HBase - त्वरित गाइड
1970 के बाद से, आरडीबीएमएस डेटा भंडारण और रखरखाव से संबंधित समस्याओं का समाधान है। बड़े डेटा के आगमन के बाद, कंपनियों ने बड़े डेटा को संसाधित करने के लाभ का एहसास किया और Hadoop जैसे समाधान के लिए चयन करना शुरू कर दिया।
Hadoop बड़े डेटा को संग्रहीत करने के लिए वितरित फ़ाइल सिस्टम का उपयोग करता है, और इसे संसाधित करने के लिए MapReduce। Hadoop के विभिन्न स्वरूपों जैसे मनमाना, अर्ध- या यहां तक कि असंरचित के विशाल डेटा के भंडारण और प्रसंस्करण में उत्कृष्टता।
Hadoop की सीमाएँ
Hadoop केवल बैच प्रोसेसिंग कर सकता है, और डेटा केवल क्रमबद्ध तरीके से एक्सेस किया जाएगा। इसका मतलब है कि एक व्यक्ति को नौकरियों के सबसे सरल के लिए भी पूरे डेटासेट को खोजना होगा।
जब एक और विशाल डेटा सेट में एक बड़ा डेटासेट संसाधित होता है, जिसे क्रमिक रूप से भी संसाधित किया जाना चाहिए। इस बिंदु पर, समय की एकल इकाई (रैंडम एक्सेस) में डेटा के किसी भी बिंदु तक पहुंचने के लिए एक नए समाधान की आवश्यकता होती है।
Hadoop रैंडम एक्सेस डेटाबेस
HBase, Cassandra, couchDB, Dynamo, और MongoDB जैसे एप्लिकेशन कुछ ऐसे डेटाबेस हैं जो बड़ी मात्रा में डेटा संग्रहीत करते हैं और डेटा को यादृच्छिक तरीके से एक्सेस करते हैं।
HBase क्या है?
HBase एक वितरित स्तंभ-उन्मुख डेटाबेस है, जो Hadoop फ़ाइल सिस्टम के शीर्ष पर बनाया गया है। यह एक ओपन-सोर्स प्रोजेक्ट है और क्षैतिज रूप से स्केलेबल है।
HBase एक डेटा मॉडल है जो Google की बड़ी तालिका के समान है जिसे संरचित डेटा की भारी मात्रा में त्वरित यादृच्छिक पहुँच प्रदान करने के लिए डिज़ाइन किया गया है। यह Hadoop फाइल सिस्टम (HDFS) द्वारा प्रदान की गई गलती सहिष्णुता का लाभ उठाता है।
यह Hadoop पारिस्थितिकी तंत्र का एक हिस्सा है जो Hadoop फ़ाइल सिस्टम में डेटा के लिए यादृच्छिक वास्तविक समय पढ़ने / लिखने की सुविधा प्रदान करता है।
एचडीएसएफ में डेटा को सीधे या HBase के माध्यम से स्टोर किया जा सकता है। एचबीएफएस में एचबीएफएस का उपयोग करते हुए डेटा उपभोक्ता बेतरतीब ढंग से डेटा पढ़ता / एक्सेस करता है। HBase, Hadoop फाइल सिस्टम के शीर्ष पर बैठता है और पढ़ने और लिखने की सुविधा प्रदान करता है।

HBase और HDFS
| HDFS | HBase |
|---|---|
| एचडीएफएस एक वितरित फ़ाइल प्रणाली है जो बड़ी फ़ाइलों को संग्रहीत करने के लिए उपयुक्त है। | HBase एक डेटाबेस है जो HDFS के ऊपर बनाया गया है। |
| HDFS तेज व्यक्तिगत रिकॉर्ड लुकअप का समर्थन नहीं करता है। | HBase बड़ी तालिकाओं के लिए तीव्र लुकअप प्रदान करता है। |
| यह उच्च विलंबता बैच प्रसंस्करण प्रदान करता है; बैच प्रसंस्करण की कोई अवधारणा नहीं। | यह अरबों रिकॉर्ड (रैंडम एक्सेस) से एकल पंक्तियों तक कम विलंबता पहुंच प्रदान करता है। |
| यह डेटा की केवल अनुक्रमिक पहुंच प्रदान करता है। | HBase आंतरिक रूप से Hash तालिकाओं का उपयोग करता है और यादृच्छिक पहुँच प्रदान करता है, और यह डेटा को तेज लुकअप के लिए अनुक्रमित HDFS फ़ाइलों में संग्रहीत करता है। |
HBase में भंडारण तंत्र
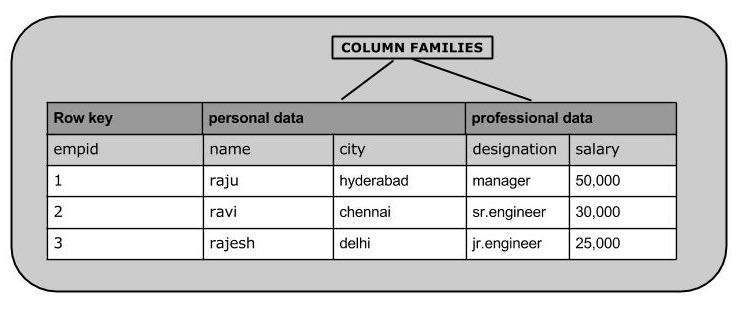
HBase एक है column-oriented databaseऔर इसमें तालिकाएँ पंक्ति द्वारा क्रमबद्ध हैं। टेबल स्कीमा केवल कॉलम परिवारों को परिभाषित करता है, जो कि प्रमुख मूल्य जोड़े हैं। एक तालिका में कई कॉलम परिवार होते हैं और प्रत्येक कॉलम परिवार में किसी भी संख्या में कॉलम हो सकते हैं। बाद के कॉलम मान डिस्क पर संचित रूप से संग्रहीत होते हैं। तालिका के प्रत्येक सेल मान में टाइमस्टैम्प है। संक्षेप में, एक HBase में:
- तालिका पंक्तियों का एक संग्रह है।
- रो कॉलम परिवारों का एक संग्रह है।
- कॉलम परिवार स्तंभों का एक संग्रह है।
- स्तंभ कुंजी मूल्य जोड़े का एक संग्रह है।
नीचे दिए गए HBase में तालिका का एक उदाहरण स्कीमा है।
| Rowid | कॉलम परिवार | कॉलम परिवार | कॉलम परिवार | कॉलम परिवार | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| col1 | col2 | col3 | col1 | col2 | col3 | col1 | col2 | col3 | col1 | col2 | col3 | |
| 1 | ||||||||||||
| 2 | ||||||||||||
| 3 | ||||||||||||
कॉलम ओरिएंटेड और रो ओरिएंटेड
स्तंभ-उन्मुख डेटाबेस वे हैं जो डेटा तालिकाओं के बजाय डेटा तालिकाओं को स्तंभों के अनुभागों के रूप में संग्रहीत करते हैं। शीघ्र ही, उनके पास कॉलम परिवार होंगे।
| पंक्ति-उन्मुख डेटाबेस | कॉलम-ओरिएंटेड डेटाबेस |
|---|---|
| यह ऑनलाइन लेनदेन प्रक्रिया (OLTP) के लिए उपयुक्त है। | यह ऑनलाइन एनालिटिकल प्रोसेसिंग (OLAP) के लिए उपयुक्त है। |
| ऐसे डेटाबेस छोटी संख्या में पंक्तियों और स्तंभों के लिए डिज़ाइन किए गए हैं। | स्तंभ-उन्मुख डेटाबेस विशाल तालिकाओं के लिए डिज़ाइन किए गए हैं। |
स्तंभ-उन्मुख डेटाबेस में निम्नलिखित छवि कॉलम परिवारों को दिखाती है:
HBase और RDBMS
| HBase | आरडीबीएमएस |
|---|---|
| HBase स्कीमा-कम है, इसमें निश्चित कॉलम स्कीमा की अवधारणा नहीं है; केवल स्तंभ परिवारों को परिभाषित करता है। | एक RDBMS अपने स्कीमा द्वारा शासित होता है, जो तालिकाओं की पूरी संरचना का वर्णन करता है। |
| यह चौड़ी टेबल के लिए बनाया गया है। HBase क्षैतिज रूप से स्केलेबल है। | यह पतली और छोटी तालिकाओं के लिए निर्मित है। बड़े पैमाने पर। |
| HBase में कोई लेनदेन नहीं है। | RDBMS ट्रांजेक्शनल है। |
| इसमें डी-सामान्यीकृत डेटा है। | इसमें सामान्यीकृत डेटा होगा। |
| यह सेमी-स्ट्रक्चर्ड के साथ-साथ स्ट्रक्चर्ड डेटा के लिए अच्छा है। | यह संरचित डेटा के लिए अच्छा है। |
HBase की विशेषताएं
- HBase रैखिक रूप से स्केलेबल है।
- इसमें स्वचालित विफलता समर्थन है।
- यह लगातार पढ़ने और लिखने के लिए प्रदान करता है।
- यह एक स्रोत और एक गंतव्य के रूप में, Hadoop के साथ एकीकृत होता है।
- इसमें क्लाइंट के लिए आसान जावा एपीआई है।
- यह समूहों में डेटा प्रतिकृति प्रदान करता है।
HBase का उपयोग कहां करें
अपाचे HBase बिग डेटा के लिए यादृच्छिक, वास्तविक समय पढ़ने / लिखने के लिए उपयोग किया जाता है।
यह कमोडिटी हार्डवेयर के क्लस्टर के शीर्ष पर बहुत बड़ी तालिकाओं को होस्ट करता है।
Apache HBase Google के बिगटेबल के बाद बनाया गया एक गैर-संबंधपरक डेटाबेस है। Bigtable Google फ़ाइल सिस्टम पर कार्य करता है, इसी तरह Apache HBase, Hadoop और HDFS के शीर्ष पर काम करता है।
HBase के अनुप्रयोग
- जब भी भारी आवेदन लिखने की आवश्यकता होती है तो इसका उपयोग किया जाता है।
- HBase का उपयोग तब किया जाता है जब भी हमें उपलब्ध डेटा को तीव्र यादृच्छिक पहुँच प्रदान करने की आवश्यकता होती है।
- फेसबुक, ट्विटर, याहू और एडोब जैसी कंपनियां आंतरिक रूप से HBase का उपयोग करती हैं।
HBase इतिहास
| साल | प्रतिस्पर्धा |
|---|---|
| नवंबर 2006 | Google ने BigTable पर पेपर जारी किया। |
| फरवरी 2007 | प्रारंभिक HBase प्रोटोटाइप एक Hadoop योगदान के रूप में बनाया गया था। |
| अक्टूबर 2007 | Hadoop 0.15.0 के साथ पहला प्रयोग करने योग्य HBase जारी किया गया था। |
| जनवरी 2008 | HBase Hadoop की उप परियोजना बन गया। |
| अक्टूबर 2008 | HBase 0.18.1 जारी किया गया था। |
| जनवरी 2009 | HBase 0.19.0 जारी किया गया था। |
| सितम्बर 2009 | HBase 0.20.0 जारी किया गया था। |
| मई 2010 | HBase Apache शीर्ष-स्तरीय परियोजना बन गई। |
HBase में, तालिकाओं को क्षेत्रों में विभाजित किया जाता है और क्षेत्र सर्वरों द्वारा परोसा जाता है। क्षेत्र लंबवत रूप से कॉलम परिवारों द्वारा "स्टोर" में विभाजित हैं। स्टोर को एचडीएफएस में फाइलों के रूप में सहेजा जाता है। नीचे दिखाया गया HBase की वास्तुकला है।
Note: स्टोरेज स्ट्रक्चर को समझाने के लिए 'स्टोर' शब्द का इस्तेमाल क्षेत्रों के लिए किया जाता है।
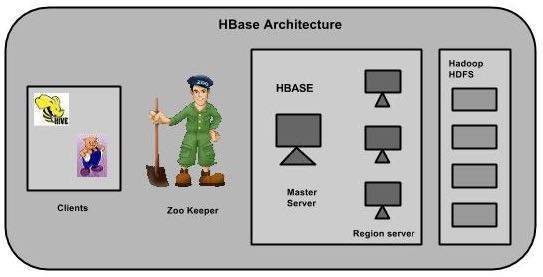
HBase के तीन प्रमुख घटक हैं: क्लाइंट लाइब्रेरी, एक मास्टर सर्वर और क्षेत्र सर्वर। आवश्यकता के अनुसार रीजन सर्वर को जोड़ा या हटाया जा सकता है।
लिए मास्टर
मास्टर सर्वर -
इस क्षेत्र के सर्वर के लिए क्षेत्रों को असाइन करता है और इस कार्य के लिए Apache ZooKeeper की मदद लेता है।
क्षेत्र सर्वरों पर क्षेत्रों के संतुलन को संभालता है। यह व्यस्त सर्वरों को उतारता है और क्षेत्रों को कम व्यस्त सर्वरों में स्थानांतरित करता है।
लोड संतुलन पर बातचीत करके क्लस्टर की स्थिति बनाए रखता है।
स्कीमा परिवर्तन और अन्य मेटाडेटा संचालन जैसे टेबल और स्तंभ परिवारों के निर्माण के लिए जिम्मेदार है।
क्षेत्रों
क्षेत्र कुछ भी नहीं हैं, लेकिन तालिकाएँ जो विभाजित हैं और क्षेत्र सर्वरों में फैली हुई हैं।
क्षेत्र सर्वर
क्षेत्र सर्वर के क्षेत्र हैं -
- ग्राहक के साथ संवाद करें और डेटा से संबंधित संचालन को संभालें।
- इसके तहत सभी क्षेत्रों के लिए अनुरोध पढ़ें और लिखें।
- क्षेत्र आकार सीमा का पालन करके क्षेत्र का आकार तय करें।
जब हम क्षेत्र सर्वर में गहराई से देखते हैं, तो इसमें नीचे दिखाए अनुसार क्षेत्र और स्टोर होते हैं:
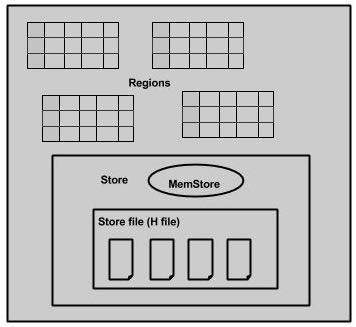
स्टोर में मेमोरी स्टोर और HFiles हैं। मेमस्टोर एक कैश मेमोरी की तरह है। कुछ भी जो HBase में दर्ज किया गया है, शुरू में यहाँ संग्रहीत किया जाता है। बाद में, डेटा को Hfiles में ब्लॉक के रूप में स्थानांतरित और सहेजा जाता है और मेमस्टोर को फ्लश कर दिया जाता है।
चिड़ियाघर संचालक
ज़ुकाइपर एक ओपन-सोर्स प्रोजेक्ट है जो कॉन्फ़िगरेशन की जानकारी बनाए रखने, नामकरण, वितरित सिंक्रनाइज़ेशन प्रदान करने जैसी सेवाएं प्रदान करता है।
ज़ुकीपर में अलग-अलग क्षेत्र के सर्वरों का प्रतिनिधित्व करने वाले अल्पकालिक नोड होते हैं। उपलब्ध सर्वरों की खोज के लिए मास्टर सर्वर इन नोड्स का उपयोग करते हैं।
उपलब्धता के अलावा, नोड्स का उपयोग सर्वर विफलताओं या नेटवर्क विभाजन को ट्रैक करने के लिए भी किया जाता है।
ग्राहक ज़ुकीपर के माध्यम से क्षेत्र के सर्वर के साथ संवाद करते हैं।
छद्म और स्टैंडअलोन मोड में, HBase खुद zookeeper का ख्याल रखेगा।
यह अध्याय बताता है कि कैसे HBase स्थापित है और शुरू में कॉन्फ़िगर किया गया है। Java और Hadoop को HBase के साथ आगे बढ़ना आवश्यक है, इसलिए आपको अपने सिस्टम में java और Hadoop को डाउनलोड और इंस्टॉल करना होगा।
पूर्व-स्थापना सेटअप
Hadoop को Linux वातावरण में स्थापित करने से पहले, हमें लिनक्स का उपयोग करना होगा ssh(सुरक्षित कवच)। लिनक्स पर्यावरण की स्थापना के लिए नीचे दिए गए चरणों का पालन करें।
एक उपयोगकर्ता बनाना
सबसे पहले, Hadoop फाइल सिस्टम को Unix फाइल सिस्टम से अलग करने के लिए Hadoop के लिए एक अलग उपयोगकर्ता बनाने की सिफारिश की गई है। उपयोगकर्ता बनाने के लिए नीचे दिए गए चरणों का पालन करें।
- कमांड "su" का उपयोग करके रूट खोलें।
- "Useradd उपयोगकर्ता नाम" कमांड का उपयोग करके रूट खाते से एक उपयोगकर्ता बनाएं।
- अब आप "su उपयोगकर्ता नाम" कमांड का उपयोग करके एक मौजूदा उपयोगकर्ता खाता खोल सकते हैं।
लिनक्स टर्मिनल खोलें और उपयोगकर्ता बनाने के लिए निम्न कमांड टाइप करें।
$ su
password:
# useradd hadoop
# passwd hadoop
New passwd:
Retype new passwdSSH सेटअप और मुख्य पीढ़ी
SSH सेटअप को प्रारंभ, रोकें और वितरित किए गए डेमन शेल ऑपरेशन जैसे क्लस्टर पर विभिन्न ऑपरेशन करने के लिए आवश्यक है। Hadoop के विभिन्न उपयोगकर्ताओं को प्रमाणित करने के लिए, Hadoop उपयोगकर्ता के लिए सार्वजनिक / निजी कुंजी जोड़ी प्रदान करना और इसे विभिन्न उपयोगकर्ताओं के साथ साझा करना आवश्यक है।
SSH का उपयोग करके एक महत्वपूर्ण मूल्य युग्म उत्पन्न करने के लिए निम्न कमांड का उपयोग किया जाता है। सार्वजनिक कुंजियों की प्रतिलिपि id_rsa.pub को अधिकृत_keys पर भेजें, और मालिक को, क्रमशः अधिकृत_की फ़ाइल में अनुमतियाँ पढ़ें और लिखें।
$ ssh-keygen -t rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keysSsh सत्यापित करें
ssh localhostजावा को स्थापित करना
Hadoop और HBase के लिए जावा मुख्य शर्त है। सबसे पहले, आपको "जावा-वर्सन" का उपयोग करके अपने सिस्टम में जावा के अस्तित्व को सत्यापित करना चाहिए। जावा संस्करण कमांड का सिंटैक्स नीचे दिया गया है।
$ java -versionयदि सब कुछ ठीक काम करता है, तो यह आपको निम्नलिखित आउटपुट देगा।
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)यदि आपके सिस्टम में जावा स्थापित नहीं है, तो जावा स्थापित करने के लिए नीचे दिए गए चरणों का पालन करें।
चरण 1
निम्नलिखित लिंक ओरेकल जावा पर जाकर java (JDK <नवीनतम संस्करण> - X64.tar.gz) डाउनलोड करें ।
फिर jdk-7u71-linux-x64.tar.gz आपके सिस्टम में डाउनलोड हो जाएगा।
चरण 2
आम तौर पर आपको डाउनलोड फ़ोल्डर में डाउनलोड की गई जावा फ़ाइल मिलेगी। इसे सत्यापित करें और निकालेंjdk-7u71-linux-x64.gz निम्न आदेशों का उपयोग करके फ़ाइल।
$ cd Downloads/
$ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz
$ ls
jdk1.7.0_71 jdk-7u71-linux-x64.gzचरण 3
जावा को सभी उपयोगकर्ताओं के लिए उपलब्ध कराने के लिए, आपको इसे "/ usr / स्थानीय /" स्थान पर ले जाना होगा। रूट खोलें और निम्न कमांड टाइप करें।
$ su
password:
# mv jdk1.7.0_71 /usr/local/
# exitचरण 4
स्थापित करने के लिए PATH तथा JAVA_HOME चर, निम्नलिखित कमांड को इसमें जोड़ें ~/.bashrc फ़ाइल।
export JAVA_HOME=/usr/local/jdk1.7.0_71
export PATH= $PATH:$JAVA_HOME/binअब वर्तमान में चल रहे सिस्टम में सभी परिवर्तनों को लागू करें।
$ source ~/.bashrcचरण 5
जावा विकल्प को कॉन्फ़िगर करने के लिए निम्नलिखित कमांड का उपयोग करें:
# alternatives --install /usr/bin/java java usr/local/java/bin/java 2
# alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2
# alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2
# alternatives --set java usr/local/java/bin/java
# alternatives --set javac usr/local/java/bin/javac
# alternatives --set jar usr/local/java/bin/jarअब सत्यापित करें java -version ऊपर बताए अनुसार टर्मिनल से कमांड।
Hadoop डाउनलोड करना
जावा को स्थापित करने के बाद, आपको Hadoop को स्थापित करना होगा। सबसे पहले, नीचे दिखाए गए अनुसार "Hadoop संस्करण" कमांड का उपयोग करके Hadoop के अस्तित्व को सत्यापित करें।
hadoop versionयदि सब कुछ ठीक काम करता है, तो यह आपको निम्नलिखित आउटपुट देगा।
Hadoop 2.6.0
Compiled by jenkins on 2014-11-13T21:10Z
Compiled with protoc 2.5.0
From source with checksum 18e43357c8f927c0695f1e9522859d6a
This command was run using
/home/hadoop/hadoop/share/hadoop/common/hadoop-common-2.6.0.jarयदि आपका सिस्टम Hadoop का पता लगाने में असमर्थ है, तो अपने सिस्टम में Hadoop डाउनलोड करें। ऐसा करने के लिए नीचे दिए गए आदेशों का पालन करें।
निम्नलिखित कमांड का उपयोग करके अपाचे सॉफ्टवेयर फाउंडेशन से हैडऑप-2.6.0 डाउनलोड करें और निकालें ।
$ su
password:
# cd /usr/local
# wget http://mirrors.advancedhosters.com/apache/hadoop/common/hadoop-
2.6.0/hadoop-2.6.0-src.tar.gz
# tar xzf hadoop-2.6.0-src.tar.gz
# mv hadoop-2.6.0/* hadoop/
# exitHadoop स्थापित करना
किसी भी आवश्यक मोड में Hadoop स्थापित करें। यहां, हम छद्म वितरित मोड में HBase कार्यक्षमता का प्रदर्शन कर रहे हैं, इसलिए छद्म वितरित मोड में Hadoop स्थापित करें।
स्थापित करने के लिए निम्न चरणों का उपयोग किया जाता है Hadoop 2.4.1।
चरण 1 - Hadoop की स्थापना
आप निम्न आदेशों को जोड़कर Hadoop वातावरण चर सेट कर सकते हैं ~/.bashrc फ़ाइल।
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOMEअब वर्तमान में चल रहे सिस्टम में सभी परिवर्तनों को लागू करें।
$ source ~/.bashrcचरण 2 - Hadoop कॉन्फ़िगरेशन
आप "HADOOP_HOME / etc / hadoop" स्थान में सभी Hadoop कॉन्फ़िगरेशन फ़ाइलों को पा सकते हैं। आपको अपने Hadoop बुनियादी ढांचे के अनुसार उन कॉन्फ़िगरेशन फ़ाइलों में परिवर्तन करने की आवश्यकता है।
$ cd $HADOOP_HOME/etc/hadoopजावा में Hadoop कार्यक्रमों को विकसित करने के लिए, आपको जावा पर्यावरण चर को रीसेट करना होगा hadoop-env.sh फ़ाइल को प्रतिस्थापित करके JAVA_HOME आपके सिस्टम में जावा के स्थान के साथ मूल्य।
export JAVA_HOME=/usr/local/jdk1.7.0_71Hadoop को कॉन्फ़िगर करने के लिए आपको निम्न फ़ाइलों को संपादित करना होगा।
core-site.xml
core-site.xml फ़ाइल में Hadoop उदाहरण के लिए उपयोग की जाने वाली पोर्ट संख्या, फ़ाइल सिस्टम के लिए आवंटित मेमोरी, डेटा संग्रहीत करने के लिए मेमोरी की सीमा और रीड / राइट बफ़र्स के आकार जैसी जानकारी शामिल है।
कोर- site.xml खोलें और <कॉन्फ़िगरेशन> और </ कॉन्फ़िगरेशन> टैग के बीच निम्न गुण जोड़ें।
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xml
hdfs-site.xml फ़ाइल में प्रतिकृति डेटा का मान, नामेनोड पथ और आपके स्थानीय फ़ाइल सिस्टम के डेटाैनॉड पथ जैसे जानकारी शामिल हैं, जहाँ आप Hadoop अवसंरचना को संग्रहीत करना चाहते हैं।
आइए हम निम्नलिखित आंकड़ों को मानते हैं।
dfs.replication (data replication value) = 1
(In the below given path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanodeइस फ़ाइल को खोलें और <कॉन्फ़िगरेशन>, </ कॉन्फ़िगरेशन> टैग के बीच निम्न गुण जोड़ें।
<configuration>
<property>
<name>dfs.replication</name >
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>Note: उपरोक्त फ़ाइल में, सभी संपत्ति मान उपयोगकर्ता-परिभाषित हैं और आप अपने Hadoop अवसंरचना के अनुसार परिवर्तन कर सकते हैं।
yarn-site.xml
इस फ़ाइल का उपयोग यार्न को Hadoop में कॉन्फ़िगर करने के लिए किया जाता है। यार्न- site.xml फ़ाइल खोलें और <कॉन्फ़िगरेशन $ gt ;, </ कॉन्फ़िगरेशन $ gt के बीच में निम्नलिखित संपत्ति जोड़ें; इस फ़ाइल में टैग।
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
यह फ़ाइल निर्दिष्ट करने के लिए उपयोग की जाती है कि हम किस MapReduce ढांचे का उपयोग कर रहे हैं। डिफ़ॉल्ट रूप से, Hadoop में यार्न-site.xml का टेम्प्लेट होता है। सबसे पहले, फ़ाइल से कॉपी करना आवश्यक हैmapred-site.xml.template सेवा mapred-site.xml निम्न कमांड का उपयोग करके फ़ाइल।
$ cp mapred-site.xml.template mapred-site.xmlखुला हुआ mapred-site.xml <कॉन्फ़िगरेशन> और </ कॉन्फ़िगरेशन> टैग के बीच निम्न गुणों को फ़ाइल करें और जोड़ें।
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>Hadoop स्थापना का सत्यापन
Hadoop स्थापना को सत्यापित करने के लिए निम्न चरणों का उपयोग किया जाता है।
चरण 1 - नाम नोड सेटअप
निम्नानुसार "hdfs namenode -format" कमांड का उपयोग करके नामेनोड सेट करें।
$ cd ~ $ hdfs namenode -formatअपेक्षित परिणाम इस प्रकार है।
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.4.1
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to
retain 1 images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/चरण 2 - सत्यापन Hadoop dfs
Dfs शुरू करने के लिए निम्न कमांड का उपयोग किया जाता है। इस आदेश को निष्पादित करने से आपका Hadoop फ़ाइल सिस्टम प्रारंभ हो जाएगा।
$ start-dfs.shअपेक्षित आउटपुट निम्नानुसार है।
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]चरण 3 - यार्न स्क्रिप्ट का सत्यापन
यार्न स्क्रिप्ट शुरू करने के लिए निम्न कमांड का उपयोग किया जाता है। इस आदेश को निष्पादित करने से आपके यार्न डेमन शुरू हो जाएंगे।
$ start-yarn.shअपेक्षित आउटपुट निम्नानुसार है।
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-
2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out
localhost: starting nodemanager, logging to /home/hadoop/hadoop-
2.4.1/logs/yarn-hadoop-nodemanager-localhost.outचरण 4 - ब्राउज़र पर Hadoop तक पहुँचना
Hadoop तक पहुँचने के लिए डिफ़ॉल्ट पोर्ट संख्या 50070 है। अपने ब्राउज़र पर Hadoop सेवाएँ प्राप्त करने के लिए निम्न url का उपयोग करें।
http://localhost:50070
चरण 5 - क्लस्टर के सभी अनुप्रयोगों को सत्यापित करें
क्लस्टर के सभी अनुप्रयोगों तक पहुँचने के लिए डिफ़ॉल्ट पोर्ट संख्या 8088 है। इस सेवा पर जाने के लिए निम्न url का उपयोग करें।
http://localhost:8088/
HBase स्थापित कर रहा है
हम HBase को तीन मोड में से किसी में भी स्थापित कर सकते हैं: स्टैंडअलोन मोड, स्यूडो डिस्ट्रिब्यूटेड मोड और फुल्ली डिस्ट्रिब्यूटेड मोड।
स्टैंडअलोन मोड में HBase स्थापित करना
HBase फ़ॉर्म का नवीनतम स्थिर संस्करण डाउनलोड करें http://www.interior-dsgn.com/apache/hbase/stable/"wget" कमांड का उपयोग करना, और टार "zxvf" कमांड का उपयोग करके इसे निकालना। निम्न आदेश देखें।
$cd usr/local/ $wget http://www.interior-dsgn.com/apache/hbase/stable/hbase-0.98.8-
hadoop2-bin.tar.gz
$tar -zxvf hbase-0.98.8-hadoop2-bin.tar.gzसुपर उपयोगकर्ता मोड में जाएं और HBase फ़ोल्डर को नीचे दिखाए गए अनुसार / usr / स्थानीय पर ले जाएं।
$su
$password: enter your password here
mv hbase-0.99.1/* Hbase/स्टैंडअलोन मोड में HBase को कॉन्फ़िगर करना
HBase के साथ आगे बढ़ने से पहले, आपको निम्न फ़ाइलों को संपादित करना होगा और HBase को कॉन्फ़िगर करना होगा।
hbase-env.sh
HBase के लिए जावा होम सेट करें और खोलें hbase-env.shफ़ाइल को गोपनीय फ़ोल्डर से। JAVA_HOME पर्यावरण चर संपादित करें और नीचे दिखाए गए अनुसार अपने वर्तमान JAVA_HOME चर में मौजूदा पथ बदलें।
cd /usr/local/Hbase/conf
gedit hbase-env.shयह HBase की env.sh फ़ाइल खोलेगा। अब मौजूदा की जगहJAVA_HOME नीचे दिखाए गए अनुसार अपने वर्तमान मूल्य के साथ मूल्य।
export JAVA_HOME=/usr/lib/jvm/java-1.7.0HBase-site.xml
यह HBase की मुख्य कॉन्फ़िगरेशन फ़ाइल है। / Usr / लोकल / HBase में HBase होम फोल्डर को खोलकर डेटा निर्देशिका को एक उपयुक्त स्थान पर सेट करें। गोपनीय फ़ोल्डर के अंदर, आपको कई फाइलें मिलेंगी, खोलेंhbase-site.xml फ़ाइल के रूप में नीचे दिखाया गया है।
#cd /usr/local/HBase/
#cd conf
# gedit hbase-site.xmlके अंदर hbase-site.xmlफ़ाइल, आपको <कॉन्फ़िगरेशन> और </ कॉन्फ़िगरेशन> टैग मिलेंगे। उनके भीतर, "hbase.rootdir" नाम के साथ संपत्ति कुंजी के तहत HBase निर्देशिका सेट करें जैसा कि नीचे दिखाया गया है।
<configuration>
//Here you have to set the path where you want HBase to store its files.
<property>
<name>hbase.rootdir</name>
<value>file:/home/hadoop/HBase/HFiles</value>
</property>
//Here you have to set the path where you want HBase to store its built in zookeeper files.
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hadoop/zookeeper</value>
</property>
</configuration>इसके साथ, HBase स्थापना और कॉन्फ़िगरेशन भाग सफलतापूर्वक पूरा हो गया है। हम उपयोग करके HBase शुरू कर सकते हैंstart-hbase.shHBase के बिन फ़ोल्डर में दी गई स्क्रिप्ट। उसके लिए, HBase होम फोल्डर खोलें और नीचे दिखाए अनुसार HBase स्टार्ट स्क्रिप्ट चलाएँ।
$cd /usr/local/HBase/bin
$./start-hbase.shयदि आप सबकुछ ठीक हो जाता है, जब आप HBase स्टार्ट स्क्रिप्ट को चलाने की कोशिश करते हैं, तो यह आपको एक संदेश कहेगा कि HBase शुरू हो गया है।
starting master, logging to /usr/local/HBase/bin/../logs/hbase-tpmaster-localhost.localdomain.outछद्म-वितरित मोड में HBase स्थापित करना
आइए अब जांचते हैं कि छद्म वितरित मोड में HBase कैसे स्थापित होता है।
HBase को कॉन्फ़िगर करना
HBase के साथ आगे बढ़ने से पहले, अपने स्थानीय सिस्टम या किसी दूरस्थ सिस्टम पर Hadoop और HDFS को कॉन्फ़िगर करें और सुनिश्चित करें कि वे चल रहे हैं। यदि यह चल रहा है तो HBase को रोकें।
hbase-site.xml
निम्नलिखित गुणों को जोड़ने के लिए hbase-site.xml फ़ाइल संपादित करें।
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>यह उल्लेख करेगा कि HBase को किस मोड में चलाया जाना चाहिए। स्थानीय फ़ाइल सिस्टम से एक ही फ़ाइल में, hdfs: //// URI सिंटैक्स का उपयोग करके hbase.rootdir, अपना HDFS उदाहरण पता बदलें। हम 8030 पोर्ट पर लोकलहोस्ट पर एचडीएफएस चला रहे हैं।
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:8030/hbase</value>
</property>HBase शुरू करना
कॉन्फ़िगरेशन समाप्त होने के बाद, HBase होम फ़ोल्डर में ब्राउज़ करें और निम्न कमांड का उपयोग करके HBase को प्रारंभ करें।
$cd /usr/local/HBase
$bin/start-hbase.shNote: HBase शुरू करने से पहले, सुनिश्चित करें कि Hadoop चल रहा है।
HDFS में HBase निर्देशिका की जाँच
HBase HDFS में अपनी निर्देशिका बनाता है। बनाई गई निर्देशिका को देखने के लिए, Hadoop bin में ब्राउज़ करें और निम्न कमांड टाइप करें।
$ ./bin/hadoop fs -ls /hbaseयदि सबकुछ ठीक हो जाता है, तो यह आपको निम्न आउटपुट देगा।
Found 7 items
drwxr-xr-x - hbase users 0 2014-06-25 18:58 /hbase/.tmp
drwxr-xr-x - hbase users 0 2014-06-25 21:49 /hbase/WALs
drwxr-xr-x - hbase users 0 2014-06-25 18:48 /hbase/corrupt
drwxr-xr-x - hbase users 0 2014-06-25 18:58 /hbase/data
-rw-r--r-- 3 hbase users 42 2014-06-25 18:41 /hbase/hbase.id
-rw-r--r-- 3 hbase users 7 2014-06-25 18:41 /hbase/hbase.version
drwxr-xr-x - hbase users 0 2014-06-25 21:49 /hbase/oldWALsमास्टर शुरू करना और रोकना
"Local-master-backup.sh" का उपयोग करके आप 10 सर्वर तक शुरू कर सकते हैं। HBase के होम फ़ोल्डर को खोलें, इसे शुरू करने के लिए मास्टर और निम्नलिखित कमांड को निष्पादित करें।
$ ./bin/local-master-backup.sh 2 4बैकअप मास्टर को मारने के लिए, आपको इसकी प्रक्रिया आईडी की आवश्यकता होती है, जिसे नाम की फ़ाइल में संग्रहीत किया जाएगा “/tmp/hbase-USER-X-master.pid.” आप निम्न कमांड का उपयोग करके बैकअप मास्टर को मार सकते हैं।
$ cat /tmp/hbase-user-1-master.pid |xargs kill -9स्टार्टिंग और स्टॉपिंग रीजर्वर्स
आप निम्न आदेश का उपयोग करके एकल सिस्टम से कई क्षेत्र सर्वर चला सकते हैं।
$ .bin/local-regionservers.sh start 2 3एक क्षेत्र सर्वर को रोकने के लिए, निम्न कमांड का उपयोग करें।
$ .bin/local-regionservers.sh stop 3
HBaseShell प्रारंभ करना
HBase को सफलतापूर्वक स्थापित करने के बाद, आप HBase Shell शुरू कर सकते हैं। नीचे दिए गए चरणों के अनुक्रम हैं जिन्हें HBase शेल शुरू करने के लिए पालन किया जाना है। टर्मिनल खोलें, और सुपर उपयोगकर्ता के रूप में लॉगिन करें।
Hadoop फ़ाइल सिस्टम प्रारंभ करें
Hadoop home sbin फ़ोल्डर के माध्यम से ब्राउज़ करें और Hadoop फ़ाइल सिस्टम को नीचे दिखाए अनुसार शुरू करें।
$cd $HADOOP_HOME/sbin
$start-all.shHBase प्रारंभ करें
HBase रूट निर्देशिका बिन फ़ोल्डर के माध्यम से ब्राउज़ करें और HBase प्रारंभ करें।
$cd /usr/local/HBase
$./bin/start-hbase.shHBase मास्टर सर्वर प्रारंभ करें
यह वही डायरेक्टरी होगी। इसे नीचे दिखाए अनुसार शुरू करें।
$./bin/local-master-backup.sh start 2 (number signifies specific
server.)प्रारंभ क्षेत्र
नीचे दिखाए अनुसार क्षेत्र सर्वर शुरू करें।
$./bin/./local-regionservers.sh start 3HBase शैल प्रारंभ करें
आप निम्न आदेश का उपयोग करके HBase शेल शुरू कर सकते हैं।
$cd bin
$./hbase shellयह आपको HBase शेल प्रॉम्प्ट देगा जैसा कि नीचे दिखाया गया है।
2014-12-09 14:24:27,526 INFO [main] Configuration.deprecation:
hadoop.native.lib is deprecated. Instead, use io.native.lib.available
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version 0.98.8-hadoop2, r6cfc8d064754251365e070a10a82eb169956d5fe, Fri
Nov 14 18:26:29 PST 2014
hbase(main):001:0>HBase वेब इंटरफ़ेस
HBase के वेब इंटरफ़ेस तक पहुंचने के लिए, ब्राउज़र में निम्न यूआरएल टाइप करें।
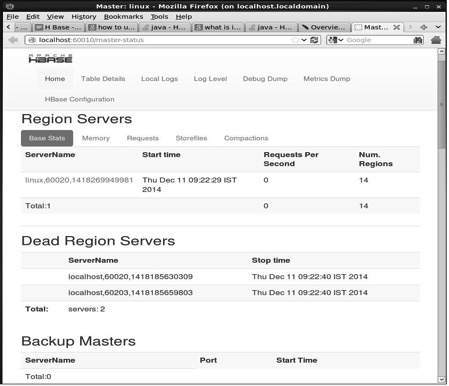
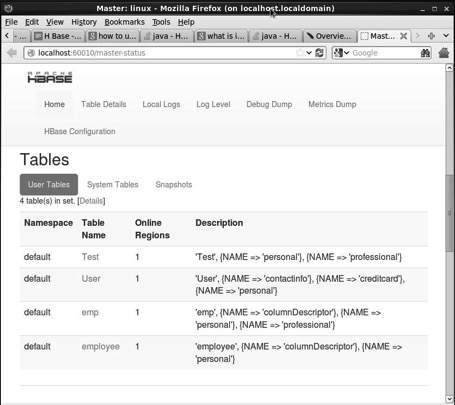
http://localhost:60010यह इंटरफ़ेस आपके वर्तमान में चल रहे क्षेत्र सर्वर, बैकअप मास्टर्स और HBase टेबल को सूचीबद्ध करता है।
HBase क्षेत्र सर्वर और बैकअप मास्टर्स
HBase टेबल्स
जावा पर्यावरण की स्थापना
हम जावा पुस्तकालयों का उपयोग करके HBase के साथ भी संवाद कर सकते हैं, लेकिन Java API का उपयोग करते हुए HBase तक पहुँचने से पहले आपको उन पुस्तकालयों के लिए classpath निर्धारित करना होगा।
कक्षापथ की स्थापना
प्रोग्रामिंग के साथ आगे बढ़ने से पहले, क्लासपाथ को HBase लाइब्रेरीज़ में सेट करें .bashrcफ़ाइल। खुला हुआ.bashrc नीचे दिखाए गए संपादकों में से किसी में।
$ gedit ~/.bashrcHBase लाइब्रेरीज़ के लिए classpath सेट करें (HBase में लिबास फ़ोल्डर) जैसा कि नीचे दिखाया गया है।
export CLASSPATH = $CLASSPATH://home/hadoop/hbase/lib/*यह जावा एपीआई का उपयोग करते हुए HBase तक पहुँचने के दौरान "वर्ग नहीं मिला" अपवाद को रोकने के लिए है।
यह अध्याय बताता है कि HBase इंटरैक्टिव शेल कैसे शुरू करें जो HBase के साथ आता है।
HBase शैल
HBase में एक शेल होता है जिसके उपयोग से आप HBase के साथ संवाद कर सकते हैं। HBase अपने डेटा को संग्रहीत करने के लिए Hadoop फ़ाइल सिस्टम का उपयोग करता है। इसमें एक मास्टर सर्वर और क्षेत्र सर्वर होंगे। डेटा संग्रहण क्षेत्रों (तालिकाओं) के रूप में होगा। इन क्षेत्रों को विभाजित किया जाएगा और क्षेत्र सर्वरों में संग्रहीत किया जाएगा।
मास्टर सर्वर इन क्षेत्र सर्वरों का प्रबंधन करता है और ये सभी कार्य एचडीएफएस पर होते हैं। नीचे दिए गए कुछ आदेश HBase शेल द्वारा समर्थित हैं।
जनरल कमांड्स
status - उदाहरण के लिए, सर्वरों की संख्या, HBase की स्थिति प्रदान करता है।
version - उपयोग किए जा रहे HBase का संस्करण प्रदान करता है।
table_help - तालिका-संदर्भ आदेशों के लिए सहायता प्रदान करता है।
whoami - उपयोगकर्ता के बारे में जानकारी प्रदान करता है।
डेटा परिभाषा भाषा
ये आदेश हैं जो HBase में तालिकाओं पर काम करते हैं।
create - एक टेबल बनाता है।
list - HBase में सभी तालिकाओं को सूचीबद्ध करता है।
disable - एक टेबल को निष्क्रिय करता है।
is_disabled - सत्यापित करता है कि क्या कोई तालिका अक्षम है।
enable - एक मेज सक्षम करता है।
is_enabled - सत्यापित करता है कि क्या तालिका सक्षम है।
describe - एक तालिका का विवरण प्रदान करता है।
alter - एक टेबल बदल देता है।
exists - सत्यापित करता है कि क्या कोई तालिका मौजूद है।
drop - HBase से एक टेबल गिरता है।
drop_all - कमांड में दिए गए 'रेगेक्स' से मेल खाती टेबल।
Java Admin API- उपरोक्त सभी आदेशों से पहले, जावा प्रोग्रामिंग के माध्यम से डीडीएल कार्यक्षमताओं को प्राप्त करने के लिए एक व्यवस्थापक एपीआई प्रदान करता है। के अंतर्गतorg.apache.hadoop.hbase.client पैकेज, HBaseAdmin और HTableDescriptor इस पैकेज में दो महत्वपूर्ण वर्ग हैं जो DDL कार्यात्मकता प्रदान करते हैं।
डेटा हेरफेर भाषा
put - एक विशेष तालिका में एक निर्दिष्ट पंक्ति में एक निर्दिष्ट स्तंभ पर एक सेल मान डालता है।
get - पंक्ति या सेल की सामग्री को लाती है।
delete - एक तालिका में एक सेल मान हटाता है।
deleteall - दी गई पंक्ति में सभी कोशिकाओं को हटाता है।
scan - टेबल डेटा को स्कैन और वापस करता है।
count - एक तालिका में पंक्तियों की संख्या गिनता और वापस करता है।
truncate - एक निर्दिष्ट तालिका को निष्क्रिय करता है, छोड़ता है, और फिर से बनाता है।
Java client API - उपरोक्त सभी आदेशों से पहले, जावा ग्राहक को DML कार्यात्मकता प्राप्त करने के लिए API प्रदान करता है, CRUD प्रोग्रामिंग के माध्यम से, org.apache.hadoop.hbase.client पैकेज के तहत (और अपडेट को हटाएं) अपडेट करें। HTable Put तथा Get इस पैकेज में महत्वपूर्ण वर्ग हैं।
HBase शैल शुरू करना
HBase शेल तक पहुंचने के लिए, आपको HBase होम फ़ोल्डर में नेविगेट करना होगा।
cd /usr/localhost/
cd Hbaseआप का उपयोग कर HBase इंटरैक्टिव शेल शुरू कर सकते हैं “hbase shell” जैसा कि नीचे दिखाया गया है।
./bin/hbase shellयदि आपने अपने सिस्टम में सफलतापूर्वक HBase स्थापित किया है, तो यह आपको HBase शेल प्रॉम्प्ट देता है जैसा कि नीचे दिखाया गया है।
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version 0.94.23, rf42302b28aceaab773b15f234aa8718fff7eea3c, Wed Aug 27
00:54:09 UTC 2014
hbase(main):001:0>किसी भी समय इंटरैक्टिव शेल कमांड से बाहर निकलने के लिए, बाहर निकलें या <ctrl + c> का उपयोग करें। आगे बढ़ने से पहले शेल कार्यप्रणाली की जाँच करें। उपयोगlist इस उद्देश्य के लिए कमान। Listएक आदेश है जिसका उपयोग HBase में सभी तालिकाओं की सूची प्राप्त करने के लिए किया जाता है। सबसे पहले, नीचे दिखाए गए अनुसार इस कमांड का उपयोग करके आपके सिस्टम में HBase की स्थापना और कॉन्फ़िगरेशन को सत्यापित करें।
hbase(main):001:0> listजब आप यह कमांड टाइप करते हैं, तो यह आपको निम्न आउटपुट देता है।
hbase(main):001:0> list
TABLEHBase में सामान्य कमांड स्थिति, संस्करण, table_help और whoami हैं। यह अध्याय इन आदेशों की व्याख्या करता है।
स्थिति
यह कमांड सिस्टम की स्थिति देता है जिसमें सिस्टम पर चल रहे सर्वरों का विवरण शामिल है। इसका सिंटैक्स इस प्रकार है:
hbase(main):009:0> statusयदि आप इस कमांड को निष्पादित करते हैं, तो यह निम्न आउटपुट देता है।
hbase(main):009:0> status
3 servers, 0 dead, 1.3333 average loadसंस्करण
यह कमांड आपके सिस्टम में उपयोग किए गए HBase के संस्करण को लौटाता है। इसका सिंटैक्स इस प्रकार है:
hbase(main):010:0> versionयदि आप इस कमांड को निष्पादित करते हैं, तो यह निम्न आउटपुट देता है।
hbase(main):009:0> version
0.98.8-hadoop2, r6cfc8d064754251365e070a10a82eb169956d5fe, Fri Nov 14
18:26:29 PST 2014table_help
यह निर्देश आपको बताता है कि तालिका-संदर्भित आदेशों का क्या और कैसे उपयोग किया जाए। नीचे दिए गए इस आदेश का उपयोग करने के लिए वाक्यविन्यास है।
hbase(main):02:0> table_helpजब आप इस कमांड का उपयोग करते हैं, तो यह टेबल से संबंधित कमांड के लिए मदद विषय दिखाता है। नीचे दिए गए इस आदेश का आंशिक उत्पादन है।
hbase(main):002:0> table_help
Help for table-reference commands.
You can either create a table via 'create' and then manipulate the table
via commands like 'put', 'get', etc.
See the standard help information for how to use each of these commands.
However, as of 0.96, you can also get a reference to a table, on which
you can invoke commands.
For instance, you can get create a table and keep around a reference to
it via:
hbase> t = create 't', 'cf'…...मैं कौन हूँ
यह कमांड HBase का उपयोगकर्ता विवरण लौटाता है। यदि आप इस कमांड को निष्पादित करते हैं, तो वर्तमान HBase उपयोगकर्ता को नीचे दिखाए अनुसार लौटाता है।
hbase(main):008:0> whoami
hadoop (auth:SIMPLE)
groups: hadoopHBase को जावा में लिखा गया है, इसलिए यह HBase के साथ संवाद करने के लिए जावा एपीआई प्रदान करता है। HBase के साथ संचार करने के लिए जावा एपीआई सबसे तेज़ तरीका है। नीचे दिया गया संदर्भित जावा एडमिन एपीआई है जो तालिकाओं को प्रबंधित करने के लिए उपयोग किए जाने वाले कार्यों को शामिल करता है।
कक्षा HBaseAdmin
HBaseAdminव्यवस्थापक का प्रतिनिधित्व करने वाला एक वर्ग है। यह वर्ग किसका हैorg.apache.hadoop.hbase.clientपैकेज। इस वर्ग का उपयोग करके, आप एक व्यवस्थापक के कार्य कर सकते हैं। आप व्यवस्थापक का उपयोग करके उदाहरण प्राप्त कर सकते हैंConnection.getAdmin() तरीका।
तरीके और विवरण
| क्र.सं. | तरीके और विवरण |
|---|---|
| 1 | void createTable(HTableDescriptor desc) एक नई तालिका बनाता है। |
| 2 | void createTable(HTableDescriptor desc, byte[][] splitKeys) निर्दिष्ट विभाजन कुंजियों द्वारा परिभाषित खाली क्षेत्रों के प्रारंभिक सेट के साथ एक नई तालिका बनाता है। |
| 3 | void deleteColumn(byte[] tableName, String columnName) तालिका से स्तंभ हटाता है। |
| 4 | void deleteColumn(String tableName, String columnName) एक तालिका से एक कॉलम हटाएं। |
| 5 | void deleteTable(String tableName) एक तालिका हटाता है। |
क्लास डिस्क्रिप्टिव
इस वर्ग में HBase तालिका के बारे में विवरण शामिल हैं:
- सभी स्तंभ परिवारों के विवरणकर्ता,
- यदि तालिका एक कैटलॉग तालिका है,
- यदि तालिका केवल पढ़ी जाती है,
- मेम स्टोर का अधिकतम आकार,
- जब क्षेत्र विभाजित होना चाहिए,
- इसके साथ जुड़े सह-प्रोसेसर, आदि।
कंस्ट्रक्टर्स
| क्र.सं. | कंस्ट्रक्टर और सारांश |
|---|---|
| 1 | HTableDescriptor(TableName name) एक तालिका वर्णनकर्ता को तालिका नाम वस्तु को निर्दिष्ट करता है। |
तरीके और विवरण
| क्र.सं. | तरीके और विवरण |
|---|---|
| 1 | HTableDescriptor addFamily(HColumnDescriptor family) दिए गए डिस्क्रिप्टर में एक कॉलम परिवार जोड़ता है |
HBase शेल का उपयोग करके एक तालिका बनाना
आप का उपयोग कर एक तालिका बना सकते हैं createकमांड, यहां आपको टेबल का नाम और कॉलम परिवार का नाम बताना होगा। syntax HBase शेल में एक टेबल बनाने के लिए नीचे दिखाया गया है।
create ‘<table name>’,’<column family>’उदाहरण
नीचे दी गई सूची नामक एक तालिका का एक नमूना स्कीमा है। इसके दो स्तंभ परिवार हैं: "व्यक्तिगत डेटा" और "पेशेवर डेटा"।
| पंक्ति कुंजी | व्यक्तिगत डेटा | पेशेवर डेटा |
|---|---|---|
आप इस तालिका को नीचे दिखाए गए अनुसार HBase शेल में बना सकते हैं।
hbase(main):002:0> create 'emp', 'personal data', 'professional data'और यह आपको निम्न आउटपुट देगा।
0 row(s) in 1.1300 seconds
=> Hbase::Table - empसत्यापन
आप यह सत्यापित कर सकते हैं कि क्या तालिका का उपयोग करके बनाया गया है listजैसा कि नीचे दिखाया गया है। यहां आप बनाई गई एम्पायर टेबल का अवलोकन कर सकते हैं।
hbase(main):002:0> list
TABLE
emp
2 row(s) in 0.0340 secondsजावा एपीआई का उपयोग कर एक तालिका बनाना
आप का उपयोग करके HBase में एक तालिका बना सकते हैं createTable() उसकि विधि HBaseAdminकक्षा। यह वर्ग किसका हैorg.apache.hadoop.hbase.clientपैकेज। नीचे दिए गए कदम जावा एपीआई का उपयोग करके HBase में एक टेबल बनाने के लिए हैं।
Step1: झटपट HBaseAdmin
इस वर्ग को एक पैरामीटर के रूप में कॉन्फ़िगरेशन ऑब्जेक्ट की आवश्यकता होती है, इसलिए प्रारंभ में कॉन्फ़िगरेशन क्लास को तत्काल बंद कर दें और इस उदाहरण को HBaseAdmin में पास करें।
Configuration conf = HBaseConfiguration.create();
HBaseAdmin admin = new HBaseAdmin(conf);Step2: TableDescriptor बनाएं
HTableDescriptor एक वर्ग है जो के अंतर्गत आता है org.apache.hadoop.hbaseकक्षा। यह वर्ग तालिका नामों और स्तंभ परिवारों के एक कंटेनर की तरह है।
//creating table descriptor
HTableDescriptor table = new HTableDescriptor(toBytes("Table name"));
//creating column family descriptor
HColumnDescriptor family = new HColumnDescriptor(toBytes("column family"));
//adding coloumn family to HTable
table.addFamily(family);चरण 3: व्यवस्थापक के माध्यम से निष्पादित करें
का उपयोग करते हुए createTable() उसकि विधि HBaseAdmin वर्ग, आप व्यवस्थापक मोड में बनाई गई तालिका निष्पादित कर सकते हैं।
admin.createTable(table);नीचे दिए गए व्यवस्थापक के माध्यम से एक तालिका बनाने का पूरा कार्यक्रम है।
import java.io.IOException;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.conf.Configuration;
public class CreateTable {
public static void main(String[] args) throws IOException {
// Instantiating configuration class
Configuration con = HBaseConfiguration.create();
// Instantiating HbaseAdmin class
HBaseAdmin admin = new HBaseAdmin(con);
// Instantiating table descriptor class
HTableDescriptor tableDescriptor = new
HTableDescriptor(TableName.valueOf("emp"));
// Adding column families to table descriptor
tableDescriptor.addFamily(new HColumnDescriptor("personal"));
tableDescriptor.addFamily(new HColumnDescriptor("professional"));
// Execute the table through admin
admin.createTable(tableDescriptor);
System.out.println(" Table created ");
}
}उपरोक्त कार्यक्रम को संकलित और निष्पादित करें जैसा कि नीचे दिखाया गया है।
$javac CreateTable.java
$java CreateTableनिम्नलिखित आउटपुट होना चाहिए:
Table createdHBase शेल का उपयोग करके एक तालिका की सूची बनाना
सूची वह कमांड है जिसका उपयोग HBase में सभी तालिकाओं को सूचीबद्ध करने के लिए किया जाता है। नीचे दी गई सूची कमांड का सिंटैक्स है।
hbase(main):001:0 > listजब आप इस कमांड को टाइप करते हैं और HBase प्रॉम्प्ट में निष्पादित करते हैं, तो यह HBase की सभी तालिकाओं की सूची को नीचे दिखाए गए अनुसार प्रदर्शित करेगा।
hbase(main):001:0> list
TABLE
empयहां आप एम्प नाम की एक तालिका देख सकते हैं।
जावा एपीआई का उपयोग करके टेबल्स की सूची बनाना
जावा एपीआई का उपयोग करके HBase से तालिकाओं की सूची प्राप्त करने के लिए नीचे दिए गए चरणों का पालन करें।
चरण 1
आपके पास एक विधि है listTables() कक्षा मैं HBaseAdminHBase में सभी तालिकाओं की सूची प्राप्त करने के लिए। यह विधि एक सरणी देता हैHTableDescriptor वस्तुओं।
//creating a configuration object
Configuration conf = HBaseConfiguration.create();
//Creating HBaseAdmin object
HBaseAdmin admin = new HBaseAdmin(conf);
//Getting all the list of tables using HBaseAdmin object
HTableDescriptor[] tableDescriptor = admin.listTables();चरण 2
की लंबाई प्राप्त कर सकते हैं HTableDescriptor[] की लंबाई चर का उपयोग कर सरणी HTableDescriptorकक्षा। इस ऑब्जेक्ट का उपयोग करके तालिकाओं का नाम प्राप्त करेंgetNameAsString()तरीका। इनका उपयोग करके 'फॉर' लूप चलाएँ और HBase में तालिकाओं की सूची प्राप्त करें।
नीचे दिए गए प्रोग्राम में जावा एपीआई का उपयोग करते हुए HBase में सभी तालिकाओं को सूचीबद्ध करने का कार्यक्रम है।
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class ListTables {
public static void main(String args[])throws MasterNotRunningException, IOException{
// Instantiating a configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);
// Getting all the list of tables using HBaseAdmin object
HTableDescriptor[] tableDescriptor = admin.listTables();
// printing all the table names.
for (int i=0; i<tableDescriptor.length;i++ ){
System.out.println(tableDescriptor[i].getNameAsString());
}
}
}उपरोक्त कार्यक्रम को संकलित और निष्पादित करें जैसा कि नीचे दिखाया गया है।
$javac ListTables.java
$java ListTablesनिम्नलिखित आउटपुट होना चाहिए:
User
empHBase शेल का उपयोग करके तालिका को अक्षम करना
किसी तालिका को हटाने या उसकी सेटिंग्स को बदलने के लिए, आपको पहले अक्षम कमांड का उपयोग करके तालिका को अक्षम करना होगा। आप इसे सक्षम कमांड का उपयोग करके फिर से सक्षम कर सकते हैं।
नीचे दी गई सारणी को निष्क्रिय करने का सिंटैक्स है:
disable ‘emp’उदाहरण
नीचे दिया गया एक उदाहरण है जो दिखाता है कि तालिका को कैसे अक्षम किया जाए।
hbase(main):025:0> disable 'emp'
0 row(s) in 1.2760 secondsसत्यापन
तालिका को अक्षम करने के बाद, आप अभी भी इसके अस्तित्व को समझ सकते हैं list तथा existsआदेशों। आप इसे स्कैन नहीं कर सकते। यह आपको निम्न त्रुटि देगा।
hbase(main):028:0> scan 'emp'
ROW COLUMN + CELL
ERROR: emp is disabled.अक्षम है
इस कमांड का उपयोग यह पता लगाने के लिए किया जाता है कि क्या टेबल अक्षम है। इसका वाक्य विन्यास इस प्रकार है।
hbase> is_disabled 'table name'निम्न उदाहरण सत्यापित करता है कि क्या नाम वाली तालिका अक्षम है। यदि यह अक्षम है, तो यह सही लौटेगा और यदि नहीं, तो यह गलत होगा।
hbase(main):031:0> is_disabled 'emp'
true
0 row(s) in 0.0440 secondsसबको सक्षम कर दो
इस कमांड का उपयोग दिए गए regex से मेल खाने वाली सभी तालिकाओं को निष्क्रिय करने के लिए किया जाता है। के लिए वाक्यविन्यासdisable_all कमांड नीचे दी गई है।
hbase> disable_all 'r.*'मान लीजिए कि HBase में 5 तालियाँ हैं, अर्थात् राज, रजनी, राजेंद्र, राजेश, और राजू। निम्न कोड के साथ शुरू होने वाले सभी तालिकाओं को अक्षम कर देगाraj.
hbase(main):002:07> disable_all 'raj.*'
raja
rajani
rajendra
rajesh
raju
Disable the above 5 tables (y/n)?
y
5 tables successfully disabledजावा एपीआई का उपयोग कर एक टेबल को अक्षम करें
यह सत्यापित करने के लिए कि क्या कोई तालिका अक्षम है, isTableDisabled() पद्धति का उपयोग किया जाता है और तालिका को अक्षम करने के लिए, disableTable()विधि का उपयोग किया जाता है। ये विधियाँ हैंHBaseAdminकक्षा। तालिका को अक्षम करने के लिए नीचे दिए गए चरणों का पालन करें।
चरण 1
इन्स्तांत करना HBaseAdmin नीचे दिखाया गया है।
// Creating configuration object
Configuration conf = HBaseConfiguration.create();
// Creating HBaseAdmin object
HBaseAdmin admin = new HBaseAdmin(conf);चरण 2
सत्यापित करें कि क्या तालिका का उपयोग करके अक्षम किया गया है isTableDisabled() तरीका नीचे दिखाया गया है।
Boolean b = admin.isTableDisabled("emp");चरण 3
यदि तालिका अक्षम नहीं है, तो इसे नीचे दिखाए अनुसार अक्षम करें।
if(!b){
admin.disableTable("emp");
System.out.println("Table disabled");
}नीचे यह सत्यापित करने के लिए पूरा कार्यक्रम दिया गया है कि तालिका अक्षम है या नहीं; यदि नहीं, तो इसे कैसे निष्क्रिय करना है।
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class DisableTable{
public static void main(String args[]) throws MasterNotRunningException, IOException{
// Instantiating configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);
// Verifying weather the table is disabled
Boolean bool = admin.isTableDisabled("emp");
System.out.println(bool);
// Disabling the table using HBaseAdmin object
if(!bool){
admin.disableTable("emp");
System.out.println("Table disabled");
}
}
}उपरोक्त कार्यक्रम को संकलित और निष्पादित करें जैसा कि नीचे दिखाया गया है।
$javac DisableTable.java
$java DsiableTableनिम्नलिखित आउटपुट होना चाहिए:
false
Table disabledHBase शेल का उपयोग करके तालिका को सक्षम करना
तालिका को सक्षम करने के लिए सिंटैक्स:
enable ‘emp’उदाहरण
नीचे दी गई तालिका को सक्षम करने के लिए एक उदाहरण है।
hbase(main):005:0> enable 'emp'
0 row(s) in 0.4580 secondsसत्यापन
तालिका को सक्षम करने के बाद, इसे स्कैन करें। यदि आप स्कीमा देख सकते हैं, तो आपकी तालिका सफलतापूर्वक सक्षम है।
hbase(main):006:0> scan 'emp'
ROW COLUMN + CELL
1 column = personal data:city, timestamp = 1417516501, value = hyderabad
1 column = personal data:name, timestamp = 1417525058, value = ramu
1 column = professional data:designation, timestamp = 1417532601, value = manager
1 column = professional data:salary, timestamp = 1417524244109, value = 50000
2 column = personal data:city, timestamp = 1417524574905, value = chennai
2 column = personal data:name, timestamp = 1417524556125, value = ravi
2 column = professional data:designation, timestamp = 14175292204, value = sr:engg
2 column = professional data:salary, timestamp = 1417524604221, value = 30000
3 column = personal data:city, timestamp = 1417524681780, value = delhi
3 column = personal data:name, timestamp = 1417524672067, value = rajesh
3 column = professional data:designation, timestamp = 14175246987, value = jr:engg
3 column = professional data:salary, timestamp = 1417524702514, value = 25000
3 row(s) in 0.0400 secondsसक्षम किया गया है
इस कमांड का उपयोग यह पता लगाने के लिए किया जाता है कि टेबल सक्षम है या नहीं। इसका सिंटैक्स इस प्रकार है:
hbase> is_enabled 'table name'निम्न कोड सत्यापित करता है कि क्या नाम तालिका है empसक्षम किया गया है। यदि यह सक्षम है, तो यह सही लौटेगा और यदि नहीं, तो यह गलत होगा।
hbase(main):031:0> is_enabled 'emp'
true
0 row(s) in 0.0440 secondsजावा एपीआई का उपयोग कर एक तालिका सक्षम करें
यह सत्यापित करने के लिए कि क्या कोई तालिका सक्षम है, isTableEnabled()विधि का उपयोग किया जाता है; और एक तालिका को सक्षम करने के लिए,enableTable()विधि का उपयोग किया जाता है। ये तरीके हैंHBaseAdminकक्षा। तालिका को सक्षम करने के लिए नीचे दिए गए चरणों का पालन करें।
चरण 1
इन्स्तांत करना HBaseAdmin नीचे दिखाया गया है।
// Creating configuration object
Configuration conf = HBaseConfiguration.create();
// Creating HBaseAdmin object
HBaseAdmin admin = new HBaseAdmin(conf);चरण 2
सत्यापित करें कि क्या तालिका का उपयोग करके सक्षम किया गया है isTableEnabled() तरीका नीचे दिखाया गया है।
Boolean bool = admin.isTableEnabled("emp");चरण 3
यदि तालिका अक्षम नहीं है, तो इसे नीचे दिखाए अनुसार अक्षम करें।
if(!bool){
admin.enableTable("emp");
System.out.println("Table enabled");
}नीचे दी गई तालिका को सक्षम करने के लिए यह सत्यापित करने के लिए पूरा कार्यक्रम है और यदि यह नहीं है, तो इसे कैसे सक्षम करें।
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class EnableTable{
public static void main(String args[]) throws MasterNotRunningException, IOException{
// Instantiating configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);
// Verifying whether the table is disabled
Boolean bool = admin.isTableEnabled("emp");
System.out.println(bool);
// Enabling the table using HBaseAdmin object
if(!bool){
admin.enableTable("emp");
System.out.println("Table Enabled");
}
}
}उपरोक्त कार्यक्रम को संकलित और निष्पादित करें जैसा कि नीचे दिखाया गया है।
$javac EnableTable.java
$java EnableTableनिम्नलिखित आउटपुट होना चाहिए:
false
Table Enabledवर्णन
यह आदेश तालिका का विवरण लौटाता है। इसका सिंटैक्स इस प्रकार है:
hbase> describe 'table name'नीचे दिए गए वर्णन कमांड का आउटपुट है emp तालिका।
hbase(main):006:0> describe 'emp'
DESCRIPTION
ENABLED
'emp', {NAME ⇒ 'READONLY', DATA_BLOCK_ENCODING ⇒ 'NONE', BLOOMFILTER
⇒ 'ROW', REPLICATION_SCOPE ⇒ '0', COMPRESSION ⇒ 'NONE', VERSIONS ⇒
'1', TTL true
⇒ 'FOREVER', MIN_VERSIONS ⇒ '0', KEEP_DELETED_CELLS ⇒ 'false',
BLOCKSIZE ⇒ '65536', IN_MEMORY ⇒ 'false', BLOCKCACHE ⇒ 'true'}, {NAME
⇒ 'personal
data', DATA_BLOCK_ENCODING ⇒ 'NONE', BLOOMFILTER ⇒ 'ROW',
REPLICATION_SCOPE ⇒ '0', VERSIONS ⇒ '5', COMPRESSION ⇒ 'NONE',
MIN_VERSIONS ⇒ '0', TTL
⇒ 'FOREVER', KEEP_DELETED_CELLS ⇒ 'false', BLOCKSIZE ⇒ '65536',
IN_MEMORY ⇒ 'false', BLOCKCACHE ⇒ 'true'}, {NAME ⇒ 'professional
data', DATA_BLO
CK_ENCODING ⇒ 'NONE', BLOOMFILTER ⇒ 'ROW', REPLICATION_SCOPE ⇒ '0',
VERSIONS ⇒ '1', COMPRESSION ⇒ 'NONE', MIN_VERSIONS ⇒ '0', TTL ⇒
'FOREVER', K
EEP_DELETED_CELLS ⇒ 'false', BLOCKSIZE ⇒ '65536', IN_MEMORY ⇒
'false', BLOCKCACHE ⇒ 'true'}, {NAME ⇒ 'table_att_unset',
DATA_BLOCK_ENCODING ⇒ 'NO
NE', BLOOMFILTER ⇒ 'ROW', REPLICATION_SCOPE ⇒ '0', COMPRESSION ⇒
'NONE', VERSIONS ⇒ '1', TTL ⇒ 'FOREVER', MIN_VERSIONS ⇒ '0',
KEEP_DELETED_CELLS
⇒ 'false', BLOCKSIZE ⇒ '6बदलने
Alter एक मौजूदा तालिका में परिवर्तन करने के लिए उपयोग की जाने वाली कमांड है। इस कमांड का उपयोग करके, आप कॉलम परिवार के सेल की अधिकतम संख्या को बदल सकते हैं, टेबल स्कोप ऑपरेटरों को सेट और डिलीट कर सकते हैं, और एक टेबल से कॉलम परिवार को हटा सकते हैं।
एक कॉलम परिवार की कोशिकाओं की अधिकतम संख्या को बदलना
नीचे दिए गए एक कॉलम परिवार की अधिकतम कोशिकाओं को बदलने के लिए वाक्यविन्यास है।
hbase> alter 't1', NAME ⇒ 'f1', VERSIONS ⇒ 5निम्नलिखित उदाहरण में, कोशिकाओं की अधिकतम संख्या 5 पर सेट है।
hbase(main):003:0> alter 'emp', NAME ⇒ 'personal data', VERSIONS ⇒ 5
Updating all regions with the new schema...
0/1 regions updated.
1/1 regions updated.
Done.
0 row(s) in 2.3050 secondsटेबल स्कोप ऑपरेटर्स
परिवर्तन का उपयोग करके, आप MAX_FILESIZE, READONLY, MEMSTORE_FLUSHSIZE, DEFERRED_LOG_FLUSH, आदि जैसे टेबल स्कोप ऑपरेटरों को सेट और निकाल सकते हैं।
सेटिंग केवल पढ़ने के लिए
नीचे दी गई सारणी केवल पढ़ने के लिए वाक्य रचना है।
hbase>alter 't1', READONLY(option)निम्नलिखित उदाहरण में, हमने बनाया है emp टेबल केवल पढ़ा।
hbase(main):006:0> alter 'emp', READONLY
Updating all regions with the new schema...
0/1 regions updated.
1/1 regions updated.
Done.
0 row(s) in 2.2140 secondsटेबल स्कोप ऑपरेटर्स को हटाना
हम टेबल स्कोप ऑपरेटरों को भी हटा सकते हैं। नीचे दी गई सूची तालिका से 'MAX_FILESIZE' निकालने का सिंटैक्स है।
hbase> alter 't1', METHOD ⇒ 'table_att_unset', NAME ⇒ 'MAX_FILESIZE'एक स्तंभ परिवार को हटाना
परिवर्तन का उपयोग करके, आप एक कॉलम परिवार को भी हटा सकते हैं। नीचे दिए गए परिवर्तन का उपयोग करके एक कॉलम परिवार को हटाने के लिए वाक्यविन्यास है।
hbase> alter ‘ table name ’, ‘delete’ ⇒ ‘ column family ’नीचे दिया गया एक उदाहरण 'एम्पायर' टेबल से एक कॉलम परिवार को हटाने के लिए है।
मान लें कि HBase में एक कर्मचारी नाम की एक तालिका है। इसमें निम्न डेटा शामिल हैं:
hbase(main):006:0> scan 'employee'
ROW COLUMN+CELL
row1 column = personal:city, timestamp = 1418193767, value = hyderabad
row1 column = personal:name, timestamp = 1418193806767, value = raju
row1 column = professional:designation, timestamp = 1418193767, value = manager
row1 column = professional:salary, timestamp = 1418193806767, value = 50000
1 row(s) in 0.0160 secondsअब हम कॉलम परिवार नाम हटाते हैं professional बदल कमांड का उपयोग करना।
hbase(main):007:0> alter 'employee','delete'⇒'professional'
Updating all regions with the new schema...
0/1 regions updated.
1/1 regions updated.
Done.
0 row(s) in 2.2380 secondsअब परिवर्तन के बाद तालिका में डेटा सत्यापित करें। स्तंभ परिवार को ध्यान से देखें, तो 'व्यावसायिक' अधिक नहीं है, क्योंकि हमने इसे हटा दिया है।
hbase(main):003:0> scan 'employee'
ROW COLUMN + CELL
row1 column = personal:city, timestamp = 14181936767, value = hyderabad
row1 column = personal:name, timestamp = 1418193806767, value = raju
1 row(s) in 0.0830 secondsजावा एपीआई का उपयोग करके एक कॉलम परिवार जोड़ना
आप विधि का उपयोग करके एक स्तंभ परिवार को एक तालिका में जोड़ सकते हैं addColumn() का HBAseAdminकक्षा। स्तंभ परिवार को तालिका में जोड़ने के लिए नीचे दिए गए चरणों का पालन करें।
चरण 1
झटपट HBaseAdmin कक्षा।
// Instantiating configuration object
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);चरण 2
addColumn() विधि के लिए एक टेबल नाम और एक ऑब्जेक्ट की आवश्यकता होती है HColumnDescriptorकक्षा। इसलिए तत्कालHColumnDescriptorकक्षा। के निर्माताHColumnDescriptorबदले में एक कॉलम परिवार के नाम की आवश्यकता होती है जिसे जोड़ा जाना है। यहाँ हम मौजूदा "कर्मचारी" तालिका में "contactDetails" नामक एक कॉलम परिवार जोड़ रहे हैं।
// Instantiating columnDescriptor object
HColumnDescriptor columnDescriptor = new
HColumnDescriptor("contactDetails");चरण 3
कॉलम परिवार का उपयोग कर जोड़ें addColumnतरीका। तालिका का नाम और पास करेंHColumnDescriptor इस पद्धति के मापदंडों के रूप में वर्ग वस्तु।
// Adding column family
admin.addColumn("employee", new HColumnDescriptor("columnDescriptor"));नीचे दिए गए एक मौजूदा तालिका में एक कॉलम परिवार को जोड़ने का पूरा कार्यक्रम है।
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class AddColoumn{
public static void main(String args[]) throws MasterNotRunningException, IOException{
// Instantiating configuration class.
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class.
HBaseAdmin admin = new HBaseAdmin(conf);
// Instantiating columnDescriptor class
HColumnDescriptor columnDescriptor = new HColumnDescriptor("contactDetails");
// Adding column family
admin.addColumn("employee", columnDescriptor);
System.out.println("coloumn added");
}
}उपरोक्त कार्यक्रम को संकलित और निष्पादित करें जैसा कि नीचे दिखाया गया है।
$javac AddColumn.java
$java AddColumnउपरोक्त संकलन केवल तभी काम करता है, जब आपने क्लासपैथ " .bashrc"। यदि आपने नहीं किया है, तो अपनी .java फ़ाइल संकलित करने के लिए नीचे दी गई प्रक्रिया का पालन करें।
//if "/home/home/hadoop/hbase " is your Hbase home folder then.
$javac -cp /home/hadoop/hbase/lib/*: Demo.javaयदि सबकुछ ठीक हो जाता है, तो यह निम्न आउटपुट का उत्पादन करेगा:
column addedजावा एपीआई का उपयोग करके एक कॉलम परिवार को हटाना
आप विधि का उपयोग करके एक स्तंभ परिवार को तालिका से हटा सकते हैं deleteColumn() का HBAseAdminकक्षा। स्तंभ परिवार को तालिका में जोड़ने के लिए नीचे दिए गए चरणों का पालन करें।
चरण 1
झटपट HBaseAdmin कक्षा।
// Instantiating configuration object
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);चरण 2
कॉलम परिवार का उपयोग कर जोड़ें deleteColumn()तरीका। इस पद्धति के पैरामीटर के रूप में तालिका का नाम और स्तंभ परिवार का नाम पास करें।
// Deleting column family
admin.deleteColumn("employee", "contactDetails");नीचे दी गई एक मौजूदा तालिका से एक कॉलम परिवार को हटाने का पूरा कार्यक्रम है।
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class DeleteColoumn{
public static void main(String args[]) throws MasterNotRunningException, IOException{
// Instantiating configuration class.
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class.
HBaseAdmin admin = new HBaseAdmin(conf);
// Deleting a column family
admin.deleteColumn("employee","contactDetails");
System.out.println("coloumn deleted");
}
}उपरोक्त कार्यक्रम को संकलित और निष्पादित करें जैसा कि नीचे दिखाया गया है।
$javac DeleteColumn.java $java DeleteColumnनिम्नलिखित आउटपुट होना चाहिए:
column deletedHBase शेल का उपयोग करके तालिका का अस्तित्व
आप का उपयोग करके तालिका के अस्तित्व को सत्यापित कर सकते हैं existsआदेश। निम्न उदाहरण दिखाता है कि इस कमांड का उपयोग कैसे किया जाए।
hbase(main):024:0> exists 'emp'
Table emp does exist
0 row(s) in 0.0750 seconds
==================================================================
hbase(main):015:0> exists 'student'
Table student does not exist
0 row(s) in 0.0480 secondsजावा एपीआई का उपयोग करते हुए टेबल के अस्तित्व का सत्यापन
आप HBase में तालिका के अस्तित्व को सत्यापित कर सकते हैं tableExists() की विधि HBaseAdmin कक्षा। HBase में तालिका के अस्तित्व को सत्यापित करने के लिए नीचे दिए गए चरणों का पालन करें।
चरण 1
Instantiate the HBaseAdimn class
// Instantiating configuration object
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);चरण 2
का उपयोग कर तालिका के अस्तित्व की पुष्टि करें tableExists( ) तरीका।
नीचे दिए गए java API का उपयोग करके HBase में तालिका के अस्तित्व का परीक्षण करने के लिए जावा प्रोग्राम है।
import java.io.IOException;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class TableExists{
public static void main(String args[])throws IOException{
// Instantiating configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);
// Verifying the existance of the table
boolean bool = admin.tableExists("emp");
System.out.println( bool);
}
}उपरोक्त कार्यक्रम को संकलित और निष्पादित करें जैसा कि नीचे दिखाया गया है।
$javac TableExists.java $java TableExistsनिम्नलिखित आउटपुट होना चाहिए:
trueHBase शेल का उपयोग करके एक तालिका को छोड़ना
का उपयोग करते हुए dropकमांड, आप एक तालिका हटा सकते हैं। तालिका छोड़ने से पहले, आपको इसे अक्षम करना होगा।
hbase(main):018:0> disable 'emp'
0 row(s) in 1.4580 seconds
hbase(main):019:0> drop 'emp'
0 row(s) in 0.3060 secondsसत्यापित करें कि क्या तालिका मौजूद कमांड का उपयोग करके हटा दी गई है।
hbase(main):020:07gt; exists 'emp'
Table emp does not exist
0 row(s) in 0.0730 secondsdrop_all
इस कमांड का उपयोग कमांड में दिए गए "रेगेक्स" से मेल खाने वाली तालिकाओं को गिराने के लिए किया जाता है। इसका सिंटैक्स इस प्रकार है:
hbase> drop_all ‘t.*’Note: तालिका छोड़ने से पहले, आपको इसे अक्षम करना होगा।
उदाहरण
मान लें कि राज, रजनी, राजेंद्र, राजेश, और राजू नाम की टेबल हैं।
hbase(main):017:0> list
TABLE
raja
rajani
rajendra
rajesh
raju
9 row(s) in 0.0270 secondsये सभी टेबल अक्षरों से शुरू होते हैं raj। सबसे पहले, आइए इन सभी तालिकाओं को निष्क्रिय कर देंdisable_all जैसा कि नीचे दिखाया गया है।
hbase(main):002:0> disable_all 'raj.*'
raja
rajani
rajendra
rajesh
raju
Disable the above 5 tables (y/n)?
y
5 tables successfully disabledअब आप इन सभी का उपयोग करके हटा सकते हैं drop_all जैसा कि नीचे दिया गया है।
hbase(main):018:0> drop_all 'raj.*'
raja
rajani
rajendra
rajesh
raju
Drop the above 5 tables (y/n)?
y
5 tables successfully droppedजावा एपीआई का उपयोग कर एक टेबल को हटाना
आप किसी तालिका का उपयोग करके हटा सकते हैं deleteTable() में विधि HBaseAdminकक्षा। जावा एपीआई का उपयोग करके तालिका को हटाने के लिए नीचे दिए गए चरणों का पालन करें।
चरण 1
HBaseAdmin वर्ग को तुरंत।
// creating a configuration object
Configuration conf = HBaseConfiguration.create();
// Creating HBaseAdmin object
HBaseAdmin admin = new HBaseAdmin(conf);चरण 2
तालिका का उपयोग करके अक्षम करें disableTable() की विधि HBaseAdmin कक्षा।
admin.disableTable("emp1");चरण 3
अब तालिका का उपयोग करके हटाएं deleteTable() की विधि HBaseAdmin कक्षा।
admin.deleteTable("emp12");नीचे दिए गए HBase में एक तालिका को हटाने के लिए पूरा जावा प्रोग्राम है।
import java.io.IOException;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class DeleteTable {
public static void main(String[] args) throws IOException {
// Instantiating configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);
// disabling table named emp
admin.disableTable("emp12");
// Deleting emp
admin.deleteTable("emp12");
System.out.println("Table deleted");
}
}उपरोक्त कार्यक्रम को संकलित और निष्पादित करें जैसा कि नीचे दिखाया गया है।
$javac DeleteTable.java $java DeleteTableनिम्नलिखित आउटपुट होना चाहिए:
Table deletedबाहर जाएं
आप शेल टाइप करके बाहर निकलें exit आदेश।
hbase(main):021:0> exitरुकना HBase
HBase को रोकने के लिए, HBase होम फ़ोल्डर में ब्राउज़ करें और निम्न कमांड टाइप करें।
./bin/stop-hbase.shJava API का उपयोग करके HBase को रोकना
आप का उपयोग करके HBase को बंद कर सकते हैं shutdown() की विधि HBaseAdminकक्षा। HBase को बंद करने के लिए नीचे दिए गए चरणों का पालन करें:
चरण 1
HbaseAdmin वर्ग को तुरंत।
// Instantiating configuration object
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin object
HBaseAdmin admin = new HBaseAdmin(conf);चरण 2
HBase का उपयोग करके शट डाउन करें shutdown() की विधि HBaseAdmin कक्षा।
admin.shutdown();नीचे दिए गए HBase को रोकने का कार्यक्रम है।
import java.io.IOException;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class ShutDownHbase{
public static void main(String args[])throws IOException {
// Instantiating configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);
// Shutting down HBase
System.out.println("Shutting down hbase");
admin.shutdown();
}
}उपरोक्त कार्यक्रम को संकलित और निष्पादित करें जैसा कि नीचे दिखाया गया है।
$javac ShutDownHbase.java $java ShutDownHbaseनिम्नलिखित आउटपुट होना चाहिए:
Shutting down hbaseयह अध्याय HBase के लिए जावा क्लाइंट एपीआई का वर्णन करता है जिसका उपयोग प्रदर्शन के लिए किया जाता है CRUDHBase तालिकाओं पर संचालन। HBase जावा में लिखा गया है और इसमें एक जावा मूल एपीआई है। इसलिए यह डेटा मैनीपुलेशन लैंग्वेज (डीएमएल) को प्रोग्रामेटिक एक्सेस प्रदान करता है।
कक्षा HBase कॉन्फ़िगरेशन
HBase कॉन्फ़िगरेशन फ़ाइलों को कॉन्फ़िगरेशन में जोड़ता है। यह वर्ग किसका हैorg.apache.hadoop.hbase पैकेज।
तरीके और विवरण
| क्र.सं. | तरीके और विवरण |
|---|---|
| 1 | static org.apache.hadoop.conf.Configuration create() यह विधि HBase संसाधनों के साथ कॉन्फ़िगरेशन बनाती है। |
कक्षा HTable
HTable एक HBase आंतरिक वर्ग है जो HBase तालिका का प्रतिनिधित्व करता है। यह तालिका का एक कार्यान्वयन है जिसका उपयोग एकल HBase तालिका के साथ संचार करने के लिए किया जाता है। यह वर्ग किसका हैorg.apache.hadoop.hbase.client कक्षा।
कंस्ट्रक्टर्स
| क्र.सं. | कंस्ट्रक्टर और विवरण |
|---|---|
| 1 | HTable() |
| 2 | HTable(TableName tableName, ClusterConnection connection, ExecutorService pool) इस कंस्ट्रक्टर का उपयोग करके, आप HBase तालिका तक पहुंचने के लिए एक ऑब्जेक्ट बना सकते हैं। |
तरीके और विवरण
| क्र.सं. | तरीके और विवरण |
|---|---|
| 1 | void close() HTable के सभी संसाधनों को जारी करता है। |
| 2 | void delete(Delete delete) निर्दिष्ट कोशिकाओं / पंक्ति को हटाता है। |
| 3 | boolean exists(Get get) इस पद्धति का उपयोग करके, आप तालिका में स्तंभ के अस्तित्व का परीक्षण कर सकते हैं, जैसा कि गेट द्वारा निर्दिष्ट किया गया है। |
| 4 | Result get(Get get) एक निश्चित पंक्ति से कुछ कोशिकाओं को निकालता है। |
| 5 | org.apache.hadoop.conf.Configuration getConfiguration() इस उदाहरण द्वारा उपयोग की गई कॉन्फ़िगरेशन ऑब्जेक्ट लौटाता है। |
| 6 | TableName getName() इस तालिका की तालिका नाम आवृत्ति लौटाता है। |
| 7 | HTableDescriptor getTableDescriptor() इस तालिका के लिए तालिका विवरणक लौटाता है। |
| 8 | byte[] getTableName() इस तालिका का नाम लौटाता है। |
| 9 | void put(Put put) इस पद्धति का उपयोग करके, आप तालिका में डेटा सम्मिलित कर सकते हैं। |
कक्षा पुट
एकल पंक्ति के लिए पुट संचालन करने के लिए इस वर्ग का उपयोग किया जाता है। यह के अंतर्गत आता हैorg.apache.hadoop.hbase.client पैकेज।
कंस्ट्रक्टर्स
| क्र.सं. | कंस्ट्रक्टर और विवरण |
|---|---|
| 1 | Put(byte[] row) इस निर्माता का उपयोग करके, आप निर्दिष्ट पंक्ति के लिए पुट ऑपरेशन बना सकते हैं। |
| 2 | Put(byte[] rowArray, int rowOffset, int rowLength) इस कंस्ट्रक्टर का उपयोग करके, आप स्थानीय रखने के लिए उत्तीर्ण पंक्ति कुंजी की एक प्रति बना सकते हैं। |
| 3 | Put(byte[] rowArray, int rowOffset, int rowLength, long ts) इस कंस्ट्रक्टर का उपयोग करके, आप स्थानीय रखने के लिए उत्तीर्ण पंक्ति कुंजी की एक प्रति बना सकते हैं। |
| 4 | Put(byte[] row, long ts) इस निर्माता का उपयोग करके, हम दिए गए टाइमस्टैम्प का उपयोग करके निर्दिष्ट पंक्ति के लिए पुट ऑपरेशन बना सकते हैं। |
तरीकों
| क्र.सं. | तरीके और विवरण |
|---|---|
| 1 | Put add(byte[] family, byte[] qualifier, byte[] value) इस पुट ऑपरेशन में निर्दिष्ट कॉलम और मूल्य जोड़ता है। |
| 2 | Put add(byte[] family, byte[] qualifier, long ts, byte[] value) निर्दिष्ट कॉलम और मान जोड़ता है, निर्दिष्ट टाइमस्टैम्प के साथ इसके पुट ऑपरेशन के संस्करण के रूप में। |
| 3 | Put add(byte[] family, ByteBuffer qualifier, long ts, ByteBuffer value) निर्दिष्ट कॉलम और मान जोड़ता है, निर्दिष्ट टाइमस्टैम्प के साथ इसके पुट ऑपरेशन के संस्करण के रूप में। |
| 4 | Put add(byte[] family, ByteBuffer qualifier, long ts, ByteBuffer value) निर्दिष्ट कॉलम और मान जोड़ता है, निर्दिष्ट टाइमस्टैम्प के साथ इसके पुट ऑपरेशन के संस्करण के रूप में। |
कक्षा प्राप्त करें
इस कक्षा का उपयोग एक पंक्ति में गेट संचालन करने के लिए किया जाता है। यह वर्ग किसका हैorg.apache.hadoop.hbase.client पैकेज।
निर्माता
| क्र.सं. | कंस्ट्रक्टर और विवरण |
|---|---|
| 1 | Get(byte[] row) इस निर्माता का उपयोग करके, आप निर्दिष्ट पंक्ति के लिए एक गेट ऑपरेशन बना सकते हैं। |
| 2 | Get(Get get) |
तरीकों
| क्र.सं. | तरीके और विवरण |
|---|---|
| 1 | Get addColumn(byte[] family, byte[] qualifier) निर्दिष्ट क्वालीफायर के साथ विशिष्ट परिवार से कॉलम को पुनः प्राप्त करता है। |
| 2 | Get addFamily(byte[] family) निर्दिष्ट परिवार के सभी स्तंभों को पुनः प्राप्त करता है। |
कक्षा हटाना
इस क्लास का उपयोग एक पंक्ति में डिलीट ऑपरेशन करने के लिए किया जाता है। संपूर्ण पंक्ति को हटाने के लिए, हटाने के लिए पंक्ति के साथ एक ऑब्जेक्ट हटाएं। यह वर्ग किसका हैorg.apache.hadoop.hbase.client पैकेज।
निर्माता
| क्र.सं. | कंस्ट्रक्टर और विवरण |
|---|---|
| 1 | Delete(byte[] row) निर्दिष्ट पंक्ति के लिए एक हटाएँ कार्रवाई बनाता है। |
| 2 | Delete(byte[] rowArray, int rowOffset, int rowLength) निर्दिष्ट पंक्ति और टाइमस्टैम्प के लिए एक हटाएँ कार्रवाई बनाता है। |
| 3 | Delete(byte[] rowArray, int rowOffset, int rowLength, long ts) निर्दिष्ट पंक्ति और टाइमस्टैम्प के लिए एक हटाएँ कार्रवाई बनाता है। |
| 4 | Delete(byte[] row, long timestamp) निर्दिष्ट पंक्ति और टाइमस्टैम्प के लिए एक हटाएँ कार्रवाई बनाता है। |
तरीकों
| क्र.सं. | तरीके और विवरण |
|---|---|
| 1 | Delete addColumn(byte[] family, byte[] qualifier) निर्दिष्ट कॉलम के नवीनतम संस्करण को हटाता है। |
| 2 | Delete addColumns(byte[] family, byte[] qualifier, long timestamp) निर्दिष्ट टाइमस्टैम्प से कम या बराबर टाइमस्टैम्प के साथ निर्दिष्ट कॉलम के सभी संस्करणों को हटाता है। |
| 3 | Delete addFamily(byte[] family) निर्दिष्ट परिवार के सभी स्तंभों के सभी संस्करणों को हटाता है। |
| 4 | Delete addFamily(byte[] family, long timestamp) निर्दिष्ट टाइमस्टैम्प से कम या बराबर टाइमस्टैम्प वाले निर्दिष्ट परिवार के सभी कॉलम हटाता है। |
कक्षा का परिणाम
इस वर्ग का उपयोग गेट या स्कैन क्वेरी की एकल पंक्ति परिणाम प्राप्त करने के लिए किया जाता है।
कंस्ट्रक्टर्स
| क्र.सं. | कंस्ट्रक्टर्स |
|---|---|
| 1 | Result() इस निर्माता का उपयोग करके, आप बिना KeyValue पेलोड के एक खाली परिणाम बना सकते हैं; यदि आप कच्चे सेल () कहते हैं तो अशक्त है। |
तरीकों
| क्र.सं. | तरीके और विवरण |
|---|---|
| 1 | byte[] getValue(byte[] family, byte[] qualifier) इस पद्धति का उपयोग निर्दिष्ट कॉलम के नवीनतम संस्करण को प्राप्त करने के लिए किया जाता है। |
| 2 | byte[] getRow() इस विधि का उपयोग उस पंक्ति कुंजी को पुनः प्राप्त करने के लिए किया जाता है जो उस पंक्ति से मेल खाती है जिससे यह परिणाम बनाया गया था। |
HBase शेल का उपयोग करके डेटा सम्मिलित करना
यह अध्याय दर्शाता है कि HBase तालिका में डेटा कैसे बनाया जाए। HBase तालिका में डेटा बनाने के लिए, निम्नलिखित कमांड और विधियों का उपयोग किया जाता है:
put आदेश,
add() उसकि विधि Put कक्षा, और
put() उसकि विधि HTable कक्षा।
एक उदाहरण के रूप में, हम HBase में निम्न तालिका बनाने जा रहे हैं।
का उपयोग करते हुए putकमांड, आप एक तालिका में पंक्तियाँ सम्मिलित कर सकते हैं। इसका सिंटैक्स इस प्रकार है:
put ’<table name>’,’row1’,’<colfamily:colname>’,’<value>’पहली पंक्ति सम्मिलित करना
नीचे दी गई सूची के अनुसार पहली पंक्ति के मानों को हम एम्पायर टेबल में डालें।
hbase(main):005:0> put 'emp','1','personal data:name','raju'
0 row(s) in 0.6600 seconds
hbase(main):006:0> put 'emp','1','personal data:city','hyderabad'
0 row(s) in 0.0410 seconds
hbase(main):007:0> put 'emp','1','professional
data:designation','manager'
0 row(s) in 0.0240 seconds
hbase(main):007:0> put 'emp','1','professional data:salary','50000'
0 row(s) in 0.0240 secondsउसी तरह पुट कमांड का उपयोग करके शेष पंक्तियों को डालें। यदि आप पूरी तालिका सम्मिलित करते हैं, तो आपको निम्न आउटपुट मिलेगा।
hbase(main):022:0> scan 'emp'
ROW COLUMN+CELL
1 column=personal data:city, timestamp=1417524216501, value=hyderabad
1 column=personal data:name, timestamp=1417524185058, value=ramu
1 column=professional data:designation, timestamp=1417524232601,
value=manager
1 column=professional data:salary, timestamp=1417524244109, value=50000
2 column=personal data:city, timestamp=1417524574905, value=chennai
2 column=personal data:name, timestamp=1417524556125, value=ravi
2 column=professional data:designation, timestamp=1417524592204,
value=sr:engg
2 column=professional data:salary, timestamp=1417524604221, value=30000
3 column=personal data:city, timestamp=1417524681780, value=delhi
3 column=personal data:name, timestamp=1417524672067, value=rajesh
3 column=professional data:designation, timestamp=1417524693187,
value=jr:engg
3 column=professional data:salary, timestamp=1417524702514,
value=25000जावा एपीआई का उपयोग करके डेटा सम्मिलित करना
आप का उपयोग करके Hbase में डेटा सम्मिलित कर सकते हैं add() की विधि Putकक्षा। आप इसे का उपयोग कर बचा सकते हैंput() की विधि HTableकक्षा। इन वर्गों के हैंorg.apache.hadoop.hbase.clientपैकेज। नीचे दिए गए कदम HBase की तालिका में डेटा बनाने के लिए हैं।
चरण 1: कॉन्फ़िगरेशन क्लास को तुरंत
Configurationवर्ग HBase विन्यास फाइल को अपनी वस्तु में जोड़ता है। आप का उपयोग करके एक कॉन्फ़िगरेशन ऑब्जेक्ट बना सकते हैंcreate() की विधि HbaseConfiguration नीचे दिखाया गया है।
Configuration conf = HbaseConfiguration.create();चरण 2: HTable कक्षा को तुरंत लिखें
आपके पास एक वर्ग है जिसे बुलाया गया है HTable, HBase में तालिका का कार्यान्वयन। इस वर्ग का उपयोग एकल HBase तालिका के साथ संवाद करने के लिए किया जाता है। इस वर्ग को त्वरित करते समय, यह कॉन्फ़िगरेशन ऑब्जेक्ट और टेबल नाम को मापदंडों के रूप में स्वीकार करता है। आप नीचे दिखाए गए अनुसार HTable क्लास को इंस्टेंट कर सकते हैं।
HTable hTable = new HTable(conf, tableName);चरण 3: पुटक्लास को त्वरित करें
HBase तालिका में डेटा सम्मिलित करने के लिए, add()विधि और इसके वेरिएंट का उपयोग किया जाता है। यह विधि किसकी हैPut, इसलिए पुट क्लास को इंस्टेंट करें। इस वर्ग को उस पंक्ति के नाम की आवश्यकता होती है जिसे आप स्ट्रिंग प्रारूप में डेटा सम्मिलित करना चाहते हैं। आप तत्काल कर सकते हैंPut नीचे दिखाया गया है।
Put p = new Put(Bytes.toBytes("row1"));चरण 4: सम्मिलित करें
add() उसकि विधि Putक्लास का उपयोग डेटा डालने के लिए किया जाता है। इसके लिए कॉलम परिवार, कॉलम क्वालिफायर (कॉलम नाम) का प्रतिनिधित्व करने वाले 3 बाइट सरणियों की आवश्यकता होती है, और क्रमशः डाले जाने वाले मूल्य। नीचे दिखाए अनुसार () विधि का उपयोग करके HBase तालिका में डेटा डालें।
p.add(Bytes.toBytes("coloumn family "), Bytes.toBytes("column
name"),Bytes.toBytes("value"));चरण 5: तालिका में डेटा सहेजें
आवश्यक पंक्तियाँ डालने के बाद, पुट आवृत्ति को जोड़कर परिवर्तनों को सहेजें put() नीचे दिखाए अनुसार HTable वर्ग की विधि।
hTable.put(p);चरण 6: HTable इंस्टेंस को बंद करें
HBase तालिका में डेटा बनाने के बाद, बंद करें HTable उदाहरण का उपयोग करते हुए close() तरीका नीचे दिखाया गया है।
hTable.close();नीचे दिए गए HBase तालिका में डेटा बनाने का पूरा कार्यक्रम है।
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes;
public class InsertData{
public static void main(String[] args) throws IOException {
// Instantiating Configuration class
Configuration config = HBaseConfiguration.create();
// Instantiating HTable class
HTable hTable = new HTable(config, "emp");
// Instantiating Put class
// accepts a row name.
Put p = new Put(Bytes.toBytes("row1"));
// adding values using add() method
// accepts column family name, qualifier/row name ,value
p.add(Bytes.toBytes("personal"),
Bytes.toBytes("name"),Bytes.toBytes("raju"));
p.add(Bytes.toBytes("personal"),
Bytes.toBytes("city"),Bytes.toBytes("hyderabad"));
p.add(Bytes.toBytes("professional"),Bytes.toBytes("designation"),
Bytes.toBytes("manager"));
p.add(Bytes.toBytes("professional"),Bytes.toBytes("salary"),
Bytes.toBytes("50000"));
// Saving the put Instance to the HTable.
hTable.put(p);
System.out.println("data inserted");
// closing HTable
hTable.close();
}
}उपरोक्त कार्यक्रम को संकलित और निष्पादित करें जैसा कि नीचे दिखाया गया है।
$javac InsertData.java $java InsertDataनिम्नलिखित आउटपुट होना चाहिए:
data insertedHBase शेल का उपयोग करके डेटा अपडेट करना
आप मौजूदा सेल वैल्यू को अपडेट कर सकते हैं putआदेश। ऐसा करने के लिए, बस एक ही वाक्यविन्यास का पालन करें और नीचे दिखाए गए अनुसार अपने नए मूल्य का उल्लेख करें।
put ‘table name’,’row ’,'Column family:column name',’new value’नया दिया गया मान मौजूदा मान को प्रतिस्थापित करता है, पंक्ति को अद्यतन करता है।
उदाहरण
मान लीजिए HBase में एक टेबल है जिसे कहा जाता है emp निम्नलिखित आंकड़ों के साथ।
hbase(main):003:0> scan 'emp'
ROW COLUMN + CELL
row1 column = personal:name, timestamp = 1418051555, value = raju
row1 column = personal:city, timestamp = 1418275907, value = Hyderabad
row1 column = professional:designation, timestamp = 14180555,value = manager
row1 column = professional:salary, timestamp = 1418035791555,value = 50000
1 row(s) in 0.0100 secondsनिम्नलिखित आदेश दिल्ली में 'राजू' नामक कर्मचारी के शहर मूल्य को अपडेट करेगा।
hbase(main):002:0> put 'emp','row1','personal:city','Delhi'
0 row(s) in 0.0400 secondsअपडेट की गई तालिका निम्नानुसार है जहां आप देख सकते हैं कि राजू शहर को 'दिल्ली' में बदल दिया गया है।
hbase(main):003:0> scan 'emp'
ROW COLUMN + CELL
row1 column = personal:name, timestamp = 1418035791555, value = raju
row1 column = personal:city, timestamp = 1418274645907, value = Delhi
row1 column = professional:designation, timestamp = 141857555,value = manager
row1 column = professional:salary, timestamp = 1418039555, value = 50000
1 row(s) in 0.0100 secondsजावा एपीआई का उपयोग कर डेटा को अपडेट करना
आप किसी विशेष सेल में डेटा का उपयोग करके अपडेट कर सकते हैं put()तरीका। तालिका के मौजूदा सेल मान को अपडेट करने के लिए नीचे दिए गए चरणों का पालन करें।
चरण 1: कॉन्फ़िगरेशन क्लास को तुरंत
Configurationवर्ग HBase विन्यास फाइल को अपनी वस्तु में जोड़ता है। आप का उपयोग करके एक कॉन्फ़िगरेशन ऑब्जेक्ट बना सकते हैंcreate() की विधि HbaseConfiguration नीचे दिखाया गया है।
Configuration conf = HbaseConfiguration.create();चरण 2: HTable कक्षा को तुरंत लिखें
आपके पास एक वर्ग है जिसे बुलाया गया है HTable, HBase में तालिका का कार्यान्वयन। इस वर्ग का उपयोग एकल HBase तालिका के साथ संवाद करने के लिए किया जाता है। इस वर्ग को त्वरित करते समय, यह कॉन्फ़िगरेशन ऑब्जेक्ट और तालिका नाम को मापदंडों के रूप में स्वीकार करता है। आप नीचे दिखाए गए अनुसार HTable वर्ग को देख सकते हैं।
HTable hTable = new HTable(conf, tableName);चरण 3: पुट क्लास को त्वरित करें
HBase तालिका में डेटा सम्मिलित करने के लिए, add()विधि और इसके वेरिएंट का उपयोग किया जाता है। यह विधि किसकी हैPut, इसलिए तुरंत putकक्षा। इस वर्ग को उस पंक्ति के नाम की आवश्यकता होती है जिसे आप स्ट्रिंग प्रारूप में डेटा सम्मिलित करना चाहते हैं। आप तत्काल कर सकते हैंPut नीचे दिखाया गया है।
Put p = new Put(Bytes.toBytes("row1"));चरण 4: एक मौजूदा सेल को अपडेट करें
add() उसकि विधि Putक्लास का उपयोग डेटा डालने के लिए किया जाता है। इसके लिए कॉलम परिवार, कॉलम क्वालिफायर (कॉलम नाम) का प्रतिनिधित्व करने वाले 3 बाइट सरणियों की आवश्यकता होती है, और क्रमशः डाले जाने वाले मूल्य। का उपयोग करके HBase तालिका में डेटा डालेंadd() तरीका नीचे दिखाया गया है।
p.add(Bytes.toBytes("coloumn family "), Bytes.toBytes("column
name"),Bytes.toBytes("value"));
p.add(Bytes.toBytes("personal"),
Bytes.toBytes("city"),Bytes.toBytes("Delih"));चरण 5: तालिका में डेटा सहेजें
आवश्यक पंक्तियाँ डालने के बाद, पुट आवृत्ति को जोड़कर परिवर्तनों को सहेजें put() HTable वर्ग की विधि जैसा कि नीचे दिखाया गया है।
hTable.put(p);चरण 6: HTable इंस्टेंस को बंद करें
HBase तालिका में डेटा बनाने के बाद, बंद करें HTable नीचे दिखाए अनुसार () विधि का उपयोग कर उदाहरण।
hTable.close();नीचे दिए गए किसी विशेष तालिका में डेटा को अपडेट करने का पूरा कार्यक्रम है।
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes;
public class UpdateData{
public static void main(String[] args) throws IOException {
// Instantiating Configuration class
Configuration config = HBaseConfiguration.create();
// Instantiating HTable class
HTable hTable = new HTable(config, "emp");
// Instantiating Put class
//accepts a row name
Put p = new Put(Bytes.toBytes("row1"));
// Updating a cell value
p.add(Bytes.toBytes("personal"),
Bytes.toBytes("city"),Bytes.toBytes("Delih"));
// Saving the put Instance to the HTable.
hTable.put(p);
System.out.println("data Updated");
// closing HTable
hTable.close();
}
}उपरोक्त कार्यक्रम को संकलित और निष्पादित करें जैसा कि नीचे दिखाया गया है।
$javac UpdateData.java $java UpdateDataनिम्नलिखित आउटपुट होना चाहिए:
data UpdatedHBase शेल का उपयोग करके डेटा पढ़ना
get कमान और get() उसकि विधि HTableHBase में तालिका से डेटा पढ़ने के लिए कक्षा का उपयोग किया जाता है। का उपयोग करते हुएgetकमांड, आप एक बार में डेटा की एक पंक्ति प्राप्त कर सकते हैं। इसका सिंटैक्स इस प्रकार है:
get ’<table name>’,’row1’उदाहरण
निम्न उदाहरण दिखाता है कि प्राप्त कमांड का उपयोग कैसे करें। की पहली पंक्ति को स्कैन करते हैंemp तालिका।
hbase(main):012:0> get 'emp', '1'
COLUMN CELL
personal : city timestamp = 1417521848375, value = hyderabad
personal : name timestamp = 1417521785385, value = ramu
professional: designation timestamp = 1417521885277, value = manager
professional: salary timestamp = 1417521903862, value = 50000
4 row(s) in 0.0270 secondsएक विशिष्ट कॉलम पढ़ना
नीचे दिए गए एक विशेष कॉलम को पढ़ने के लिए सिंटैक्स दिया गया है get तरीका।
hbase> get 'table name', ‘rowid’, {COLUMN ⇒ ‘column family:column name ’}उदाहरण
नीचे दिए गए उदाहरण HBase तालिका में एक विशिष्ट कॉलम पढ़ने के लिए है।
hbase(main):015:0> get 'emp', 'row1', {COLUMN ⇒ 'personal:name'}
COLUMN CELL
personal:name timestamp = 1418035791555, value = raju
1 row(s) in 0.0080 secondsजावा एपीआई का उपयोग करते हुए डेटा पढ़ना
HBase तालिका से डेटा पढ़ने के लिए, का उपयोग करें get()HTable वर्ग की विधि। इस विधि के लिए एक उदाहरण की आवश्यकता हैGetकक्षा। HBase तालिका से डेटा पुनर्प्राप्त करने के लिए नीचे दिए गए चरणों का पालन करें।
चरण 1: कॉन्फ़िगरेशन क्लास को तुरंत
Configurationवर्ग HBase विन्यास फाइल को अपनी वस्तु में जोड़ता है। आप का उपयोग करके एक कॉन्फ़िगरेशन ऑब्जेक्ट बना सकते हैंcreate() की विधि HbaseConfiguration नीचे दिखाया गया है।
Configuration conf = HbaseConfiguration.create();चरण 2: HTable कक्षा को तुरंत लिखें
आपके पास एक वर्ग है जिसे बुलाया गया है HTable, HBase में तालिका का कार्यान्वयन। इस वर्ग का उपयोग एकल HBase तालिका के साथ संवाद करने के लिए किया जाता है। इस वर्ग को त्वरित करते समय, यह कॉन्फ़िगरेशन ऑब्जेक्ट और तालिका नाम को मापदंडों के रूप में स्वीकार करता है। आप नीचे दिखाए गए अनुसार HTable वर्ग को देख सकते हैं।
HTable hTable = new HTable(conf, tableName);चरण 3: क्लास को तुरंत प्राप्त करें
आप का उपयोग करके HBase तालिका से डेटा पुनः प्राप्त कर सकते हैं get() की विधि HTableकक्षा। यह विधि किसी पंक्ति से किसी सेल को निकालती है। यह एक की आवश्यकता हैGetपैरामीटर के रूप में क्लास ऑब्जेक्ट। इसे नीचे दिखाए अनुसार बनाएँ।
Get get = new Get(toBytes("row1"));चरण 4: डेटा पढ़ें
डेटा पुनर्प्राप्त करते समय, आप आईडी द्वारा एकल पंक्ति प्राप्त कर सकते हैं, या पंक्ति आईडी के सेट द्वारा पंक्तियों का एक सेट प्राप्त कर सकते हैं, या संपूर्ण तालिका या पंक्तियों के सबसेट को स्कैन कर सकते हैं।
आप में ऐड मेथड वेरिएंट का उपयोग करके एक HBase टेबल डेटा प्राप्त कर सकते हैं Get कक्षा।
किसी विशिष्ट स्तंभ परिवार से एक विशिष्ट स्तंभ प्राप्त करने के लिए, निम्न विधि का उपयोग करें।
get.addFamily(personal)किसी विशिष्ट स्तंभ परिवार से सभी कॉलम प्राप्त करने के लिए, निम्न विधि का उपयोग करें।
get.addColumn(personal, name)चरण 5: परिणाम प्राप्त करें
अपना उत्तीर्ण करके परिणाम प्राप्त करें Get की विधि प्राप्त करने के लिए वर्ग उदाहरण HTableकक्षा। यह विधि लौटती हैResultक्लास ऑब्जेक्ट, जो अनुरोधित परिणाम रखता है। नीचे दिए गए का उपयोग हैget() तरीका।
Result result = table.get(g);चरण 6: परिणाम उदाहरण से पढ़ना मान
Result वर्ग प्रदान करता है getValue()इसके उदाहरण से मान पढ़ने की विधि। मानों को पढ़ने के लिए नीचे दिखाए अनुसार इसका उपयोग करेंResult उदाहरण।
byte [] value = result.getValue(Bytes.toBytes("personal"),Bytes.toBytes("name"));
byte [] value1 = result.getValue(Bytes.toBytes("personal"),Bytes.toBytes("city"));नीचे दिए गए एक HBase तालिका से मान पढ़ने के लिए पूरा कार्यक्रम है।
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.util.Bytes;
public class RetriveData{
public static void main(String[] args) throws IOException, Exception{
// Instantiating Configuration class
Configuration config = HBaseConfiguration.create();
// Instantiating HTable class
HTable table = new HTable(config, "emp");
// Instantiating Get class
Get g = new Get(Bytes.toBytes("row1"));
// Reading the data
Result result = table.get(g);
// Reading values from Result class object
byte [] value = result.getValue(Bytes.toBytes("personal"),Bytes.toBytes("name"));
byte [] value1 = result.getValue(Bytes.toBytes("personal"),Bytes.toBytes("city"));
// Printing the values
String name = Bytes.toString(value);
String city = Bytes.toString(value1);
System.out.println("name: " + name + " city: " + city);
}
}उपरोक्त कार्यक्रम को संकलित और निष्पादित करें जैसा कि नीचे दिखाया गया है।
$javac RetriveData.java $java RetriveDataनिम्नलिखित आउटपुट होना चाहिए:
name: Raju city: Delhiतालिका में एक विशिष्ट कक्ष हटाना
का उपयोग करते हुए deleteकमांड, आप किसी तालिका में एक विशिष्ट सेल हटा सकते हैं। का वाक्य विन्यासdelete कमांड इस प्रकार है:
delete ‘<table name>’, ‘<row>’, ‘<column name >’, ‘<time stamp>’उदाहरण
यहां एक विशिष्ट सेल को हटाने के लिए एक उदाहरण दिया गया है। यहां हम वेतन हटा रहे हैं।
hbase(main):006:0> delete 'emp', '1', 'personal data:city',
1417521848375
0 row(s) in 0.0060 secondsतालिका में सभी कक्ष हटाना
"डिलीटल" कमांड का उपयोग करके, आप एक पंक्ति में सभी कोशिकाओं को हटा सकते हैं। नीचे दिए गए डिलीट कमांड का सिंटैक्स है।
deleteall ‘<table name>’, ‘<row>’,उदाहरण
यहाँ "डिलीट" कमांड का एक उदाहरण है, जहाँ हम एम्पायर टेबल की पंक्ति 1 की सभी कोशिकाओं को हटा रहे हैं।
hbase(main):007:0> deleteall 'emp','1'
0 row(s) in 0.0240 secondsतालिका का उपयोग करके सत्यापित करें scanआदेश। तालिका को हटाने के बाद तालिका का एक स्नैपशॉट नीचे दिया गया है।
hbase(main):022:0> scan 'emp'
ROW COLUMN + CELL
2 column = personal data:city, timestamp = 1417524574905, value = chennai
2 column = personal data:name, timestamp = 1417524556125, value = ravi
2 column = professional data:designation, timestamp = 1417524204, value = sr:engg
2 column = professional data:salary, timestamp = 1417524604221, value = 30000
3 column = personal data:city, timestamp = 1417524681780, value = delhi
3 column = personal data:name, timestamp = 1417524672067, value = rajesh
3 column = professional data:designation, timestamp = 1417523187, value = jr:engg
3 column = professional data:salary, timestamp = 1417524702514, value = 25000जावा एपीआई का उपयोग करके डेटा हटाना
आप का उपयोग करके एक HBase तालिका से डेटा हटा सकते हैं delete() की विधि HTableकक्षा। तालिका से डेटा हटाने के लिए नीचे दिए गए चरणों का पालन करें।
चरण 1: कॉन्फ़िगरेशन क्लास को तुरंत
Configurationवर्ग HBase विन्यास फाइल को अपनी वस्तु में जोड़ता है। आप का उपयोग करके एक कॉन्फ़िगरेशन ऑब्जेक्ट बना सकते हैंcreate() की विधि HbaseConfiguration नीचे दिखाया गया है।
Configuration conf = HbaseConfiguration.create();चरण 2: HTable कक्षा को तुरंत लिखें
आपके पास एक वर्ग है जिसे बुलाया गया है HTable, HBase में तालिका का कार्यान्वयन। इस वर्ग का उपयोग एकल HBase तालिका के साथ संवाद करने के लिए किया जाता है। इस वर्ग को त्वरित करते समय, यह कॉन्फ़िगरेशन ऑब्जेक्ट और तालिका नाम को मापदंडों के रूप में स्वीकार करता है। आप नीचे दिखाए गए अनुसार HTable वर्ग को देख सकते हैं।
HTable hTable = new HTable(conf, tableName);स्टेप 3: डिलीट क्लास को इंस्टेंट करें
झटपट Deleteजिस पंक्ति को हटाना है उसकी पंक्ति को बाइट सरणी प्रारूप में पास करके वर्ग। आप इस निर्माणकर्ता के लिए टाइमस्टैम्प और रोवलॉक भी पास कर सकते हैं।
Delete delete = new Delete(toBytes("row1"));चरण 4: हटाए जाने के लिए डेटा का चयन करें
के डिलीट मेथड्स का उपयोग कर आप डेटा को डिलीट कर सकते हैं Deleteकक्षा। इस वर्ग में विभिन्न हटाने के तरीके हैं। उन विधियों का उपयोग करके हटाए जाने वाले कॉलम या कॉलम परिवारों को चुनें। निम्नलिखित उदाहरणों पर एक नज़र डालें जो डिलीट क्लास के तरीकों का उपयोग दिखाते हैं।
delete.deleteColumn(Bytes.toBytes("personal"), Bytes.toBytes("name"));
delete.deleteFamily(Bytes.toBytes("professional"));चरण 5: डेटा हटाएं
चयनित डेटा को पास करके हटाएं delete उदाहरण के लिए delete() की विधि HTable नीचे दिखाया गया है।
table.delete(delete);चरण 6: HTableInstance को बंद करें
डेटा हटाने के बाद, बंद करें HTable उदाहरण।
table.close();नीचे दिए गए HBase तालिका से डेटा हटाने का पूरा कार्यक्रम है।
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.util.Bytes;
public class DeleteData {
public static void main(String[] args) throws IOException {
// Instantiating Configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HTable class
HTable table = new HTable(conf, "employee");
// Instantiating Delete class
Delete delete = new Delete(Bytes.toBytes("row1"));
delete.deleteColumn(Bytes.toBytes("personal"), Bytes.toBytes("name"));
delete.deleteFamily(Bytes.toBytes("professional"));
// deleting the data
table.delete(delete);
// closing the HTable object
table.close();
System.out.println("data deleted.....");
}
}उपरोक्त कार्यक्रम को संकलित और निष्पादित करें जैसा कि नीचे दिखाया गया है।
$javac Deletedata.java $java DeleteDataनिम्नलिखित आउटपुट होना चाहिए:
data deletedHBase शेल का उपयोग करके स्कैन करना
scanHTable में डेटा देखने के लिए कमांड का उपयोग किया जाता है। स्कैन कमांड का उपयोग करके, आप टेबल डेटा प्राप्त कर सकते हैं। इसका सिंटैक्स इस प्रकार है:
scan ‘<table name>’उदाहरण
निम्न उदाहरण दिखाता है कि स्कैन कमांड का उपयोग करके तालिका से डेटा कैसे पढ़ें। यहां हम पढ़ रहे हैंemp तालिका।
hbase(main):010:0> scan 'emp'
ROW COLUMN + CELL
1 column = personal data:city, timestamp = 1417521848375, value = hyderabad
1 column = personal data:name, timestamp = 1417521785385, value = ramu
1 column = professional data:designation, timestamp = 1417585277,value = manager
1 column = professional data:salary, timestamp = 1417521903862, value = 50000
1 row(s) in 0.0370 secondsजावा एपीआई का उपयोग कर स्कैनिंग
जावा एपीआई का उपयोग करके पूरे टेबल डेटा को स्कैन करने का पूरा कार्यक्रम इस प्रकार है।
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
public class ScanTable{
public static void main(String args[]) throws IOException{
// Instantiating Configuration class
Configuration config = HBaseConfiguration.create();
// Instantiating HTable class
HTable table = new HTable(config, "emp");
// Instantiating the Scan class
Scan scan = new Scan();
// Scanning the required columns
scan.addColumn(Bytes.toBytes("personal"), Bytes.toBytes("name"));
scan.addColumn(Bytes.toBytes("personal"), Bytes.toBytes("city"));
// Getting the scan result
ResultScanner scanner = table.getScanner(scan);
// Reading values from scan result
for (Result result = scanner.next(); result != null; result = Scanner.next())
System.out.println("Found row : " + result);
//closing the scanner
scanner.close();
}
}उपरोक्त कार्यक्रम को संकलित और निष्पादित करें जैसा कि नीचे दिखाया गया है।
$javac ScanTable.java $java ScanTableनिम्नलिखित आउटपुट होना चाहिए:
Found row :
keyvalues={row1/personal:city/1418275612888/Put/vlen=5/mvcc=0,
row1/personal:name/1418035791555/Put/vlen=4/mvcc=0}गिनती
आप किसी तालिका की पंक्तियों की संख्या का उपयोग करके गणना कर सकते हैं countआदेश। इसका सिंटैक्स इस प्रकार है:
count ‘<table name>’पहली पंक्ति को हटाने के बाद, एम्प टेबल में दो पंक्तियाँ होंगी। इसे नीचे दिखाए अनुसार सत्यापित करें।
hbase(main):023:0> count 'emp'
2 row(s) in 0.090 seconds
⇒ 2काट-छांट
यह कमांड ड्रॉप्स को निष्क्रिय करता है और एक टेबल को फिर से बनाता है। का वाक्य विन्यासtruncate इस प्रकार है:
hbase> truncate 'table name'उदाहरण
नीचे दिया गया ट्रंकट कमांड का उदाहरण है। यहाँ पर हमने छंटनी की हैemp तालिका।
hbase(main):011:0> truncate 'emp'
Truncating 'one' table (it may take a while):
- Disabling table...
- Truncating table...
0 row(s) in 1.5950 secondsतालिका को छोटा करने के बाद, सत्यापित करने के लिए स्कैन कमांड का उपयोग करें। आपको शून्य पंक्तियों वाली एक तालिका मिलेगी।
hbase(main):017:0> scan ‘emp’
ROW COLUMN + CELL
0 row(s) in 0.3110 secondsहम HBase में उपयोगकर्ताओं को अनुमति दे सकते हैं और रद्द कर सकते हैं। सुरक्षा उद्देश्य के लिए तीन कमांड हैं: अनुदान, निरस्त और user_permission।
अनुदान
grantएक विशिष्ट उपयोगकर्ता के लिए टेबल पर विशिष्ट अधिकार जैसे कि पढ़ना, लिखना, निष्पादित करना और व्यवस्थापन देना। अनुदान कमांड का सिंटैक्स निम्नानुसार है:
hbase> grant <user> <permissions> [<table> [<column family> [<column; qualifier>]]हम RWXCA के सेट से उपयोगकर्ता को शून्य या अधिक विशेषाधिकार प्रदान कर सकते हैं, जहां
- आर - पढ़े गए विशेषाधिकार का प्रतिनिधित्व करता है।
- डब्ल्यू - लेखन विशेषाधिकार का प्रतिनिधित्व करता है।
- एक्स - निष्पादित विशेषाधिकार का प्रतिनिधित्व करता है।
- सी - विशेषाधिकार बनाने का प्रतिनिधित्व करता है।
- A - व्यवस्थापक विशेषाधिकार का प्रतिनिधित्व करता है।
नीचे एक उदाहरण दिया गया है जो 'Tutorialspoint' नाम के उपयोगकर्ता को सभी विशेषाधिकार प्रदान करता है।
hbase(main):018:0> grant 'Tutorialspoint', 'RWXCA'वापस लेना
revokeकिसी तालिका के उपयोगकर्ता के अधिकारों को रद्द करने के लिए कमांड का उपयोग किया जाता है। इसका सिंटैक्स इस प्रकार है:
hbase> revoke <user>निम्न कोड 'Tutorialspoint' नाम के उपयोगकर्ता की सभी अनुमतियों को रद्द करता है।
hbase(main):006:0> revoke 'Tutorialspoint'user_permission
इस आदेश का उपयोग किसी विशेष तालिका के लिए सभी अनुमतियों को सूचीबद्ध करने के लिए किया जाता है। का वाक्य विन्यासuser_permission इस प्रकार है:
hbase>user_permission ‘tablename’निम्न कोड 'एम्प' टेबल के सभी उपयोगकर्ता अनुमतियों को सूचीबद्ध करता है।
hbase(main):013:0> user_permission 'emp'