Microsoft संज्ञानात्मक टूलकिट - त्वरित गाइड
इस अध्याय में, हम सीखेंगे कि CNTK क्या है, इसकी विशेषताएं, इसके संस्करण 1.0 और 2.0 के बीच अंतर और संस्करण 2.7 के महत्वपूर्ण हाइलाइट्स।
Microsoft संज्ञानात्मक टूलकिट (CNTK) क्या है?
Microsoft संज्ञानात्मक टूलकिट (CNTK), जिसे पहले कम्प्यूटेशनल नेटवर्क टूलकिट के रूप में जाना जाता है, एक स्वतंत्र, आसान-उपयोग, ओपन-सोर्स, वाणिज्यिक-ग्रेड टूलकिट है जो हमें मानव मस्तिष्क की तरह सीखने के लिए गहन शिक्षण एल्गोरिदम को प्रशिक्षित करने में सक्षम बनाता है। यह हमें कुछ लोकप्रिय गहरी सीखने की प्रणाली बनाने में सक्षम बनाता हैfeed-forward neural network time series prediction systems and Convolutional neural network (CNN) image classifiers।
इष्टतम प्रदर्शन के लिए, इसकी रूपरेखा कार्य C ++ में लिखे गए हैं। हालाँकि हम इसके फ़ंक्शन को C ++ का उपयोग करके कॉल कर सकते हैं, लेकिन उसी के लिए सबसे अधिक उपयोग किया जाने वाला दृष्टिकोण पायथन प्रोग्राम का उपयोग करना है।
CNTK की विशेषताएं
Microsoft CNTK के नवीनतम संस्करण में दी गई कुछ विशेषताएं और क्षमताएं निम्नलिखित हैं:
निर्मित घटकों
CNTK में अत्यधिक अनुकूलित अंतर्निर्मित घटक हैं जो पायथन, C ++ या ब्रेनस्क्रिप्ट से बहुआयामी घने या विरल डेटा को संभाल सकते हैं।
हम CNN, FNN, RNN, बैच सामान्यीकरण और अनुक्रम-से-अनुक्रम को ध्यान से लागू कर सकते हैं।
यह पायथन से GPU पर नए उपयोगकर्ता-परिभाषित कोर-घटकों को जोड़ने के लिए हमें कार्यक्षमता प्रदान करता है।
यह स्वचालित हाइपरपैरेट ट्यूनिंग भी प्रदान करता है।
हम रेनफोर्समेंट लर्निंग, जनरेटिव एडवरसरील नेटवर्क्स (GANs), सुपरवाइज्ड और साथ ही अनसुपरविंड लर्निंग को लागू कर सकते हैं।
बड़े डेटासेट के लिए, CNTK में बिल्ट-इन ऑप्टिमाइज़्ड रीडर्स हैं।
संसाधनों का कुशलता से उपयोग
CNTK हमें 1-बिट SGD के माध्यम से कई GPU / मशीनों पर उच्च सटीकता के साथ समानता प्रदान करता है।
GPU मेमोरी में सबसे बड़े मॉडल को फिट करने के लिए, यह मेमोरी शेयरिंग और अन्य अंतर्निहित तरीके प्रदान करता है।
हमारे अपने नेटवर्क को आसानी से व्यक्त करें
CNTK के पास आपके अपने नेटवर्क, शिक्षार्थियों, पाठकों, प्रशिक्षण और पायथन, C ++ और ब्रेनस्क्रिप्ट से मूल्यांकन को परिभाषित करने के लिए पूर्ण API हैं।
CNTK का उपयोग करके, हम आसानी से पायथन, C ++, C # या ब्रेनस्क्रिप्ट वाले मॉडल का मूल्यांकन कर सकते हैं।
यह उच्च-स्तर के साथ-साथ निम्न-स्तर के एपीआई प्रदान करता है।
हमारे डेटा के आधार पर, यह स्वतः ही अनुमान को आकार दे सकता है।
इसने प्रतीकात्मक रूप से प्रतीकात्मक आवर्तक तंत्रिका नेटवर्क (RNN) छोरों को अनुकूलित किया है।
मापने मॉडल प्रदर्शन
CNTK आपके द्वारा बनाए गए तंत्रिका नेटवर्क के प्रदर्शन को मापने के लिए विभिन्न घटक प्रदान करता है।
आपके मॉडल और संबद्ध ऑप्टिमाइज़र से लॉग डेटा उत्पन्न करता है, जिसका उपयोग हम प्रशिक्षण प्रक्रिया की निगरानी के लिए कर सकते हैं।
संस्करण 1.0 बनाम संस्करण 2.0
निम्न तालिका CNTK संस्करण 1.0 और 2.0 की तुलना करती है:
| संस्करण 1.0 | संस्करण 2.0 |
|---|---|
| यह 2016 में रिलीज़ हुई थी। | यह 1.0 संस्करण का एक महत्वपूर्ण पुनर्लेखन है और जून 2017 में जारी किया गया था। |
| इसने ब्रेनस्क्रिप्ट नामक एक स्वामित्व स्क्रिप्टिंग भाषा का उपयोग किया। | इसकी रूपरेखा कार्यों को C ++, पायथन का उपयोग करके बुलाया जा सकता है। हम अपने मॉड्यूल को C # या Java में आसानी से लोड कर सकते हैं। ब्रेनस्क्रिप्ट भी संस्करण 2.0 द्वारा समर्थित है। |
| यह विंडोज और लिनक्स सिस्टम दोनों पर चलता है लेकिन सीधे मैक ओएस पर नहीं। | यह विंडोज (विन 8.1, विन 10, सर्वर 2012 आर 2 और बाद में) और लिनक्स सिस्टम दोनों पर चलता है लेकिन सीधे मैक ओएस पर नहीं। |
संस्करण 2.7 के महत्वपूर्ण हाइलाइट्स
Version 2.7Microsoft संज्ञानात्मक टूलकिट का अंतिम मुख्य रिलीज़ किया गया संस्करण है। इसमें ONNX 1.4.1 का पूरा सपोर्ट है। CNTK के इस अंतिम रिलीज़ किए गए संस्करण के कुछ महत्वपूर्ण आकर्षण निम्नलिखित हैं।
ONNX 1.4.1 के लिए पूर्ण समर्थन।
विंडोज और लिनक्स सिस्टम दोनों के लिए CUDA 10 के लिए समर्थन।
यह ONNX निर्यात में अग्रिम आवर्तक तंत्रिका नेटवर्क (RNN) लूप का समर्थन करता है।
यह ONNX प्रारूप में 2GB से अधिक मॉडल निर्यात कर सकता है।
यह ब्रेनस्क्रिप्ट स्क्रिप्टिंग भाषा की प्रशिक्षण कार्रवाई में FP16 का समर्थन करता है।
यहां, हम विंडोज और लिनक्स पर CNTK की स्थापना के बारे में समझेंगे। इसके अलावा, अध्याय CNTK पैकेज, एनाकोंडा, CNTK फ़ाइलें, निर्देशिका संरचना और CNTK लाइब्रेरी संगठन स्थापित करने के लिए चरण स्थापित करने के बारे में बताता है।
आवश्यक शर्तें
CNTK को स्थापित करने के लिए, हमें अपने कंप्यूटर पर पायथन स्थापित करना चाहिए। आप लिंक पर जा सकते हैंhttps://www.python.org/downloads/और अपने OS, यानी विंडोज और लिनक्स / यूनिक्स के लिए नवीनतम संस्करण का चयन करें। पायथन पर बुनियादी ट्यूटोरियल के लिए, आप लिंक का उल्लेख कर सकते हैंhttps://www.tutorialspoint.com/python3/index.htm।

CNTK को विंडोज के साथ-साथ लिनक्स के लिए भी सपोर्ट किया जाता है ताकि हम उन दोनों से चलें।
विंडोज पर इंस्टॉल करना
विंडोज पर CNTK चलाने के लिए, हम इसका उपयोग करेंगे Anaconda versionअजगर का। हम जानते हैं कि, एनाकोंडा पायथन का पुनर्वितरण है। इसमें अतिरिक्त पैकेज जैसे शामिल हैंScipy तथाScikit-learn जिसका उपयोग CNTK द्वारा विभिन्न उपयोगी गणना करने के लिए किया जाता है।
तो, पहले अपनी मशीन पर एनाकोंडा स्थापित करने के चरण देखें -
Step 1.फर्स्ट सेटअप को पब्लिक वेबसाइट से डाउनलोड करें https://www.anaconda.com/distribution/।
Step 2 - सेटअप फ़ाइलें डाउनलोड करने के बाद, इंस्टॉलेशन शुरू करें और लिंक से निर्देशों का पालन करें https://docs.anaconda.com/anaconda/install/।
Step 3- एक बार स्थापित होने के बाद, एनाकोंडा कुछ अन्य उपयोगिताओं को भी स्थापित करेगा, जो स्वचालित रूप से आपके कंप्यूटर पैटियन चर में सभी एनाकोंडा निष्पादन योग्य शामिल करेगा। हम इस संकेत से अपने पायथन पर्यावरण को प्रबंधित कर सकते हैं, पैकेज स्थापित कर सकते हैं और पायथन स्क्रिप्ट चला सकते हैं।
CNTK पैकेज स्थापित करना
एक बार एनाकोंडा इंस्टालेशन हो जाने के बाद, आप निम्नलिखित कार्य का उपयोग करके पाइप निष्पादन योग्य के माध्यम से CNTK पैकेज को स्थापित करने के लिए सबसे सामान्य तरीके का उपयोग कर सकते हैं।
pip install cntkआपकी मशीन पर कॉग्निटिव टूलकिट स्थापित करने के लिए कई अन्य तरीके हैं। Microsoft के पास दस्तावेज़ का एक साफ सेट है जो अन्य स्थापना विधियों के बारे में विस्तार से बताता है। कृपया लिंक का अनुसरण करेंhttps://docs.microsoft.com/en-us/cognitive-toolkit/Setup-CNTK-on-your-machine।
लिनक्स पर स्थापित करना
लिनक्स पर CNTK की स्थापना विंडोज पर इसकी स्थापना से थोड़ी अलग है। यहां, लिनक्स के लिए हम CNTK को स्थापित करने के लिए एनाकोंडा का उपयोग करने जा रहे हैं, लेकिन एनाकोंडा के लिए ग्राफिकल इंस्टॉलर के बजाय, हम लिनक्स पर टर्मिनल-आधारित इंस्टॉलर का उपयोग करेंगे। यद्यपि, इंस्टॉलर लगभग सभी लिनक्स वितरणों के साथ काम करेगा, हमने विवरण को उबंटू तक सीमित कर दिया।
तो, पहले अपनी मशीन पर एनाकोंडा स्थापित करने के चरण देखें -
एनाकोंडा स्थापित करने के लिए कदम
Step 1- एनाकोंडा स्थापित करने से पहले, सुनिश्चित करें कि सिस्टम पूरी तरह से अद्यतित है। जाँच करने के लिए, पहले एक टर्मिनल के अंदर निम्नलिखित दो कमांड निष्पादित करें -
sudo apt update
sudo apt upgradeStep 2 - कंप्यूटर अपडेट होने के बाद, सार्वजनिक वेबसाइट से URL प्राप्त करें https://www.anaconda.com/distribution/ नवीनतम एनाकोंडा स्थापना फ़ाइलों के लिए।
Step 3 - URL की कॉपी हो जाने के बाद, एक टर्मिनल विंडो खोलें और निम्नलिखित कमांड निष्पादित करें -
wget -0 anaconda-installer.sh url SHAPE \* MERGEFORMAT
y
f
x
| }बदलो url एनाकोंडा वेबसाइट से कॉपी किए गए यूआरएल के साथ प्लेसहोल्डर।
Step 4 - अगला, निम्नलिखित कमांड की सहायता से, हम एनाकोंडा स्थापित कर सकते हैं -
sh ./anaconda-installer.shउपरोक्त आदेश डिफ़ॉल्ट रूप से स्थापित होगा Anaconda3 हमारे घर निर्देशिका के अंदर।
CNTK पैकेज स्थापित करना
एक बार एनाकोंडा इंस्टालेशन हो जाने के बाद, आप निम्नलिखित कार्य का उपयोग करके पाइप निष्पादन योग्य के माध्यम से CNTK पैकेज को स्थापित करने के लिए सबसे सामान्य तरीके का उपयोग कर सकते हैं।
pip install cntkCNTK फ़ाइलों और निर्देशिका संरचना की जाँच करना
एक बार जब CNTK पायथन पैकेज के रूप में स्थापित हो जाता है, तो हम इसकी फ़ाइल और निर्देशिका संरचना की जांच कर सकते हैं। यह पर हैC:\Users\

CNTK स्थापना का सत्यापन
एक बार CNTK पायथन पैकेज के रूप में स्थापित हो जाने के बाद, आपको यह सत्यापित करना चाहिए कि CNTK को सही तरीके से स्थापित किया गया है। एनाकोंडा कमांड शेल से, प्रवेश करके पायथन इंटरप्रेटर शुरू करेंipython. फिर, आयात करें CNTK निम्नलिखित कमांड दर्ज करके।
import cntk as cआयात करने के बाद, निम्न कमांड की मदद से इसके संस्करण की जाँच करें -
print(c.__version__)दुभाषिया स्थापित CNTK संस्करण के साथ प्रतिक्रिया करेगा। यदि यह प्रतिक्रिया नहीं करता है, तो स्थापना के साथ एक समस्या होगी।
CNTK पुस्तकालय संगठन
तकनीकी रूप से एक अजगर पैकेज CNTK, 13 उच्च-स्तरीय उप-संकुल और 8 छोटे उप-संकुल में आयोजित किया जाता है। निम्न तालिका में 10 सबसे अधिक उपयोग किए जाने वाले पैकेज शामिल हैं:
| अनु क्रमांक | पैकेज का नाम और विवरण |
|---|---|
| 1 | cntk.io डेटा पढ़ने के लिए कार्य करता है। उदाहरण के लिए: next_minibatch () |
| 2 | cntk.layers तंत्रिका नेटवर्क बनाने के लिए उच्च-स्तरीय फ़ंक्शन शामिल हैं। उदाहरण के लिए: घना () |
| 3 | cntk.learners प्रशिक्षण के लिए कार्य शामिल हैं। उदाहरण के लिए: sgd () |
| 4 | cntk.losses प्रशिक्षण त्रुटि को मापने के लिए कार्य करता है। उदाहरण के लिए: squared_error () |
| 5 | cntk.metrics मॉडल त्रुटि को मापने के लिए कार्य करता है। उदाहरण के लिए: classificatoin_error |
| 6 | cntk.ops तंत्रिका नेटवर्क बनाने के लिए निम्न-स्तरीय फ़ंक्शन शामिल हैं। उदाहरण के लिए: तनह () |
| 7 | cntk.random यादृच्छिक संख्या उत्पन्न करने के लिए कार्य करता है। उदाहरण के लिए: सामान्य () |
| 8 | cntk.train प्रशिक्षण कार्य शामिल हैं। उदाहरण के लिए: train_minibatch () |
| 9 | cntk.initializer मॉडल पैरामीटर इनिशियलाइज़र शामिल हैं। उदाहरण के लिए: सामान्य () और वर्दी () |
| 10 | cntk.variables निम्न-स्तरीय निर्माण शामिल हैं। उदाहरण के लिए: पैरामीटर () और चर () |
माइक्रोसॉफ्ट कॉग्निटिव टूलकिट दो अलग-अलग बिल्ड वर्जन अर्थात् CPU-only और GPU-only प्रदान करता है।
सीपीयू केवल संस्करण का निर्माण करता है
CNTK का CPU-केवल बिल्ड संस्करण अनुकूलित Intel MKLML का उपयोग करता है, जहाँ MKLML MKL (मैथ कर्नेल लाइब्रेरी) का सबसेट है और Intel MKL-DNN के साथ MKL-DNN के लिए Intel MKL के समाप्त संस्करण के रूप में जारी किया गया है।
GPU केवल संस्करण का निर्माण करता है
दूसरी ओर, CNTK का GPU-only बिल्ड संस्करण अत्यधिक अनुकूलित NVIDIA पुस्तकालयों का उपयोग करता है CUB तथा cuDNN। यह कई GPU और कई मशीनों में वितरित प्रशिक्षण का समर्थन करता है। CNTK में तेजी से वितरित प्रशिक्षण के लिए, GPU- बिल्ड संस्करण भी शामिल है -
MSR-विकसित 1bit-quantized SGD।
ब्लॉक-गति डब्ल्यूडीएम समानांतर प्रशिक्षण एल्गोरिदम।
Windows पर CNTK के साथ GPU सक्षम करना
पिछले अनुभाग में, हमने देखा कि सीपीयू के साथ उपयोग करने के लिए CNTK के मूल संस्करण को कैसे स्थापित किया जाए। अब चर्चा करते हैं कि हम GPU के साथ उपयोग करने के लिए CNTK कैसे स्थापित कर सकते हैं। लेकिन, इसमें गहरी डुबकी लगाने से पहले, आपके पास एक समर्थित ग्राफिक्स कार्ड होना चाहिए।
वर्तमान में, CNTK कम से कम CUDA 3.0 समर्थन के साथ NVIDIA ग्राफिक्स कार्ड का समर्थन करता है। यह सुनिश्चित करने के लिए, आप देख सकते हैंhttps://developer.nvidia.com/cuda-gpus क्या आपका GPU CUDA का समर्थन करता है।
तो, हमें विंडोज ओएस पर CNTK के साथ GPU को सक्षम करने के लिए चरण देखें -
Step 1 - आपके द्वारा उपयोग किए जा रहे ग्राफिक्स कार्ड के आधार पर, सबसे पहले आपको अपने ग्राफिक्स कार्ड के लिए नवीनतम GeForce या Quadro ड्राइवरों की आवश्यकता होगी।
Step 2 - जब आप ड्राइवरों को डाउनलोड करते हैं, तो आपको NVIDIA वेबसाइट से विंडोज के लिए CUDA टूलकिट संस्करण 9.0 स्थापित करने की आवश्यकता होती है https://developer.nvidia.com/cuda-90-download-archive?target_os=Windows&target_arch=x86_64। इंस्टॉल करने के बाद, इंस्टॉलर चलाएं और निर्देशों का पालन करें।
Step 3 - इसके बाद, आपको NVIDIA वेबसाइट से cuDNN बायनेरी स्थापित करने की आवश्यकता है https://developer.nvidia.com/rdp/form/cudnn-download-survey। CUDA 9.0 संस्करण के साथ, cuDNN 7.4.1 अच्छी तरह से काम करता है। मूलतः, cuDNN CUDA के शीर्ष पर एक परत है, जिसका उपयोग CNTK द्वारा किया जाता है।
Step 4 - cuDNN बायनेरिज़ को डाउनलोड करने के बाद, आपको ज़िप फ़ाइल को अपने CUDA टूलकिट इंस्टॉलेशन के रूट फ़ोल्डर में निकालने की आवश्यकता है।
Step 5- यह अंतिम चरण है जो CNTK के अंदर GPU उपयोग को सक्षम करेगा। विंडोज ओएस पर एनाकोंडा प्रॉम्प्ट के अंदर निम्नलिखित कमांड निष्पादित करें -
pip install cntk-gpuलिनक्स पर CNTK के साथ GPU सक्षम करना
आइए देखें कि हम लिनक्स ओएस पर CNTK के साथ GPU कैसे सक्षम कर सकते हैं -
CUDA टूलकिट डाउनलोड करना
सबसे पहले, आपको CUDA टूलकिट को NVIDIA की वेबसाइट https://developer.nvidia.com/cuda-90-download-archive?target_os=Linux&target_arch=x86_64&tar_distro=Ubuntu&target_version=1604&target_type = runfel = से इंस्टॉल करना होगा ।
इंस्टॉलर चलाना
अब, जब आप डिस्क पर बायनेरिज़ रखते हैं, तो टर्मिनल खोलकर इंस्टॉलर चलाएं और निम्न कमांड और स्क्रीन पर दिए गए निर्देश को निष्पादित करें -
sh cuda_9.0.176_384.81_linux-runबैश प्रोफाइल स्क्रिप्ट को संशोधित करें
अपने लिनक्स मशीन पर CUDA टूलकिट स्थापित करने के बाद, आपको BASH प्रोफ़ाइल स्क्रिप्ट को संशोधित करना होगा। इसके लिए, पहले टेक्स्ट एडिटर में $ HOME / .bashrc फ़ाइल खोलें। अब, स्क्रिप्ट के अंत में, निम्नलिखित पंक्तियाँ शामिल करें -
export PATH=/usr/local/cuda-9.0/bin${PATH:+:${PATH}} export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib64\ ${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
InstallingCuDNN लाइब्रेरी स्थापित करना
अंत में हमें cuDNN बायनेरिज़ को स्थापित करने की आवश्यकता है। इसे NVIDIA की वेबसाइट से डाउनलोड किया जा सकता हैhttps://developer.nvidia.com/rdp/form/cudnn-download-survey। CUDA 9.0 संस्करण के साथ, cuDNN 7.4.1 अच्छी तरह से काम करता है। मूलतः, cuDNN CUDA के शीर्ष पर एक परत है, जिसका उपयोग CNTK द्वारा किया जाता है।
एक बार लिनक्स के लिए संस्करण को डाउनलोड करने के बाद, इसे निकालें /usr/local/cuda-9.0 निम्नलिखित कमांड का उपयोग करके फ़ोल्डर -
tar xvzf -C /usr/local/cuda-9.0/ cudnn-9.0-linux-x64-v7.4.1.5.tgzआवश्यकतानुसार फ़ाइल नाम का पथ बदलें।
इस अध्याय में, हम CNTK और उसके वर्गीकरण के क्रमों के बारे में विस्तार से जानेंगे।
tensors
जिस अवधारणा पर CNTK काम करता है tensor। मूल रूप से, CNTK निविष्टियाँ, आउटपुट और साथ ही मापदंडों को व्यवस्थित किया जाता हैtensors, जिसे अक्सर सामान्यीकृत मैट्रिक्स के रूप में सोचा जाता है। हर टेनर एक हैrank -
रैंक 0 का टेंसर एक अदिश राशि है।
रैंक 1 का टेंसर एक वेक्टर है।
रैंक 2 का टेंसर अमेट्रिक्स है।
यहाँ, इन विभिन्न आयामों को संदर्भित किया गया है axes.
स्थैतिक कुल्हाड़ियों और गतिशील कुल्हाड़ियों
जैसा कि नाम से पता चलता है, पूरे नेटवर्क में स्थिर अक्षों की लंबाई समान होती है। दूसरी ओर, गतिशील कुल्हाड़ियों की लंबाई उदाहरण के लिए अलग-अलग हो सकती है। वास्तव में, उनकी लंबाई आमतौर पर प्रत्येक मिनीबैच प्रस्तुत किए जाने से पहले ज्ञात नहीं होती है।
डायनेमिक ऐक्सिस स्टैटिक ऐक्स की तरह होते हैं क्योंकि वे टेंसर में निहित संख्याओं के सार्थक समूहन को भी परिभाषित करते हैं।
उदाहरण
इसे स्पष्ट करने के लिए, आइए देखें कि CNTK में लघु वीडियो क्लिप का एक छोटा भाग कैसे दिखाया जाता है। मान लीजिए कि वीडियो क्लिप का रिज़ॉल्यूशन सभी 640 * 480 है। और, क्लिप को रंग में भी शूट किया जाता है, जो आमतौर पर तीन चैनलों के साथ एन्कोडेड होता है। यह आगे का मतलब है कि हमारे मिनीबैच में निम्नलिखित हैं -
लंबाई 640, 480 और 3 की 3 स्थिर कुल्हाड़ियों क्रमशः।
दो गतिशील कुल्हाड़ियों; वीडियो की लंबाई और मिनीबैच कुल्हाड़ियों।
इसका मतलब है कि अगर एक मिनीबैच में 16 वीडियो हैं, जिनमें से प्रत्येक 240 फ्रेम लंबा है, तो इसका प्रतिनिधित्व किया जाएगा 16*240*3*640*480 tensors।
CNTK में दृश्यों के साथ काम करना
हमें लोंग-शॉर्ट टर्म मेमोरी नेटवर्क के बारे में पहले सीखकर CNTK में अनुक्रम को समझें।
लॉन्ग-शॉर्ट टर्म मेमोरी नेटवर्क (LSTM)

Hochreiter & Schmidhuber द्वारा दीर्घकालिक-अल्पकालिक मेमोरी (LSTM) नेटवर्क पेश किए गए थे। इसने चीजों को लंबे समय तक याद रखने के लिए एक मूल आवर्तक परत प्राप्त करने की समस्या को हल किया। LSTM की वास्तुकला चित्र में ऊपर दी गई है। जैसा कि हम देख सकते हैं कि इसमें इनपुट न्यूरॉन्स, मेमोरी सेल्स और आउटपुट न्यूरॉन्स हैं। लुप्त होती क्रमिक समस्या से निपटने के लिए, दीर्घकालिक अल्पकालिक मेमोरी नेटवर्क एक स्पष्ट मेमोरी सेल (पिछले मूल्यों को संग्रहीत करता है) और निम्न गेट्स का उपयोग करता है -
Forget gate- जैसा कि नाम से ही स्पष्ट है कि यह मेमोरी सेल को पिछले मूल्यों को भूल जाने के लिए कहता है। मेमोरी सेल मानों को तब तक स्टोर करता है जब तक कि गेट 'गेट गेट' उन्हें भूल जाने के लिए नहीं कहता है।
Input gate - जैसा कि नाम से ही स्पष्ट है, यह सेल में नया सामान जोड़ता है।
Output gate - जैसा कि नाम से पता चलता है, आउटपुट गेट तय करता है कि सेल से वैक्टर के साथ अगले छिपे हुए राज्य में कब जाया जाए।
CNTK में दृश्यों के साथ काम करना बहुत आसान है। आइए इसे निम्न उदाहरण की मदद से देखते हैं -
import sys
import os
from cntk import Trainer, Axis
from cntk.io import MinibatchSource, CTFDeserializer, StreamDef, StreamDefs,\
INFINITELY_REPEAT
from cntk.learners import sgd, learning_parameter_schedule_per_sample
from cntk import input_variable, cross_entropy_with_softmax, \
classification_error, sequence
from cntk.logging import ProgressPrinter
from cntk.layers import Sequential, Embedding, Recurrence, LSTM, Dense
def create_reader(path, is_training, input_dim, label_dim):
return MinibatchSource(CTFDeserializer(path, StreamDefs(
features=StreamDef(field='x', shape=input_dim, is_sparse=True),
labels=StreamDef(field='y', shape=label_dim, is_sparse=False)
)), randomize=is_training,
max_sweeps=INFINITELY_REPEAT if is_training else 1)
def LSTM_sequence_classifier_net(input, num_output_classes, embedding_dim,
LSTM_dim, cell_dim):
lstm_classifier = Sequential([Embedding(embedding_dim),
Recurrence(LSTM(LSTM_dim, cell_dim)),
sequence.last,
Dense(num_output_classes)])
return lstm_classifier(input)
def train_sequence_classifier():
input_dim = 2000
cell_dim = 25
hidden_dim = 25
embedding_dim = 50
num_output_classes = 5
features = sequence.input_variable(shape=input_dim, is_sparse=True)
label = input_variable(num_output_classes)
classifier_output = LSTM_sequence_classifier_net(
features, num_output_classes, embedding_dim, hidden_dim, cell_dim)
ce = cross_entropy_with_softmax(classifier_output, label)
pe = classification_error(classifier_output, label)
rel_path = ("../../../Tests/EndToEndTests/Text/" +
"SequenceClassification/Data/Train.ctf")
path = os.path.join(os.path.dirname(os.path.abspath(__file__)), rel_path)
reader = create_reader(path, True, input_dim, num_output_classes)
input_map = {
features: reader.streams.features,
label: reader.streams.labels
}
lr_per_sample = learning_parameter_schedule_per_sample(0.0005)
progress_printer = ProgressPrinter(0)
trainer = Trainer(classifier_output, (ce, pe),
sgd(classifier_output.parameters, lr=lr_per_sample),progress_printer)
minibatch_size = 200
for i in range(255):
mb = reader.next_minibatch(minibatch_size, input_map=input_map)
trainer.train_minibatch(mb)
evaluation_average = float(trainer.previous_minibatch_evaluation_average)
loss_average = float(trainer.previous_minibatch_loss_average)
return evaluation_average, loss_average
if __name__ == '__main__':
error, _ = train_sequence_classifier()
print(" error: %f" % error)average since average since examples
loss last metric last
------------------------------------------------------
1.61 1.61 0.886 0.886 44
1.61 1.6 0.714 0.629 133
1.6 1.59 0.56 0.448 316
1.57 1.55 0.479 0.41 682
1.53 1.5 0.464 0.449 1379
1.46 1.4 0.453 0.441 2813
1.37 1.28 0.45 0.447 5679
1.3 1.23 0.448 0.447 11365
error: 0.333333उपरोक्त कार्यक्रम का विस्तृत विवरण अगले खंडों में कवर किया जाएगा, खासकर जब हम रिकरंट न्यूरल नेटवर्क का निर्माण करेंगे।
यह अध्याय CNTK में एक लॉजिस्टिक रिग्रेशन मॉडल के निर्माण से संबंधित है।
लॉजिस्टिक रिग्रेशन मॉडल की मूल बातें
लॉजिस्टिक रिग्रेशन, सबसे सरल एमएल तकनीकों में से एक, विशेष रूप से बाइनरी वर्गीकरण के लिए एक तकनीक है। दूसरे शब्दों में, ऐसी परिस्थितियों में एक भविष्यवाणी मॉडल बनाना जहां भविष्यवाणी करने के लिए चर का मूल्य सिर्फ दो स्पष्ट मूल्यों में से एक हो सकता है। लॉजिस्टिक रिग्रेशन का सबसे सरल उदाहरण यह अनुमान लगाना है कि क्या व्यक्ति पुरुष या महिला है, जो व्यक्ति की उम्र, आवाज, बाल और इसी तरह पर आधारित है।
उदाहरण
आइए एक और उदाहरण की मदद से गणितीय रूप से लॉजिस्टिक रिग्रेशन की अवधारणा को समझते हैं -
मान लीजिए, हम एक ऋण आवेदन की क्रेडिट योग्यता की भविष्यवाणी करना चाहते हैं; आवेदक के आधार पर 0 का अर्थ है अस्वीकार, और 1 का अर्थ है अनुमोदनdebt , income तथा credit rating। हम एक्स 1 के साथ ऋण, एक्स 2 के साथ आय और एक्स 3 के साथ क्रेडिट रेटिंग का प्रतिनिधित्व करते हैं।
लॉजिस्टिक रिग्रेशन में, हम एक वेट वैल्यू निर्धारित करते हैं, जिसका प्रतिनिधित्व करते हैं wप्रत्येक सुविधा के लिए और एक एकल पूर्वाग्रह मान के लिए, द्वारा प्रतिनिधित्व किया b।
अब मान लीजिए,
X1 = 3.0
X2 = -2.0
X3 = 1.0और मान लें कि हम वजन और पूर्वाग्रह निर्धारित करते हैं -
W1 = 0.65, W2 = 1.75, W3 = 2.05 and b = 0.33अब, कक्षा की भविष्यवाणी करने के लिए, हमें निम्नलिखित सूत्र को लागू करना होगा -
Z = (X1*W1)+(X2*W2)+(X3+W3)+b
i.e. Z = (3.0)*(0.65) + (-2.0)*(1.75) + (1.0)*(2.05) + 0.33
= 0.83अगला, हमें गणना करने की आवश्यकता है P = 1.0/(1.0 + exp(-Z))। यहां, एक्सप () फ़ंक्शन यूलर का नंबर है।
P = 1.0/(1.0 + exp(-0.83)
= 0.6963P मान की व्याख्या इस संभावना के रूप में की जा सकती है कि वर्ग १ है। यदि P <०.५ है, तो वर्ग कक्षा है = ० या फिर भविष्यवाणी (P> = ०.५) वर्ग = १ है।
वजन और पूर्वाग्रह के मूल्यों को निर्धारित करने के लिए, हमें ज्ञात इनपुट भविष्यवक्ता मूल्यों और ज्ञात सही वर्ग लेबल मूल्यों वाले प्रशिक्षण डेटा का एक सेट प्राप्त करना होगा। उसके बाद, हम वज़न और पूर्वाग्रह के मूल्यों को खोजने के लिए एक एल्गोरिथ्म, आमतौर पर ग्रेडिएंट डिसेंट का उपयोग कर सकते हैं।
LR मॉडल कार्यान्वयन उदाहरण
इस LR मॉडल के लिए, हम निम्नलिखित डेटा सेट का उपयोग करने जा रहे हैं -
1.0, 2.0, 0
3.0, 4.0, 0
5.0, 2.0, 0
6.0, 3.0, 0
8.0, 1.0, 0
9.0, 2.0, 0
1.0, 4.0, 1
2.0, 5.0, 1
4.0, 6.0, 1
6.0, 5.0, 1
7.0, 3.0, 1
8.0, 5.0, 1CNTK में इस LR मॉडल कार्यान्वयन को शुरू करने के लिए, हमें पहले निम्नलिखित पैकेजों को आयात करना होगा -
import numpy as np
import cntk as Cकार्यक्रम मुख्य () फ़ंक्शन के साथ संरचित है -
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")अब, हमें प्रशिक्षण डेटा को मेमोरी में लोड करने की आवश्यकता है -
data_file = ".\\dataLRmodel.txt"
print("Loading data from " + data_file + "\n")
features_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",", skiprows=0, usecols=[0,1])
labels_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",", skiprows=0, usecols=[2], ndmin=2)अब, हम एक प्रशिक्षण कार्यक्रम बनाएंगे जो एक लॉजिस्टिक रिग्रेशन मॉडल तैयार करेगा जो प्रशिक्षण डेटा के साथ संगत है -
features_dim = 2
labels_dim = 1
X = C.ops.input_variable(features_dim, np.float32)
y = C.input_variable(labels_dim, np.float32)
W = C.parameter(shape=(features_dim, 1)) # trainable cntk.Parameter
b = C.parameter(shape=(labels_dim))
z = C.times(X, W) + b
p = 1.0 / (1.0 + C.exp(-z))
model = pअब, हमें Lerner और ट्रेनर बनाने की आवश्यकता इस प्रकार है -
ce_error = C.binary_cross_entropy(model, y) # CE a bit more principled for LR
fixed_lr = 0.010
learner = C.sgd(model.parameters, fixed_lr)
trainer = C.Trainer(model, (ce_error), [learner])
max_iterations = 4000LR मॉडल प्रशिक्षण
एक बार, हमने LR मॉडल बनाया है, अगला, प्रशिक्षण प्रक्रिया शुरू करने का समय है -
np.random.seed(4)
N = len(features_mat)
for i in range(0, max_iterations):
row = np.random.choice(N,1) # pick a random row from training items
trainer.train_minibatch({ X: features_mat[row], y: labels_mat[row] })
if i % 1000 == 0 and i > 0:
mcee = trainer.previous_minibatch_loss_average
print(str(i) + " Cross-entropy error on curr item = %0.4f " % mcee)अब, निम्नलिखित कोड की मदद से, हम मॉडल वज़न और पूर्वाग्रह प्रिंट कर सकते हैं -
np.set_printoptions(precision=4, suppress=True)
print("Model weights: ")
print(W.value)
print("Model bias:")
print(b.value)
print("")
if __name__ == "__main__":
main()लॉजिस्टिक रिग्रेशन मॉडल का प्रशिक्षण - पूरा उदाहरण
import numpy as np
import cntk as C
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
data_file = ".\\dataLRmodel.txt" # provide the name and the location of data file
print("Loading data from " + data_file + "\n")
features_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",", skiprows=0, usecols=[0,1])
labels_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",", skiprows=0, usecols=[2], ndmin=2)
features_dim = 2
labels_dim = 1
X = C.ops.input_variable(features_dim, np.float32)
y = C.input_variable(labels_dim, np.float32)
W = C.parameter(shape=(features_dim, 1)) # trainable cntk.Parameter
b = C.parameter(shape=(labels_dim))
z = C.times(X, W) + b
p = 1.0 / (1.0 + C.exp(-z))
model = p
ce_error = C.binary_cross_entropy(model, y) # CE a bit more principled for LR
fixed_lr = 0.010
learner = C.sgd(model.parameters, fixed_lr)
trainer = C.Trainer(model, (ce_error), [learner])
max_iterations = 4000
np.random.seed(4)
N = len(features_mat)
for i in range(0, max_iterations):
row = np.random.choice(N,1) # pick a random row from training items
trainer.train_minibatch({ X: features_mat[row], y: labels_mat[row] })
if i % 1000 == 0 and i > 0:
mcee = trainer.previous_minibatch_loss_average
print(str(i) + " Cross-entropy error on curr item = %0.4f " % mcee)
np.set_printoptions(precision=4, suppress=True)
print("Model weights: ")
print(W.value)
print("Model bias:")
print(b.value)
if __name__ == "__main__":
main()उत्पादन
Using CNTK version = 2.7
1000 cross entropy error on curr item = 0.1941
2000 cross entropy error on curr item = 0.1746
3000 cross entropy error on curr item = 0.0563
Model weights:
[-0.2049]
[0.9666]]
Model bias:
[-2.2846]प्रशिक्षित एलआर मॉडल का उपयोग कर भविष्यवाणी
एक बार जब LR मॉडल को प्रशिक्षित किया गया है, तो हम इसे निम्नानुसार भविष्यवाणी के लिए उपयोग कर सकते हैं -
सबसे पहले, हमारा मूल्यांकन कार्यक्रम खस्ता पैकेज को आयात करता है और प्रशिक्षण डेटा को एक फीचर मैट्रिक्स और एक क्लास लेबल मैट्रिक्स में उसी तरह लोड करता है जिस तरह से प्रशिक्षण कार्यक्रम हम ऊपर लागू करते हैं -
import numpy as np
def main():
data_file = ".\\dataLRmodel.txt" # provide the name and the location of data file
features_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",",
skiprows=0, usecols=(0,1))
labels_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",",
skiprows=0, usecols=[2], ndmin=2)अगला, यह वज़न और पूर्वाग्रह के मूल्यों को निर्धारित करने का समय है जो हमारे प्रशिक्षण कार्यक्रम द्वारा निर्धारित किए गए थे -
print("Setting weights and bias values \n")
weights = np.array([0.0925, 1.1722], dtype=np.float32)
bias = np.array([-4.5400], dtype=np.float32)
N = len(features_mat)
features_dim = 2अगला हमारा मूल्यांकन कार्यक्रम प्रत्येक प्रशिक्षण मदों के माध्यम से चलने से लॉजिस्टिक रिग्रेशन संभावना की गणना करेगा -
print("item pred_prob pred_label act_label result")
for i in range(0, N): # each item
x = features_mat[i]
z = 0.0
for j in range(0, features_dim):
z += x[j] * weights[j]
z += bias[0]
pred_prob = 1.0 / (1.0 + np.exp(-z))
pred_label = 0 if pred_prob < 0.5 else 1
act_label = labels_mat[i]
pred_str = ‘correct’ if np.absolute(pred_label - act_label) < 1.0e-5 \
else ‘WRONG’
print("%2d %0.4f %0.0f %0.0f %s" % \ (i, pred_prob, pred_label, act_label, pred_str))अब हम यह दर्शाते हैं कि भविष्यवाणी कैसे करें -
x = np.array([9.5, 4.5], dtype=np.float32)
print("\nPredicting class for age, education = ")
print(x)
z = 0.0
for j in range(0, features_dim):
z += x[j] * weights[j]
z += bias[0]
p = 1.0 / (1.0 + np.exp(-z))
print("Predicted p = " + str(p))
if p < 0.5: print("Predicted class = 0")
else: print("Predicted class = 1")पूर्ण भविष्यवाणी मूल्यांकन कार्यक्रम
import numpy as np
def main():
data_file = ".\\dataLRmodel.txt" # provide the name and the location of data file
features_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",",
skiprows=0, usecols=(0,1))
labels_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",",
skiprows=0, usecols=[2], ndmin=2)
print("Setting weights and bias values \n")
weights = np.array([0.0925, 1.1722], dtype=np.float32)
bias = np.array([-4.5400], dtype=np.float32)
N = len(features_mat)
features_dim = 2
print("item pred_prob pred_label act_label result")
for i in range(0, N): # each item
x = features_mat[i]
z = 0.0
for j in range(0, features_dim):
z += x[j] * weights[j]
z += bias[0]
pred_prob = 1.0 / (1.0 + np.exp(-z))
pred_label = 0 if pred_prob < 0.5 else 1
act_label = labels_mat[i]
pred_str = ‘correct’ if np.absolute(pred_label - act_label) < 1.0e-5 \
else ‘WRONG’
print("%2d %0.4f %0.0f %0.0f %s" % \ (i, pred_prob, pred_label, act_label, pred_str))
x = np.array([9.5, 4.5], dtype=np.float32)
print("\nPredicting class for age, education = ")
print(x)
z = 0.0
for j in range(0, features_dim):
z += x[j] * weights[j]
z += bias[0]
p = 1.0 / (1.0 + np.exp(-z))
print("Predicted p = " + str(p))
if p < 0.5: print("Predicted class = 0")
else: print("Predicted class = 1")
if __name__ == "__main__":
main()उत्पादन
वजन और पूर्वाग्रह मान सेट करना।
Item pred_prob pred_label act_label result
0 0.3640 0 0 correct
1 0.7254 1 0 WRONG
2 0.2019 0 0 correct
3 0.3562 0 0 correct
4 0.0493 0 0 correct
5 0.1005 0 0 correct
6 0.7892 1 1 correct
7 0.8564 1 1 correct
8 0.9654 1 1 correct
9 0.7587 1 1 correct
10 0.3040 0 1 WRONG
11 0.7129 1 1 correct
Predicting class for age, education =
[9.5 4.5]
Predicting p = 0.526487952
Predicting class = 1यह अध्याय CNTK के संबंध में तंत्रिका नेटवर्क की अवधारणाओं से संबंधित है।
जैसा कि हम जानते हैं कि, न्यूरॉन्स की कई परतों का उपयोग तंत्रिका नेटवर्क बनाने के लिए किया जाता है। लेकिन, सवाल यह उठता है कि CNTK में हम एक NN की परतों को कैसे मॉडल कर सकते हैं? यह परत मॉड्यूल में परिभाषित परत कार्यों की सहायता से किया जा सकता है।
परत समारोह
दरअसल, CNTK में, परतों के साथ काम करने से एक अलग कार्यात्मक प्रोग्रामिंग महसूस होता है। परत समारोह एक नियमित कार्य की तरह दिखता है और यह पूर्वनिर्धारित मापदंडों के एक सेट के साथ एक गणितीय कार्य करता है। आइए देखें कि हम लेयर फंक्शन की मदद से सबसे बेसिक लेयर टाइप Dense कैसे बना सकते हैं।
उदाहरण
निम्नलिखित मूल चरणों की सहायता से, हम सबसे बुनियादी परत प्रकार बना सकते हैं -
Step 1 - सबसे पहले, हमें CNTK के लेयर्स पैकेज से डेंस लेयर फंक्शन को इंपोर्ट करना होगा।
from cntk.layers import DenseStep 2 - CNTK रूट पैकेज से आगे, हमें input_variable फ़ंक्शन को आयात करना होगा।
from cntk import input_variableStep 3- अब, हमें input_variable फ़ंक्शन का उपयोग करके एक नया इनपुट चर बनाने की आवश्यकता है। हमें इसका आकार भी प्रदान करना होगा।
feature = input_variable(100)Step 4 - आख़िर में, हम जो न्यूरॉन्स चाहते हैं, उनकी संख्या प्रदान करने के साथ घने फ़ंक्शन का उपयोग करके एक नई परत बनाएंगे।
layer = Dense(40)(feature)अब, हम घने परत को इनपुट से जोड़ने के लिए कॉन्फ़िगर किए गए डेंस लेयर फ़ंक्शन को इनवॉइस कर सकते हैं।
पूरा कार्यान्वयन उदाहरण
from cntk.layers import Dense
from cntk import input_variable
feature= input_variable(100)
layer = Dense(40)(feature)परतों को अनुकूलित करना
जैसा कि हमने देखा है कि सीएनटीके हमें एनएन के निर्माण के लिए चूक का एक बहुत अच्छा सेट प्रदान करता है। पर आधारितactivationफ़ंक्शन और अन्य सेटिंग्स जो हम चुनते हैं, व्यवहार और साथ ही एनएन का प्रदर्शन अलग है। यह एक और बहुत उपयोगी उपजी एल्गोरिथ्म है। यही कारण है, यह समझना अच्छा है कि हम क्या कॉन्फ़िगर कर सकते हैं।
एक घने परत को कॉन्फ़िगर करने के लिए कदम
एनएन में प्रत्येक परत के पास अपने अद्वितीय कॉन्फ़िगरेशन विकल्प हैं और जब हम घने परत के बारे में बात करते हैं, तो हमारे पास परिभाषित करने के लिए महत्वपूर्ण सेटिंग्स हैं -
shape - जैसा कि नाम से पता चलता है, यह परत के आउटपुट आकार को परिभाषित करता है जो उस परत में न्यूरॉन्स की संख्या को निर्धारित करता है।
activation - यह उस लेयर के एक्टिवेशन फंक्शन को परिभाषित करता है, इसलिए यह इनपुट डेटा को ट्रांसफॉर्म कर सकता है।
init- यह उस परत के आरंभीकरण समारोह को परिभाषित करता है। जब हम एनएन का प्रशिक्षण शुरू करते हैं तो यह परत के मापदंडों को इनिशियलाइज़ करेगा।
आइए उन चरणों को देखें जिनकी सहायता से हम a को कॉन्फ़िगर कर सकते हैं Dense परत -
Step1 - सबसे पहले, हमें आयात करने की आवश्यकता है Dense CNTK के लेयर्स पैकेज से लेयर फंक्शन।
from cntk.layers import DenseStep2 - CNTK ऑप्स पैकेज से आगे, हमें आयात करने की आवश्यकता है sigmoid operator। इसका उपयोग सक्रियण फ़ंक्शन के रूप में कॉन्फ़िगर करने के लिए किया जाएगा।
from cntk.ops import sigmoidStep3 - अब, इनिलाइज़र पैकेज से, हमें आयात करने की आवश्यकता है glorot_uniform प्रारंभकर्ता।
from cntk.initializer import glorot_uniformStep4 - अंत में, हम पहले तर्क के रूप में न्यूरॉन्स की संख्या प्रदान करने के साथ घने फ़ंक्शन का उपयोग करके एक नई परत बनाएंगे। इसके अलावा, प्रदान करेंsigmoid ऑपरेटर के रूप में activation समारोह और glorot_uniform के रूप में init परत के लिए कार्य करते हैं।
layer = Dense(50, activation = sigmoid, init = glorot_uniform)पूरा कार्यान्वयन उदाहरण -
from cntk.layers import Dense
from cntk.ops import sigmoid
from cntk.initializer import glorot_uniform
layer = Dense(50, activation = sigmoid, init = glorot_uniform)मापदंडों का अनुकूलन
अब तक, हमने देखा है कि एनएन की संरचना कैसे बनाई जाए और विभिन्न सेटिंग्स को कैसे कॉन्फ़िगर किया जाए। यहां, हम देखेंगे, हम एक एनएन के मापदंडों को कैसे अनुकूलित कर सकते हैं। दो घटकों के संयोजन की मदद से अर्थात्learners तथा trainers, हम एक एनएन के मापदंडों को अनुकूलित कर सकते हैं।
ट्रेनर घटक
पहला घटक जो एक एनएन के मापदंडों को अनुकूलित करने के लिए उपयोग किया जाता है trainerघटक। यह मूल रूप से backpropagation प्रक्रिया को लागू करता है। अगर हम इसके काम करने के बारे में बात करते हैं, तो यह भविष्यवाणी प्राप्त करने के लिए एनएन के माध्यम से डेटा पास करता है।
उसके बाद, यह एनएन में मापदंडों के लिए नए मूल्यों को प्राप्त करने के लिए सीखने वाले नामक एक अन्य घटक का उपयोग करता है। एक बार जब यह नया मान प्राप्त करता है, तो यह इन नए मूल्यों को लागू करता है और प्रक्रिया को दोहराता है जब तक कि एक निकास मानदंड पूरा नहीं होता है।
सीखने वाला घटक
दूसरा घटक जो एक एनएन के मापदंडों को अनुकूलित करने के लिए उपयोग किया जाता है learner घटक, जो मूल रूप से ढाल वंश एल्गोरिथ्म के प्रदर्शन के लिए जिम्मेदार है।
CNTK पुस्तकालय में शामिल शिक्षार्थी
CNTK लाइब्रेरी में शामिल कुछ दिलचस्प शिक्षार्थियों की सूची निम्नलिखित है -
Stochastic Gradient Descent (SGD) - यह शिक्षार्थी बिना किसी अतिरिक्त के मूल स्टोचैस्टिक ग्रेडिएंट वंश का प्रतिनिधित्व करता है।
Momentum Stochastic Gradient Descent (MomentumSGD) - SGD के साथ, यह शिक्षार्थी स्थानीय मैक्सिमा की समस्या को दूर करने के लिए गति को लागू करता है।
RMSProp - यह सीखने वाला, वंश की दर को नियंत्रित करने के लिए, सीखने की दर में गिरावट का उपयोग करता है।
Adam - यह सीखने वाला, समय के साथ वंश की दर को कम करने के लिए, क्षयकारी गति का उपयोग करता है।
Adagrad - यह शिक्षार्थी, साथ ही साथ अक्सर होने वाली विशेषताओं के लिए, विभिन्न शिक्षण दर का उपयोग करता है।
CNTK - पहला न्यूरल नेटवर्क बनाना
यह अध्याय CNTK में एक तंत्रिका नेटवर्क बनाने पर विस्तार से बताएगा।
नेटवर्क संरचना बनाएँ
हमारे पहले एनएन के निर्माण के लिए CNTK अवधारणाओं को लागू करने के लिए, हम सीएनपी चौड़ाई और लंबाई के भौतिक गुणों और पंखुड़ी की चौड़ाई और लंबाई के आधार पर आईरिस फूलों की प्रजातियों को वर्गीकृत करने के लिए एनएन का उपयोग करने जा रहे हैं। डेटासेट जो हम आईरिस डेटासेट का उपयोग करेंगे, जिसमें आइरिस फूलों की विभिन्न किस्मों के भौतिक गुणों का वर्णन किया गया है -
- सिपाही की लंबाई
- सिपाही की चौड़ाई
- पंखुड़ी की लंबाई
- पेटल की चौड़ाई
- कक्षा यानी आईरिस सेटोसा या आईरिस वर्सिकोलर या आईरिस वर्जिनिका
यहां, हम एक नियमित एनएन का निर्माण करेंगे, जिसे फीडफोर्वर्ड एनएन कहा जाएगा। आइए, एनएन की संरचना बनाने के लिए कार्यान्वयन कदम देखें -
Step 1 - सबसे पहले, हम आवश्यक घटक जैसे कि हमारे परत प्रकार, सक्रियण फ़ंक्शन और एक फ़ंक्शन आयात करेंगे जो हमें CNTK लाइब्रेरी से हमारे एनएन के लिए एक इनपुट चर को परिभाषित करने की अनुमति देता है।
from cntk import default_options, input_variable
from cntk.layers import Dense, Sequential
from cntk.ops import log_softmax, reluStep 2- उसके बाद, हम अनुक्रमिक फ़ंक्शन का उपयोग करके अपना मॉडल बनाएंगे। एक बार बनाने के बाद, हम इसे अपनी इच्छित परतों के साथ खिलाएंगे। यहां, हम अपने एनएन में दो अलग-अलग परतें बनाने जा रहे हैं; एक चार न्यूरॉन्स के साथ और दूसरा तीन न्यूरॉन्स के साथ।
model = Sequential([Dense(4, activation=relu), Dense(3, activation=log_sogtmax)])Step 3- अंत में, एनएन संकलित करने के लिए, हम नेटवर्क को इनपुट चर से बांध देंगे। इसमें चार न्यूरॉन्स के साथ एक इनपुट परत और तीन न्यूरॉन्स के साथ एक आउटपुट परत है।
feature= input_variable(4)
z = model(feature)सक्रियण फ़ंक्शन लागू करना
चुनने के लिए बहुत सारे सक्रियण कार्य हैं और सही सक्रियण फ़ंक्शन चुनने से निश्चित रूप से एक बड़ा अंतर होगा कि हमारे गहन शिक्षण मॉडल कितना अच्छा प्रदर्शन करेंगे।
आउटपुट लेयर पर
चुनना activation आउटपुट लेयर पर फ़ंक्शन हमारे मॉडल के साथ जिस तरह की समस्या को हल करने जा रहा है, उस पर निर्भर करेगा।
एक प्रतिगमन समस्या के लिए, हमें एक का उपयोग करना चाहिए linear activation function आउटपुट लेयर पर।
एक द्विआधारी वर्गीकरण समस्या के लिए, हमें एक का उपयोग करना चाहिए sigmoid activation function आउटपुट लेयर पर।
बहु-श्रेणी वर्गीकरण समस्या के लिए, हमें एक का उपयोग करना चाहिए softmax activation function आउटपुट लेयर पर।
यहां, हम तीन वर्गों में से एक की भविष्यवाणी के लिए एक मॉडल बनाने जा रहे हैं। इसका मतलब है कि हमें उपयोग करने की आवश्यकता हैsoftmax activation function उत्पादन परत पर।
छिपी हुई परत पर
चुनना activation छिपी हुई परत पर कार्य करने के लिए प्रदर्शन की निगरानी के लिए कुछ प्रयोग की आवश्यकता होती है, यह देखने के लिए कि कौन सा सक्रियण फ़ंक्शन अच्छा काम करता है।
एक वर्गीकरण समस्या में, हमें संभावना का अनुमान लगाने की आवश्यकता है कि एक नमूना एक विशिष्ट वर्ग का है। इसलिए हमें ए की जरूरत हैactivation functionयह हमें संभाव्य मूल्य देता है। इस लक्ष्य तक पहुँचने के लिए,sigmoid activation function हमारी मदद कर सकते हैं।
सिग्मॉइड फ़ंक्शन से जुड़ी प्रमुख समस्याओं में से एक गायब होने वाली ढाल समस्या है। ऐसी समस्या को दूर करने के लिए, हम उपयोग कर सकते हैंReLU activation function जो सभी नकारात्मक मूल्यों को शून्य तक कवर करता है और सकारात्मक मूल्यों के लिए एक पास-थ्रू फिल्टर के रूप में काम करता है।
एक हानि समारोह उठा रहा है
एक बार, हमारे पास हमारे एनएन मॉडल के लिए संरचना है, हमें इसे अनुकूलित करना होगा। अनुकूलन के लिए हमें एक की आवश्यकता हैloss function। भिन्नactivation functions, हमारे पास चुनने के लिए बहुत कम नुकसान कार्य हैं। हालांकि, एक हानि फ़ंक्शन चुनना हमारे मॉडल के साथ जिस तरह की समस्या का समाधान करने जा रहा है, उस पर निर्भर करेगा।
उदाहरण के लिए, एक वर्गीकरण समस्या में, हमें एक हानि फ़ंक्शन का उपयोग करना चाहिए जो एक अनुमानित वर्ग और एक वास्तविक वर्ग के बीच अंतर को माप सकता है।
लॉस फंकशन
वर्गीकरण की समस्या के लिए, हम अपने एनएन मॉडल के साथ हल करने जा रहे हैं, categorical cross entropyनुकसान समारोह सबसे अच्छा उम्मीदवार है। CNTK में, इसे लागू किया जाता हैcross_entropy_with_softmax जिससे आयात किया जा सकता है cntk.losses पैकेज, निम्नानुसार है
label= input_variable(3)
loss = cross_entropy_with_softmax(z, label)मैट्रिक्स
हमारे एनएन मॉडल के लिए संरचना और लागू करने के लिए एक हानि फ़ंक्शन होने के साथ, हमारे पास हमारे सभी नए मॉडल को अनुकूलित करने के लिए नुस्खा बनाने की शुरुआत करने के लिए सभी सामग्रियां हैं। लेकिन, इसमें गहरी डुबकी लगाने से पहले, हमें मैट्रिक्स के बारे में सीखना चाहिए।
cntk.metricsCNTK नाम का पैकेज है cntk.metricsजिससे हम उन मेट्रिक्स को आयात कर सकते हैं जिनका हम उपयोग करने जा रहे हैं। जैसा कि हम एक वर्गीकरण मॉडल का निर्माण कर रहे हैं, हम उपयोग करेंगेclassification_error मैट्रिक जो 0 और 1 के बीच एक संख्या का उत्पादन करेगा। 0 और 1 के बीच की संख्या सही रूप से अनुमानित नमूनों का प्रतिशत इंगित करती है -
सबसे पहले, हमें मीट्रिक को आयात करना होगा cntk.metrics पैकेज -
from cntk.metrics import classification_error
error_rate = classification_error(z, label)उपरोक्त फ़ंक्शन को वास्तव में इनपुट के रूप में एनएन और अपेक्षित लेबल के आउटपुट की आवश्यकता होती है।
CNTK - प्रशिक्षण द न्यूरल नेटवर्क
यहां, हम CNTK में न्यूरल नेटवर्क के प्रशिक्षण के बारे में समझेंगे।
CNTK में एक मॉडल का प्रशिक्षण
पिछले अनुभाग में, हमने गहन शिक्षण मॉडल के सभी घटकों को परिभाषित किया है। अब इसे प्रशिक्षित करने का समय आ गया है। जैसा कि हमने पहले चर्चा की, हम CNTK में NN मॉडल को प्रशिक्षित कर सकते हैंlearner तथा trainer।
एक शिक्षार्थी चुनना और प्रशिक्षण स्थापित करना
इस खंड में, हम परिभाषित करेंगे learner। CNTK कई प्रदान करता हैlearnersमें से चुनना। हमारे मॉडल के लिए, पिछले अनुभागों में परिभाषित किया गया है, हम उपयोग करेंगेStochastic Gradient Descent (SGD) learner।
तंत्रिका नेटवर्क को प्रशिक्षित करने के लिए, हमें कॉन्फ़िगर करें learner तथा trainer निम्नलिखित चरणों की मदद से -
Step 1 - सबसे पहले, हमें आयात करने की आवश्यकता है sgd से कार्य करते हैं cntk.lerners पैकेज।
from cntk.learners import sgdStep 2 - इसके बाद, हमें आयात करने की आवश्यकता है Trainer से कार्य करते हैं cntk.train.trainer पैकेज
from cntk.train.trainer import TrainerStep 3 - अब, हम एक बनाने की जरूरत है learner। इसे बनाकर बनाया जा सकता हैsgd मॉडल के मापदंडों और सीखने की दर के लिए एक मूल्य प्रदान करने के साथ कार्य करते हैं।
learner = sgd(z.parametrs, 0.01)Step 4 - आख़िर में, हमें इनिशियलाइज़ करने की ज़रूरत है trainer। यह नेटवर्क, के संयोजन प्रदान किया जाना चाहिएloss तथा metric इसके साथ learner।
trainer = Trainer(z, (loss, error_rate), [learner])अनुकूलन की गति को नियंत्रित करने वाली सीखने की दर 0.1 से 0.001 के बीच छोटी संख्या होनी चाहिए।
एक शिक्षार्थी चुनना और प्रशिक्षण स्थापित करना - पूरा उदाहरण
from cntk.learners import sgd
from cntk.train.trainer import Trainer
learner = sgd(z.parametrs, 0.01)
trainer = Trainer(z, (loss, error_rate), [learner])ट्रेनर में डाटा फीड करना
एक बार जब हमने ट्रेनर को चुना और कॉन्फ़िगर किया, तो यह डेटासेट लोड करने का समय है। हमने बचा लिया हैiris डाटासेट के रूप में।CSV फ़ाइल और हम डेटा नामकरण पैकेज का उपयोग करेंगे pandas डेटासेट लोड करने के लिए।
.CSV फ़ाइल से डेटासेट लोड करने के लिए चरण
Step 1 - सबसे पहले, हमें आयात करने की आवश्यकता है pandas पैकेज।
from import pandas as pdStep 2 - अब, हमें नामांकित फ़ंक्शन को लागू करने की आवश्यकता है read_csv डिस्क से .csv फ़ाइल लोड करने के लिए फ़ंक्शन।
df_source = pd.read_csv(‘iris.csv’, names = [‘sepal_length’, ‘sepal_width’,
‘petal_length’, ‘petal_width’, index_col=False)एक बार जब हम डेटासेट लोड कर लेते हैं, तो हमें इसे एक फीचर और एक लेबल में विभाजित करने की आवश्यकता होती है।
डेटासेट को फीचर्स और लेबल में विभाजित करने के चरण
Step 1- सबसे पहले, हमें डेटासेट से सभी पंक्तियों और पहले चार कॉलमों का चयन करना होगा। इसका उपयोग करके किया जा सकता हैiloc समारोह।
x = df_source.iloc[:, :4].valuesStep 2- इसके बाद हमें आईरिस डेटासेट से प्रजाति कॉलम का चयन करना होगा। हम अंतर्निहित का उपयोग करने के लिए मूल्यों की संपत्ति का उपयोग करेंगेnumpy सरणी।
x = df_source[‘species’].valuesसांख्यिक वेक्टर प्रतिनिधित्व के लिए प्रजाति कॉलम को एनकोड करने के चरण
जैसा कि हमने पहले चर्चा की थी, हमारा मॉडल वर्गीकरण पर आधारित है, इसके लिए संख्यात्मक इनपुट मूल्यों की आवश्यकता होती है। इसलिए, यहाँ हमें सांख्यिक सदिश निरूपण के लिए प्रजाति कॉलम को एनकोड करना होगा। आइए देखें इसे करने के चरण -
Step 1- पहले, हमें सरणी में सभी तत्वों पर पुनरावृति करने के लिए एक सूची अभिव्यक्ति बनाने की आवश्यकता है। फिर प्रत्येक मान के लिए लेबल_ मैपिंग शब्दकोश में एक प्रदर्शन करें।
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}Step 2- अगला, इस परिवर्तित संख्यात्मक मान को एक-हॉट एन्कोडेड वेक्टर में कनवर्ट करें। हम उपयोग करेंगेone_hot कार्य निम्नानुसार है -
def one_hot(index, length):
result = np.zeros(length)
result[index] = 1
return resultStep 3 - अंत में, हमें इस परिवर्तित सूची को एक में बदलना होगा numpy सरणी।
y = np.array([one_hot(label_mapping[v], 3) for v in y])ओवरफिटिंग का पता लगाने के लिए कदम
स्थिति, जब आपका मॉडल नमूनों को याद करता है, लेकिन प्रशिक्षण के नमूनों से नियमों को कम नहीं कर सकता है, ओवरफिटिंग है। निम्नलिखित चरणों की मदद से, हम अपने मॉडल पर ओवरफिटिंग का पता लगा सकते हैं -
Step 1 - पहला, से sklearn पैकेज, आयात train_test_split से कार्य करते हैं model_selection मापांक।
from sklearn.model_selection import train_test_splitStep 2 - इसके बाद, हमें train_test_split फ़ंक्शन को x और लेबल y के साथ निम्न प्रकार से लागू करना होगा -
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0-2,
stratify=y)हमने कुल डेटा का 20% अलग सेट करने के लिए 0.2 का एक test_size निर्दिष्ट किया।
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}हमारे मॉडल को प्रशिक्षण सेट और सत्यापन सेट खिलाने के लिए कदम
Step 1 - हमारे मॉडल को प्रशिक्षित करने के लिए, सबसे पहले, हम इनवॉइस करेंगे train_minibatchतरीका। फिर इसे एक शब्दकोश दें जो इनपुट डेटा को इनपुट वैरिएबल में मैप करता है जिसका उपयोग हमने एनएन और उसके संबंधित नुकसान फ़ंक्शन को परिभाषित करने के लिए किया है।
trainer.train_minibatch({ features: X_train, label: y_train})Step 2 - अगला, कॉल करें train_minibatch लूप के लिए निम्नलिखित का उपयोग करके -
for _epoch in range(10):
trainer.train_minbatch ({ feature: X_train, label: y_train})
print(‘Loss: {}, Acc: {}’.format(
trainer.previous_minibatch_loss_average,
trainer.previous_minibatch_evaluation_average))ट्रेनर में डेटा फीड करना - पूरा उदाहरण
from import pandas as pd
df_source = pd.read_csv(‘iris.csv’, names = [‘sepal_length’, ‘sepal_width’, ‘petal_length’, ‘petal_width’, index_col=False)
x = df_source.iloc[:, :4].values
x = df_source[‘species’].values
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}
def one_hot(index, length):
result = np.zeros(length)
result[index] = 1
return result
y = np.array([one_hot(label_mapping[v], 3) for v in y])
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0-2, stratify=y)
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}
trainer.train_minibatch({ features: X_train, label: y_train})
for _epoch in range(10):
trainer.train_minbatch ({ feature: X_train, label: y_train})
print(‘Loss: {}, Acc: {}’.format(
trainer.previous_minibatch_loss_average,
trainer.previous_minibatch_evaluation_average))एनएन के प्रदर्शन को मापने
हमारे एनएन मॉडल को अनुकूलित करने के लिए, जब भी हम ट्रेनर के माध्यम से डेटा पास करते हैं, तो यह उस मीट्रिक के माध्यम से मॉडल के प्रदर्शन को मापता है जिसे हमने ट्रेनर के लिए कॉन्फ़िगर किया था। प्रशिक्षण के दौरान एनएन मॉडल के प्रदर्शन का ऐसा माप प्रशिक्षण डेटा पर है। लेकिन दूसरी ओर, मॉडल प्रदर्शन के पूर्ण विश्लेषण के लिए हमें परीक्षण डेटा का भी उपयोग करना होगा।
इसलिए, परीक्षण डेटा का उपयोग करके मॉडल के प्रदर्शन को मापने के लिए, हम इसे लागू कर सकते हैं test_minibatch पर विधि trainer निम्नानुसार है -
trainer.test_minibatch({ features: X_test, label: y_test})एनएन के साथ भविष्यवाणी करना
एक बार जब आप एक गहन शिक्षण मॉडल को प्रशिक्षित करते हैं, तो सबसे महत्वपूर्ण बात यह है कि इसका उपयोग करके भविष्यवाणियां करें। उपरोक्त प्रशिक्षित एनएन से भविष्यवाणी करने के लिए, हम दिए गए चरणों का पालन कर सकते हैं
Step 1 - पहले, हमें निम्नलिखित फ़ंक्शन का उपयोग करके परीक्षण सेट से एक यादृच्छिक आइटम लेने की आवश्यकता है -
np.random.choiceStep 2 - अगला, हमें परीक्षण सेट से नमूना डेटा का उपयोग करके चयन करने की आवश्यकता है sample_index।
Step 3 - अब, संख्यात्मक आउटपुट को एनएन में वास्तविक लेबल में बदलने के लिए, एक उलटा मैपिंग बनाएं।
Step 4 - अब, चयनित का उपयोग करें sampleडेटा। एक समारोह के रूप में एनएन जेड को आमंत्रित करके एक भविष्यवाणी करें।
Step 5- अब, एक बार जब आप अनुमानित आउटपुट प्राप्त कर लेते हैं, तो उस न्यूरॉन के सूचकांक को लें, जिसमें अनुमानित मूल्य के रूप में उच्चतम मूल्य है। यह का उपयोग करके किया जा सकता हैnp.argmax से कार्य करते हैं numpy पैकेज।
Step 6 - आख़िर में, इंडेक्स वैल्यू को असली लेबल में बदलकर उपयोग करें inverted_mapping।
एनएन के साथ भविष्यवाणी करना - पूरा उदाहरण
sample_index = np.random.choice(X_test.shape[0])
sample = X_test[sample_index]
inverted_mapping = {
1:’Iris-setosa’,
2:’Iris-versicolor’,
3:’Iris-virginica’
}
prediction = z(sample)
predicted_label = inverted_mapping[np.argmax(prediction)]
print(predicted_label)उत्पादन
उपरोक्त डीप लर्निंग मॉडल को प्रशिक्षित करने और इसे चलाने के बाद, आपको निम्न आउटपुट मिलेगा -
Iris-versicolorCNTK - इन-मेमोरी और बड़े डेटासेट
इस अध्याय में, हम सीएनटीके में इन-मेमोरी और बड़े डेटासेट के साथ काम करने के तरीके के बारे में जानेंगे।
मेमोरी डेटासेट में छोटे से प्रशिक्षण
जब हम CNTK ट्रेनर में डेटा फीड करने की बात करते हैं, तो कई तरीके हो सकते हैं, लेकिन यह डेटा के डेटासेट और प्रारूप के आकार पर निर्भर करेगा। डेटा सेट छोटे इन-मेमोरी या बड़े डेटासेट हो सकते हैं।
इस खंड में, हम इन-मेमोरी डेटासेट के साथ काम करने जा रहे हैं। इसके लिए, हम निम्नलिखित दो रूपरेखाओं का उपयोग करेंगे -
- Numpy
- Pandas
Numpy सरणियों का उपयोग करना
यहां, हम CNTK में एक सुव्यवस्थित रूप से उत्पन्न डेटासेट के साथ काम करेंगे। इस उदाहरण में, हम एक द्विआधारी वर्गीकरण समस्या के लिए डेटा का अनुकरण करने जा रहे हैं। मान लीजिए, हमारे पास 4 विशेषताओं के साथ टिप्पणियों का एक सेट है और हमारे गहन शिक्षण मॉडल के साथ दो संभावित लेबल की भविष्यवाणी करना चाहते हैं।
कार्यान्वयन उदाहरण
इसके लिए, पहले हमें लेबल का एक सेट उत्पन्न करना चाहिए जिसमें लेबल के एक-गर्म वेक्टर प्रतिनिधित्व होता है, हम भविष्यवाणी करना चाहते हैं। इसे निम्नलिखित चरणों की सहायता से किया जा सकता है -
Step 1 - आयात करें numpy पैकेज निम्नानुसार है -
import numpy as np
num_samples = 20000Step 2 - इसके बाद, उपयोग करके एक लेबल मैपिंग जनरेट करें np.eye कार्य निम्नानुसार है -
label_mapping = np.eye(2)Step 3 - अब उपयोग करके np.random.choice फ़ंक्शन, 20000 यादृच्छिक नमूने निम्नानुसार एकत्रित करें -
y = label_mapping[np.random.choice(2,num_samples)].astype(np.float32)Step 4 - अब np.random.random फ़ंक्शन का उपयोग करके अंत में, यादृच्छिक फ्लोटिंग पॉइंट मानों की एक सरणी उत्पन्न करें -
x = np.random.random(size=(num_samples, 4)).astype(np.float32)एक बार, हम यादृच्छिक फ़्लोटिंग-पॉइंट मानों की एक सरणी उत्पन्न करते हैं, हमें उन्हें 32-बिट फ़्लोटिंग पॉइंट नंबरों में बदलने की आवश्यकता है ताकि इसे CNTK द्वारा अपेक्षित प्रारूप से मिलान किया जा सके। ऐसा करने के लिए नीचे दिए गए चरणों का पालन करें -
Step 5 इस प्रकार cntk.layers मॉड्यूल से घने और अनुक्रमिक परत कार्यों को आयात करें -
from cntk.layers import Dense, SequentialStep 6- अब, हमें नेटवर्क में परतों के लिए सक्रियण फ़ंक्शन को आयात करने की आवश्यकता है। आयात करते हैंsigmoid सक्रियण समारोह के रूप में -
from cntk import input_variable, default_options
from cntk.ops import sigmoidStep 7- अब, हमें नेटवर्क को प्रशिक्षित करने के लिए नुकसान फ़ंक्शन को आयात करने की आवश्यकता है। आयात करते हैंbinary_cross_entropy हानि समारोह के रूप में -
from cntk.losses import binary_cross_entropyStep 8- अगला, हमें नेटवर्क के लिए डिफ़ॉल्ट विकल्पों को परिभाषित करने की आवश्यकता है। यहां, हम प्रदान करेंगेsigmoidडिफ़ॉल्ट सेटिंग के रूप में सक्रियण फ़ंक्शन। इसके अलावा, अनुक्रमिक परत फ़ंक्शन का उपयोग करके मॉडल बनाएं:
with default_options(activation=sigmoid):
model = Sequential([Dense(6),Dense(2)])Step 9 - अगला, इनिशियलाइज़ a input_variable नेटवर्क के लिए इनपुट के रूप में सेवारत 4 इनपुट सुविधाओं के साथ।
features = input_variable(4)Step 10 - अब, इसे पूरा करने के लिए, हमें NN में वैरिएबल कनेक्ट करने की आवश्यकता है।
z = model(features)तो, अब हमारे पास एनएन है, निम्नलिखित चरणों की मदद से, हमें इन-मेमोरी डेटासेट का उपयोग करके प्रशिक्षित करें -
Step 11 - इस एनएन को प्रशिक्षित करने के लिए, सबसे पहले हमें सीखने वाले को आयात करना होगा cntk.learnersमापांक। हम आयात करेंगेsgd शिक्षार्थी इस प्रकार है -
from cntk.learners import sgdStep 12 - इसके साथ ही आयात करें ProgressPrinter से cntk.logging मॉड्यूल के रूप में अच्छी तरह से।
from cntk.logging import ProgressPrinter
progress_writer = ProgressPrinter(0)Step 13 - अगला, लेबल के लिए एक नया इनपुट चर परिभाषित करें -
labels = input_variable(2)Step 14 - एनएन मॉडल को प्रशिक्षित करने के लिए, अगले, हमें एक नुकसान का उपयोग करने की आवश्यकता है binary_cross_entropyसमारोह। इसके अलावा, मॉडल जेड और लेबल चर प्रदान करें।
loss = binary_cross_entropy(z, labels)Step 15 - अगला, इनिशियलाइज़ करें sgd शिक्षार्थी इस प्रकार है -
learner = sgd(z.parameters, lr=0.1)Step 16- अंत में, नुकसान फ़ंक्शन पर ट्रेन विधि को कॉल करें। इसके अलावा, इसे इनपुट डेटा के साथ प्रदान करें,sgd सीखने वाला और progress_printer.-
training_summary=loss.train((x,y),parameter_learners=[learner],callbacks=[progress_writer])पूरा कार्यान्वयन उदाहरण
import numpy as np
num_samples = 20000
label_mapping = np.eye(2)
y = label_mapping[np.random.choice(2,num_samples)].astype(np.float32)
x = np.random.random(size=(num_samples, 4)).astype(np.float32)
from cntk.layers import Dense, Sequential
from cntk import input_variable, default_options
from cntk.ops import sigmoid
from cntk.losses import binary_cross_entropy
with default_options(activation=sigmoid):
model = Sequential([Dense(6),Dense(2)])
features = input_variable(4)
z = model(features)
from cntk.learners import sgd
from cntk.logging import ProgressPrinter
progress_writer = ProgressPrinter(0)
labels = input_variable(2)
loss = binary_cross_entropy(z, labels)
learner = sgd(z.parameters, lr=0.1)
training_summary=loss.train((x,y),parameter_learners=[learner],callbacks=[progress_writer])उत्पादन
Build info:
Built time: *** ** **** 21:40:10
Last modified date: *** *** ** 21:08:46 2019
Build type: Release
Build target: CPU-only
With ASGD: yes
Math lib: mkl
Build Branch: HEAD
Build SHA1:ae9c9c7c5f9e6072cc9c94c254f816dbdc1c5be6 (modified)
MPI distribution: Microsoft MPI
MPI version: 7.0.12437.6
-------------------------------------------------------------------
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.1
1.52 1.52 0 0 32
1.51 1.51 0 0 96
1.48 1.46 0 0 224
1.45 1.42 0 0 480
1.42 1.4 0 0 992
1.41 1.39 0 0 2016
1.4 1.39 0 0 4064
1.39 1.39 0 0 8160
1.39 1.39 0 0 16352पंडों डेटाफ्रैम का उपयोग करना
Numpy सरणियाँ वे क्या शामिल कर सकते हैं और डेटा भंडारण के सबसे बुनियादी तरीकों में से एक में बहुत सीमित हैं। उदाहरण के लिए, एक एकल n- आयामी सरणी में एकल डेटा प्रकार का डेटा हो सकता है। लेकिन दूसरी ओर, कई वास्तविक दुनिया के मामलों में हमें एक पुस्तकालय की आवश्यकता होती है जो एक डेटासेट में एक से अधिक डेटा प्रकारों को संभाल सकता है।
पंडों नामक पायथन पुस्तकालयों में से एक इस तरह के डेटासेट के साथ काम करना आसान बनाता है। यह एक DataFrame (DF) की अवधारणा का परिचय देता है और हमें DF प्रारूप के रूप में विभिन्न स्वरूपों में संग्रहीत डिस्क से डेटासेट लोड करने की अनुमति देता है। उदाहरण के लिए, हम CSV को CSV, JSON, Excel आदि के रूप में संग्रहीत पढ़ सकते हैं।
आप पायथन पंडों पुस्तकालय को और अधिक विस्तार से जान सकते हैं https://www.tutorialspoint.com/python_pandas/index.htm.
कार्यान्वयन उदाहरण
इस उदाहरण में, हम चार गुणों के आधार पर आईरिस फूलों की तीन संभावित प्रजातियों को वर्गीकृत करने के उदाहरण का उपयोग करने जा रहे हैं। हमने पिछले खंडों में भी इस गहन शिक्षण मॉडल को बनाया है। मॉडल इस प्रकार है -
from cntk.layers import Dense, Sequential
from cntk import input_variable, default_options
from cntk.ops import sigmoid, log_softmax
from cntk.losses import binary_cross_entropy
model = Sequential([
Dense(4, activation=sigmoid),
Dense(3, activation=log_softmax)
])
features = input_variable(4)
z = model(features)उपरोक्त मॉडल में एक छिपी हुई परत और तीन न्यूरॉन्स के साथ एक आउटपुट परत होती है, जिससे हम अनुमान लगा सकते हैं कि कक्षाओं की संख्या कितनी है।
अगला, हम उपयोग करेंगे train विधि और lossनेटवर्क को प्रशिक्षित करने के लिए कार्य करते हैं। इसके लिए, पहले हमें आइरिस डेटा को लोड और प्रीप्रोसेस करना होगा, ताकि यह एनएन के लिए अपेक्षित लेआउट और डेटा प्रारूप से मेल खाए। इसे निम्नलिखित चरणों की सहायता से किया जा सकता है -
Step 1 - आयात करें numpy तथा Pandas पैकेज निम्नानुसार है -
import numpy as np
import pandas as pdStep 2 - अगला, उपयोग करें read_csv डेटासेट को मेमोरी में लोड करने का कार्य -
df_source = pd.read_csv(‘iris.csv’, names = [‘sepal_length’, ‘sepal_width’,
‘petal_length’, ‘petal_width’, ‘species’], index_col=False)Step 3 - अब, हमें एक ऐसा शब्दकोष बनाने की जरूरत है, जो डेटासेट में लेबल को उनके संबंधित संख्यात्मक प्रतिनिधित्व के साथ मैप कर रहा हो।
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}Step 4 - अब, का उपयोग करके iloc सूचकांक पर DataFrame, पहले चार कॉलम निम्नानुसार चुनें -
x = df_source.iloc[:, :4].valuesStep 5AsNext, हमें डेटा कॉलम को डेटासेट के लिए लेबल के रूप में चुनना होगा। इसे निम्नानुसार किया जा सकता है -
y = df_source[‘species’].valuesStep 6 - अब, हमें डेटासेट में उन लेबलों को मैप करना होगा, जिनका उपयोग करके किया जा सकता है label_mapping। इसका भी प्रयोग करेंone_hot एन्कोडिंग उन्हें एक-हॉट एन्कोडिंग सरणियों में बदलने के लिए।
y = np.array([one_hot(label_mapping[v], 3) for v in y])Step 7 - अगला, CNTK के साथ सुविधाओं और मैप किए गए लेबल का उपयोग करने के लिए, हमें उन दोनों को फ़्लोट में बदलने की आवश्यकता है -
x= x.astype(np.float32)
y= y.astype(np.float32)जैसा कि हम जानते हैं कि, लेबल को तार के रूप में डेटासेट में संग्रहीत किया जाता है और CNTK इन स्ट्रिंग्स के साथ काम नहीं कर सकता है। यही कारण है, यह लेबल का प्रतिनिधित्व करने वाले एक-गर्म एन्कोडेड वैक्टर की आवश्यकता है। इसके लिए, हम एक फ़ंक्शन को परिभाषित कर सकते हैंone_hot निम्नानुसार है -
def one_hot(index, length):
result = np.zeros(length)
result[index] = index
return resultअब, हमारे पास सही प्रारूप में सुन्न सरणी है, निम्नलिखित चरणों की मदद से हम अपने मॉडल को प्रशिक्षित करने के लिए उनका उपयोग कर सकते हैं -
Step 8- सबसे पहले, हमें नेटवर्क को प्रशिक्षित करने के लिए नुकसान फ़ंक्शन को आयात करना होगा। आयात करते हैंbinary_cross_entropy_with_softmax हानि समारोह के रूप में -
from cntk.losses import binary_cross_entropy_with_softmaxStep 9 - इस एनएन को प्रशिक्षित करने के लिए, हमें सीखने वाले को आयात करने की भी आवश्यकता है cntk.learnersमापांक। हम आयात करेंगेsgd शिक्षार्थी इस प्रकार है -
from cntk.learners import sgdStep 10 - इसके साथ ही आयात करें ProgressPrinter से cntk.logging मॉड्यूल के रूप में अच्छी तरह से।
from cntk.logging import ProgressPrinter
progress_writer = ProgressPrinter(0)Step 11 - अगला, लेबल के लिए एक नया इनपुट चर परिभाषित करें -
labels = input_variable(3)Step 12 - एनएन मॉडल को प्रशिक्षित करने के लिए, अगले, हमें एक नुकसान का उपयोग करने की आवश्यकता है binary_cross_entropy_with_softmaxसमारोह। मॉडल z और लेबल चर भी प्रदान करें।
loss = binary_cross_entropy_with_softmax (z, labels)Step 13 - अगला, इनिशियलाइज़ करें sgd शिक्षार्थी इस प्रकार है -
learner = sgd(z.parameters, 0.1)Step 14- अंत में, नुकसान फ़ंक्शन पर ट्रेन विधि को कॉल करें। इसके अलावा, इसे इनपुट डेटा के साथ प्रदान करें,sgd सीखने वाला और progress_printer।
training_summary=loss.train((x,y),parameter_learners=[learner],callbacks=
[progress_writer],minibatch_size=16,max_epochs=5)पूरा कार्यान्वयन उदाहरण
from cntk.layers import Dense, Sequential
from cntk import input_variable, default_options
from cntk.ops import sigmoid, log_softmax
from cntk.losses import binary_cross_entropy
model = Sequential([
Dense(4, activation=sigmoid),
Dense(3, activation=log_softmax)
])
features = input_variable(4)
z = model(features)
import numpy as np
import pandas as pd
df_source = pd.read_csv(‘iris.csv’, names = [‘sepal_length’, ‘sepal_width’, ‘petal_length’, ‘petal_width’, ‘species’], index_col=False)
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}
x = df_source.iloc[:, :4].values
y = df_source[‘species’].values
y = np.array([one_hot(label_mapping[v], 3) for v in y])
x= x.astype(np.float32)
y= y.astype(np.float32)
def one_hot(index, length):
result = np.zeros(length)
result[index] = index
return result
from cntk.losses import binary_cross_entropy_with_softmax
from cntk.learners import sgd
from cntk.logging import ProgressPrinter
progress_writer = ProgressPrinter(0)
labels = input_variable(3)
loss = binary_cross_entropy_with_softmax (z, labels)
learner = sgd(z.parameters, 0.1)
training_summary=loss.train((x,y),parameter_learners=[learner],callbacks=[progress_writer],minibatch_size=16,max_epochs=5)उत्पादन
Build info:
Built time: *** ** **** 21:40:10
Last modified date: *** *** ** 21:08:46 2019
Build type: Release
Build target: CPU-only
With ASGD: yes
Math lib: mkl
Build Branch: HEAD
Build SHA1:ae9c9c7c5f9e6072cc9c94c254f816dbdc1c5be6 (modified)
MPI distribution: Microsoft MPI
MPI version: 7.0.12437.6
-------------------------------------------------------------------
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.1
1.1 1.1 0 0 16
0.835 0.704 0 0 32
1.993 1.11 0 0 48
1.14 1.14 0 0 112
[………]बड़े डेटासेट के साथ प्रशिक्षण
पिछले अनुभाग में, हमने Numpy और पांडा का उपयोग करते हुए छोटे इन-मेमोरी डेटासेट के साथ काम किया, लेकिन सभी डेटासेट इतने छोटे नहीं हैं। विशेष रूप से छवियां, वीडियो, ध्वनि नमूने वाले डेटासेट बड़े हैं।MinibatchSourceएक घटक है, जो इतने बड़े डेटासेट के साथ काम करने के लिए CNTK द्वारा प्रदान किए गए डेटा को चंक्स में लोड कर सकता है। की कुछ विशेषताएंMinibatchSource घटक इस प्रकार हैं -
MinibatchSource डेटा स्रोत से पढ़े गए नमूनों को स्वचालित रूप से यादृच्छिक करके एनएन को ओवरफिटिंग से रोक सकते हैं।
इसमें अंतर्निर्मित परिवर्तन पाइपलाइन है जिसका उपयोग डेटा को बढ़ाने के लिए किया जा सकता है।
यह प्रशिक्षण प्रक्रिया से अलग पृष्ठभूमि थ्रेड पर डेटा लोड करता है।
निम्नलिखित अनुभागों में, हम यह पता लगाने जा रहे हैं कि बड़े डेटासेट के साथ काम करने के लिए आउट-ऑफ-मेमोरी डेटा के साथ मिनीबच स्रोत का उपयोग कैसे किया जाए। हम यह भी पता लगाएंगे, कि हम किसी एनएन को प्रशिक्षण देने के लिए इसका उपयोग कैसे कर सकते हैं।
MinibatchSource उदाहरण बनाना
पिछले भाग में, हमने आईरिस फूल उदाहरण का उपयोग किया है और पंडों डेटाफ्रैम का उपयोग करते हुए छोटे इन-मेमोरी डेटासेट के साथ काम किया है। यहां, हम उस कोड की जगह लेंगे जो एक पांडा डीएफ से डेटा का उपयोग करता हैMinibatchSource। सबसे पहले, हमें एक उदाहरण बनाने की आवश्यकता हैMinibatchSource निम्नलिखित चरणों की मदद से -
कार्यान्वयन उदाहरण
Step 1 - पहला, से cntk.io मॉड्यूल इस प्रकार के लिए मिनीबैचसोर्स के घटकों को आयात करता है -
from cntk.io import StreamDef, StreamDefs, MinibatchSource, CTFDeserializer,
INFINITY_REPEATStep 2 - अब, का उपयोग करके StreamDef वर्ग, लेबल के लिए एक स्ट्रीम परिभाषा क्रेट करें।
labels_stream = StreamDef(field=’labels’, shape=3, is_sparse=False)Step 3 - इसके बाद, इनपुट फ़ाइल से दर्ज की गई विशेषताओं को पढ़ने के लिए बनाएं, का एक और उदाहरण बनाएं StreamDef निम्नलिखित नुसार।
feature_stream = StreamDef(field=’features’, shape=4, is_sparse=False)Step 4 - अब, हमें प्रदान करने की आवश्यकता है iris.ctf इनपुट के रूप में फ़ाइल करें और आरंभ करें deserializer निम्नानुसार है -
deserializer = CTFDeserializer(‘iris.ctf’, StreamDefs(labels=
label_stream, features=features_stream)Step 5 - अंत में, हमें उदाहरण प्रस्तुत करने की आवश्यकता है minisourceBatch का उपयोग करके deserializer निम्नानुसार है -
Minibatch_source = MinibatchSource(deserializer, randomize=True)एक MinibatchSource उदाहरण बनाना - पूर्ण कार्यान्वयन उदाहरण
from cntk.io import StreamDef, StreamDefs, MinibatchSource, CTFDeserializer, INFINITY_REPEAT
labels_stream = StreamDef(field=’labels’, shape=3, is_sparse=False)
feature_stream = StreamDef(field=’features’, shape=4, is_sparse=False)
deserializer = CTFDeserializer(‘iris.ctf’, StreamDefs(labels=label_stream, features=features_stream)
Minibatch_source = MinibatchSource(deserializer, randomize=True)MCTF फ़ाइल बनाना
जैसा कि आपने ऊपर देखा है, हम 'iris.ctf' फ़ाइल से डेटा ले रहे हैं। इसमें CNTK टेक्स्ट फॉर्मेट (CTF) नामक फाइल फॉर्मेट है। डेटा प्राप्त करने के लिए CTF फ़ाइल बनाना अनिवार्य हैMinibatchSourceउदाहरण हमने ऊपर बनाया है। आइए देखें कि हम सीटीएफ फाइल कैसे बना सकते हैं।
कार्यान्वयन उदाहरण
Step 1 - सबसे पहले, हमें निम्नानुसार पंडों और खस्ता पैकेजों को आयात करना होगा -
import pandas as pd
import numpy as npStep 2- इसके बाद, हमें अपनी डेटा फ़ाइल, अर्थात iris.csv को मेमोरी में लोड करना होगा। फिर, इसे स्टोर करेंdf_source चर।
df_source = pd.read_csv(‘iris.csv’, names = [‘sepal_length’, ‘sepal_width’, ‘petal_length’, ‘petal_width’, ‘species’], index_col=False)Step 3 - अब, का उपयोग करके ilocसुविधाओं के रूप में अनुक्रमणिका, पहले चार कॉलम की सामग्री लें। इसके अलावा, प्रजाति कॉलम के डेटा का उपयोग इस प्रकार करें -
features = df_source.iloc[: , :4].values
labels = df_source[‘species’].valuesStep 4- अगला, हमें लेबल नाम और इसके संख्यात्मक प्रतिनिधित्व के बीच एक मानचित्रण बनाने की आवश्यकता है। इसे बनाकर किया जा सकता हैlabel_mapping निम्नानुसार है -
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}Step 5 - अब, लेबल को एक गर्म एन्कोडेड वैक्टर के एक सेट में इस प्रकार परिवर्तित करें -
labels = [one_hot(label_mapping[v], 3) for v in labels]अब, जैसा कि हमने पहले किया था, एक उपयोगिता फ़ंक्शन कहा जाता है one_hotलेबल को एनकोड करने के लिए। इसे निम्नानुसार किया जा सकता है -
def one_hot(index, length):
result = np.zeros(length)
result[index] = 1
return resultजैसा कि, हमने डेटा लोड और प्रीप्रोसेस किया है, इसे CTF फ़ाइल स्वरूप में डिस्क पर संग्रहीत करने का समय है। हम इसे पायथन कोड की मदद से कर सकते हैं -
With open(‘iris.ctf’, ‘w’) as output_file:
for index in range(0, feature.shape[0]):
feature_values = ‘ ‘.join([str(x) for x in np.nditer(features[index])])
label_values = ‘ ‘.join([str(x) for x in np.nditer(labels[index])])
output_file.write(‘features {} | labels {} \n’.format(feature_values, label_values))MCTF फ़ाइल बनाना - पूर्ण कार्यान्वयन उदाहरण
import pandas as pd
import numpy as np
df_source = pd.read_csv(‘iris.csv’, names = [‘sepal_length’, ‘sepal_width’, ‘petal_length’, ‘petal_width’, ‘species’], index_col=False)
features = df_source.iloc[: , :4].values
labels = df_source[‘species’].values
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}
labels = [one_hot(label_mapping[v], 3) for v in labels]
def one_hot(index, length):
result = np.zeros(length)
result[index] = 1
return result
With open(‘iris.ctf’, ‘w’) as output_file:
for index in range(0, feature.shape[0]):
feature_values = ‘ ‘.join([str(x) for x in np.nditer(features[index])])
label_values = ‘ ‘.join([str(x) for x in np.nditer(labels[index])])
output_file.write(‘features {} | labels {} \n’.format(feature_values, label_values))डाटा फीड करना
एक बार जब आप बनाएँ MinibatchSource,उदाहरण के लिए, हमें इसे प्रशिक्षित करने की आवश्यकता है। जब हम छोटे इन-मेमोरी डेटासेट के साथ काम करते हैं तो हम उसी तरह के प्रशिक्षण तर्क का उपयोग कर सकते हैं। यहां, हम उपयोग करेंगेMinibatchSource उदाहरण के तौर पर ट्रेन फंक्शन के लिए इनपुट फंक्शन ऑन लॉस फंक्शन इस प्रकार है -
कार्यान्वयन उदाहरण
Step 1 - प्रशिक्षण सत्र के आउटपुट को लॉग करने के लिए, पहले ProgressPrinter से आयात करें cntk.logging मॉड्यूल निम्नानुसार है -
from cntk.logging import ProgressPrinterStep 2 - अगला, प्रशिक्षण सत्र स्थापित करने के लिए, आयात करें trainer तथा training_session से cntk.train मॉड्यूल निम्नानुसार है -
from cntk.train import Trainer,Step 3 - अब, हमें स्थिरांक के कुछ सेट को परिभाषित करने की आवश्यकता है minibatch_size, samples_per_epoch तथा num_epochs निम्नानुसार है -
minbatch_size = 16
samples_per_epoch = 150
num_epochs = 30Step 4 - अगला, प्रशिक्षण के दौरान डेटा को पढ़ने के लिए CNTK को जानने के लिए, हमें नेटवर्क के लिए इनपुट चर और मिनीबैच स्रोत में धाराओं के बीच मानचित्रण को परिभाषित करने की आवश्यकता है।
input_map = {
features: minibatch.source.streams.features,
labels: minibatch.source.streams.features
}Step 5 - अगला, प्रशिक्षण प्रक्रिया के आउटपुट को लॉग करने के लिए, इनिशियलाइज़ करें progress_printer एक नया के साथ चर ProgressPrinter उदाहरण इस प्रकार है -
progress_writer = ProgressPrinter(0)Step 6 - अंत में, हमें ट्रेन की विधि को नुकसान पर लागू करने की आवश्यकता है -
train_history = loss.train(minibatch_source,
parameter_learners=[learner],
model_inputs_to_streams=input_map,
callbacks=[progress_writer],
epoch_size=samples_per_epoch,
max_epochs=num_epochs)डेटा खिलाना - पूर्ण कार्यान्वयन उदाहरण
from cntk.logging import ProgressPrinter
from cntk.train import Trainer, training_session
minbatch_size = 16
samples_per_epoch = 150
num_epochs = 30
input_map = {
features: minibatch.source.streams.features,
labels: minibatch.source.streams.features
}
progress_writer = ProgressPrinter(0)
train_history = loss.train(minibatch_source,
parameter_learners=[learner],
model_inputs_to_streams=input_map,
callbacks=[progress_writer],
epoch_size=samples_per_epoch,
max_epochs=num_epochs)उत्पादन
-------------------------------------------------------------------
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.1
1.21 1.21 0 0 32
1.15 0.12 0 0 96
[………]CNTK - प्रदर्शन को मापने
यह अध्याय बताएगा कि CNKT में मॉडल प्रदर्शन को कैसे मापें।
मॉडल के प्रदर्शन को मान्य करने की रणनीति
एमएल मॉडल बनाने के बाद, हम डेटा नमूनों के एक सेट का उपयोग करके इसे प्रशिक्षित करते थे। इस प्रशिक्षण के कारण हमारा एमएल मॉडल कुछ सामान्य नियमों को सीखता है और प्राप्त करता है। एमएल मॉडल का प्रदर्शन तब मायने रखता है जब हम मॉडल के लिए, नए नमूने, यानी प्रशिक्षण के समय प्रदान किए गए विभिन्न नमूनों को खिलाते हैं। मॉडल उस मामले में अलग तरह से व्यवहार करता है। यह उन नए नमूनों पर एक अच्छी भविष्यवाणी करने से भी बदतर हो सकता है।
लेकिन मॉडल को नए नमूनों के लिए अच्छी तरह से काम करना चाहिए क्योंकि उत्पादन के माहौल में हमें प्रशिक्षण उद्देश्य के लिए नमूना डेटा का उपयोग करने की तुलना में अलग इनपुट मिलेगा। यही कारण है कि, हमें प्रशिक्षण उद्देश्य के लिए उपयोग किए गए नमूनों से अलग नमूनों का एक सेट का उपयोग करके एमएल मॉडल को मान्य करना चाहिए। यहां, हम एनएन को मान्य करने के लिए डेटासेट बनाने के लिए दो अलग-अलग तकनीकों पर चर्चा करने जा रहे हैं।
होल्ड-आउट डेटासेट
एनएन को मान्य करने के लिए डेटासेट बनाने के लिए यह सबसे आसान तरीकों में से एक है। जैसा कि नाम का अर्थ है, इस पद्धति में हम प्रशिक्षण से नमूने का एक सेट (20% कहते हैं) वापस लेंगे और इसका उपयोग हमारे एमएल मॉडल के प्रदर्शन का परीक्षण करने के लिए करेंगे। निम्नलिखित आरेख प्रशिक्षण और सत्यापन नमूनों के बीच का अनुपात दर्शाता है -

होल्ड-आउट डेटासेट मॉडल सुनिश्चित करता है कि हमारे एमएल मॉडल को प्रशिक्षित करने के लिए हमारे पास पर्याप्त डेटा है और साथ ही हमारे पास मॉडल के प्रदर्शन का अच्छा माप प्राप्त करने के लिए उचित संख्या में नमूने होंगे।
प्रशिक्षण सेट और परीक्षण सेट में शामिल करने के लिए, मुख्य डेटासेट से यादृच्छिक नमूने चुनने के लिए यह एक अच्छा अभ्यास है। यह प्रशिक्षण और परीक्षण सेट के बीच एक समान वितरण सुनिश्चित करता है।
निम्नलिखित एक उदाहरण है जिसमें हम उपयोग करके स्वयं होल्ड-आउट डेटासेट का उत्पादन कर रहे हैं train_test_split से कार्य करते हैं scikit-learn पुस्तकालय।
उदाहरण
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
# Here above test_size = 0.2 represents that we provided 20% of the data as test data.
from sklearn.neighbors import KNeighborsClassifier
from sklearn import metrics
classifier_knn = KNeighborsClassifier(n_neighbors=3)
classifier_knn.fit(X_train, y_train)
y_pred = classifier_knn.predict(X_test)
# Providing sample data and the model will make prediction out of that data
sample = [[5, 5, 3, 2], [2, 4, 3, 5]]
preds = classifier_knn.predict(sample)
pred_species = [iris.target_names[p] for p in preds] print("Predictions:", pred_species)उत्पादन
Predictions: ['versicolor', 'virginica']CNTK का उपयोग करते समय, हमें हर बार जब हम अपने मॉडल को प्रशिक्षित करते हैं, तो हमारे डेटासेट के क्रम को यादृच्छिक बनाने की आवश्यकता होती है क्योंकि -
डीप लर्निंग एल्गोरिदम यादृच्छिक-संख्या जनरेटर से अत्यधिक प्रभावित होते हैं।
जिस क्रम में हम प्रशिक्षण के दौरान एनएन को नमूने प्रदान करते हैं, उसके प्रदर्शन को बहुत प्रभावित करता है।
होल्ड-आउट डेटासेट तकनीक का उपयोग करने का मुख्य पहलू यह है कि यह अविश्वसनीय है क्योंकि कभी-कभी हमें बहुत अच्छे परिणाम मिलते हैं लेकिन कभी-कभी, हम खराब परिणाम देते हैं।
K- गुना क्रॉस सत्यापन
हमारे एमएल मॉडल को अधिक विश्वसनीय बनाने के लिए, के-फोल्ड क्रॉस सत्यापन नामक एक तकनीक है। प्रकृति में K- गुना क्रॉस सत्यापन तकनीक पिछली तकनीक के समान है, लेकिन यह इसे कई बार दोहराता है-आमतौर पर लगभग 5 से 10 बार। निम्नलिखित आरेख इसकी अवधारणा का प्रतिनिधित्व करता है -

K- गुना क्रॉस सत्यापन का कार्य करना
K- गुना क्रॉस सत्यापन के कार्य को निम्नलिखित चरणों की सहायता से समझा जा सकता है -
Step 1- जैसे कि हैंड-आउट डेटासेट तकनीक, के-फोल्ड क्रॉस सत्यापन तकनीक में, पहले हमें डेटासेट को एक प्रशिक्षण और परीक्षण सेट में विभाजित करना होगा। आदर्श रूप से, अनुपात 80-20 है, अर्थात प्रशिक्षण सेट का 80% और परीक्षण सेट का 20%।
Step 2 - अगला, हमें प्रशिक्षण सेट का उपयोग करके अपने मॉडल को प्रशिक्षित करने की आवश्यकता है।
Step 3अंतिम बार, हम अपने मॉडल के प्रदर्शन को मापने के लिए परीक्षण सेट का उपयोग करेंगे। होल्ड-आउट डेटासेट तकनीक और के-क्रॉस सत्यापन तकनीक के बीच एकमात्र अंतर यह है कि उपरोक्त प्रक्रिया आमतौर पर 5 से 10 बार दोहराई जाती है और अंत में सभी प्रदर्शन मैट्रिक्स पर गणना की जाती है। यह औसत अंतिम प्रदर्शन मेट्रिक्स होगा।
आइए एक छोटे डेटासेट के साथ एक उदाहरण देखें -
उदाहरण
from numpy import array
from sklearn.model_selection import KFold
data = array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0])
kfold = KFold(5, True, 1)
for train, test in kfold.split(data):
print('train: %s, test: %s' % (data[train],(data[test]))उत्पादन
train: [0.1 0.2 0.4 0.5 0.6 0.7 0.8 0.9], test: [0.3 1. ]
train: [0.1 0.2 0.3 0.4 0.6 0.8 0.9 1. ], test: [0.5 0.7]
train: [0.2 0.3 0.5 0.6 0.7 0.8 0.9 1. ], test: [0.1 0.4]
train: [0.1 0.3 0.4 0.5 0.6 0.7 0.9 1. ], test: [0.2 0.8]
train: [0.1 0.2 0.3 0.4 0.5 0.7 0.8 1. ], test: [0.6 0.9]जैसा कि हम देखते हैं, अधिक यथार्थवादी प्रशिक्षण और परीक्षण परिदृश्य का उपयोग करने के कारण, k- गुना क्रॉस सत्यापन तकनीक हमें अधिक स्थिर प्रदर्शन माप प्रदान करती है लेकिन, नकारात्मक पक्ष पर, गहन शिक्षण मॉडल को मान्य करते समय बहुत समय लगता है।
CNTK k- क्रॉस सत्यापन के लिए समर्थन नहीं करता है, इसलिए हमें ऐसा करने के लिए अपनी स्क्रिप्ट लिखने की आवश्यकता है।
अंडरफुटिंग और ओवरफिटिंग का पता लगाना
क्या, हम हैंड-आउट डेटासेट या के-फोल्ड क्रॉस-वैलिडेशन तकनीक का उपयोग करते हैं, हम पाएंगे कि मैट्रिक्स का आउटपुट प्रशिक्षण के लिए उपयोग किए गए डेटासेट और सत्यापन के लिए उपयोग किए जाने वाले डेटासेट के लिए अलग होगा।
ओवरफिटिंग का पता लगाना
ओवरफिटिंग नामक घटना एक ऐसी स्थिति है जहां हमारे एमएल मॉडल, प्रशिक्षण डेटा को असाधारण रूप से अच्छी तरह से मॉडल करते हैं, लेकिन परीक्षण डेटा पर अच्छा प्रदर्शन करने में विफल रहता है, अर्थात परीक्षण डेटा की भविष्यवाणी करने में सक्षम नहीं था।
यह तब होता है जब एक एमएल मॉडल प्रशिक्षण डेटा से एक विशिष्ट पैटर्न और शोर को इस हद तक सीखता है, कि यह उस मॉडल को प्रशिक्षण डेटा से नए यानी अनदेखे डेटा को सामान्य बनाने की क्षमता को नकारात्मक रूप से प्रभावित करता है। यहाँ, शोर एक अप्रासंगिक सूचना या डेटासेट में यादृच्छिकता है।
निम्नलिखित दो तरीके हैं जिनकी मदद से हम मौसम का पता लगा सकते हैं कि हमारा मॉडल ओवरफिट है या नहीं -
ओवरफिट मॉडल उन्हीं नमूनों पर अच्छा प्रदर्शन करेगा जो हमने प्रशिक्षण के लिए उपयोग किए थे, लेकिन यह नए नमूनों पर बहुत खराब प्रदर्शन करेगा, यानी प्रशिक्षण के लिए अलग-अलग नमूने।
सत्यापन के दौरान मॉडल ओवरफिट है यदि परीक्षण सेट पर मीट्रिक उसी मीट्रिक से कम है, तो हम अपने प्रशिक्षण सेट पर उपयोग करते हैं।
अंडरफुटिंग का पता लगाना
हमारे एमएल में एक और स्थिति पैदा हो सकती है। यह एक ऐसी स्थिति है, जहां हमारे एमएल मॉडल ने प्रशिक्षण डेटा को अच्छी तरह से मॉडल नहीं किया है और उपयोगी आउटपुट की भविष्यवाणी करने में विफल रहता है। जब हम पहले युग का प्रशिक्षण शुरू करते हैं, तो हमारा मॉडल कमज़ोर हो जाएगा, लेकिन प्रशिक्षण प्रगति के रूप में कम कमतर हो जाएगा।
पता लगाने के तरीकों में से एक, कि क्या हमारा मॉडल अंडरफिट है या नहीं, प्रशिक्षण सेट और परीक्षण सेट के लिए मैट्रिक्स को देखना है या नहीं। यदि परीक्षण सेट पर मीट्रिक प्रशिक्षण सेट पर मीट्रिक से अधिक है तो हमारा मॉडल कमतर होगा।
CNTK - तंत्रिका नेटवर्क वर्गीकरण
इस अध्याय में, हम अध्ययन करेंगे कि CNTK का उपयोग करके तंत्रिका नेटवर्क को कैसे वर्गीकृत किया जाए।
परिचय
वर्गीकरण को दिए गए इनपुट डेटा के लिए श्रेणीबद्ध आउटपुट लेबल या प्रतिक्रियाओं की भविष्यवाणी करने की प्रक्रिया के रूप में परिभाषित किया जा सकता है। वर्गीकृत उत्पादन, जो कि मॉडल ने प्रशिक्षण चरण में सीखा है, के आधार पर "ब्लैक" या "व्हाइट" या "स्पैम" या "नो स्पैम" जैसे रूप हो सकते हैं।
दूसरी ओर, गणितीय रूप से, यह मानचित्रण फ़ंक्शन को कहने का कार्य है f इनपुट चर से एक्स कहते हैं कि आउटपुट चर से Y कहते हैं।
वर्गीकरण समस्या का एक उत्कृष्ट उदाहरण ई-मेल में स्पैम का पता लगाना हो सकता है। यह स्पष्ट है कि आउटपुट की केवल दो श्रेणियां हो सकती हैं, "स्पैम" और "नो स्पैम"।
इस तरह के वर्गीकरण को लागू करने के लिए, हमें सबसे पहले उस क्लासिफायर का प्रशिक्षण करना होगा, जहां "स्पैम" और "नो स्पैम" ईमेल का उपयोग प्रशिक्षण डेटा के रूप में किया जाएगा। एक बार, क्लासिफायरवार सफलतापूर्वक प्रशिक्षित, इसका उपयोग किसी अज्ञात ईमेल का पता लगाने के लिए किया जा सकता है।
यहाँ, हम एक 4-5-3 NN बनाने जा रहे हैं जिसमें आईरिस फूल डेटासेट का उपयोग किया गया है -
4-इनपुट नोड्स (प्रत्येक पूर्वसूचक मूल्य के लिए एक)।
5-छिपे हुए प्रसंस्करण नोड्स।
3-आउटपुट नोड्स (क्योंकि आईरिस डाटासेट में तीन संभावित प्रजातियां हैं)।
डेटासेट लोड हो रहा है
हम आईरिस फूल डेटासेट का उपयोग करेंगे, जिससे हम आइरिस फूलों की प्रजातियों को सेपाल चौड़ाई और लंबाई के भौतिक गुणों और पंखुड़ी की चौड़ाई और लंबाई के आधार पर वर्गीकृत करना चाहते हैं। डेटासेट में आईरिस फूलों की विभिन्न किस्मों के भौतिक गुणों का वर्णन है -
सिपाही की लंबाई
सिपाही की चौड़ाई
पंखुड़ी की लंबाई
पेटल की चौड़ाई
कक्षा यानी आईरिस सेटोसा या आईरिस वर्सिकोलर या आईरिस वर्जिनिका
हमारे पास है iris.CSVफ़ाइल जो हमने पिछले अध्यायों में भी इस्तेमाल की थी। की सहायता से इसे लोड किया जा सकता हैPandasपुस्तकालय। लेकिन, इसका उपयोग करने से पहले या इसे हमारे वर्गीकरण के लिए लोड करने से पहले, हमें प्रशिक्षण और परीक्षण फ़ाइलों को तैयार करने की आवश्यकता है, ताकि इसे CNTK के साथ आसानी से उपयोग किया जा सके।
प्रशिक्षण और परीक्षण फाइलें तैयार करना
Iris डाटासेट एमएल परियोजनाओं के लिए सबसे लोकप्रिय डेटासेट में से एक है। इसमें 150 डेटा आइटम हैं और कच्चा डेटा निम्नानुसार है -
5.1 3.5 1.4 0.2 setosa
4.9 3.0 1.4 0.2 setosa
…
7.0 3.2 4.7 1.4 versicolor
6.4 3.2 4.5 1.5 versicolor
…
6.3 3.3 6.0 2.5 virginica
5.8 2.7 5.1 1.9 virginicaजैसा कि पहले बताया गया है, प्रत्येक पंक्ति पर पहले चार मान विभिन्न किस्मों के भौतिक गुणों का वर्णन करते हैं, जैसे कि सेपल लंबाई, सेपल की चौड़ाई, पेटल की लंबाई, आइरिस के फूलों की पंखुड़ी की चौड़ाई।
लेकिन, हमें प्रारूप में डेटा को परिवर्तित करना चाहिए, जिसे आसानी से CNTK द्वारा उपयोग किया जा सकता है और यह प्रारूप .ctf फ़ाइल है (हमने पिछले अनुभाग में भी एक iris.ctf बनाया है)। यह इस प्रकार दिखेगा -
|attribs 5.1 3.5 1.4 0.2|species 1 0 0
|attribs 4.9 3.0 1.4 0.2|species 1 0 0
…
|attribs 7.0 3.2 4.7 1.4|species 0 1 0
|attribs 6.4 3.2 4.5 1.5|species 0 1 0
…
|attribs 6.3 3.3 6.0 2.5|species 0 0 1
|attribs 5.8 2.7 5.1 1.9|species 0 0 1उपरोक्त आंकड़ों में; - एट्रिब्स टैग फीचर वैल्यू की शुरुआत को चिह्नित करता है और! प्रजाति वर्ग लेबल मूल्यों को टैग करती है। हम अपनी इच्छा के किसी अन्य टैग नामों का भी उपयोग कर सकते हैं, यहां तक कि हम आइटम आईडी भी जोड़ सकते हैं। उदाहरण के लिए, निम्नलिखित आंकड़ों को देखें -
|ID 001 |attribs 5.1 3.5 1.4 0.2|species 1 0 0 |#setosa
|ID 002 |attribs 4.9 3.0 1.4 0.2|species 1 0 0 |#setosa
…
|ID 051 |attribs 7.0 3.2 4.7 1.4|species 0 1 0 |#versicolor
|ID 052 |attribs 6.4 3.2 4.5 1.5|species 0 1 0 |#versicolor
…आईरिस डेटासेट में कुल 150 डेटा आइटम हैं और इस उदाहरण के लिए, हम 80-20 होल्ड-आउट डेटासेट नियम का उपयोग कर रहे हैं अर्थात प्रशिक्षण उद्देश्य के लिए 80% (120 आइटम) डेटा आइटम और शेष 20% (30 आइटम) परीक्षण के लिए डेटा आइटम। उद्देश्य।
वर्गीकरण मॉडल का निर्माण
सबसे पहले, हमें डेटा फ़ाइलों को CNTK प्रारूप में संसाधित करने की आवश्यकता है और इसके लिए हम नामांकित सहायक फ़ंक्शन का उपयोग करने जा रहे हैं create_reader निम्नानुसार है -
def create_reader(path, input_dim, output_dim, rnd_order, sweeps):
x_strm = C.io.StreamDef(field='attribs', shape=input_dim, is_sparse=False)
y_strm = C.io.StreamDef(field='species', shape=output_dim, is_sparse=False)
streams = C.io.StreamDefs(x_src=x_strm, y_src=y_strm)
deserial = C.io.CTFDeserializer(path, streams)
mb_src = C.io.MinibatchSource(deserial, randomize=rnd_order, max_sweeps=sweeps)
return mb_srcअब, हमें अपने एनएन के लिए आर्किटेक्चर तर्क को सेट करने की आवश्यकता है और डेटा फ़ाइलों का स्थान भी प्रदान करना होगा। यह निम्नलिखित अजगर कोड की मदद से किया जा सकता है -
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
input_dim = 4
hidden_dim = 5
output_dim = 3
train_file = ".\\...\\" #provide the name of the training file(120 data items)
test_file = ".\\...\\" #provide the name of the test file(30 data items)अब निम्नलिखित कोड लाइन की मदद से हमारा कार्यक्रम अप्रशिक्षित एनएन बनाएगा -
X = C.ops.input_variable(input_dim, np.float32)
Y = C.ops.input_variable(output_dim, np.float32)
with C.layers.default_options(init=C.initializer.uniform(scale=0.01, seed=1)):
hLayer = C.layers.Dense(hidden_dim, activation=C.ops.tanh, name='hidLayer')(X)
oLayer = C.layers.Dense(output_dim, activation=None, name='outLayer')(hLayer)
nnet = oLayer
model = C.ops.softmax(nnet)अब, जब हमने दोहरी अप्रशिक्षित मॉडल बनाया, तो हमें एक लर्नर एल्गोरिथम ऑब्जेक्ट सेट करने की आवश्यकता है और बाद में इसका उपयोग ट्रेनर ट्रेनिंग ऑब्जेक्ट बनाने के लिए करें। हम SGD शिक्षार्थी और उपयोग करने जा रहे हैंcross_entropy_with_softmax हानि समारोह -
tr_loss = C.cross_entropy_with_softmax(nnet, Y)
tr_clas = C.classification_error(nnet, Y)
max_iter = 2000
batch_size = 10
learn_rate = 0.01
learner = C.sgd(nnet.parameters, learn_rate)
trainer = C.Trainer(nnet, (tr_loss, tr_clas), [learner])सीखने के एल्गोरिथ्म को निम्नानुसार कोड करें -
max_iter = 2000
batch_size = 10
lr_schedule = C.learning_parameter_schedule_per_sample([(1000, 0.05), (1, 0.01)])
mom_sch = C.momentum_schedule([(100, 0.99), (0, 0.95)], batch_size)
learner = C.fsadagrad(nnet.parameters, lr=lr_schedule, momentum=mom_sch)
trainer = C.Trainer(nnet, (tr_loss, tr_clas), [learner])अब, जब हम ट्रेनर ऑब्जेक्ट के साथ समाप्त हो गए, तो हमें प्रशिक्षण डेटा पढ़ने के लिए एक पाठक फ़ंक्शन बनाने की आवश्यकता है
rdr = create_reader(train_file, input_dim, output_dim, rnd_order=True, sweeps=C.io.INFINITELY_REPEAT)
iris_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }अब हमारे एनएन मॉडल को प्रशिक्षित करने का समय आ गया है
for i in range(0, max_iter):
curr_batch = rdr.next_minibatch(batch_size, input_map=iris_input_map) trainer.train_minibatch(curr_batch)
if i % 500 == 0:
mcee = trainer.previous_minibatch_loss_average
macc = (1.0 - trainer.previous_minibatch_evaluation_average) * 100
print("batch %4d: mean loss = %0.4f, accuracy = %0.2f%% " \ % (i, mcee, macc))एक बार, हमने प्रशिक्षण के साथ किया है, आइए परीक्षण डेटा आइटम का उपयोग करके मॉडल का मूल्यांकन करें -
print("\nEvaluating test data \n")
rdr = create_reader(test_file, input_dim, output_dim, rnd_order=False, sweeps=1)
iris_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
num_test = 30
all_test = rdr.next_minibatch(num_test, input_map=iris_input_map) acc = (1.0 - trainer.test_minibatch(all_test)) * 100
print("Classification accuracy = %0.2f%%" % acc)हमारे प्रशिक्षित एनएन मॉडल की सटीकता का मूल्यांकन करने के बाद, हम इसका उपयोग अनदेखी डेटा पर एक भविष्यवाणी करने के लिए करेंगे -
np.set_printoptions(precision = 1, suppress=True)
unknown = np.array([[6.4, 3.2, 4.5, 1.5]], dtype=np.float32)
print("\nPredicting Iris species for input features: ")
print(unknown[0]) pred_prob = model.eval(unknown)
np.set_printoptions(precision = 4, suppress=True)
print("Prediction probabilities are: ")
print(pred_prob[0])पूरा वर्गीकरण मॉडल
Import numpy as np
Import cntk as C
def create_reader(path, input_dim, output_dim, rnd_order, sweeps):
x_strm = C.io.StreamDef(field='attribs', shape=input_dim, is_sparse=False)
y_strm = C.io.StreamDef(field='species', shape=output_dim, is_sparse=False)
streams = C.io.StreamDefs(x_src=x_strm, y_src=y_strm)
deserial = C.io.CTFDeserializer(path, streams)
mb_src = C.io.MinibatchSource(deserial, randomize=rnd_order, max_sweeps=sweeps)
return mb_src
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
input_dim = 4
hidden_dim = 5
output_dim = 3
train_file = ".\\...\\" #provide the name of the training file(120 data items)
test_file = ".\\...\\" #provide the name of the test file(30 data items)
X = C.ops.input_variable(input_dim, np.float32)
Y = C.ops.input_variable(output_dim, np.float32)
with C.layers.default_options(init=C.initializer.uniform(scale=0.01, seed=1)):
hLayer = C.layers.Dense(hidden_dim, activation=C.ops.tanh, name='hidLayer')(X)
oLayer = C.layers.Dense(output_dim, activation=None, name='outLayer')(hLayer)
nnet = oLayer
model = C.ops.softmax(nnet)
tr_loss = C.cross_entropy_with_softmax(nnet, Y)
tr_clas = C.classification_error(nnet, Y)
max_iter = 2000
batch_size = 10
learn_rate = 0.01
learner = C.sgd(nnet.parameters, learn_rate)
trainer = C.Trainer(nnet, (tr_loss, tr_clas), [learner])
max_iter = 2000
batch_size = 10
lr_schedule = C.learning_parameter_schedule_per_sample([(1000, 0.05), (1, 0.01)])
mom_sch = C.momentum_schedule([(100, 0.99), (0, 0.95)], batch_size)
learner = C.fsadagrad(nnet.parameters, lr=lr_schedule, momentum=mom_sch)
trainer = C.Trainer(nnet, (tr_loss, tr_clas), [learner])
rdr = create_reader(train_file, input_dim, output_dim, rnd_order=True, sweeps=C.io.INFINITELY_REPEAT)
iris_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
for i in range(0, max_iter):
curr_batch = rdr.next_minibatch(batch_size, input_map=iris_input_map) trainer.train_minibatch(curr_batch)
if i % 500 == 0:
mcee = trainer.previous_minibatch_loss_average
macc = (1.0 - trainer.previous_minibatch_evaluation_average) * 100
print("batch %4d: mean loss = %0.4f, accuracy = %0.2f%% " \ % (i, mcee, macc))
print("\nEvaluating test data \n")
rdr = create_reader(test_file, input_dim, output_dim, rnd_order=False, sweeps=1)
iris_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
num_test = 30
all_test = rdr.next_minibatch(num_test, input_map=iris_input_map) acc = (1.0 - trainer.test_minibatch(all_test)) * 100
print("Classification accuracy = %0.2f%%" % acc)
np.set_printoptions(precision = 1, suppress=True)
unknown = np.array([[7.0, 3.2, 4.7, 1.4]], dtype=np.float32)
print("\nPredicting species for input features: ")
print(unknown[0])
pred_prob = model.eval(unknown)
np.set_printoptions(precision = 4, suppress=True)
print("Prediction probabilities: ")
print(pred_prob[0])
if __name__== ”__main__”:
main()उत्पादन
Using CNTK version = 2.7
batch 0: mean loss = 1.0986, mean accuracy = 40.00%
batch 500: mean loss = 0.6677, mean accuracy = 80.00%
batch 1000: mean loss = 0.5332, mean accuracy = 70.00%
batch 1500: mean loss = 0.2408, mean accuracy = 100.00%
Evaluating test data
Classification accuracy = 94.58%
Predicting species for input features:
[7.0 3.2 4.7 1.4]
Prediction probabilities:
[0.0847 0.736 0.113]प्रशिक्षित मॉडल को सहेजना
इस आइरिस डेटासेट में केवल 150 डेटा आइटम हैं, इसलिए एनएन क्लासिफायर मॉडल को प्रशिक्षित करने में केवल कुछ सेकंड लगते हैं, लेकिन सौ या हजार डेटा आइटम वाले बड़े डेटासेट पर प्रशिक्षण में घंटे या दिन भी लग सकते हैं।
हम अपने मॉडल को बचा सकते हैं, इसलिए हमें इसे खरोंच से नहीं बचाना होगा। निम्नलिखित पायथन कोड की मदद से, हम अपने प्रशिक्षित एनएन को बचा सकते हैं -
nn_classifier = “.\\neuralclassifier.model” #provide the name of the file
model.save(nn_classifier, format=C.ModelFormat.CNTKv2)निम्नलिखित के तर्क हैं save() ऊपर इस्तेमाल किया समारोह -
फ़ाइल नाम का पहला तर्क है save()समारोह। इसे फ़ाइल के पथ के साथ भी लिखा जा सकता है।
एक और पैरामीटर है format पैरामीटर जिसका डिफ़ॉल्ट मान है C.ModelFormat.CNTKv2।
प्रशिक्षित मॉडल लोड हो रहा है
एक बार जब आप प्रशिक्षित मॉडल को बचा लेते हैं, तो उस मॉडल को लोड करना बहुत आसान होता है। हमें केवल इसका उपयोग करने की आवश्यकता हैload ()समारोह। आइए इसे निम्नलिखित उदाहरण में देखें -
import numpy as np
import cntk as C
model = C.ops.functions.Function.load(“.\\neuralclassifier.model”)
np.set_printoptions(precision = 1, suppress=True)
unknown = np.array([[7.0, 3.2, 4.7, 1.4]], dtype=np.float32)
print("\nPredicting species for input features: ")
print(unknown[0])
pred_prob = model.eval(unknown)
np.set_printoptions(precision = 4, suppress=True)
print("Prediction probabilities: ")
print(pred_prob[0])सहेजे गए मॉडल का लाभ यह है कि, एक बार जब आप किसी सहेजे गए मॉडल को लोड करते हैं, तो इसका ठीक उसी तरह उपयोग किया जा सकता है जैसे कि मॉडल को अभी प्रशिक्षित किया गया था।
CNTK - तंत्रिका नेटवर्क बाइनरी वर्गीकरण
आइए हम समझते हैं, इस अध्याय में CNTK का उपयोग करके तंत्रिका नेटवर्क बाइनरी वर्गीकरण क्या है।
एनएन का उपयोग कर द्विआधारी वर्गीकरण बहु-श्रेणी वर्गीकरण की तरह है, केवल एक चीज यह है कि तीन या अधिक के बजाय सिर्फ दो आउटपुट नोड हैं। यहां, हम दो तकनीकों अर्थात् एक-नोड और दो-नोड तकनीक का उपयोग करके तंत्रिका नेटवर्क का उपयोग करके द्विआधारी वर्गीकरण करने जा रहे हैं। वन-नोड तकनीक दो-नोड तकनीक से अधिक सामान्य है।
डेटासेट लोड हो रहा है
एनएन का उपयोग करके इन दोनों तकनीकों को लागू करने के लिए, हम बैंकनेट डेटासेट का उपयोग करेंगे। डेटासेट को UCI मशीन लर्निंग रिपॉजिटरी से डाउनलोड किया जा सकता है, जो यहां उपलब्ध हैhttps://archive.ics.uci.edu/ml/datasets/banknote+authentication.
हमारे उदाहरण के लिए, हम कक्षा जालसाजी = 0 वाले 50 प्रामाणिक डेटा आइटम का उपयोग कर रहे हैं, और वर्ग फर्जीवाड़ा = 1 वाले पहले 50 नकली आइटम।
प्रशिक्षण और परीक्षण फाइलें तैयार करना
पूर्ण डेटासेट में 1372 डेटा आइटम हैं। कच्चे डेटासेट निम्नानुसार दिखाई देते हैं -
3.6216, 8.6661, -2.8076, -0.44699, 0
4.5459, 8.1674, -2.4586, -1.4621, 0
…
-1.3971, 3.3191, -1.3927, -1.9948, 1
0.39012, -0.14279, -0.031994, 0.35084, 1अब, पहले हमें इस कच्चे डेटा को दो-नोड CNTK प्रारूप में बदलने की आवश्यकता है, जो निम्नानुसार होगा -
|stats 3.62160000 8.66610000 -2.80730000 -0.44699000 |forgery 0 1 |# authentic
|stats 4.54590000 8.16740000 -2.45860000 -1.46210000 |forgery 0 1 |# authentic
. . .
|stats -1.39710000 3.31910000 -1.39270000 -1.99480000 |forgery 1 0 |# fake
|stats 0.39012000 -0.14279000 -0.03199400 0.35084000 |forgery 1 0 |# fakeकच्चे डेटा से CNTK- प्रारूप डेटा बनाने के लिए आप निम्न अजगर कार्यक्रम का उपयोग कर सकते हैं -
fin = open(".\\...", "r") #provide the location of saved dataset text file.
for line in fin:
line = line.strip()
tokens = line.split(",")
if tokens[4] == "0":
print("|stats %12.8f %12.8f %12.8f %12.8f |forgery 0 1 |# authentic" % \
(float(tokens[0]), float(tokens[1]), float(tokens[2]), float(tokens[3])) )
else:
print("|stats %12.8f %12.8f %12.8f %12.8f |forgery 1 0 |# fake" % \
(float(tokens[0]), float(tokens[1]), float(tokens[2]), float(tokens[3])) )
fin.close()दो-नोड बाइनरी वर्गीकरण मॉडल
दो-नोड वर्गीकरण और बहु-श्रेणी वर्गीकरण के बीच बहुत कम अंतर है। यहां हमें सबसे पहले, डेटा फ़ाइलों को CNTK प्रारूप में संसाधित करने की आवश्यकता है और इसके लिए हम नामांकित सहायक फ़ंक्शन का उपयोग करने जा रहे हैंcreate_reader निम्नानुसार है -
def create_reader(path, input_dim, output_dim, rnd_order, sweeps):
x_strm = C.io.StreamDef(field='stats', shape=input_dim, is_sparse=False)
y_strm = C.io.StreamDef(field='forgery', shape=output_dim, is_sparse=False)
streams = C.io.StreamDefs(x_src=x_strm, y_src=y_strm)
deserial = C.io.CTFDeserializer(path, streams)
mb_src = C.io.MinibatchSource(deserial, randomize=rnd_order, max_sweeps=sweeps)
return mb_srcअब, हमें अपने एनएन के लिए आर्किटेक्चर तर्क को सेट करने की आवश्यकता है और डेटा फ़ाइलों का स्थान भी प्रदान करना होगा। यह निम्नलिखित अजगर कोड की मदद से किया जा सकता है -
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
input_dim = 4
hidden_dim = 10
output_dim = 2
train_file = ".\\...\\" #provide the name of the training file
test_file = ".\\...\\" #provide the name of the test fileअब निम्नलिखित कोड लाइन की मदद से हमारा कार्यक्रम अप्रशिक्षित एनएन बनाएगा -
X = C.ops.input_variable(input_dim, np.float32)
Y = C.ops.input_variable(output_dim, np.float32)
with C.layers.default_options(init=C.initializer.uniform(scale=0.01, seed=1)):
hLayer = C.layers.Dense(hidden_dim, activation=C.ops.tanh, name='hidLayer')(X)
oLayer = C.layers.Dense(output_dim, activation=None, name='outLayer')(hLayer)
nnet = oLayer
model = C.ops.softmax(nnet)अब, जब हमने दोहरी अप्रशिक्षित मॉडल बनाया, तो हमें एक लर्नर एल्गोरिथम ऑब्जेक्ट सेट करने की आवश्यकता है और बाद में इसका उपयोग ट्रेनर ट्रेनिंग ऑब्जेक्ट बनाने के लिए करें। हम SGD शिक्षार्थी और cross_entropy_with_softmax हानि फ़ंक्शन का उपयोग करने जा रहे हैं -
tr_loss = C.cross_entropy_with_softmax(nnet, Y)
tr_clas = C.classification_error(nnet, Y)
max_iter = 500
batch_size = 10
learn_rate = 0.01
learner = C.sgd(nnet.parameters, learn_rate)
trainer = C.Trainer(nnet, (tr_loss, tr_clas), [learner])अब, जब हम ट्रेनर ऑब्जेक्ट के साथ समाप्त हो गए, तो हमें प्रशिक्षण डेटा को पढ़ने के लिए एक पाठक फ़ंक्शन बनाने की आवश्यकता है -
rdr = create_reader(train_file, input_dim, output_dim, rnd_order=True, sweeps=C.io.INFINITELY_REPEAT)
banknote_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }अब, हमारे एनएन मॉडल को प्रशिक्षित करने का समय आ गया है -
for i in range(0, max_iter):
curr_batch = rdr.next_minibatch(batch_size, input_map=iris_input_map) trainer.train_minibatch(curr_batch)
if i % 500 == 0:
mcee = trainer.previous_minibatch_loss_average
macc = (1.0 - trainer.previous_minibatch_evaluation_average) * 100
print("batch %4d: mean loss = %0.4f, accuracy = %0.2f%% " \ % (i, mcee, macc))एक बार प्रशिक्षण पूरा होने के बाद, आइए हम परीक्षण डेटा आइटम का उपयोग करके मॉडल का मूल्यांकन करें -
print("\nEvaluating test data \n")
rdr = create_reader(test_file, input_dim, output_dim, rnd_order=False, sweeps=1)
banknote_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
num_test = 20
all_test = rdr.next_minibatch(num_test, input_map=iris_input_map) acc = (1.0 - trainer.test_minibatch(all_test)) * 100
print("Classification accuracy = %0.2f%%" % acc)हमारे प्रशिक्षित एनएन मॉडल की सटीकता का मूल्यांकन करने के बाद, हम इसका उपयोग अनदेखी डेटा पर एक भविष्यवाणी करने के लिए करेंगे -
np.set_printoptions(precision = 1, suppress=True)
unknown = np.array([[0.6, 1.9, -3.3, -0.3]], dtype=np.float32)
print("\nPredicting Banknote authenticity for input features: ")
print(unknown[0])
pred_prob = model.eval(unknown)
np.set_printoptions(precision = 4, suppress=True)
print("Prediction probabilities are: ")
print(pred_prob[0])
if pred_prob[0,0] < pred_prob[0,1]:
print(“Prediction: authentic”)
else:
print(“Prediction: fake”)दो-नोड वर्गीकरण मॉडल को पूरा करें
def create_reader(path, input_dim, output_dim, rnd_order, sweeps):
x_strm = C.io.StreamDef(field='stats', shape=input_dim, is_sparse=False)
y_strm = C.io.StreamDef(field='forgery', shape=output_dim, is_sparse=False)
streams = C.io.StreamDefs(x_src=x_strm, y_src=y_strm)
deserial = C.io.CTFDeserializer(path, streams)
mb_src = C.io.MinibatchSource(deserial, randomize=rnd_order, max_sweeps=sweeps)
return mb_src
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
input_dim = 4
hidden_dim = 10
output_dim = 2
train_file = ".\\...\\" #provide the name of the training file
test_file = ".\\...\\" #provide the name of the test file
X = C.ops.input_variable(input_dim, np.float32)
Y = C.ops.input_variable(output_dim, np.float32)
withC.layers.default_options(init=C.initializer.uniform(scale=0.01, seed=1)):
hLayer = C.layers.Dense(hidden_dim, activation=C.ops.tanh, name='hidLayer')(X)
oLayer = C.layers.Dense(output_dim, activation=None, name='outLayer')(hLayer)
nnet = oLayer
model = C.ops.softmax(nnet)
tr_loss = C.cross_entropy_with_softmax(nnet, Y)
tr_clas = C.classification_error(nnet, Y)
max_iter = 500
batch_size = 10
learn_rate = 0.01
learner = C.sgd(nnet.parameters, learn_rate)
trainer = C.Trainer(nnet, (tr_loss, tr_clas), [learner])
rdr = create_reader(train_file, input_dim, output_dim, rnd_order=True, sweeps=C.io.INFINITELY_REPEAT)
banknote_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
for i in range(0, max_iter):
curr_batch = rdr.next_minibatch(batch_size, input_map=iris_input_map) trainer.train_minibatch(curr_batch)
if i % 500 == 0:
mcee = trainer.previous_minibatch_loss_average
macc = (1.0 - trainer.previous_minibatch_evaluation_average) * 100
print("batch %4d: mean loss = %0.4f, accuracy = %0.2f%% " \ % (i, mcee, macc))
print("\nEvaluating test data \n")
rdr = create_reader(test_file, input_dim, output_dim, rnd_order=False, sweeps=1)
banknote_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
num_test = 20
all_test = rdr.next_minibatch(num_test, input_map=iris_input_map) acc = (1.0 - trainer.test_minibatch(all_test)) * 100
print("Classification accuracy = %0.2f%%" % acc)
np.set_printoptions(precision = 1, suppress=True)
unknown = np.array([[0.6, 1.9, -3.3, -0.3]], dtype=np.float32)
print("\nPredicting Banknote authenticity for input features: ")
print(unknown[0])
pred_prob = model.eval(unknown)
np.set_printoptions(precision = 4, suppress=True)
print("Prediction probabilities are: ")
print(pred_prob[0])
if pred_prob[0,0] < pred_prob[0,1]:
print(“Prediction: authentic”)
else:
print(“Prediction: fake”)
if __name__== ”__main__”:
main()उत्पादन
Using CNTK version = 2.7
batch 0: mean loss = 0.6928, accuracy = 80.00%
batch 50: mean loss = 0.6877, accuracy = 70.00%
batch 100: mean loss = 0.6432, accuracy = 80.00%
batch 150: mean loss = 0.4978, accuracy = 80.00%
batch 200: mean loss = 0.4551, accuracy = 90.00%
batch 250: mean loss = 0.3755, accuracy = 90.00%
batch 300: mean loss = 0.2295, accuracy = 100.00%
batch 350: mean loss = 0.1542, accuracy = 100.00%
batch 400: mean loss = 0.1581, accuracy = 100.00%
batch 450: mean loss = 0.1499, accuracy = 100.00%
Evaluating test data
Classification accuracy = 84.58%
Predicting banknote authenticity for input features:
[0.6 1.9 -3.3 -0.3]
Prediction probabilities are:
[0.7847 0.2536]
Prediction: fakeएक नोड बाइनरी वर्गीकरण मॉडल
कार्यान्वयन कार्यक्रम लगभग वैसा ही है जैसा हमने दो-नोड वर्गीकरण के लिए ऊपर किया है। मुख्य परिवर्तन यह है कि दो-नोड वर्गीकरण तकनीक का उपयोग करते समय।
हम CNTK बिल्ट-इन वर्गीकरण_रोर () फ़ंक्शन का उपयोग कर सकते हैं, लेकिन एक-नोड वर्गीकरण के मामले में CNTK वर्गीकरण_रोर () फ़ंक्शन का समर्थन नहीं करता है। यही कारण है कि हमें एक कार्यक्रम-परिभाषित फ़ंक्शन को लागू करने की आवश्यकता है -
def class_acc(mb, x_var, y_var, model):
num_correct = 0; num_wrong = 0
x_mat = mb[x_var].asarray()
y_mat = mb[y_var].asarray()
for i in range(mb[x_var].shape[0]):
p = model.eval(x_mat[i]
y = y_mat[i]
if p[0,0] < 0.5 and y[0,0] == 0.0 or p[0,0] >= 0.5 and y[0,0] == 1.0:
num_correct += 1
else:
num_wrong += 1
return (num_correct * 100.0)/(num_correct + num_wrong)उस बदलाव के साथ आइए पूरा एक नोड वर्गीकरण उदाहरण देखें -
एक-नोड वर्गीकरण मॉडल को पूरा करें
import numpy as np
import cntk as C
def create_reader(path, input_dim, output_dim, rnd_order, sweeps):
x_strm = C.io.StreamDef(field='stats', shape=input_dim, is_sparse=False)
y_strm = C.io.StreamDef(field='forgery', shape=output_dim, is_sparse=False)
streams = C.io.StreamDefs(x_src=x_strm, y_src=y_strm)
deserial = C.io.CTFDeserializer(path, streams)
mb_src = C.io.MinibatchSource(deserial, randomize=rnd_order, max_sweeps=sweeps)
return mb_src
def class_acc(mb, x_var, y_var, model):
num_correct = 0; num_wrong = 0
x_mat = mb[x_var].asarray()
y_mat = mb[y_var].asarray()
for i in range(mb[x_var].shape[0]):
p = model.eval(x_mat[i]
y = y_mat[i]
if p[0,0] < 0.5 and y[0,0] == 0.0 or p[0,0] >= 0.5 and y[0,0] == 1.0:
num_correct += 1
else:
num_wrong += 1
return (num_correct * 100.0)/(num_correct + num_wrong)
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
input_dim = 4
hidden_dim = 10
output_dim = 1
train_file = ".\\...\\" #provide the name of the training file
test_file = ".\\...\\" #provide the name of the test file
X = C.ops.input_variable(input_dim, np.float32)
Y = C.ops.input_variable(output_dim, np.float32)
with C.layers.default_options(init=C.initializer.uniform(scale=0.01, seed=1)):
hLayer = C.layers.Dense(hidden_dim, activation=C.ops.tanh, name='hidLayer')(X)
oLayer = C.layers.Dense(output_dim, activation=None, name='outLayer')(hLayer)
model = oLayer
tr_loss = C.cross_entropy_with_softmax(model, Y)
max_iter = 1000
batch_size = 10
learn_rate = 0.01
learner = C.sgd(model.parameters, learn_rate)
trainer = C.Trainer(model, (tr_loss), [learner])
rdr = create_reader(train_file, input_dim, output_dim, rnd_order=True, sweeps=C.io.INFINITELY_REPEAT)
banknote_input_map = {X : rdr.streams.x_src, Y : rdr.streams.y_src }
for i in range(0, max_iter):
curr_batch = rdr.next_minibatch(batch_size, input_map=iris_input_map) trainer.train_minibatch(curr_batch)
if i % 100 == 0:
mcee=trainer.previous_minibatch_loss_average
ca = class_acc(curr_batch, X,Y, model)
print("batch %4d: mean loss = %0.4f, accuracy = %0.2f%% " \ % (i, mcee, ca))
print("\nEvaluating test data \n")
rdr = create_reader(test_file, input_dim, output_dim, rnd_order=False, sweeps=1)
banknote_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
num_test = 20
all_test = rdr.next_minibatch(num_test, input_map=iris_input_map)
acc = class_acc(all_test, X,Y, model)
print("Classification accuracy = %0.2f%%" % acc)
np.set_printoptions(precision = 1, suppress=True)
unknown = np.array([[0.6, 1.9, -3.3, -0.3]], dtype=np.float32)
print("\nPredicting Banknote authenticity for input features: ")
print(unknown[0])
pred_prob = model.eval({X:unknown})
print("Prediction probability: ")
print(“%0.4f” % pred_prob[0,0])
if pred_prob[0,0] < 0.5:
print(“Prediction: authentic”)
else:
print(“Prediction: fake”)
if __name__== ”__main__”:
main()उत्पादन
Using CNTK version = 2.7
batch 0: mean loss = 0.6936, accuracy = 10.00%
batch 100: mean loss = 0.6882, accuracy = 70.00%
batch 200: mean loss = 0.6597, accuracy = 50.00%
batch 300: mean loss = 0.5298, accuracy = 70.00%
batch 400: mean loss = 0.4090, accuracy = 100.00%
batch 500: mean loss = 0.3790, accuracy = 90.00%
batch 600: mean loss = 0.1852, accuracy = 100.00%
batch 700: mean loss = 0.1135, accuracy = 100.00%
batch 800: mean loss = 0.1285, accuracy = 100.00%
batch 900: mean loss = 0.1054, accuracy = 100.00%
Evaluating test data
Classification accuracy = 84.00%
Predicting banknote authenticity for input features:
[0.6 1.9 -3.3 -0.3]
Prediction probability:
0.8846
Prediction: fakeCNTK - तंत्रिका नेटवर्क प्रतिगमन
अध्याय CNTK के संबंध में तंत्रिका नेटवर्क प्रतिगमन को समझने में आपकी सहायता करेगा।
परिचय
जैसा कि हम जानते हैं कि, एक या एक से अधिक भविष्यवाणियों के संख्यात्मक मान का अनुमान लगाने के लिए, हम प्रतिगमन का उपयोग करते हैं। आइए, 100 शहरों में से एक में एक घर के औसत मूल्य की भविष्यवाणी करने का एक उदाहरण लेते हैं। ऐसा करने के लिए, हमारे पास डेटा शामिल है -
प्रत्येक शहर के लिए एक अपराध आँकड़ा।
प्रत्येक शहर में घरों की आयु।
प्रत्येक शहर से एक प्रमुख स्थान की दूरी का एक उपाय।
प्रत्येक शहर में छात्र-से-शिक्षक अनुपात।
प्रत्येक शहर के लिए एक नस्लीय जनसांख्यिकीय सांख्यिकीय।
प्रत्येक शहर में मंझला घर का मूल्य।
इन पांच भविष्यवाणियों के आधार पर, हम मंझला घर मूल्य की भविष्यवाणी करना चाहते हैं। और इसके लिए हम − की तर्ज पर एक रेखीय प्रतिगमन मॉडल बना सकते हैं
Y = a0+a1(crime)+a2(house-age)+(a3)(distance)+(a4)(ratio)+(a5)(racial)उपरोक्त समीकरण में -
Y एक अनुमानित औसत मूल्य है
a0 एक स्थिर और है
a1 के माध्यम से a5 सभी निरंतर हैं जिन पाँच भविष्यवक्ताओं के साथ हम ऊपर चर्चा कर चुके हैं।
हमारे पास तंत्रिका नेटवर्क का उपयोग करने का एक वैकल्पिक तरीका भी है। यह अधिक सटीक भविष्यवाणी मॉडल बनाएगा।
यहां, हम CNTK का उपयोग करके एक तंत्रिका नेटवर्क प्रतिगमन मॉडल बना रहे हैं।
डेटासेट लोड हो रहा है
CNTK का उपयोग करके न्यूरल नेटवर्क रिग्रेशन को लागू करने के लिए, हम बोस्टन एरिया हाउस वैल्यू डेटासेट का उपयोग करेंगे। डेटासेट को UCI मशीन लर्निंग रिपॉजिटरी से डाउनलोड किया जा सकता है, जो यहां उपलब्ध हैhttps://archive.ics.uci.edu/ml/machine-learning-databases/housing/। इस डाटासेट में कुल 14 चर और 506 उदाहरण हैं।
लेकिन, हमारे कार्यान्वयन कार्यक्रम के लिए हम 14 चर और 100 उदाहरणों में से छह का उपयोग करने जा रहे हैं। 6 में से 5, भविष्यवक्ता के रूप में और एक मूल्य-से-पूर्वानुमान के रूप में। 100 उदाहरणों से, हम प्रशिक्षण के लिए 80 और परीक्षण उद्देश्य के लिए 20 का उपयोग करेंगे। जिस मूल्य की हम भविष्यवाणी करना चाहते हैं वह एक शहर में मंझला घर की कीमत है। आइए देखते हैं पांच भविष्यवक्ता जिनका हम उपयोग करेंगे -
Crime per capita in the town - हम उम्मीद करेंगे कि छोटे भविष्यवक्ता इस भविष्यवक्ता से जुड़े होंगे।
Proportion of owner - 1940 से पहले निर्मित कब्जे वाली इकाइयाँ - हम उम्मीद करेंगे कि छोटे मूल्य इस भविष्यवक्ता से जुड़े होंगे क्योंकि बड़े मूल्य का मतलब पुराने घर से है।
Weighed distance of the town to five Boston employment centers.
Area school pupil-to-teacher ratio.
An indirect metric of the proportion of black residents in the town.
प्रशिक्षण और परीक्षण फाइलें तैयार करना
जैसा कि हमने पहले किया था, पहले हमें कच्चे डेटा को CNTK प्रारूप में बदलने की आवश्यकता है। हम प्रशिक्षण उद्देश्य के लिए पहले 80 डेटा आइटम का उपयोग करने जा रहे हैं, इसलिए टैब-सीमांकित CNTK प्रारूप इस प्रकार है -
|predictors 1.612820 96.90 3.76 21.00 248.31 |medval 13.50
|predictors 0.064170 68.20 3.36 19.20 396.90 |medval 18.90
|predictors 0.097440 61.40 3.38 19.20 377.56 |medval 20.00
. . .अगले 20 आइटम, जिसे CNTK प्रारूप में भी परिवर्तित किया गया है, परीक्षण उद्देश्य के लिए उपयोग किया जाएगा।
प्रतिगमन मॉडल का निर्माण
सबसे पहले, हमें डेटा फ़ाइलों को CNTK प्रारूप में संसाधित करने की आवश्यकता है और उसके लिए, हम नामांकित सहायक फ़ंक्शन का उपयोग करने जा रहे हैं create_reader निम्नानुसार है -
def create_reader(path, input_dim, output_dim, rnd_order, sweeps):
x_strm = C.io.StreamDef(field='predictors', shape=input_dim, is_sparse=False)
y_strm = C.io.StreamDef(field='medval', shape=output_dim, is_sparse=False)
streams = C.io.StreamDefs(x_src=x_strm, y_src=y_strm)
deserial = C.io.CTFDeserializer(path, streams)
mb_src = C.io.MinibatchSource(deserial, randomize=rnd_order, max_sweeps=sweeps)
return mb_srcअगला, हमें एक सहायक फ़ंक्शन बनाने की आवश्यकता है जो CNTK मिनी-बैच ऑब्जेक्ट को स्वीकार करता है और एक कस्टम सटीकता मीट्रिक की गणना करता है।
def mb_accuracy(mb, x_var, y_var, model, delta):
num_correct = 0
num_wrong = 0
x_mat = mb[x_var].asarray()
y_mat = mb[y_var].asarray()
for i in range(mb[x_var].shape[0]):
v = model.eval(x_mat[i])
y = y_mat[i]
if np.abs(v[0,0] – y[0,0]) < delta:
num_correct += 1
else:
num_wrong += 1
return (num_correct * 100.0)/(num_correct + num_wrong)अब, हमें अपने एनएन के लिए आर्किटेक्चर तर्क को सेट करने की आवश्यकता है और डेटा फ़ाइलों का स्थान भी प्रदान करना होगा। यह निम्नलिखित अजगर कोड की मदद से किया जा सकता है -
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
input_dim = 5
hidden_dim = 20
output_dim = 1
train_file = ".\\...\\" #provide the name of the training file(80 data items)
test_file = ".\\...\\" #provide the name of the test file(20 data items)अब निम्नलिखित कोड लाइन की मदद से हमारा कार्यक्रम अप्रशिक्षित एनएन बनाएगा -
X = C.ops.input_variable(input_dim, np.float32)
Y = C.ops.input_variable(output_dim, np.float32)
with C.layers.default_options(init=C.initializer.uniform(scale=0.01, seed=1)):
hLayer = C.layers.Dense(hidden_dim, activation=C.ops.tanh, name='hidLayer')(X)
oLayer = C.layers.Dense(output_dim, activation=None, name='outLayer')(hLayer)
model = C.ops.alias(oLayer)अब, जब हमने दोहरी अप्रशिक्षित मॉडल बनाया है, तो हमें एक लर्नर एल्गोरिथम ऑब्जेक्ट सेट करने की आवश्यकता है। हम SGD शिक्षार्थी और उपयोग करने जा रहे हैंsquared_error हानि समारोह -
tr_loss = C.squared_error(model, Y)
max_iter = 3000
batch_size = 5
base_learn_rate = 0.02
sch=C.learning_parameter_schedule([base_learn_rate, base_learn_rate/2], minibatch_size=batch_size, epoch_size=int((max_iter*batch_size)/2))
learner = C.sgd(model.parameters, sch)
trainer = C.Trainer(model, (tr_loss), [learner])अब, एक बार जब हम लर्निंग एल्गोरिथम ऑब्जेक्ट के साथ समाप्त हो जाते हैं, तो हमें प्रशिक्षण डेटा को पढ़ने के लिए एक रीडर फ़ंक्शन बनाने की आवश्यकता है -
rdr = create_reader(train_file, input_dim, output_dim, rnd_order=True, sweeps=C.io.INFINITELY_REPEAT)
boston_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }अब, हमारे एनएन मॉडल को प्रशिक्षित करने का समय आ गया है -
for i in range(0, max_iter):
curr_batch = rdr.next_minibatch(batch_size, input_map=boston_input_map) trainer.train_minibatch(curr_batch)
if i % int(max_iter/10) == 0:
mcee = trainer.previous_minibatch_loss_average
acc = mb_accuracy(curr_batch, X, Y, model, delta=3.00)
print("batch %4d: mean squared error = %8.4f, accuracy = %5.2f%% " \ % (i, mcee, acc))एक बार जब हमने प्रशिक्षण के साथ कर लिया है, तो आइए परीक्षण डेटा आइटम का उपयोग करके मॉडल का मूल्यांकन करें -
print("\nEvaluating test data \n")
rdr = create_reader(test_file, input_dim, output_dim, rnd_order=False, sweeps=1)
boston_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
num_test = 20
all_test = rdr.next_minibatch(num_test, input_map=boston_input_map)
acc = mb_accuracy(all_test, X, Y, model, delta=3.00)
print("Prediction accuracy = %0.2f%%" % acc)हमारे प्रशिक्षित एनएन मॉडल की सटीकता का मूल्यांकन करने के बाद, हम इसका उपयोग अनदेखी डेटा पर एक भविष्यवाणी करने के लिए करेंगे -
np.set_printoptions(precision = 2, suppress=True)
unknown = np.array([[0.09, 50.00, 4.5, 17.00, 350.00], dtype=np.float32)
print("\nPredicting median home value for feature/predictor values: ")
print(unknown[0])
pred_prob = model.eval({X: unknown)
print("\nPredicted value is: ")
print(“$%0.2f (x1000)” %pred_value[0,0])पूर्ण प्रतिगमन मॉडल
import numpy as np
import cntk as C
def create_reader(path, input_dim, output_dim, rnd_order, sweeps):
x_strm = C.io.StreamDef(field='predictors', shape=input_dim, is_sparse=False)
y_strm = C.io.StreamDef(field='medval', shape=output_dim, is_sparse=False)
streams = C.io.StreamDefs(x_src=x_strm, y_src=y_strm)
deserial = C.io.CTFDeserializer(path, streams)
mb_src = C.io.MinibatchSource(deserial, randomize=rnd_order, max_sweeps=sweeps)
return mb_src
def mb_accuracy(mb, x_var, y_var, model, delta):
num_correct = 0
num_wrong = 0
x_mat = mb[x_var].asarray()
y_mat = mb[y_var].asarray()
for i in range(mb[x_var].shape[0]):
v = model.eval(x_mat[i])
y = y_mat[i]
if np.abs(v[0,0] – y[0,0]) < delta:
num_correct += 1
else:
num_wrong += 1
return (num_correct * 100.0)/(num_correct + num_wrong)
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
input_dim = 5
hidden_dim = 20
output_dim = 1
train_file = ".\\...\\" #provide the name of the training file(80 data items)
test_file = ".\\...\\" #provide the name of the test file(20 data items)
X = C.ops.input_variable(input_dim, np.float32)
Y = C.ops.input_variable(output_dim, np.float32)
with C.layers.default_options(init=C.initializer.uniform(scale=0.01, seed=1)):
hLayer = C.layers.Dense(hidden_dim, activation=C.ops.tanh, name='hidLayer')(X)
oLayer = C.layers.Dense(output_dim, activation=None, name='outLayer')(hLayer)
model = C.ops.alias(oLayer)
tr_loss = C.squared_error(model, Y)
max_iter = 3000
batch_size = 5
base_learn_rate = 0.02
sch = C.learning_parameter_schedule([base_learn_rate, base_learn_rate/2], minibatch_size=batch_size, epoch_size=int((max_iter*batch_size)/2))
learner = C.sgd(model.parameters, sch)
trainer = C.Trainer(model, (tr_loss), [learner])
rdr = create_reader(train_file, input_dim, output_dim, rnd_order=True, sweeps=C.io.INFINITELY_REPEAT)
boston_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
for i in range(0, max_iter):
curr_batch = rdr.next_minibatch(batch_size, input_map=boston_input_map) trainer.train_minibatch(curr_batch)
if i % int(max_iter/10) == 0:
mcee = trainer.previous_minibatch_loss_average
acc = mb_accuracy(curr_batch, X, Y, model, delta=3.00)
print("batch %4d: mean squared error = %8.4f, accuracy = %5.2f%% " \ % (i, mcee, acc))
print("\nEvaluating test data \n")
rdr = create_reader(test_file, input_dim, output_dim, rnd_order=False, sweeps=1)
boston_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
num_test = 20
all_test = rdr.next_minibatch(num_test, input_map=boston_input_map)
acc = mb_accuracy(all_test, X, Y, model, delta=3.00)
print("Prediction accuracy = %0.2f%%" % acc)
np.set_printoptions(precision = 2, suppress=True)
unknown = np.array([[0.09, 50.00, 4.5, 17.00, 350.00], dtype=np.float32)
print("\nPredicting median home value for feature/predictor values: ")
print(unknown[0])
pred_prob = model.eval({X: unknown)
print("\nPredicted value is: ")
print(“$%0.2f (x1000)” %pred_value[0,0])
if __name__== ”__main__”:
main()उत्पादन
Using CNTK version = 2.7
batch 0: mean squared error = 385.6727, accuracy = 0.00%
batch 300: mean squared error = 41.6229, accuracy = 20.00%
batch 600: mean squared error = 28.7667, accuracy = 40.00%
batch 900: mean squared error = 48.6435, accuracy = 40.00%
batch 1200: mean squared error = 77.9562, accuracy = 80.00%
batch 1500: mean squared error = 7.8342, accuracy = 60.00%
batch 1800: mean squared error = 47.7062, accuracy = 60.00%
batch 2100: mean squared error = 40.5068, accuracy = 40.00%
batch 2400: mean squared error = 46.5023, accuracy = 40.00%
batch 2700: mean squared error = 15.6235, accuracy = 60.00%
Evaluating test data
Prediction accuracy = 64.00%
Predicting median home value for feature/predictor values:
[0.09 50. 4.5 17. 350.]
Predicted value is:
$21.02(x1000)प्रशिक्षित मॉडल को सहेजना
इस बोस्टन होम वैल्यू डेटासेट में केवल 506 डेटा आइटम हैं (जिनमें से हमने केवल 100 पर मुकदमा किया है)। इसलिए, एनएन रजिस्ट्रार मॉडल को प्रशिक्षित करने में केवल कुछ सेकंड लगते हैं, लेकिन सौ या हजार डेटा आइटम वाले बड़े डेटासेट पर प्रशिक्षण में घंटे या दिन भी लग सकते हैं।
हम अपने मॉडल को बचा सकते हैं, ताकि हमें इसे खरोंच से बचाना न पड़े। निम्नलिखित पायथन कोड की मदद से, हम अपने प्रशिक्षित एनएन को बचा सकते हैं -
nn_regressor = “.\\neuralregressor.model” #provide the name of the file
model.save(nn_regressor, format=C.ModelFormat.CNTKv2)ऊपर उपयोग किए गए सेव () फ़ंक्शन के तर्क निम्नलिखित हैं -
फ़ाइल नाम का पहला तर्क है save()समारोह। यह फ़ाइल के पथ के साथ भी लिखा जा सकता है।
एक और पैरामीटर है format पैरामीटर जिसका डिफ़ॉल्ट मान है C.ModelFormat.CNTKv2।
प्रशिक्षित मॉडल लोड हो रहा है
एक बार जब आप प्रशिक्षित मॉडल को बचा लेते हैं, तो उस मॉडल को लोड करना बहुत आसान होता है। हमें केवल लोड () फ़ंक्शन का उपयोग करने की आवश्यकता है। आइए इसे निम्नलिखित उदाहरण में देखें -
import numpy as np
import cntk as C
model = C.ops.functions.Function.load(“.\\neuralregressor.model”)
np.set_printoptions(precision = 2, suppress=True)
unknown = np.array([[0.09, 50.00, 4.5, 17.00, 350.00], dtype=np.float32)
print("\nPredicting area median home value for feature/predictor values: ")
print(unknown[0])
pred_prob = model.eval({X: unknown)
print("\nPredicted value is: ")
print(“$%0.2f (x1000)” %pred_value[0,0])सहेजे गए मॉडल का लाभ यह है कि एक बार जब आप किसी सहेजे गए मॉडल को लोड करते हैं, तो इसका ठीक उसी तरह उपयोग किया जा सकता है जैसे कि मॉडल को अभी प्रशिक्षित किया गया था।
CNTK - वर्गीकरण मॉडल
यह अध्याय आपको यह समझने में मदद करेगा कि CNTK में वर्गीकरण मॉडल के प्रदर्शन को कैसे मापें। आइए हम भ्रम मैट्रिक्स से शुरू करें।
असमंजस का जाल
कन्फ्यूजन मैट्रिक्स - अनुमानित आउटपुट बनाम अनुमानित आउटपुट के साथ एक तालिका एक वर्गीकरण समस्या के प्रदर्शन को मापने का सबसे आसान तरीका है, जहां आउटपुट दो या अधिक प्रकार की कक्षाओं का हो सकता है।
यह समझने के लिए कि यह कैसे काम करता है, हम एक द्विआधारी वर्गीकरण मॉडल के लिए एक भ्रम मैट्रिक्स बनाने जा रहे हैं जो भविष्यवाणी करता है कि क्रेडिट कार्ड लेनदेन सामान्य था या धोखाधड़ी। इसे निम्नानुसार दिखाया गया है -
| वास्तविक धोखाधड़ी | वास्तविक सामान्य | |
|---|---|---|
| Predicted fraud |
सच्चा सकारात्मक |
सकारात्मक झूठी |
| Predicted normal |
मिथ्या नकारात्मक |
सच्चा नकारात्मक |
जैसा कि हम देख सकते हैं, उपरोक्त नमूना भ्रम मैट्रिक्स में 2 कॉलम हैं, एक वर्ग धोखाधड़ी के लिए और दूसरा वर्ग सामान्य के लिए। उसी तरह हमारे पास 2 पंक्तियाँ हैं, एक को वर्ग धोखाधड़ी के लिए जोड़ा जाता है और दूसरे को वर्ग सामान्य के लिए जोड़ा जाता है। निम्नलिखित भ्रम मैट्रिक्स से जुड़े शब्दों की व्याख्या है -
True Positives - जब डेटा बिंदु का वास्तविक वर्ग और अनुमानित वर्ग दोनों 1 है।
True Negatives - जब डेटा बिंदु का वास्तविक वर्ग और अनुमानित कक्षा दोनों है।
False Positives - जब डेटा बिंदु का वास्तविक वर्ग 0 है और डेटा बिंदु का अनुमानित वर्ग 1 है।
False Negatives - जब डेटा बिंदु का वास्तविक वर्ग 1 है और डेटा बिंदु का अनुमानित वर्ग 0 है।
आइए देखें, कैसे हम भ्रम मैट्रिक्स से विभिन्न चीजों की संख्या की गणना कर सकते हैं -
Accuracy- यह हमारे एमएल वर्गीकरण मॉडल द्वारा की गई सही भविष्यवाणियों की संख्या है। इसकी गणना निम्न सूत्र की सहायता से की जा सकती है -
Precision−यह बताता है कि हमने कितने नमूनों की सही-सही भविष्यवाणी की थी। इसकी गणना निम्न सूत्र की सहायता से की जा सकती है -
Recall or Sensitivity- स्मरण करो हमारे एमएल वर्गीकरण मॉडल द्वारा लौटाए गए सकारात्मक की संख्या है। दूसरे शब्दों में, यह हमें बताता है कि डेटासेट में धोखाधड़ी के कितने मामलों का वास्तव में मॉडल द्वारा पता लगाया गया था। इसकी गणना निम्न सूत्र की सहायता से की जा सकती है -
Specificity- वापस बुलाने के लिए, यह हमारे एमएल वर्गीकरण मॉडल द्वारा लौटाए गए नकारात्मक की संख्या देता है। इसकी गणना निम्न सूत्र की सहायता से की जा सकती है -




एफ उपाय
हम एफ-माप का उपयोग कन्फ्यूजन मैट्रिक्स के विकल्प के रूप में कर सकते हैं। इसके पीछे मुख्य कारण, हम एक ही समय में रिकॉल और परिशुद्धता को अधिकतम नहीं कर सकते हैं। इन मैट्रिक्स के बीच बहुत मजबूत संबंध है और इसे निम्नलिखित उदाहरण की मदद से समझा जा सकता है -
मान लीजिए, हम सेल के नमूनों को कैंसर या सामान्य के रूप में वर्गीकृत करने के लिए एक डीएल मॉडल का उपयोग करना चाहते हैं। यहां, अधिकतम सटीकता तक पहुंचने के लिए हमें भविष्यवाणियों की संख्या 1 को कम करने की आवश्यकता है। हालांकि, यह हमें लगभग 100 प्रतिशत सटीकता तक पहुंचा सकता है, लेकिन याद रखना वास्तव में कम हो जाएगा।
दूसरी ओर, यदि हम अधिकतम याद तक पहुंचना चाहते हैं, तो हमें यथासंभव भविष्यवाणियां करने की आवश्यकता है। हालाँकि, यह हमें लगभग 100 प्रतिशत याद तक पहुंचा सकता है, लेकिन सटीकता वास्तव में कम हो जाएगी।
व्यवहार में, हमें सटीक और याद के बीच संतुलन बनाने का तरीका खोजने की आवश्यकता है। एफ-माप मीट्रिक हमें ऐसा करने की अनुमति देता है, क्योंकि यह सटीक और याद के बीच एक हार्मोनिक औसत व्यक्त करता है।

इस सूत्र को एफ 1-माप कहा जाता है, जहां बी नामक अतिरिक्त शब्द को सटीक और याद के बराबर अनुपात प्राप्त करने के लिए 1 पर सेट किया जाता है। याद करने पर जोर देने के लिए, हम कारक B को 2 पर सेट कर सकते हैं। दूसरी ओर, परिशुद्धता पर जोर देने के लिए, हम कारक B को 0.5 पर सेट कर सकते हैं।
वर्गीकरण प्रदर्शन को मापने के लिए CNTK का उपयोग करना
पिछले अनुभाग में हमने आइरिस फूल डेटासेट का उपयोग करके एक वर्गीकरण मॉडल बनाया है। यहां, हम भ्रम मैट्रिक्स और एफ-माप मीट्रिक का उपयोग करके इसके प्रदर्शन को मापेंगे।
भ्रम मैट्रिक्स बनाना
हमने पहले ही मॉडल बनाया है, इसलिए हम सत्यापन प्रक्रिया शुरू कर सकते हैं, जिसमें शामिल हैं confusion matrix, उसी पर। सबसे पहले, हम इसकी मदद से भ्रम मैट्रिक्स बनाने जा रहे हैंconfusion_matrix से कार्य करते हैं scikit-learn। इसके लिए, हमें अपने परीक्षण नमूनों के लिए वास्तविक लेबल और समान परीक्षण नमूनों के लिए अनुमानित लेबल की आवश्यकता है।
आइए पायथन कोड का उपयोग करके भ्रम मैट्रिक्स की गणना करें -
from sklearn.metrics import confusion_matrix
y_true = np.argmax(y_test, axis=1)
y_pred = np.argmax(z(X_test), axis=1)
matrix = confusion_matrix(y_true=y_true, y_pred=y_pred)
print(matrix)उत्पादन
[[10 0 0]
[ 0 1 9]
[ 0 0 10]]हम निम्नानुसार भ्रम मैट्रिक्स की कल्पना करने के लिए हीटमैप फ़ंक्शन का उपयोग कर सकते हैं -
import seaborn as sns
import matplotlib.pyplot as plt
g = sns.heatmap(matrix,
annot=True,
xticklabels=label_encoder.classes_.tolist(),
yticklabels=label_encoder.classes_.tolist(),
cmap='Blues')
g.set_yticklabels(g.get_yticklabels(), rotation=0)
plt.show()
हमारे पास एक एकल प्रदर्शन संख्या भी होनी चाहिए, जिसका उपयोग हम मॉडल की तुलना करने के लिए कर सकते हैं। इसके लिए, हमें उपयोग करके वर्गीकरण त्रुटि की गणना करने की आवश्यकता हैclassification_error वर्गीकरण मॉडल बनाते समय CNTK में मेट्रिक्स पैकेज से कार्य किया जाता है।
अब वर्गीकरण त्रुटि की गणना करने के लिए, डेटासेट के साथ हानि फ़ंक्शन पर परीक्षण विधि निष्पादित करें। उसके बाद, CNTK इस फ़ंक्शन के लिए इनपुट के रूप में प्रदान किए गए नमूने लेगा और इनपुट फीचर्स X_ के आधार पर एक भविष्यवाणी करेगाtest।
loss.test([X_test, y_test])उत्पादन
{'metric': 0.36666666666, 'samples': 30}एफ-माप को लागू करना
एफ-माप को लागू करने के लिए, CNTK में फ़ंक्शन भी शामिल है जिसे fmeasures कहा जाता है। हम सेल को रिप्लेस करके NN को प्रशिक्षित करते हुए इस फ़ंक्शन का उपयोग कर सकते हैंcntk.metrics.classification_errorके साथ एक कॉल करने के लिए cntk.losses.fmeasure मानदंड कारखाना कार्य को परिभाषित करते समय निम्नानुसार है -
import cntk
@cntk.Function
def criterion_factory(output, target):
loss = cntk.losses.cross_entropy_with_softmax(output, target)
metric = cntk.losses.fmeasure(output, target)
return loss, metricCntk.losses.fmeasure फ़ंक्शन का उपयोग करने के बाद, हम के लिए अलग-अलग आउटपुट प्राप्त करेंगे loss.test विधि कॉल इस प्रकार है -
loss.test([X_test, y_test])उत्पादन
{'metric': 0.83101488749, 'samples': 30}CNTK - प्रतिगमन मॉडल
यहां, हम प्रतिगमन मॉडल के संबंध में प्रदर्शन को मापने के बारे में अध्ययन करेंगे।
एक प्रतिगमन मॉडल को मान्य करने की मूल बातें
जैसा कि हम जानते हैं कि प्रतिगमन मॉडल वर्गीकरण मॉडल की तुलना में अलग हैं, इस अर्थ में कि, व्यक्तियों के नमूनों के लिए सही या गलत का कोई बाइनरी माप नहीं है। प्रतिगमन मॉडल में, हम मापना चाहते हैं कि भविष्यवाणी वास्तविक मूल्य के कितने करीब है। भविष्यवाणी मूल्य के करीब आउटपुट के करीब है, मॉडल बेहतर प्रदर्शन करता है।
यहां, हम विभिन्न त्रुटि दर कार्यों का उपयोग करके प्रतिगमन के लिए उपयोग किए जाने वाले एनएन के प्रदर्शन को मापने जा रहे हैं।
त्रुटि मार्जिन की गणना
जैसा कि पहले चर्चा की गई थी, एक प्रतिगमन मॉडल को मान्य करते समय, हम यह नहीं कह सकते कि कोई भविष्यवाणी सही है या गलत। हम चाहते हैं कि हमारी भविष्यवाणी वास्तविक मूल्य के करीब हो। लेकिन, यहां एक छोटी सी त्रुटि मार्जिन स्वीकार्य है।
त्रुटि मार्जिन की गणना करने का सूत्र इस प्रकार है -

यहाँ,
Predicted value = टोपी द्वारा y का संकेत दिया
Real value = y द्वारा भविष्यवाणी की गई
सबसे पहले, हमें अनुमानित और वास्तविक मूल्य के बीच की दूरी की गणना करने की आवश्यकता है। फिर, एक समग्र त्रुटि दर प्राप्त करने के लिए, हमें इन चुकता दूरी को योग करने और औसत की गणना करने की आवश्यकता है। इसे कहते हैंmean squared त्रुटि समारोह।
लेकिन, यदि हम प्रदर्शन के आंकड़े चाहते हैं जो एक त्रुटि मार्जिन व्यक्त करते हैं, तो हमें एक सूत्र की आवश्यकता होती है जो पूर्ण त्रुटि को व्यक्त करता है। के लिए सूत्रmean absolute त्रुटि समारोह निम्नानुसार है -

उपर्युक्त सूत्र अनुमानित और वास्तविक मूल्य के बीच की पूर्ण दूरी तय करता है।
प्रतिगमन प्रदर्शन को मापने के लिए CNTK का उपयोग करना
यहां, हम देखेंगे कि विभिन्न मैट्रिक्स का उपयोग कैसे करें, हमने CNTK के साथ संयोजन में चर्चा की। हम एक प्रतिगमन मॉडल का उपयोग करेंगे, जो नीचे दिए गए चरणों का उपयोग करके कारों के लिए प्रति गैलन मील की दूरी पर भविष्यवाणी करता है।
कार्यान्वयन चरणplement
Step 1 - सबसे पहले, हमें आवश्यक घटकों को आयात करना होगा cntk पैकेज निम्नानुसार है -
from cntk import default_option, input_variable
from cntk.layers import Dense, Sequential
from cntk.ops import reluStep 2 - इसके बाद, हमें एक डिफ़ॉल्ट सक्रियण फ़ंक्शन को परिभाषित करने की आवश्यकता है default_optionsकार्य करता है। फिर, एक नया अनुक्रमिक परत सेट बनाएँ और 64 न्यूरॉन्स के साथ दो घने परतें प्रदान करें। फिर, हम अनुक्रमिक परत सेट में एक अतिरिक्त घने परत (जो आउटपुट परत के रूप में कार्य करेंगे) को जोड़ते हैं और 1 न्यूरॉन को सक्रियण के बिना निम्नानुसार देते हैं -
with default_options(activation=relu):
model = Sequential([Dense(64),Dense(64),Dense(1,activation=None)])Step 3- नेटवर्क बन जाने के बाद, हमें एक इनपुट फीचर बनाने की जरूरत है। हमें यह सुनिश्चित करने की आवश्यकता है कि, इसमें वैसी ही विशेषताएं हैं जैसी कि हम प्रशिक्षण के लिए उपयोग करने जा रहे हैं।
features = input_variable(X.shape[1])Step 4 - अब, हमें एक और बनाने की आवश्यकता है input_variable आकार के साथ 1. इसका उपयोग एनएन के लिए अपेक्षित मूल्य को संग्रहीत करने के लिए किया जाएगा।
target = input_variable(1)
z = model(features)अब, हमें मॉडल को प्रशिक्षित करने की आवश्यकता है और ऐसा करने के लिए, हम डेटासेट को विभाजित करने और निम्नलिखित कार्यान्वयन चरणों का उपयोग करके प्रीप्रोसेसिंग करने जा रहे हैं -
Step 5LFirst, -1 और +1 के बीच मान प्राप्त करने के लिए sklearn.preprocessing से StandardScaler आयात करें। इससे हमें NN में धीरे-धीरे होने वाली समस्याओं का पता लगाने में मदद मिलेगी।
from sklearn.preprocessing import StandardScalarStep 6 - इसके बाद, sklearn.model_selection से निम्न के रूप में import_test_split आयात करें
from sklearn.model_selection import train_test_splitStep 7 - ड्रॉप करें mpg का उपयोग करके डेटासेट से स्तंभ dropतरीका। अंतिम बार डेटासेट का उपयोग करके एक प्रशिक्षण और सत्यापन सेट में विभाजित करेंtrain_test_split कार्य निम्नानुसार है -
x = df_cars.drop(columns=[‘mpg’]).values.astype(np.float32)
y=df_cars.iloc[: , 0].values.reshape(-1, 1).astype(np.float32)
scaler = StandardScaler()
X = scaler.fit_transform(x)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)Step 8 - अब, हमें आकार के साथ एक और input_variable बनाने की आवश्यकता है। इसका उपयोग NN के लिए अपेक्षित मान को संग्रहीत करने के लिए किया जाएगा।
target = input_variable(1)
z = model(features)हमने डेटा को प्रीप्रोसेस करने के साथ-साथ विभाजित किया है, अब हमें एनएन को प्रशिक्षित करने की आवश्यकता है। जैसा कि प्रतिगमन मॉडल बनाते समय पिछले वर्गों में किया गया था, हमें नुकसान के संयोजन को परिभाषित करने की आवश्यकता है औरmetric मॉडल को प्रशिक्षित करने के लिए कार्य करते हैं।
import cntk
def absolute_error(output, target):
return cntk.ops.reduce_mean(cntk.ops.abs(output – target))
@ cntk.Function
def criterion_factory(output, target):
loss = squared_error(output, target)
metric = absolute_error(output, target)
return loss, metricअब, आइए नजर डालें कि प्रशिक्षित मॉडल का उपयोग कैसे किया जाए। हमारे मॉडल के लिए, हम नुकसान और मीट्रिक संयोजन के रूप में मानदंड_फैक्टिंग का उपयोग करेंगे।
from cntk.losses import squared_error
from cntk.learners import sgd
from cntk.logging import ProgressPrinter
progress_printer = ProgressPrinter(0)
loss = criterion_factory (z, target)
learner = sgd(z.parameters, 0.001)
training_summary=loss.train((x_train,y_train),parameter_learners=[learner],callbacks=[progress_printer],minibatch_size=16,max_epochs=10)पूरा कार्यान्वयन उदाहरण
from cntk import default_option, input_variable
from cntk.layers import Dense, Sequential
from cntk.ops import relu
with default_options(activation=relu):
model = Sequential([Dense(64),Dense(64),Dense(1,activation=None)])
features = input_variable(X.shape[1])
target = input_variable(1)
z = model(features)
from sklearn.preprocessing import StandardScalar
from sklearn.model_selection import train_test_split
x = df_cars.drop(columns=[‘mpg’]).values.astype(np.float32)
y=df_cars.iloc[: , 0].values.reshape(-1, 1).astype(np.float32)
scaler = StandardScaler()
X = scaler.fit_transform(x)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
target = input_variable(1)
z = model(features)
import cntk
def absolute_error(output, target):
return cntk.ops.reduce_mean(cntk.ops.abs(output – target))
@ cntk.Function
def criterion_factory(output, target):
loss = squared_error(output, target)
metric = absolute_error(output, target)
return loss, metric
from cntk.losses import squared_error
from cntk.learners import sgd
from cntk.logging import ProgressPrinter
progress_printer = ProgressPrinter(0)
loss = criterion_factory (z, target)
learner = sgd(z.parameters, 0.001)
training_summary=loss.train((x_train,y_train),parameter_learners=[learner],callbacks=[progress_printer],minibatch_size=16,max_epochs=10)उत्पादन
-------------------------------------------------------------------
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.001
690 690 24.9 24.9 16
654 636 24.1 23.7 48
[………]हमारे प्रतिगमन मॉडल को मान्य करने के लिए, हमें यह सुनिश्चित करने की आवश्यकता है कि, मॉडल नए डेटा को संभालता है और साथ ही साथ यह प्रशिक्षण डेटा के साथ भी करता है। इसके लिए, हमें आह्वान करने की आवश्यकता हैtest पर विधि loss तथा metric परीक्षण डेटा के साथ संयोजन निम्नानुसार है -
loss.test([X_test, y_test])आउटपुट
{'metric': 1.89679785619, 'samples': 79}CNTK - आउट-ऑफ-मेमोरी डेटासेट
इस अध्याय में, आउट-ऑफ-मेमोरी डेटासेट के प्रदर्शन को मापने के तरीके के बारे में बताया जाएगा।
पिछले वर्गों में, हमने अपने एनएन के प्रदर्शन को मान्य करने के लिए विभिन्न तरीकों के बारे में चर्चा की है, लेकिन जिन तरीकों पर हमने चर्चा की है, वे ऐसे डेटासेट्स हैं जो मेमोरी में फिट होते हैं।
यहां, यह सवाल उठता है कि आउट-ऑफ-मेमोरी डेटासेट के बारे में क्या है, क्योंकि उत्पादन परिदृश्य में, हमें प्रशिक्षित करने के लिए बहुत सारे डेटा की आवश्यकता होती है NN। इस खंड में, हम चर्चा करने जा रहे हैं कि मिनीबच स्रोतों और मैनुअल मिनीबैच लूप के साथ काम करते समय प्रदर्शन को कैसे मापें।
न्यूनतम स्रोत
स्मृति डेटासेट, यानी मिनीबैच स्रोतों के साथ काम करते समय, हमें नुकसान के लिए थोड़ा अलग सेटअप की आवश्यकता होती है, साथ ही मीट्रिक, जो हमने छोटे डेटासेट्स-इन-मेमोरी डेटासेट के साथ काम करते समय उपयोग की थी। सबसे पहले, हम देखेंगे कि एनएन मॉडल के ट्रेनर को डेटा खिलाने का तरीका कैसे सेट करें।
निम्नलिखित कार्यान्वयन चरण हैं
Step 1 - पहला, से cntk.io मॉड्यूल निम्न के रूप में मिनीबच स्रोत बनाने के लिए घटकों को आयात करता है
from cntk.io import StreamDef, StreamDefs, MinibatchSource, CTFDeserializer,
INFINITY_REPEATStep 2 - इसके बाद एक नया फंक्शन बनाएं जिसका नाम है create_datasource। इस फंक्शन में डिफ़ॉल्ट मान के साथ फ़ाइल नाम और सीमा दो पैरामीटर होंगेINFINITELY_REPEAT।
def create_datasource(filename, limit =INFINITELY_REPEAT)Step 3 - अब, फ़ंक्शन के भीतर, का उपयोग करके StreamDefक्लास उन लेबलों के लिए एक स्ट्रीम परिभाषा बनाता है जो उन लेबल फ़ील्ड से पढ़ते हैं जिनमें तीन सुविधाएँ होती हैं। हमें भी सेट करने की जरूरत हैis_sparse सेवा False इस प्रकार
labels_stream = StreamDef(field=’labels’, shape=3, is_sparse=False)Step 4 - इसके बाद, इनपुट फ़ाइल से दर्ज की गई विशेषताओं को पढ़ने के लिए बनाएं, का एक और उदाहरण बनाएं StreamDef निम्नलिखित नुसार।
feature_stream = StreamDef(field=’features’, shape=4, is_sparse=False)Step 5 - अब, इनिशियलाइज़ करें CTFDeserializerउदाहरण वर्ग। फ़ाइल नाम और स्ट्रीम निर्दिष्ट करें, जिन्हें हमें निम्नानुसार चित्रित करने की आवश्यकता है -
deserializer = CTFDeserializer(filename, StreamDefs(labels=
label_stream, features=features_stream)Step 6 - इसके बाद, हमें deserializer का उपयोग करके minisourceBatch का उदाहरण बनाने की आवश्यकता है -
Minibatch_source = MinibatchSource(deserializer, randomize=True, max_sweeps=limit)
return minibatch_sourceStep 7- अंत में, हमें प्रशिक्षण और परीक्षण स्रोत प्रदान करना होगा, जिसे हमने पिछले खंडों में भी बनाया था। हम आईरिस फूल डेटासेट का उपयोग कर रहे हैं।
training_source = create_datasource(‘Iris_train.ctf’)
test_source = create_datasource(‘Iris_test.ctf’, limit=1)एक बार जब आप बनाएँ MinibatchSourceउदाहरण के लिए, हमें इसे प्रशिक्षित करने की आवश्यकता है। हम एक ही प्रशिक्षण तर्क का उपयोग कर सकते हैं, जैसा कि जब हम छोटे इन-मेमोरी डेटासेट के साथ काम करते थे। यहां, हम उपयोग करेंगेMinibatchSource उदाहरण के लिए, नुकसान के कार्य पर ट्रेन पद्धति के इनपुट निम्नानुसार हैं -
निम्नलिखित कार्यान्वयन चरण हैं
Step 1 - प्रशिक्षण सत्र के उत्पादन में प्रवेश करने के लिए, पहले आयात करें ProgressPrinter से cntk.logging मॉड्यूल निम्नानुसार है -
from cntk.logging import ProgressPrinterStep 2 - अगला, प्रशिक्षण सत्र स्थापित करने के लिए, आयात करें trainer तथा training_session से cntk.train मॉड्यूल निम्नानुसार है
from cntk.train import Trainer, training_sessionStep 3 - अब, हमें स्थिरांक के कुछ सेट को परिभाषित करने की आवश्यकता है minibatch_size, samples_per_epoch तथा num_epochs इस प्रकार
minbatch_size = 16
samples_per_epoch = 150
num_epochs = 30
max_samples = samples_per_epoch * num_epochsStep 4 - अगला, CNTK में प्रशिक्षण के दौरान डेटा को पढ़ने का तरीका जानने के लिए, हमें नेटवर्क के लिए इनपुट चर और मिनीबैच स्रोत में धाराओं के बीच मानचित्रण को परिभाषित करने की आवश्यकता है।
input_map = {
features: training_source.streams.features,
labels: training_source.streams.labels
}Step 5 - प्रशिक्षण प्रक्रिया के आउटपुट को लॉग इन करने के लिए अगला, आरंभ करें progress_printer एक नया के साथ चर ProgressPrinterउदाहरण। इसके अलावा, इनिशियलाइज़ करेंtrainer और इसे निम्नानुसार मॉडल प्रदान करें
progress_writer = ProgressPrinter(0)
trainer: training_source.streams.labelsStep 6 - अंत में, प्रशिक्षण प्रक्रिया शुरू करने के लिए, हमें इनवॉइस करने की आवश्यकता है training_session कार्य निम्नानुसार है -
session = training_session(trainer,
mb_source=training_source,
mb_size=minibatch_size,
model_inputs_to_streams=input_map,
max_samples=max_samples,
test_config=test_config)
session.train()एक बार जब हम मॉडल को प्रशिक्षित कर लेते हैं, तो हम इस सेटअप का सत्यापन जोड़कर a का उपयोग कर सकते हैं TestConfig ऑब्जेक्ट और इसे असाइन करें test_config के खोजशब्द तर्क train_session समारोह।
निम्नलिखित कार्यान्वयन चरण हैं
Step 1 - सबसे पहले, हमें आयात करने की आवश्यकता है TestConfig मॉड्यूल से वर्ग cntk.train इस प्रकार
from cntk.train import TestConfigStep 2 - अब, हमें एक नया उदाहरण बनाने की आवश्यकता है TestConfig उसके साथ test_source input as के रूप में
Test_config = TestConfig(test_source)पूरा उदाहरण
from cntk.io import StreamDef, StreamDefs, MinibatchSource, CTFDeserializer, INFINITY_REPEAT
def create_datasource(filename, limit =INFINITELY_REPEAT)
labels_stream = StreamDef(field=’labels’, shape=3, is_sparse=False)
feature_stream = StreamDef(field=’features’, shape=4, is_sparse=False)
deserializer = CTFDeserializer(filename, StreamDefs(labels=label_stream, features=features_stream)
Minibatch_source = MinibatchSource(deserializer, randomize=True, max_sweeps=limit)
return minibatch_source
training_source = create_datasource(‘Iris_train.ctf’)
test_source = create_datasource(‘Iris_test.ctf’, limit=1)
from cntk.logging import ProgressPrinter
from cntk.train import Trainer, training_session
minbatch_size = 16
samples_per_epoch = 150
num_epochs = 30
max_samples = samples_per_epoch * num_epochs
input_map = {
features: training_source.streams.features,
labels: training_source.streams.labels
}
progress_writer = ProgressPrinter(0)
trainer: training_source.streams.labels
session = training_session(trainer,
mb_source=training_source,
mb_size=minibatch_size,
model_inputs_to_streams=input_map,
max_samples=max_samples,
test_config=test_config)
session.train()
from cntk.train import TestConfig
Test_config = TestConfig(test_source)उत्पादन
-------------------------------------------------------------------
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.1
1.57 1.57 0.214 0.214 16
1.38 1.28 0.264 0.289 48
[………]
Finished Evaluation [1]: Minibatch[1-1]:metric = 69.65*30;मैनुअल मिनीबैच लूप
जैसा कि हम ऊपर देखते हैं, सीएनटीके में नियमित एपीआई के साथ प्रशिक्षण के दौरान मैट्रिक्स का उपयोग करके, प्रशिक्षण के दौरान और बाद में अपने एनएन मॉडल के प्रदर्शन को मापना आसान है। लेकिन, दूसरी तरफ, मैन्युअल मिनीबैच लूप के साथ काम करते समय चीजें इतनी आसान नहीं होंगी।
यहां, हम नीचे दिए गए मॉडल का उपयोग कर रहे हैं, जो 4 सेगमेंट के साथ दिए गए हैं और आइरिस फ्लावर डेटासेट से 3 आउटपुट हैं, जो पिछले वर्गों में भी बनाए गए हैं
from cntk import default_options, input_variable
from cntk.layers import Dense, Sequential
from cntk.ops import log_softmax, relu, sigmoid
from cntk.learners import sgd
model = Sequential([
Dense(4, activation=sigmoid),
Dense(3, activation=log_softmax)
])
features = input_variable(4)
labels = input_variable(3)
z = model(features)अगला, मॉडल के लिए नुकसान को क्रॉस-एन्ट्रापी नुकसान फ़ंक्शन के संयोजन के रूप में परिभाषित किया गया है, और एफ-माप मीट्रिक जैसा कि पिछले वर्गों में उपयोग किया गया है। हम उपयोग करने जा रहे हैंcriterion_factory उपयोगिता, इसे CNTK फ़ंक्शन ऑब्जेक्ट के रूप में बनाने के लिए जैसा कि नीचे दिखाया गया है
import cntk
from cntk.losses import cross_entropy_with_softmax, fmeasure
@cntk.Function
def criterion_factory(outputs, targets):
loss = cross_entropy_with_softmax(outputs, targets)
metric = fmeasure(outputs, targets, beta=1)
return loss, metric
loss = criterion_factory(z, labels)
learner = sgd(z.parameters, 0.1)
label_mapping = {
'Iris-setosa': 0,
'Iris-versicolor': 1,
'Iris-virginica': 2
}अब, जैसा कि हमने नुकसान फ़ंक्शन को परिभाषित किया है, हम देखेंगे कि हम ट्रेनर में इसका उपयोग कैसे कर सकते हैं, एक मैनुअल प्रशिक्षण सत्र स्थापित करने के लिए।
कार्यान्वयन चरण निम्नलिखित हैं -
Step 1 - पहले, हमें आवश्यक पैकेजों को आयात करना होगा numpy तथा pandas डेटा को लोड और प्रीप्रोसेस करना।
import pandas as pd
import numpy as npStep 2 - अगला, प्रशिक्षण के दौरान जानकारी लॉग करने के लिए, आयात करें ProgressPrinter निम्नानुसार वर्ग
from cntk.logging import ProgressPrinterStep 3 - फिर, हमें cntk.train मॉड्यूल से ट्रेनर मॉड्यूल को निम्नानुसार आयात करना होगा -
from cntk.train import TrainerStep 4 - अगला, का एक नया उदाहरण बनाएँ ProgressPrinter निम्नानुसार है -
progress_writer = ProgressPrinter(0)Step 5 - अब, हमें नुकसान, सीखने वाले और मापदंडों के साथ ट्रेनर को इनिशियलाइज़ करना होगा progress_writer निम्नानुसार है -
trainer = Trainer(z, loss, learner, progress_writer)Step 6WeNext, मॉडल को प्रशिक्षित करने के लिए, हम एक लूप बनाएंगे जो तीस बार डेटासेट पर प्रसारित होगा। यह बाहरी प्रशिक्षण लूप होगा।
for _ in range(0,30):Step 7- अब, हमें पंडों का उपयोग करके डिस्क से डेटा लोड करने की आवश्यकता है। फिर, डाटासेट को लोड करने के लिएmini-batches, ठीक chunksize कीवर्ड तर्क 16 के लिए।
input_data = pd.read_csv('iris.csv',
names=['sepal_length', 'sepal_width','petal_length','petal_width', 'species'],
index_col=False, chunksize=16)Step 8 - अब, लूप के लिए एक आंतरिक प्रशिक्षण बनाएं mini-batches।
for df_batch in input_data:Step 9 - अब इस लूप के अंदर, पहले चार कॉलम को पढ़ें iloc अनुक्रमणिका, के रूप में features से ट्रेन करने के लिए और उन्हें float32 में बदलने के लिए -
feature_values = df_batch.iloc[:,:4].values
feature_values = feature_values.astype(np.float32)Step 10 - अब, पिछले कॉलम को पढ़े जाने वाले लेबल के रूप में निम्नानुसार पढ़ें -
label_values = df_batch.iloc[:,-1]Step 11 - अगला, हम एक-गर्म वैक्टर का उपयोग लेबल स्ट्रिंग्स को उनकी संख्यात्मक प्रस्तुति में परिवर्तित करने के लिए करेंगे -
label_values = label_values.map(lambda x: label_mapping[x])Step 12- उसके बाद, लेबल की संख्यात्मक प्रस्तुति लें। इसके बाद, उन्हें एक सुपीरियर एरे में बदलें, इसलिए उनके साथ काम करना आसान है -
label_values = label_values.valuesStep 13 - अब, हमें एक नया संख्यात्मक सारणी बनाने की आवश्यकता है जिसमें लेबल मानों के समान पंक्तियाँ हैं जिन्हें हमने परिवर्तित किया है।
encoded_labels = np.zeros((label_values.shape[0], 3))Step 14 - अब, एक-हॉट एन्कोडेड लेबल बनाने के लिए, संख्यात्मक लेबल मानों के आधार पर कॉलम चुनें।
encoded_labels[np.arange(label_values.shape[0]), label_values] = 1.Step 15 - अंत में, हमें आह्वान करने की आवश्यकता है train_minibatch ट्रेनर पर विधि और मिनीबैच के लिए संसाधित फीचर्स और लेबल प्रदान करें।
trainer.train_minibatch({features: feature_values, labels: encoded_labels})पूरा उदाहरण
from cntk import default_options, input_variable
from cntk.layers import Dense, Sequential
from cntk.ops import log_softmax, relu, sigmoid
from cntk.learners import sgd
model = Sequential([
Dense(4, activation=sigmoid),
Dense(3, activation=log_softmax)
])
features = input_variable(4)
labels = input_variable(3)
z = model(features)
import cntk
from cntk.losses import cross_entropy_with_softmax, fmeasure
@cntk.Function
def criterion_factory(outputs, targets):
loss = cross_entropy_with_softmax(outputs, targets)
metric = fmeasure(outputs, targets, beta=1)
return loss, metric
loss = criterion_factory(z, labels)
learner = sgd(z.parameters, 0.1)
label_mapping = {
'Iris-setosa': 0,
'Iris-versicolor': 1,
'Iris-virginica': 2
}
import pandas as pd
import numpy as np
from cntk.logging import ProgressPrinter
from cntk.train import Trainer
progress_writer = ProgressPrinter(0)
trainer = Trainer(z, loss, learner, progress_writer)
for _ in range(0,30):
input_data = pd.read_csv('iris.csv',
names=['sepal_length', 'sepal_width','petal_length','petal_width', 'species'],
index_col=False, chunksize=16)
for df_batch in input_data:
feature_values = df_batch.iloc[:,:4].values
feature_values = feature_values.astype(np.float32)
label_values = df_batch.iloc[:,-1]
label_values = label_values.map(lambda x: label_mapping[x])
label_values = label_values.values
encoded_labels = np.zeros((label_values.shape[0], 3))
encoded_labels[np.arange(label_values.shape[0]),
label_values] = 1.
trainer.train_minibatch({features: feature_values, labels: encoded_labels})उत्पादन
-------------------------------------------------------------------
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.1
1.45 1.45 -0.189 -0.189 16
1.24 1.13 -0.0382 0.0371 48
[………]उपरोक्त आउटपुट में, हमें प्रशिक्षण के दौरान नुकसान और मीट्रिक दोनों के लिए आउटपुट मिला। ऐसा इसलिए है क्योंकि हमने एक फ़ंक्शन ऑब्जेक्ट में एक मीट्रिक और हानि को संयोजित किया और ट्रेनर कॉन्फ़िगरेशन में प्रगति प्रिंटर का उपयोग किया।
अब, मॉडल प्रदर्शन का मूल्यांकन करने के लिए, हमें मॉडल के प्रशिक्षण के साथ ही कार्य करने की आवश्यकता है, लेकिन इस बार, हमें एक का उपयोग करने की आवश्यकता है Evaluatorउदाहरण के लिए मॉडल का परीक्षण करें। इसे निम्नलिखित पायथन कोड− में दिखाया गया है
from cntk import Evaluator
evaluator = Evaluator(loss.outputs[1], [progress_writer])
input_data = pd.read_csv('iris.csv',
names=['sepal_length', 'sepal_width','petal_length','petal_width', 'species'],
index_col=False, chunksize=16)
for df_batch in input_data:
feature_values = df_batch.iloc[:,:4].values
feature_values = feature_values.astype(np.float32)
label_values = df_batch.iloc[:,-1]
label_values = label_values.map(lambda x: label_mapping[x])
label_values = label_values.values
encoded_labels = np.zeros((label_values.shape[0], 3))
encoded_labels[np.arange(label_values.shape[0]), label_values] = 1.
evaluator.test_minibatch({ features: feature_values, labels:
encoded_labels})
evaluator.summarize_test_progress()अब, हम आउटपुट को निम्न की तरह कुछ प्राप्त करेंगे
उत्पादन
Finished Evaluation [1]: Minibatch[1-11]:metric = 74.62*143;CNTK - मॉडल की निगरानी
इस अध्याय में, हम समझेंगे कि CNTK में किसी मॉडल की निगरानी कैसे करें।
परिचय
पिछले वर्गों में, हमने अपने एनएन मॉडल पर कुछ सत्यापन किया है। लेकिन, क्या प्रशिक्षण के दौरान हमारे मॉडल की निगरानी करना भी आवश्यक और संभव है?
हां, पहले से ही हमने उपयोग किया है ProgressWriterहमारे मॉडल की निगरानी करने के लिए कक्षा और ऐसा करने के कई और तरीके हैं। तरीकों में गहराई से जाने से पहले, आइए एक नजर डालते हैं कि CNTK में निगरानी कैसे काम करती है और हम इसका उपयोग अपने NN मॉडल में समस्याओं का पता लगाने के लिए कैसे कर सकते हैं।
CNTK में कॉलबैक
दरअसल, प्रशिक्षण और सत्यापन के दौरान, सीएनटीके हमें एपीआई में कई स्थानों पर कॉलबैक को निर्दिष्ट करने की अनुमति देता है। सबसे पहले, जब CNTK कॉलबैक को आमंत्रित करता है, तो करीब से देखें।
जब CNTK कॉलबैक लागू करता है?
CNTK जब प्रशिक्षण और परीक्षण सेट क्षणों पर कॉलबैक को आमंत्रित करेगा
एक मिनीबैच पूरा हो गया है।
प्रशिक्षण के दौरान डेटासेट पर एक पूर्ण स्वीप पूरा हो गया है।
परीक्षण का एक छोटा सा परीक्षण पूरा हो गया है।
डेटासेट पर एक पूर्ण स्वीप परीक्षण के दौरान पूरा हो गया है।
कॉलबैक निर्दिष्ट करना
CNTK के साथ काम करते समय, हम API में कई स्थानों पर कॉलबैक निर्दिष्ट कर सकते हैं। उदाहरण के लिए−
जब एक नुकसान समारोह पर कॉल ट्रेन?
यहां, जब हम ट्रेन को नुकसान फ़ंक्शन पर बुलाते हैं, तो हम कॉलबैक तर्क के माध्यम से कॉलबैक का एक सेट निम्नानुसार निर्दिष्ट कर सकते हैं
training_summary=loss.train((x_train,y_train),
parameter_learners=[learner],
callbacks=[progress_writer]),
minibatch_size=16, max_epochs=15)मिनीबच स्रोतों के साथ काम करते समय या मैनुअल मिनीबैच लूप का उपयोग करते समय
इस मामले में, हम बनाते समय निगरानी के उद्देश्य के लिए कॉलबैक निर्दिष्ट कर सकते हैं Trainer इस प्रकार
from cntk.logging import ProgressPrinter
callbacks = [
ProgressPrinter(0)
]
Trainer = Trainer(z, (loss, metric), learner, [callbacks])विभिन्न निगरानी उपकरण
आइए हम विभिन्न निगरानी उपकरणों के बारे में अध्ययन करें।
ProgressPrinter
इस ट्यूटोरियल को पढ़ते हुए, आप पाएंगे ProgressPrinterसबसे अधिक उपयोग किए जाने वाले निगरानी उपकरण के रूप में। की कुछ विशेषताएंProgressPrinter निगरानी उपकरण − हैं
ProgressPrinterक्लास हमारे मॉडल की निगरानी करने के लिए बुनियादी कंसोल-आधारित लॉगिंग लागू करता है। यह उस डिस्क पर लॉग इन कर सकता है जिसे हम चाहते हैं।
वितरित प्रशिक्षण परिदृश्य में काम करते हुए विशेष रूप से उपयोगी।
परिदृश्य में काम करते समय यह बहुत उपयोगी है जहां हम अपने पायथन प्रोग्राम के आउटपुट को देखने के लिए कंसोल पर लॉग इन नहीं कर सकते हैं।
निम्नलिखित कोड की मदद से, हम एक उदाहरण बना सकते हैं ProgressPrinter-
ProgressPrinter(0, log_to_file=’test.txt’)हमें आउटपुट कुछ मिलेगा जो हमने पहले के सेक्शन में देखा है
Test.txt
CNTKCommandTrainInfo: train : 300
CNTKCommandTrainInfo: CNTKNoMoreCommands_Total : 300
CNTKCommandTrainBegin: train
-------------------------------------------------------------------
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.1
1.45 1.45 -0.189 -0.189 16
1.24 1.13 -0.0382 0.0371 48
[………]TensorBoard
ProgressPrinter का उपयोग करने के नुकसानों में से एक यह है कि, हम यह नहीं देख सकते हैं कि समय के साथ नुकसान और मीट्रिक प्रगति कितनी कठिन है। TensorBoardProgressWriter CNTK में प्रोग्रेसप्रिन्टर क्लास का एक बेहतरीन विकल्प है।
इसका उपयोग करने से पहले, हमें निम्नलिखित कमांड की मदद से इसे स्थापित करना होगा -
pip install tensorboardअब, TensorBoard का उपयोग करने के लिए, हमें सेट अप करने की आवश्यकता है TensorBoardProgressWriter हमारे प्रशिक्षण कोड में निम्नानुसार है
import time
from cntk.logging import TensorBoardProgressWriter
tensorbrd_writer = TensorBoardProgressWriter(log_dir=’logs/{}’.format(time.time()),freq=1,model=z)करीबी विधि को कॉल करने के लिए यह एक अच्छा अभ्यास है TensorBoardProgressWriter उदाहरण के प्रशिक्षण के बाद किया NNनमूना।
हम कल्पना कर सकते हैं TensorBoard निम्नलिखित कमांड की सहायता से लॉगिंग डेटा -
Tensorboard –logdir logsCNTK - संवेदी तंत्रिका नेटवर्क
इस अध्याय में, हम CNTK में एक कन्वेंशनल न्यूरल नेटवर्क (CNN) के निर्माण का अध्ययन करते हैं।
परिचय
संवेदी तंत्रिका नेटवर्क (CNN) भी न्यूरॉन्स से बने होते हैं, जिनमें सीखने योग्य भार और पूर्वाग्रह होते हैं। इसलिए इस तरीके से, वे सामान्य तंत्रिका नेटवर्क (एनएन) की तरह हैं।
यदि हम साधारण एनएन के काम को याद करते हैं, तो प्रत्येक न्यूरॉन एक या अधिक इनपुट प्राप्त करता है, एक भारित राशि लेता है और यह अंतिम आउटपुट का उत्पादन करने के लिए एक सक्रियण फ़ंक्शन से गुजरता है। यहाँ, यह सवाल उठता है कि अगर CNN और साधारण NN में इतनी समानताएँ हैं तो इन दोनों नेटवर्क को एक दूसरे से अलग क्या बनाता है?
क्या उन्हें अलग बनाता है इनपुट डेटा और परतों के प्रकार का उपचार? इनपुट डेटा की संरचना को सामान्य एनएन में नजरअंदाज कर दिया जाता है और नेटवर्क में फीड करने से पहले सभी डेटा को 1-डी सरणी में बदल दिया जाता है।
लेकिन, कन्वेन्शियल न्यूरल नेटवर्क आर्किटेक्चर छवियों की 2 डी संरचना पर विचार कर सकते हैं, उन्हें प्रोसेस कर सकते हैं और इसे उन गुणों को निकालने की अनुमति दे सकते हैं जो छवियों के लिए विशिष्ट हैं। इसके अलावा, CNN को एक या अधिक संकेंद्रित परतें और पूलिंग परत होने का लाभ है, जो CNN के मुख्य बिल्डिंग ब्लॉक हैं।
ये परतें मानक बहुपरत एनएन में एक या एक से अधिक पूरी तरह से जुड़ी हुई परतों द्वारा पीछा की जाती हैं। तो, हम सीएनएन के बारे में सोच सकते हैं, पूरी तरह से जुड़े नेटवर्क के विशेष मामले के रूप में।
संवादी तंत्रिका नेटवर्क (CNN) वास्तुकला
सीएनएन की वास्तुकला मूल रूप से परतों की एक सूची है जो 3-आयामी, यानी चौड़ाई, ऊंचाई और छवि की मात्रा की गहराई को 3-आयामी आउटपुट वॉल्यूम में बदल देती है। यहां ध्यान देने वाली एक महत्वपूर्ण बात यह है कि, वर्तमान परत में प्रत्येक न्यूरॉन पिछली परत से आउटपुट के एक छोटे से पैच से जुड़ा होता है, जो इनपुट छवि पर एक एन * एन फिल्टर को ओवरले करने जैसा है।
यह एम फिल्टर का उपयोग करता है, जो मूल रूप से एक्सट्रैक्टर्स हैं जो किनारों, कोने और इसी तरह की विशेषताओं को निकालते हैं। निम्नलिखित परतें हैं [INPUT-CONV-RELU-POOL-FC] इसका उपयोग संवैधानिक तंत्रिका नेटवर्क (CNNs) के निर्माण के लिए किया जाता है -
INPUT- जैसा कि नाम से ही स्पष्ट है, यह परत कच्चे पिक्सेल मान रखती है। कच्चे पिक्सेल मानों का मतलब छवि का डेटा है जैसा कि यह है। उदाहरण, INPUT [64 × 64 × 3] चौड़ाई -64, ऊंचाई -64 और गहराई -3 की 3-चैनल आरजीबी छवि है।
CONV- यह परत CNNs के निर्माण खंडों में से एक है क्योंकि इस परत में अधिकांश गणना की जाती है। उदाहरण - यदि हम उपर्युक्त INPUT [6 × 64 × 3] पर 6 फिल्टर का उपयोग करते हैं, तो इसका परिणाम हो सकता है [64 × 64 × 6]।
RELUAppliesAlso को रेक्टिफाइड लीनियर यूनिट लेयर कहा जाता है, जो पिछली लेयर के आउटपुट में एक्टिवेशन फंक्शन लागू करता है। अन्य तरीके से, एक गैर-रैखिकता को RELU द्वारा नेटवर्क में जोड़ा जाएगा।
POOL- यह परत, अर्थात पूलिंग परत CNNs का एक अन्य बिल्डिंग ब्लॉक है। इस परत का मुख्य कार्य डाउन-सैंपलिंग है, जिसका अर्थ है कि यह इनपुट के हर स्लाइस पर स्वतंत्र रूप से काम करता है और इसे स्थानिक रूप से आकार देता है।
FC- इसे फुली कनेक्टेड लेयर या अधिक विशेष रूप से आउटपुट लेयर कहा जाता है। इसका उपयोग आउटपुट वर्ग स्कोर की गणना करने के लिए किया जाता है और परिणामी आउटपुट का आकार 1 * 1 * L होता है जहां L वर्ग स्कोर के अनुरूप संख्या है।
नीचे दिया गया चित्र CNNs the की विशिष्ट वास्तुकला का प्रतिनिधित्व करता है

CNN संरचना का निर्माण
हमने CNN की वास्तुकला और मूलभूत बातों को देखा है, अब हम CNTK का उपयोग करके दृढ़ नेटवर्क का निर्माण करने जा रहे हैं। यहां, हम पहले देखेंगे कि सीएनएन की संरचना को एक साथ कैसे रखा जाए और फिर हम इस पर ध्यान देंगे कि इसके मापदंडों को कैसे प्रशिक्षित किया जाए।
अंत में हम देखेंगे, कि हम विभिन्न संरचना को विभिन्न लेयर सेटअप के साथ बदलकर तंत्रिका नेटवर्क को कैसे बेहतर बना सकते हैं। हम MNIST छवि डेटासेट का उपयोग करने जा रहे हैं।
तो, पहले एक सीएनएन संरचना बनाते हैं। आमतौर पर, जब हम छवियों में पैटर्न को पहचानने के लिए CNN का निर्माण करते हैं, तो हम निम्नलिखित करते हैं
हम कनवल्शन और पूलिंग लेयर्स के संयोजन का उपयोग करते हैं।
नेटवर्क के अंत में एक या अधिक छिपी हुई परत।
अंत में, हम वर्गीकरण उद्देश्य के लिए एक सॉफ्टमैक्स परत के साथ नेटवर्क खत्म करते हैं।
निम्नलिखित चरणों की मदद से, हम नेटवर्क संरचना का निर्माण कर सकते हैं
Step 1- सबसे पहले, हमें सीएनएन के लिए आवश्यक परतों को आयात करना होगा।
from cntk.layers import Convolution2D, Sequential, Dense, MaxPoolingStep 2- इसके बाद, हमें CNN के लिए सक्रियण कार्यों को आयात करना होगा।
from cntk.ops import log_softmax, reluStep 3- इसके बाद, बाद में कनवल्शनल लेयर्स को इनिशियलाइज़ करने के लिए, हमें इंपोर्ट करना होगा glorot_uniform_initializer इस प्रकार
from cntk.initializer import glorot_uniformStep 4- अगला, इनपुट चर बनाने के लिए आयात करें input_variableसमारोह। और आयात करते हैंdefault_option फ़ंक्शन, एनएन के विन्यास को थोड़ा आसान बनाने के लिए।
from cntk import input_variable, default_optionsStep 5- अब इनपुट छवियों को स्टोर करने के लिए, एक नया बनाएं input_variable। इसमें तीन चैनल होंगे, जैसे लाल, हरा और नीला। इसका आकार 28 गुणा 28 पिक्सेल होगा।
features = input_variable((3,28,28))Step 6−Next, हमें एक और बनाने की आवश्यकता है input_variable भविष्यवाणी करने के लिए लेबलों को स्टोर करना।
labels = input_variable(10)Step 7- अब, हम बनाने की जरूरत है default_optionएनएन के लिए। और, हमें इसका उपयोग करने की आवश्यकता हैglorot_uniform आरंभीकरण समारोह के रूप में।
with default_options(initialization=glorot_uniform, activation=relu):Step 8- अगला, एनएन की संरचना निर्धारित करने के लिए, हमें एक नया बनाने की आवश्यकता है Sequential लेयर सेट।
Step 9- अब हमें एक जोड़ने की जरूरत है Convolutional2D एक के साथ परत filter_shape 5 और ए strides का समायोजन 1, के अंदर Sequentialलेयर सेट। इसके अलावा, पैडिंग को सक्षम करें, ताकि मूल आयामों को बनाए रखने के लिए छवि गद्देदार हो।
model = Sequential([
Convolution2D(filter_shape=(5,5), strides=(1,1), num_filters=8, pad=True),Step 10- अब यह एक जोड़ने का समय है MaxPooling के साथ परत filter_shape 2 के, और ए strides छवि को आधे से संपीड़ित करने के लिए 2 की सेटिंग।
MaxPooling(filter_shape=(2,2), strides=(2,2)),Step 11- अब, जैसा कि हमने चरण 9 में किया था, हमें एक और जोड़ने की आवश्यकता है Convolutional2D एक के साथ परत filter_shape 5 और ए strides1 की सेटिंग, 16 फ़िल्टर का उपयोग करें। इसके अलावा, पैडिंग को सक्षम करें, ताकि, पिछली पूलिंग परत द्वारा निर्मित छवि का आकार बनाए रखा जाए।
Convolution2D(filter_shape=(5,5), strides=(1,1), num_filters=16, pad=True),Step 12- अब, जैसा कि हमने चरण 10 में किया था, एक और जोड़ें MaxPooling एक के साथ परत filter_shape की 3 और ए strides छवि को एक तिहाई तक कम करने के लिए 3 की सेटिंग।
MaxPooling(filter_shape=(3,3), strides=(3,3)),Step 13- अंत में, 10 संभव वर्गों के लिए दस न्यूरॉन्स के साथ एक घने परत जोड़ें, नेटवर्क भविष्यवाणी कर सकता है। नेटवर्क को वर्गीकरण मॉडल में बदलने के लिए, a का उपयोग करेंlog_siftmax सक्रियण समारोह।
Dense(10, activation=log_softmax)
])CNN संरचना बनाने के लिए पूरा उदाहरण
from cntk.layers import Convolution2D, Sequential, Dense, MaxPooling
from cntk.ops import log_softmax, relu
from cntk.initializer import glorot_uniform
from cntk import input_variable, default_options
features = input_variable((3,28,28))
labels = input_variable(10)
with default_options(initialization=glorot_uniform, activation=relu):
model = Sequential([
Convolution2D(filter_shape=(5,5), strides=(1,1), num_filters=8, pad=True),
MaxPooling(filter_shape=(2,2), strides=(2,2)),
Convolution2D(filter_shape=(5,5), strides=(1,1), num_filters=16, pad=True),
MaxPooling(filter_shape=(3,3), strides=(3,3)),
Dense(10, activation=log_softmax)
])
z = model(features)छवियों के साथ प्रशिक्षण सीएनएन
जैसा कि हमने नेटवर्क की संरचना बनाई है, यह नेटवर्क को प्रशिक्षित करने का समय है। लेकिन हमारे नेटवर्क का प्रशिक्षण शुरू करने से पहले, हमें मिनीबच स्रोत स्थापित करने की आवश्यकता है, क्योंकि छवियों के साथ काम करने वाले एनएन को अधिकांश कंप्यूटरों की तुलना में अधिक मेमोरी की आवश्यकता होती है।
हमने पिछले अनुभागों में पहले से ही मिनीबैच स्रोत बनाए हैं। दो लघु स्रोत स्थापित करने के लिए पायथन कोड निम्नलिखित है -
जैसा हमारे पास है create_datasource फ़ंक्शन, हम मॉडल को प्रशिक्षित करने के लिए अब दो अलग-अलग डेटा स्रोत (प्रशिक्षण और परीक्षण) बना सकते हैं।
train_datasource = create_datasource('mnist_train')
test_datasource = create_datasource('mnist_test', max_sweeps=1, train=False)अब, जैसा कि हमने छवियां तैयार की हैं, हम अपने एनएन का प्रशिक्षण शुरू कर सकते हैं। जैसा कि हमने पिछले अनुभागों में किया था, हम प्रशिक्षण को बंद करने के लिए नुकसान फ़ंक्शन पर ट्रेन पद्धति का उपयोग कर सकते हैं। इसके लिए कोड निम्नलिखित है -
from cntk import Function
from cntk.losses import cross_entropy_with_softmax
from cntk.metrics import classification_error
from cntk.learners import sgd
@Function
def criterion_factory(output, targets):
loss = cross_entropy_with_softmax(output, targets)
metric = classification_error(output, targets)
return loss, metric
loss = criterion_factory(z, labels)
learner = sgd(z.parameters, lr=0.2)पिछले कोड की मदद से, हमने NN के लिए नुकसान और सीखने का सेटअप किया है। निम्न कोड NN code को प्रशिक्षित और मान्य करेगा
from cntk.logging import ProgressPrinter
from cntk.train import TestConfig
progress_writer = ProgressPrinter(0)
test_config = TestConfig(test_datasource)
input_map = {
features: train_datasource.streams.features,
labels: train_datasource.streams.labels
}
loss.train(train_datasource,
max_epochs=10,
minibatch_size=64,
epoch_size=60000,
parameter_learners=[learner],
model_inputs_to_streams=input_map,
callbacks=[progress_writer, test_config])पूर्ण कार्यान्वयन उदाहरण
from cntk.layers import Convolution2D, Sequential, Dense, MaxPooling
from cntk.ops import log_softmax, relu
from cntk.initializer import glorot_uniform
from cntk import input_variable, default_options
features = input_variable((3,28,28))
labels = input_variable(10)
with default_options(initialization=glorot_uniform, activation=relu):
model = Sequential([
Convolution2D(filter_shape=(5,5), strides=(1,1), num_filters=8, pad=True),
MaxPooling(filter_shape=(2,2), strides=(2,2)),
Convolution2D(filter_shape=(5,5), strides=(1,1), num_filters=16, pad=True),
MaxPooling(filter_shape=(3,3), strides=(3,3)),
Dense(10, activation=log_softmax)
])
z = model(features)
import os
from cntk.io import MinibatchSource, StreamDef, StreamDefs, ImageDeserializer, INFINITELY_REPEAT
import cntk.io.transforms as xforms
def create_datasource(folder, train=True, max_sweeps=INFINITELY_REPEAT):
mapping_file = os.path.join(folder, 'mapping.bin')
image_transforms = []
if train:
image_transforms += [
xforms.crop(crop_type='randomside', side_ratio=0.8),
xforms.scale(width=28, height=28, channels=3, interpolations='linear')
]
stream_definitions = StreamDefs(
features=StreamDef(field='image', transforms=image_transforms),
labels=StreamDef(field='label', shape=10)
)
deserializer = ImageDeserializer(mapping_file, stream_definitions)
return MinibatchSource(deserializer, max_sweeps=max_sweeps)
train_datasource = create_datasource('mnist_train')
test_datasource = create_datasource('mnist_test', max_sweeps=1, train=False)
from cntk import Function
from cntk.losses import cross_entropy_with_softmax
from cntk.metrics import classification_error
from cntk.learners import sgd
@Function
def criterion_factory(output, targets):
loss = cross_entropy_with_softmax(output, targets)
metric = classification_error(output, targets)
return loss, metric
loss = criterion_factory(z, labels)
learner = sgd(z.parameters, lr=0.2)
from cntk.logging import ProgressPrinter
from cntk.train import TestConfig
progress_writer = ProgressPrinter(0)
test_config = TestConfig(test_datasource)
input_map = {
features: train_datasource.streams.features,
labels: train_datasource.streams.labels
}
loss.train(train_datasource,
max_epochs=10,
minibatch_size=64,
epoch_size=60000,
parameter_learners=[learner],
model_inputs_to_streams=input_map,
callbacks=[progress_writer, test_config])उत्पादन
-------------------------------------------------------------------
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.2
142 142 0.922 0.922 64
1.35e+06 1.51e+07 0.896 0.883 192
[………]छवि परिवर्तन
जैसा कि हमने देखा है, छवि मान्यता के लिए उपयोग किए जाने वाले एनएन को प्रशिक्षित करना मुश्किल है और, उन्हें प्रशिक्षित करने के लिए बहुत अधिक डेटा की आवश्यकता होती है। एक और मुद्दा यह है कि, वे प्रशिक्षण के दौरान उपयोग की जाने वाली छवियों पर अधिक प्रभाव डालते हैं। हमें एक उदाहरण के साथ देखते हैं, जब हम एक ईमानदार स्थिति में चेहरे की तस्वीरें लेते हैं, तो हमारे मॉडल को एक कठिन समय पहचानने वाले चेहरे की पहचान होगी जो दूसरी दिशा में घुमाए जाते हैं।
इस तरह की समस्या को दूर करने के लिए, हम छवि वृद्धि का उपयोग कर सकते हैं और CNTK विशिष्ट परिवर्तनों का समर्थन करता है, जब छवियों के लिए मिनीबच स्रोत बनाते हैं। हम कई परिवर्तनों का उपयोग निम्नानुसार कर सकते हैं
हम कोड के कुछ ही लाइनों के साथ प्रशिक्षण के लिए बेतरतीब ढंग से फसल छवियों का उपयोग कर सकते हैं।
हम एक पैमाने और रंग का भी उपयोग कर सकते हैं।
आइए पायथन कोड का पालन करने की मदद से देखते हैं, कैसे हम पहले मिनीबेट स्रोत बनाने के लिए उपयोग किए जाने वाले फ़ंक्शन के भीतर एक क्रॉपिंग परिवर्तन शामिल करके परिवर्तनों की सूची बदल सकते हैं।
import os
from cntk.io import MinibatchSource, StreamDef, StreamDefs, ImageDeserializer, INFINITELY_REPEAT
import cntk.io.transforms as xforms
def create_datasource(folder, train=True, max_sweeps=INFINITELY_REPEAT):
mapping_file = os.path.join(folder, 'mapping.bin')
image_transforms = []
if train:
image_transforms += [
xforms.crop(crop_type='randomside', side_ratio=0.8),
xforms.scale(width=28, height=28, channels=3, interpolations='linear')
]
stream_definitions = StreamDefs(
features=StreamDef(field='image', transforms=image_transforms),
labels=StreamDef(field='label', shape=10)
)
deserializer = ImageDeserializer(mapping_file, stream_definitions)
return MinibatchSource(deserializer, max_sweeps=max_sweeps)उपरोक्त कोड की मदद से, हम इमेज ट्रांसफ़ॉर्म के एक सेट को शामिल करने के लिए फ़ंक्शन को बढ़ा सकते हैं, ताकि, जब हम प्रशिक्षण लेंगे तो हम बेतरतीब ढंग से छवि को क्रॉप कर सकते हैं, इसलिए हमें छवि के अधिक भिन्नरूप मिलते हैं।
CNTK - आवर्तक तंत्रिका नेटवर्क
अब, समझते हैं कि CNTK में एक आवर्तक तंत्रिका नेटवर्क (RNN) का निर्माण कैसे किया जाता है।
परिचय
हमने सीखा कि कैसे एक तंत्रिका नेटवर्क के साथ छवियों को वर्गीकृत किया जाए, और यह गहन शिक्षा में प्रतिष्ठित नौकरियों में से एक है। लेकिन, एक और क्षेत्र जहां न्यूरल नेटवर्क का विस्तार होता है और बहुत सारे शोध हो रहे हैं, वह है रेकरल न्यूरल नेटवर्क्स (आरएनएन)। यहां, हम यह जानने जा रहे हैं कि आरएनएन क्या है और इसका उपयोग उन परिदृश्यों में कैसे किया जा सकता है, जहां हमें समय-श्रृंखला डेटा से निपटने की आवश्यकता है।
आवर्तक तंत्रिका नेटवर्क क्या है?
आवर्तक तंत्रिका नेटवर्क (RNN) को NN की विशेष नस्ल के रूप में परिभाषित किया जा सकता है जो समय के साथ तर्क करने में सक्षम हैं। RNN मुख्य रूप से परिदृश्यों में उपयोग किए जाते हैं, जहां हमें समय के साथ बदलते मूल्यों यानी समय-श्रृंखला डेटा से निपटने की आवश्यकता होती है। इसे बेहतर तरीके से समझने के लिए, चलो नियमित तंत्रिका नेटवर्क और आवर्तक तंत्रिका नेटवर्क के बीच एक छोटी सी तुलना करते हैं -
जैसा कि हम जानते हैं कि, एक नियमित तंत्रिका नेटवर्क में, हम केवल एक इनपुट प्रदान कर सकते हैं। यह इसे केवल एक भविष्यवाणी में परिणाम तक सीमित करता है। आपको एक उदाहरण देने के लिए, हम नियमित तंत्रिका नेटवर्क का उपयोग करके पाठ नौकरी का अनुवाद कर सकते हैं।
दूसरी ओर, आवर्तक तंत्रिका नेटवर्क में, हम नमूनों का एक क्रम प्रदान कर सकते हैं, जिसके परिणामस्वरूप एक ही भविष्यवाणी होती है। दूसरे शब्दों में, RNN का उपयोग करके हम इनपुट अनुक्रम के आधार पर आउटपुट अनुक्रम की भविष्यवाणी कर सकते हैं। उदाहरण के लिए, अनुवाद कार्यों में RNN के साथ काफी सफल प्रयोग हुए हैं।
आवर्तक तंत्रिका नेटवर्क का उपयोग
आरएनएन का उपयोग कई तरीकों से किया जा सकता है। उनमें से कुछ इस प्रकार हैं -
एकल आउटपुट की भविष्यवाणी करना
चरणों में गहरी डुबकी लगाने से पहले, कि RNN एक अनुक्रम के आधार पर किसी एकल आउटपुट की भविष्यवाणी कैसे कर सकता है, आइए देखें कि मूल RNN कैसा दिखता है

जैसा कि हम उपरोक्त आरेख में कर सकते हैं, आरएनएन में इनपुट के लिए एक लूपबैक कनेक्शन होता है और जब भी, हम मूल्यों का एक क्रम फ़ीड करते हैं यह समय के चरणों के अनुसार प्रत्येक तत्व को अनुक्रम में संसाधित करेगा।
इसके अलावा, लूपबैक कनेक्शन के कारण, RNN अनुक्रम में अगले तत्व के लिए इनपुट के साथ उत्पन्न आउटपुट को जोड़ सकता है। इस तरह, आरएनएन पूरे अनुक्रम पर एक मेमोरी का निर्माण करेगा जिसका उपयोग भविष्यवाणी करने के लिए किया जा सकता है।
RNN के साथ भविष्यवाणी करने के लिए, हम निम्न चरणों का पालन कर सकते हैं
सबसे पहले, एक प्रारंभिक छिपी हुई स्थिति बनाने के लिए, हमें इनपुट अनुक्रम के पहले तत्व को खिलाने की आवश्यकता है।
उसके बाद, एक अद्यतन छिपे हुए राज्य का उत्पादन करने के लिए, हमें प्रारंभिक छिपे हुए राज्य को लेने और इनपुट अनुक्रम में दूसरे तत्व के साथ संयोजन करने की आवश्यकता है।
अंत में, अंतिम छिपे हुए राज्य का उत्पादन करने और आरएनएन के लिए आउटपुट की भविष्यवाणी करने के लिए, हमें इनपुट अनुक्रम में अंतिम तत्व लेने की आवश्यकता है।
इस तरह, इस लूपबैक कनेक्शन की मदद से हम RNN को समय के साथ होने वाले पैटर्न को पहचानना सिखा सकते हैं।
एक अनुक्रम की भविष्यवाणी
RNN के ऊपर चर्चा की गई मूल मॉडल को अन्य उपयोग के मामलों में भी बढ़ाया जा सकता है। उदाहरण के लिए, हम एकल इनपुट के आधार पर मूल्यों के अनुक्रम की भविष्यवाणी करने के लिए इसका उपयोग कर सकते हैं। इस परिदृश्य में, RNN के साथ भविष्यवाणी करने के लिए हम निम्न चरणों का पालन कर सकते हैं -
सबसे पहले, एक प्रारंभिक छिपी हुई स्थिति बनाने और आउटपुट अनुक्रम में पहले तत्व की भविष्यवाणी करने के लिए, हमें तंत्रिका नेटवर्क में एक इनपुट नमूना खिलाने की आवश्यकता है।
उसके बाद, एक अद्यतन छिपे हुए राज्य और आउटपुट अनुक्रम में दूसरे तत्व का उत्पादन करने के लिए, हमें उसी नमूने के साथ प्रारंभिक छिपे हुए राज्य को संयोजित करने की आवश्यकता है।
अंत में, छिपे हुए राज्य को एक बार अपडेट करने के लिए और आउटपुट अनुक्रम में अंतिम तत्व की भविष्यवाणी करने के लिए, हम नमूना दूसरी बार खिलाते हैं।
अनुक्रम की भविष्यवाणी
जैसा कि हमने देखा है कि किसी अनुक्रम के आधार पर किसी एकल मान की भविष्यवाणी कैसे की जाती है और एकल मूल्य के आधार पर किसी अनुक्रम का पूर्वानुमान कैसे लगाया जाता है। अब देखते हैं कि हम दृश्यों के लिए दृश्यों की भविष्यवाणी कैसे कर सकते हैं। इस परिदृश्य में, RNN के साथ भविष्यवाणी करने के लिए हम निम्न चरणों का पालन कर सकते हैं -
सबसे पहले, एक प्रारंभिक छिपी हुई स्थिति बनाने और आउटपुट अनुक्रम में पहले तत्व की भविष्यवाणी करने के लिए, हमें इनपुट अनुक्रम में पहला तत्व लेने की आवश्यकता है।
उसके बाद, छिपे हुए राज्य को अपडेट करने और आउटपुट अनुक्रम में दूसरे तत्व की भविष्यवाणी करने के लिए, हमें प्रारंभिक छिपे हुए राज्य को लेने की आवश्यकता है।
अंत में, आउटपुट अनुक्रम में अंतिम तत्व की भविष्यवाणी करने के लिए, हमें इनपुट अनुक्रम में अद्यतन छिपे हुए राज्य और अंतिम तत्व को लेने की आवश्यकता है।
RNN का कार्य करना
आवर्तक तंत्रिका नेटवर्क (RNN) के कार्य को समझने के लिए हमें पहले यह समझने की आवश्यकता है कि नेटवर्क के काम में आवर्तक परतें कैसे होती हैं। तो पहले चर्चा करते हैं कि मानक आवर्तक परत के साथ आउटपुट का अनुमान कैसे लगाया जा सकता है।
मानक RNN परत के साथ आउटपुट की भविष्यवाणी करना
जैसा कि हमने पहले भी चर्चा की थी कि आरएनएन में एक मूल परत तंत्रिका नेटवर्क में एक नियमित परत से काफी अलग है। पिछले भाग में, हमने आरेख में RNN की मूल वास्तुकला का भी प्रदर्शन किया। पहली बार चरण-क्रम के लिए छिपी हुई स्थिति को अद्यतन करने के लिए हम निम्नलिखित सूत्र का उपयोग कर सकते हैं -

उपरोक्त समीकरण में, हम प्रारंभिक छिपे हुए राज्य और वजन के एक सेट के बीच डॉट उत्पाद की गणना करके नए छिपे हुए राज्य की गणना करते हैं।
अब अगले चरण के लिए, वर्तमान समय के चरण के लिए छिपे हुए राज्य का उपयोग अनुक्रम में अगली बार के चरण के लिए प्रारंभिक छिपे हुए राज्य के रूप में किया जाता है। इसीलिए, दूसरी बार चरण के लिए छिपी हुई स्थिति को अद्यतन करने के लिए, हम पहली बार चरण में की गई गणना को इस प्रकार दोहरा सकते हैं -
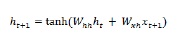
अगला, हम नीचे दिए गए अनुक्रम में तीसरे और अंतिम चरण के लिए छिपे हुए राज्य को अपडेट करने की प्रक्रिया को दोहरा सकते हैं -

और जब हमने उपरोक्त सभी चरणों को अनुक्रम में संसाधित किया है, तो हम आउटपुट की गणना निम्नानुसार कर सकते हैं -

उपरोक्त सूत्र के लिए, हमने अंतिम समय के कदम से तीसरे वजन और छिपे हुए राज्य का उपयोग किया है।
उन्नत आवर्तक इकाइयाँ
मूल आवर्तक परत के साथ मुख्य मुद्दा लुप्त होती क्रमिक समस्या का है और इस कारण यह दीर्घकालिक सहसंबंध सीखने में बहुत अच्छा नहीं है। सरल शब्दों में बुनियादी आवर्तक परत लंबे अनुक्रमों को बहुत अच्छी तरह से संभालती नहीं है। यही कारण है कि कुछ अन्य आवर्तक परत प्रकार हैं जो लंबे अनुक्रमों के साथ काम करने के लिए बहुत अधिक अनुकूल हैं: -
लॉन्ग-शॉर्ट टर्म मेमोरी (LSTM)

Hochreiter & Schmidhuber द्वारा दीर्घकालिक-अल्पकालिक मेमोरी (LSTM) नेटवर्क पेश किए गए थे। इसने चीजों को लंबे समय तक याद रखने के लिए एक मूल आवर्तक परत प्राप्त करने की समस्या को हल किया। LSTM की वास्तुकला चित्र में ऊपर दी गई है। जैसा कि हम देख सकते हैं कि इसमें इनपुट न्यूरॉन्स, मेमोरी सेल्स और आउटपुट न्यूरॉन्स हैं। लुप्त होती क्रमिक समस्या से निपटने के लिए, दीर्घकालिक अल्पकालिक मेमोरी नेटवर्क एक स्पष्ट मेमोरी सेल (पिछले मूल्यों को संग्रहीत करता है) और निम्न गेट्स का उपयोग करता है -
Forget gate- जैसा कि नाम का तात्पर्य है, यह मेमोरी सेल को पिछले मूल्यों को भूल जाने के लिए कहता है। मेमोरी सेल मानों को तब तक स्टोर करता है जब तक कि गेट 'गेट गेट' उन्हें भूल जाने के लिए नहीं कहता है।
Input gate- जैसा कि नाम से ही स्पष्ट है, यह सेल में नया सामान जोड़ता है।
Output gate- जैसा कि नाम से पता चलता है, आउटपुट गेट तय करता है कि सेल से वैक्टर के साथ अगले छिपे हुए राज्य में कब जाया जाए।
गेटेड आवर्तक इकाइयाँ (GRUs)

Gradient recurrent units(GRUs) LSTMs नेटवर्क की थोड़ी भिन्नता है। इसका एक कम द्वार है और LSTM की तुलना में थोड़ा अलग है। इसकी वास्तुकला ऊपर चित्र में दिखाई गई है। इसमें इनपुट न्यूरॉन्स, गेटेड मेमोरी सेल और आउटपुट न्यूरॉन्स होते हैं। गेटेड आवर्तक इकाइयों के नेटवर्क में निम्नलिखित दो द्वार हैं -
Update gate- यह निम्नलिखित दो चीजों को निर्धारित करता है
अंतिम राज्य से कितनी मात्रा में जानकारी रखनी चाहिए?
पिछली परत से कितनी मात्रा में जानकारी दी जानी चाहिए?
Reset gate- रीसेट गेट की कार्यक्षमता बहुत हद तक LSTMs नेटवर्क के गेट की तरह है। एकमात्र अंतर यह है कि यह थोड़ा अलग तरीके से स्थित है।
लॉन्ग-शॉर्ट टर्म मेमोरी नेटवर्क के विपरीत, गेटेड रिकरंट यूनिट नेटवर्क थोड़े तेज और चलाने में आसान होते हैं।
RNN संरचना का निर्माण
इससे पहले कि हम शुरू कर सकते हैं, हमारे किसी भी डेटा स्रोत से आउटपुट के बारे में भविष्यवाणी करना, हमें पहले आरएनएन का निर्माण करना होगा और आरएनएन का निर्माण करना बहुत ही आवश्यक है क्योंकि हमने पिछले अनुभाग में नियमित तंत्रिका नेटवर्क का निर्माण किया था। निम्नलिखित one− बनाने के लिए कोड है
from cntk.losses import squared_error
from cntk.io import CTFDeserializer, MinibatchSource, INFINITELY_REPEAT, StreamDefs, StreamDef
from cntk.learners import adam
from cntk.logging import ProgressPrinter
from cntk.train import TestConfig
BATCH_SIZE = 14 * 10
EPOCH_SIZE = 12434
EPOCHS = 10कई परतों को जकड़ना
हम CNTK में कई आवर्तक परतों को भी ढेर कर सकते हैं। उदाहरण के लिए, हम लेयर्स के निम्नलिखित संयोजन का उपयोग कर सकते हैं
from cntk import sequence, default_options, input_variable
from cntk.layers import Recurrence, LSTM, Dropout, Dense, Sequential, Fold
features = sequence.input_variable(1)
with default_options(initial_state = 0.1):
model = Sequential([
Fold(LSTM(15)),
Dense(1)
])(features)
target = input_variable(1, dynamic_axes=model.dynamic_axes)जैसा कि हम उपरोक्त कोड में देख सकते हैं, हमारे पास निम्नलिखित दो तरीके हैं जिनसे हम CNTK में RNN को मॉडल कर सकते हैं -
सबसे पहले, यदि हम केवल आवर्तक परत का अंतिम आउटपुट चाहते हैं, तो हम इसका उपयोग कर सकते हैं Fold एक आवर्तक परत, जैसे GRU, LSTM, या RNNStep के साथ संयोजन में परत।
दूसरा, वैकल्पिक रास्ते के रूप में, हम भी इसका उपयोग कर सकते हैं Recurrence खंड मैथा।
प्रशिक्षण RNN समय श्रृंखला डेटा के साथ
एक बार जब हम मॉडल का निर्माण करते हैं, तो देखते हैं कि हम CNTK में RNN को कैसे प्रशिक्षित कर सकते हैं -
from cntk import Function
@Function
def criterion_factory(z, t):
loss = squared_error(z, t)
metric = squared_error(z, t)
return loss, metric
loss = criterion_factory(model, target)
learner = adam(model.parameters, lr=0.005, momentum=0.9)अब प्रशिक्षण प्रक्रिया में डेटा को लोड करने के लिए, हमें CTF फ़ाइलों के एक सेट से अनुक्रमों को हटाना होगा। निम्नलिखित कोड हैcreate_datasource फ़ंक्शन, जो प्रशिक्षण और परीक्षण डेटा स्रोत बनाने के लिए एक उपयोगी उपयोगिता फ़ंक्शन है।
target_stream = StreamDef(field='target', shape=1, is_sparse=False)
features_stream = StreamDef(field='features', shape=1, is_sparse=False)
deserializer = CTFDeserializer(filename, StreamDefs(features=features_stream, target=target_stream))
datasource = MinibatchSource(deserializer, randomize=True, max_sweeps=sweeps)
return datasource
train_datasource = create_datasource('Training data filename.ctf')#we need to provide the location of training file we created from our dataset.
test_datasource = create_datasource('Test filename.ctf', sweeps=1) #we need to provide the location of testing file we created from our dataset.अब, जैसा कि हमारे पास डेटा स्रोत, मॉडल और नुकसान फ़ंक्शन का सेटअप है, हम प्रशिक्षण प्रक्रिया शुरू कर सकते हैं। यह काफी हद तक वैसा ही है जैसा कि हमने बुनियादी तंत्रिका नेटवर्क वाले पिछले खंडों में किया था।
progress_writer = ProgressPrinter(0)
test_config = TestConfig(test_datasource)
input_map = {
features: train_datasource.streams.features,
target: train_datasource.streams.target
}
history = loss.train(
train_datasource,
epoch_size=EPOCH_SIZE,
parameter_learners=[learner],
model_inputs_to_streams=input_map,
callbacks=[progress_writer, test_config],
minibatch_size=BATCH_SIZE,
max_epochs=EPOCHS
)हम निम्नानुसार उत्पादन प्राप्त करेंगे -
आउटपुट
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.005
0.4 0.4 0.4 0.4 19
0.4 0.4 0.4 0.4 59
0.452 0.495 0.452 0.495 129
[…]मॉडल को मान्य करना
वास्तव में एक आरएनएन के साथ पुनर्वित्त किसी भी अन्य सीएनके मॉडल के साथ भविष्यवाणियां करने के समान है। अंतर केवल इतना है, हमें एकल नमूनों के बजाय अनुक्रम प्रदान करने की आवश्यकता है।
अब, जैसा कि हमारे आरएनएन को अंततः प्रशिक्षण के साथ किया जाता है, हम कुछ नमूनों के अनुक्रम का उपयोग करके परीक्षण करके मॉडल को मान्य कर सकते हैं -
import pickle
with open('test_samples.pkl', 'rb') as test_file:
test_samples = pickle.load(test_file)
model(test_samples) * NORMALIZEआउटपुट
array([[ 8081.7905],
[16597.693 ],
[13335.17 ],
...,
[11275.804 ],
[15621.697 ],
[16875.555 ]], dtype=float32)