Big Data Analytics - Siklus Hidup Data
Siklus Hidup Data Mining Tradisional
Untuk menyediakan kerangka kerja untuk mengatur pekerjaan yang dibutuhkan oleh organisasi dan memberikan wawasan yang jelas dari Big Data, ada baiknya untuk menganggapnya sebagai siklus dengan tahapan yang berbeda. Ini sama sekali tidak linier, artinya semua tahapan terkait satu sama lain. Siklus ini memiliki kemiripan yang dangkal dengan siklus data mining yang lebih tradisional seperti yang dijelaskan dalamCRISP methodology.
Metodologi CRISP-DM
Itu CRISP-DM methodologyyang merupakan singkatan dari Proses Standar Lintas Industri untuk Penambangan Data, adalah siklus yang menggambarkan pendekatan yang umum digunakan yang digunakan para ahli penambangan data untuk mengatasi masalah dalam penambangan data BI tradisional. Itu masih digunakan dalam tim penambangan data BI tradisional.
Perhatikan ilustrasi berikut. Ini menunjukkan tahapan utama dari siklus seperti yang dijelaskan oleh metodologi CRISP-DM dan bagaimana mereka saling terkait.
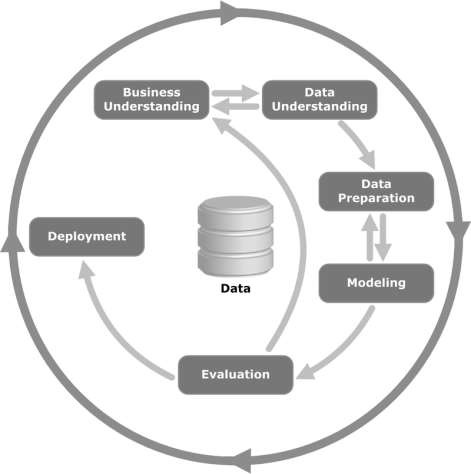
CRISP-DM dibuat pada tahun 1996 dan tahun berikutnya, itu dimulai sebagai proyek Uni Eropa di bawah inisiatif pendanaan ESPRIT. Proyek ini dipimpin oleh lima perusahaan: SPSS, Teradata, Daimler AG, NCR Corporation, dan OHRA (perusahaan asuransi). Proyek tersebut akhirnya dimasukkan ke dalam SPSS. Metodologi ini sangat berorientasi pada detail bagaimana proyek data mining harus ditentukan.
Sekarang mari kita belajar lebih banyak tentang setiap tahapan yang terlibat dalam siklus hidup CRISP-DM -
Business Understanding- Fase awal ini berfokus pada pemahaman tujuan dan persyaratan proyek dari perspektif bisnis, dan kemudian mengubah pengetahuan ini menjadi definisi masalah data mining. Sebuah rencana awal dirancang untuk mencapai tujuan. Model keputusan, khususnya yang dibangun dengan menggunakan Decision Model dan standar Notation dapat digunakan.
Data Understanding - Tahap pemahaman data dimulai dengan pengumpulan data awal dan dilanjutkan dengan aktivitas untuk membiasakan diri dengan data, mengidentifikasi masalah kualitas data, menemukan wawasan pertama ke dalam data, atau mendeteksi subset yang menarik untuk membentuk hipotesis untuk informasi tersembunyi.
Data Preparation- Tahap persiapan data mencakup semua kegiatan untuk membangun dataset akhir (data yang akan dimasukkan ke dalam alat pemodelan) dari data mentah awal. Tugas persiapan data mungkin dilakukan beberapa kali, dan tidak dalam urutan yang ditentukan. Tugas termasuk pemilihan tabel, catatan, dan atribut serta transformasi dan pembersihan data untuk alat pemodelan.
Modeling- Dalam fase ini, berbagai teknik pemodelan dipilih dan diterapkan dan parameternya dikalibrasi ke nilai optimal. Biasanya, ada beberapa teknik untuk jenis masalah data mining yang sama. Beberapa teknik memiliki persyaratan khusus berupa datanya. Oleh karena itu, sering kali diperlukan untuk mundur ke tahap persiapan data.
Evaluation- Pada tahap proyek ini, Anda telah membangun model (atau model) yang tampaknya memiliki kualitas tinggi, dari perspektif analisis data. Sebelum melanjutkan ke penerapan akhir model, penting untuk mengevaluasi model secara menyeluruh dan meninjau langkah-langkah yang dilakukan untuk membangun model, untuk memastikan model tersebut mencapai tujuan bisnis dengan benar.
Tujuan utamanya adalah untuk menentukan apakah ada beberapa masalah bisnis penting yang belum dipertimbangkan secara memadai. Di akhir fase ini, keputusan tentang penggunaan hasil data mining harus dibuat.
Deployment- Penciptaan model umumnya bukanlah akhir dari proyek. Meskipun tujuan model adalah untuk menambah pengetahuan tentang data, pengetahuan yang diperoleh perlu diatur dan disajikan dengan cara yang berguna bagi pelanggan.
Bergantung pada persyaratannya, fase penerapan dapat sesederhana membuat laporan atau serumit penerapan penilaian data berulang (misalnya alokasi segmen) atau proses penggalian data.
Dalam banyak kasus, ini akan menjadi pelanggan, bukan analis data, yang akan melakukan langkah-langkah penerapan. Bahkan jika analis menerapkan model, penting bagi pelanggan untuk memahami tindakan yang perlu dilakukan untuk benar-benar menggunakan model yang dibuat.
Metodologi SEMMA
SEMMA adalah metodologi lain yang dikembangkan oleh SAS untuk pemodelan data mining. Itu singkatanScukup, Explore, MOdify, Model, dan Asses. Berikut adalah deskripsi singkat tahapannya -
Sample- Prosesnya dimulai dengan pengambilan sampel data, misalnya memilih dataset untuk pemodelan. Dataset harus cukup besar untuk memuat informasi yang memadai untuk diambil, namun cukup kecil untuk digunakan secara efisien. Fase ini juga berhubungan dengan partisi data.
Explore - Fase ini mencakup pemahaman data dengan menemukan hubungan yang diantisipasi dan tak terduga antara variabel, dan juga kelainan, dengan bantuan visualisasi data.
Modify - Fase Modifikasi berisi metode untuk memilih, membuat dan mengubah variabel dalam persiapan untuk pemodelan data.
Model - Pada fase Model, fokusnya adalah menerapkan berbagai teknik pemodelan (data mining) pada variabel yang disiapkan untuk membuat model yang mungkin memberikan hasil yang diinginkan.
Assess - Evaluasi hasil pemodelan menunjukkan keandalan dan kegunaan model yang dibuat.
Perbedaan utama antara CRISM-DM dan SEMMA adalah SEMMA berfokus pada aspek pemodelan, sedangkan CRISP-DM lebih mementingkan tahapan siklus sebelum pemodelan seperti memahami masalah bisnis yang akan diselesaikan, memahami dan memproses data yang akan diproses. digunakan sebagai masukan, misalnya, algoritme pembelajaran mesin.
Siklus Hidup Big Data
Dalam konteks data besar saat ini, pendekatan sebelumnya tidak lengkap atau kurang optimal. Misalnya, metodologi SEMMA mengabaikan sepenuhnya pengumpulan data dan pemrosesan awal dari sumber data yang berbeda. Tahapan ini biasanya merupakan sebagian besar pekerjaan dalam proyek data besar yang sukses.
Siklus analitik data besar dapat dijelaskan dengan tahap berikut -
- Definisi Masalah Bisnis
- Research
- Penilaian Sumber Daya Manusia
- Akuisisi Data
- Data Munging
- Penyimpanan data
- Analisis Data Eksplorasi
- Persiapan Data untuk Pemodelan dan Penilaian
- Modeling
- Implementation
Di bagian ini, kami akan menyoroti masing-masing tahapan siklus hidup data besar ini.
Definisi Masalah Bisnis
Ini adalah poin yang umum dalam BI tradisional dan siklus hidup analitik data besar. Biasanya, ini adalah tahap non-sepele dari proyek data besar untuk menentukan masalah dan mengevaluasi dengan benar seberapa besar potensi keuntungan yang mungkin dimilikinya untuk suatu organisasi. Tampaknya jelas untuk menyebutkan hal ini, tetapi harus dievaluasi berapa keuntungan dan biaya yang diharapkan dari proyek tersebut.
Penelitian
Analisis apa yang telah dilakukan perusahaan lain dalam situasi yang sama. Ini melibatkan mencari solusi yang masuk akal untuk perusahaan Anda, meskipun itu melibatkan penyesuaian solusi lain dengan sumber daya dan persyaratan yang dimiliki perusahaan Anda. Dalam tahap ini, metodologi untuk tahap-tahap selanjutnya harus ditentukan.
Penilaian Sumber Daya Manusia
Setelah masalah ditentukan, masuk akal untuk melanjutkan analisis jika staf saat ini dapat menyelesaikan proyek dengan sukses. Tim BI tradisional mungkin tidak mampu memberikan solusi yang optimal untuk semua tahapan, jadi ini harus dipertimbangkan sebelum memulai proyek jika ada kebutuhan untuk melakukan outsourcing sebagian dari proyek atau mempekerjakan lebih banyak orang.
Akuisisi Data
Bagian ini adalah kunci dalam siklus hidup data besar; ini menentukan jenis profil yang diperlukan untuk mengirimkan produk data yang dihasilkan. Pengumpulan data adalah langkah proses yang tidak sepele; biasanya melibatkan pengumpulan data tidak terstruktur dari sumber yang berbeda. Sebagai contoh, ini bisa melibatkan penulisan crawler untuk mengambil ulasan dari situs web. Ini melibatkan berurusan dengan teks, mungkin dalam bahasa berbeda yang biasanya membutuhkan banyak waktu untuk diselesaikan.
Data Munging
Setelah data diambil, misalnya dari web, perlu disimpan dalam format yang mudah digunakan. Untuk melanjutkan dengan contoh tinjauan, anggaplah data diambil dari situs berbeda yang masing-masing memiliki tampilan data yang berbeda.
Misalkan satu sumber data memberikan ulasan dalam hal peringkat dalam bintang, oleh karena itu dimungkinkan untuk membaca ini sebagai pemetaan untuk variabel respons y ∈ {1, 2, 3, 4, 5}. Sumber data lain memberikan review dengan menggunakan sistem dua panah, satu untuk up voting dan satunya lagi untuk down voting. Ini akan menyiratkan variabel respons dari formuliry ∈ {positive, negative}.
Untuk menggabungkan kedua sumber data, keputusan harus dibuat agar kedua representasi respons ini setara. Hal ini dapat melibatkan konversi representasi respons sumber data pertama ke bentuk kedua, dengan mempertimbangkan satu bintang sebagai negatif dan lima bintang sebagai positif. Proses ini seringkali membutuhkan alokasi waktu yang besar agar dapat disampaikan dengan kualitas yang baik.
Penyimpanan data
Setelah data diproses, terkadang perlu disimpan dalam database. Teknologi data besar menawarkan banyak alternatif terkait hal ini. Alternatif yang paling umum adalah menggunakan Sistem File Hadoop untuk penyimpanan yang menyediakan pengguna SQL versi terbatas, yang dikenal sebagai Bahasa Kueri HIVE. Hal ini memungkinkan sebagian besar tugas analitik dilakukan dengan cara yang sama seperti yang akan dilakukan di gudang data BI tradisional, dari perspektif pengguna. Opsi penyimpanan lain yang perlu dipertimbangkan adalah MongoDB, Redis, dan SPARK.
Tahapan siklus ini terkait dengan pengetahuan sumber daya manusia dalam hal kemampuan mereka untuk mengimplementasikan arsitektur yang berbeda. Versi modifikasi dari gudang data tradisional masih digunakan dalam aplikasi skala besar. Misalnya, teradata dan IBM menawarkan database SQL yang dapat menangani terabyte data; solusi open source seperti postgreSQL dan MySQL masih digunakan untuk aplikasi skala besar.
Meskipun ada perbedaan dalam cara kerja penyimpanan yang berbeda di latar belakang, dari sisi klien, sebagian besar solusi menyediakan API SQL. Karenanya, memiliki pemahaman yang baik tentang SQL masih merupakan keterampilan utama yang harus dimiliki untuk analitik data besar.
Tahap apriori ini tampaknya menjadi topik yang paling penting, dalam praktiknya, ini tidak benar. Ini bahkan bukan tahap yang penting. Sangat mungkin untuk mengimplementasikan solusi data besar yang akan bekerja dengan data waktu nyata, jadi dalam hal ini, kita hanya perlu mengumpulkan data untuk mengembangkan model dan kemudian mengimplementasikannya secara waktu nyata. Jadi tidak perlu menyimpan data secara formal sama sekali.
Analisis Data Eksplorasi
Setelah data dibersihkan dan disimpan sedemikian rupa sehingga wawasan dapat diambil darinya, fase eksplorasi data wajib dilakukan. Tahapan ini bertujuan untuk memahami data yang biasanya dilakukan dengan teknik statistik dan juga memplot data. Ini adalah tahap yang baik untuk mengevaluasi apakah definisi masalah masuk akal atau layak.
Persiapan Data untuk Pemodelan dan Penilaian
Tahap ini melibatkan pembentukan kembali data dibersihkan yang diambil sebelumnya dan menggunakan prapemrosesan statistik untuk imputasi nilai yang hilang, deteksi outlier, normalisasi, ekstraksi fitur dan pemilihan fitur.
Pemodelan
Tahap sebelumnya harus sudah menghasilkan beberapa dataset untuk pelatihan dan pengujian, misalnya model prediktif. Tahap ini melibatkan mencoba model yang berbeda dan berharap dapat memecahkan masalah bisnis yang dihadapi. Dalam praktiknya, biasanya model tersebut diharapkan akan memberikan beberapa wawasan tentang bisnis. Terakhir, model atau kombinasi model terbaik dipilih untuk mengevaluasi kinerjanya pada set data yang tertinggal.
Penerapan
Pada tahap ini produk data yang dikembangkan diimplementasikan dalam pipeline data perusahaan. Ini melibatkan pengaturan skema validasi saat produk data bekerja, untuk melacak kinerjanya. Misalnya, dalam kasus penerapan model prediktif, tahap ini akan melibatkan penerapan model ke data baru dan setelah respons tersedia, evaluasi model.