H2O - Panduan Cepat
Pernahkah Anda diminta untuk mengembangkan model Machine Learning pada database yang sangat besar? Biasanya, pelanggan akan memberi Anda database dan meminta Anda membuat prediksi tertentu seperti siapa yang akan menjadi pembeli potensial; jika ada deteksi dini kasus penipuan, dll. Untuk menjawab pertanyaan ini, tugas Anda adalah mengembangkan algoritme Pembelajaran Mesin yang akan memberikan jawaban atas pertanyaan pelanggan. Mengembangkan algoritme Machine Learning dari awal bukanlah tugas yang mudah dan mengapa Anda harus melakukan ini saat ada beberapa library Machine Learning siap pakai yang tersedia di pasar.
Saat ini, Anda lebih suka menggunakan pustaka ini, menerapkan algoritme yang teruji dengan baik dari pustaka ini dan melihat kinerjanya. Jika kinerja tidak berada dalam batas yang dapat diterima, Anda akan mencoba menyempurnakan algoritme saat ini atau mencoba algoritme yang sama sekali berbeda.
Demikian pula, Anda dapat mencoba beberapa algoritme pada kumpulan data yang sama dan kemudian mengambil yang terbaik yang secara memuaskan memenuhi persyaratan pelanggan. Di sinilah H2O datang untuk menyelamatkan Anda. Ini adalah framework Machine Learning open source dengan implementasi teruji penuh dari beberapa algoritme ML yang diterima secara luas. Anda hanya perlu mengambil algoritme dari repositori besarnya dan menerapkannya ke kumpulan data Anda. Ini berisi algoritma statistik dan ML yang paling banyak digunakan.
Untuk menyebutkan beberapa di sini termasuk mesin yang ditingkatkan gradien (GBM), model linier umum (GLM), pembelajaran mendalam dan banyak lagi. Tidak hanya itu, ia juga mendukung fungsionalitas AutoML yang akan memberi peringkat kinerja berbagai algoritme pada kumpulan data Anda, sehingga mengurangi upaya Anda untuk menemukan model berkinerja terbaik. H2O digunakan di seluruh dunia oleh lebih dari 18000 organisasi dan berinteraksi dengan baik dengan R dan Python untuk kemudahan pengembangan Anda. Ini adalah platform dalam memori yang memberikan kinerja luar biasa.
Dalam tutorial ini, Anda akan belajar menginstal H2O pada mesin Anda dengan opsi Python dan R. Kami akan memahami cara menggunakan ini di baris perintah sehingga Anda memahami cara kerjanya. Jika Anda pecinta Python, Anda dapat menggunakan Jupyter atau IDE lain pilihan Anda untuk mengembangkan aplikasi H2O. Jika Anda lebih suka R, Anda dapat menggunakan RStudio untuk pengembangan.
Dalam tutorial ini, kami akan mempertimbangkan contoh untuk memahami bagaimana cara bekerja dengan H2O. Kami juga akan belajar bagaimana mengubah algoritma dalam kode program Anda dan membandingkan kinerjanya dengan yang sebelumnya. H2O juga menyediakan alat berbasis web untuk menguji berbagai algoritme pada kumpulan data Anda. Ini disebut Arus.
Tutorial akan memperkenalkan Anda pada penggunaan Flow. Bersamaan dengan itu, kami akan membahas penggunaan AutoML yang akan mengidentifikasi algoritme berperforma terbaik pada kumpulan data Anda. Apakah Anda tidak tertarik untuk mempelajari H2O? Teruskan membaca!
H2O dapat dikonfigurasi dan digunakan dengan lima opsi berbeda seperti yang tercantum di bawah ini -
Instal dengan Python
Instal di R
Flow GUI berbasis web
Hadoop
Anaconda Cloud
Di bagian kami selanjutnya, Anda akan melihat petunjuk untuk pemasangan H2O berdasarkan opsi yang tersedia. Anda mungkin menggunakan salah satu opsi.
Instal dengan Python
Untuk menjalankan H2O dengan Python, penginstalan membutuhkan beberapa dependensi. Jadi mari kita mulai menginstal set dependensi minimum untuk menjalankan H2O.
Menginstal Dependensi
Untuk menginstal dependensi, jalankan perintah pip berikut -
$ pip install requestsBuka jendela konsol Anda dan ketik perintah di atas untuk menginstal paket permintaan. Tangkapan layar berikut menunjukkan eksekusi perintah di atas pada mesin Mac kami -
Setelah menginstal permintaan, Anda perlu menginstal tiga paket lagi seperti yang ditunjukkan di bawah ini -
$ pip install tabulate
$ pip install "colorama >= 0.3.8"
$ pip install futureDaftar dependensi terbaru tersedia di halaman H2O GitHub. Pada saat penulisan ini, dependensi berikut terdaftar di halaman.
python 2. H2O — Installation
pip >= 9.0.1
setuptools
colorama >= 0.3.7
future >= 0.15.2Menghapus Versi Lama
Setelah menginstal dependensi di atas, Anda perlu menghapus semua instalasi H2O yang ada. Untuk melakukannya, jalankan perintah berikut -
$ pip uninstall h2oMenginstal Versi Terbaru
Sekarang, mari kita instal H2O versi terbaru menggunakan perintah berikut -
$ pip install -f http://h2o-release.s3.amazonaws.com/h2o/latest_stable_Py.html h2oSetelah instalasi berhasil, Anda akan melihat tampilan pesan berikut di layar -
Installing collected packages: h2o
Successfully installed h2o-3.26.0.1Menguji Instalasi
Untuk menguji penginstalan, kami akan menjalankan salah satu aplikasi sampel yang disediakan di penginstalan H2O. Pertama mulai prompt Python dengan mengetikkan perintah berikut -
$ Python3Setelah interpreter Python dimulai, ketikkan pernyataan Python berikut pada command prompt Python -
>>>import h2oPerintah di atas mengimpor paket H2O dalam program Anda. Selanjutnya, inisialisasi sistem H2O menggunakan perintah berikut -
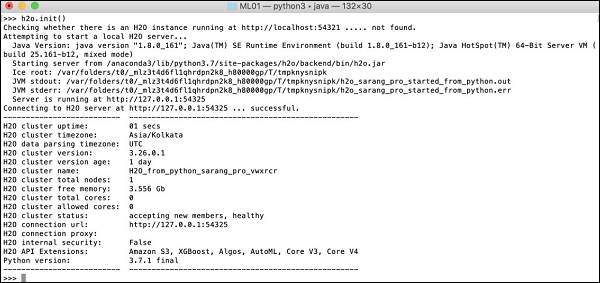
>>>h2o.init()Layar Anda akan menampilkan informasi cluster dan akan terlihat berikut ini pada tahap ini -
Sekarang, Anda siap menjalankan kode sampel. Ketik perintah berikut pada prompt Python dan jalankan.
>>>h2o.demo("glm")Demo terdiri dari notebook Python dengan serangkaian perintah. Setelah menjalankan setiap perintah, hasilnya akan segera ditampilkan di layar dan Anda akan diminta untuk menekan tombol untuk melanjutkan ke langkah berikutnya. Tangkapan layar sebagian tentang menjalankan pernyataan terakhir di notebook ditampilkan di sini -
Pada tahap ini instalasi Python Anda sudah selesai dan Anda siap untuk eksperimen Anda sendiri.
Instal di R
Menginstal pengembangan H2O untuk R sangat mirip dengan menginstalnya untuk Python, kecuali Anda akan menggunakan perintah R untuk instalasi.
Memulai Konsol R.
Mulai konsol R dengan mengklik ikon aplikasi R di mesin Anda. Layar konsol akan muncul seperti yang ditunjukkan pada tangkapan layar berikut -
Instalasi H2O Anda akan dilakukan pada prompt R di atas. Jika Anda lebih suka menggunakan RStudio, ketikkan perintah di subwindow R console.
Menghapus Versi Lama
Untuk memulainya, hapus versi lama menggunakan perintah berikut pada prompt R -
> if ("package:h2o" %in% search()) { detach("package:h2o", unload=TRUE) }
> if ("h2o" %in% rownames(installed.packages())) { remove.packages("h2o") }Mendownload Dependensi
Unduh dependensi untuk H2O menggunakan kode berikut -
> pkgs <- c("RCurl","jsonlite")
for (pkg in pkgs) {
if (! (pkg %in% rownames(installed.packages()))) { install.packages(pkg) }
}Menginstal H2O
Instal H2O dengan mengetikkan perintah berikut pada prompt R -
> install.packages("h2o", type = "source", repos = (c("http://h2o-release.s3.amazonaws.com/h2o/latest_stable_R")))Tangkapan layar berikut menunjukkan keluaran yang diharapkan -
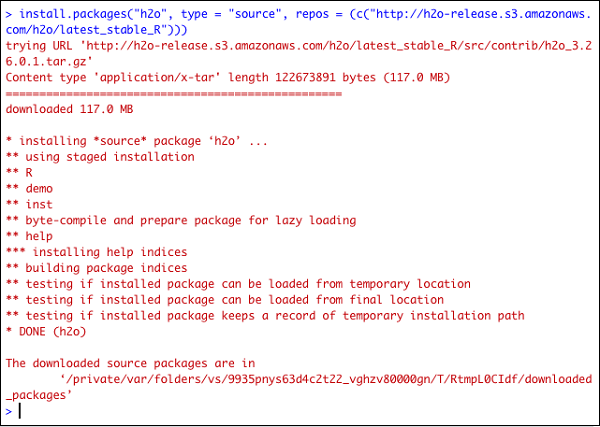
Ada cara lain untuk memasang H2O di R.
Instal di R dari CRAN
Untuk menginstal R dari CRAN, gunakan perintah berikut pada prompt R -
> install.packages("h2o")Anda akan diminta untuk memilih cermin -
--- Please select a CRAN mirror for use in this session ---
Kotak dialog yang menampilkan daftar situs cermin ditampilkan di layar Anda. Pilih lokasi terdekat atau cermin pilihan Anda.
Menguji Instalasi
Pada prompt R, ketik dan jalankan kode berikut -
> library(h2o)
> localH2O = h2o.init()
> demo(h2o.kmeans)Output yang dihasilkan akan seperti yang ditunjukkan pada tangkapan layar berikut -
Instalasi H2O Anda di R sudah selesai sekarang.
Menginstal Alur GUI Web
Untuk menginstal GUI Flow unduh file instalasi dari situs H20. Buka zip file yang diunduh di folder pilihan Anda. Perhatikan keberadaan file h2o.jar pada saat instalasi. Jalankan file ini di jendela perintah menggunakan perintah berikut -
$ java -jar h2o.jarSetelah beberapa saat, berikut ini akan muncul di jendela konsol Anda.
07-24 16:06:37.304 192.168.1.18:54321 3294 main INFO: H2O started in 7725ms
07-24 16:06:37.304 192.168.1.18:54321 3294 main INFO:
07-24 16:06:37.305 192.168.1.18:54321 3294 main INFO: Open H2O Flow in your web browser: http://192.168.1.18:54321
07-24 16:06:37.305 192.168.1.18:54321 3294 main INFO:Untuk memulai Flow, buka URL yang diberikan http://localhost:54321di browser Anda. Layar berikut akan muncul -
Pada tahap ini, penginstalan Flow Anda selesai.
Instal di Hadoop / Anaconda Cloud
Kecuali Anda adalah pengembang berpengalaman, Anda tidak akan berpikir untuk menggunakan H2O pada Big Data. Di sini cukup dikatakan bahwa model H2O berjalan secara efisien pada database besar yang berukuran beberapa terabyte. Jika data Anda ada di instalasi Hadoop atau di Cloud, ikuti langkah-langkah yang diberikan di situs H2O untuk menginstalnya untuk database Anda masing-masing.
Sekarang setelah Anda berhasil menginstal dan menguji H2O pada mesin Anda, Anda siap untuk pengembangan nyata. Pertama, kita akan melihat perkembangan dari Command prompt. Dalam pelajaran kita selanjutnya, kita akan belajar bagaimana melakukan pengujian model di H2O Flow.
Berkembang di Command Prompt
Sekarang, mari kita pertimbangkan untuk menggunakan H2O untuk mengklasifikasikan tanaman dari kumpulan data iris terkenal yang tersedia secara gratis untuk mengembangkan aplikasi Pembelajaran Mesin.
Mulai penerjemah Python dengan mengetikkan perintah berikut di jendela shell Anda -
$ Python3Ini memulai interpreter Python. Impor platform h2o menggunakan perintah berikut -
>>> import h2oKami akan menggunakan algoritma Random Forest untuk klasifikasi. Ini disediakan dalam paket H2ORandomForestEstimator. Kami mengimpor paket ini menggunakan pernyataan import sebagai berikut -
>>> from h2o.estimators import H2ORandomForestEstimatorKami menginisialisasi lingkungan H2o dengan memanggil metode initnya.
>>> h2o.init()Pada inisialisasi yang berhasil, Anda akan melihat pesan berikut di konsol bersama dengan informasi cluster.
Checking whether there is an H2O instance running at http://localhost:54321 . connected.Sekarang, kita akan mengimpor data iris menggunakan metode import_file di H2O.
>>> data = h2o.import_file('iris.csv')Kemajuan akan ditampilkan seperti yang ditunjukkan pada tangkapan layar berikut -

Setelah file dimuat di memori, Anda dapat memverifikasi ini dengan menampilkan 10 baris pertama dari tabel yang dimuat. Anda menggunakanhead metode untuk melakukannya -
>>> data.head()Anda akan melihat keluaran berikut dalam format tabel.
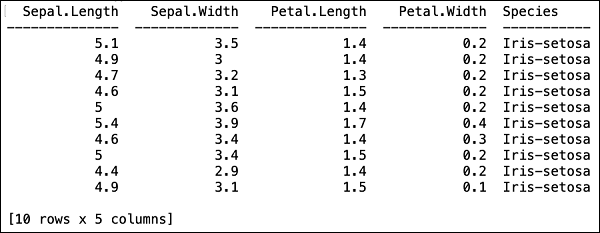
Tabel juga menampilkan nama kolom. Kami akan menggunakan empat kolom pertama sebagai fitur untuk algoritme ML kami dan kelas kolom terakhir sebagai keluaran yang diprediksi. Kami menetapkan ini dalam panggilan ke algoritme ML kami dengan terlebih dahulu membuat dua variabel berikut.
>>> features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
>>> output = 'class'Selanjutnya, kami membagi data menjadi pelatihan dan pengujian dengan memanggil metode split_frame.
>>> train, test = data.split_frame(ratios = [0.8])Data tersebut terbagi dalam rasio 80:20. Kami menggunakan 80% data untuk pelatihan dan 20% untuk pengujian.
Sekarang, kami memuat model Random Forest ke dalam sistem.
>>> model = H2ORandomForestEstimator(ntrees = 50, max_depth = 20, nfolds = 10)Dalam panggilan di atas, kami menetapkan jumlah pohon menjadi 50, kedalaman maksimum untuk pohon menjadi 20 dan jumlah lipatan untuk validasi silang menjadi 10. Sekarang kita perlu melatih model. Kami melakukannya dengan memanggil metode kereta sebagai berikut -
>>> model.train(x = features, y = output, training_frame = train)Metode kereta menerima fitur dan keluaran yang kita buat sebelumnya sebagai dua parameter pertama. Set data pelatihan disetel ke train, yang merupakan 80% dari set data lengkap kami. Selama pelatihan, Anda akan melihat kemajuan seperti yang ditunjukkan di sini -
Sekarang, setelah proses pembangunan model selesai, sekarang saatnya untuk menguji model tersebut. Kami melakukan ini dengan memanggil metode model_performance pada objek model yang dilatih.
>>> performance = model.model_performance(test_data=test)Dalam pemanggilan metode di atas, kami mengirimkan data uji sebagai parameter kami.
Sekarang saatnya untuk melihat hasilnya, yaitu performa model kita. Anda melakukan ini hanya dengan mencetak kinerja.
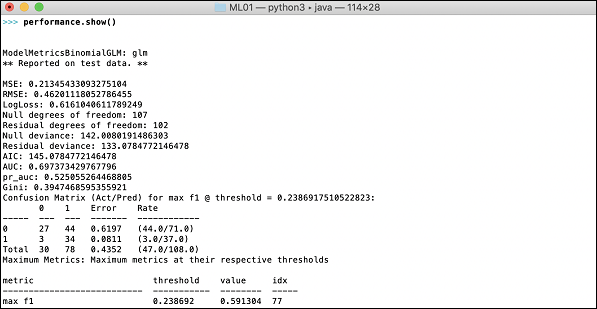
>>> print (performance)Ini akan memberi Anda output berikut -
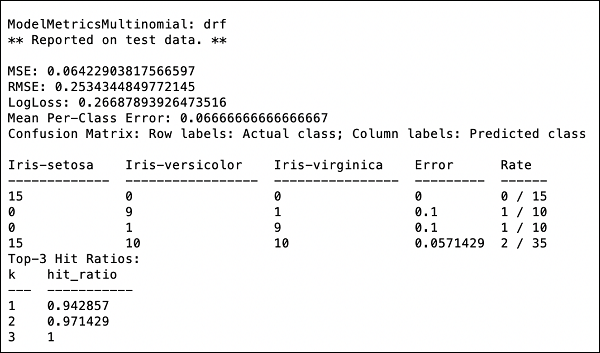
Outputnya menunjukkan Mean Square Error (MSE), Root Mean Square Error (RMSE), LogLoss dan bahkan Confusion Matrix.
Berlari di Jupyter
Kami telah melihat eksekusi dari perintah dan juga memahami tujuan setiap baris kode. Anda dapat menjalankan seluruh kode di lingkungan Jupyter, baik baris demi baris atau seluruh program dalam satu waktu. Daftar lengkap diberikan di sini -
import h2o
from h2o.estimators import H2ORandomForestEstimator
h2o.init()
data = h2o.import_file('iris.csv')
features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
output = 'class'
train, test = data.split_frame(ratios=[0.8])
model = H2ORandomForestEstimator(ntrees = 50, max_depth = 20, nfolds = 10)
model.train(x = features, y = output, training_frame = train)
performance = model.model_performance(test_data=test)
print (performance)Jalankan kode dan amati hasilnya. Sekarang Anda dapat menghargai betapa mudahnya menerapkan dan menguji algoritme Random Forest pada kumpulan data Anda. Kekuatan H20 jauh melampaui kemampuan ini. Bagaimana jika Anda ingin mencoba model lain pada set data yang sama untuk melihat apakah Anda bisa mendapatkan kinerja yang lebih baik. Ini dijelaskan di bagian selanjutnya.
Menerapkan Algoritma Berbeda
Sekarang, kita akan belajar bagaimana menerapkan algoritma Gradient Boosting ke dataset sebelumnya untuk melihat bagaimana kinerjanya. Dalam daftar lengkap di atas, Anda hanya perlu membuat dua perubahan kecil seperti yang disorot dalam kode di bawah -
import h2o
from h2o.estimators import H2OGradientBoostingEstimator
h2o.init()
data = h2o.import_file('iris.csv')
features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
output = 'class'
train, test = data.split_frame(ratios = [0.8])
model = H2OGradientBoostingEstimator
(ntrees = 50, max_depth = 20, nfolds = 10)
model.train(x = features, y = output, training_frame = train)
performance = model.model_performance(test_data = test)
print (performance)Jalankan kode dan Anda akan mendapatkan output berikut -
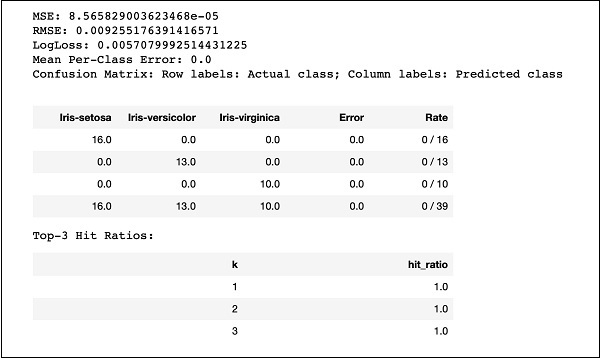
Bandingkan saja hasil seperti MSE, RMSE, Confusion Matrix, dll. Dengan keluaran sebelumnya dan putuskan mana yang akan digunakan untuk penerapan produksi. Faktanya, Anda dapat menerapkan beberapa algoritme berbeda untuk memutuskan algoritme terbaik yang memenuhi tujuan Anda.
Pada pelajaran terakhir, Anda belajar membuat model ML berbasis H2O menggunakan antarmuka baris perintah. H2O Flow memenuhi tujuan yang sama, tetapi dengan antarmuka berbasis web.
Dalam pelajaran berikut, saya akan menunjukkan kepada Anda bagaimana memulai H2O Flow dan menjalankan aplikasi contoh.
Memulai Arus H2O
Instalasi H2O yang Anda download sebelumnya berisi file h2o.jar. Untuk memulai H2O Flow, pertama-tama jalankan jar ini dari command prompt -
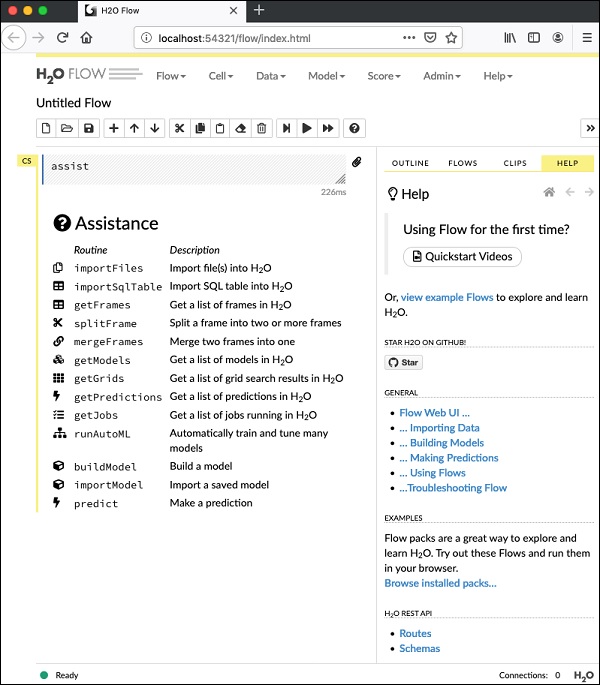
$ java -jar h2o.jarKetika toples berhasil, Anda akan mendapatkan pesan berikut di konsol -
Open H2O Flow in your web browser: http://192.168.1.10:54321Sekarang, buka browser pilihan Anda dan ketik URL di atas. Anda akan melihat desktop berbasis web H2O seperti yang ditunjukkan di sini -
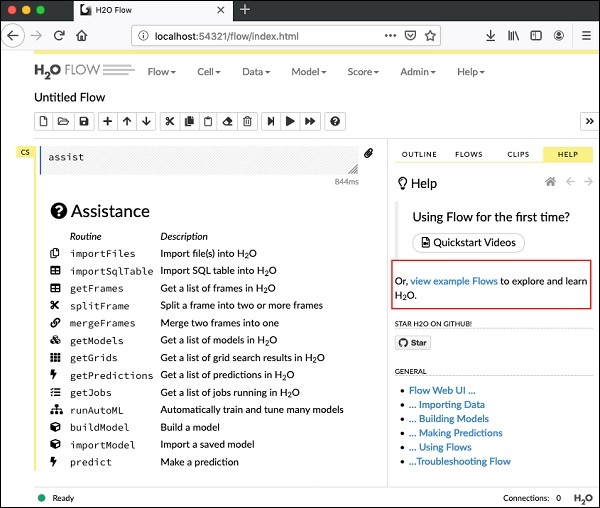
Ini pada dasarnya adalah notebook yang mirip dengan Colab atau Jupyter. Saya akan menunjukkan kepada Anda cara memuat dan menjalankan aplikasi contoh di notebook ini sambil menjelaskan berbagai fitur di Flow. Klik pada contoh tampilan tautan Arus pada layar di atas untuk melihat daftar contoh yang diberikan.
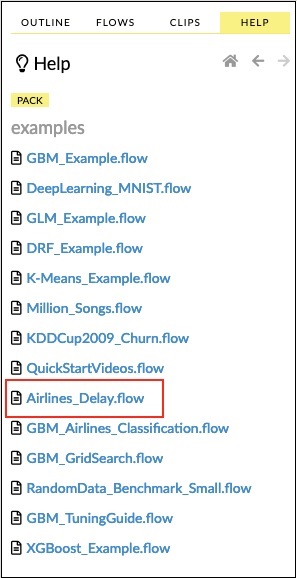
Saya akan menjelaskan contoh Aliran penundaan Maskapai dari sampel.
Klik tautan Airlines Delay Flow dalam daftar sampel seperti yang ditunjukkan pada gambar di bawah -
Setelah Anda mengonfirmasi, buku catatan baru akan dimuat.
Menghapus Semua Output
Sebelum kami menjelaskan pernyataan kode di notebook, mari kita hapus semua output dan kemudian jalankan notebook secara bertahap. Untuk menghapus semua output, pilih opsi menu berikut -
Flow / Clear All Cell ContentsIni ditunjukkan pada tangkapan layar berikut -
Setelah semua output dihapus, kami akan menjalankan setiap sel di notebook satu per satu dan memeriksa outputnya.
Menjalankan Sel Pertama
Klik sel pertama. Bendera merah muncul di sebelah kiri yang menunjukkan bahwa sel tersebut dipilih. Ini seperti yang ditunjukkan pada gambar di bawah -

Isi sel ini hanyalah komentar program yang ditulis dalam bahasa MarkDown (MD). Konten menjelaskan apa yang dilakukan aplikasi yang dimuat. Untuk menjalankan sel, klik ikon Jalankan seperti yang ditunjukkan pada gambar di bawah -

Anda tidak akan melihat keluaran apa pun di bawah sel karena tidak ada kode yang dapat dieksekusi di sel saat ini. Kursor sekarang bergerak secara otomatis ke sel berikutnya, yang siap dieksekusi.
Mengimpor Data
Sel berikutnya berisi pernyataan Python berikut -
importFiles ["https://s3.amazonaws.com/h2o-airlines-unpacked/allyears2k.csv"]Pernyataan tersebut mengimpor file allyears2k.csv dari Amazon AWS ke dalam sistem. Saat Anda menjalankan sel, itu mengimpor file dan memberi Anda output berikut.
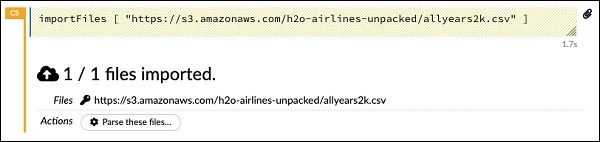
Menyiapkan Parser Data
Sekarang, kita perlu mengurai data dan membuatnya sesuai dengan algoritme ML kita. Ini dilakukan dengan menggunakan perintah berikut -
setupParse paths: [ "https://s3.amazonaws.com/h2o-airlines-unpacked/allyears2k.csv" ]Setelah menjalankan pernyataan di atas, dialog konfigurasi pengaturan muncul. Dialog ini memungkinkan Anda untuk beberapa pengaturan untuk mengurai file. Ini seperti yang ditunjukkan pada gambar di bawah -
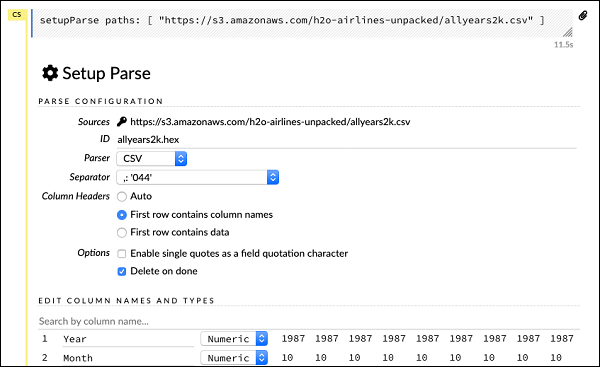
Dalam dialog ini, Anda dapat memilih pengurai yang diinginkan dari daftar drop-down yang diberikan dan mengatur parameter lain seperti pemisah bidang, dll.
Mengurai Data
Pernyataan berikutnya, yang sebenarnya mengurai datafile menggunakan konfigurasi di atas, adalah pernyataan yang panjang dan seperti yang ditunjukkan di sini -
parseFiles
paths: ["https://s3.amazonaws.com/h2o-airlines-unpacked/allyears2k.csv"]
destination_frame: "allyears2k.hex"
parse_type: "CSV"
separator: 44
number_columns: 31
single_quotes: false
column_names: ["Year","Month","DayofMonth","DayOfWeek","DepTime","CRSDepTime",
"ArrTime","CRSArrTime","UniqueCarrier","FlightNum","TailNum",
"ActualElapsedTime","CRSElapsedTime","AirTime","ArrDelay","DepDelay",
"Origin","Dest","Distance","TaxiIn","TaxiOut","Cancelled","CancellationCode",
"Diverted","CarrierDelay","WeatherDelay","NASDelay","SecurityDelay",
"LateAircraftDelay","IsArrDelayed","IsDepDelayed"]
column_types: ["Enum","Enum","Enum","Enum","Numeric","Numeric","Numeric"
,"Numeric","Enum","Enum","Enum","Numeric","Numeric","Numeric","Numeric",
"Numeric","Enum","Enum","Numeric","Numeric","Numeric","Enum","Enum",
"Numeric","Numeric","Numeric","Numeric","Numeric","Numeric","Enum","Enum"]
delete_on_done: true
check_header: 1
chunk_size: 4194304Perhatikan bahwa parameter yang telah Anda siapkan di kotak konfigurasi tercantum dalam kode di atas. Sekarang, jalankan sel ini. Setelah beberapa saat, penguraian selesai dan Anda akan melihat output berikut -
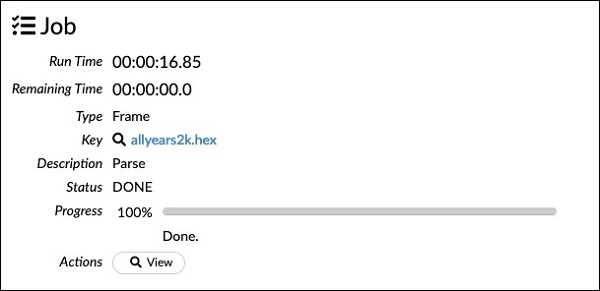
Memeriksa Dataframe
Setelah diproses, ini menghasilkan kerangka data, yang dapat diperiksa menggunakan pernyataan berikut -
getFrameSummary "allyears2k.hex"Setelah menjalankan pernyataan di atas, Anda akan melihat output berikut -
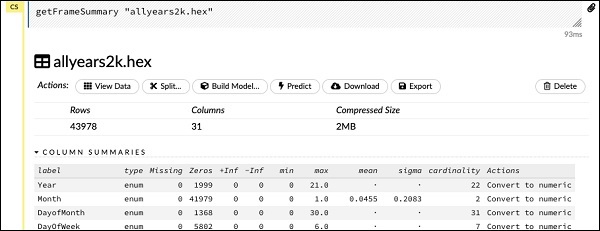
Sekarang, data Anda siap untuk dimasukkan ke dalam algoritma Pembelajaran Mesin.
Pernyataan berikutnya adalah komentar program yang mengatakan kita akan menggunakan model regresi dan menentukan regularisasi preset dan nilai lambda.
Membangun Model
Selanjutnya, muncul pernyataan terpenting dan itu adalah membangun model itu sendiri. Ini ditentukan dalam pernyataan berikut -
buildModel 'glm', {
"model_id":"glm_model","training_frame":"allyears2k.hex",
"ignored_columns":[
"DayofMonth","DepTime","CRSDepTime","ArrTime","CRSArrTime","TailNum",
"ActualElapsedTime","CRSElapsedTime","AirTime","ArrDelay","DepDelay",
"TaxiIn","TaxiOut","Cancelled","CancellationCode","Diverted","CarrierDelay",
"WeatherDelay","NASDelay","SecurityDelay","LateAircraftDelay","IsArrDelayed"],
"ignore_const_cols":true,"response_column":"IsDepDelayed","family":"binomial",
"solver":"IRLSM","alpha":[0.5],"lambda":[0.00001],"lambda_search":false,
"standardize":true,"non_negative":false,"score_each_iteration":false,
"max_iterations":-1,"link":"family_default","intercept":true,
"objective_epsilon":0.00001,"beta_epsilon":0.0001,"gradient_epsilon":0.0001,
"prior":-1,"max_active_predictors":-1
}Kami menggunakan glm, yang merupakan rangkaian Model Linear Umum dengan tipe keluarga yang disetel ke binomial. Anda dapat melihat ini disorot dalam pernyataan di atas. Dalam kasus kami, keluaran yang diharapkan adalah biner dan itulah mengapa kami menggunakan tipe binomial. Anda dapat memeriksa parameter lain sendiri; misalnya, lihat alpha dan lambda yang telah kita tentukan sebelumnya. Lihat dokumentasi model GLM untuk penjelasan tentang semua parameter.
Sekarang, jalankan pernyataan ini. Setelah dieksekusi, keluaran berikut akan dihasilkan -

Pastinya, waktu eksekusi di mesin Anda akan berbeda. Sekarang, sampai pada bagian paling menarik dari kode contoh ini.
Meneliti Output
Kami hanya menampilkan model yang telah kami buat menggunakan pernyataan berikut -
getModel "glm_model"Perhatikan glm_model adalah ID model yang kita tentukan sebagai parameter model_id saat membuat model di pernyataan sebelumnya. Ini memberi kita keluaran besar yang merinci hasil dengan beberapa parameter yang bervariasi. Keluaran sebagian dari laporan tersebut ditunjukkan pada gambar di bawah -
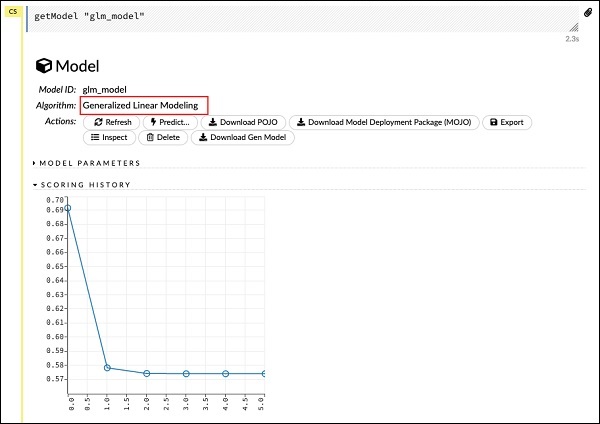
Seperti yang Anda lihat di output, dikatakan bahwa ini adalah hasil dari menjalankan algoritma Generalized Linear Modeling pada dataset Anda.
Tepat di atas SEJARAH PENILAIAN, Anda melihat tag PARAMETER MODEL, perluas dan Anda akan melihat daftar semua parameter yang digunakan saat membangun model. Ini ditunjukkan pada gambar di bawah.
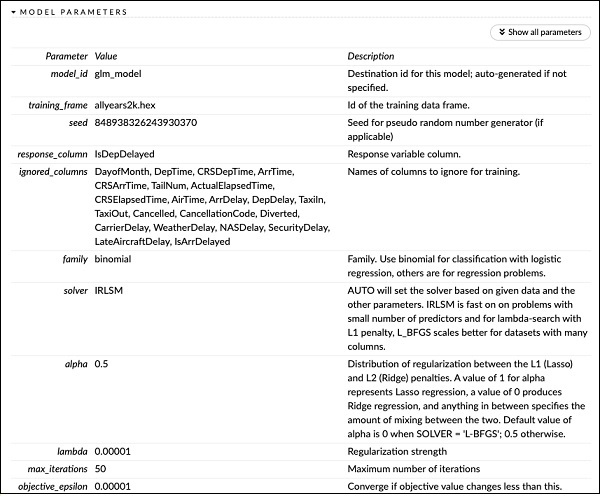
Demikian pula, setiap tag memberikan hasil mendetail dari jenis tertentu. Perluas sendiri berbagai tag untuk mempelajari keluaran dari berbagai jenis.
Membangun Model Lain
Selanjutnya, kami akan membuat model Pembelajaran Mendalam pada kerangka data kami. Pernyataan berikutnya dalam kode contoh hanyalah komentar program. Pernyataan berikut sebenarnya adalah perintah membangun model. Seperti yang ditunjukkan di sini -
buildModel 'deeplearning', {
"model_id":"deeplearning_model","training_frame":"allyear
s2k.hex","ignored_columns":[
"DepTime","CRSDepTime","ArrTime","CRSArrTime","FlightNum","TailNum",
"ActualElapsedTime","CRSElapsedTime","AirTime","ArrDelay","DepDelay",
"TaxiIn","TaxiOut","Cancelled","CancellationCode","Diverted",
"CarrierDelay","WeatherDelay","NASDelay","SecurityDelay",
"LateAircraftDelay","IsArrDelayed"],
"ignore_const_cols":true,"res ponse_column":"IsDepDelayed",
"activation":"Rectifier","hidden":[200,200],"epochs":"100",
"variable_importances":false,"balance_classes":false,
"checkpoint":"","use_all_factor_levels":true,
"train_samples_per_iteration":-2,"adaptive_rate":true,
"input_dropout_ratio":0,"l1":0,"l2":0,"loss":"Automatic","score_interval":5,
"score_training_samples":10000,"score_duty_cycle":0.1,"autoencoder":false,
"overwrite_with_best_model":true,"target_ratio_comm_to_comp":0.02,
"seed":6765686131094811000,"rho":0.99,"epsilon":1e-8,"max_w2":"Infinity",
"initial_weight_distribution":"UniformAdaptive","classification_stop":0,
"diagnostics":true,"fast_mode":true,"force_load_balance":true,
"single_node_mode":false,"shuffle_training_data":false,"missing_values_handling":
"MeanImputation","quiet_mode":false,"sparse":false,"col_major":false,
"average_activation":0,"sparsity_beta":0,"max_categorical_features":2147483647,
"reproducible":false,"export_weights_and_biases":false
}Seperti yang Anda lihat pada kode di atas, kami menetapkan deeplearning untuk membangun model dengan beberapa parameter yang disetel ke nilai yang sesuai seperti yang ditentukan dalam dokumentasi model deeplearning. Ketika Anda menjalankan pernyataan ini, dibutuhkan waktu lebih lama daripada pembuatan model GLM. Anda akan melihat keluaran berikut saat pembuatan model selesai, meskipun dengan waktu yang berbeda.

Menelaah Output Model Pembelajaran Mendalam
Ini menghasilkan jenis keluaran, yang dapat diperiksa dengan menggunakan pernyataan berikut seperti pada kasus sebelumnya.
getModel "deeplearning_model"Kami akan mempertimbangkan keluaran kurva KOP seperti yang ditunjukkan di bawah ini untuk referensi cepat.
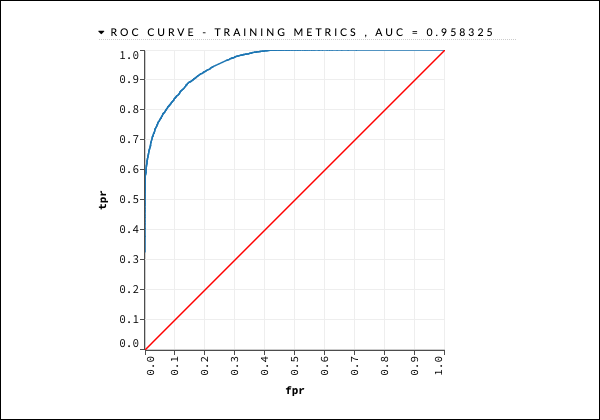
Seperti dalam kasus sebelumnya, perluas berbagai tab dan pelajari keluaran yang berbeda.
Menyimpan Model
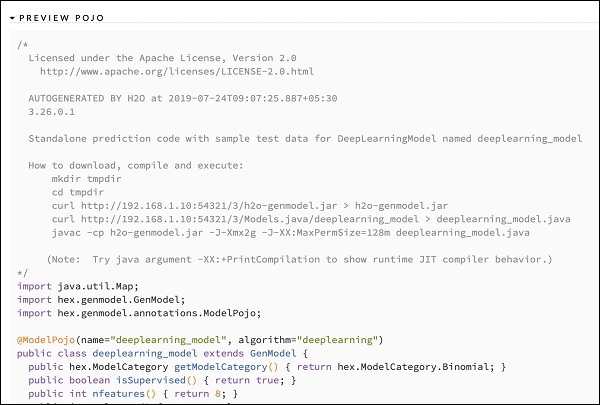
Setelah Anda mempelajari output dari berbagai model, Anda memutuskan untuk menggunakan salah satu model di lingkungan produksi Anda. H20 memungkinkan Anda menyimpan model ini sebagai POJO (Objek Java Lama Biasa).
Perluas tag terakhir PREVIEW POJO di keluaran dan Anda akan melihat kode Java untuk model Anda yang telah disetel dengan baik. Gunakan ini di lingkungan produksi Anda.
Selanjutnya, kita akan belajar tentang fitur H2O yang sangat menarik. Kami akan mempelajari cara menggunakan AutoML untuk menguji dan memberi peringkat berbagai algoritme berdasarkan kinerjanya.
Untuk menggunakan AutoML, mulai notebook Jupyter baru dan ikuti langkah-langkah yang ditunjukkan di bawah ini.
Mengimpor AutoML
Impor pertama paket H2O dan AutoML ke dalam proyek menggunakan dua pernyataan berikut -
import h2o
from h2o.automl import H2OAutoMLInisialisasi H2O
Inisialisasi h2o menggunakan pernyataan berikut -
h2o.init()Anda harus melihat informasi cluster di layar seperti yang ditunjukkan pada gambar di bawah -
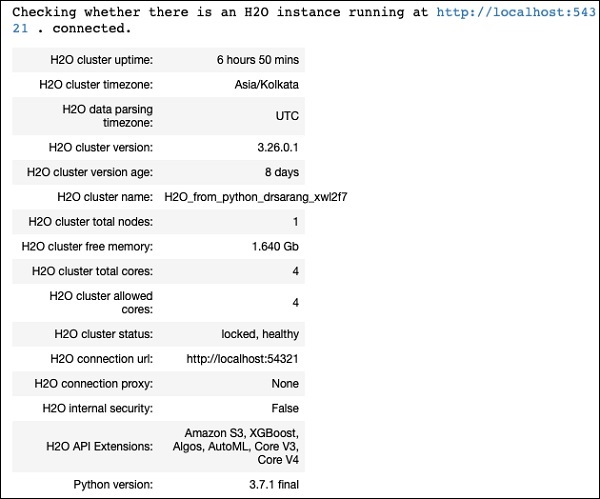
Memuat Data
Kami akan menggunakan dataset iris.csv yang sama dengan yang Anda gunakan sebelumnya dalam tutorial ini. Muat data menggunakan pernyataan berikut -
data = h2o.import_file('iris.csv')Mempersiapkan Set Data
Kita perlu memutuskan fitur dan kolom prediksi. Kami menggunakan fitur dan kolom predikasi yang sama seperti dalam kasus kami sebelumnya. Atur fitur dan kolom keluaran menggunakan dua pernyataan berikut -
features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
output = 'class'Pisahkan data dalam rasio 80:20 untuk pelatihan dan pengujian -
train, test = data.split_frame(ratios=[0.8])Menerapkan AutoML
Sekarang, kita siap untuk menerapkan AutoML pada dataset kita. AutoML akan berjalan untuk jumlah waktu tetap yang kami tetapkan dan memberi kami model yang dioptimalkan. Kami menyiapkan AutoML menggunakan pernyataan berikut -
aml = H2OAutoML(max_models = 30, max_runtime_secs=300, seed = 1)Parameter pertama menentukan jumlah model yang ingin kita evaluasi dan bandingkan.
Parameter kedua menentukan waktu untuk menjalankan algoritma.
Kami sekarang memanggil metode kereta pada objek AutoML seperti yang ditunjukkan di sini -
aml.train(x = features, y = output, training_frame = train)Kami menetapkan x sebagai larik fitur yang kami buat sebelumnya, y sebagai variabel output untuk menunjukkan nilai yang diprediksi dan kerangka data sebagai train Himpunan data.
Jalankan kode, Anda harus menunggu selama 5 menit (kami menetapkan max_runtime_secs ke 300) hingga Anda mendapatkan output berikut -

Mencetak Papan Peringkat
Saat pemrosesan AutoML selesai, ini membuat papan peringkat yang memeringkat semua 30 algoritme yang telah dievaluasi. Untuk melihat 10 catatan pertama dari papan peringkat, gunakan kode berikut -
lb = aml.leaderboard
lb.head()Setelah dieksekusi, kode di atas akan menghasilkan keluaran berikut -
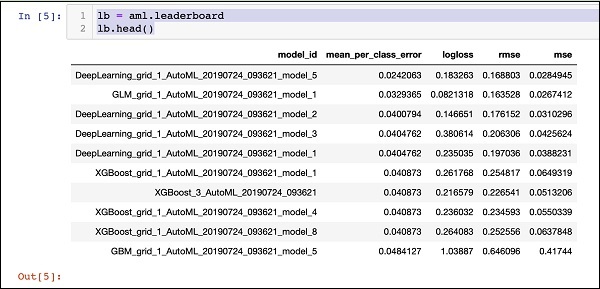
Yang jelas, algoritma DeepLearning sudah mendapatkan skor maksimal.
Memprediksi pada Data Uji
Sekarang, Anda memiliki model yang diberi peringkat, Anda dapat melihat kinerja model berperingkat teratas pada data pengujian Anda. Untuk melakukannya, jalankan pernyataan kode berikut -
preds = aml.predict(test)Pemrosesan berlanjut untuk beberapa saat dan Anda akan melihat keluaran berikut setelah selesai.

Hasil Pencetakan
Cetak hasil prediksi menggunakan pernyataan berikut -
print (preds)Setelah menjalankan pernyataan di atas, Anda akan melihat hasil berikut -
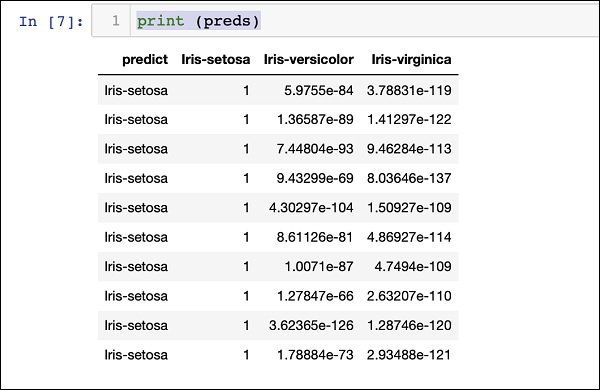
Mencetak Peringkat untuk Semua
Jika Anda ingin melihat peringkat dari semua algoritma yang diuji, jalankan pernyataan kode berikut -
lb.head(rows = lb.nrows)Setelah menjalankan pernyataan di atas, output berikut akan dibuat (sebagian ditampilkan) -
Kesimpulan
H2O menyediakan platform open source yang mudah digunakan untuk menerapkan algoritme ML yang berbeda pada kumpulan data tertentu. Ini menyediakan beberapa algoritma statistik dan ML termasuk pembelajaran yang mendalam. Selama pengujian, Anda dapat menyempurnakan parameter untuk algoritme ini. Anda dapat melakukannya dengan menggunakan baris perintah atau antarmuka berbasis web yang disediakan bernama Flow. H2O juga mendukung AutoML yang memberikan peringkat di antara beberapa algoritme berdasarkan kinerjanya. H2O juga bekerja dengan baik di Big Data. Ini jelas merupakan keuntungan bagi Ilmuwan Data untuk menerapkan model Pembelajaran Mesin yang berbeda pada kumpulan data mereka dan mengambil yang terbaik untuk memenuhi kebutuhan mereka.