CNTK - आवर्तक तंत्रिका नेटवर्क
अब, समझते हैं कि CNTK में एक आवर्तक तंत्रिका नेटवर्क (RNN) का निर्माण कैसे किया जाता है।
परिचय
हमने सीखा कि कैसे एक तंत्रिका नेटवर्क के साथ छवियों को वर्गीकृत किया जाए, और यह गहन शिक्षा में प्रतिष्ठित नौकरियों में से एक है। लेकिन, एक अन्य क्षेत्र जहां न्यूरल नेटवर्क का विस्तार होता है और बहुत सारे शोध हो रहे हैं, वह है रेकरल न्यूरल नेटवर्क (आरएनएन)। यहां, हम यह जानने जा रहे हैं कि आरएनएन क्या है और इसका उपयोग उन परिदृश्यों में कैसे किया जा सकता है, जहां हमें समय-श्रृंखला डेटा से निपटने की आवश्यकता है।
आवर्तक तंत्रिका नेटवर्क क्या है?
आवर्तक तंत्रिका नेटवर्क (RNN) को NN की विशेष नस्ल के रूप में परिभाषित किया जा सकता है जो समय के साथ तर्क करने में सक्षम हैं। RNN मुख्य रूप से परिदृश्यों में उपयोग किए जाते हैं, जहां हमें समय के साथ बदलते मूल्यों यानी समय-श्रृंखला डेटा से निपटने की आवश्यकता होती है। इसे बेहतर तरीके से समझने के लिए, चलो नियमित तंत्रिका नेटवर्क और आवर्तक तंत्रिका नेटवर्क के बीच एक छोटी सी तुलना करते हैं -
जैसा कि हम जानते हैं कि, एक नियमित तंत्रिका नेटवर्क में, हम केवल एक इनपुट प्रदान कर सकते हैं। यह इसे केवल एक भविष्यवाणी में परिणाम तक सीमित करता है। आपको एक उदाहरण देने के लिए, हम नियमित तंत्रिका नेटवर्क का उपयोग करके पाठ नौकरी का अनुवाद कर सकते हैं।
दूसरी ओर, आवर्तक तंत्रिका नेटवर्क में, हम नमूनों का एक क्रम प्रदान कर सकते हैं, जिसके परिणामस्वरूप एक ही भविष्यवाणी होती है। दूसरे शब्दों में, RNN का उपयोग करके हम इनपुट अनुक्रम के आधार पर आउटपुट अनुक्रम की भविष्यवाणी कर सकते हैं। उदाहरण के लिए, अनुवाद कार्यों में RNN के साथ काफी सफल प्रयोग हुए हैं।
आवर्तक तंत्रिका नेटवर्क का उपयोग
आरएनएन का उपयोग कई तरीकों से किया जा सकता है। उनमें से कुछ इस प्रकार हैं -
एकल आउटपुट की भविष्यवाणी करना
चरणों में गहरी डुबकी लगाने से पहले, कि RNN किसी अनुक्रम के आधार पर किसी एकल आउटपुट की भविष्यवाणी कैसे कर सकता है, आइए देखें कि मूल RNN कैसा दिखता है

जैसा कि हम उपरोक्त आरेख में कर सकते हैं, आरएनएन में इनपुट के लिए एक लूपबैक कनेक्शन होता है और जब भी, हम एक क्रम का मान फीड करते हैं, यह समय के चरणों के अनुसार अनुक्रम में प्रत्येक तत्व को संसाधित करेगा।
इसके अलावा, लूपबैक कनेक्शन के कारण, आरएनएन अनुक्रम में अगले तत्व के लिए इनपुट के साथ उत्पन्न आउटपुट को जोड़ सकता है। इस तरह, आरएनएन पूरे अनुक्रम पर एक मेमोरी का निर्माण करेगा जिसका उपयोग भविष्यवाणी करने के लिए किया जा सकता है।
RNN के साथ भविष्यवाणी करने के लिए, हम निम्न चरणों का पालन कर सकते हैं
सबसे पहले, एक प्रारंभिक छिपी हुई स्थिति बनाने के लिए, हमें इनपुट अनुक्रम के पहले तत्व को खिलाने की आवश्यकता है।
उसके बाद, एक अद्यतन छिपे हुए राज्य का उत्पादन करने के लिए, हमें प्रारंभिक छिपे हुए राज्य को लेने और इनपुट अनुक्रम में दूसरे तत्व के साथ संयोजन करने की आवश्यकता है।
अंत में, अंतिम छिपे हुए राज्य का उत्पादन करने और आरएनएन के लिए आउटपुट की भविष्यवाणी करने के लिए, हमें इनपुट अनुक्रम में अंतिम तत्व लेने की आवश्यकता है।
इस तरह, इस लूपबैक कनेक्शन की मदद से हम RNN को समय के साथ होने वाले पैटर्न को पहचानना सिखा सकते हैं।
एक अनुक्रम की भविष्यवाणी
RNN के ऊपर चर्चा किए गए मूल मॉडल को अन्य उपयोग के मामलों में भी बढ़ाया जा सकता है। उदाहरण के लिए, हम एकल इनपुट के आधार पर मूल्यों के अनुक्रम की भविष्यवाणी करने के लिए इसका उपयोग कर सकते हैं। इस परिदृश्य में, RNN के साथ भविष्यवाणी करने के लिए हम निम्न चरणों का पालन कर सकते हैं -
सबसे पहले, एक प्रारंभिक छिपी हुई स्थिति बनाने और आउटपुट अनुक्रम में पहले तत्व की भविष्यवाणी करने के लिए, हमें तंत्रिका नेटवर्क में एक इनपुट नमूना खिलाने की आवश्यकता है।
उसके बाद, एक अद्यतन छिपे हुए राज्य और उत्पादन अनुक्रम में दूसरे तत्व का उत्पादन करने के लिए, हमें उसी नमूने के साथ प्रारंभिक छिपे हुए राज्य को संयोजित करने की आवश्यकता है।
अंत में, छिपे हुए राज्य को एक बार अपडेट करने के लिए और आउटपुट अनुक्रम में अंतिम तत्व की भविष्यवाणी करने के लिए, हम नमूना दूसरी बार खिलाते हैं।
अनुक्रम की भविष्यवाणी
जैसा कि हमने देखा है कि किसी अनुक्रम के आधार पर किसी एकल मान की भविष्यवाणी कैसे की जाती है और किसी एकल मान के आधार पर अनुक्रम का पूर्वानुमान कैसे लगाया जाता है। अब देखते हैं कि हम दृश्यों के लिए दृश्यों की भविष्यवाणी कैसे कर सकते हैं। इस परिदृश्य में, RNN के साथ भविष्यवाणी करने के लिए हम निम्न चरणों का पालन कर सकते हैं -
सबसे पहले, एक प्रारंभिक छिपी हुई स्थिति बनाने और आउटपुट अनुक्रम में पहले तत्व की भविष्यवाणी करने के लिए, हमें इनपुट अनुक्रम में पहला तत्व लेने की आवश्यकता है।
उसके बाद, छिपे हुए राज्य को अपडेट करने और आउटपुट अनुक्रम में दूसरे तत्व की भविष्यवाणी करने के लिए, हमें प्रारंभिक छिपे हुए राज्य को लेने की आवश्यकता है।
अंत में, आउटपुट अनुक्रम में अंतिम तत्व की भविष्यवाणी करने के लिए, हमें इनपुट अनुक्रम में अद्यतन छिपे हुए राज्य और अंतिम तत्व को लेने की आवश्यकता है।
RNN का कार्य करना
आवर्तक तंत्रिका नेटवर्क (RNN) के कार्य को समझने के लिए हमें पहले यह समझने की आवश्यकता है कि नेटवर्क के काम में आवर्तक परतें कैसे होती हैं। तो पहले आइए चर्चा करें कि मानक आवर्तक परत के साथ आउटपुट का अनुमान कैसे लगाया जा सकता है।
मानक RNN परत के साथ आउटपुट की भविष्यवाणी करना
जैसा कि हमने पहले भी चर्चा की थी कि आरएनएन में एक बुनियादी परत तंत्रिका नेटवर्क में एक नियमित परत से काफी अलग है। पिछले भाग में, हमने आरेख में RNN की मूल वास्तुकला का भी प्रदर्शन किया। पहली बार चरण-क्रम के लिए छिपी हुई स्थिति को अद्यतन करने के लिए हम निम्नलिखित सूत्र का उपयोग कर सकते हैं -

उपरोक्त समीकरण में, हम प्रारंभिक छिपे हुए राज्य और वजन के एक सेट के बीच डॉट उत्पाद की गणना करके नए छिपे हुए राज्य की गणना करते हैं।
अब अगले चरण के लिए, वर्तमान समय के चरण के लिए छिपे हुए राज्य का उपयोग अनुक्रम में अगली बार के चरण के लिए प्रारंभिक छिपे हुए राज्य के रूप में किया जाता है। इसीलिए, दूसरी बार चरण के लिए छिपी हुई स्थिति को अद्यतन करने के लिए, हम पहली बार चरण में की गई गणना को इस प्रकार दोहरा सकते हैं -
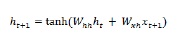
अगला, हम नीचे दिए गए अनुक्रम में तीसरे और अंतिम चरण के लिए छिपे हुए राज्य को अपडेट करने की प्रक्रिया को दोहरा सकते हैं -

और जब हमने अनुक्रम में सभी उपरोक्त चरणों को संसाधित किया है, तो हम आउटपुट की गणना निम्नानुसार कर सकते हैं -

उपरोक्त सूत्र के लिए, हमने अंतिम समय चरण से तीसरे वजन और छिपे हुए राज्य का उपयोग किया है।
उन्नत आवर्तक इकाइयाँ
मूल आवर्तक परत के साथ मुख्य मुद्दा लुप्त होती क्रमिक समस्या का है और इस वजह से यह दीर्घकालिक संबंध सीखने में बहुत अच्छा नहीं है। सरल शब्दों में बुनियादी आवर्तक परत लंबे अनुक्रमों को बहुत अच्छी तरह से संभालती नहीं है। यही कारण है कि कुछ अन्य आवर्तक परत प्रकार हैं जो लंबे अनुक्रमों के साथ काम करने के लिए बहुत अधिक अनुकूल हैं: -
लॉन्ग-शॉर्ट टर्म मेमोरी (LSTM)

Hochreiter & Schmidhuber द्वारा दीर्घकालिक अल्पकालिक मेमोरी (LSTM) नेटवर्क पेश किए गए थे। इसने चीजों को लंबे समय तक याद रखने के लिए एक मूल आवर्तक परत प्राप्त करने की समस्या को हल किया। LSTM की वास्तुकला आरेख में ऊपर दी गई है। जैसा कि हम देख सकते हैं कि इसमें इनपुट न्यूरॉन्स, मेमोरी सेल्स और आउटपुट न्यूरॉन्स हैं। लुप्त होती क्रमिक समस्या से निपटने के लिए, दीर्घकालिक अल्पकालिक मेमोरी नेटवर्क एक स्पष्ट मेमोरी सेल (पिछले मूल्यों को संग्रहीत करता है) और निम्न गेट्स का उपयोग करता है -
Forget gate- जैसा कि नाम का तात्पर्य है, यह मेमोरी सेल को पिछले मूल्यों को भूल जाने के लिए कहता है। मेमोरी सेल मानों को तब तक स्टोर करता है जब तक कि गेट 'गेट गेट' उन्हें भूल जाने के लिए नहीं कहता है।
Input gate- जैसा कि नाम से ही स्पष्ट है, यह सेल में नया सामान जोड़ता है।
Output gate- जैसा कि नाम से पता चलता है, आउटपुट गेट तय करता है कि सेल से वैक्टर के साथ अगले छिपे हुए राज्य में कब जाया जाए।
गेटेड आवर्तक इकाइयों (GRUs)

Gradient recurrent units(GRUs) LSTMs नेटवर्क की थोड़ी भिन्नता है। इसमें एक कम गेट है और LSTM की तुलना में थोड़ा अलग है। इसकी वास्तुकला को उपरोक्त आरेख में दिखाया गया है। इसमें इनपुट न्यूरॉन्स, गेटेड मेमोरी सेल और आउटपुट न्यूरॉन्स होते हैं। गेटेड आवर्तक इकाइयों के नेटवर्क में निम्नलिखित दो द्वार हैं -
Update gate- यह निम्नलिखित दो चीजों को निर्धारित करता है
अंतिम राज्य से कितनी मात्रा में जानकारी रखनी चाहिए?
पिछली परत से कितनी मात्रा में जानकारी दी जानी चाहिए?
Reset gate- रीसेट गेट की कार्यक्षमता बहुत हद तक LSTMs नेटवर्क के गेट की तरह है। एकमात्र अंतर यह है कि यह थोड़ा अलग तरीके से स्थित है।
लॉन्ग-शॉर्ट टर्म मेमोरी नेटवर्क के विपरीत, गेटेड रिकरंट यूनिट नेटवर्क थोड़े तेज और चलाने में आसान होते हैं।
RNN संरचना का निर्माण
शुरू करने से पहले, हम अपने किसी भी डेटा स्रोत से आउटपुट के बारे में भविष्यवाणी कर सकते हैं, हमें पहले आरएनएन का निर्माण करने की आवश्यकता है और आरएनएन का निर्माण करने के लिए काफी समान है क्योंकि हमने पिछले अनुभाग में नियमित तंत्रिका नेटवर्क का निर्माण किया था। निम्नलिखित one− बनाने के लिए कोड है
from cntk.losses import squared_error
from cntk.io import CTFDeserializer, MinibatchSource, INFINITELY_REPEAT, StreamDefs, StreamDef
from cntk.learners import adam
from cntk.logging import ProgressPrinter
from cntk.train import TestConfig
BATCH_SIZE = 14 * 10
EPOCH_SIZE = 12434
EPOCHS = 10कई परतों को जकड़ना
हम CNTK में कई आवर्तक परतों को भी ढेर कर सकते हैं। उदाहरण के लिए, हम लेयर्स के निम्नलिखित संयोजन का उपयोग कर सकते हैं
from cntk import sequence, default_options, input_variable
from cntk.layers import Recurrence, LSTM, Dropout, Dense, Sequential, Fold
features = sequence.input_variable(1)
with default_options(initial_state = 0.1):
model = Sequential([
Fold(LSTM(15)),
Dense(1)
])(features)
target = input_variable(1, dynamic_axes=model.dynamic_axes)जैसा कि हम उपरोक्त कोड में देख सकते हैं, हमारे पास निम्नलिखित दो तरीके हैं जिनसे हम CNTK में RNN को मॉडल कर सकते हैं -
सबसे पहले, यदि हम केवल आवर्तक परत का अंतिम आउटपुट चाहते हैं, तो हम इसका उपयोग कर सकते हैं Fold एक आवर्तक परत, जैसे GRU, LSTM, या RNNStep के साथ संयोजन में परत।
दूसरा, वैकल्पिक रास्ते के रूप में, हम भी इसका उपयोग कर सकते हैं Recurrence खंड मैथा।
प्रशिक्षण RNN समय श्रृंखला डेटा के साथ
एक बार जब हम मॉडल का निर्माण करते हैं, तो देखते हैं कि हम CNTK में RNN को कैसे प्रशिक्षित कर सकते हैं -
from cntk import Function
@Function
def criterion_factory(z, t):
loss = squared_error(z, t)
metric = squared_error(z, t)
return loss, metric
loss = criterion_factory(model, target)
learner = adam(model.parameters, lr=0.005, momentum=0.9)अब प्रशिक्षण प्रक्रिया में डेटा को लोड करने के लिए, हमें CTF फ़ाइलों के एक सेट से अनुक्रमों को हटाना होगा। निम्नलिखित कोड हैcreate_datasource फ़ंक्शन, जो प्रशिक्षण और परीक्षण डेटा स्रोत दोनों बनाने के लिए एक उपयोगी उपयोगिता फ़ंक्शन है।
target_stream = StreamDef(field='target', shape=1, is_sparse=False)
features_stream = StreamDef(field='features', shape=1, is_sparse=False)
deserializer = CTFDeserializer(filename, StreamDefs(features=features_stream, target=target_stream))
datasource = MinibatchSource(deserializer, randomize=True, max_sweeps=sweeps)
return datasource
train_datasource = create_datasource('Training data filename.ctf')#we need to provide the location of training file we created from our dataset.
test_datasource = create_datasource('Test filename.ctf', sweeps=1) #we need to provide the location of testing file we created from our dataset.अब, जैसा कि हमारे पास डेटा स्रोत, मॉडल और नुकसान फ़ंक्शन का सेटअप है, हम प्रशिक्षण प्रक्रिया शुरू कर सकते हैं। यह काफी हद तक वैसा ही है जैसा हमने बुनियादी तंत्रिका नेटवर्क वाले पिछले खंडों में किया था।
progress_writer = ProgressPrinter(0)
test_config = TestConfig(test_datasource)
input_map = {
features: train_datasource.streams.features,
target: train_datasource.streams.target
}
history = loss.train(
train_datasource,
epoch_size=EPOCH_SIZE,
parameter_learners=[learner],
model_inputs_to_streams=input_map,
callbacks=[progress_writer, test_config],
minibatch_size=BATCH_SIZE,
max_epochs=EPOCHS
)हम निम्नानुसार उत्पादन प्राप्त करेंगे -
आउटपुट
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.005
0.4 0.4 0.4 0.4 19
0.4 0.4 0.4 0.4 59
0.452 0.495 0.452 0.495 129
[…]मॉडल को मान्य करना
वास्तव में एक आरएनएन के साथ पुनर्वित्त किसी भी अन्य सीएनके मॉडल के साथ भविष्यवाणियां करने के समान है। एकमात्र अंतर यह है कि, हमें एकल नमूनों के बजाय अनुक्रम प्रदान करने की आवश्यकता है।
अब, जैसा कि हमारे आरएनएन को अंततः प्रशिक्षण के साथ किया जाता है, हम कुछ नमूनों के अनुक्रम का उपयोग करके परीक्षण करके मॉडल को मान्य कर सकते हैं -
import pickle
with open('test_samples.pkl', 'rb') as test_file:
test_samples = pickle.load(test_file)
model(test_samples) * NORMALIZEआउटपुट
array([[ 8081.7905],
[16597.693 ],
[13335.17 ],
...,
[11275.804 ],
[15621.697 ],
[16875.555 ]], dtype=float32)