ओपनएनएलपी - त्वरित गाइड
एनएलपी उपकरण का एक सेट है जिसका उपयोग प्राकृतिक भाषा स्रोतों जैसे कि वेब पेज और टेक्स्ट दस्तावेजों से सार्थक और उपयोगी जानकारी प्राप्त करने के लिए किया जाता है।
ओपन एनएलपी क्या है?
अमरीका की एक मूल जनजाति OpenNLPएक ओपन-सोर्स जावा लाइब्रेरी है जिसका उपयोग प्राकृतिक भाषा पाठ को संसाधित करने के लिए किया जाता है। आप इस लाइब्रेरी का उपयोग करके एक कुशल टेक्स्ट प्रोसेसिंग सर्विस बना सकते हैं।
OpenNLP सेवाएं प्रदान करता है जैसे कि टोकेनाइजेशन, वाक्य विभाजन, पार्ट-ऑफ-स्पीच टैगिंग, नाम निकाय निष्कर्षण, चैंकिंग, पार्सिंग और सह-संदर्भ रिज़ॉल्यूशन, आदि।
ओपनएनएलपी की विशेषताएं
ओपनएनएलपी की उल्लेखनीय विशेषताएं निम्नलिखित हैं -
Named Entity Recognition (NER) - ओपन एनएलपी एनईआर का समर्थन करता है, जिसके उपयोग से आप प्रश्नों को संसाधित करते समय भी स्थानों, लोगों और चीजों के नाम निकाल सकते हैं।
Summarize - का उपयोग करना summarize सुविधा, आप एनएलपी में अनुच्छेदों, लेखों, दस्तावेजों या उनके संग्रह को संक्षेप में प्रस्तुत कर सकते हैं।
Searching - ओपनएनएलपी में, दिए गए पाठ में किसी दिए गए खोज स्ट्रिंग या इसके पर्यायवाची शब्द को पहचाना जा सकता है, भले ही दिए गए शब्द को बदल दिया जाए या गलत वर्तनी हो।
Tagging (POS) - एनएलपी में टैगिंग का उपयोग आगे के विश्लेषण के लिए पाठ को विभिन्न व्याकरणिक तत्वों में विभाजित करने के लिए किया जाता है।
Translation - एनएलपी में, अनुवाद एक भाषा को दूसरे में अनुवाद करने में मदद करता है।
Information grouping - एनएलपी में यह विकल्प दस्तावेज़ की सामग्री में भाषण के हिस्सों की तरह ही पाठ्य सूचनाओं को समूहित करता है।
Natural Language Generation - इसका उपयोग डेटाबेस से जानकारी उत्पन्न करने और मौसम विश्लेषण या चिकित्सा रिपोर्ट जैसी सूचना रिपोर्टों को स्वचालित करने के लिए किया जाता है।
Feedback Analysis - जैसा कि नाम से ही स्पष्ट है कि उत्पादों के संबंध में लोगों से विभिन्न प्रकार के फीडबैक एनएलपी द्वारा प्राप्त किए जाते हैं, ताकि यह विश्लेषण किया जा सके कि उत्पाद उनके दिलों को जीतने में कितना सफल है।
Speech recognition - हालांकि मानव भाषण का विश्लेषण करना मुश्किल है, एनएलपी में इस आवश्यकता के लिए कुछ अंतर्निहित विशेषताएं हैं।
एनएलपी एपीआई खोलें
अपाचे ओपनएनएलपी लाइब्रेरी प्राकृतिक भाषा प्रसंस्करण के विभिन्न कार्यों को करने के लिए कक्षाएं और इंटरफेस प्रदान करती है जैसे कि वाक्य का पता लगाना, टोकेनाइजेशन, एक नाम ढूंढना, भाषण के हिस्सों को टैग करना, एक वाक्य चुन, पार्सिंग, सह-संदर्भ रिज़ॉल्यूशन, और दस्तावेज़ श्रेणीकरण।
इन कार्यों के अलावा, हम इनमें से किसी भी कार्य के लिए अपने स्वयं के मॉडल का प्रशिक्षण और मूल्यांकन भी कर सकते हैं।
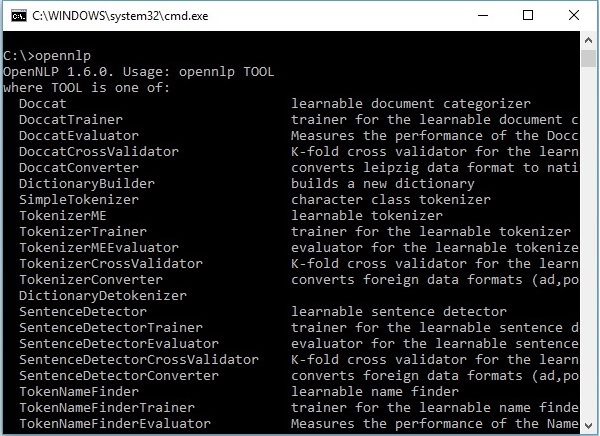
ओपनएनएलपी सीएलआई
लाइब्रेरी के अलावा, ओपनएनएलपी एक कमांड लाइन इंटरफेस (सीएलआई) भी प्रदान करता है, जहां हम मॉडल को प्रशिक्षित और मूल्यांकन कर सकते हैं। हम इस विषय पर इस ट्यूटोरियल के अंतिम अध्याय में विस्तार से चर्चा करेंगे।
एनएलपी मॉडल खोलें
विभिन्न एनएलपी कार्यों को करने के लिए, ओपनएनएलपी पूर्वनिर्धारित मॉडल का एक सेट प्रदान करता है। इस सेट में विभिन्न भाषाओं के लिए मॉडल शामिल हैं।
मॉडल डाउनलोड करना
आप OpenNLP द्वारा प्रदान किए गए पूर्वनिर्धारित मॉडल को डाउनलोड करने के लिए नीचे दिए गए चरणों का पालन कर सकते हैं।
Step 1 - निम्नलिखित लिंक पर क्लिक करके ओपनएनएलपी मॉडल का सूचकांक पृष्ठ खोलें - http://opennlp.sourceforge.net/models-1.5/।

Step 2- दिए गए लिंक पर जाने पर, आपको विभिन्न भाषाओं के घटकों की सूची और उन्हें डाउनलोड करने के लिंक देखने को मिलेंगे। यहां, आप OpenNLP द्वारा प्रदान किए गए सभी पूर्वनिर्धारित मॉडल की सूची प्राप्त कर सकते हैं।
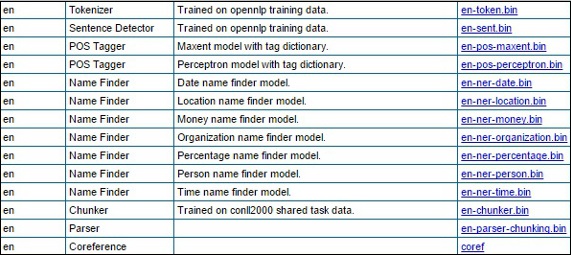
इन सभी मॉडलों को फ़ोल्डर में डाउनलोड करें C:/OpenNLP_models/>, उनके संबंधित लिंक पर क्लिक करके। ये सभी मॉडल भाषा पर निर्भर हैं और इनका उपयोग करते समय, आपको यह सुनिश्चित करना होगा कि मॉडल भाषा इनपुट टेक्स्ट की भाषा से मेल खाती है।
ओपनएनएलपी का इतिहास
2010 में, OpenNLP ने Apache ऊष्मायन में प्रवेश किया।
2011 में, अपाचे ओपनएनएलपी 1.5.2 इन्क्यूबेटिंग जारी किया गया था, और उसी वर्ष में, यह एक शीर्ष-स्तरीय एपरेक प्रोजेक्ट के रूप में स्नातक हुआ।
2015 में, ओपनएनएलपी 1.6.0 जारी किया गया था।
इस अध्याय में, हम चर्चा करेंगे कि आप अपने सिस्टम में ओपनएनएलपी वातावरण कैसे सेट कर सकते हैं। चलो स्थापना प्रक्रिया के साथ शुरू करते हैं।
ओपनएनएलपी स्थापित करना
निम्नलिखित डाउनलोड करने के चरण हैं Apache OpenNLP library आपके सिस्टम में
Step 1 - का होमपेज खोलें Apache OpenNLP निम्नलिखित लिंक पर क्लिक करके - https://opennlp.apache.org/।
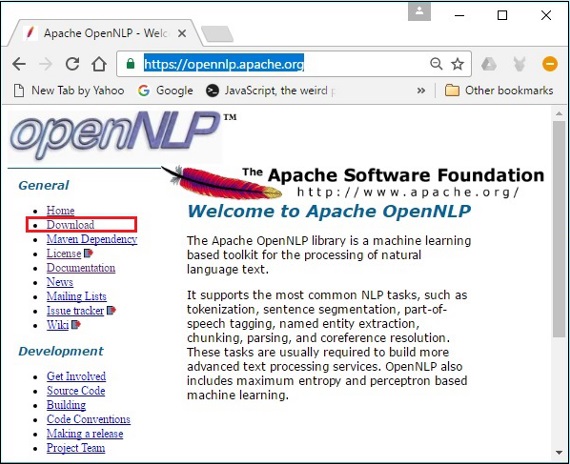
Step 2 - अब, पर क्लिक करें Downloadsसंपर्क। क्लिक करने पर, आपको एक पृष्ठ पर निर्देशित किया जाएगा, जहाँ आप विभिन्न दर्पण पा सकते हैं, जो आपको अपाचे सॉफ्टवेयर फाउंडेशन डिस्ट्रीब्यूशन डायरेक्टरी पर पुनर्निर्देशित करेगा।
Step 3- इस पृष्ठ में आप विभिन्न अपाचे वितरण डाउनलोड करने के लिए लिंक पा सकते हैं। उनके माध्यम से ब्राउज़ करें और ओपनएनएलपी वितरण खोजें और इसे क्लिक करें।
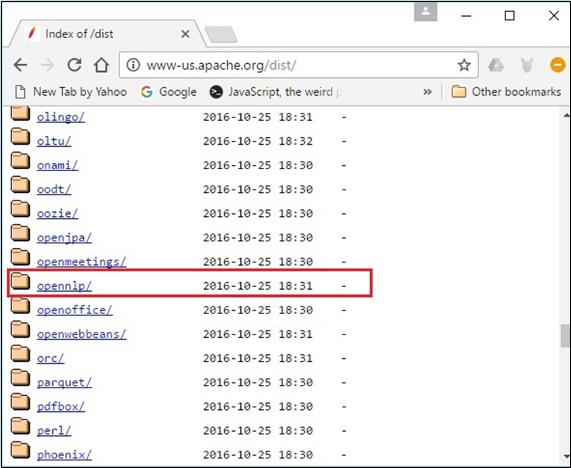
Step 4 - क्लिक करने पर, आप उस डायरेक्टरी पर पुनर्निर्देशित हो जाएंगे जहां आप ओपनएनएलपी वितरण के सूचकांक को देख सकते हैं, जैसा कि नीचे दिखाया गया है।
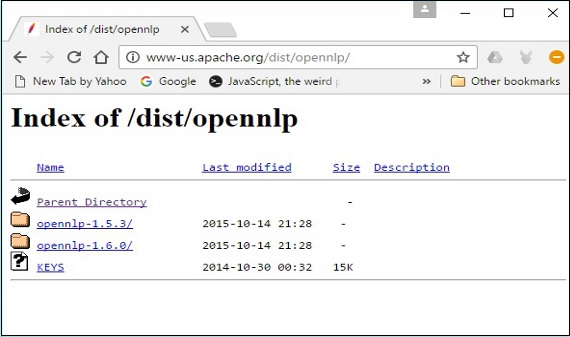
उपलब्ध वितरण से नवीनतम संस्करण पर क्लिक करें।
Step 5- प्रत्येक वितरण विभिन्न स्वरूपों में ओपनएनएलपी लाइब्रेरी के स्रोत और बाइनरी फाइलें प्रदान करता है। स्रोत और बाइनरी फ़ाइलें डाउनलोड करें,apache-opennlp-1.6.0-bin.zip तथा apache-opennlp1.6.0-src.zip (विंडोज के लिए)।

कक्षापथ की स्थापना
ओपनएनएलपी लाइब्रेरी को डाउनलोड करने के बाद, आपको इसका रास्ता तय करना होगा binनिर्देशिका। मान लें कि आपने OpenNLP लाइब्रेरी को अपने सिस्टम के E ड्राइव में डाउनलोड किया है।
अब, नीचे दिए गए चरणों का पालन करें -
Step 1 - 'मेरा कंप्यूटर' पर राइट-क्लिक करें और 'गुण' चुनें।
Step 2 - 'उन्नत' टैब के तहत 'पर्यावरण चर' बटन पर क्लिक करें।
Step 3 - का चयन करें path चर और क्लिक करें Edit बटन, जैसा कि निम्नलिखित स्क्रीनशॉट में दिखाया गया है।
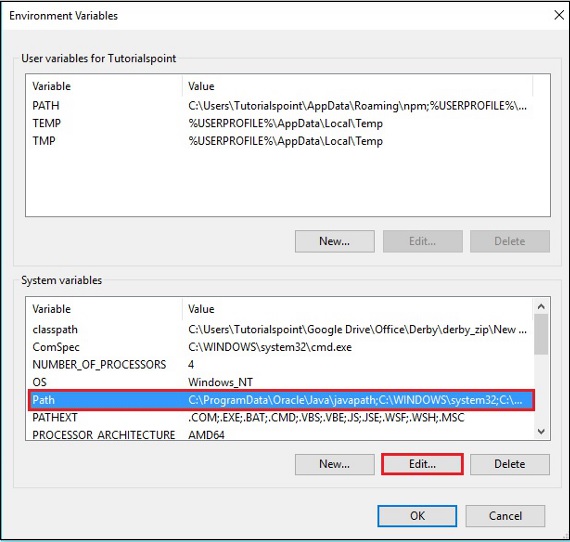
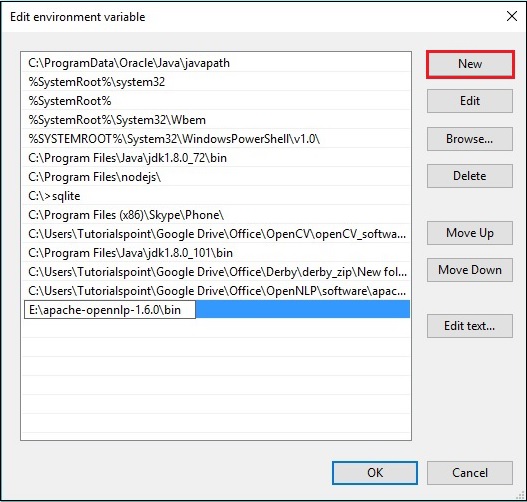
Step 4 - एन्वायर्नमेंटल वेरिएबल एडिट विंडो में, क्लिक करें New बटन और OpenNLP निर्देशिका के लिए पथ जोड़ें E:\apache-opennlp-1.6.0\bin और क्लिक करें OK बटन, जैसा कि निम्नलिखित स्क्रीनशॉट में दिखाया गया है।
ग्रहण स्थापना
आप OpenNLP लाइब्रेरी के लिए ग्रहण वातावरण सेट कर सकते हैं, या तो सेट करके Build path JAR फ़ाइलों के लिए या का उपयोग करके pom.xml।
JAR फ़ाइलों के लिए बिल्ड पथ सेट करें
ग्रहण में ओपनएनएलपी स्थापित करने के लिए नीचे दिए गए चरणों का पालन करें -
Step 1 - सुनिश्चित करें कि आपके पास आपके सिस्टम में ग्रहण वातावरण स्थापित है।
Step 2- ग्रहण खोलें। फ़ाइल पर क्लिक करें → नया → एक नई परियोजना खोलें, जैसा कि नीचे दिखाया गया है।
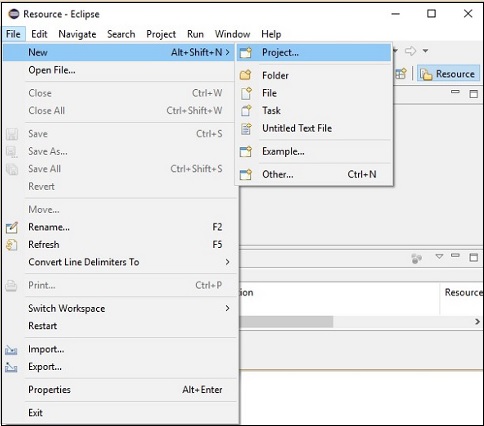
Step 3 - आपको मिल जाएगा New Projectजादूगर। इस विज़ार्ड में, जावा प्रोजेक्ट चुनें और क्लिक करके आगे बढ़ेंNext बटन।
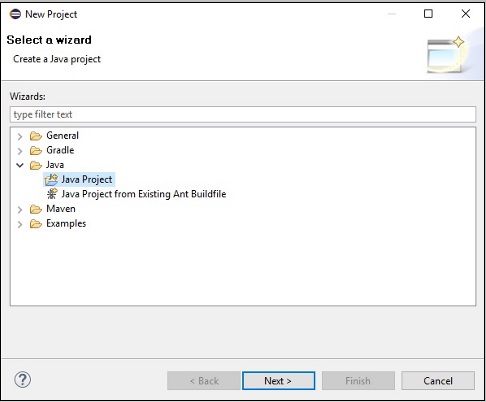
Step 4 - इसके बाद, आप प्राप्त करेंगे New Java Project wizard। यहां, आपको एक नई परियोजना बनाने और क्लिक करने की आवश्यकता हैNext बटन, जैसा कि नीचे दिखाया गया है।
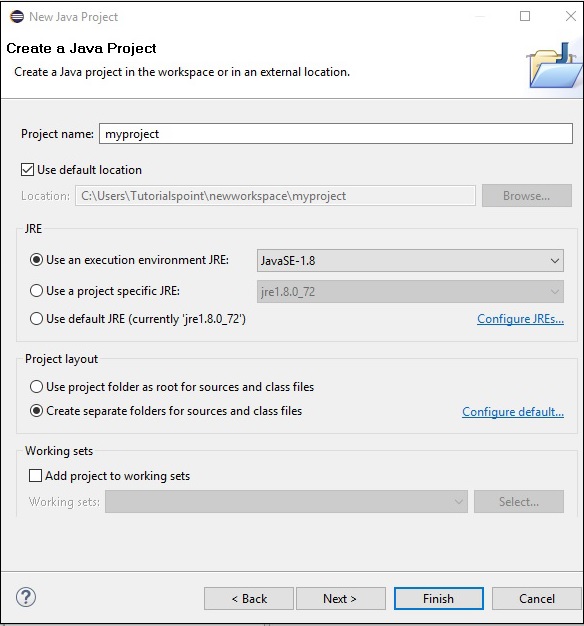
Step 5 - नया प्रोजेक्ट बनाने के बाद उस पर राइट क्लिक करें, सेलेक्ट करें Build Path और क्लिक करें Configure Build Path।
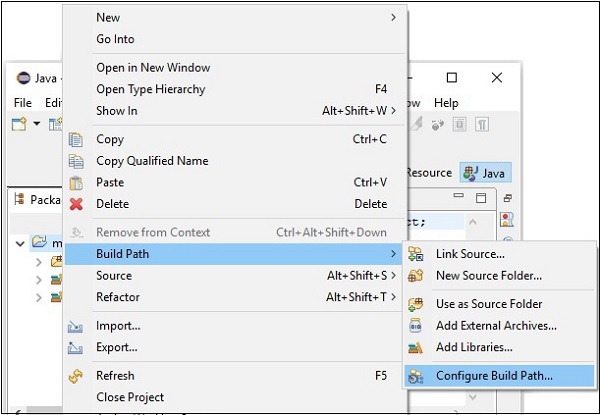
Step 6 - इसके बाद, आप प्राप्त करेंगे Java Build Pathजादूगर। यहां, क्लिक करेंAdd External JARs बटन, जैसा कि नीचे दिखाया गया है।
Step 7 - जार फ़ाइलों का चयन करें opennlp-tools-1.6.0.jar तथा opennlp-uima-1.6.0.jar में स्थित lib का फ़ोल्डर apache-opennlp-1.6.0 folder।
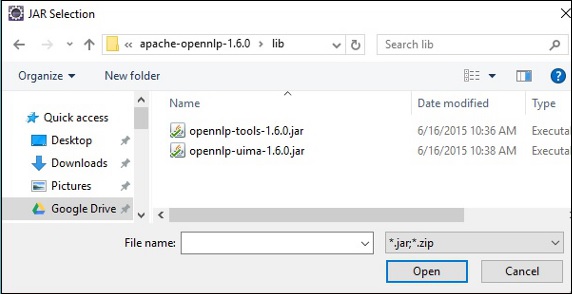
क्लिक करने पर Open उपरोक्त स्क्रीन में बटन, चयनित फाइलें आपके पुस्तकालय में जोड़ दी जाएंगी।
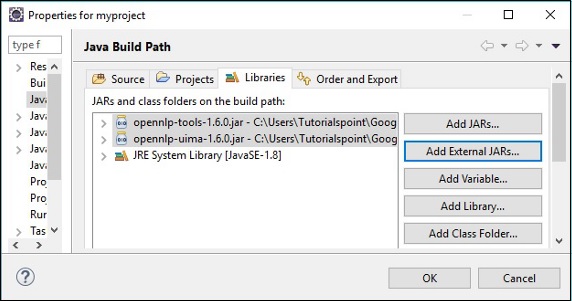
क्लिक करने पर OK, आप वर्तमान परियोजना के लिए आवश्यक JAR फ़ाइलों को सफलतापूर्वक जोड़ देंगे और आप नीचे दिखाए गए अनुसार पुस्तकालयों का विस्तार करके इन जोड़ा पुस्तकालयों को सत्यापित कर सकते हैं।

Pom.xml का उपयोग करना
इस परियोजना को मावेन परियोजना में परिवर्तित करें और इसके लिए निम्न कोड जोड़ें pom.xml।
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>myproject</groupId>
<artifactId>myproject</artifactId>
<version>0.0.1-SNAPSHOT</version>
<build>
<sourceDirectory>src</sourceDirectory>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.apache.opennlp</groupId>
<artifactId>opennlp-tools</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.opennlp</groupId>
<artifactId>opennlp-uima</artifactId>
<version>1.6.0</version>
</dependency>
</dependencies>
</project>इस अध्याय में, हम उन वर्गों और विधियों के बारे में चर्चा करेंगे जिनका उपयोग हम इस ट्यूटोरियल के बाद के अध्यायों में करेंगे।
वाक्य का पता लगाना
सेंटेंसमॉडल वर्ग
यह वर्ग पूर्वनिर्धारित मॉडल का प्रतिनिधित्व करता है जिसका उपयोग दिए गए कच्चे पाठ में वाक्यों का पता लगाने के लिए किया जाता है। यह वर्ग पैकेज का हैopennlp.tools.sentdetect।
इस वर्ग का निर्माणकर्ता स्वीकार करता है InputStream ऑब्जेक्ट डिटेक्टर मॉडल फ़ाइल (एन-सेंड.बिन) की वस्तु।
SentenceDetectorME वर्ग
यह वर्ग पैकेज का है opennlp.tools.sentdetectऔर इसमें कच्चे पाठ को वाक्यों में विभाजित करने के तरीके शामिल हैं। यह वर्ग किसी वाक्य के अंत का संकेत देने के लिए एक स्ट्रिंग में एंड-ऑफ़ेंसेंस वर्णों का मूल्यांकन करने के लिए अधिकतम एन्ट्रोपी मॉडल का उपयोग करता है।
इस वर्ग के महत्वपूर्ण तरीके निम्नलिखित हैं।
| S.No | तरीके और विवरण |
|---|---|
| 1 | sentDetect() इस पद्धति का उपयोग इसके लिए पारित कच्चे पाठ में वाक्यों का पता लगाने के लिए किया जाता है। यह एक स्ट्रिंग चर को एक पैरामीटर के रूप में स्वीकार करता है और एक स्ट्रिंग सरणी देता है जो दिए गए कच्चे पाठ से वाक्य रखता है। |
| 2 | sentPosDetect() इस पद्धति का उपयोग दिए गए पाठ में वाक्यों की स्थिति का पता लगाने के लिए किया जाता है। यह विधि एक स्ट्रिंग चर को स्वीकार करती है, वाक्य का प्रतिनिधित्व करती है और प्रकार की वस्तुओं की एक सरणी लौटाती हैSpan। नाम का वर्ग Span का opennlp.tools.util पैकेज का उपयोग सेट के प्रारंभ और अंत पूर्णांक को संग्रहीत करने के लिए किया जाता है। |
| 3 | getSentenceProbabilities() यह विधि सबसे हाल की कॉल से जुड़ी संभावनाओं को वापस लौटा देती है sentDetect() तरीका। |
tokenization
टोकेनाइज़रमॉडल वर्ग
यह वर्ग पूर्वनिर्धारित मॉडल का प्रतिनिधित्व करता है जिसका उपयोग दिए गए वाक्य को टोकन करने के लिए किया जाता है। यह वर्ग पैकेज का हैopennlp.tools.tokenizer।
इस वर्ग का निर्माणकर्ता स्वीकार करता है InputStream टोकनर मॉडल फ़ाइल (entoken.bin) की वस्तु।
कक्षाओं
टोकेनाइजेशन करने के लिए, ओपनएनएलपी लाइब्रेरी तीन मुख्य कक्षाएं प्रदान करती है। सभी तीन वर्ग नामक इंटरफ़ेस को लागू करते हैंTokenizer।
| S.No | कक्षाएं और विवरण |
|---|---|
| 1 | SimpleTokenizer यह वर्ग वर्ण वर्गों का उपयोग करके दिए गए कच्चे पाठ को टोकन देता है। |
| 2 | WhitespaceTokenizer यह वर्ग दिए गए पाठ को टोकन करने के लिए व्हाट्सएप का उपयोग करता है। |
| 3 | TokenizerME यह वर्ग टोकन को अलग करने के लिए कच्चे पाठ को परिवर्तित करता है। यह अपने निर्णय लेने के लिए अधिकतम एन्ट्रापी का उपयोग करता है। |
इन वर्गों में निम्नलिखित विधियाँ शामिल हैं।
| S.No | तरीके और विवरण |
|---|---|
| 1 | tokenize() इस विधि का उपयोग कच्चे पाठ को टोकन करने के लिए किया जाता है। यह विधि एक स्ट्रिंग चर को पैरामीटर के रूप में स्वीकार करती है, और स्ट्रिंग्स (टोकन) की एक सरणी लौटाती है। |
| 2 | sentPosDetect() इस विधि का उपयोग टोकन की स्थिति या स्पान प्राप्त करने के लिए किया जाता है। यह स्ट्रिंग के रूप में वाक्य (या) कच्चे पाठ को स्वीकार करता है और प्रकार की वस्तुओं की एक सरणी देता हैSpan। |
उपरोक्त दो विधियों के अलावा, TokenizerME कक्षा में है getTokenProbabilities() तरीका।
| S.No | तरीके और विवरण |
|---|---|
| 1 | getTokenProbabilities() इस पद्धति का उपयोग सबसे हाल की कॉल से जुड़ी संभावनाओं को प्राप्त करने के लिए किया जाता है tokenizePos() तरीका। |
NameEntityRecognition
टोकननफाइंडरमॉडल वर्ग
यह वर्ग पूर्वनिर्धारित मॉडल का प्रतिनिधित्व करता है जिसका उपयोग दिए गए वाक्य में नामित संस्थाओं को खोजने के लिए किया जाता है। यह वर्ग पैकेज का हैopennlp.tools.namefind।
इस वर्ग का निर्माणकर्ता स्वीकार करता है InputStream नाम खोजक मॉडल फ़ाइल का उद्देश्य (enner-person.bin)।
NameFinderME वर्ग
वर्ग पैकेज के अंतर्गत आता है opennlp.tools.namefindऔर इसमें NER कार्य करने की विधियाँ सम्मिलित हैं। यह वर्ग दिए गए कच्चे पाठ में नामित संस्थाओं को खोजने के लिए अधिकतम एन्ट्रापी मॉडल का उपयोग करता है।
| S.No | तरीके और विवरण |
|---|---|
| 1 | find() इस विधि का उपयोग कच्चे पाठ में नामों का पता लगाने के लिए किया जाता है। यह एक स्ट्रिंग चर को एक पैरामीटर के रूप में कच्चे पाठ का प्रतिनिधित्व करता है और, प्रकार की वस्तुओं की एक सरणी देता है। |
| 2 | probs() इस विधि का उपयोग अंतिम डिकोड किए गए अनुक्रम की संभावनाओं को प्राप्त करने के लिए किया जाता है। |
भाषण के भाग ढूँढना
POSModel वर्ग
यह वर्ग पूर्वनिर्धारित मॉडल का प्रतिनिधित्व करता है जिसका उपयोग दिए गए वाक्य के बोलने के हिस्सों को टैग करने के लिए किया जाता है। यह वर्ग पैकेज का हैopennlp.tools.postag।
इस वर्ग का निर्माणकर्ता स्वीकार करता है InputStream पोज़-टैगर मॉडल फ़ाइल का उद्देश्य (enpos-maxent.bin)।
POSTaggerME वर्ग
यह वर्ग पैकेज का है opennlp.tools.postagऔर इसका उपयोग दिए गए कच्चे पाठ के भाषण के हिस्सों की भविष्यवाणी करने के लिए किया जाता है। यह अपने निर्णय लेने के लिए अधिकतम एन्ट्रापी का उपयोग करता है।
| S.No | तरीके और विवरण |
|---|---|
| 1 | tag() इस विधि का उपयोग टोकन POS टैग्स के वाक्य को निर्दिष्ट करने के लिए किया जाता है। यह विधि एक पैरामीटर के रूप में टोकन (स्ट्रिंग) के एक सरणी को स्वीकार करती है, और एक टैग (सरणी) लौटाती है। |
| 2 | getSentenceProbabilities() इस पद्धति का उपयोग हाल ही में टैग किए गए वाक्य के प्रत्येक टैग के लिए प्रायिकता प्राप्त करने के लिए किया जाता है। |
वाक्य को पार्स करना
ParserModel वर्ग
यह वर्ग पूर्वनिर्धारित मॉडल का प्रतिनिधित्व करता है जिसका उपयोग दिए गए वाक्य को पार्स करने के लिए किया जाता है। यह वर्ग पैकेज का हैopennlp.tools.parser।
इस वर्ग का निर्माणकर्ता स्वीकार करता है InputStream पार्सर मॉडल फ़ाइल का उद्देश्य (en-parserchunking.bin)।
Parser Factory class
यह वर्ग पैकेज का है opennlp.tools.parser और इसका उपयोग पार्सर बनाने के लिए किया जाता है।
| S.No | तरीके और विवरण |
|---|---|
| 1 | create() यह एक स्थिर विधि है और इसका उपयोग पार्सर ऑब्जेक्ट बनाने के लिए किया जाता है। यह विधि पार्सर मॉडल फ़ाइल के Filestream ऑब्जेक्ट को स्वीकार करती है। |
ParserTool वर्ग
यह वर्ग किसका है opennlp.tools.cmdline.parser पैकेज और, इसका उपयोग सामग्री को पार्स करने के लिए किया जाता है।
| S.No | तरीके और विवरण |
|---|---|
| 1 | parseLine() की यह विधि ParserToolक्लास का उपयोग ओपनएनएलपी में कच्चे पाठ को पार्स करने के लिए किया जाता है। इस विधि को स्वीकार करता है -
|
ठस
ChunkerModel वर्ग
यह वर्ग पूर्वनिर्धारित मॉडल का प्रतिनिधित्व करता है जो एक वाक्य को छोटे खंडों में विभाजित करने के लिए उपयोग किया जाता है। यह वर्ग पैकेज का हैopennlp.tools.chunker।
इस वर्ग का निर्माणकर्ता स्वीकार करता है InputStream की वस्तु chunker मॉडल फ़ाइल (enchunker.bin)।
ChunkerME वर्ग
यह वर्ग नाम के पैकेज का है opennlp.tools.chunker और इसका उपयोग दिए गए वाक्य को छोटे छोटे भाग में विभाजित करने के लिए किया जाता है।
| S.No | तरीके और विवरण |
|---|---|
| 1 | chunk() इस विधि का उपयोग दिए गए वाक्य को छोटे छोटे भाग में विभाजित करने के लिए किया जाता है। यह एक वाक्य के टोकन स्वीकार करता है औरPकला Oच Sमापदंडों के रूप में चोटियों का टैग। |
| 2 | probs() यह विधि अंतिम डिकोड किए गए अनुक्रम की संभावनाओं को वापस करती है। |
एक प्राकृतिक भाषा को संसाधित करते समय, वाक्यों की शुरुआत और अंत तय करना समस्याओं को संबोधित करने में से एक है। इस प्रक्रिया के रूप में जाना जाता हैSentence Boundary Disambiguation (SBD) या बस वाक्य तोड़ने।
दी गई पाठ में वाक्यों का पता लगाने के लिए हम जिन तकनीकों का उपयोग करते हैं, वह पाठ की भाषा पर निर्भर करती है।
जावा का उपयोग करके वाक्य का पता लगाना
हम जावा में दिए गए पाठ में वाक्यों का पता लगा सकते हैं, रेगुलर एक्सप्रेशंस और सरल नियमों का एक सेट।
उदाहरण के लिए, हमें एक अवधि, एक प्रश्न चिह्न, या विस्मयादिबोधक चिह्न दिए गए पाठ में एक वाक्य समाप्त होता है, तो हम वाक्य का उपयोग करके विभाजन को समाप्त कर सकते हैं split() की विधि Stringकक्षा। यहां, हमें स्ट्रिंग प्रारूप में एक नियमित अभिव्यक्ति पास करनी होगी।
निम्नलिखित कार्यक्रम है जो जावा नियमित अभिव्यक्तियों का उपयोग करके दिए गए पाठ में वाक्यों को निर्धारित करता है (split method)। इस प्रोग्राम को नाम के साथ फाइल में सेव करेंSentenceDetection_RE.java।
public class SentenceDetection_RE {
public static void main(String args[]){
String sentence = " Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
String simple = "[.?!]";
String[] splitString = (sentence.split(simple));
for (String string : splitString)
System.out.println(string);
}
}निम्न कमांड का उपयोग करके कमांड प्रॉम्प्ट से सहेजे गए जावा फ़ाइल को संकलित और निष्पादित करें।
javac SentenceDetection_RE.java
java SentenceDetection_REनिष्पादित करने पर, उपरोक्त प्रोग्राम एक पीडीएफ दस्तावेज़ बनाता है जो निम्नलिखित संदेश प्रदर्शित करता है।
Hi
How are you
Welcome to Tutorialspoint
We provide free tutorials on various technologiesओपनएनएलपी का उपयोग करते हुए सजा का पता लगाना
वाक्यों का पता लगाने के लिए, ओपनएनएलपी एक पूर्वनिर्धारित मॉडल, एक फ़ाइल का उपयोग करता है जिसका नाम है en-sent.bin। इस पूर्वनिर्धारित मॉडल को दिए गए कच्चे पाठ में वाक्यों का पता लगाने के लिए प्रशिक्षित किया गया है।
opennlp.tools.sentdetect पैकेज में वर्ग और इंटरफेस होते हैं जिनका उपयोग वाक्य का पता लगाने के कार्य को करने के लिए किया जाता है।
OpenNLP लाइब्रेरी का उपयोग करते हुए एक वाक्य का पता लगाने के लिए, आपको निम्न की आवश्यकता है -
लोड करें en-sent.bin का उपयोग कर मॉडल SentenceModel कक्षा
झटपट SentenceDetectorME कक्षा।
का उपयोग कर वाक्यों का पता लगाएं sentDetect() इस वर्ग की विधि।
एक प्रोग्राम लिखने के लिए निम्नलिखित चरणों का पालन करना चाहिए जो दिए गए कच्चे पाठ से वाक्यों का पता लगाता है।
चरण 1: मॉडल लोड हो रहा है
वाक्य का पता लगाने के लिए मॉडल को नामित वर्ग द्वारा दर्शाया गया है SentenceModel, जो पैकेज के अंतर्गत आता है opennlp.tools.sentdetect।
एक वाक्य पहचान मॉडल लोड करने के लिए -
बनाओ InputStream मॉडल का उद्देश्य (FileInputStream झटपट करें और इसके निर्माणकर्ता को स्ट्रिंग प्रारूप में मॉडल का पथ पास करें)।
झटपट SentenceModel कक्षा और पास InputStream (मॉडल) इसके निर्माता के लिए एक पैरामीटर के रूप में निम्न कोड ब्लॉक में दिखाया गया है -
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/ensent.bin");
SentenceModel model = new SentenceModel(inputStream);चरण 2: SentenceDetectorME वर्ग को त्वरित करना
SentenceDetectorME पैकेज की कक्षा opennlp.tools.sentdetectकच्चे पाठ को वाक्यों में विभाजित करने के तरीके शामिल हैं। यह वर्ग अधिकतम एंट्रोपी मॉडल का उपयोग करके एक वाक्य के अंत का संकेत देने के लिए एक स्ट्रिंग में अंत-वाक्य वाक्य का मूल्यांकन करने के लिए उपयोग करता है।
इस वर्ग को त्वरित करें और पिछले चरण में बनाई गई मॉडल ऑब्जेक्ट को पास करें, जैसा कि नीचे दिखाया गया है।
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);चरण 3: वाक्य का पता लगाना
sentDetect() की विधि SentenceDetectorMEकक्षा का उपयोग इसके लिए पारित कच्चे पाठ में वाक्यों का पता लगाने के लिए किया जाता है। यह विधि एक स्ट्रिंग चर को एक पैरामीटर के रूप में स्वीकार करती है।
इस विधि में वाक्य के स्ट्रिंग प्रारूप को पास करके इस विधि को लागू करें।
//Detecting the sentence
String sentences[] = detector.sentDetect(sentence);Example
निम्नलिखित कार्यक्रम है जो एक दिए गए कच्चे पाठ में वाक्यों का पता लगाता है। इस प्रोग्राम को नाम वाली फ़ाइल में सेव करेंSentenceDetectionME.java।
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
public class SentenceDetectionME {
public static void main(String args[]) throws Exception {
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);
//Detecting the sentence
String sentences[] = detector.sentDetect(sentence);
//Printing the sentences
for(String sent : sentences)
System.out.println(sent);
}
}निम्न आदेशों का उपयोग करके कमांड प्रॉम्प्ट से सहेजी गई जावा फ़ाइल को संकलित करें और निष्पादित करें -
javac SentenceDetectorME.java
java SentenceDetectorMEनिष्पादित करने पर, उपरोक्त कार्यक्रम दिए गए स्ट्रिंग को पढ़ता है और इसमें वाक्यों का पता लगाता है और निम्नलिखित आउटपुट को प्रदर्शित करता है।
Hi. How are you?
Welcome to Tutorialspoint.
We provide free tutorials on various technologiesवाक्यों की स्थिति का पता लगाना
हम सेंटपोसडेक्ट () विधि के प्रयोग से वाक्यों की स्थिति का भी पता लगा सकते हैं SentenceDetectorME class।
एक प्रोग्राम लिखने के लिए निम्नलिखित चरणों का पालन करना चाहिए जो दिए गए कच्चे पाठ से वाक्यों की स्थिति का पता लगाता है।
चरण 1: मॉडल लोड हो रहा है
वाक्य का पता लगाने के लिए मॉडल को नामित वर्ग द्वारा दर्शाया गया है SentenceModel, जो पैकेज के अंतर्गत आता है opennlp.tools.sentdetect।
एक वाक्य पहचान मॉडल लोड करने के लिए -
बनाओ InputStream मॉडल का उद्देश्य (FileInputStream झटपट करें और इसके निर्माणकर्ता को स्ट्रिंग प्रारूप में मॉडल का पथ पास करें)।
झटपट SentenceModel कक्षा और पास InputStream (ऑब्जेक्ट) इसके निर्माता के लिए एक पैरामीटर के रूप में, जैसा कि निम्नलिखित कोड ब्लॉक में दिखाया गया है।
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);चरण 2: SentenceDetectorME वर्ग को त्वरित करना
SentenceDetectorME पैकेज की कक्षा opennlp.tools.sentdetectकच्चे पाठ को वाक्यों में विभाजित करने के तरीके शामिल हैं। यह वर्ग अधिकतम एंट्रोपी मॉडल का उपयोग करके एक वाक्य के अंत का संकेत देने के लिए एक स्ट्रिंग में अंत-वाक्य वाक्य का मूल्यांकन करने के लिए उपयोग करता है।
इस वर्ग को तुरंत लिखें और पिछले चरण में बनाए गए मॉडल ऑब्जेक्ट को पास करें।
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);चरण 3: वाक्य की स्थिति का पता लगाना
sentPosDetect() की विधि SentenceDetectorMEकक्षा का उपयोग उसमें दिए गए कच्चे पाठ में वाक्यों की स्थिति का पता लगाने के लिए किया जाता है। यह विधि एक स्ट्रिंग चर को एक पैरामीटर के रूप में स्वीकार करती है।
इस विधि के पैरामीटर के रूप में वाक्य के स्ट्रिंग प्रारूप को पास करके इस विधि को लागू करें।
//Detecting the position of the sentences in the paragraph
Span[] spans = detector.sentPosDetect(sentence);चरण 4: वाक्यों की स्पैन प्रिंटिंग
sentPosDetect() की विधि SentenceDetectorME वर्ग प्रकार की वस्तुओं की एक सरणी देता है Span। स्पान नाम की कक्षाopennlp.tools.util पैकेज का उपयोग सेट के प्रारंभ और अंत पूर्णांक को संग्रहीत करने के लिए किया जाता है।
आप द्वारा दिए गए स्पैन को स्टोर कर सकते हैं sentPosDetect() स्पैन सरणी में विधि और उन्हें प्रिंट करें, जैसा कि निम्नलिखित कोड ब्लॉक में दिखाया गया है।
//Printing the sentences and their spans of a sentence
for (Span span : spans)
System.out.println(paragraph.substring(span);Example
निम्नलिखित कार्यक्रम है जो दिए गए कच्चे पाठ में वाक्यों का पता लगाता है। इस प्रोग्राम को नाम वाली फ़ाइल में सेव करेंSentenceDetectionME.java।
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
import opennlp.tools.util.Span;
public class SentencePosDetection {
public static void main(String args[]) throws Exception {
String paragraph = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);
//Detecting the position of the sentences in the raw text
Span spans[] = detector.sentPosDetect(paragraph);
//Printing the spans of the sentences in the paragraph
for (Span span : spans)
System.out.println(span);
}
}निम्न आदेशों का उपयोग करके कमांड प्रॉम्प्ट से सहेजी गई जावा फ़ाइल को संकलित करें और निष्पादित करें -
javac SentencePosDetection.java
java SentencePosDetectionनिष्पादित करने पर, उपरोक्त कार्यक्रम दिए गए स्ट्रिंग को पढ़ता है और इसमें वाक्यों का पता लगाता है और निम्नलिखित आउटपुट को प्रदर्शित करता है।
[0..16)
[17..43)
[44..93)उनके पदों के साथ वाक्य
substring() स्ट्रिंग कक्षा की विधि स्वीकार करती है begin और यह end offsetsऔर संबंधित स्ट्रिंग लौटाता है। हम इस पद्धति का उपयोग वाक्यों और उनके स्पैन (स्थिति) को एक साथ प्रिंट करने के लिए कर सकते हैं, जैसा कि निम्नलिखित कोड ब्लॉक में दिखाया गया है।
for (Span span : spans)
System.out.println(sen.substring(span.getStart(), span.getEnd())+" "+ span);नीचे दिए गए कच्चे पाठ से वाक्यों का पता लगाने और उन्हें उनके पदों के साथ प्रदर्शित करने का कार्यक्रम निम्नलिखित है। इस प्रोग्राम को नाम वाली फ़ाइल में सहेजेंSentencesAndPosDetection.java।
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
import opennlp.tools.util.Span;
public class SentencesAndPosDetection {
public static void main(String args[]) throws Exception {
String sen = "Hi. How are you? Welcome to Tutorialspoint."
+ " We provide free tutorials on various technologies";
//Loading a sentence model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);
//Detecting the position of the sentences in the paragraph
Span[] spans = detector.sentPosDetect(sen);
//Printing the sentences and their spans of a paragraph
for (Span span : spans)
System.out.println(sen.substring(span.getStart(), span.getEnd())+" "+ span);
}
}निम्न आदेशों का उपयोग करके कमांड प्रॉम्प्ट से सहेजी गई जावा फ़ाइल को संकलित करें और निष्पादित करें -
javac SentencesAndPosDetection.java
java SentencesAndPosDetectionनिष्पादित करने पर, उपरोक्त कार्यक्रम दिए गए स्ट्रिंग को पढ़ता है और उनके पदों के साथ वाक्यों का पता लगाता है और निम्नलिखित आउटपुट प्रदर्शित करता है।
Hi. How are you? [0..16)
Welcome to Tutorialspoint. [17..43)
We provide free tutorials on various technologies [44..93)वाक्य संभावना जांच
getSentenceProbabilities() की विधि SentenceDetectorME क्लास सबसे हाल की कॉल से जुड़ी संभावनाओं को रिटर्नडेट () विधि में लौटाता है।
//Getting the probabilities of the last decoded sequence
double[] probs = detector.getSentenceProbabilities();कॉलडिट के साथ जुड़ी संभावनाएं () विधि को प्रिंट करने का कार्यक्रम निम्नलिखित है। इस प्रोग्राम को नाम के साथ फाइल में सेव करेंSentenceDetectionMEProbs.java।
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
public class SentenceDetectionMEProbs {
public static void main(String args[]) throws Exception {
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);
//Detecting the sentence
String sentences[] = detector.sentDetect(sentence);
//Printing the sentences
for(String sent : sentences)
System.out.println(sent);
//Getting the probabilities of the last decoded sequence
double[] probs = detector.getSentenceProbabilities();
System.out.println(" ");
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}निम्न आदेशों का उपयोग करके कमांड प्रॉम्प्ट से सहेजी गई जावा फ़ाइल को संकलित करें और निष्पादित करें -
javac SentenceDetectionMEProbs.java
java SentenceDetectionMEProbsनिष्पादित करने पर, उपरोक्त कार्यक्रम दिए गए स्ट्रिंग को पढ़ता है और वाक्यों का पता लगाता है और उन्हें प्रिंट करता है। इसके अलावा, यह सबसे हाल ही की कॉल से जुड़ी संभावनाओं को सेंटडक्ट () विधि में भी लौटाता है, जैसा कि नीचे दिखाया गया है।
Hi. How are you?
Welcome to Tutorialspoint.
We provide free tutorials on various technologies
0.9240246995179983
0.9957680129995953
1.0दिए गए वाक्य को छोटे भागों (टोकन) में काटने की प्रक्रिया के रूप में जाना जाता है tokenization। सामान्य तौर पर, दिए गए कच्चे पाठ को सीमांकक (ज्यादातर व्हाट्सएप) के एक सेट के आधार पर टोकन किया जाता है।
टोकेनाइजेशन का उपयोग वर्तनी-जांच, प्रोसेसिंग खोजों, भाषण के कुछ हिस्सों की पहचान, वाक्य का पता लगाने, दस्तावेजों के दस्तावेज वर्गीकरण आदि जैसे कार्यों में किया जाता है।
ओपनएनएलपी का उपयोग कर टोकन
opennlp.tools.tokenize पैकेज में वे कक्षाएं और इंटरफेस होते हैं जिनका उपयोग टोकन प्रदर्शन करने के लिए किया जाता है।
दिए गए वाक्यों को सरल अंशों में बदलने के लिए, OpenNLP लाइब्रेरी तीन अलग-अलग कक्षाएं प्रदान करती है -
SimpleTokenizer - यह वर्ग चरित्र वर्गों का उपयोग करके दिए गए कच्चे पाठ को टोकन देता है।
WhitespaceTokenizer - यह वर्ग दिए गए पाठ को टोकन करने के लिए व्हाट्सएप का उपयोग करता है।
TokenizerME- यह वर्ग कच्चे पाठ को अलग टोकन में परिवर्तित करता है। यह अपने निर्णय लेने के लिए अधिकतम एन्ट्रापी का उपयोग करता है।
SimpleTokenizer
का उपयोग कर एक वाक्य tokenize SimpleTokenizer वर्ग, आप की जरूरत है -
संबंधित वर्ग की एक वस्तु बनाएं।
का उपयोग करके वाक्य को टोकन दें tokenize() तरीका।
टोकन प्रिंट करें।
प्रोग्राम को लिखने के लिए निम्नलिखित चरणों का पालन करना चाहिए जो दिए गए कच्चे पाठ को टोकन देता है।
Step 1 - संबंधित वर्ग को त्वरित करना
दोनों वर्गों में, उन्हें तुरंत तैयार करने के लिए कोई रचनाकार उपलब्ध नहीं हैं। इसलिए, हमें स्थिर चर का उपयोग करके इन वर्गों की वस्तुओं को बनाने की आवश्यकता हैINSTANCE।
SimpleTokenizer tokenizer = SimpleTokenizer.INSTANCE;Step 2 - वाक्यों को टोकें
इन दोनों वर्गों में एक विधि कहा जाता है tokenize()। यह विधि स्ट्रिंग प्रारूप में एक कच्चे पाठ को स्वीकार करती है। आह्वान करने पर, यह दिए गए स्ट्रिंग को टोकन देता है और स्ट्रिंग्स (टोकन) की एक सरणी देता है।
का उपयोग करके वाक्य को टोकन दें tokenizer() नीचे दिखाए अनुसार विधि।
//Tokenizing the given sentence
String tokens[] = tokenizer.tokenize(sentence);Step 3 - टोकन प्रिंट करें
वाक्य को टोकन करने के बाद, आप टोकन का उपयोग करके प्रिंट कर सकते हैं for loop, जैसा की नीचे दिखाया गया।
//Printing the tokens
for(String token : tokens)
System.out.println(token);Example
निम्नलिखित प्रोग्राम है जो SimpleTokenizer वर्ग का उपयोग करके दिए गए वाक्य को टोकन देता है। इस प्रोग्राम को नाम के साथ फाइल में सेव करेंSimpleTokenizerExample.java।
import opennlp.tools.tokenize.SimpleTokenizer;
public class SimpleTokenizerExample {
public static void main(String args[]){
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Instantiating SimpleTokenizer class
SimpleTokenizer simpleTokenizer = SimpleTokenizer.INSTANCE;
//Tokenizing the given sentence
String tokens[] = simpleTokenizer.tokenize(sentence);
//Printing the tokens
for(String token : tokens) {
System.out.println(token);
}
}
}निम्न आदेशों का उपयोग करके कमांड प्रॉम्प्ट से सहेजी गई जावा फ़ाइल को संकलित करें और निष्पादित करें -
javac SimpleTokenizerExample.java
java SimpleTokenizerExampleनिष्पादित करने पर, उपरोक्त कार्यक्रम दिए गए स्ट्रिंग (कच्चे पाठ) को पढ़ता है, इसे टोकन करता है, और निम्नलिखित आउटपुट प्रदर्शित करता है -
Hi
.
How
are
you
?
Welcome
to
Tutorialspoint
.
We
provide
free
tutorials
on
various
technologiesWhitespaceTokenizer
का उपयोग कर एक वाक्य tokenize WhitespaceTokenizer वर्ग, आप की जरूरत है -
संबंधित वर्ग की एक वस्तु बनाएं।
का उपयोग करके वाक्य को टोकन दें tokenize() तरीका।
टोकन प्रिंट करें।
प्रोग्राम को लिखने के लिए निम्नलिखित चरणों का पालन करना चाहिए जो दिए गए कच्चे पाठ को टोकन देता है।
Step 1 - संबंधित वर्ग को त्वरित करना
दोनों वर्गों में, उन्हें तुरंत तैयार करने के लिए कोई रचनाकार उपलब्ध नहीं हैं। इसलिए, हमें स्थिर चर का उपयोग करके इन वर्गों की वस्तुओं को बनाने की आवश्यकता हैINSTANCE।
WhitespaceTokenizer tokenizer = WhitespaceTokenizer.INSTANCE;Step 2 - वाक्यों को टोकें
इन दोनों वर्गों में एक विधि कहा जाता है tokenize()। यह विधि स्ट्रिंग प्रारूप में एक कच्चे पाठ को स्वीकार करती है। आह्वान करने पर, यह दिए गए स्ट्रिंग को टोकन देता है और स्ट्रिंग्स (टोकन) की एक सरणी देता है।
का उपयोग करके वाक्य को टोकन दें tokenizer() नीचे दिखाए अनुसार विधि।
//Tokenizing the given sentence
String tokens[] = tokenizer.tokenize(sentence);Step 3 - टोकन प्रिंट करें
वाक्य को टोकन करने के बाद, आप टोकन का उपयोग करके प्रिंट कर सकते हैं for loop, जैसा की नीचे दिखाया गया।
//Printing the tokens
for(String token : tokens)
System.out.println(token);Example
निम्नलिखित प्रोग्राम है जो दिए गए वाक्य का उपयोग करके टोकन देता है WhitespaceTokenizerकक्षा। इस प्रोग्राम को नाम के साथ फाइल में सेव करेंWhitespaceTokenizerExample.java।
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class WhitespaceTokenizerExample {
public static void main(String args[]){
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Instantiating whitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer = WhitespaceTokenizer.INSTANCE;
//Tokenizing the given paragraph
String tokens[] = whitespaceTokenizer.tokenize(sentence);
//Printing the tokens
for(String token : tokens)
System.out.println(token);
}
}निम्न आदेशों का उपयोग करके कमांड प्रॉम्प्ट से सहेजी गई जावा फ़ाइल को संकलित करें और निष्पादित करें -
javac WhitespaceTokenizerExample.java
java WhitespaceTokenizerExampleनिष्पादित करने पर, उपरोक्त कार्यक्रम दिए गए स्ट्रिंग (कच्चे पाठ) को पढ़ता है, इसे टोकन करता है, और निम्न आउटपुट को प्रदर्शित करता है।
Hi.
How
are
you?
Welcome
to
Tutorialspoint.
We
provide
free
tutorials
on
various
technologiesटोकनिनेयर वर्ग
ओपनएनएलपी भी पूर्वनिर्धारित मॉडल का उपयोग करता है, एक फ़ाइल जिसका नाम de-token.bin है, वाक्यों को टोकने के लिए। यह दिए गए कच्चे पाठ में वाक्यों को टोकन करने के लिए प्रशिक्षित किया जाता है।
TokenizerME की कक्षा opennlp.tools.tokenizerपैकेज का उपयोग इस मॉडल को लोड करने के लिए किया जाता है, और ओपनएनएलपी लाइब्रेरी का उपयोग करके दिए गए कच्चे पाठ को टोकन दिया जाता है। ऐसा करने के लिए, आपको यह करने की आवश्यकता है -
लोड करें en-token.bin का उपयोग कर मॉडल TokenizerModel कक्षा।
झटपट TokenizerME कक्षा।
का उपयोग कर वाक्यों को टोकन tokenize() इस वर्ग की विधि।
प्रोग्राम को लिखने के लिए निम्नलिखित चरणों का पालन करना चाहिए जो दिए गए कच्चे पाठ से वाक्यों का उपयोग करता है TokenizerME कक्षा।
Step 1 - मॉडल लोड हो रहा है
टोकेनाइजेशन का मॉडल नामित वर्ग द्वारा दर्शाया गया है TokenizerModel, जो पैकेज के अंतर्गत आता है opennlp.tools.tokenize।
एक टोकन मॉडल लोड करने के लिए -
बनाओ InputStream मॉडल का उद्देश्य (FileInputStream झटपट करें और इसके निर्माणकर्ता को स्ट्रिंग प्रारूप में मॉडल का पथ पास करें)।
झटपट TokenizerModel कक्षा और पास InputStream (ऑब्जेक्ट) इसके निर्माता के लिए एक पैरामीटर के रूप में, जैसा कि निम्नलिखित कोड ब्लॉक में दिखाया गया है।
//Loading the Tokenizer model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);Step 2 - टोकेनाइज़रईएम क्लास को इंस्टेंट करना
TokenizerME पैकेज की कक्षा opennlp.tools.tokenizeकच्चे पाठ को छोटे भागों (टोकन) में काटने के तरीके शामिल हैं। यह अपने निर्णय लेने के लिए अधिकतम एन्ट्रापी का उपयोग करता है।
इस वर्ग को तुरंत लिखें और पिछले चरण में बनाई गई मॉडल ऑब्जेक्ट को नीचे दिखाए अनुसार पास करें।
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);Step 3 - सजा को टोकन देना
tokenize() की विधि TokenizerMEक्लास का उपयोग इसके लिए पास किए गए कच्चे पाठ को टोकन देने के लिए किया जाता है। यह विधि एक स्ट्रिंग चर को पैरामीटर के रूप में स्वीकार करती है, और स्ट्रिंग्स (टोकन) की एक सरणी लौटाती है।
इस विधि के वाक्य के स्ट्रिंग प्रारूप को पास करके इस विधि को लागू करें, निम्नानुसार।
//Tokenizing the given raw text
String tokens[] = tokenizer.tokenize(paragraph);Example
निम्नलिखित कार्यक्रम है जो दिए गए कच्चे पाठ को टोकन देता है। इस प्रोग्राम को नाम के साथ फाइल में सेव करेंTokenizerMEExample.java।
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
public class TokenizerMEExample {
public static void main(String args[]) throws Exception{
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Loading the Tokenizer model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Tokenizing the given raw text
String tokens[] = tokenizer.tokenize(sentence);
//Printing the tokens
for (String a : tokens)
System.out.println(a);
}
}निम्न आदेशों का उपयोग करके कमांड प्रॉम्प्ट से सहेजी गई जावा फ़ाइल को संकलित करें और निष्पादित करें -
javac TokenizerMEExample.java
java TokenizerMEExampleनिष्पादित करने पर, उपरोक्त कार्यक्रम दिए गए स्ट्रिंग को पढ़ता है और इसमें वाक्यों का पता लगाता है और निम्नलिखित आउटपुट प्रदर्शित करता है -
Hi
.
How
are
you
?
Welcome
to
Tutorialspoint
.
We
provide
free
tutorials
on
various
technologieटोकन के पदों को पुनः प्राप्त करना
हम भी स्थिति प्राप्त कर सकते हैं या spans का उपयोग कर टोकन की tokenizePos()तरीका। यह पैकेज के टोकनाइज़र इंटरफ़ेस की विधि हैopennlp.tools.tokenize। चूंकि सभी (तीन) टोकनाइज़र कक्षाएं इस इंटरफ़ेस को लागू करती हैं, आप उन सभी में यह विधि पा सकते हैं।
यह विधि एक स्ट्रिंग के रूप में वाक्य या कच्चे पाठ को स्वीकार करती है और प्रकार की वस्तुओं की एक सरणी लौटाती है Span।
आप टोकन का उपयोग करके स्थिति प्राप्त कर सकते हैं tokenizePos() विधि, इस प्रकार है -
//Retrieving the tokens
tokenizer.tokenizePos(sentence);पदों की छपाई (स्पैन)
नाम का वर्ग Span का opennlp.tools.util पैकेज का उपयोग सेट के प्रारंभ और अंत पूर्णांक को संग्रहीत करने के लिए किया जाता है।
आप द्वारा दिए गए स्पैन को स्टोर कर सकते हैं tokenizePos() स्पैन सरणी में विधि और उन्हें प्रिंट करें, जैसा कि निम्नलिखित कोड ब्लॉक में दिखाया गया है।
//Retrieving the tokens
Span[] tokens = tokenizer.tokenizePos(sentence);
//Printing the spans of tokens
for( Span token : tokens)
System.out.println(token);एक साथ मुद्रण टोकन और उनकी स्थिति
substring() स्ट्रिंग कक्षा की विधि स्वीकार करती है begin और यह endऑफसेट और संबंधित स्ट्रिंग लौटाता है। हम इस विधि का उपयोग टोकन और उनके स्पैन (स्थिति) को एक साथ प्रिंट करने के लिए कर सकते हैं, जैसा कि निम्नलिखित कोड ब्लॉक में दिखाया गया है।
//Printing the spans of tokens
for(Span token : tokens)
System.out.println(token +" "+sent.substring(token.getStart(), token.getEnd()));Example(SimpleTokenizer)
निम्नलिखित प्रोग्राम है जो कच्चे पाठ के टोकन स्पैन को पुनः प्राप्त करता है SimpleTokenizerकक्षा। यह उनके पदों के साथ-साथ टोकन भी प्रिंट करता है। इस प्रोग्राम को नाम वाली फ़ाइल में सेव करेंSimpleTokenizerSpans.java।
import opennlp.tools.tokenize.SimpleTokenizer;
import opennlp.tools.util.Span;
public class SimpleTokenizerSpans {
public static void main(String args[]){
String sent = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Instantiating SimpleTokenizer class
SimpleTokenizer simpleTokenizer = SimpleTokenizer.INSTANCE;
//Retrieving the boundaries of the tokens
Span[] tokens = simpleTokenizer.tokenizePos(sent);
//Printing the spans of tokens
for( Span token : tokens)
System.out.println(token +" "+sent.substring(token.getStart(), token.getEnd()));
}
}निम्न आदेशों का उपयोग करके कमांड प्रॉम्प्ट से सहेजी गई जावा फ़ाइल को संकलित करें और निष्पादित करें -
javac SimpleTokenizerSpans.java
java SimpleTokenizerSpansनिष्पादित करने पर, उपरोक्त कार्यक्रम दिए गए स्ट्रिंग (कच्चे पाठ) को पढ़ता है, इसे टोकन करता है, और निम्नलिखित आउटपुट प्रदर्शित करता है -
[0..2) Hi
[2..3) .
[4..7) How
[8..11) are
[12..15) you
[15..16) ?
[17..24) Welcome
[25..27) to
[28..42) Tutorialspoint
[42..43) .
[44..46) We
[47..54) provide
[55..59) free
[60..69) tutorials
[70..72) on
[73..80) various
[81..93) technologiesExample (WhitespaceTokenizer)
निम्नलिखित प्रोग्राम है जो कच्चे पाठ के टोकन स्पैन को पुनः प्राप्त करता है WhitespaceTokenizerकक्षा। यह उनके पदों के साथ-साथ टोकन भी प्रिंट करता है। इस प्रोग्राम को नाम के साथ फाइल में सेव करेंWhitespaceTokenizerSpans.java।
import opennlp.tools.tokenize.WhitespaceTokenizer;
import opennlp.tools.util.Span;
public class WhitespaceTokenizerSpans {
public static void main(String args[]){
String sent = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Instantiating SimpleTokenizer class
WhitespaceTokenizer whitespaceTokenizer = WhitespaceTokenizer.INSTANCE;
//Retrieving the tokens
Span[] tokens = whitespaceTokenizer.tokenizePos(sent);
//Printing the spans of tokens
for( Span token : tokens)
System.out.println(token +"
"+sent.substring(token.getStart(), token.getEnd()));
}
}निम्न कमांड का उपयोग करके कमांड प्रॉम्प्ट से सहेजे गए जावा फ़ाइल को संकलित और निष्पादित करें
javac WhitespaceTokenizerSpans.java
java WhitespaceTokenizerSpansनिष्पादित करने पर, उपरोक्त कार्यक्रम दिए गए स्ट्रिंग (कच्चे पाठ) को पढ़ता है, इसे टोकन करता है, और निम्न आउटपुट को प्रदर्शित करता है।
[0..3) Hi.
[4..7) How
[8..11) are
[12..16) you?
[17..24) Welcome
[25..27) to
[28..43) Tutorialspoint.
[44..46) We
[47..54) provide
[55..59) free
[60..69) tutorials
[70..72) on
[73..80) various
[81..93) technologiesExample (TokenizerME)
निम्नलिखित प्रोग्राम है जो कच्चे पाठ के टोकन स्पैन को पुनः प्राप्त करता है TokenizerMEकक्षा। यह उनके पदों के साथ-साथ टोकन भी प्रिंट करता है। इस प्रोग्राम को नाम के साथ फाइल में सेव करेंTokenizerMESpans.java।
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class TokenizerMESpans {
public static void main(String args[]) throws Exception{
String sent = "Hello John how are you welcome to Tutorialspoint";
//Loading the Tokenizer model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Retrieving the positions of the tokens
Span tokens[] = tokenizer.tokenizePos(sent);
//Printing the spans of tokens
for(Span token : tokens)
System.out.println(token +" "+sent.substring(token.getStart(), token.getEnd()));
}
}निम्न आदेशों का उपयोग करके कमांड प्रॉम्प्ट से सहेजी गई जावा फ़ाइल को संकलित करें और निष्पादित करें -
javac TokenizerMESpans.java
java TokenizerMESpansनिष्पादित करने पर, उपरोक्त कार्यक्रम दिए गए स्ट्रिंग (कच्चे पाठ) को पढ़ता है, इसे टोकन करता है, और निम्नलिखित आउटपुट प्रदर्शित करता है -
[0..5) Hello
[6..10) John
[11..14) how
[15..18) are
[19..22) you
[23..30) welcome
[31..33) to
[34..48) Tutorialspointटोकनर संभावना
टोकनएपएमई क्लास की getTokenProbabilities () पद्धति का उपयोग टोकनपेपोस () पद्धति के लिए सबसे हालिया कॉल से जुड़ी संभावनाओं को प्राप्त करने के लिए किया जाता है।
//Getting the probabilities of the recent calls to tokenizePos() method
double[] probs = detector.getSentenceProbabilities();इसके बाद tokenizePos () पद्धति से कॉल से जुड़ी संभावनाओं को प्रिंट करने का कार्यक्रम है। इस प्रोग्राम को नाम के साथ फाइल में सेव करेंTokenizerMEProbs.java।
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class TokenizerMEProbs {
public static void main(String args[]) throws Exception{
String sent = "Hello John how are you welcome to Tutorialspoint";
//Loading the Tokenizer model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Retrieving the positions of the tokens
Span tokens[] = tokenizer.tokenizePos(sent);
//Getting the probabilities of the recent calls to tokenizePos() method
double[] probs = tokenizer.getTokenProbabilities();
//Printing the spans of tokens
for(Span token : tokens)
System.out.println(token +" "+sent.substring(token.getStart(), token.getEnd()));
System.out.println(" ");
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}निम्न आदेशों का उपयोग करके कमांड प्रॉम्प्ट से सहेजी गई जावा फ़ाइल को संकलित करें और निष्पादित करें -
javac TokenizerMEProbs.java
java TokenizerMEProbsनिष्पादित करने पर, उपरोक्त कार्यक्रम दिए गए स्ट्रिंग को पढ़ता है और वाक्यों को टोकता है और उन्हें प्रिंट करता है। इसके अलावा, यह टोकेनाइजरपोस () पद्धति के लिए सबसे हालिया कॉल से जुड़ी संभावनाओं को भी लौटाता है।
[0..5) Hello
[6..10) John
[11..14) how
[15..18) are
[19..22) you
[23..30) welcome
[31..33) to
[34..48) Tutorialspoint
1.0
1.0
1.0
1.0
1.0
1.0
1.0
1.0किसी दिए गए पाठ से नाम, लोगों, स्थानों और अन्य संस्थाओं को खोजने की प्रक्रिया के रूप में जाना जाता है Nपरिवेश क्षेत्र amed Entity Rपारिस्थितिकी (एनईआर)। इस अध्याय में, हम चर्चा करेंगे कि ओपनएनएलपी लाइब्रेरी का उपयोग करके जावा प्रोग्राम के माध्यम से एनईआर को कैसे आगे बढ़ाया जाए।
नामित एनएलपी का उपयोग कर एंटिटी मान्यता
विभिन्न एनईआर कार्यों को करने के लिए, ओपनएनएलपी अलग-अलग पूर्वनिर्धारित मॉडल का उपयोग करता है, जैसे- en-nerdate.bn, en-ner-location.bin, en-ner-Organization.bin, en-ner-person.bin और en-ner-time। बिन। ये सभी फाइलें पूर्वनिर्धारित मॉडल हैं जिन्हें किसी दिए गए कच्चे पाठ में संबंधित संस्थाओं का पता लगाने के लिए प्रशिक्षित किया जाता है।
opennlp.tools.namefindपैकेज में वे वर्ग और इंटरफ़ेस होते हैं जिनका उपयोग NER कार्य करने के लिए किया जाता है। ओपनएनआरपी लाइब्रेरी का उपयोग करके एनईआर कार्य करने के लिए, आपको निम्न की आवश्यकता है -
संबंधित मॉडल का उपयोग करके लोड करें TokenNameFinderModel कक्षा।
झटपट NameFinder कक्षा।
नाम खोजें और उन्हें प्रिंट करें।
एक प्रोग्राम लिखने के लिए निम्नलिखित चरणों का पालन करना चाहिए जो किसी दिए गए कच्चे पाठ से नाम संस्थाओं का पता लगाता है।
चरण 1: मॉडल लोड हो रहा है
वाक्य का पता लगाने के लिए मॉडल को नामित वर्ग द्वारा दर्शाया गया है TokenNameFinderModel, जो पैकेज के अंतर्गत आता है opennlp.tools.namefind।
एक एनईआर मॉडल लोड करने के लिए -
बनाओ InputStream मॉडल का उद्देश्य (FileInputStream झटपट करें और इसके निर्माण में स्ट्रिंग प्रारूप में उपयुक्त एनईआर मॉडल का मार्ग पास करें)।
झटपट TokenNameFinderModel कक्षा और पास InputStream (ऑब्जेक्ट) इसके निर्माता के लिए एक पैरामीटर के रूप में, जैसा कि निम्नलिखित कोड ब्लॉक में दिखाया गया है।
//Loading the NER-person model
InputStream inputStreamNameFinder = new FileInputStream(".../en-nerperson.bin");
TokenNameFinderModel model = new TokenNameFinderModel(inputStreamNameFinder);चरण 2: NameFinderME वर्ग को त्वरित करना
NameFinderME पैकेज की कक्षा opennlp.tools.namefindएनईआर कार्यों को करने के लिए तरीके हैं। यह वर्ग दिए गए कच्चे पाठ में नामित संस्थाओं को खोजने के लिए अधिकतम एंट्रोपी मॉडल का उपयोग करता है।
इस वर्ग को तुरंत लिखें और पिछले चरण में बनाए गए मॉडल ऑब्जेक्ट को नीचे दिखाए गए अनुसार दर्ज करें -
//Instantiating the NameFinderME class
NameFinderME nameFinder = new NameFinderME(model);चरण 3: वाक्य में नाम ढूँढना
find() की विधि NameFinderMEकक्षा का उपयोग इसके लिए पारित कच्चे पाठ में नामों का पता लगाने के लिए किया जाता है। यह विधि एक स्ट्रिंग चर को एक पैरामीटर के रूप में स्वीकार करती है।
इस विधि में वाक्य के स्ट्रिंग प्रारूप को पास करके इस विधि को लागू करें।
//Finding the names in the sentence
Span nameSpans[] = nameFinder.find(sentence);चरण 4: वाक्य में नामों के स्पैन को प्रिंट करना
find() की विधि NameFinderMEवर्ग प्रकार की वस्तुओं की एक सरणी देता है। स्पान नाम की कक्षाopennlp.tools.util पैकेज का उपयोग स्टोर करने के लिए किया जाता है start तथा end सेट का पूर्णांक।
आप द्वारा दिए गए स्पैन को स्टोर कर सकते हैं find() स्पैन सरणी में विधि और उन्हें प्रिंट करें, जैसा कि निम्नलिखित कोड ब्लॉक में दिखाया गया है।
//Printing the sentences and their spans of a sentence
for (Span span : spans)
System.out.println(paragraph.substring(span);NER Example
निम्नलिखित कार्यक्रम है जो दिए गए वाक्य को पढ़ता है और इसमें व्यक्तियों के नामों के विस्तार को पहचानता है। इस प्रोग्राम को नाम के साथ फाइल में सेव करेंNameFinderME_Example.java।
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.namefind.NameFinderME;
import opennlp.tools.namefind.TokenNameFinderModel;
import opennlp.tools.util.Span;
public class NameFinderME_Example {
public static void main(String args[]) throws Exception{
/Loading the NER - Person model InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-ner-person.bin");
TokenNameFinderModel model = new TokenNameFinderModel(inputStream);
//Instantiating the NameFinder class
NameFinderME nameFinder = new NameFinderME(model);
//Getting the sentence in the form of String array
String [] sentence = new String[]{
"Mike",
"and",
"Smith",
"are",
"good",
"friends"
};
//Finding the names in the sentence
Span nameSpans[] = nameFinder.find(sentence);
//Printing the spans of the names in the sentence
for(Span s: nameSpans)
System.out.println(s.toString());
}
}निम्न आदेशों का उपयोग करके कमांड प्रॉम्प्ट से सहेजी गई जावा फ़ाइल को संकलित करें और निष्पादित करें -
javac NameFinderME_Example.java
java NameFinderME_Exampleनिष्पादित करने पर, उपरोक्त कार्यक्रम दिए गए स्ट्रिंग (कच्चे पाठ) को पढ़ता है, इसमें व्यक्तियों के नाम का पता लगाता है, और उनके पदों (स्पैन) को प्रदर्शित करता है, जैसा कि नीचे दिखाया गया है।
[0..1) person
[2..3) personउनके पदों के साथ नाम
substring() स्ट्रिंग कक्षा की विधि स्वीकार करती है begin और यह end offsetsऔर संबंधित स्ट्रिंग लौटाता है। हम इस पद्धति का उपयोग नामों और उनके स्पैन (स्थिति) को एक साथ प्रिंट करने के लिए कर सकते हैं, जैसा कि निम्नलिखित कोड ब्लॉक में दिखाया गया है।
for(Span s: nameSpans)
System.out.println(s.toString()+" "+tokens[s.getStart()]);निम्नलिखित दिए गए कच्चे पाठ से नामों का पता लगाने और उन्हें अपने पदों के साथ प्रदर्शित करने का कार्यक्रम है। इस प्रोग्राम को नाम के साथ फाइल में सेव करेंNameFinderSentences.java।
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.namefind.NameFinderME;
import opennlp.tools.namefind.TokenNameFinderModel;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class NameFinderSentences {
public static void main(String args[]) throws Exception{
//Loading the tokenizer model
InputStream inputStreamTokenizer = new
FileInputStream("C:/OpenNLP_models/entoken.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStreamTokenizer);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Tokenizing the sentence in to a string array
String sentence = "Mike is senior programming
manager and Rama is a clerk both are working at
Tutorialspoint";
String tokens[] = tokenizer.tokenize(sentence);
//Loading the NER-person model
InputStream inputStreamNameFinder = new
FileInputStream("C:/OpenNLP_models/enner-person.bin");
TokenNameFinderModel model = new TokenNameFinderModel(inputStreamNameFinder);
//Instantiating the NameFinderME class
NameFinderME nameFinder = new NameFinderME(model);
//Finding the names in the sentence
Span nameSpans[] = nameFinder.find(tokens);
//Printing the names and their spans in a sentence
for(Span s: nameSpans)
System.out.println(s.toString()+" "+tokens[s.getStart()]);
}
}निम्न आदेशों का उपयोग करके कमांड प्रॉम्प्ट से सहेजी गई जावा फ़ाइल को संकलित करें और निष्पादित करें -
javac NameFinderSentences.java
java NameFinderSentencesनिष्पादित करने पर, उपरोक्त कार्यक्रम दिए गए स्ट्रिंग (कच्चे पाठ) को पढ़ता है, इसमें व्यक्तियों के नाम का पता लगाता है, और नीचे दिखाए गए अनुसार उनके पदों (स्पैन) को प्रदर्शित करता है।
[0..1) person Mikeस्थान के नाम का पता लगाना
विभिन्न मॉडलों को लोड करके, आप विभिन्न नामित संस्थाओं का पता लगा सकते हैं। निम्नलिखित एक जावा प्रोग्राम है जो लोड करता हैen-ner-location.binमॉडल और दिए गए वाक्य में स्थान के नाम का पता लगाता है। इस प्रोग्राम को नाम के साथ फाइल में सेव करेंLocationFinder.java।
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.namefind.NameFinderME;
import opennlp.tools.namefind.TokenNameFinderModel;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class LocationFinder {
public static void main(String args[]) throws Exception{
InputStream inputStreamTokenizer = new
FileInputStream("C:/OpenNLP_models/entoken.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStreamTokenizer);
//String paragraph = "Mike and Smith are classmates";
String paragraph = "Tutorialspoint is located in Hyderabad";
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
String tokens[] = tokenizer.tokenize(paragraph);
//Loading the NER-location moodel
InputStream inputStreamNameFinder = new
FileInputStream("C:/OpenNLP_models/en- ner-location.bin");
TokenNameFinderModel model = new TokenNameFinderModel(inputStreamNameFinder);
//Instantiating the NameFinderME class
NameFinderME nameFinder = new NameFinderME(model);
//Finding the names of a location
Span nameSpans[] = nameFinder.find(tokens);
//Printing the spans of the locations in the sentence
for(Span s: nameSpans)
System.out.println(s.toString()+" "+tokens[s.getStart()]);
}
}निम्न आदेशों का उपयोग करके कमांड प्रॉम्प्ट से सहेजी गई जावा फ़ाइल को संकलित करें और निष्पादित करें -
javac LocationFinder.java
java LocationFinderनिष्पादित करने पर, उपरोक्त कार्यक्रम दिए गए स्ट्रिंग (कच्चे पाठ) को पढ़ता है, इसमें व्यक्तियों के नाम का पता लगाता है, और उनके पदों (स्पैन) को प्रदर्शित करता है, जैसा कि नीचे दिखाया गया है।
[4..5) location HyderabadNameFinder संभावना
probs()की विधि NameFinderME वर्ग का उपयोग अंतिम डिकोड किए गए अनुक्रम की संभावनाओं को प्राप्त करने के लिए किया जाता है।
double[] probs = nameFinder.probs();निम्नलिखित संभावनाओं को मुद्रित करने का कार्यक्रम है। इस प्रोग्राम को नाम के साथ फाइल में सेव करेंTokenizerMEProbs.java।
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class TokenizerMEProbs {
public static void main(String args[]) throws Exception{
String sent = "Hello John how are you welcome to Tutorialspoint";
//Loading the Tokenizer model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Retrieving the positions of the tokens
Span tokens[] = tokenizer.tokenizePos(sent);
//Getting the probabilities of the recent calls to tokenizePos() method
double[] probs = tokenizer.getTokenProbabilities();
//Printing the spans of tokens
for( Span token : tokens)
System.out.println(token +"
"+sent.substring(token.getStart(), token.getEnd()));
System.out.println(" ");
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}निम्न आदेशों का उपयोग करके कमांड प्रॉम्प्ट से सहेजी गई जावा फ़ाइल को संकलित करें और निष्पादित करें -
javac TokenizerMEProbs.java
java TokenizerMEProbsनिष्पादित करने पर, उपरोक्त कार्यक्रम दिए गए स्ट्रिंग को पढ़ता है, वाक्यों को टोकन देता है, और उन्हें प्रिंट करता है। इसके अलावा, यह अंतिम डिकोड किए गए अनुक्रम की संभावनाओं को भी लौटाता है, जैसा कि नीचे दिखाया गया है।
[0..5) Hello
[6..10) John
[11..14) how
[15..18) are
[19..22) you
[23..30) welcome
[31..33) to
[34..48) Tutorialspoint
1.0
1.0
1.0
1.0
1.0
1.0
1.0
1.0ओपनएनएलपी का उपयोग करके, आप किसी दिए गए वाक्य के भाषण के हिस्सों का भी पता लगा सकते हैं और उन्हें प्रिंट कर सकते हैं। भाषण के हिस्सों के पूर्ण नाम के बजाय, OpenNLP भाषण के प्रत्येक भागों के संक्षिप्त रूपों का उपयोग करता है। निम्न तालिका OpenNLP और उनके अर्थ द्वारा पता लगाए गए भाषणों के विभिन्न भागों को इंगित करता है।
| शब्दभेद | भाषण के कुछ हिस्सों का मतलब |
|---|---|
| एनएन | संज्ञा, एकवचन या द्रव्यमान |
| डीटी | निर्धारक |
| वीबी | क्रिया, आधार रूप |
| VBD | क्रिया, भूत काल |
| VBZ | क्रिया, तीसरा व्यक्ति विलक्षण वर्तमान |
| में | पूर्वसर्ग या अधीनस्थ संयोजन |
| एनएनपी | व्यक्तिवाचक संज्ञा, एकवचन |
| सेवा | सेवा |
| जे जे | विशेषण |
भाषण के हिस्सों को टैग करना
एक वाक्य के भाषण के हिस्सों को टैग करने के लिए, ओपनएनएलपी एक मॉडल, एक फ़ाइल का उपयोग करता है जिसका नाम है en-posmaxent.bin। यह एक पूर्वनिर्धारित मॉडल है जिसे दिए गए कच्चे पाठ के भाषण के हिस्सों को टैग करने के लिए प्रशिक्षित किया जाता है।
POSTaggerME की कक्षा opennlp.tools.postagपैकेज का उपयोग इस मॉडल को लोड करने के लिए किया जाता है, और ओपनएनएलपी लाइब्रेरी का उपयोग करके दिए गए कच्चे पाठ के भाषण के हिस्सों को टैग किया जाता है। ऐसा करने के लिए, आपको यह करने की आवश्यकता है -
लोड करें en-pos-maxent.bin का उपयोग कर मॉडल POSModel कक्षा।
झटपट POSTaggerME कक्षा।
वाक्य को स्पष्ट करें।
टैग का उपयोग कर उत्पन्न करें tag() तरीका।
टोकन और टैग का उपयोग करके प्रिंट करें POSSample कक्षा।
प्रोग्राम को लिखने के लिए निम्नलिखित चरणों का पालन करना चाहिए जो दिए गए कच्चे पाठ में भाषण के कुछ हिस्सों को टैग करता है POSTaggerME कक्षा।
चरण 1: मॉडल लोड करें
पीओएस टैगिंग के लिए मॉडल को नामित वर्ग द्वारा दर्शाया गया है POSModel, जो पैकेज के अंतर्गत आता है opennlp.tools.postag।
एक टोकन मॉडल लोड करने के लिए -
बनाओ InputStream मॉडल का उद्देश्य (FileInputStream झटपट करें और इसके निर्माणकर्ता को स्ट्रिंग प्रारूप में मॉडल का पथ पास करें)।
झटपट POSModel कक्षा और पास InputStream (मॉडल) इसके निर्माता के लिए एक पैरामीटर के रूप में, जैसा कि निम्नलिखित कोड ब्लॉक में दिखाया गया है -
//Loading Parts of speech-maxent model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModel(inputStream);चरण 2: POSTaggerME वर्ग को त्वरित करना
POSTaggerME पैकेज की कक्षा opennlp.tools.postagका उपयोग दिए गए कच्चे पाठ के भाषण के हिस्सों की भविष्यवाणी करने के लिए किया जाता है। यह अपने निर्णय लेने के लिए अधिकतम एन्ट्रापी का उपयोग करता है।
इस वर्ग को तुरंत लिखें और पिछले चरण में बनाई गई मॉडल ऑब्जेक्ट को पास करें, जैसा कि नीचे दिखाया गया है -
//Instantiating POSTaggerME class
POSTaggerME tagger = new POSTaggerME(model);चरण 3: वाक्य को टोकन देना
tokenize() की विधि whitespaceTokenizerक्लास का उपयोग इसके लिए पास किए गए कच्चे पाठ को टोकन देने के लिए किया जाता है। यह विधि एक स्ट्रिंग चर को पैरामीटर के रूप में स्वीकार करती है, और स्ट्रिंग्स (टोकन) की एक सरणी लौटाती है।
झटपट whitespaceTokenizer इस विधि के वाक्य के स्ट्रिंग प्रारूप को पारित करके इस विधि को वर्ग और आह्वान करें।
//Tokenizing the sentence using WhitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);चरण 4: टैग उत्पन्न करना
tag() की विधि whitespaceTokenizerवर्ग टोकन के वाक्य को पीओएस टैग प्रदान करता है। यह विधि टोकन की एक सरणी (स्ट्रिंग) को एक पैरामीटर के रूप में स्वीकार करती है और टैग (सरणी) लौटाती है।
आह्वान किया tag() पिछले चरण में उत्पन्न टोकन को पास करके विधि।
//Generating tags
String[] tags = tagger.tag(tokens);चरण 5: टोकन और टैग को प्रिंट करना
POSSampleवर्ग पीओएस-टैग किए गए वाक्य का प्रतिनिधित्व करता है। इस वर्ग को तुरंत करने के लिए, हमें टोकन की एक (पाठ की) और टैग की एक सरणी की आवश्यकता होगी।
toString()इस वर्ग की विधि टैग किए गए वाक्य को वापस करती है। टोकन को पास करके और पिछले चरणों में बनाए गए टैग सरण को इस श्रेणी में पलटें और उसका चालान करेंtoString() विधि, जैसा कि निम्नलिखित कोड ब्लॉक में दिखाया गया है।
//Instantiating the POSSample class
POSSample sample = new POSSample(tokens, tags);
System.out.println(sample.toString());Example
निम्नलिखित कार्यक्रम है जो एक दिए गए कच्चे पाठ में भाषण के कुछ हिस्सों को टैग करता है। इस प्रोग्राम को नाम के साथ फाइल में सेव करेंPosTaggerExample.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSSample;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class PosTaggerExample {
public static void main(String args[]) throws Exception{
//Loading Parts of speech-maxent model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModel(inputStream);
//Instantiating POSTaggerME class
POSTaggerME tagger = new POSTaggerME(model);
String sentence = "Hi welcome to Tutorialspoint";
//Tokenizing the sentence using WhitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Generating tags
String[] tags = tagger.tag(tokens);
//Instantiating the POSSample class
POSSample sample = new POSSample(tokens, tags);
System.out.println(sample.toString());
}
}निम्न आदेशों का उपयोग करके कमांड प्रॉम्प्ट से सहेजी गई जावा फ़ाइल को संकलित करें और निष्पादित करें -
javac PosTaggerExample.java
java PosTaggerExampleनिष्पादित करने पर, उपरोक्त कार्यक्रम दिए गए पाठ को पढ़ता है और इन वाक्यों के भाषण के कुछ हिस्सों का पता लगाता है और उन्हें प्रदर्शित करता है, जैसा कि नीचे दिखाया गया है।
Hi_NNP welcome_JJ to_TO Tutorialspoint_VBपीओएस टैगर प्रदर्शन
निम्नलिखित कार्यक्रम है जो किसी दिए गए कच्चे पाठ के भाषण के हिस्सों को टैग करता है। यह प्रदर्शन की निगरानी भी करता है और टैगर के प्रदर्शन को प्रदर्शित करता है। इस प्रोग्राम को नाम के साथ फाइल में सेव करेंPosTagger_Performance.java।
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.cmdline.PerformanceMonitor;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSSample;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class PosTagger_Performance {
public static void main(String args[]) throws Exception{
//Loading Parts of speech-maxent model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModel(inputStream);
//Creating an object of WhitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Instantiating POSTaggerME class
POSTaggerME tagger = new POSTaggerME(model);
//Generating tags
String[] tags = tagger.tag(tokens);
//Instantiating POSSample class
POSSample sample = new POSSample(tokens, tags);
System.out.println(sample.toString());
//Monitoring the performance of POS tagger
PerformanceMonitor perfMon = new PerformanceMonitor(System.err, "sent");
perfMon.start();
perfMon.incrementCounter();
perfMon.stopAndPrintFinalResult();
}
}निम्न आदेशों का उपयोग करके कमांड प्रॉम्प्ट से सहेजी गई जावा फ़ाइल को संकलित करें और निष्पादित करें -
javac PosTaggerExample.java
java PosTaggerExampleनिष्पादित करने पर, उपरोक्त कार्यक्रम दिए गए पाठ को पढ़ता है और इन वाक्यों के बोलने के हिस्सों को टैग करता है और उन्हें प्रदर्शित करता है। इसके अलावा, यह पीओएस टैगर के प्रदर्शन पर भी नज़र रखता है और उसे प्रदर्शित करता है।
Hi_NNP welcome_JJ to_TO Tutorialspoint_VB
Average: 0.0 sent/s
Total: 1 sent
Runtime: 0.0sपीओएस टैगर संभावना
probs() की विधि POSTaggerME क्लास का उपयोग हाल ही में टैग किए गए वाक्य के प्रत्येक टैग की संभावनाओं को खोजने के लिए किया जाता है।
//Getting the probabilities of the recent calls to tokenizePos() method
double[] probs = detector.getSentenceProbabilities();निम्नलिखित प्रोग्राम है जो अंतिम टैग किए गए वाक्य के प्रत्येक टैग के लिए संभावनाओं को प्रदर्शित करता है। इस प्रोग्राम को नाम के साथ फाइल में सेव करेंPosTaggerProbs.java।
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSSample;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class PosTaggerProbs {
public static void main(String args[]) throws Exception{
//Loading Parts of speech-maxent model
InputStream inputStream = new FileInputStream("C:/OpenNLP_mdl/en-pos-maxent.bin");
POSModel model = new POSModel(inputStream);
//Creating an object of WhitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Instantiating POSTaggerME class
POSTaggerME tagger = new POSTaggerME(model);
//Generating tags
String[] tags = tagger.tag(tokens);
//Instantiating the POSSample class
POSSample sample = new POSSample(tokens, tags);
System.out.println(sample.toString());
//Probabilities for each tag of the last tagged sentence.
double [] probs = tagger.probs();
System.out.println(" ");
//Printing the probabilities
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}निम्न आदेशों का उपयोग करके कमांड प्रॉम्प्ट से सहेजी गई जावा फ़ाइल को संकलित करें और निष्पादित करें -
javac TokenizerMEProbs.java
java TokenizerMEProbsनिष्पादित करने पर, उपरोक्त कार्यक्रम दिए गए कच्चे पाठ को पढ़ता है, इसमें प्रत्येक टोकन के भाषण के हिस्सों को टैग करता है, और उन्हें प्रदर्शित करता है। इसके अलावा, यह दिए गए वाक्य में भाषण के प्रत्येक भागों के लिए संभावनाओं को भी प्रदर्शित करता है, जैसा कि नीचे दिखाया गया है।
Hi_NNP welcome_JJ to_TO Tutorialspoint_VB
0.6416834779738033
0.42983612874819177
0.8584513635863117
0.4394784478206072ओपनएनएलपी एपीआई का उपयोग करके, आप दिए गए वाक्यों को पार्स कर सकते हैं। इस अध्याय में, हम OpenNLP API का उपयोग करके कच्चे पाठ को पार्स करने के तरीके के बारे में चर्चा करेंगे।
ओपनएनएलपी लाइब्रेरी का उपयोग करके कच्चे पाठ को पार्स करना
वाक्यों का पता लगाने के लिए, ओपनएनएलपी एक पूर्वनिर्धारित मॉडल, एक फ़ाइल नाम का उपयोग करता है en-parserchunking.bin। यह एक पूर्वनिर्धारित मॉडल है जिसे दिए गए कच्चे पाठ को पार्स करने के लिए प्रशिक्षित किया गया है।
Parser की कक्षा opennlp.tools.Parser पैकेज पार्स घटक और धारण करने के लिए उपयोग किया जाता है ParserTool की कक्षा opennlp.tools.cmdline.parser पैकेज का उपयोग सामग्री को पार्स करने के लिए किया जाता है।
प्रोग्राम को लिखने के लिए निम्नलिखित चरणों का पालन करना चाहिए जो दिए गए कच्चे पाठ का उपयोग करता है ParserTool कक्षा।
चरण 1: मॉडल लोड हो रहा है
पार्सिंग पाठ के लिए मॉडल को नामित वर्ग द्वारा दर्शाया गया है ParserModel, जो पैकेज के अंतर्गत आता है opennlp.tools.parser।
एक टोकन मॉडल लोड करने के लिए -
बनाओ InputStream मॉडल का उद्देश्य (FileInputStream झटपट करें और इसके निर्माणकर्ता को स्ट्रिंग प्रारूप में मॉडल का पथ पास करें)।
झटपट ParserModel कक्षा और पास InputStream (ऑब्जेक्ट) इसके निर्माता के लिए एक पैरामीटर के रूप में, जैसा कि निम्नलिखित कोड ब्लॉक में दिखाया गया है।
//Loading parser model
InputStream inputStream = new FileInputStream(".../en-parserchunking.bin");
ParserModel model = new ParserModel(inputStream);चरण 2: पार्सर वर्ग की एक वस्तु बनाना
Parser पैकेज की कक्षा opennlp.tools.parserपार्स घटक रखने के लिए एक डेटा संरचना का प्रतिनिधित्व करता है। आप स्थैतिक का उपयोग करके इस वर्ग का एक ऑब्जेक्ट बना सकते हैंcreate() की विधि ParserFactory कक्षा।
आह्वान किया create() की विधि ParserFactory पिछले चरण में बनाई गई मॉडल ऑब्जेक्ट को पास करके, जैसा कि नीचे दिखाया गया है -
//Creating a parser Parser parser = ParserFactory.create(model);चरण 3: वाक्य को पार्स करना
parseLine() की विधि ParserToolक्लास का उपयोग ओपनएनएलपी में कच्चे पाठ को पार्स करने के लिए किया जाता है। इस विधि को स्वीकार करता है -
स्ट्रिंग का पाठ को दर्शाने वाला चर।
एक पार्सर वस्तु।
एक पूर्णांक जो पारस की संख्या को दर्शाता है।
इस विधि को निम्नलिखित मापदंडों को वाक्य के माध्यम से लागू करें: पिछले चरणों में बनाई गई पार्स वस्तु, और एक पूर्णांक जो पार्स की आवश्यक संख्या का प्रतिनिधित्व करता है।
//Parsing the sentence
String sentence = "Tutorialspoint is the largest tutorial library.";
Parse topParses[] = ParserTool.parseLine(sentence, parser, 1);Example
निम्नलिखित कार्यक्रम है जो दिए गए कच्चे पाठ को पार्स करता है। इस प्रोग्राम को नाम के साथ फाइल में सेव करेंParserExample.java।
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.cmdline.parser.ParserTool;
import opennlp.tools.parser.Parse;
import opennlp.tools.parser.Parser;
import opennlp.tools.parser.ParserFactory;
import opennlp.tools.parser.ParserModel;
public class ParserExample {
public static void main(String args[]) throws Exception{
//Loading parser model
InputStream inputStream = new FileInputStream(".../en-parserchunking.bin");
ParserModel model = new ParserModel(inputStream);
//Creating a parser
Parser parser = ParserFactory.create(model);
//Parsing the sentence
String sentence = "Tutorialspoint is the largest tutorial library.";
Parse topParses[] = ParserTool.parseLine(sentence, parser, 1);
for (Parse p : topParses)
p.show();
}
}निम्न आदेशों का उपयोग करके कमांड प्रॉम्प्ट से सहेजी गई जावा फ़ाइल को संकलित करें और निष्पादित करें -
javac ParserExample.java
java ParserExampleनिष्पादित करने पर, उपरोक्त कार्यक्रम दिए गए कच्चे पाठ को पढ़ता है, इसे पार्स करता है, और निम्नलिखित आउटपुट प्रदर्शित करता है -
(TOP (S (NP (NN Tutorialspoint)) (VP (VBZ is) (NP (DT the) (JJS largest) (NN
tutorial) (NN library.)))))वाक्यों को चैंकाने से तात्पर्य शब्दों के भागों जैसे शब्द समूहों और क्रिया समूहों में एक वाक्य को तोड़ना / विभाजित करना है।
ओपनएनएलपी का उपयोग करके एक वाक्य चुन लेना
वाक्यों का पता लगाने के लिए, ओपनएनएलपी एक मॉडल, एक फ़ाइल का उपयोग करता है जिसका नाम है en-chunker.bin। यह एक पूर्वनिर्धारित मॉडल है जिसे दिए गए कच्चे पाठ में वाक्यों को सुनाने के लिए प्रशिक्षित किया गया है।
opennlp.tools.chunker पैकेज में वे वर्ग और इंटरफ़ेस होते हैं जिनका उपयोग गैर-पुनरावर्ती वाक्य-विन्यास एनोटेशन जैसे संज्ञा वाक्यांश विखंडन को खोजने के लिए किया जाता है।
आप विधि का उपयोग करके एक वाक्य को काट सकते हैं chunk() का ChunkerMEकक्षा। यह विधि एक वाक्य और पीओएस टैग के टोकन को पैरामीटर के रूप में स्वीकार करती है। इसलिए, चैंकिंग की प्रक्रिया शुरू करने से पहले, सबसे पहले आपको वाक्य को टोकन करने और इसके पीओएस टैग के कुछ हिस्सों को उत्पन्न करने की आवश्यकता है।
ओपनएनएलपीपी लाइब्रेरी का उपयोग करके एक वाक्य को चैंकाने के लिए, आपको निम्न की आवश्यकता है -
वाक्य को स्पष्ट करें।
इसके लिए पीओएस टैग तैयार करें।
लोड करें en-chunker.bin का उपयोग कर मॉडल ChunkerModel कक्षा
झटपट ChunkerME कक्षा।
का उपयोग कर वाक्यों का हिस्सा chunk() इस वर्ग की विधि।
नीचे दिए गए कच्चे पाठ से वाक्यों को क्रमबद्ध करने के लिए एक कार्यक्रम लिखने के लिए निम्नलिखित चरणों का पालन किया जाता है।
चरण 1: वाक्य को टोकन देना
का उपयोग कर वाक्यों को टोकन tokenize() की विधि whitespaceTokenizer वर्ग, जैसा कि निम्नलिखित कोड ब्लॉक में दिखाया गया है।
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);चरण 2: पीओएस टैग उत्पन्न करना
का उपयोग करके वाक्य के पीओएस टैग उत्पन्न करें tag() की विधि POSTaggerME वर्ग, जैसा कि निम्नलिखित कोड ब्लॉक में दिखाया गया है।
//Generating the POS tags
File file = new File("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModelLoader().load(file);
//Constructing the tagger
POSTaggerME tagger = new POSTaggerME(model);
//Generating tags from the tokens
String[] tags = tagger.tag(tokens);चरण 3: मॉडल लोड हो रहा है
एक वाक्य को चैंकाने के लिए मॉडल को नामित वर्ग द्वारा दर्शाया गया है ChunkerModel, जो पैकेज के अंतर्गत आता है opennlp.tools.chunker।
एक वाक्य पहचान मॉडल लोड करने के लिए -
बनाओ InputStream मॉडल का उद्देश्य (FileInputStream झटपट करें और इसके निर्माणकर्ता को स्ट्रिंग प्रारूप में मॉडल का पथ पास करें)।
झटपट ChunkerModel कक्षा और पास InputStream (मॉडल) इसके निर्माता के लिए एक पैरामीटर के रूप में, जैसा कि निम्नलिखित कोड ब्लॉक में दिखाया गया है -
//Loading the chunker model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-chunker.bin");
ChunkerModel chunkerModel = new ChunkerModel(inputStream);चरण 4: chunkerME वर्ग को त्वरित करना
chunkerME पैकेज की कक्षा opennlp.tools.chunkerइसमें वाक्यों को सुनाने के तरीके शामिल हैं। यह एक अधिकतम-एन्ट्रापी-आधारित चंकर है।
इस वर्ग को तुरंत लिखें और पिछले चरण में बनाए गए मॉडल ऑब्जेक्ट को पास करें।
//Instantiate the ChunkerME class
ChunkerME chunkerME = new ChunkerME(chunkerModel);चरण 5: वाक्य को चुनकर
chunk() की विधि ChunkerMEकक्षा का उपयोग उसमें दिए गए कच्चे पाठ में वाक्यों को सुनाने के लिए किया जाता है। यह विधि मापदंडों के रूप में टोकन और टैग का प्रतिनिधित्व करने वाले दो स्ट्रिंग सरणियों को स्वीकार करती है।
पैरामीटर के रूप में पिछले चरणों में बनाए गए टोकन सरणी और टैग सरणी पास करके इस विधि को लागू करें।
//Generating the chunks
String result[] = chunkerME.chunk(tokens, tags);Example
इसके बाद दिए गए कच्चे पाठ में वाक्यों को सुनाने का कार्यक्रम है। इस प्रोग्राम को नाम के साथ फाइल में सेव करेंChunkerExample.java।
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import opennlp.tools.chunker.ChunkerME;
import opennlp.tools.chunker.ChunkerModel;
import opennlp.tools.cmdline.postag.POSModelLoader;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class ChunkerExample{
public static void main(String args[]) throws IOException {
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Generating the POS tags
//Load the parts of speech model
File file = new File("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModelLoader().load(file);
//Constructing the tagger
POSTaggerME tagger = new POSTaggerME(model);
//Generating tags from the tokens
String[] tags = tagger.tag(tokens);
//Loading the chunker model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-chunker.bin");
ChunkerModel chunkerModel = new ChunkerModel(inputStream);
//Instantiate the ChunkerME class
ChunkerME chunkerME = new ChunkerME(chunkerModel);
//Generating the chunks
String result[] = chunkerME.chunk(tokens, tags);
for (String s : result)
System.out.println(s);
}
}निम्न कमांड का उपयोग करके कमांड प्रॉम्प्ट से सहेजी गई जावा फ़ाइल को संकलित करें और निष्पादित करें -
javac ChunkerExample.java
java ChunkerExampleनिष्पादित करने पर, उपरोक्त कार्यक्रम दिए गए स्ट्रिंग को पढ़ता है और इसमें दिए गए वाक्यों को चुनता है, और उन्हें नीचे दिखाए अनुसार प्रदर्शित करता है।
Loading POS Tagger model ... done (1.040s)
B-NP
I-NP
B-VP
I-VPटोकन की स्थिति का पता लगाना
हम का उपयोग करके विखंडू की स्थिति या स्पैन का भी पता लगा सकते हैं chunkAsSpans() की विधि ChunkerMEकक्षा। यह विधि स्पान प्रकार की वस्तुओं की एक सरणी देती है। स्पान नाम की कक्षाopennlp.tools.util पैकेज का उपयोग स्टोर करने के लिए किया जाता है start तथा end सेट का पूर्णांक।
आप द्वारा दिए गए स्पैन को स्टोर कर सकते हैं chunkAsSpans() स्पैन सरणी में विधि और उन्हें प्रिंट करें, जैसा कि निम्नलिखित कोड ब्लॉक में दिखाया गया है।
//Generating the tagged chunk spans
Span[] span = chunkerME.chunkAsSpans(tokens, tags);
for (Span s : span)
System.out.println(s.toString());Example
निम्नलिखित कार्यक्रम है जो दिए गए कच्चे पाठ में वाक्यों का पता लगाता है। इस प्रोग्राम को नाम के साथ फाइल में सेव करेंChunkerSpansEample.java।
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import opennlp.tools.chunker.ChunkerME;
import opennlp.tools.chunker.ChunkerModel;
import opennlp.tools.cmdline.postag.POSModelLoader;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
import opennlp.tools.util.Span;
public class ChunkerSpansEample{
public static void main(String args[]) throws IOException {
//Load the parts of speech model
File file = new File("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModelLoader().load(file);
//Constructing the tagger
POSTaggerME tagger = new POSTaggerME(model);
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Generating tags from the tokens
String[] tags = tagger.tag(tokens);
//Loading the chunker model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-chunker.bin");
ChunkerModel chunkerModel = new ChunkerModel(inputStream);
ChunkerME chunkerME = new ChunkerME(chunkerModel);
//Generating the tagged chunk spans
Span[] span = chunkerME.chunkAsSpans(tokens, tags);
for (Span s : span)
System.out.println(s.toString());
}
}निम्न आदेशों का उपयोग करके कमांड प्रॉम्प्ट से सहेजी गई जावा फ़ाइल को संकलित करें और निष्पादित करें -
javac ChunkerSpansEample.java
java ChunkerSpansEampleनिष्पादित करने पर, उपरोक्त कार्यक्रम में दिए गए स्ट्रिंग को पढ़ता है और इसमें विखंडू को फैलाता है, और निम्नलिखित आउटपुट प्रदर्शित करता है -
Loading POS Tagger model ... done (1.059s)
[0..2) NP
[2..4) VPChunker प्रायिकता का पता लगाने
probs() की विधि ChunkerME वर्ग अंतिम डिकोड किए गए अनुक्रम की संभावनाओं को लौटाता है।
//Getting the probabilities of the last decoded sequence
double[] probs = chunkerME.probs();निम्नलिखित प्रोग्राम द्वारा अंतिम डिकोड किए गए अनुक्रम की संभावनाओं को प्रिंट करने का कार्यक्रम है chunker। इस प्रोग्राम को नाम के साथ फाइल में सेव करेंChunkerProbsExample.java।
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import opennlp.tools.chunker.ChunkerME;
import opennlp.tools.chunker.ChunkerModel;
import opennlp.tools.cmdline.postag.POSModelLoader;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class ChunkerProbsExample{
public static void main(String args[]) throws IOException {
//Load the parts of speech model
File file = new File("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModelLoader().load(file);
//Constructing the tagger
POSTaggerME tagger = new POSTaggerME(model);
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Generating tags from the tokens
String[] tags = tagger.tag(tokens);
//Loading the chunker model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-chunker.bin");
ChunkerModel cModel = new ChunkerModel(inputStream);
ChunkerME chunkerME = new ChunkerME(cModel);
//Generating the chunk tags
chunkerME.chunk(tokens, tags);
//Getting the probabilities of the last decoded sequence
double[] probs = chunkerME.probs();
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}निम्न आदेशों का उपयोग करके कमांड प्रॉम्प्ट से सहेजी गई जावा फ़ाइल को संकलित करें और निष्पादित करें -
javac ChunkerProbsExample.java
java ChunkerProbsExampleनिष्पादित करने पर, उपरोक्त कार्यक्रम दिए गए स्ट्रिंग को पढ़ता है, इसे चुनता है, और अंतिम डिकोड किए गए अनुक्रम की संभावनाओं को प्रिंट करता है।
0.9592746040797778
0.6883933131241501
0.8830563473996004
0.8951150529746051ओपनएनएलपी कमांड लाइन के माध्यम से विभिन्न कार्यों को करने के लिए एक कमांड लाइन इंटरफेस (सीएलआई) प्रदान करता है। इस अध्याय में, हम यह दिखाने के लिए कुछ उदाहरण लेंगे कि हम ओपनएनएलपी कमांड लाइन इंटरफेस का उपयोग कैसे कर सकते हैं।
tokenizing
input.txt
Hi. How are you? Welcome to Tutorialspoint. We provide free tutorials on various technologiesवाक्य - विन्यास
> opennlp TokenizerME path_for_models../en-token.bin <inputfile..> outputfile..आदेश
C:\> opennlp TokenizerME C:\OpenNLP_models/en-token.bin <input.txt >output.txtउत्पादन
Loading Tokenizer model ... done (0.207s)
Average: 214.3 sent/s
Total: 3 sent
Runtime: 0.014soutput.txt
Hi . How are you ? Welcome to Tutorialspoint . We provide free tutorials on various technologiesवाक्य का पता लगाना
input.txt
Hi. How are you? Welcome to Tutorialspoint. We provide free tutorials on various technologiesवाक्य - विन्यास
> opennlp SentenceDetector path_for_models../en-token.bin <inputfile..> outputfile..आदेश
C:\> opennlp SentenceDetector C:\OpenNLP_models/en-sent.bin <input.txt > output_sendet.txtउत्पादन
Loading Sentence Detector model ... done (0.067s)
Average: 750.0 sent/s
Total: 3 sent
Runtime: 0.004sOutput_sendet.txt
Hi. How are you?
Welcome to Tutorialspoint.
We provide free tutorials on various technologiesजिसका नाम एंटिटी रिकग्निशन रखा गया है
input.txt
<START:person> <START:person> Mike <END> <END> is senior programming manager and
<START:person> Rama <END> is a clerk both are working at Tutorialspointवाक्य - विन्यास
> opennlp TokenNameFinder path_for_models../en-token.bin <inputfile..आदेश
C:\>opennlp TokenNameFinder C:\OpenNLP_models\en-ner-person.bin <input_namefinder.txtउत्पादन
Loading Token Name Finder model ... done (0.730s)
<START:person> <START:person> Mike <END> <END> is senior programming manager and
<START:person> Rama <END> is a clerk both are working at Tutorialspoint
Average: 55.6 sent/s
Total: 1 sent
Runtime: 0.018sभाषण टैगिंग के भाग
Input.txt
Hi. How are you? Welcome to Tutorialspoint. We provide free tutorials on various technologiesवाक्य - विन्यास
> opennlp POSTagger path_for_models../en-token.bin <inputfile..आदेश
C:\>opennlp POSTagger C:\OpenNLP_models/en-pos-maxent.bin < input.txtउत्पादन
Loading POS Tagger model ... done (1.315s)
Hi._NNP How_WRB are_VBP you?_JJ Welcome_NNP to_TO Tutorialspoint._NNP We_PRP
provide_VBP free_JJ tutorials_NNS on_IN various_JJ technologies_NNS
Average: 66.7 sent/s
Total: 1 sent
Runtime: 0.015s