DBMS - Indipendenza dei dati
Se un sistema di database non è a più livelli, diventa difficile apportare modifiche al sistema di database. I sistemi di database sono progettati in più livelli come abbiamo appreso in precedenza.
Indipendenza dei dati
Un sistema di database normalmente contiene molti dati oltre ai dati degli utenti. Ad esempio, memorizza i dati sui dati, noti come metadati, per individuare e recuperare facilmente i dati. È piuttosto difficile modificare o aggiornare una serie di metadati una volta archiviati nel database. Ma man mano che un DBMS si espande, deve cambiare nel tempo per soddisfare i requisiti degli utenti. Se tutti i dati dipendessero, diventerebbe un lavoro noioso e altamente complesso.
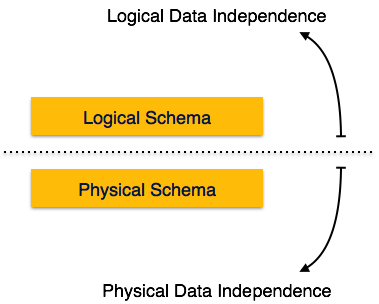
I metadati stessi seguono un'architettura a strati, in modo che quando modifichiamo i dati a un livello, non influiscono sui dati a un altro livello. Questi dati sono indipendenti ma mappati tra loro.
Indipendenza logica dei dati
I dati logici sono dati sul database, ovvero memorizzano informazioni su come i dati vengono gestiti all'interno. Ad esempio, una tabella (relazione) memorizzata nel database e tutti i suoi vincoli, applicati a quella relazione.
L'indipendenza logica dei dati è una sorta di meccanismo che si libera dai dati effettivi memorizzati sul disco. Se apportiamo alcune modifiche al formato della tabella, non dovrebbe cambiare i dati che risiedono sul disco.
Indipendenza fisica dei dati
Tutti gli schemi sono logici e i dati effettivi vengono memorizzati in formato bit sul disco. L'indipendenza fisica dei dati è il potere di modificare i dati fisici senza influire sullo schema o sui dati logici.
Ad esempio, nel caso in cui desideriamo modificare o aggiornare il sistema di archiviazione stesso, supponiamo di voler sostituire i dischi rigidi con SSD, non dovrebbe avere alcun impatto sui dati logici o sugli schemi.