Apache Flume - Sumber Generator Urutan
Pada bab sebelumnya, kita telah melihat bagaimana mengambil data dari sumber twitter ke HDFS. Bab ini menjelaskan cara mengambil data dariSequence generator.
Prasyarat
Untuk menjalankan contoh yang diberikan dalam bab ini, Anda perlu menginstal HDFS bersama Flume. Oleh karena itu, verifikasi instalasi Hadoop dan mulai HDFS sebelum melanjutkan lebih jauh. (Lihat bab sebelumnya untuk mempelajari cara memulai HDFS).
Konfigurasi Flume
Kita harus mengkonfigurasi sumber, saluran, dan wastafel menggunakan file konfigurasi di confmap. Contoh yang diberikan dalam bab ini menggunakan asequence generator source, Sebuah memory channel, dan HDFS sink.
Sumber Generator Urutan
Ini adalah sumber yang menghasilkan peristiwa terus menerus. Ia memelihara penghitung yang dimulai dari 0 dan bertambah 1. Digunakan untuk tujuan pengujian. Saat mengonfigurasi sumber ini, Anda harus memberikan nilai ke properti berikut -
Channels
Source type - seq
Saluran
Kami menggunakan memorysaluran. Untuk mengkonfigurasi saluran memori, Anda harus memberikan nilai untuk jenis saluran tersebut. Diberikan di bawah ini adalah daftar properti yang perlu Anda sediakan saat mengkonfigurasi saluran memori -
type- Ini memegang jenis saluran. Dalam contoh kami, jenisnya adalah MemChannel.
Capacity- Ini adalah jumlah maksimum acara yang disimpan di saluran. Nilai defaultnya adalah 100. (opsional)
TransactionCapacity- Ini adalah jumlah maksimum acara yang diterima atau dikirim saluran. Standarnya adalah 100. (opsional).
HDFS Sink
Wastafel ini menulis data ke dalam HDFS. Untuk mengonfigurasi sink ini, Anda harus memberikan detail berikut.
Channel
type - hdfs
hdfs.path - jalur direktori di HDFS tempat penyimpanan data.
Dan kami dapat memberikan beberapa nilai opsional berdasarkan skenario. Diberikan di bawah ini adalah properti opsional dari sink HDFS yang kita konfigurasikan dalam aplikasi kita.
fileType - Ini adalah format file yang diperlukan dari file HDFS kami. SequenceFile, DataStream dan CompressedStreamadalah tiga jenis yang tersedia dengan aliran ini. Dalam contoh kami, kami menggunakanDataStream.
writeFormat - Bisa berupa teks atau dapat ditulis.
batchSize- Ini adalah jumlah peristiwa yang ditulis ke file sebelum di-flush ke HDFS. Nilai defaultnya adalah 100.
rollsize- Ini adalah ukuran file untuk memicu gulungan. Nilai defaultnya adalah 100.
rollCount- Ini adalah jumlah kejadian yang ditulis ke dalam file sebelum digulung. Nilai defaultnya adalah 10.
Contoh - File Konfigurasi
Diberikan di bawah ini adalah contoh file konfigurasi. Salin konten ini dan simpan sebagaiseq_gen .conf di folder conf Flume.
# Naming the components on the current agent
SeqGenAgent.sources = SeqSource
SeqGenAgent.channels = MemChannel
SeqGenAgent.sinks = HDFS
# Describing/Configuring the source
SeqGenAgent.sources.SeqSource.type = seq
# Describing/Configuring the sink
SeqGenAgent.sinks.HDFS.type = hdfs
SeqGenAgent.sinks.HDFS.hdfs.path = hdfs://localhost:9000/user/Hadoop/seqgen_data/
SeqGenAgent.sinks.HDFS.hdfs.filePrefix = log
SeqGenAgent.sinks.HDFS.hdfs.rollInterval = 0
SeqGenAgent.sinks.HDFS.hdfs.rollCount = 10000
SeqGenAgent.sinks.HDFS.hdfs.fileType = DataStream
# Describing/Configuring the channel
SeqGenAgent.channels.MemChannel.type = memory
SeqGenAgent.channels.MemChannel.capacity = 1000
SeqGenAgent.channels.MemChannel.transactionCapacity = 100
# Binding the source and sink to the channel
SeqGenAgent.sources.SeqSource.channels = MemChannel
SeqGenAgent.sinks.HDFS.channel = MemChannelEksekusi
Jelajahi direktori home Flume dan jalankan aplikasi seperti yang ditunjukkan di bawah ini.
$ cd $FLUME_HOME
$./bin/flume-ng agent --conf $FLUME_CONF --conf-file $FLUME_CONF/seq_gen.conf
--name SeqGenAgentJika semuanya berjalan lancar, sumber mulai menghasilkan nomor urut yang akan didorong ke HDFS dalam bentuk file log.
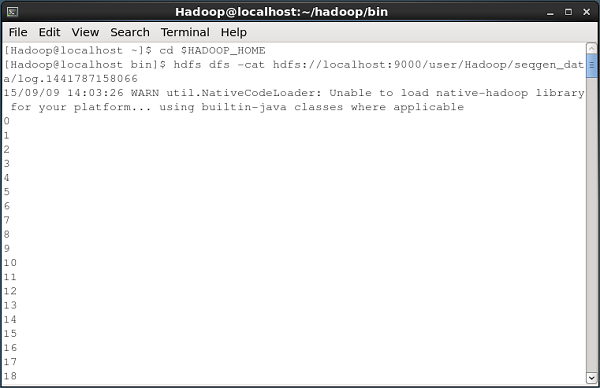
Diberikan di bawah ini adalah snapshot dari jendela prompt perintah yang mengambil data yang dihasilkan oleh generator urutan ke dalam HDFS.

Memverifikasi HDFS
Anda dapat mengakses UI Web Administrasi Hadoop menggunakan URL berikut -
http://localhost:50070/Klik pada dropdown bernama Utilitiesdi sisi kanan halaman. Anda dapat melihat dua opsi seperti yang ditunjukkan pada diagram di bawah ini.
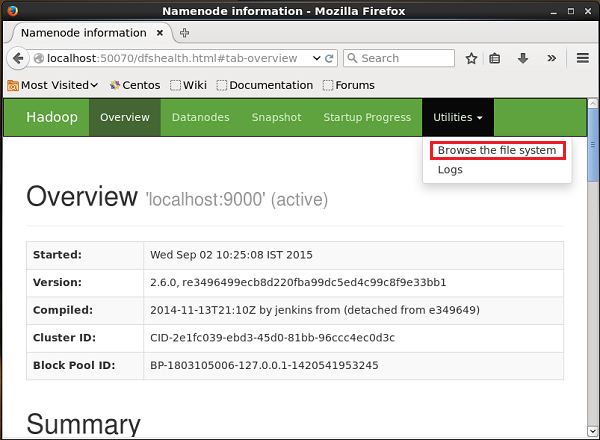
Klik Browse the file system dan masuk ke jalur direktori HDFS tempat Anda menyimpan data yang dihasilkan oleh generator urutan.
Dalam contoh kita, jalurnya adalah /user/Hadoop/ seqgen_data /. Kemudian, Anda dapat melihat daftar file log yang dibuat oleh generator urutan, yang disimpan di HDFS seperti yang diberikan di bawah ini.

Memverifikasi Isi File
Semua file log ini berisi angka dalam format berurutan. Anda dapat memverifikasi konten file ini di sistem file menggunakancat perintah seperti yang ditunjukkan di bawah ini.