HBase - अवलोकन
1970 के बाद से, आरडीबीएमएस डेटा भंडारण और रखरखाव से संबंधित समस्याओं का समाधान है। बड़े डेटा के आगमन के बाद, कंपनियों ने बड़े डेटा को संसाधित करने के लाभ का एहसास किया और Hadoop जैसे समाधान के लिए चयन करना शुरू कर दिया।
Hadoop बड़े डेटा को संग्रहीत करने के लिए वितरित फ़ाइल सिस्टम का उपयोग करता है, और इसे संसाधित करने के लिए MapReduce। Hadoop के विभिन्न स्वरूपों जैसे मनमाना, अर्ध- या यहां तक कि असंरचित के विशाल डेटा के भंडारण और प्रसंस्करण में उत्कृष्टता प्राप्त करता है।
Hadoop की सीमाएँ
Hadoop केवल बैच प्रोसेसिंग कर सकता है, और डेटा केवल क्रमिक तरीके से एक्सेस किया जाएगा। इसका मतलब है कि एक व्यक्ति को नौकरियों के सबसे सरल के लिए भी पूरे डेटासेट को खोजना होगा।
जब एक और विशाल डेटा सेट में एक बड़ा डेटासेट संसाधित होता है, जिसे क्रमिक रूप से भी संसाधित किया जाना चाहिए। इस बिंदु पर, समय की एकल इकाई (रैंडम एक्सेस) में डेटा के किसी भी बिंदु तक पहुंचने के लिए एक नए समाधान की आवश्यकता होती है।
Hadoop रैंडम एक्सेस डेटाबेस
HBase, Cassandra, couchDB, Dynamo, और MongoDB जैसे एप्लिकेशन कुछ ऐसे डेटाबेस हैं जो बड़ी मात्रा में डेटा संग्रहीत करते हैं और डेटा को यादृच्छिक तरीके से एक्सेस करते हैं।
HBase क्या है?
HBase एक वितरित स्तंभ-उन्मुख डेटाबेस है, जो Hadoop फ़ाइल सिस्टम के शीर्ष पर बनाया गया है। यह एक ओपन-सोर्स प्रोजेक्ट है और क्षैतिज रूप से स्केलेबल है।
HBase एक डेटा मॉडल है जो Google की बड़ी तालिका के समान है जिसे संरचित डेटा की भारी मात्रा में त्वरित यादृच्छिक पहुँच प्रदान करने के लिए डिज़ाइन किया गया है। यह Hadoop फाइल सिस्टम (HDFS) द्वारा प्रदान की गई गलती सहिष्णुता का लाभ उठाता है।
यह Hadoop पारिस्थितिकी तंत्र का एक हिस्सा है जो Hadoop फाइल सिस्टम में डेटा को यादृच्छिक रूप से पढ़ने / लिखने की सुविधा प्रदान करता है।
एचडीएसएफ में डेटा को सीधे या एचबीएएस के माध्यम से स्टोर किया जा सकता है। डेटा उपभोक्ता एचबीएफएस में डेटा को आसानी से पढ़ता / एक्सेस करता है, जो HBase का उपयोग करता है। HBase Hadoop फाइल सिस्टम के शीर्ष पर बैठता है और पढ़ने और लिखने की सुविधा प्रदान करता है।

HBase और HDFS
| HDFS | HBase |
|---|---|
| एचडीएफएस एक वितरित फ़ाइल प्रणाली है जो बड़ी फ़ाइलों को संग्रहीत करने के लिए उपयुक्त है। | HBase एक डेटाबेस है जो HDFS के ऊपर बनाया गया है। |
| HDFS तेज व्यक्तिगत रिकॉर्ड लुकअप का समर्थन नहीं करता है। | HBase बड़ी तालिकाओं के लिए तीव्र लुकअप प्रदान करता है। |
| यह उच्च विलंबता बैच प्रसंस्करण प्रदान करता है; बैच प्रसंस्करण की कोई अवधारणा नहीं। | यह अरबों रिकॉर्ड्स (रैंडम एक्सेस) से एकल पंक्तियों तक कम विलंबता पहुंच प्रदान करता है। |
| यह डेटा की केवल अनुक्रमिक पहुंच प्रदान करता है। | HBase आंतरिक रूप से Hash तालिकाओं का उपयोग करता है और यादृच्छिक पहुँच प्रदान करता है, और यह डेटा को तेज लुकअप के लिए अनुक्रमित HDFS फ़ाइलों में संग्रहीत करता है। |
HBase में भंडारण तंत्र
HBase एक है column-oriented databaseऔर इसमें तालिकाएँ पंक्ति द्वारा क्रमबद्ध हैं। टेबल स्कीमा केवल कॉलम परिवारों को परिभाषित करता है, जो प्रमुख मूल्य जोड़े हैं। एक तालिका में कई कॉलम परिवार होते हैं और प्रत्येक कॉलम परिवार में किसी भी संख्या में कॉलम हो सकते हैं। बाद के स्तंभ मान डिस्क पर सन्निहित रूप से संग्रहीत किए जाते हैं। तालिका के प्रत्येक सेल मान में टाइमस्टैम्प है। संक्षेप में, एक HBase में:
- तालिका पंक्तियों का एक संग्रह है।
- पंक्ति स्तंभ परिवारों का एक संग्रह है।
- कॉलम परिवार स्तंभों का एक संग्रह है।
- स्तंभ कुंजी मूल्य जोड़े का एक संग्रह है।
नीचे दिए गए HBase में तालिका का एक उदाहरण स्कीमा है।
| Rowid | कॉलम परिवार | कॉलम परिवार | कॉलम परिवार | कॉलम परिवार | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| col1 | col2 | col3 | col1 | col2 | col3 | col1 | col2 | col3 | col1 | col2 | col3 | |
| 1 | ||||||||||||
| 2 | ||||||||||||
| 3 | ||||||||||||
कॉलम ओरिएंटेड और रो ओरिएंटेड
स्तंभ-उन्मुख डेटाबेस वे हैं जो डेटा तालिकाओं के बजाय डेटा तालिकाओं को स्तंभों के वर्गों के रूप में संग्रहीत करते हैं। शीघ्र ही, उनके पास कॉलम परिवार होंगे।
| पंक्ति-उन्मुख डेटाबेस | कॉलम-ओरिएंटेड डेटाबेस |
|---|---|
| यह ऑनलाइन लेनदेन प्रक्रिया (ओएलटीपी) के लिए उपयुक्त है। | यह ऑनलाइन एनालिटिकल प्रोसेसिंग (OLAP) के लिए उपयुक्त है। |
| ऐसे डेटाबेस छोटी संख्या में पंक्तियों और स्तंभों के लिए डिज़ाइन किए गए हैं। | स्तंभ-उन्मुख डेटाबेस विशाल तालिकाओं के लिए डिज़ाइन किए गए हैं। |
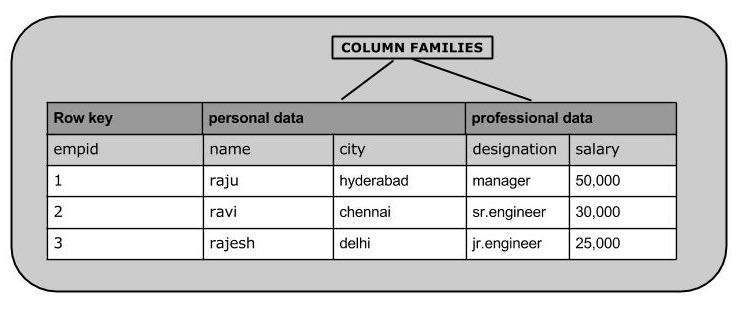
स्तंभ-उन्मुख डेटाबेस में निम्न छवि कॉलम परिवारों को दिखाती है:
HBase और RDBMS
| HBase | आरडीबीएमएस |
|---|---|
| HBase स्कीमा-कम है, इसमें निश्चित कॉलम स्कीमा की अवधारणा नहीं है; केवल स्तंभ परिवारों को परिभाषित करता है। | RDBMS अपने स्कीमा द्वारा शासित होता है, जो तालिकाओं की पूरी संरचना का वर्णन करता है। |
| यह चौड़ी टेबल के लिए बनाया गया है। HBase क्षैतिज रूप से स्केलेबल है। | यह पतली और छोटी तालिकाओं के लिए निर्मित है। मुश्किल से पैमाना। |
| HBase में कोई लेनदेन नहीं है। | RDBMS ट्रांजेक्शनल है। |
| इसमें डेटा को सामान्यीकृत किया गया है। | इसमें सामान्यीकृत डेटा होगा। |
| यह सेमी-स्ट्रक्चर्ड के साथ-साथ स्ट्रक्चर्ड डेटा के लिए अच्छा है। | यह संरचित डेटा के लिए अच्छा है। |
HBase की विशेषताएं
- HBase रैखिक रूप से स्केलेबल है।
- इसमें स्वचालित विफलता समर्थन है।
- यह लगातार पढ़ने और लिखने के लिए प्रदान करता है।
- यह एक स्रोत और एक गंतव्य के रूप में Hadoop के साथ एकीकृत होता है।
- यह ग्राहक के लिए आसान जावा एपीआई है।
- यह समूहों में डेटा प्रतिकृति प्रदान करता है।
HBase का उपयोग कहां करें
अपाचे HBase का उपयोग बिग डेटा के लिए यादृच्छिक, वास्तविक समय पढ़ने / लिखने के लिए किया जाता है।
यह कमोडिटी हार्डवेयर के समूहों के शीर्ष पर बहुत बड़ी तालिकाओं का आयोजन करता है।
Apache HBase Google के बिगटेबल के बाद बनाया गया एक गैर-संबंधपरक डेटाबेस है। Bigtable Google फ़ाइल सिस्टम पर कार्य करता है, इसी तरह Apache HBase, Hadoop और HDFS के शीर्ष पर काम करता है।
HBase के अनुप्रयोग
- जब भी भारी आवेदन लिखने की आवश्यकता होती है तो इसका उपयोग किया जाता है।
- HBase का उपयोग तब किया जाता है जब भी हमें उपलब्ध डेटा को तीव्र यादृच्छिक पहुँच प्रदान करने की आवश्यकता होती है।
- फेसबुक, ट्विटर, याहू और एडोब जैसी कंपनियां आंतरिक रूप से HBase का उपयोग करती हैं।
HBase इतिहास
| साल | प्रतिस्पर्धा |
|---|---|
| नवंबर 2006 | Google ने BigTable पर पेपर जारी किया। |
| फरवरी 2007 | प्रारंभिक HBase प्रोटोटाइप एक Hadoop योगदान के रूप में बनाया गया था। |
| अक्टूबर 2007 | Hadoop 0.15.0 के साथ पहला प्रयोग योग्य HBase जारी किया गया था। |
| जनवरी 2008 | HBase Hadoop का सब प्रोजेक्ट बन गया। |
| अक्टूबर 2008 | HBase 0.18.1 जारी किया गया था। |
| जनवरी 2009 | HBase 0.19.0 जारी किया गया था। |
| सितम्बर 2009 | HBase 0.20.0 जारी किया गया था। |
| मई 2010 | HBase अपाचे शीर्ष-स्तरीय परियोजना बन गई। |