इस प्रकार है -
Classification- यह उन वस्तुओं के वर्ग की भविष्यवाणी करता है जिनका वर्ग लेबल अज्ञात है। इसका उद्देश्य एक व्युत्पन्न मॉडल खोजना है जो डेटा कक्षाओं या अवधारणाओं का वर्णन और अंतर करता है। व्युत्पन्न मॉडल प्रशिक्षण डेटा के विश्लेषण सेट यानी डेटा ऑब्जेक्ट पर आधारित है जिसका क्लास लेबल अच्छी तरह से जाना जाता है।
Prediction- इसका उपयोग कक्षा के लेबल के बजाय लापता या अनुपलब्ध संख्यात्मक डेटा मूल्यों की भविष्यवाणी करने के लिए किया जाता है। प्रतिगमन विश्लेषण आमतौर पर भविष्यवाणी के लिए उपयोग किया जाता है। उपलब्ध आंकड़ों के आधार पर वितरण के रुझानों की पहचान के लिए भी भविष्यवाणी का उपयोग किया जा सकता है।
Outlier Analysis - आउटलेयर को डेटा ऑब्जेक्ट के रूप में परिभाषित किया जा सकता है जो उपलब्ध डेटा के सामान्य व्यवहार या मॉडल का अनुपालन नहीं करते हैं।
Evolution Analysis - एवोल्यूशन विश्लेषण उन वस्तुओं के लिए विवरण और मॉडल नियमितताओं या रुझानों को संदर्भित करता है जिनका व्यवहार समय के साथ बदलता है।
डाटा माइनिंग टास्क प्रिमिटिव
- हम डेटा माइनिंग कार्य को डेटा माइनिंग क्वेरी के रूप में निर्दिष्ट कर सकते हैं।
- यह क्वेरी सिस्टम का इनपुट है।
- डेटा माइनिंग कार्य प्रिमिटिव के संदर्भ में डेटा माइनिंग क्वेरी को परिभाषित किया गया है।
Note- ये आदिम हमें डेटा खनन प्रणाली के साथ एक इंटरैक्टिव तरीके से संवाद करने की अनुमति देते हैं। यहां डेटा माइनिंग टास्क प्रिमिटिव की सूची दी गई है -
- खनन के लिए प्रासंगिक कार्य का डेटा सेट करें।
- खनन करने के लिए ज्ञान की तरह।
- खोज प्रक्रिया में उपयोग किया जाने वाला पृष्ठभूमि ज्ञान।
- पैटर्न के मूल्यांकन के लिए दिलचस्प उपाय और सीमाएं।
- खोजे गए पैटर्न को देखने के लिए प्रतिनिधित्व।
खनन के लिए प्रासंगिक कार्य का डेटा सेट करें
यह डेटाबेस का वह भाग है जिसमें उपयोगकर्ता रुचि रखता है। इस भाग में निम्नलिखित शामिल हैं -
- डेटाबेस विशेषताएँ
- ब्याज के डेटा वेयरहाउस आयाम
खनन करने के लिए ज्ञान की तरह
यह प्रदर्शन किए जाने वाले कार्यों के प्रकार को संदर्भित करता है। ये कार्य हैं -
- Characterization
- Discrimination
- एसोसिएशन और सहसंबंध विश्लेषण
- Classification
- Prediction
- Clustering
- बाह्य विश्लेषण
- विकास विश्लेषण
पृष्ठभूमि का ज्ञान
पृष्ठभूमि ज्ञान डेटा को अमूर्त के कई स्तरों पर खनन करने की अनुमति देता है। उदाहरण के लिए, कॉन्सेप्ट पदानुक्रम पृष्ठभूमि ज्ञान में से एक है जो डेटा को अमूर्त के कई स्तरों पर खनन करने की अनुमति देता है।
पैटर्न के मूल्यांकन के लिए दिलचस्प उपाय और सीमाएं
इसका उपयोग ज्ञान की खोज की प्रक्रिया द्वारा खोजे जाने वाले प्रतिमानों के मूल्यांकन के लिए किया जाता है। विभिन्न प्रकार के ज्ञान के लिए अलग-अलग दिलचस्प उपाय हैं।
खोजे गए पैटर्न को देखने के लिए प्रतिनिधित्व
यह उस रूप को संदर्भित करता है जिसमें खोजे गए पैटर्न प्रदर्शित किए जाने हैं। इन अभ्यावेदन में निम्नलिखित शामिल हो सकते हैं। -
- Rules
- Tables
- Charts
- Graphs
- निर्णय के पेड़
- Cubes
डेटा माइनिंग एक आसान काम नहीं है, क्योंकि उपयोग किए गए एल्गोरिदम बहुत जटिल हो सकते हैं और डेटा हमेशा एक स्थान पर उपलब्ध नहीं होता है। इसे विभिन्न विषम डेटा स्रोतों से एकीकृत करने की आवश्यकता है। ये कारक कुछ मुद्दे भी बनाते हैं। यहाँ इस ट्यूटोरियल में, हम प्रमुख मुद्दों के बारे में चर्चा करेंगे -
- खनन पद्धति और उपयोगकर्ता सहभागिता
- प्रदर्शन के कारण
- विविध डेटा प्रकार के मुद्दे
निम्नलिखित आरेख प्रमुख मुद्दों का वर्णन करता है।

खनन पद्धति और उपयोगकर्ता सहभागिता के मुद्दे
यह निम्नलिखित प्रकार के मुद्दों को संदर्भित करता है -
Mining different kinds of knowledge in databases- विभिन्न उपयोगकर्ताओं को विभिन्न प्रकार के ज्ञान में रुचि हो सकती है। इसलिए डेटा खनन के लिए ज्ञान खोज कार्य की एक विस्तृत श्रृंखला को कवर करना आवश्यक है।
Interactive mining of knowledge at multiple levels of abstraction - डेटा माइनिंग प्रक्रिया को संवादात्मक बनाने की आवश्यकता है क्योंकि यह उपयोगकर्ताओं को रिटर्न परिणामों के आधार पर डेटा माइनिंग अनुरोधों को प्रदान करने और उन्हें परिष्कृत करने के लिए खोज पर ध्यान केंद्रित करने की अनुमति देता है।
Incorporation of background knowledge- खोज प्रक्रिया का मार्गदर्शन करने और खोजे गए पैटर्न को व्यक्त करने के लिए, पृष्ठभूमि ज्ञान का उपयोग किया जा सकता है। न केवल संक्षिप्त शब्दों में, बल्कि अमूर्तता के कई स्तरों पर खोजे गए पैटर्न को व्यक्त करने के लिए पृष्ठभूमि ज्ञान का उपयोग किया जा सकता है।
Data mining query languages and ad hoc data mining - डेटा माइनिंग क्वेरी भाषा जो उपयोगकर्ता को तदर्थ खनन कार्यों का वर्णन करने की अनुमति देती है, उसे डेटा वेयरहाउस क्वेरी भाषा के साथ एकीकृत किया जाना चाहिए और कुशल और लचीले डेटा खनन के लिए अनुकूलित किया जाना चाहिए।
Presentation and visualization of data mining results- एक बार पैटर्न की खोज हो जाने के बाद इसे उच्च स्तरीय भाषाओं, और दृश्य अभ्यावेदन में व्यक्त करने की आवश्यकता होती है। इन अभ्यावेदन को आसानी से समझा जा सकता है।
Handling noisy or incomplete data- डेटा नियमितताओं को खनन करते समय शोर और अधूरी वस्तुओं को संभालने के लिए डेटा सफाई के तरीकों की आवश्यकता होती है। यदि डेटा सफाई के तरीके नहीं हैं, तो खोजे गए पैटर्न की सटीकता खराब होगी।
Pattern evaluation - खोजे गए पैटर्न दिलचस्प होने चाहिए क्योंकि या तो वे सामान्य ज्ञान का प्रतिनिधित्व करते हैं या नवीनता की कमी होती है।
प्रदर्शन के कारण
प्रदर्शन से संबंधित मुद्दे निम्नानुसार हो सकते हैं -
Efficiency and scalability of data mining algorithms - डेटाबेस में डेटा की भारी मात्रा से जानकारी को प्रभावी ढंग से निकालने के लिए, डेटा माइनिंग एल्गोरिदम कुशल और स्केलेबल होना चाहिए।
Parallel, distributed, and incremental mining algorithms- डेटाबेस के विशाल आकार, डेटा का व्यापक वितरण और डेटा माइनिंग विधियों की जटिलता जैसे कारक समानांतर और वितरित डेटा माइनिंग एल्गोरिदम के विकास को प्रेरित करते हैं। ये एल्गोरिदम डेटा को विभाजन में विभाजित करते हैं जिसे आगे एक समानांतर फैशन में संसाधित किया जाता है। फिर विभाजन से परिणाम विलय कर दिया जाता है। वृद्धिशील एल्गोरिदम, डेटा को फिर से खरोंच किए बिना डेटाबेस अपडेट करें।
विविध डेटा प्रकार के मुद्दे
Handling of relational and complex types of data - डेटाबेस में जटिल डेटा ऑब्जेक्ट्स, मल्टीमीडिया डेटा ऑब्जेक्ट्स, स्थानिक डेटा, टेम्पोरल डेटा आदि हो सकते हैं। इन सभी तरह के डेटा को माइन करना एक सिस्टम के लिए संभव नहीं है।
Mining information from heterogeneous databases and global information systems- यह डेटा LAN या WAN के विभिन्न डेटा स्रोतों पर उपलब्ध है। ये डेटा स्रोत संरचित, अर्ध संरचित या असंरचित हो सकते हैं। इसलिए इनसे मिले ज्ञान से डेटा माइनिंग में चुनौतियां बढ़ जाती हैं।
डेटा वेयरहाउस
एक डेटा वेयरहाउस प्रबंधन की निर्णय लेने की प्रक्रिया का समर्थन करने के लिए निम्नलिखित विशेषताओं को प्रदर्शित करता है -
Subject Oriented- डेटा वेयरहाउस विषय उन्मुख है क्योंकि यह हमें संगठन के चालू संचालन के बजाय किसी विषय के बारे में जानकारी प्रदान करता है। ये विषय उत्पाद, ग्राहक, आपूर्तिकर्ता, बिक्री, राजस्व आदि हो सकते हैं। डेटा वेयरहाउस चालू परिचालन पर ध्यान केंद्रित नहीं करता है, बल्कि यह निर्णय लेने के लिए मॉडलिंग और डेटा के विश्लेषण पर केंद्रित है।
Integrated - डेटा वेयरहाउस का निर्माण विषम स्रोतों से डेटा के एकीकरण द्वारा किया जाता है जैसे कि रिलेशनल डेटाबेस, फ़्लैट फ़ाइल्स आदि। यह एकीकरण डेटा के प्रभावी विश्लेषण को बढ़ाता है।
Time Variant- डेटा वेयरहाउस में एकत्रित डेटा की पहचान एक विशेष समय अवधि के साथ की जाती है। डेटा वेयरहाउस में डेटा ऐतिहासिक दृष्टिकोण से जानकारी प्रदान करता है।
Non-volatile- Nonvolatile का मतलब है कि जब नया डेटा इसमें जोड़ा जाता है तो पिछला डेटा हटाया नहीं जाता है। डेटा वेयरहाउस को ऑपरेशनल डेटाबेस से अलग रखा जाता है इसलिए डेटा डेटाबेस में ऑपरेशनल डेटाबेस में बार-बार बदलाव परिलक्षित नहीं होता है।
विवरण भण्डारण
डेटा वेयरहाउसिंग डेटा वेयरहाउस के निर्माण और उपयोग की प्रक्रिया है। एक डेटा वेयरहाउस का निर्माण कई विषम स्रोतों से डेटा को एकीकृत करके किया जाता है। यह विश्लेषणात्मक रिपोर्टिंग, संरचित और / या तदर्थ प्रश्नों और निर्णय लेने का समर्थन करता है।
डेटा वेयरहाउसिंग में डेटा सफाई, डेटा एकीकरण और डेटा समेकन शामिल हैं। विषम डेटाबेस को एकीकृत करने के लिए, हमारे पास निम्नलिखित दो दृष्टिकोण हैं -
- प्रश्न प्रेरित दृष्टिकोण
- अद्यतन प्रेरित दृष्टिकोण
प्रश्न-चालित दृष्टिकोण
यह विषम डेटाबेस को एकीकृत करने के लिए पारंपरिक दृष्टिकोण है। इस दृष्टिकोण का उपयोग कई विषम डेटाबेस के शीर्ष पर रैपर और इंटीग्रेटर्स के निर्माण के लिए किया जाता है। इन इंटीग्रेटर्स को मध्यस्थों के रूप में भी जाना जाता है।
क्वेरी संचालित एप्रोच की प्रक्रिया
जब कोई क्वेरी क्लाइंट पक्ष को जारी की जाती है, तो मेटाडेटा शब्दकोश क्वेरी को क्वेरी में अनुवादित करता है, जिसमें शामिल व्यक्तिगत विषम साइट के लिए उपयुक्त है।
अब इन क्वेरी को मैप किया जाता है और स्थानीय क्वेरी प्रोसेसर को भेजा जाता है।
विषम स्थलों से परिणाम एक वैश्विक उत्तर सेट में एकीकृत होते हैं।
नुकसान
इस दृष्टिकोण के निम्नलिखित नुकसान हैं -
क्वेरी ड्रिवन दृष्टिकोण को जटिल एकीकरण और फ़िल्टरिंग प्रक्रियाओं की आवश्यकता है।
यह बहुत ही अक्षम है और लगातार प्रश्नों के लिए बहुत महंगा है।
एकत्रीकरण की आवश्यकता वाले प्रश्नों के लिए यह दृष्टिकोण महंगा है।
अद्यतन-प्रेरित दृष्टिकोण
आज के डेटा वेयरहाउस सिस्टम पहले से चर्चा किए गए पारंपरिक दृष्टिकोण के बजाय अपडेट-संचालित दृष्टिकोण का पालन करते हैं। अपडेट-संचालित दृष्टिकोण में, कई विषम स्रोतों से जानकारी अग्रिम में एकीकृत की जाती है और एक गोदाम में संग्रहीत की जाती है। यह जानकारी प्रत्यक्ष क्वेरी और विश्लेषण के लिए उपलब्ध है।
लाभ
इस दृष्टिकोण के निम्नलिखित फायदे हैं -
यह दृष्टिकोण उच्च प्रदर्शन प्रदान करता है।
डेटा को पहले से ही अर्थ डेटा स्टोर में कॉपी, संसाधित, एकीकृत, एनोटेट, संक्षेप और पुनर्गठन किया जा सकता है।
क्वेरी संसाधन को स्थानीय स्रोतों पर प्रसंस्करण के साथ इंटरफ़ेस की आवश्यकता नहीं होती है।
डेटा वेयरहाउसिंग (OLAP) से डेटा माइनिंग (OLAM) तक
ऑनलाइन एनालिटिकल माइनिंग ऑनलाइन एनालिटिकल प्रोसेसिंग के साथ डाटा माइनिंग और माइनिंग नॉलेज के साथ बहुआयामी डेटाबेस में एकीकृत करता है। यहाँ आरेख है जो OLAP और OLAM दोनों के एकीकरण को दर्शाता है -

OLAM का महत्व
निम्नलिखित कारणों से OLAM महत्वपूर्ण है -
High quality of data in data warehouses- डेटा माइनिंग टूल्स को एकीकृत, सुसंगत और साफ किए गए डेटा पर काम करना आवश्यक है। डेटा के प्रीप्रोसेसिंग में ये कदम बहुत महंगा है। ऐसे प्रीप्रोसेसिंग द्वारा निर्मित डेटा वेयरहाउस OLAP और डेटा खनन के लिए उच्च गुणवत्ता वाले डेटा के मूल्यवान स्रोत हैं।
Available information processing infrastructure surrounding data warehouses - सूचना प्रसंस्करण बुनियादी ढांचा कई विषम डेटाबेस, वेब-एक्सेसिंग और सेवा सुविधाओं, रिपोर्टिंग और OLAP विश्लेषण टूल तक पहुंच, एकीकरण, समेकन और परिवर्तन को संदर्भित करता है।
OLAP−based exploratory data analysis- प्रभावी डेटा माइनिंग के लिए खोजपूर्ण डेटा विश्लेषण आवश्यक है। OLAM डेटा खनन के लिए डेटा के विभिन्न सबसेट पर और अमूर्त के विभिन्न स्तरों पर सुविधा प्रदान करता है।
Online selection of data mining functions - कई डेटा माइनिंग फ़ंक्शंस के साथ ओएलएपी को एकीकृत करना और ऑनलाइन एनालिटिकल माइनिंग उपयोगकर्ताओं को वांछित डेटा माइनिंग फ़ंक्शंस का चयन करने और गतिशील रूप से डेटा माइनिंग स्वैप करने की सुविधा प्रदान करता है।
डेटा माइनिंग
डेटा माइनिंग को डेटा के विशाल सेट से जानकारी निकालने के रूप में परिभाषित किया गया है। दूसरे शब्दों में हम कह सकते हैं कि डेटा माइनिंग डेटा से ज्ञान खनन कर रहा है। इस जानकारी का उपयोग निम्नलिखित में से किसी भी अनुप्रयोग के लिए किया जा सकता है -
- बाजार का विश्लेषण
- धोखाधड़ी का पता लगाना
- ग्राहक प्रतिधारण
- प्रोडक्शन नियंत्रण
- विज्ञान अन्वेषण
डाटा माइनिंग इंजन
डेटा माइनिंग सिस्टम के लिए डेटा माइनिंग इंजन बहुत आवश्यक है। इसमें कार्यात्मक मॉड्यूल का एक सेट होता है जो निम्नलिखित कार्य करता है -
- Characterization
- एसोसिएशन और सहसंबंध विश्लेषण
- Classification
- Prediction
- समूह विश्लेषण
- बाह्य विश्लेषण
- विकास का विश्लेषण
ज्ञानधार
यह डोमेन ज्ञान है। इस ज्ञान का उपयोग खोज को निर्देशित करने या परिणामस्वरूप पैटर्न की रोचकता का मूल्यांकन करने के लिए किया जाता है।
ज्ञान डिस्कवरी
कुछ लोग डेटा माइनिंग को नॉलेज डिस्कवरी के समान मानते हैं, जबकि अन्य डेटा माइनिंग को नॉलेज डिस्कवरी की प्रक्रिया में एक आवश्यक कदम मानते हैं। ज्ञान की खोज प्रक्रिया में शामिल चरणों की सूची इस प्रकार है -
- डेटा की सफाई
- डेटा एकीकरण
- डेटा चयन
- डेटा परिवर्तन
- डेटा माइनिंग
- पैटर्न का मूल्यांकन
- ज्ञान प्रस्तुति
प्रयोक्ता इंटरफ़ेस
उपयोगकर्ता इंटरफ़ेस डेटा खनन प्रणाली का मॉड्यूल है जो उपयोगकर्ताओं और डेटा खनन प्रणाली के बीच संचार में मदद करता है। उपयोगकर्ता इंटरफ़ेस निम्नलिखित कार्य करने की अनुमति देता है -
- डेटा माइनिंग क्वेरी कार्य निर्दिष्ट करके सिस्टम के साथ सहभागिता करें।
- खोज पर ध्यान केंद्रित करने में सहायता के लिए जानकारी प्रदान करना।
- मध्यवर्ती डेटा खनन परिणामों के आधार पर खनन।
- डेटाबेस और डेटा वेयरहाउस स्कीमा या डेटा स्ट्रक्चर्स ब्राउज़ करें।
- खनन पैटर्न का मूल्यांकन करें।
- विभिन्न रूपों में पैटर्न की कल्पना करें।
डेटा एकीकरण
डेटा इंटीग्रेशन एक डेटा प्रीप्रोसेसिंग तकनीक है जो डेटा को कई विषम डेटा स्रोतों से एक सुसंगत डेटा स्टोर में विलय कर देती है। डेटा एकीकरण में असंगत डेटा शामिल हो सकता है और इसलिए डेटा सफाई की आवश्यकता होती है।
डेटा की सफाई
डेटा सफाई एक ऐसी तकनीक है जो शोर डेटा को हटाने और डेटा में विसंगतियों को दूर करने के लिए लागू की जाती है। डेटा की सफाई में गलत डेटा को सही करने के लिए रूपांतरण शामिल हैं। डेटा वेयरहाउस के लिए डेटा तैयार करते समय डेटा की सफाई डेटा प्रीप्रोसेसिंग चरण के रूप में की जाती है।
डेटा चयन
डेटा चयन वह प्रक्रिया है जहां डेटा को विश्लेषण कार्य के लिए प्रासंगिक डेटाबेस से पुनर्प्राप्त किया जाता है। कभी-कभी डेटा चयन प्रक्रिया से पहले डेटा परिवर्तन और समेकन किया जाता है।
समूहों
क्लस्टर इसी तरह की वस्तुओं के समूह को संदर्भित करता है। क्लस्टर विश्लेषण से तात्पर्य उन वस्तुओं के समूह से है जो एक-दूसरे से बहुत मिलते-जुलते हैं लेकिन अन्य समूहों में मौजूद वस्तुओं से अत्यधिक भिन्न होते हैं।
डेटा परिवर्तन
इस चरण में, डेटा को सारांश या एकत्रीकरण कार्यों को करके, खनन के लिए उपयुक्त रूपों में रूपांतरित या समेकित किया जाता है।
नॉलेज डिस्कवरी क्या है?
कुछ लोग डेटा खनन को ज्ञान की खोज से अलग नहीं करते हैं, जबकि अन्य डेटा खनन को ज्ञान की खोज की प्रक्रिया में एक आवश्यक कदम के रूप में देखते हैं। ज्ञान की खोज प्रक्रिया में शामिल चरणों की सूची इस प्रकार है -
Data Cleaning - इस चरण में, शोर और असंगत डेटा हटा दिया जाता है।
Data Integration - इस चरण में, कई डेटा स्रोत संयुक्त हैं।
Data Selection - इस चरण में, विश्लेषण कार्य से संबंधित डेटा डेटाबेस से पुनर्प्राप्त किया जाता है।
Data Transformation - इस चरण में, डेटा को सारांश या एकत्रीकरण संचालन करके खनन के लिए उपयुक्त रूपों में रूपांतरित या समेकित किया जाता है।
Data Mining - इस चरण में, डेटा पैटर्न निकालने के लिए बुद्धिमान तरीके लागू किए जाते हैं।
Pattern Evaluation - इस चरण में, डेटा पैटर्न का मूल्यांकन किया जाता है।
Knowledge Presentation - इस चरण में, ज्ञान का प्रतिनिधित्व किया जाता है।
निम्नलिखित चित्र ज्ञान की खोज की प्रक्रिया को दर्शाता है -

डेटा माइनिंग सिस्टम की एक विशाल विविधता उपलब्ध है। डेटा माइनिंग सिस्टम निम्नलिखित से तकनीकों को एकीकृत कर सकते हैं -
- स्थानिक डेटा विश्लेषण
- सूचना पुनर्प्राप्ति
- पैटर्न मान्यता
- छवि विश्लेषण
- संकेत प्रसंस्करण
- कंप्यूटर ग्राफिक्स
- वेब प्रौद्योगिकी
- Business
- Bioinformatics
डाटा माइनिंग सिस्टम वर्गीकरण
एक डाटा माइनिंग सिस्टम को निम्न मानदंडों के अनुसार वर्गीकृत किया जा सकता है -
- डेटाबेस प्रौद्योगिकी
- Statistics
- मशीन लर्निंग
- सूचना विज्ञान
- Visualization
- अन्य अनुशासन

इनके अलावा, डेटा खनन प्रणाली को भी वर्गीकृत किया जा सकता है (ए) डेटाबेस खनन, (बी) ज्ञान खनन, (सी) तकनीकों का उपयोग किया है, और (डी) अनुप्रयोगों अनुकूलित।
डेटाबेस मिस्ड पर आधारित वर्गीकरण
हम खनन किए गए डेटाबेस के प्रकार के अनुसार डेटा माइनिंग सिस्टम को वर्गीकृत कर सकते हैं। डेटाबेस सिस्टम को विभिन्न मानदंडों के अनुसार वर्गीकृत किया जा सकता है जैसे डेटा मॉडल, डेटा के प्रकार, आदि। और डेटा माइनिंग सिस्टम को तदनुसार वर्गीकृत किया जा सकता है।
उदाहरण के लिए, यदि हम डेटा मॉडल के अनुसार डेटाबेस को वर्गीकृत करते हैं, तो हमारे पास रिलेशनल, ट्रांजेक्शनल, ऑब्जेक्ट-रिलेशनल या डेटा वेयरहाउस माइनिंग सिस्टम हो सकता है।
वर्गीकरण ज्ञान के प्रकार पर आधारित है
हम खनन किए गए ज्ञान के अनुसार डेटा माइनिंग सिस्टम को वर्गीकृत कर सकते हैं। इसका अर्थ है कि डेटा माइनिंग सिस्टम को कार्यात्मकताओं के आधार पर वर्गीकृत किया जाता है जैसे -
- Characterization
- Discrimination
- एसोसिएशन और सहसंबंध विश्लेषण
- Classification
- Prediction
- बाह्य विश्लेषण
- विकास विश्लेषण
वर्गीकृत तकनीक के आधार पर वर्गीकरण
हम जिस तरह की तकनीकों का इस्तेमाल करते हैं, उसके अनुसार डेटा माइनिंग सिस्टम को वर्गीकृत कर सकते हैं। हम इन तकनीकों का वर्णन कर सकते हैं जिसमें शामिल उपयोगकर्ता बातचीत की डिग्री या नियोजित विश्लेषण के तरीके हैं।
वर्गीकृत किए गए अनुप्रयोगों के आधार पर वर्गीकरण
हम अनुकूलित किए गए एप्लिकेशन के अनुसार डेटा माइनिंग सिस्टम को वर्गीकृत कर सकते हैं। ये आवेदन इस प्रकार हैं -
- Finance
- Telecommunications
- DNA
- शेयर बाजार
एक DB / DW प्रणाली के साथ एक डाटा खनन प्रणाली का घालमेल
यदि डेटा माइनिंग सिस्टम डेटाबेस या डेटा वेयरहाउस सिस्टम के साथ एकीकृत नहीं है, तो संचार करने के लिए कोई सिस्टम नहीं होगा। इस योजना को गैर-युग्मन योजना के रूप में जाना जाता है। इस योजना में, मुख्य ध्यान डेटा खनन डिजाइन पर और उपलब्ध डेटा सेटों के खनन के लिए कुशल और प्रभावी एल्गोरिदम विकसित करने पर है।
एकीकरण योजनाओं की सूची इस प्रकार है -
No Coupling- इस योजना में, डेटा माइनिंग सिस्टम डेटाबेस या डेटा वेयरहाउस फ़ंक्शंस में से किसी का भी उपयोग नहीं करता है। यह एक विशेष स्रोत से डेटा प्राप्त करता है और कुछ डेटा माइनिंग एल्गोरिदम का उपयोग करके उस डेटा को संसाधित करता है। डेटा माइनिंग रिजल्ट दूसरी फाइल में स्टोर हो जाता है।
Loose Coupling- इस योजना में, डेटा माइनिंग सिस्टम डेटाबेस और डेटा वेयरहाउस सिस्टम के कुछ कार्यों का उपयोग कर सकता है। यह इन प्रणालियों द्वारा प्रबंधित डेटा श्वसन से डेटा प्राप्त करता है और उस डेटा पर डेटा खनन करता है। यह तब खनन परिणाम को फ़ाइल में या डेटाबेस में या डेटा वेयरहाउस में निर्दिष्ट स्थान पर संग्रहीत करता है।
Semi−tight Coupling - इस योजना में, डेटा माइनिंग सिस्टम को डेटाबेस या डेटा वेयरहाउस सिस्टम के साथ जोड़ा जाता है और इसके अलावा, डेटाबेस में कुछ डेटा माइनिंग प्राइमिटिव के कुशल कार्यान्वयन प्रदान किए जा सकते हैं।
Tight coupling- इस युग्मन योजना में, डेटा माइनिंग सिस्टम को डेटाबेस या डेटा वेयरहाउस सिस्टम में आसानी से एकीकृत किया जाता है। डेटा माइनिंग सबसिस्टम को सूचना प्रणाली के एक कार्यात्मक घटक के रूप में माना जाता है।
डेटा माइनिंग क्वेरी लैंग्वेज (DMQL) को हान, फू, वांग, एट अल द्वारा प्रस्तावित किया गया था। DBMiner डाटा खनन प्रणाली के लिए। डेटा माइनिंग क्वेरी लैंग्वेज वास्तव में स्ट्रक्चर्ड क्वेरी लैंग्वेज (SQL) पर आधारित है। डेटा माइनिंग क्वेरी लैंग्वेज को तदर्थ और इंटरेक्टिव डेटा माइनिंग को सपोर्ट करने के लिए डिज़ाइन किया जा सकता है। यह DMQL प्रिमिटिव निर्दिष्ट करने के लिए कमांड प्रदान करता है। DMQL डेटाबेस और डेटा वेयरहाउस के साथ भी काम कर सकता है। DMQL का उपयोग डेटा खनन कार्यों को परिभाषित करने के लिए किया जा सकता है। विशेष रूप से हम DMQL में डेटा वेयरहाउस और डेटा marts को परिभाषित करने के तरीके की जांच करते हैं।
टास्क-प्रासंगिक डेटा विनिर्देश के लिए सिंटैक्स
यहाँ टास्क प्रासंगिक डेटा निर्दिष्ट करने के लिए DMQL का वाक्य विन्यास है -
use database database_name
or
use data warehouse data_warehouse_name
in relevance to att_or_dim_list
from relation(s)/cube(s) [where condition]
order by order_list
group by grouping_listज्ञान के प्रकार को निर्दिष्ट करने के लिए सिंटैक्स
यहां हम वर्ण-विन्यास, भेदभाव, संघ, वर्गीकरण और भविष्यवाणी के लिए वाक्यविन्यास पर चर्चा करेंगे।
निस्र्पण
लक्षण वर्णन के लिए वाक्य रचना है -
mine characteristics [as pattern_name]
analyze {measure(s) }विश्लेषण खंड, कुल उपायों को निर्दिष्ट करता है, जैसे कि गिनती, योग, या गिनती%।
उदाहरण के लिए -
Description describing customer purchasing habits.
mine characteristics as customerPurchasing
analyze count%भेदभाव
भेदभाव के लिए वाक्य रचना है -
mine comparison [as {pattern_name]}
For {target_class } where {t arget_condition }
{versus {contrast_class_i }
where {contrast_condition_i}}
analyze {measure(s) }उदाहरण के लिए, एक उपयोगकर्ता बड़े व्ययकर्ताओं को उन ग्राहकों के रूप में परिभाषित कर सकता है जो लागत वाले आइटम खरीदते हैं $100 or more on an average; and budget spenders as customers who purchase items at less than $औसतन 100। इनमें से प्रत्येक श्रेणी के ग्राहकों के लिए भेदभावपूर्ण विवरण का खनन DMQL में निर्दिष्ट किया जा सकता है -
mine comparison as purchaseGroups
for bigSpenders where avg(I.price) ≥$100 versus budgetSpenders where avg(I.price)< $100
analyze countसंगति
एसोसिएशन के लिए वाक्य रचना is− है
mine associations [ as {pattern_name} ]
{matching {metapattern} }उदाहरण के लिए -
mine associations as buyingHabits
matching P(X:customer,W) ^ Q(X,Y) ≥ buys(X,Z)जहां X ग्राहक संबंध की कुंजी है; P और Q विधेय चर हैं; और W, Y और Z ऑब्जेक्ट चर हैं।
वर्गीकरण
वर्गीकरण के लिए वाक्य रचना है -
mine classification [as pattern_name]
analyze classifying_attribute_or_dimensionउदाहरण के लिए, मेरा पैटर्न, ग्राहक क्रेडिट रेटिंग को वर्गीकृत करना, जहां कक्षाएं विशेषता credit_rating द्वारा निर्धारित की जाती हैं, और मेरा वर्गीकरण classifyCustomerCreditRating के रूप में निर्धारित किया जाता है।
analyze credit_ratingपूर्वानुमान
भविष्यवाणी के लिए वाक्य रचना है -
mine prediction [as pattern_name]
analyze prediction_attribute_or_dimension
{set {attribute_or_dimension_i= value_i}}संकल्पना पदानुक्रम विशिष्टता के लिए सिंटैक्स
अवधारणा पदानुक्रम निर्दिष्ट करने के लिए, निम्नलिखित सिंटैक्स का उपयोग करें -
use hierarchy <hierarchy> for <attribute_or_dimension>हम विभिन्न सिंटैक्स का उपयोग विभिन्न प्रकार की पदानुक्रमों को परिभाषित करने के लिए करते हैं जैसे कि
-schema hierarchies
define hierarchy time_hierarchy on date as [date,month quarter,year]
-
set-grouping hierarchies
define hierarchy age_hierarchy for age on customer as
level1: {young, middle_aged, senior} < level0: all
level2: {20, ..., 39} < level1: young
level3: {40, ..., 59} < level1: middle_aged
level4: {60, ..., 89} < level1: senior
-operation-derived hierarchies
define hierarchy age_hierarchy for age on customer as
{age_category(1), ..., age_category(5)}
:= cluster(default, age, 5) < all(age)
-rule-based hierarchies
define hierarchy profit_margin_hierarchy on item as
level_1: low_profit_margin < level_0: all
if (price - cost)< $50 level_1: medium-profit_margin < level_0: all if ((price - cost) > $50) and ((price - cost) ≤ $250))
level_1: high_profit_margin < level_0: allरोचकता के लिए सिंटैक्स माप विशिष्टता
दिलचस्प उपाय और सीमाएं उपयोगकर्ता द्वारा कथन के साथ निर्दिष्ट की जा सकती हैं -
with <interest_measure_name> threshold = threshold_valueउदाहरण के लिए -
with support threshold = 0.05
with confidence threshold = 0.7पैटर्न प्रस्तुति और विज़ुअलाइज़ेशन विशिष्टता के लिए सिंटैक्स
हमारे पास एक सिंटैक्स है, जो उपयोगकर्ताओं को एक या अधिक रूपों में खोज किए गए पैटर्न के प्रदर्शन को निर्दिष्ट करने की अनुमति देता है।
display as <result_form>उदाहरण के लिए -
display as tableDMQL की पूर्ण विशिष्टता
एक कंपनी के बाजार प्रबंधक के रूप में, आप उन ग्राहकों की खरीद की आदतों को चिह्नित करना चाहेंगे जो $ 100 से कम कीमत पर वस्तुओं की खरीद कर सकते हैं; ग्राहक की आयु के संबंध में, खरीदी गई वस्तु का प्रकार और वह स्थान जहाँ वस्तु खरीदी गई थी। आप उस विशेषता वाले ग्राहकों का प्रतिशत जानना चाहेंगे। विशेष रूप से, आप केवल कनाडा में की गई खरीदारी में रुचि रखते हैं, और अमेरिकन एक्सप्रेस क्रेडिट कार्ड से भुगतान किया जाता है। आप तालिका के रूप में परिणामी विवरण देखना चाहेंगे।
use database AllElectronics_db
use hierarchy location_hierarchy for B.address
mine characteristics as customerPurchasing
analyze count%
in relevance to C.age,I.type,I.place_made
from customer C, item I, purchase P, items_sold S, branch B
where I.item_ID = S.item_ID and P.cust_ID = C.cust_ID and
P.method_paid = "AmEx" and B.address = "Canada" and I.price ≥ 100
with noise threshold = 5%
display as tableडेटा खनन भाषाएँ मानकीकरण
डेटा माइनिंग भाषाओं का मानकीकरण निम्नलिखित उद्देश्यों को पूरा करेगा -
डेटा माइनिंग समाधानों के व्यवस्थित विकास में मदद करता है।
कई डेटा माइनिंग सिस्टम और फ़ंक्शंस के बीच अंतर को बेहतर बनाता है।
शिक्षा और तेजी से सीखने को बढ़ावा देता है।
उद्योग और समाज में डेटा माइनिंग सिस्टम के उपयोग को बढ़ावा देता है।
डेटा विश्लेषण के दो रूप हैं जिनका उपयोग महत्वपूर्ण वर्गों का वर्णन करने वाले मॉडल निकालने या भविष्य के डेटा रुझानों की भविष्यवाणी करने के लिए किया जा सकता है। ये दो रूप इस प्रकार हैं -
- Classification
- Prediction
वर्गीकरण मॉडल श्रेणीबद्ध श्रेणी के लेबल की भविष्यवाणी करते हैं; और भविष्यवाणी मॉडल निरंतर मूल्यवान कार्यों की भविष्यवाणी करते हैं। उदाहरण के लिए, हम बैंक ऋण अनुप्रयोगों को या तो सुरक्षित या जोखिमपूर्ण के रूप में वर्गीकृत करने के लिए एक वर्गीकरण मॉडल का निर्माण कर सकते हैं, या उनकी आय और व्यवसाय को देखते हुए कंप्यूटर उपकरणों पर संभावित ग्राहकों के डॉलर में व्यय की भविष्यवाणी करने के लिए एक भविष्यवाणी मॉडल।
वर्गीकरण क्या है?
निम्नलिखित मामलों के उदाहरण हैं जहां डेटा विश्लेषण कार्य वर्गीकरण है -
एक बैंक ऋण अधिकारी डेटा का विश्लेषण करना चाहता है ताकि यह पता चल सके कि कौन सा ग्राहक (ऋण आवेदक) जोखिम भरा है या कौन से सुरक्षित हैं।
एक कंपनी में एक विपणन प्रबंधक को किसी दिए गए प्रोफ़ाइल के साथ एक ग्राहक का विश्लेषण करने की आवश्यकता होती है, जो एक नया कंप्यूटर खरीदेगा।
उपरोक्त दोनों उदाहरणों में, एक मॉडल या क्लासिफायरियर का निर्माण श्रेणीबद्ध लेबल की भविष्यवाणी करने के लिए किया गया है। ये लेबल ऋण आवेदन डेटा के लिए जोखिम भरे या सुरक्षित हैं और विपणन डेटा के लिए हाँ या नहीं।
भविष्यवाणी क्या है?
निम्नलिखित मामलों के उदाहरण हैं जहां डेटा विश्लेषण कार्य भविष्यवाणी है -
मान लीजिए कि विपणन प्रबंधक को यह अनुमान लगाने की आवश्यकता है कि किसी दिए गए ग्राहक को अपनी कंपनी में बिक्री के दौरान कितना खर्च करना होगा। इस उदाहरण में हम एक संख्यात्मक मूल्य की भविष्यवाणी करने के लिए परेशान हैं। इसलिए डेटा विश्लेषण कार्य संख्यात्मक भविष्यवाणी का एक उदाहरण है। इस मामले में, एक मॉडल या भविष्यवक्ता का निर्माण किया जाएगा जो एक निरंतर-मूल्यवान-फ़ंक्शन या ऑर्डर किए गए मूल्य की भविष्यवाणी करता है।
Note - प्रतिगमन विश्लेषण एक सांख्यिकीय पद्धति है जिसका उपयोग अक्सर संख्यात्मक भविष्यवाणी के लिए किया जाता है।
वर्गीकरण कैसे काम करता है?
हमने ऊपर चर्चा की है कि बैंक ऋण आवेदन की मदद से, वर्गीकरण के काम को समझते हैं। डेटा वर्गीकरण प्रक्रिया में दो चरण शामिल हैं -
- क्लासिफायर या मॉडल का निर्माण
- वर्गीकरण के लिए वर्गीकरण का उपयोग करना
क्लासिफायर या मॉडल का निर्माण
यह चरण सीखने का चरण या सीखने का चरण है।
इस चरण में वर्गीकरण एल्गोरिदम क्लासिफायरियर का निर्माण करते हैं।
क्लासिफायर को डेटाबेस ट्यूप और उनके संबंधित क्लास लेबल से बने प्रशिक्षण सेट से बनाया गया है।
प्रत्येक टपल जो प्रशिक्षण सेट का गठन करता है उसे एक श्रेणी या वर्ग के रूप में संदर्भित किया जाता है। इन टुपल्स को नमूना, वस्तु या डेटा बिंदुओं के रूप में भी संदर्भित किया जा सकता है।

वर्गीकरण के लिए वर्गीकरण का उपयोग करना
इस चरण में, वर्गीकरण के लिए वर्गीकरण का उपयोग किया जाता है। वर्गीकरण नियमों की सटीकता का अनुमान लगाने के लिए परीक्षण डेटा का उपयोग किया जाता है। वर्गीकरण नियमों को नए डेटा ट्यूपल्स पर लागू किया जा सकता है यदि सटीकता को स्वीकार्य माना जाता है।

वर्गीकरण और भविष्यवाणी के मुद्दे
प्रमुख मुद्दा वर्गीकरण और भविष्यवाणी के लिए डेटा तैयार कर रहा है। डेटा तैयार करने में निम्नलिखित गतिविधियाँ शामिल हैं -
Data Cleaning- डेटा सफाई में शोर और लापता मूल्यों के उपचार को शामिल करना शामिल है। चौरसाई तकनीक को लागू करके शोर को हटा दिया जाता है और लापता मानों की समस्या को उस विशेषता के लिए आमतौर पर होने वाले मूल्य के साथ लापता मूल्य को बदलकर हल किया जाता है।
Relevance Analysis- डेटाबेस में अप्रासंगिक विशेषताएं भी हो सकती हैं। सहसंबंध विश्लेषण का उपयोग यह जानने के लिए किया जाता है कि क्या दिए गए दो गुण संबंधित हैं या नहीं।
Data Transformation and reduction - डेटा को निम्न में से किसी भी विधि द्वारा रूपांतरित किया जा सकता है।
Normalization- सामान्यीकरण का उपयोग करके डेटा को रूपांतरित किया जाता है। सामान्यीकरण में दिए गए विशेषता के लिए सभी मूल्यों को स्केल करना शामिल है ताकि उन्हें एक छोटी निर्दिष्ट सीमा के भीतर गिराने के लिए बनाया जा सके। सामान्यीकरण का उपयोग तब किया जाता है जब सीखने के चरण में तंत्रिका नेटवर्क या माप से जुड़े तरीकों का उपयोग किया जाता है।
Generalization- डेटा को उच्च अवधारणा में सामान्य करके भी रूपांतरित किया जा सकता है। इस उद्देश्य के लिए हम अवधारणा पदानुक्रमों का उपयोग कर सकते हैं।
Note - डेटा को कुछ अन्य तरीकों जैसे तरंग परिवर्तन, बायनिंग, हिस्टोग्राम विश्लेषण और क्लस्टरिंग द्वारा भी कम किया जा सकता है।
वर्गीकरण और भविष्यवाणी के तरीकों की तुलना
यहाँ वर्गीकरण और भविष्यवाणी के तरीकों की तुलना करने के लिए मानदंड है -
Accuracy- क्लासिफायर की सटीकता से तात्पर्य क्लासिफायर की क्षमता से है। यह कक्षा के लेबल का सही अनुमान लगाता है और भविष्यवक्ता की सटीकता से यह संकेत मिलता है कि किसी दिए गए भविष्यवक्ता ने नए डेटा के लिए अनुमानित विशेषता के मूल्य का अनुमान लगाया है।
Speed - यह क्लासिफायर या प्रेडिक्टर के निर्माण और उपयोग में कम्प्यूटेशनल लागत को संदर्भित करता है।
Robustness - यह दिए गए शोर डेटा से सही भविष्यवाणी करने के लिए क्लासिफायर या भविष्यवक्ता की क्षमता को संदर्भित करता है।
Scalability- स्केलेबिलिटी क्लासिफायर या भविष्यवक्ता के कुशलता से निर्माण करने की क्षमता को संदर्भित करता है; बड़ी मात्रा में डेटा दिया गया।
Interpretability - यह संदर्भित करता है कि क्लासिफायर या भविष्यवक्ता किस हद तक समझता है।
एक निर्णय पेड़ एक संरचना है जिसमें एक रूट नोड, शाखाएं, और पत्ती नोड शामिल हैं। प्रत्येक आंतरिक नोड एक विशेषता पर परीक्षण को दर्शाता है, प्रत्येक शाखा एक परीक्षण के परिणाम को दर्शाता है, और प्रत्येक पत्ती नोड एक कक्षा लेबल रखता है। पेड़ में सबसे ऊपरी नोड रूट नोड है।
निम्नलिखित निर्णय पेड़ अवधारणा buy_computer के लिए है जो इंगित करता है कि किसी कंपनी के ग्राहक को कंप्यूटर खरीदने की संभावना है या नहीं। प्रत्येक आंतरिक नोड एक विशेषता पर एक परीक्षण का प्रतिनिधित्व करता है। प्रत्येक पत्ती नोड एक वर्ग का प्रतिनिधित्व करता है।

निर्णय वृक्ष होने के लाभ इस प्रकार हैं -
- इसके लिए किसी भी डोमेन ज्ञान की आवश्यकता नहीं है।
- समझ लेना आसान है।
- निर्णय वृक्ष के सीखने और वर्गीकरण के चरण सरल और तेज हैं।
निर्णय ट्री इंडक्शन एल्गोरिथम
1980 में जे। रॉस क्विनलान नामक एक मशीन शोधकर्ता ने एक निर्णय ट्री एल्गोरिदम विकसित किया जिसे ID3 (Iterative Dichotomiser) के नाम से जाना जाता है। बाद में, उन्होंने C4.5 प्रस्तुत किया, जो ID3 का उत्तराधिकारी था। ID3 और C4.5 एक लालची दृष्टिकोण अपनाते हैं। इस एल्गोरिथ्म में, कोई पीछे नहीं है; पेड़ों का निर्माण शीर्ष-नीचे पुनरावर्ती विभाजन और जीत के तरीके से किया जाता है।
Generating a decision tree form training tuples of data partition D
Algorithm : Generate_decision_tree
Input:
Data partition, D, which is a set of training tuples
and their associated class labels.
attribute_list, the set of candidate attributes.
Attribute selection method, a procedure to determine the
splitting criterion that best partitions that the data
tuples into individual classes. This criterion includes a
splitting_attribute and either a splitting point or splitting subset.
Output:
A Decision Tree
Method
create a node N;
if tuples in D are all of the same class, C then
return N as leaf node labeled with class C;
if attribute_list is empty then
return N as leaf node with labeled
with majority class in D;|| majority voting
apply attribute_selection_method(D, attribute_list)
to find the best splitting_criterion;
label node N with splitting_criterion;
if splitting_attribute is discrete-valued and
multiway splits allowed then // no restricted to binary trees
attribute_list = splitting attribute; // remove splitting attribute
for each outcome j of splitting criterion
// partition the tuples and grow subtrees for each partition
let Dj be the set of data tuples in D satisfying outcome j; // a partition
if Dj is empty then
attach a leaf labeled with the majority
class in D to node N;
else
attach the node returned by Generate
decision tree(Dj, attribute list) to node N;
end for
return N;पेड़ की छँटाई
शोर या आउटलेयर के कारण प्रशिक्षण डेटा में विसंगतियों को दूर करने के लिए ट्री प्रूनिंग का प्रदर्शन किया जाता है। कांटेदार पेड़ छोटे और कम जटिल होते हैं।
ट्री प्रूनिंग दृष्टिकोण
एक पेड़ के लिए दो दृष्टिकोण हैं -
Pre-pruning - इसके निर्माण को जल्दी रोककर पेड़ को काट दिया जाता है।
Post-pruning - यह दृष्टिकोण एक पूर्ण विकसित पेड़ से उप-पेड़ को हटा देता है।
लागत जटिलता
लागत जटिलता को निम्न दो मापदंडों द्वारा मापा जाता है -
- पेड़ में पत्तियों की संख्या, और
- पेड़ की त्रुटि दर।
बायेसियन वर्गीकरण बेयस के प्रमेय पर आधारित है। बायेसियन क्लासिफायर, सांख्यिकीय क्लासिफायरियर हैं। बायेसियन क्लासिफायर क्लास सदस्यता संभावनाओं की भविष्यवाणी कर सकते हैं जैसे कि संभावना यह है कि किसी दिए गए ट्यूपल एक विशेष वर्ग के हैं।
बे का प्रमेय
बेयस के प्रमेय का नाम थॉमस बेयस के नाम पर रखा गया है। संभाव्यता के दो प्रकार हैं -
- पश्चगामी संभावना [P (H / X)]
- पूर्व संभाव्यता [P (H)]
जहाँ X डेटा टपल है और H कुछ परिकल्पना है।
बेयस के प्रमेय के अनुसार,
बायेसियन विश्वास नेटवर्क
बायेशियन विश्वास नेटवर्क संयुक्त सशर्त संभाव्यता वितरण निर्दिष्ट करते हैं। उन्हें विश्वास नेटवर्क, बेइज़ियन नेटवर्क या प्रोबेबिलिस्टिक नेटवर्क के रूप में भी जाना जाता है।
एक विश्वास नेटवर्क वर्ग सशर्त स्वतंत्रताओं को चर के सबसेट के बीच परिभाषित करने की अनुमति देता है।
यह कार्य-कारण संबंध का एक चित्रमय मॉडल प्रदान करता है, जिस पर शिक्षण किया जा सकता है।
हम वर्गीकरण के लिए एक प्रशिक्षित बायेसियन नेटवर्क का उपयोग कर सकते हैं।
दो घटक हैं जो बायेसियन विश्वास नेटवर्क को परिभाषित करते हैं -
- निर्देशित अचक्रीय ग्राफ
- सशर्त संभाव्यता तालिकाओं का एक सेट
निर्देशित अचक्रीय ग्राफ
- एक निर्देशित चक्रीय ग्राफ में प्रत्येक नोड एक यादृच्छिक चर का प्रतिनिधित्व करता है।
- ये चर असतत या निरंतर मूल्यवान हो सकते हैं।
- ये चर डेटा में दी गई वास्तविक विशेषता के अनुरूप हो सकते हैं।
निर्देशित एसाइक्लिक ग्राफ प्रतिनिधित्व
निम्नलिखित आरेख छह बूलियन चर के लिए एक निर्देशित चक्रीय ग्राफ दिखाता है।

आरेख में चाप कारण ज्ञान का प्रतिनिधित्व करने की अनुमति देता है। उदाहरण के लिए, फेफड़े का कैंसर किसी व्यक्ति के फेफड़ों के कैंसर के पारिवारिक इतिहास से प्रभावित होता है, साथ ही व्यक्ति धूम्रपान करने वाला है या नहीं। यह ध्यान देने योग्य है कि वेरिएबल पॉजिटिव एक्सरे इस बात से स्वतंत्र है कि मरीज को फेफड़े के कैंसर का पारिवारिक इतिहास है या कि मरीज धूम्रपान करने वाला है, यह देखते हुए कि हमें पता है कि मरीज को फेफड़े का कैंसर है।
सशर्त संभाव्यता तालिका
चर LungCancer (LC) के मानों के लिए सशर्त संभाव्यता तालिका, इसके मूल नोड्स, FamilyHistory (FH), और Smoker (S) के मूल्यों के प्रत्येक संभावित संयोजन को निम्नानुसार दर्शाती है -

IF-THEN रूल्स
नियम-आधारित क्लासिफायर वर्गीकरण के लिए IF-THEN नियमों के एक सेट का उपयोग करता है। हम निम्नलिखित में से एक नियम व्यक्त कर सकते हैं -
आइए एक नियम R1 पर विचार करें,
R1: IF age = youth AND student = yes
THEN buy_computer = yesPoints to remember −
नियम का IF भाग कहा जाता है rule antecedent या precondition।
नियम के भाग को कहा जाता है rule consequent।
पूर्ववर्ती भाग में स्थिति एक या अधिक विशेषता परीक्षणों से युक्त होती है और ये परीक्षण तार्किक रूप से Anded होते हैं।
परिणामी भाग में कक्षा की भविष्यवाणी होती है।
Note - हम नियम R1 को निम्नानुसार भी लिख सकते हैं -
R1: (age = youth) ^ (student = yes))(buys computer = yes)यदि किसी दिए गए टपल के लिए स्थिति सही है, तो पूर्ववर्ती संतुष्ट है।
नियम निकालना
यहाँ हम सीखेंगे कि एक निर्णय ट्री से IF-THEN नियम निकालकर नियम-आधारित क्लासिफायर कैसे बनाया जाए।
Points to remember −
निर्णय पेड़ से एक नियम निकालने के लिए -
रूट से लीफ नोड तक प्रत्येक पथ के लिए एक नियम बनाया गया है।
एक नियम पूर्वक बनाने के लिए, प्रत्येक विभाजन मानदंड तार्किक रूप से एंडेड है।
पत्ता नोड वर्ग भविष्यवाणी करता है, जिसके परिणामस्वरूप नियम होता है।
अनुक्रमिक आवरण एल्गोरिथ्म का उपयोग नियम प्रेरण
अनुक्रमिक कवरिंग एल्गोरिदम का उपयोग IF-THEN नियमों को निकालने के लिए किया जा सकता है जो प्रशिक्षण डेटा बनाते हैं। हमें पहले एक निर्णय वृक्ष उत्पन्न करने की आवश्यकता नहीं है। इस एल्गोरिथ्म में, दिए गए वर्ग के लिए प्रत्येक नियम उस वर्ग के कई ट्यूपल्स को कवर करता है।
कुछ अनुक्रमिक कवरिंग एल्गोरिदम AQ, CN2 और RIPPER हैं। सामान्य रणनीति के अनुसार नियमों को एक बार में सीखा जाता है। हर बार नियम सीखे जाने पर, नियम द्वारा कवर किया गया एक ट्यूपल हटा दिया जाता है और बाकी ट्यूपल्स के लिए प्रक्रिया जारी रहती है। ऐसा इसलिए है क्योंकि निर्णय वृक्ष में प्रत्येक पत्ती का मार्ग एक नियम से मेल खाता है।
Note - डिसीजन ट्री इंडक्शन को एक साथ नियमों का एक सेट सीखने के रूप में माना जा सकता है।
निम्नलिखित अनुक्रमिक शिक्षण एल्गोरिथ्म है जहाँ एक समय में एक कक्षा के लिए नियम सीखे जाते हैं। जब हम एक वर्ग CE से नियम सीखते हैं, तो हम चाहते हैं कि नियम केवल कक्षा C से सभी ट्यूपल्स को कवर करे और कोई भी अन्य वर्ग tuple न बनाए।
Algorithm: Sequential Covering
Input:
D, a data set class-labeled tuples,
Att_vals, the set of all attributes and their possible values.
Output: A Set of IF-THEN rules.
Method:
Rule_set={ }; // initial set of rules learned is empty
for each class c do
repeat
Rule = Learn_One_Rule(D, Att_valls, c);
remove tuples covered by Rule form D;
until termination condition;
Rule_set=Rule_set+Rule; // add a new rule to rule-set
end for
return Rule_Set;नियम प्रूनिंग
नियम का कारण है निम्नलिखित कारण से -
गुणवत्ता का मूल्यांकन प्रशिक्षण डेटा के मूल सेट पर किया जाता है। नियम प्रशिक्षण डेटा पर अच्छा प्रदर्शन कर सकता है लेकिन बाद के डेटा पर कम अच्छा है। इसलिए नियम प्रूनिंग की आवश्यकता है।
कंजंक्ट को हटाकर नियम का पालन किया जाता है। नियम आर छंटा हुआ है, यदि आर के छंटे हुए संस्करण में टुपल्स के स्वतंत्र सेट पर जो मूल्यांकन किया गया था, उससे अधिक गुणवत्ता है।
एफओआईएल नियम प्रूनिंग के लिए सरल और प्रभावी तरीका है। किसी नियम R के लिए,
जहां सकारात्मक और नकारात्मक क्रमशः आर द्वारा कवर सकारात्मक ट्यूपल्स की संख्या है।
Note- प्रूनिंग सेट पर R की सटीकता के साथ यह मान बढ़ेगा। इसलिए, यदि FOIL_Prune मान R के छंटे हुए संस्करण के लिए अधिक है, तो हम R को R से जोड़ते हैं।
यहां हम अन्य वर्गीकरण विधियों जैसे जेनेटिक एल्गोरिदम, रफ सेट दृष्टिकोण और फज़ी सेट दृष्टिकोण के बारे में चर्चा करेंगे।
आनुवंशिक एल्गोरिदम
आनुवंशिक एल्गोरिथम का विचार प्राकृतिक विकास से लिया गया है। आनुवंशिक एल्गोरिथम में, सबसे पहले, प्रारंभिक आबादी बनाई जाती है। इस प्रारंभिक जनसंख्या में बेतरतीब ढंग से उत्पन्न नियम शामिल हैं। हम बिट्स की एक स्ट्रिंग द्वारा प्रत्येक नियम का प्रतिनिधित्व कर सकते हैं।
उदाहरण के लिए, दिए गए प्रशिक्षण सेट में, नमूने दो बुलियन विशेषताओं जैसे A1 और A2 द्वारा वर्णित हैं। और इस दिए गए प्रशिक्षण सेट में C1 और C2 जैसे दो वर्ग शामिल हैं।
हम नियम को कूटबद्ध कर सकते हैं IF A1 AND NOT A2 THEN C2 थोड़े से तार में 100। इस बिट प्रतिनिधित्व में, दो सबसे बाएं बिट क्रमशः ए 1 और ए 2 का प्रतिनिधित्व करते हैं।
इसी तरह, नियम IF NOT A1 AND NOT A2 THEN C1 के रूप में एन्कोड किया जा सकता है 001।
Note- यदि विशेषता में K मान है जहां K> 2 है, तो हम K मान का उपयोग विशेषता मानों को एनकोड करने के लिए कर सकते हैं। कक्षाएं भी उसी तरीके से एन्कोडेड हैं।
याद करने के लिए अंक -
फिटेस्ट के अस्तित्व की धारणा के आधार पर, एक नई आबादी का गठन किया जाता है जिसमें वर्तमान आबादी में सबसे योग्य नियम और इन नियमों के साथ-साथ मूल्यों का भी समावेश होता है।
एक नियम की फिटनेस का मूल्यांकन प्रशिक्षण नमूनों के एक सेट पर इसकी वर्गीकरण सटीकता से किया जाता है।
संतान पैदा करने के लिए क्रॉसओवर और म्यूटेशन जैसे आनुवंशिक ऑपरेटरों को लागू किया जाता है।
क्रॉसओवर में, नियमों की जोड़ी से प्रतिस्थापन को नियमों की एक नई जोड़ी बनाने के लिए स्वैप किया जाता है।
उत्परिवर्तन में, एक नियम के स्ट्रिंग में यादृच्छिक रूप से चयनित बिट्स उल्टे होते हैं।
रफ सेट अप्रोच
हम आवेग और शोर डेटा के भीतर संरचनात्मक संबंधों की खोज करने के लिए किसी न किसी सेट दृष्टिकोण का उपयोग कर सकते हैं।
Note- यह दृष्टिकोण केवल असतत-मूल्यवान विशेषताओं पर लागू किया जा सकता है। इसलिए, इसके उपयोग से पहले निरंतर-मूल्यवान विशेषताओं का विवेक होना चाहिए।
रफ सेट थ्योरी दिए गए प्रशिक्षण डेटा के भीतर समतुल्यता वर्गों की स्थापना पर आधारित है। समतुल्य वर्ग बनाने वाले टुपल्स अप्रत्यक्ष हैं। इसका मतलब है कि नमूने डेटा का वर्णन करने वाली विशेषताओं के संबंध में समान हैं।
दिए गए वास्तविक विश्व डेटा में कुछ वर्ग हैं, जो उपलब्ध विशेषताओं के संदर्भ में भिन्न नहीं हो सकते हैं। हम किसी न किसी सेट का उपयोग कर सकते हैंroughly ऐसी कक्षाओं को परिभाषित करें।
किसी दिए गए वर्ग C के लिए, रफ सेट परिभाषा को दो सेटों द्वारा अनुमानित किया गया है -
Lower Approximation of C - C के निचले सन्निकटन में सभी डेटा ट्यूपल शामिल हैं, जो कि विशेषता के ज्ञान के आधार पर, वर्ग C से संबंधित हैं।
Upper Approximation of C - C के ऊपरी सन्निकटन में सभी टुपल्स होते हैं, जो कि गुणों के ज्ञान के आधार पर C से संबंधित नहीं हैं।
निम्नलिखित चित्र वर्ग C के ऊपरी और निचले अनुमोदन को दर्शाता है -

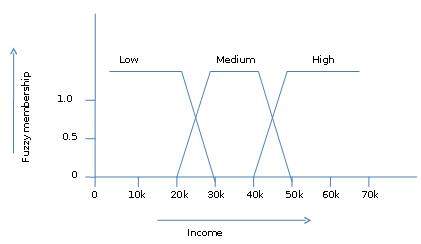
फ़ज़ी सेट दृष्टिकोण
Fuzzy Set Theory को Possibility Theory भी कहा जाता है। इस सिद्धांत को 1965 में लोटी ज़ादेह द्वारा एक विकल्प के रूप में प्रस्तावित किया गया थाtwo-value logic तथा probability theory। यह सिद्धांत हमें अमूर्तता के उच्च स्तर पर काम करने की अनुमति देता है। यह हमें डेटा के अभेद्य माप से निपटने के लिए साधन भी प्रदान करता है।
फ़ज़ी सेट सिद्धांत हमें अस्पष्ट या अयोग्य तथ्यों से निपटने की भी अनुमति देता है। उदाहरण के लिए, उच्च आय के एक सेट का सदस्य होना सटीक में है (जैसे यदि$50,000 is high then what about $49,000 और $ 48,000)। पारंपरिक सीआरआईएसपी सेट के विपरीत, जहां तत्व या तो एस या इसके पूरक से संबंधित है, लेकिन फ़ज़ी सेट सिद्धांत में तत्व एक से अधिक फ़ज़ी सेट से संबंधित हो सकता है।
उदाहरण के लिए, आय का मूल्य $ 49,000 मध्यम और उच्च फ़ज़ी सेट दोनों के लिए है, लेकिन अलग-अलग डिग्री के लिए। इस आय मूल्य के लिए फ़ज़ी सेट नोटेशन इस प्रकार है -
mmedium_income($49k)=0.15 and mhigh_income($49k)=0.96जहाँ 'm' सदस्यता फ़ंक्शन है जो क्रमशः मध्यम_इनके और high_income के फ़ज़ी सेटों पर संचालित होता है। इस संकेतन को आरेखीय रूप से निम्न प्रकार से दिखाया जा सकता है -
क्लस्टर वस्तुओं का एक समूह है जो एक ही वर्ग से संबंधित है। दूसरे शब्दों में, एक क्लस्टर में समान ऑब्जेक्ट्स को समूहीकृत किया जाता है और डिसिमिलर ऑब्जेक्ट को दूसरे क्लस्टर में समूहीकृत किया जाता है।
क्लस्टरिंग क्या है?
क्लस्टरिंग अमूर्त वस्तुओं के समूह को समान वस्तुओं के वर्गों में बनाने की प्रक्रिया है।
Points to Remember
डेटा ऑब्जेक्ट के क्लस्टर को एक समूह के रूप में माना जा सकता है।
क्लस्टर विश्लेषण करते समय, हम पहले डेटा के समूह को डेटा समानता के आधार पर समूहों में विभाजित करते हैं और फिर समूहों को लेबल असाइन करते हैं।
वर्गीकरण पर क्लस्टरिंग का मुख्य लाभ यह है कि, यह परिवर्तनों के अनुकूल है और विभिन्न समूहों को अलग करने वाली उपयोगी विशेषताओं को एकल करने में मदद करता है।
क्लस्टर विश्लेषण के अनुप्रयोग
क्लस्टरिंग विश्लेषण का व्यापक रूप से कई अनुप्रयोगों में उपयोग किया जाता है जैसे कि बाजार अनुसंधान, पैटर्न मान्यता, डेटा विश्लेषण और छवि प्रसंस्करण।
क्लस्टरिंग भी विपणक को उनके ग्राहक आधार में अलग-अलग समूहों को खोजने में मदद कर सकता है। और वे खरीद पैटर्न के आधार पर अपने ग्राहक समूहों को चिह्नित कर सकते हैं।
जीव विज्ञान के क्षेत्र में, इसका उपयोग पौधे और जानवरों के वर्गीकरण को प्राप्त करने के लिए किया जा सकता है, जीन को समान कार्यात्मकताओं के साथ वर्गीकृत किया जा सकता है और आबादी में निहित संरचनाओं में अंतर्दृष्टि प्राप्त कर सकता है।
क्लस्टरिंग भी एक पृथ्वी अवलोकन डेटाबेस में इसी तरह के भूमि उपयोग के क्षेत्रों की पहचान करने में मदद करता है। यह घर के प्रकार, मूल्य और भौगोलिक स्थिति के अनुसार किसी शहर में घरों के समूहों की पहचान करने में भी मदद करता है।
क्लस्टरिंग सूचना खोज के लिए वेब पर दस्तावेजों को वर्गीकृत करने में भी मदद करता है।
क्लस्टरिंग का उपयोग क्रेडिट कार्ड धोखाधड़ी का पता लगाने जैसे बाह्य पहचान अनुप्रयोगों में भी किया जाता है।
डेटा माइनिंग फ़ंक्शन के रूप में, क्लस्टर विश्लेषण प्रत्येक क्लस्टर की विशेषताओं का निरीक्षण करने के लिए डेटा के वितरण में अंतर्दृष्टि प्राप्त करने के लिए एक उपकरण के रूप में कार्य करता है।
डाटा माइनिंग में क्लस्टरिंग की आवश्यकताएं
निम्नलिखित बिंदुओं पर प्रकाश डालते हैं कि डेटा माइनिंग में क्लस्टरिंग की आवश्यकता क्यों है -
Scalability - हमें बड़े डेटाबेस से निपटने के लिए अत्यधिक मापनीय क्लस्टरिंग एल्गोरिदम की आवश्यकता है।
Ability to deal with different kinds of attributes - एल्गोरिदम किसी भी तरह के डेटा जैसे कि अंतराल-आधारित (संख्यात्मक) डेटा, श्रेणीबद्ध, और बाइनरी डेटा पर लागू होने में सक्षम होना चाहिए।
Discovery of clusters with attribute shape- क्लस्टरिंग एल्गोरिदम को मनमाने आकार के समूहों का पता लगाने में सक्षम होना चाहिए। उन्हें केवल दूरी के उपायों के लिए बाध्य नहीं किया जाना चाहिए जो छोटे आकार के गोलाकार क्लस्टर खोजने के लिए करते हैं।
High dimensionality - क्लस्टरिंग एल्गोरिदम न केवल कम-आयामी डेटा बल्कि उच्च आयामी स्थान को भी संभालने में सक्षम होना चाहिए।
Ability to deal with noisy data- डेटाबेस में शोर, गुम या गलत डेटा होता है। कुछ एल्गोरिदम ऐसे डेटा के प्रति संवेदनशील होते हैं और खराब गुणवत्ता वाले क्लस्टर को जन्म दे सकते हैं।
Interpretability - क्लस्टरिंग परिणाम व्याख्या योग्य, समझने योग्य और प्रयोग करने योग्य होना चाहिए।
क्लस्टरिंग तरीके
क्लस्टरिंग विधियों को निम्नलिखित श्रेणियों में वर्गीकृत किया जा सकता है -
- विभाजन विधि
- पदानुक्रमित विधि
- घनत्व-आधारित विधि
- ग्रिड-आधारित विधि
- मॉडल आधारित पद्धति
- बाधा आधारित विधि
विभाजन विधि
मान लीजिए कि हमें 'n' ऑब्जेक्ट का डेटाबेस दिया गया है और विभाजन विधि डेटा के 'k' विभाजन का निर्माण करती है। प्रत्येक विभाजन एक क्लस्टर और k। N का प्रतिनिधित्व करेगा। इसका अर्थ है कि यह डेटा को k समूहों में वर्गीकृत करेगा, जो निम्न आवश्यकताओं को पूरा करता है -
प्रत्येक समूह में कम से कम एक वस्तु होती है।
प्रत्येक वस्तु को ठीक एक समूह से संबंधित होना चाहिए।
Points to remember −
विभाजन की दी गई संख्या (जैसे k) के लिए, विभाजन विधि एक प्रारंभिक विभाजन बनाएगी।
फिर यह वस्तुओं को एक समूह से दूसरे समूह में ले जाकर विभाजन को बेहतर बनाने के लिए पुनरावृत्ति पुनर्वास तकनीक का उपयोग करता है।
पदानुक्रमित तरीके
यह विधि डेटा ऑब्जेक्ट्स के दिए गए सेट का एक पदानुक्रमित विघटन बनाता है। हम पदानुक्रमित विधियों का वर्गीकरण इस आधार पर कर सकते हैं कि पदानुक्रमित अपघटन कैसे बनता है। यहाँ दो दृष्टिकोण हैं -
- एग्लोमेरेटिव दृष्टिकोण
- विभाजन का दृष्टिकोण
एग्लोमेरेटिव दृष्टिकोण
इस दृष्टिकोण को बॉटम-अप दृष्टिकोण के रूप में भी जाना जाता है। इसमें, हम प्रत्येक वस्तु के साथ एक अलग समूह बनाते हैं। यह उन वस्तुओं या समूहों को मिलाता रहता है जो एक दूसरे के करीब हैं। यह तब तक करता रहता है जब तक कि सभी समूहों को एक में विलय नहीं किया जाता है या जब तक कि समाप्ति की स्थिति नहीं होती है।
विभाजन का दृष्टिकोण
इस दृष्टिकोण को टॉप-डाउन दृष्टिकोण के रूप में भी जाना जाता है। इसमें, हम एक ही क्लस्टर में सभी वस्तुओं से शुरू करते हैं। निरंतर पुनरावृत्ति में, एक क्लस्टर छोटे समूहों में विभाजित होता है। यह तब तक नीचे है जब तक कि प्रत्येक वस्तु एक क्लस्टर में या समाप्ति की स्थिति रखती है। यह विधि कठोर है, अर्थात, एक बार विलय या विभाजन हो जाने के बाद, इसे कभी भी पूर्ववत नहीं किया जा सकता है।
पदानुक्रमित क्लस्टरिंग की गुणवत्ता में सुधार के लिए दृष्टिकोण
यहां दो दृष्टिकोण दिए गए हैं जो पदानुक्रमित क्लस्टरिंग की गुणवत्ता में सुधार करने के लिए उपयोग किए जाते हैं -
प्रत्येक पदानुक्रमित विभाजन पर ऑब्जेक्ट लिंकेज का सावधानीपूर्वक विश्लेषण करें।
पहले समूह की वस्तुओं को सूक्ष्म-समूहों में समूहित करें और फिर सूक्ष्म-समूहों पर स्थूल-क्लस्टरिंग करते हुए पदानुक्रमित समूह का उपयोग करके पदानुक्रमित समूह को एकीकृत करें।
घनत्व-आधारित विधि
यह विधि घनत्व की धारणा पर आधारित है। मूल विचार यह है कि दिए गए क्लस्टर को तब तक जारी रखा जाए जब तक कि पड़ोस में घनत्व कुछ सीमा से अधिक न हो जाए, अर्थात दिए गए क्लस्टर के भीतर प्रत्येक डेटा बिंदु के लिए, दिए गए क्लस्टर के त्रिज्या में कम से कम न्यूनतम अंक होने चाहिए।
ग्रिड-आधारित पद्धति
इसमें पिंड मिलकर एक ग्रिड का निर्माण करते हैं। ऑब्जेक्ट स्पेस को एक ग्रिड संरचना बनाने वाली कोशिकाओं की परिमित संख्या में परिमाणित किया जाता है।
Advantages
इस विधि का प्रमुख लाभ तेजी से प्रसंस्करण समय है।
यह केवल परिमाणित स्थान में प्रत्येक आयाम में कोशिकाओं की संख्या पर निर्भर है।
मॉडल-आधारित विधियाँ
इस पद्धति में, किसी मॉडल को दिए गए मॉडल के लिए डेटा का सबसे अच्छा फिट खोजने के लिए प्रत्येक क्लस्टर के लिए एक परिकल्पना की जाती है। यह विधि घनत्व फ़ंक्शन को क्लस्टर करके क्लस्टर का पता लगाती है। यह डेटा बिंदुओं के स्थानिक वितरण को दर्शाता है।
यह विधि मानक आँकड़ों के आधार पर समूहों की संख्या को स्वचालित रूप से निर्धारित करने के लिए एक रास्ता भी प्रदान करती है, जो बाहरी या शोर को ध्यान में रखते हैं। इसलिए यह मजबूत क्लस्टरिंग विधियों की पैदावार देता है।
बाधा आधारित विधि
इस पद्धति में, क्लस्टरिंग उपयोगकर्ता या अनुप्रयोग-उन्मुख बाधाओं के निगमन द्वारा किया जाता है। एक बाधा उपयोगकर्ता की अपेक्षा या वांछित क्लस्टरिंग परिणामों के गुणों को संदर्भित करती है। बाधाएं हमें क्लस्टरिंग प्रक्रिया के साथ संचार का एक इंटरैक्टिव तरीका प्रदान करती हैं। बाधाओं को उपयोगकर्ता या आवेदन की आवश्यकता के द्वारा निर्दिष्ट किया जा सकता है।
पाठ डेटाबेस में दस्तावेज़ों का विशाल संग्रह होता है। वे इन सूचनाओं को समाचार स्रोतों, पुस्तकों, डिजिटल पुस्तकालयों, ई-मेल संदेशों, वेब पेजों आदि जैसे कई स्रोतों से एकत्र करते हैं। सूचना की मात्रा में वृद्धि के कारण, पाठ डेटाबेस तेजी से बढ़ रहे हैं। कई पाठ डेटाबेस में, डेटा अर्ध-संरचित है।
उदाहरण के लिए, एक दस्तावेज़ में कुछ संरचित फ़ील्ड शामिल हो सकते हैं, जैसे शीर्षक, लेखक, प्रकाशन_डेट, आदि। लेकिन संरचना डेटा के साथ-साथ दस्तावेज़ में असंरचित पाठ घटक भी होते हैं, जैसे कि सार और सामग्री। दस्तावेजों में क्या हो सकता है यह जानने के बिना, डेटा से उपयोगी जानकारी का विश्लेषण और निकालने के लिए प्रभावी प्रश्न तैयार करना मुश्किल है। उपयोगकर्ताओं को दस्तावेजों की तुलना करने और उनके महत्व और प्रासंगिकता को रैंक करने के लिए उपकरणों की आवश्यकता होती है। इसलिए, पाठ खनन लोकप्रिय हो गया है और डेटा खनन में एक आवश्यक विषय है।
सूचना पुनर्प्राप्ति
सूचना पुनर्प्राप्ति बड़ी संख्या में पाठ-आधारित दस्तावेजों से सूचना की पुनर्प्राप्ति से संबंधित है। कुछ डेटाबेस सिस्टम आमतौर पर सूचना पुनर्प्राप्ति प्रणाली में मौजूद नहीं होते हैं क्योंकि दोनों विभिन्न प्रकार के डेटा को संभालते हैं। सूचना पुनर्प्राप्ति प्रणाली के उदाहरणों में शामिल हैं -
- ऑनलाइन लाइब्रेरी कैटलॉग सिस्टम
- ऑनलाइन दस्तावेज़ प्रबंधन प्रणाली
- वेब सर्च सिस्टम आदि।
Note- सूचना पुनर्प्राप्ति प्रणाली में मुख्य समस्या उपयोगकर्ता के प्रश्न के आधार पर दस्तावेज़ संग्रह में प्रासंगिक दस्तावेजों का पता लगाना है। इस तरह की उपयोगकर्ता की क्वेरी में कुछ कीवर्ड होते हैं जिनमें एक सूचना की आवश्यकता होती है।
ऐसी खोज समस्याओं में, उपयोगकर्ता एक संग्रह से प्रासंगिक जानकारी को बाहर निकालने की पहल करता है। यह उचित है जब उपयोगकर्ता को तदर्थ जानकारी की आवश्यकता होती है, अर्थात, अल्पकालिक आवश्यकता। लेकिन अगर उपयोगकर्ता के पास दीर्घकालिक जानकारी की आवश्यकता है, तो पुनर्प्राप्ति प्रणाली उपयोगकर्ता के लिए किसी भी नव सूचना आइटम को धकेलने की पहल भी कर सकती है।
सूचना तक इस तरह की पहुंच को सूचना फ़िल्टरिंग कहा जाता है। और संबंधित प्रणालियों को फ़िल्टरिंग सिस्टम या अनुशंसित सिस्टम के रूप में जाना जाता है।
पाठ पुनर्प्राप्ति के लिए बुनियादी उपाय
हमें एक सिस्टम की सटीकता की जांच करने की आवश्यकता है जब यह उपयोगकर्ता के इनपुट के आधार पर कई दस्तावेजों को पुनर्प्राप्त करता है। किसी क्वेरी के लिए प्रासंगिक दस्तावेज़ों के सेट को {Relevant} और पुनः प्राप्त दस्तावेज़ के सेट को {Retrieved} के रूप में दर्शाया जाता है। प्रासंगिक और पुनर्प्राप्त किए गए दस्तावेज़ों के सेट को {Relevant} Ret {Retrieved} के रूप में दर्शाया जा सकता है। इसे वेन आरेख के रूप में निम्नानुसार दिखाया जा सकता है -
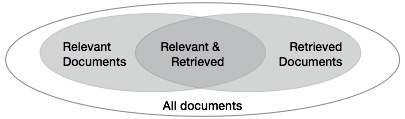
पाठ पुनर्प्राप्ति की गुणवत्ता का आकलन करने के लिए तीन मौलिक उपाय हैं -
- Precision
- Recall
- F-score
शुद्धता
परिशुद्धता प्राप्त दस्तावेजों का प्रतिशत है जो वास्तव में क्वेरी के लिए प्रासंगिक हैं। परिशुद्धता के रूप में परिभाषित किया जा सकता है -
Precision= |{Relevant} ∩ {Retrieved}| / |{Retrieved}|याद
स्मरण उन दस्तावेजों का प्रतिशत है जो क्वेरी के लिए प्रासंगिक हैं और वास्तव में पुनर्प्राप्त किए गए थे। स्मरण के रूप में परिभाषित किया गया है -
Recall = |{Relevant} ∩ {Retrieved}| / |{Relevant}|एफ स्कोर
एफ-स्कोर आमतौर पर इस्तेमाल किया जाने वाला व्यापार है। सूचना पुनर्प्राप्ति प्रणाली को अक्सर सटीक या इसके विपरीत व्यापार बंद करने की आवश्यकता होती है। एफ-स्कोर को स्मरण या सटीकता के हार्मोनिक मतलब के रूप में परिभाषित किया गया है -
F-score = recall x precision / (recall + precision) / 2वर्ल्ड वाइड वेब में भारी मात्रा में जानकारी है जो डेटा खनन के लिए एक समृद्ध स्रोत प्रदान करती है।
वेब खनन में चुनौतियां
वेब निम्नलिखित टिप्पणियों के आधार पर संसाधन और ज्ञान की खोज के लिए बड़ी चुनौतियां पेश करता है -
The web is too huge- वेब का आकार बहुत बड़ा है और तेजी से बढ़ रहा है। ऐसा लगता है कि डेटा वेयरहाउसिंग और डेटा माइनिंग के लिए वेब बहुत बड़ा है।
Complexity of Web pages- वेब पृष्ठों में एकीकृत संरचना नहीं होती है। वे पारंपरिक पाठ दस्तावेज़ की तुलना में बहुत जटिल हैं। वेब के डिजिटल लाइब्रेरी में भारी मात्रा में दस्तावेज़ हैं। इन पुस्तकालयों को किसी विशेष क्रमबद्ध क्रम के अनुसार व्यवस्थित नहीं किया जाता है।
Web is dynamic information source- वेब पर जानकारी तेजी से अपडेट की जाती है। समाचार, स्टॉक मार्केट, मौसम, खेल, खरीदारी, आदि जैसे डेटा नियमित रूप से अपडेट किए जाते हैं।
Diversity of user communities- वेब पर उपयोगकर्ता समुदाय तेजी से विस्तार कर रहा है। इन उपयोगकर्ताओं की पृष्ठभूमि, रुचियां और उपयोग के उद्देश्य अलग-अलग हैं। 100 मिलियन से अधिक वर्कस्टेशन हैं जो इंटरनेट से जुड़े हैं और अभी भी तेजी से बढ़ रहे हैं।
Relevancy of Information - यह माना जाता है कि एक विशेष व्यक्ति को आमतौर पर वेब के केवल छोटे हिस्से में दिलचस्पी होती है, जबकि वेब के बाकी हिस्से में वह जानकारी होती है जो उपयोगकर्ता के लिए प्रासंगिक नहीं होती है और वांछित परिणाम प्राप्त कर सकती है।
खनन वेब पेज लेआउट संरचना
वेब पेज की मूल संरचना दस्तावेज़ ऑब्जेक्ट मॉडल (DOM) पर आधारित है। DOM स्ट्रक्चर एक ट्री जैसे स्ट्रक्चर को संदर्भित करता है, जहां पेज में HTML टैग DOM ट्री में नोड से मेल खाता है। हम HTML में पूर्वनिर्धारित टैग का उपयोग करके वेब पेज को खंडित कर सकते हैं। HTML सिंटैक्स लचीला होता है, इसलिए वेब पेज W3C विनिर्देशों का पालन नहीं करते हैं। W3C के विनिर्देशों का पालन नहीं करने से DOM ट्री संरचना में त्रुटि हो सकती है।
DOM संरचना को शुरू में ब्राउज़र में प्रस्तुति के लिए पेश किया गया था न कि वेब पेज के शब्दार्थ संरचना के विवरण के लिए। DOM संरचना किसी वेब पेज के विभिन्न हिस्सों के बीच अर्थ संबंध को सही ढंग से पहचान नहीं सकती है।
विज़न-आधारित पेज विभाजन (VIPS)
वीआइपी का उद्देश्य अपनी दृश्य प्रस्तुति के आधार पर एक वेब पेज की शब्दार्थ संरचना को निकालना है।
इस तरह की शब्दार्थ संरचना एक पेड़ की संरचना से मेल खाती है। इस पेड़ में प्रत्येक नोड एक ब्लॉक से मेल खाती है।
एक मान प्रत्येक नोड को सौंपा गया है। इस मान को कोहरेंस की डिग्री कहा जाता है। दृश्य मान के आधार पर ब्लॉक में सुसंगत सामग्री को इंगित करने के लिए यह मान असाइन किया गया है।
VIPS एल्गोरिथ्म पहले HTML डोम ट्री से सभी उपयुक्त ब्लॉक निकालता है। उसके बाद यह इन ब्लॉकों के बीच विभाजकों का पता लगाता है।
विभाजक एक वेब पेज में क्षैतिज या ऊर्ध्वाधर लाइनों को संदर्भित करते हैं जो नेत्रहीन रूप से बिना किसी ब्लॉक के पार करते हैं।
वेब पेज का शब्दार्थ इन ब्लॉकों के आधार पर बनाया गया है।
निम्नलिखित आंकड़ा VIPS एल्गोरिथ्म की प्रक्रिया को दर्शाता है -

डेटा खनन का व्यापक रूप से विभिन्न क्षेत्रों में उपयोग किया जाता है। आज कई वाणिज्यिक डेटा खनन प्रणाली उपलब्ध हैं और फिर भी इस क्षेत्र में कई चुनौतियाँ हैं। इस ट्यूटोरियल में, हम एप्लिकेशन और डेटा माइनिंग के चलन पर चर्चा करेंगे।
डेटा खनन अनुप्रयोग
यहां उन क्षेत्रों की सूची दी गई है जहां डेटा खनन का व्यापक रूप से उपयोग किया जाता है -
- वित्तीय डेटा विश्लेषण
- खुदरा उद्योग
- दूरसंचार उद्योग
- जैविक डेटा विश्लेषण
- अन्य वैज्ञानिक अनुप्रयोग
- अतिक्रमण का पता लगाना
वित्तीय डेटा विश्लेषण
बैंकिंग और वित्तीय उद्योग में वित्तीय डेटा आम तौर पर विश्वसनीय और उच्च गुणवत्ता का होता है जो व्यवस्थित डेटा विश्लेषण और डेटा खनन की सुविधा देता है। कुछ विशिष्ट मामले इस प्रकार हैं -
बहुआयामी डेटा विश्लेषण और डेटा खनन के लिए डेटा वेयरहाउस का डिज़ाइन और निर्माण।
ऋण भुगतान की भविष्यवाणी और ग्राहक ऋण नीति विश्लेषण।
लक्षित विपणन के लिए ग्राहकों का वर्गीकरण और क्लस्टरिंग।
मनी लॉन्ड्रिंग और अन्य वित्तीय अपराधों का पता लगाना।
खुदरा उद्योग
रिटेल इंडस्ट्री में डाटा माइनिंग का अपना शानदार अनुप्रयोग है क्योंकि यह बिक्री, ग्राहक क्रय इतिहास, माल परिवहन, उपभोग और सेवाओं से बड़ी मात्रा में डेटा एकत्र करता है। यह स्वाभाविक है कि वेब की बढ़ती सहजता, उपलब्धता और लोकप्रियता के कारण एकत्र किए गए डेटा की मात्रा का तेजी से विस्तार होता रहेगा।
खुदरा उद्योग में डेटा माइनिंग ग्राहक खरीदने के पैटर्न और रुझानों की पहचान करने में मदद करता है जो ग्राहक सेवा की गुणवत्ता में सुधार और अच्छे ग्राहक प्रतिधारण और संतुष्टि का कारण बनता है। खुदरा उद्योग में डेटा खनन के उदाहरणों की सूची इस प्रकार है -
डेटा माइनिंग के लाभों के आधार पर डेटा वेयरहाउस का डिज़ाइन और निर्माण।
बिक्री, ग्राहकों, उत्पादों, समय और क्षेत्र का बहुआयामी विश्लेषण।
बिक्री अभियानों की प्रभावशीलता का विश्लेषण।
ग्राहक प्रतिधारण।
उत्पाद की सिफारिश और वस्तुओं का क्रॉस-रेफरेंसिंग।
दूरसंचार उद्योग
आज दूरसंचार उद्योग सबसे उभरते हुए उद्योगों में से एक है जो फैक्स, पेजर, सेल्युलर फोन, इंटरनेट मैसेंजर, इमेज, ई-मेल, वेब डाटा ट्रांसमिशन आदि जैसी विभिन्न सेवाएं प्रदान करता है। नए कंप्यूटर और संचार प्रौद्योगिकी के विकास के कारण, दूरसंचार उद्योग तेजी से विस्तार कर रहा है। यही कारण है कि व्यापार को मदद और समझने के लिए डेटा खनन बहुत महत्वपूर्ण हो गया है।
दूरसंचार उद्योग में डेटा खनन से दूरसंचार पैटर्न की पहचान करने, धोखाधड़ी गतिविधियों को पकड़ने, संसाधन का बेहतर उपयोग करने और सेवा की गुणवत्ता में सुधार करने में मदद मिलती है। यहां उन उदाहरणों की सूची दी गई है जिनके लिए डेटा माइनिंग दूरसंचार सेवाओं में सुधार करता है -
दूरसंचार डेटा का बहुआयामी विश्लेषण।
धोखाधड़ी पैटर्न विश्लेषण।
असामान्य पैटर्न की पहचान।
बहुआयामी संघ और अनुक्रमिक पैटर्न विश्लेषण।
मोबाइल दूरसंचार सेवाएं।
दूरसंचार डेटा विश्लेषण में विज़ुअलाइज़ेशन टूल का उपयोग।
जैविक डेटा विश्लेषण
हाल के दिनों में, हमने जीनोलॉजी, प्रोटिओमिक्स, कार्यात्मक जीनोमिक्स और बायोमेडिकल रिसर्च जैसे जीव विज्ञान के क्षेत्र में जबरदस्त वृद्धि देखी है। जैविक डेटा खनन जैव सूचना विज्ञान का एक बहुत महत्वपूर्ण हिस्सा है। जैविक डेटा विश्लेषण के लिए डेटा खनन में योगदान करने वाले पहलू निम्नलिखित हैं -
विषम, वितरित जीनोमिक और प्रोटिओमिक डेटाबेस का सिमेंटिक एकीकरण।
संरेखण, अनुक्रमण, समानता खोज और तुलनात्मक विश्लेषण कई न्यूक्लियोटाइड अनुक्रम।
संरचनात्मक पैटर्न की खोज और आनुवंशिक नेटवर्क और प्रोटीन रास्ते का विश्लेषण।
एसोसिएशन और पथ विश्लेषण।
आनुवंशिक डेटा विश्लेषण में विज़ुअलाइज़ेशन उपकरण।
अन्य वैज्ञानिक अनुप्रयोग
ऊपर चर्चा किए गए एप्लिकेशन अपेक्षाकृत छोटे और सजातीय डेटा सेट को संभालते हैं, जिसके लिए सांख्यिकीय तकनीक उपयुक्त हैं। भू-विज्ञान, खगोल विज्ञान आदि जैसे वैज्ञानिक डोमेन से बड़ी मात्रा में डेटा एकत्र किया गया है, विभिन्न क्षेत्रों जैसे जलवायु और पारिस्थितिक तंत्र मॉडलिंग, रासायनिक इंजीनियरिंग, द्रव गतिशीलता, आदि में तेजी से संख्यात्मक सिमुलेशन के कारण बड़ी संख्या में डेटा सेट उत्पन्न हो रहे हैं। निम्नलिखित वैज्ञानिक अनुप्रयोगों के क्षेत्र में डेटा खनन के अनुप्रयोग हैं -
- डेटा वेयरहाउस और डेटा प्रीप्रोसेसिंग।
- ग्राफ आधारित खनन।
- विज़ुअलाइज़ेशन और डोमेन विशिष्ट ज्ञान।
अतिक्रमण का पता लगाना
घुसपैठ किसी भी प्रकार की कार्रवाई को संदर्भित करता है जो अखंडता, गोपनीयता या नेटवर्क संसाधनों की उपलब्धता को खतरा देता है। कनेक्टिविटी की इस दुनिया में, सुरक्षा प्रमुख मुद्दा बन गया है। इंटरनेट के बढ़ते उपयोग और नेटवर्क और घुसपैठ और हमला करने के लिए उपकरणों की उपलब्धता के कारण घुसपैठ का पता लगाना नेटवर्क प्रशासन का एक महत्वपूर्ण घटक बन गया। यहां उन क्षेत्रों की सूची दी गई है जिनमें घुसपैठ का पता लगाने के लिए डेटा माइनिंग तकनीक लागू की जा सकती है -
घुसपैठ का पता लगाने के लिए डेटा माइनिंग एल्गोरिदम का विकास।
एसोसिएशन और सहसंबंध विश्लेषण, विभेदक विशेषताओं के चयन और निर्माण में मदद करने के लिए एकत्रीकरण।
स्ट्रीम डेटा का विश्लेषण।
वितरित डाटा माइनिंग।
विज़ुअलाइज़ेशन और क्वेरी उपकरण।
डाटा माइनिंग सिस्टम उत्पाद
कई डेटा माइनिंग सिस्टम उत्पाद और डोमेन विशिष्ट डेटा माइनिंग एप्लिकेशन हैं। पिछले सिस्टम में नए डेटा माइनिंग सिस्टम और एप्लिकेशन जोड़े जा रहे हैं। साथ ही, डाटा माइनिंग भाषाओं को मानकीकृत करने का प्रयास किया जा रहा है।
डाटा माइनिंग सिस्टम चुनना
डेटा माइनिंग सिस्टम का चयन निम्नलिखित विशेषताओं पर निर्भर करता है -
Data Types- डेटा माइनिंग सिस्टम स्वरूपित पाठ, रिकॉर्ड-आधारित डेटा और संबंधपरक डेटा को संभाल सकता है। डेटा ASCII टेक्स्ट, रिलेशनल डेटाबेस डेटा या डेटा वेयरहाउस डेटा में भी हो सकता है। इसलिए, हमें यह जांचना चाहिए कि डेटा माइनिंग सिस्टम क्या सटीक प्रारूप को संभाल सकता है।
System Issues- हमें विभिन्न ऑपरेटिंग सिस्टम के साथ डेटा माइनिंग सिस्टम की अनुकूलता पर विचार करना चाहिए। एक डेटा माइनिंग सिस्टम केवल एक ऑपरेटिंग सिस्टम या कई पर चल सकता है। डेटा माइनिंग सिस्टम भी हैं जो वेब-आधारित उपयोगकर्ता इंटरफेस प्रदान करते हैं और एक्सएमएल डेटा को इनपुट के रूप में अनुमति देते हैं।
Data Sources- डेटा स्रोत उन डेटा प्रारूपों को संदर्भित करते हैं जिनमें डेटा खनन प्रणाली संचालित होगी। कुछ डेटा माइनिंग सिस्टम केवल ASCII टेक्स्ट फ़ाइलों पर काम कर सकते हैं जबकि अन्य कई रिलेशनल स्रोतों पर। डेटा माइनिंग सिस्टम को ODBC कनेक्शन के लिए ODBC कनेक्शन या OLE DB का भी समर्थन करना चाहिए।
Data Mining functions and methodologies - कुछ डेटा माइनिंग सिस्टम हैं जो वर्गीकरण के रूप में केवल एक डेटा माइनिंग फ़ंक्शन प्रदान करते हैं, जबकि कुछ कई डेटा माइनिंग फ़ंक्शंस प्रदान करते हैं जैसे कि कॉन्सेप्ट विवरण, खोज-संचालित OLAP विश्लेषण, एसोसिएशन माइनिंग, लिंकेज विश्लेषण, सांख्यिकीय विश्लेषण, वर्गीकरण, भविष्यवाणी, क्लस्टरिंग, बाह्य विश्लेषण, समानता खोज, आदि।
Coupling data mining with databases or data warehouse systems- डेटा माइनिंग सिस्टम को डेटाबेस या डेटा वेयरहाउस सिस्टम के साथ जोड़ा जाना चाहिए। युग्मित घटकों को एक समान सूचना प्रसंस्करण वातावरण में एकीकृत किया जाता है। नीचे सूचीबद्ध युग्मन के प्रकार इस प्रकार हैं -
- कोई कपलिंग नहीं
- ढीला युग्मन
- अर्ध चुस्त कपलिंग
- कसा हुआ संयोजन
Scalability - डेटा माइनिंग में दो स्केलेबिलिटी मुद्दे हैं -
Row (Database size) Scalability- एक डेटा माइनिंग सिस्टम को पंक्ति स्केलेबल माना जाता है जब संख्या या पंक्तियों को 10 गुना बढ़ाया जाता है। किसी क्वेरी को निष्पादित करने में 10 से अधिक बार नहीं लगता है।
Column (Dimension) Salability - एक डेटा माइनिंग सिस्टम को कॉलम स्केलेबल माना जाता है यदि खनन क्वेरी निष्पादन का समय कॉलम की संख्या के साथ रैखिक रूप से बढ़ता है।
Visualization Tools - डाटा माइनिंग में विज़ुअलाइज़ेशन को निम्नानुसार वर्गीकृत किया जा सकता है -
- डेटा विज़ुअलाइज़ेशन
- खनन परिणाम दृश्य
- खनन प्रक्रिया दृश्य
- दृश्य डेटा खनन
Data Mining query language and graphical user interface- उपयोगकर्ता-निर्देशित, इंटरैक्टिव डेटा खनन को बढ़ावा देने के लिए एक आसान-से-उपयोग वाला ग्राफिकल यूजर इंटरफेस महत्वपूर्ण है। रिलेशनल डेटाबेस सिस्टम के विपरीत, डेटा माइनिंग सिस्टम अंतर्निहित डेटा माइनिंग क्वेरी भाषा साझा नहीं करते हैं।
डेटा माइनिंग में रुझान
डेटा माइनिंग कॉन्सेप्ट अभी भी विकसित हो रहे हैं और यहां नवीनतम रुझान हैं जो हमें इस क्षेत्र में देखने को मिलते हैं -
आवेदन अन्वेषण।
स्केलेबल और इंटरेक्टिव डेटा माइनिंग के तरीके।
डेटाबेस सिस्टम, डेटा वेयरहाउस सिस्टम और वेब डेटाबेस सिस्टम के साथ डेटा माइनिंग का एकीकरण।
डेटा माइनिंग क्वेरी भाषा का SStandardization।
दृश्य डेटा खनन।
जटिल प्रकार के डेटा के खनन के लिए नए तरीके।
जैविक डेटा खनन।
डाटा माइनिंग और सॉफ्टवेयर इंजीनियरिंग।
वेब खनन।
वितरित डाटा माइनिंग।
रियल टाइम डाटा माइनिंग।
मल्टी डेटाबेस डेटा माइनिंग।
डेटा माइनिंग में गोपनीयता सुरक्षा और सूचना सुरक्षा।
डेटा माइनिंग की सैद्धांतिक नींव
डेटा माइनिंग की सैद्धांतिक नींव में निम्नलिखित अवधारणाएं शामिल हैं -
Data Reduction- इस सिद्धांत का मूल विचार डेटा प्रतिनिधित्व को कम करना है जो बहुत बड़े डेटाबेस पर प्रश्नों के त्वरित अनुमानित उत्तर प्राप्त करने की आवश्यकता के जवाब में गति के लिए सटीकता को ट्रेड करता है। डेटा में कमी की कुछ तकनीकें इस प्रकार हैं -
विलक्षण मान अपघटन
Wavelets
Regression
लॉग-लीनियर मॉडल
Histograms
Clustering
Sampling
सूचकांक वृक्षों का निर्माण
Data Compression - इस सिद्धांत का मूल विचार निम्नलिखित के संदर्भ में एन्कोडिंग द्वारा दिए गए डेटा को संपीड़ित करना है -
Bits
एसोसिएशन के नियम
निर्णय के पेड़
Clusters
Pattern Discovery- इस सिद्धांत का मूल विचार एक डेटाबेस में होने वाले पैटर्न की खोज करना है। निम्नलिखित क्षेत्र हैं जो इस सिद्धांत में योगदान करते हैं -
मशीन लर्निंग
तंत्रिका नेटवर्क
एसोसिएशन खनन
अनुक्रमिक पैटर्न मिलान
Clustering
Probability Theory- यह सिद्धांत सांख्यिकीय सिद्धांत पर आधारित है। इस सिद्धांत के पीछे मूल विचार यादृच्छिक चर के संयुक्त संभाव्यता वितरण की खोज करना है।
Probability Theory - इस सिद्धांत के अनुसार, डेटा माइनिंग उन पैटर्नों को खोजता है जो केवल उस हद तक दिलचस्प हैं, जिनका उपयोग कुछ उद्यम की निर्णय लेने की प्रक्रिया में किया जा सकता है।
Microeconomic View- इस सिद्धांत के अनुसार, एक डेटाबेस स्कीमा में एक डेटाबेस में संग्रहीत डेटा और पैटर्न होते हैं। इसलिए, डेटा माइनिंग डेटाबेस पर इंडक्शन करने का कार्य है।
Inductive databases- डेटाबेस-उन्मुख तकनीकों के अलावा, डेटा विश्लेषण के लिए सांख्यिकीय तकनीक उपलब्ध हैं। इन तकनीकों को वैज्ञानिक डेटा और आर्थिक और सामाजिक विज्ञान से डेटा के लिए भी लागू किया जा सकता है।
सांख्यिकीय डेटा खनन
सांख्यिकीय डेटा खनन तकनीकों में से कुछ इस प्रकार हैं -
Regression- प्रतिगमन विधियों का उपयोग एक या एक से अधिक भविष्य कहनेवाला चर से प्रतिक्रिया चर के मूल्य का अनुमान लगाने के लिए किया जाता है जहां चर संख्यात्मक होते हैं। नीचे सूचीबद्ध हैं प्रतिगमन के रूप -
Linear
Multiple
Weighted
Polynomial
Nonparametric
Robust
Generalized Linear Models - सामान्यीकृत रैखिक मॉडल में शामिल हैं -
रसद प्रतिगमन
पोइसन रिग्रेशन
मॉडल का सामान्यीकरण एक श्रेणीबद्ध प्रतिक्रिया चर को भविष्यवाणियों के एक सेट से संबंधित होने की अनुमति देता है, जो कि रैखिक प्रतिगमन का उपयोग करके संख्यात्मक प्रतिक्रिया चर के मॉडलिंग के समान है।
Analysis of Variance - यह तकनीक विश्लेषण करती है -
संख्यात्मक प्रतिक्रिया चर द्वारा वर्णित दो या अधिक आबादी के लिए प्रायोगिक डेटा।
एक या अधिक श्रेणीबद्ध चर (कारक)।
Mixed-effect Models- इन मॉडलों का उपयोग समूहीकृत डेटा के विश्लेषण के लिए किया जाता है। ये मॉडल एक या अधिक कारकों के अनुसार समूहीकृत डेटा में एक प्रतिक्रिया चर और कुछ सह-चर के बीच संबंध का वर्णन करते हैं।
Factor Analysis- कारक विश्लेषण का उपयोग एक श्रेणीगत प्रतिक्रिया चर की भविष्यवाणी करने के लिए किया जाता है। यह विधि मानती है कि स्वतंत्र चर एक बहुभिन्नरूपी सामान्य वितरण का पालन करते हैं।
Time Series Analysis - समय-श्रृंखला डेटा का विश्लेषण करने के तरीके निम्नलिखित हैं -
ऑटो-रिग्रेशन मेथड्स।
Univariate ARIMA (ऑटोरिएरिव इंटीग्रेटेड मूविंग एवरेज) मॉडलिंग।
लंबी-स्मृति समय-श्रृंखला मॉडलिंग।
दृश्य डेटा खनन
विजुअल डेटा माइनिंग बड़े डेटा सेट से निहित ज्ञान की खोज के लिए डेटा और / या ज्ञान विज़ुअलाइज़ेशन तकनीकों का उपयोग करता है। विज़ुअल डेटा माइनिंग को निम्नलिखित विषयों के एकीकरण के रूप में देखा जा सकता है -
डेटा विज़ुअलाइज़ेशन
डेटा माइनिंग
विज़ुअल डेटा माइनिंग निम्नलिखित से निकटता से संबंधित है -
कंप्यूटर ग्राफिक्स
मल्टीमीडिया सिस्टम
ह्यूमन कंप्यूटर इंटरेक्शन
पैटर्न मान्यता
उच्च प्रदर्शन कंप्यूटिंग
आम तौर पर डेटा विज़ुअलाइज़ेशन और डेटा माइनिंग को निम्नलिखित तरीकों से एकीकृत किया जा सकता है -
Data Visualization - डेटाबेस या डेटा वेयरहाउस में डेटा को नीचे सूचीबद्ध कई दृश्य रूपों में देखा जा सकता है -
Boxplots
3-डी क्यूब्स
डेटा वितरण चार्ट
Curves
Surfaces
लिंक ग्राफ आदि।
Data Mining Result Visualization- डेटा माइनिंग रिजल्ट विज़ुअलाइज़ेशन दृश्य रूपों में डेटा खनन के परिणामों की प्रस्तुति है। ये दृश्य रूप बिखरे हुए प्लॉट, बॉक्सप्लाट्स आदि हो सकते हैं।
Data Mining Process Visualization- डाटा माइनिंग प्रोसेस विज़ुअलाइज़ेशन डेटा माइनिंग की कई प्रक्रियाओं को प्रस्तुत करता है। यह उपयोगकर्ताओं को यह देखने की अनुमति देता है कि डेटा कैसे निकाला जाता है। यह उपयोगकर्ताओं को यह देखने की भी अनुमति देता है कि किस डेटाबेस या डेटा वेयरहाउस से डेटा को साफ, एकीकृत, प्रीप्रोसेड और खनन किया जाता है।
ऑडियो डेटा खनन
ऑडियो डेटा माइनिंग डेटा के पैटर्न या डेटा माइनिंग परिणामों की विशेषताओं को इंगित करने के लिए ऑडियो सिग्नल का उपयोग करता है। पैटर्न को ध्वनि और संगीत में बदलकर, हम पिचों और धुनों को सुन सकते हैं, चित्रों को देखने के बजाय, ताकि कुछ भी दिलचस्प पहचान सकें।
डाटा माइनिंग और सहयोगी फ़िल्टरिंग
आज उपभोक्ता खरीदारी करते समय कई तरह की वस्तुओं और सेवाओं में आते हैं। लाइव ग्राहक लेनदेन के दौरान, एक सिफ़ारिश प्रणाली उत्पाद की सिफारिशें करके उपभोक्ता की मदद करती है। सहयोगात्मक फ़िल्टरिंग दृष्टिकोण आमतौर पर ग्राहकों को उत्पादों की सिफारिश करने के लिए उपयोग किया जाता है। ये सिफारिशें अन्य ग्राहकों की राय पर आधारित हैं।