Progettazione del compilatore - Parser top-down
Abbiamo imparato nell'ultimo capitolo che la tecnica di analisi top-down analizza l'input e inizia a costruire un albero di analisi dal nodo radice spostandosi gradualmente verso i nodi foglia. I tipi di analisi dall'alto verso il basso sono illustrati di seguito:
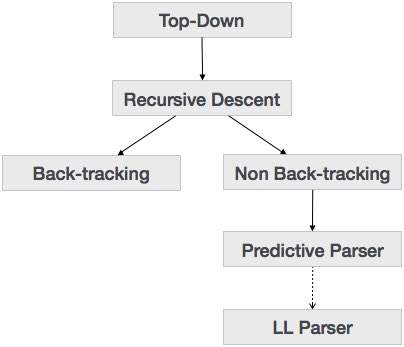
Analisi della discesa ricorsiva
La discesa ricorsiva è una tecnica di analisi dall'alto verso il basso che costruisce l'albero di analisi dall'alto e l'input viene letto da sinistra a destra. Utilizza procedure per ogni terminale e entità non terminale. Questa tecnica di analisi analizza in modo ricorsivo l'input per creare un albero di analisi, che può richiedere o meno il back-tracking. Ma la grammatica ad esso associata (se non viene presa in considerazione) non può evitare il back-tracking. Una forma di analisi discendente ricorsiva che non richiede alcun tracciamento a ritroso è nota comepredictive parsing.
Questa tecnica di analisi è considerata ricorsiva in quanto utilizza una grammatica libera dal contesto che è di natura ricorsiva.
Back-tracking
I parser top-down iniziano dal nodo radice (simbolo di inizio) e abbinano la stringa di input alle regole di produzione per sostituirli (se corrispondono). Per capirlo, prendi il seguente esempio di CFG:
S → rXd | rZd
X → oa | ea
Z → aiPer una stringa di input: read, un parser top-down, si comporterà in questo modo:
Inizierà con S dalle regole di produzione e abbinerà il suo rendimento alla lettera più a sinistra dell'input, cioè 'r'. La stessa produzione di S (S → rXd) corrisponde ad essa. Quindi il parser top-down avanza alla successiva lettera di input (cioè "e"). Il parser cerca di espandere 'X' non terminale e controlla la sua produzione da sinistra (X → oa). Non corrisponde al simbolo di input successivo. Quindi il parser top-down torna indietro per ottenere la successiva regola di produzione di X, (X → ea).
Ora il parser abbina tutte le lettere di input in modo ordinato. La stringa viene accettata.
|
|
|
|
|
Parser predittivo
Il parser predittivo è un parser di discesa ricorsivo, che ha la capacità di prevedere quale produzione deve essere utilizzata per sostituire la stringa di input. Il parser predittivo non soffre di backtracking.
Per svolgere le sue attività, il parser predittivo utilizza un puntatore di previsione, che punta ai successivi simboli di input. Per rendere libero il tracciamento del parser, il parser predittivo pone alcuni vincoli alla grammatica e accetta solo una classe di grammatica nota come grammatica LL (k).
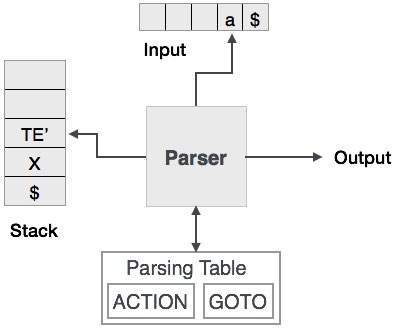
L'analisi predittiva utilizza uno stack e una tabella di analisi per analizzare l'input e generare un albero di analisi. Sia lo stack che l'input contengono un simbolo di fine$per denotare che lo stack è vuoto e l'input è consumato. Il parser fa riferimento alla tabella di analisi per prendere qualsiasi decisione sulla combinazione di elementi di input e stack.
Nell'analisi discendente ricorsiva, il parser può avere più di una produzione tra cui scegliere per una singola istanza di input, mentre nel parser predittivo, ogni passaggio ha al massimo una produzione da scegliere. Potrebbero esserci casi in cui non esiste una produzione corrispondente alla stringa di input, rendendo la procedura di analisi non riuscita.
LL Parser
Un Parser LL accetta la grammatica LL. La grammatica LL è un sottoinsieme della grammatica libera dal contesto ma con alcune limitazioni per ottenere la versione semplificata, al fine di ottenere una facile implementazione. La grammatica LL può essere implementata per mezzo di entrambi gli algoritmi, ovvero discendenza ricorsiva o guidata da tabella.
Il parser LL è indicato come LL (k). La prima L in LL (k) sta analizzando l'input da sinistra a destra, la seconda L in LL (k) sta per derivazione più a sinistra e k stesso rappresenta il numero di look ahead. Generalmente k = 1, quindi LL (k) può anche essere scritto come LL (1).
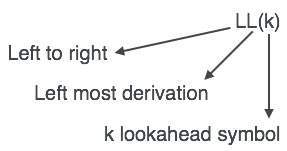
Algoritmo di analisi LL
Possiamo attenerci al deterministico LL (1) per la spiegazione del parser, poiché la dimensione della tabella cresce esponenzialmente con il valore di k. In secondo luogo, se una data grammatica non è LL (1), di solito non è LL (k), per ogni dato k.
Di seguito è riportato un algoritmo per l'analisi LL (1):
Input:
string ω
parsing table M for grammar G
Output:
If ω is in L(G) then left-most derivation of ω,
error otherwise.
Initial State : $S on stack (with S being start symbol)
ω$ in the input buffer
SET ip to point the first symbol of ω$.
repeat
let X be the top stack symbol and a the symbol pointed by ip.
if X∈ Vt or $
if X = a
POP X and advance ip.
else
error()
endif
else /* X is non-terminal */
if M[X,a] = X → Y1, Y2,... Yk
POP X
PUSH Yk, Yk-1,... Y1 /* Y1 on top */
Output the production X → Y1, Y2,... Yk
else
error()
endif
endif
until X = $ /* empty stack */Una grammatica G è LL (1) se A → α | β sono due distinte produzioni di G:
per nessun terminale, sia α che β derivano stringhe che iniziano con a.
al massimo uno tra α e β può derivare una stringa vuota.
se β → t, allora α non deriva alcuna stringa che inizi con un terminale in FOLLOW (A).