DBMS - Indicizzazione
Sappiamo che i dati vengono memorizzati sotto forma di record. Ogni record ha un campo chiave, che lo aiuta a essere riconosciuto in modo univoco.
L'indicizzazione è una tecnica della struttura dei dati per recuperare in modo efficiente i record dai file di database in base ad alcuni attributi su cui è stata eseguita l'indicizzazione. L'indicizzazione nei sistemi di database è simile a ciò che vediamo nei libri.
L'indicizzazione è definita in base ai suoi attributi di indicizzazione. L'indicizzazione può essere dei seguenti tipi:
Primary Index- L'indice primario è definito su un file di dati ordinato. Il file di dati viene ordinato su un filekey field. Il campo chiave è generalmente la chiave primaria della relazione.
Secondary Index - L'indice secondario può essere generato da un campo che è una chiave candidata e ha un valore univoco in ogni record, o una non chiave con valori duplicati.
Clustering Index- L'indice di clustering è definito su un file di dati ordinato. Il file di dati è ordinato su un campo non chiave.
L'indicizzazione ordinata è di due tipi:
- Indice denso
- Indice sparse
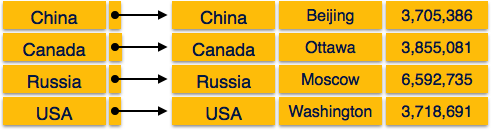
Indice denso
In un indice denso, esiste un record di indice per ogni valore della chiave di ricerca nel database. Ciò rende la ricerca più veloce ma richiede più spazio per memorizzare i record dell'indice stesso. I record di indice contengono il valore della chiave di ricerca e un puntatore al record effettivo sul disco.
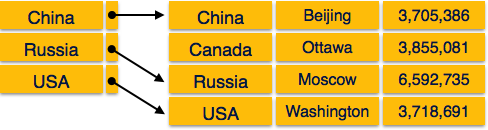
Indice sparse
Nell'indice sparse, i record dell'indice non vengono creati per ogni chiave di ricerca. Un record di indice qui contiene una chiave di ricerca e un puntatore effettivo ai dati sul disco. Per cercare un record, procediamo prima per record di indice e raggiungiamo la posizione effettiva dei dati. Se i dati che stiamo cercando non sono quelli che raggiungiamo direttamente seguendo l'indice, il sistema avvia la ricerca sequenziale fino a trovare i dati desiderati.
Indice multilivello
I record di indice comprendono valori delle chiavi di ricerca e puntatori di dati. L'indice multilivello viene memorizzato sul disco insieme ai file di database effettivi. Man mano che la dimensione del database cresce, aumenta anche la dimensione degli indici. C'è un'immensa necessità di mantenere i record dell'indice nella memoria principale in modo da velocizzare le operazioni di ricerca. Se viene utilizzato un indice a livello singolo, non è possibile mantenere in memoria un indice di grandi dimensioni che porta a più accessi al disco.
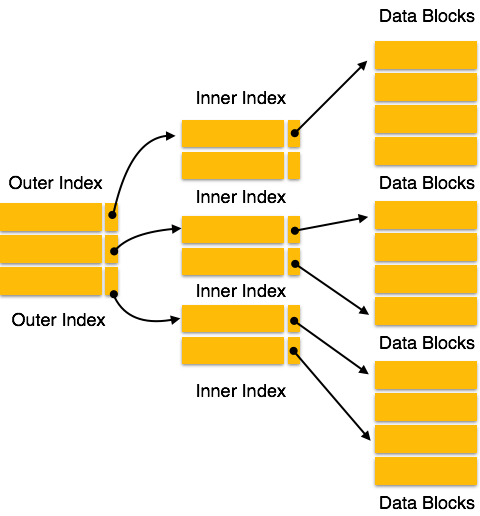
L'indice multilivello aiuta a scomporre l'indice in diversi indici più piccoli al fine di rendere il livello più esterno così piccolo da poter essere salvato in un singolo blocco del disco, che può essere facilmente sistemato ovunque nella memoria principale.
B + Albero
L' albero AB + è un albero di ricerca binario bilanciato che segue un formato di indice a più livelli. I nodi foglia di un albero B + indicano i puntatori ai dati effettivi. B + tree assicura che tutti i nodi fogliari rimangano alla stessa altezza, quindi bilanciati. Inoltre, i nodi foglia sono collegati utilizzando un elenco di collegamenti; pertanto, un albero B + può supportare sia l'accesso casuale che l'accesso sequenziale.
Struttura di B + Albero
Ogni nodo foglia è alla stessa distanza dal nodo radice. L' albero AB + è nell'ordinen dove nè fisso per ogni albero B + .
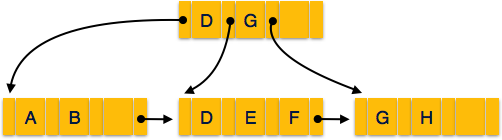
Internal nodes -
- I nodi interni (non foglia) contengono almeno puntatori ⌈n / 2⌉, tranne il nodo radice.
- Al massimo, un nodo interno può contenere n puntatori.
Leaf nodes -
- I nodi foglia contengono almeno puntatori a record ⌈n / 2⌉ e valori chiave ⌈n / 2⌉.
- Al massimo, un nodo foglia può contenere n record di puntatori e n valori chiave.
- Ogni nodo foglia contiene un puntatore a blocchi P per puntare al nodo foglia successivo e forma un elenco collegato.
B + Inserimento ad albero
Gli alberi B + vengono riempiti dal basso e ogni voce viene eseguita sul nodo foglia.
- Se un nodo foglia trabocca -
Dividi il nodo in due parti.
Partizione in i = ⌊(m+1)/2⌋.
Primo i le voci vengono memorizzate in un nodo.
Il resto delle voci (i + 1 in poi) vengono spostate in un nuovo nodo.
ith la chiave è duplicata nel genitore della foglia.
Se un nodo non foglia trabocca:
Dividi il nodo in due parti.
Partiziona il nodo in i = ⌈(m+1)/2⌉.
Iscrizioni fino a i sono conservati in un nodo.
Il resto delle voci viene spostato in un nuovo nodo.
B + Cancellazione albero
Le voci dell'albero B + vengono eliminate nei nodi foglia.
La voce di destinazione viene cercata ed eliminata.
Se è un nodo interno, elimina e sostituisci con la voce dalla posizione sinistra.
Dopo l'eliminazione, viene testato l'underflow,
Se si verifica un underflow, distribuire le voci dai nodi lasciati ad esso.
Se la distribuzione non è possibile da sinistra, allora
Distribuisci dai nodi direttamente ad esso.
Se la distribuzione non è possibile da sinistra o da destra, allora
Unisci il nodo con sinistra e destra ad esso.