SAP BODS - Panduan Cepat
Gudang data dikenal sebagai repositori pusat untuk menyimpan data dari satu atau beberapa sumber data yang heterogen. Gudang data digunakan untuk melaporkan dan menganalisis informasi dan menyimpan data historis dan terkini. Data dalam sistem DW digunakan untuk pelaporan Analitis, yang kemudian digunakan oleh Analis Bisnis, Manajer Penjualan atau pekerja Pengetahuan untuk pengambilan keputusan.
Data dalam sistem DW dimuat dari sistem transaksi operasional seperti Penjualan, Pemasaran, SDM, SCM, dll. Data tersebut dapat melewati penyimpanan data operasional atau transformasi lain sebelum dimuat ke sistem DW untuk pemrosesan informasi.
Gudang Data - Fitur Utama
Fitur utama dari Sistem DW adalah -
Ini adalah tempat penyimpanan data pusat di mana data disimpan dari satu atau lebih sumber data yang heterogen.
Sistem DW menyimpan data saat ini dan data historis. Biasanya sistem DW menyimpan data historis 5-10 tahun.
Sistem DW selalu dipisahkan dari sistem transaksi operasional.
Data dalam sistem DW digunakan untuk berbagai jenis rentang pelaporan analitik dari perbandingan Kuartalan hingga Tahunan.
Kebutuhan Sistem DW
Misalkan Anda memiliki agen pinjaman rumah di mana datanya berasal dari berbagai aplikasi seperti- pemasaran, penjualan, ERP, HRM, MM, dll. Data ini diekstrak, diubah, dan dimuat di Gudang Data.
Misalnya, jika Anda harus membandingkan penjualan triwulanan / tahunan suatu produk, Anda tidak dapat menggunakan basis data transaksi operasional, karena ini akan membuat sistem transaksi hang. Oleh karena itu, Data Warehouse digunakan untuk tujuan ini.
Perbedaan antara DW dan ODB
Perbedaan antara Data Warehouse dan Operational Database (Transactional Database) adalah sebagai berikut -
Sistem Transaksional dirancang untuk beban kerja dan transaksi yang diketahui seperti memperbarui catatan pengguna, mencari catatan, dll. Namun, transaksi Data Warehouse lebih kompleks dan menyajikan bentuk data umum.
Sistem Transaksional berisi data terkini dari suatu organisasi dan Data warehouse biasanya berisi data historis.
Sistem transaksional mendukung pemrosesan paralel dari beberapa transaksi. Kontrol konkurensi dan mekanisme pemulihan diperlukan untuk menjaga konsistensi database.
Kueri database operasional memungkinkan untuk membaca dan mengubah operasi (menghapus dan memperbarui) sementara kueri OLAP hanya memerlukan akses baca-saja dari data yang disimpan (pernyataan Select).
Arsitektur DW
Data Warehousing melibatkan pembersihan data, integrasi data, dan konsolidasi data.

Gudang Data memiliki arsitektur 3 lapis - Data Source Layer, Integration Layer, dan Presentation Layer. Ilustrasi yang diberikan di atas menunjukkan arsitektur umum dari sistem Data Warehouse.
Ada empat jenis sistem Data Warehousing.
- Data Mart
- Pemrosesan Analitik Online (OLAP)
- Pemrosesan Transaksional Online (OLTP)
- Analisis Prediktif (PA)
Data Mart
Data Mart dikenal sebagai bentuk paling sederhana dari sistem Data Warehouse dan biasanya terdiri dari satu area fungsional dalam organisasi seperti penjualan, keuangan atau pemasaran, dll.
Data Mart dalam sebuah organisasi dan dibuat serta dikelola oleh satu departemen. Karena dimiliki oleh satu departemen, departemen biasanya mendapatkan data hanya dari beberapa atau satu jenis sumber / aplikasi. Sumber ini dapat berupa sistem operasional internal, gudang data, atau sistem eksternal.
Pemrosesan Analitik Online
Dalam sistem OLAP, jumlah transaksi lebih sedikit dibandingkan dengan sistem transaksional. Kueri yang dieksekusi bersifat kompleks dan melibatkan agregasi data.
Apa itu Agregasi?
Kami menyimpan tabel dengan data agregat seperti tahunan (1 baris), triwulanan (4 baris), bulanan (12 baris) atau lebih, jika seseorang harus melakukan perbandingan tahun ke tahun, hanya satu baris yang akan diproses. Namun, dalam tabel yang tidak digabungkan ini akan membandingkan semua baris.
SELECT SUM(salary)
FROM employee
WHERE title = 'Programmer';Tindakan Efektif dalam sistem OLAP
Waktu respons dikenal sebagai salah satu ukuran paling efektif dan utama dalam sebuah OLAPsistem. Kumpulan data yang disimpan disimpan dalam skema multi-dimensi seperti skema bintang (Ketika data disusun ke dalam kelompok hierarki, sering disebut dimensi dan menjadi fakta dan fakta agregat, itu disebut Skema).
Latensi sistem OLAP adalah beberapa jam dibandingkan dengan data mart di mana latensi diharapkan mendekati satu hari.
Pemrosesan Transaksi Online
Dalam sistem OLTP, ada banyak transaksi online pendek seperti INSERT, UPDATE, dan DELETE.
Dalam sistem OLTP, ukuran yang efektif adalah waktu pemrosesan transaksi yang singkat dan sangat singkat. Ini mengontrol integritas data dalam lingkungan multi-akses. Untuk sistem OLTP, jumlah transaksi per detik mengukureffectiveness. Sistem gudang data OLTP berisi data terkini dan terperinci dan dikelola dalam skema di model entitas (3NF).
Contoh
Sistem transaksi sehari-hari di toko ritel, tempat catatan pelanggan dimasukkan, diperbarui, dan dihapus setiap hari. Ini menyediakan pemrosesan kueri yang sangat cepat. Database OLTP berisi data terperinci dan terkini. Skema yang digunakan untuk menyimpan database OLTP adalah model Entity.
Perbedaan antara OLTP dan OLAP
Ilustrasi berikut menunjukkan perbedaan utama antara file OLTP dan OLAP sistem.

Indexes - Sistem OLTP hanya memiliki sedikit indeks sedangkan dalam sistem OLAP terdapat banyak indeks untuk pengoptimalan kinerja.
Joins- Dalam sistem OLTP, sejumlah besar gabungan dan data dinormalisasi. Namun, dalam sistem OLAP, gabungan lebih sedikit dan dinormalisasi.
Aggregation - Dalam sistem OLTP, data tidak diagregasi saat dalam database OLAP lebih banyak agregasi digunakan.
Analisis Prediktif
Analisis prediktif dikenal sebagai menemukan pola tersembunyi dalam data yang disimpan dalam sistem DW dengan menggunakan fungsi matematika yang berbeda untuk memprediksi hasil masa depan.
Sistem Analisis Prediktif berbeda dengan sistem OLAP dalam hal penggunaannya. Ini digunakan untuk fokus pada hasil di masa depan. Sistem OALP berfokus pada pemrosesan data saat ini dan historis untuk pelaporan analitik.
Ada berbagai Gudang Data / sistem basis data yang tersedia di pasar yang memenuhi kemampuan sistem DW. Vendor yang paling umum untuk sistem gudang data adalah -
- Microsoft SQL Server
- Oracle Exadata
- IBM Netezza
- Teradata
- Sybase IQ
- Gudang Bisnis SAP (SAP BW)
Gudang Bisnis SAP
SAP Business Warehouseadalah bagian dari platform rilis SAP NetWeaver. Sebelum NetWeaver 7.4, itu disebut sebagai Gudang Bisnis SAP NetWeaver.
Data warehousing di SAP BW berarti integrasi data, transformasi, pembersihan data, penyimpanan dan pementasan data. Proses DW meliputi pemodelan data pada sistem BW, pementasan dan administrasi. Alat utama, yang digunakan untuk mengelola tugas DW di sistem BW, adalah meja kerja administrasi.
Fitur Utama
SAP BW menyediakan kemampuan seperti Business Intelligence, yang mencakup Layanan Analitik dan Perencanaan Bisnis, Pelaporan Analitik, Pemrosesan dan informasi kueri, dan pergudangan data Perusahaan.
Ini menyediakan kombinasi database dan alat manajemen database yang membantu dalam pengambilan keputusan.
Fitur utama lainnya dari sistem BW termasuk Business Application Programming Interface (BAPI) yang mendukung koneksi ke aplikasi non-SAP R / 3, ekstraksi dan pemuatan data otomatis, prosesor OLAP terintegrasi, repositori metadata, alat administrasi, dukungan multi-bahasa, dan antarmuka web diaktifkan.
SAP BW pertama kali diperkenalkan pada tahun 1998 oleh SAP, sebuah perusahaan Jerman. Sistem SAP BW didasarkan pada pendekatan berdasarkan model untuk membuat Gudang Data Perusahaan mudah, sederhana dan lebih efisien untuk data SAP R3.
Sejak 16 tahun terakhir, SAP BW telah berkembang sebagai salah satu sistem kunci bagi banyak perusahaan untuk mengelola kebutuhan pergudangan data perusahaan mereka.
Penjelajah Bisnis (BEx) memberikan pilihan untuk pelaporan yang fleksibel, analisis strategis dan pelaporan operasi di perusahaan.
Ini digunakan untuk melakukan fungsi pelaporan, eksekusi query dan analisis dalam sistem BI. Anda juga dapat memproses data saat ini dan data historis hingga berbagai tingkat detail melalui Web dan dalam format Excel.
Menggunakan BEx penyiaran informasi, konten BI dapat di-share melalui email sebagai dokumen atau dalam bentuk link sebagai live data atau dapat juga di publikasikan menggunakan fungsi SAP EP.
Objek & Produk Bisnis
SAP Business Objects dikenal sebagai alat Business Intelligence yang paling umum dan digunakan untuk memanipulasi data, mengakses pengguna, menganalisis, memformat dan menerbitkan informasi pada platform yang berbeda. Ini adalah seperangkat alat berbasis front-end, yang memungkinkan pengguna bisnis dan pembuat keputusan untuk menampilkan, mengurutkan, dan menganalisis data intelijen bisnis terkini dan historis.
Ini terdiri dari alat-alat berikut -
Intelijen Web
Web Intelligence (WebI) disebut sebagai alat pelaporan terperinci Objek Bisnis yang paling umum yang mendukung berbagai fitur analisis data seperti bor, hierarki, bagan, pengukuran yang dihitung, dll. Hal ini memungkinkan pengguna akhir untuk membuat kueri ad-hoc di panel kueri dan untuk melakukan analisis data baik online maupun offline.
SAP Business Objects Xcelsius / Dasbor
Dasbor memberikan visualisasi data dan kemampuan papan dasbor kepada pengguna akhir dan Anda dapat membuat dasbor interaktif menggunakan alat ini.
Anda juga dapat menambahkan berbagai jenis bagan dan grafik dan membuat dasbor dinamis untuk visualisasi data dan ini sebagian besar digunakan dalam rapat keuangan dalam suatu organisasi.
Laporan Crystal
Crystal Reports digunakan untuk pelaporan dengan piksel sempurna. Hal ini memungkinkan pengguna untuk membuat dan mendesain laporan dan kemudian menggunakannya untuk tujuan pencetakan.
Penjelajah
Explorer memungkinkan pengguna untuk mencari konten di penyimpanan BI dan kecocokan terbaik ditampilkan dalam bentuk grafik. Tidak perlu menuliskan pertanyaan untuk melakukan pencarian.
Berbagai komponen dan alat lainnya yang diperkenalkan untuk pelaporan mendetail, visualisasi data, dan tujuan dasbor adalah Studio Desain, edisi Analisis untuk Microsoft Office, BI Repository, dan platform Business Objects Mobile.
ETL adalah singkatan dari Extract, Transform and Load. Alat ETL mengekstrak data dari sistem sumber RDBMS yang berbeda, mengubah data seperti menerapkan kalkulasi, menggabungkan, dll. Dan kemudian memuat data ke sistem Data Warehouse. Data tersebut dimuat dalam sistem DW dalam bentuk tabel dimensi dan fakta.
Ekstraksi
Area staging diperlukan selama pemuatan ETL. Ada berbagai alasan mengapa area pementasan diperlukan.
Sistem sumber hanya tersedia untuk periode waktu tertentu untuk mengekstrak data. Periode waktu ini kurang dari total waktu muat data. Oleh karena itu, staging area memungkinkan Anda mengekstrak data dari sistem sumber dan menyimpannya di area staging sebelum slot waktu berakhir.
Area pentahapan diperlukan ketika Anda ingin mendapatkan data dari beberapa sumber data bersama-sama atau jika Anda ingin menggabungkan dua atau lebih sistem secara bersamaan. Misalnya, Anda tidak akan dapat menjalankan kueri SQL yang menggabungkan dua tabel dari dua database yang berbeda secara fisik.
Slot waktu ekstraksi data untuk sistem yang berbeda bervariasi sesuai zona waktu dan jam operasional.
Data yang diekstrak dari sistem sumber dapat digunakan di beberapa sistem gudang data, penyimpanan Data Operasi, dll.
ETL memungkinkan Anda melakukan transformasi kompleks dan membutuhkan area ekstra untuk menyimpan data.

Mengubah
Dalam transformasi data, Anda menerapkan sekumpulan fungsi pada data yang diekstrak untuk memuatnya ke sistem target. Data, yang tidak memerlukan transformasi apa pun dikenal sebagai perpindahan langsung atau melewati data.
Anda dapat menerapkan transformasi yang berbeda pada data yang diekstrak dari sistem sumber. Misalnya, Anda dapat melakukan penghitungan yang disesuaikan. Jika Anda menginginkan jumlah pendapatan penjualan dan ini tidak ada dalam database, Anda dapat menerapkanSUM rumus selama transformasi dan memuat data.
Misalnya, jika Anda memiliki nama depan dan nama belakang dalam tabel di kolom yang berbeda, Anda dapat menggunakan penggabungan sebelum memuat.
Beban
Selama fase Pemuatan, data dimuat ke sistem target akhir dan dapat berupa file datar atau sistem Gudang Data.
SAP BO Data Services adalah alat ETL yang digunakan untuk integrasi Data, kualitas data, pembuatan profil data, dan pemrosesan data. Ini memungkinkan Anda untuk mengintegrasikan, mengubah sistem data-ke-data warehouse untuk pelaporan analitis.
Layanan Data BO terdiri dari antarmuka pengembangan UI, repositori metadata, konektivitas data ke sistem sumber dan target, serta konsol manajemen untuk penjadwalan pekerjaan.
Integrasi Data & Manajemen Data
SAP BO Data Services adalah alat integrasi dan manajemen data dan terdiri dari Data Integrator Job Server dan Data Integrator Designer.
Fitur Utama
Anda dapat menerapkan berbagai transformasi data menggunakan bahasa Integrator Data untuk menerapkan transformasi data kompleks dan membuat fungsi yang disesuaikan.
Data Integrator Designer digunakan untuk menyimpan pekerjaan waktu nyata dan batch serta proyek baru dalam repositori.
DI Designer juga menyediakan opsi untuk pengembangan ETL berbasis tim dengan menyediakan repositori pusat dengan semua fungsi dasar.
Server pekerjaan Integrator Data bertanggung jawab untuk memproses pekerjaan yang dibuat menggunakan DI Designer.
Administrator Web
Administrator web Integrator Data digunakan oleh administrator sistem dan administrator basis data untuk memelihara repositori dalam layanan Data. Layanan Data mencakup Repositori Metadata, Repositori Pusat untuk pengembangan berbasis tim, Server Pekerjaan, dan Layanan Web.
Fungsi utama DI Web Administrator
- Ini digunakan untuk menjadwalkan, memantau dan melaksanakan pekerjaan batch.
- Ini digunakan untuk konfigurasi dan memulai dan menghentikan server real-time.
- Ini digunakan untuk mengonfigurasi Job Server, Access Server, dan penggunaan repositori.
- Ini digunakan untuk mengkonfigurasi adaptor.
- Ini digunakan untuk mengonfigurasi dan mengendalikan semua alat di Layanan Data BO.
Fungsi Manajemen Data menekankan pada kualitas data. Ini melibatkan pembersihan data, peningkatan dan konsolidasi data untuk mendapatkan data yang benar dalam sistem DW.
Pada bab ini, kita akan belajar tentang arsitektur SAP BODS. Ilustrasi tersebut memperlihatkan arsitektur sistem BODS dengan Staging area.
Lapisan Sumber
Lapisan sumber mencakup berbagai sumber data seperti aplikasi SAP dan sistem RDBMS non-SAP dan integrasi data berlangsung di area pementasan.
SAP Business Objects Data Services mencakup komponen yang berbeda seperti Data Service Designer, Data Services Management Console, Repository Manager, Data Services Server Manager, Work bench, dll. Sistem target dapat berupa sistem DW seperti SAP HANA, SAP BW atau non-SAP Sistem gudang data.

Tangkapan layar berikut menunjukkan berbagai komponen SAP BODS.

Anda juga dapat membagi arsitektur BODS di lapisan berikut -
- Lapisan Aplikasi Web
- Lapisan Server Database
- Lapisan Layanan Layanan Data
Ilustrasi berikut menunjukkan arsitektur BODS.

Evolusi Produk - ATL, DI & DQ
Acta Technology Inc. mengembangkan SAP Business Objects Data Services dan kemudian Business Objects Company mengakuisisi itu. Acta Technology Inc. adalah perusahaan yang berbasis di AS dan bertanggung jawab atas pengembangan platform integrasi data pertama. Dua produk perangkat lunak ETL yang dikembangkan oleh Acta Inc. adalahData Integration (DI) alat dan Data Management atau Data Quality (DQ) alat.
Business Objects, sebuah perusahaan Perancis mengakuisisi Acta Technology Inc. pada tahun 2002 dan kemudian, kedua produk tersebut diganti namanya menjadi Business Objects Data Integration (BODI) alat dan Business Objects Data Quality (BODQ) alat.
SAP mengakuisisi Business Objects pada tahun 2007 dan kedua produk tersebut diubah namanya menjadi SAP BODI dan SAP BODQ. Pada tahun 2008, SAP mengintegrasikan kedua produk tersebut ke dalam satu produk perangkat lunak yang dinamakan SAP Business Objects Data Services (BODS).
SAP BODS menyediakan integrasi data dan solusi manajemen data dan dalam versi BODS sebelumnya, solusi pemrosesan data teks disertakan.
BODS - Objek
Semua entitas yang digunakan dalam BO Data Services Designer disebut Objects. Semua objek seperti proyek, pekerjaan, metadata, dan fungsi sistem disimpan di perpustakaan objek lokal. Semua objek bersifat hierarkis.
Objek utamanya berisi berikut ini -
Properties- Mereka digunakan untuk mendeskripsikan suatu objek dan tidak mempengaruhi operasinya. Contoh - Nama suatu objek, Tanggal pembuatannya, dll.
Options - Yang mengontrol pengoperasian objek.
Jenis Objek
Ada dua jenis objek dalam sistem - Objek yang dapat digunakan kembali dan objek Penggunaan Tunggal. Jenis objek menentukan bagaimana objek itu digunakan dan diambil.
Objek yang Dapat Digunakan Kembali
Sebagian besar objek yang disimpan di repositori dapat digunakan kembali. Saat objek yang dapat digunakan kembali didefinisikan dan disimpan di repositori lokal, Anda dapat menggunakan kembali objek tersebut dengan membuat Panggilan ke definisi. Setiap objek yang dapat digunakan kembali hanya memiliki satu definisi dan semua panggilan ke objek itu merujuk ke definisi itu. Sekarang, jika definisi suatu objek diubah di satu tempat, Anda mengubah definisi objek di semua tempat di mana objek itu muncul.
Pustaka objek digunakan untuk memuat definisi objek dan ketika sebuah objek diseret dan dilepaskan dari perpustakaan, referensi baru ke objek yang ada dibuat.
Objek Penggunaan Tunggal
Semua objek yang ditentukan secara khusus untuk pekerjaan atau aliran data dikenal sebagai objek sekali pakai. Misalnya, transformasi khusus yang digunakan dalam pemuatan data apa pun.
BODS - Object Hierarchy
Semua objek bersifat hierarkis. Diagram berikut menunjukkan hierarki objek dalam sistem SAP BODS -

BODS - Alat dan Fungsi
Berdasarkan arsitektur yang diilustrasikan di bawah ini, kami memiliki banyak alat yang ditentukan dalam Layanan Data Objek Bisnis SAP. Setiap alat memiliki fungsinya sendiri sesuai lanskap sistem.

Di bagian atas, Anda memiliki Layanan Platform Informasi yang diinstal untuk pengguna dan manajemen keamanan hak. BODS bergantung pada konsol Manajemen Pusat (CMC) untuk akses pengguna dan fitur keamanan. Ini berlaku untuk versi 4.x. Di versi sebelumnya, ini dilakukan di Konsol Manajemen.
Data Services Designer adalah alat pengembang, yang digunakan untuk membuat objek yang terdiri dari pemetaan data, transformasi, dan logika. Ini berbasis GUI dan bekerja sebagai desainer untuk Layanan Data.
Gudang
Repositori digunakan untuk menyimpan metadata objek yang digunakan dalam Layanan Data BO. Setiap Repositori harus terdaftar di Konsol Manajemen Pusat dan ditautkan dengan satu atau banyak server pekerjaan, yang bertanggung jawab untuk melaksanakan pekerjaan yang Anda buat.
Jenis Repositori
Ada tiga jenis Repositori.
Local Repository - Digunakan untuk menyimpan metadata dari semua objek yang dibuat di Data Services Designer seperti proyek, pekerjaan, aliran data, aliran kerja, dll.
Central Repository- Ini digunakan untuk mengontrol manajemen versi objek dan digunakan untuk pengembangan multi guna. Central Repository menyimpan semua versi objek aplikasi. Karenanya, ini memungkinkan Anda untuk pindah ke versi sebelumnya.
Profiler Repository- Ini digunakan untuk mengelola semua metadata yang terkait dengan tugas profiler yang dilakukan di desainer SAP BODS. CMS Repository menyimpan metadata dari semua tugas yang dilakukan di CMC pada platform BI. Information Steward Repository menyimpan semua metadata dari tugas dan objek pembuatan profil yang dibuat dalam pengurus informasi.
Server Pekerjaan
Server pekerjaan digunakan untuk menjalankan pekerjaan waktu nyata dan pekerjaan batch yang Anda buat. Ia mendapatkan informasi pekerjaan dari repositori masing-masing dan memulai mesin data untuk menjalankan pekerjaan. Server pekerjaan dapat menjalankan pekerjaan waktu nyata atau terjadwal dan menggunakan multithreading dalam cache memori, dan pemrosesan paralel untuk memberikan pengoptimalan kinerja.
Akses Server
Access Server di Data Services dikenal sebagai sistem perantara pesan waktu nyata, yang mengambil permintaan pesan, berpindah ke layanan waktu nyata dan menampilkan pesan dalam kerangka waktu tertentu.
Konsol Manajemen Layanan Data
Konsol Manajemen Layanan Data digunakan untuk melakukan aktivitas administrasi seperti penjadwalan pekerjaan, menghasilkan laporan kualitas dalam sistem DS, validasi data, dokumentasi, dll.
BODS - Standar Penamaan
Sebaiknya gunakan konvensi penamaan standar untuk semua objek di semua sistem karena ini memungkinkan Anda mengidentifikasi objek di Repositori dengan mudah.
Tabel menunjukkan daftar konvensi penamaan yang direkomendasikan yang harus digunakan untuk semua pekerjaan dan objek lainnya.
| Awalan | Akhiran | Obyek |
|---|---|---|
| DF_ | t / a | Aliran data |
| EDF_ | _Memasukkan | Aliran data tersemat |
| EDF_ | _Keluaran | Aliran data tersemat |
| RTJob_ | t / a | Pekerjaan real-time |
| WF_ | t / a | Alur kerja |
| PEKERJAAN_ | t / a | Pekerjaan |
| t / a | _DS | Penyimpanan data |
| DC_ | t / a | Konfigurasi data |
| SC_ | t / a | Sistem konfigurasi |
| t / a | _Memory_DS | Penyimpanan data memori |
| PROC_ | t / a | Prosedur tersimpan |
Dasar-dasar BO Data Service mencakup objek utama dalam mendesain alur kerja seperti Proyek, Pekerjaan, Alur kerja, aliran data, Repositori.
BODS - Repositori & Jenis
Repositori digunakan untuk menyimpan metadata objek yang digunakan dalam Layanan Data BO. Setiap Repositori harus terdaftar di Konsol Manajemen Pusat, CMC, dan ditautkan dengan satu atau banyak server pekerjaan, yang bertanggung jawab untuk menjalankan pekerjaan yang Anda buat.
Jenis Repositori
Ada tiga jenis Repositori.
Local Repository - Digunakan untuk menyimpan metadata dari semua objek yang dibuat di Data Services Designer seperti proyek, pekerjaan, aliran data, aliran kerja, dll.
Central Repository- Ini digunakan untuk mengontrol manajemen versi objek dan digunakan untuk pengembangan multi guna. Central Repository menyimpan semua versi objek aplikasi. Karenanya, ini memungkinkan Anda untuk pindah ke versi sebelumnya.
Profiler Repository- Ini digunakan untuk mengelola semua metadata yang terkait dengan tugas profiler yang dilakukan di desainer SAP BODS. CMS Repository menyimpan metadata dari semua tugas yang dilakukan di CMC pada platform BI. Information Steward Repository menyimpan semua metadata dari tugas dan objek pembuatan profil yang dibuat dalam pengurus informasi.
Untuk membuat BODS Repository, Anda harus menginstal database. Anda dapat menggunakan SQL Server, database Oracle, My SQL, SAP HANA, Sybase, dll.
Membuat Repositori
Anda harus membuat pengguna berikut di database saat menginstal BODS dan membuat Repositori. Pengguna ini diminta untuk masuk ke server yang berbeda seperti Server CMS, Server Audit, dll.
Buat BODS Pengguna yang Diidentifikasi oleh Bodsserver1
- Hibah Terhubung ke BODS;
- Grant Create Session kepada BODS;
- Berikan DBA kepada BODS;
- Hibah Buat Tabel Apa Saja untuk BODS;
- Hibah Buat Tampilan Apa Pun ke BODS;
- Berikan Drop Tabel Apapun kepada BODS;
- Berikan Drop Any View kepada BODS;
- Berikan Sisipkan Tabel apa pun kepada BODS;
- Berikan Pembaruan Tabel apa pun kepada BODS;
- Berikan Hapus Semua tabel kepada BODS;
- Ubah KUOTA BADAN PENGGUNA TANPA BATAS PADA PENGGUNA;
Buat CMS Pengguna yang Diidentifikasi oleh CMSserver1
- Hibah Hubungkan ke CMS;
- Hibah Buat Sesi ke CMS;
- Berikan DBA ke CMS;
- Berikan Buat Tabel Apa Pun ke CMS;
- Hibah Buat Tampilan Apa Pun ke CMS;
- Berikan Drop Tabel Apapun ke CMS;
- Berikan Drop Any View ke CMS;
- Berikan Sisipkan Tabel ke CMS;
- Berikan Pembaruan Setiap tabel ke CMS;
- Berikan Hapus Semua tabel ke CMS;
- Ubah KUOTA CMS PENGGUNA TAK TERBATAS PADA PENGGUNA;
Buat Pengguna CMSAUDIT Diidentifikasi oleh CMSAUDITserver1
- Hibah Hubungkan ke CMSAUDIT;
- Grant Membuat Sesi ke CMSAUDIT;
- Berikan DBA kepada CMSAUDIT;
- Berikan Buat Tabel Apa Pun ke CMSAUDIT;
- Grant Create Any View ke CMSAUDIT;
- Berikan Drop Tabel Apapun ke CMSAUDIT;
- Berikan Drop Any View ke CMSAUDIT;
- Berikan Sisipkan Tabel Apa Saja ke CMSAUDIT;
- Berikan Pembaruan Setiap tabel ke CMSAUDIT;
- Berikan Hapus Semua tabel ke CMSAUDIT;
- Ubah KUOTA CMSAUDIT PENGGUNA TANPA BATAS PADA PENGGUNA;
Untuk membuat Repositori baru setelah instalasi
Step 1 - Buat database Local_Repodan buka Manajer Repositori Layanan Data. Konfigurasi database sebagai repositori lokal.

Jendela baru akan terbuka.
Step 2 - Masukkan detail di kolom berikut -
Jenis repositori, Jenis database, Nama server database, Port, Nama pengguna dan kata sandi.

Step 3 - Klik Createtombol. Anda akan mendapatkan pesan berikut -

Step 4 - Sekarang masuk ke CMC Konsol Manajemen Pusat SAP BI Platform dengan nama pengguna dan kata sandi.
Step 5 - Di halaman Beranda CMC, klik Data Services.

Step 6 - Dari Data Services menu, Klik Configure a new Data Services Gudang.

Step 7 - Masukkan detail seperti yang diberikan di jendela baru.
- Nama Repositori: Local_Repo
- Tipe Basis Data: SAP HANA
- Nama Server Basis Data: terbaik
- Nama Database: LOCAL_REPO
- Nama pengguna:
- Password:*****

Step 8 - Klik tombolnya Test Connection dan jika berhasil, klik Save. Setelah Anda menyimpannya, itu akan berada di bawah tab Repositori di CMC.
Step 9 - Terapkan hak akses dan keamanan pada repositori lokal di CMC → User and Groups.
Step 10 - Setelah akses diberikan, masuk ke Desainer Layanan Data → Pilih Repositori → Masukkan Nama pengguna dan kata sandi untuk login.

Memperbarui Repositori
Untuk memperbarui repositori, ikuti langkah-langkah yang diberikan.
Step 1 - Untuk memperbarui Repositori setelah instalasi, buat database Local_Repo dan buka Manajer Repositori Layanan Data.
Step 2 - Konfigurasi database sebagai repositori lokal.

Jendela baru akan terbuka.
Step 3 - Masukkan detail untuk bidang berikut.
Jenis repositori, Jenis database, Nama server database, Port, Nama pengguna dan kata sandi.

Anda akan melihat hasilnya seperti yang ditunjukkan pada gambar di bawah ini.

Konsol Manajemen Layanan Data (DSMC) digunakan untuk melakukan aktivitas administrasi seperti menjadwalkan pekerjaan, menghasilkan laporan kualitas dalam sistem DS, validasi data, dokumentasi, dll.
Anda dapat mengakses Konsol Manajemen Layanan Data dengan cara berikut -
Anda dapat mengakses Konsol Manajemen Layanan Data dengan masuk ke Start → All Programs → Data Services → Data Service Management Console.
Anda juga dapat mengakses konsol manajemen layanan data melalui Designer jika Anda sudah masuk.
Untuk mengakses konsol manajemen layanan data melalui Designer Home Page ikuti langkah-langkah yang diberikan di bawah ini.

Untuk mengakses konsol manajemen layanan data melalui Alat, ikuti langkah-langkah yang diberikan -
Step 1 - Pergi ke Tools → Data Services Management Console seperti yang ditunjukkan pada gambar berikut.

Step 2 - Setelah Anda masuk ke Data Services Management Console, layar beranda akan terbuka seperti yang ditunjukkan pada gambar di bawah. Di bagian atas, Anda dapat melihat nama pengguna yang Anda gunakan untuk masuk.
Di halaman beranda, Anda akan melihat opsi berikut -
- Administrator
- Dokumentasi Otomatis
- Validasi data
- Analisis Dampak dan Silsilah
- Dasbor Operasional
- Laporan Kualitas Data

Fungsi utama dari setiap modul Konsol Manajemen Layanan Data dijelaskan dalam bab ini.
Modul Administrator
Opsi Administrator digunakan untuk mengelola -
- Pengguna dan Peran
- Untuk menambahkan koneksi ke server akses dan repositori
- Untuk mengakses data pekerjaan yang diterbitkan untuk layanan web
- Untuk penjadwalan dan pemantauan pekerjaan batch
- Untuk memeriksa status server akses dan layanan waktu nyata.
Setelah Anda mengklik Administratortab, Anda dapat melihat banyak tautan di panel kiri. Mereka adalah - Status, Batch, Layanan Web, Koneksi SAP, Grup Server, Manajemen Repositori Profiler dan Riwayat Eksekusi Pekerjaan.

Node
Berbagai node di bawah modul Administrator dibahas di bawah ini.
Status
Status node digunakan untuk memeriksa status batch dan pekerjaan real time, mengakses status server, repositori adaptor dan profiler, dan status sistem lainnya.
Klik Status → Pilih Repositori
Di panel kanan, Anda akan melihat tab dari opsi berikut -
Batch Job Status- Ini digunakan untuk memeriksa status pekerjaan batch. Anda dapat memeriksa informasi pekerjaan seperti Trace, Monitor, Error, dan Performance Monitor, Start Time, End Time, Duration, dll.

Batch Job Configuration - Konfigurasi pekerjaan batch digunakan untuk memeriksa jadwal pekerjaan individu atau Anda dapat menambahkan tindakan seperti Jalankan, Tambah Jadwal, Ekspor Perintah Eksekusi.
Repositories Schedules - Digunakan untuk melihat dan mengonfigurasi jadwal untuk semua pekerjaan di repositori.
Batch Node
Di bawah node Batch Job, Anda akan melihat opsi yang sama seperti di atas.
| No Sr | Opsi & Deskripsi |
|---|---|
| 1 | Batch Job Status Lihat status eksekusi terakhir dan informasi mendalam tentang setiap pekerjaan. |
| 2 | Batch Job Configuration Konfigurasi opsi eksekusi dan penjadwalan untuk pekerjaan individu. |
| 3 | Repository Schedules Lihat dan konfigurasikan jadwal untuk semua pekerjaan di repositori. |
Node Layanan Web
Layanan Web digunakan untuk mempublikasikan pekerjaan waktu nyata dan pekerjaan batch sebagai operasi layanan web dan untuk memeriksa status operasi ini. Ini juga digunakan untuk menjaga keamanan pekerjaan yang diterbitkan sebagai layanan web dan untuk dilihatWSDL mengajukan.

Koneksi SAP
Koneksi SAP digunakan untuk memeriksa status atau untuk mengonfigurasi RFC server interface di Konsol Manajemen Layanan Data.
Untuk memeriksa status antarmuka server RFC, buka tab Status Antarmuka Server RFC. Untuk menambahkan Antarmuka Server RFC baru, pada tab konfigurasi, klikAdd.
Ketika jendela baru terbuka, masukkan detail konfigurasi server RFC klik Apply.

Grup Server
Ini digunakan untuk mengelompokkan semua server pekerjaan yang terkait dengan repositori yang sama ke dalam satu grup server. Tab ini digunakan untuk load balancing saat menjalankan pekerjaan di layanan data.
Saat sebuah pekerjaan dijalankan, ia memeriksa server pekerjaan yang sesuai dan jika tidak berfungsi, ia memindahkan pekerjaan ke server pekerjaan lain dalam grup yang sama. Ini banyak digunakan dalam produksi untuk load balancing.

Repositori Profil
Saat Anda menghubungkan repositori profil ke administrator, ini memungkinkan Anda untuk memperluas node repositori profil. Anda dapat pergi ke halaman status Tugas Profil.
Node Manajemen
Untuk menggunakan fitur dari tab Administrator, Anda perlu menambahkan koneksi ke layanan Data menggunakan node manajemen. Node Manajemen terdiri dari opsi konfigurasi yang berbeda untuk aplikasi administrasi.

Riwayat Pelaksanaan Pekerjaan
Ini digunakan untuk memeriksa riwayat pelaksanaan pekerjaan atau aliran data. Dengan menggunakan opsi ini, Anda dapat memeriksa riwayat eksekusi dari satu tugas batch atau semua tugas batch yang Anda buat.
Saat Anda memilih pekerjaan, informasi ditampilkan dalam bentuk tabel, yang terdiri dari Nama tempat penyimpanan, Nama pekerjaan, waktu mulai, waktu berakhir, waktu pelaksanaan, status, dll.

Data Service Designer adalah alat pengembang, yang digunakan untuk membuat objek yang terdiri dari pemetaan data, transformasi, dan logika. Ini berbasis GUI dan bekerja sebagai desainer untuk Layanan Data.
Anda dapat membuat berbagai objek menggunakan Desainer Layanan Data seperti Proyek, Pekerjaan, Alur Kerja, Arus Data, pemetaan, transformasi, dll.
Untuk memulai Desainer Layanan Data ikuti langkah-langkah yang diberikan di bawah ini.
Step 1 - Arahkan ke Mulai → Semua Program → Layanan Data SAP 4.2 → Perancang Layanan Data.

Step 2 - Pilih Repositori dan masukkan kata sandi untuk login.

Setelah Anda memilih Repositori dan login ke Data Services Designer, layar beranda akan muncul seperti yang ditunjukkan pada gambar di bawah ini.

Di panel kiri, Anda memiliki area proyek, tempat Anda dapat membuat proyek baru, Pekerjaan, aliran data, aliran kerja, dll. Di area Proyek, Anda memiliki perpustakaan Objek Lokal, yang terdiri dari semua objek yang dibuat di Layanan Data.
Di panel bawah, Anda dapat membuka objek yang ada dengan masuk ke opsi tertentu seperti Proyek, Pekerjaan, Aliran Data, Alur Kerja, dll. Setelah Anda memilih salah satu objek dari panel bawah, itu akan menunjukkan kepada Anda semua objek serupa sudah. dibuat dalam Repositori di bawah perpustakaan objek lokal.
Di sisi kanan, Anda memiliki layar beranda, yang dapat digunakan untuk -
- Buat Proyek
- Proyek terbuka
- Buat penyimpanan data
- Buat Repositori
- Impor dari file datar
- Konsol Manajemen Layanan Data
Untuk mengembangkan aliran ETL, Anda harus terlebih dahulu membuat penyimpanan data untuk sumber dan sistem target. Ikuti langkah-langkah yang diberikan untuk mengembangkan aliran ETL -
Step 1 - Klik Create Data Stores.

Jendela baru akan terbuka.
Step 2 - Masukkan Datastore nama, Datastoretipe dan tipe database seperti yang ditunjukkan di bawah ini. Anda dapat memilih database yang berbeda sebagai sistem sumber seperti yang ditunjukkan pada gambar di bawah.

Step 3- Untuk menggunakan sistem ECC sebagai sumber data, pilih Aplikasi SAP sebagai tipe Datastore. Masukkan nama pengguna dan kata sandi dan padaAdvance tab, masukkan nomor sistem dan nomor klien.

Step 4- Klik OK dan Datastore akan ditambahkan ke daftar pustaka objek Lokal. Jika Anda memperluas Datastore, itu tidak menampilkan tabel apa pun.

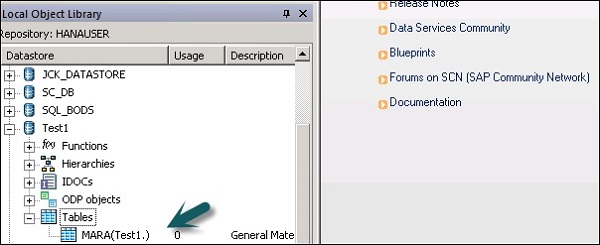
Step 5 - Untuk mengekstrak tabel apa pun dari sistem ECC untuk dimuat di sistem target, klik kanan pada Tabel → Impor berdasarkan Nama.

Step 6 - Masukkan nama tabel dan klik Import. Di sini, Tabel – Mara digunakan, yang merupakan tabel default dalam sistem ECC.
Step 7 - Dengan cara yang sama, buat file Datastoreuntuk sistem target. Dalam contoh ini, HANA digunakan sebagai sistem target.

Setelah Anda mengklik OK, ini Datastore akan ditambahkan ke perpustakaan objek lokal dan tidak akan ada tabel di dalamnya.
Buat Arus ETL
Untuk membuat aliran ETL, buat proyek baru.
Step 1 - Klik opsi, Create Project. Masukkan Nama Proyek dan klikCreate. Ini akan ditambahkan ke Area Proyek.

Step 2 - Klik kanan pada nama Proyek dan buat pekerjaan batch baru / pekerjaan waktu nyata.

Step 3- Masukkan nama pekerjaan dan tekan Enter. Anda harus menambahkan alur kerja dan aliran data ke ini. Pilih alur kerja dan klik area kerja untuk ditambahkan ke pekerjaan. Masukkan nama alur kerja dan klik dua kali untuk ditambahkan ke area Proyek.
Step 4- Dengan cara yang sama, pilih Aliran data dan bawa ke area Proyek. Masukkan nama aliran data dan klik dua kali untuk menambahkannya di bawah proyek baru.

Step 5- Sekarang seret tabel sumber di bawah datastore ke area Kerja. Sekarang Anda dapat menyeret tabel target dengan tipe data serupa ke area kerja atau Anda dapat membuat tabel templat baru.
Untuk membuat tabel template baru, klik kanan tabel sumber, Add New → Template Table.

Step 6- Masukkan nama tabel dan pilih Datastore dari daftar sebagai Datastore target. Nama Pemilik mewakili nama Skema tempat tabel harus dibuat.

Tabel akan ditambahkan ke area kerja dengan nama tabel ini.
Step 7- Tarik garis dari tabel sumber ke tabel target. KlikSave All opsi di atas.

Sekarang Anda dapat menjadwalkan pekerjaan menggunakan Konsol Manajemen Layanan Data atau Anda dapat menjalankannya secara manual dengan mengklik kanan pada nama Pekerjaan dan Jalankan.
Datastore digunakan untuk mengatur koneksi antara aplikasi dan database. Anda dapat langsung membuat Datastore atau dapat dibuat dengan bantuan adaptor. Datastore memungkinkan aplikasi / perangkat lunak untuk membaca atau menulis metadata dari aplikasi atau database dan menulis ke database atau aplikasi tersebut.
Di Business Objects Data Services, Anda bisa menyambungkan ke sistem berikut menggunakan Datastore -
- Sistem mainframe dan Database
- Aplikasi dan perangkat lunak dengan adaptor tertulis pengguna
- Aplikasi SAP, SAP BW, Oracle Apps, Siebel, dll.
Layanan Data Objek Bisnis SAP menyediakan opsi untuk terhubung ke antarmuka Mainframe menggunakan AttunityPenyambung. MenggunakanAttunity, hubungkan Datastore ke daftar sumber yang diberikan di bawah ini -
- DB2 UDB untuk OS / 390
- DB2 UDB untuk OS / 400
- IMS/DB
- VSAM
- Adabas
- File Datar di OS / 390 dan OS / 400

Menggunakan konektor Attunity, Anda dapat terhubung ke data mainframe dengan bantuan perangkat lunak. Perangkat lunak ini perlu diinstal secara manual di server mainframe dan server pekerjaan klien lokal menggunakan antarmuka ODBC.
Masukkan detail seperti lokasi Host, Port, ruang kerja Attunity, dll.
Buat Datastore untuk Database
Untuk membuat Datastore untuk database, ikuti langkah-langkah yang diberikan di bawah ini.
Step 1- Masukkan nama Datastore, tipe Datastore dan tipe database seperti yang ditunjukkan pada gambar di bawah ini. Anda dapat memilih database yang berbeda sebagai sistem sumber yang diberikan dalam daftar.

Step 2- Untuk menggunakan sistem ECC sebagai sumber data, pilih Aplikasi SAP sebagai tipe Datastore. Masukkan nama pengguna dan kata sandi. KlikAdvance tab dan masukkan nomor sistem dan nomor klien.

Step 3- Klik OK dan Datastore akan ditambahkan ke daftar pustaka objek Lokal. Jika Anda memperluas Datastore, tidak ada tabel untuk ditampilkan.
Di bab ini, kita akan belajar cara mengedit atau mengubah Datastore. Untuk mengubah atau mengedit Datastore, ikuti langkah-langkah yang diberikan di bawah ini.
Step 1- Untuk mengedit Datastore, klik kanan pada nama Datastore dan klik Edit. Ini akan membuka editor Datastore.

Anda dapat mengedit informasi koneksi untuk konfigurasi Datastore saat ini.
Step 2 - Klik Advance tombol dan Anda dapat mengedit nomor klien, id sistem, dan properti lainnya.
Step 3 - Klik Edit opsi untuk menambah, mengedit, dan menghapus konfigurasi.

Step 4 - Klik OK dan perubahan akan diterapkan.
Anda dapat membuat Datastore menggunakan memori sebagai tipe database. Memory Datastores digunakan untuk meningkatkan kinerja aliran data dalam pekerjaan waktu nyata karena menyimpan data dalam memori untuk memfasilitasi akses cepat dan tidak perlu pergi ke sumber data asli.
Memori Datastore digunakan untuk menyimpan skema tabel memori di repositori. Tabel memori ini mendapatkan data dari tabel dalam database Relasional atau menggunakan file data hierarki seperti pesan XML dan IDocs. Tabel memori tetap hidup sampai pekerjaan dijalankan dan data dalam tabel memori tidak dapat dibagi antara pekerjaan waktu nyata yang berbeda.
Membuat Memory Datastore
Untuk membuat Memory Datastore, ikuti langkah-langkah yang diberikan di bawah ini.
Step 1 - Klik Buat Datastore dan masukkan nama Datastore “Memory_DS_TEST”. Tabel memori disajikan dengan tabel RDBMS normal dan dapat diidentifikasi dengan konvensi penamaan.
Step 2 - Pada Tipe Datastore, Pilih Database dan pada tipe database pilih Memory. Klik OK.

Step 3 - Sekarang pergi ke Proyek → Baru → Proyek seperti yang ditunjukkan pada gambar di bawah.

Step 4- Buat Pekerjaan Baru dengan mengklik kanan. Tambahkan Alur Kerja dan Aliran Data seperti yang ditunjukkan di bawah ini.
Step 5- Pilih tabel Templat dan seret dan lepas ke area kerja. Jendela Buat tabel akan terbuka.

Step 6- Masukkan nama tabel dan Di Datastore, pilih Memory Datastore. Jika Anda menginginkan id baris yang dihasilkan sistem, pilihcreate row idkotak centang. Klik OK.
Step 7 - Hubungkan tabel Memori ini ke aliran data dan klik Save All di atas.

Tabel Memori sebagai Sumber dan Target
Untuk menggunakan Tabel Memori sebagai Target -
Step 1- Pergi ke perpustakaan objek lokal, klik tab Datastore. Perluas Memory Datastore → Perluas tabel.
Step 2- Pilih tabel Memori yang ingin Anda gunakan sebagai tabel sumber atau target dan seret ke alur kerja. Hubungkan tabel memori ini sebagai sumber atau target dalam aliran data.
Step 3 - Klik save tombol untuk menyimpan pekerjaan.
Ada berbagai vendor database, yang hanya menyediakan jalur komunikasi satu arah dari satu database ke database lain. Jalur ini dikenal sebagai tautan basis data. Di SQL Server, server tertaut memungkinkan jalur komunikasi satu arah dari satu database ke database lainnya.
Contoh
Pertimbangkan server database lokal bernama “Product” menyimpan link database untuk mengakses informasi pada server database jarak jauh yang dipanggil Customer. Sekarang, pengguna yang terhubung ke server database jauh Pelanggan tidak dapat menggunakan link yang sama untuk mengakses data di Produk server database. Pengguna yang terhubung ke“Customer” harus memiliki link terpisah dalam kamus data server untuk mengakses data di server database Produk.
Jalur komunikasi antara dua database ini disebut link database. Datastore, yang dibuat di antara hubungan database tertaut ini dikenal sebagai Datastore tertaut.
Ada kemungkinan untuk menghubungkan satu Datastore ke Datastore lain dan mengimpor link database eksternal sebagai opsi Datastore.

Adapter Datastore memungkinkan Anda mengimpor metadata aplikasi ke dalam repositori. Anda dapat mengakses metadata aplikasi dan memindahkan batch dan data waktu nyata antara berbagai aplikasi dan perangkat lunak.
Ada Kit Pengembangan Perangkat Lunak Adaptor - SDK yang disediakan oleh SAP yang dapat digunakan untuk mengembangkan adaptor yang disesuaikan. Adaptor ini ditampilkan di desainer Layanan Data oleh Adapter Datastores.
Untuk mengekstrak atau memuat data menggunakan adaptor, Anda harus menentukan setidaknya satu Datastore untuk tujuan ini.
Adaptor Datastore - Definisi
Untuk menentukan Adaptive Datastore, ikuti langkah-langkah yang diberikan -
Step 1 - Klik Create Datastore→ Masukkan nama untuk Datastore. Pilih Tipe Datastore sebagai Adaptor. PilihJob Server dari daftar dan Adaptor Instance Name dan klik OK.

Untuk menelusuri metadata aplikasi
Klik kanan pada nama Datastore dan klik Open. Ini akan membuka jendela baru yang menampilkan metadata sumber. Klik tanda + untuk memeriksa objek dan klik kanan pada objek yang akan diimpor.
Format file didefinisikan sebagai sekumpulan properti untuk menyajikan struktur file datar. Ini mendefinisikan struktur metadata. Format file digunakan untuk menyambungkan ke database sumber dan target ketika data disimpan di file dan bukan di database.
Format file digunakan untuk fungsi berikut -
- Buat template format file untuk menentukan struktur file.
- Buat format file sumber dan target tertentu di dataflow.
Jenis file berikut dapat digunakan sebagai file sumber atau target menggunakan format file -
- Delimited
- Transportasi SAP
- Teks Tidak Terstruktur
- Biner Tidak Terstruktur
- Lebar Tetap
Editor Format File
Editor Format File digunakan untuk mengatur properti untuk templat format file dan format file sumber dan target.
Mode berikut tersedia di editor format file -
New mode - Memungkinkan Anda membuat template format file baru.
Edit mode - Ini memungkinkan Anda untuk mengedit template format file yang ada.
Source mode - Ini memungkinkan Anda untuk mengedit format file dari file sumber tertentu.
Target mode - Ini memungkinkan Anda untuk mengedit format file dari file target tertentu.
Ada tiga area kerja untuk File Format Editor -
Properties Values - Digunakan untuk mengedit nilai properti format file.
Column Attributes - Digunakan untuk mengedit dan menentukan kolom atau bidang di file.
Data Preview - Ini digunakan untuk melihat bagaimana pengaturan memengaruhi data sampel.
Membuat Format File
Untuk membuat Format File ikuti langkah-langkah yang diberikan di bawah ini.
Step 1 - Pergi ke Local Object Library → Flat files.

Step 2 - Klik kanan pada opsi Flat Files → New.

Jendela baru File Format Editor akan terbuka.
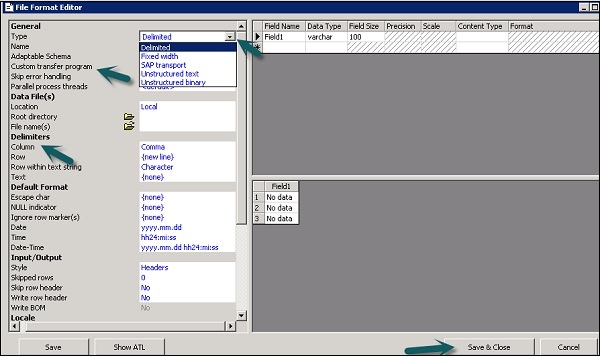
Step 3- Pilih jenis Format File. Masukkan nama yang mendeskripsikan template format file. Untuk file Delimited dan Fixed width, Anda dapat membaca dan memuat menggunakan Custom Transfer Program. Masukkan properti lain untuk mendeskripsikan file yang diwakili oleh template ini.
Anda juga dapat menentukan struktur kolom dalam atribut kolom area kerja untuk beberapa format file tertentu. Setelah semua properti ditentukan, klikSave tombol.
Mengedit Format File
Untuk mengedit Format File, ikuti langkah-langkah yang diberikan di bawah ini.
Step 1 - Di Local Object Library, pergi ke Format tab.
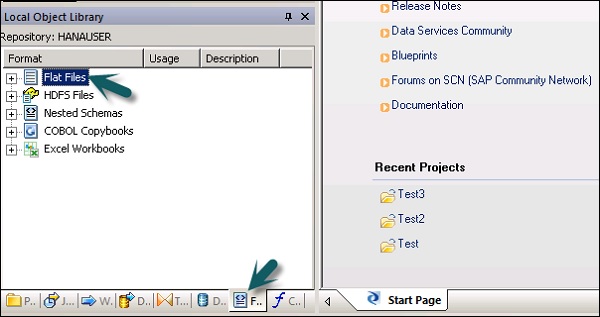
Step 2- Pilih format File yang ingin Anda edit. Klik kanan fileEdit pilihan.

Lakukan perubahan di editor format file dan klik Save tombol.
Anda dapat membuat format file buku salinan COBOL yang memperlambat Anda untuk membuat hanya formatnya. Anda dapat mengonfigurasi sumber nanti setelah Anda menambahkan format ke dataflow.
Anda dapat membuat format file dan menghubungkannya ke file data pada saat yang bersamaan. Ikuti langkah-langkah yang diberikan di bawah ini.
Step 1 - Buka Perpustakaan Objek Lokal → Format File → Buku Salinan COBOL.

Step 2 - Klik kanan file New pilihan.

Step 3- Masukkan nama Format. Buka tab Format → Pilih buku salinan COBOL yang akan diimpor. Ekstensi dari file tersebut adalah.cpy.
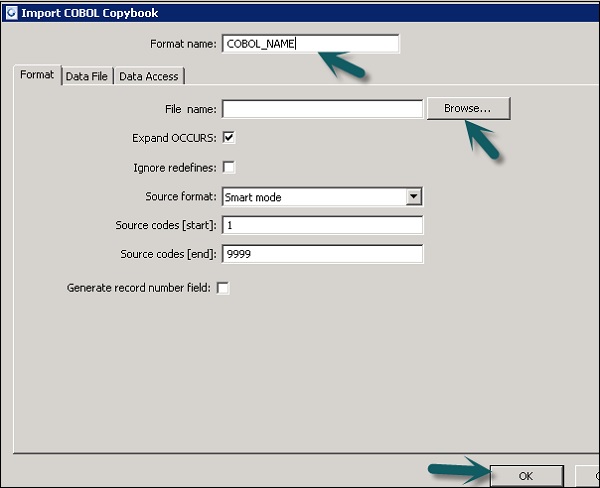
Step 4 - Klik OK. Format file ini ditambahkan ke perpustakaan Objek Lokal. Kotak dialog COBOL Copybook Schema name terbuka. Jika diperlukan, ganti nama skema dan klikOK.
Dengan menggunakan database datastore, Anda bisa mengekstrak data dari tabel dan fungsi di database. Saat Anda melakukan impor data untuk metadata,Tool memungkinkan Anda mengedit nama kolom, tipe data, deskripsi, dll.
Anda dapat mengedit objek berikut -
- Nama Tabel
- Nama kolom
- Deskripsi Tabel
- Deskripsi Kolom
- Jenis Data Kolom
- Jenis Isi Kolom
- Atribut Tabel
- Kunci utama
- Nama pemilik
Mengimpor Metadata
Untuk mengimpor Metadata, ikuti langkah-langkah yang diberikan di bawah ini -
Step 1 - Buka Local Object Library → buka Datastore yang ingin Anda gunakan.

Step 2 - Klik Kanan pada Datastore → Buka.
Di ruang kerja, semua item yang tersedia untuk diimpor akan ditampilkan. Pilih item yang ingin Anda impor metadata.

Di perpustakaan Objek, masuk ke datastore untuk melihat daftar objek yang diimpor.
Anda dapat menggunakan buku kerja Microsoft Excel sebagai sumber data menggunakan format file di Layanan Data. Buku kerja Excel harus tersedia di sistem file Windows atau sistem File Unix.
| Sr.No. | Akses & Deskripsi |
|---|---|
| 1 | In the object library, click the Formats tab. Buku kerja Excel formal menjelaskan struktur yang ditentukan dalam buku kerja Excel (dilambangkan dengan ekstensi .xls). Anda menyimpan templat format untuk rentang data Excel di pustaka objek. Anda menggunakan template untuk menentukan format sumber tertentu dalam aliran data. SAP Data Services mengakses buku kerja Excel sebagai sumber saja (bukan sebagai target). |
Klik kanan file New opsi dan pilih Excel Workbook seperti yang ditunjukkan pada gambar di bawah.

Ekstraksi Data dari XML FILE DTD, XSD
Anda juga dapat mengimpor format file skema XML atau DTD.
Step 1 - Buka Perpustakaan objek Lokal → tab Format → Skema Bersarang.
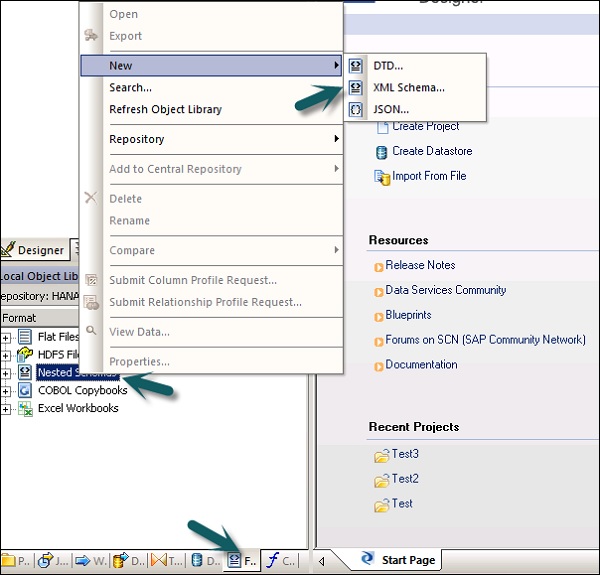
Step 2 - Tunjuk ke New(Anda dapat memilih file DTD atau Skema XML atau format file JSON). Masukkan nama format file dan pilih file yang ingin Anda impor. Klik OK.
Ekstraksi Data dari Copybooks COBOL
Anda juga dapat mengimpor format file dalam buku salinan COBOL. Pergi ke Local Object Library → Format → COBOL Copybooks.

Aliran data digunakan untuk mengekstrak, mentransformasikan, dan memuat data dari sumber ke sistem target. Semua transformasi, pemuatan, dan pemformatan terjadi dalam aliran data.
Setelah Anda menentukan aliran data dalam sebuah proyek, ini dapat ditambahkan ke alur kerja atau pekerjaan ETL. Aliran data dapat mengirim atau menerima objek / informasi dengan menggunakan parameter. Aliran data diberi nama dalam formatDF_Name.

Contoh Arus Data
Mari kita asumsikan bahwa Anda ingin memuat tabel fakta dalam sistem DW dengan data dari dua tabel di sistem sumber.
Aliran Data berisi objek-objek berikut -
- Dua Tabel Sumber
- Bergabung di antara dua tabel dan ditentukan dalam transformasi kueri
- Tabel target

Ada tiga jenis objek yang dapat ditambahkan ke aliran Data. Mereka adalah -
- Source
- Target
- Transforms
Step 1 - Pergi ke Local Object Library dan seret kedua tabel ke ruang kerja.

Step 2 - Untuk menambahkan Transformasi Kueri, seret dari bilah alat sebelah kanan.
Step 3 - Gabung kedua tabel dan buat tabel target template dengan mengklik kanan kotak Query → Add New → New Template table.

Step 4 - Masukkan nama tabel Target, Nama penyimpanan data dan Pemilik (nama Skema) di mana tabel akan dibuat.
Step 5 - Seret tabel target di depan dan gabungkan ke transformasi Kueri.
Parameter yang Melewati
Anda juga dapat melewatkan parameter yang berbeda masuk dan keluar dari aliran data. Saat meneruskan parameter ke aliran data, objek dalam aliran data merujuk parameter tersebut. Dengan menggunakan parameter, Anda dapat meneruskan operasi yang berbeda ke aliran data.
Contoh - Misalkan Anda telah memasukkan parameter ke tabel tentang pembaruan terakhir. Ini memungkinkan Anda untuk mengekstrak hanya baris yang dimodifikasi sejak pembaruan terakhir.
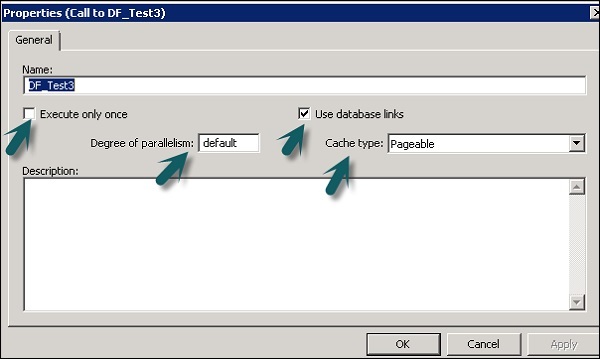
Anda dapat mengubah properti aliran data seperti Jalankan sekali, jenis cache, tautan database, paralelisme, dll.
Step 1 - Untuk mengubah properti aliran data, klik kanan pada Aliran data → Properti
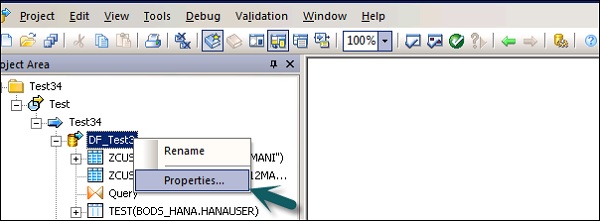
Anda dapat mengatur berbagai properti untuk aliran data. Properti diberikan di bawah ini.
| No Sr | Properti & Deskripsi |
|---|---|
| 1 | Execute only once Saat Anda menentukan bahwa aliran data hanya boleh dijalankan satu kali, tugas batch tidak akan pernah menjalankan kembali aliran data tersebut setelah aliran data berhasil diselesaikan, kecuali jika aliran data terdapat dalam alur kerja yang merupakan unit pemulihan yang dijalankan ulang dan belum berhasil diselesaikan di tempat lain di luar unit pemulihan. Direkomendasikan agar Anda tidak menandai aliran data sebagai Jalankan hanya sekali jika alur kerja induk adalah unit pemulihan. |
| 2 | Use database links Link database adalah jalur komunikasi antara satu server database dan lainnya. Link database memungkinkan pengguna lokal untuk mengakses data pada database jarak jauh, yang dapat berada di komputer lokal atau komputer jarak jauh dengan tipe database yang sama atau berbeda. |
| 3 | Degree of parallelism Degree Of Parallelism (DOP) adalah properti aliran data yang menentukan berapa kali setiap transformasi dalam aliran data mereplikasi untuk memproses subset paralel data. |
| 4 | Cache type Anda dapat menyimpan data dalam cache untuk meningkatkan kinerja operasi seperti gabungan, grup, pengurutan, pemfilteran, pencarian, dan perbandingan tabel. Anda dapat memilih salah satu dari nilai berikut untuk opsi jenis Cache pada jendela Properti aliran data Anda -
|
Step 2 - Ubah properti seperti Jalankan hanya sekali, Derajat paralelisme, dan jenis cache.
Sumber dan Objek Target
Aliran data dapat mengekstrak atau memuat data secara langsung menggunakan objek berikut -
Source objects - Objek Sumber menentukan sumber dari mana data diekstraksi atau Anda membaca datanya.
Target objects - Objek Target mendefinisikan target yang Anda muat atau tulis data.
Jenis objek sumber berikut dapat digunakan dan metode akses yang berbeda digunakan untuk objek sumber.
| Meja | File yang diformat dengan kolom dan baris seperti yang digunakan dalam database relasional | Langsung atau melalui adaptor |
| Tabel template | Tabel template yang telah dibuat dan disimpan di aliran data lain (digunakan dalam pengembangan) | Langsung |
| Mengajukan | File datar dengan batas atau lebar tetap | Langsung |
| Dokumen | File dengan format khusus aplikasi (tidak dapat dibaca oleh SQL atau parser XML) | Melalui adaptor |
| File XML | File yang diformat dengan tag XML | Langsung |
| Pesan XML | Digunakan sebagai sumber dalam pekerjaan waktu nyata | Langsung |
Objek Target berikut dapat digunakan dan metode akses yang berbeda dapat diterapkan.
| Meja | File yang diformat dengan kolom dan baris seperti yang digunakan dalam database relasional | Langsung atau melalui adaptor |
| Tabel template | Tabel yang formatnya didasarkan pada keluaran dari transformasi sebelumnya (digunakan dalam pengembangan) | Langsung |
| Mengajukan | File datar dengan batas atau lebar tetap | Langsung |
| Dokumen | File dengan format khusus aplikasi (tidak dapat dibaca oleh SQL atau parser XML) | Melalui adaptor |
| File XML | File yang diformat dengan tag XML | Langsung |
| File template XML | File XML yang formatnya didasarkan pada keluaran transformasi sebelumnya (digunakan dalam pengembangan, terutama untuk men-debug aliran data) | Langsung |
Alur kerja digunakan untuk menentukan proses eksekusi. Tujuan utama dari alur kerja adalah untuk mempersiapkan eksekusi aliran data dan untuk mengatur keadaan sistem, setelah eksekusi aliran data selesai.
Pekerjaan Batch dalam proyek ETL mirip dengan Alur Kerja dengan satu-satunya perbedaan bahwa pekerjaan tidak memiliki parameter.
Berbagai objek dapat ditambahkan ke alur kerja. Mereka adalah -
- Alur kerja
- Aliran data
- Scripts
- Loops
- Conditions
- Coba atau Tangkap Blok
Anda juga dapat membuat alur kerja memanggil alur kerja lain atau dapat memanggil alur kerja itu sendiri.
Note - Dalam alur kerja, langkah-langkah dijalankan dalam urutan kiri ke kanan.
Contoh Alur Kerja
Misalkan ada tabel fakta yang ingin Anda perbarui dan Anda telah membuat aliran data dengan transformasi. Sekarang, jika Anda ingin memindahkan data dari sistem sumber, Anda harus memeriksa modifikasi terakhir untuk tabel fakta sehingga Anda hanya mengekstrak baris yang ditambahkan setelah pembaruan terakhir.
Untuk mencapai ini, Anda harus membuat satu skrip, yang menentukan tanggal pembaruan terakhir dan kemudian meneruskan ini sebagai parameter input ke aliran data.
Anda juga harus memeriksa apakah koneksi data ke tabel fakta tertentu aktif atau tidak. Jika tidak aktif, Anda perlu menyiapkan blok penangkap, yang secara otomatis mengirim email ke administrator untuk memberi tahu tentang masalah ini.
Alur kerja dapat dibuat menggunakan metode berikut -
- Perpustakaan Objek
- Palet Alat
Membuat Alur Kerja menggunakan Object Library
Untuk membuat alur kerja menggunakan Object Library, ikuti langkah-langkah yang diberikan di bawah ini.
Step 1 - Pergi ke Object Library → tab Workflow.

Step 2 - Klik kanan file New pilihan.

Step 3 - Masukkan nama Alur Kerja.
Membuat alur kerja menggunakan palet alat
Untuk membuat alur kerja menggunakan palet alat, klik ikon di sisi kanan dan seret alur kerja di ruang kerja.
Anda juga dapat mengatur untuk mengeksekusi alur kerja hanya sekali dengan masuk ke properti alur kerja.
Persyaratan
Anda juga dapat menambahkan Persyaratan ke alur kerja. Ini memungkinkan Anda untuk mengimplementasikan logika If / Else / Then pada alur kerja.
| Sr.No. | Bersyarat & Deskripsi |
|---|---|
| 1 | If Ekspresi Boolean yang mengevaluasi TRUE atau FALSE. Anda dapat menggunakan fungsi, variabel, dan operator standar untuk membuat ekspresi. |
| 2 | Then Elemen alur kerja untuk dieksekusi jika If ekspresi terevaluasi menjadi TRUE. |
| 3 | Else (Opsional) Elemen alur kerja yang akan dijalankan jika If ekspresi terevaluasi menjadi FALSE. |
Untuk mendefinisikan Kondisional
Step 1 - Pergi ke Workflow → Klik ikon Conditional pada palet alat di sisi kanan.
Step 2 - Klik dua kali nama Conditional untuk membuka file If-Then–Else editor bersyarat.
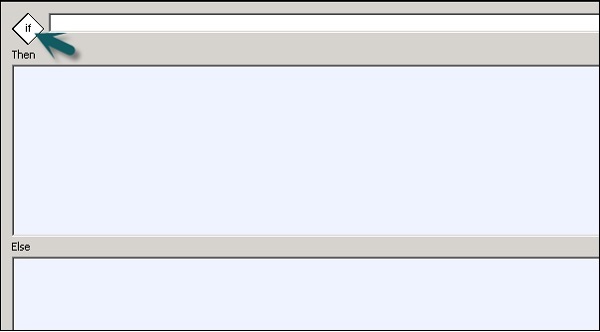
Step 3- Masukkan Ekspresi Boolean yang mengontrol Kondisional. Klik OK.
Step 4 - Seret aliran Data yang ingin Anda jalankan Then and Else jendela sesuai ekspresi dalam kondisi IF.

Setelah Anda menyelesaikan kondisi, Anda dapat men-debug dan memvalidasi kondisional.
Transformasi digunakan untuk memanipulasi kumpulan data sebagai input dan membuat satu atau beberapa output. Ada berbagai transformasi yang dapat digunakan di Layanan Data. Jenis transformasi bergantung pada versi dan produk yang dibeli.
Jenis Transformasi berikut tersedia -
Integrasi data
Transformasi Integrasi Data digunakan untuk ekstraksi data, transformasi dan pemuatan ke sistem DW. Ini memastikan integritas data dan meningkatkan produktivitas pengembang.
- Data_Generator
- Data_Transfer
- Effective_Date
- Hierarchy_flattening
- Table_Comparision, dll.
Kualitas data
Transformasi Kualitas Data digunakan untuk meningkatkan kualitas data. Anda dapat menerapkan parse, mengoreksi, standar, memperkaya kumpulan data dari sistem sumber.
- Associate
- Pembersihan Data
- Walk Sequencer DSF2, dll.
Peron
Platform digunakan untuk pergerakan dataset. Dengan menggunakan ini, Anda dapat menghasilkan, memetakan, dan menggabungkan baris dari dua atau lebih sumber data.
- Case
- Merge
- Kueri, dll.
Pemrosesan Data Teks
Pemrosesan Data Teks memungkinkan Anda memproses data teks dalam jumlah besar.
Di bab ini, Anda akan melihat cara menambahkan Transform ke Arus Data.
Step 1 - Pergi ke Object Library → tab Transform.
Step 2- Pilih Transformasi yang ingin Anda tambahkan ke aliran data. Jika Anda menambahkan transformasi yang memiliki opsi untuk memilih konfigurasi, sebuah prompt akan terbuka.
Step 3 - Gambarkan koneksi aliran data untuk menghubungkan sumber ke transformasi.
Step 4 - Klik dua kali nama Transformasi untuk membuka editor transformasi.
Setelah definisi selesai, klik OK untuk menutup editor.
Ini adalah transformasi paling umum yang digunakan dalam Layanan Data dan Anda dapat melakukan fungsi berikut -
- Pemfilteran data dari sumber
- Menggabungkan data dari berbagai sumber
- Melakukan fungsi dan transformasi pada data
- Pemetaan kolom dari skema input ke output
- Menetapkan kunci utama
- Tambahkan kolom, skema dan fungsi baru yang dihasilkan ke skema keluaran
Karena Transformasi kueri adalah transformasi yang paling umum digunakan, pintasan disediakan untuk kueri ini di palet alat.
Untuk menambahkan transformasi Query, ikuti langkah-langkah yang diberikan di bawah ini -
Step 1- Klik palet alat transformasi kueri. Klik di mana saja di ruang kerja Aliran data. Hubungkan ini ke input dan output.

Saat Anda mengklik dua kali ikon Transformasi kueri, ini akan membuka editor kueri yang digunakan untuk melakukan operasi kueri.
Area berikut ini hadir dalam transformasi Kueri -
- Skema Input
- Skema Keluaran
- Parameters
Skema Input dan Output berisi Kolom, Skema Bersarang, dan Fungsi. Skema Masuk dan Skema Keluar menunjukkan skema yang saat ini dipilih dalam transformasi.
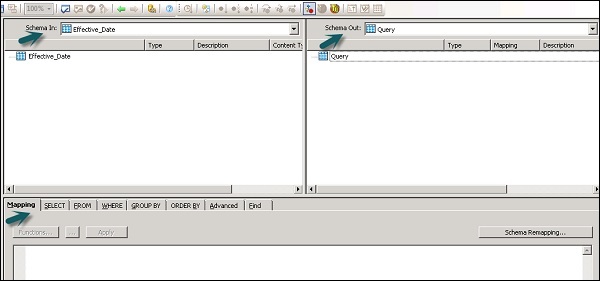
Untuk mengubah skema keluaran, pilih skema dalam daftar, klik kanan dan pilih Make Current.

Transformasi Kualitas Data
Transformasi Kualitas Data tidak dapat langsung dihubungkan ke transformasi hulu, yang berisi tabel bertingkat. Untuk menghubungkan transformasi ini, Anda harus menambahkan transformasi kueri atau transformasi pipeline XML antara transformasi dari tabel bersarang dan transformasi kualitas data.
Bagaimana cara menggunakan Transformasi Kualitas Data?
Step 1 - Pergi ke Object Library → tab Transform
Step 2 - Perluas transformasi Kualitas Data dan tambahkan konfigurasi transformasi atau transformasi yang ingin Anda tambahkan ke aliran data.
Step 3- Gambarkan koneksi aliran data. Klik dua kali nama transformasi, itu membuka editor transformasi. Dalam skema masukan, pilih kolom masukan yang ingin Anda petakan.
Note - Untuk menggunakan Associate Transform, Anda dapat menambahkan field yang ditentukan pengguna ke tab input.
Transformasi Pengolahan Data Teks
Transformasi Pemrosesan Data Teks memungkinkan Anda mengekstrak informasi spesifik dari teks volume besar. Anda dapat mencari fakta dan entitas seperti pelanggan, produk, dan fakta keuangan, khusus untuk suatu organisasi.
Transformasi ini juga memeriksa hubungan antara entitas dan memungkinkan ekstraksi. Data yang diekstrak, menggunakan pemrosesan data teks, dapat digunakan di Business Intelligence, Pelaporan, kueri, dan analitik.
Transformasi Ekstraksi Entitas
Di Layanan Data, pemrosesan data teks dilakukan dengan bantuan Ekstraksi Entitas, yang mengekstrak entitas dan fakta dari data tidak terstruktur.
Ini melibatkan analisis dan pemrosesan data teks dalam jumlah besar, mencari entitas, menugaskannya ke jenis yang sesuai, dan menyajikan metadata dalam format standar.
Transformasi Ekstraksi Entitas dapat mengekstrak informasi dari teks, HTML, XML, atau konten format biner tertentu (seperti PDF) dan menghasilkan keluaran terstruktur. Anda dapat menggunakan output dalam beberapa cara berdasarkan alur kerja Anda. Anda dapat menggunakannya sebagai input untuk transformasi lain atau menulis ke beberapa sumber output seperti tabel database atau file datar. Keluarannya dihasilkan dalam pengkodean UTF-16.
Entity Extract Transform can be used in the following scenarios −
Menemukan informasi spesifik dari volume teks yang besar.
Menemukan informasi terstruktur dari teks tidak terstruktur dengan informasi yang ada untuk membuat koneksi baru.
Pelaporan dan analisis kualitas produk.
Perbedaan antara TDP dan Data Cleansing
Pengolahan data teks digunakan untuk menemukan informasi yang relevan dari data teks tidak terstruktur. Namun, pembersihan data digunakan untuk standarisasi dan pembersihan data terstruktur.
| Parameter | Pemrosesan Data Teks | Pembersihan data |
|---|---|---|
| Tipe masukan | Data Tidak Terstruktur | Data Terstruktur |
| Ukuran Input | Lebih dari 5KB | Kurang dari 5KB |
| Lingkup Input | Domain luas dengan banyak variasi | Variasi terbatas |
| Potensi Penggunaan | Potensi informasi yang berarti dari data tidak terstruktur | Kualitas data untuk disimpan di Repository |
| Keluaran | Buat anotasi dalam bentuk entitas, jenis, dll. Input tidak diubah | Buat bidang standar, Input diubah |
Administrasi Layanan Data mencakup pembuatan pekerjaan waktu nyata dan batch, tugas penjadwalan, aliran data yang disematkan, variabel dan parameter, mekanisme pemulihan, profil data, penyesuaian kinerja, dll.
Pekerjaan Waktu Nyata
Anda dapat membuat pekerjaan waktu nyata untuk memproses pesan waktu nyata di desainer Layanan Data. Seperti pekerjaan batch, pekerjaan waktu nyata mengekstrak data, mengubah, dan memuatnya.
Setiap pekerjaan waktu nyata dapat mengekstrak data dari satu pesan. Anda juga dapat mengekstrak data dari sumber lain seperti tabel atau file.
Pekerjaan waktu nyata tidak dijalankan dengan bantuan pemicu, tidak seperti pekerjaan batch. Mereka dijalankan sebagai layanan waktu nyata oleh administrator. Layanan waktu nyata menunggu pesan dari server akses. Server akses menerima pesan ini dan meneruskannya ke layanan waktu nyata, yang dikonfigurasi untuk memproses jenis pesan. Layanan waktu nyata menjalankan pesan dan mengembalikan hasilnya dan terus memproses pesan sampai mereka mendapatkan instruksi untuk berhenti mengeksekusi.
Pekerjaan Waktu Nyata vs Batch
Transformasi seperti cabang dan logika kontrol lebih sering digunakan dalam pekerjaan waktu nyata, yang tidak terjadi pada pekerjaan batch di desainer.
Pekerjaan waktu nyata tidak dijalankan sebagai respons dari jadwal atau pemicu internal tidak seperti pekerjaan batch.
Menciptakan Pekerjaan Real Time
Pekerjaan waktu nyata dapat dibuat menggunakan objek yang sama seperti aliran data, alur kerja, loop, kondisional, skrip, dll.
Anda dapat menggunakan model data berikut untuk membuat pekerjaan waktu nyata -
- Model aliran data tunggal
- Model aliran data ganda
Model aliran data tunggal
Anda dapat membuat pekerjaan waktu nyata dengan aliran data tunggal dalam putaran pemrosesan waktu nyata dan ini mencakup satu sumber pesan dan target pesan tunggal.
Creating Real Time job using single data model −
Untuk membuat pekerjaan Real Time menggunakan model data tunggal, ikuti langkah-langkah yang diberikan.
Step 1 - Buka Desainer Layanan Data → Proyek Baru → Proyek → Masukkan Nama Proyek

Step 2 - Klik kanan pada ruang putih di area Proyek → Pekerjaan waktu nyata baru.

Ruang kerja menunjukkan dua komponen pekerjaan waktu nyata -
- RT_Process_begins
- Step_ends
Ini menunjukkan awal dan akhir pekerjaan waktu nyata.

Step 3 - Untuk membuat pekerjaan waktu nyata dengan aliran data tunggal, pilih aliran data dari palet alat di panel kanan dan seret ke ruang kerja.
Klik di dalam loop, Anda dapat menggunakan satu sumber pesan dan satu target pesan dalam loop pemrosesan waktu nyata. Hubungkan tanda awal dan akhir ke aliran data.

Step 4 - Tambahkan objek konfigurasi dalam aliran data sesuai kebutuhan dan simpan pekerjaan.
Model aliran data ganda
Ini memungkinkan Anda membuat pekerjaan waktu nyata dengan beberapa aliran data dalam putaran pemrosesan waktu nyata. Anda juga perlu memastikan bahwa data di setiap model data sepenuhnya diproses sebelum berpindah ke pesan berikutnya.
Menguji Pekerjaan Waktu Nyata
Anda dapat menguji pekerjaan waktu nyata dengan meneruskan pesan contoh sebagai pesan sumber dari file. Anda dapat memeriksa apakah Layanan Data menghasilkan pesan target yang diharapkan.
Untuk memastikan bahwa pekerjaan Anda memberikan hasil yang diharapkan, Anda dapat menjalankan pekerjaan dalam mode data tampilan. Dengan menggunakan mode ini, Anda dapat menangkap data keluaran untuk memastikan bahwa pekerjaan waktu nyata Anda berfungsi dengan baik.
Aliran Data Tersemat
Aliran data yang disematkan dikenal sebagai aliran data, yang disebut dari aliran data lain dalam desain. Aliran data yang disematkan dapat berisi beberapa sumber dan target tetapi hanya satu input atau output yang meneruskan data ke aliran data utama.
Jenis aliran data yang disematkan berikut ini dapat digunakan -
One Input - Aliran data tertanam ditambahkan di akhir aliran data.
One Output - Aliran data tersemat ditambahkan di awal aliran data.
No input or output - Mereplikasi aliran data yang ada.
Aliran data tersemat dapat digunakan untuk tujuan berikut -
Untuk mempermudah tampilan aliran data.
Jika Anda ingin menyimpan logika aliran dan menggunakannya kembali di aliran data lain.
Untuk debugging, di mana Anda membuat bagian aliran data sebagai aliran data tersemat dan menjalankannya secara terpisah.
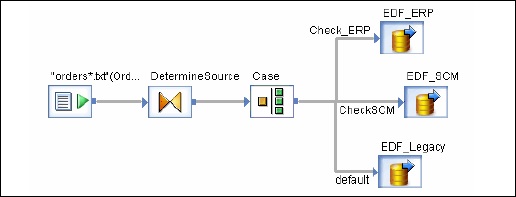
Anda dapat memilih objek di aliran data yang ada. Ada dua cara untuk membuat Aliran Data tersemat.
Pilihan 1
Klik kanan pada objek dan pilih untuk membuatnya menjadi aliran Data Tersemat.

pilihan 2
Seret aliran data lengkap dan validasi dari pustaka objek ke aliran data terbuka di ruang kerja. Selanjutnya buka aliran data yang telah dibuat. Pilih objek yang ingin Anda gunakan sebagai port input dan output dan klikmake port untuk objek itu.

Layanan Data menambahkan objek itu sebagai titik koneksi untuk aliran data yang disematkan.
Variabel dan Parameter
Anda dapat menggunakan variabel lokal dan global dengan aliran data dan alur kerja, yang memberikan lebih banyak fleksibilitas dalam mendesain pekerjaan.
Fitur utamanya adalah -
Tipe data variabel bisa berupa angka, integer, desimal, tanggal atau string teks seperti karakter.
Variabel dapat digunakan dalam aliran data dan alur kerja sebagai fungsi di Where ayat.
Variabel lokal dalam layanan data dibatasi untuk objek tempat mereka dibuat.
Variabel global terbatas pada pekerjaan tempat mereka dibuat. Dengan menggunakan variabel global, Anda dapat mengubah nilai untuk variabel global default pada waktu proses.
Ekspresi yang digunakan dalam alur kerja dan arus data dikenal sebagai parameters.
Semua variabel dan parameter dalam alur kerja dan arus data ditampilkan di jendela variabel dan parameter.
Untuk melihat variabel dan parameter, ikuti langkah-langkah yang diberikan di bawah ini -
Buka Alat → Variabel.

Jendela baru Variables and parametersditampilkan. Ini memiliki dua tab - Definisi dan Panggilan.
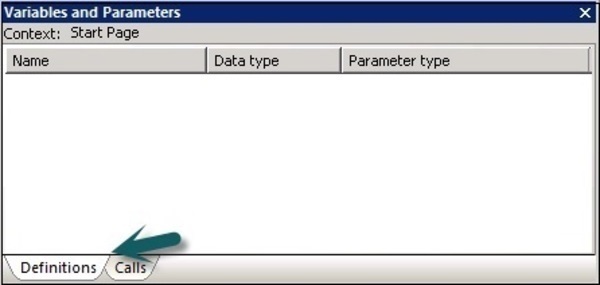
Itu Definitionstab memungkinkan Anda membuat dan melihat variabel dan parameter. Anda dapat menggunakan variabel dan parameter lokal di aliran kerja dan tingkat aliran data. Variabel global dapat digunakan di tingkat pekerjaan.
Pekerjaan |
Variabel lokal Variabel global |
Sebuah skrip atau kondisional dalam pekerjaan Objek apa pun dalam pekerjaan |
Alur kerja |
Variabel lokal Parameter |
Alur kerja ini atau diturunkan ke alur kerja lain atau aliran data menggunakan parameter. Objek induk untuk meneruskan variabel lokal. Alur kerja juga dapat mengembalikan variabel atau parameter ke objek induk. |
Aliran data |
Parameter |
Klausa WHERE, pemetaan kolom, atau fungsi di aliran data. Aliran data. Aliran data tidak dapat mengembalikan nilai keluaran. |
Di tab panggilan, Anda dapat melihat nama parameter yang ditentukan untuk semua objek dalam definisi objek induk.
Mendefinisikan Variabel Lokal
Untuk menentukan Variabel Lokal, Buka pekerjaan Real time.
Step 1- Buka Alat → Variabel. BaruVariables and Parameters jendela akan terbuka.
Step 2 - Buka Variabel → Klik kanan → Sisipkan

Ini akan membuat parameter baru $NewVariable0.
Step 3- Masukkan nama variabel baru. Pilih tipe data dari daftar.

Setelah ditentukan, tutup jendelanya. Dengan cara yang sama, Anda dapat menentukan parameter untuk aliran data dan alur kerja.

Jika pekerjaan Anda tidak berhasil, Anda harus memperbaiki kesalahan dan menjalankan kembali pekerjaan tersebut. Jika ada pekerjaan yang gagal, ada kemungkinan beberapa tabel telah dimuat, diubah, atau dimuat sebagian. Anda perlu menjalankan kembali pekerjaan untuk mendapatkan semua data dan untuk menghapus duplikat atau data yang hilang.
Dua teknik yang dapat digunakan untuk pemulihan adalah sebagai berikut -
Automatic Recovery - Ini memungkinkan Anda untuk menjalankan pekerjaan yang tidak berhasil dalam mode pemulihan.
Manually Recovery - Ini memungkinkan Anda untuk menjalankan kembali pekerjaan tanpa mempertimbangkan menjalankan kembali sebagian waktu sebelumnya.
To run a job with Recovery option enabled in Designer
Step 1 - Klik kanan pada nama pekerjaan → Jalankan.

Step 2 - Simpan semua perubahan dan Jalankan → Ya.
Step 3- Buka tab Eksekusi → kotak centang Aktifkan Pemulihan. Jika kotak ini tidak dicentang, Layanan data tidak akan memulihkan pekerjaan, jika gagal.

To run a job in Recovery mode from Designer
Step 1- Klik kanan dan jalankan pekerjaan seperti di atas. Simpan perubahan.
Step 2- Pergi ke Opsi Eksekusi. Anda harus memastikan bahwa opsi tersebutRecover from last failed execution kotak dicentang.
Note- Opsi ini tidak diaktifkan, jika pekerjaan belum dijalankan. Ini dikenal sebagai Pemulihan otomatis dari pekerjaan yang gagal.

Data Services Designer menyediakan fitur Data Profiling untuk memastikan dan meningkatkan kualitas dan struktur data sumber.
Data Profiler memungkinkan Anda untuk -
Temukan anomali dalam data sumber, validasi dan tindakan korektif, serta kualitas data sumber.
Tentukan struktur dan hubungan data sumber untuk pelaksanaan pekerjaan, alur kerja, dan aliran data yang lebih baik.
Temukan konten sumber dan sistem target untuk menentukan bahwa pekerjaan Anda memberikan hasil yang diharapkan.
Data Profiler memberikan informasi berikut tentang eksekusi server Profiler -
Analisis Kolom
Basic Profiling - Termasuk informasi seperti min, max, avg, dll.
Detailed Profiling - Termasuk informasi seperti hitungan berbeda, persen berbeda, median, dll.
Analisis Hubungan
Anomali data antara dua kolom yang Anda tentukan hubungannya.
Fitur profil data dapat digunakan pada data dari sumber data berikut -
- SQL Server
- Oracle
- DB2
- Konektor Perhatian
- Sybase IQ
- Teradata
Menghubungkan ke Server Profiler
Untuk menyambung ke Server Profil -
Step 1 - Buka Tools → Profiler Server Login

Step 2 - Masukkan detail seperti Sistem, Nama Pengguna, Kata Sandi dan Otentikasi.
Step 3 - Klik Log on tombol.
Saat Anda terhubung, daftar repositori profiler akan ditampilkan. PilihRepository dan klik Connect.
Kinerja pekerjaan ETL tergantung pada sistem tempat Anda menggunakan perangkat lunak Layanan Data, jumlah gerakan, dll.
Ada berbagai faktor lain yang berkontribusi pada kinerja dalam tugas ETL. Mereka adalah -
Source Data Base - Database sumber harus diatur untuk melakukan Selectpernyataan dengan cepat. Ini dapat dilakukan dengan meningkatkan ukuran database I / O, meningkatkan ukuran buffer bersama untuk menyimpan lebih banyak data dan tidak mengizinkan paralel untuk tabel kecil, dll.
Source Operating System- Sistem Operasi Sumber harus dikonfigurasi untuk membaca data dengan cepat dari disk. Setel protokol baca ke depan ke 64KB.
Target Database - Target Database harus dikonfigurasi untuk melakukan INSERT dan UPDATEsegera. Ini dapat dilakukan dengan -
- Menonaktifkan pencatatan Arsip.
- Menonaktifkan Redo logging untuk semua tabel.
- Memaksimalkan ukuran buffer bersama.
Target Operating System- Sistem Operasi Target harus dikonfigurasi untuk menulis data ke disk dengan cepat. Anda dapat mengaktifkan asinkron I / O untuk membuat operasi Input / output secepat mungkin.
Network - Bandwidth jaringan harus cukup untuk mentransfer data dari sumber ke sistem target.
BODS Repository Database - Untuk meningkatkan kinerja tugas BODS, hal berikut dapat dilakukan -
Monitor Sample Rate - Jika Anda memproses sejumlah besar kumpulan data dalam tugas ETL, pantau Rasio Sampel ke nilai yang lebih tinggi untuk mengurangi jumlah panggilan I / O ke file log sehingga meningkatkan kinerja.
Anda juga dapat mengecualikan log Layanan Data dari pemindaian virus jika pemindaian virus dikonfigurasi di server pekerjaan karena dapat menyebabkan penurunan kinerja.
Job Server OS - Dalam Layanan Data, satu aliran data dalam pekerjaan memulai satu ‘al_engine’proses, yang memulai empat utas. Untuk performa maksimal, pertimbangkan desain yang menjalankannya‘al_engine’proses per CPU pada satu waktu. OS Job Server harus disetel sedemikian rupa sehingga semua utas tersebar ke semua CPU yang tersedia.
Layanan Data SAP BO mendukung pengembangan multipengguna di mana setiap pengguna dapat mengerjakan aplikasi di repositori lokalnya sendiri. Setiap tim menggunakan repositori pusat untuk menyimpan salinan utama aplikasi dan semua versi objek dalam aplikasi.
Fitur utamanya adalah -
Di Layanan Data SAP, Anda dapat membuat repositori pusat untuk menyimpan salinan tim dari suatu aplikasi. Ini berisi semua informasi yang juga tersedia di repositori lokal. Namun, itu hanya menyediakan lokasi penyimpanan untuk informasi objek. Untuk membuat perubahan apa pun, Anda harus bekerja di repositori lokal.
Anda dapat menyalin objek dari repositori pusat ke repositori lokal. Namun, jika Anda harus membuat perubahan apa pun, Anda perlu memeriksa objek itu di repositori pusat. Karena itu, pengguna lain tidak dapat memeriksa objek itu di repositori pusat dan karenanya, mereka tidak dapat membuat perubahan pada objek yang sama.
Setelah Anda membuat perubahan pada objek, Anda perlu check in untuk objek tersebut. Ini memungkinkan Layanan Data untuk menyimpan objek baru yang dimodifikasi di repositori pusat.
Layanan Data memungkinkan banyak pengguna dengan repositori lokal untuk terhubung ke repositori pusat pada saat yang sama tetapi hanya satu pengguna yang dapat memeriksa dan membuat perubahan pada objek tertentu.
Repositori pusat juga menyimpan sejarah setiap objek. Ini memungkinkan Anda untuk kembali ke versi sebelumnya dari suatu objek, jika perubahan tidak terjadi seperti yang diperlukan.
Banyak Pengguna
Layanan Data SAP BO memungkinkan banyak pengguna untuk mengerjakan aplikasi yang sama pada waktu yang sama. Istilah berikut harus dipertimbangkan dalam lingkungan multi-pengguna -
| Sr.No. | Multi-pengguna & Deskripsi |
|---|---|
| 1 | Highest level object Objek tingkat tertinggi adalah objek yang tidak bergantung pada objek apa pun dalam hierarki objek. Misalnya, jika Job 1 terdiri dari Work Flow 1 dan Data Flow 1, maka Job 1 adalah objek level tertinggi. |
| 2 | Object dependents Dependensi objek adalah objek yang terkait di bawah objek level tertinggi dalam hierarki. Misalnya, jika Pekerjaan 1 terdiri dari Alur Kerja 1 yang berisi Aliran Data 1, maka Alur Kerja 1 dan Aliran Data 1 merupakan tanggungan dari Pekerjaan 1. Selanjutnya, Aliran Data 1 merupakan tanggungan Alur Kerja 1. |
| 3 | Object version Versi objek adalah turunan dari objek. Setiap kali Anda menambahkan atau memeriksa objek ke repositori pusat, perangkat lunak membuat versi baru dari objek tersebut. Versi terbaru suatu objek adalah versi terakhir atau terbaru yang dibuat. |
Untuk memperbarui repositori lokal di lingkungan multipengguna, Anda bisa mendapatkan salinan terbaru dari setiap objek dari repositori pusat. Untuk mengedit sebuah objek, Anda dapat menggunakan opsi check out dan check in.
Ada berbagai parameter keamanan yang dapat diterapkan pada repositori pusat untuk membuatnya aman.
Berbagai parameter keamanan adalah -
Authentication - Ini memungkinkan hanya pengguna asli untuk masuk ke repositori pusat.
Authorization - Ini memungkinkan pengguna untuk menetapkan tingkat izin yang berbeda untuk setiap objek.
Auditing- Ini digunakan untuk memelihara riwayat semua perubahan yang dilakukan pada suatu objek. Anda dapat memeriksa semua versi sebelumnya dan kembali ke versi lama.
Membuat Repositori Pusat yang Tidak Aman
Dalam lingkungan pengembangan multipengguna, selalu disarankan untuk bekerja dalam metode repositori pusat.
Untuk membuat repositori pusat yang tidak aman, ikuti langkah-langkah yang diberikan -
Step 1 - Buat database, menggunakan sistem manajemen database, yang akan bertindak sebagai repositori pusat.
Step 2 - Pergi ke Manajer Repositori.

Step 3- Pilih jenis Repositori sebagai Central. Masukkan detail database seperti Nama Pengguna dan Kata Sandi dan klikCreate.

Step 4 - Untuk menentukan koneksi ke Central Repository, Tools → Central Repository.

Step 5 - Pilih Repositori di koneksi Repositori Pusat dan klik Add ikon.

Step 6 - Masukkan kata sandi untuk repositori pusat dan klik Activate tombol.
Membuat Repositori Pusat yang Aman
Untuk membuat Central Repository yang aman, buka Repository Manager. Pilih Jenis Repositori sebagai Pusat. KlikEnable Security Kotak centang.

Untuk pengembangan yang sukses di lingkungan multipengguna, disarankan untuk menerapkan beberapa proses seperti check in dan check out.
Anda dapat menggunakan proses berikut dalam lingkungan multipengguna -
- Filtering
- Memeriksa objek
- Membatalkan pembayaran
- Memeriksa di Objek
- Memberi Label pada Objek
Pemfilteran berlaku saat Anda menambahkan objek apa pun, check in, check out, dan memberi label objek ke repositori pusat.
Migrasi Pekerjaan Multipengguna
Dalam Layanan Data SAP, migrasi pekerjaan dapat diterapkan pada level yang berbeda yaitu Level Aplikasi, Level Repositori, level Upgrade.
Anda tidak dapat menyalin konten dari satu repositori pusat ke repositori pusat lainnya secara langsung; Anda perlu menggunakan repositori lokal.
Langkah pertama adalah mendapatkan versi terbaru dari semua objek dari repositori pusat ke repositori lokal. Aktifkan repositori pusat tempat Anda ingin menyalin konten. Tambahkan semua objek yang ingin Anda salin dari repositori lokal ke repositori pusat.
Migrasi Repositori Pusat
Jika Anda memperbarui versi Layanan Data SAP, Anda juga perlu memperbarui versi Repositori.
Poin-poin berikut harus dipertimbangkan ketika memigrasi repositori pusat untuk meningkatkan versi -
Buat cadangan dari repositori pusat semua tabel dan objek.
Untuk mempertahankan versi objek dalam layanan data, pertahankan repositori pusat untuk setiap versi. Buat riwayat pusat baru dengan versi baru perangkat lunak Layanan Data dan salin semua objek ke penyimpanan ini.
Jika Anda menginstal versi baru Layanan Data, itu selalu disarankan, Anda harus memutakhirkan repositori pusat Anda ke versi baru objek.
Tingkatkan repositori lokal Anda ke versi yang sama, karena versi berbeda dari repositori pusat dan lokal mungkin tidak berfungsi pada saat yang sama.
Sebelum memigrasi repositori pusat, periksa semua objek. Karena Anda tidak mengupgrade repositori pusat dan lokal secara bersamaan, jadi ada kebutuhan untuk memeriksa semua objek. Setelah repositori pusat Anda ditingkatkan ke versi yang lebih baru, Anda tidak akan dapat memeriksa objek dari repositori lokal, yang memiliki versi Layanan Data yang lebih lama.