Desain Penyusun - Analisis Semantik
Kami telah mempelajari bagaimana parser membuat pohon parse dalam fase analisis sintaks. Parse-tree biasa yang dibangun dalam fase itu umumnya tidak berguna bagi kompiler, karena tidak membawa informasi apa pun tentang cara mengevaluasi hierarki tersebut. Produksi tata bahasa bebas konteks, yang membuat aturan-aturan bahasa, tidak mengakomodasi cara menafsirkannya.
Sebagai contoh
E → E + TProduksi CFG di atas tidak memiliki aturan semantik yang terkait dengannya, dan tidak dapat membantu dalam memahami produksi.
Semantik
Semantik suatu bahasa memberi arti pada konstruksinya, seperti token dan struktur sintaksis. Semantik membantu menafsirkan simbol, tipenya, dan hubungannya satu sama lain. Analisis semantik menilai apakah struktur sintaks yang dibangun dalam program sumber memiliki arti atau tidak.
CFG + semantic rules = Syntax Directed DefinitionsSebagai contoh:
int a = “value”;seharusnya tidak mengeluarkan kesalahan dalam tahap analisis leksikal dan sintaksis, karena secara leksikal dan struktural benar, tetapi harus menghasilkan kesalahan semantik karena jenis tugas berbeda. Aturan-aturan ini ditetapkan oleh tata bahasa dan dievaluasi dalam analisis semantik. Tugas berikut harus dilakukan dalam analisis semantik:
- Resolusi lingkup
- Ketik pemeriksaan
- Pemeriksaan terikat larik
Kesalahan Semantik
Kami telah menyebutkan beberapa kesalahan semantik yang diharapkan dapat dikenali oleh penganalisis semantik:
- Jenis tidak cocok
- Variabel tidak dideklarasikan
- Penyalahgunaan pengenal cadangan.
- Beberapa deklarasi variabel dalam satu ruang lingkup.
- Mengakses variabel di luar cakupan.
- Ketidakcocokan parameter aktual dan formal.
Atribut Tata Bahasa
Tata bahasa atribut adalah bentuk khusus tata bahasa bebas konteks di mana beberapa informasi tambahan (atribut) ditambahkan ke satu atau lebih non-terminalnya untuk memberikan informasi yang peka konteks. Setiap atribut memiliki domain nilai yang terdefinisi dengan baik, seperti integer, float, karakter, string, dan ekspresi.
Atribut tata bahasa adalah media untuk memberikan semantik ke tata bahasa bebas konteks dan dapat membantu menentukan sintaks dan semantik bahasa pemrograman. Atribut grammar (jika dilihat sebagai parse-tree) dapat mengirimkan nilai atau informasi di antara node dari sebuah pohon.
Example:
E → E + T { E.value = E.value + T.value }Bagian kanan CFG berisi aturan semantik yang menentukan bagaimana tata bahasa harus diinterpretasikan. Di sini, nilai non-terminal E dan T dijumlahkan dan hasilnya disalin ke non-terminal E.
Atribut semantik dapat ditetapkan ke nilainya dari domain mereka pada saat penguraian dan dievaluasi pada saat penugasan atau kondisi. Berdasarkan cara atribut mendapatkan nilainya, atribut secara luas dapat dibagi menjadi dua kategori: atribut yang disintesiskan dan atribut yang diwariskan.
Atribut yang disintesis
Atribut ini mendapatkan nilai dari nilai atribut node turunannya. Sebagai ilustrasi, asumsikan produksi berikut:
S → ABCJika S mengambil nilai dari simpul anaknya (A, B, C), maka itu dikatakan sebagai atribut yang disintesis, karena nilai ABC disintesiskan ke S.
Seperti pada contoh kita sebelumnya (E → E + T), simpul induk E mendapatkan nilainya dari simpul anaknya. Atribut yang disintesis tidak pernah mengambil nilai dari node induknya atau node saudaranya.
Atribut yang diwarisi
Berbeda dengan atribut yang disintesis, atribut yang diwariskan dapat mengambil nilai dari induk dan / atau saudara kandung. Seperti pada produksi berikut ini,
S → ABCA bisa mendapatkan nilai dari S, B dan C. B bisa mengambil nilai dari S, A, dan C. Begitu juga, C bisa mengambil nilai dari S, A, dan B.
Expansion : Ketika sebuah non-terminal diperluas ke terminal sesuai dengan aturan tata bahasa
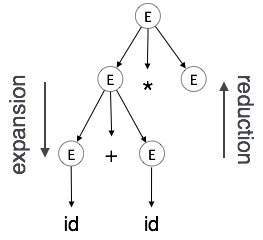
Reduction: Ketika sebuah terminal direduksi menjadi non-terminal yang sesuai menurut aturan tata bahasa. Pohon sintaks diuraikan dari atas ke bawah dan dari kiri ke kanan. Setiap kali reduksi terjadi, kami menerapkan aturan semantik yang sesuai (tindakan).
Analisis semantik menggunakan Syntax Directed Translations untuk melakukan tugas-tugas di atas.
Penganalisis semantik menerima AST (Abstract Syntax Tree) dari tahap sebelumnya (analisis sintaks).
Penganalisis semantik melampirkan informasi atribut dengan AST, yang disebut AST Atribut.
Atribut adalah dua nilai tuple, <nama atribut, nilai atribut>
Sebagai contoh:
int value = 5;
<type, “integer”>
<presentvalue, “5”>Untuk setiap produksi, kami melampirkan aturan semantik.
SDT dengan atribut S.
Jika SDT hanya menggunakan atribut yang disintesis, itu disebut sebagai SDT yang dikaitkan dengan S. Atribut ini dievaluasi menggunakan SDT yang diatribusikan S yang tindakan semantiknya ditulis setelah produksi (sisi kanan).
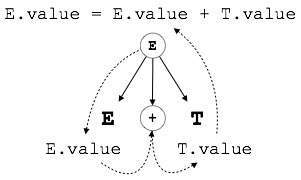
Seperti yang digambarkan di atas, atribut dalam SDT dengan atribut S dievaluasi dalam penguraian bottom-up, karena nilai node induk bergantung pada nilai node turunan.
SDT dengan atribut L.
Bentuk SDT ini menggunakan atribut yang disintesis dan diwariskan dengan batasan untuk tidak mengambil nilai dari saudara kanan.
Dalam SDT yang diatribusikan L, non-terminal bisa mendapatkan nilai dari node induk, anak, dan saudara kandungnya. Seperti pada produksi berikutnya
S → ABCS dapat mengambil nilai dari A, B, dan C (disintesis). A dapat mengambil nilai dari S saja. B bisa mengambil nilai dari S dan A. C bisa mendapatkan nilai dari S, A, dan B. Tidak ada non-terminal yang bisa mendapatkan nilai dari sibling ke kanannya.
Atribut dalam SDT yang diatribusikan L dievaluasi dengan cara penguraian kedalaman-pertama dan kiri-ke-kanan.
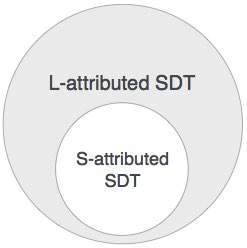
Kita dapat menyimpulkan bahwa jika suatu definisi diberi atribut S, maka definisi tersebut juga diberi atribut L karena definisi atribut L menyertakan definisi atribut S.