ओपनएनएलपी - अवलोकन
एनएलपी उपकरण का एक सेट है जिसका उपयोग प्राकृतिक भाषा स्रोतों जैसे कि वेब पेज और टेक्स्ट दस्तावेजों से सार्थक और उपयोगी जानकारी प्राप्त करने के लिए किया जाता है।
ओपन एनएलपी क्या है?
अमरीका की एक मूल जनजाति OpenNLPएक ओपन-सोर्स जावा लाइब्रेरी है जिसका उपयोग प्राकृतिक भाषा पाठ को संसाधित करने के लिए किया जाता है। आप इस लाइब्रेरी का उपयोग करके एक कुशल टेक्स्ट प्रोसेसिंग सर्विस बना सकते हैं।
OpenNLP सेवाएं प्रदान करता है जैसे कि टोकेनाइजेशन, वाक्य विभाजन, पार्ट-ऑफ-स्पीच टैगिंग, नाम निकाय निष्कर्षण, चैंकिंग, पार्सिंग और सह-संदर्भ रिज़ॉल्यूशन, आदि।
ओपनएनएलपी की विशेषताएं
ओपनएनएलपी की उल्लेखनीय विशेषताएं निम्नलिखित हैं -
Named Entity Recognition (NER) - ओपन एनएलपी एनईआर का समर्थन करता है, जिसके उपयोग से आप प्रश्नों को संसाधित करते समय भी स्थानों, लोगों और चीजों के नाम निकाल सकते हैं।
Summarize - का उपयोग करना summarize सुविधा, आप एनएलपी में अनुच्छेदों, लेखों, दस्तावेजों या उनके संग्रह को संक्षेप में प्रस्तुत कर सकते हैं।
Searching - ओपनएनएलपी में, दिए गए पाठ में किसी दिए गए खोज स्ट्रिंग या इसके पर्यायवाची शब्द को पहचाना जा सकता है, भले ही दिए गए शब्द को बदल दिया जाए या गलत वर्तनी हो।
Tagging (POS) - एनएलपी में टैगिंग का उपयोग आगे के विश्लेषण के लिए पाठ को विभिन्न व्याकरणिक तत्वों में विभाजित करने के लिए किया जाता है।
Translation - एनएलपी में, अनुवाद एक भाषा को दूसरे में अनुवाद करने में मदद करता है।
Information grouping - एनएलपी में यह विकल्प दस्तावेज़ की सामग्री में भाषण के हिस्सों की तरह ही पाठ्य सूचनाओं को समूहित करता है।
Natural Language Generation - इसका उपयोग डेटाबेस से जानकारी उत्पन्न करने और मौसम विश्लेषण या मेडिकल रिपोर्ट जैसी सूचना रिपोर्टों को स्वचालित करने के लिए किया जाता है।
Feedback Analysis - जैसा कि नाम से ही स्पष्ट है कि एनएलपी द्वारा उत्पादों के संबंध में लोगों से विभिन्न प्रकार के फीडबैक एकत्रित किए जाते हैं, ताकि यह विश्लेषण किया जा सके कि उत्पाद उनके दिलों को जीतने में कितना सफल है।
Speech recognition - हालांकि मानव भाषण का विश्लेषण करना मुश्किल है, एनएलपी में इस आवश्यकता के लिए कुछ अंतर्निहित विशेषताएं हैं।
एनएलपी एपीआई खोलें
अपाचे ओपनएनएलपी लाइब्रेरी प्राकृतिक भाषा प्रसंस्करण के विभिन्न कार्यों को करने के लिए कक्षाएं और इंटरफेस प्रदान करती है जैसे कि वाक्य का पता लगाना, टोकेनाइजेशन, एक नाम ढूंढना, भाषण के हिस्सों को टैग करना, एक वाक्य चुनकर, पार्स करना, सह-संदर्भ रिज़ॉल्यूशन, और दस्तावेज़ श्रेणीकरण।
इन कार्यों के अलावा, हम इनमें से किसी भी कार्य के लिए अपने स्वयं के मॉडल का प्रशिक्षण और मूल्यांकन भी कर सकते हैं।
ओपनएनएलपी सीएलआई
लाइब्रेरी के अलावा, ओपनएनएलपी एक कमांड लाइन इंटरफेस (सीएलआई) भी प्रदान करता है, जहां हम मॉडल को प्रशिक्षित और मूल्यांकन कर सकते हैं। हम इस विषय पर इस ट्यूटोरियल के अंतिम अध्याय में विस्तार से चर्चा करेंगे।
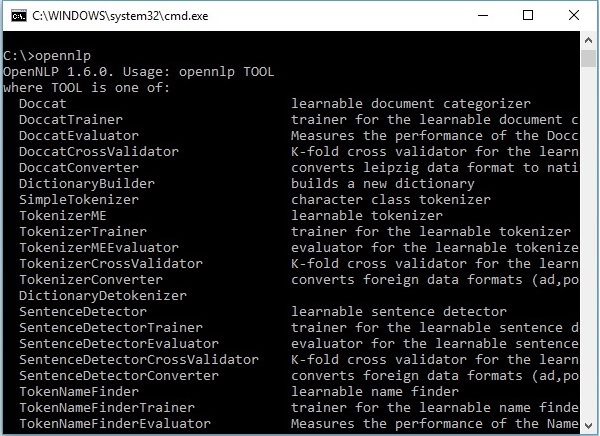
एनएलपी मॉडल खोलें
विभिन्न एनएलपी कार्यों को करने के लिए, ओपनएनएलपी पूर्वनिर्धारित मॉडल का एक सेट प्रदान करता है। इस सेट में विभिन्न भाषाओं के लिए मॉडल शामिल हैं।
मॉडल डाउनलोड करना
आप OpenNLP द्वारा प्रदान किए गए पूर्वनिर्धारित मॉडल को डाउनलोड करने के लिए नीचे दिए गए चरणों का पालन कर सकते हैं।
Step 1 - निम्नलिखित लिंक पर क्लिक करके ओपनएनएलपी मॉडल का सूचकांक पृष्ठ खोलें - http://opennlp.sourceforge.net/models-1.5/।

Step 2- दिए गए लिंक पर जाने पर, आपको विभिन्न भाषाओं के घटकों की सूची और उन्हें डाउनलोड करने के लिंक देखने को मिलेंगे। यहां, आप OpenNLP द्वारा प्रदान किए गए सभी पूर्वनिर्धारित मॉडल की सूची प्राप्त कर सकते हैं।
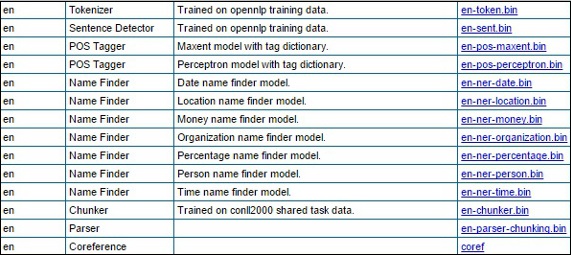
इन सभी मॉडलों को फ़ोल्डर में डाउनलोड करें C:/OpenNLP_models/>, उनके संबंधित लिंक पर क्लिक करके। ये सभी मॉडल भाषा पर निर्भर हैं और इनका उपयोग करते समय, आपको यह सुनिश्चित करना होगा कि मॉडल भाषा इनपुट टेक्स्ट की भाषा से मेल खाती है।
ओपनएनएलपी का इतिहास
2010 में, OpenNLP ने Apache ऊष्मायन में प्रवेश किया।
2011 में, अपाचे ओपनएनएलपी 1.5.2 इन्क्यूबेटिंग जारी किया गया था, और उसी वर्ष में, यह एक शीर्ष-स्तरीय एपरेक प्रोजेक्ट के रूप में स्नातक हुआ।
2015 में, ओपनएनएलपी 1.6.0 जारी किया गया था।