Elasticsearch - Panduan Cepat
Elasticsearch adalah server pencarian berbasis Apache Lucene. Ini dikembangkan oleh Shay Banon dan diterbitkan pada tahun 2010. Sekarang dikelola oleh Elasticsearch BV. Versi terbaru adalah 7.0.0.
Elasticsearch adalah mesin analitik dan pencarian teks lengkap terdistribusi dan open source. Ini dapat diakses dari antarmuka layanan web RESTful dan menggunakan dokumen JSON (JavaScript Object Notation) tanpa skema untuk menyimpan data. Itu dibangun di atas bahasa pemrograman Java dan karenanya Elasticsearch dapat berjalan di platform yang berbeda. Ini memungkinkan pengguna untuk menjelajahi sejumlah besar data dengan kecepatan sangat tinggi.
Fitur Umum
Fitur umum Elasticsearch adalah sebagai berikut -
Elasticsearch dapat diskalakan hingga petabyte data terstruktur dan tidak terstruktur.
Elasticsearch dapat digunakan sebagai pengganti penyimpanan dokumen seperti MongoDB dan RavenDB.
Elasticsearch menggunakan denormalisasi untuk meningkatkan kinerja pencarian.
Elasticsearch adalah salah satu mesin pencari perusahaan yang populer, dan saat ini digunakan oleh banyak organisasi besar seperti Wikipedia, The Guardian, StackOverflow, GitHub, dll.
Elasticsearch adalah open source dan tersedia di bawah lisensi Apache versi 2.0.
Konsep Utama
Konsep utama Elasticsearch adalah sebagai berikut -
Node
Ini mengacu pada satu contoh Elasticsearch yang sedang berjalan. Server fisik dan virtual tunggal mengakomodasi banyak node tergantung pada kemampuan sumber daya fisiknya seperti RAM, penyimpanan, dan daya pemrosesan.
Gugus
Ini adalah kumpulan dari satu atau lebih node. Cluster menyediakan pengindeksan kolektif dan kemampuan pencarian di semua node untuk seluruh data.
Indeks
Ini adalah kumpulan berbagai jenis dokumen dan propertinya. Indeks juga menggunakan konsep pecahan untuk meningkatkan kinerja. Misalnya, sekumpulan dokumen berisi data aplikasi jejaring sosial.
Dokumen
Ini adalah kumpulan bidang dengan cara tertentu yang ditentukan dalam format JSON. Setiap dokumen termasuk dalam suatu tipe dan berada di dalam indeks. Setiap dokumen dikaitkan dengan pengenal unik yang disebut UID.
Beling
Indeks dibagi secara horizontal menjadi pecahan. Ini berarti setiap pecahan berisi semua properti dokumen tetapi berisi lebih sedikit objek JSON daripada indeks. Pemisahan horizontal membuat shard menjadi node independen, yang dapat disimpan di node mana pun. Pecahan utama adalah bagian horizontal asli dari sebuah indeks dan kemudian pecahan utama ini direplikasi menjadi pecahan replika.
Replika
Elasticsearch memungkinkan pengguna membuat replika indeks dan shard mereka. Replikasi tidak hanya membantu dalam meningkatkan ketersediaan data jika terjadi kegagalan, tetapi juga meningkatkan kinerja pencarian dengan melakukan operasi pencarian paralel pada replika ini.
Keuntungan
Elasticsearch dikembangkan di Java, yang membuatnya kompatibel di hampir semua platform.
Elasticsearch bersifat waktu nyata, dengan kata lain setelah satu detik dokumen yang ditambahkan dapat dicari di mesin ini
Elasticsearch didistribusikan, yang memudahkan penskalaan dan integrasi di organisasi besar mana pun.
Membuat cadangan penuh mudah dilakukan dengan menggunakan konsep gateway, yang ada di Elasticsearch.
Menangani multi-tenancy sangat mudah di Elasticsearch jika dibandingkan dengan Apache Solr.
Elasticsearch menggunakan objek JSON sebagai respons, yang memungkinkan untuk memanggil server Elasticsearch dengan banyak bahasa pemrograman berbeda.
Elasticsearch mendukung hampir semua jenis dokumen kecuali yang tidak mendukung rendering teks.
Kekurangan
Elasticsearch tidak memiliki dukungan multi-bahasa dalam hal penanganan data permintaan dan respons (hanya mungkin di JSON) tidak seperti di Apache Solr, yang memungkinkan dalam format CSV, XML, dan JSON.
Kadang-kadang, Elasticsearch mengalami masalah situasi otak terbelah.
Perbandingan antara Elasticsearch dan RDBMS
Di Elasticsearch, indeks mirip dengan tabel di RDBMS (Relation Database Management System). Setiap tabel adalah kumpulan baris seperti setiap indeks adalah kumpulan dokumen di Elasticsearch.
Tabel berikut memberikan perbandingan langsung antara suku-suku ini−
| Elasticsearch | RDBMS |
|---|---|
| Gugus | Database |
| Beling | Beling |
| Indeks | Meja |
| Bidang | Kolom |
| Dokumen | Baris |
Pada bab ini, kita akan memahami prosedur instalasi Elasticsearch secara detail.
Untuk menginstal Elasticsearch di komputer lokal Anda, Anda harus mengikuti langkah-langkah yang diberikan di bawah ini -
Step 1- Periksa versi java yang diinstal di komputer Anda. Ini harus java 7 atau lebih tinggi. Anda dapat memeriksanya dengan melakukan hal berikut -
Di Sistem Operasi Windows (OS) (menggunakan command prompt) -
> java -versionDi UNIX OS (Menggunakan Terminal) -
$ echo $JAVA_HOMEStep 2 - Bergantung pada sistem operasi Anda, unduh Elasticsearch dari www.elastic.co seperti yang disebutkan di bawah -
Untuk OS windows, unduh file ZIP.
Untuk UNIX OS, unduh file TAR.
Untuk Debian OS, unduh file DEB.
Untuk Red Hat dan distribusi Linux lainnya, unduh file RPN.
Utilitas APT dan Yum juga dapat digunakan untuk menginstal Elasticsearch di banyak distribusi Linux.
Step 3 - Proses instalasi untuk Elasticsearch sederhana dan dijelaskan di bawah untuk OS yang berbeda -
Windows OS- Buka zip paket zip dan Elasticsearch diinstal.
UNIX OS- Ekstrak file tar di lokasi mana pun dan Elasticsearch diinstal.
$wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch7.0.0-linux-x86_64.tar.gz $tar -xzf elasticsearch-7.0.0-linux-x86_64.tar.gzUsing APT utility for Linux OS- Unduh dan pasang Kunci Penandatanganan Publik
$ wget -qo - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo
apt-key add -Simpan definisi repositori seperti yang ditunjukkan di bawah ini -
$ echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" |
sudo tee -a /etc/apt/sources.list.d/elastic-7.x.listJalankan pembaruan menggunakan perintah berikut -
$ sudo apt-get updateSekarang Anda dapat menginstal dengan menggunakan perintah berikut -
$ sudo apt-get install elasticsearchDownload and install the Debian package manually using the command given here −
$wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch7.0.0-amd64.deb $sudo dpkg -i elasticsearch-7.0.0-amd64.deb0Using YUM utility for Debian Linux OS
Unduh dan pasang Kunci Penandatanganan Publik -
$ rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearchTAMBAHKAN teks berikut dalam file dengan akhiran .repo di direktori “/etc/yum.repos.d/” Anda. Misalnya, elasticsearch.repo
elasticsearch-7.x]
name=Elasticsearch repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-mdSekarang Anda dapat menginstal Elasticsearch dengan menggunakan perintah berikut
sudo yum install elasticsearchStep 4- Buka direktori home Elasticsearch dan di dalam folder bin. Jalankan file elasticsearch.bat dalam kasus Windows atau Anda dapat melakukan hal yang sama menggunakan command prompt dan melalui terminal dalam kasus file UNIX rum Elasticsearch.
Di Windows
> cd elasticsearch-2.1.0/bin
> elasticsearchDi Linux
$ cd elasticsearch-2.1.0/bin
$ ./elasticsearchNote - Dalam kasus windows, Anda mungkin mendapatkan kesalahan yang menyatakan JAVA_HOME tidak disetel, harap setel di variabel lingkungan ke "C: \ Program Files \ Java \ jre1.8.0_31" atau lokasi tempat Anda menginstal java.
Step 5- Port default untuk antarmuka web Elasticsearch adalah 9200 atau Anda dapat mengubahnya dengan mengubah http.port di dalam file elasticsearch.yml yang ada di direktori bin. Anda dapat memeriksa apakah server aktif dan berjalan dengan menjelajahhttp://localhost:9200. Ini akan mengembalikan objek JSON, yang berisi informasi tentang Elasticsearch yang diinstal dengan cara berikut -
{
"name" : "Brain-Child",
"cluster_name" : "elasticsearch", "version" : {
"number" : "2.1.0",
"build_hash" : "72cd1f1a3eee09505e036106146dc1949dc5dc87",
"build_timestamp" : "2015-11-18T22:40:03Z",
"build_snapshot" : false,
"lucene_version" : "5.3.1"
},
"tagline" : "You Know, for Search"
}Step 6- Pada langkah ini, mari kita instal Kibana. Ikuti kode masing-masing yang diberikan di bawah ini untuk menginstal di Linux dan Windows -
For Installation on Linux −
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.0.0-linuxx86_64.tar.gz
tar -xzf kibana-7.0.0-linux-x86_64.tar.gz
cd kibana-7.0.0-linux-x86_64/
./bin/kibanaFor Installation on Windows −
Unduh Kibana untuk Windows dari https://www.elastic.co/products/kibana. Setelah Anda mengklik tautan tersebut, Anda akan menemukan halaman beranda seperti yang ditunjukkan di bawah ini -
Buka zip dan buka direktori home Kibana lalu jalankan.
CD c:\kibana-7.0.0-windows-x86_64
.\bin\kibana.batDi bab ini, mari kita pelajari cara menambahkan beberapa indeks, pemetaan, dan data ke Elasticsearch. Perhatikan bahwa sebagian dari data ini akan digunakan dalam contoh yang dijelaskan dalam tutorial ini.
Buat Indeks
Anda dapat menggunakan perintah berikut untuk membuat indeks -
PUT schoolTanggapan
Jika indeks dibuat, Anda dapat melihat output berikut -
{"acknowledged": true}Tambahkan data
Elasticsearch akan menyimpan dokumen yang kami tambahkan ke indeks seperti yang ditunjukkan pada kode berikut. Dokumen tersebut diberi beberapa ID yang digunakan untuk mengidentifikasi dokumen tersebut.
Badan Permintaan
POST school/_doc/10
{
"name":"Saint Paul School", "description":"ICSE Afiliation",
"street":"Dawarka", "city":"Delhi", "state":"Delhi", "zip":"110075",
"location":[28.5733056, 77.0122136], "fees":5000,
"tags":["Good Faculty", "Great Sports"], "rating":"4.5"
}Tanggapan
{
"_index" : "school",
"_type" : "_doc",
"_id" : "10",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}Di sini, kami menambahkan dokumen serupa lainnya.
POST school/_doc/16
{
"name":"Crescent School", "description":"State Board Affiliation",
"street":"Tonk Road",
"city":"Jaipur", "state":"RJ", "zip":"176114","location":[26.8535922,75.7923988],
"fees":2500, "tags":["Well equipped labs"], "rating":"4.5"
}Tanggapan
{
"_index" : "school",
"_type" : "_doc",
"_id" : "16",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 9,
"_primary_term" : 7
}Dengan cara ini, kami akan terus menambahkan data contoh apa pun yang kami perlukan untuk pekerjaan kami di bab-bab selanjutnya.
Menambahkan Data Sampel di Kibana
Kibana adalah alat yang digerakkan oleh GUI untuk mengakses data dan membuat visualisasi. Di bagian ini, mari kita pahami bagaimana kita bisa menambahkan data sampel ke dalamnya.
Di beranda Kibana, pilih opsi berikut untuk menambahkan contoh data e-niaga -
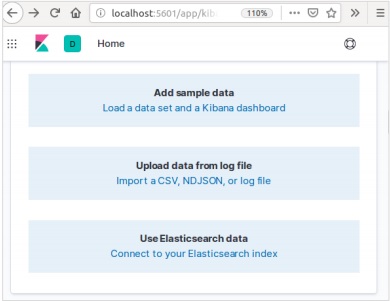
Layar berikutnya akan menampilkan beberapa visualisasi dan tombol untuk Menambahkan data -
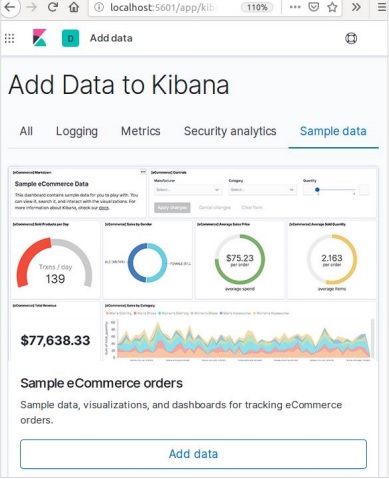
Mengklik Add Data akan menampilkan layar berikut yang mengonfirmasi bahwa data telah ditambahkan ke indeks bernama eCommerce.
Di sistem atau perangkat lunak apa pun, ketika kami meningkatkan ke versi yang lebih baru, kami perlu mengikuti beberapa langkah untuk mempertahankan pengaturan aplikasi, konfigurasi, data, dan hal-hal lain. Langkah-langkah ini diperlukan untuk membuat aplikasi stabil di sistem baru atau untuk menjaga integritas data (mencegah data rusak).
Anda harus mengikuti langkah-langkah berikut untuk memutakhirkan Elasticsearch -
Baca dokumen Upgrade dari https://www.elastic.co/
Uji versi yang ditingkatkan di lingkungan non produksi Anda seperti di lingkungan UAT, E2E, SIT, atau DEV.
Perhatikan bahwa rollback ke versi Elasticsearch sebelumnya tidak dapat dilakukan tanpa backup data. Karenanya, backup data disarankan sebelum meningkatkan ke versi yang lebih tinggi.
Kita dapat meningkatkan menggunakan restart cluster penuh atau upgrade bergulir. Upgrade bergulir untuk versi baru. Perhatikan bahwa tidak ada penghentian layanan, saat Anda menggunakan metode peningkatan bertahap untuk migrasi.
Langkah-langkah untuk Upgrade
Uji upgrade di lingkungan dev sebelum mengupgrade cluster produksi Anda.
Cadangkan data Anda. Anda tidak dapat memutar kembali ke versi sebelumnya kecuali Anda memiliki snapshot dari data Anda.
Pertimbangkan untuk menutup tugas pembelajaran mesin sebelum Anda memulai proses peningkatan. Meskipun tugas pembelajaran mesin dapat terus berjalan selama peningkatan berkelanjutan, hal itu meningkatkan biaya tambahan pada kluster selama proses peningkatan.
Tingkatkan komponen Elastic Stack Anda dengan urutan sebagai berikut -
- Elasticsearch
- Kibana
- Logstash
- Beats
- Server APM
Mengupgrade dari 6.6 atau Sebelumnya
Untuk memutakhirkan langsung ke Elasticsearch 7.1.0 dari versi 6.0-6.6, Anda harus mengindeks ulang indeks 5.x apa pun secara manual yang perlu Anda teruskan, dan melakukan restart cluster penuh.
Mulai Ulang Cluster Penuh
Proses restart cluster penuh melibatkan mematikan setiap node di cluster, meningkatkan setiap node menjadi 7x dan kemudian memulai ulang cluster.
Berikut adalah langkah-langkah tingkat tinggi yang perlu dilakukan untuk memulai ulang cluster penuh -
- Nonaktifkan alokasi pecahan
- Hentikan pengindeksan dan lakukan pembersihan tersinkronisasi
- Matikan semua node
- Tingkatkan semua node
- Tingkatkan semua plugin
- Mulai setiap node yang ditingkatkan
- Tunggu semua node bergabung dengan cluster dan laporkan status kuning
- Aktifkan kembali alokasi
Setelah alokasi diaktifkan kembali, cluster mulai mengalokasikan pecahan replika ke node data. Pada titik ini, aman untuk melanjutkan pengindeksan dan pencarian, tetapi cluster Anda akan pulih lebih cepat jika Anda dapat menunggu hingga semua pecahan utama dan replika berhasil dialokasikan dan status semua node berwarna hijau.
Application Programming Interface (API) dalam web adalah sekumpulan panggilan fungsi atau instruksi pemrograman lainnya untuk mengakses komponen perangkat lunak dalam aplikasi web tersebut. Misalnya, API Facebook membantu pengembang membuat aplikasi dengan mengakses data atau fungsi lain dari Facebook; itu bisa berupa tanggal lahir atau pembaruan status.
Elasticsearch menyediakan REST API, yang diakses oleh JSON melalui HTTP. Elasticsearch menggunakan beberapa konvensi yang akan kita bahas sekarang.
Beberapa Indeks
Sebagian besar operasi, terutama pencarian dan operasi lainnya, di API ditujukan untuk satu atau lebih dari satu indeks. Ini membantu pengguna untuk mencari di banyak tempat atau semua data yang tersedia hanya dengan mengeksekusi kueri satu kali. Banyak notasi berbeda digunakan untuk melakukan operasi dalam beberapa indeks. Kami akan membahas beberapa di antaranya di sini, di bab ini.
Notasi Dipisahkan Koma
POST /index1,index2,index3/_searchBadan Permintaan
{
"query":{
"query_string":{
"query":"any_string"
}
}
}Tanggapan
Objek JSON dari index1, index2, index3 memiliki any_string di dalamnya.
_all Kata Kunci untuk Semua Indeks
POST /_all/_searchBadan Permintaan
{
"query":{
"query_string":{
"query":"any_string"
}
}
}Tanggapan
JSON objek dari semua indeks dan memiliki any_string di dalamnya.
Karakter pengganti (*, +, -)
POST /school*/_searchBadan Permintaan
{
"query":{
"query_string":{
"query":"CBSE"
}
}
}Tanggapan
JSON objek dari semua indeks yang dimulai dengan sekolah yang memiliki CBSE di dalamnya.
Sebagai alternatif, Anda juga dapat menggunakan kode berikut -
POST /school*,-schools_gov /_searchBadan Permintaan
{
"query":{
"query_string":{
"query":"CBSE"
}
}
}Tanggapan
Objek JSON dari semua indeks yang dimulai dengan "sekolah" tetapi tidak dari sekolah_gov dan memiliki CBSE di dalamnya.
Ada juga beberapa parameter string kueri URL -
- ignore_unavailable- Tidak ada kesalahan yang akan terjadi atau tidak ada operasi yang akan dihentikan, jika satu atau lebih indeks yang ada di URL tidak ada. Misalnya, indeks sekolah ada, tetapi toko buku tidak ada.
POST /school*,book_shops/_searchBadan Permintaan
{
"query":{
"query_string":{
"query":"CBSE"
}
}
}Badan Permintaan
{
"error":{
"root_cause":[{
"type":"index_not_found_exception", "reason":"no such index",
"resource.type":"index_or_alias", "resource.id":"book_shops",
"index":"book_shops"
}],
"type":"index_not_found_exception", "reason":"no such index",
"resource.type":"index_or_alias", "resource.id":"book_shops",
"index":"book_shops"
},"status":404
}Perhatikan kode berikut -
POST /school*,book_shops/_search?ignore_unavailable = trueBadan Permintaan
{
"query":{
"query_string":{
"query":"CBSE"
}
}
}Respon (tidak ada kesalahan)
JSON objek dari semua indeks yang dimulai dengan sekolah yang memiliki CBSE di dalamnya.
allow_no_indices
truenilai parameter ini akan mencegah kesalahan, jika URL dengan karakter pengganti tidak menghasilkan indeks. Misalnya, tidak ada indeks yang dimulai dengan sekolah_sekolah -
POST /schools_pri*/_search?allow_no_indices = trueBadan Permintaan
{
"query":{
"match_all":{}
}
}Respon (Tidak ada kesalahan)
{
"took":1,"timed_out": false, "_shards":{"total":0, "successful":0, "failed":0},
"hits":{"total":0, "max_score":0.0, "hits":[]}
}expand_wildcards
Parameter ini memutuskan apakah karakter pengganti perlu diperluas untuk membuka indeks atau indeks tertutup atau melakukan keduanya. Nilai parameter ini bisa terbuka dan tertutup atau tidak ada dan semuanya.
Misalnya, sekolah indeks dekat -
POST /schools/_closeTanggapan
{"acknowledged":true}Perhatikan kode berikut -
POST /school*/_search?expand_wildcards = closedBadan Permintaan
{
"query":{
"match_all":{}
}
}Tanggapan
{
"error":{
"root_cause":[{
"type":"index_closed_exception", "reason":"closed", "index":"schools"
}],
"type":"index_closed_exception", "reason":"closed", "index":"schools"
}, "status":403
}Tanggal Dukungan Matematika dalam Nama Indeks
Elasticsearch menawarkan fungsionalitas untuk mencari indeks menurut tanggal dan waktu. Kami perlu menentukan tanggal dan waktu dalam format tertentu. Misalnya, accountdetail-2015.12.30, indeks akan menyimpan rincian rekening bank pada tanggal 30 Desember 2015. Operasi matematika dapat dilakukan untuk mendapatkan rincian untuk tanggal tertentu atau rentang tanggal dan waktu.
Format untuk nama indeks matematika tanggal -
<static_name{date_math_expr{date_format|time_zone}}>
/<accountdetail-{now-2d{YYYY.MM.dd|utc}}>/_searchstatic_name adalah bagian dari ekspresi yang tetap sama di setiap indeks matematika tanggal seperti detail akun. date_math_expr berisi ekspresi matematika yang menentukan tanggal dan waktu secara dinamis seperti now-2d. date_format berisi format di mana tanggal ditulis dalam indeks seperti YYYY.MM.dd. Jika tanggal hari ini adalah 30 Desember 2015, maka <accountdetail- {now-2d {YYYY.MM.dd}}> akan mengembalikan accountdetail-2015.12.28.
| Ekspresi | Memutuskan untuk |
|---|---|
| <accountdetail- {now-d}> | akundetail-2015.12.29 |
| <accountdetail- {now-M}> | accountdetail-2015.11.30 |
| <accountdetail- {sekarang {YYYY.MM}}> | akundetail-2015.12 |
Kami sekarang akan melihat beberapa opsi umum yang tersedia di Elasticsearch yang dapat digunakan untuk mendapatkan respons dalam format tertentu.
Hasil Cantik
Kita bisa mendapatkan respons dalam objek JSON yang diformat dengan baik hanya dengan menambahkan parameter kueri URL, yaitu pretty = true.
POST /schools/_search?pretty = trueBadan Permintaan
{
"query":{
"match_all":{}
}
}Tanggapan
……………………..
{
"_index" : "schools", "_type" : "school", "_id" : "1", "_score" : 1.0,
"_source":{
"name":"Central School", "description":"CBSE Affiliation",
"street":"Nagan", "city":"paprola", "state":"HP", "zip":"176115",
"location": [31.8955385, 76.8380405], "fees":2000,
"tags":["Senior Secondary", "beautiful campus"], "rating":"3.5"
}
}
………………….Output yang Dapat Dibaca Manusia
Opsi ini dapat mengubah respons statistik baik menjadi bentuk yang dapat dibaca manusia (Jika manusia = benar) atau bentuk yang dapat dibaca komputer (jika manusia = salah). Sebagai contoh, jika human = true maka distance_kilometer = 20KM dan jika human = false maka distance_meter = 20000, saat respon perlu digunakan oleh program komputer lain.
Filter Respon
Kita bisa memfilter respons ke lebih sedikit bidang dengan menambahkannya di parameter field_path. Sebagai contoh,
POST /schools/_search?filter_path = hits.totalBadan Permintaan
{
"query":{
"match_all":{}
}
}Tanggapan
{"hits":{"total":3}}Elasticsearch menyediakan API dokumen tunggal dan API multi-dokumen, di mana panggilan API masing-masing menargetkan satu dokumen dan beberapa dokumen.
Index API
Ini membantu untuk menambah atau memperbarui dokumen JSON dalam indeks ketika permintaan dibuat ke indeks masing-masing dengan pemetaan tertentu. Misalnya, permintaan berikut akan menambahkan objek JSON ke sekolah indeks dan di bawah pemetaan sekolah -
PUT schools/_doc/5
{
name":"City School", "description":"ICSE", "street":"West End",
"city":"Meerut",
"state":"UP", "zip":"250002", "location":[28.9926174, 77.692485],
"fees":3500,
"tags":["fully computerized"], "rating":"4.5"
}Saat menjalankan kode di atas, kami mendapatkan hasil sebagai berikut -
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}Pembuatan Indeks Otomatis
Ketika permintaan dibuat untuk menambahkan objek JSON ke indeks tertentu dan jika indeks itu tidak ada, maka API ini secara otomatis membuat indeks tersebut dan juga pemetaan yang mendasari untuk objek JSON tersebut. Fungsionalitas ini dapat dinonaktifkan dengan mengubah nilai parameter berikut menjadi false, yang ada di file elasticsearch.yml.
action.auto_create_index:false
index.mapper.dynamic:falseAnda juga dapat membatasi pembuatan indeks secara otomatis, di mana hanya nama indeks dengan pola tertentu yang diperbolehkan dengan mengubah nilai parameter berikut -
action.auto_create_index:+acc*,-bank*Note - Di sini + menunjukkan diizinkan dan - menunjukkan tidak diizinkan.
Pembuatan versi
Elasticsearch juga menyediakan fasilitas kontrol versi. Kita dapat menggunakan parameter kueri versi untuk menentukan versi dokumen tertentu.
PUT schools/_doc/5?version=7&version_type=external
{
"name":"Central School", "description":"CBSE Affiliation", "street":"Nagan",
"city":"paprola", "state":"HP", "zip":"176115", "location":[31.8955385, 76.8380405],
"fees":2200, "tags":["Senior Secondary", "beautiful campus"], "rating":"3.3"
}Saat menjalankan kode di atas, kami mendapatkan hasil sebagai berikut -
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 7,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 1
}Pembuatan versi adalah proses waktu nyata dan tidak terpengaruh oleh operasi pencarian waktu nyata.
Ada dua jenis pembuatan versi yang paling penting -
Versi Internal
Pembuatan versi internal adalah versi default yang dimulai dengan 1 dan bertambah dengan setiap pembaruan, termasuk penghapusan.
Versi Eksternal
Ini digunakan ketika versi dokumen disimpan di sistem eksternal seperti sistem versi pihak ketiga. Untuk mengaktifkan fungsionalitas ini, kita perlu menyetel version_type ke external. Di sini Elasticsearch akan menyimpan nomor versi yang ditentukan oleh sistem eksternal dan tidak akan menaikkannya secara otomatis.
Jenis Operasi
Jenis operasi digunakan untuk memaksa operasi pembuatan. Ini membantu untuk menghindari penimpaan dokumen yang sudah ada.
PUT chapter/_doc/1?op_type=create
{
"Text":"this is chapter one"
}Saat menjalankan kode di atas, kami mendapatkan hasil sebagai berikut -
{
"_index" : "chapter",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}Pembuatan ID otomatis
Ketika ID tidak ditentukan dalam operasi indeks, maka Elasticsearch secara otomatis menghasilkan id untuk dokumen itu.
POST chapter/_doc/
{
"user" : "tpoint",
"post_date" : "2018-12-25T14:12:12",
"message" : "Elasticsearch Tutorial"
}Saat menjalankan kode di atas, kami mendapatkan hasil sebagai berikut -
{
"_index" : "chapter",
"_type" : "_doc",
"_id" : "PVghWGoB7LiDTeV6LSGu",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}Dapatkan API
API membantu mengekstrak tipe objek JSON dengan melakukan permintaan get untuk dokumen tertentu.
pre class="prettyprint notranslate" > GET schools/_doc/5Saat menjalankan kode di atas, kami mendapatkan hasil sebagai berikut -
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 7,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
}Operasi ini real time dan tidak terpengaruh oleh refresh rate Indeks.
Anda juga dapat menentukan versinya, lalu Elasticsearch hanya akan mengambil versi dokumen itu.
Anda juga dapat menentukan _all dalam permintaan, sehingga Elasticsearch dapat mencari id dokumen itu di setiap jenis dan akan mengembalikan dokumen pertama yang cocok.
Anda juga dapat menentukan bidang yang Anda inginkan dalam hasil Anda dari dokumen tertentu itu.
GET schools/_doc/5?_source_includes=name,feesSaat menjalankan kode di atas, kami mendapatkan hasil sebagai berikut -
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 7,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"fees" : 2200,
"name" : "Central School"
}
}Anda juga dapat mengambil bagian sumber dalam hasil Anda dengan hanya menambahkan bagian _source di permintaan get Anda.
GET schools/_doc/5?_sourceSaat menjalankan kode di atas, kami mendapatkan hasil sebagai berikut -
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 7,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
}Anda juga dapat menyegarkan pecahan sebelum melakukan operasi get dengan menyetel parameter penyegaran ke true.
Hapus API
Anda dapat menghapus indeks, pemetaan, atau dokumen tertentu dengan mengirimkan permintaan HTTP DELETE ke Elasticsearch.
DELETE schools/_doc/4Saat menjalankan kode di atas, kami mendapatkan hasil sebagai berikut -
{
"found":true, "_index":"schools", "_type":"school", "_id":"4", "_version":2,
"_shards":{"total":2, "successful":1, "failed":0}
}Versi dokumen dapat ditentukan untuk menghapus versi tertentu itu. Parameter perutean dapat ditentukan untuk menghapus dokumen dari pengguna tertentu dan operasi gagal jika dokumen tersebut bukan milik pengguna tertentu. Dalam operasi ini, Anda dapat menentukan opsi refresh dan timeout yang sama seperti GET API.
Perbarui API
Skrip digunakan untuk melakukan operasi ini dan pembuatan versi digunakan untuk memastikan bahwa tidak ada pembaruan yang terjadi selama get dan indeks ulang. Misalnya, Anda dapat memperbarui biaya sekolah menggunakan skrip -
POST schools/_update/4
{
"script" : {
"source": "ctx._source.name = params.sname",
"lang": "painless",
"params" : {
"sname" : "City Wise School"
}
}
}Saat menjalankan kode di atas, kami mendapatkan hasil sebagai berikut -
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "4",
"_version" : 3,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 4,
"_primary_term" : 2
}Anda dapat memeriksa pembaruan dengan mengirimkan permintaan get ke dokumen yang diperbarui.
API ini digunakan untuk mencari konten di Elasticsearch. Seorang pengguna dapat mencari dengan mengirimkan permintaan get dengan string kueri sebagai parameter atau mereka dapat mengirim kueri di badan pesan permintaan posting. Terutama semua APIS pencarian adalah multi-indeks, multi-tipe.
Multi-Indeks
Elasticsearch memungkinkan kita untuk mencari dokumen yang ada di semua indeks atau di beberapa indeks tertentu. Misalnya, jika kita perlu mencari semua dokumen dengan nama yang berisi pusat, kita dapat melakukan seperti yang ditunjukkan di sini -
GET /_all/_search?q=city:paprolaSaat menjalankan kode di atas, kami mendapatkan respons berikut -
{
"took" : 33,
"timed_out" : false,
"_shards" : {
"total" : 7,
"successful" : 7,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.9808292,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 0.9808292,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
}
]
}
}Pencarian URI
Banyak parameter dapat diteruskan dalam operasi pencarian menggunakan Uniform Resource Identifier -
| S.No | Parameter & Deskripsi |
|---|---|
| 1 | Q Parameter ini digunakan untuk menentukan string kueri. |
| 2 | lenient Parameter ini digunakan untuk menentukan string kueri. Kesalahan berbasis format dapat diabaikan hanya dengan menyetel parameter ini ke true. Ini salah secara default. |
| 3 | fields Parameter ini digunakan untuk menentukan string kueri. |
| 4 | sort Kita bisa mendapatkan hasil yang diurutkan dengan menggunakan parameter ini, nilai yang mungkin untuk parameter ini adalah fieldName, fieldName: asc / fieldname: desc |
| 5 | timeout Kami dapat membatasi waktu pencarian dengan menggunakan parameter ini dan respons hanya berisi klik dalam waktu yang ditentukan. Secara default, tidak ada waktu tunggu. |
| 6 | terminate_after Kami dapat membatasi respons ke sejumlah dokumen tertentu untuk setiap pecahan, setelah mencapai permintaan yang akan dihentikan lebih awal. Secara default, tidak ada terminate_after. |
| 7 | from Mulai dari indeks klik hingga kembali. Default-nya 0. |
| 8 | size Ini menunjukkan jumlah klik untuk dikembalikan. Default-nya 10. |
Minta Pencarian Badan
Kita juga bisa menentukan query menggunakan query DSL di request body dan ada banyak contoh yang sudah diberikan di bab sebelumnya. Salah satu contohnya diberikan di sini -
POST /schools/_search
{
"query":{
"query_string":{
"query":"up"
}
}
}Saat menjalankan kode di atas, kami mendapatkan respons berikut -
{
"took" : 11,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.47000363,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 0.47000363,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
}
}Kerangka agregasi mengumpulkan semua data yang dipilih oleh kueri penelusuran dan terdiri dari banyak blok penyusun, yang membantu menyusun ringkasan data yang kompleks. Struktur dasar agregasi ditampilkan di sini -
"aggregations" : {
"" : {
"" : {
}
[,"meta" : { [] } ]?
[,"aggregations" : { []+ } ]?
}
[,"" : { ... } ]*
}Ada berbagai jenis agregasi, masing-masing dengan tujuannya sendiri-sendiri. Mereka dibahas secara rinci dalam bab ini.
Agregasi Metrik
Agregasi ini membantu dalam menghitung matriks dari nilai bidang dokumen gabungan dan terkadang beberapa nilai dapat dihasilkan dari skrip.
Matriks numerik dapat memiliki nilai tunggal seperti agregasi rata-rata atau statistik sejenis yang memiliki banyak nilai.
Agregasi Rata-rata
Agregasi ini digunakan untuk mendapatkan rata-rata dari setiap kolom numerik yang ada dalam dokumen gabungan. Sebagai contoh,
POST /schools/_search
{
"aggs":{
"avg_fees":{"avg":{"field":"fees"}}
}
}Saat menjalankan kode di atas, kami mendapatkan hasil sebagai berikut -
{
"took" : 41,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
},
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
},
"aggregations" : {
"avg_fees" : {
"value" : 2850.0
}
}
}Agregasi Kardinalitas
Agregasi ini memberikan jumlah nilai berbeda dari bidang tertentu.
POST /schools/_search?size=0
{
"aggs":{
"distinct_name_count":{"cardinality":{"field":"fees"}}
}
}Saat menjalankan kode di atas, kami mendapatkan hasil sebagai berikut -
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"distinct_name_count" : {
"value" : 2
}
}
}Note - Nilai kardinalitasnya adalah 2 karena terdapat dua nilai yang berbeda dalam fee.
Agregasi Statistik yang Diperluas
Agregasi ini menghasilkan semua statistik tentang bidang numerik tertentu dalam dokumen gabungan.
POST /schools/_search?size=0
{
"aggs" : {
"fees_stats" : { "extended_stats" : { "field" : "fees" } }
}
}Saat menjalankan kode di atas, kami mendapatkan hasil sebagai berikut -
{
"took" : 8,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"fees_stats" : {
"count" : 2,
"min" : 2200.0,
"max" : 3500.0,
"avg" : 2850.0,
"sum" : 5700.0,
"sum_of_squares" : 1.709E7,
"variance" : 422500.0,
"std_deviation" : 650.0,
"std_deviation_bounds" : {
"upper" : 4150.0,
"lower" : 1550.0
}
}
}
}Agregasi Maks
Agregasi ini menemukan nilai maksimum bidang numerik tertentu dalam dokumen gabungan.
POST /schools/_search?size=0
{
"aggs" : {
"max_fees" : { "max" : { "field" : "fees" } }
}
}Saat menjalankan kode di atas, kami mendapatkan hasil sebagai berikut -
{
"took" : 16,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"max_fees" : {
"value" : 3500.0
}
}
}Agregasi Min
Agregasi ini menemukan nilai min dari bidang numerik tertentu dalam dokumen gabungan.
POST /schools/_search?size=0
{
"aggs" : {
"min_fees" : { "min" : { "field" : "fees" } }
}
}Saat menjalankan kode di atas, kami mendapatkan hasil sebagai berikut -
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"min_fees" : {
"value" : 2200.0
}
}
}Jumlah Agregasi
Agregasi ini menghitung jumlah bidang numerik tertentu dalam dokumen gabungan.
POST /schools/_search?size=0
{
"aggs" : {
"total_fees" : { "sum" : { "field" : "fees" } }
}
}Saat menjalankan kode di atas, kami mendapatkan hasil sebagai berikut -
{
"took" : 8,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"total_fees" : {
"value" : 5700.0
}
}
}Ada beberapa agregasi metrik lain yang digunakan dalam kasus khusus seperti agregasi batas geografis dan agregasi sentroid geografis untuk tujuan lokasi geografis.
Statistik Agregasi
Agregasi metrik multi-nilai yang menghitung statistik atas nilai numerik yang diekstrak dari dokumen gabungan.
POST /schools/_search?size=0
{
"aggs" : {
"grades_stats" : { "stats" : { "field" : "fees" } }
}
}Saat menjalankan kode di atas, kami mendapatkan hasil sebagai berikut -
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"grades_stats" : {
"count" : 2,
"min" : 2200.0,
"max" : 3500.0,
"avg" : 2850.0,
"sum" : 5700.0
}
}
}Metadata Agregasi
Anda dapat menambahkan beberapa data tentang agregasi pada saat permintaan dengan menggunakan tag meta dan bisa mendapatkannya sebagai tanggapan.
POST /schools/_search?size=0
{
"aggs" : {
"min_fees" : { "avg" : { "field" : "fees" } ,
"meta" :{
"dsc" :"Lowest Fees This Year"
}
}
}
}Saat menjalankan kode di atas, kami mendapatkan hasil sebagai berikut -
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"min_fees" : {
"meta" : {
"dsc" : "Lowest Fees This Year"
},
"value" : 2850.0
}
}
}API ini bertanggung jawab untuk mengelola semua aspek indeks seperti pengaturan, alias, pemetaan, templat indeks.
Buat Indeks
API ini membantu Anda membuat indeks. Indeks dapat dibuat secara otomatis ketika pengguna meneruskan objek JSON ke indeks apa pun atau dapat dibuat sebelumnya. Untuk membuat indeks, Anda hanya perlu mengirim permintaan PUT dengan pengaturan, pemetaan dan alias atau hanya permintaan sederhana tanpa isi.
PUT collegesSaat menjalankan kode di atas, kami mendapatkan output seperti yang ditunjukkan di bawah ini -
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "colleges"
}Kami juga dapat menambahkan beberapa pengaturan ke perintah di atas -
PUT colleges
{
"settings" : {
"index" : {
"number_of_shards" : 3,
"number_of_replicas" : 2
}
}
}Saat menjalankan kode di atas, kami mendapatkan output seperti yang ditunjukkan di bawah ini -
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "colleges"
}Hapus Indeks
API ini membantu Anda menghapus indeks apa pun. Anda hanya perlu meneruskan permintaan penghapusan dengan nama Indeks tersebut.
DELETE /collegesAnda dapat menghapus semua indeks hanya dengan menggunakan _all atau *.
Dapatkan Indeks
API ini dapat dipanggil dengan hanya mengirimkan permintaan get ke satu atau lebih dari satu indeks. Ini mengembalikan informasi tentang indeks.
GET collegesSaat menjalankan kode di atas, kami mendapatkan output seperti yang ditunjukkan di bawah ini -
{
"colleges" : {
"aliases" : {
"alias_1" : { },
"alias_2" : {
"filter" : {
"term" : {
"user" : "pkay"
}
},
"index_routing" : "pkay",
"search_routing" : "pkay"
}
},
"mappings" : { },
"settings" : {
"index" : {
"creation_date" : "1556245406616",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "3ExJbdl2R1qDLssIkwDAug",
"version" : {
"created" : "7000099"
},
"provided_name" : "colleges"
}
}
}
}Anda bisa mendapatkan informasi dari semua indeks dengan menggunakan _all atau *.
Indeks Ada
Keberadaan indeks dapat ditentukan hanya dengan mengirimkan permintaan get ke indeks tersebut. Jika respon HTTP adalah 200, itu ada; jika 404, itu tidak ada.
HEAD collegesSaat menjalankan kode di atas, kami mendapatkan output seperti yang ditunjukkan di bawah ini -
200-OKPengaturan Indeks
Anda bisa mendapatkan pengaturan indeks hanya dengan menambahkan kata kunci _settings di akhir URL.
GET /colleges/_settingsSaat menjalankan kode di atas, kami mendapatkan output seperti yang ditunjukkan di bawah ini -
{
"colleges" : {
"settings" : {
"index" : {
"creation_date" : "1556245406616",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "3ExJbdl2R1qDLssIkwDAug",
"version" : {
"created" : "7000099"
},
"provided_name" : "colleges"
}
}
}
}Statistik Indeks
API ini membantu Anda mengekstrak statistik tentang indeks tertentu. Anda hanya perlu mengirim permintaan get dengan URL indeks dan kata kunci _stats di bagian akhir.
GET /_statsSaat menjalankan kode di atas, kami mendapatkan output seperti yang ditunjukkan di bawah ini -
………………………………………………
},
"request_cache" : {
"memory_size_in_bytes" : 849,
"evictions" : 0,
"hit_count" : 1171,
"miss_count" : 4
},
"recovery" : {
"current_as_source" : 0,
"current_as_target" : 0,
"throttle_time_in_millis" : 0
}
} ………………………………………………Menyiram
Proses pembersihan indeks memastikan bahwa data apa pun yang saat ini hanya tersimpan di log transaksi juga disimpan secara permanen di Lucene. Ini mengurangi waktu pemulihan karena data tersebut tidak perlu diindeks ulang dari log transaksi setelah indeks Lucene dibuka.
POST colleges/_flushSaat menjalankan kode di atas, kami mendapatkan output seperti yang ditunjukkan di bawah ini -
{
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
}
}Biasanya hasil dari berbagai API Elasticsearch ditampilkan dalam format JSON. Tapi JSON tidak selalu mudah dibaca. Jadi fitur Cat API yang tersedia di Elasticsearch membantu dalam memberikan format hasil yang lebih mudah dibaca dan dipahami. Ada berbagai parameter yang digunakan dalam cat API yang tujuan servernya berbeda, misalnya - istilah V membuat output menjadi verbose.
Mari kita pelajari tentang cat API lebih detail di bab ini.
Verbose
Output verbose memberikan tampilan yang bagus dari hasil perintah cat. Dalam contoh yang diberikan di bawah ini, kami mendapatkan detail dari berbagai indeks yang ada di cluster.
GET /_cat/indices?vSaat menjalankan kode di atas, kami mendapatkan respons seperti yang ditunjukkan di bawah ini -
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open schools RkMyEn2SQ4yUgzT6EQYuAA 1 1 2 1 21.6kb 21.6kb
yellow open index_4_analysis zVmZdM1sTV61YJYrNXf1gg 1 1 0 0 283b 283b
yellow open sensor-2018-01-01 KIrrHwABRB-ilGqTu3OaVQ 1 1 1 0 4.2kb 4.2kb
yellow open colleges 3ExJbdl2R1qDLssIkwDAug 1 1 0 0 283b 283bHeader
Parameter h, juga disebut header, digunakan untuk menampilkan hanya kolom yang disebutkan dalam perintah.
GET /_cat/nodes?h=ip,portSaat menjalankan kode di atas, kami mendapatkan respons seperti yang ditunjukkan di bawah ini -
127.0.0.1 9300Menyortir
Perintah sortir menerima string kueri yang dapat mengurutkan tabel berdasarkan kolom tertentu dalam kueri. Pengurutan default adalah ascending tetapi ini dapat diubah dengan menambahkan: desc ke kolom.
Contoh di bawah ini, memberikan hasil template yang disusun dalam urutan menurun dari pola indeks yang diajukan.
GET _cat/templates?v&s=order:desc,index_patternsSaat menjalankan kode di atas, kami mendapatkan respons seperti yang ditunjukkan di bawah ini -
name index_patterns order version
.triggered_watches [.triggered_watches*] 2147483647
.watch-history-9 [.watcher-history-9*] 2147483647
.watches [.watches*] 2147483647
.kibana_task_manager [.kibana_task_manager] 0 7000099Menghitung
Parameter count memberikan jumlah total dokumen di seluruh cluster.
GET /_cat/count?vSaat menjalankan kode di atas, kami mendapatkan respons seperti yang ditunjukkan di bawah ini -
epoch timestamp count
1557633536 03:58:56 17809API cluster digunakan untuk mendapatkan informasi tentang cluster dan node-nya dan untuk membuat perubahan di dalamnya. Untuk memanggil API ini, kita perlu menentukan nama node, alamat atau _local.
GET /_nodes/_localSaat menjalankan kode di atas, kami mendapatkan respons seperti yang ditunjukkan di bawah ini -
………………………………………………
cluster_name" : "elasticsearch",
"nodes" : {
"FKH-5blYTJmff2rJ_lQOCg" : {
"name" : "ubuntu",
"transport_address" : "127.0.0.1:9300",
"host" : "127.0.0.1",
"ip" : "127.0.0.1",
"version" : "7.0.0",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "b7e28a7",
"total_indexing_buffer" : 106502553,
"roles" : [
"master",
"data",
"ingest"
],
"attributes" : {
………………………………………………Kesehatan Cluster
API ini digunakan untuk mendapatkan status kesehatan cluster dengan menambahkan kata kunci 'kesehatan'.
GET /_cluster/healthSaat menjalankan kode di atas, kami mendapatkan respons seperti yang ditunjukkan di bawah ini -
{
"cluster_name" : "elasticsearch",
"status" : "yellow",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 7,
"active_shards" : 7,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 4,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 63.63636363636363
}Status Cluster
API ini digunakan untuk mendapatkan informasi status tentang sebuah cluster dengan menambahkan URL kata kunci 'negara bagian'. Informasi negara berisi versi, master node, node lain, tabel routing, metadata dan blok.
GET /_cluster/stateSaat menjalankan kode di atas, kami mendapatkan respons seperti yang ditunjukkan di bawah ini -
………………………………………………
{
"cluster_name" : "elasticsearch",
"cluster_uuid" : "IzKu0OoVTQ6LxqONJnN2eQ",
"version" : 89,
"state_uuid" : "y3BlwvspR1eUQBTo0aBjig",
"master_node" : "FKH-5blYTJmff2rJ_lQOCg",
"blocks" : { },
"nodes" : {
"FKH-5blYTJmff2rJ_lQOCg" : {
"name" : "ubuntu",
"ephemeral_id" : "426kTGpITGixhEzaM-5Qyg",
"transport
}
………………………………………………Statistik Cluster
API ini membantu untuk mengambil statistik tentang cluster dengan menggunakan kata kunci 'statistik'. API ini mengembalikan nomor pecahan, ukuran penyimpanan, penggunaan memori, jumlah node, peran, OS, dan sistem file.
GET /_cluster/statsSaat menjalankan kode di atas, kami mendapatkan respons seperti yang ditunjukkan di bawah ini -
………………………………………….
"cluster_name" : "elasticsearch",
"cluster_uuid" : "IzKu0OoVTQ6LxqONJnN2eQ",
"timestamp" : 1556435464704,
"status" : "yellow",
"indices" : {
"count" : 7,
"shards" : {
"total" : 7,
"primaries" : 7,
"replication" : 0.0,
"index" : {
"shards" : {
"min" : 1,
"max" : 1,
"avg" : 1.0
},
"primaries" : {
"min" : 1,
"max" : 1,
"avg" : 1.0
},
"replication" : {
"min" : 0.0,
"max" : 0.0,
"avg" : 0.0
}
………………………………………….Pengaturan Pembaruan Cluster
API ini memungkinkan Anda untuk memperbarui pengaturan cluster dengan menggunakan kata kunci 'pengaturan'. Ada dua jenis pengaturan - persisten (diterapkan saat restart) dan sementara (tidak bertahan saat cluster restart penuh).
Statistik Node
API ini digunakan untuk mengambil statistik dari satu node cluster lagi. Statistik node hampir sama dengan cluster.
GET /_nodes/statsSaat menjalankan kode di atas, kami mendapatkan respons seperti yang ditunjukkan di bawah ini -
{
"_nodes" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"cluster_name" : "elasticsearch",
"nodes" : {
"FKH-5blYTJmff2rJ_lQOCg" : {
"timestamp" : 1556437348653,
"name" : "ubuntu",
"transport_address" : "127.0.0.1:9300",
"host" : "127.0.0.1",
"ip" : "127.0.0.1:9300",
"roles" : [
"master",
"data",
"ingest"
],
"attributes" : {
"ml.machine_memory" : "4112797696",
"xpack.installed" : "true",
"ml.max_open_jobs" : "20"
},
………………………………………………………….Node hot_threads
API ini membantu Anda mengambil informasi tentang hot thread saat ini di setiap node dalam cluster.
GET /_nodes/hot_threadsSaat menjalankan kode di atas, kami mendapatkan respons seperti yang ditunjukkan di bawah ini -
:::{ubuntu}{FKH-5blYTJmff2rJ_lQOCg}{426kTGpITGixhEzaM5Qyg}{127.0.0.1}{127.0.0.1:9300}{ml.machine_memory=4112797696,
xpack.installed=true, ml.max_open_jobs=20}
Hot threads at 2019-04-28T07:43:58.265Z, interval=500ms, busiestThreads=3,
ignoreIdleThreads=true:Di Elasticsearch, pencarian dilakukan dengan menggunakan query berbasis JSON. Kueri terdiri dari dua klausa -
Leaf Query Clauses - Klausa ini adalah kecocokan, istilah atau rentang, yang mencari nilai tertentu di bidang tertentu.
Compound Query Clauses - Kueri ini adalah kombinasi klausa kueri daun dan kueri gabungan lainnya untuk mengekstrak informasi yang diinginkan.
Elasticsearch mendukung sejumlah besar kueri. Sebuah kueri dimulai dengan kata kunci kueri dan kemudian memiliki kondisi dan filter di dalamnya dalam bentuk objek JSON. Berbagai jenis kueri telah dijelaskan di bawah ini.
Cocokkan Semua Kueri
Ini adalah pertanyaan paling dasar; itu mengembalikan semua konten dan dengan skor 1,0 untuk setiap objek.
POST /schools/_search
{
"query":{
"match_all":{}
}
}Saat menjalankan kode di atas, kami mendapatkan hasil sebagai berikut -
{
"took" : 7,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
},
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
}
}Kueri Teks Lengkap
Kueri ini digunakan untuk menelusuri seluruh teks seperti bab atau artikel berita. Kueri ini bekerja sesuai dengan penganalisis yang terkait dengan indeks atau dokumen tersebut. Di bagian ini, kita akan membahas berbagai jenis kueri teks lengkap.
Cocokkan kueri
Kueri ini mencocokkan teks atau frasa dengan nilai satu atau beberapa bidang.
POST /schools*/_search
{
"query":{
"match" : {
"rating":"4.5"
}
}
}Saat menjalankan kode di atas, kami mendapatkan respons seperti yang ditunjukkan di bawah ini -
{
"took" : 44,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.47000363,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 0.47000363,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
}
}Query Multi Match
Kueri ini cocok dengan teks atau frase dengan lebih dari satu bidang.
POST /schools*/_search
{
"query":{
"multi_match" : {
"query": "paprola",
"fields": [ "city", "state" ]
}
}
}Saat menjalankan kode di atas, kami mendapatkan respons seperti yang ditunjukkan di bawah ini -
{
"took" : 12,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.9808292,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 0.9808292,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
}
]
}
}Kueri String Kueri
Kueri ini menggunakan query parser dan query_string keyword.
POST /schools*/_search
{
"query":{
"query_string":{
"query":"beautiful"
}
}
}Saat menjalankan kode di atas, kami mendapatkan respons seperti yang ditunjukkan di bawah ini -
{
"took" : 60,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
………………………………….Kueri Tingkat Istilah
Kueri ini terutama berhubungan dengan data terstruktur seperti angka, tanggal, dan enum.
POST /schools*/_search
{
"query":{
"term":{"zip":"176115"}
}
}Saat menjalankan kode di atas, kami mendapatkan respons seperti yang ditunjukkan di bawah ini -
……………………………..
hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 0.9808292,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
}
}
]
…………………………………………..Pertanyaan Rentang
Kueri ini digunakan untuk menemukan objek yang memiliki nilai di antara rentang nilai yang diberikan. Untuk ini, kita perlu menggunakan operator seperti -
- gte - lebih besar dari sama dengan
- gt - lebih besar dari
- lte - kurang dari sama dengan
- lt - kurang dari
Misalnya, perhatikan kode yang diberikan di bawah ini -
POST /schools*/_search
{
"query":{
"range":{
"rating":{
"gte":3.5
}
}
}
}Saat menjalankan kode di atas, kami mendapatkan respons seperti yang ditunjukkan di bawah ini -
{
"took" : 24,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
}
}Ada juga jenis kueri tingkat istilah lain seperti -
Exists query - Jika bidang tertentu memiliki nilai bukan nol.
Missing query - Ini sangat berlawanan dengan kueri yang ada, kueri ini mencari objek tanpa bidang atau bidang tertentu yang memiliki nilai null.
Wildcard or regexp query - Kueri ini menggunakan ekspresi reguler untuk menemukan pola dalam objek.
Kueri Gabungan
Kueri ini adalah kumpulan kueri berbeda yang digabungkan satu sama lain dengan menggunakan operator Boolean seperti dan, atau, bukan atau untuk indeks berbeda atau memiliki panggilan fungsi, dll.
POST /schools/_search
{
"query": {
"bool" : {
"must" : {
"term" : { "state" : "UP" }
},
"filter": {
"term" : { "fees" : "2200" }
},
"minimum_should_match" : 1,
"boost" : 1.0
}
}
}Saat menjalankan kode di atas, kami mendapatkan respons seperti yang ditunjukkan di bawah ini -
{
"took" : 6,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}Kueri Geo
Kueri ini berhubungan dengan lokasi geografis dan titik geografis. Kueri ini membantu menemukan sekolah atau objek geografis lainnya yang dekat dengan lokasi mana pun. Anda perlu menggunakan tipe data geo point.
PUT /geo_example
{
"mappings": {
"properties": {
"location": {
"type": "geo_shape"
}
}
}
}Saat menjalankan kode di atas, kami mendapatkan respons seperti yang ditunjukkan di bawah ini -
{ "acknowledged" : true,
"shards_acknowledged" : true,
"index" : "geo_example"
}Sekarang kami memposting data dalam indeks yang dibuat di atas.
POST /geo_example/_doc?refresh
{
"name": "Chapter One, London, UK",
"location": {
"type": "point",
"coordinates": [11.660544, 57.800286]
}
}Saat menjalankan kode di atas, kami mendapatkan respons seperti yang ditunjukkan di bawah ini -
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
"_index" : "geo_example",
"_type" : "_doc",
"_id" : "hASWZ2oBbkdGzVfiXHKD",
"_score" : 1.0,
"_source" : {
"name" : "Chapter One, London, UK",
"location" : {
"type" : "point",
"coordinates" : [
11.660544,
57.800286
]
}
}
}
}Pemetaan adalah garis besar dokumen yang disimpan dalam indeks. Ini mendefinisikan tipe data seperti geo_point atau string dan format bidang yang ada dalam dokumen dan aturan untuk mengontrol pemetaan bidang yang ditambahkan secara dinamis.
PUT bankaccountdetails
{
"mappings":{
"properties":{
"name": { "type":"text"}, "date":{ "type":"date"},
"balance":{ "type":"double"}, "liability":{ "type":"double"}
}
}
}Ketika kami menjalankan kode di atas, kami mendapatkan respons seperti yang ditunjukkan di bawah ini -
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "bankaccountdetails"
}Jenis Data Bidang
Elasticsearch mendukung sejumlah tipe data berbeda untuk bidang dalam dokumen. Tipe data yang digunakan untuk menyimpan bidang di Elasticsearch dibahas secara mendetail di sini.
Jenis Data Inti
Ini adalah tipe data dasar seperti teks, kata kunci, tanggal, panjang, ganda, boolean atau ip, yang didukung oleh hampir semua sistem.
Tipe Data Kompleks
Tipe data ini adalah kombinasi dari tipe data inti. Ini termasuk array, objek JSON, dan tipe data bertingkat. Contoh tipe data bersarang ditampilkan di bawah & minus
POST /tabletennis/_doc/1
{
"group" : "players",
"user" : [
{
"first" : "dave", "last" : "jones"
},
{
"first" : "kevin", "last" : "morris"
}
]
}Ketika kami menjalankan kode di atas, kami mendapatkan respons seperti yang ditunjukkan di bawah ini -
{
"_index" : "tabletennis",
"_type" : "_doc",
"_id" : "1",
_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}Kode contoh lain ditunjukkan di bawah ini -
POST /accountdetails/_doc/1
{
"from_acc":"7056443341", "to_acc":"7032460534",
"date":"11/1/2016", "amount":10000
}Ketika kami menjalankan kode di atas, kami mendapatkan respons seperti yang ditunjukkan di bawah ini -
{ "_index" : "accountdetails",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}Kami dapat memeriksa dokumen di atas dengan menggunakan perintah berikut -
GET /accountdetails/_mappings?include_type_name=falsePenghapusan Jenis Pemetaan
Indeks yang dibuat di Elasticsearch 7.0.0 atau yang lebih baru tidak lagi menerima pemetaan _default_. Indeks yang dibuat di 6.x akan terus berfungsi seperti sebelumnya di Elasticsearch 6.x. Jenis tidak digunakan lagi di API di 7.0.
Saat kueri diproses selama operasi pencarian, konten dalam indeks apa pun dianalisis oleh modul analisis. Modul ini terdiri dari analyzer, tokenizer, tokenfilters, dan charfilters. Jika tidak ada penganalisis yang ditentukan, maka secara default penganalisis, token, filter, dan tokenizer bawaan didaftarkan dengan modul analisis.
Dalam contoh berikut, kami menggunakan penganalisis standar yang digunakan saat penganalisis lain tidak ditentukan. Ini akan menganalisis kalimat berdasarkan tata bahasa dan menghasilkan kata-kata yang digunakan dalam kalimat tersebut.
POST _analyze
{
"analyzer": "standard",
"text": "Today's weather is beautiful"
}Saat menjalankan kode di atas, kami mendapatkan respons seperti yang ditunjukkan di bawah ini -
{
"tokens" : [
{
"token" : "today's",
"start_offset" : 0,
"end_offset" : 7,
"type" : "",
"position" : 0
},
{
"token" : "weather",
"start_offset" : 8,
"end_offset" : 15,
"type" : "",
"position" : 1
},
{
"token" : "is",
"start_offset" : 16,
"end_offset" : 18,
"type" : "",
"position" : 2
},
{
"token" : "beautiful",
"start_offset" : 19,
"end_offset" : 28,
"type" : "",
"position" : 3
}
]
}Mengonfigurasi penganalisis Standar
Kami dapat mengonfigurasi penganalisis standar dengan berbagai parameter untuk mendapatkan persyaratan khusus kami.
Dalam contoh berikut, kami mengonfigurasi penganalisis standar agar memiliki max_token_length 5.
Untuk ini, pertama-tama kita membuat indeks dengan penganalisis yang memiliki parameter max_length_token.
PUT index_4_analysis
{
"settings": {
"analysis": {
"analyzer": {
"my_english_analyzer": {
"type": "standard",
"max_token_length": 5,
"stopwords": "_english_"
}
}
}
}
}Selanjutnya kami menerapkan penganalisis dengan teks seperti yang ditunjukkan di bawah ini. Harap dicatat bagaimana token tidak muncul karena memiliki dua spasi di awal dan dua spasi di akhir. Untuk kata “ada”, ada spasi di awal dan spasi di ujungnya. Mengambil semuanya, itu menjadi 4 huruf dengan spasi dan itu tidak membuatnya menjadi kata. Harus ada karakter nonspace setidaknya di awal atau di akhir, untuk membuatnya menjadi kata yang dihitung.
POST index_4_analysis/_analyze
{
"analyzer": "my_english_analyzer",
"text": "Today's weather is beautiful"
}Saat menjalankan kode di atas, kami mendapatkan respons seperti yang ditunjukkan di bawah ini -
{
"tokens" : [
{
"token" : "today",
"start_offset" : 0,
"end_offset" : 5,
"type" : "",
"position" : 0
},
{
"token" : "s",
"start_offset" : 6,
"end_offset" : 7,
"type" : "",
"position" : 1
},
{
"token" : "weath",
"start_offset" : 8,
"end_offset" : 13,
"type" : "",
"position" : 2
},
{
"token" : "er",
"start_offset" : 13,
"end_offset" : 15,
"type" : "",
"position" : 3
},
{
"token" : "beaut",
"start_offset" : 19,
"end_offset" : 24,
"type" : "",
"position" : 5
},
{
"token" : "iful",
"start_offset" : 24,
"end_offset" : 28,
"type" : "",
"position" : 6
}
]
}Daftar berbagai penganalisis dan deskripsinya diberikan dalam tabel di bawah ini -
| S.No | Penganalisis & Deskripsi |
|---|---|
| 1 | Standard analyzer (standard) stopwords dan setelan max_token_length dapat disetel untuk penganalisis ini. Secara default, daftar stopwords kosong dan max_token_length adalah 255. |
| 2 | Simple analyzer (simple) Penganalisis ini terdiri dari tokenizer huruf kecil. |
| 3 | Whitespace analyzer (whitespace) Penganalisis ini terdiri dari tokenizer spasi putih. |
| 4 | Stop analyzer (stop) stopwords dan stopwords_path dapat dikonfigurasi. Secara default, stopwords diinisialisasi ke kata stop bahasa Inggris dan stopwords_path berisi jalur ke file teks dengan kata-kata berhenti. |
Tokenizer
Tokenizer digunakan untuk menghasilkan token dari teks di Elasticsearch. Teks dapat dipecah menjadi token dengan mempertimbangkan spasi atau tanda baca lainnya. Elasticsearch memiliki banyak tokenizer bawaan, yang dapat digunakan di penganalisis khusus.
Contoh tokenizer yang memecah teks menjadi beberapa istilah setiap kali ia menemukan karakter yang bukan huruf, tetapi juga huruf kecil semua istilah, ditampilkan di bawah -
POST _analyze
{
"tokenizer": "lowercase",
"text": "It Was a Beautiful Weather 5 Days ago."
}Saat menjalankan kode di atas, kami mendapatkan respons seperti yang ditunjukkan di bawah ini -
{
"tokens" : [
{
"token" : "it",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
},
{
"token" : "was",
"start_offset" : 3,
"end_offset" : 6,
"type" : "word",
"position" : 1
},
{
"token" : "a",
"start_offset" : 7,
"end_offset" : 8,
"type" : "word",
"position" : 2
},
{
"token" : "beautiful",
"start_offset" : 9,
"end_offset" : 18,
"type" : "word",
"position" : 3
},
{
"token" : "weather",
"start_offset" : 19,
"end_offset" : 26,
"type" : "word",
"position" : 4
},
{
"token" : "days",
"start_offset" : 29,
"end_offset" : 33,
"type" : "word",
"position" : 5
},
{
"token" : "ago",
"start_offset" : 34,
"end_offset" : 37,
"type" : "word",
"position" : 6
}
]
}Daftar Tokenizer dan deskripsinya ditampilkan di sini pada tabel yang diberikan di bawah ini -
| S.No | Tokenizer & Deskripsi |
|---|---|
| 1 | Standard tokenizer (standard) Ini dibangun di atas tokenizer berbasis tata bahasa dan max_token_length dapat dikonfigurasi untuk tokenizer ini. |
| 2 | Edge NGram tokenizer (edgeNGram) Pengaturan seperti min_gram, max_gram, token_chars dapat diatur untuk tokenizer ini. |
| 3 | Keyword tokenizer (keyword) Ini menghasilkan seluruh input sebagai output dan buffer_size dapat diatur untuk ini. |
| 4 | Letter tokenizer (letter) Ini menangkap seluruh kata sampai ditemukan non-huruf. |
Elasticsearch terdiri dari sejumlah modul, yang bertanggung jawab atas fungsinya. Modul ini memiliki dua jenis pengaturan sebagai berikut -
Static Settings- Pengaturan ini perlu dikonfigurasi di file config (elasticsearch.yml) sebelum memulai Elasticsearch. Anda perlu memperbarui semua node perhatian di cluster untuk mencerminkan perubahan dengan pengaturan ini.
Dynamic Settings - Pengaturan ini dapat disetel di Elasticsearch langsung.
Kami akan membahas berbagai modul Elasticsearch di bagian selanjutnya dari bab ini.
Perutean Tingkat Kluster dan Alokasi Pecahan
Pengaturan level cluster menentukan alokasi shard ke node yang berbeda dan realokasi shard ke cluster rebalance. Ini adalah pengaturan berikut untuk mengontrol alokasi shard.
Alokasi Shard Tingkat Cluster
| Pengaturan | Nilai yang memungkinkan | Deskripsi |
|---|---|---|
| cluster.routing.allocation.enable | ||
| semua | Nilai default ini memungkinkan alokasi shard untuk semua jenis shard. | |
| pendahuluan | Ini memungkinkan alokasi shard hanya untuk shard utama. | |
| new_primaries | Ini memungkinkan alokasi shard hanya untuk shard utama untuk indeks baru. | |
| tidak ada | Ini tidak mengizinkan alokasi shard apa pun. | |
| cluster.routing.allocation .node_concurrent_recoveries | Nilai numerik (secara default 2) | Ini membatasi jumlah pemulihan shard secara bersamaan. |
| cluster.routing.allocation .node_initial_primaries_recoveries | Nilai numerik (secara default 4) | Ini membatasi jumlah pemulihan primer awal paralel. |
| cluster.routing.allocation .same_shard.host | Nilai Boolean (secara default salah) | Ini membatasi alokasi lebih dari satu replika pecahan yang sama di node fisik yang sama. |
| indices.recovery.concurrent _streams | Nilai numerik (secara default 3) | Ini mengontrol jumlah aliran jaringan terbuka per node pada saat pemulihan shard dari pecahan peer. |
| indices.recovery.concurrent _small_file_streams | Nilai numerik (secara default 2) | Ini mengontrol jumlah aliran terbuka per node untuk file kecil yang berukuran kurang dari 5mb pada saat pemulihan pecahan. |
| cluster.routing.rebalance.enable | ||
| semua | Nilai default ini memungkinkan penyeimbangan untuk semua jenis pecahan. | |
| pendahuluan | Hal ini memungkinkan penyeimbangan shard hanya untuk shard utama. | |
| replika | Hal ini memungkinkan penyeimbangan pecahan hanya untuk pecahan replika. | |
| tidak ada | Ini tidak memungkinkan penyeimbangan pecahan apa pun. | |
| cluster.routing.allocation .allow_rebalance | ||
| selalu | Nilai default ini selalu memungkinkan penyeimbangan kembali. | |
| indices_primaries _active | Ini memungkinkan penyeimbangan ulang ketika semua pecahan utama dalam cluster dialokasikan. | |
| Indeks_semua_aktif | Hal ini memungkinkan penyeimbangan ulang ketika semua pecahan utama dan replika dialokasikan. | |
| cluster.routing.allocation.cluster _concurrent_rebalance | Nilai numerik (secara default 2) | Ini membatasi jumlah shard balancing bersamaan dalam cluster. |
| cluster.routing.allocation .balance.shard | Nilai float (secara default 0.45f) | Ini menentukan faktor bobot untuk pecahan yang dialokasikan pada setiap node. |
| cluster.routing.allocation .balance.index | Nilai float (secara default 0,55f) | Ini menentukan rasio jumlah pecahan per indeks yang dialokasikan pada node tertentu. |
| cluster.routing.allocation .balance.threshold | Nilai float non negatif (secara default 1.0f) | Ini adalah nilai pengoptimalan minimum dari operasi yang harus dilakukan. |
Alokasi Shard Berbasis Disk
| Pengaturan | Nilai yang memungkinkan | Deskripsi |
|---|---|---|
| cluster.routing.allocation.disk.threshold_enabled | Nilai Boolean (secara default benar) | Ini mengaktifkan dan menonaktifkan penentu alokasi disk. |
| cluster.routing.allocation.disk.watermark.low | Nilai string (secara default 85%) | Ini menunjukkan penggunaan disk secara maksimal; setelah titik ini, tidak ada pecahan lain yang dapat dialokasikan ke disk tersebut. |
| cluster.routing.allocation.disk.watermark.high | Nilai string (secara default 90%) | Ini menunjukkan penggunaan maksimum pada saat alokasi; jika titik ini tercapai pada saat alokasi, maka Elasticsearch akan mengalokasikan pecahan tersebut ke disk lain. |
| cluster.info.update.interval | Nilai string (secara default 30 detik) | Ini adalah interval antara pemeriksaan penggunaan disk. |
| cluster.routing.allocation.disk.include_relocations | Nilai Boolean (secara default benar) | Ini memutuskan apakah akan mempertimbangkan shard yang saat ini dialokasikan, saat menghitung penggunaan disk. |
Penemuan
Modul ini membantu cluster untuk menemukan dan memelihara status semua node di dalamnya. Status cluster berubah ketika node ditambahkan atau dihapus darinya. Pengaturan nama cluster digunakan untuk membuat perbedaan logis antara cluster yang berbeda. Ada beberapa modul yang membantu Anda menggunakan API yang disediakan oleh vendor cloud dan seperti yang diberikan di bawah ini -
- Penemuan Azure
- Penemuan EC2
- Penemuan mesin komputasi Google
- Penemuan Zen
pintu gerbang
Modul ini mempertahankan status cluster dan data shard di seluruh cluster dimulai ulang. Berikut ini adalah pengaturan statis modul ini -
| Pengaturan | Nilai yang memungkinkan | Deskripsi |
|---|---|---|
| gateway.expected_nodes | nilai numerik (secara default 0) | Jumlah node yang diharapkan berada di cluster untuk pemulihan shard lokal. |
| gateway.expected_master_nodes | nilai numerik (secara default 0) | Jumlah node master yang diharapkan berada di cluster sebelum memulai pemulihan. |
| gateway.expected_data_nodes | nilai numerik (secara default 0) | Jumlah node data yang diharapkan di cluster sebelum memulai pemulihan. |
| gateway.recover_after_time | Nilai string (secara default 5m) | Ini adalah interval antara pemeriksaan penggunaan disk. |
| cluster.routing.allocation. disk.include_relocations | Nilai Boolean (secara default benar) | Ini menentukan waktu menunggu proses pemulihan untuk dimulai terlepas dari jumlah node yang bergabung dalam cluster. gateway.recover_ after_nodes |
HTTP
Modul ini mengelola komunikasi antara klien HTTP dan Elasticsearch API. Modul ini dapat dinonaktifkan dengan mengubah nilai http.enabled menjadi false.
Berikut ini adalah pengaturan (dikonfigurasi di elasticsearch.yml) untuk mengontrol modul ini -
| S.No | Pengaturan & Deskripsi |
|---|---|
| 1 | http.port Ini adalah port untuk mengakses Elasticsearch dan berkisar antara 9200-9300. |
| 2 | http.publish_port Porta ini untuk klien http dan juga berguna jika ada firewall. |
| 3 | http.bind_host Ini adalah alamat host untuk layanan http. |
| 4 | http.publish_host Ini adalah alamat host untuk klien http. |
| 5 | http.max_content_length Ini adalah ukuran maksimum konten dalam permintaan http. Nilai defaultnya adalah 100mb. |
| 6 | http.max_initial_line_length Ini adalah ukuran maksimum URL dan nilai defaultnya adalah 4kb. |
| 7 | http.max_header_size Ini adalah ukuran header http maksimum dan nilai defaultnya adalah 8kb. |
| 8 | http.compression Ini mengaktifkan atau menonaktifkan dukungan untuk kompresi dan nilai default-nya salah. |
| 9 | http.pipelinig Ini mengaktifkan atau menonaktifkan pipelining HTTP. |
| 10 | http.pipelining.max_events Ini membatasi jumlah acara yang akan diantrekan sebelum menutup permintaan HTTP. |
Indeks
Modul ini memelihara pengaturan, yang ditetapkan secara global untuk setiap indeks. Pengaturan berikut terutama terkait dengan penggunaan memori -
Pemutus arus
Ini digunakan untuk mencegah operasi menyebabkan OutOfMemroyError. Pengaturan ini terutama membatasi ukuran heap JVM. Misalnya, pengaturan indices.breaker.total.limit, yang defaultnya adalah 70% dari heap JVM.
Cache Data Lapangan
Ini digunakan terutama saat menggabungkan di bidang. Direkomendasikan untuk memiliki cukup memori untuk mengalokasikannya. Jumlah memori yang digunakan untuk cache data lapangan dapat dikontrol menggunakan pengaturan indices.fielddata.cache.size.
Cache Kueri Node
Memori ini digunakan untuk menyimpan hasil query. Cache ini menggunakan kebijakan pengusiran Least recent used (LRU). Indices.queries.cahce.size mengatur ukuran memori dari cache ini.
Penyangga Pengindeksan
Buffer ini menyimpan dokumen yang baru dibuat dalam indeks dan menghapusnya ketika buffer sudah penuh. Pengaturan seperti indices.memory.index_buffer_size mengontrol jumlah heap yang dialokasikan untuk buffer ini.
Cache Permintaan Pecahan
Cache ini digunakan untuk menyimpan data pencarian lokal untuk setiap pecahan. Cache dapat diaktifkan selama pembuatan indeks atau dapat dinonaktifkan dengan mengirimkan parameter URL.
Disable cache - ?request_cache = true
Enable cache "index.requests.cache.enable": truePemulihan Indeks
Ini mengontrol sumber daya selama proses pemulihan. Berikut ini adalah pengaturannya -
| Pengaturan | Nilai default |
|---|---|
| indices.recovery.concurrent_streams | 3 |
| indices.recovery.concurrent_small_file_streams | 2 |
| indices.recovery.file_chunk_size | 512kb |
| indices.recovery.translog_ops | 1000 |
| indices.recovery.translog_size | 512kb |
| indices.recovery.compress | benar |
| indices.recovery.max_bytes_per_sec | 40mb |
Interval TTL
Interval Time to Live (TTL) menentukan waktu dokumen, setelah itu dokumen dihapus. Berikut ini adalah pengaturan dinamis untuk mengontrol proses ini -
| Pengaturan | Nilai default |
|---|---|
| indices.ttl.interval | 60-an |
| indices.ttl.bulk_size | 1000 |
Node
Setiap node memiliki pilihan untuk menjadi node data atau tidak. Anda dapat mengubah properti ini dengan mengubahnode.datapengaturan. Menetapkan nilai sebagaifalse mendefinisikan bahwa node bukanlah node data.
Ini adalah modul yang dibuat untuk setiap indeks dan mengontrol pengaturan dan perilaku indeks. Misalnya, berapa banyak pecahan yang dapat digunakan indeks atau jumlah replika yang dapat dimiliki oleh pecahan utama untuk indeks tersebut, dll. Ada dua jenis pengaturan indeks -
- Static - Ini hanya dapat disetel pada waktu pembuatan indeks atau pada indeks tertutup.
- Dynamic - Ini dapat diubah pada indeks langsung.
Pengaturan Indeks Statis
Tabel berikut menunjukkan daftar pengaturan indeks statis -
| Pengaturan | Nilai yang memungkinkan | Deskripsi |
|---|---|---|
| index.number_of_shards | Default-nya adalah 5, Maksimum 1024 | Jumlah pecahan utama yang harus dimiliki indeks. |
| index.shard.check_on_startup | Default-nya adalah false. Bisa Benar | Apakah pecahan harus diperiksa korupsinya atau tidak sebelum dibuka. |
| index.codec | Kompresi LZ4. | Jenis kompresi yang digunakan untuk menyimpan data. |
| index.routing_partition_size | 1 | Jumlah pecahan yang dapat dituju oleh nilai perutean khusus. |
| index.load_fixed_bitset_filters_eagerly | Salah | Menunjukkan apakah filter cache telah dimuat sebelumnya untuk kueri bertingkat |
Pengaturan Indeks Dinamis
Tabel berikut menunjukkan daftar pengaturan indeks dinamis -
| Pengaturan | Nilai yang memungkinkan | Deskripsi |
|---|---|---|
| index.number_of_replicas | Default-nya adalah 1 | Jumlah replika yang dimiliki setiap pecahan utama. |
| index.auto_expand_replicas | Tanda hubung yang dipisahkan batas bawah dan atas (0-5) | Perluas otomatis jumlah replika berdasarkan jumlah node data di cluster. |
| index.search.idle.after | 30 detik | Berapa lama pecahan tidak dapat menerima pencarian atau mendapatkan permintaan hingga dianggap sebagai pencarian menganggur. |
| index.refresh_interval | 1 detik | Seberapa sering melakukan operasi penyegaran, yang membuat perubahan terbaru pada indeks terlihat untuk pencarian. |
| index.blocks.read_only | 1 benar / salah | Setel ke benar untuk membuat indeks dan metadata indeks hanya baca, salah untuk memungkinkan penulisan dan perubahan metadata. |
Terkadang kita perlu mengubah dokumen sebelum mengindeksnya. Misalnya, kami ingin menghapus bidang dari dokumen atau mengganti nama bidang lalu mengindeksnya. Ini ditangani oleh node Ingest.
Setiap node di cluster memiliki kemampuan untuk menyerap, tetapi juga dapat disesuaikan untuk diproses hanya oleh node tertentu.
Langkah-langkah yang Terlibat
Ada dua langkah yang terlibat dalam kerja node ingest -
- Membuat pipa
- Membuat dokumen
Buat Pipeline
Pertama buat pipeline yang berisi prosesor dan kemudian jalankan pipeline, seperti yang ditunjukkan di bawah ini -
PUT _ingest/pipeline/int-converter
{
"description": "converts the content of the seq field to an integer",
"processors" : [
{
"convert" : {
"field" : "seq",
"type": "integer"
}
}
]
}Saat menjalankan kode di atas, kami mendapatkan hasil sebagai berikut -
{
"acknowledged" : true
}Buat Dokumen
Selanjutnya kami membuat dokumen menggunakan konverter pipa.
PUT /logs/_doc/1?pipeline=int-converter
{
"seq":"21",
"name":"Tutorialspoint",
"Addrs":"Hyderabad"
}Saat menjalankan kode di atas, kami mendapatkan respons seperti yang ditunjukkan di bawah ini -
{
"_index" : "logs",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}Selanjutnya kita mencari dokumen yang dibuat di atas dengan menggunakan perintah GET seperti yang ditunjukkan di bawah ini -
GET /logs/_doc/1Saat menjalankan kode di atas, kami mendapatkan hasil sebagai berikut -
{
"_index" : "logs",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"Addrs" : "Hyderabad",
"name" : "Tutorialspoint",
"seq" : 21
}
}Anda dapat melihat di atas bahwa 21 telah menjadi integer.
Tanpa Pipa
Sekarang kita membuat dokumen tanpa menggunakan pipeline.
PUT /logs/_doc/2
{
"seq":"11",
"name":"Tutorix",
"Addrs":"Secunderabad"
}
GET /logs/_doc/2Saat menjalankan kode di atas, kami mendapatkan hasil sebagai berikut -
{
"_index" : "logs",
"_type" : "_doc",
"_id" : "2",
"_version" : 1,
"_seq_no" : 1,
"_primary_term" : 1,
"found" : true,
"_source" : {
"seq" : "11",
"name" : "Tutorix",
"Addrs" : "Secunderabad"
}
}Anda dapat melihat di atas bahwa 11 adalah string tanpa pipa yang digunakan.
Mengelola siklus hidup indeks melibatkan pelaksanaan tindakan manajemen berdasarkan faktor-faktor seperti ukuran pecahan dan persyaratan kinerja. API pengelolaan siklus hidup indeks (ILM) memungkinkan Anda mengotomatiskan cara Anda ingin mengelola indeks dari waktu ke waktu.
Bab ini memberikan daftar ILM API dan penggunaannya.
API Manajemen Kebijakan
| Nama API | Tujuan | Contoh |
|---|---|---|
| Buat kebijakan siklus hidup. | Membuat kebijakan siklus hidup. Jika kebijakan yang ditentukan ada, kebijakan tersebut diganti dan versi kebijakan bertambah. | PUT_ilm / policy / policy_id |
| Dapatkan kebijakan siklus hidup. | Mengembalikan definisi kebijakan yang ditentukan. Termasuk versi kebijakan dan tanggal terakhir diubah. Jika tidak ada kebijakan yang ditentukan, kembalikan semua kebijakan yang ditentukan. | GET_ilm / policy / policy_id |
| Hapus kebijakan siklus hidup | Menghapus definisi kebijakan siklus hidup yang ditentukan. Anda tidak dapat menghapus kebijakan yang sedang digunakan. Jika kebijakan digunakan untuk mengelola indeks apa pun, permintaan gagal dan mengembalikan kesalahan. | DELETE_ilm / policy / policy_id |
API Manajemen Indeks
| Nama API | Tujuan | Contoh |
|---|---|---|
| Pindah ke API langkah siklus hidup. | Memindahkan indeks secara manual ke langkah yang ditentukan dan menjalankan langkah itu. | POST_ilm / pindah / indeks |
| Coba lagi kebijakan. | Menyetel kebijakan kembali ke langkah di mana kesalahan terjadi dan menjalankan langkah tersebut. | Indeks POST / _ilm / coba lagi |
| Hapus kebijakan dari edit API indeks. | Menghapus kebijakan siklus hidup yang ditetapkan dan berhenti mengelola indeks yang ditentukan. Jika pola indeks ditentukan, menghapus kebijakan yang ditetapkan dari semua indeks yang cocok. | Indeks POST / _ilm / hapus |
API Manajemen Operasi
| Nama API | Tujuan | Contoh |
|---|---|---|
| Dapatkan API status pengelolaan siklus hidup indeks. | Mengembalikan status plugin ILM. Bidang operation_mode dalam respons menunjukkan salah satu dari tiga status: STARTED, STOPPING, atau STOPPED. | DAPATKAN / _ilm / status |
| Mulai API pengelolaan siklus hidup indeks. | Memulai plugin ILM jika saat ini dihentikan. ILM dimulai secara otomatis saat cluster terbentuk. | POST / _ilm / mulai |
| Hentikan API pengelolaan siklus hidup indeks. | Menghentikan semua operasi manajemen siklus hidup dan menghentikan plugin ILM. Ini berguna ketika Anda melakukan pemeliharaan pada kluster dan perlu mencegah ILM melakukan tindakan apa pun pada indeks Anda. | POST / _ilm / berhenti |
| Jelaskan API siklus hidup. | Mengambil informasi tentang status siklus hidup indeks saat ini, seperti fase, tindakan, dan langkah yang saat ini dijalankan. Menunjukkan kapan indeks memasuki masing-masing, definisi fase berjalan, dan informasi tentang kegagalan apa pun. | DAPATKAN indeks / _ilm / jelaskan |
Ini adalah komponen yang memungkinkan kueri seperti SQL dijalankan secara real-time terhadap Elasticsearch. Anda dapat menganggap Elasticsearch SQL sebagai penerjemah, yang memahami SQL dan Elasticsearch serta membuatnya mudah untuk membaca dan memproses data secara real-time, dalam skala besar dengan memanfaatkan kemampuan Elasticsearch.
Keuntungan dari Elasticsearch SQL
It has native integration - Setiap kueri dieksekusi secara efisien terhadap node yang relevan sesuai dengan penyimpanan yang mendasarinya.
No external parts - Tidak perlu perangkat keras tambahan, proses, waktu proses, atau pustaka untuk menanyakan Elasticsearch.
Lightweight and efficient - itu merangkul dan mengekspos SQL untuk memungkinkan pencarian teks lengkap yang tepat, dalam waktu nyata.
Contoh
PUT /schoollist/_bulk?refresh
{"index":{"_id": "CBSE"}}
{"name": "GleanDale", "Address": "JR. Court Lane", "start_date": "2011-06-02",
"student_count": 561}
{"index":{"_id": "ICSE"}}
{"name": "Top-Notch", "Address": "Gachibowli Main Road", "start_date": "1989-
05-26", "student_count": 482}
{"index":{"_id": "State Board"}}
{"name": "Sunshine", "Address": "Main Street", "start_date": "1965-06-01",
"student_count": 604}Saat menjalankan kode di atas, kami mendapatkan respons seperti yang ditunjukkan di bawah ini -
{
"took" : 277,
"errors" : false,
"items" : [
{
"index" : {
"_index" : "schoollist",
"_type" : "_doc",
"_id" : "CBSE",
"_version" : 1,
"result" : "created",
"forced_refresh" : true,
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : {
"_index" : "schoollist",
"_type" : "_doc",
"_id" : "ICSE",
"_version" : 1,
"result" : "created",
"forced_refresh" : true,
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : {
"_index" : "schoollist",
"_type" : "_doc",
"_id" : "State Board",
"_version" : 1,
"result" : "created",
"forced_refresh" : true,
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1,
"status" : 201
}
}
]
}Kueri SQL
Contoh berikut menunjukkan bagaimana kami membingkai kueri SQL -
POST /_sql?format=txt
{
"query": "SELECT * FROM schoollist WHERE start_date < '2000-01-01'"
}Saat menjalankan kode di atas, kami mendapatkan respons seperti yang ditunjukkan di bawah ini -
Address | name | start_date | student_count
--------------------+---------------+------------------------+---------------
Gachibowli Main Road|Top-Notch |1989-05-26T00:00:00.000Z|482
Main Street |Sunshine |1965-06-01T00:00:00.000Z|604Note - Dengan mengubah kueri SQL di atas, Anda bisa mendapatkan kumpulan hasil yang berbeda.
Untuk memantau kesehatan cluster, fitur pemantauan mengumpulkan metrik dari setiap node dan menyimpannya di Indeks Elasticsearch. Semua pengaturan yang terkait dengan pemantauan di Elasticsearch harus diatur di file elasticsearch.yml untuk setiap node atau, jika memungkinkan, dalam pengaturan cluster dinamis.
Untuk memulai pemantauan, kita perlu memeriksa pengaturan cluster, yang dapat dilakukan dengan cara berikut -
GET _cluster/settings
{
"persistent" : { },
"transient" : { }
}Setiap komponen dalam stack bertanggung jawab untuk memantau dirinya sendiri dan kemudian meneruskan dokumen tersebut ke cluster produksi Elasticsearch untuk perutean dan pengindeksan (penyimpanan). Proses perutean dan pengindeksan di Elasticsearch ditangani oleh apa yang disebut kolektor dan eksportir.
Kolektor
Kolektor berjalan sekali per setiap interval pengumpulan untuk mendapatkan data dari API publik di Elasticsearch yang dipilihnya untuk dipantau. Setelah pendataan selesai, data tersebut diserahkan secara massal kepada eksportir untuk dikirim ke cluster monitoring.
Hanya ada satu kolektor per jenis data yang dikumpulkan. Setiap kolektor dapat membuat nol atau lebih dokumen pemantauan.
Eksportir
Eksportir mengambil data yang dikumpulkan dari sumber Elastic Stack dan mengarahkannya ke cluster pemantauan. Ada kemungkinan untuk mengkonfigurasi lebih dari satu eksportir, tetapi pengaturan umum dan default adalah menggunakan satu eksportir. Eksportir dapat dikonfigurasi pada level node dan cluster.
Ada dua jenis eksportir di Elasticsearch -
local - Eksportir ini merutekan data kembali ke cluster yang sama
http - Eksportir pilihan, yang dapat Anda gunakan untuk merutekan data ke cluster Elasticsearch yang didukung, yang dapat diakses melalui HTTP.
Sebelum eksportir dapat merutekan data pemantauan, mereka harus menyiapkan sumber daya Elasticsearch tertentu. Sumber daya ini mencakup template dan pipeline serap
Pekerjaan rollup adalah tugas berkala yang merangkum data dari indeks yang ditentukan oleh pola indeks dan memasukkannya ke dalam indeks baru. Dalam contoh berikut, kami membuat indeks bernama sensor dengan stempel waktu tanggal yang berbeda. Kemudian kami membuat pekerjaan rollup untuk menggulung data dari indeks ini secara berkala menggunakan pekerjaan cron.
PUT /sensor/_doc/1
{
"timestamp": 1516729294000,
"temperature": 200,
"voltage": 5.2,
"node": "a"
}Saat menjalankan kode di atas, kami mendapatkan hasil sebagai berikut -
{
"_index" : "sensor",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}Sekarang, tambahkan dokumen kedua dan seterusnya untuk dokumen lain juga.
PUT /sensor-2018-01-01/_doc/2
{
"timestamp": 1413729294000,
"temperature": 201,
"voltage": 5.9,
"node": "a"
}Buat Pekerjaan Rollup
PUT _rollup/job/sensor
{
"index_pattern": "sensor-*",
"rollup_index": "sensor_rollup",
"cron": "*/30 * * * * ?",
"page_size" :1000,
"groups" : {
"date_histogram": {
"field": "timestamp",
"interval": "60m"
},
"terms": {
"fields": ["node"]
}
},
"metrics": [
{
"field": "temperature",
"metrics": ["min", "max", "sum"]
},
{
"field": "voltage",
"metrics": ["avg"]
}
]
}Parameter cron mengontrol kapan dan seberapa sering pekerjaan diaktifkan. Saat jadwal cron tugas rollup terpicu, jadwal akan mulai bergulir dari tempat ia tinggalkan setelah aktivasi terakhir
Setelah pekerjaan dijalankan dan beberapa data diproses, kita dapat menggunakan Query DSL untuk melakukan beberapa pencarian.
GET /sensor_rollup/_rollup_search
{
"size": 0,
"aggregations": {
"max_temperature": {
"max": {
"field": "temperature"
}
}
}
}Indeks yang sering dicari disimpan dalam memori karena membutuhkan waktu untuk membangunnya kembali dan membantu dalam pencarian yang efisien. Di sisi lain, mungkin ada indeks yang jarang kita akses. Indeks tersebut tidak perlu menempati memori dan dapat dibangun kembali saat dibutuhkan. Indeks semacam itu dikenal sebagai indeks beku.
Elasticsearch membangun struktur data sementara dari setiap pecahan indeks beku setiap kali pecahan dicari dan membuang struktur data ini segera setelah pencarian selesai. Karena Elasticsearch tidak mempertahankan struktur data transien ini dalam memori, indeks yang dibekukan menggunakan heap yang jauh lebih sedikit daripada indeks normal. Hal ini memungkinkan rasio disk-ke-heap yang jauh lebih tinggi daripada yang memungkinkan.
Contoh Pembekuan dan Pembekuan
Contoh berikut membekukan dan mencairkan indeks -
POST /index_name/_freeze
POST /index_name/_unfreezePencarian pada indeks yang dibekukan diperkirakan akan berjalan lambat. Indeks yang dibekukan tidak dimaksudkan untuk beban pencarian yang tinggi. Ada kemungkinan bahwa pencarian indeks beku mungkin memerlukan beberapa detik atau menit untuk menyelesaikannya, bahkan jika pencarian yang sama diselesaikan dalam milidetik ketika indeks tidak dibekukan.
Mencari Indeks Beku
Jumlah indeks beku yang dimuat secara bersamaan per node dibatasi oleh jumlah utas di threadpool search_throttled, yaitu 1 secara default. Untuk menyertakan indeks yang dibekukan, permintaan pencarian harus dijalankan dengan parameter kueri - ignore_throttled = false.
GET /index_name/_search?q=user:tpoint&ignore_throttled=falseMemantau Indeks Beku
Indeks beku adalah indeks biasa yang menggunakan pembatasan penelusuran dan implementasi pecahan yang efisien memori.
GET /_cat/indices/index_name?v&h=i,sthElasticsearch menyediakan file jar, yang dapat ditambahkan ke java IDE dan dapat digunakan untuk menguji kode yang terkait dengan Elasticsearch. Berbagai pengujian dapat dilakukan dengan menggunakan kerangka kerja yang disediakan oleh Elasticsearch. Dalam bab ini, kita akan membahas tes ini secara rinci -
- Pengujian unit
- Tes integrasi
- Pengujian acak
Prasyarat
Untuk memulai pengujian, Anda perlu menambahkan dependensi pengujian Elasticsearch ke program Anda. Anda dapat menggunakan maven untuk tujuan ini dan dapat menambahkan yang berikut ini di pom.xml.
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>2.1.0</version>
</dependency>EsSetup telah diinisialisasi untuk memulai dan menghentikan node Elasticsearch dan juga untuk membuat indeks.
EsSetup esSetup = new EsSetup();esSetup.execute () fungsi dengan createIndex akan membuat indeks, Anda perlu menentukan pengaturan, jenis dan datanya.
Pengujian Unit
Uji unit dilakukan dengan menggunakan framework uji JUnit dan Elasticsearch. Node dan indeks dapat dibuat dengan menggunakan kelas Elasticsearch dan metode pengujian dapat digunakan untuk melakukan pengujian. Kelas ESTestCase dan ESTokenStreamTestCase digunakan untuk pengujian ini.
Tes integrasi
Pengujian integrasi menggunakan banyak node dalam satu cluster. Kelas ESIntegTestCase digunakan untuk pengujian ini. Ada berbagai metode yang mempermudah pekerjaan mempersiapkan kasus uji.
| S.No | Metode & Deskripsi |
|---|---|
| 1 | refresh() Semua indeks di cluster di-refresh |
| 2 | ensureGreen() Memastikan status cluster kesehatan hijau |
| 3 | ensureYellow() Memastikan status cluster kesehatan kuning |
| 4 | createIndex(name) Buat indeks dengan nama yang diteruskan ke metode ini |
| 5 | flush() Semua indeks dalam cluster di-flush |
| 6 | flushAndRefresh() flush () dan refresh () |
| 7 | indexExists(name) Memverifikasi keberadaan indeks tertentu |
| 8 | clusterService() Mengembalikan kelas java layanan cluster |
| 9 | cluster() Mengembalikan kelas cluster pengujian |
Metode Uji Cluster
| S.No | Metode & Deskripsi |
|---|---|
| 1 | ensureAtLeastNumNodes(n) Memastikan jumlah minimum node di cluster lebih dari atau sama dengan jumlah yang ditentukan. |
| 2 | ensureAtMostNumNodes(n) Memastikan jumlah maksimum node di cluster kurang dari atau sama dengan jumlah yang ditentukan. |
| 3 | stopRandomNode() Untuk menghentikan node acak dalam sebuah cluster |
| 4 | stopCurrentMasterNode() Untuk menghentikan node master |
| 5 | stopRandomNonMaster() Untuk menghentikan node acak di cluster, yang bukan node master. |
| 6 | buildNode() Buat node baru |
| 7 | startNode(settings) Mulai node baru |
| 8 | nodeSettings() Ganti metode ini untuk mengubah pengaturan node. |
Mengakses Klien
Klien digunakan untuk mengakses node yang berbeda dalam sebuah cluster dan melakukan beberapa tindakan. Metode ESIntegTestCase.client () digunakan untuk mendapatkan klien acak. Elasticsearch juga menawarkan metode lain untuk mengakses klien dan metode tersebut dapat diakses menggunakan metode ESIntegTestCase.internalCluster ().
| S.No | Metode & Deskripsi |
|---|---|
| 1 | iterator() Ini membantu Anda mengakses semua klien yang tersedia. |
| 2 | masterClient() Ini mengembalikan klien, yang berkomunikasi dengan node master. |
| 3 | nonMasterClient() Ini mengembalikan klien, yang tidak berkomunikasi dengan node master. |
| 4 | clientNodeClient() Ini mengembalikan klien saat ini di node klien. |
Pengujian Acak
Pengujian ini digunakan untuk menguji kode pengguna dengan setiap data yang memungkinkan, sehingga tidak akan ada kegagalan di masa mendatang dengan semua jenis data. Data acak adalah pilihan terbaik untuk melakukan pengujian ini.
Menghasilkan Data Acak
Dalam pengujian ini, kelas Random dibuat instance-nya oleh instance yang disediakan oleh RandomizedTest dan menawarkan banyak metode untuk mendapatkan berbagai jenis data.
| metode | Nilai kembali |
|---|---|
| getRandom () | Contoh kelas acak |
| randomBoolean () | Boolean acak |
| randomByte () | Byte acak |
| randomShort () | Pendek acak |
| randomInt () | Bilangan bulat acak |
| randomLong () | Panjang acak |
| randomFloat () | Float acak |
| randomDouble () | Ganda acak |
| randomLocale () | Lokal acak |
| randomTimeZone () | Zona waktu acak |
| randomFrom () | Elemen acak dari array |
Pernyataan
Kelas ElasticsearchAssertions dan ElasticsearchGeoAssertions berisi pernyataan, yang digunakan untuk melakukan beberapa pemeriksaan umum pada saat pengujian. Misalnya, perhatikan kode yang diberikan di sini -
SearchResponse seearchResponse = client().prepareSearch();
assertHitCount(searchResponse, 6);
assertFirstHit(searchResponse, hasId("6"));
assertSearchHits(searchResponse, "1", "2", "3", "4",”5”,”6”);Dasbor Kibana adalah kumpulan visualisasi dan pencarian. Anda dapat mengatur, mengubah ukuran, dan mengedit konten dasbor dan kemudian menyimpan dasbor sehingga Anda dapat membagikannya. Pada bab ini, kita akan melihat bagaimana membuat dan mengedit dashboard.
Pembuatan Dashboard
Dari Beranda Kibana, pilih opsi dasbor dari bilah kontrol kiri seperti yang ditunjukkan di bawah ini. Ini akan meminta Anda untuk membuat dasbor baru.
Untuk menambahkan visualisasi ke dasbor, kami memilih menu Tambah dan pilih dari visualisasi yang dibuat sebelumnya tersedia. Kami memilih opsi visualisasi berikut dari daftar.
Saat memilih visualisasi di atas, kami mendapatkan dasbor seperti yang ditunjukkan di sini. Kita nantinya dapat menambah dan mengedit dasbor untuk mengubah elemen dan menambahkan elemen baru.
Memeriksa Elemen
Kita dapat memeriksa elemen Dashboard dengan memilih menu panel visualisasi dan memilih Inspect. Ini akan memunculkan data di balik elemen yang juga dapat diunduh.
Berbagi Dasbor
Kita dapat membagikan dashboard dengan memilih menu share dan memilih opsi untuk mendapatkan hyperlink seperti yang ditunjukkan di bawah ini -

Fungsionalitas temukan yang tersedia di beranda Kibana memungkinkan kita menjelajahi kumpulan data dari berbagai sudut. Anda dapat mencari dan memfilter data untuk pola indeks yang dipilih. Data biasanya tersedia dalam bentuk distribusi nilai selama periode waktu tertentu.
Untuk menjelajahi contoh data e-niaga, kami mengklik Discoverikon seperti yang ditunjukkan pada gambar di bawah ini. Ini akan memunculkan data bersama dengan grafik.
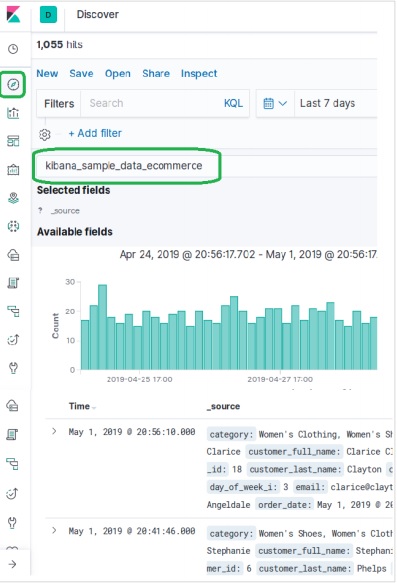
Memfilter berdasarkan Waktu
Untuk memfilter data dengan interval waktu tertentu kami menggunakan opsi filter waktu seperti yang ditunjukkan di bawah ini. Secara default, filter disetel pada 15 menit.
Memfilter menurut Bidang
Kumpulan data juga dapat difilter menurut bidang menggunakan Add Filterpilihan seperti yang ditunjukkan di bawah ini. Di sini kami menambahkan satu atau lebih bidang dan mendapatkan hasil yang sesuai setelah filter diterapkan. Dalam contoh kami, kami memilih bidangday_of_week dan kemudian operator untuk bidang itu sebagai is dan nilai sebagai Sunday.
Selanjutnya, kita klik Simpan dengan kondisi filter di atas. Kumpulan hasil yang berisi kondisi filter yang diterapkan ditunjukkan di bawah ini.
Tabel data adalah jenis visualisasi yang digunakan untuk menampilkan data mentah dari agregasi yang tersusun. Ada berbagai jenis agregasi yang disajikan dengan menggunakan tabel Data. Untuk membuat Tabel Data, kita harus melalui langkah-langkah yang dibahas di sini secara rinci.
Membayangkan
Di layar Beranda Kibana kami menemukan nama opsi Visualisasi yang memungkinkan kami membuat visualisasi dan agregasi dari indeks yang disimpan di Elasticsearch. Gambar berikut menunjukkan opsi.
Pilih Tabel Data
Selanjutnya, kami memilih opsi Tabel Data dari berbagai opsi visualisasi yang tersedia. Opsinya ditampilkan pada gambar berikut & miuns;
Pilih Metrik
Kami kemudian memilih metrik yang diperlukan untuk membuat visualisasi tabel data. Pilihan ini menentukan jenis agregasi yang akan kita gunakan. Kami memilih bidang spesifik yang ditunjukkan di bawah ini dari kumpulan data e-niaga untuk ini.
Saat menjalankan konfigurasi di atas untuk Tabel Data, kami mendapatkan hasil seperti yang ditunjukkan pada gambar di sini -
Peta Wilayah menunjukkan metrik pada Peta geografis. Ini berguna dalam melihat data yang ditambatkan ke wilayah geografis yang berbeda dengan intensitas yang berbeda-beda. Warna yang lebih gelap biasanya menunjukkan nilai yang lebih tinggi dan warna yang lebih terang menunjukkan nilai yang lebih rendah.
Langkah-langkah untuk membuat visualisasi ini dijelaskan secara detail sebagai berikut -
Membayangkan
Pada langkah ini kita pergi ke tombol visualisasi yang tersedia di bilah kiri layar Beranda Kibana dan kemudian memilih opsi untuk menambahkan Visualisasi baru.
Layar berikut menunjukkan bagaimana kami memilih opsi Peta wilayah.
Pilih Metrik
Layar berikutnya meminta kita untuk memilih metrik yang akan digunakan dalam membuat Peta Wilayah. Di sini kami memilih Harga rata-rata sebagai metrik dan country_iso_code sebagai bidang di keranjang yang akan digunakan dalam membuat visualisasi.
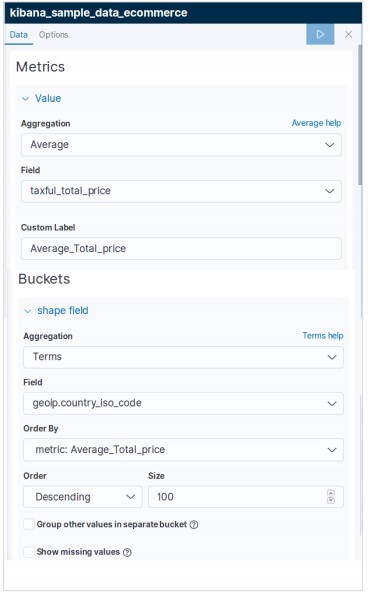
Hasil akhir di bawah ini menunjukkan Peta Wilayah setelah kami menerapkan seleksi. Harap perhatikan corak warna dan nilainya yang disebutkan dalam label.
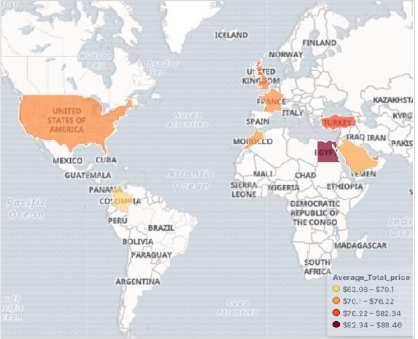
Bagan pai adalah salah satu alat visualisasi paling sederhana dan terkenal. Ini mewakili data sebagai irisan lingkaran yang masing-masing diberi warna berbeda. Label bersama dengan nilai data persentase dapat disajikan bersama dengan lingkaran. Lingkaran juga bisa berbentuk donat.
Membayangkan
Di layar Beranda Kibana, kami menemukan nama opsi Visualisasi yang memungkinkan kami membuat visualisasi dan agregasi dari indeks yang disimpan di Elasticsearch. Kami memilih untuk menambahkan visualisasi baru dan memilih diagram lingkaran seperti opsi yang ditunjukkan di bawah ini.
Pilih Metrik
Layar berikutnya meminta kami untuk memilih metrik yang akan digunakan dalam membuat Diagram Lingkaran. Di sini kami memilih hitungan harga unit dasar sebagai metrik dan Agregasi Bucket sebagai histogram. Juga, interval minimum dipilih sebagai 20. Jadi, harga akan ditampilkan sebagai blok nilai dengan 20 sebagai kisaran.
Hasil di bawah ini menunjukkan diagram lingkaran setelah kami menerapkan pilihan. Harap perhatikan corak warna dan nilainya yang disebutkan dalam label.

Opsi Diagram Lingkaran
Saat berpindah ke tab opsi di bawah diagram lingkaran kita dapat melihat berbagai opsi konfigurasi untuk mengubah tampilan serta pengaturan tampilan data di diagram lingkaran. Dalam contoh berikut, diagram lingkaran muncul sebagai donat dan label muncul di bagian atas.
Bagan area adalah perpanjangan dari bagan garis di mana area antara bagan garis dan sumbu disorot dengan beberapa warna. Bagan batang merepresentasikan data yang diatur ke dalam berbagai nilai dan kemudian diplotkan ke sumbu. Ini dapat terdiri dari batang horizontal atau batang vertikal.
Pada bab ini kita akan melihat ketiga jenis grafik yang dibuat menggunakan Kibana. Seperti yang telah dibahas di bab sebelumnya, kami akan terus menggunakan data di indeks e-niaga.
Bagan Area
Di layar Beranda Kibana, kami menemukan nama opsi Visualisasi yang memungkinkan kami membuat visualisasi dan agregasi dari indeks yang disimpan di Elasticsearch. Kami memilih untuk menambahkan visualisasi baru dan memilih Bagan Area seperti opsi yang ditunjukkan pada gambar yang diberikan di bawah ini.
Pilih Metrik
Layar berikutnya meminta kita untuk memilih metrik yang akan digunakan dalam membuat Bagan Area. Di sini kami memilih jumlah sebagai jenis metrik agregasi. Kemudian kami memilih bidang total_quantity sebagai bidang yang akan digunakan sebagai metrik. Pada sumbu X, kami memilih bidang order_date dan memisahkan rangkaian dengan metrik yang diberikan dalam ukuran 5.

Saat menjalankan konfigurasi di atas, kita mendapatkan diagram area berikut sebagai output -
Bagan Batang Horisontal
Demikian pula, untuk diagram batang Horizontal kami memilih visualisasi baru dari layar Beranda Kibana dan memilih opsi untuk Batang Horizontal. Kemudian kami memilih metrik seperti yang ditunjukkan pada gambar di bawah ini. Di sini kami memilih Jumlah sebagai agregasi untuk jumlah produk yang diberi nama. Kemudian kami memilih kotak dengan histogram tanggal untuk tanggal pesanan lapangan.
Saat menjalankan konfigurasi di atas, kita dapat melihat diagram batang horizontal seperti di bawah ini -
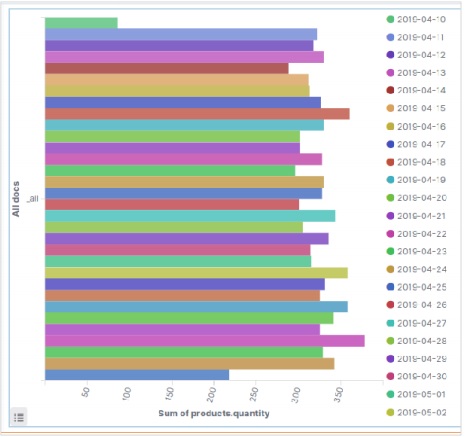
Bagan Batang Vertikal
Untuk grafik batang vertikal, kami memilih visualisasi baru dari layar Beranda Kibana dan memilih opsi untuk Batang Vertikal. Kemudian kami memilih metrik seperti yang ditunjukkan pada gambar di bawah ini.
Di sini kami memilih Jumlah sebagai agregasi untuk bidang bernama kuantitas produk. Kemudian kami memilih bucket dengan histogram tanggal untuk tanggal pesanan lapangan dengan interval mingguan.
Saat menjalankan konfigurasi di atas, grafik akan dibuat seperti yang ditunjukkan di bawah ini -
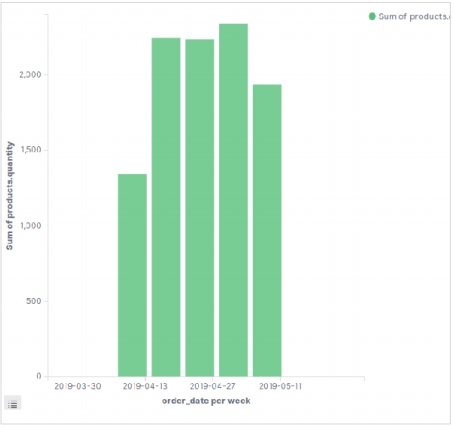
Deret waktu merupakan representasi dari urutan data dalam urutan waktu tertentu. Misalnya, data untuk setiap hari mulai dari hari pertama setiap bulan hingga hari terakhir. Interval antara titik data tetap konstan. Setiap kumpulan data yang memiliki komponen waktu di dalamnya dapat direpresentasikan sebagai deret waktu.
Dalam bab ini, kita akan menggunakan contoh kumpulan data e-niaga dan memplot jumlah pesanan setiap hari untuk membuat deret waktu.
Pilih Metrik
Pertama, kami memilih pola indeks, bidang data dan interval yang akan digunakan untuk membuat deret waktu. Dari contoh kumpulan data e-niaga, kami memilih order_date sebagai bidang dan 1d sebagai intervalnya. Kami menggunakanPanel Optionstab untuk membuat pilihan ini. Juga kami membiarkan nilai lain di tab ini sebagai default untuk mendapatkan warna dan format default untuk deret waktu.
Dalam Data tab, kami memilih hitungan sebagai opsi agregasi, kelompokkan berdasarkan opsi sebagai segalanya dan beri label untuk diagram deret waktu.
Hasil
Hasil akhir dari konfigurasi ini muncul sebagai berikut. Harap dicatat bahwa kami menggunakan jangka waktuMonth to Dateuntuk grafik ini. Jangka waktu yang berbeda akan memberikan hasil yang berbeda pula.
Awan tag mewakili teks yang sebagian besar merupakan kata kunci dan metadata dalam bentuk yang menarik secara visual. Mereka disejajarkan dalam berbagai sudut dan diwakili dalam warna dan ukuran font yang berbeda. Ini membantu dalam menemukan istilah yang paling menonjol dalam data. Keunggulan dapat ditentukan oleh satu atau lebih faktor seperti frekuensi istilah, keunikan tag atau berdasarkan beberapa bobot yang melekat pada istilah tertentu, dll. Di bawah ini kita melihat langkah-langkah untuk membuat Tag Cloud.
Membayangkan
Di layar Beranda Kibana, kami menemukan nama opsi Visualisasi yang memungkinkan kami membuat visualisasi dan agregasi dari indeks yang disimpan di Elasticsearch. Kami memilih untuk menambahkan visualisasi baru dan memilih Tag Cloud seperti opsi yang ditunjukkan di bawah ini -
Pilih Metrik
Layar berikutnya meminta kita untuk memilih metrik yang akan digunakan dalam membuat Tag Cloud. Di sini kami memilih hitungan sebagai jenis metrik agregasi. Kemudian kita memilih field nama produk sebagai kata kunci yang akan digunakan sebagai tag.
Hasil yang ditampilkan di sini menunjukkan diagram lingkaran setelah kami menerapkan pilihan. Harap perhatikan corak warna dan nilainya yang disebutkan dalam label.

Tag Cloud Options
Saat pindah ke optionsdi bawah tab Tag Cloud kita bisa melihat berbagai pilihan konfigurasi untuk mengubah tampilan serta susunan tampilan data di Tag Cloud. Pada contoh di bawah ini, Tag Cloud muncul dengan tag yang tersebar di kedua arah horizontal dan vertikal.
Peta panas adalah jenis visualisasi di mana bayangan warna yang berbeda mewakili area yang berbeda dalam grafik. Nilainya dapat terus berubah dan karenanya warna r corak warna bervariasi bersama nilainya. Mereka sangat berguna untuk merepresentasikan data yang terus berubah dan juga data diskrit.
Dalam bab ini kita akan menggunakan kumpulan data bernama sample_data_flights untuk membuat bagan peta panas. Di dalamnya kami mempertimbangkan variabel bernama negara asal dan negara tujuan penerbangan dan menghitung.
Di layar Beranda Kibana, kami menemukan nama opsi Visualisasi yang memungkinkan kami membuat visualisasi dan agregasi dari indeks yang disimpan di Elasticsearch. Kami memilih untuk menambahkan visualisasi baru dan memilih Peta Panas seperti opsi yang ditunjukkan di bawah & mimus;
Pilih Metrik
Layar berikutnya meminta kita untuk memilih metrik yang akan digunakan dalam membuat Diagram Peta Panas. Di sini kami memilih hitungan sebagai jenis metrik agregasi. Kemudian untuk bucket di Y-Axis, kami memilih Terms sebagai agregasi untuk field OriginCountry. Untuk X-Axis, kami memilih agregasi yang sama tetapi DestCountry sebagai bidang yang akan digunakan. Dalam kedua kasus, kami memilih ukuran ember sebagai 5.

Saat menjalankan konfigurasi yang ditunjukkan di atas, kita mendapatkan grafik peta panas yang dihasilkan sebagai berikut.
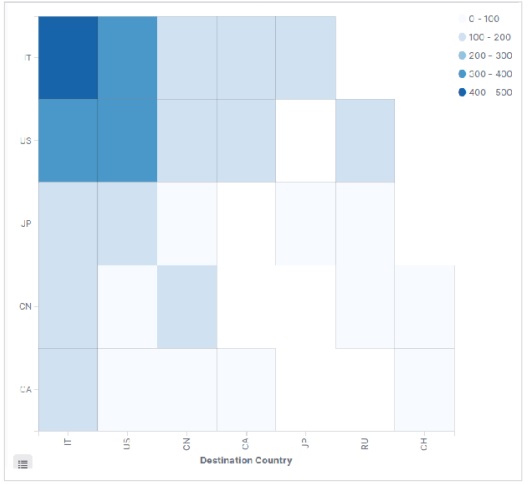
Note - Anda harus mengizinkan rentang tanggal sebagai Tahun Ini sehingga grafik mengumpulkan data selama satu tahun untuk menghasilkan bagan peta panas yang efektif.
Aplikasi kanvas merupakan bagian dari Kibana yang memungkinkan kita untuk membuat tampilan data yang dinamis, multi halaman dan piksel yang sempurna. Kemampuannya untuk membuat infografis dan bukan hanya bagan dan metriklah yang membuatnya unik dan menarik. Pada bab ini kita akan melihat berbagai fitur kanvas dan cara menggunakan bantalan kerja kanvas.
Membuka Kanvas
Buka beranda Kibana dan pilih opsi seperti yang ditunjukkan pada diagram di bawah ini. Ini membuka daftar bantalan kerja kanvas yang Anda miliki. Kami memilih pelacakan Pendapatan e-niaga untuk studi kami.
Menggandakan Workpad
Kami mengkloning file [eCommerce] Revenue Trackingworkpad untuk digunakan dalam penelitian kami. Untuk mengkloningnya, kami menyorot baris dengan nama workpad ini dan kemudian menggunakan tombol clone seperti yang ditunjukkan pada diagram di bawah ini -
Sebagai hasil dari klon di atas, kita akan mendapatkan work pad baru bernama [eCommerce] Revenue Tracking – Copy yang pada pembukaannya akan menampilkan infografik di bawah ini.
Ini menggambarkan total penjualan dan Pendapatan menurut kategori bersama dengan gambar dan bagan yang bagus.
Memodifikasi Workpad
Kita dapat mengubah gaya dan gambar di workpad dengan menggunakan opsi yang tersedia di tab sisi kanan. Di sini kami bertujuan untuk mengubah warna latar belakang workpad dengan memilih warna yang berbeda seperti yang ditunjukkan pada diagram di bawah ini. Pemilihan warna segera berlaku dan kami mendapatkan hasil seperti yang ditunjukkan di bawah ini -

Kibana juga dapat membantu dalam memvisualisasikan data log dari berbagai sumber. Log adalah sumber analisis penting untuk kesehatan infrastruktur, kebutuhan performa dan analisis pelanggaran keamanan, dll. Kibana dapat terhubung ke berbagai log seperti log server web, log elasticsearch, dan log cloudwatch, dll.
Log Logstash
Di Kibana, kita dapat terhubung ke log logstash untuk visualisasi. Pertama kita memilih tombol Log dari layar beranda Kibana seperti yang ditunjukkan di bawah ini -
Kemudian kami memilih opsi Ubah Konfigurasi Sumber yang memberi kami opsi untuk memilih Logstash sebagai sumber. Layar di bawah ini juga menunjukkan jenis opsi lain yang kami miliki sebagai sumber log.
Anda dapat mengalirkan data untuk tailing log langsung atau menjeda streaming untuk fokus pada data log historis. Saat Anda streaming log, log terbaru muncul di bagian bawah konsol.
Untuk referensi lebih lanjut, Anda dapat merujuk ke tutorial Logstash kami .