Apache Flume - Mengambil Data Twitter
Menggunakan Flume, kita dapat mengambil data dari berbagai layanan dan mengirimkannya ke penyimpanan terpusat (HDFS dan HBase). Bab ini menjelaskan cara mengambil data dari layanan Twitter dan menyimpannya dalam HDFS menggunakan Apache Flume.
Seperti yang dibahas dalam Arsitektur Flume, server web menghasilkan data log dan data ini dikumpulkan oleh agen di Flume. Saluran menyangga data ini ke wastafel, yang akhirnya mendorongnya ke penyimpanan terpusat.
Dalam contoh yang diberikan di bab ini, kita akan membuat aplikasi dan mendapatkan tweet darinya menggunakan sumber twitter eksperimental yang disediakan oleh Apache Flume. Kami akan menggunakan saluran memori untuk menyangga tweet ini dan wastafel HDFS untuk mendorong tweet ini ke HDFS.

Untuk mengambil data Twitter, kita harus mengikuti langkah-langkah yang diberikan di bawah ini -
- Buat Aplikasi twitter
- Instal / Mulai HDFS
- Konfigurasi Flume
Membuat Aplikasi Twitter
Untuk mendapatkan tweet dari Twitter maka perlu dibuat aplikasi Twitter. Ikuti langkah-langkah yang diberikan di bawah ini untuk membuat aplikasi Twitter.
Langkah 1
Untuk membuat aplikasi Twitter, klik tautan berikut https://apps.twitter.com/. Masuk ke akun Twitter Anda. Anda akan mendapatkan jendela Manajemen Aplikasi Twitter tempat Anda dapat membuat, menghapus, dan mengelola Aplikasi Twitter.
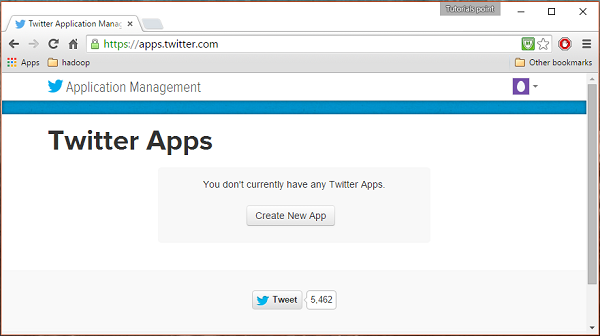
Langkah 2
Klik pada Create New Apptombol. Anda akan diarahkan ke jendela di mana Anda akan mendapatkan formulir aplikasi di mana Anda harus mengisi detail Anda untuk membuat Aplikasi. Saat mengisi alamat situs web, berikan pola URL lengkap, misalnya,http://example.com.
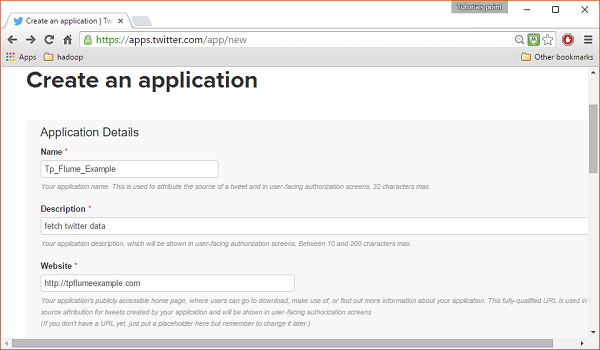
LANGKAH 3
Isi detailnya, terima Developer Agreement setelah selesai, klik Create your Twitter application buttonyang ada di bagian bawah halaman. Jika semuanya berjalan dengan baik, Aplikasi akan dibuat dengan detail yang diberikan seperti yang ditunjukkan di bawah ini.
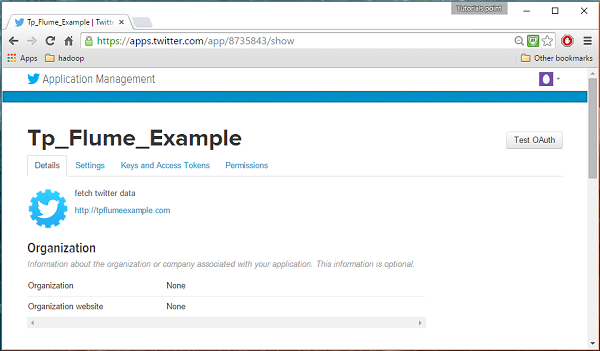
LANGKAH 4
Dibawah keys and Access Tokens tab di bagian bawah halaman, Anda dapat melihat tombol bernama Create my access token. Klik di atasnya untuk menghasilkan token akses.
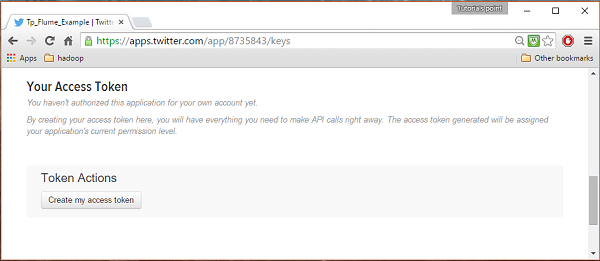
LANGKAH 5
Terakhir, klik file Test OAuthtombol yang ada di sisi kanan atas halaman. Ini akan mengarah ke halaman yang menampilkan fileConsumer key, Consumer secret, Access token, dan Access token secret. Salin detail ini. Ini berguna untuk mengkonfigurasi agen di Flume.

Memulai HDFS
Karena kami menyimpan data di HDFS, kami perlu menginstal / memverifikasi Hadoop. Mulai Hadoop dan buat folder di dalamnya untuk menyimpan data Flume. Ikuti langkah-langkah yang diberikan di bawah ini sebelum mengkonfigurasi Flume.
Langkah 1: Instal / Verifikasi Hadoop
Pasang Hadoop . Jika Hadoop sudah diinstal di sistem Anda, verifikasi penginstalan menggunakan perintah versi Hadoop, seperti yang ditunjukkan di bawah ini.
$ hadoop versionJika sistem Anda berisi Hadoop, dan jika Anda telah menyetel variabel jalur, maka Anda akan mendapatkan keluaran berikut -
Hadoop 2.6.0
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r
e3496499ecb8d220fba99dc5ed4c99c8f9e33bb1
Compiled by jenkins on 2014-11-13T21:10Z
Compiled with protoc 2.5.0
From source with checksum 18e43357c8f927c0695f1e9522859d6a
This command was run using /home/Hadoop/hadoop/share/hadoop/common/hadoop-common-2.6.0.jarLangkah 2: Memulai Hadoop
Jelajahi sbin direktori Hadoop dan mulai benang dan Hadoop dfs (sistem file terdistribusi) seperti yang ditunjukkan di bawah ini.
cd /$Hadoop_Home/sbin/
$ start-dfs.sh
localhost: starting namenode, logging to
/home/Hadoop/hadoop/logs/hadoop-Hadoop-namenode-localhost.localdomain.out
localhost: starting datanode, logging to
/home/Hadoop/hadoop/logs/hadoop-Hadoop-datanode-localhost.localdomain.out
Starting secondary namenodes [0.0.0.0]
starting secondarynamenode, logging to
/home/Hadoop/hadoop/logs/hadoop-Hadoop-secondarynamenode-localhost.localdomain.out
$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to
/home/Hadoop/hadoop/logs/yarn-Hadoop-resourcemanager-localhost.localdomain.out
localhost: starting nodemanager, logging to
/home/Hadoop/hadoop/logs/yarn-Hadoop-nodemanager-localhost.localdomain.outLangkah 3: Buat Direktori di HDFS
Di Hadoop DFS, Anda dapat membuat direktori menggunakan perintah mkdir. Jelajahi dan buat direktori dengan namatwitter_data di jalur yang diperlukan seperti yang ditunjukkan di bawah ini.
$cd /$Hadoop_Home/bin/
$ hdfs dfs -mkdir hdfs://localhost:9000/user/Hadoop/twitter_dataKonfigurasi Flume
Kita harus mengkonfigurasi sumber, saluran, dan wastafel menggunakan file konfigurasi di confmap. Contoh yang diberikan dalam bab ini menggunakan sumber eksperimental yang disediakan oleh Apache Flume bernamaTwitter 1% Firehose Saluran memori dan HDFS sink.
Sumber Api 1% Twitter
Sumber ini sangat eksperimental. Ini menghubungkan ke 1% sampel Twitter Firehose menggunakan streaming API dan terus mengunduh tweet, mengubahnya menjadi format Avro, dan mengirim peristiwa Avro ke sink Flume hilir.
Kami akan mendapatkan sumber ini secara default bersama dengan instalasi Flume. Itujar file yang sesuai dengan sumber ini dapat ditemukan di lib folder seperti yang ditunjukkan di bawah ini.

Menyetel jalur kelas
Mengatur classpath variabel ke lib folder Flume masuk Flume-env.sh file seperti yang ditunjukkan di bawah ini.
export CLASSPATH=$CLASSPATH:/FLUME_HOME/lib/*Sumber ini membutuhkan detail seperti Consumer key, Consumer secret, Access token, dan Access token secretdari aplikasi Twitter. Saat mengonfigurasi sumber ini, Anda harus memberikan nilai ke properti berikut -
Channels
Source type : org.apache.flume.source.twitter.TwitterSource
consumerKey - Kunci konsumen OAuth
consumerSecret - Rahasia konsumen OAuth
accessToken - Token akses OAuth
accessTokenSecret - Rahasia token OAuth
maxBatchSize- Jumlah maksimum pesan twitter yang harus ada dalam kelompok twitter. Nilai defaultnya adalah 1000 (opsional).
maxBatchDurationMillis- Jumlah maksimum milidetik untuk menunggu sebelum menutup batch. Nilai defaultnya adalah 1000 (opsional).
Saluran
Kami menggunakan saluran memori. Untuk mengkonfigurasi saluran memori, Anda harus memberikan nilai pada jenis saluran.
type- Ini memegang jenis saluran. Dalam contoh kami, jenisnya adalahMemChannel.
Capacity- Ini adalah jumlah maksimum acara yang disimpan di saluran. Nilai defaultnya adalah 100 (opsional).
TransactionCapacity- Ini adalah jumlah maksimum acara yang diterima atau dikirim saluran. Nilai defaultnya adalah 100 (opsional).
HDFS Sink
Wastafel ini menulis data ke dalam HDFS. Untuk mengonfigurasi sink ini, Anda harus memberikan detail berikut.
Channel
type - hdfs
hdfs.path - jalur direktori di HDFS tempat penyimpanan data.
Dan kami dapat memberikan beberapa nilai opsional berdasarkan skenario. Diberikan di bawah ini adalah properti opsional dari sink HDFS yang kita konfigurasikan dalam aplikasi kita.
fileType - Ini adalah format file yang diperlukan dari file HDFS kami. SequenceFile, DataStream dan CompressedStreamadalah tiga jenis yang tersedia dengan aliran ini. Dalam contoh kami, kami menggunakanDataStream.
writeFormat - Bisa berupa teks atau dapat ditulis.
batchSize- Ini adalah jumlah peristiwa yang ditulis ke file sebelum di-flush ke HDFS. Nilai defaultnya adalah 100.
rollsize- Ini adalah ukuran file untuk memicu gulungan. Nilai defaultnya adalah 100.
rollCount- Ini adalah jumlah kejadian yang ditulis ke dalam file sebelum digulung. Nilai defaultnya adalah 10.
Contoh - File Konfigurasi
Diberikan di bawah ini adalah contoh file konfigurasi. Salin konten ini dan simpan sebagaitwitter.conf di folder conf Flume.
# Naming the components on the current agent.
TwitterAgent.sources = Twitter
TwitterAgent.channels = MemChannel
TwitterAgent.sinks = HDFS
# Describing/Configuring the source
TwitterAgent.sources.Twitter.type = org.apache.flume.source.twitter.TwitterSource
TwitterAgent.sources.Twitter.consumerKey = Your OAuth consumer key
TwitterAgent.sources.Twitter.consumerSecret = Your OAuth consumer secret
TwitterAgent.sources.Twitter.accessToken = Your OAuth consumer key access token
TwitterAgent.sources.Twitter.accessTokenSecret = Your OAuth consumer key access token secret
TwitterAgent.sources.Twitter.keywords = tutorials point,java, bigdata, mapreduce, mahout, hbase, nosql
# Describing/Configuring the sink
TwitterAgent.sinks.HDFS.type = hdfs
TwitterAgent.sinks.HDFS.hdfs.path = hdfs://localhost:9000/user/Hadoop/twitter_data/
TwitterAgent.sinks.HDFS.hdfs.fileType = DataStream
TwitterAgent.sinks.HDFS.hdfs.writeFormat = Text
TwitterAgent.sinks.HDFS.hdfs.batchSize = 1000
TwitterAgent.sinks.HDFS.hdfs.rollSize = 0
TwitterAgent.sinks.HDFS.hdfs.rollCount = 10000
# Describing/Configuring the channel
TwitterAgent.channels.MemChannel.type = memory
TwitterAgent.channels.MemChannel.capacity = 10000
TwitterAgent.channels.MemChannel.transactionCapacity = 100
# Binding the source and sink to the channel
TwitterAgent.sources.Twitter.channels = MemChannel
TwitterAgent.sinks.HDFS.channel = MemChannelEksekusi
Jelajahi direktori home Flume dan jalankan aplikasi seperti yang ditunjukkan di bawah ini.
$ cd $FLUME_HOME
$ bin/flume-ng agent --conf ./conf/ -f conf/twitter.conf
Dflume.root.logger=DEBUG,console -n TwitterAgentJika semuanya berjalan dengan baik, streaming tweet ke HDFS akan dimulai. Diberikan di bawah ini adalah snapshot dari jendela command prompt saat mengambil tweet.
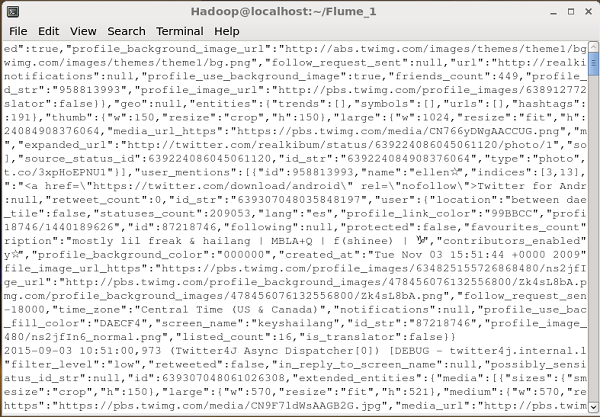
Memverifikasi HDFS
Anda dapat mengakses UI Web Administrasi Hadoop menggunakan URL yang diberikan di bawah ini.
http://localhost:50070/Klik pada dropdown bernama Utilitiesdi sisi kanan halaman. Anda dapat melihat dua opsi seperti yang ditunjukkan pada snapshot yang diberikan di bawah ini.
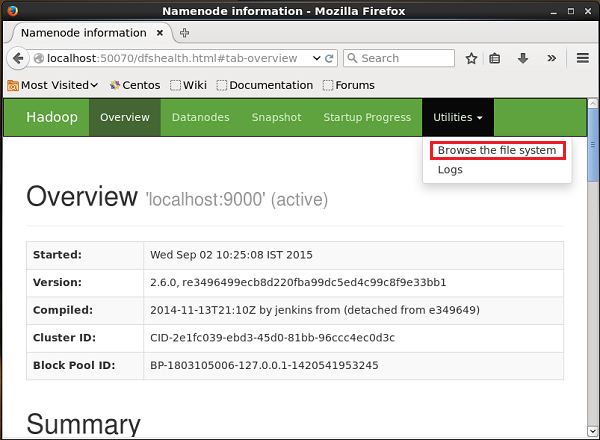
Klik Browse the file systemdan masukkan jalur direktori HDFS tempat Anda menyimpan tweet. Dalam contoh kita, jalurnya adalah/user/Hadoop/twitter_data/. Kemudian, Anda dapat melihat daftar file log twitter yang disimpan dalam HDFS seperti yang diberikan di bawah ini.
