SAS - Kumpulan Data Gabungan
Beberapa kumpulan data SAS dapat digabungkan untuk memberikan satu kumpulan data menggunakan SETpernyataan. Jumlah total pengamatan dalam kumpulan data yang digabungkan adalah jumlah dari jumlah pengamatan dalam kumpulan data asli. Urutan observasi berurutan. Semua observasi dari kumpulan data pertama diikuti oleh semua observasi dari kumpulan data kedua, dan seterusnya.
Idealnya semua kumpulan data gabungan memiliki variabel yang sama, tetapi jika mereka memiliki jumlah variabel yang berbeda, maka hasilnya semua variabel muncul, dengan nilai yang hilang untuk kumpulan data yang lebih kecil.
Sintaksis
Sintaks dasar untuk pernyataan SET di SAS adalah -
SET data-set 1 data-set 2 data-set 3.....;Berikut ini adalah deskripsi parameter yang digunakan -
data-set1,data-set2 adalah nama kumpulan data yang ditulis satu per satu.
Contoh
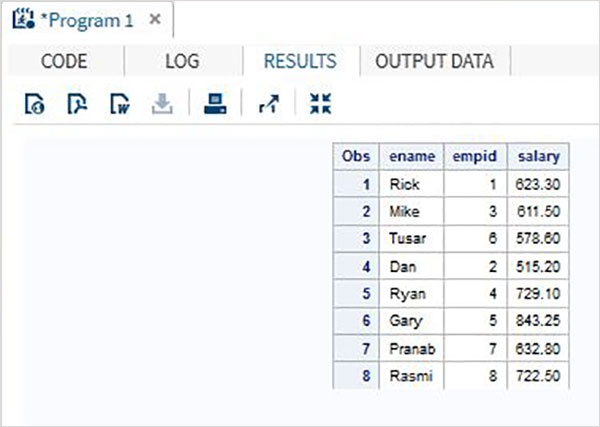
Pertimbangkan data karyawan dari sebuah organisasi yang tersedia dalam dua kumpulan data berbeda, satu untuk departemen TI dan satu lagi untuk departemen Non-Itu. Untuk mendapatkan detail lengkap dari semua karyawan, kami menggabungkan kedua set data menggunakan pernyataan SET yang ditunjukkan seperti di bawah ini.
DATA ITDEPT;
INPUT empid name $ salary ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid name $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT NON_ITDEPT;
RUN;
PROC PRINT DATA = All_Dept;
RUN;Ketika kode di atas dijalankan, kita mendapatkan output sebagai berikut.
Skenario
Ketika kita memiliki banyak variasi dalam kumpulan data untuk penggabungan, hasil dari variabel dapat berbeda tetapi jumlah total pengamatan dalam kumpulan data yang digabungkan selalu merupakan jumlah dari pengamatan di setiap kumpulan data. Kami akan mempertimbangkan banyak skenario di bawah ini tentang variasi ini.
Jumlah variabel yang berbeda
Jika salah satu kumpulan data asli memiliki lebih banyak variabel daripada yang lain, kumpulan data tersebut masih dapat digabungkan, tetapi dalam kumpulan data yang lebih kecil variabel tersebut tampak hilang.
Contoh
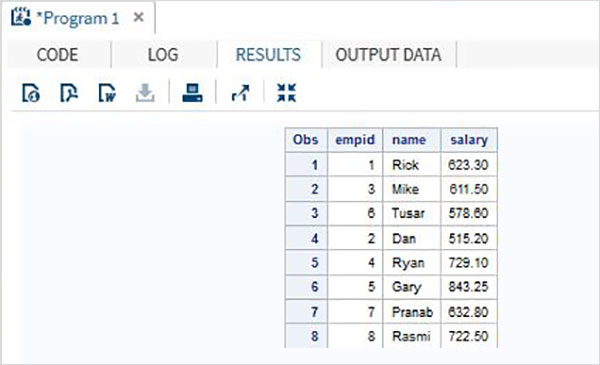
Dalam contoh di bawah ini, kumpulan data pertama memiliki variabel tambahan bernama DOJ. Hasilnya nilai DOJ untuk kumpulan data kedua akan tampak hilang.
DATA ITDEPT;
INPUT empid name $ salary DOJ date9. ;
DATALINES;
1 Rick 623.3 02APR2001
3 Mike 611.5 21OCT2000
6 Tusar 578.6 01MAR2009
;
RUN;
DATA NON_ITDEPT;
INPUT empid name $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT NON_ITDEPT;
RUN;
PROC PRINT DATA = All_Dept;
RUN;Ketika kode di atas dijalankan, kita mendapatkan output sebagai berikut.

Nama variabel yang berbeda
Dalam skenario ini, kumpulan data memiliki jumlah variabel yang sama tetapi nama variabel berbeda di antara mereka. Dalam hal ini penggabungan normal akan menghasilkan semua variabel dalam kumpulan hasil dan memberikan hasil yang hilang untuk dua variabel yang berbeda. Meskipun kami tidak dapat mengubah nama variabel dalam kumpulan data asli, kami dapat menerapkan fungsi RENAME dalam kumpulan data gabungan yang kami buat. Itu akan menghasilkan hasil yang sama seperti penggabungan normal tetapi tentu saja dengan satu nama variabel baru menggantikan dua nama variabel berbeda yang ada dalam kumpulan data asli.
Contoh
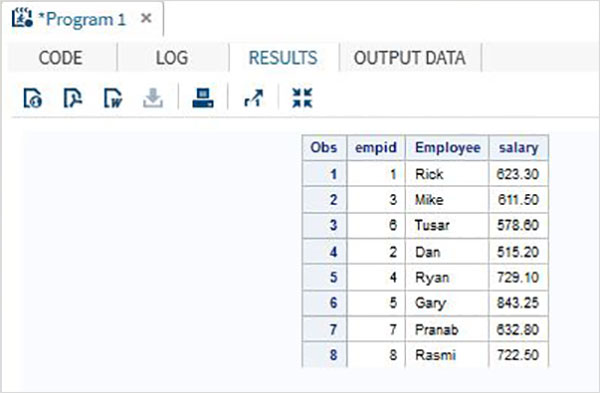
Pada contoh di bawah kumpulan data ITDEPT memiliki nama variabel ename sedangkan kumpulan data NON_ITDEPT memiliki nama variabel empname.Namun kedua variabel tersebut mewakili tipe (karakter) yang sama. Kami menerapkanRENAME fungsi dalam pernyataan SET seperti yang ditunjukkan di bawah ini.
DATA ITDEPT;
INPUT empid ename $ salary ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid empname $ salary ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
SET ITDEPT(RENAME =(ename = Employee) ) NON_ITDEPT(RENAME =(empname = Employee) );
RUN;
PROC PRINT DATA = All_Dept;
RUN;Ketika kode di atas dijalankan, kita mendapatkan output sebagai berikut.
Panjang variabel yang berbeda
Jika panjang variabel dalam dua kumpulan data berbeda dari kumpulan data yang digabungkan akan memiliki nilai di mana beberapa data dipotong untuk variabel dengan panjang yang lebih kecil. Itu terjadi jika kumpulan data pertama memiliki panjang yang lebih kecil. Untuk mengatasi ini kami menerapkan panjang yang lebih tinggi ke kedua kumpulan data seperti yang ditunjukkan di bawah ini.
Contoh
Pada contoh di bawah variabel enamememiliki panjang 5 di kumpulan data pertama dan 7 di kumpulan data kedua. Saat menggabungkan kita menerapkan pernyataan LENGTH dalam kumpulan data gabungan untuk mengatur panjang ename menjadi 7.
DATA ITDEPT;
INPUT empid 1-2 ename $ 3-7 salary 8-14 ;
DATALINES;
1 Rick 623.3
3 Mike 611.5
6 Tusar 578.6
;
RUN;
DATA NON_ITDEPT;
INPUT empid 1-2 ename $ 3-9 salary 10-16 ;
DATALINES;
2 Dan 515.2
4 Ryan 729.1
5 Gary 843.25
7 Pranab 632.8
8 Rasmi 722.5
RUN;
DATA All_Dept;
LENGTH ename $ 7 ;
SET ITDEPT NON_ITDEPT ;
RUN;
PROC PRINT DATA = All_Dept;
RUN;Ketika kode di atas dijalankan, kita mendapatkan output sebagai berikut.