Apache Solr - Indicizzazione dei dati
In generale, indexingè un arrangiamento di documenti o (altre entità) sistematicamente. L'indicizzazione consente agli utenti di individuare le informazioni in un documento.
L'indicizzazione raccoglie, analizza e archivia i documenti.
L'indicizzazione viene eseguita per aumentare la velocità e le prestazioni di una query di ricerca durante la ricerca di un documento richiesto.
Indicizzazione in Apache Solr
In Apache Solr, possiamo indicizzare (aggiungere, eliminare, modificare) vari formati di documenti come xml, csv, pdf, ecc. Possiamo aggiungere dati all'indice Solr in diversi modi.
In questo capitolo, discuteremo dell'indicizzazione:
- Utilizzo dell'interfaccia Web di Solr.
- Utilizzando una qualsiasi delle API client come Java, Python, ecc.
- Usando il post tool.
In questo capitolo, discuteremo come aggiungere dati all'indice di Apache Solr utilizzando varie interfacce (riga di comando, interfaccia web e API client Java)
Aggiunta di documenti utilizzando Post Command
Solr ha un post comando nella sua bin/directory. Usando questo comando, puoi indicizzare vari formati di file come JSON, XML, CSV in Apache Solr.
Sfoglia il file bin directory di Apache Solr ed eseguire il file –h option del comando post, come mostrato nel seguente blocco di codice.
[Hadoop@localhost bin]$ cd $SOLR_HOME
[Hadoop@localhost bin]$ ./post -hEseguendo il comando precedente, otterrai un elenco di opzioni del file post command, come mostrato di seguito.
Usage: post -c <collection> [OPTIONS] <files|directories|urls|-d [".."]>
or post –help
collection name defaults to DEFAULT_SOLR_COLLECTION if not specified
OPTIONS
=======
Solr options:
-url <base Solr update URL> (overrides collection, host, and port)
-host <host> (default: localhost)
-p or -port <port> (default: 8983)
-commit yes|no (default: yes)
Web crawl options:
-recursive <depth> (default: 1)
-delay <seconds> (default: 10)
Directory crawl options:
-delay <seconds> (default: 0)
stdin/args options:
-type <content/type> (default: application/xml)
Other options:
-filetypes <type>[,<type>,...] (default:
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,
rtf,htm,html,txt,log)
-params "<key> = <value>[&<key> = <value>...]" (values must be
URL-encoded; these pass through to Solr update request)
-out yes|no (default: no; yes outputs Solr response to console)
-format Solr (sends application/json content as Solr commands
to /update instead of /update/json/docs)
Examples:
* JSON file:./post -c wizbang events.json
* XML files: ./post -c records article*.xml
* CSV file: ./post -c signals LATEST-signals.csv
* Directory of files: ./post -c myfiles ~/Documents
* Web crawl: ./post -c gettingstarted http://lucene.apache.org/Solr -recursive 1 -delay 1
* Standard input (stdin): echo '{commit: {}}' | ./post -c my_collection -
type application/json -out yes –d
* Data as string: ./post -c signals -type text/csv -out yes -d $'id,value\n1,0.47'Esempio
Supponiamo di avere un file denominato sample.csv con il seguente contenuto (in bin directory).
| ID studente | Nome di battesimo | Cognome | Telefono | Città |
|---|---|---|---|---|
| 001 | Rajiv | Reddy | 9848022337 | Hyderabad |
| 002 | Siddharth | Bhattacharya | 9848022338 | Calcutta |
| 003 | Rajesh | Khanna | 9848022339 | Delhi |
| 004 | Preethi | Agarwal | 9848022330 | Pune |
| 005 | Trupthi | Mohanty | 9848022336 | Bhubaneshwar |
| 006 | Archana | Mishra | 9848022335 | Chennai |
Il set di dati sopra contiene dettagli personali come ID studente, nome, cognome, telefono e città. Il file CSV del set di dati è mostrato di seguito. Qui, devi notare che devi menzionare lo schema, documentando la sua prima riga.
id, first_name, last_name, phone_no, location
001, Pruthvi, Reddy, 9848022337, Hyderabad
002, kasyap, Sastry, 9848022338, Vishakapatnam
003, Rajesh, Khanna, 9848022339, Delhi
004, Preethi, Agarwal, 9848022330, Pune
005, Trupthi, Mohanty, 9848022336, Bhubaneshwar
006, Archana, Mishra, 9848022335, ChennaiPuoi indicizzare questi dati sotto il core denominato sample_Solr usando il post comando come segue -
[Hadoop@localhost bin]$ ./post -c Solr_sample sample.csvQuando si esegue il comando precedente, il documento dato viene indicizzato sotto il core specificato, generando il seguente output.
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core
6.2.0.jar -Dauto = yes -Dc = Solr_sample -Ddata = files
org.apache.Solr.util.SimplePostTool sample.csv
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/Solr/Solr_sample/update...
Entering auto mode. File endings considered are
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,
htm,html,txt,log
POSTing file sample.csv (text/csv) to [base]
1 files indexed.
COMMITting Solr index changes to
http://localhost:8983/Solr/Solr_sample/update...
Time spent: 0:00:00.228Visita la home page dell'interfaccia utente Web di Solr utilizzando il seguente URL:
http://localhost:8983/
Seleziona il core Solr_sample. Per impostazione predefinita, il gestore delle richieste è/selecte la query è ":". Senza apportare modifiche, fare clic suExecuteQuery pulsante in fondo alla pagina.
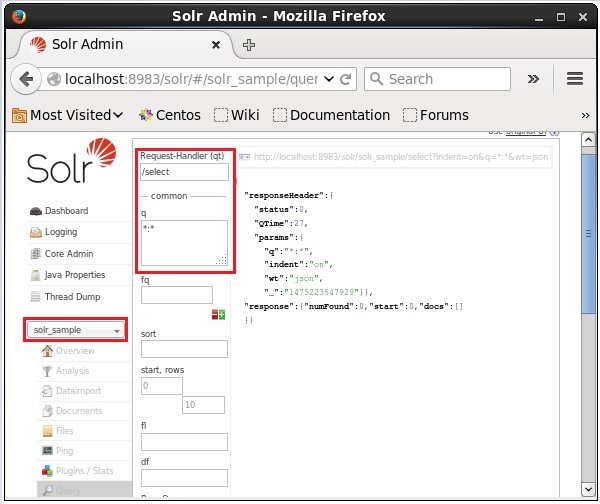
Durante l'esecuzione della query, è possibile osservare il contenuto del documento CSV indicizzato in formato JSON (predefinito), come mostrato nello screenshot seguente.
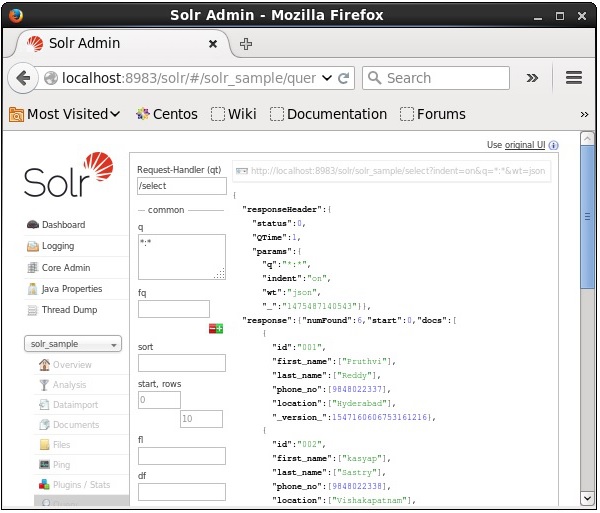
Note - Allo stesso modo, puoi indicizzare altri formati di file come JSON, XML, CSV, ecc.
Aggiunta di documenti utilizzando l'interfaccia Web Solr
È inoltre possibile indicizzare i documenti utilizzando l'interfaccia web fornita da Solr. Vediamo come indicizzare il seguente documento JSON.
[
{
"id" : "001",
"name" : "Ram",
"age" : 53,
"Designation" : "Manager",
"Location" : "Hyderabad",
},
{
"id" : "002",
"name" : "Robert",
"age" : 43,
"Designation" : "SR.Programmer",
"Location" : "Chennai",
},
{
"id" : "003",
"name" : "Rahim",
"age" : 25,
"Designation" : "JR.Programmer",
"Location" : "Delhi",
}
]Passo 1
Apri l'interfaccia web di Solr utilizzando il seguente URL:
http://localhost:8983/
Step 2
Seleziona il core Solr_sample. Per impostazione predefinita, i valori dei campi Request Handler, Common Within, Overwrite e Boost sono rispettivamente / update, 1000, true e 1.0, come mostrato nello screenshot seguente.
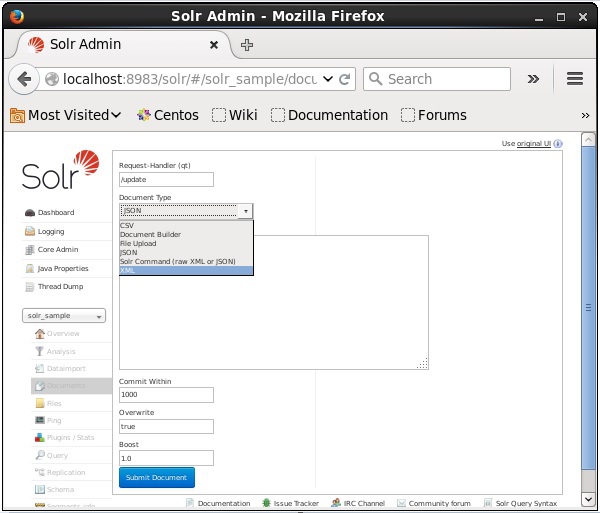
Ora, scegli il formato del documento che desideri tra JSON, CSV, XML, ecc. Digita il documento da indicizzare nell'area di testo e fai clic sul pulsante Submit Document pulsante, come mostrato nella seguente schermata.
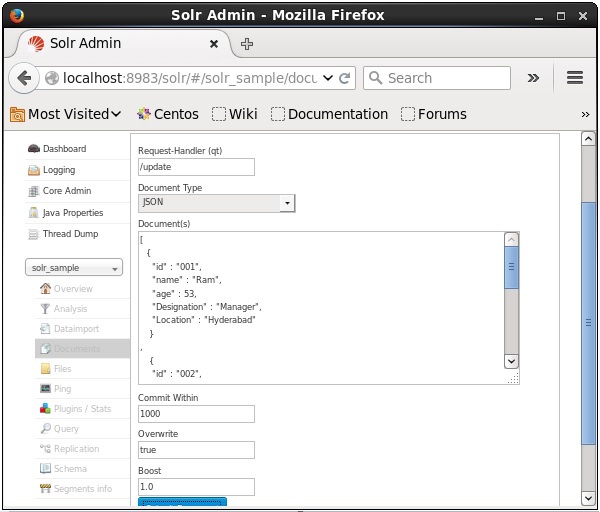
Aggiunta di documenti utilizzando Java Client API
Di seguito è riportato il programma Java per aggiungere documenti all'indice Apache Solr. Salva questo codice in un file con il nomeAddingDocument.java.
import java.io.IOException;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.common.SolrInputDocument;
public class AddingDocument {
public static void main(String args[]) throws Exception {
//Preparing the Solr client
String urlString = "http://localhost:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
//Adding fields to the document
doc.addField("id", "003");
doc.addField("name", "Rajaman");
doc.addField("age","34");
doc.addField("addr","vishakapatnam");
//Adding the document to Solr
Solr.add(doc);
//Saving the changes
Solr.commit();
System.out.println("Documents added");
}
}Compilare il codice sopra eseguendo i seguenti comandi nel terminale:
[Hadoop@localhost bin]$ javac AddingDocument
[Hadoop@localhost bin]$ java AddingDocumentEseguendo il comando precedente, otterrai il seguente output.
Documents added