एमएल - दृश्य के साथ डेटा को समझना
परिचय
पिछले अध्याय में, हमने आंकड़ों के साथ डेटा को समझने के लिए कुछ पायथन व्यंजनों के साथ मशीन लर्निंग एल्गोरिदम के लिए डेटा के महत्व पर चर्चा की है। डेटा को समझने के लिए विज़ुअलाइज़ेशन नामक एक और तरीका है।
डेटा विज़ुअलाइज़ेशन की मदद से, हम देख सकते हैं कि डेटा कैसा दिखता है और डेटा की विशेषताओं द्वारा किस प्रकार का सहसंबंध होता है। यह देखने का सबसे तेज़ तरीका है कि क्या सुविधाएँ आउटपुट के अनुरूप हैं। निम्नलिखित पायथन व्यंजनों की मदद से, हम आंकड़ों के साथ एमएल डेटा को समझ सकते हैं।

Univariate Plots: अंडरस्टैंडिंग एट्रीब्यूट्स इंडिपेंडेंटली
विज़ुअलाइज़ेशन का सबसे सरल प्रकार एकल-चर या "यूनीवेरिएट" विज़ुअलाइज़ेशन है। अविभाज्य विज़ुअलाइज़ेशन की मदद से, हम अपने डेटासेट की प्रत्येक विशेषता को स्वतंत्र रूप से समझ सकते हैं। निम्नलिखित दृश्यों में कुछ तकनीकें हैं जो एकतरफा दृश्य को लागू करती हैं -
हिस्टोग्राम
हिस्टोग्राम्स डेटा को डिब्बे में समूहित करता है और डेटासेट में प्रत्येक विशेषता के वितरण के बारे में विचार प्राप्त करने का सबसे तेज़ तरीका है। हिस्टोग्राम की कुछ विशेषताएं निम्नलिखित हैं -
यह हमें विज़ुअलाइज़ेशन के लिए बनाए गए प्रत्येक बिन में टिप्पणियों की संख्या की एक संख्या प्रदान करता है।
बिन के आकार से, हम वितरण को आसानी से देख सकते हैं अर्थात मौसम यह गाऊसी, तिरछा या घातीय है।
हिस्टोग्राम भी संभव आउटलेर्स को देखने में हमारी मदद करते हैं।
उदाहरण
नीचे दिखाया गया कोड, पायमोन लिपि का एक उदाहरण है, जो पीमा इंडियन डायबिटीज डेटासेट की विशेषताओं का हिस्टोग्राम बनाता है। यहाँ, हम histograms उत्पन्न करने के लिए पंडों DataFrame पर hist () फ़ंक्शन का उपयोग करेंगे औरmatplotlib उन्हें साजिश रचने के लिए।
from matplotlib import pyplot
from pandas import read_csv
path = r"C:\pima-indians-diabetes.csv"
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(path, names=names)
data.hist()
pyplot.show()उत्पादन
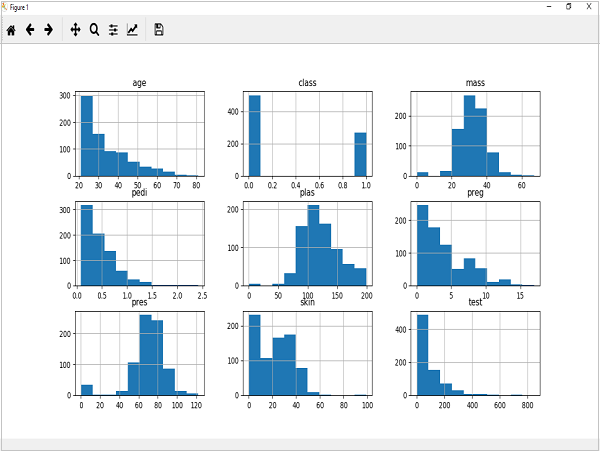
उपरोक्त आउटपुट से पता चलता है कि इसने डेटासेट में प्रत्येक विशेषता के लिए हिस्टोग्राम बनाया है। इससे, हम देख सकते हैं कि शायद उम्र, पैडी और परीक्षण विशेषता में घातीय वितरण हो सकता है जबकि द्रव्यमान और प्लास में गौसियन वितरण होता है।
घनत्व प्लॉट
प्रत्येक विशेषता वितरण प्राप्त करने के लिए एक और त्वरित और आसान तकनीक घनत्व प्लॉट्स है। यह हिस्टोग्राम की तरह भी है, लेकिन प्रत्येक बिन के शीर्ष के माध्यम से एक चिकनी वक्र खींचा गया है। हम उन्हें सार हिस्टोग्राम कह सकते हैं।
उदाहरण
निम्नलिखित उदाहरण में, पायथन लिपि पीमा इंडियन डायबिटीज डेटासेट की विशेषताओं के वितरण के लिए घनत्व प्लॉट उत्पन्न करेगी।
from matplotlib import pyplot
from pandas import read_csv
path = r"C:\pima-indians-diabetes.csv"
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(path, names=names)
data.plot(kind='density', subplots=True, layout=(3,3), sharex=False)
pyplot.show()उत्पादन
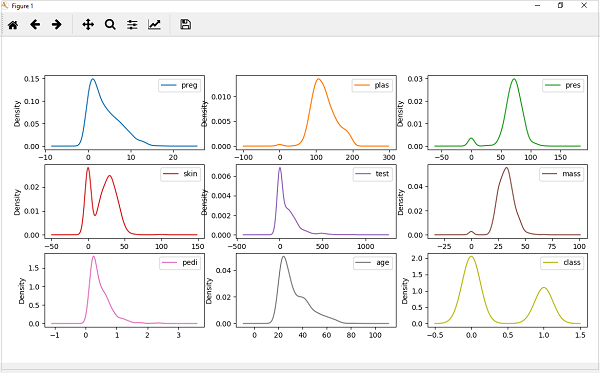
उपरोक्त आउटपुट से, घनत्व प्लॉट और हिस्टोग्राम के बीच के अंतर को आसानी से समझा जा सकता है।
बॉक्स और व्हिस्कर प्लॉट
बॉक्स और व्हिस्कर भूखंड, जिसे संक्षेप में बॉक्सप्लेट भी कहा जाता है, प्रत्येक विशेषता के वितरण की समीक्षा करने के लिए एक और उपयोगी तकनीक है। इस तकनीक की विशेषताएं निम्नलिखित हैं -
यह प्रकृति में अविभाज्य है और प्रत्येक विशेषता के वितरण को सारांशित करता है।
यह मध्य मूल्य के लिए एक रेखा खींचता है अर्थात मध्य के लिए।
यह 25% और 75% के आसपास एक बॉक्स खींचता है।
यह मूंछ भी खींचता है जो हमें डेटा के प्रसार के बारे में एक विचार देगा।
मूंछ के बाहर डॉट्स बाहरी मूल्यों को दर्शाता है। मध्यम डेटा के प्रसार के आकार की तुलना में बाह्य मान 1.5 गुना अधिक होगा।
उदाहरण
निम्नलिखित उदाहरण में, पायथन लिपि पीमा इंडियन डायबिटीज डेटासेट की विशेषताओं के वितरण के लिए घनत्व प्लॉट उत्पन्न करेगी।
from matplotlib import pyplot
from pandas import read_csv
path = r"C:\pima-indians-diabetes.csv"
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(path, names=names)
data.plot(kind='box', subplots=True, layout=(3,3), sharex=False,sharey=False)
pyplot.show()उत्पादन

विशेषता के वितरण के उपरोक्त कथानक से, यह देखा जा सकता है कि उम्र, परीक्षण और त्वचा छोटे मूल्यों की ओर तिरछी दिखाई देती है।
बहुभिन्नरूपी भूखंड: कई चर के बीच सहभागिता
एक अन्य प्रकार का दृश्य बहु-चर या "बहुभिन्नरूपी" दृश्य है। बहुभिन्नरूपी विज़ुअलाइज़ेशन की मदद से, हम अपने डेटासेट की कई विशेषताओं के बीच बातचीत को समझ सकते हैं। बहुभिन्नरूपी दृश्य को लागू करने के लिए पायथन में कुछ तकनीकें निम्नलिखित हैं -
सहसंबंध मैट्रिक्स प्लॉट
सहसंबंध दो चर के बीच परिवर्तनों के बारे में एक संकेत है। हमारे पिछले अध्यायों में, हमने पियर्सन के सहसंबंध गुणांक और सहसंबंध के महत्व पर भी चर्चा की है। हम सहसंबंध मैट्रिक्स को यह दिखाने के लिए साजिश कर सकते हैं कि कौन सा चर दूसरे चर के संबंध में उच्च या निम्न सहसंबंध है।
उदाहरण
निम्नलिखित उदाहरण में, पायथन लिपि, पिमा इंडियन डायबिटीज डेटासेट के लिए सहसंबंध मैट्रिक्स उत्पन्न और तैयार करेगी। इसे पंडों डेटाफ्रेम पर क्रॉस () फ़ंक्शन की सहायता से उत्पन्न किया जा सकता है और प्लिपॉट की मदद से प्लॉट किया जा सकता है।
from matplotlib import pyplot
from pandas import read_csv
import numpy
Path = r"C:\pima-indians-diabetes.csv"
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(Path, names=names)
correlations = data.corr()
fig = pyplot.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(correlations, vmin=-1, vmax=1)
fig.colorbar(cax)
ticks = numpy.arange(0,9,1)
ax.set_xticks(ticks)
ax.set_yticks(ticks)
ax.set_xticklabels(names)
ax.set_yticklabels(names)
pyplot.show()उत्पादन

सहसंबंध मैट्रिक्स के उपरोक्त आउटपुट से, हम देख सकते हैं कि यह सममित है यानी नीचे बाईं ओर शीर्ष दाएं के समान है। यह भी देखा गया है कि प्रत्येक चर एक दूसरे के साथ सकारात्मक रूप से सहसंबद्ध है।
स्कैटर मैट्रिक्स प्लॉट
तितर बितर भूखंड दिखाता है कि एक चर दूसरे से कितना प्रभावित होता है या उनके बीच संबंध दो आयामों में डॉट्स की मदद से होता है। स्कैटर प्लॉट कॉन्सेप्ट में लाइन ग्राफ की तरह ही होते हैं जो डेटा पॉइंट्स को प्लॉट करने के लिए हॉरिजॉन्टल और वर्टिकल ऐक्स का इस्तेमाल करते हैं।
उदाहरण
निम्नलिखित उदाहरण में, पायथन लिपि, पिमा इंडियन डायबिटीज डेटासेट के लिए स्कैटर मैट्रिक्स उत्पन्न और तैयार करेगी। इसे पंडास डेटाफ्रैम पर स्कैटर_मेट्रिक्स () फ़ंक्शन की मदद से उत्पन्न किया जा सकता है और प्लमप्लॉट की मदद से प्लॉट किया जा सकता है।
from matplotlib import pyplot
from pandas import read_csv
from pandas.tools.plotting import scatter_matrix
path = r"C:\pima-indians-diabetes.csv"
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(path, names=names)
scatter_matrix(data)
pyplot.show()उत्पादन
