Apprendimento della quantizzazione vettoriale
Learning Vector Quantization (LVQ), diverso da Vector quantization (VQ) e Kohonen Self-Organizing Maps (KSOM), è fondamentalmente una rete competitiva che utilizza l'apprendimento supervisionato. Possiamo definirlo come un processo di classificazione dei modelli in cui ogni unità di output rappresenta una classe. Poiché utilizza l'apprendimento supervisionato, la rete riceverà una serie di modelli di formazione con classificazione nota insieme a una distribuzione iniziale della classe di output. Dopo aver completato il processo di addestramento, LVQ classificherà un vettore di input assegnandolo alla stessa classe dell'unità di output.
Architettura
La figura seguente mostra l'architettura di LVQ che è abbastanza simile all'architettura di KSOM. Come possiamo vedere, ci sono“n” numero di unità di input e “m”numero di unità di output. Gli strati sono completamente interconnessi con i pesi su di essi.

Parametri utilizzati
Di seguito sono riportati i parametri utilizzati nel processo di addestramento LVQ e nel diagramma di flusso
x= vettore di allenamento (x 1 , ..., x i , ..., x n )
T = classe per vettore di addestramento x
wj = vettore peso per jth unità di uscita
Cj = classe associata a jth unità di uscita
Algoritmo di formazione
Step 1 - Inizializza i vettori di riferimento, operazione che può essere eseguita come segue -
Step 1(a) - Dal set di vettori di addestramento fornito, prendi il primo "m"(Numero di cluster) vettori di allenamento e usali come vettori di peso. I vettori rimanenti possono essere utilizzati per l'allenamento.
Step 1(b) - Assegna il peso iniziale e la classificazione in modo casuale.
Step 1(c) - Applicare il metodo di clustering K-means.
Step 2 - Inizializza il vettore di riferimento $ \ alpha $
Step 3 - Continuare con i passaggi 4-9, se la condizione per l'arresto di questo algoritmo non è soddisfatta.
Step 4 - Segui i passaggi 5-6 per ogni vettore di input di addestramento x.
Step 5 - Calcola il quadrato della distanza euclidea per j = 1 to m e i = 1 to n
$$ D (j) \: = \: \ displaystyle \ sum \ limits_ {i = 1} ^ n \ displaystyle \ sum \ limits_ {j = 1} ^ m (x_ {i} \: - \: w_ {ij }) ^ 2 $$
Step 6 - Ottieni l'unità vincente J dove D(j) è minimo.
Step 7 - Calcola il nuovo peso dell'unità vincente con la seguente relazione -
Se T = Cj quindi $ w_ {j} (nuovo) \: = \: w_ {j} (vecchio) \: + \: \ alpha [x \: - \: w_ {j} (vecchio)] $
Se T ≠ Cj quindi $ w_ {j} (nuovo) \: = \: w_ {j} (vecchio) \: - \: \ alpha [x \: - \: w_ {j} (vecchio)] $
Step 8 - Riduci il tasso di apprendimento $ \ alpha $.
Step 9- Test per la condizione di arresto. Potrebbe essere il seguente:
- Numero massimo di epoche raggiunto.
- Tasso di apprendimento ridotto a un valore trascurabile.
Diagramma di flusso
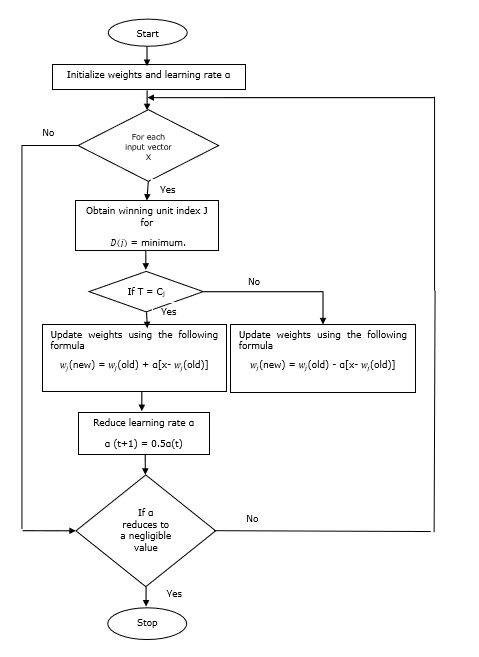
Varianti
Altre tre varianti, ovvero LVQ2, LVQ2.1 e LVQ3, sono state sviluppate da Kohonen. La complessità in tutte queste tre varianti, dovuta al concetto che il vincitore così come il secondo classificato impareranno, è maggiore che in LVQ.
LVQ2
Come discusso, il concetto di altre varianti di LVQ sopra, la condizione di LVQ2 è formata da finestra. Questa finestra sarà basata sui seguenti parametri:
x - il vettore di input corrente
yc - il vettore di riferimento più vicino a x
yr - l'altro vettore di riferimento, quello più vicino a x
dc - la distanza da x per yc
dr - la distanza da x per yr
Il vettore di input x cade nella finestra, se
$$ \ frac {d_ {c}} {d_ {r}} \:> \: 1 \: - \: \ theta \: \: e \: \: \ frac {d_ {r}} {d_ {c }} \:> \: 1 \: + \: \ theta $$
Qui $ \ theta $ è il numero di campioni di addestramento.
L'aggiornamento può essere effettuato con la seguente formula:
$ y_ {c} (t \: + \: 1) \: = \: y_ {c} (t) \: + \: \ alpha (t) [x (t) \: - \: y_ {c} (t)] $ (belongs to different class)
$ y_ {r} (t \: + \: 1) \: = \: y_ {r} (t) \: + \: \ alpha (t) [x (t) \: - \: y_ {r} (t)] $ (belongs to same class)
Qui $ \ alpha $ è il tasso di apprendimento.
LVQ2.1
In LVQ2.1, prenderemo i due vettori più vicini, vale a dire yc1 e yc2 e la condizione per la finestra è la seguente:
$$ Min \ begin {bmatrix} \ frac {d_ {c1}} {d_ {c2}}, \ frac {d_ {c2}} {d_ {c1}} \ end {bmatrix} \:> \ :( 1 \ : - \: \ theta) $$
$$ Max \ begin {bmatrix} \ frac {d_ {c1}} {d_ {c2}}, \ frac {d_ {c2}} {d_ {c1}} \ end {bmatrix} \: <\ :( 1 \ : + \: \ theta) $$
L'aggiornamento può essere effettuato con la seguente formula:
$ y_ {c1} (t \: + \: 1) \: = \: y_ {c1} (t) \: + \: \ alpha (t) [x (t) \: - \: y_ {c1} (t)] $ (belongs to different class)
$ y_ {c2} (t \: + \: 1) \: = \: y_ {c2} (t) \: + \: \ alpha (t) [x (t) \: - \: y_ {c2} (t)] $ (belongs to same class)
Qui $ \ alpha $ è il tasso di apprendimento.
LVQ3
In LVQ3, prenderemo i due vettori più vicini, vale a dire yc1 e yc2 e la condizione per la finestra è la seguente:
$$ Min \ begin {bmatrix} \ frac {d_ {c1}} {d_ {c2}}, \ frac {d_ {c2}} {d_ {c1}} \ end {bmatrix} \:> \ :( 1 \ : - \: \ theta) (1 \: + \: \ theta) $$
Qui $ \ theta \ circa 0,2 $
L'aggiornamento può essere effettuato con la seguente formula:
$ y_ {c1} (t \: + \: 1) \: = \: y_ {c1} (t) \: + \: \ beta (t) [x (t) \: - \: y_ {c1} (t)] $ (belongs to different class)
$ y_ {c2} (t \: + \: 1) \: = \: y_ {c2} (t) \: + \: \ beta (t) [x (t) \: - \: y_ {c2} (t)] $ (belongs to same class)
Qui $ \ beta $ è il multiplo del tasso di apprendimento $ \ alpha $ e $\beta\:=\:m \alpha(t)$ per ogni 0.1 < m < 0.5