Intelligenza artificiale - Guida rapida
Dall'invenzione dei computer o delle macchine, la loro capacità di eseguire vari compiti è cresciuta in modo esponenziale. Gli esseri umani hanno sviluppato la potenza dei sistemi informatici in termini di diversi domini di lavoro, velocità crescente e dimensioni ridotte rispetto al tempo.
Una branca dell'informatica chiamata Intelligenza Artificiale persegue la creazione di computer o macchine intelligenti come gli esseri umani.
Cos'è l'intelligenza artificiale?
Secondo il padre dell'intelligenza artificiale, John McCarthy, è "La scienza e l'ingegneria per creare macchine intelligenti, in particolare programmi per computer intelligenti".
L'intelligenza artificiale è un modo di making a computer, a computer-controlled robot, or a software think intelligently, nello stesso modo in cui pensano gli esseri umani intelligenti.
L'intelligenza artificiale si ottiene studiando come pensa il cervello umano e come gli esseri umani apprendono, decidono e lavorano mentre cercano di risolvere un problema, e quindi utilizzando i risultati di questo studio come base per lo sviluppo di software e sistemi intelligenti.
Filosofia dell'IA
Pur sfruttando la potenza dei sistemi informatici, la curiosità umana, lo ha portato a chiedersi: "Può una macchina pensare e comportarsi come fanno gli umani?"
Pertanto, lo sviluppo dell'IA è iniziato con l'intenzione di creare un'intelligenza simile nelle macchine che troviamo e consideriamo alta negli esseri umani.
Obiettivi dell'IA
To Create Expert Systems - I sistemi che mostrano un comportamento intelligente, apprendono, dimostrano, spiegano e consigliano i propri utenti.
To Implement Human Intelligence in Machines - Creazione di sistemi che capiscono, pensano, apprendono e si comportano come gli esseri umani.
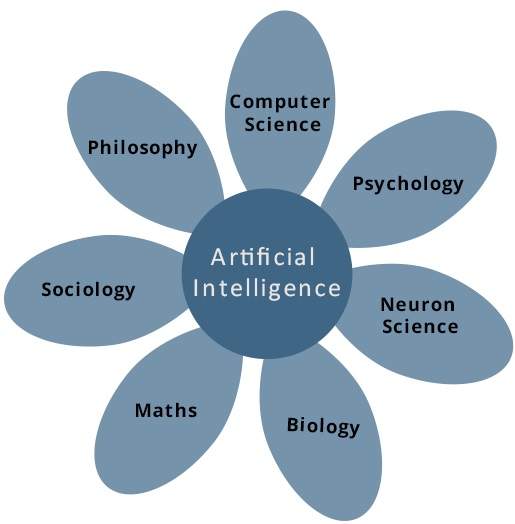
Cosa contribuisce all'intelligenza artificiale?
L'intelligenza artificiale è una scienza e una tecnologia basata su discipline come informatica, biologia, psicologia, linguistica, matematica e ingegneria. Uno dei principali obiettivi dell'IA è nello sviluppo delle funzioni del computer associate all'intelligenza umana, come il ragionamento, l'apprendimento e la risoluzione dei problemi.
Delle seguenti aree, una o più aree possono contribuire a costruire un sistema intelligente.
Programmazione senza e con AI
La programmazione senza e con AI è diversa nei seguenti modi:
| Programmazione senza AI | Programmazione con AI |
|---|---|
| Un programma per computer senza AI può rispondere a specific domande che intende risolvere. | Un programma per computer con AI può rispondere a generic domande che intende risolvere. |
| La modifica nel programma porta a un cambiamento nella sua struttura. | I programmi di intelligenza artificiale possono assorbire nuove modifiche mettendo insieme informazioni altamente indipendenti. Quindi è possibile modificare anche una minima parte di informazioni del programma senza influire sulla sua struttura. |
| La modifica non è semplice e veloce. Potrebbe influire negativamente sul programma. | Modifica del programma rapida e semplice. |
Cos'è la tecnica AI?
Nel mondo reale, la conoscenza ha alcune proprietà indesiderate:
- Il suo volume è enorme, quasi inimmaginabile.
- Non è ben organizzato o ben formattato.
- Continua a cambiare costantemente.
La tecnica AI è un modo per organizzare e utilizzare la conoscenza in modo efficiente in modo tale che:
- Dovrebbe essere percepibile dalle persone che lo forniscono.
- Dovrebbe essere facilmente modificabile per correggere gli errori.
- Dovrebbe essere utile in molte situazioni sebbene sia incompleto o impreciso.
Le tecniche di intelligenza artificiale aumentano la velocità di esecuzione del programma complesso di cui è dotato.
Applicazioni dell'IA
L'intelligenza artificiale è stata dominante in vari campi come:
Gaming - L'intelligenza artificiale gioca un ruolo cruciale in giochi strategici come scacchi, poker, tris, ecc., Dove la macchina può pensare a un gran numero di posizioni possibili in base alla conoscenza euristica.
Natural Language Processing - È possibile interagire con il computer che comprende il linguaggio naturale parlato dagli esseri umani.
Expert Systems- Esistono alcune applicazioni che integrano macchina, software e informazioni speciali per impartire ragionamenti e consigli. Forniscono spiegazioni e consigli agli utenti.
Vision Systems- Questi sistemi comprendono, interpretano e comprendono l'input visivo sul computer. Per esempio,
Un aeroplano spia scatta fotografie, che vengono utilizzate per ricavare informazioni spaziali o mappe delle aree.
I medici utilizzano un sistema clinico esperto per diagnosticare il paziente.
La polizia utilizza un software per computer in grado di riconoscere il volto del criminale con il ritratto memorizzato realizzato dall'artista forense.
Speech Recognition- Alcuni sistemi intelligenti sono in grado di ascoltare e comprendere la lingua in termini di frasi e il loro significato mentre un essere umano le parla. Può gestire diversi accenti, parole gergali, rumore in sottofondo, cambiamenti nel rumore umano dovuto al freddo, ecc.
Handwriting Recognition- Il software di riconoscimento della grafia legge il testo scritto su carta con una penna o sullo schermo con uno stilo. Può riconoscere le forme delle lettere e convertirle in testo modificabile.
Intelligent Robots- I robot sono in grado di eseguire i compiti assegnati da un essere umano. Hanno sensori per rilevare dati fisici dal mondo reale come luce, calore, temperatura, movimento, suono, urti e pressione. Hanno processori efficienti, più sensori e un'enorme memoria, per mostrare intelligenza. Inoltre, sono in grado di imparare dai propri errori e possono adattarsi al nuovo ambiente.
Storia dell'IA
Ecco la storia dell'IA durante il 20 ° secolo -
| Anno | Pietra miliare / innovazione |
|---|---|
| 1923 | L'opera teatrale di Karel Čapek intitolata “Rossum's Universal Robots” (RUR) si apre a Londra, primo uso della parola "robot" in inglese. |
| 1943 | Posa delle basi per reti neurali. |
| 1945 | Isaac Asimov, alunni della Columbia University, ha coniato il termine Robotics . |
| 1950 | Alan Turing ha introdotto Turing Test per la valutazione dell'intelligence e ha pubblicato Computing Machinery and Intelligence. Claude Shannon ha pubblicato un'analisi dettagliata del gioco degli scacchi come ricerca. |
| 1956 | John McCarthy ha coniato il termine Intelligenza Artificiale . Dimostrazione del primo programma di intelligenza artificiale in corso presso la Carnegie Mellon University. |
| 1958 | John McCarthy inventa il linguaggio di programmazione LISP per l'IA. |
| 1964 | La dissertazione di Danny Bobrow al MIT ha mostrato che i computer possono comprendere il linguaggio naturale abbastanza bene da risolvere correttamente i problemi delle parole algebriche. |
| 1965 | Joseph Weizenbaum del MIT ha costruito ELIZA , un problema interattivo che porta avanti un dialogo in inglese. |
| 1969 | Gli scienziati dello Stanford Research Institute hanno sviluppato Shakey , un robot dotato di locomozione, percezione e risoluzione dei problemi. |
| 1973 | Il gruppo Assembly Robotics dell'Università di Edimburgo ha costruito Freddy , il famoso robot scozzese, in grado di utilizzare la visione per individuare e assemblare i modelli. |
| 1979 | Fu costruito il primo veicolo autonomo controllato da computer, Stanford Cart. |
| 1985 | Harold Cohen ha creato e dimostrato il programma di disegno Aaron . |
| 1990 | Principali progressi in tutte le aree dell'IA -
|
| 1997 | Il programma Deep Blue Chess batte l'allora campione mondiale di scacchi, Garry Kasparov. |
| 2000 | Gli animali domestici robot interattivi diventano disponibili in commercio. Il MIT mostra Kismet , un robot con una faccia che esprime emozioni. Il robot Nomad esplora le regioni remote dell'Antartide e individua i meteoriti. |
Mentre studi l'intelligenza artificiale, devi sapere cos'è l'intelligenza. Questo capitolo tratta l'idea di intelligenza, tipi e componenti dell'intelligenza.
Cos'è l'intelligenza?
La capacità di un sistema di calcolare, ragionare, percepire relazioni e analogie, apprendere dall'esperienza, archiviare e recuperare informazioni dalla memoria, risolvere problemi, comprendere idee complesse, usare fluentemente il linguaggio naturale, classificare, generalizzare e adattare nuove situazioni.
Tipi di intelligenza
Come descritto da Howard Gardner, uno psicologo dello sviluppo americano, l'Intelligence è disponibile in molteplici:
| Intelligenza | Descrizione | Esempio |
|---|---|---|
| Intelligenza linguistica | La capacità di parlare, riconoscere e utilizzare meccanismi di fonologia (suoni del parlato), sintassi (grammatica) e semantica (significato). | Narratori, oratori |
| Intelligenza musicale | La capacità di creare, comunicare e comprendere significati fatti di suono, comprensione del tono, ritmo. | Musicisti, cantanti, compositori |
| Intelligenza logico-matematica | La capacità di usare e comprendere le relazioni in assenza di azioni o oggetti. Comprensione di idee complesse e astratte. | Matematici, scienziati |
| Intelligenza spaziale | La capacità di percepire le informazioni visive o spaziali, modificarle e ricreare immagini visive senza riferimento agli oggetti, costruire immagini 3D e spostarle e ruotarle. | Lettori di mappe, astronauti, fisici |
| Intelligenza corporeo-cinestetica | La capacità di utilizzare la totalità o una parte del corpo per risolvere problemi o prodotti di moda, controllare le capacità motorie fini e grossolane e manipolare gli oggetti. | Giocatori, ballerini |
| Intelligenza intrapersonale | La capacità di distinguere i propri sentimenti, intenzioni e motivazioni. | Gautama Buddhha |
| Intelligenza interpersonale | La capacità di riconoscere e fare distinzioni tra i sentimenti, le convinzioni e le intenzioni di altre persone. | Comunicatori di massa, intervistatori |
Puoi dire che una macchina o un sistema lo sono artificially intelligent quando è dotato di almeno una e al massimo tutte le intelligenze al suo interno.
Di cosa è composta l'intelligenza?
L'intelligenza è intangibile. È composto da:
- Reasoning
- Learning
- Risoluzione dei problemi
- Perception
- Intelligenza linguistica

Esaminiamo brevemente tutti i componenti:
Reasoning- È l'insieme di processi che ci consente di fornire le basi per il giudizio, il processo decisionale e la previsione. Esistono sostanzialmente due tipi:
| Ragionamento induttivo | Ragionamento deduttivo |
|---|---|
| Conduce osservazioni specifiche per fare dichiarazioni generali di ampio respiro. | Inizia con una dichiarazione generale ed esamina le possibilità per raggiungere una conclusione logica e specifica. |
| Anche se tutte le premesse sono vere in un'affermazione, il ragionamento induttivo consente che la conclusione sia falsa. | Se qualcosa è vero per una classe di cose in generale, è vero anche per tutti i membri di quella classe. |
| Esempio: "Nita è un'insegnante. Nita è studiosa. Pertanto, tutti gli insegnanti sono studiosi." | Esempio: "Tutte le donne di età superiore ai 60 anni sono nonne. Shalini ha 65 anni. Pertanto, Shalini è una nonna." |
Learning- È l'attività di acquisire conoscenze o abilità studiando, praticando, ricevendo insegnamenti o sperimentando qualcosa. L'apprendimento aumenta la consapevolezza degli argomenti dello studio.
La capacità di apprendimento è posseduta da esseri umani, alcuni animali e sistemi abilitati all'intelligenza artificiale. L'apprendimento è classificato come:
Auditory Learning- È imparare ascoltando e ascoltando. Ad esempio, gli studenti che ascoltano lezioni audio registrate.
Episodic Learning- Imparare ricordando sequenze di eventi a cui si è assistito o vissuto. Questo è lineare e ordinato.
Motor Learning- Sta imparando dal movimento preciso dei muscoli. Ad esempio, raccogliere oggetti, scrivere, ecc.
Observational Learning- Imparare guardando e imitando gli altri. Ad esempio, il bambino cerca di imparare imitando il suo genitore.
Perceptual Learning- È imparare a riconoscere gli stimoli che si sono visti prima. Ad esempio, identificare e classificare oggetti e situazioni.
Relational Learning- Si tratta di imparare a differenziare tra vari stimoli sulla base di proprietà relazionali, piuttosto che proprietà assolute. Ad esempio, aggiungendo "un po 'meno" di sale al momento della cottura delle patate che sono risultate salate l'ultima volta, quando sono state cotte aggiungendo, diciamo, un cucchiaio di sale.
Spatial Learning - È l'apprendimento attraverso stimoli visivi come immagini, colori, mappe, ecc. Ad esempio, una persona può creare una tabella di marcia in mente prima di seguire effettivamente la strada.
Stimulus-Response Learning- È imparare a eseguire un comportamento particolare quando è presente un certo stimolo. Ad esempio, un cane alza l'orecchio quando sente il campanello.
Problem Solving - È il processo in cui si percepisce e si cerca di arrivare a una soluzione desiderata da una situazione presente prendendo una strada, che è bloccata da ostacoli noti o sconosciuti.
La risoluzione dei problemi include anche decision making, che è il processo di selezione della migliore alternativa adatta tra più alternative disponibili per raggiungere l'obiettivo desiderato.
Perception - È il processo di acquisizione, interpretazione, selezione e organizzazione delle informazioni sensoriali.
La percezione presume sensing. Negli esseri umani, la percezione è aiutata dagli organi sensoriali. Nel dominio dell'IA, il meccanismo di percezione mette insieme i dati acquisiti dai sensori in modo significativo.
Linguistic Intelligence- È la capacità di usare, comprendere, parlare e scrivere il linguaggio verbale e scritto. È importante nella comunicazione interpersonale.
Differenza tra intelligenza umana e intelligenza artificiale
Gli esseri umani percepiscono in base a modelli mentre le macchine percepiscono in base a un insieme di regole e dati.
Gli esseri umani immagazzinano e richiamano le informazioni secondo schemi, le macchine lo fanno cercando algoritmi. Ad esempio, il numero 40404040 è facile da ricordare, memorizzare e richiamare poiché il suo schema è semplice.
Gli esseri umani possono capire l'oggetto completo anche se una parte di esso manca o è distorta; mentre le macchine non possono farlo correttamente.
Il dominio dell'intelligenza artificiale è enorme in ampiezza e larghezza. Nel procedere, consideriamo le aree di ricerca ampiamente comuni e prospere nel dominio dell'IA:

Riconoscimento vocale e vocale
Entrambi i termini sono comuni nella robotica, nei sistemi esperti e nell'elaborazione del linguaggio naturale. Sebbene questi termini siano usati in modo intercambiabile, i loro obiettivi sono diversi.
| Riconoscimento vocale | Riconoscimento vocale |
|---|---|
| Il riconoscimento vocale mira alla comprensione e alla comprensione WHAT è stato parlato. | L'obiettivo del riconoscimento vocale è riconoscere WHO sta parlando. |
| Viene utilizzato nell'elaborazione a mano libera, nella mappa o nella navigazione nei menu. | Viene utilizzato per identificare una persona analizzandone il tono, il tono della voce e l'accento, ecc. |
| La macchina non necessita di formazione per il riconoscimento vocale poiché non dipende dal parlante. | Questo sistema di riconoscimento necessita di formazione in quanto è orientato alla persona. |
| I sistemi di riconoscimento vocale indipendenti dal parlante sono difficili da sviluppare. | I sistemi di riconoscimento vocale dipendenti dal parlante sono relativamente facili da sviluppare. |
Utilizzo di sistemi di riconoscimento vocale e vocale
L'input dell'utente pronunciato al microfono va alla scheda audio del sistema. Il convertitore trasforma il segnale analogico in segnale digitale equivalente per l'elaborazione del parlato. Il database viene utilizzato per confrontare i modelli sonori per riconoscere le parole. Infine, viene fornito un feedback inverso al database.
Questo testo nella lingua di origine diventa input per il motore di traduzione, che lo converte nel testo della lingua di destinazione. Sono supportati con GUI interattiva, ampio database di vocabolario, ecc.
Applicazioni della vita reale delle aree di ricerca
Esiste una vasta gamma di applicazioni in cui l'IA è al servizio delle persone comuni nella loro vita quotidiana:
| Sr.No. | Aree di ricerca | Applicazione nella vita reale |
|---|---|---|
| 1 | Expert Systems Esempi: sistemi di monitoraggio del volo, sistemi clinici. |

|
| 2 | Natural Language Processing Esempi: funzione Google Now, riconoscimento vocale, output vocale automatico. |

|
| 3 | Neural Networks Esempi - Sistemi di riconoscimento di pattern come riconoscimento facciale, riconoscimento dei caratteri, riconoscimento della grafia. |

|
| 4 | Robotics Esempi: robot industriali per lo spostamento, la spruzzatura, la verniciatura, il controllo di precisione, la perforazione, la pulizia, il rivestimento, l'intaglio, ecc. |

|
| 5 | Fuzzy Logic Systems Esempi: elettronica di consumo, automobili, ecc. |

|
Classificazione dei compiti dell'IA
Il dominio dell'IA è classificato in Formal tasks, Mundane tasks, e Expert tasks.

| Ambiti di attività dell'intelligenza artificiale | ||
|---|---|---|
| Compiti banali (ordinari) | Compiti formali | Attività degli esperti |
Percezione
|
|
|
Elaborazione del linguaggio naturale
|
Giochi
|
Analisi scientifica |
| Buon senso | Verifica | Analisi finanziaria |
| Ragionamento | Dimostrazione di teoremi | Diagnosi medica |
| Piallatura | Creatività | |
Robotica
|
||
Gli esseri umani imparano mundane (ordinary) taskssin dalla loro nascita. Imparano dalla percezione, parlando, usando il linguaggio e le locomotive. Imparano i compiti formali e quelli esperti in un secondo momento, in quest'ordine.
Per gli esseri umani, i compiti banali sono i più facili da imparare. Lo stesso era considerato vero prima di tentare di implementare attività banali nelle macchine. In precedenza, tutto il lavoro dell'IA era concentrato nel dominio dei compiti banali.
Successivamente, si è scoperto che la macchina richiede più conoscenza, rappresentazione della conoscenza complessa e algoritmi complicati per gestire compiti banali. Questo è il motivowhy AI work is more prospering in the Expert Tasks domain ora, poiché il dominio delle attività degli esperti richiede una conoscenza esperta senza buon senso, che può essere più facile da rappresentare e gestire.
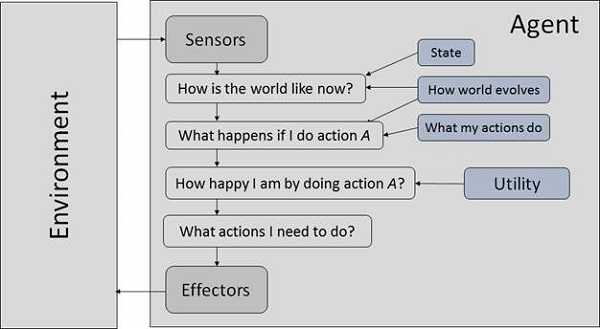
Un sistema AI è composto da un agente e dal suo ambiente. Gli agenti agiscono nel loro ambiente. L'ambiente può contenere altri agenti.
Cosa sono l'agente e l'ambiente?
Un agent è tutto ciò che può percepire il suo ambiente attraverso sensors e agisce su quell'ambiente attraverso effectors.
UN human agent ha organi sensoriali come occhi, orecchie, naso, lingua e pelle paralleli ai sensori e altri organi come mani, gambe, bocca, per effettori.
UN robotic agent sostituisce le telecamere e i telemetri a infrarossi per i sensori e vari motori e attuatori per gli effettori.
UN software agent ha codificato stringhe di bit come programmi e azioni.

Terminologia dell'agente
Performance Measure of Agent - Sono i criteri che determinano il successo di un agente.
Behavior of Agent - È l'azione che l'agente esegue dopo una data sequenza di percezioni.
Percept - Sono gli input percettivi dell'agente in una data istanza.
Percept Sequence - È la storia di tutto ciò che un agente ha percepito fino ad oggi.
Agent Function - È una mappa dalla sequenza del precetto a un'azione.
Razionalità
La razionalità non è altro che lo stato di essere ragionevole, ragionevole e avere un buon senso del giudizio.
La razionalità riguarda le azioni e i risultati attesi a seconda di ciò che l'agente ha percepito. L'esecuzione di azioni con l'obiettivo di ottenere informazioni utili è una parte importante della razionalità.
Cos'è Ideal Rational Agent?
Un agente razionale ideale è quello che è in grado di compiere azioni attese per massimizzare la propria misura di prestazione, sulla base di:
- La sua sequenza percettiva
- La sua base di conoscenza incorporata
La razionalità di un agente dipende da quanto segue:
Il performance measures, che determinano il grado di successo.
Agente Percept Sequence finora.
L'agente prior knowledge about the environment.
Il actions che l'agente può eseguire.
Un agente razionale esegue sempre l'azione giusta, dove l'azione giusta indica l'azione che fa sì che l'agente abbia più successo nella sequenza percettiva data. Il problema risolto dall'agente è caratterizzato da misurazione delle prestazioni, ambiente, attuatori e sensori (PEAS).
La struttura degli agenti intelligenti
La struttura dell'agente può essere vista come:
- Agente = Architettura + Programma agente
- Architettura = la macchina su cui viene eseguito un agente.
- Programma agente = un'implementazione di una funzione agente.
Agenti riflessi semplici
- Scelgono le azioni solo in base alla percezione corrente.
- Sono razionali solo se una decisione corretta viene presa solo sulla base del precetto corrente.
- Il loro ambiente è completamente osservabile.
Condition-Action Rule - È una regola che mappa uno stato (condizione) in un'azione.

Agenti riflessi basati su modelli
Usano un modello del mondo per scegliere le loro azioni. Mantengono uno stato interno.
Model - conoscenza di “come accadono le cose nel mondo”.
Internal State - È una rappresentazione di aspetti inosservati dello stato attuale che dipendono dalla storia percettiva.
Updating the state requires the information about −
- Come si evolve il mondo.
- Come le azioni dell'agente influenzano il mondo.

Agenti basati sugli obiettivi
Scelgono le loro azioni per raggiungere gli obiettivi. L'approccio basato sugli obiettivi è più flessibile dell'agente riflesso poiché la conoscenza a supporto di una decisione è modellata in modo esplicito, consentendo così modifiche.
Goal - È la descrizione di situazioni desiderabili.

Agenti basati su utilità
Scelgono le azioni in base a una preferenza (utilità) per ogni stato.
Gli obiettivi sono inadeguati quando:
Ci sono obiettivi contrastanti, di cui solo pochi possono essere raggiunti.
Gli obiettivi hanno una certa incertezza di essere raggiunti e devi valutare la probabilità di successo rispetto all'importanza di un obiettivo.
La natura degli ambienti
Alcuni programmi funzionano interamente artificial environment limitato a input da tastiera, database, file system del computer e output di caratteri su uno schermo.
Al contrario, alcuni agenti software (robot software o softbot) esistono in domini softbot ricchi e illimitati. Il simulatore ha un filevery detailed, complex environment. L'agente software deve scegliere tra una lunga serie di azioni in tempo reale. Un softbot progettato per scansionare le preferenze online del cliente e mostrare articoli interessanti al cliente lavora inreal così come un artificial ambiente.
La più famosa artificial environment è il Turing Test environment, in cui un agente reale e altri agenti artificiali vengono testati su un terreno uguale. Questo è un ambiente molto impegnativo in quanto è molto difficile per un agente software da eseguire come un essere umano.
Test di Turing
Il successo di un comportamento intelligente di un sistema può essere misurato con Turing Test.
Partecipano alla prova due persone e una macchina da valutare. Delle due persone, una interpreta il ruolo del tester. Ognuno di loro si trova in stanze diverse. Il tester non sa chi è macchina e chi è umano. Interroga le domande digitandole e inviandole a entrambe le intelligenze, alle quali riceve le risposte digitate.
Questo test mira a ingannare il tester. Se il tester non riesce a determinare la risposta della macchina dalla risposta umana, si dice che la macchina sia intelligente.
Proprietà dell'ambiente
L'ambiente ha molteplici proprietà:
Discrete / Continuous- Se esiste un numero limitato di stati dell'ambiente distinti e chiaramente definiti, l'ambiente è discreto (ad esempio, gli scacchi); altrimenti è continuo (ad esempio, guida).
Observable / Partially Observable- Se è possibile determinare lo stato completo dell'ambiente in ogni punto temporale dalle percezioni è osservabile; altrimenti è solo parzialmente osservabile.
Static / Dynamic- Se l'ambiente non cambia mentre un agente sta agendo, allora è statico; altrimenti è dinamico.
Single agent / Multiple agents - L'ambiente può contenere altri agenti che possono essere dello stesso tipo o diverso da quello dell'agente.
Accessible / Inaccessible - Se l'apparato sensoriale dell'agente può avere accesso allo stato completo dell'ambiente, allora l'ambiente è accessibile a quell'agente.
Deterministic / Non-deterministic- Se lo stato successivo dell'ambiente è completamente determinato dallo stato corrente e dalle azioni dell'agente, l'ambiente è deterministico; altrimenti è non deterministico.
Episodic / Non-episodic- In un ambiente episodico, ogni episodio consiste nell'agente che percepisce e poi agisce. La qualità della sua azione dipende proprio dall'episodio stesso. Gli episodi successivi non dipendono dalle azioni negli episodi precedenti. Gli ambienti episodici sono molto più semplici perché l'agente non ha bisogno di pensare al futuro.
La ricerca è la tecnica universale di risoluzione dei problemi nell'IA. Ci sono alcuni giochi per giocatore singolo come giochi di tessere, sudoku, cruciverba, ecc. Gli algoritmi di ricerca ti aiutano a cercare una posizione particolare in tali giochi.
Problemi di individuazione del percorso di un singolo agente
I giochi come 3X3 a otto tessere, 4X4 a quindici tessere e 5X5 a ventiquattro tessere sono sfide di individuazione del percorso per singolo agente. Sono costituiti da una matrice di tessere con una tessera vuota. Il giocatore è tenuto a disporre le tessere facendo scorrere una tessera verticalmente o orizzontalmente in uno spazio vuoto con l'obiettivo di raggiungere un obiettivo.
Gli altri esempi di problemi di individuazione del percorso di un singolo agente sono il problema del venditore ambulante, il cubo di Rubik e la dimostrazione dei teoremi.
Terminologia di ricerca
Problem Space- È l'ambiente in cui avviene la ricerca. (Un insieme di stati e un insieme di operatori per modificare questi stati)
Problem Instance - È lo stato iniziale + lo stato dell'obiettivo.
Problem Space Graph- Rappresenta lo stato del problema. Gli stati sono mostrati dai nodi e gli operatori sono mostrati dai bordi.
Depth of a problem - Lunghezza di un percorso più breve o sequenza più breve di operatori dallo stato iniziale allo stato obiettivo.
Space Complexity - Il numero massimo di nodi archiviati in memoria.
Time Complexity - Il numero massimo di nodi che vengono creati.
Admissibility - Una proprietà di un algoritmo per trovare sempre una soluzione ottimale.
Branching Factor - Il numero medio di nodi figlio nel grafico dello spazio problema.
Depth - Lunghezza del percorso più breve dallo stato iniziale allo stato obiettivo.
Strategie di ricerca per la forza bruta
Sono molto semplici, poiché non richiedono alcuna conoscenza specifica del dominio. Funzionano bene con un numero limitato di stati possibili.
Requisiti -
- Descrizione dello stato
- Un insieme di operatori validi
- Stato iniziale
- Descrizione dello stato dell'obiettivo
Ricerca in ampiezza
Inizia dal nodo radice, esplora prima i nodi vicini e si sposta verso i vicini di livello successivo. Genera un albero alla volta finché non viene trovata la soluzione. Può essere implementato utilizzando la struttura dati della coda FIFO. Questo metodo fornisce il percorso più breve alla soluzione.
Se branching factor(numero medio di nodi figli per un dato nodo) = be profondità = d, quindi numero di nodi a livello d = b d .
Il numero totale di nodi creati nel caso peggiore è b + b 2 + b 3 +… + b d .
Disadvantage- Poiché ogni livello di nodi viene salvato per crearne uno successivo, consuma molto spazio di memoria. Lo spazio necessario per memorizzare i nodi è esponenziale.
La sua complessità dipende dal numero di nodi. Può controllare i nodi duplicati.

Ricerca in profondità
È implementato in ricorsione con la struttura dati dello stack LIFO. Crea lo stesso insieme di nodi del metodo Breadth-First, solo nell'ordine diverso.
Poiché i nodi sul percorso singolo vengono archiviati in ogni iterazione dalla radice al nodo foglia, lo spazio richiesto per archiviare i nodi è lineare. Con il fattore di ramificazione b e la profondità come m , lo spazio di archiviazione è bm.
Disadvantage- Questo algoritmo potrebbe non terminare e continuare all'infinito su un percorso. La soluzione a questo problema è scegliere una profondità di taglio. Se il cut-off ideale è d , e se il cut-off scelto è minore di d , allora questo algoritmo potrebbe fallire. Se il valore limite scelto è maggiore di d , il tempo di esecuzione aumenta.
La sua complessità dipende dal numero di percorsi. Non può controllare i nodi duplicati.

Ricerca bidirezionale
Cerca in avanti dallo stato iniziale e all'indietro dallo stato obiettivo fino a quando entrambi si incontrano per identificare uno stato comune.
Il percorso dallo stato iniziale viene concatenato con il percorso inverso dallo stato obiettivo. Ogni ricerca viene eseguita solo fino alla metà del percorso totale.
Ricerca costi uniforme
L'ordinamento viene effettuato aumentando il costo del percorso verso un nodo. Espande sempre il nodo meno costoso. È identico alla ricerca Breadth First se ogni transizione ha lo stesso costo.
Esplora percorsi in ordine crescente di costo.
Disadvantage- Possono esserci più percorsi lunghi con il costo ≤ C *. La ricerca a costo uniforme deve esplorarli tutti.
Approfondimento iterativo Ricerca approfondita
Esegue la ricerca in profondità fino al livello 1, ricomincia, esegue una ricerca completa in profondità fino al livello 2 e continua in questo modo finché non viene trovata la soluzione.
Non crea mai un nodo finché non vengono generati tutti i nodi inferiori. Salva solo una pila di nodi. L'algoritmo termina quando trova una soluzione alla profondità d . Il numero di nodi creati alla profondità d è b d e alla profondità d-1 è b d-1.
Confronto di varie complessità di algoritmi
Vediamo le prestazioni degli algoritmi in base a vari criteri:
| Criterio | Larghezza prima | Prima la profondità | Bidirezionale | Costo uniforme | Approfondimento interattivo |
|---|---|---|---|---|---|
| Tempo | b d | b m | b d / 2 | b d | b d |
| Spazio | b d | b m | b d / 2 | b d | b d |
| Ottimalità | sì | No | sì | sì | sì |
| Completezza | sì | No | sì | sì | sì |
Strategie di ricerca informate (euristiche)
Per risolvere problemi di grandi dimensioni con un numero elevato di stati possibili, è necessario aggiungere conoscenze specifiche del problema per aumentare l'efficienza degli algoritmi di ricerca.
Funzioni di valutazione euristica
Calcolano il costo del percorso ottimale tra due stati. Una funzione euristica per i giochi con tessere scorrevoli viene calcolata contando il numero di mosse che ogni tessera fa dal suo stato obiettivo e aggiungendo questo numero di mosse per tutte le tessere.
Ricerca euristica pura
Espande i nodi nell'ordine dei loro valori euristici. Crea due elenchi, un elenco chiuso per i nodi già espansi e un elenco aperto per i nodi creati ma non espansi.
In ogni iterazione, un nodo con un valore euristico minimo viene espanso, tutti i suoi nodi figli vengono creati e inseriti nell'elenco chiuso. Quindi, la funzione euristica viene applicata ai nodi figlio e vengono inseriti nell'elenco aperto in base al loro valore euristico. I percorsi più brevi vengono salvati e quelli più lunghi vengono eliminati.
Una ricerca
È la forma più nota di ricerca Best First. Evita di espandere i percorsi che sono già costosi, ma espande prima i percorsi più promettenti.
f (n) = g (n) + h (n), dove
- g (n) il costo (finora) per raggiungere il nodo
- h (n) costo stimato per arrivare dal nodo all'obiettivo
- f (n) costo totale stimato del percorso fino all'obiettivo. Viene implementato utilizzando la coda di priorità aumentando f (n).
Greedy Best First Search
Espande il nodo che si stima sia più vicino all'obiettivo. Espande i nodi in base a f (n) = h (n). Viene implementato utilizzando la coda di priorità.
Disadvantage- Può rimanere bloccato in loop. Non è ottimale.
Algoritmi di ricerca locale
Partono da una soluzione potenziale e poi passano a una soluzione vicina. Possono restituire una soluzione valida anche se viene interrotta in qualsiasi momento prima della fine.
Ricerca in salita
È un algoritmo iterativo che inizia con una soluzione arbitraria a un problema e tenta di trovare una soluzione migliore modificando in modo incrementale un singolo elemento della soluzione. Se la modifica produce una soluzione migliore, una modifica incrementale viene considerata come una nuova soluzione. Questo processo viene ripetuto fino a quando non ci sono ulteriori miglioramenti.
funzione Hill-Climbing (problema), restituisce uno stato che è un massimo locale.
inputs: problem, a problem
local variables: current, a node
neighbor, a node
current <-Make_Node(Initial-State[problem])
loop
do neighbor <- a highest_valued successor of current
if Value[neighbor] ≤ Value[current] then
return State[current]
current <- neighbor
endDisadvantage - Questo algoritmo non è né completo né ottimale.
Ricerca travi locali
In questo algoritmo, contiene k numero di stati in un dato momento. All'inizio, questi stati vengono generati in modo casuale. I successori di questi k stati vengono calcolati con l'aiuto della funzione obiettivo. Se uno di questi successori è il valore massimo della funzione obiettivo, l'algoritmo si ferma.
In caso contrario, gli stati (k stati iniziali e k numero di successori degli stati = 2k) vengono inseriti in un pool. Il pool viene quindi ordinato numericamente. I k stati più alti vengono selezionati come nuovi stati iniziali. Questo processo continua fino a quando non viene raggiunto un valore massimo.
funzione BeamSearch ( problema, k ), restituisce uno stato di soluzione.
start with k randomly generated states
loop
generate all successors of all k states
if any of the states = solution, then return the state
else select the k best successors
endRicottura simulata
La ricottura è il processo di riscaldamento e raffreddamento di un metallo per modificarne la struttura interna e modificarne le proprietà fisiche. Quando il metallo si raffredda, la sua nuova struttura viene catturata e il metallo conserva le sue proprietà appena ottenute. Nel processo di ricottura simulata, la temperatura viene mantenuta variabile.
Inizialmente impostiamo la temperatura alta e poi lasciamo che si "raffreddi" lentamente mentre l'algoritmo procede. Quando la temperatura è alta, l'algoritmo può accettare soluzioni peggiori con alta frequenza.
Inizio
- Inizializza k = 0; L = numero intero di variabili;
- Da i → j, cerca la differenza di prestazioni Δ.
- Se Δ <= 0 allora accetta altrimenti se exp (-Δ / T (k))> casuale (0,1) allora accetta;
- Ripetere i passaggi 1 e 2 per i passaggi L (k).
- k = k + 1;
Ripetere i passaggi da 1 a 4 finché i criteri non vengono soddisfatti.
Fine
Problema del commesso viaggiatore
In questo algoritmo, l'obiettivo è trovare un tour a basso costo che parta da una città, visiti tutte le città lungo il percorso esattamente una volta e termini nella stessa città di partenza.
Start
Find out all (n -1)! Possible solutions, where n is the total number of cities.
Determine the minimum cost by finding out the cost of each of these (n -1)! solutions.
Finally, keep the one with the minimum cost.
end
Fuzzy Logic Systems (FLS) produce un output accettabile ma definito in risposta a un input incompleto, ambiguo, distorto o impreciso (fuzzy).
Cos'è la logica fuzzy?
Fuzzy Logic (FL) è un metodo di ragionamento che assomiglia al ragionamento umano. L'approccio di FL imita il modo di prendere decisioni nell'uomo che coinvolge tutte le possibilità intermedie tra i valori digitali SI e NO.
Il blocco logico convenzionale che un computer può capire prende un input preciso e produce un output definito come VERO o FALSO, che è equivalente a SI o NO dell'uomo.
L'inventore della logica fuzzy, Lotfi Zadeh, ha osservato che, a differenza dei computer, il processo decisionale umano include una gamma di possibilità tra SÌ e NO, come:
| Certamente sì |
| POSSIBILMENTE SI |
| NON POSSO DIRLO |
| POSSIBILMENTE NO |
| ASSOLUTAMENTE NO |
La logica fuzzy lavora sui livelli di possibilità di input per ottenere l'output definito.
Implementazione
Può essere implementato in sistemi con varie dimensioni e capacità che vanno da piccoli microcontrollori a grandi sistemi di controllo basati su workstation in rete.
Può essere implementato in hardware, software o una combinazione di entrambi.
Perché Fuzzy Logic?
La logica fuzzy è utile per scopi commerciali e pratici.
- Può controllare macchine e prodotti di consumo.
- Potrebbe non fornire un ragionamento accurato, ma un ragionamento accettabile.
- La logica fuzzy aiuta ad affrontare l'incertezza nell'ingegneria.
Architettura dei sistemi logici fuzzy
Ha quattro parti principali come mostrato:
Fuzzification Module- Trasforma gli input di sistema, che sono numeri nitidi, in insiemi fuzzy. Divide il segnale di ingresso in cinque passaggi come:
| LP | x è grande positivo |
| MP | x è medio positivo |
| S | x è piccolo |
| MN | x è medio negativo |
| LN | x è grande negativo |
Knowledge Base - Memorizza le regole IF-THEN fornite da esperti.
Inference Engine - Simula il processo di ragionamento umano facendo inferenze fuzzy sugli input e sulle regole IF-THEN.
Defuzzification Module - Trasforma l'insieme fuzzy ottenuto dal motore di inferenza in un valore nitido.

Il membership functions work on insiemi fuzzy di variabili.
Funzione di appartenenza
Le funzioni di appartenenza consentono di quantificare il termine linguistico e di rappresentare graficamente un insieme fuzzy. UNmembership functionper un insieme fuzzy A sull'universo del discorso X è definito come μ A : X → [0,1].
Qui, ogni elemento di X è mappato su un valore compreso tra 0 e 1. Viene chiamatomembership value o degree of membership. Essa quantifica il grado di appartenenza dell'elemento nella X all'insieme fuzzy A .
- L'asse x rappresenta l'universo del discorso.
- L'asse y rappresenta i gradi di appartenenza all'intervallo [0, 1].
Possono esserci più funzioni di appartenenza applicabili per fuzzificare un valore numerico. Le funzioni di appartenenza semplici vengono utilizzate poiché l'uso di funzioni complesse non aggiunge maggiore precisione nell'output.
Tutte le funzioni di appartenenza per LP, MP, S, MN, e LN sono mostrati come di seguito -

Le forme delle funzioni di appartenenza triangolari sono più comuni tra le varie altre forme di funzioni di appartenenza come trapezoidale, singleton e gaussiana.
Qui, l'ingresso al fuzzificatore a 5 livelli varia da -10 volt a +10 volt. Quindi cambia anche l'output corrispondente.
Esempio di un sistema logico fuzzy
Consideriamo un impianto di condizionamento con sistema fuzzy logic a 5 livelli. Questo sistema regola la temperatura del condizionatore d'aria confrontando la temperatura ambiente e il valore della temperatura target.
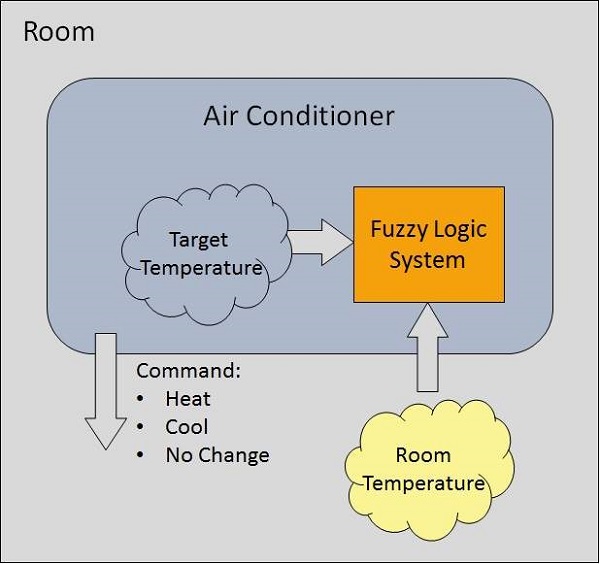
Algoritmo
- Definire variabili e termini linguistici (inizio)
- Costruisci funzioni di appartenenza per loro. (inizio)
- Costruisci la base di conoscenza delle regole (inizio)
- Converti dati nitidi in set di dati fuzzy utilizzando le funzioni di appartenenza. (sfocatura)
- Valuta le regole nella rule base. (Motore di inferenza)
- Combina i risultati di ciascuna regola. (Motore di inferenza)
- Converti i dati di output in valori non fuzzy. (defuzzificazione)
Sviluppo
Step 1 − Define linguistic variables and terms
Le variabili linguistiche sono variabili di input e output sotto forma di semplici parole o frasi. Per temperatura ambiente, freddo, caldo, caldo, ecc. Sono termini linguistici.
Temperatura (t) = {molto freddo, freddo, caldo, molto caldo, caldo}
Ogni membro di questo set è un termine linguistico e può coprire una parte dei valori di temperatura complessivi.
Step 2 − Construct membership functions for them
Le funzioni di appartenenza della variabile di temperatura sono le seguenti:
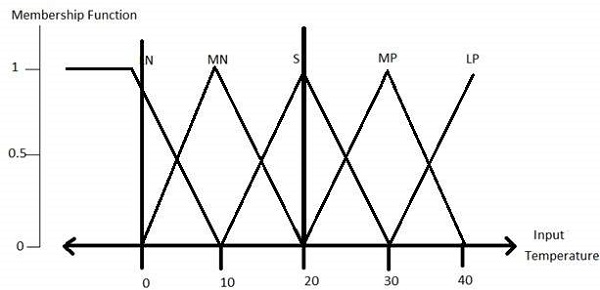
Step3 − Construct knowledge base rules
Creare una matrice di valori di temperatura ambiente rispetto ai valori di temperatura target che ci si aspetta possa fornire un sistema di condizionamento d'aria.
| Temperatura ambiente. /Bersaglio | Molto freddo | Freddo | Caldo | Caldo | Molto caldo |
|---|---|---|---|---|---|
| Molto freddo | Nessun cambiamento | Calore | Calore | Calore | Calore |
| Freddo | Freddo | Nessun cambiamento | Calore | Calore | Calore |
| Caldo | Freddo | Freddo | Nessun cambiamento | Calore | Calore |
| Caldo | Freddo | Freddo | Freddo | Nessun cambiamento | Calore |
| Molto caldo | Freddo | Freddo | Freddo | Freddo | Nessun cambiamento |
Costruisci una serie di regole nella knowledge base sotto forma di strutture IF-THEN-ELSE.
| Sr. No. | Condizione | Azione |
|---|---|---|
| 1 | SE la temperatura = (Fredda O Molto_ Fredda) E il target = Caldo ALLORA | Calore |
| 2 | SE temperatura = (caldo OR Very_Hot) AND target = caldo ALLORA | Freddo |
| 3 | IF (temperatura = caldo) AND (target = caldo) ALLORA | Nessun cambiamento |
Step 4 − Obtain fuzzy value
Le operazioni sugli insiemi fuzzy eseguono la valutazione delle regole. Le operazioni utilizzate per OR e AND sono rispettivamente Max e Min. Combina tutti i risultati della valutazione per formare un risultato finale. Questo risultato è un valore sfocato.
Step 5 − Perform defuzzification
La defuzzificazione viene quindi eseguita in base alla funzione di appartenenza per la variabile di output.

Aree di applicazione della logica fuzzy
Le aree di applicazione chiave della logica fuzzy sono le seguenti:
Automotive Systems
- Cambio automatico
- Quattro ruote sterzanti
- Controllo ambientale del veicolo
Consumer Electronic Goods
- Sistemi Hi-Fi
- Photocopiers
- Fotocamere e videocamere
- Television
Domestic Goods
- Forni a microonde
- Refrigerators
- Toasters
- Aspirapolvere
- Washing Machines
Environment Control
- Air Conditioners/Dryers/Heaters
- Humidifiers
Advantages of FLSs
Mathematical concepts within fuzzy reasoning are very simple.
You can modify a FLS by just adding or deleting rules due to flexibility of fuzzy logic.
Fuzzy logic Systems can take imprecise, distorted, noisy input information.
FLSs are easy to construct and understand.
Fuzzy logic is a solution to complex problems in all fields of life, including medicine, as it resembles human reasoning and decision making.
Disadvantages of FLSs
- There is no systematic approach to fuzzy system designing.
- They are understandable only when simple.
- They are suitable for the problems which do not need high accuracy.
Natural Language Processing (NLP) refers to AI method of communicating with an intelligent systems using a natural language such as English.
Processing of Natural Language is required when you want an intelligent system like robot to perform as per your instructions, when you want to hear decision from a dialogue based clinical expert system, etc.
The field of NLP involves making computers to perform useful tasks with the natural languages humans use. The input and output of an NLP system can be −
- Speech
- Written Text
Components of NLP
There are two components of NLP as given −
Natural Language Understanding (NLU)
Understanding involves the following tasks −
- Mappatura dell'input fornito in linguaggio naturale in rappresentazioni utili.
- Analizzare diversi aspetti della lingua.
Generazione del linguaggio naturale (NLG)
È il processo di produzione di frasi e frasi significative sotto forma di linguaggio naturale da una rappresentazione interna.
Si tratta di:
Text planning - Include il recupero del contenuto pertinente dalla knowledge base.
Sentence planning - Include la scelta delle parole richieste, la formazione di frasi significative, l'impostazione del tono della frase.
Text Realization - Sta mappando il piano della frase nella struttura della frase.
L'NLU è più difficile dell'NLG.
Difficoltà in NLU
NL ha una forma e una struttura estremamente ricche.
È molto ambiguo. Possono esserci diversi livelli di ambiguità:
Lexical ambiguity - È a un livello molto primitivo come il livello di parola.
Ad esempio, considerare la parola "tavola" come un nome o un verbo?
Syntax Level ambiguity - Una frase può essere analizzata in diversi modi.
Ad esempio, "Ha sollevato lo scarafaggio con il berretto rosso". - Ha usato il berretto per sollevare lo scarafaggio o ha sollevato uno scarafaggio con il berretto rosso?
Referential ambiguity- Riferirsi a qualcosa usando i pronomi. Ad esempio, Rima è andata a Gauri. Ha detto: "Sono stanca". - Esattamente chi è stanco?
Un input può significare significati diversi.
Molti input possono significare la stessa cosa.
Terminologia della PNL
Phonology - È lo studio dell'organizzazione sistematica del suono.
Morphology - È uno studio della costruzione di parole da unità significative primitive.
Morpheme - È l'unità primitiva di significato in una lingua.
Syntax- Si riferisce alla disposizione delle parole per formare una frase. Coinvolge anche la determinazione del ruolo strutturale delle parole nella frase e nelle frasi.
Semantics - Si occupa del significato delle parole e di come combinare le parole in frasi e frasi significative.
Pragmatics - Si occupa dell'utilizzo e della comprensione delle frasi in diverse situazioni e di come viene influenzata l'interpretazione della frase.
Discourse - Si occupa di come la frase immediatamente precedente può influenzare l'interpretazione della frase successiva.
World Knowledge - Include la conoscenza generale del mondo.
Passi nella PNL
Ci sono cinque passaggi generali:
Lexical Analysis- Implica l'identificazione e l'analisi della struttura delle parole. Il lessico di una lingua indica la raccolta di parole e frasi in una lingua. L'analisi lessicale sta dividendo l'intera porzione di testo in paragrafi, frasi e parole.
Syntactic Analysis (Parsing)- Implica l'analisi delle parole nella frase per la grammatica e la disposizione delle parole in un modo che mostri la relazione tra le parole. La frase come "La scuola va al ragazzo" viene rifiutata dall'analizzatore sintattico inglese.

Semantic Analysis- Trae il significato esatto o il significato del dizionario dal testo. Viene verificata la significatività del testo. Viene eseguito mappando strutture sintattiche e oggetti nel dominio delle attività. L'analizzatore semantico ignora frasi come "gelato caldo".
Discourse Integration- Il significato di qualsiasi frase dipende dal significato della frase appena prima di essa. Inoltre, determina anche il significato della frase immediatamente successiva.
Pragmatic Analysis- Durante questo, ciò che è stato detto viene reinterpretato su ciò che effettivamente significava. Si tratta di derivare quegli aspetti del linguaggio che richiedono la conoscenza del mondo reale.
Aspetti di implementazione dell'analisi sintattica
Esistono numerosi algoritmi che i ricercatori hanno sviluppato per l'analisi sintattica, ma consideriamo solo i seguenti semplici metodi:
- Grammatica senza contesto
- Parser dall'alto verso il basso
Vediamoli in dettaglio -
Grammatica senza contesto
È la grammatica che consiste di regole con un unico simbolo sul lato sinistro delle regole di riscrittura. Creiamo una grammatica per analizzare una frase -
"L'uccello becca i chicchi"
Articles (DET)- a | un | il
Nouns- uccello | uccelli | grano | grani
Noun Phrase (NP)- Articolo + Sostantivo | Articolo + Aggettivo + Sostantivo
= DET N | DET ADJ N
Verbs- becca | beccare | beccato
Verb Phrase (VP)- NP V | V NP
Adjectives (ADJ)- bellissimo | piccolo | cinguettio
L'albero di analisi suddivide la frase in parti strutturate in modo che il computer possa comprenderla ed elaborarla facilmente. Affinché l'algoritmo di analisi possa costruire questo albero di analisi, è necessario costruire un insieme di regole di riscrittura, che descrivono quali strutture ad albero sono legali.
Queste regole dicono che un certo simbolo può essere espanso nell'albero da una sequenza di altri simboli. Secondo la regola logica del primo ordine, se ci sono due stringhe Frase sostantiva (NP) e Frase verbale (VP), la stringa combinata da NP seguita da VP è una frase. Le regole di riscrittura per la frase sono le seguenti:
S → NP VP
NP → DET N | DET ADJ N
VP → V NP
Lexocon −
DET → a | il
AGG → bello | appollaiarsi
N → uccello | uccelli | grano | grani
V → becco | becca | beccare
L'albero di analisi può essere creato come mostrato -

Ora considera le regole di riscrittura di cui sopra. Dal momento che V può essere sostituito da entrambi, "beccare" o "beccare", frasi come "L'uccello becca i chicchi" possono essere ammesse erroneamente. cioè l'errore di accordo soggetto-verbo è approvato come corretto.
Merit - Lo stile grammaticale più semplice, quindi ampiamente utilizzato.
Demerits −
Non sono molto precisi. Ad esempio, "I chicchi beccano l'uccello", è sintatticamente corretto secondo il parser, ma anche se non ha senso, il parser lo considera una frase corretta.
Per ottenere un'elevata precisione, è necessario preparare più set di grammatica. Potrebbe richiedere un insieme di regole completamente diverso per analizzare variazioni singolari e plurali, frasi passive, ecc., Che possono portare alla creazione di un enorme insieme di regole che sono ingestibili.
Parser dall'alto verso il basso
Qui, il parser inizia con il simbolo S e tenta di riscriverlo in una sequenza di simboli terminali che corrispondono alle classi delle parole nella frase di input fino a quando non è costituito interamente da simboli terminali.
Questi vengono quindi controllati con la frase di input per vedere se corrisponde. In caso contrario, il processo viene riavviato con un diverso insieme di regole. Questo viene ripetuto finché non viene trovata una regola specifica che descrive la struttura della frase.
Merit - È semplice da implementare.
Demerits −
- È inefficiente, poiché il processo di ricerca deve essere ripetuto se si verifica un errore.
- Bassa velocità di lavoro.
I sistemi esperti (ES) sono uno dei principali domini di ricerca dell'IA. Viene introdotto dai ricercatori della Stanford University, Computer Science Department.
Cosa sono i sistemi esperti?
I sistemi esperti sono le applicazioni informatiche sviluppate per risolvere problemi complessi in un particolare dominio, a livello di straordinaria intelligenza e competenza umana.
Caratteristiche dei sistemi esperti
- Alte prestazioni
- Understandable
- Reliable
- Altamente reattivo
Capacità di sistemi esperti
I sistemi esperti sono in grado di:
- Advising
- Istruire e assistere l'essere umano nel processo decisionale
- Demonstrating
- Trovare una soluzione
- Diagnosing
- Explaining
- Interpretazione dell'input
- Previsione dei risultati
- Giustificando la conclusione
- Suggerire opzioni alternative a un problema
Sono incapaci di -
- Sostituire i decisori umani
- Possedere capacità umane
- Produzione di output accurati per una base di conoscenza inadeguata
- Affinare le proprie conoscenze
Componenti di sistemi esperti
I componenti di ES includono:
- base di conoscenza
- Motore di inferenza
- Interfaccia utente
Vediamoli brevemente uno per uno -

base di conoscenza
Contiene conoscenze specifiche del dominio e di alta qualità.
La conoscenza è necessaria per mostrare intelligenza. Il successo di qualsiasi ES dipende principalmente dalla raccolta di conoscenze estremamente accurate e precise.
Cos'è la conoscenza?
I dati sono una raccolta di fatti. Le informazioni sono organizzate come dati e fatti sul dominio delle attività.Data, information, e past experience combinati insieme sono definiti come conoscenza.
Componenti della Knowledge Base
La base di conoscenza di un ES è un archivio di conoscenze sia fattuali che euristiche.
Factual Knowledge - Sono le informazioni ampiamente accettate dagli ingegneri della conoscenza e dagli studiosi nel dominio dei compiti.
Heuristic Knowledge - Si tratta di pratica, giudizio accurato, capacità di valutazione e indovinare.
Rappresentazione della conoscenza
È il metodo utilizzato per organizzare e formalizzare la conoscenza nella knowledge base. È sotto forma di regole IF-THEN-ELSE.
Acquisizione della conoscenza
Il successo di qualsiasi sistema esperto dipende principalmente dalla qualità, completezza e accuratezza delle informazioni memorizzate nella knowledge base.
La base di conoscenza è formata da letture di vari esperti, studiosi e Knowledge Engineers. L'ingegnere della conoscenza è una persona con le qualità di empatia, apprendimento rapido e capacità di analisi dei casi.
Acquisisce informazioni dall'esperto in materia registrandolo, intervistandolo e osservandolo al lavoro, ecc. Quindi classifica e organizza le informazioni in modo significativo, sotto forma di regole IF-THEN-ELSE, per essere utilizzate dalla macchina di interferenza. L'ingegnere della conoscenza monitora anche lo sviluppo dell'ES.
Motore di inferenza
L'uso di procedure e regole efficienti da parte del motore di inferenza è essenziale per dedurre una soluzione corretta e impeccabile.
In caso di ES basato sulla conoscenza, il motore di inferenza acquisisce e manipola la conoscenza dalla base di conoscenza per arrivare a una particolare soluzione.
In caso di ES basato su regole,
Applica le regole ripetutamente ai fatti, che sono ottenuti dalla precedente applicazione della regola.
Aggiunge nuove conoscenze alla knowledge base, se necessario.
Risolve il conflitto di regole quando più regole sono applicabili a un caso particolare.
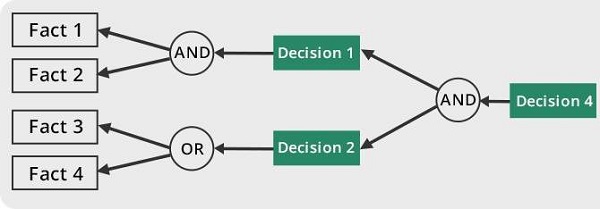
Per consigliare una soluzione, il motore di inferenza utilizza le seguenti strategie:
- Concatenamento in avanti
- Concatenamento all'indietro
Concatenamento in avanti
È una strategia di un sistema esperto per rispondere alla domanda, “What can happen next?”
Qui, il motore di inferenza segue la catena di condizioni e derivazioni e alla fine ne deduce il risultato. Considera tutti i fatti e le regole e li ordina prima di giungere a una soluzione.
Questa strategia viene seguita per lavorare su conclusioni, risultati o effetti. Ad esempio, la previsione dello stato del mercato azionario come effetto delle variazioni dei tassi di interesse.

Concatenamento all'indietro
Con questa strategia, un sistema esperto trova la risposta alla domanda, “Why this happened?”
Sulla base di quanto già accaduto, l'Inference Engine cerca di scoprire quali condizioni si sarebbero potute verificare in passato per questo risultato. Questa strategia viene seguita per scoprire la causa o il motivo. Ad esempio, la diagnosi di cancro del sangue negli esseri umani.
Interfaccia utente
L'interfaccia utente fornisce l'interazione tra l'utente dell'ES e l'ES stesso. Generalmente è Natural Language Processing in modo da essere utilizzato dall'utente esperto nel dominio delle attività. L'utente dell'ES non deve essere necessariamente un esperto di intelligenza artificiale.
Spiega come l'ES sia arrivato a una particolare raccomandazione. La spiegazione può apparire nelle seguenti forme:
- Linguaggio naturale visualizzato sullo schermo.
- Narrazioni verbali in linguaggio naturale.
- Elenco dei numeri di regola visualizzati sullo schermo.
L'interfaccia utente consente di risalire facilmente alla credibilità delle detrazioni.
Requisiti di efficiente interfaccia utente ES
Dovrebbe aiutare gli utenti a raggiungere i loro obiettivi nel modo più breve possibile.
Dovrebbe essere progettato per funzionare per le pratiche di lavoro esistenti o desiderate dell'utente.
La sua tecnologia dovrebbe essere adattabile alle esigenze dell'utente; non il contrario.
Dovrebbe fare un uso efficiente dell'input dell'utente.
Limitazioni dei sistemi esperti
Nessuna tecnologia può offrire una soluzione semplice e completa. I sistemi di grandi dimensioni sono costosi, richiedono tempi di sviluppo significativi e risorse informatiche. Gli ES hanno i loro limiti che includono:
- Limitazioni della tecnologia
- Difficile acquisizione della conoscenza
- Gli ES sono difficili da mantenere
- Elevati costi di sviluppo
Applicazioni di Expert System
La tabella seguente mostra dove è possibile applicare ES.
| Applicazione | Descrizione |
|---|---|
| Dominio di progettazione | Design dell'obiettivo della fotocamera, design automobilistico. |
| Dominio medico | Sistemi di diagnosi per dedurre la causa della malattia da dati osservati, conduzione di operazioni mediche sull'uomo. |
| Sistemi di monitoraggio | Confronto continuo dei dati con il sistema osservato o con un comportamento prescritto come il monitoraggio delle perdite in un lungo oleodotto. |
| Sistemi di controllo dei processi | Controllo di un processo fisico basato sul monitoraggio. |
| Dominio della conoscenza | Individuazione di guasti nei veicoli, nei computer. |
| Finanza / Commercio | Rilevamento di possibili frodi, transazioni sospette, negoziazione in borsa, pianificazione delle compagnie aeree, pianificazione delle merci. |
Tecnologia di sistema esperta
Sono disponibili diversi livelli di tecnologie ES. Le tecnologie dei sistemi esperti includono:
Expert System Development Environment- L'ambiente di sviluppo ES include hardware e strumenti. Sono -
Postazioni di lavoro, minicomputer, mainframe.
Linguaggi di programmazione simbolica di alto livello come LISt Programming (LISP) e PROgrammation en LOGique (PROLOG).
Database di grandi dimensioni.
Tools - Riducono in larga misura lo sforzo e il costo coinvolti nello sviluppo di un sistema esperto.
Potenti editor e strumenti di debug con multi-finestre.
Forniscono una prototipazione rapida
Avere definizioni integrate di modello, rappresentazione della conoscenza e progettazione dell'inferenza.
Shells- Una shell non è altro che un sistema esperto senza base di conoscenza. Una shell fornisce agli sviluppatori l'acquisizione di conoscenze, il motore di inferenza, l'interfaccia utente e la funzione di spiegazione. Ad esempio, di seguito vengono fornite alcune shell:
Java Expert System Shell (JESS) che fornisce API Java completamente sviluppate per la creazione di un sistema esperto.
Vidwan , una shell sviluppata presso il National Center for Software Technology, Mumbai nel 1993. Consente la codifica della conoscenza sotto forma di regole IF-THEN.
Sviluppo di sistemi esperti: passaggi generali
Il processo di sviluppo di ES è iterativo. I passaggi nello sviluppo dell'ES includono:
Identifica il dominio del problema
- Il problema deve essere adatto a un sistema esperto per risolverlo.
- Trova gli esperti nel dominio delle attività per il progetto ES.
- Stabilire l'economicità del sistema.
Progettare il sistema
Identifica la tecnologia ES
Conoscere e stabilire il grado di integrazione con gli altri sistemi e database.
Renditi conto di come i concetti possono rappresentare al meglio la conoscenza del dominio.
Sviluppa il prototipo
Dalla Knowledge Base: l'ingegnere della conoscenza lavora a -
- Acquisisci la conoscenza del dominio dall'esperto.
- Rappresentalo sotto forma di regole If-THEN-ELSE.
Prova e perfeziona il prototipo
L'ingegnere della conoscenza utilizza casi di esempio per testare il prototipo per eventuali carenze nelle prestazioni.
Gli utenti finali testano i prototipi dell'ES.
Sviluppa e completa l'ES
Testare e garantire l'interazione dell'ES con tutti gli elementi del suo ambiente, inclusi gli utenti finali, i database e altri sistemi di informazione.
Documenta bene il progetto ES.
Formare l'utente a utilizzare ES.
Mantenere il sistema
Mantieni aggiornata la knowledge base tramite revisione e aggiornamento regolari.
Fornire nuove interfacce con altri sistemi di informazione, man mano che questi sistemi si evolvono.
Vantaggi dei sistemi esperti
Availability - Sono facilmente disponibili grazie alla produzione in serie di software.
Less Production Cost- Il costo di produzione è ragionevole. Questo li rende convenienti.
Speed- Offrono una grande velocità. Riducono la quantità di lavoro svolto da un individuo.
Less Error Rate - Il tasso di errore è basso rispetto agli errori umani.
Reducing Risk - Possono lavorare in ambienti pericolosi per l'uomo.
Steady response - Lavorano costantemente senza diventare mobili, tesi o affaticati.
La robotica è un dominio dell'intelligenza artificiale che si occupa dello studio della creazione di robot intelligenti ed efficienti.
Cosa sono i robot?
I robot sono gli agenti artificiali che agiscono nell'ambiente del mondo reale.
Obbiettivo
I robot hanno lo scopo di manipolare gli oggetti percependo, raccogliendo, spostando, modificando le proprietà fisiche dell'oggetto, distruggendolo o per avere un effetto liberando così la manodopera dallo svolgere funzioni ripetitive senza annoiarsi, distrarsi o esaurirsi.
Cos'è la robotica?
La robotica è una branca dell'IA, composta da ingegneria elettrica, ingegneria meccanica e informatica per la progettazione, la costruzione e l'applicazione dei robot.
Aspetti della robotica
I robot hanno mechanical construction, forma o forma progettata per svolgere un compito particolare.
Loro hanno electrical components che alimentano e controllano i macchinari.
Contengono un certo livello di computer program che determina cosa, quando e come un robot fa qualcosa.
Differenza nel sistema robotico e in altri programmi AI
Ecco la differenza tra i due:
| Programmi AI | Robot |
|---|---|
| Di solito operano in mondi stimolati dal computer. | Operano nel mondo fisico reale |
| L'input per un programma AI è in simboli e regole. | Gli input ai robot sono segnali analogici sotto forma di forme d'onda o immagini del parlato |
| Hanno bisogno di computer di uso generale su cui operare. | Hanno bisogno di hardware speciale con sensori ed effettori. |
Locomozione robotica
La locomozione è il meccanismo che rende un robot capace di muoversi nel suo ambiente. Esistono vari tipi di locomozione:
- Legged
- Wheeled
- Combinazione di locomozione con gambe e ruote
- Slittamento / slittamento cingolato
Locomozione con le gambe
Questo tipo di locomozione consuma più energia durante la dimostrazione di camminare, saltare, trotto, saltare, salire o scendere, ecc.
Richiede un numero maggiore di motori per eseguire un movimento. È adatto per terreni accidentati e lisci dove una superficie irregolare o troppo liscia gli fa consumare più potenza per una locomozione a ruote. È un po 'difficile da implementare a causa di problemi di stabilità.
Viene fornito con la varietà di una, due, quattro e sei gambe. Se un robot ha più gambe, la coordinazione delle gambe è necessaria per la locomozione.
Il numero totale di possibili gaits (una sequenza periodica di eventi di sollevamento e rilascio per ciascuna delle gambe totali) un robot può viaggiare dipende dal numero delle sue gambe.
Se un robot ha k gambe, il numero di eventi possibili N = (2k-1) !.
Nel caso di un robot a due gambe (k = 2), il numero di eventi possibili è N = (2k-1)! = (2 * 2-1)! = 3! = 6.
Quindi ci sono sei possibili eventi diversi -
- Sollevamento della gamba sinistra
- Rilascio della gamba sinistra
- Sollevamento della gamba destra
- Rilascio della gamba destra
- Sollevando entrambe le gambe insieme
- Rilasciando entrambe le gambe insieme
In caso di k = 6 segmenti, ci sono 39916800 eventi possibili. Quindi la complessità dei robot è direttamente proporzionale al numero di gambe.

Locomozione a ruote
Richiede un numero inferiore di motori per eseguire un movimento. È poco facile da implementare poiché ci sono meno problemi di stabilità in caso di più numero di ruote. È efficiente dal punto di vista energetico rispetto alla locomozione a gambe.
Standard wheel - Ruota attorno all'asse della ruota e attorno al contatto
Castor wheel - Ruota attorno all'asse della ruota e allo snodo dello sterzo sfalsato.
Swedish 45o and Swedish 90o wheels - Omni-ruota, ruota attorno al punto di contatto, attorno all'asse della ruota e attorno ai rulli.
Ball or spherical wheel - Ruota omnidirezionale, tecnicamente difficile da realizzare.

Locomozione di slittamento / slittamento
In questo tipo, i veicoli usano i binari come in un carro armato. Il robot viene sterzato spostando i cingoli con velocità diverse nella stessa direzione o nella direzione opposta. Offre stabilità grazie all'ampia area di contatto tra pista e terreno.

Componenti di un robot
I robot sono costruiti con quanto segue:
Power Supply - I robot sono alimentati da batterie, energia solare, idraulica o pneumatica.
Actuators - Trasformano l'energia in movimento.
Electric motors (AC/DC) - Sono necessari per il movimento rotatorio.
Pneumatic Air Muscles - Si contraggono quasi del 40% quando viene aspirata aria.
Muscle Wires - Si contraggono del 5% al passaggio della corrente elettrica.
Piezo Motors and Ultrasonic Motors - Ideale per robot industriali.
Sensors- Forniscono la conoscenza delle informazioni in tempo reale sull'ambiente del compito. I robot sono dotati di sensori di visione per poter calcolare la profondità nell'ambiente. Un sensore tattile imita le proprietà meccaniche dei recettori tattili della punta delle dita umane.
Visione computerizzata
Questa è una tecnologia di intelligenza artificiale con cui i robot possono vedere. La visione artificiale gioca un ruolo fondamentale nei settori della sicurezza, protezione, salute, accesso e intrattenimento.
La visione artificiale estrae, analizza e comprende automaticamente informazioni utili da una singola immagine o da una serie di immagini. Questo processo implica lo sviluppo di algoritmi per realizzare la comprensione visiva automatica.
Hardware del sistema di visione artificiale
Ciò comporta:
- Alimentazione elettrica
- Dispositivo di acquisizione delle immagini come la fotocamera
- Un processore
- Un software
- Un dispositivo di visualizzazione per il monitoraggio del sistema
- Accessori come supporti per fotocamere, cavi e connettori
Compiti di visione artificiale
OCR - Nel dominio dei computer, Optical Character Reader, un software per convertire i documenti scansionati in testo modificabile, che accompagna uno scanner.
Face Detection- Molte fotocamere all'avanguardia sono dotate di questa funzione, che consente di leggere il viso e scattare la foto di quell'espressione perfetta. Viene utilizzato per consentire a un utente di accedere al software in caso di corrispondenza corretta.
Object Recognition - Sono installati in supermercati, telecamere, auto di fascia alta come BMW, GM e Volvo.
Estimating Position - Stima la posizione di un oggetto rispetto alla telecamera come nella posizione del tumore nel corpo umano.
Domini applicativi della visione artificiale
- Agriculture
- Veicoli autonomi
- Biometrics
- Riconoscimento dei caratteri
- Forense, sicurezza e sorveglianza
- Ispezione di qualità industriale
- Riconoscimento facciale
- Analisi dei gesti
- Geoscience
- Immagini mediche
- Monitoraggio dell'inquinamento
- Controllo di processo
- Rilevamento remoto
- Robotics
- Transport
Applicazioni della robotica
La robotica è stata determinante nei vari domini come:
Industries - I robot sono utilizzati per la movimentazione di materiale, taglio, saldatura, rivestimento colorato, foratura, lucidatura, ecc.
Military- I robot autonomi possono raggiungere zone inaccessibili e pericolose durante la guerra. Un robot di nome Daksh , sviluppato dalla Defense Research and Development Organization (DRDO), è in funzione per distruggere oggetti pericolosi per la vita in sicurezza.
Medicine - I robot sono in grado di eseguire centinaia di test clinici contemporaneamente, riabilitare persone disabili permanenti ed eseguire interventi chirurgici complessi come i tumori cerebrali.
Exploration - I robot scalatori usati per l'esplorazione spaziale, i droni sottomarini usati per l'esplorazione dell'oceano sono solo per citarne alcuni.
Entertainment - Gli ingegneri della Disney hanno creato centinaia di robot per la realizzazione di film.
Ancora un'altra area di ricerca nell'IA, le reti neurali, si ispira alla rete neurale naturale del sistema nervoso umano.
Cosa sono le reti neurali artificiali (ANN)?
L'inventore del primo neurocomputer, il dottor Robert Hecht-Nielsen, definisce una rete neurale come -
"... un sistema di elaborazione costituito da una serie di elementi di elaborazione semplici e altamente interconnessi, che elaborano le informazioni in base alla loro risposta dinamica dello stato a input esterni."
Struttura di base delle ANN
L'idea di ANNs si basa sulla convinzione che il funzionamento del cervello umano effettuando le giuste connessioni, possa essere imitato usando silicio e fili come viventi neurons e dendrites.
Il cervello umano è composto da 86 miliardi di cellule nervose chiamate neurons. Sono collegati ad altre migliaia di celle da Axons.Gli stimoli dall'ambiente esterno o gli input dagli organi sensoriali sono accettati dai dendriti. Questi input creano impulsi elettrici, che viaggiano rapidamente attraverso la rete neurale. Un neurone può quindi inviare il messaggio ad un altro neurone per gestire il problema o non inviarlo in avanti.

Le ANN sono composte da più file nodes, che imitano il biologico neuronsdel cervello umano. I neuroni sono collegati da collegamenti e interagiscono tra loro. I nodi possono prendere dati di input ed eseguire semplici operazioni sui dati. Il risultato di queste operazioni viene trasmesso ad altri neuroni. L'output in ogni nodo è chiamato proprioactivation o node value.
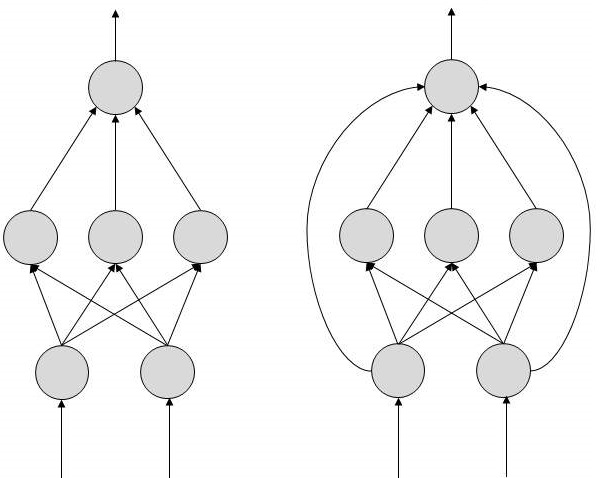
Ogni collegamento è associato a weight.Le ANN sono in grado di apprendere, cosa che avviene alterando i valori di peso. La figura seguente mostra una semplice ANN -

Tipi di reti neurali artificiali
Esistono due topologie di reti neurali artificiali: FeedForward e Feedback.
FeedForward ANN
In questa ANN, il flusso di informazioni è unidirezionale. Un'unità invia informazioni ad un'altra unità da cui non riceve alcuna informazione. Non ci sono cicli di feedback. Sono utilizzati nella generazione / riconoscimento / classificazione dei modelli. Hanno ingressi e uscite fissi.
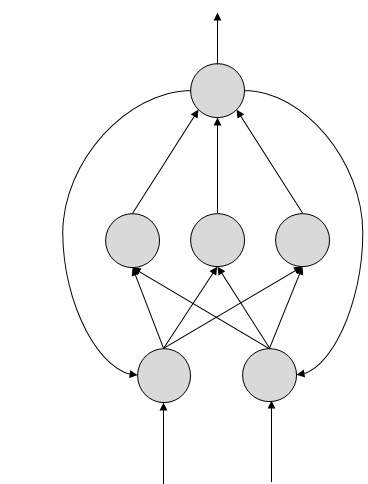
FeedBack ANN
Qui sono consentiti i cicli di feedback. Sono usati nelle memorie indirizzabili del contenuto.
Funzionamento delle ANN
Nei diagrammi topologici mostrati, ogni freccia rappresenta una connessione tra due neuroni e indica il percorso per il flusso di informazioni. Ogni connessione ha un peso, un numero intero che controlla il segnale tra i due neuroni.
Se la rete genera un output "buono o desiderato", non è necessario regolare i pesi. Tuttavia, se la rete genera un output “scarso o indesiderato” o un errore, il sistema modifica i pesi per migliorare i risultati successivi.
Apprendimento automatico nelle ANN
Le ANN sono in grado di apprendere e hanno bisogno di essere addestrate. Esistono diverse strategie di apprendimento:
Supervised Learning- Coinvolge un insegnante che è studioso della stessa ANN. Ad esempio, l'insegnante fornisce alcuni dati di esempio di cui l'insegnante conosce già le risposte.
Ad esempio, riconoscimento di pattern. La ANN escogita ipotesi mentre riconosce. Quindi l'insegnante fornisce alla ANN con le risposte. La rete quindi confronta le ipotesi con le risposte "corrette" dell'insegnante e apporta le modifiche in base agli errori.
Unsupervised Learning- È necessario quando non sono disponibili set di dati di esempio con risposte note. Ad esempio, la ricerca di uno schema nascosto. In questo caso, il raggruppamento, ovvero la divisione di un insieme di elementi in gruppi secondo un modello sconosciuto, viene eseguito sulla base dei set di dati esistenti presenti.
Reinforcement Learning- Questa strategia si basa sull'osservazione. La ANN prende una decisione osservando il suo ambiente. Se l'osservazione è negativa, la rete regola i suoi pesi per poter prendere una decisione richiesta diversa la volta successiva.
Algoritmo di propagazione posteriore
È l'algoritmo di addestramento o apprendimento. Impara con l'esempio. Se si sottopone all'algoritmo l'esempio di ciò che si desidera che la rete faccia, cambia i pesi della rete in modo che possa produrre l'output desiderato per un particolare input al termine dell'addestramento.
Le reti di Back Propagation sono ideali per semplici attività di riconoscimento e mappatura dei modelli.
Reti bayesiane (BN)
Queste sono le strutture grafiche utilizzate per rappresentare la relazione probabilistica tra un insieme di variabili casuali. Vengono chiamate anche reti bayesianeBelief Networks o Bayes Nets. Motivo di BN sul dominio incerto.
In queste reti, ogni nodo rappresenta una variabile casuale con proposizioni specifiche. Ad esempio, in un dominio di diagnosi medica, il nodo Cancro rappresenta la proposizione che un paziente abbia il cancro.
I bordi che collegano i nodi rappresentano le dipendenze probabilistiche tra quelle variabili casuali. Se su due nodi, uno sta influenzando l'altro, devono essere collegati direttamente nelle direzioni dell'effetto. La forza della relazione tra le variabili è quantificata dalla probabilità associata a ciascun nodo.
C'è un unico vincolo sugli archi in un BN che non puoi restituire a un nodo semplicemente seguendo gli archi diretti. Quindi i BN sono chiamati Directed Acyclic Graphs (DAG).
I BN sono in grado di gestire variabili multivalore contemporaneamente. Le variabili BN sono composte da due dimensioni:
- Gamma di preposizioni
- Probabilità assegnata a ciascuna delle preposizioni.
Consideriamo un insieme finito X = {X 1 , X 2 ,…, X n } di variabili casuali discrete, dove ogni variabile X i può assumere valori da un insieme finito, indicato con Val (X i ). Se c'è un collegamento diretto dalla variabile X i alla variabile, X j , allora la variabile X i sarà una madre della variabile X j che mostra le dipendenze dirette tra le variabili.
La struttura di BN è ideale per combinare conoscenze pregresse e dati osservati. BN può essere utilizzato per apprendere le relazioni causali e comprendere vari domini problematici e per prevedere eventi futuri, anche in caso di dati mancanti.
Costruire una rete bayesiana
Un ingegnere della conoscenza può costruire una rete bayesiana. Ci sono una serie di passaggi che l'ingegnere della conoscenza deve compiere durante la sua costruzione.
Example problem- Cancro ai polmoni. Un paziente ha sofferto di affanno. Va dal dottore, sospettando di avere un cancro ai polmoni. Il medico sa che, a parte il cancro ai polmoni, ci sono varie altre possibili malattie che il paziente potrebbe avere come la tubercolosi e la bronchite.
Gather Relevant Information of Problem
- Il paziente è un fumatore? Se sì, allora alte probabilità di cancro e bronchite.
- Il paziente è esposto all'inquinamento atmosferico? Se sì, che tipo di inquinamento atmosferico?
- Fare una radiografia positiva ai raggi X indicherebbe la tubercolosi o il cancro ai polmoni.
Identify Interesting Variables
L'ingegnere della conoscenza cerca di rispondere alle domande:
- Quali nodi rappresentare?
- Quali valori possono assumere? In quale stato possono essere?
Per ora consideriamo i nodi, con solo valori discreti. La variabile deve assumere esattamente uno di questi valori alla volta.
Common types of discrete nodes are -
Boolean nodes - Rappresentano proposizioni, assumendo valori binari VERO (T) e FALSO (F).
Ordered values- Un nodo Inquinamento potrebbe rappresentare e assumere valori da {basso, medio, alto} che descrivono il grado di esposizione di un paziente all'inquinamento.
Integral values- Un nodo chiamato Età potrebbe rappresentare l'età del paziente con valori possibili da 1 a 120. Anche in questa fase iniziale, vengono effettuate scelte di modellazione.
Possibili nodi e valori per l'esempio di cancro ai polmoni -
| Nome nodo | genere | Valore | Creazione di nodi |
|---|---|---|---|
| Inquinamento | Binario | {BASSO, ALTO, MEDIO} |

|
| Fumatore | Booleano | {VERO, VERO} | |
| Cancro ai polmoni | Booleano | {VERO, VERO} | |
| Raggi X | Binario | {Positivo negativo} |
Create Arcs between Nodes
La topologia della rete dovrebbe catturare le relazioni qualitative tra le variabili.
Ad esempio, cosa causa un cancro ai polmoni in un paziente? - Inquinamento e fumo. Quindi aggiungere gli archi dal nodo Inquinamento e dal nodo Smoker al nodo Lung-Cancer.
Allo stesso modo, se il paziente ha un cancro ai polmoni, il risultato dei raggi X sarà positivo. Quindi aggiungi archi dal nodo Cancro al polmone al nodo X-Ray.

Specify Topology
Convenzionalmente, i BN sono disposti in modo che gli archi puntino dall'alto verso il basso. L'insieme dei nodi padre di un nodo X è dato da Parents (X).
Il nodo Lung-Cancer ha due genitori (ragioni o cause): Inquinamento e Smoker , mentre il nodo Smoker è unancestordel nodo X-Ray . Allo stesso modo, X-Ray è un figlio (conseguenza o effetti) del nodo Lung-Cancer esuccessordi nodi Smoker e Pollution.
Conditional Probabilities
Ora quantifica le relazioni tra i nodi collegati: questo viene fatto specificando una distribuzione di probabilità condizionale per ogni nodo. Poiché qui vengono considerate solo variabili discrete, questo assume la forma di aConditional Probability Table (CPT).
Innanzitutto, per ogni nodo dobbiamo esaminare tutte le possibili combinazioni di valori di quei nodi padre. Ciascuna di queste combinazioni è chiamatainstantiationdel set genitore. Per ogni distinta istanziazione dei valori del nodo genitore, dobbiamo specificare la probabilità che il figlio prenderà.
Ad esempio, i genitori del nodo Cancro al polmone sono Inquinamento e Fumo. Prendono i possibili valori = {(H, T), (H, F), (L, T), (L, F)}. Il CPT specifica la probabilità di cancro per ciascuno di questi casi come <0,05, 0,02, 0,03, 0,001> rispettivamente.
Ogni nodo avrà probabilità condizionata associata come segue:

Applicazioni delle reti neurali
Possono svolgere compiti facili per un essere umano ma difficili per una macchina -
Aerospace - Velivoli autopilota, rilevamento guasti aeromobili.
Automotive - Sistemi di guida automobilistica.
Military - Orientamento e governo dell'arma, tracciamento del bersaglio, discriminazione degli oggetti, riconoscimento facciale, identificazione di segnali / immagini.
Electronics - Previsione della sequenza di codice, layout del chip IC, analisi dei guasti del chip, visione artificiale, sintesi vocale.
Financial - Valutazione immobiliare, consulente di prestito, screening ipotecario, rating di obbligazioni societarie, programma di trading di portafoglio, analisi finanziaria aziendale, previsione del valore della valuta, lettori di documenti, valutatori di domande di credito.
Industrial - Controllo del processo di produzione, progettazione e analisi del prodotto, sistemi di ispezione della qualità, analisi della qualità della saldatura, previsione della qualità della carta, analisi della progettazione del prodotto chimico, modellazione dinamica dei sistemi del processo chimico, analisi della manutenzione della macchina, offerta di progetti, pianificazione e gestione.
Medical - Analisi delle cellule tumorali, analisi EEG ed ECG, progettazione protesica, ottimizzazione del tempo di trapianto.
Speech - Riconoscimento vocale, classificazione vocale, conversione da testo a discorso.
Telecommunications - Compressione di immagini e dati, servizi di informazione automatizzati, traduzione della lingua parlata in tempo reale.
Transportation - Diagnosi del sistema frenante del camion, pianificazione del veicolo, sistemi di routing.
Software - Pattern Recognition nel riconoscimento facciale, riconoscimento ottico dei caratteri, ecc.
Time Series Prediction - Le ANN sono utilizzate per fare previsioni su stock e calamità naturali.
Signal Processing - Le reti neurali possono essere addestrate per elaborare un segnale audio e filtrarlo in modo appropriato negli apparecchi acustici.
Control - Le ANN vengono spesso utilizzate per prendere decisioni di guida dei veicoli fisici.
Anomaly Detection - Poiché le ANN sono esperte nel riconoscere i modelli, possono anche essere addestrate a generare un output quando si verifica qualcosa di insolito che non si adatta al modello.
L'intelligenza artificiale si sta sviluppando con una velocità così incredibile, a volte sembra magica. C'è un'opinione tra ricercatori e sviluppatori che l'intelligenza artificiale potrebbe crescere così immensamente che sarebbe difficile da controllare per gli esseri umani.
Gli esseri umani hanno sviluppato sistemi di intelligenza artificiale introducendo in essi ogni possibile intelligenza che potevano, per la quale gli umani stessi ora sembrano minacciati.
Minaccia alla privacy
Un programma di intelligenza artificiale che riconosce il parlato e comprende il linguaggio naturale è teoricamente in grado di comprendere ogni conversazione su e-mail e telefoni.
Minaccia alla dignità umana
I sistemi di intelligenza artificiale hanno già iniziato a sostituire gli esseri umani in pochi settori. Non dovrebbe sostituire le persone nei settori in cui occupano posizioni dignitose attinenti all'etica come infermieristica, chirurgo, giudice, agente di polizia, ecc.
Minaccia alla sicurezza
I sistemi di intelligenza artificiale che si autoalimentano possono diventare così potenti degli umani che potrebbe essere molto difficile impedire il raggiungimento dei loro obiettivi, il che potrebbe portare a conseguenze indesiderate.
Ecco l'elenco dei termini usati di frequente nel dominio dell'IA:
| Suor n | Termine e significato |
|---|---|
| 1 | Agent Gli agenti sono sistemi o programmi software in grado di agire in modo autonomo, propositivo e orientato verso uno o più obiettivi. Sono anche chiamati assistenti, broker, bot, droidi, agenti intelligenti e agenti software. |
| 2 | Autonomous Robot Robot libero da controlli o influenze esterne e in grado di controllarsi autonomamente. |
| 3 | Backward Chaining Strategia per lavorare all'indietro per Motivo / Causa di un problema. |
| 4 | Blackboard È la memoria all'interno del computer, che viene utilizzata per la comunicazione tra i sistemi esperti cooperanti. |
| 5 | Environment È la parte del mondo reale o computazionale abitata dall'agente. |
| 6 | Forward Chaining Strategia di andare avanti per la conclusione / soluzione di un problema. |
| 7 | Heuristics È la conoscenza basata su prove ed errori, valutazioni e sperimentazione. |
| 8 | Knowledge Engineering Acquisizione di conoscenze da esperti umani e altre risorse. |
| 9 | Percepts È il formato in cui l'agente ottiene le informazioni sull'ambiente. |
| 10 | Pruning Ignorare considerazioni non necessarie e irrilevanti nei sistemi di intelligenza artificiale. |
| 11 | Rule È un formato per rappresentare la base di conoscenza in Expert System. È nella forma di SE-ALLORA-ALTRO. |
| 12 | Shell Una shell è un software che aiuta nella progettazione del motore di inferenza, della knowledge base e dell'interfaccia utente di un sistema esperto. |
| 13 | Task È l'obiettivo che l'agente cerca di raggiungere. |
| 14 | Turing Test Un test sviluppato da Allan Turing per testare l'intelligenza di una macchina rispetto all'intelligenza umana. |