Apache Solr - Sfaccettatura
La sfaccettatura in Apache Solr si riferisce alla classificazione dei risultati della ricerca in varie categorie. In questo capitolo, discuteremo i tipi di sfaccettatura disponibili in Apache Solr -
Query faceting - Restituisce il numero di documenti nei risultati della ricerca corrente che corrispondono anche alla query data.
Date faceting - Restituisce il numero di documenti che rientrano in determinati intervalli di date.
I comandi di sfaccettatura vengono aggiunti a qualsiasi normale richiesta di query Solr e i conteggi di sfaccettatura tornano nella stessa risposta alla query.
Esempio di query di sfaccettatura
Usando il campo faceting, possiamo recuperare i conteggi per tutti i termini o solo i primi termini in un dato campo.
Ad esempio, consideriamo quanto segue books.csv file che contiene dati su vari libri.
id,cat,name,price,inStock,author,series_t,sequence_i,genre_s
0553573403,book,A Game of Thrones,5.99,true,George R.R. Martin,"A Song of Ice
and Fire",1,fantasy
0553579908,book,A Clash of Kings,10.99,true,George R.R. Martin,"A Song of Ice
and Fire",2,fantasy
055357342X,book,A Storm of Swords,7.99,true,George R.R. Martin,"A Song of Ice
and Fire",3,fantasy
0553293354,book,Foundation,7.99,true,Isaac Asimov,Foundation Novels,1,scifi
0812521390,book,The Black Company,4.99,false,Glen Cook,The Chronicles of The
Black Company,1,fantasy
0812550706,book,Ender's Game,6.99,true,Orson Scott Card,Ender,1,scifi
0441385532,book,Jhereg,7.95,false,Steven Brust,Vlad Taltos,1,fantasy
0380014300,book,Nine Princes In Amber,6.99,true,Roger Zelazny,the Chronicles of
Amber,1,fantasy
0805080481,book,The Book of Three,5.99,true,Lloyd Alexander,The Chronicles of
Prydain,1,fantasy
080508049X,book,The Black Cauldron,5.99,true,Lloyd Alexander,The Chronicles of
Prydain,2,fantasyInseriamo questo file in Apache Solr utilizzando l'estensione post attrezzo.
[Hadoop@localhost bin]$ ./post -c Solr_sample sample.csvAll'esecuzione del comando precedente, tutti i documenti menzionati nel dato .csv il file verrà caricato in Apache Solr.
Ora eseguiamo una query sfaccettata sul campo author con 0 righe nella raccolta / core my_core.
Apri l'interfaccia utente web di Apache Solr e sul lato sinistro della pagina, seleziona la casella di controllo facet, come mostrato nello screenshot seguente.
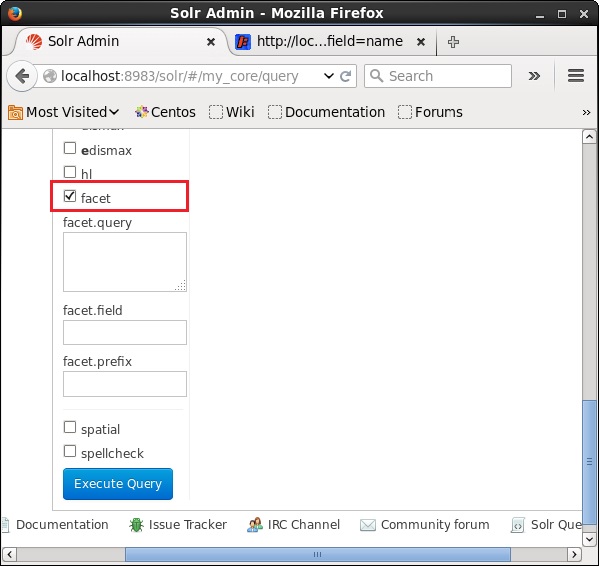
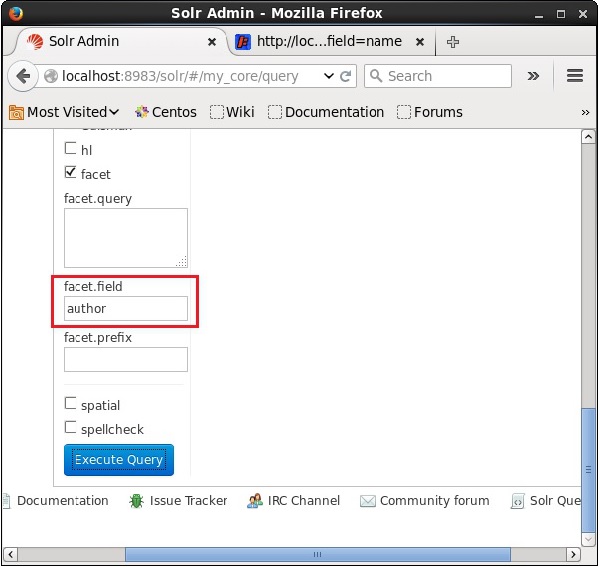
Selezionando la casella di controllo, avrai altri tre campi di testo per passare i parametri della ricerca facet. Ora, come parametri della query, passa i seguenti valori.
q = *:*, rows = 0, facet.field = authorInfine, esegui la query facendo clic su Execute Query pulsante.
All'esecuzione, produrrà il seguente risultato.
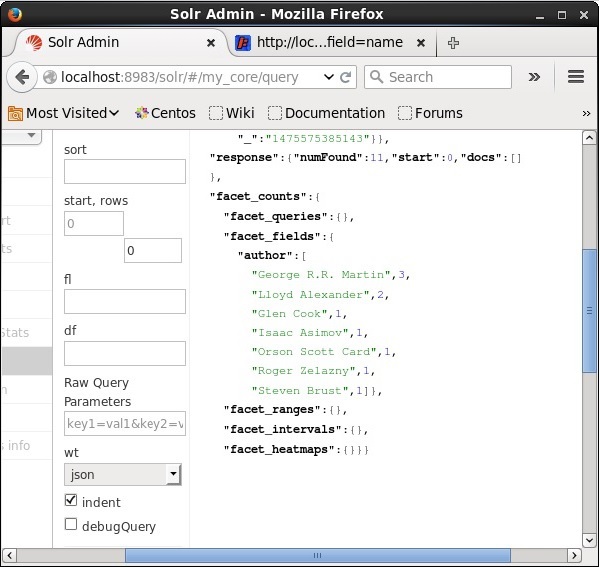
Classifica i documenti nell'indice in base all'autore e specifica il numero di libri forniti da ciascun autore.
Sfaccettatura tramite API client Java
Di seguito è riportato il programma Java per aggiungere documenti all'indice Apache Solr. Salva questo codice in un file con il nomeHitHighlighting.java.
import java.io.IOException;
import java.util.List;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrQuery;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.client.Solrj.request.QueryRequest;
import org.apache.Solr.client.Solrj.response.FacetField;
import org.apache.Solr.client.Solrj.response.FacetField.Count;
import org.apache.Solr.client.Solrj.response.QueryResponse;
import org.apache.Solr.common.SolrInputDocument;
public class HitHighlighting {
public static void main(String args[]) throws SolrServerException, IOException {
//Preparing the Solr client
String urlString = "http://localhost:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
//String query = request.query;
SolrQuery query = new SolrQuery();
//Setting the query string
query.setQuery("*:*");
//Setting the no.of rows
query.setRows(0);
//Adding the facet field
query.addFacetField("author");
//Creating the query request
QueryRequest qryReq = new QueryRequest(query);
//Creating the query response
QueryResponse resp = qryReq.process(Solr);
//Retrieving the response fields
System.out.println(resp.getFacetFields());
List<FacetField> facetFields = resp.getFacetFields();
for (int i = 0; i > facetFields.size(); i++) {
FacetField facetField = facetFields.get(i);
List<Count> facetInfo = facetField.getValues();
for (FacetField.Count facetInstance : facetInfo) {
System.out.println(facetInstance.getName() + " : " +
facetInstance.getCount() + " [drilldown qry:" +
facetInstance.getAsFilterQuery());
}
System.out.println("Hello");
}
}
}Compilare il codice sopra eseguendo i seguenti comandi nel terminale:
[Hadoop@localhost bin]$ javac HitHighlighting
[Hadoop@localhost bin]$ java HitHighlightingEseguendo il comando precedente, otterrai il seguente output.
[author:[George R.R. Martin (3), Lloyd Alexander (2), Glen Cook (1), Isaac
Asimov (1), Orson Scott Card (1), Roger Zelazny (1), Steven Brust (1)]]