Cassandra - Guida rapida
Apache Cassandra è un database distribuito altamente scalabile e ad alte prestazioni progettato per gestire grandi quantità di dati su molti server commodity, fornendo un'elevata disponibilità senza un singolo punto di errore. È un tipo di database NoSQL. Cerchiamo prima di capire cosa fa un database NoSQL.
NoSQLDatabase
Un database NoSQL (a volte chiamato non solo SQL) è un database che fornisce un meccanismo per archiviare e recuperare dati diversi dalle relazioni tabulari utilizzate nei database relazionali. Questi database sono privi di schemi, supportano una facile replica, hanno API semplici, eventualmente coerenti e possono gestire enormi quantità di dati.
L'obiettivo principale di un database NoSQL è avere
- semplicità del design,
- ridimensionamento orizzontale e
- controllo più preciso sulla disponibilità.
I database NoSql utilizzano strutture di dati differenti rispetto ai database relazionali. Rende alcune operazioni più veloci in NoSQL. L'idoneità di un dato database NoSQL dipende dal problema che deve risolvere.
NoSQL contro database relazionale
La tabella seguente elenca i punti che differenziano un database relazionale da un database NoSQL.
| Database relazionale | Database NoSql |
|---|---|
| Supporta un potente linguaggio di query. | Supporta un linguaggio di query molto semplice. |
| Ha uno schema fisso. | Nessuno schema fisso. |
| Segue ACID (Atomicity, Consistency, Isolation, and Durability). | È solo "alla fine coerente". |
| Supporta le transazioni. | Non supporta le transazioni. |
Oltre a Cassandra, abbiamo i seguenti database NoSQL che sono piuttosto popolari:
Apache HBase- HBase è un database distribuito open source, non relazionale, modellato sul BigTable di Google ed è scritto in Java. È sviluppato come parte del progetto Apache Hadoop e funziona su HDFS, fornendo funzionalità simili a BigTable per Hadoop.
MongoDB - MongoDB è un sistema di database orientato ai documenti multipiattaforma che evita di utilizzare la tradizionale struttura di database relazionale basata su tabelle a favore di documenti simili a JSON con schemi dinamici che rendono più semplice e veloce l'integrazione dei dati in alcuni tipi di applicazioni.
Cos'è Apache Cassandra?
Apache Cassandra è un sistema di archiviazione (database) open source, distribuito e decentralizzato / distribuito, per la gestione di grandi quantità di dati strutturati sparsi in tutto il mondo. Fornisce un servizio ad alta disponibilità senza un singolo punto di errore.
Di seguito sono elencati alcuni dei punti notevoli di Apache Cassandra -
È scalabile, a tolleranza di errore e coerente.
È un database orientato alle colonne.
Il suo design di distribuzione si basa su Dynamo di Amazon e il suo modello di dati su Bigtable di Google.
Creato su Facebook, differisce nettamente dai sistemi di gestione dei database relazionali.
Cassandra implementa un modello di replica in stile Dynamo senza un singolo punto di errore, ma aggiunge un modello di dati "famiglia di colonne" più potente.
Cassandra è utilizzata da alcune delle più grandi aziende come Facebook, Twitter, Cisco, Rackspace, ebay, Twitter, Netflix e altre.
Caratteristiche di Cassandra
Cassandra è diventata così popolare grazie alle sue eccezionali caratteristiche tecniche. Di seguito sono riportate alcune delle caratteristiche di Cassandra:
Elastic scalability- Cassandra è altamente scalabile; consente di aggiungere più hardware per accogliere più clienti e più dati secondo i requisiti.
Always on architecture - Cassandra non ha un singolo punto di errore ed è continuamente disponibile per applicazioni business-critical che non possono permettersi un errore.
Fast linear-scale performance- Cassandra è scalabile in modo lineare, ovvero aumenta il throughput all'aumentare del numero di nodi nel cluster. Pertanto mantiene un rapido tempo di risposta.
Flexible data storage- Cassandra ospita tutti i possibili formati di dati, inclusi: strutturato, semi-strutturato e non strutturato. Può adattarsi dinamicamente alle modifiche alle strutture dei dati in base alle proprie esigenze.
Easy data distribution - Cassandra offre la flessibilità di distribuire i dati dove necessario replicando i dati su più data center.
Transaction support - Cassandra supporta proprietà come Atomicity, Consistency, Isolation e Durability (ACID).
Fast writes- Cassandra è stata progettata per funzionare su hardware economico. Esegue scritture incredibilmente veloci e può memorizzare centinaia di terabyte di dati, senza sacrificare l'efficienza di lettura.
Storia di Cassandra
- Cassandra è stata sviluppata su Facebook per la ricerca nella posta in arrivo.
- È stato reso open source da Facebook nel luglio 2008.
- Cassandra è stata accettata in Apache Incubator nel marzo 2009.
- È stato realizzato un progetto di primo livello Apache dal febbraio 2010.
L'obiettivo di progettazione di Cassandra è gestire i carichi di lavoro dei big data su più nodi senza alcun singolo punto di errore. Cassandra ha un sistema distribuito peer-to-peer tra i suoi nodi e i dati vengono distribuiti tra tutti i nodi in un cluster.
Tutti i nodi in un cluster svolgono lo stesso ruolo. Ogni nodo è indipendente e allo stesso tempo interconnesso ad altri nodi.
Ogni nodo in un cluster può accettare richieste di lettura e scrittura, indipendentemente da dove si trovano effettivamente i dati nel cluster.
Quando un nodo si interrompe, le richieste di lettura / scrittura possono essere servite da altri nodi nella rete.
Replica dei dati in Cassandra
In Cassandra, uno o più nodi in un cluster agiscono come repliche per un dato dato. Se viene rilevato che alcuni dei nodi hanno risposto con un valore non aggiornato, Cassandra restituirà il valore più recente al client. Dopo aver restituito il valore più recente, Cassandra esegue un fileread repair in background per aggiornare i valori non aggiornati.
La figura seguente mostra una vista schematica di come Cassandra utilizza la replica dei dati tra i nodi di un cluster per garantire l'assenza di un singolo punto di errore.
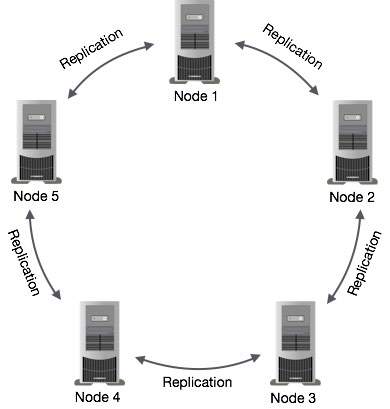
Note - Cassandra usa il Gossip Protocol in background per consentire ai nodi di comunicare tra loro e rilevare eventuali nodi difettosi nel cluster.
Componenti di Cassandra
I componenti chiave di Cassandra sono i seguenti:
Node - È il luogo in cui vengono archiviati i dati.
Data center - È una raccolta di nodi correlati.
Cluster - Un cluster è un componente che contiene uno o più data center.
Commit log- Il registro di commit è un meccanismo di ripristino da arresto anomalo in Cassandra. Ogni operazione di scrittura viene scritta nel log di commit.
Mem-table- Una tabella mem è una struttura dati residente in memoria. Dopo il log di commit, i dati verranno scritti nella mem-table. A volte, per una famiglia a colonna singola, ci saranno più tabelle mem.
SSTable - È un file su disco in cui i dati vengono scaricati dalla mem-table quando il suo contenuto raggiunge un valore di soglia.
Bloom filter- Questi non sono altro che algoritmi rapidi e non deterministici per verificare se un elemento è un membro di un insieme. È un tipo speciale di cache. Si accede ai filtri Bloom dopo ogni query.
Cassandra Query Language
Gli utenti possono accedere a Cassandra tramite i suoi nodi utilizzando Cassandra Query Language (CQL). CQL tratta il database(Keyspace)come contenitore di tavoli. I programmatori usanocqlsh: un prompt per lavorare con CQL o driver del linguaggio dell'applicazione separati.
I client si avvicinano a uno qualsiasi dei nodi per le operazioni di lettura e scrittura. Quel nodo (coordinatore) riproduce un proxy tra il client ei nodi che contengono i dati.
Scrivi operazioni
Ogni attività di scrittura dei nodi viene catturata dal commit logsscritto nei nodi. Successivamente i dati verranno acquisiti e archiviati nel filemem-table. Ogni volta che la tabella mem è piena, i dati verranno scritti nel file SStablefile di dati. Tutte le scritture vengono automaticamente partizionate e replicate in tutto il cluster. Cassandra consolida periodicamente gli SSTables, scartando i dati non necessari.
Leggi operazioni
Durante le operazioni di lettura, Cassandra ottiene i valori dalla tabella mem e controlla il filtro bloom per trovare lo SSTable appropriato che contenga i dati richiesti.
Il modello di dati di Cassandra è significativamente diverso da quello che normalmente vediamo in un RDBMS. Questo capitolo fornisce una panoramica di come Cassandra memorizza i propri dati.
Grappolo
Il database Cassandra è distribuito su più macchine che operano insieme. Il contenitore più esterno è noto come Cluster. Per la gestione dei guasti, ogni nodo contiene una replica e, in caso di guasto, la replica prende in carico. Cassandra dispone i nodi in un cluster, in un formato ad anello, e assegna loro i dati.
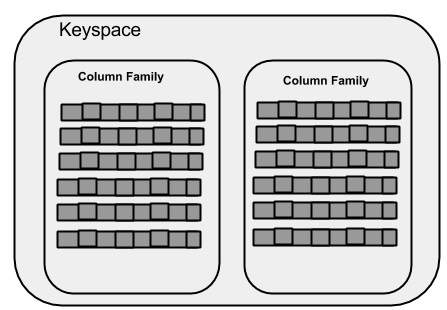
Keyspace
Keyspace è il contenitore più esterno per i dati in Cassandra. Gli attributi di base di un Keyspace in Cassandra sono:
Replication factor - È il numero di macchine nel cluster che riceveranno copie degli stessi dati.
Replica placement strategy- Non è altro che la strategia per posizionare le repliche sul ring. Abbiamo strategie comesimple strategy (strategia rack-aware), old network topology strategy (strategia basata su rack) e network topology strategy (strategia condivisa da datacenter).
Column families- Keyspace è un contenitore per un elenco di una o più famiglie di colonne. Una famiglia di colonne, a sua volta, è un contenitore di una raccolta di righe. Ogni riga contiene colonne ordinate. Le famiglie di colonne rappresentano la struttura dei dati. Ogni spazio delle chiavi ha almeno una e spesso molte famiglie di colonne.
La sintassi per creare un Keyspace è la seguente:
CREATE KEYSPACE Keyspace name
WITH replication = {'class': 'SimpleStrategy', 'replication_factor' : 3};La figura seguente mostra una vista schematica di un Keyspace.
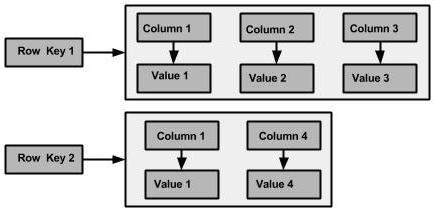
Famiglia di colonne
Una famiglia di colonne è un contenitore per una raccolta ordinata di righe. Ogni riga, a sua volta, è una raccolta ordinata di colonne. La tabella seguente elenca i punti che differenziano una famiglia di colonne da una tabella di database relazionali.
| Tabella relazionale | Famiglia colonna Cassandra |
|---|---|
| Uno schema in un modello relazionale è fisso. Una volta definite determinate colonne per una tabella, durante l'inserimento dei dati, in ogni riga tutte le colonne devono essere riempite almeno con un valore nullo. | In Cassandra, sebbene le famiglie di colonne siano definite, le colonne non lo sono. È possibile aggiungere liberamente qualsiasi colonna a qualsiasi famiglia di colonne in qualsiasi momento. |
| Le tabelle relazionali definiscono solo le colonne e l'utente compila la tabella con i valori. | In Cassandra, una tabella contiene colonne o può essere definita come una famiglia di super colonne. |
Una famiglia di colonne Cassandra ha i seguenti attributi:
keys_cached - Rappresenta il numero di posizioni da conservare nella cache per SSTable.
rows_cached - Rappresenta il numero di righe il cui intero contenuto verrà memorizzato nella cache.
preload_row_cache - Specifica se si desidera prepopolare la cache delle righe.
Note − A differenza delle tabelle relazionali in cui lo schema di una famiglia di colonne non è fisso, Cassandra non forza le singole righe ad avere tutte le colonne.
La figura seguente mostra un esempio di una famiglia di colonne Cassandra.
Colonna
Una colonna è la struttura dati di base di Cassandra con tre valori, ovvero nome chiave o colonna, valore e timestamp. Di seguito è riportata la struttura di una colonna.

SuperColumn
Una supercolonna è una colonna speciale, quindi è anche una coppia chiave-valore. Ma una super colonna memorizza una mappa di sottocolonne.
Generalmente le famiglie di colonne vengono memorizzate su disco in singoli file. Pertanto, per ottimizzare le prestazioni, è importante mantenere le colonne che è probabile che interrogherai insieme nella stessa famiglia di colonne e una super colonna può essere utile qui. Di seguito è riportata la struttura di una super colonna.

Modelli di dati di Cassandra e RDBMS
La tabella seguente elenca i punti che differenziano il modello di dati di Cassandra da quello di un RDBMS.
| RDBMS | Cassandra |
|---|---|
| RDBMS si occupa di dati strutturati. | Cassandra si occupa di dati non strutturati. |
| Ha uno schema fisso. | Cassandra ha uno schema flessibile. |
| In RDBMS, una tabella è un array di array. (RIGA x COLONNA) | In Cassandra, una tabella è un elenco di "coppie chiave-valore nidificate". (ROW x tasto COLUMN x valore COLUMN) |
| Il database è il contenitore più esterno che contiene i dati corrispondenti a un'applicazione. | Keyspace è il contenitore più esterno che contiene i dati corrispondenti a un'applicazione. |
| Le tabelle sono le entità di un database. | Le tabelle o le famiglie di colonne sono l'entità di uno spazio delle chiavi. |
| Row è un record individuale in RDBMS. | Row è un'unità di replica in Cassandra. |
| La colonna rappresenta gli attributi di una relazione. | Column è un'unità di archiviazione in Cassandra. |
| RDBMS supporta i concetti di chiavi esterne, join. | Le relazioni sono rappresentate utilizzando le raccolte. |
È possibile accedere a Cassandra utilizzando cqlsh e driver di diverse lingue. Questo capitolo spiega come configurare gli ambienti cqlsh e java per lavorare con Cassandra.
Configurazione preinstallazione
Prima di installare Cassandra in ambiente Linux, è necessario configurare Linux utilizzando ssh(Secure Shell). Seguire i passaggi indicati di seguito per configurare l'ambiente Linux.
Crea un utente
All'inizio, si consiglia di creare un utente separato per Hadoop per isolare il file system Hadoop dal file system Unix. Seguire i passaggi indicati di seguito per creare un utente.
Apri root usando il comando “su”.
Crea un utente dall'account root utilizzando il comando “useradd username”.
Ora puoi aprire un account utente esistente utilizzando il comando “su username”.
Apri il terminale Linux e digita i seguenti comandi per creare un utente.
$ su
password:
# useradd hadoop
# passwd hadoop
New passwd:
Retype new passwdConfigurazione SSH e generazione di chiavi
La configurazione di SSH è necessaria per eseguire diverse operazioni su un cluster come l'avvio, l'arresto e le operazioni della shell del demone distribuita. Per autenticare diversi utenti di Hadoop, è necessario fornire una coppia di chiavi pubblica / privata per un utente Hadoop e condividerla con utenti diversi.
I seguenti comandi vengono utilizzati per generare una coppia chiave-valore utilizzando SSH:
- copia le chiavi pubbliche da id_rsa.pub in authorized_keys,
- e fornire al proprietario,
- rispettivamente i permessi di lettura e scrittura per il file authorized_keys.
$ ssh-keygen -t rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keys- Verifica ssh:
ssh localhostInstallazione di Java
Java è il prerequisito principale per Cassandra. Prima di tutto, dovresti verificare l'esistenza di Java nel tuo sistema usando il seguente comando:
$ java -versionSe tutto funziona bene, ti darà il seguente output.
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)Se non hai Java nel tuo sistema, segui i passaggi indicati di seguito per l'installazione di Java.
Passo 1
Scarica java (JDK <ultima versione> - X64.tar.gz) dal seguente link:
Then jdk-7u71-linux-x64.tar.gz will be downloaded onto your system.
Passo 2
Generalmente troverai il file java scaricato nella cartella Download. Verificalo ed estrai il filejdk-7u71-linux-x64.gz file utilizzando i seguenti comandi.
$ cd Downloads/
$ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz
$ ls
jdk1.7.0_71 jdk-7u71-linux-x64.gzPassaggio 3
Per rendere Java disponibile a tutti gli utenti, è necessario spostarlo nella posizione "/ usr / local /". Apri root e digita i seguenti comandi.
$ su
password:
# mv jdk1.7.0_71 /usr/local/
# exitPassaggio 4
Per l'allestimento PATH e JAVA_HOME variabili, aggiungi i seguenti comandi a ~/.bashrc file.
export JAVA_HOME = /usr/local/jdk1.7.0_71
export PATH = $PATH:$JAVA_HOME/binOra applica tutte le modifiche al sistema in esecuzione corrente.
$ source ~/.bashrcPassaggio 5
Utilizzare i seguenti comandi per configurare le alternative java.
# alternatives --install /usr/bin/java java usr/local/java/bin/java 2
# alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2
# alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2
# alternatives --set java usr/local/java/bin/java
# alternatives --set javac usr/local/java/bin/javac
# alternatives --set jar usr/local/java/bin/jarOra usa il file java -version comando dal terminale come spiegato sopra.
Impostazione del percorso
Impostare il percorso del percorso Cassandra in "/.bashrc" come mostrato di seguito.
[hadoop@linux ~]$ gedit ~/.bashrc
export CASSANDRA_HOME = ~/cassandra
export PATH = $PATH:$CASSANDRA_HOME/binScarica Cassandra
Apache Cassandra è disponibile su Download Link Cassandra utilizzando il seguente comando.
$ wget http://supergsego.com/apache/cassandra/2.1.2/apache-cassandra-2.1.2-bin.tar.gzDecomprimere Cassandra utilizzando il comando zxvf come mostrato di seguito.
$ tar zxvf apache-cassandra-2.1.2-bin.tar.gz.Crea una nuova directory denominata cassandra e sposta il contenuto del file scaricato come mostrato di seguito.
$ mkdir Cassandra $ mv apache-cassandra-2.1.2/* cassandra.Configura Cassandra
Apri il cassandra.yaml: file, che sarà disponibile nel file bin elenco di Cassandra.
$ gedit cassandra.yamlNote - Se hai installato Cassandra da un pacchetto deb o rpm, i file di configurazione si troveranno in /etc/cassandra elenco di Cassandra.
Il comando precedente apre il file cassandra.yamlfile. Verificare le seguenti configurazioni. Per impostazione predefinita, questi valori verranno impostati sulle directory specificate.
data_file_directories “/var/lib/cassandra/data”
commitlog_directory “/var/lib/cassandra/commitlog”
save_caches_directory “/var/lib/cassandra/saved_caches”
Assicurati che queste directory esistano e possano essere scritte, come mostrato di seguito.
Crea directory
Come superutente, crea le due directory /var/lib/cassandra e /var./log/cassandra in cui Cassandra scrive i suoi dati.
[root@linux cassandra]# mkdir /var/lib/cassandra
[root@linux cassandra]# mkdir /var/log/cassandraConcedi autorizzazioni alle cartelle
Assegna autorizzazioni di lettura e scrittura alle cartelle appena create come mostrato di seguito.
[root@linux /]# chmod 777 /var/lib/cassandra
[root@linux /]# chmod 777 /var/log/cassandraAvvia Cassandra
Per avviare Cassandra, apri la finestra del terminale, vai alla home directory / home di Cassandra, dove hai decompresso Cassandra, ed esegui il seguente comando per avviare il tuo server Cassandra.
$ cd $CASSANDRA_HOME $./bin/cassandra -fL'utilizzo dell'opzione –f dice a Cassandra di rimanere in primo piano invece di eseguire come processo in background. Se tutto va bene, puoi vedere l'avvio del server Cassandra.
Ambiente di programmazione
Per configurare Cassandra a livello di codice, scarica i seguenti file jar:
- slf4j-api-1.7.5.jar
- cassandra-driver-core-2.0.2.jar
- guava-16.0.1.jar
- metrics-core-3.0.2.jar
- netty-3.9.0.Final.jar
Mettili in una cartella separata. Ad esempio, stiamo scaricando questi vasi in una cartella denominata“Cassandra_jars”.
Imposta il percorso di classe per questa cartella in “.bashrc”file come mostrato di seguito.
[hadoop@linux ~]$ gedit ~/.bashrc //Set the following class path in the .bashrc file. export CLASSPATH = $CLASSPATH:/home/hadoop/Cassandra_jars/*Ambiente Eclipse
Apri Eclipse e crea un nuovo progetto chiamato Cassandra _Examples.
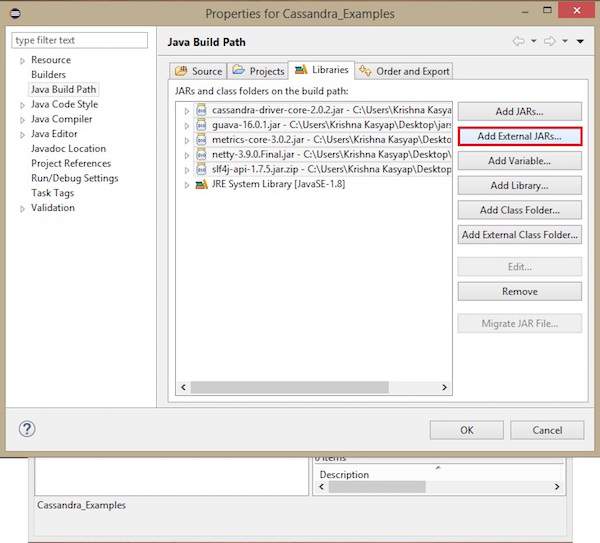
Fare clic con il tasto destro sul progetto, selezionare Build Path→Configure Build Path come mostrato di seguito.
Si aprirà la finestra delle proprietà. Nella scheda Librerie, selezionaAdd External JARs. Vai alla directory in cui hai salvato i tuoi file jar. Seleziona tutti i cinque file jar e fai clic su OK come mostrato di seguito.
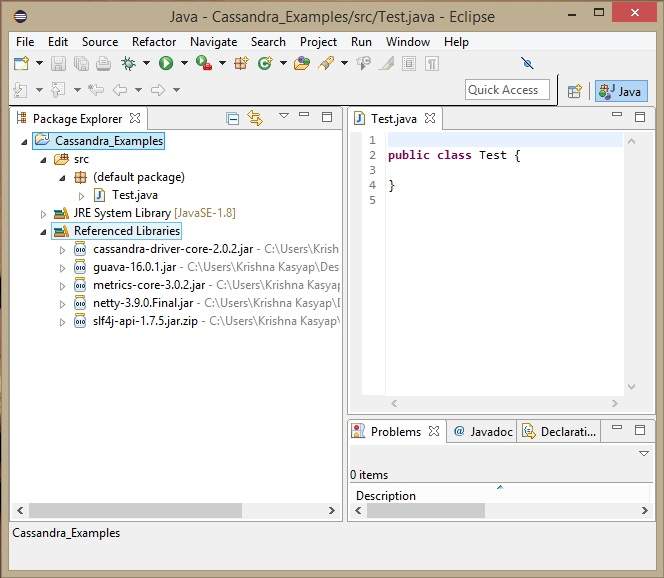
In Librerie referenziate, puoi vedere tutti i vasi richiesti aggiunti come mostrato di seguito:
Dipendenze di Maven
Di seguito è riportato il pom.xml per la creazione di un progetto Cassandra utilizzando Maven.
<project xmlns = "http://maven.apache.org/POM/4.0.0"
xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation = "http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<build>
<sourceDirectory>src</sourceDirectory>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.5</version>
</dependency>
<dependency>
<groupId>com.datastax.cassandra</groupId>
<artifactId>cassandra-driver-core</artifactId>
<version>2.0.2</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>16.0.1</version>
</dependency>
<dependency>
<groupId>com.codahale.metrics</groupId>
<artifactId>metrics-core</artifactId>
<version>3.0.2</version>
</dependency>
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty</artifactId>
<version>3.9.0.Final</version>
</dependency>
</dependencies>
</project>Questo capitolo copre tutte le classi importanti in Cassandra.
Grappolo
Questa classe è il punto di ingresso principale del conducente. Appartiene acom.datastax.driver.core pacchetto.
Metodi
| S. No. | Metodi e descrizione |
|---|---|
| 1 | Session connect() Crea una nuova sessione sul cluster corrente e lo inizializza. |
| 2 | void close() Viene utilizzato per chiudere l'istanza del cluster. |
| 3 | static Cluster.Builder builder() Viene utilizzato per creare una nuova istanza di Cluster.Builder. |
Cluster.Builder
Questa classe viene utilizzata per creare un'istanza di Cluster.Builder classe.
Metodi
| S. No | Metodi e descrizione |
|---|---|
| 1 | Cluster.Builder addContactPoint(String address) Questo metodo aggiunge un punto di contatto al cluster. |
| 2 | Cluster build() Questo metodo crea il cluster con i punti di contatto forniti. |
Sessione
Questa interfaccia contiene le connessioni al cluster Cassandra. Usando questa interfaccia, puoi eseguireCQLinterrogazioni. Appartiene acom.datastax.driver.core pacchetto.
Metodi
| S. No. | Metodi e descrizione |
|---|---|
| 1 | void close() Questo metodo viene utilizzato per chiudere l'istanza della sessione corrente. |
| 2 | ResultSet execute(Statement statement) Questo metodo viene utilizzato per eseguire una query. Richiede un oggetto istruzione. |
| 3 | ResultSet execute(String query) Questo metodo viene utilizzato per eseguire una query. Richiede una query sotto forma di un oggetto String. |
| 4 | PreparedStatement prepare(RegularStatement statement) Questo metodo prepara la query fornita. La query deve essere fornita sotto forma di dichiarazione. |
| 5 | PreparedStatement prepare(String query) Questo metodo prepara la query fornita. La query deve essere fornita sotto forma di una stringa. |
Questo capitolo introduce la shell del linguaggio di query Cassandra e spiega come usare i suoi comandi.
Per impostazione predefinita, Cassandra fornisce un prompt Cassandra query language shell (cqlsh)che consente agli utenti di comunicare con esso. Usando questa shell, puoi eseguireCassandra Query Language (CQL).
Usando cqlsh, puoi
- definire uno schema,
- inserire dati e
- eseguire una query.
Avvio di cqlsh
Avvia cqlsh utilizzando il comando cqlshcome mostrato di seguito. Fornisce il prompt cqlsh di Cassandra come output.
[hadoop@linux bin]$ cqlsh
Connected to Test Cluster at 127.0.0.1:9042.
[cqlsh 5.0.1 | Cassandra 2.1.2 | CQL spec 3.2.0 | Native protocol v3]
Use HELP for help.
cqlsh>Cqlsh- Come discusso in precedenza, questo comando viene utilizzato per avviare il prompt di cqlsh. Inoltre, supporta anche alcune altre opzioni. La tabella seguente spiega tutte le opzioni dicqlsh e il loro utilizzo.
| Opzioni | Utilizzo |
|---|---|
| cqlsh --help | Mostra gli argomenti della guida sulle opzioni di cqlsh comandi. |
| cqlsh --version | Fornisce la versione del cqlsh che stai utilizzando. |
| cqlsh --color | Indica alla shell di utilizzare l'output colorato. |
| cqlsh --debug | Mostra ulteriori informazioni di debug. |
| cqlsh --execute cql_statement |
Indica alla shell di accettare ed eseguire un comando CQL. |
| cqlsh --file = “file name” | Se usi questa opzione, Cassandra esegue il comando nel file dato ed esce. |
| cqlsh --no-color | Indica a Cassandra di non utilizzare output a colori. |
| cqlsh -u “user name” | Utilizzando questa opzione, puoi autenticare un utente. Il nome utente predefinito è: cassandra. |
| cqlsh-p “pass word” | Usando questa opzione, puoi autenticare un utente con una password. La password predefinita è: cassandra. |
Comandi Cqlsh
Cqlsh ha alcuni comandi che consentono agli utenti di interagire con esso. I comandi sono elencati di seguito.
Comandi della shell documentati
Di seguito sono riportati i comandi della shell documentati da Cqlsh. Questi sono i comandi usati per eseguire attività come visualizzare gli argomenti della guida, uscire da cqlsh, descrivere, ecc.
HELP - Visualizza gli argomenti della guida per tutti i comandi cqlsh.
CAPTURE - Cattura l'output di un comando e lo aggiunge a un file.
CONSISTENCY - Mostra il livello di coerenza corrente o imposta un nuovo livello di coerenza.
COPY - Copia i dati da e verso Cassandra.
DESCRIBE - Descrive l'attuale ammasso di Cassandra e dei suoi oggetti.
EXPAND - Espande l'output di una query verticalmente.
EXIT - Usando questo comando, puoi terminare cqlsh.
PAGING - Abilita o disabilita la paginazione delle query.
SHOW - Visualizza i dettagli della sessione cqlsh corrente come la versione di Cassandra, l'host o le ipotesi sul tipo di dati.
SOURCE - Esegue un file che contiene istruzioni CQL.
TRACING - Abilita o disabilita la traccia delle richieste.
Comandi di definizione dei dati CQL
CREATE KEYSPACE - Crea un KeySpace in Cassandra.
USE - Si collega a un KeySpace creato.
ALTER KEYSPACE - Modifica le proprietà di un KeySpace.
DROP KEYSPACE - Rimuove un KeySpace
CREATE TABLE - Crea una tabella in un KeySpace.
ALTER TABLE - Modifica le proprietà della colonna di una tabella.
DROP TABLE - Rimuove un tavolo.
TRUNCATE - Rimuove tutti i dati da una tabella.
CREATE INDEX - Definisce un nuovo indice su una singola colonna di una tabella.
DROP INDEX - Elimina un indice denominato.
Comandi di manipolazione dei dati CQL
INSERT - Aggiunge colonne per una riga in una tabella.
UPDATE - Aggiorna una colonna di una riga.
DELETE - Elimina i dati da una tabella.
BATCH - Esegue più istruzioni DML contemporaneamente.
Clausole CQL
SELECT - Questa clausola legge i dati da una tabella
WHERE - La clausola where viene utilizzata insieme a select per leggere dati specifici.
ORDERBY - La clausola orderby viene utilizzata insieme a select per leggere dati specifici in un ordine specifico.
Cassandra fornisce comandi shell documentati oltre ai comandi CQL. Di seguito sono riportati i comandi della shell documentati da Cassandra.
Aiuto
Il comando HELP mostra una sinossi e una breve descrizione di tutti i comandi cqlsh. Di seguito è riportato l'utilizzo del comando di aiuto.
cqlsh> help
Documented shell commands:
===========================
CAPTURE COPY DESCRIBE EXPAND PAGING SOURCE
CONSISTENCY DESC EXIT HELP SHOW TRACING.
CQL help topics:
================
ALTER CREATE_TABLE_OPTIONS SELECT
ALTER_ADD CREATE_TABLE_TYPES SELECT_COLUMNFAMILY
ALTER_ALTER CREATE_USER SELECT_EXPR
ALTER_DROP DELETE SELECT_LIMIT
ALTER_RENAME DELETE_COLUMNS SELECT_TABLECatturare
Questo comando acquisisce l'output di un comando e lo aggiunge a un file. Ad esempio, dai un'occhiata al codice seguente che cattura l'output in un file denominatoOutputfile.
cqlsh> CAPTURE '/home/hadoop/CassandraProgs/Outputfile'Quando digitiamo un comando nel terminale, l'output verrà catturato dal file fornito. Di seguito è riportato il comando utilizzato e l'istantanea del file di output.
cqlsh:tutorialspoint> select * from emp;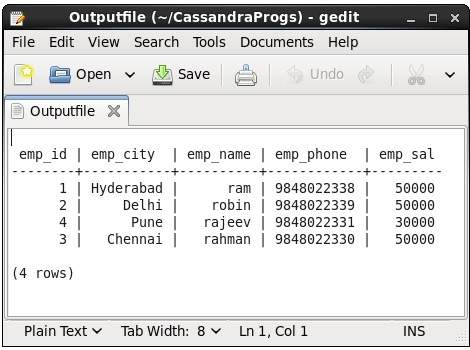
È possibile disattivare l'acquisizione utilizzando il comando seguente.
cqlsh:tutorialspoint> capture off;Consistenza
Questo comando mostra il livello di coerenza corrente o imposta un nuovo livello di coerenza.
cqlsh:tutorialspoint> CONSISTENCY
Current consistency level is 1.copia
Questo comando copia i dati da e verso Cassandra in un file. Di seguito è riportato un esempio per copiare la tabella denominataemp al file myfile.
cqlsh:tutorialspoint> COPY emp (emp_id, emp_city, emp_name, emp_phone,emp_sal) TO ‘myfile’;
4 rows exported in 0.034 seconds.Se apri e verifichi il file fornito, puoi trovare i dati copiati come mostrato di seguito.
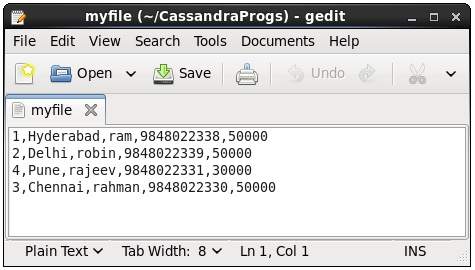
Descrivere
Questo comando descrive l'attuale cluster di Cassandra e i suoi oggetti. Le varianti di questo comando sono spiegate di seguito.
Describe cluster - Questo comando fornisce informazioni sul cluster.
cqlsh:tutorialspoint> describe cluster;
Cluster: Test Cluster
Partitioner: Murmur3Partitioner
Range ownership:
-658380912249644557 [127.0.0.1]
-2833890865268921414 [127.0.0.1]
-6792159006375935836 [127.0.0.1]Describe Keyspaces- Questo comando elenca tutti gli spazi delle chiavi in un cluster. Di seguito è riportato l'utilizzo di questo comando.
cqlsh:tutorialspoint> describe keyspaces;
system_traces system tp tutorialspointDescribe tables- Questo comando elenca tutte le tabelle in uno spazio delle chiavi. Di seguito è riportato l'utilizzo di questo comando.
cqlsh:tutorialspoint> describe tables;
empDescribe table- Questo comando fornisce la descrizione di una tabella. Di seguito è riportato l'utilizzo di questo comando.
cqlsh:tutorialspoint> describe table emp;
CREATE TABLE tutorialspoint.emp (
emp_id int PRIMARY KEY,
emp_city text,
emp_name text,
emp_phone varint,
emp_sal varint
) WITH bloom_filter_fp_chance = 0.01
AND caching = '{"keys":"ALL", "rows_per_partition":"NONE"}'
AND comment = ''
AND compaction = {'min_threshold': '4', 'class':
'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy',
'max_threshold': '32'}
AND compression = {'sstable_compression':
'org.apache.cassandra.io.compress.LZ4Compressor'}
AND dclocal_read_repair_chance = 0.1
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0.0
AND speculative_retry = '99.0PERCENTILE';
CREATE INDEX emp_emp_sal_idx ON tutorialspoint.emp (emp_sal);Descrivi il tipo
Questo comando viene utilizzato per descrivere un tipo di dati definito dall'utente. Di seguito è riportato l'utilizzo di questo comando.
cqlsh:tutorialspoint> describe type card_details;
CREATE TYPE tutorialspoint.card_details (
num int,
pin int,
name text,
cvv int,
phone set<int>,
mail text
);Descrivi i tipi
Questo comando elenca tutti i tipi di dati definiti dall'utente. Di seguito è riportato l'utilizzo di questo comando. Supponiamo che ci siano due tipi di dati definiti dall'utente:card e card_details.
cqlsh:tutorialspoint> DESCRIBE TYPES;
card_details cardEspandere
Questo comando viene utilizzato per espandere l'output. Prima di utilizzare questo comando, devi attivare il comando di espansione. Di seguito è riportato l'utilizzo di questo comando.
cqlsh:tutorialspoint> expand on;
cqlsh:tutorialspoint> select * from emp;
@ Row 1
-----------+------------
emp_id | 1
emp_city | Hyderabad
emp_name | ram
emp_phone | 9848022338
emp_sal | 50000
@ Row 2
-----------+------------
emp_id | 2
emp_city | Delhi
emp_name | robin
emp_phone | 9848022339
emp_sal | 50000
@ Row 3
-----------+------------
emp_id | 4
emp_city | Pune
emp_name | rajeev
emp_phone | 9848022331
emp_sal | 30000
@ Row 4
-----------+------------
emp_id | 3
emp_city | Chennai
emp_name | rahman
emp_phone | 9848022330
emp_sal | 50000
(4 rows)Note - È possibile disattivare l'opzione di espansione utilizzando il seguente comando.
cqlsh:tutorialspoint> expand off;
Disabled Expanded output.Uscita
Questo comando viene utilizzato per terminare la shell cql.
Spettacolo
Questo comando visualizza i dettagli della sessione cqlsh corrente come la versione di Cassandra, l'host o le ipotesi sul tipo di dati. Di seguito è riportato l'utilizzo di questo comando.
cqlsh:tutorialspoint> show host;
Connected to Test Cluster at 127.0.0.1:9042.
cqlsh:tutorialspoint> show version;
[cqlsh 5.0.1 | Cassandra 2.1.2 | CQL spec 3.2.0 | Native protocol v3]fonte
Usando questo comando, puoi eseguire i comandi in un file. Supponiamo che il nostro file di input sia il seguente:
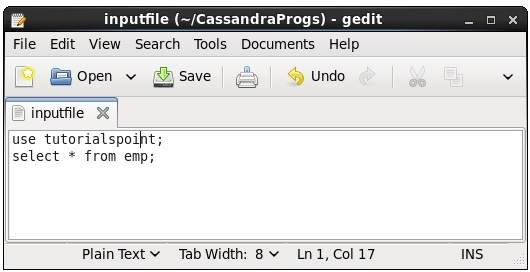
Quindi puoi eseguire il file contenente i comandi come mostrato di seguito.
cqlsh:tutorialspoint> source '/home/hadoop/CassandraProgs/inputfile';
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | Delhi | robin | 9848022339 | 50000
3 | Pune | rajeev | 9848022331 | 30000
4 | Chennai | rahman | 9848022330 | 50000
(4 rows)Creazione di uno spazio chiavi utilizzando Cqlsh
Un keyspace in Cassandra è uno spazio dei nomi che definisce la replica dei dati sui nodi. Un cluster contiene un keyspace per nodo. Di seguito è riportata la sintassi per la creazione di uno spazio delle chiavi utilizzando l'istruzioneCREATE KEYSPACE.
Sintassi
CREATE KEYSPACE <identifier> WITH <properties>cioè
CREATE KEYSPACE “KeySpace Name”
WITH replication = {'class': ‘Strategy name’, 'replication_factor' : ‘No.Of replicas’};
CREATE KEYSPACE “KeySpace Name”
WITH replication = {'class': ‘Strategy name’, 'replication_factor' : ‘No.Of replicas’}
AND durable_writes = ‘Boolean value’;L'istruzione CREATE KEYSPACE ha due proprietà: replication e durable_writes.
Replica
L'opzione di replica è specificare il file Replica Placement strategye il numero di repliche desiderate. La tabella seguente elenca tutte le strategie di posizionamento delle repliche.
| Nome della strategia | Descrizione |
|---|---|
| Simple Strategy' | Specifica un semplice fattore di replica per il cluster. |
| Network Topology Strategy | Utilizzando questa opzione, è possibile impostare il fattore di replica per ogni data center in modo indipendente. |
| Old Network Topology Strategy | Questa è una strategia di replica legacy. |
Usando questa opzione, puoi indicare a Cassandra se usare commitlogper gli aggiornamenti sull'attuale KeySpace. Questa opzione non è obbligatoria e per impostazione predefinita è impostata su true.
Esempio
Di seguito è riportato un esempio di creazione di un KeySpace.
Qui stiamo creando un KeySpace denominato TutorialsPoint.
Stiamo utilizzando la prima strategia di posizionamento della replica, ovvero Simple Strategy.
E stiamo scegliendo il fattore di replica su 1 replica.
cqlsh.> CREATE KEYSPACE tutorialspoint
WITH replication = {'class':'SimpleStrategy', 'replication_factor' : 3};Verifica
È possibile verificare se la tabella è stata creata o meno utilizzando il comando Describe. Se si utilizza questo comando sugli spazi dei tasti, verranno visualizzati tutti gli spazi dei tasti creati come mostrato di seguito.
cqlsh> DESCRIBE keyspaces;
tutorialspoint system system_tracesQui puoi osservare il KeySpace appena creato tutorialspoint.
Durable_writes
Per impostazione predefinita, le proprietà lasting_writes di una tabella sono impostate su true,tuttavia può essere impostato su false. Non è possibile impostare questa proprietà susimplex strategy.
Esempio
Di seguito è riportato l'esempio che dimostra l'utilizzo della proprietà di scrittura durevole.
cqlsh> CREATE KEYSPACE test
... WITH REPLICATION = { 'class' : 'NetworkTopologyStrategy', 'datacenter1' : 3 }
... AND DURABLE_WRITES = false;Verifica
È possibile verificare se la proprietà durevole_writes di test KeySpace è stata impostata su false interrogando lo spazio chiavi di sistema. Questa query ti fornisce tutti i KeySpace insieme alle loro proprietà.
cqlsh> SELECT * FROM system_schema.keyspaces;
keyspace_name | durable_writes | strategy_class | strategy_options
----------------+----------------+------------------------------------------------------+----------------------------
test | False | org.apache.cassandra.locator.NetworkTopologyStrategy | {"datacenter1" : "3"}
tutorialspoint | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor" : "4"}
system | True | org.apache.cassandra.locator.LocalStrategy | { }
system_traces | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor" : "2"}
(4 rows)Qui puoi osservare che la proprietà lasting_writes di test KeySpace è stata impostata su false.
Utilizzando un Keyspace
È possibile utilizzare un KeySpace creato utilizzando la parola chiave USE. La sua sintassi è la seguente:
Syntax:USE <identifier>Esempio
Nell'esempio seguente, stiamo usando KeySpace tutorialspoint.
cqlsh> USE tutorialspoint;
cqlsh:tutorialspoint>Creazione di un Keyspace utilizzando l'API Java
Puoi creare un Keyspace usando execute() metodo di Sessionclasse. Seguire i passaggi indicati di seguito per creare uno spazio chiavi utilizzando l'API Java.
Passaggio 1: creare un oggetto cluster
Prima di tutto, crea un'istanza di Cluster.builder classe di com.datastax.driver.core pacchetto come mostrato di seguito.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Aggiungere un punto di contatto (indirizzo IP del nodo) utilizzando addContactPoint() metodo di Cluster.Builderoggetto. Questo metodo restituisceCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Utilizzando il nuovo oggetto builder, creare un oggetto cluster. Per fare ciò, hai un metodo chiamatobuild() nel Cluster.Builderclasse. Il codice seguente mostra come creare un oggetto cluster.
//Building a cluster
Cluster cluster = builder.build();È possibile creare un oggetto cluster in una singola riga di codice come mostrato di seguito.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Passaggio 2: creare un oggetto sessione
Crea un'istanza di Session oggetto utilizzando il connect() metodo di Cluster classe come mostrato di seguito.
Session session = cluster.connect( );Questo metodo crea una nuova sessione e la inizializza. Se si dispone già di uno spazio delle chiavi, è possibile impostarlo su quello esistente passando il nome dello spazio delle chiavi in formato stringa a questo metodo come mostrato di seguito.
Session session = cluster.connect(“ Your keyspace name ” );Passaggio 3: eseguire la query
Puoi eseguire CQL query utilizzando il execute() metodo di Sessionclasse. Passa la query in formato stringa o come fileStatement oggetto di classe al execute()metodo. Qualunque cosa passi a questo metodo in formato stringa verrà eseguita nel filecqlsh.
In questo esempio, stiamo creando un KeySpace denominato tp. Stiamo utilizzando la prima strategia di posizionamento della replica, ovvero Simple Strategy, e stiamo scegliendo il fattore di replica su 1 replica.
È necessario memorizzare la query in una variabile stringa e passarla al metodo execute () come mostrato di seguito.
String query = "CREATE KEYSPACE tp WITH replication "
+ "= {'class':'SimpleStrategy', 'replication_factor':1}; ";
session.execute(query);Passaggio 4: utilizzare KeySpace
È possibile utilizzare un KeySpace creato utilizzando il metodo execute () come mostrato di seguito.
execute(“ USE tp ” );Di seguito è riportato il programma completo per creare e utilizzare un keyspace in Cassandra utilizzando l'API Java.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Create_KeySpace {
public static void main(String args[]){
//Query
String query = "CREATE KEYSPACE tp WITH replication "
+ "= {'class':'SimpleStrategy', 'replication_factor':1};";
//creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect();
//Executing the query
session.execute(query);
//using the KeySpace
session.execute("USE tp");
System.out.println("Keyspace created");
}
}Salva il programma sopra con il nome della classe seguito da .java, vai alla posizione in cui è stato salvato. Compilare ed eseguire il programma come mostrato di seguito.
$javac Create_KeySpace.java
$java Create_KeySpaceIn condizioni normali, produrrà il seguente output:
Keyspace createdModifica di un KeySpace
ALTER KEYSPACE può essere utilizzato per alterare proprietà come il numero di repliche e le lasting_writes di un KeySpace. Di seguito è riportata la sintassi di questo comando.
Sintassi
ALTER KEYSPACE <identifier> WITH <properties>cioè
ALTER KEYSPACE “KeySpace Name”
WITH replication = {'class': ‘Strategy name’, 'replication_factor' : ‘No.Of replicas’};Le proprietà di ALTER KEYSPACEsono gli stessi di CREATE KEYSPACE. Ha due proprietà:replication e durable_writes.
Replica
L'opzione di replica specifica la strategia di posizionamento della replica e il numero di repliche desiderate.
Durable_writes
Usando questa opzione, puoi indicare a Cassandra se usare commitlog per gli aggiornamenti sul KeySpace corrente. Questa opzione non è obbligatoria e per impostazione predefinita è impostata su true.
Esempio
Di seguito è riportato un esempio di modifica di un KeySpace.
Qui stiamo modificando un KeySpace denominato TutorialsPoint.
Stiamo cambiando il fattore di replica da 1 a 3.
cqlsh.> ALTER KEYSPACE tutorialspoint
WITH replication = {'class':'NetworkTopologyStrategy', 'replication_factor' : 3};Alterazione di Durable_writes
Puoi anche modificare la proprietà lasting_writes di un KeySpace. Di seguito è riportata la proprietà lasting_writes ditest KeySpace.
SELECT * FROM system_schema.keyspaces;
keyspace_name | durable_writes | strategy_class | strategy_options
----------------+----------------+------------------------------------------------------+----------------------------
test | False | org.apache.cassandra.locator.NetworkTopologyStrategy | {"datacenter1":"3"}
tutorialspoint | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor":"4"}
system | True | org.apache.cassandra.locator.LocalStrategy | { }
system_traces | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor":"2"}
(4 rows)ALTER KEYSPACE test
WITH REPLICATION = {'class' : 'NetworkTopologyStrategy', 'datacenter1' : 3}
AND DURABLE_WRITES = true;Ancora una volta, se verifichi le proprietà di KeySpaces, produrrà il seguente output.
SELECT * FROM system_schema.keyspaces;
keyspace_name | durable_writes | strategy_class | strategy_options
----------------+----------------+------------------------------------------------------+----------------------------
test | True | org.apache.cassandra.locator.NetworkTopologyStrategy | {"datacenter1":"3"}
tutorialspoint | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor":"4"}
system | True | org.apache.cassandra.locator.LocalStrategy | { }
system_traces | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor":"2"}
(4 rows)Modifica di un Keyspace utilizzando l'API Java
È possibile modificare uno spazio delle chiavi utilizzando il execute() metodo di Sessionclasse. Seguire i passaggi indicati di seguito per modificare uno spazio delle chiavi utilizzando l'API Java
Passaggio 1: creare un oggetto cluster
Prima di tutto, crea un'istanza di Cluster.builder classe di com.datastax.driver.core pacchetto come mostrato di seguito.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Aggiungi un punto di contatto (indirizzo IP del nodo) utilizzando il file addContactPoint() metodo di Cluster.Builderoggetto. Questo metodo restituisceCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Utilizzando il nuovo oggetto builder, creare un oggetto cluster. Per fare ciò, hai un metodo chiamatobuild() nel Cluster.Builderclasse. Il codice seguente mostra come creare un oggetto cluster.
//Building a cluster
Cluster cluster = builder.build();È possibile creare l'oggetto cluster utilizzando una singola riga di codice come mostrato di seguito.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Passaggio 2: creare un oggetto sessione
Crea un'istanza di Session oggetto utilizzando il connect() metodo di Clusterclasse come mostrato di seguito.
Session session = cluster.connect( );Questo metodo crea una nuova sessione e la inizializza. Se si dispone già di uno spazio delle chiavi, è possibile impostarlo su quello esistente passando il nome dello spazio delle chiavi in formato stringa a questo metodo come mostrato di seguito.
Session session = cluster.connect(“ Your keyspace name ” );Passaggio 3: eseguire la query
È possibile eseguire query CQL utilizzando il metodo execute () della classe Session. Passa la query in formato stringa o come fileStatementoggetto di classe al metodo execute (). Qualunque cosa passi a questo metodo in formato stringa verrà eseguita nel filecqlsh.
In questo esempio,
Stiamo modificando uno spazio delle chiavi denominato tp. Stiamo modificando l'opzione di replica da Simple Strategy a Network Topology Strategy.
Stiamo modificando il file durable_writes a falso
È necessario memorizzare la query in una variabile stringa e passarla al metodo execute () come mostrato di seguito.
//Query
String query = "ALTER KEYSPACE tp WITH replication " + "= {'class':'NetworkTopologyStrategy', 'datacenter1':3}" +" AND DURABLE_WRITES = false;";
session.execute(query);Di seguito è riportato il programma completo per creare e utilizzare un keyspace in Cassandra utilizzando l'API Java.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Alter_KeySpace {
public static void main(String args[]){
//Query
String query = "ALTER KEYSPACE tp WITH replication " + "= {'class':'NetworkTopologyStrategy', 'datacenter1':3}"
+ "AND DURABLE_WRITES = false;";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect();
//Executing the query
session.execute(query);
System.out.println("Keyspace altered");
}
}Salva il programma sopra con il nome della classe seguito da .java, vai alla posizione in cui è stato salvato. Compilare ed eseguire il programma come mostrato di seguito.
$javac Alter_KeySpace.java
$java Alter_KeySpaceIn condizioni normali, produce il seguente output:
Keyspace AlteredRilascio di un Keyspace
È possibile rilasciare un KeySpace utilizzando il comando DROP KEYSPACE. Di seguito è riportata la sintassi per rilasciare un KeySpace.
Sintassi
DROP KEYSPACE <identifier>cioè
DROP KEYSPACE “KeySpace name”Esempio
Il codice seguente elimina lo spazio delle chiavi tutorialspoint.
cqlsh> DROP KEYSPACE tutorialspoint;Verifica
Verificare gli spazi delle chiavi utilizzando il comando Describe e controlla se la tabella viene rilasciata come mostrato di seguito.
cqlsh> DESCRIBE keyspaces;
system system_tracesPoiché abbiamo eliminato il punto tutorial dello spazio chiavi, non lo troverai nell'elenco degli spazi delle chiavi.
Rilascio di un Keyspace utilizzando l'API Java
È possibile creare uno spazio delle chiavi utilizzando il metodo execute () della classe Session. Seguire i passaggi indicati di seguito per rilasciare uno spazio chiavi utilizzando l'API Java.
Passaggio 1: creare un oggetto cluster
Prima di tutto, crea un'istanza di Cluster.builder classe di com.datastax.driver.core pacchetto come mostrato di seguito.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Aggiungi un punto di contatto (indirizzo IP del nodo) utilizzando il file addContactPoint() metodo di Cluster.Builderoggetto. Questo metodo restituisceCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Utilizzando il nuovo oggetto builder, creare un oggetto cluster. Per fare ciò, hai un metodo chiamatobuild() nel Cluster.Builderclasse. Il codice seguente mostra come creare un oggetto cluster.
//Building a cluster
Cluster cluster = builder.build();È possibile creare un oggetto cluster utilizzando una singola riga di codice come mostrato di seguito.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Passaggio 2: creare un oggetto sessione
Crea un'istanza dell'oggetto Session utilizzando il metodo connect () della classe Cluster come mostrato di seguito.
Session session = cluster.connect( );Questo metodo crea una nuova sessione e la inizializza. Se si dispone già di uno spazio delle chiavi, è possibile impostarlo su quello esistente passando il nome dello spazio delle chiavi in formato stringa a questo metodo come mostrato di seguito.
Session session = cluster.connect(“ Your keyspace name”);Passaggio 3: eseguire la query
È possibile eseguire query CQL utilizzando il metodo execute () della classe Session. Passa la query in formato stringa o come oggetto della classe Statement al metodo execute (). Qualunque cosa tu passi a questo metodo in formato stringa verrà eseguita su cqlsh.
Nell'esempio seguente, stiamo eliminando uno spazio delle chiavi denominato tp. È necessario memorizzare la query in una variabile stringa e passarla al metodo execute () come mostrato di seguito.
String query = "DROP KEYSPACE tp; ";
session.execute(query);Di seguito è riportato il programma completo per creare e utilizzare un keyspace in Cassandra utilizzando l'API Java.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Drop_KeySpace {
public static void main(String args[]){
//Query
String query = "Drop KEYSPACE tp";
//creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect();
//Executing the query
session.execute(query);
System.out.println("Keyspace deleted");
}
}Salva il programma sopra con il nome della classe seguito da .java, vai alla posizione in cui è stato salvato. Compilare ed eseguire il programma come mostrato di seguito.
$javac Delete_KeySpace.java
$java Delete_KeySpaceIn condizioni normali, dovrebbe produrre il seguente output:
Keyspace deletedCreazione di una tabella
Puoi creare una tabella usando il comando CREATE TABLE. Di seguito è riportata la sintassi per la creazione di una tabella.
Sintassi
CREATE (TABLE | COLUMNFAMILY) <tablename>
('<column-definition>' , '<column-definition>')
(WITH <option> AND <option>)Definizione di una colonna
È possibile definire una colonna come mostrato di seguito.
column name1 data type,
column name2 data type,
example:
age int,
name textChiave primaria
La chiave primaria è una colonna utilizzata per identificare in modo univoco una riga. Pertanto, la definizione di una chiave primaria è obbligatoria durante la creazione di una tabella. Una chiave primaria è composta da una o più colonne di una tabella. È possibile definire una chiave primaria di una tabella come mostrato di seguito.
CREATE TABLE tablename(
column1 name datatype PRIMARYKEY,
column2 name data type,
column3 name data type.
)or
CREATE TABLE tablename(
column1 name datatype PRIMARYKEY,
column2 name data type,
column3 name data type,
PRIMARY KEY (column1)
)Esempio
Di seguito è riportato un esempio per creare una tabella in Cassandra utilizzando cqlsh. Eccoci qui
Utilizzo dello spazio per chiavi tutorialspoint
Creazione di una tabella denominata emp
Conterrà dettagli come nome, ID, città, stipendio e numero di telefono del dipendente. L'ID dipendente è la chiave primaria.
cqlsh> USE tutorialspoint;
cqlsh:tutorialspoint>; CREATE TABLE emp(
emp_id int PRIMARY KEY,
emp_name text,
emp_city text,
emp_sal varint,
emp_phone varint
);Verifica
L'istruzione select ti darà lo schema. Verificare la tabella utilizzando l'istruzione select come mostrato di seguito.
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+----------+----------+-----------+---------
(0 rows)Qui puoi osservare la tabella creata con le colonne date. Poiché abbiamo eliminato il punto tutorial dello spazio chiavi, non lo troverai nell'elenco degli spazi delle chiavi.
Creazione di una tabella utilizzando l'API Java
È possibile creare una tabella utilizzando il metodo execute () della classe Session. Seguire i passaggi indicati di seguito per creare una tabella utilizzando l'API Java.
Passaggio 1: creare un oggetto cluster
Prima di tutto, crea un'istanza di Cluster.builder classe di com.datastax.driver.core pacchetto come mostrato di seguito.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Aggiungi un punto di contatto (indirizzo IP del nodo) utilizzando il file addContactPoint() metodo di Cluster.Builderoggetto. Questo metodo restituisceCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Utilizzando il nuovo oggetto builder, creare un oggetto cluster. Per fare ciò, hai un metodo chiamatobuild() nel Cluster.Builderclasse. Il codice seguente mostra come creare un oggetto cluster.
//Building a cluster
Cluster cluster = builder.build();È possibile creare un oggetto cluster utilizzando una singola riga di codice come mostrato di seguito.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Passaggio 2: creare un oggetto sessione
Crea un'istanza dell'oggetto Session utilizzando il connect() metodo di Cluster classe come mostrato di seguito.
Session session = cluster.connect( );Questo metodo crea una nuova sessione e la inizializza. Se si dispone già di uno spazio delle chiavi, è possibile impostarlo su quello esistente passando il nome dello spazio delle chiavi in formato stringa a questo metodo come mostrato di seguito.
Session session = cluster.connect(“ Your keyspace name ” );Qui stiamo usando il keyspace denominato tp. Pertanto, creare l'oggetto sessione come mostrato di seguito.
Session session = cluster.connect(“ tp” );Passaggio 3: eseguire la query
È possibile eseguire query CQL utilizzando il metodo execute () della classe Session. Passa la query in formato stringa o come oggetto della classe Statement al metodo execute (). Qualunque cosa tu passi a questo metodo in formato stringa verrà eseguita su cqlsh.
Nell'esempio seguente, stiamo creando una tabella denominata emp. È necessario memorizzare la query in una variabile stringa e passarla al metodo execute () come mostrato di seguito.
//Query
String query = "CREATE TABLE emp(emp_id int PRIMARY KEY, "
+ "emp_name text, "
+ "emp_city text, "
+ "emp_sal varint, "
+ "emp_phone varint );";
session.execute(query);Di seguito è riportato il programma completo per creare e utilizzare un keyspace in Cassandra utilizzando l'API Java.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Create_Table {
public static void main(String args[]){
//Query
String query = "CREATE TABLE emp(emp_id int PRIMARY KEY, "
+ "emp_name text, "
+ "emp_city text, "
+ "emp_sal varint, "
+ "emp_phone varint );";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Table created");
}
}Salva il programma sopra con il nome della classe seguito da .java, vai alla posizione in cui è stato salvato. Compilare ed eseguire il programma come mostrato di seguito.
$javac Create_Table.java
$java Create_TableIn condizioni normali, dovrebbe produrre il seguente output:
Table createdModificare una tabella
È possibile modificare una tabella utilizzando il comando ALTER TABLE. Di seguito è riportata la sintassi per la creazione di una tabella.
Sintassi
ALTER (TABLE | COLUMNFAMILY) <tablename> <instruction>Utilizzando il comando ALTER, è possibile eseguire le seguenti operazioni:
Aggiungi una colonna
Rilascia una colonna
Aggiunta di una colonna
Utilizzando il comando ALTER, puoi aggiungere una colonna a una tabella. Durante l'aggiunta di colonne, è necessario fare attenzione che il nome della colonna non sia in conflitto con i nomi delle colonne esistenti e che la tabella non sia definita con l'opzione di archiviazione compatta. Di seguito è riportata la sintassi per aggiungere una colonna a una tabella.
ALTER TABLE table name
ADD new column datatype;Example
Di seguito è riportato un esempio per aggiungere una colonna a una tabella esistente. Qui stiamo aggiungendo una colonna chiamataemp_email di tipo di dati di testo alla tabella denominata emp.
cqlsh:tutorialspoint> ALTER TABLE emp
... ADD emp_email text;Verification
Utilizzare l'istruzione SELECT per verificare se la colonna viene aggiunta o meno. Qui puoi osservare la colonna emp_email appena aggiunta.
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_email | emp_name | emp_phone | emp_sal
--------+----------+-----------+----------+-----------+---------Far cadere una colonna
Utilizzando il comando ALTER, è possibile eliminare una colonna da una tabella. Prima di eliminare una colonna da una tabella, verificare che la tabella non sia definita con l'opzione di archiviazione compatta. Di seguito è riportata la sintassi per eliminare una colonna da una tabella utilizzando il comando ALTER.
ALTER table name
DROP column name;Example
Di seguito è riportato un esempio per eliminare una colonna da una tabella. Qui stiamo eliminando la colonna denominataemp_email.
cqlsh:tutorialspoint> ALTER TABLE emp DROP emp_email;Verification
Verificare se la colonna viene eliminata utilizzando l'estensione select dichiarazione, come mostrato di seguito.
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+----------+----------+-----------+---------
(0 rows)Da emp_email è stata cancellata, non la trovi più.
Modifica di una tabella utilizzando l'API Java
È possibile creare una tabella utilizzando il metodo execute () della classe Session. Seguire i passaggi indicati di seguito per modificare una tabella utilizzando l'API Java.
Passaggio 1: creare un oggetto cluster
Prima di tutto, crea un'istanza di Cluster.builder classe di com.datastax.driver.core pacchetto come mostrato di seguito.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Aggiungi un punto di contatto (indirizzo IP del nodo) utilizzando il file addContactPoint() metodo di Cluster.Builderoggetto. Questo metodo restituisceCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Utilizzando il nuovo oggetto builder, creare un oggetto cluster. Per fare ciò, hai un metodo chiamatobuild() nel Cluster.Builderclasse. Il codice seguente mostra come creare un oggetto cluster.
//Building a cluster
Cluster cluster = builder.build();È possibile creare un oggetto cluster utilizzando una singola riga di codice come mostrato di seguito.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Passaggio 2: creare un oggetto sessione
Crea un'istanza dell'oggetto Session utilizzando il metodo connect () della classe Cluster come mostrato di seguito.
Session session = cluster.connect( );Questo metodo crea una nuova sessione e la inizializza. Se si dispone già di un keyspace, è possibile impostarlo su quello esistente passando il nome KeySpace in formato stringa a questo metodo come mostrato di seguito.
Session session = cluster.connect(“ Your keyspace name ” );
Session session = cluster.connect(“ tp” );Qui stiamo usando il KeySpace denominato tp. Pertanto, creare l'oggetto sessione come mostrato di seguito.
Passaggio 3: eseguire la query
È possibile eseguire query CQL utilizzando il metodo execute () della classe Session. Passa la query in formato stringa o come oggetto della classe Statement al metodo execute (). Qualunque cosa passi a questo metodo in formato stringa verrà eseguita nel filecqlsh.
Nell'esempio seguente, stiamo aggiungendo una colonna a una tabella denominata emp. Per fare ciò, è necessario memorizzare la query in una variabile stringa e passarla al metodo execute () come mostrato di seguito.
//Query
String query1 = "ALTER TABLE emp ADD emp_email text";
session.execute(query);Di seguito è riportato il programma completo per aggiungere una colonna a una tabella esistente.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Add_column {
public static void main(String args[]){
//Query
String query = "ALTER TABLE emp ADD emp_email text";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Column added");
}
}Salva il programma sopra con il nome della classe seguito da .java, vai alla posizione in cui è stato salvato. Compilare ed eseguire il programma come mostrato di seguito.
$javac Add_Column.java
$java Add_ColumnIn condizioni normali, dovrebbe produrre il seguente output:
Column addedEliminazione di una colonna
Di seguito è riportato il programma completo per eliminare una colonna da una tabella esistente.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Delete_Column {
public static void main(String args[]){
//Query
String query = "ALTER TABLE emp DROP emp_email;";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//executing the query
session.execute(query);
System.out.println("Column deleted");
}
}Salva il programma sopra con il nome della classe seguito da .java, vai alla posizione in cui è stato salvato. Compilare ed eseguire il programma come mostrato di seguito.
$javac Delete_Column.java
$java Delete_ColumnIn condizioni normali, dovrebbe produrre il seguente output:
Column deletedFar cadere un tavolo
È possibile eliminare una tabella utilizzando il comando Drop Table. La sua sintassi è la seguente:
Sintassi
DROP TABLE <tablename>Esempio
Il codice seguente elimina una tabella esistente da un KeySpace.
cqlsh:tutorialspoint> DROP TABLE emp;Verifica
Utilizzare il comando Descrivi per verificare se la tabella è stata eliminata o meno. Poiché la tabella emp è stata eliminata, non la troverai nell'elenco delle famiglie di colonne.
cqlsh:tutorialspoint> DESCRIBE COLUMNFAMILIES;
employeeEliminazione di una tabella utilizzando l'API Java
È possibile eliminare una tabella utilizzando il metodo execute () della classe Session. Seguire i passaggi indicati di seguito per eliminare una tabella utilizzando l'API Java.
Passaggio 1: creare un oggetto cluster
Prima di tutto, crea un'istanza di Cluster.builder classe di com.datastax.driver.core pacchetto come mostrato di seguito -
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Aggiungere un punto di contatto (indirizzo IP del nodo) utilizzando addContactPoint() metodo di Cluster.Builderoggetto. Questo metodo restituisceCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Utilizzando il nuovo oggetto builder, creare un oggetto cluster. Per fare ciò, hai un metodo chiamatobuild() nel Cluster.Builderclasse. Il codice seguente mostra come creare un oggetto cluster.
//Building a cluster
Cluster cluster = builder.build();È possibile creare un oggetto cluster utilizzando una singola riga di codice come mostrato di seguito.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Passaggio 2: creare un oggetto sessione
Crea un'istanza dell'oggetto Session utilizzando il metodo connect () della classe Cluster come mostrato di seguito.
Session session = cluster.connect( );Questo metodo crea una nuova sessione e la inizializza. Se si dispone già di un keyspace, è possibile impostarlo su quello esistente passando il nome KeySpace in formato stringa a questo metodo come mostrato di seguito.
Session session = cluster.connect(“Your keyspace name”);Qui stiamo usando il keyspace denominato tp. Pertanto, creare l'oggetto sessione come mostrato di seguito.
Session session = cluster.connect(“tp”);Passaggio 3: eseguire la query
È possibile eseguire query CQL utilizzando il metodo execute () della classe Session. Passa la query in formato stringa o come oggetto della classe Statement al metodo execute (). Qualunque cosa passi a questo metodo in formato stringa verrà eseguita nel filecqlsh.
Nell'esempio seguente, stiamo eliminando una tabella denominata emp. È necessario memorizzare la query in una variabile stringa e passarla al metodo execute () come mostrato di seguito.
// Query
String query = "DROP TABLE emp1;”;
session.execute(query);Di seguito è riportato il programma completo per eliminare una tabella in Cassandra utilizzando l'API Java.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Drop_Table {
public static void main(String args[]){
//Query
String query = "DROP TABLE emp1;";
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Table dropped");
}
}Salva il programma sopra con il nome della classe seguito da .java, vai alla posizione in cui è stato salvato. Compilare ed eseguire il programma come mostrato di seguito.
$javac Drop_Table.java
$java Drop_TableIn condizioni normali, dovrebbe produrre il seguente output:
Table droppedTroncare una tabella
È possibile troncare una tabella utilizzando il comando TRUNCATE. Quando si tronca una tabella, tutte le righe della tabella vengono eliminate definitivamente. Di seguito è riportata la sintassi di questo comando.
Sintassi
TRUNCATE <tablename>Esempio
Supponiamo che ci sia una tabella chiamata student con i seguenti dati.
| s_id | s_name | s_branch | s_aggregate |
|---|---|---|---|
| 1 | ariete | IT | 70 |
| 2 | rahman | EEE | 75 |
| 3 | robbin | Mech | 72 |
Quando esegui l'istruzione select per ottenere la tabella student, ti darà il seguente output.
cqlsh:tp> select * from student;
s_id | s_aggregate | s_branch | s_name
------+-------------+----------+--------
1 | 70 | IT | ram
2 | 75 | EEE | rahman
3 | 72 | MECH | robbin
(3 rows)Ora tronca la tabella usando il comando TRUNCATE.
cqlsh:tp> TRUNCATE student;Verifica
Verificare se la tabella viene troncata eseguendo il file selectdichiarazione. Di seguito è riportato l'output dell'istruzione select sulla tabella degli studenti dopo il troncamento.
cqlsh:tp> select * from student;
s_id | s_aggregate | s_branch | s_name
------+-------------+----------+--------
(0 rows)Troncamento di una tabella utilizzando l'API Java
Puoi troncare una tabella usando il metodo execute () della classe Session. Seguire i passaggi indicati di seguito per troncare una tabella.
Passaggio 1: creare un oggetto cluster
Prima di tutto, crea un'istanza di Cluster.builder classe di com.datastax.driver.core pacchetto come mostrato di seguito.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Aggiungi un punto di contatto (indirizzo IP del nodo) utilizzando il file addContactPoint() metodo di Cluster.Builderoggetto. Questo metodo restituisceCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Utilizzando il nuovo oggetto builder, creare un oggetto cluster. Per fare ciò, hai un metodo chiamatobuild() nel Cluster.Builderclasse. Il codice seguente mostra come creare un oggetto cluster.
//Building a cluster
Cluster cluster = builder.build();È possibile creare un oggetto cluster utilizzando una singola riga di codice come mostrato di seguito.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Passaggio 2: creazione di un oggetto sessione
Crea un'istanza dell'oggetto Session utilizzando il metodo connect () della classe Cluster come mostrato di seguito.
Session session = cluster.connect( );Questo metodo crea una nuova sessione e la inizializza. Se si dispone già di uno spazio chiavi, è possibile impostarlo su quello esistente passando il nome KeySpace in formato stringa a questo metodo come mostrato di seguito.
Session session = cluster.connect(“ Your keyspace name ” );
Session session = cluster.connect(“ tp” );Qui stiamo usando il keyspace denominato tp. Pertanto, creare l'oggetto sessione come mostrato di seguito.
Passaggio 3: eseguire la query
È possibile eseguire query CQL utilizzando il metodo execute () della classe Session. Passa la query in formato stringa o come oggetto della classe Statement al metodo execute (). Qualunque cosa passi a questo metodo in formato stringa verrà eseguita nel filecqlsh.
Nell'esempio seguente, stiamo troncando una tabella denominata emp. Devi memorizzare la query in una variabile stringa e passarla al fileexecute() metodo come mostrato di seguito.
//Query
String query = "TRUNCATE emp;;”;
session.execute(query);Di seguito è riportato il programma completo per troncare una tabella in Cassandra utilizzando l'API Java.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Truncate_Table {
public static void main(String args[]){
//Query
String query = "Truncate student;";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Table truncated");
}
}Salva il programma sopra con il nome della classe seguito da .java, vai alla posizione in cui è stato salvato. Compilare ed eseguire il programma come mostrato di seguito.
$javac Truncate_Table.java
$java Truncate_TableIn condizioni normali, dovrebbe produrre il seguente output:
Table truncatedCreazione di un indice utilizzando Cqlsh
Puoi creare un indice in Cassandra usando il comando CREATE INDEX. La sua sintassi è la seguente:
CREATE INDEX <identifier> ON <tablename>Di seguito è riportato un esempio per creare un indice in una colonna. Qui stiamo creando un indice per una colonna 'emp_name' in una tabella denominata emp.
cqlsh:tutorialspoint> CREATE INDEX name ON emp1 (emp_name);Creazione di un indice utilizzando l'API Java
È possibile creare un indice in una colonna di una tabella utilizzando il metodo execute () della classe Session. Seguire i passaggi indicati di seguito per creare un indice in una colonna in una tabella.
Passaggio 1: creare un oggetto cluster
Prima di tutto, crea un'istanza di Cluster.builder classe di com.datastax.driver.core pacchetto come mostrato di seguito.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Aggiungi un punto di contatto (indirizzo IP del nodo) utilizzando il file addContactPoint() metodo di Cluster.Builderoggetto. Questo metodo restituisceCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Utilizzando il nuovo oggetto builder, creare un oggetto cluster. Per fare ciò, hai un metodo chiamatobuild() nel Cluster.Builderclasse. Il codice seguente mostra come creare un oggetto cluster.
//Building a cluster
Cluster cluster = builder.build();È possibile creare l'oggetto cluster utilizzando una singola riga di codice come mostrato di seguito.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Passaggio 2: creare un oggetto sessione
Crea un'istanza dell'oggetto Session utilizzando il metodo connect () di Cluster classe come mostrato di seguito.
Session session = cluster.connect( );Questo metodo crea una nuova sessione e la inizializza. Se si dispone già di uno spazio chiavi, è possibile impostarlo su quello esistente passando il nome KeySpace in formato stringa a questo metodo come mostrato di seguito.
Session session = cluster.connect(“ Your keyspace name ” );Qui stiamo usando il KeySpace chiamato tp. Pertanto, creare l'oggetto sessione come mostrato di seguito.
Session session = cluster.connect(“ tp” );Passaggio 3: eseguire la query
È possibile eseguire query CQL utilizzando il metodo execute () della classe Session. Passa la query in formato stringa o come oggetto della classe Statement al metodo execute (). Qualunque cosa passi a questo metodo in formato stringa verrà eseguita nel filecqlsh.
Nell'esempio seguente, stiamo creando un indice per una colonna chiamata emp_name, in una tabella denominata emp. È necessario memorizzare la query in una variabile stringa e passarla al metodo execute () come mostrato di seguito.
//Query
String query = "CREATE INDEX name ON emp1 (emp_name);";
session.execute(query);Di seguito è riportato il programma completo per creare un indice di una colonna in una tabella in Cassandra utilizzando l'API Java.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Create_Index {
public static void main(String args[]){
//Query
String query = "CREATE INDEX name ON emp1 (emp_name);";
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Index created");
}
}Salva il programma sopra con il nome della classe seguito da .java, vai alla posizione in cui è stato salvato. Compilare ed eseguire il programma come mostrato di seguito.
$javac Create_Index.java
$java Create_IndexIn condizioni normali, dovrebbe produrre il seguente output:
Index createdEliminazione di un indice
Puoi rilasciare un indice usando il comando DROP INDEX. La sua sintassi è la seguente:
DROP INDEX <identifier>Di seguito è riportato un esempio per eliminare un indice di una colonna in una tabella. Qui stiamo rilasciando l'indice del nome della colonna nella tabella emp.
cqlsh:tp> drop index name;Eliminazione di un indice utilizzando l'API Java
È possibile eliminare un indice di una tabella utilizzando il metodo execute () della classe Session. Seguire i passaggi indicati di seguito per eliminare un indice da una tabella.
Passaggio 1: creare un oggetto cluster
Crea un'istanza di Cluster.builder classe di com.datastax.driver.core pacchetto come mostrato di seguito.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Aggiungi un punto di contatto (indirizzo IP del nodo) utilizzando il file addContactPoint() metodo di Cluster.Builder object. Questo metodo restituisceCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Utilizzando il nuovo oggetto builder, creare un oggetto cluster. Per fare ciò, hai un metodo chiamatobuild() nel Cluster.Builderclasse. Il codice seguente mostra come creare un oggetto cluster.
//Building a cluster
Cluster cluster = builder.build();È possibile creare un oggetto cluster utilizzando una singola riga di codice come mostrato di seguito.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Passaggio 2: creare un oggetto sessione
Crea un'istanza dell'oggetto Session utilizzando il metodo connect () della classe Cluster come mostrato di seguito.
Session session = cluster.connect( );Questo metodo crea una nuova sessione e la inizializza. Se si dispone già di uno spazio chiavi, è possibile impostarlo su quello esistente passando il nome KeySpace in formato stringa a questo metodo come mostrato di seguito.
Session session = cluster.connect(“ Your keyspace name ” );Qui stiamo usando il KeySpace denominato tp. Pertanto, creare l'oggetto sessione come mostrato di seguito.
Session session = cluster.connect(“ tp” );Passaggio 3: eseguire la query
È possibile eseguire query CQL utilizzando il metodo execute () della classe Session. Passa la query in formato stringa o come fileStatementoggetto di classe al metodo execute (). Qualunque cosa passi a questo metodo in formato stringa verrà eseguita nel filecqlsh.
Nell'esempio seguente, stiamo eliminando un "nome" di indice di emptavolo. È necessario memorizzare la query in una variabile stringa e passarla al metodo execute () come mostrato di seguito.
//Query
String query = "DROP INDEX user_name;";
session.execute(query);Di seguito è riportato il programma completo per rilasciare un indice in Cassandra utilizzando l'API Java.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Drop_Index {
public static void main(String args[]){
//Query
String query = "DROP INDEX user_name;";
//Creating cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();.
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Index dropped");
}
}Salva il programma sopra con il nome della classe seguito da .java, vai alla posizione in cui è stato salvato. Compilare ed eseguire il programma come mostrato di seguito.
$javac Drop_index.java
$java Drop_indexIn condizioni normali, dovrebbe produrre il seguente output:
Index droppedUtilizzo di dichiarazioni batch
Utilizzando BATCH,è possibile eseguire più istruzioni di modifica (inserire, aggiornare, eliminare) contemporaneamente. La sua sintassi è la seguente:
BEGIN BATCH
<insert-stmt>/ <update-stmt>/ <delete-stmt>
APPLY BATCHEsempio
Supponiamo che ci sia una tabella in Cassandra chiamata emp con i seguenti dati:
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | ariete | Hyderabad | 9848022338 | 50000 |
| 2 | pettirosso | Delhi | 9848022339 | 50000 |
| 3 | rahman | Chennai | 9848022330 | 45000 |
In questo esempio, eseguiremo le seguenti operazioni:
- Inserisci una nuova riga con i seguenti dettagli (4, rajeev, pune, 9848022331, 30000).
- Aggiorna lo stipendio del dipendente con l'ID di riga 3 a 50000.
- Elimina la città del dipendente con l'ID di riga 2.
Per eseguire le operazioni di cui sopra in una volta sola, utilizzare il seguente comando BATCH:
cqlsh:tutorialspoint> BEGIN BATCH
... INSERT INTO emp (emp_id, emp_city, emp_name, emp_phone, emp_sal) values( 4,'Pune','rajeev',9848022331, 30000);
... UPDATE emp SET emp_sal = 50000 WHERE emp_id =3;
... DELETE emp_city FROM emp WHERE emp_id = 2;
... APPLY BATCH;Verifica
Dopo aver apportato le modifiche, verificare la tabella utilizzando l'istruzione SELECT. Dovrebbe produrre il seguente output:
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | null | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | 50000
4 | Pune | rajeev | 9848022331 | 30000
(4 rows)Qui puoi osservare la tabella con i dati modificati.
Dichiarazioni batch utilizzando l'API Java
Le istruzioni batch possono essere scritte in modo programmatico in una tabella utilizzando il metodo execute () della classe Session. Seguire i passaggi indicati di seguito per eseguire più istruzioni utilizzando l'istruzione batch con l'aiuto dell'API Java.
Passaggio 1: creare un oggetto cluster
Crea un'istanza di Cluster.builder classe di com.datastax.driver.core pacchetto come mostrato di seguito.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Aggiungi un punto di contatto (indirizzo IP del nodo) utilizzando il file addContactPoint() metodo di Cluster.Builderoggetto. Questo metodo restituisceCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Utilizzando il nuovo oggetto builder, creare un oggetto cluster. Per fare ciò, hai un metodo chiamatobuild() nel Cluster.Builderclasse. Utilizzare il codice seguente per creare l'oggetto cluster:
//Building a cluster
Cluster cluster = builder.build();È possibile creare l'oggetto cluster utilizzando una singola riga di codice come mostrato di seguito.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Passaggio 2: creare un oggetto sessione
Crea un'istanza dell'oggetto Session utilizzando il metodo connect () della classe Cluster come mostrato di seguito.
Session session = cluster.connect( );Questo metodo crea una nuova sessione e la inizializza. Se si dispone già di uno spazio chiavi, è possibile impostarlo su quello esistente passando il nome KeySpace in formato stringa a questo metodo come mostrato di seguito.
Session session = cluster.connect(“ Your keyspace name ”);Qui stiamo usando il KeySpace denominato tp. Pertanto, creare l'oggetto sessione come mostrato di seguito.
Session session = cluster.connect(“tp”);Passaggio 3: eseguire la query
È possibile eseguire query CQL utilizzando il metodo execute () della classe Session. Passa la query in formato stringa o come oggetto della classe Statement al metodo execute (). Qualunque cosa passi a questo metodo in formato stringa verrà eseguita nel filecqlsh.
In questo esempio, eseguiremo le seguenti operazioni:
- Inserisci una nuova riga con i seguenti dettagli (4, rajeev, pune, 9848022331, 30000).
- Aggiorna lo stipendio del dipendente con l'ID di riga 3 a 50000.
- Elimina la città del dipendente con l'ID di riga 2.
È necessario memorizzare la query in una variabile stringa e passarla al metodo execute () come mostrato di seguito.
String query1 = ” BEGIN BATCH INSERT INTO emp (emp_id, emp_city, emp_name, emp_phone, emp_sal) values( 4,'Pune','rajeev',9848022331, 30000);
UPDATE emp SET emp_sal = 50000 WHERE emp_id =3;
DELETE emp_city FROM emp WHERE emp_id = 2;
APPLY BATCH;”;Di seguito è riportato il programma completo per eseguire più istruzioni contemporaneamente su una tabella in Cassandra utilizzando l'API Java.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Batch {
public static void main(String args[]){
//query
String query =" BEGIN BATCH INSERT INTO emp (emp_id, emp_city,
emp_name, emp_phone, emp_sal) values( 4,'Pune','rajeev',9848022331, 30000);"
+ "UPDATE emp SET emp_sal = 50000 WHERE emp_id =3;"
+ "DELETE emp_city FROM emp WHERE emp_id = 2;"
+ "APPLY BATCH;";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Changes done");
}
}Salva il programma sopra con il nome della classe seguito da .java, vai alla posizione in cui è stato salvato. Compilare ed eseguire il programma come mostrato di seguito.
$javac Batch.java
$java BatchIn condizioni normali, dovrebbe produrre il seguente output:
Changes doneCreazione di dati in una tabella
È possibile inserire dati nelle colonne di una riga in una tabella utilizzando il comando INSERT. Di seguito è riportata la sintassi per la creazione di dati in una tabella.
INSERT INTO <tablename>
(<column1 name>, <column2 name>....)
VALUES (<value1>, <value2>....)
USING <option>Esempio
Supponiamo che ci sia una tabella chiamata emp con colonne (emp_id, emp_name, emp_city, emp_phone, emp_sal) e devi inserire i seguenti dati nel emp tavolo.
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | ariete | Hyderabad | 9848022338 | 50000 |
| 2 | pettirosso | Hyderabad | 9848022339 | 40000 |
| 3 | rahman | Chennai | 9848022330 | 45000 |
Utilizzare i comandi forniti di seguito per riempire la tabella con i dati richiesti.
cqlsh:tutorialspoint> INSERT INTO emp (emp_id, emp_name, emp_city,
emp_phone, emp_sal) VALUES(1,'ram', 'Hyderabad', 9848022338, 50000);
cqlsh:tutorialspoint> INSERT INTO emp (emp_id, emp_name, emp_city,
emp_phone, emp_sal) VALUES(2,'robin', 'Hyderabad', 9848022339, 40000);
cqlsh:tutorialspoint> INSERT INTO emp (emp_id, emp_name, emp_city,
emp_phone, emp_sal) VALUES(3,'rahman', 'Chennai', 9848022330, 45000);Verifica
Dopo aver inserito i dati, utilizzare l'istruzione SELECT per verificare se i dati sono stati inseriti o meno. Se verifichi la tabella emp usando l'istruzione SELECT, ti darà il seguente output.
cqlsh:tutorialspoint> SELECT * FROM emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | Hyderabad | robin | 9848022339 | 40000
3 | Chennai | rahman | 9848022330 | 45000
(3 rows)Qui puoi osservare che la tabella è stata popolata con i dati che abbiamo inserito.
Creazione di dati utilizzando l'API Java
È possibile creare dati in una tabella utilizzando il metodo execute () della classe Session. Seguire i passaggi indicati di seguito per creare dati in una tabella utilizzando l'API Java.
Passaggio 1: creare un oggetto cluster
Crea un'istanza di Cluster.builder classe di com.datastax.driver.core pacchetto come mostrato di seguito.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Aggiungi un punto di contatto (indirizzo IP del nodo) utilizzando il file addContactPoint() metodo di Cluster.Builderoggetto. Questo metodo restituisceCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint("127.0.0.1");Utilizzando il nuovo oggetto builder, creare un oggetto cluster. Per fare ciò, hai un metodo chiamatobuild() nel Cluster.Builderclasse. Il codice seguente mostra come creare un oggetto cluster.
//Building a cluster
Cluster cluster = builder.build();È possibile creare un oggetto cluster utilizzando una singola riga di codice come mostrato di seguito.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Passaggio 2: creare un oggetto sessione
Crea un'istanza dell'oggetto Session utilizzando il metodo connect () della classe Cluster come mostrato di seguito.
Session session = cluster.connect( );Questo metodo crea una nuova sessione e la inizializza. Se si dispone già di uno spazio chiavi, è possibile impostarlo su quello esistente passando il nome KeySpace in formato stringa a questo metodo come mostrato di seguito.
Session session = cluster.connect(“ Your keyspace name ” );Qui stiamo usando il KeySpace chiamato tp. Pertanto, creare l'oggetto sessione come mostrato di seguito.
Session session = cluster.connect(“ tp” );Passaggio 3: eseguire la query
È possibile eseguire query CQL utilizzando il metodo execute () della classe Session. Passa la query in formato stringa o come fileStatementoggetto di classe al metodo execute (). Qualunque cosa passi a questo metodo in formato stringa verrà eseguita nel filecqlsh.
Nell'esempio seguente, stiamo inserendo dati in una tabella chiamata emp. È necessario memorizzare la query in una variabile stringa e passarla al metodo execute () come mostrato di seguito.
String query1 = “INSERT INTO emp (emp_id, emp_name, emp_city, emp_phone, emp_sal)
VALUES(1,'ram', 'Hyderabad', 9848022338, 50000);” ;
String query2 = “INSERT INTO emp (emp_id, emp_name, emp_city, emp_phone, emp_sal)
VALUES(2,'robin', 'Hyderabad', 9848022339, 40000);” ;
String query3 = “INSERT INTO emp (emp_id, emp_name, emp_city, emp_phone, emp_sal)
VALUES(3,'rahman', 'Chennai', 9848022330, 45000);” ;
session.execute(query1);
session.execute(query2);
session.execute(query3);Di seguito è riportato il programma completo per inserire dati in una tabella in Cassandra utilizzando l'API Java.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Create_Data {
public static void main(String args[]){
//queries
String query1 = "INSERT INTO emp (emp_id, emp_name, emp_city, emp_phone, emp_sal)"
+ " VALUES(1,'ram', 'Hyderabad', 9848022338, 50000);" ;
String query2 = "INSERT INTO emp (emp_id, emp_name, emp_city,
emp_phone, emp_sal)"
+ " VALUES(2,'robin', 'Hyderabad', 9848022339, 40000);" ;
String query3 = "INSERT INTO emp (emp_id, emp_name, emp_city, emp_phone, emp_sal)"
+ " VALUES(3,'rahman', 'Chennai', 9848022330, 45000);" ;
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query1);
session.execute(query2);
session.execute(query3);
System.out.println("Data created");
}
}Salva il programma sopra con il nome della classe seguito da .java, vai alla posizione in cui è stato salvato. Compilare ed eseguire il programma come mostrato di seguito.
$javac Create_Data.java
$java Create_DataIn condizioni normali, dovrebbe produrre il seguente output:
Data createdAggiornamento dei dati in una tabella
UPDATEè il comando utilizzato per aggiornare i dati in una tabella. Le seguenti parole chiave vengono utilizzate durante l'aggiornamento dei dati in una tabella:
Where - Questa clausola viene utilizzata per selezionare la riga da aggiornare.
Set - Imposta il valore utilizzando questa parola chiave.
Must - Include tutte le colonne che compongono la chiave primaria.
Durante l'aggiornamento delle righe, se una determinata riga non è disponibile, UPDATE crea una nuova riga. Di seguito è riportata la sintassi del comando UPDATE -
UPDATE <tablename>
SET <column name> = <new value>
<column name> = <value>....
WHERE <condition>Esempio
Supponiamo che ci sia una tabella denominata emp. Questa tabella memorizza i dettagli dei dipendenti di una determinata azienda e contiene i seguenti dettagli:
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | ariete | Hyderabad | 9848022338 | 50000 |
| 2 | pettirosso | Hyderabad | 9848022339 | 40000 |
| 3 | rahman | Chennai | 9848022330 | 45000 |
Aggiorniamo ora emp_city di robin a Delhi e il suo stipendio a 50000. Di seguito è riportata la query per eseguire gli aggiornamenti richiesti.
cqlsh:tutorialspoint> UPDATE emp SET emp_city='Delhi',emp_sal=50000
WHERE emp_id=2;Verifica
Utilizzare l'istruzione SELECT per verificare se i dati sono stati aggiornati o meno. Se verifichi la tabella emp utilizzando l'istruzione SELECT, produrrà il seguente output.
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | Delhi | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | 45000
(3 rows)Qui puoi osservare che i dati della tabella sono stati aggiornati.
Aggiornamento dei dati utilizzando l'API Java
È possibile aggiornare i dati in una tabella utilizzando il metodo execute () della classe Session. Seguire i passaggi indicati di seguito per aggiornare i dati in una tabella utilizzando l'API Java.
Passaggio 1: creare un oggetto cluster
Crea un'istanza di Cluster.builder classe di com.datastax.driver.core pacchetto come mostrato di seguito.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Aggiungi un punto di contatto (indirizzo IP del nodo) utilizzando il file addContactPoint() metodo di Cluster.Builderoggetto. Questo metodo restituisceCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint("127.0.0.1");Utilizzando il nuovo oggetto builder, creare un oggetto cluster. Per fare ciò, hai un metodo chiamatobuild() nel Cluster.Builderclasse. Usa il codice seguente per creare l'oggetto cluster.
//Building a cluster
Cluster cluster = builder.build();È possibile creare l'oggetto cluster utilizzando una singola riga di codice come mostrato di seguito.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Passaggio 2: creare un oggetto sessione
Crea un'istanza dell'oggetto Session utilizzando il metodo connect () della classe Cluster come mostrato di seguito.
Session session = cluster.connect( );Questo metodo crea una nuova sessione e la inizializza. Se si dispone già di uno spazio chiavi, è possibile impostarlo su quello esistente passando il nome KeySpace in formato stringa a questo metodo come mostrato di seguito.
Session session = cluster.connect(“ Your keyspace name”);Qui stiamo usando il KeySpace denominato tp. Pertanto, creare l'oggetto sessione come mostrato di seguito.
Session session = cluster.connect(“tp”);Passaggio 3: eseguire la query
È possibile eseguire query CQL utilizzando il metodo execute () della classe Session. Passa la query in formato stringa o come oggetto della classe Statement al metodo execute (). Qualunque cosa passi a questo metodo in formato stringa verrà eseguita nel filecqlsh.
Nell'esempio seguente, stiamo aggiornando la tabella emp. È necessario memorizzare la query in una variabile stringa e passarla al metodo execute () come mostrato di seguito:
String query = “ UPDATE emp SET emp_city='Delhi',emp_sal=50000
WHERE emp_id = 2;” ;Di seguito è riportato il programma completo per aggiornare i dati in una tabella utilizzando l'API Java.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Update_Data {
public static void main(String args[]){
//query
String query = " UPDATE emp SET emp_city='Delhi',emp_sal=50000"
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Data updated");
}
}Salva il programma sopra con il nome della classe seguito da .java, vai alla posizione in cui è stato salvato. Compilare ed eseguire il programma come mostrato di seguito.
$javac Update_Data.java
$java Update_DataIn condizioni normali, dovrebbe produrre il seguente output:
Data updatedLettura dei dati utilizzando la clausola Select
La clausola SELECT viene utilizzata per leggere i dati da una tabella in Cassandra. Usando questa clausola, puoi leggere un'intera tabella, una singola colonna o una cella particolare. Di seguito è riportata la sintassi della clausola SELECT.
SELECT FROM <tablename>Esempio
Supponiamo che ci sia una tabella nello spazio delle chiavi denominato emp con i seguenti dettagli -
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | ariete | Hyderabad | 9848022338 | 50000 |
| 2 | pettirosso | nullo | 9848022339 | 50000 |
| 3 | rahman | Chennai | 9848022330 | 50000 |
| 4 | rajeev | Pune | 9848022331 | 30000 |
L'esempio seguente mostra come leggere un'intera tabella utilizzando la clausola SELECT. Qui stiamo leggendo una tabella chiamataemp.
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | null | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | 50000
4 | Pune | rajeev | 9848022331 | 30000
(4 rows)Lettura delle colonne obbligatorie
L'esempio seguente mostra come leggere una particolare colonna in una tabella.
cqlsh:tutorialspoint> SELECT emp_name, emp_sal from emp;
emp_name | emp_sal
----------+---------
ram | 50000
robin | 50000
rajeev | 30000
rahman | 50000
(4 rows)Dove la clausola
Utilizzando la clausola WHERE, è possibile applicare un vincolo alle colonne richieste. La sua sintassi è la seguente:
SELECT FROM <table name> WHERE <condition>;Note - Una clausola WHERE può essere utilizzata solo sulle colonne che fanno parte della chiave primaria o hanno un indice secondario su di esse.
Nell'esempio seguente, stiamo leggendo i dettagli di un dipendente il cui stipendio è 50000. Prima di tutto, imposta l'indice secondario sulla colonna emp_sal.
cqlsh:tutorialspoint> CREATE INDEX ON emp(emp_sal);
cqlsh:tutorialspoint> SELECT * FROM emp WHERE emp_sal=50000;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | null | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | 50000Lettura dei dati utilizzando l'API Java
È possibile leggere i dati da una tabella utilizzando il metodo execute () della classe Session. Seguire i passaggi indicati di seguito per eseguire più istruzioni utilizzando l'istruzione batch con l'aiuto dell'API Java.
Passaggio 1: creare un oggetto cluster
Crea un'istanza di Cluster.builder classe di com.datastax.driver.core pacchetto come mostrato di seguito.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Aggiungi un punto di contatto (indirizzo IP del nodo) utilizzando il file addContactPoint() metodo di Cluster.Builderoggetto. Questo metodo restituisceCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Utilizzando il nuovo oggetto builder, creare un oggetto cluster. Per fare ciò, hai un metodo chiamatobuild() nel Cluster.Builderclasse. Usa il codice seguente per creare l'oggetto cluster.
//Building a cluster
Cluster cluster = builder.build();È possibile creare l'oggetto cluster utilizzando una singola riga di codice come mostrato di seguito.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Passaggio 2: creare un oggetto sessione
Crea un'istanza dell'oggetto Session utilizzando il metodo connect () della classe Cluster come mostrato di seguito.
Session session = cluster.connect( );Questo metodo crea una nuova sessione e la inizializza. Se si dispone già di uno spazio chiavi, è possibile impostarlo su quello esistente passando il nome KeySpace in formato stringa a questo metodo come mostrato di seguito.
Session session = cluster.connect(“Your keyspace name”);Qui stiamo usando il KeySpace chiamato tp. Pertanto, creare l'oggetto sessione come mostrato di seguito.
Session session = cluster.connect(“tp”);Passaggio 3: eseguire la query
È possibile eseguire query CQL utilizzando il metodo execute () della classe Session. Passa la query in formato stringa o come oggetto della classe Statement al metodo execute (). Qualunque cosa passi a questo metodo in formato stringa verrà eseguita nel filecqlsh.
In questo esempio, stiamo recuperando i dati da emptavolo. Memorizza la query in una stringa e passala al metodo execute () della classe di sessione come mostrato di seguito.
String query = ”SELECT 8 FROM emp”;
session.execute(query);Esegui la query utilizzando il metodo execute () della classe Session.
Passaggio 4: ottenere l'oggetto ResultSet
Le query di selezione restituiranno il risultato sotto forma di un file ResultSet oggetto, quindi memorizzare il risultato nell'oggetto di RESULTSET classe come mostrato di seguito.
ResultSet result = session.execute( );Di seguito è riportato il programma completo per leggere i dati da una tabella.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.ResultSet;
import com.datastax.driver.core.Session;
public class Read_Data {
public static void main(String args[])throws Exception{
//queries
String query = "SELECT * FROM emp";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tutorialspoint");
//Getting the ResultSet
ResultSet result = session.execute(query);
System.out.println(result.all());
}
}Salva il programma sopra con il nome della classe seguito da .java, vai alla posizione in cui è stato salvato. Compilare ed eseguire il programma come mostrato di seguito.
$javac Read_Data.java
$java Read_DataIn condizioni normali, dovrebbe produrre il seguente output:
[Row[1, Hyderabad, ram, 9848022338, 50000], Row[2, Delhi, robin,
9848022339, 50000], Row[4, Pune, rajeev, 9848022331, 30000], Row[3,
Chennai, rahman, 9848022330, 50000]]Lettura dei dati utilizzando la clausola Select
La clausola SELECT viene utilizzata per leggere i dati da una tabella in Cassandra. Usando questa clausola, puoi leggere un'intera tabella, una singola colonna o una cella particolare. Di seguito è riportata la sintassi della clausola SELECT.
SELECT FROM <tablename>Esempio
Supponiamo che ci sia una tabella nello spazio delle chiavi denominato emp con i seguenti dettagli -
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | ariete | Hyderabad | 9848022338 | 50000 |
| 2 | pettirosso | nullo | 9848022339 | 50000 |
| 3 | rahman | Chennai | 9848022330 | 50000 |
| 4 | rajeev | Pune | 9848022331 | 30000 |
L'esempio seguente mostra come leggere un'intera tabella utilizzando la clausola SELECT. Qui stiamo leggendo una tabella chiamataemp.
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | null | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | 50000
4 | Pune | rajeev | 9848022331 | 30000
(4 rows)Lettura delle colonne obbligatorie
L'esempio seguente mostra come leggere una particolare colonna in una tabella.
cqlsh:tutorialspoint> SELECT emp_name, emp_sal from emp;
emp_name | emp_sal
----------+---------
ram | 50000
robin | 50000
rajeev | 30000
rahman | 50000
(4 rows)Dove la clausola
Utilizzando la clausola WHERE, è possibile applicare un vincolo alle colonne richieste. La sua sintassi è la seguente:
SELECT FROM <table name> WHERE <condition>;Note - Una clausola WHERE può essere utilizzata solo sulle colonne che fanno parte della chiave primaria o hanno un indice secondario su di esse.
Nell'esempio seguente, stiamo leggendo i dettagli di un dipendente il cui stipendio è 50000. Prima di tutto, imposta l'indice secondario sulla colonna emp_sal.
cqlsh:tutorialspoint> CREATE INDEX ON emp(emp_sal);
cqlsh:tutorialspoint> SELECT * FROM emp WHERE emp_sal=50000;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | null | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | 50000Lettura dei dati utilizzando l'API Java
È possibile leggere i dati da una tabella utilizzando il metodo execute () della classe Session. Seguire i passaggi indicati di seguito per eseguire più istruzioni utilizzando l'istruzione batch con l'aiuto dell'API Java.
Passaggio 1: creare un oggetto cluster
Crea un'istanza di Cluster.builder classe di com.datastax.driver.core pacchetto come mostrato di seguito.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Aggiungi un punto di contatto (indirizzo IP del nodo) utilizzando il file addContactPoint() metodo di Cluster.Builderoggetto. Questo metodo restituisceCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Utilizzando il nuovo oggetto builder, creare un oggetto cluster. Per fare ciò, hai un metodo chiamatobuild() nel Cluster.Builderclasse. Usa il codice seguente per creare l'oggetto cluster.
//Building a cluster
Cluster cluster = builder.build();È possibile creare l'oggetto cluster utilizzando una singola riga di codice come mostrato di seguito.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Passaggio 2: creare un oggetto sessione
Crea un'istanza dell'oggetto Session utilizzando il metodo connect () della classe Cluster come mostrato di seguito.
Session session = cluster.connect( );Questo metodo crea una nuova sessione e la inizializza. Se si dispone già di uno spazio chiavi, è possibile impostarlo su quello esistente passando il nome KeySpace in formato stringa a questo metodo come mostrato di seguito.
Session session = cluster.connect(“Your keyspace name”);Qui stiamo usando il KeySpace chiamato tp. Pertanto, creare l'oggetto sessione come mostrato di seguito.
Session session = cluster.connect(“tp”);Passaggio 3: eseguire la query
È possibile eseguire query CQL utilizzando il metodo execute () della classe Session. Passa la query in formato stringa o come oggetto della classe Statement al metodo execute (). Qualunque cosa passi a questo metodo in formato stringa verrà eseguita nel filecqlsh.
In questo esempio, stiamo recuperando i dati da emptavolo. Memorizza la query in una stringa e passala al metodo execute () della classe di sessione come mostrato di seguito.
String query = ”SELECT 8 FROM emp”;
session.execute(query);Esegui la query utilizzando il metodo execute () della classe Session.
Passaggio 4: ottenere l'oggetto ResultSet
Le query di selezione restituiranno il risultato sotto forma di un file ResultSet oggetto, quindi memorizzare il risultato nell'oggetto di RESULTSET classe come mostrato di seguito.
ResultSet result = session.execute( );Di seguito è riportato il programma completo per leggere i dati da una tabella.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.ResultSet;
import com.datastax.driver.core.Session;
public class Read_Data {
public static void main(String args[])throws Exception{
//queries
String query = "SELECT * FROM emp";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tutorialspoint");
//Getting the ResultSet
ResultSet result = session.execute(query);
System.out.println(result.all());
}
}Salva il programma sopra con il nome della classe seguito da .java, vai alla posizione in cui è stato salvato. Compilare ed eseguire il programma come mostrato di seguito.
$javac Read_Data.java
$java Read_DataIn condizioni normali, dovrebbe produrre il seguente output:
[Row[1, Hyderabad, ram, 9848022338, 50000], Row[2, Delhi, robin,
9848022339, 50000], Row[4, Pune, rajeev, 9848022331, 30000], Row[3,
Chennai, rahman, 9848022330, 50000]]Eliminazione di dati da una tabella
È possibile eliminare i dati da una tabella utilizzando il comando DELETE. La sua sintassi è la seguente:
DELETE FROM <identifier> WHERE <condition>;Esempio
Supponiamo che ci sia un tavolo in Cassandra chiamato emp con i seguenti dati:
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | ariete | Hyderabad | 9848022338 | 50000 |
| 2 | pettirosso | Hyderabad | 9848022339 | 40000 |
| 3 | rahman | Chennai | 9848022330 | 45000 |
La seguente istruzione cancella la colonna emp_sal dell'ultima riga -
cqlsh:tutorialspoint> DELETE emp_sal FROM emp WHERE emp_id=3;Verifica
Utilizzare l'istruzione SELECT per verificare se i dati sono stati eliminati o meno. Se verifichi la tabella emp usando SELECT, produrrà il seguente output:
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | Delhi | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | null
(3 rows)Poiché abbiamo cancellato lo stipendio di Rahman, osserverai un valore nullo al posto dello stipendio.
Eliminazione di un'intera riga
Il comando seguente elimina un'intera riga da una tabella.
cqlsh:tutorialspoint> DELETE FROM emp WHERE emp_id=3;Verifica
Utilizzare l'istruzione SELECT per verificare se i dati sono stati eliminati o meno. Se verifichi la tabella emp usando SELECT, produrrà il seguente output:
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | Delhi | robin | 9848022339 | 50000
(2 rows)Poiché abbiamo eliminato l'ultima riga, nella tabella sono rimaste solo due righe.
Eliminazione dei dati utilizzando l'API Java
È possibile eliminare i dati in una tabella utilizzando il metodo execute () della classe Session. Seguire i passaggi indicati di seguito per eliminare i dati da una tabella utilizzando l'API Java.
Passaggio 1: creare un oggetto cluster
Crea un'istanza di Cluster.builder classe di com.datastax.driver.core pacchetto come mostrato di seguito.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Aggiungi un punto di contatto (indirizzo IP del nodo) utilizzando il file addContactPoint() metodo di Cluster.Builderoggetto. Questo metodo restituisceCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Utilizzando il nuovo oggetto builder, creare un oggetto cluster. Per fare ciò, hai un metodo chiamatobuild() nel Cluster.Builderclasse. Usa il codice seguente per creare un oggetto cluster.
//Building a cluster
Cluster cluster = builder.build();È possibile creare l'oggetto cluster utilizzando una singola riga di codice come mostrato di seguito.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Passaggio 2: creare un oggetto sessione
Crea un'istanza dell'oggetto Session utilizzando il metodo connect () della classe Cluster come mostrato di seguito.
Session session = cluster.connect();Questo metodo crea una nuova sessione e la inizializza. Se si dispone già di uno spazio chiavi, è possibile impostarlo su quello esistente passando il nome KeySpace in formato stringa a questo metodo come mostrato di seguito.
Session session = cluster.connect(“ Your keyspace name ”);Qui stiamo usando il KeySpace chiamato tp. Pertanto, creare l'oggetto sessione come mostrato di seguito.
Session session = cluster.connect(“tp”);Passaggio 3: eseguire la query
È possibile eseguire query CQL utilizzando il metodo execute () della classe Session. Passa la query in formato stringa o come oggetto della classe Statement al metodo execute (). Qualunque cosa passi a questo metodo in formato stringa verrà eseguita nel filecqlsh.
Nell'esempio seguente, stiamo eliminando i dati da una tabella denominata emp. Devi memorizzare la query in una variabile stringa e passarla al file execute() metodo come mostrato di seguito.
String query1 = ”DELETE FROM emp WHERE emp_id=3; ”;
session.execute(query);Di seguito è riportato il programma completo per eliminare i dati da una tabella in Cassandra utilizzando l'API Java.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Delete_Data {
public static void main(String args[]){
//query
String query = "DELETE FROM emp WHERE emp_id=3;";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Data deleted");
}
}Salva il programma sopra con il nome della classe seguito da .java, vai alla posizione in cui è stato salvato. Compilare ed eseguire il programma come mostrato di seguito.
$javac Delete_Data.java
$java Delete_DataIn condizioni normali, dovrebbe produrre il seguente output:
Data deletedCQL fornisce un ricco set di tipi di dati incorporati, inclusi i tipi di raccolta. Insieme a questi tipi di dati, gli utenti possono anche creare i propri tipi di dati personalizzati. La tabella seguente fornisce un elenco dei tipi di dati incorporati disponibili in CQL.
| Tipo di dati | Costanti | Descrizione |
|---|---|---|
| ascii | stringhe | Rappresenta una stringa di caratteri ASCII |
| bigint | bigint | Rappresenta un segno lungo a 64 bit |
| blob | blob | Rappresenta byte arbitrari |
| Booleano | booleani | Rappresenta vero o falso |
| counter | interi | Rappresenta la colonna del contatore |
| decimale | interi, float | Rappresenta decimale a precisione variabile |
| Doppio | interi | Rappresenta la virgola mobile IEEE-754 a 64 bit |
| galleggiante | interi, float | Rappresenta la virgola mobile IEEE-754 a 32 bit |
| inet | stringhe | Rappresenta un indirizzo IP, IPv4 o IPv6 |
| int | interi | Rappresenta un int con segno a 32 bit |
| testo | stringhe | Rappresenta una stringa con codifica UTF8 |
| timestamp | interi, stringhe | Rappresenta un timestamp |
| timeuuid | uuidi | Rappresenta l'UUID di tipo 1 |
| uuid | uuidi | Rappresenta il tipo 1 o il tipo 4 |
| UUID | ||
| varchar | stringhe | Rappresenta una stringa con codifica uTF8 |
| varint | interi | Rappresenta un numero intero a precisione arbitraria |
Tipi di raccolta
Cassandra Query Language fornisce anche una raccolta di tipi di dati. La tabella seguente fornisce un elenco delle raccolte disponibili in CQL.
| Collezione | Descrizione |
|---|---|
| elenco | Un elenco è una raccolta di uno o più elementi ordinati. |
| carta geografica | Una mappa è una raccolta di coppie chiave-valore. |
| impostato | Un set è una raccolta di uno o più elementi. |
Tipi di dati definiti dall'utente
Cqlsh fornisce agli utenti la possibilità di creare i propri tipi di dati. Di seguito sono riportati i comandi utilizzati durante la gestione dei tipi di dati definiti dall'utente.
CREATE TYPE - Crea un tipo di dati definito dall'utente.
ALTER TYPE - Modifica un tipo di dati definito dall'utente.
DROP TYPE - Elimina un tipo di dati definito dall'utente.
DESCRIBE TYPE - Descrive un tipo di dati definito dall'utente.
DESCRIBE TYPES - Descrive i tipi di dati definiti dall'utente.
CQL offre la possibilità di utilizzare i tipi di dati Collection. Utilizzando questi tipi di raccolta, è possibile memorizzare più valori in una singola variabile. Questo capitolo spiega come utilizzare le raccolte in Cassandra.
Elenco
List viene utilizzato nei casi in cui
- l'ordine degli elementi deve essere mantenuto, e
- un valore deve essere memorizzato più volte.
È possibile ottenere i valori di un tipo di dati elenco utilizzando l'indice degli elementi nell'elenco.
Creazione di una tabella con elenco
Di seguito è riportato un esempio per creare una tabella di esempio con due colonne, nome ed e-mail. Per memorizzare più email, utilizziamo list.
cqlsh:tutorialspoint> CREATE TABLE data(name text PRIMARY KEY, email list<text>);Inserimento di dati in un elenco
Durante l'inserimento dei dati negli elementi di un elenco, immettere tutti i valori separati da virgola all'interno di parentesi quadre [] come mostrato di seguito.
cqlsh:tutorialspoint> INSERT INTO data(name, email) VALUES ('ramu',
['[email protected]','[email protected]'])Aggiornamento di un elenco
Di seguito è riportato un esempio per aggiornare il tipo di dati dell'elenco in una tabella chiamata data. Qui stiamo aggiungendo un'altra email all'elenco.
cqlsh:tutorialspoint> UPDATE data
... SET email = email +['[email protected]']
... where name = 'ramu';Verifica
Se verifichi la tabella utilizzando l'istruzione SELECT, otterrai il seguente risultato:
cqlsh:tutorialspoint> SELECT * FROM data;
name | email
------+--------------------------------------------------------------
ramu | ['[email protected]', '[email protected]', '[email protected]']
(1 rows)IMPOSTATO
Set è un tipo di dati utilizzato per memorizzare un gruppo di elementi. Gli elementi di un set verranno restituiti in un ordine ordinato.
Creazione di una tabella con set
L'esempio seguente crea una tabella di esempio con due colonne, nome e telefono. Per memorizzare più numeri di telefono, utilizziamo set.
cqlsh:tutorialspoint> CREATE TABLE data2 (name text PRIMARY KEY, phone set<varint>);Inserimento di dati in un set
Durante l'inserimento di dati negli elementi di un set, immettere tutti i valori separati da virgola all'interno di parentesi graffe {} come mostrato di seguito.
cqlsh:tutorialspoint> INSERT INTO data2(name, phone)VALUES ('rahman', {9848022338,9848022339});Aggiornamento di un set
Il codice seguente mostra come aggiornare un set in una tabella denominata data2. Qui stiamo aggiungendo un altro numero di telefono al set.
cqlsh:tutorialspoint> UPDATE data2
... SET phone = phone + {9848022330}
... where name = 'rahman';Verifica
Se verifichi la tabella utilizzando l'istruzione SELECT, otterrai il seguente risultato:
cqlsh:tutorialspoint> SELECT * FROM data2;
name | phone
--------+--------------------------------------
rahman | {9848022330, 9848022338, 9848022339}
(1 rows)CARTA GEOGRAFICA
La mappa è un tipo di dati utilizzato per memorizzare una coppia di elementi chiave-valore.
Creazione di una tabella con mappa
L'esempio seguente mostra come creare una tabella di esempio con due colonne, nome e indirizzo. Per memorizzare più valori di indirizzo, utilizziamo map.
cqlsh:tutorialspoint> CREATE TABLE data3 (name text PRIMARY KEY, address
map<timestamp, text>);Inserimento di dati in una mappa
Durante l'inserimento dei dati negli elementi di una mappa, immettere tutti i file key : value coppie separate da virgola all'interno di parentesi graffe {} come mostrato di seguito.
cqlsh:tutorialspoint> INSERT INTO data3 (name, address)
VALUES ('robin', {'home' : 'hyderabad' , 'office' : 'Delhi' } );Aggiornamento di un set
Il codice seguente mostra come aggiornare il tipo di dati della mappa in una tabella denominata data3. Qui stiamo cambiando il valore dell'ufficio chiave, cioè stiamo cambiando l'indirizzo dell'ufficio di una persona di nome robin.
cqlsh:tutorialspoint> UPDATE data3
... SET address = address+{'office':'mumbai'}
... WHERE name = 'robin';Verifica
Se verifichi la tabella utilizzando l'istruzione SELECT, otterrai il seguente risultato:
cqlsh:tutorialspoint> select * from data3;
name | address
-------+-------------------------------------------
robin | {'home': 'hyderabad', 'office': 'mumbai'}
(1 rows)CQL offre la possibilità di creare e utilizzare tipi di dati definiti dall'utente. È possibile creare un tipo di dati per gestire più campi. Questo capitolo spiega come creare, modificare ed eliminare un tipo di dati definito dall'utente.
Creazione di un tipo di dati definito dall'utente
Il comando CREATE TYPEviene utilizzato per creare un tipo di dati definito dall'utente. La sua sintassi è la seguente:
CREATE TYPE <keyspace name>. <data typename>
( variable1, variable2).Esempio
Di seguito è riportato un esempio per la creazione di un tipo di dati definito dall'utente. In questo esempio, stiamo creando un filecard_details tipo di dati contenente i seguenti dettagli.
| Campo | Nome del campo | Tipo di dati |
|---|---|---|
| carta di credito n | num | int |
| perno della carta di credito | pin | int |
| nome sulla carta di credito | nome | testo |
| cvv | cvv | int |
| Dati di contatto del titolare della carta | Telefono | impostato |
cqlsh:tutorialspoint> CREATE TYPE card_details (
... num int,
... pin int,
... name text,
... cvv int,
... phone set<int>
... );Note - Il nome utilizzato per il tipo di dati definito dall'utente non deve coincidere con i nomi dei tipi riservati.
Verifica
Utilizzare il DESCRIBE comando per verificare se il tipo creato è stato creato o meno.
CREATE TYPE tutorialspoint.card_details (
num int,
pin int,
name text,
cvv int,
phone set<int>
);Modifica di un tipo di dati definito dall'utente
ALTER TYPE- comando viene utilizzato per modificare un tipo di dati esistente. Utilizzando ALTER, puoi aggiungere un nuovo campo o rinominare un campo esistente.
Aggiunta di un campo a un tipo
Utilizzare la seguente sintassi per aggiungere un nuovo campo a un tipo di dati definito dall'utente esistente.
ALTER TYPE typename
ADD field_name field_type;Il codice seguente aggiunge un nuovo campo al file Card_detailstipo di dati. Qui stiamo aggiungendo un nuovo campo chiamato email.
cqlsh:tutorialspoint> ALTER TYPE card_details ADD email text;Verifica
Utilizzare il DESCRIBE comando per verificare se il nuovo campo viene aggiunto o meno.
cqlsh:tutorialspoint> describe type card_details;
CREATE TYPE tutorialspoint.card_details (
num int,
pin int,
name text,
cvv int,
phone set<int>,
);Ridenominazione di un campo in un tipo
Utilizzare la seguente sintassi per rinominare un tipo di dati definito dall'utente esistente.
ALTER TYPE typename
RENAME existing_name TO new_name;Il codice seguente modifica il nome del campo in un tipo. Qui stiamo rinominando il campo email in mail.
cqlsh:tutorialspoint> ALTER TYPE card_details RENAME email TO mail;Verifica
Utilizzare il DESCRIBE comando per verificare se il nome del tipo è cambiato o meno.
cqlsh:tutorialspoint> describe type card_details;
CREATE TYPE tutorialspoint.card_details (
num int,
pin int,
name text,
cvv int,
phone set<int>,
mail text
);Eliminazione di un tipo di dati definito dall'utente
DROP TYPEè il comando utilizzato per eliminare un tipo di dati definito dall'utente. Di seguito è riportato un esempio per eliminare un tipo di dati definito dall'utente.
Esempio
Prima di eliminare, verificare l'elenco di tutti i tipi di dati definiti dall'utente utilizzando DESCRIBE_TYPES comando come mostrato di seguito.
cqlsh:tutorialspoint> DESCRIBE TYPES;
card_details cardDai due tipi, elimina il tipo denominato card come mostrato di seguito.
cqlsh:tutorialspoint> drop type card;Utilizzare il DESCRIBE comando per verificare se il tipo di dati è stato eliminato o meno.
cqlsh:tutorialspoint> describe types;
card_details