अनुमान तकनीक - त्वरित गाइड
Estimation एक अनुमान या अनुमान लगाने की प्रक्रिया है, जो एक ऐसा मूल्य है जिसका उपयोग किसी उद्देश्य के लिए किया जा सकता है, भले ही इनपुट डेटा अधूरा, अनिश्चित या अस्थिर हो।
अनुमान निर्धारित करता है कि एक विशिष्ट प्रणाली या उत्पाद बनाने में कितना पैसा, प्रयास, संसाधन और समय लगेगा। अनुमान पर आधारित है -
- पिछला डेटा / पिछला अनुभव
- उपलब्ध दस्तावेज / ज्ञान
- Assumptions
- पहचाने गए जोखिम
सॉफ्टवेयर परियोजना के आकलन के चार मूल चरण हैं -
- विकास उत्पाद के आकार का अनुमान लगाएं।
- व्यक्ति-महीनों या व्यक्ति-घंटों में प्रयास का अनुमान लगाएं।
- कैलेंडर महीनों में अनुसूची का अनुमान लगाएं।
- अनुमानित मुद्रा में परियोजना लागत का अनुमान लगाएं।
अनुमान पर अवलोकन
अनुमान एक परियोजना में एक बार का कार्य नहीं होना चाहिए। यह दौरान हो सकता है -
- एक परियोजना प्राप्त करना।
- परियोजना की योजना बनाना।
- आवश्यकता के रूप में परियोजना का निष्पादन।
अनुमान की प्रक्रिया शुरू होने से पहले परियोजना के दायरे को समझना चाहिए। यह ऐतिहासिक प्रोजेक्ट डेटा के लिए सहायक होगा।
परियोजना मीट्रिक मात्रात्मक अनुमानों की पीढ़ी के लिए एक ऐतिहासिक परिप्रेक्ष्य और मूल्यवान इनपुट प्रदान कर सकते हैं।
योजना के लिए तकनीकी प्रबंधकों और सॉफ्टवेयर टीम की आवश्यकता होती है, क्योंकि यह जिम्मेदारी और जवाबदेही की ओर अग्रसर होती है।
पिछला अनुभव बहुत मदद कर सकता है।
अनुमानों पर पहुंचने और परिणामी मूल्यों को समेटने के लिए कम से कम दो आकलन तकनीकों का उपयोग करें। मिलान अनुमानों के बारे में जानने के लिए अगले भाग में अपघटन तकनीकों का संदर्भ लें।
योजनाएं पुनरावृत्त होनी चाहिए और समय बीतने के साथ समायोजन की अनुमति दें और अधिक विवरण ज्ञात हों।
सामान्य परियोजना का अनुमान दृष्टिकोण
व्यापक रूप से उपयोग किया जाने वाला प्रोजेक्ट अनुमान दृष्टिकोण है Decomposition Technique। अपघटन तकनीक एक विभाजित और दृष्टिकोण को जीत लेती है। किसी प्रोजेक्ट को प्रमुख कार्य या संबंधित सॉफ़्टवेयर इंजीनियरिंग गतिविधियों में तोड़कर आकार, प्रयास और लागत का आकलन चरणबद्ध तरीके से किया जाता है।
Step 1 - बनाए जाने वाले सॉफ्टवेयर के दायरे को समझें।
Step 2 - सॉफ्टवेयर आकार का एक अनुमान उत्पन्न करें।
गुंजाइश के बयान के साथ शुरू करो।
सॉफ्टवेयर को उन कार्यों में बदल दें जिनका प्रत्येक व्यक्ति अलग-अलग अनुमान लगा सकता है।
प्रत्येक फ़ंक्शन के आकार की गणना करें।
अपने बेसलाइन उत्पादकता मेट्रिक्स के आकार मूल्यों को लागू करके प्रयास और लागत का अनुमान लगाएं।
संपूर्ण परियोजना के लिए एक समग्र अनुमान लगाने के लिए फ़ंक्शन अनुमानों को मिलाएं।
Step 3- प्रयास और लागत का एक अनुमान उत्पन्न करें। आप किसी प्रोजेक्ट को संबंधित सॉफ़्टवेयर इंजीनियरिंग गतिविधियों में तोड़कर प्रयास और लागत अनुमान तक पहुँच सकते हैं।
उन गतिविधियों के अनुक्रम को पहचानें जिन्हें पूरा करने के लिए परियोजना की आवश्यकता होती है।
गतिविधियों को उन कार्यों में विभाजित करें जिन्हें मापा जा सकता है।
प्रत्येक कार्य को पूरा करने के लिए आवश्यक प्रयास (व्यक्ति घंटों / दिनों में) का अनुमान लगाएं।
गतिविधि के लिए अनुमान लगाने के लिए गतिविधि के कार्यों के प्रयासों के अनुमानों को मिलाएं।
डेटाबेस से प्रत्येक गतिविधि के लिए लागत इकाइयों (यानी, लागत / इकाई प्रयास) को प्राप्त करें।
प्रत्येक गतिविधि के लिए कुल प्रयास और लागत की गणना करें।
समग्र गतिविधि और संपूर्ण परियोजना के लिए लागत अनुमान बनाने के लिए प्रत्येक गतिविधि के लिए प्रयास और लागत अनुमानों को मिलाएं।
Step 4- अनुमानित अनुमान: चरण 3 से प्राप्त मानों की तुलना चरण 2 से प्राप्त लोगों से करें। यदि अनुमानों के दोनों सेट सहमत हैं, तो आपकी संख्या बहुत विश्वसनीय है। अन्यथा, यदि व्यापक रूप से भिन्न अनुमानों के संबंध में आगे की जांच हो, तो
परियोजना के दायरे को पर्याप्त रूप से नहीं समझा गया है या इसका गलत अर्थ निकाला गया है।
फ़ंक्शन और / या गतिविधि का टूटना सटीक नहीं है।
अनुमान तकनीकों के लिए उपयोग किया जाने वाला ऐतिहासिक डेटा आवेदन के लिए अनुचित है, या अप्रचलित है, या गलत तरीके से लागू किया गया है।
Step 5 - विचलन का कारण निर्धारित करें और फिर अनुमानों को समेटें।
अनुमान सटीकता
सटीकता इस बात का संकेत है कि वास्तविकता के कितने करीब है। जब भी आप कोई अनुमान लगाते हैं, तो हर कोई जानना चाहता है कि संख्या वास्तविकता के कितने करीब है। आप चाहते हैं कि हर अनुमान जितना संभव हो उतना सटीक हो, जो आपके पास उत्पन्न करने के समय आपके पास है। और निश्चित रूप से आप एक तरह से एक अनुमान प्रस्तुत नहीं करना चाहते हैं जो संख्याओं में विश्वास की झूठी भावना को प्रेरित करता है।
अनुमानों की सटीकता को प्रभावित करने वाले महत्वपूर्ण कारक हैं -
सभी अनुमानों के इनपुट डेटा की सटीकता।
किसी भी अनुमान गणना की सटीकता।
मॉडल को कैलिब्रेट करने के लिए उपयोग किए जाने वाले ऐतिहासिक डेटा या उद्योग के डेटा का आप कितनी बारीकी से अनुमान लगा रहे हैं।
आपके संगठन की सॉफ़्टवेयर विकास प्रक्रिया की भविष्यवाणी।
उत्पाद की आवश्यकताओं और पर्यावरण दोनों की स्थिरता जो सॉफ्टवेयर इंजीनियरिंग प्रयास का समर्थन करती है।
वास्तविक परियोजना की सावधानीपूर्वक योजना बनाई गई थी या नहीं, इसकी निगरानी और नियंत्रण किया गया था, और कोई भी बड़ा आश्चर्य नहीं हुआ जिससे अप्रत्याशित देरी हुई।
विश्वसनीय अनुमान प्राप्त करने के लिए कुछ दिशानिर्देश निम्नलिखित हैं -
- ऐसी ही परियोजनाओं पर आधार का अनुमान जो पहले ही पूरी हो चुकी हैं।
- परियोजना लागत और प्रयास अनुमान उत्पन्न करने के लिए अपेक्षाकृत सरल अपघटन तकनीकों का उपयोग करें।
- सॉफ़्टवेयर लागत और प्रयास अनुमान के लिए एक या अधिक अनुभवजन्य अनुमान मॉडल का उपयोग करें।
इस अध्याय में अनुमान दिशानिर्देश पर अनुभाग देखें।
सटीकता सुनिश्चित करने के लिए, आपको हमेशा कम से कम दो तकनीकों का उपयोग करने और परिणामों की तुलना करने का अनुमान लगाने की सलाह दी जाती है।
अनुमान मुद्दे
अक्सर, परियोजना प्रबंधक आकार का अनुमान लगाने के लिए समय-सारिणी का अनुमान लगाने का सहारा लेते हैं। यह शीर्ष प्रबंधन या विपणन टीम द्वारा निर्धारित समयसीमा के कारण हो सकता है। हालांकि, जो भी कारण है, अगर ऐसा किया जाता है, तो बाद के चरण में गुंजाइश परिवर्तनों को समायोजित करने के लिए शेड्यूल का अनुमान लगाना मुश्किल होगा।
अनुमान लगाते समय, कुछ धारणाएं बनाई जा सकती हैं। अनुमान पत्र में इन सभी मान्यताओं को नोट करना महत्वपूर्ण है, क्योंकि कुछ अभी भी अनुमान पत्र में मान्यताओं को दस्तावेज नहीं करते हैं।
यहां तक कि अच्छे अनुमानों में अंतर्निहित धारणाएं, जोखिम और अनिश्चितता है, और फिर भी उन्हें अक्सर सटीक मानकर व्यवहार किया जाता है।
अनुमानों को व्यक्त करने का सबसे अच्छा तरीका यह कहकर संभावित परिणामों की एक सीमा के रूप में है, उदाहरण के लिए, कि यह परियोजना किसी विशेष तारीख को पूरा होने के बजाय 5 से 7 महीने का समय लेगी या यह एक निश्चित संख्या में पूरा नहीं होगा। महीनों का। उस सीमा तक करने से सावधान रहें जो बहुत संकीर्ण है क्योंकि वह निश्चित तिथि के लिए प्रतिबद्ध है।
आप अनिश्चितता के साथ प्रायिकता मान भी शामिल कर सकते हैं। उदाहरण के लिए, 90% संभावना है कि परियोजना एक निश्चित तारीख को या उससे पहले पूरी हो जाएगी।
संगठन सटीक प्रोजेक्ट डेटा एकत्र नहीं करते हैं। चूंकि अनुमानों की सटीकता ऐतिहासिक डेटा पर निर्भर करती है, इसलिए यह एक मुद्दा होगा।
किसी भी परियोजना के लिए, एक न्यूनतम संभव अनुसूची है जो आपको आवश्यक कार्यक्षमता को शामिल करने और गुणवत्ता उत्पादन का उत्पादन करने की अनुमति देगा। यदि प्रबंधन और / या क्लाइंट द्वारा शेड्यूल की कमी है, तो आप डिलीवर होने के लिए स्कोप और कार्यक्षमता पर बातचीत कर सकते हैं।
शेड्यूल ओवररन से बचने के लिए गुंजाइश ढोंगी को संभालने पर ग्राहक के साथ सहमत हों।
अंतिम अनुमान में आकस्मिकता को समायोजित करने में विफलता मुद्दों का कारण बनती है। उदाहरण के लिए, बैठकें, संगठनात्मक कार्यक्रम।
संसाधन उपयोग को 80% से कम माना जाना चाहिए। ऐसा इसलिए है क्योंकि संसाधन केवल 80% समय के लिए उत्पादक होंगे। यदि आप 80% से अधिक उपयोग पर संसाधन प्रदान करते हैं, तो स्लिपेज होने के लिए बाध्य है।
अनुमान दिशानिर्देश
किसी परियोजना का आकलन करते समय निम्नलिखित दिशानिर्देशों को ध्यान में रखना चाहिए -
आकलन के दौरान, अन्य लोगों के अनुभवों से पूछें। इसके अलावा, अपने खुद के अनुभवों को काम पर रखें।
मान लें कि संसाधन अपने समय के केवल 80 प्रतिशत के लिए उत्पादक होंगे। इसलिए, आकलन के दौरान संसाधन उपयोग को 80% से कम लें।
कई प्रोजेक्ट्स पर काम करने वाले संसाधन अपने बीच में समय गंवाने के कारण कार्यों को पूरा करने में अधिक समय लेते हैं।
किसी भी अनुमान में प्रबंधन समय शामिल करें।
हमेशा समस्या सुलझाने, बैठकों और अन्य अप्रत्याशित घटनाओं के लिए आकस्मिकता में निर्माण करें।
उचित परियोजना अनुमान लगाने के लिए पर्याप्त समय दें। जल्दबाजी में किए गए अनुमान गलत, उच्च जोखिम वाले अनुमान हैं। बड़ी विकास परियोजनाओं के लिए, अनुमान कदम को वास्तव में एक मिनी परियोजना माना जाना चाहिए।
जहाँ संभव हो, अपने संगठन की समान पिछली परियोजनाओं के दस्तावेज़ डेटा का उपयोग करें। यह सबसे सटीक अनुमान में परिणाम देगा। यदि आपके संगठन ने ऐतिहासिक डेटा नहीं रखा है, तो अब इसे इकट्ठा करना शुरू करने का एक अच्छा समय है।
डेवलपर-आधारित अनुमानों का उपयोग करें, क्योंकि जो लोग काम करेंगे उनके अलावा अन्य लोगों द्वारा तैयार किए गए अनुमान कम सटीक होंगे।
अनुमान लगाने के लिए कई अलग-अलग लोगों का उपयोग करें और कई अलग-अलग अनुमान तकनीकों का उपयोग करें।
अनुमानों पर फिर से विचार करें। अभिसरण का निरीक्षण करें या अनुमानों के बीच फैलाएं। अभिसरण का अर्थ है कि आपको एक अच्छा अनुमान मिला है। वाइडबैंड-डेल्फी तकनीक का उपयोग लोगों के एक समूह का उपयोग करके इकट्ठा करने और चर्चा करने के लिए किया जा सकता है, एक सटीक, निष्पक्ष अनुमान का उत्पादन करने का इरादा।
अपने जीवन चक्र में कई बार परियोजना का पुनर्मूल्यांकन करें।
ए Function Point(FP) माप की एक इकाई है जो व्यवसाय की कार्यक्षमता की मात्रा को व्यक्त करने के लिए, एक सूचना प्रणाली (एक उत्पाद के रूप में) एक उपयोगकर्ता को प्रदान करता है। एफपी सॉफ्टवेयर आकार को मापते हैं। कार्यात्मक आकार के लिए उन्हें व्यापक रूप से एक उद्योग मानक के रूप में स्वीकार किया जाता है।
एफपी पर आधारित सॉफ्टवेयर को आकार देने के लिए, कई मान्यता प्राप्त मानक और / या सार्वजनिक विनिर्देश अस्तित्व में आए हैं। 2013 तक, ये हैं -
आईएसओ मानक
COSMIC- आईएसओ / आईईसी 19761: 2011 सॉफ्टवेयर इंजीनियरिंग। एक कार्यात्मक आकार माप पद्धति।
FiSMA - आईएसओ / आईईसी 29881: 2008 सूचना प्रौद्योगिकी - सॉफ्टवेयर और सिस्टम इंजीनियरिंग - FiSMA 1.1 कार्यात्मक आकार माप विधि।
IFPUG - आईएसओ / आईईसी 20926: 2009 सॉफ्टवेयर और सिस्टम इंजीनियरिंग - सॉफ्टवेयर माप - IFPUG कार्यात्मक आकार माप विधि।
Mark-II - ISO / IEC 20968: 2002 सॉफ्टवेयर इंजीनियरिंग - Ml II फंक्शन प्वाइंट एनालिसिस - काउंटिंग प्रैक्टिस मैनुअल।
NESMA - आईएसओ / आईईसी 24570: 2005 सॉफ्टवेयर इंजीनियरिंग - NESMA फ़ंक्शन आकार माप विधि संस्करण 2.1 - फ़ंक्शन प्वाइंट विश्लेषण के आवेदन के लिए परिभाषाएं और गिनती दिशानिर्देश।
ऑटोमेटेड फंक्शन प्वाइंट के लिए ऑब्जेक्ट मैनेजमेंट ग्रुप स्पेसिफिकेशन
ऑब्जेक्ट मैनेजमेंट ग्रुप (ओएमजी), एक खुली सदस्यता और नो-फॉर-प्रॉफिट कंप्यूटर उद्योग मानकों के कंसोर्टियम ने, आईटी सॉफ्टवेयर गुणवत्ता के लिए कंसोर्टियम के नेतृत्व वाले ऑटोमेटेड फंक्शन प्वाइंट (एएफपी) विनिर्देश को अपनाया है। यह अंतर्राष्ट्रीय कार्य बिंदु उपयोगकर्ता समूह (IFPUG) के दिशानिर्देशों के अनुसार FP गिनती को स्वचालित करने के लिए एक मानक प्रदान करता है।
Function Point Analysis (FPA) techniqueसॉफ़्टवेयर के भीतर निहित कार्यों को निर्धारित करता है जो सॉफ़्टवेयर उपयोगकर्ताओं के लिए सार्थक हैं। एफपी आवश्यकताओं की संख्या के आधार पर विकसित किए जा रहे कार्यों की संख्या पर विचार करता है।
Function Points (FP) Countingनियमों, प्रक्रियाओं और दिशानिर्देशों के एक मानक सेट द्वारा नियंत्रित किया जाता है, जैसा कि अंतर्राष्ट्रीय फ़ंक्शन प्वाइंट उपयोगकर्ता समूह (IFPUG) द्वारा परिभाषित किया गया है। इन्हें काउंटिंग प्रैक्टिसेस मैनुअल (CPM) में प्रकाशित किया गया है।
समारोह बिंदु विश्लेषण का इतिहास
फंक्शन प्वॉइंट्स की अवधारणा को 1979 में आईबीएम के एलन अल्ब्रेक्ट ने पेश किया था। 1984 में, अल्ब्रेक्ट ने इस विधि को परिष्कृत किया। पहला फंक्शन प्वाइंट दिशानिर्देश 1984 में प्रकाशित किया गया था। इंटरनेशनल फंक्शन पॉइंट यूज़र्स ग्रुप (IFPUG) फंक्शन पॉइंट एनालिसिस मीट्रिक सॉफ्टवेयर उपयोगकर्ताओं का एक विश्वव्यापी संगठन है। International Function Point Users Group (IFPUG)एक गैर-लाभकारी, सदस्य-शासित संगठन है जिसकी स्थापना 1986 में की गई थी। IFPUG के पास फंक्शन पॉइंट एनालिसिस (FPA) है जो कि ISO मानक 20296: 2009 में परिभाषित किया गया है जो IFPUG के कार्यात्मक आकार माप (FSM) विधि को लागू करने के लिए परिभाषा, नियम और कदम निर्दिष्ट करता है। IFPUG फंक्शन प्वाइंट काउंटिंग प्रैक्टिस मैनुअल (CPM) रखता है। सीपीएम 2.0 को 1987 में रिलीज़ किया गया था, और तब से इसमें कई पुनरावृत्तियाँ हुई हैं। सीपीएम रिलीज़ 4.3 2010 में था।
CPM रिलीज़ 4.3.1 निगमित आईएसओ संपादकीय संशोधनों के साथ 2010 में हुआ था। ISO Standard (IFPUG FSM) - कार्यात्मक आकार मापन जो CPM 4.3.1 का एक हिस्सा है, जो इसे वितरित की जाने वाली कार्यक्षमता के संदर्भ में सॉफ़्टवेयर को मापने के लिए एक तकनीक है। सीपीएम आईएसओ / आईईसी 14143-1 सूचना प्रौद्योगिकी - सॉफ्टवेयर मापन के तहत एक अंतरराष्ट्रीय स्तर पर अनुमोदित मानक है।
प्राथमिक प्रक्रिया (EP)
प्राथमिक प्रक्रिया कार्यात्मक उपयोगकर्ता की आवश्यकता की सबसे छोटी इकाई है जो -
- उपयोगकर्ता के लिए सार्थक है।
- एक पूर्ण लेन-देन को नियंत्रित करता है।
- आत्म-निहित है और एक सुसंगत स्थिति में गिने जा रहे एप्लिकेशन के व्यवसाय को छोड़ देता है।
कार्यों
दो प्रकार के कार्य हैं -
- डेटा फ़ंक्शंस
- लेन-देन के कार्य
डेटा फ़ंक्शंस
डेटा फ़ंक्शन दो प्रकार के होते हैं -
- आंतरिक तार्किक फ़ाइलें
- बाहरी इंटरफ़ेस फ़ाइलें
डेटा फ़ंक्शंस आंतरिक और बाहरी संसाधनों से बने होते हैं जो सिस्टम को प्रभावित करते हैं।
Internal Logical Files
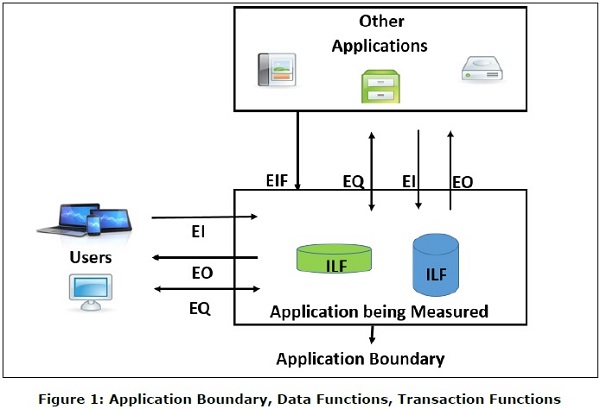
आंतरिक तार्किक फ़ाइल (ILF) तार्किक रूप से संबंधित डेटा या नियंत्रण जानकारी का एक उपयोगकर्ता पहचान समूह है जो पूरी तरह से आवेदन सीमा के भीतर रहता है। ILF का प्राथमिक उद्देश्य गिना जा रहा है कि एक या एक से अधिक प्राथमिक प्रक्रियाओं के माध्यम से बनाए रखा डेटा है। एक ILF का अंतर्निहित अर्थ है कि यह आंतरिक रूप से बनाए रखा गया है, इसकी कुछ तार्किक संरचना है और इसे एक फ़ाइल में संग्रहीत किया जाता है। (चित्र 1 देखें)
External Interface Files
बाहरी इंटरफ़ेस फ़ाइल (EIF) तार्किक रूप से संबंधित डेटा या नियंत्रण जानकारी का एक उपयोगकर्ता पहचान योग्य समूह है जो केवल संदर्भ उद्देश्यों के लिए एप्लिकेशन द्वारा उपयोग किया जाता है। डेटा पूरी तरह से एप्लिकेशन सीमा के बाहर रहता है और एक अन्य एप्लिकेशन द्वारा ILF में बनाए रखा जाता है। एक ईआईएफ का अंतर्निहित अर्थ है कि यह बाहरी रूप से बनाए रखा गया है, फ़ाइल से डेटा प्राप्त करने के लिए एक इंटरफ़ेस विकसित किया जाना है। (चित्र 1 देखें)
लेन-देन के कार्य
लेनदेन के तीन प्रकार हैं।
- बाहरी इनपुट्स
- बाहरी आउटपुट
- बाहरी पूछताछ
लेन-देन के कार्य उन प्रक्रियाओं से बने होते हैं जिनका उपयोग उपयोगकर्ता, बाहरी अनुप्रयोगों और मापा जाने वाले अनुप्रयोग के बीच किया जाता है।
External Inputs
एक्सटर्नल इनपुट (EI) एक ट्रांजेक्शन फंक्शन है, जिसमें डेटा “इन” एप्लिकेशन को सीमा के बाहर से अंदर तक ले जाता है। यह डेटा अनुप्रयोग के लिए बाहरी आ रहा है।
- डेटा एक डेटा इनपुट स्क्रीन या किसी अन्य एप्लिकेशन से आ सकता है।
- एक ईआई कैसे एक आवेदन की जानकारी मिलती है।
- डेटा या तो नियंत्रण जानकारी या व्यावसायिक जानकारी हो सकती है।
- डेटा का उपयोग एक या अधिक आंतरिक तार्किक फ़ाइलों को बनाए रखने के लिए किया जा सकता है।
- यदि डेटा नियंत्रण जानकारी है, तो उसे आंतरिक तार्किक फ़ाइल को अपडेट करने की आवश्यकता नहीं है। (चित्र 1 देखें)
External Outputs
एक्सटर्नल आउटपुट (EO) एक ट्रांजेक्शन फंक्शन है जिसमें डेटा सिस्टम का "आउट" आता है। इसके अतिरिक्त, एक ईओ एक आईएलएफ को अपडेट कर सकता है। डेटा अन्य एप्लिकेशन को भेजी गई रिपोर्ट या आउटपुट फाइल बनाता है। (चित्र 1 देखें)
External Inquiries
एक्सटर्नल इन्क्वायरी (EQ) एक इनपुट फंक्शन है जिसमें इनपुट और आउटपुट दोनों कंपोनेंट होते हैं जिससे डेटा रिट्रीवल होता है। (चित्र 1 देखें)
आरईटी, डीईटी, एफटीआर की परिभाषा
रिकॉर्ड तत्व प्रकार
रिकॉर्ड एलिमेंट टाइप (RET) ILF या EIF के भीतर तत्वों का सबसे बड़ा उपयोगकर्ता पहचान योग्य उपसमूह है। उन्हें पहचानने में मदद करने के लिए डेटा के तार्किक समूहों को देखना सबसे अच्छा है।
डेटा तत्व प्रकार
डेटा तत्व प्रकार (डीईटी) एक एफटीआर के भीतर डेटा उपसमूह है। वे अद्वितीय और उपयोगकर्ता पहचानने योग्य हैं।
फ़ाइल प्रकार संदर्भित
फ़ाइल प्रकार संदर्भित (FTR) ईआई, ईओ, या ईक्यू के भीतर सबसे बड़ा उपयोगकर्ता पहचान योग्य उपसमूह है जिसे संदर्भित किया जाता है।
लेन-देन के कार्य ईआई, ईओ, ईक्यू को एफटीआर और डीईटी की गणना करके मापा जाता है कि उनमें निम्नलिखित गणना नियम शामिल हैं। इसी तरह, डेटा फ़ंक्शंस ILF और EIF को डीईटी और आरईटी की गणना करके मापा जाता है, जिसमें वे गिनती के नियमों का पालन करते हैं। लेनदेन कार्यों और डेटा फ़ंक्शन के उपायों का उपयोग एफपी की गिनती में किया जाता है जिसके परिणामस्वरूप कार्यात्मक आकार या फ़ंक्शन बिंदु होते हैं।
FP गिनती प्रक्रिया में निम्नलिखित चरण शामिल हैं -
Step 1 - गिनती के प्रकार का निर्धारण करें।
Step 2 - गिनती की सीमा निर्धारित करें।
Step 3 - उपयोगकर्ता द्वारा आवश्यक प्रत्येक प्राथमिक प्रक्रिया (EP) को पहचानें।
Step 4 - विशिष्ट ईपी निर्धारित करें।
Step 5 - डेटा कार्यों को मापें।
Step 6 - व्यवहारिक कार्यों को मापें।
Step 7 - कार्यात्मक आकार की गणना करें (अनुचित फ़ंक्शन बिंदु गणना)।
Step 8 - निर्धारित मान समायोजन कारक (VAF)।
Step 9 - समायोजित फंक्शन प्वाइंट काउंट की गणना करें।
Note- सामान्य प्रणाली अभिलक्षण (GSCs) CPM 4.3.1 में वैकल्पिक किए जाते हैं और परिशिष्ट में ले जाया जाता है। इसलिए, चरण 8 और चरण 9 को छोड़ दिया जा सकता है।
चरण 1: गणना के प्रकार का निर्धारण करें
तीन प्रकार के फंक्शन पॉइंट काउंट हैं -
- डेवलपमेंट फंक्शन प्वाइंट काउंट
- आवेदन समारोह बिंदु गणना
- एन्हांसमेंट फंक्शन प्वाइंट काउंट
डेवलपमेंट फंक्शन प्वाइंट काउंट
फंक्शन पॉइंट को एक विकास परियोजना के सभी चरणों में आवश्यकता से लेकर कार्यान्वयन चरण तक गिना जा सकता है। इस प्रकार की गिनती नए विकास कार्यों से जुड़ी है और इसमें प्रोटोटाइप शामिल हो सकते हैं, जिन्हें अस्थायी समाधान के रूप में आवश्यक हो सकता है, जो रूपांतरण प्रयास का समर्थन करता है। इस प्रकार की गिनती को बेसलाइन फंक्शन पॉइंट काउंट कहा जाता है।
आवेदन समारोह बिंदु गणना
अनुप्रयोग की गणना फ़ंक्शन बिंदुओं के रूप में गणना की जाती है, और किसी भी रूपांतरण प्रयास (प्रोटोटाइप या अस्थायी समाधान) और मौजूदा कार्यक्षमता को बाहर रखा जा सकता है।
एन्हांसमेंट फंक्शन प्वाइंट काउंट
जब उत्पादन के बाद सॉफ्टवेयर में बदलाव किए जाते हैं, तो उन्हें एन्हांसमेंट माना जाता है। ऐसी वृद्धि परियोजनाओं को आकार देने के लिए, फंक्शन पॉइंट काउंट को एप्लीकेशन में जोड़ा गया, परिवर्तित या हटा दिया गया है।
चरण 2: गणना की सीमा निर्धारित करें
सीमा मापी जा रही एप्लिकेशन और बाहरी अनुप्रयोगों या उपयोगकर्ता डोमेन के बीच की सीमा को इंगित करता है। (चित्र 1 देखें)
सीमा निर्धारित करने के लिए, समझें -
- फंक्शन पॉइंट काउंट का उद्देश्य
- मापी जा रही आवेदन की गुंजाइश
- कैसे और कौन से एप्लिकेशन क्या डेटा बनाए रखते हैं
- व्यावसायिक क्षेत्र जो अनुप्रयोगों का समर्थन करते हैं
चरण 3: उपयोगकर्ता द्वारा आवश्यक प्रत्येक प्राथमिक प्रक्रिया को पहचानें
गतिविधि की सबसे छोटी इकाई में कार्यात्मक उपयोगकर्ता आवश्यकताओं की रचना और / या विघटित करें, जो निम्नलिखित सभी मानदंडों को पूरा करता है -
- उपयोगकर्ता के लिए सार्थक है।
- एक पूर्ण लेन-देन को नियंत्रित करता है।
- स्वयंभू है।
- एक सुसंगत स्थिति में गिने जा रहे एप्लिकेशन के व्यवसाय को छोड़ देता है।
उदाहरण के लिए, कार्यात्मक उपयोगकर्ता की आवश्यकता - "कर्मचारी की जानकारी बनाए रखें" को कर्मचारी, कर्मचारी बदलने, कर्मचारी को हटाने और कर्मचारी के बारे में पूछताछ करने जैसी छोटी गतिविधियों में विघटित किया जा सकता है।
इस प्रकार से पहचानी जाने वाली गतिविधि की प्रत्येक इकाई एक प्राथमिक प्रक्रिया (EP) है।
चरण 4: अद्वितीय प्राथमिक प्रक्रियाओं का निर्धारण करें
पहले से पहचाने गए दो ईपी की तुलना करें, यदि उन्हें एक ईपी (समान ईपी) के रूप में गिना जाए -
- डीईटी के एक ही सेट की आवश्यकता है।
- FTR के समान सेट की आवश्यकता है।
- ईपी को पूरा करने के लिए प्रसंस्करण तर्क के समान सेट की आवश्यकता होती है।
एक ईपी को कई ईपीएस में प्रसंस्करण तर्क के कई रूपों के साथ विभाजित न करें।
उदाहरण के लिए, यदि आपने एक ईपी के रूप में 'कर्मचारी जोड़ें' की पहचान की है, तो यह इस बात के लिए दो ईपी में विभाजित नहीं होना चाहिए कि एक कर्मचारी आश्रित हो सकता है या नहीं। ईपी अभी भी 'कर्मचारी जोड़ें' है, और आश्रितों के लिए खाते में प्रसंस्करण तर्क और डीईटी में भिन्नता है।
चरण 5: डेटा फ़ंक्शंस को मापें
प्रत्येक डेटा फ़ंक्शन को या तो ILF या EIF के रूप में वर्गीकृत करें।
एक डेटा फ़ंक्शन को एक के रूप में वर्गीकृत किया जाएगा -
आंतरिक लॉजिकल फ़ाइल (ILF), यदि यह मापी जा रही एप्लिकेशन द्वारा बनाए रखा जाता है।
बाहरी इंटरफ़ेस फ़ाइल (ईआईएफ) यदि इसे संदर्भित किया जाता है, लेकिन मापी जा रही एप्लिकेशन द्वारा बनाए नहीं रखा जाता है।
ILF और EIF में व्यावसायिक डेटा, नियंत्रण डेटा और नियम आधारित डेटा हो सकते हैं। उदाहरण के लिए, टेलीफोन स्विचिंग तीन प्रकार से होती है - व्यवसाय डेटा, नियम डेटा और नियंत्रण डेटा। व्यावसायिक डेटा वास्तविक कॉल है। नियम डेटा यह है कि नेटवर्क के माध्यम से कॉल को कैसे रूट किया जाना चाहिए, और डेटा को नियंत्रित करना है कि स्विच एक दूसरे के साथ कैसे संवाद करते हैं।
ILF और EIF की गिनती के लिए निम्नलिखित दस्तावेज पर विचार करें -
- प्रस्तावित प्रणाली के लिए उद्देश्य और बाधाएं।
- वर्तमान प्रणाली के बारे में दस्तावेज़ीकरण, यदि ऐसी प्रणाली मौजूद है।
- उपयोगकर्ताओं के कथित उद्देश्यों, समस्याओं और जरूरतों का दस्तावेजीकरण।
- डेटा मॉडल।
चरण 5.1: प्रत्येक डेटा फ़ंक्शन के लिए डीईटी की गणना करें
आईएलएफ / ईआईएफ के लिए डीईटी की गणना के लिए निम्नलिखित नियम लागू करें -
प्रत्येक अद्वितीय उपयोगकर्ता पहचान योग्य, गैर-दोहराया क्षेत्र के लिए एक निष्कर्ष की गणना करें या EPF के निष्पादन के माध्यम से ILF या EIF से पुनर्प्राप्त किया जाता है।
केवल उन्हीं डीईटी को गिनें जो उस एप्लिकेशन द्वारा उपयोग किए जा रहे हैं जो दो या दो से अधिक एप्लिकेशन बनाए रखने और / या एक ही डेटा फ़ंक्शन को रेफर करने पर मापा जाता है।
किसी अन्य ILF या EIF के साथ संबंध स्थापित करने के लिए उपयोगकर्ता द्वारा आवश्यक प्रत्येक विशेषता के लिए एक डीईटी की गणना करें।
यह निर्धारित करने के लिए कि वे एक ही डीईटी के रूप में वर्गीकृत हैं और गिने जाते हैं या क्या उन्हें कई डीईटी के रूप में गिना जाता है, निर्धारित करने के लिए संबंधित विशेषताओं की समीक्षा करें। समूहीकरण इस बात पर निर्भर करेगा कि ईपी आवेदन के भीतर विशेषताओं का उपयोग कैसे करते हैं।
चरण 5.2: प्रत्येक डेटा फ़ंक्शन के लिए रीट की गणना करें
ILF / EIF के लिए RET की गणना के लिए निम्नलिखित नियम लागू करें -
- प्रत्येक डेटा फ़ंक्शन के लिए एक आरईटी की गणना करें।
- डीईटी के निम्नलिखित अतिरिक्त तार्किक उप-समूहों में से प्रत्येक के लिए एक अतिरिक्त आरईटी की गणना करें।
- गैर-प्रमुख विशेषताओं के साथ सहयोगी इकाई।
- उप-प्रकार (पहले उप-प्रकार के अलावा)।
- अनिवार्य इकाई: 1 के अलावा अन्य संबंध में, सहायक इकाई।
चरण 5.3: प्रत्येक डेटा फ़ंक्शन के लिए कार्यात्मक जटिलता निर्धारित करें
| RETS | डेटा तत्व प्रकार (डीईटी) | ||
|---|---|---|---|
| 1-19 | 20-50 | >50 | |
| 1 | एल | एल | ए |
| 2 से 5 | एल | ए | एच |
| > 5 | ए | एच | एच |
कार्यात्मक जटिलता: L = कम; A = औसत; H = ऊँचा
चरण 5.4: प्रत्येक डेटा फ़ंक्शन के लिए कार्यात्मक आकार को मापें
| कार्यात्मक जटिलता | ILF के लिए FP गणना | ईआईएफ के लिए एफपी गणना |
|---|---|---|
| कम | 7 | 5 |
| औसत | 10 | 7 |
| उच्च | 15 | 10 |
चरण 6: मापनीय कार्य को मापें
लेन-देन के कार्यों को मापने के लिए आवश्यक कदम निम्नलिखित हैं -
चरण 6.1: प्रत्येक ट्रांजेक्शनल फ़ंक्शन को वर्गीकृत करें
लेन-देन के कार्यों को एक बाहरी इनपुट, बाहरी आउटपुट या एक बाहरी पूछताछ के रूप में वर्गीकृत किया जाना चाहिए।
बाहरी इनपुट
एक्सटर्नल इनपुट (EI) एक एलिमेंटरी प्रोसेस है जो बाउंड्री के बाहर से आने वाले डेटा या कंट्रोल को प्रोसेस करता है। एक ईआई का प्राथमिक इरादा एक या अधिक ILFs और / या सिस्टम के व्यवहार को बदलने के लिए बनाए रखना है।
निम्नलिखित सभी नियम लागू होने चाहिए -
डेटा या नियंत्रण की जानकारी आवेदन सीमा के बाहर से प्राप्त होती है।
कम से कम एक ILF बनाए रखा जाता है यदि सीमा में प्रवेश करने वाला डेटा सिस्टम के व्यवहार को बदलने वाली जानकारी को नियंत्रित नहीं करता है।
पहचाने गए ईपी के लिए, तीन कथनों में से एक को लागू करना होगा -
प्रसंस्करण तर्क आवेदन के लिए अन्य ईआई द्वारा निष्पादित प्रसंस्करण तर्क से अद्वितीय है।
पहचाने गए डेटा तत्वों का सेट अनुप्रयोग के अन्य ईआई के लिए पहचाने गए सेटों से अलग है।
ILF या संदर्भित ईआईएफ आवेदन में अन्य ईआई द्वारा संदर्भित फाइलों से अलग हैं।
बाहरी आउटपुट
एक्सटर्नल आउटपुट (EO) एक एलिमेंटरी प्रोसेस है, जो एप्लिकेशन की सीमा के बाहर डेटा या कंट्रोल की जानकारी भेजता है। ईओ में बाहरी जांच से परे अतिरिक्त प्रसंस्करण शामिल है।
एक ईओ का प्राथमिक इरादा किसी उपयोगकर्ता को डेटा या नियंत्रण जानकारी की पुनर्प्राप्ति के अलावा या उसके अलावा प्रसंस्करण तर्क के माध्यम से जानकारी प्रस्तुत करना है।
प्रसंस्करण तर्क होना चाहिए -
- कम से कम एक गणितीय सूत्र या गणना को शामिल करें।
- व्युत्पन्न डेटा बनाएँ।
- एक या अधिक ILF बनाए रखें।
- सिस्टम के व्यवहार को बदल दें।
निम्नलिखित सभी नियम लागू होने चाहिए -
- आवेदन की सीमा के लिए बाहरी डेटा या नियंत्रण जानकारी भेजता है।
- पहचाने गए ईपी के लिए, तीन कथनों में से एक को लागू करना होगा -
- प्रसंस्करण तर्क आवेदन के लिए अन्य ईओ द्वारा निष्पादित प्रसंस्करण तर्क से अद्वितीय है।
- पहचाने गए डेटा तत्वों का सेट अनुप्रयोग के अन्य ईओ से अलग है।
- ILF या संदर्भित ईआईएफ आवेदन में अन्य ईओ द्वारा संदर्भित फाइलों से अलग हैं।
इसके अतिरिक्त, निम्नलिखित में से एक नियम लागू होना चाहिए -
- प्रसंस्करण तर्क में कम से कम एक गणितीय सूत्र या गणना शामिल है।
- प्रसंस्करण तर्क कम से कम एक ILF बनाए रखता है।
- प्रोसेसिंग लॉजिक सिस्टम के व्यवहार को बदल देता है।
बाहरी पूछताछ
एक्सटर्नल इंक्वायरी (EQ) एक एलिमेंटरी प्रोसेस है जो सीमा के बाहर डेटा या कंट्रोल की जानकारी भेजता है। एक EQ का प्राथमिक उद्देश्य उपयोगकर्ता को डेटा या नियंत्रण जानकारी की पुनर्प्राप्ति के माध्यम से जानकारी प्रस्तुत करना है।
प्रसंस्करण तर्क में कोई गणितीय सूत्र या गणना नहीं है, और कोई व्युत्पन्न डेटा नहीं बनाता है। प्रसंस्करण के दौरान कोई भी आईएलएफ बनाए नहीं रखा जाता है, न ही सिस्टम में बदलाव किया जाता है।
निम्नलिखित सभी नियम लागू होने चाहिए -
- आवेदन की सीमा के लिए बाहरी डेटा या नियंत्रण जानकारी भेजता है।
- पहचाने गए ईपी के लिए, तीन कथनों में से एक को लागू करना होगा -
- प्रसंस्करण तर्क आवेदन के लिए अन्य EQ द्वारा किए गए प्रसंस्करण तर्क से अद्वितीय है।
- पहचाने गए डेटा तत्वों का सेट अनुप्रयोग में अन्य EQ से भिन्न है।
- ILF या संदर्भित ईआईएफ आवेदन में अन्य EQs द्वारा संदर्भित फाइलों से अलग हैं।
इसके अतिरिक्त, निम्नलिखित सभी नियम लागू होने चाहिए -
- प्रोसेसिंग लॉजिक एक ILF या EIF से डेटा या नियंत्रण जानकारी प्राप्त करता है।
- प्रसंस्करण तर्क में गणितीय सूत्र या गणना शामिल नहीं है।
- प्रसंस्करण तर्क प्रणाली के व्यवहार में परिवर्तन नहीं करता है।
- प्रसंस्करण तर्क आईएलएफ को बनाए नहीं रखता है।
चरण 6.2: प्रत्येक ट्रांजेक्शनल फ़ंक्शन के लिए डीईटी की गणना करें
ईआई के लिए डीईटी की गणना के लिए निम्नलिखित नियम लागू करें -
सीमा के पार (प्रवेश करती है और / या बाहर) सब कुछ की समीक्षा करें।
प्रत्येक अद्वितीय उपयोगकर्ता पहचानने योग्य, गैर-दोहराया विशेषता के लिए एक डीईटी की गणना करें जो ट्रांजेक्शनल फ़ंक्शन के प्रसंस्करण के दौरान सीमा को पार (प्रवेश और / या बाहर करता है) करता है।
अनुप्रयोग प्रतिक्रिया संदेश भेजने की क्षमता के लिए केवल एक डीईटी प्रति ट्रांजेक्शनल फ़ंक्शन की गणना करें, भले ही कई संदेश हों।
क्रिया को आरंभ करने की क्षमता के लिए केवल एक डीईटी प्रति ट्रांजेक्शनल फ़ंक्शन की गणना करें, भले ही ऐसा करने के लिए कई साधन हों।
डीईटी के रूप में निम्नलिखित मदों की गणना न करें -
एक सीमा समारोह के माध्यम से सीमा के भीतर उत्पन्न विशेषताएँ और सीमा से बाहर निकलने के बिना एक ILF को बचाया।
रिपोर्ट शीर्षक, स्क्रीन या पैनल पहचानकर्ता, कॉलम शीर्षक और विशेषता शीर्षक जैसे साहित्य।
एप्लिकेशन जनरेट किए गए स्टैम्प जैसे दिनांक और समय विशेषताएँ।
पेजिंग चर, पेज नंबर और पोजिशनिंग जानकारी, उदाहरण के लिए, '211 के 37 से 54 तक पंक्तियाँ'।
नेविगेशन सहायक जैसे "पिछली", "अगली", "पहली", "अंतिम" और उनके चित्रमय समकक्षों का उपयोग करके सूची के भीतर नेविगेट करने की क्षमता।
ईओ / ईक्यू के लिए डीईटी की गणना के लिए निम्नलिखित नियम लागू करें -
सीमा के पार (प्रवेश करती है और / या बाहर) सब कुछ की समीक्षा करें।
प्रत्येक अद्वितीय उपयोगकर्ता पहचानने योग्य, गैर-दोहराया विशेषता के लिए एक डीईटी की गणना करें जो ट्रांजेक्शनल फ़ंक्शन के प्रसंस्करण के दौरान सीमा को पार (प्रवेश और / या बाहर करता है) करता है।
अनुप्रयोग प्रतिक्रिया संदेश भेजने की क्षमता के लिए केवल एक डीईटी प्रति ट्रांजेक्शनल फ़ंक्शन की गणना करें, भले ही कई संदेश हों।
क्रिया को आरंभ करने की क्षमता के लिए केवल एक डीईटी प्रति ट्रांजेक्शनल फ़ंक्शन की गणना करें, भले ही ऐसा करने के लिए कई साधन हों।
डीईटी के रूप में निम्नलिखित मदों की गणना न करें -
सीमा को पार किए बिना सीमा के भीतर उत्पन्न विशेषताएँ।
रिपोर्ट शीर्षक, स्क्रीन या पैनल पहचानकर्ता, कॉलम शीर्षक और विशेषता शीर्षक जैसे साहित्य।
एप्लिकेशन जनरेट किए गए स्टैम्प जैसे दिनांक और समय विशेषताएँ।
पेजिंग चर, पेज नंबर और पोजिशनिंग जानकारी, उदाहरण के लिए, '211 के 37 से 54 तक पंक्तियाँ'।
नेविगेशन सहायक जैसे "पिछली", "अगली", "पहली", "अंतिम" और उनके चित्रमय समकक्षों का उपयोग करके सूची के भीतर नेविगेट करने की क्षमता।
चरण 6.3: प्रत्येक ट्रांजेक्शनल फ़ंक्शन के लिए FTR की गणना करें
EI के लिए FTR की गणना के लिए निम्नलिखित नियम लागू करें -
- प्रत्येक ILF के लिए एक FTR की गणना बनाए रखें।
- EI के प्रसंस्करण के दौरान पढ़े प्रत्येक ILF या EIF के लिए एक FTR की गणना करें।
- प्रत्येक ILF के लिए केवल एक FTR की गणना करें जो दोनों को बनाए रखा और पढ़ा जाता है।
EO / EQ के लिए FTR की गणना के लिए निम्नलिखित नियम लागू करें -
- EP की प्रोसेसिंग के दौरान पढ़े प्रत्येक ILF या EIF के लिए FTR की गणना करें।
इसके अतिरिक्त, ईओ के लिए एफटीआर की गणना के लिए निम्नलिखित नियम लागू करें -
- ईपी के प्रसंस्करण के दौरान बनाए रखा प्रत्येक ILF के लिए एक FTR की गणना करें।
- प्रत्येक ILF के लिए केवल एक FTR की गणना करें जो EP द्वारा बनाए और पढ़ा जाता है।
चरण 6.4: प्रत्येक ट्रांजेक्शनल फ़ंक्शन के लिए कार्यात्मक जटिलता निर्धारित करें
| FTRs | डेटा तत्व प्रकार (डीईटी) | ||
|---|---|---|---|
| 1-4 | 5-15 | >=16 | |
| 0-1 | एल | एल | ए |
| 2 | एल | ए | एच |
| > = 3 | ए | एच | एच |
कार्यात्मक जटिलता: L = कम; A = औसत; H = ऊँचा
प्रत्येक EO / EQ के लिए कार्यात्मक जटिलता निर्धारित करें, इस अपवाद के साथ कि EQ में न्यूनतम 1 FTR होना चाहिए -
EQ में न्यूनतम 1 FTR होना चाहिए FTRs |
डेटा तत्व प्रकार (डीईटी) | ||
|---|---|---|---|
| 1-4 | 5-15 | > = 16 | |
| 0-1 | एल | एल | ए |
| 2 | एल | ए | एच |
| > = 3 | ए | एच | एच |
कार्यात्मक जटिलता: L = कम; A = औसत; H = ऊँचा
चरण 6.5: प्रत्येक ट्रांजेक्शनल फ़ंक्शन के लिए कार्यात्मक आकार को मापें
प्रत्येक ईआई के लिए कार्यात्मक आकार को उसकी कार्यात्मक जटिलता से मापें।
| जटिलता | एफपी गणना |
|---|---|
| कम | 3 |
| औसत | 4 |
| उच्च | 6 |
प्रत्येक ईओ / EQ के लिए कार्यात्मक आकार को उसकी कार्यात्मक जटिलता से मापें।
| जटिलता | ईओ के लिए एफपी गणना | ईक्यू के लिए एफपी गणना |
|---|---|---|
| कम | 4 | 3 |
| औसत | 5 | 4 |
| उच्च | 6 | 6 |
चरण 7: कार्यात्मक आकार की गणना करें (अनपेक्षित फ़ंक्शन बिंदु गणना)
कार्यात्मक आकार की गणना करने के लिए, किसी को नीचे दिए गए चरणों का पालन करना चाहिए -
चरण 7.1
चरण 1 में आपको जो भी मिला है उसे याद करें। गणना का प्रकार निर्धारित करें।
चरण 7.2.२
प्रकार के आधार पर कार्यात्मक आकार या फ़ंक्शन बिंदु गणना की गणना करें।
- विकास समारोह बिंदु गणना के लिए, चरण 7.3 पर जाएं।
- आवेदन समारोह बिंदु गिनती के लिए, चरण 7.4 पर जाएं।
- एन्हांसमेंट फंक्शन प्वाइंट काउंट के लिए, स्टेप 7.5 पर जाएं।
कदम 7.3
विकास कार्य बिंदु गणना में कार्यक्षमता के दो घटक होते हैं -
अनुप्रयोग कार्यक्षमता परियोजना के लिए उपयोगकर्ता की आवश्यकताओं में शामिल है।
रूपांतरण कार्यक्षमता परियोजना के लिए उपयोगकर्ता की आवश्यकताओं में शामिल है। रूपांतरण कार्यक्षमता में केवल डेटा को परिवर्तित करने और / या अन्य उपयोगकर्ता-निर्दिष्ट रूपांतरण आवश्यकताओं को प्रदान करने वाले फ़ंक्शन शामिल हैं, जैसे विशेष रूपांतरण रिपोर्ट। उदाहरण के लिए एक मौजूदा एप्लिकेशन को एक नई प्रणाली के साथ बदला जा सकता है।
DFP = ADD + CFP
कहाँ पे,
DFP = विकास कार्य बिंदु गणना
ADD = विकास परियोजना द्वारा उपयोगकर्ता को दिए गए कार्यों का आकार
CFP = रूपांतरण कार्यक्षमता का आकार
ADD = एफपी काउंट (ILFs) + FP Count (EIFs) + FP Count (EIs) + FP Count (EOs) + FP Count (EQs)
CFP = एफपी काउंट (ILFs) + FP Count (EIFs) + FP Count (EIs) + FP Count (EOs) + FP Count (EQs)
चरण 7.4.४
अनुप्रयोग फ़ंक्शन बिंदु गणना की गणना करें
AFP = ADD
कहाँ पे,
AFP = एप्लीकेशन फंक्शन प्वाइंट काउंट
ADD = विकास परियोजना द्वारा उपयोगकर्ता के लिए दिए गए कार्यों का आकार (किसी भी रूपांतरण कार्यक्षमता के आकार को छोड़कर), या कार्यक्षमता जब भी आवेदन की गणना की जाती है।
ADD = एफपी काउंट (ILFs) + FP Count (EIFs) + FP Count (EIs) + FP Count (EOs) + FP Count (EQs)
चरण 7.5.५
एन्हांसमेंट फंक्शन प्वाइंट काउंट कार्यक्षमता के निम्नलिखित चार घटकों पर विचार करता है -
- कार्यक्षमता जो अनुप्रयोग में जोड़ी जाती है।
- कार्यक्षमता जो अनुप्रयोग में संशोधित है।
- रूपांतरण की कार्यक्षमता।
- कार्यक्षमता जो एप्लिकेशन से हटा दी गई है।
EFP = ADD + CHGA + CFP + DEL
कहाँ पे,
EFP = एन्हांसमेंट फंक्शन प्वाइंट काउंट
ADD = संवर्द्धन परियोजना द्वारा जोड़े जा रहे कार्यों का आकार
CHGA = संवर्द्धन परियोजना द्वारा किए जा रहे कार्यों के आकार
CFP = रूपांतरण कार्यक्षमता का आकार
DEL = एन्हांसमेंट प्रोजेक्ट द्वारा हटाए जा रहे कार्यों का आकार
ADD = एफपी काउंट (ILFs) + FP Count (EIFs) + FP Count (EIs) + FP Count (EOs) + FP Count (EQs)
CHGA = एफपी काउंट (ILFs) + FP Count (EIFs) + FP Count (EIs) + FP Count (EOs) + FP Count (EQs)
CFP = एफपी काउंट (ILFs) + FP Count (EIFs) + FP Count (EIs) + FP Count (EOs) + FP Count (EQs)
DEL = एफपी काउंट (ILFs) + FP काउंट (EIFs) + FP COUNT (EIs) + FP काउंट (EOs) + FP काउंट (EQs)
चरण 8: मान समायोजन कारक निर्धारित करें
GSCs को CPM 4.3.1 में वैकल्पिक बनाया गया है और परिशिष्ट में ले जाया गया है। इसलिए, चरण 8 और चरण 9 को छोड़ दिया जा सकता है।
वैल्यू एडजस्टमेंट फैक्टर (VAF) 14 जीएससी पर आधारित है जो कि गिने जा रहे एप्लिकेशन की सामान्य कार्यक्षमता को रेट करता है। जीएससी उपयोगकर्ता व्यवसाय के लिए प्रौद्योगिकी से स्वतंत्र बाधाएं हैं। प्रत्येक विशेषता में प्रभाव की डिग्री निर्धारित करने के लिए संबंधित विवरण हैं।
| सामान्य प्रणाली की विशेषता | संक्षिप्त विवरण |
|---|---|
| डाटा संचार | आवेदन या प्रणाली के साथ सूचना के हस्तांतरण या आदान-प्रदान में सहायता के लिए कितनी संचार सुविधाएं हैं? |
| वितरित डाटा प्रोसेसिंग | वितरित डेटा और प्रसंस्करण कार्य कैसे संभाले जाते हैं? |
| प्रदर्शन | क्या उपयोगकर्ता को प्रतिक्रिया समय या थ्रूपुट की आवश्यकता थी? |
| भारी इस्तेमाल किया विन्यास | वर्तमान हार्डवेयर प्लेटफॉर्म का उपयोग कितना भारी है, जहां एप्लिकेशन निष्पादित किया जाएगा? |
| लेन-देन की दर | दैनिक, साप्ताहिक, मासिक आदि लेनदेन को कितनी बार निष्पादित किया जाता है? |
| ऑन लाइन डाटा एंट्री | सूचना का कितना प्रतिशत ऑनलाइन दर्ज किया जाता है? |
| अंतिम-उपयोगकर्ता दक्षता | क्या एप्लिकेशन को एंड-यूज़र दक्षता के लिए डिज़ाइन किया गया था? |
| ऑनलाइन अपडेट | ऑनलाइन लेनदेन द्वारा कितने ILF अपडेट किए जाते हैं? |
| जटिल प्रसंस्करण | क्या आवेदन में व्यापक तार्किक या गणितीय प्रसंस्करण है? |
| पुनर्प्रयोग | क्या एप्लिकेशन को एक या कई उपयोगकर्ता की जरूरतों को पूरा करने के लिए विकसित किया गया था? |
| स्थापना आसानी | रूपांतरण और स्थापना कितना मुश्किल है? |
| परिचालन में आसानी | प्रभावी और / या स्वचालित स्टार्ट-अप, बैक-अप और पुनर्प्राप्ति प्रक्रियाएं कैसे हैं? |
| एकाधिक साइटें | क्या एप्लिकेशन विशेष रूप से डिज़ाइन किया गया, विकसित किया गया, और कई संगठनों के लिए कई साइटों पर स्थापित होने का समर्थन किया गया? |
| परिवर्तन की सुविधा | क्या एप्लिकेशन को विशेष रूप से डिजाइन, विकसित और परिवर्तन की सुविधा के लिए समर्थन किया गया था? |
प्रभाव सीमा की डिग्री शून्य से पांच के पैमाने पर होती है, जिसमें कोई प्रभाव नहीं होता है।
| रेटिंग | प्रभाव की डिग्री |
|---|---|
| 0 | न उपस्थित, न कोई प्रभाव |
| 1 | आकस्मिक प्रभाव |
| 2 | मध्यम प्रभाव |
| 3 | औसत प्रभाव |
| 4 | महत्वपूर्ण प्रभाव |
| 5 | मजबूत प्रभाव भर में |
14 जीएससी में से प्रत्येक के लिए प्रभाव की डिग्री निर्धारित करें।
इस प्रकार प्राप्त 14 जीएससी के मूल्यों के योग को टोटल डिग्री ऑफ इन्फ्लुएंस (TDI) कहा जाता है।
TDI = ∑14 Degrees of Influence
अगला, मान समायोजन कारक (VAF) की गणना करें
VAF = (TDI × 0.01) + 0.65
प्रत्येक GSC 0 से 5 तक भिन्न हो सकता है, TDI (0 × 14) से (5 × 14), अर्थात 0 (जब सभी GSCs कम हैं) से भिन्न हो सकते हैं 70 (जब सभी GSCs उच्च हैं) अर्थात 0 DI TDI। 70। इसलिए, VAF ०.६५ (जब सभी GSCs कम हैं) से लेकर १.३५ (जब सभी GSCs अधिक हैं) रेंज में भिन्न हो सकते हैं, अर्थात, ०.६५ F VAF 35 १.३५।
चरण 9: समायोजित फंक्शन प्वाइंट गणना की गणना करें
एफपीए दृष्टिकोण के अनुसार जो वीएएफ का उपयोग करता है (वी 4.3.1 से पहले सीपीएम संस्करण), यह द्वारा निर्धारित किया जाता है,
Adjusted FP Count = Unadjusted FP Count × VAF
जहां, अनपेक्षित एफपी गणना कार्यात्मक आकार है जिसे आपने चरण 7 में गणना की है।
VAF 0.65 से 1.35 तक भिन्न हो सकता है, VAF अंतिम समायोजित एफपी गणना पर vary 35% का प्रभाव डालती है।
फंक्शन पॉइंट्स के फायदे
कार्य बिंदु उपयोगी हैं -
समस्या के आकार के बजाय समाधान के आकार को मापने में।
चूंकि फ़ंक्शन पॉइंट काउंट के लिए केवल आवश्यकताएं ही आवश्यक हैं।
चूंकि यह तकनीक से स्वतंत्र है।
चूंकि यह प्रोग्रामिंग भाषाओं से स्वतंत्र है।
परीक्षण परियोजनाओं के आकलन में।
समग्र परियोजना लागत, अनुसूची और प्रयास का अनुमान लगाने में।
अनुबंध वार्ता में, क्योंकि यह व्यापार समूहों के साथ आसान संचार की एक विधि प्रदान करता है।
जैसा कि यह सॉफ्टवेयर में वास्तविक उपयोगों, इंटरफेस और उद्देश्यों के लिए एक मान देता है और असाइन करता है।
अन्य मेट्रिक्स जैसे घंटे, लागत, हेडकाउंट, अवधि और अन्य एप्लिकेशन मेट्रिक्स के साथ अनुपात बनाने में।
एफपी रिपोजिटरी
इंटरनेशनल सॉफ्टवेयर बेंचमार्किंग स्टैंडर्ड्स ग्रुप (ISBSG) IT डेटा के लिए दो रिपॉजिटरी का विकास और रखरखाव करता है।
- विकास और संवर्धन परियोजनाएँ
- रखरखाव और समर्थन अनुप्रयोग
विकास और संवर्धन परियोजनाओं के भंडार में 6,000 से अधिक परियोजनाएं हैं।
डेटा को Microsoft Excel प्रारूप में वितरित किया गया है, जिससे आगे के विश्लेषण के लिए यह आसान हो जाता है कि आप इसके साथ क्या करना चाहते हैं, या आप किसी अन्य उद्देश्य के लिए भी डेटा का उपयोग कर सकते हैं।
ISBSG भंडार लाइसेंस से खरीदा जा सकता है: http://www.isbsg.com/
ISBSG ऑनलाइन खरीद के लिए IFPUG सदस्यों के लिए 10% छूट प्रदान करता है जब डिस्काउंट कोड "IFPUGMembers" का उपयोग किया जाता है।
ISBSG सॉफ्टवेयर प्रोजेक्ट डेटा रिलीज़ के अपडेट यहां मिल सकते हैं: http://www.ifpug.org/isbsg/
COSMIC और IFPUG ने सॉफ्टवेयर नॉन-फंक्शनल और प्रोजेक्ट रिक्वायरमेंट्स के लिए शब्दों की शब्दावली का निर्माण करने के लिए सहयोग किया। इसे - cosmic-sizing.org से डाउनलोड किया जा सकता है
ए Use-Case उपयोगकर्ता और सिस्टम के बीच संबंधित इंटरैक्शन की एक श्रृंखला है जो उपयोगकर्ता को एक लक्ष्य प्राप्त करने में सक्षम बनाता है।
उपयोग-मामले एक प्रणाली की कार्यात्मक आवश्यकताओं को पकड़ने का एक तरीका है। सिस्टम के उपयोगकर्ता को 'अभिनेता' के रूप में जाना जाता है। उपयोग-मामले मूल रूप से पाठ रूप में हैं।
उपयोग-केस अंक - परिभाषा
Use-Case Points (UCP)एक सॉफ्टवेयर आकलन तकनीक है जिसका उपयोग उपयोग के मामलों के साथ सॉफ्टवेयर आकार को मापने के लिए किया जाता है। यूसीपी की अवधारणा एफपी के समान है।
किसी परियोजना में UCPs की संख्या निम्नलिखित पर आधारित है -
- प्रणाली में उपयोग के मामलों की संख्या और जटिलता।
- प्रणाली पर अभिनेताओं की संख्या और जटिलता।
विभिन्न गैर-कार्यात्मक आवश्यकताएं (जैसे पोर्टेबिलिटी, प्रदर्शन, रखरखाव) जो उपयोग के मामलों के रूप में नहीं लिखी गई हैं।
वह वातावरण जिसमें परियोजना विकसित की जाएगी (जैसे भाषा, टीम की प्रेरणा, आदि)
यूसीपी के साथ अनुमान के लिए सभी उपयोग के मामलों को एक लक्ष्य के साथ लिखा जाना चाहिए और लगभग समान स्तर पर, समान मात्रा में विवरण देना चाहिए। इसलिए, अनुमान से पहले, परियोजना टीम को यह सुनिश्चित करना चाहिए कि उन्होंने अपने उपयोग के मामलों को परिभाषित लक्ष्यों और विस्तृत स्तर पर लिखा है। उपयोग का मामला आम तौर पर एक सत्र के भीतर पूरा होता है और लक्ष्य प्राप्त होने के बाद, उपयोगकर्ता किसी अन्य गतिविधि पर जा सकता है।
उपयोग-मामले के बिंदुओं का इतिहास
1993 में गुस्ताव कार्नर द्वारा यूज़-केस पॉइंट आकलन पद्धति शुरू की गई थी। काम को बाद में तर्कसंगत सॉफ्टवेयर द्वारा लाइसेंस दिया गया था जो आईबीएम में विलय हो गया था।
उपयोग-केस अंक गणना प्रक्रिया
उपयोग-केस पॉइंट्स की गिनती प्रक्रिया के निम्नलिखित चरण हैं -
- अनधिकृत यूसीपी की गणना करें
- तकनीकी जटिलता के लिए समायोजित करें
- पर्यावरणीय जटिलता के लिए समायोजित करें
- समायोजित यूसीपी की गणना करें
चरण 1: अनधिकृत उपयोग-केस अंकों की गणना करें।
आप निम्न चरणों द्वारा सबसे पहले अनजाने उपयोग-केस पॉइंट की गणना करते हैं -
- अनधिकृत उपयोग-केस वजन निर्धारित करें
- अनधिकृत अभिनेता वजन निर्धारित करें
- अनधिकृत उपयोग-केस अंकों की गणना करें
Step 1.1 - अनधिकृत उपयोग-केस वजन निर्धारित करें।
Step 1.1.1 - प्रत्येक उपयोग-मामले में लेनदेन की संख्या का पता लगाएं।
यदि उपयोग-मामले उपयोगकर्ता लक्ष्य स्तर के साथ लिखे गए हैं, तो लेन-देन उपयोग-मामले में एक कदम के बराबर है। उपयोग-केस में चरणों की गणना करके लेनदेन की संख्या का पता लगाएं।
Step 1.1.2- उपयोग-केस में लेनदेन की संख्या के आधार पर प्रत्येक उपयोग-मामले को सरल, औसत या जटिल के रूप में वर्गीकृत करें। निम्न तालिका में दिखाए अनुसार उपयोग-केस भार भी असाइन करें -
| उपयोग-मामला जटिलता | लेन-देन की संख्या | उपयोग-केस वजन |
|---|---|---|
| सरल | ≤3 | 5 |
| औसत | 4 से 7 | 10 |
| जटिल | > 7 | 15 |
Step 1.1.3- प्रत्येक उपयोग-केस के लिए दोहराएं और सभी उपयोग-केस भार प्राप्त करें। अनधिकृत उपयोग-केस वजन (UUCW) सभी उपयोग-केस भार का योग है।
Step 1.1.4 निम्नलिखित तालिका का उपयोग कर अनधिकृत उपयोग केस वेट (UUCW) खोजें -
| उपयोग-मामला जटिलता | उपयोग-केस वजन | उपयोग-मामलों की संख्या | उत्पाद |
|---|---|---|---|
| सरल | 5 | NSUC | 5 × एनएसयूसी |
| औसत | 10 | NAUC | 10 × NAUC |
| जटिल | 15 | NCUC | 15 × NCUC |
| Unadjusted Use-Case Weight (UUCW) | 5 × NSUC + 10 × NAUC + 15 × NCUC | ||
कहाँ पे,
एनएसयूसी नहीं है। सरल उपयोग मामलों के।
NAUC नहीं है। औसत उपयोग के मामले।
एनसीयूसी नहीं है। जटिल उपयोग के मामले।
Step 1.2 - निर्धारित अनुचित वजन का निर्धारण करें।
उपयोग-मामले में एक अभिनेता एक व्यक्ति, एक अन्य कार्यक्रम, आदि हो सकता है। कुछ अभिनेताओं, जैसे कि परिभाषित एपीआई के साथ एक प्रणाली, बहुत सरल आवश्यकताएं हैं और केवल उपयोग-केस की जटिलता को थोड़ा बढ़ाती हैं।
कुछ अभिनेताओं, जैसे कि एक प्रोटोकॉल के माध्यम से बातचीत करने वाली प्रणाली की अधिक आवश्यकताएं होती हैं और उपयोग-मामले की जटिलता को कुछ हद तक बढ़ाती है।
अन्य अभिनेता, जैसे GUI के माध्यम से बातचीत करने वाले उपयोगकर्ता का उपयोग-केस की जटिलता पर महत्वपूर्ण प्रभाव पड़ता है। इन अंतरों के आधार पर, आप अभिनेताओं को सरल, औसत और जटिल के रूप में वर्गीकृत कर सकते हैं।
Step 1.2.1 - अभिनेताओं को सरल, औसत और जटिल के रूप में वर्गीकृत करें और निम्नलिखित तालिका में दिखाए अनुसार अभिनेता भार को असाइन करें -
| अभिनेता जटिलता | उदाहरण | अभिनेता का वजन |
|---|---|---|
| सरल | परिभाषित एपीआई के साथ एक प्रणाली | 1 |
| औसत | एक प्रोटोकॉल के माध्यम से बातचीत करने वाला सिस्टम | 2 |
| जटिल | एक उपयोगकर्ता GUI के माध्यम से बातचीत | 3 |
Step 1.2.2- प्रत्येक अभिनेता के लिए दोहराएं और सभी अभिनेता वजन प्राप्त करें। अन्यायपूर्ण अभिनेता वजन (UAW) सभी अभिनेता वजन का योग है।
Step 1.2.3 - निम्न तालिका का उपयोग कर अनजाने अभिनेता वजन (UAW) खोजें -
| अभिनेता जटिलता | अभिनेता का वजन | अभिनेताओं की संख्या | उत्पाद |
|---|---|---|---|
| सरल | 1 | एनएसए | 1 × एनएसए |
| औसत | 2 | NAA | 2 × एनएए |
| जटिल | 3 | एनसीए | 3 × एनसीए |
| Unadjusted Actor Weight (UAW) | 1 × NSA + 2 × NAA + 3 × NCA | ||
कहाँ पे,
एनएसए नहीं है। साधारण अभिनेताओं की।
NAA नहीं है। औसत अभिनेताओं की।
एनसीए नहीं है। जटिल अभिनेताओं की।
Step 1.3 - अनधिकृत उपयोग-केस पॉइंट की गणना करें।
Unadjusted Use-Case वजन (UUCW) और Unadjusted Actor Weight (UAW) मिलकर सिस्टम के अनजाने आकार को अनजाने उपयोग-केस पॉइंट्स के रूप में संदर्भित करते हैं।
Unadjusted Use-Case Points (UUCP) = UUCW + UAW
अगले कदम तकनीकी जटिलता और पर्यावरण जटिलता के लिए अनधिकृत उपयोग-केस अंक (UUCP) को समायोजित करने के लिए हैं।
चरण 2: तकनीकी जटिलता के लिए समायोजित करें
Step 2.1 13 ऐसे कारकों पर विचार करें जो उपयोग-केस पॉइंट्स पर एक परियोजना की तकनीकी जटिलता और उनके संबंधित वजन के प्रभाव में योगदान करते हैं जैसा कि निम्नलिखित तालिका में दिया गया है -
| फ़ैक्टर | विवरण | वजन |
|---|---|---|
| टी 1 | वितरित प्रणाली | 2.0 |
| टी 2 | प्रतिक्रिया समय या थ्रूपुट प्रदर्शन उद्देश्य | 1.0 |
| T3 | उपयोगकर्ता दक्षता समाप्त करें | 1.0 |
| टी -4 | जटिल आंतरिक प्रसंस्करण | 1.0 |
| T5 | कोड पुन: प्रयोज्य होना चाहिए | 1.0 |
| T6 | इन्सटाल करना आसान | .5 |
| T7 | प्रयोग करने में आसान | .5 |
| T8 | पोर्टेबल | 2.0 |
| T9 | बदलने में आसान | 1.0 |
| T10 | समवर्ती | 1.0 |
| T11 | विशेष सुरक्षा उद्देश्य शामिल हैं | 1.0 |
| T12 | तीसरे पक्ष के लिए सीधी पहुँच प्रदान करता है | 1.0 |
| T13 | विशेष उपयोगकर्ता प्रशिक्षण सुविधाओं की आवश्यकता है | 1.0 |
इनमें से कई कारक परियोजना की गैर-जरूरी आवश्यकताओं का प्रतिनिधित्व करते हैं।
Step 2.2 - 13 कारकों में से प्रत्येक के लिए, परियोजना का मूल्यांकन करें और 0 (अप्रासंगिक) से 5 (बहुत महत्वपूर्ण) की दर।
Step 2.3 - फैक्टर के इम्पैक्ट वेट से फैक्टर के इम्पैक्ट और प्रोजेक्ट के लिए रेटेड वैल्यू की गणना करें
Impact of the Factor = Impact Weight × Rated Value
Step (2.4)- सभी कारकों के प्रभाव की गणना करें। यह नीचे दिए गए तालिका में दिए गए अनुसार कुल तकनीकी कारक (TFactor) देता है -
| फ़ैक्टर | विवरण | वजन (W) | रेटेड मूल्य (0 से 5) (आरवी) | प्रभाव (I = W × RV) |
|---|---|---|---|---|
| टी 1 | वितरित प्रणाली | 2.0 | ||
| टी 2 | प्रतिक्रिया समय या थ्रूपुट प्रदर्शन उद्देश्य | 1.0 | ||
| T3 | उपयोगकर्ता दक्षता समाप्त करें | 1.0 | ||
| टी -4 | जटिल आंतरिक प्रसंस्करण | 1.0 | ||
| T5 | कोड पुन: प्रयोज्य होना चाहिए | 1.0 | ||
| T6 | इन्सटाल करना आसान | .5 | ||
| T7 | प्रयोग करने में आसान | .5 | ||
| T8 | पोर्टेबल | 2.0 | ||
| T9 | बदलने में आसान | 1.0 | ||
| T10 | समवर्ती | 1.0 | ||
| T11 | विशेष सुरक्षा उद्देश्य शामिल हैं | 1.0 | ||
| T12 | तीसरे पक्ष के लिए सीधी पहुँच प्रदान करता है | 1.0 | ||
| T13 | विशेष उपयोगकर्ता प्रशिक्षण सुविधाओं की आवश्यकता है | 1.0 | ||
| Total Technical Factor (TFactor) | ||||
Step 2.5 - तकनीकी जटिलता कारक (TCF) की गणना निम्नानुसार करें -
TCF = 0.6 + (0.01 × TFactor)
चरण 3: पर्यावरणीय जटिलता के लिए समायोजित करें
Step 3.1 - 8 पर्यावरणीय कारकों पर विचार करें जो परियोजना के निष्पादन और उनकी संबंधित भार को प्रभावित कर सकते हैं जैसा कि निम्नलिखित तालिका में दिया गया है -
| फ़ैक्टर | विवरण | वजन |
|---|---|---|
| एफ 1 | प्रयोग किया जाता है कि परियोजना मॉडल के साथ परिचित | 1.5 |
| F2 | आवेदन का अनुभव | .5 |
| F3 | वस्तु-उन्मुख अनुभव | 1.0 |
| F4 | लीड विश्लेषक क्षमता | .5 |
| F5 | प्रेरणा | 1.0 |
| F6 | स्थिर आवश्यकताओं | 2.0 |
| F7 | अंशकालिक कर्मचारी | -1.0 |
| F8 | प्रोग्रामिंग भाषा में कठिनाई | -1.0 |
Step 3.2 - 8 कारकों में से प्रत्येक के लिए, परियोजना का मूल्यांकन करें और 0 (अप्रासंगिक) से 5 (बहुत महत्वपूर्ण) की दर।
Step 3.3 - फैक्टर के इम्पैक्ट वेट से फैक्टर के इम्पैक्ट और प्रोजेक्ट के लिए रेटेड वैल्यू की गणना करें
Impact of the Factor = Impact Weight × Rated Value
Step 3.4- सभी कारकों के प्रभाव की गणना करें। यह निम्न तालिका में दिए गए अनुसार कुल पर्यावरण कारक (EFactor) देता है -
| फ़ैक्टर | विवरण | वजन (W) | रेटेड मूल्य (0 से 5) (आरवी) | प्रभाव (I = W × RV) |
|---|---|---|---|---|
| एफ 1 | प्रयोग किया जाता है कि परियोजना मॉडल के साथ परिचित | 1.5 | ||
| F2 | आवेदन का अनुभव | .5 | ||
| F3 | वस्तु-उन्मुख अनुभव | 1.0 | ||
| F4 | लीड विश्लेषक क्षमता | .5 | ||
| F5 | प्रेरणा | 1.0 | ||
| F6 | स्थिर आवश्यकताओं | 2.0 | ||
| F7 | अंशकालिक कर्मचारी | -1.0 | ||
| F8 | प्रोग्रामिंग भाषा में कठिनाई | -1.0 | ||
| Total Environment Factor (EFactor) | ||||
Step 3.5 पर्यावरणीय कारक (EF) की गणना निम्नानुसार करें -
1.4 + (-0.03 × EFactor)
चरण 4: समायोजित उपयोग-केस पॉइंट (UCP) की गणना करें
समायोजित उपयोग-केस अंक (UCP) की गणना निम्नानुसार करें -
UCP = UUCP × TCF × EF
उपयोग-केस पॉइंट्स के लाभ और नुकसान
उपयोग के मामले अंक के लाभ
यूसीपी उपयोग के मामलों पर आधारित होते हैं और इसे परियोजना के जीवन चक्र में बहुत पहले ही मापा जा सकता है।
UCP (आकार का अनुमान) उस टीम के आकार, कौशल और अनुभव से स्वतंत्र होगा जो परियोजना को लागू करता है।
UCP आधारित अनुमान वास्तविक लोगों के करीब पाए जाते हैं जब अनुभवी लोगों द्वारा अनुमान लगाया जाता है।
यूसीपी का उपयोग करना आसान है और अतिरिक्त विश्लेषण के लिए कॉल नहीं करता है।
आवश्यकताओं का वर्णन करने के लिए उपयोग के मामलों को व्यापक रूप से पसंद की विधि के रूप में उपयोग किया जा रहा है। ऐसे मामलों में, यूसीपी सबसे उपयुक्त आकलन तकनीक है।
उपयोग-केस पॉइंट्स का नुकसान
यूसीपी का उपयोग केवल तब किया जा सकता है जब उपयोग के मामलों के रूप में आवश्यकताओं को लिखा जाता है।
लक्ष्य-उन्मुख, अच्छी तरह से लिखित उपयोग के मामलों पर निर्भर। यदि उपयोग के मामले ठीक या समान रूप से संरचित नहीं हैं, तो परिणामस्वरूप यूसीपी सटीक नहीं हो सकता है।
तकनीकी और पर्यावरणीय कारकों का UCP पर उच्च प्रभाव पड़ता है। तकनीकी और पर्यावरणीय कारकों को मान प्रदान करते समय देखभाल की आवश्यकता होती है।
UCP समग्र परियोजना आकार के प्रारंभिक अनुमान के लिए उपयोगी है, लेकिन वे एक टीम के पुनरावृति-से-चलने के काम को चलाने में बहुत कम उपयोगी हैं।
Delphi Methodएक संरचित संचार तकनीक है, जो मूल रूप से एक व्यवस्थित, इंटरैक्टिव पूर्वानुमान पद्धति के रूप में विकसित की गई है जो विशेषज्ञों के एक पैनल पर निर्भर है। विशेषज्ञ दो या अधिक राउंड में प्रश्नावली का जवाब देते हैं। प्रत्येक राउंड के बाद, एक फैसिलिटेटर अपने निर्णय के कारणों के साथ पिछले राउंड से विशेषज्ञों के पूर्वानुमान का एक अनाम सारांश प्रदान करता है। तब विशेषज्ञों को पैनल के अन्य सदस्यों के उत्तरों के प्रकाश में अपने पहले के उत्तरों को संशोधित करने के लिए प्रोत्साहित किया जाता है।
ऐसा माना जाता है कि इस प्रक्रिया के दौरान उत्तरों की सीमा घट जाएगी और समूह "सही" उत्तर की ओर अभिसरित हो जाएगा। अंत में, पूर्वनिर्धारित स्टॉप मानदंड (जैसे राउंड की संख्या, सर्वसम्मति की उपलब्धि, और परिणामों की स्थिरता) के बाद प्रक्रिया को रोक दिया जाता है और अंतिम राउंड के माध्य या औसत अंक परिणाम निर्धारित करते हैं।
रैंड कॉर्पोरेशन में डेल्फी विधि 1950-1960 के दशक में विकसित की गई थी।
वाइडबैंड डेल्फी तकनीक
1970 के दशक में, बैरी बोहम और जॉन ए। फ़रक्वार ने डेल्फी विधि के वाइडबैंड वेरिएंट की उत्पत्ति की। शब्द "वाइडबैंड" का उपयोग किया जाता है, क्योंकि डेल्फी विधि की तुलना में, वाइडबैंड डेल्फी तकनीक में प्रतिभागियों के बीच अधिक बातचीत और अधिक संचार शामिल था।
वाइडबैंड डेल्फी तकनीक में, आकलन टीम में 3-7 सदस्य टीम का गठन करते हुए परियोजना प्रबंधक, मॉडरेटर, विशेषज्ञ और विकास टीम के प्रतिनिधि शामिल होते हैं। दो बैठकें हैं -
- शुरुआती मीटिंग
- अनुमान बैठक
वाइडबैंड डेल्फी तकनीक - कदम
Step 1 - अनुमान टीम और एक मॉडरेटर चुनें।
Step 2- मॉडरेटर किकऑफ बैठक आयोजित करता है, जिसमें टीम को समस्या विनिर्देश और एक उच्च स्तरीय कार्य सूची, किसी भी मान्यताओं या परियोजना की बाधाओं के साथ प्रस्तुत किया जाता है। टीम समस्या और आकलन के मुद्दों पर चर्चा करती है, यदि कोई हो। वे अनुमान की इकाइयों पर भी निर्णय लेते हैं। मध्यस्थ संपूर्ण चर्चा का मार्गदर्शन करता है, और किकऑफ बैठक के बाद, समस्या विनिर्देश, उच्च स्तरीय कार्य सूची, मान्यताओं और अनुमान की इकाइयों से युक्त एक संरचित दस्तावेज तैयार करता है। फिर वह अगले चरण के लिए इस दस्तावेज़ की प्रतियां आगे बढ़ाता है।
Step 3 - प्रत्येक अनुमान टीम का सदस्य व्यक्तिगत रूप से एक विस्तृत WBS उत्पन्न करता है, WBS में प्रत्येक कार्य का अनुमान लगाता है, और बनाई गई मान्यताओं का दस्तावेजीकरण करता है।

Step 4- मॉडरेटर एस्टीमेशन मीटिंग के लिए एस्टिमेशन टीम को बुलाता है। यदि एस्टीमेशन टीम के सदस्यों में से कोई भी यह कहते हुए जवाब देता है कि अनुमान तैयार नहीं हैं, तो मध्यस्थ अधिक समय देता है और मीटिंग आमंत्रण को फिर से भेज देता है।
Step 5 - पूरी अनुमान टीम अनुमान बैठक के लिए इकट्ठा होती है।
Step 5.1 - अनुमान बैठक की शुरुआत में, मॉडरेटर टीम के प्रत्येक सदस्यों से प्रारंभिक अनुमान एकत्र करता है।
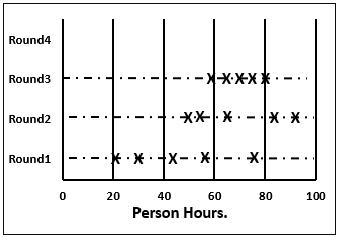
Step 5.2- वह फिर व्हाइटबोर्ड पर एक चार्ट लगाता है। वह संबंधित नामों का खुलासा किए बिना, प्रत्येक सदस्य के कुल प्रोजेक्ट अनुमान को राउंड 1 लाइन पर एक्स के रूप में प्लॉट करता है। अनुमान टीम को अनुमानों की सीमा का अंदाजा हो जाता है, जो शुरू में बड़ा हो सकता है।

Step 5.3- प्रत्येक टीम का सदस्य विस्तृत कार्य सूची को पढ़ता है जो उसने / उसने बनाई है, किसी भी तरह की मान्यताओं की पहचान करने और किसी भी प्रश्न या मुद्दों को उठाने के लिए। कार्य अनुमानों का खुलासा नहीं किया जाता है।
व्यक्तिगत विस्तृत कार्य सूचियाँ संयुक्त होने पर अधिक पूर्ण कार्य सूची में योगदान करती हैं।
Step 5.4 - टीम तब किसी भी संदेह / समस्या पर चर्चा करती है जो उनके पास आए कार्यों, मान्यताओं और अनुमान के मुद्दों के बारे में है।
Step 5.5- प्रत्येक टीम का सदस्य अपनी कार्य सूची और मान्यताओं का पुनरीक्षण करता है, और यदि आवश्यक हो तो परिवर्तन करता है। कार्य के अनुमानों को चर्चा के आधार पर समायोजन की आवश्यकता हो सकती है, जिन्हें + N Hrs के रूप में जाना जाता है। अधिक प्रयास और –N बजे के लिए। कम प्रयास के लिए।
टीम के सदस्य तब कुल परियोजना अनुमान पर पहुंचने के लिए कार्य अनुमानों में परिवर्तन को जोड़ते हैं।

Step 5.6 - मॉडरेटर टीम के सभी सदस्यों से बदले हुए अनुमानों को इकट्ठा करता है और उन्हें राउंड 2 लाइन पर प्लॉट करता है।
इस दौर में, रेंज पहले की तुलना में संकरी होगी, क्योंकि यह अधिक आम सहमति पर आधारित है।

Step 5.7 - टीम तब किए गए कार्य संशोधनों और मान्यताओं पर चर्चा करती है।
Step 5.8- प्रत्येक टीम का सदस्य अपनी कार्य सूची और मान्यताओं का पुनरीक्षण करता है, और यदि आवश्यक हो तो परिवर्तन करता है। कार्य अनुमानों को चर्चा के आधार पर समायोजन की आवश्यकता हो सकती है।
टीम के सदस्य एक बार फिर कुल परियोजना अनुमान पर पहुंचने के लिए कार्य अनुमान में बदलाव को जोड़ते हैं।
Step 5.9 - मॉडरेटर फिर से सभी सदस्यों से बदले हुए अनुमानों को इकट्ठा करता है और उन्हें राउंड 3 लाइन पर प्लॉट करता है।
फिर से, इस दौर में, रेंज पहले की तुलना में संकीर्ण होगी।
Step 5.10 - चरण 5.7, 5.8, 5.9 निम्नलिखित मानदंडों में से एक के पूरा होने तक दोहराया जाता है -
- परिणाम एक स्वीकार्य संकीर्ण सीमा में परिवर्तित हो जाते हैं।
- टीम के सभी सदस्य अपने नवीनतम अनुमानों को बदलने के लिए तैयार नहीं हैं।
- आवंटित अनुमान बैठक का समय समाप्त हो गया है।
Step 6 - परियोजना प्रबंधक तब अनुमान बैठक से परिणामों को इकट्ठा करता है।
Step 6.1 - वह व्यक्तिगत कार्य सूचियों और संबंधित अनुमानों को एक ही मास्टर कार्य सूची में संकलित करता है।
Step 6.2 - वह मान्यताओं की व्यक्तिगत सूचियों को भी जोड़ती है।
Step 6.3 - फिर वह अनुमान टीम के साथ अंतिम कार्य सूची की समीक्षा करता है।
वाइडबैंड डेल्फी तकनीक के फायदे और नुकसान
लाभ
- वाइडबैंड डेल्फी तकनीक प्रयास का आकलन करने के लिए एक आम सहमति आधारित आकलन तकनीक है।
- किसी कार्य को करने के लिए समय का आकलन करते समय उपयोगी।
- अनुभवी लोगों की भागीदारी और वे व्यक्तिगत रूप से अनुमान लगाते हुए विश्वसनीय परिणाम प्राप्त करेंगे।
- जो लोग काम करते हैं वे अनुमान लगा रहे हैं और इस प्रकार वैध अनुमान लगा रहे हैं।
- गुमनामी बनाए रखने के लिए हर किसी के लिए अपने परिणामों को आत्मविश्वास से व्यक्त करना संभव बनाता है।
- एक बहुत ही सरल तकनीक।
- मान्यताओं का दस्तावेजीकरण, चर्चा और सहमति होती है।
नुकसान
- प्रबंधन का समर्थन आवश्यक है।
- अनुमान परिणाम वह नहीं हो सकता है जो प्रबंधन सुनना चाहता है।
तीन-बिंदु अनुमान तीन मूल्यों को देखता है -
- सबसे आशावादी अनुमान (O),
- सबसे अधिक संभावना अनुमान (एम), और
- एक निराशावादी अनुमान (कम से कम अनुमान (एल))।
इंडस्ट्री में थ्री-पॉइंट एस्टीमेशन और PERT को लेकर कुछ कन्फ्यूजन रहा है। हालांकि, तकनीक अलग हैं। जैसे ही आप दो तकनीकों को सीखेंगे आपको अंतर दिखाई देगा। इसके अलावा, PERT तकनीक के अंत में, मतभेदों को समेटा और प्रस्तुत किया जाता है। यदि आप उन्हें पहले देखना चाहते हैं, तो आप कर सकते हैं।
तीन-बिंदु अनुमान (ई) सरल औसत पर आधारित है और त्रिकोणीय वितरण निम्नानुसार है।
E = (O + M + L) / 3

मानक विचलन
त्रिकोणीय वितरण में,
मीन = (ओ + एम + एल) / 3
मानक विचलन = √ [(((ओ - ई) 2 + (एम - ई) 2 + (एल - ई) 2 / / 2]
तीन-बिंदु अनुमान चरण
Step 1 - WBS पर पहुंचें।
Step 2 - प्रत्येक कार्य के लिए, तीन मान प्राप्त करें - सबसे आशावादी अनुमान (O), एक सबसे अधिक संभावना अनुमान (M), और एक निराशावादी अनुमान (L)।
Step 3 - तीन मूल्यों के माध्य की गणना करें।
Mean = (O + M + L) / 3
Step 4- कार्य के तीन-बिंदु अनुमान की गणना करें। थ्री-पॉइंट एस्टीमेट मीन है। इसलिये,
E = Mean = (O + M + L) / 3
Step 5 - कार्य के मानक विचलन की गणना करें।
Standard Deviation (SD) = √ [((O − E)2 + (M − E)2 + (L - E)2)/2]
Step 6 - WBS में सभी टास्क के लिए स्टेप 2, 3, 4 को दोहराएं।
Step 7 - परियोजना के तीन-बिंदु अनुमान की गणना करें।
E (Project) = ∑ E (Task)
Step 8 - परियोजना के मानक विचलन की गणना करें।
SD (Project) = √ (∑SD (Task)2)
प्रोजेक्ट का अनुमान कॉन्फिडेंस लेवल में बदलें
इस प्रकार गणना किए गए तीन-बिंदु अनुमान (ई) और मानक विचलन (एसडी) का उपयोग परियोजना के अनुमानों को "आत्मविश्वास स्तर" में बदलने के लिए किया जाता है।
रूपांतरण इस तरह आधारित है -
- E +/- एसडी में कॉन्फिडेंस लेवल लगभग 68% है।
- E मान +/- 1.645 × SD में कॉन्फिडेंस लेवल लगभग 90% है।
- ई मान +/- 2 × एसडी में कॉन्फिडेंस लेवल लगभग 95% है।
- ई मान +/- 3 × एसडी में कॉन्फिडेंस लेवल लगभग 99.7% है।
आमतौर पर, 95% कॉन्फिडेंस लेवल, यानी, ई वैल्यू + 2 × एसडी, सभी प्रोजेक्ट और टास्क अनुमानों के लिए उपयोग किया जाता है।
प्रोजेक्ट इवैल्यूएशन एंड रिव्यू टेक्नीक (PERT) आकलन तीन मूल्यों को मानता है: सबसे आशावादी अनुमान (O), एक सबसे अधिक संभावित अनुमान (M), और एक निराशावादी अनुमान (कम से कम संभावित अनुमान (L))। इंडस्ट्री में थ्री-पॉइंट एस्टीमेशन और PERT को लेकर कुछ कन्फ्यूजन रहा है। हालांकि, तकनीक अलग हैं। जैसे ही आप दो तकनीकों को सीखेंगे आपको अंतर दिखाई देगा। साथ ही, इस अध्याय के अंत में, मतभेदों को समेटा और प्रस्तुत किया गया है।
PERT तीन मूल्यों पर आधारित है - सबसे अधिक आशावादी अनुमान (O), एक सबसे अधिक संभावित अनुमान (M), और एक निराशावादी अनुमान (कम से कम संभावित अनुमान (L))। सबसे अधिक संभावना अनुमान अन्य दो अनुमानों (आशावादी और निराशावादी) की तुलना में 4 गुना अधिक है।
PERT अनुमान (E) भारित औसत पर आधारित है और बीटा वितरण का अनुसरण करता है।
E = (O + 4 × M + L)/6

PERT का उपयोग अक्सर क्रिटिकल पाथ मेथड (CPM) के साथ किया जाता है। सीपीएम उन कार्यों के बारे में बताता है जो परियोजना में महत्वपूर्ण हैं। यदि इन कार्यों में देरी होती है, तो परियोजना में देरी हो जाती है।
मानक विचलन
मानक विचलन (एसडी) अनुमान में परिवर्तनशीलता या अनिश्चितता को मापता है।
बीटा वितरण में,
मीन = (ओ + 4 × एम + एल) / 6
मानक विचलन (एसडी) = (एल - ओ) / 6
PERT अनुमान कदम
Step (1) - WBS पर पहुंचें।
Step (2) - प्रत्येक कार्य के लिए, तीन मान सबसे अधिक आशावादी अनुमान (O), एक सबसे अधिक संभावना अनुमान (M) और एक निराशावादी अनुमान (L) खोजें।
Step (3) - PERT माध्य = (O + 4 × M + L) / 6
पीईआरटी मीन = (ओ + 4 × एम + एल) / 3
Step (4) - कार्य के मानक विचलन की गणना करें।
मानक विचलन (एसडी) = (एल - ओ) / 6
Step (6) - WBS में सभी कार्यों के लिए चरण 2, 3, 4 को दोहराएं।
Step (7) - परियोजना के PERT अनुमान की गणना करें।
ई (परियोजना) = (ई (कार्य)
Step (8) - परियोजना के मानक विचलन की गणना करें।
एसडी (परियोजना) = √ (ΣSD (टास्क) 2 )
प्रोजेक्ट का अनुमान कॉन्फिडेंस लेवल में बदलें
PERT अनुमान (E) और मानक विचलन (SD) की गणना इस प्रकार की जाती है कि परियोजना के अनुमानों को आत्मविश्वास के स्तर में परिवर्तित किया जाए।
रूपांतरण इस तरह आधारित है
- ई +/- एसडी में आत्मविश्वास का स्तर लगभग 68% है।
- ई मान +/- 1.645 × एसडी में आत्मविश्वास का स्तर लगभग 90% है।
- ई मान +/- 2 × एसडी में आत्मविश्वास का स्तर लगभग 95% है।
- ई मान +/- 3 × एसडी में आत्मविश्वास का स्तर लगभग 99.7% है।
आमतौर पर, 95% आत्मविश्वास का स्तर, यानी, ई वैल्यू + 2 × एसडी, सभी प्रोजेक्ट और कार्य अनुमानों के लिए उपयोग किया जाता है।
तीन-बिंदु अनुमान और पीईआरटी के बीच अंतर
तीन-बिंदु अनुमान और पीईआरटी के बीच अंतर निम्नलिखित हैं -
| तीन-बिंदु का अनुमान | पीईआरटी |
|---|---|
| साधारण औसत | भारित औसत |
| त्रिकोणीय वितरण का अनुसरण करता है | बीटा वितरण का अनुसरण करता है |
| छोटे दोहराव वाली परियोजनाओं के लिए उपयोग किया जाता है | बड़े गैर-दोहरावदार परियोजनाओं के लिए उपयोग किया जाता है, आमतौर पर अनुसंधान और विकास परियोजनाएं। क्रिटिकल पाथ मेथड (CPM) के साथ प्रयोग किया जाता है |
ई = माध्य = (ओ + एम + एल) / 3 यह सरल औसत है |
ई = मीन = (ओ + 4 × एम + एल) / 6 यह भारित औसत है |
| एसडी = + [((ओ - ई) 2 + (एम - ई) 2 + (एल - ई) 2 ) / 2] | एसडी = (एल - ओ) / 6 |
Analogous Estimationअपनी वर्तमान परियोजना की अवधि या लागत का अनुमान लगाने के लिए एक समान पिछली परियोजना की जानकारी का उपयोग करता है, इसलिए शब्द, "सादृश्य"। जब आपके वर्तमान प्रोजेक्ट के बारे में सीमित जानकारी होती है, तो आप अनुरूप आकलन का उपयोग कर सकते हैं।
अक्सर, ऐसी परिस्थितियां होंगी जब परियोजना प्रबंधकों को एक नई परियोजना के लिए लागत और अवधि का अनुमान देने के लिए कहा जाएगा, क्योंकि अधिकारियों को निर्णय लेने के लिए डेटा की आवश्यकता है कि क्या परियोजना करने लायक है। आमतौर पर, न तो परियोजना प्रबंधक और न ही संगठन में किसी और ने कभी भी नए की तरह एक परियोजना की है, लेकिन अधिकारी अभी भी सटीक लागत और अवधि का अनुमान चाहते हैं।
ऐसे मामलों में, अनुरूप अनुमान सबसे अच्छा समाधान है। यह सही नहीं हो सकता है लेकिन सटीक है क्योंकि यह पिछले डेटा पर आधारित है। अनुरूप अनुमान एक आसानी से लागू होने वाली तकनीक है। प्रारंभिक अनुमानों की तुलना में परियोजना की सफलता दर 60% तक हो सकती है।
सादृश्य अनुमान - परिभाषा
अनुरूप आकलन एक ऐसी तकनीक है जो ऐतिहासिक डेटा से मापदंडों के मूल्यों का उपयोग भविष्य की गतिविधि के लिए समान पैरामीटर का अनुमान लगाने के आधार के रूप में करती है। पैरामीटर उदाहरण: स्कोप, लागत और अवधि। पैमाने के उदाहरण के उपाय - आकार, वजन और जटिलता।
क्योंकि प्रोजेक्ट मैनेजर और संभवतः टीम के अनुभव और निर्णय को आकलन प्रक्रिया पर लागू किया जाता है, इसलिए इसे ऐतिहासिक सूचना और विशेषज्ञ निर्णय का संयोजन माना जाता है।
अनुरूप अनुमान आवश्यकताएँ
अनुरूप अनुमान के लिए निम्नलिखित की आवश्यकता है -
- पिछले और चालू परियोजनाओं के डेटा
- टीम के प्रत्येक सदस्य के प्रति सप्ताह काम के घंटे
- परियोजना को पूरा करने के लिए लागत शामिल है
- वर्तमान परियोजना के करीब परियोजना
- यदि वर्तमान परियोजना नई है, और कोई भी पिछली परियोजना समान नहीं है
- पिछली परियोजनाओं के मॉड्यूल जो वर्तमान परियोजना में उन लोगों के समान हैं
- पिछली परियोजनाओं की गतिविधियाँ जो वर्तमान परियोजना के समान हैं
- इन चयनितों से डेटा
- अनुमानों पर अनुभवी निर्णय सुनिश्चित करने के लिए परियोजना प्रबंधक और आकलन टीम की भागीदारी।
अनुरूप अनुमान चरण
परियोजना प्रबंधक और टीम को सामूहिक रूप से अनुरूप आकलन करना होगा।
Step 1 - वर्तमान परियोजना के डोमेन को पहचानें।
Step 2 - वर्तमान परियोजना की तकनीक को पहचानें।
Step 3- यदि समान प्रोजेक्ट डेटा उपलब्ध है, तो संगठन डेटाबेस में देखें। यदि उपलब्ध हो, तो चरण (4) पर जाएं। अन्यथा चरण (6) पर जाएं।
Step 4 - पहचाने गए पिछले प्रोजेक्ट डेटा के साथ वर्तमान प्रोजेक्ट की तुलना करें।
Step 5- वर्तमान परियोजना की अवधि और लागत अनुमानों पर पहुंचें। यह परियोजना के अनुरूप आकलन को समाप्त करता है।
Step 6 - संगठन डेटाबेस में देखें यदि किसी पिछले प्रोजेक्ट में मौजूदा प्रोजेक्ट के समान मॉड्यूल हैं।
Step 7 - संगठन डेटाबेस में देखें कि क्या किसी पिछली परियोजनाओं में वर्तमान परियोजना के समान गतिविधियाँ हैं।
Step 8 - उन सभी को इकट्ठा करें और वर्तमान परियोजना की अवधि और लागत अनुमानों तक पहुंचने के लिए विशेषज्ञ निर्णय का उपयोग करें।
अनुरूप आकलन के लाभ
बहुत कम विवरण ज्ञात होने पर, परियोजना के प्रारंभिक चरणों में एनालॉग अनुमान अनुमान का एक बेहतर तरीका है।
तकनीक सरल है और अनुमान के लिए लिया गया समय बहुत कम है।
संगठन के पिछले प्रोजेक्ट डेटा पर आधारित तकनीक के बाद से संगठन की सफलता दर अधिक होने की उम्मीद की जा सकती है।
व्यक्तिगत कार्यों के प्रयास और अवधि का भी अनुमान लगाने के लिए अनुरूप अनुमान का उपयोग किया जा सकता है। इसलिए, डब्ल्यूबीएस में जब आप कार्यों का अनुमान लगाते हैं, तो आप सादृश्य का उपयोग कर सकते हैं।
प्रोजेक्ट मैनेजमेंट एंड सिस्टम्स इंजीनियरिंग में वर्क ब्रेकडाउन स्ट्रक्चर (WBS), एक प्रोजेक्ट के छोटे घटकों में एक वितरण योग्य उन्मुख अपघटन है। WBS एक महत्वपूर्ण परियोजना है जो टीम के काम को प्रबंधनीय वर्गों में व्यवस्थित करती है। प्रोजेक्ट मैनेजमेंट बॉडी ऑफ नॉलेज (PMBOK) WBS को "प्रोजेक्ट टीम द्वारा निष्पादित किए जाने वाले कार्य के वितरण योग्य उन्मुख पदानुक्रमित विघटन" के रूप में परिभाषित करता है।
WBS तत्व एक उत्पाद, डेटा, सेवा या इसके किसी भी संयोजन हो सकता है। डब्ल्यूबीएस अनुसूची विकास और नियंत्रण के लिए मार्गदर्शन प्रदान करने के साथ-साथ विस्तृत लागत आकलन और नियंत्रण के लिए आवश्यक ढांचा भी प्रदान करता है।
डब्ल्यूबीएस का प्रतिनिधित्व
WBS को परियोजना की कार्य गतिविधियों की एक श्रेणीबद्ध सूची के रूप में दर्शाया गया है। WBS के दो प्रारूप हैं -
- रूपरेखा देखें (प्रतिरूपित प्रारूप)
- ट्री स्ट्रक्चर व्यू (संगठनात्मक चार्ट)
आइए सबसे पहले चर्चा करते हैं कि डब्ल्यूबीएस की तैयारी के लिए आउटलाइन दृश्य का उपयोग कैसे करें।
आउटलाइन व्यू
रूपरेखा दृश्य एक बहुत उपयोगकर्ता के अनुकूल लेआउट है। यह पूरी परियोजना का एक अच्छा दृश्य प्रस्तुत करता है और साथ ही आसान संशोधनों की अनुमति देता है। यह एक परियोजना के विभिन्न चरणों को रिकॉर्ड करने के लिए संख्याओं का उपयोग करता है। यह कुछ हद तक समान दिखता है -
Software Development
Scope
- प्रोजेक्ट स्कोप निर्धारित करें
- सुरक्षित प्रोजेक्ट प्रायोजन
- प्रारंभिक संसाधनों को परिभाषित करें
- सुरक्षित कोर संसाधन
- स्कोप पूरा
Analysis/Software Requirements
- आचरण को विश्लेषण की आवश्यकता है
- प्रारंभिक सॉफ्टवेयर विनिर्देशों को ड्राफ़्ट करें
- प्रारंभिक बजट का विकास करना
- टीम के साथ सॉफ्टवेयर विनिर्देशों / बजट की समीक्षा करें
- सॉफ्टवेयर विनिर्देशों पर प्रतिक्रिया शामिल करें
- वितरण समयरेखा विकसित करें
- आगे बढ़ने के लिए स्वीकृति प्राप्त करें (अवधारणा, समय और बजट)
- आवश्यक संसाधन सुरक्षित करें
- विश्लेषण पूर्ण
Design
- प्रारंभिक सॉफ्टवेयर विनिर्देशों की समीक्षा करें
- कार्यात्मक विनिर्देश विकसित करें
- आगे बढ़ने के लिए स्वीकृति प्राप्त करें
- डिजाइन पूरा करें
Development
- कार्यात्मक विनिर्देशों की समीक्षा करें
- मॉड्यूलर / tiered डिजाइन मापदंडों को पहचानें
- कोड विकसित करें
- डेवलपर परीक्षण (प्राथमिक डिबगिंग)
- विकास पूर्ण
Testing
- उत्पाद विनिर्देशों का उपयोग करके यूनिट टेस्ट प्लान विकसित करें
- उत्पाद विनिर्देशों का उपयोग करके एकीकरण परीक्षण योजनाओं का विकास करना
Training
- अंत उपयोगकर्ताओं के लिए प्रशिक्षण विनिर्देशों का विकास करना
- प्रशिक्षण वितरण पद्धति (ऑनलाइन, कक्षा, आदि) की पहचान करें
- प्रशिक्षण सामग्री का विकास करना
- प्रशिक्षण सामग्री को अंतिम रूप दें
- प्रशिक्षण वितरण तंत्र विकसित करना
- प्रशिक्षण सामग्री पूर्ण
Deployment
- अंतिम तैनाती की रणनीति निर्धारित करें
- परिनियोजन पद्धति विकसित करें
- सुरक्षित तैनाती के संसाधन
- ट्रेन का सपोर्ट स्टाफ
- सॉफ्टवेयर तैनात करें
- परिनियोजन पूर्ण
आइए अब हम पेड़ की संरचना के दृश्य पर एक नज़र डालें।
ट्री स्ट्रक्चर व्यू
ट्री स्ट्रक्चर व्यू पूरे प्रोजेक्ट का बहुत आसान समझने वाला दृश्य प्रस्तुत करता है। निम्नलिखित दृष्टांत से पता चलता है कि पेड़ की संरचना कैसी दिखती है। इस प्रकार के संगठनात्मक चार्ट संरचना को MS-Word में उपलब्ध सुविधाओं के साथ आसानी से तैयार किया जा सकता है।

WBS के प्रकार
WBS के दो प्रकार हैं -
Functional WBS- कार्यात्मक डब्ल्यूबीएस में, सिस्टम को विकसित किए जाने वाले एप्लिकेशन में कार्यों के आधार पर तोड़ा जाता है। यह सिस्टम के आकार का अनुमान लगाने में उपयोगी है।
Activity WBS- गतिविधि WBS में, सिस्टम सिस्टम में गतिविधियों के आधार पर टूट जाता है। गतिविधियाँ आगे चलकर कार्यों में टूट जाती हैं। यह प्रणाली में प्रयास और अनुसूची का आकलन करने में उपयोगी है।
अनुमानित आकार
Step 1 - कार्यात्मक डब्ल्यूबीएस के साथ शुरू करें।
Step 2 - पत्ती नोड्स पर विचार करें।
Step 3 - आकार के अनुमानों तक पहुंचने के लिए या तो सादृश्य या वाइडबैंड डेल्फी का उपयोग करें।
अनुमानित प्रयास
Step 1- WBS के निर्माण के लिए वाइडबैंड डेल्फी तकनीक का उपयोग करें। हम सुझाव देते हैं कि कार्य 8 घंटे से अधिक नहीं होने चाहिए। यदि कोई कार्य बड़ी अवधि का है, तो उसे विभाजित करें।
Step 2 - टास्क के लिए एफर्ट के अनुमानों पर पहुंचने के लिए वाइडबैंड डेल्फी तकनीक या थ्री-पॉइंट एस्टिमेशन का उपयोग करें।
निर्धारण
WBS तैयार होने के बाद और आकार और प्रयास के अनुमान ज्ञात हो जाते हैं, आप कार्यों को निर्धारित करने के लिए तैयार हैं।
कार्यों का निर्धारण करते समय, कुछ बातों को ध्यान में रखा जाना चाहिए -
Precedence - एक कार्य जो दूसरे से पहले होना चाहिए, उसे दूसरे की पूर्वता कहा जाता है।
Concurrence - समवर्ती कार्य वे हैं जो एक ही समय में (समानांतर में) हो सकते हैं।
Critical Path - अनुक्रमिक कार्यों का विशिष्ट सेट, जिस पर परियोजना की पूर्णता तिथि निर्भर करती है।
- सभी परियोजनाओं का एक महत्वपूर्ण मार्ग है।
- गैर-महत्वपूर्ण कार्यों में तेजी लाने से अनुसूची को छोटा नहीं किया जा सकता है।
गंभीर पथ विधि
क्रिटिकल पाथ मेथड (CPM) महत्वपूर्ण पथ के निर्धारण और अनुकूलन की प्रक्रिया है। गैर-महत्वपूर्ण पथ कार्य पूर्ण होने की तारीख को प्रभावित किए बिना पहले या बाद में शुरू कर सकते हैं।
कृपया ध्यान दें कि जब आप वर्तमान को छोटा करते हैं तो महत्वपूर्ण पथ दूसरे में बदल सकता है। उदाहरण के लिए, पिछले आंकड़े में WBS के लिए, महत्वपूर्ण पथ निम्नानुसार होगा -

चूंकि परियोजना की पूर्णता तिथि अनुक्रमिक कार्यों के एक सेट पर आधारित होती है, इसलिए इन कार्यों को महत्वपूर्ण कार्य कहा जाता है।
प्रोजेक्ट पूरा होने की तारीख प्रशिक्षण, प्रलेखन और तैनाती पर आधारित नहीं है। ऐसे कार्यों को गैर-महत्वपूर्ण कार्य कहा जाता है।
कार्य निर्भरता संबंध
निश्चित समय, शेड्यूल करते समय, आपको कार्य निर्भरता संबंधों पर विचार करना पड़ सकता है। महत्वपूर्ण कार्य निर्भरता संबंध हैं -
- फिनिश-टू-स्टार्ट (FS)
- खत्म करने के लिए खत्म (एफएफ)
फिनिश-टू-स्टार्ट (FS)
टास्क-ए-स्टार्ट (एफएस) कार्य निर्भरता संबंध में, टास्क बी टास्क ए पूरा होने तक शुरू नहीं हो सकता है।

खत्म करने के लिए खत्म (एफएफ)
टास्क-ए-फिनिश (एफएफ) कार्य निर्भरता संबंध में, टास्क बी टास्क ए पूरा होने तक खत्म नहीं कर सकता है।

गैंट चार्ट
गैंट चार्ट एक प्रकार का बार चार्ट है, जिसे 1896 में करोल एडमिएकी द्वारा और 1910 के दशक में हेनरी गैंट द्वारा स्वतंत्र रूप से अनुकूलित किया गया था, जो एक प्रोजेक्ट शेड्यूल दिखाता है। गैंट चार्ट एक परियोजना के टर्मिनल तत्वों और सारांश तत्वों की शुरुआत और समाप्ति तिथियों का वर्णन करता है।
आप एक गैंट चार्ट दृश्य प्राप्त करने के लिए Microsoft प्रोजेक्ट में चित्र 2 में रूपरेखा प्रारूप ले सकते हैं।

मील के पत्थर
मील के पत्थर अपने कार्यक्रम में महत्वपूर्ण चरण हैं। उनके पास शून्य की अवधि होगी और यह फ़्लैग करने के लिए उपयोग किया जाता है कि आपने कुछ कार्यों को पूरा कर लिया है। आमतौर पर मील के पत्थर को हीरे के रूप में दिखाया जाता है।
उदाहरण के लिए, उपरोक्त गैंट चार्ट में, डिज़ाइन कम्प्लीट एंड डेवलपमेंट कम्प्लीट को मील के पत्थर के रूप में दिखाया गया है, जिसे हीरे के आकार के साथ दर्शाया गया है।
मील के पत्थर को अनुबंध की शर्तों से जोड़ा जा सकता है।
WBS के उपयोग के अनुमान का लाभ
WBS परियोजना के आकलन की प्रक्रिया को काफी हद तक सरल करता है। यह अन्य अनुमान तकनीकों पर निम्नलिखित लाभ प्रदान करता है -
WBS में, परियोजना द्वारा किए जाने वाले संपूर्ण कार्य की पहचान की जाती है। इसलिए, परियोजना हितधारकों के साथ WBS की समीक्षा करने से, आपको वांछित परियोजना डिलिवरेबल्स देने के लिए आवश्यक किसी भी कार्य को छोड़ देने की संभावना कम होगी।
WBS अधिक सटीक लागत और शेड्यूल अनुमान में परिणाम करता है।
परियोजना प्रबंधक WBS को अंतिम रूप देने के लिए टीम की भागीदारी प्राप्त करता है। टीम की यह भागीदारी परियोजना में उत्साह और जिम्मेदारी पैदा करती है।
WBS कार्य असाइनमेंट के लिए एक आधार प्रदान करता है। एक सटीक कार्य के रूप में एक विशेष टीम के सदस्य को आवंटित किया जाता है जो इसकी उपलब्धि के लिए जवाबदेह होगा।
WBS कार्य स्तर पर निगरानी और नियंत्रण करने में सक्षम बनाता है। यह आपको प्रगति को मापने और यह सुनिश्चित करने की अनुमति देता है कि आपकी परियोजना समय पर वितरित की जाएगी।
योजना पोकर अनुमान
प्लानिंग पोकर अनुमान लगाने के लिए एक आम सहमति पर आधारित तकनीक है, जिसका उपयोग ज्यादातर स्क्रेम में उपयोगकर्ता की कहानियों के प्रयास या सापेक्ष आकार का अनुमान लगाने के लिए किया जाता है।
प्लानिंग पोकर तीन अनुमान तकनीकों को जोड़ता है - वाइडबैंड डेल्फी तकनीक, एनालॉग अनुमान, और डब्ल्यूबीएस का उपयोग करके अनुमान।
नियोजन पोकर को पहली बार 2002 में जेम्स ग्रेनिंग द्वारा परिभाषित किया गया था और बाद में माइक कोहन ने अपनी पुस्तक "एजाइल एस्टिमेटिंग एंड प्लानिंग" में लोकप्रिय किया, जिसकी कंपनी के व्यापार ने इस शब्द को चिह्नित किया।
योजना पोकर अनुमान तकनीक
नियोजन पोकर अनुमान तकनीक में, उपयोगकर्ता कहानियों के लिए अनुमान नियोजन पोकर खेलकर निकाले जाते हैं। पूरी स्क्रैम टीम शामिल है और यह त्वरित लेकिन विश्वसनीय अनुमानों में परिणत होती है।
प्लानिंग पोकर ताश के पत्तों के साथ खेला जाता है। जैसा कि फाइबोनैचि अनुक्रम का उपयोग किया जाता है, कार्ड में नंबर होते हैं - 1, 2, 3, 5, 8, 13, 21, 34, आदि। ये संख्या "स्टोरी पॉइंट्स" का प्रतिनिधित्व करती है। प्रत्येक अनुमानक के पास कार्ड का एक डेक होता है। कार्ड पर संख्या सभी टीम के सदस्यों को दिखाई देने के लिए पर्याप्त बड़ी होनी चाहिए, जब टीम के सदस्यों में से कोई एक कार्ड रखता है।
टीम के सदस्यों में से एक को मॉडरेटर के रूप में चुना जाता है। मध्यस्थ उपयोगकर्ता की कहानी का विवरण पढ़ता है जिसके लिए अनुमान लगाया जा रहा है। यदि अनुमानकर्ताओं के पास कोई प्रश्न हैं, तो उत्पाद स्वामी उन्हें जवाब देता है।
प्रत्येक अनुमानक निजी तौर पर अपने अनुमान का प्रतिनिधित्व करने वाले कार्ड का चयन करता है। कार्ड तब तक नहीं दिखाए जाते जब तक सभी अनुमानकर्ताओं ने चयन नहीं किया। उस समय, सभी कार्डों को एक साथ बदल दिया जाता है और ऊपर रखा जाता है ताकि टीम के सभी सदस्य प्रत्येक अनुमान देख सकें।
पहले दौर में, यह बहुत संभावना है कि अनुमान अलग-अलग हैं। उच्च और निम्न अनुमानक अपने अनुमानों का कारण बताते हैं। ध्यान रखा जाना चाहिए कि सभी चर्चाएं केवल समझने के लिए हैं और कुछ भी व्यक्तिगत रूप से नहीं लिया जाना है। मॉडरेटर को यह सुनिश्चित करना होगा।
टीम कुछ और मिनटों के लिए कहानी और उनके अनुमानों पर चर्चा कर सकती है।
मध्यस्थ उस चर्चा पर नोट्स ले सकता है जो विशिष्ट कहानी विकसित होने पर सहायक होगी। चर्चा के बाद, प्रत्येक अनुमानक फिर से एक कार्ड का चयन करके फिर से अनुमान लगाता है। कार्ड्स को एक बार फिर से निजी रखा जाता है जब तक कि सभी ने अनुमान नहीं लगाया हो, उसी समय उन्हें किस बिंदु पर बदल दिया जाता है।
प्रक्रिया को तब तक दोहराएं जब तक कि अनुमान एक एकल अनुमान में परिवर्तित न हो जाए जो कहानी के लिए उपयोग किया जा सकता है। आकलन के दौर की संख्या एक उपयोगकर्ता कहानी से दूसरे में भिन्न हो सकती है।
योजना पोकर अनुमान के लाभ
नियोजन पोकर आकलन के तीन तरीकों को जोड़ता है -
Expert Opinion- विशेषज्ञ की राय-आधारित अनुमान दृष्टिकोण में, एक विशेषज्ञ से पूछा जाता है कि कुछ कितना समय लगेगा या कितना बड़ा होगा। विशेषज्ञ अपने अनुभव या अंतर्ज्ञान या आंत महसूस पर भरोसा करते हुए एक अनुमान प्रदान करता है। विशेषज्ञ राय अनुमान आमतौर पर ज्यादा समय नहीं लेता है और कुछ विश्लेषणात्मक तरीकों की तुलना में अधिक सटीक है।
Analogy- सादृश्य अनुमान उपयोगकर्ता कहानियों की तुलना का उपयोग करता है। अनुमान के तहत उपयोगकर्ता कहानी की तुलना पहले लागू की गई समान उपयोगकर्ता कहानियों के साथ की जाती है, सटीक परिणाम दे रही है क्योंकि अनुमान सिद्ध डेटा पर आधारित है।
Disaggregation- उपयोगकर्ता की कहानी को छोटे, आसान-से-अनुमानित उपयोगकर्ता कहानियों में विभाजित करके असहमति का अनुमान लगाया जाता है। स्प्रिंट में शामिल की जाने वाली उपयोगकर्ता कहानियां सामान्य रूप से विकसित होने के लिए दो से पांच दिनों की सीमा में होती हैं। इसलिए, उपयोगकर्ता की कहानियां जो संभवतः लंबी अवधि लेती हैं उन्हें छोटे उपयोग-मामलों में विभाजित करने की आवश्यकता होती है। यह दृष्टिकोण यह भी सुनिश्चित करता है कि कई कहानियां होंगी जो तुलनीय हैं।
परीक्षण के प्रयास किसी निश्चित समय-सीमा पर आधारित नहीं हैं। परीक्षण के पूरा होने के बावजूद कुछ पूर्व-निर्धारित समय-सीमा निर्धारित होने तक प्रयास जारी रहते हैं।
यह ज्यादातर इस तथ्य के कारण है कि परंपरागत रूप से, test effort estimation का एक हिस्सा है development estimation। केवल डब्ल्यूबीएस, जैसे वाइडबैंड डेल्फी, थ्री-पॉइंट एस्टीमेशन, पीईआरटी और डब्ल्यूबीएस का उपयोग करने वाली आकलन तकनीकों के मामले में, आप परीक्षण गतिविधियों के अनुमानों के लिए मान प्राप्त कर सकते हैं।
यदि आपने फ़ंक्शन अंक (एफपी) के रूप में अनुमान प्राप्त किया है, तो कापर जोन्स के अनुसार,
Number of Test Cases = (Number of Function Points) × 1.2
एक बार जब आपके पास परीक्षण मामलों की संख्या हो जाती है, तो आप संगठनात्मक डेटाबेस से उत्पादकता डेटा ले सकते हैं और परीक्षण के लिए आवश्यक प्रयास पर पहुंच सकते हैं।
विकास प्रयास विधि का प्रतिशत
परीक्षण प्रयास की आवश्यकता विकास के प्रत्यक्ष अनुपात या प्रतिशत का है। कोड (LOC) या फ़ंक्शन पॉइंट (FP) की पंक्तियों का उपयोग करके विकास के प्रयास का अनुमान लगाया जा सकता है। फिर, परीक्षण के लिए प्रयास का प्रतिशत संगठन डेटाबेस से प्राप्त किया जाता है। प्राप्त प्रतिशत का उपयोग परीक्षण के लिए प्रयास के अनुमान पर पहुंचने के लिए किया जाता है।
परीक्षण परियोजनाओं का अनुमान लगाना
कई संगठन अब अपने ग्राहकों को स्वतंत्र सत्यापन और सत्यापन सेवाएं प्रदान कर रहे हैं और इसका मतलब है कि परियोजना की गतिविधियाँ पूरी तरह से गतिविधियों का परीक्षण कर रही होंगी।
परीक्षण परियोजनाओं का अनुमान लगाना सॉफ्टवेयर परीक्षण जीवन चक्र के लिए विभिन्न परियोजनाओं पर अनुभव की आवश्यकता है। जब आप एक परीक्षण परियोजना का अनुमान लगा रहे हैं, तो विचार करें -
- टीम कौशल
- डोमेन की जानकारी
- आवेदन की जटिलता
- ऐतिहासिक आंकड़ा
- परियोजना के लिए बग चक्र
- संसाधनों की उपलब्धता
- उत्पादकता विविधताएं
- सिस्टम का माहौल और डाउनटाइम
परीक्षण अनुमान तकनीक
निम्नलिखित परीक्षण आकलन तकनीक सटीक साबित होती हैं और व्यापक रूप से उपयोग की जाती हैं -
- PERT सॉफ्टवेयर परीक्षण आकलन तकनीक
- UCP विधि
- WBS
- वाइडबैंड डेल्फी तकनीक
- फ़ंक्शन बिंदु / परीक्षण बिंदु विश्लेषण
- प्रतिशत वितरण
- अनुभव-आधारित परीक्षण आकलन तकनीक
PERT सॉफ्टवेयर टेस्टिंग अनुमान तकनीक
PERT सॉफ्टवेयर परीक्षण आकलन तकनीक सांख्यिकीय विधियों पर आधारित है जिसमें प्रत्येक परीक्षण कार्य को उप-कार्यों में तोड़ा जाता है और फिर प्रत्येक उप-कार्यों पर तीन प्रकार के आकलन किए जाते हैं।
इस तकनीक द्वारा उपयोग किया जाने वाला सूत्र है -
Test Estimate = (O + (4 × M) + E)/6
कहाँ पे,
O = आशावादी अनुमान (सबसे अच्छा मामला जिसमें कुछ भी गलत नहीं होता है और सभी स्थितियाँ इष्टतम हैं)।
M = सबसे अधिक संभावना अनुमान (सबसे अधिक संभावना अवधि और कुछ समस्या हो सकती है लेकिन ज्यादातर चीजें सही हो जाएंगी)।
L = निराशावादी अनुमान (सबसे खराब स्थिति जहां सब कुछ गलत हो जाता है)।
तकनीक के लिए मानक विचलन की गणना निम्नानुसार की जाती है -
Standard Deviation (SD) = (E − O)/6
उपयोग-केस प्वाइंट विधि
यूसीपी विधि उन उपयोग मामलों पर आधारित है, जहां हम अनपेक्षित अभिनेता भार की गणना करते हैं और सॉफ़्टवेयर परीक्षण आकलन का निर्धारण करने के लिए अनधिकृत उपयोग केस वेट करते हैं।
उपयोग-मामला एक दस्तावेज है जो संबंधित एप्लिकेशन के साथ बातचीत करने वाले विभिन्न उपयोगकर्ताओं, प्रणालियों या अन्य हितधारकों को निर्दिष्ट करता है। उन्हें "अभिनेता" के रूप में नामित किया गया है। बातचीत कुछ परिभाषित लक्ष्यों को पूरा करती है जो सभी हितधारकों के हित को अलग-अलग व्यवहार या परिदृश्य के रूप में कहा जाता है।
Step 1- गिनती नं। अभिनेताओं की। अभिनेताओं में सकारात्मक, नकारात्मक और असाधारण शामिल हैं।
Step 2 - के रूप में अनुचित अभिनेता वजन की गणना
Unadjusted Actor Weights = Total no. of Actors
Step 3 - उपयोग-मामलों की संख्या की गणना करें।
Step 4 - के रूप में अनपेक्षित उपयोग के मामले वजन की गणना
Unadjusted Use-Case Weights = Total no. of Use-Cases
Step 5 - अनियोजित उपयोग के मामले बिंदुओं की गणना करें
Unadjusted Use-Case Points = (Unadjusted Actor Weights + Unadjusted Use-Case Weights)
Step 6- तकनीकी / पर्यावरणीय कारक (टीईएफ) का निर्धारण करें। यदि अनुपलब्ध है, तो इसे 0.50 के रूप में लें।
Step 7 - समायोजित उपयोग-केस बिंदु की गणना करें
Adjusted Use-Case Point = Unadjusted Use-Case Points × [0.65 + (0.01 × TEF]
Step 8 - के रूप में कुल प्रयास की गणना
Total Effort = Adjusted Use-Case Point × 2
कार्य विश्लेषण संरचना
Step 1 - टेस्ट प्रोजेक्ट को छोटे टुकड़ों में तोड़कर WBS बनाएं।
Step 2 - मॉड्यूल को उप-मॉड्यूल में विभाजित करें।
Step 3 उप-मॉड्यूल को कार्यात्मकताओं में विभाजित करें।
Step 4 - कार्यात्मकताओं को उप-कार्यात्मकताओं में विभाजित करें।
Step 5 - यह सुनिश्चित करने के लिए सभी परीक्षण आवश्यकताओं की समीक्षा करें कि उन्हें WBS में जोड़ा गया है।
Step 6 - आपकी टीम को जितने कार्यों को पूरा करने की आवश्यकता है, उसका चित्र तैयार करें।
Step 7 - प्रत्येक कार्य के लिए प्रयास का अनुमान लगाएं।
Step 8 - प्रत्येक कार्य की अवधि का अनुमान लगाएं।
वाइडबैंड डेल्फी तकनीक
वाइडबैंड डेल्फी मेथड में, WBS को एक टीम में बांटा गया है, जिसमें 3-7 सदस्यों के कार्यों का पुनर्मूल्यांकन किया गया है। अंतिम अनुमान टीम की सहमति के आधार पर संक्षेपित अनुमानों का परिणाम है।
यह विधि किसी भी सांख्यिकीय सूत्र के बजाय अनुभव पर अधिक बोलती है। बैरी बोहम द्वारा इस पद्धति को लोकप्रिय बनाया गया था ताकि समूह की पुनरावृत्ति पर जोर दिया जा सके ताकि आम सहमति तक पहुंच सके जहां टीम ने परीक्षण के प्रयास का आकलन करते समय समस्याओं के विभिन्न पहलुओं की कल्पना की।
समारोह बिंदु / परीक्षण बिंदु विश्लेषण
FPs उपयोगकर्ता के दृष्टिकोण से सॉफ़्टवेयर एप्लिकेशन की कार्यक्षमता का संकेत देते हैं और इसका उपयोग सॉफ़्टवेयर प्रोजेक्ट के आकार का अनुमान लगाने के लिए एक तकनीक के रूप में किया जाता है।
परीक्षण में, अनुमान आवश्यकता विनिर्देश दस्तावेज या आवेदन के पहले बनाए गए प्रोटोटाइप पर आधारित है। किसी परियोजना के लिए एफपी की गणना करने के लिए, कुछ प्रमुख घटकों की आवश्यकता होती है। वे हैं -
Unadjusted Data Function Points (I) आंतरिक फ़ाइलें, ii) बाहरी इंटरफेस
Unadjusted Transaction Function Points (I) उपयोगकर्ता इनपुट, ii) उपयोगकर्ता आउटपुट और iii) उपयोगकर्ता पूछताछ
Capers Jones basic formula -
टेस्ट मामलों की संख्या = (फ़ंक्शन अंक की संख्या) × 1.2
Total Actual Effort (TAE) -
(टेस्ट मामलों की संख्या) × (विकास प्रयास का प्रतिशत / 100)
प्रतिशत वितरण
इस तकनीक में, सॉफ्टवेयर डेवलपमेंट लाइफ साइकिल (SDLC) के सभी चरणों को% में प्रयास सौंपा गया है। यह समान परियोजनाओं के पिछले आंकड़ों पर आधारित हो सकता है। उदाहरण के लिए -
| चरण | प्रयास का% |
|---|---|
| परियोजना प्रबंधन | 7% |
| आवश्यकताओं को | 9% |
| डिज़ाइन | 16% |
| कोडन | 26% |
| परीक्षण (सभी परीक्षण चरण) | 27% |
| प्रलेखन | 9% |
| स्थापना और प्रशिक्षण | 6% |
अगला, परीक्षण के लिए प्रयास का% (सभी परीक्षण चरण) आगे सभी परीक्षण चरणों के लिए वितरित किया जाता है -
| सभी परीक्षण चरण | प्रयास का% |
|---|---|
| घटक परीक्षण | 16 |
| स्वतंत्र परीक्षण | 84 |
| Total | 100 |
| स्वतंत्र परीक्षण | प्रयास का% |
|---|---|
| एकीकरण जांच | 24 |
| सिस्टम परीक्षण | 52 |
| स्वीकृति परीक्षण | 24 |
| Total | 100 |
| सिस्टम परीक्षण | प्रयास का% |
|---|---|
| कार्यात्मक प्रणाली परीक्षण | 65 |
| गैर-कार्यात्मक प्रणाली परीक्षण | 35 |
| Total | 100 |
| टेस्ट प्लानिंग एंड डिज़ाइन आर्किटेक्चर | 50% |
| समीक्षा चरण | 50% |
अनुभव-आधारित परीक्षण अनुमान तकनीक
यह तकनीक उपमा और विशेषज्ञों पर आधारित है। तकनीक मानती है कि आपने पहले ही पिछली परियोजनाओं में इसी तरह के अनुप्रयोगों का परीक्षण किया था और उन परियोजनाओं से मैट्रिक्स एकत्र किया था। आपने पिछले परीक्षणों के मैट्रिक्स भी एकत्र किए हैं। विषय वस्तु विशेषज्ञों से इनपुट लें, जो एप्लिकेशन (साथ ही परीक्षण) को अच्छी तरह से जानते हैं और आपके द्वारा एकत्र किए गए मीट्रिक का उपयोग करते हैं और परीक्षण के प्रयास में पहुंचते हैं।