Cassandra - Modello di dati
Il modello di dati di Cassandra è significativamente diverso da quello che normalmente vediamo in un RDBMS. Questo capitolo fornisce una panoramica di come Cassandra memorizza i propri dati.
Grappolo
Il database Cassandra è distribuito su più macchine che operano insieme. Il contenitore più esterno è noto come Cluster. Per la gestione degli errori, ogni nodo contiene una replica e, in caso di errore, la replica prende in carico. Cassandra dispone i nodi in un cluster, in un formato ad anello, e assegna loro i dati.
Keyspace
Keyspace è il contenitore più esterno per i dati in Cassandra. Gli attributi di base di un Keyspace in Cassandra sono:
Replication factor - È il numero di macchine nel cluster che riceveranno copie degli stessi dati.
Replica placement strategy- Non è altro che la strategia per posizionare le repliche sul ring. Abbiamo strategie comesimple strategy (strategia rack-aware), old network topology strategy (strategia basata su rack) e network topology strategy (strategia condivisa dal datacenter).
Column families- Keyspace è un contenitore per un elenco di una o più famiglie di colonne. Una famiglia di colonne, a sua volta, è un contenitore di una raccolta di righe. Ogni riga contiene colonne ordinate. Le famiglie di colonne rappresentano la struttura dei dati. Ogni spazio delle chiavi ha almeno una e spesso molte famiglie di colonne.
La sintassi per creare un Keyspace è la seguente:
CREATE KEYSPACE Keyspace name
WITH replication = {'class': 'SimpleStrategy', 'replication_factor' : 3};La figura seguente mostra una vista schematica di un Keyspace.
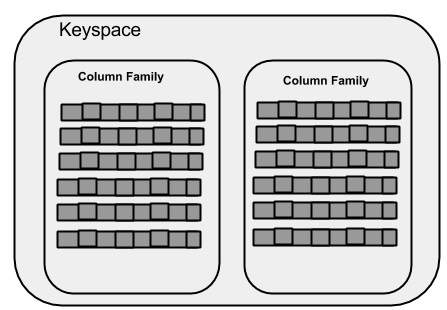
Famiglia di colonne
Una famiglia di colonne è un contenitore per una raccolta ordinata di righe. Ogni riga, a sua volta, è una raccolta ordinata di colonne. La tabella seguente elenca i punti che differenziano una famiglia di colonne da una tabella di database relazionali.
| Tabella relazionale | Famiglia colonna Cassandra |
|---|---|
| Uno schema in un modello relazionale è fisso. Una volta definite determinate colonne per una tabella, durante l'inserimento dei dati, in ogni riga tutte le colonne devono essere riempite almeno con un valore nullo. | In Cassandra, sebbene le famiglie di colonne siano definite, le colonne non lo sono. È possibile aggiungere liberamente qualsiasi colonna a qualsiasi famiglia di colonne in qualsiasi momento. |
| Le tabelle relazionali definiscono solo le colonne e l'utente compila la tabella con i valori. | In Cassandra, una tabella contiene colonne o può essere definita come una famiglia di super colonne. |
Una famiglia di colonne Cassandra ha i seguenti attributi:
keys_cached - Rappresenta il numero di posizioni da conservare nella cache per SSTable.
rows_cached - Rappresenta il numero di righe il cui intero contenuto verrà memorizzato nella cache.
preload_row_cache - Specifica se si desidera prepopolare la cache delle righe.
Note − A differenza delle tabelle relazionali in cui lo schema di una famiglia di colonne non è fisso, Cassandra non forza le singole righe ad avere tutte le colonne.
La figura seguente mostra un esempio di una famiglia di colonne Cassandra.
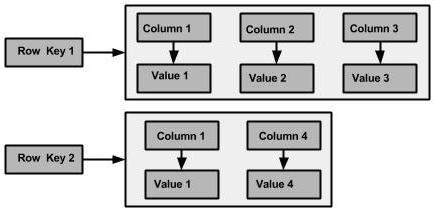
Colonna
Una colonna è la struttura dati di base di Cassandra con tre valori, vale a dire il nome della chiave o della colonna, il valore e un timestamp. Di seguito è riportata la struttura di una colonna.

SuperColumn
Una supercolonna è una colonna speciale, quindi è anche una coppia chiave-valore. Ma una super colonna memorizza una mappa di sottocolonne.
Generalmente le famiglie di colonne vengono memorizzate su disco in singoli file. Pertanto, per ottimizzare le prestazioni, è importante mantenere le colonne che è probabile che interrogherai insieme nella stessa famiglia di colonne e una super colonna può essere utile qui. Di seguito è riportata la struttura di una super colonna.

Modelli di dati di Cassandra e RDBMS
La tabella seguente elenca i punti che differenziano il modello di dati di Cassandra da quello di un RDBMS.
| RDBMS | Cassandra |
|---|---|
| RDBMS si occupa di dati strutturati. | Cassandra si occupa di dati non strutturati. |
| Ha uno schema fisso. | Cassandra ha uno schema flessibile. |
| In RDBMS, una tabella è un array di array. (RIGA x COLONNA) | In Cassandra, una tabella è un elenco di "coppie chiave-valore nidificate". (ROW x tasto COLUMN x valore COLUMN) |
| Il database è il contenitore più esterno che contiene i dati corrispondenti a un'applicazione. | Keyspace è il contenitore più esterno che contiene i dati corrispondenti a un'applicazione. |
| Le tabelle sono le entità di un database. | Le tabelle o le famiglie di colonne sono l'entità di uno spazio delle chiavi. |
| Row è un record individuale in RDBMS. | Row è un'unità di replica in Cassandra. |
| La colonna rappresenta gli attributi di una relazione. | Column è un'unità di archiviazione in Cassandra. |
| RDBMS supporta i concetti di chiavi esterne, join. | Le relazioni sono rappresentate utilizzando le raccolte. |