Hadoop - Ikhtisar HDFS
Sistem File Hadoop dikembangkan dengan menggunakan desain sistem file terdistribusi. Ini dijalankan pada perangkat keras komoditas. Tidak seperti sistem terdistribusi lainnya, HDFS sangat toleran terhadap kesalahan dan dirancang menggunakan perangkat keras berbiaya rendah.
HDFS menyimpan sejumlah besar data dan menyediakan akses yang lebih mudah. Untuk menyimpan data sebesar itu, file disimpan di beberapa mesin. File-file ini disimpan secara berlebihan untuk menyelamatkan sistem dari kemungkinan kehilangan data jika terjadi kegagalan. HDFS juga membuat aplikasi tersedia untuk pemrosesan paralel.
Fitur HDFS
- Sangat cocok untuk penyimpanan dan pemrosesan terdistribusi.
- Hadoop menyediakan antarmuka perintah untuk berinteraksi dengan HDFS.
- Server built-in dari namenode dan datanode membantu pengguna untuk dengan mudah memeriksa status cluster.
- Akses streaming ke data sistem file.
- HDFS memberikan izin file dan otentikasi.
Arsitektur HDFS
Diberikan di bawah ini adalah arsitektur Sistem File Hadoop.
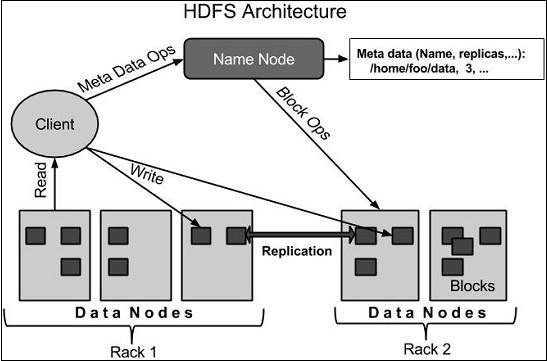
HDFS mengikuti arsitektur master-slave dan memiliki elemen berikut.
Namenode
Namenode adalah perangkat keras komoditas yang berisi sistem operasi GNU / Linux dan perangkat lunak namenode. Ini adalah perangkat lunak yang dapat dijalankan pada perangkat keras komoditas. Sistem yang memiliki kode nama bertindak sebagai server master dan melakukan tugas-tugas berikut -
Mengelola namespace sistem file.
Mengatur akses klien ke file.
Ini juga menjalankan operasi sistem file seperti mengganti nama, menutup, dan membuka file dan direktori.
Datanode
Datanode adalah perangkat keras komoditas yang memiliki sistem operasi GNU / Linux dan perangkat lunak datanode. Untuk setiap node (Commodity hardware / System) dalam sebuah cluster, akan ada datanode. Node ini mengelola penyimpanan data sistem mereka.
Datanode melakukan operasi baca-tulis pada sistem file, sesuai permintaan klien.
Mereka juga melakukan operasi seperti pembuatan blok, penghapusan, dan replikasi sesuai dengan instruksi namenode.
Blok
Umumnya data pengguna disimpan dalam file HDFS. File dalam sistem file akan dibagi menjadi satu atau lebih segmen dan / atau disimpan dalam node data individu. Segmen file ini disebut sebagai blok. Dengan kata lain, jumlah minimum data yang dapat dibaca atau ditulis oleh HDFS disebut Block. Ukuran blok default adalah 64MB, tetapi dapat ditingkatkan sesuai kebutuhan untuk mengubah konfigurasi HDFS.
Tujuan HDFS
Fault detection and recovery- Karena HDFS menyertakan sejumlah besar perangkat keras komoditas, sering terjadi kegagalan komponen. Oleh karena itu HDFS harus memiliki mekanisme untuk deteksi dan pemulihan kesalahan yang cepat dan otomatis.
Huge datasets - HDFS harus memiliki ratusan node per cluster untuk mengelola aplikasi yang memiliki dataset besar.
Hardware at data- Sebuah tugas yang diminta dapat dilakukan secara efisien, saat komputasi dilakukan di dekat data. Terutama di mana kumpulan data besar terlibat, ini mengurangi lalu lintas jaringan dan meningkatkan throughput.